
Abstract
Star trackers are crucial for satellite orientation. Improving their efficiency via reconfigurable COTS HW accommodates NewSpace missions. The current work considers SoC FPGAs to leverage both increased reprogramming and high-performance capabilities. Based on a custom sensor+FPGA system, we develop and optimize the algorithmic chain of star tracking by focusing on the acceleration of the image processing parts. We combine multiple circuit design techniques, such as low-level pipelining, word-length optimization, HW/SW co-processing, and parametric HLS+HDL coding, to fine-tune our implementation on Zynq-7020 FPGA when using real and synthetic input data. Overall, with 4-MPixel images, we achieve more than 24 FPS throughput by accelerating >95% of the computation by 8.9\(\times\), at system level, while preserving the original SW accuracy and meeting the real-time requirements of the application.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Space applications demand precise and real-time measurement of the satellite’s orientation. The use of star trackers [7] has been established as a common approach to fulfill such needs. These instruments consist of a camera sensor capturing sky images and a customized digital hardware, which detects the stars on these images, analyzes the stars’ relative positions, and determines the satellite’s three-axis attitude in the inertial space. This information is provided to the Vision-Based Navigation (VBN) systems of the spacecraft. Besides achieving arcsecond levels of accuracy in attitude determination, star trackers are employed to obtain centroids of Resident Space Objects (RSOs) and perform angles-only navigation for satellite rendezvous and formation flying. This use-case has been demonstrated in a number of satellite missions, such as AVANTI [10] and PRISMA [3].
The large amount of sensor data makes the task of detecting objects computationally intensive and, therefore, star tracking on general-purpose embedded processors becomes quite challenging. The trend of utilizing Commercial Off-The-Shelf (COTS) accelerators in space [20] has led us to examine such a solution in our proposed architecture, i.e., to combine a high-resolution camera with a high-performance COTS System-on-Chip (SoC) FPGA. In general, FPGAs are already utilized toward improving the performance of space avionics, as they outperform the conventional radiation-hardened CPUs by order(s) of magnitude in terms of speed and power efficiency [15]. In particular, the space community employs both space-grade [18, 19, 22] and COTS [20, 26, 34] FPGAs (e.g., AMD/Xilinx Zynq), for both acceleration and control purposes; various hybrid architectures exist [4, 16, 17] that include FPGAs for I/O handling, data transcoding, data compression, and general digital signal processing.
In this work, we customize the star tracking on a COTS SoC FPGA platform while focusing on the optimization of its centroiding task and the necessary preprocessing operations of the algorithmic pipeline (pixel binning and clustering). Namely, we accelerate the precise estimation of the stars’ position in night sky images. The proposed HW/SW embedded system utilizes both the Programming System (PS) and Programmable Logic (PL) of AMD/Xilinx’s Zynq-7020, as well as AMBA AXI protocols for PS–PL communication. Our system supports dynamic adjustment of image thresholding, it exploits parallelization at multiple levels via parametric circuit design, it thoroughly examines two distinct centroiding algorithms with certain trade-offs in accuracy and complexity. Furthermore, we implement the respective hardware models using both Hardware Description Language (HDL) and High-Level Synthesis (HLS) / C++ to perform extensive design space exploration and determine the most efficient solution. The experimental results show speed-up factors in the area of 8\(\times\) at system level and 13–43\(\times\) at kernel level, for accelerated functions such as preprocessing and centroiding. Thus, our HW/SW techniques lead to a star tracker with real-time performance and sufficient accuracy, which enables satellite navigation with more timely attitude determination or considerable decrease in power.
The remainder of this paper is structured as follows. Section 2 provides an overview of related works. Section 3 describes the system pipeline and the considered centroiding algorithms, while the proposed hardware designs are explained in Sect. 4. Their evaluation is included in Sect. 5 and the final conclusions are stated in Sect. 6.
2 Related work
Prior works aiming to meet distinct throughput requirements for real-time attitude determination either propose new algorithms or accelerate existing ones on hardware platforms.
Zhu et al. [36] propose a method that stores valid star pixel data in a cross-linked list, enabling clustering by processing the list structure instead of scanning the image twice. This approach achieves \(10\times\) faster processing compared to conventional Region-Growing algorithms. The clustering algorithm of [11] utilizes block adaptive threshold segmentation and intensity gradients to reduce image noise and achieve real-time high anti-interference performance. Efforts to enable real-time centroiding while retaining the top accuracy of the Gaussian Fitting (GF) algorithm are made in [6, 30] with the proposals of the Gaussian Grid (GC) and Gaussian Analytic (GA) algorithms. The GC method provides an acceleration of almost 2 orders of magnitude, but it suffers from accuracy loss. GA is as accurate as the 1D GF and as fast as CG, but it is sensitive to noise. The very noise-robust FGF [29] is one of the most promising fitting algorithms for real-time applications, as it is \(15\times\) faster than GF without compromising accuracy. Overall, these works show commonly used algorithms, such as clustering and CG [21], as well as the novel FGF that we trade-off in our study.
Regarding hardware implementations, Zhou et al. [35] propose a two-step algorithm that detects clusters through zero crossings, enabling high noise robustness, and accelerate it by \(23\times\) on a SoC FPGA. In the same context, an FPGA-based implementation of GF is proposed in [12], while the work of [33] proposes a fully custom end-to-end star tracker on FPGA, achieving an update rate of 10Hz. Marcelino et al. [23] propose a method that uses an IIR filter to perform centroiding, which is accelerated by \(3.5\times\) when an FPGA is deployed for high-speed image transmission and thresholding. In [2], the proposed ASIC-based hardware architecture performs centroid detection with one image scan, delivering an acceleration of up to \(57.5\times\). The clustering is based on a connected component labeling method and deploys tables that are updated concurrently with the image scan, while CG is used for centroiding. Inspired by this work, Wang et al. [31] propose an one-scan method that adopts a dynamic rooted tree architecture to reduce clustering’s resource cost and make feasible its implementation on FPGAs. The one-scan FPGA architecture proposed in [9] is also based on a label combination algorithm, but it adopts a local thresholding method that increases noise robustness. The FPGA-based architecture of [5] employs a neural network for star identification, providing significant update rates. Finally, the FPGA-based clustering of [13] performs filtering and adaptive thresholding based on local gradients.
3 Proposed system design and algorithmic pipeline
3.1 System overview and specifications
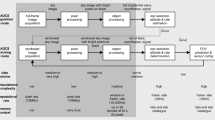
Our system utilizes a state-of-the-art star tracker configuration [23, 33], comprising a high-resolution CMOS camera sensor with custom lens and a AMD/Xilinx Zynq-7020 SoC FPGA for signal processing, i.e., star detection and attitude determination. For the PS–PL communication, we rely on the AXI-4 stream protocol [1] to transfer one pixel per clock cycle. The proposed architecture, which relies on a common high-level algorithmic structure [23, 33], is shown in Fig. 1 and discussed in the following subsections.

The proposed star tracker’s processing pipeline in a SoC FPGA (PL + PS)
The high-speed sensor–lens specifications are as follows:
-
Field of view: 15.5° \(\times\) 15.5°
-
Image resolution: 2048 \(\times\) 2048 pixels
-
Pixel depth: 12 bits
The target specifications of the star tracker are:
-
Update rate: minimum 1–2 FPS, but targeting 1 order of magnitude higher FPS to support also high-speed and precision-pointing applications (demanding control loops)
-
Mean accuracy error: \(<3\) arcseconds across boresight
Given the sensor’s attributes, the boresight accuracy specification translates into sub-pixel typical accuracy of 0.1 pixels. However, according to our analysis by using pseudo-measurements as input, the maximum accepted centroiding error is defined as 0.25 pixels. This is due to the fact that the matching algorithm takes into account both the relative distance of calculated centroids and the position information obtained from previous frames during tracking mode.
In general, star trackers are focused at infinity, such that they have a circle of confusion. Our own system’s circle of confusion is designed to be 3 pixels: a point light source will be projected on the sensor as an airy disc 3 pixels in diameter. The intensity of the airy disc follows a point spread function that depends on the lens architecture with the highest intensity at the center of the disc. Increasing the defocusing effect aids the centroid estimation but reduces the incident power on each pixel and therefore, reduces the number of stars detected. Hereafter, we consider clusters of 3\(\times\)3 and 5\(\times\)5 pixels to account for the additional opto-mechanical uncertainty added by the thermo-vacuum effects in orbit.
3.1.1 Processing flow
By intentionally defocusing the camera lens, stars in captured night sky images are blurred and generate the aforementioned 3\(\times\)3 bright region, which enables the estimation of the star’s center with sub-pixel accuracy [21]. Toward accurate star detection, the images undergo preprocessing involving two key steps: pixel binning and clustering [8, 14]. Binning generates one pixel from regions of neighboring pixels to reduce the image resolution, while clustering identifies neighboring pixels corresponding to stars by thresholding their intensity and grouping them together to form clusters. Subsequently, the centroiding algorithm is applied in these clusters to determine their centers on the image plane, called centroids. On a per-image basis, the set of centroids is forwarded to the matching task, where the set of extracted points is matched to known catalog star positions to derive the satellite’s orientation in the inertial space.
3.1.2 HW–SW partitioning
The matching task of the Star Identification involves pattern recognition algorithms [27] operating on low-dimensional vectors, which have relatively limited computational demands. Owing to sophisticated algorithms such as Pyramid [24], the preprocessing and centroiding parts of star tracking, which define the Star Detection phase, represent >95% of the total complexity. In the Lost-In-Space (LIS) scenario, these tasks handle a substantial number of pixels and account for the vast majority of the total computation. Preprocessing involves accessing entire frames, while centroiding processes multiple clusters. To ensure real-time operation, we accelerate these tasks on the PL of the SoC FPGA, which is directly connected to the camera sensor through a high-speed streaming protocol [1], while matching is executed on the PS to facilitate the exploration of SW-based optimizations.
3.2 Centroiding algorithms
For this task, we study two distinct algorithms: a simple/traditional, namely Center of Gravity (CG) [21], and a more advanced technique, namely Fast Gaussian Fitting (FGF) [29]. To the best of our knowledge, the current work introduces the first acceleration of FGF on HW. In general, notation-wise, each pixel of a cluster is given the index i and corresponds to the intensity value \(I_i\), while (\(x_i\), \(y_i\)) are its coordinates in the image plane. Similarly, the cluster’s estimated centroid is denoted as (\(x_c\), \(y_c\)).
The fastest and less complex approach to the centroiding problem is the use of the Center of Gravity (CG) algorithm [21], which is described in Equation (1).
where the sum is computed over all pixels i of the cluster. The accuracy of this method is limited by its high sensitivity to background noise [28] and the S-curve error that is induced due to undersampling [32].
The second algorithm is the Fast Gaussian Fitting (FGF) [29]. Given that the formation of a cluster is modeled by a point spread function, fitting methods approximate this function as a 2D Gaussian distribution and estimate its parameters. Although the standard GF algorithm is expected to give the most accurate results [28, 29], it requires solving a nonlinear least squares problem, resulting in a high computational load and hence, it is unaffordable for real-time applications. On the contrary, it has been proven that if a cluster consists of pixels with high enough SNR (a requirement that can be met with appropriate preprocessing), FGF can approximate the original solution in a closed-form without iterations and without loss in accuracy.
The FGF algorithm requires solving an Ordinary Least Squares problem, i.e., the following linear system of 5 equations in 5 unknown parameters.
The unknown parameters m, n, p, q, k are defined as follows.
where \(\textbf{v}=(A, x_c, y_c, \sigma _x, \sigma _y)\) are the desired Gaussian parameters, from which only \(x_c\), \(y_c\) are required. The terms \(am_i\), \(an_i\), \(ap_i\), \(aq_i\), \(ak_i\), \(a_i\) are calculated for each pixel using its coordinates and intensity as shown below.
To solve efficiently the problem, we adopt the Cholesky Decomposition method, which transforms the initial problem \(A\textbf{x}=\textbf{b}\) into two simpler problems.
where L is the lower triangular matrix derived by the Cholesky method. Once the parameter vector \(\textbf{x}=[m,\,n,\,p,\,q,\,k]^{\top }\) is found, the centroids are derived as:
3.3 Proposed customizations at algorithmic level
To fully exploit the benefits of the FPGA, we propose the following two customizations. At first, we aim to decrease the bit-widths of the circuit signals. More specifically, to calculate the CG centroids of Equation (1), we use the pixels’ relative coordinates, i.e., the distance of \(x_i\), \(y_i\) from the upper left pixel, and then we add the clusters’ absolute coordinates, i.e., the first pixel’s coordinates (X, Y). In this way, we use relative centroids and the datapaths require fewer bits in their hardware implementation. The same technique is applied in Equation (2), which calculates the FGF centroids.
Second, we exploit the fact that the FGF method [29] demonstrates the same accuracy as GF, only if the involved pixels have high enough SNR. Therefore, FGF is performed twice, once for SNR estimation and once for centroid detection. Given that such a feedback-based method is less suitable for high-throughput implementations and that the use of two distinct FGF hardware kernels would be costly in terms of resources, we adopt a custom architectural approach. Our design bases on a single pass for FGF and opts to skip the SNR estimation step. we adopt a custom architectural approach. Our design bases on a single pass for FGF and opts to skip the SNR estimation step. Our SW-level evaluation of both approaches shows that the application’s requirement for cross-boresight error of less than 3 arcseconds is met, due to the fact that the detector noise floor is relatively low for detected cluster and our custom preprocessing kernel, which is able to provide highly bright clusters with pixels of high SNR and, therefore, removes the need for the SNR estimation step. Thus, we propose a hardware-friendly system that detects centroids by performing the FGF algorithm on entire clusters only once.
4 Proposed hardware architecture
Being the focus of this paper, the current section analyzes our architecture for the Star Detection phase, i.e., it discusses various implementation and HW optimization aspects for the preprocessing and centroiding tasks, which we accelerate on the PL side of the SoC FPGA. We employ Vivado Design Suite v2023.1 for the HDL development and Vitis HLS v2023.1 for the HLS/C++ development.
4.1 Preprocessing: Binning
The block diagram of our Binning kernel is illustrated in Fig. 2. It is customized to compute the mean value of pixels within \(N \times N\) regions (\(N=2^n\), \(n\ge 1\)). It comprises a serial-to-parallel component to handle the pixels that are received serially in raster-scan order and create the pixel regions. The first \(N-1\) image rows are temporarily stored in FIFO buffers, which are directly connected to a series of D flip-flops where the pixels of the \(N \times N\) region are gathered. In turn, there is the mean calculation component. This component integrates an adder tree with a structure of \(\log _2(N^2)\) levels of full adders, as well as a divider (shifter) that calculates the mean pixel value via the arithmetic shift operation.

Block design of the Binning hardware kernel
4.2 Preprocessing: Clustering
Our Clustering kernel is based on the widely used Region-Growing method [8]. Initially, each pixel’s value is compared to a predefined threshold, and if it exceeds this threshold, a Region of Interest (RoI) is determined. The cluster identification then focuses on this RoI, where adjacent pixels are compared to a slightly lower growing threshold. Once pixels that meet some predefined rules are grouped together to form a cluster, the centroiding task can be executed.
The Clustering algorithm is customized to enable hardware-friendly computations, addressing challenges arising from its recursive nature and restrictive data type and structures. To ensure real-time operation and high performance, and considering that we cannot store the entire image in the PL memory, we partition and transfer it into stripes (pixel tiles with an overlap of M image rows).
Targeting increased adaptability in our star tracker to satisfy various mission requirements, our Clustering kernel dynamically adjusts the threshold based on the SNR ratio. In situations where invalid light sources affect the field of view, the growing threshold is experimentally determined, taking into account the noise levels in the image. In our design, this value is configured using the AXI4-Lite protocol to directly receive data from the PS without requiring a handshake.

Block design of the Clustering hardware kernel
The design of our Clustering kernel is illustrated in Fig. 3. The upThresLoc module performs streamlined thresholding on the binned pixels, and if their value exceeds the upper threshold, it generates their coordinates for storage in the mainStack. These identified pixels are referred as starting pixels and serve as the center of a square RoI. The mainStack consists of three stacks: two for the i and j coordinates of the pixel in the image, and one for its position in the \(3 \times 3\) grid. The overlapping image stripes are stored in a RAM that is used as cyclic buffer. A virtual pointer is employed to indicate the base address of each stripe, allowing pixels to be defined by their virtual coordinates in the image plane. The fsm4RAM module converts these coordinates to the corresponding RAM address and controls the memory units’ read/write operations.
The main component of Clustering is the neighChecker, which is responsible for identifying clusters. To be considered part of a cluster, a pixel must meet certain conditions and have its adjacent pixels examined. These conditions include being inside the RoI, having a value above the growing threshold, and not causing redundant latency during examination. Cases of redundant latency occur when the pixel is located at the window corners or it has already been examined. neighChecker also monitors the positional movement while searching within the RoI and tracks the outer edges of the identified cluster to compute its dimensions.
The aceMap component is a Boolean array that marks each pixel on the image plane as examined or not. The compStack component is a complementary set of stacks that store starting pixels that cannot define a RoI when the lower boundary exceeds the window row. In such cases, it is assumed that the cluster will be detected more accurately within the next sliding window. The mainFSM serves as a central unit that controls the operations of the individual components.
4.3 Interface: preprocessing–centroiding
As both Clustering and Centroiding are implemented on PL, we perform their communication through a single FIFO buffer, with the clustering pixels being streamed one-by-one. For each cluster, a set of auxiliary data packages is transferred before the pixel intensities. The first package, labeled as N, indicates the size of the incoming cluster (e.g., for a \(5 \times 5\) cluster, we set \(N = 5\)). Afterward, the cluster’s absolute coordinates (X, Y) are serially provided, and then the pixel intensities are streamed. Immediately after the reception of the last pixel, the transfer of the next cluster starts. Among the streamed information, the pixel intensities require the most bits (12) and, therefore, the bit-widths of the streaming channel and the respective ports are configured to 12. In our HLS implementation, we model this behavior with the AXI4-Stream port-level I/O protocol, in which input and output data ports are extended to 2-byte wide.
4.4 Centroiding: center of gravity
We develop our CG-based centroiding system with both VHDL and HLS, targeting to perform rapid design space exploration, as well as to extract the most efficient solution. The block diagram of the CG kernel is illustrated in Fig. 4.
4.4.1 Input block
This block is responsible for calculating the numerators and denominator of the CG formula given in Equation (1). The Control Unit (CU) controls the other components and the data flow between them and it is implemented as an FSM whose transitions depend solely on the input signals and an internal counter. Based on the N package, it calculates internally the relative coordinates and it provides them to the Multiplication–Accumulation (MAC) and Accumulation (ACC) components, together with the respective intensities. Given that clusters have a maximum size of \(5 \times 5\), 3 bits are required for the representation of the relative coordinates. The low-level HDL implementation of CU enables the system to sustain high throughput, as a new cluster can be received and processed immediately after the previous one. In the HLS design, the CU is not explicitly described, as the control logic is automatically inferred by the compiler.

Block design of the CG hardware kernel
In turn, the MAC and ACC components calculate the cluster’s numerators and denominator, respectively. Considering the maximum number of pixels per cluster (25), the numerator and denominator signals need to be 20 and 17 bits wide, respectively. For efficient computations, these modules are mapped to DSP cores by using the use_dsp48 attribute.
In HLS, the Input Block is modeled by a single perfectly nested hierarchy of two loops which contains three simple instructions. Each loop corresponds to one dimension and the loop limits are defined by the N package. Although the compiler automatically maps MACs to DSPs, it is not possible to allocate a DSP for the ACC, which is implemented using LUTs. This indicates that the HLS tool may limit the designer’s “access” to lower levels of the design. We enable parallel execution of the loop’s iteration using the Pipeline directive to improve the overall throughput and latency. In this way, an Initiation Interval (II) of 1 is achieved, which allows processing one pixel per clock cycle.
Overall, the HDL kernel processes new clusters every \(N^2+3\) cycles and provides valid results with a latency of \(N^2+4\) cycles. The HLS variant shows increased throughput and latency by 3 and 1 cycles, respectively, due to the fact that the design is treated as black box. Namely, the more abstract circuit description generates an Input Block that can receive new data only after it has completed the processing of the previous ones.
4.4.2 Divider block
We adopt the hardware-friendly fixed-point format to efficiently handle the fractional numbers within the circuit. The minimum number of fractional bits that satisfies the accuracy constraint of 0.1 pixels is \(F = 4\) as \(2^{-4}=0.0625<0.1\).
We use the AMD/Xilinx LogiCORE IP Divider Generator to implement a high-performance division component for the calculation of the relative centroids. Due to the demand for a quotient with fractional remainder and after exploring the available division architectures we adopt the Radix-2-based IP core, which is implemented only with FPGA logic cells. This core adheres to the AXI4-Stream protocol and, therefore, all payload ports are byte-extended and data are transferred with a handshake mechanism.
We implement a single division core that calculates both \(x_c\), \(y_c\) relative centroids. As the expected latency of the Clustering kernel is at least 70 cycles, we are allowed to choose the slowest throughput specification offered, and thus, we perform one division per 8 cycles. In this way, the core asserts the “ready” signal every 8 cycles and if both handshake signals are simultaneously asserted, a transfer occurs and the input data are read. The divider core generates a valid output with a latency of 27 cycles.
Considering that for each cluster two simultaneously produced data are serially processed by the divider, a FIFO for in-order buffering and retrieval is required. To maximize performance we use the AMD/Xilinx LogiCORE IP FIFO Generator core and adopt the IP Native Interface FIFO configuration with First-Word Fall-Through operation mode. As a result, the data are read one cycle after enabling the read signal, which is driven by the divider’s ready port. Additionally, to perform the parallel-to-serial conversion, we deploy one non-symmetric FIFO for storing both numerators concatenated and one for storing two duplicates of the denominator. Data are written in these FIFOs when the CU enables the write signal that determines when the valid denominator and numerators are available.
Depending on the rate at which clusters are provided, the FIFO IP core can be accordingly configured in terms of storage depth. For our application, a read depth of 32 and a write depth of 16 are sufficient, as the FIFOs are not expected to be full at any moment. As the Divider Block’s latency is not constant due to buffering, we estimate that the worst case latency, given the expected preprocessing rate, is 45 cycles.
In HLS, the deployment of a single division core is only possible if both division instructions are placed in the same loop. This loop is pipelined and the HLS compiler infers a LUT-based divider with a throughput of one input per cycle and a latency of 28 cycles. Compared to the numerous configuration options of the respective HDL IP, HLS does not allow any customizations on this core regarding throughput. Its latency is larger than that of the HDL variant by 1 cycle.
4.4.3 Output block
This block receives the relative centroids from the divider and the respective absolute coordinates from CU and yields the cluster’s location on the image plane. Given that the reduced image plane has a size of \(1024 \times 1024\) pixels, the divider’s 24-bit quotient is internally truncated and only the 14 LSBs (10 integer and 4 fractional bits) are retained. Considering also that the x, y centroids are serially calculated for each cluster, a single 14-bit output port is designed. Similarly to the Divider Block, we use the smallest non-symmetric buffer structure to store the absolute coordinates, provided in advance by the CU, and retrieve them one-by-one when valid quotients are available. In total, the Output Block contributes 1 cycle to the total latency.
In HLS, we use the Dataflow directive to enable the parallel execution of the C++ sub-functions by establishing a completely data driven handshake interface that consists of five FIFO channels. This synchronization combined with the use of the loop rewind directive in the Output Function makes the overall throughput limited only by the slowest task, i.e., the Input Function. Dataflow removes the need for explicitly defining the intermediate FIFOs; however, it results in a great increase in hardware resources. Data are always consumed one cycle after their production, allowing the use of the smallest available 2-slot FIFOs.
4.5 Centroiding: fast Gaussian fitting
Considering the high complexity of the FGF algorithm, we implement it on HW with HLS, to leverage its benefits of fast development and verification. The proposed architecture is illustrated in Fig. 5.
Given the vast amount of real number operations in the FGF algorithm, we adopt the floating-point arithmetic format. In this way, we achieve processing of both small (i.e., relative centroids) and large (i.e., matrix A elements) numbers without accuracy loss. Our single-precision floating-point HW kernel calculates only the relative centroids, while the addition for getting the absolute centroids is assigned to PS with double floating-point format. The reason is to avoid significant accuracy loss, as the absolute centroids are typically three orders of magnitude larger than the relative ones.
4.5.1 Input function
In a pipelined nested loop hierarchy, we calculate the lower triangular part of the symmetric coefficient matrix A and the constant vector \(\textbf{b}\) of the linear problem \(A\textbf{x}=\textbf{b}\) presented in Equation (2). Regarding the size of matrix A, we consider the worst case of having a full-bright \(5 \times 5\) cluster of 12-bit pixels, of that is all pixels have an intensity of \(2^{12}-1=4095\). We note that if accurate statistics regarding the clusters are available, the bit-widths can be further reduced via fine tuning. Hence, considering clusters \(\textbf{x}_i = [0,1,2,3,4]\), where \(\textbf{x}_i\) is a generalized notation for the \(x_i\), \(y_i\) relative coordinates, we summarize in Table 1 the bit-widths of the internal signals corresponding to the elements of matrix A.

Block design of the FGF hardware kernel
In HLS, we observe that the sequence of multiplications for the calculation of the terms to be summed affects the generated circuit. For example, the product \(I_i^2x_i\) (in coefficient \(a_{53}\)) can be calculated either as \(I_i^2\cdot x_i\) or \((I_ix_i)\cdot I_i\); however, the respective C++ instructions lead to different resource allocations. Through extensive testing we found that mapping these multiplications to DSP cores is vital to improve performance. The DSP utilization requires to define integer operands of appropriate bit-width in the HLS tool. For example, if an operand is narrower than 10 bits and the other one is wider, a complex structure that involves multiple LUTs and leads to long critical paths is generated. We observe that the way that the intermediate terms (partial products) are calculated is also critical for performance. For example, if the coefficient \(a_{11}\) is defined as \(I_i^2\cdot x_i^4\), although a DSP would be utilized, a long logic chain will be created for the calculation of the \(x^4=x^2x^2\) term. To achieve better frequency, we perform an exhaustive space exploration on how to perform the multiplications, and the outcomes are summarized in Table 2. For the same purpose, the intermediate term \(I_i\textbf{x}_i^2\) is calculated as \((I_i\textbf{x}_i)\textbf{x}_i\) and is implemented using only logic cells, like the other simple intermediate term \(I_i\textbf{x}_i\).
The floating-point operations in the calculation of the constant vector \(\textbf{b}\) require casting integer terms to floats, which is performed by the Conversion Block, implemented with logic cells. The logarithm, multiplication and subtraction require 13, 3 and 2 DSPs, respectively, and thus, one fully pipelined floating-point core is implemented for each operation. These floating-point cores are the critical modules regarding the function’s performance and resource utilization, as the loop’s latency and throughput are determined by them and they contribute more than half of the total logic cells utilized for the Input Function.
4.5.2 Cholesky function
This function decomposes the coefficient matrix A. Extensive analysis showed that all the Cholesky architectures provided by the HLS Linear Algebra Library model iterative algorithms with loop hierarchies and non-pipelined behavior. Such a design choice would lead to low performance. To achieve a lower II, we use the Pipeline directive in a given Cholesky function, and hence, we dissolve the loop hierarchy and create an unrolled data pipeline that allows the operations to be performed in an overlapping manner. This choice comes at the expense of resource overhead, as it requires approximately 1000 additional DFFs.
The pipeline is limited by the inherent dependencies of the Cholesky algorithm. More specifically, each diagonal element depends on the element of the same row and previous column and each element below depends on the diagonal one. This is derived from the equations presented below.
To improve the performance, we parallelize the calculation of the diagonal element and the elements below using the HLS dedicated FP reciprocal square root function frsqrt. For example, once \(\mathbf {l_{21}}\) is calculated, instead of calculating \(\mathbf {l_{22}}\) and \(\mathbf {l_{32}}=\frac{\dots }{\mathbf {l_{22}}}\) sequentially, we can calculate \(\mathbf {l_{32}}\) in parallel as \(\mathbf {l_{32}}=(a_{32}-l_{21}l_{31})\,\,\text {frsqrt }(a_{22}-\mathbf {l_{21}}^2)=\frac{a_{32}-l_{21}l_{31}}{\sqrt{a_{22}-\mathbf {l_{21}}^2}}\). In this way, we shorten the chain of dependencies and achieve a total gain in latency of approximately 140 cycles.
4.5.3 Output function
This function solves the decomposed system of Equation (5), whose first three operations are shown below.
As each parameter \(y_i\), \(x_i\) is used in the numerator of \(y_{i+1}\), \(x_{i+1}\), a dependency chain that determines the function’s latency emerges. Given that the floating-point cores are fully pipelined, the rest of the partial products are calculated in parallel and, ultimately, Equation (6) is used to estimate the relative centroids. To reduce the function’s latency, we define \(x_c = (-0.5\,x_3)\cdot \frac{1}{x_1}\), which ensures that the \((-0.5\,x_3)\) product will be available before the calculation of \(x_1\), and, thus, the final division can start immediately after. With the use of the Dataflow directive and by setting the Initiation Intervals of the other functions equal to that of the Input Function, and as a result, the system’s throughput is determined by the Input Function’s speed. Furthermore, toward easier variable handling and further performance gains, all the C++ arrays A, \(\textbf{b}\), L are implemented as sets of registers instead of BRAMs using the Array Partition directive.
5 Evaluation
To fine-tune and evaluate our HW/SW system, we utilize both real and synthetic star images. First, we present the analysis of the preprocessing and centroiding parts, separately. We include comparisons to CPU implementations for accuracy and performance/speed, as well as FPGA results for resource utilization and maximum operation frequency. Second, we discuss the performance of the combined pipeline (preprocessing & centroiding) to show the capabilities of our proof-of-concept architecture.
5.1 Experimental setup
Our target SoC FPGA is AMD/Xilinx Zynq-7020 (hosted on ZedBoard). This device is considered as a rather common COTS device for space. We use the AMD/Xilinx XSDK to create applications for Zynq’s dual-core ARM Cortex-A9 processor and establish the PS-PL communication. Moreover, we use SW on ARM to accommodate performance and accuracy evaluation of our SW & HW implementations.
5.1.1 Real and synthetic datasets
We test the preprocessing stage with grayscale images of resolution up to \(2048 \times 2048\) pixels. We utilize an unbiased dataset from a NASA repository [25], which includes the complete record of raw images captured by the Cassini spacecraft during the mission (from 20/2/2004 to 15/9/2017). These images contain an average of 100 to 300 star clusters.
To evaluate the centroiding component, we created a two-dimensional symmetric Gaussian distribution in MATLAB to generate synthetic star clusters. To study the software–hardware differences for each centroiding algorithm and focus more on the hardware implementation, we employ a single set of Gaussian parameters suitable for both the CG and FGF algorithms. In total, we use three datasets of 10K samples containing \(3 \times 3\) or \(5 \times 5\) or both \(3 \times 3\) & \(5 \times 5\) clusters.
The clusters’ centroids are expected to be located near the center, which ensures that all pixels have sufficient intensity. For each \(N \times N\) cluster originating at \((x_o,\!y_o)\) and centered at \((x_c,\!y_c)\), we have \(0.25N<x_c-x_o<0.75N\), and \(0.25N<y_c-y_o<0.75N\). Due to the threshold of preprocessing, we get relatively bright clusters at centroiding. We observed that the amplitude, A, does not affect the results considerably and we assume \(A\) \(\in\) \((0.1, 1)\). The 2D standard deviation modeling the spread of the star spot is set to \(\sigma _x\)=\(\sigma _y\) =1.25 (depends on lens configuration). We avoided including extra noise and excluding saturated pixels from our dataset (as in [29]), because we are mostly interested in evaluating HW performance rather than original algorithmic accuracy.
5.2 Preprocessing
The preprocessing system achieves a clock frequency of 232 MHz at the PL side. However, due to the slower DMA engine of the Zynq SoC, the integrated block design fails to actually meet this frequency. Therefore, data transmission without errors is achieved for 12-bit 2048\(\times\)2048 frames at 167MHz. Table 3 reports the performance results for evaluating our preprocessing system. The average total processing time at 167MHz, including the latency of the PS-PL loopback, is approximately 26ms. This implies a speed-up of \(13\times\) versus the Zynq’s ARM Cortex-A9 CPU. The speed-up is estimated to reach up to \(18\times\) when approaching 214MHz or 232MHz operating frequencies (max. reported for our implementations). When integrating Binning and Clustering, we execute them in a pipelined fashion with image stripes directly driven to Clustering to start the thresholding process. Therefore, the total processing time for preprocessing (Binning & Clustering) an input image is 26ms.
Table 4 provides an overview of the FPGA’s resource utilization. It is noteworthy that Vivado employs automatic optimization, placement, and routing techniques to enhance the netlist’s resources. As a result, the preprocessing exhibits slightly higher resource utilization compared to the clustering component, which is regarded as the more complex of the two sub-components. Ultimately, it utilizes <10\(\%\) of the total chip’s resources for every FPGA primitive.
5.3 Centroiding
5.3.1 Accuracy
We evaluate the accuracy of our custom centroiding components on FPGA by measuring the Euclidean distance between the centroids on HW \((x_h, y_h)\) and SW \((x_s, y_s)\), that is \(e = \sqrt{(x_h-x_s)^2+(y_h-y_s)^2}\). In Table 5, we present the mean centroiding error of the CG and FGF algorithms, considering the respective software models as baseline. According to the results, all our implementations satisfy the error constraints discussed in Sect. 3.1. Apparently, the floating-point arithmetic used in the FGF kernel provides considerable advantage with negligible SW–HW differences, achieving real error of \(10^{-3}\) pixels. The CG error is increased due to the use of the fixed-point division with 4 fractional bits; however, it is still lower than 0.1 pixels (system’s error requirement). For extreme cases or peculiar real-data clusters, a more fine-grained selection of fractional bits can be performed based on new statistical information to ensure that even the worst case error is accepted (inherent + HW errors).
5.3.2 Performance
Table 6 reports the HW performance-related metrics of our FPGA kernels for square clusters of \(N^2\) pixels. The latency of HDL-CG is estimated based on the premise that new clusters are provided approximately every 70 cycles, meaning that a few initialization cycles are required to store data on the previously empty FIFOs. The corresponding HLS model has lower latency due to the Dataflow directive, which automatically constructs the communication channels, as well as due to the faster divider core processing one sample per cycle. However, the HDL kernel offers better throughput, as the low-level RTL implementation enables more accurate description of circuits. We also observe that the HLS model is not able to achieve the operation frequency of the HDL kernel. The design reports show that the critical path is located within the automatically inferred division core, which explains that the performance is limited by the HLS tool.
The FGF implementation is considerably slower, due to its significantly higher complexity. The design’s throughput is limited by the floating-point cores, while their combination with the inherent data dependencies results in increased latency. The critical path is located within a floating-point subtraction core and consists of net delay at around 82%.
Table 7 shows that CG is faster than FGF regardless of the used platform and that the CG HDL model is slightly faster than the CG HLS one. In total, compared to the Zynq’s ARM Cortex-A9 CPU the CG algorithm is accelerated by 43\(\times\) and 30\(\times\) by using HDL and HLS respectively, as the execution times on the CPU are relatively low, due to the algorithm’s simplicity. The FGF algorithm is executed approximately 32 times faster on the FPGA, as its acceleration is limited by its inherent complexity. Nevertheless, the capability of processing 1 million clusters per second, combined with the almost-software accuracy makes the FGF implementation ideal for real-time applications.
5.3.3 Resource utilization
As shown in Table 8, each algorithm’s complexity reflects directly on its resources. Interestingly, HLS-CG requires more FPGA primitives compared to its HDL counterpart (possibly due to the use of BRAMs instead of shift registers LUT for the FIFOs). Overall, we observed that HLS did not match the balanced resource utilization of HDL design, which was only achieved at the expense of development effort. As expected, the FGF implementation requires significantly more resources, most of which are used for computations on input data, making the routing delay the critical path’s primary factor. We conclude here that HLS offers significant benefits when implementing highly complex kernels; however, its advantages diminish in mid-complexity designs due to HLS’s resources & path overhead (e.g., cf. Table 8) and VHDL’s manageable development time.
5.4 Integrated star tracking pipeline
5.4.1 System performance
By adopting the FGF implementation due to its accuracy superiority, we integrate our HW–SW components on Zynq-7020 and measure sufficient speed and accuracy to meet the requirements summarized in Sect. 3.1. For reference, the all-SW execution on ARM shows that the integrated chain consumes 365ms per frame on average, with preprocessing and centroiding consuming >95% of this time (also tested on RISC-V of Microsemi PolarFire SoC and consume 97%). Notably, the preprocessing accounts for the vast majority, 344ms, whereas centroiding is only 6ms. The remaining 15ms are attributed to the subsequent processing steps of the star tracker’s pipeline. For the HW–SW co-processing system, we measure \(\sim\)41ms per frame, i.e., we achieve 8.9\(\times\) acceleration at system level. More specifically, in our current mission scenario, assuming uniform star distribution on images, the proposed FGF system provides a window’s first centroid approximately 0.5ms after the beginning of pixel streaming, and following centroids of the same window are provided with an interval of 1µs. On average, a 12-bit 2048\(\times\)2048 frame with 200 stars is processed with 24.4 FPS throughput (\(\sim\)100 MPixels per second). Most of the time consumed by image transferring and on-the-fly Binning. The performance bottleneck comes from the DMA in PS-PL communication operating now at only 167MHz. If more throughput is required, the IP’s can operate at their aforementioned higher frequencies and PS-PL communication optimization can be achieved, e.g., by doubling the AXI ports/bits in Zynq.
5.4.2 Literature comparison
Table 9 summarizes the key features of the proposed architecture and the most prominent FPGA-based star detection works. Our system demonstrates the highest processing speed and the use of the FGF algorithm leads to the lowest centroiding error, that is 0.001 pixels with respect to ground truth values when no noise is added. Our design integrates the binning operation into preprocessing, and thus enables processing larger images of higher resolution and, consequently, more information, without reducing execution speed. Indicatively, our system demonstrates a throughput of 1.9 Gbit/s when frames containing 200 stars are processed. Previous works had been evaluated with images of fewer stars and of higher magnitude. When tuned to receive similar images, the proposed system prevails in terms of processing time. However, we note that some works show excellent results in specialized tasks, such as moon elimination from the FOV [13]. Although the end-to-end star tracker in [33] achieves similar overall execution time (41ms), this design uses an optimized matching algorithm and its actual image transfer and star detection require 15ms more than the proposed one. Moreover, our model was developed with parametric HDL and HLS coding, which facilitates its reuse in systems of different specifications (e.g., image or star size). Similarly, by construction, it can process frames containing stars of different sizes, that is of different magnitudes. On the contrary, [36] and [12] can only process clusters of 5\(\times\)5 and 3\(\times\)3 pixels, respectively. Overall, the proposed architecture demonstrates superior performance and star detection accuracy compared to literature, which come at the cost of higher resource utilization due to the complexity of the FGF algorithm and the use of floating-point arithmetic.
6 Conclusion
The current work presented the optimization of a star tracking algorithm on a COTS SoC FPGA, i.e., AMD/Xilinx Zynq-7020, targeting space missions with HW components of relatively lower cost but considerable flight heritage. At higher-level, the work adopted a custom sensor+FPGA system with certain mission requirements. At lower-level, the work focused on the PL acceleration of the image processing parts of the algorithmic chain, i.e., pixel thresholding, cluster growth, and centroiding. The control-oriented operations were kept on PS side to facilitate easier adaptation to mission/system details/updates. The proposed partitioning led us to accelerate >95% of the star tracking computations with factors ranging in 13–43\(\times\) depending on function and configuration. Our development based on various circuit techniques (pipelining, word-length optimization, resource reuse, parallelization), HW–SW co-design, implementation of distinct programming approaches (HLS vs HDL) and algorithms (CG vs FGF for centroiding), PS–PL co-processing over AXI communication, and parametric code to fine-tune the system after HW/SW integration. In total, we achieved 8.9\(\times\) acceleration at system level and met the real-time requirements; our star tracker processes more than 24 FPS of 12-bit 2048\(\times\)2048 pixels, with accuracy approx. 10\(^{-3}\) pixels on image plane, per star position, which leads us to attitude estimation improvement of 2 arcseconds across boresight.
References
ARM Developer: AMBA AXI-Stream Protocol Specification (2023)
Azizabadi, M., Behrad, A., Ghaznavi-Ghoushchi, M.B.: VLSI implementation of star detection and centroid calculation algorithms for star tracking applications. J. Real-Time Image Proc 9(1), 127–140 (2014)
Bodin, P., Noteborn, R., Larsson, R., Karlsson, T., D’Amico, S., Ardaens, J.S., Delpech, M., Berges, J.C.: The prisma formation flying demonstrator: Overview and conclusions from the nominal mission. Adv. Astronaut. Sci. 144(2012), 441–460 (2012)
Bruhn, F.C., Tsog, N., Kunkel, F., Flordal, O., Troxel, I.: Enabling Radiation Tolerant Heterogeneous GPU-based Onboard Data Processing in Space. CEAS Space J. 12, 551–564 (2020)
Carmeli, G., Ben-Moshe, B.: Ai-based real-time star tracker. MDPI Electronics 12(9) (2023)
Delabie, T., Schutter, J.D., Vandenbussche, B.K.: An Accurate and Efficient Gaussian Fit Centroiding Algorithm for Star Trackers. J. Astronaut. Sci. 61, 60–84 (2013)
Eisenman, A.R., Liebe, C.C., Joergensen, J.L.: New Generation of Autonomous Star Trackers. Sensors, Syst, Next-Gen Satellites 3221, 524–535 (1997)
Erlank, A.O.: Development of CubeStar: A CubeSat-Compatible Star Tracker. Stellenbosch Univ (2013)
Fan, Y., Xiao, H., Cao, W., Zuo, L., Chen, S.: Fpga implementation of real-time star centroid extraction algorithm. In: 2019 IEEE 2nd International Conference on Information Communication and Signal Processing (ICICSP), pp 395–399 (2019)
Gaias, G., Ardaens, J.S.: In-Orbit Experience and Lessons Learned from the AVANTI Experiment. Elsevier Acta Astronautica 153, 383–393 (2018)
He, Y., Wang, H., Feng, L., You, S., Lu, J., Jiang, W.: Centroid extraction algorithm based on grey-gradient for autonomous star sensor. Optik 194, 162932 (2019)
Jiang, H., Fan, X.: Centroid locating for star image object by fpga. Adv Mat Res 403–408, 1379–1383 (2011)
Jiang, J., Chen, K.: Fpga-based accurate star segmentation with moon interference. J. Real-Time Image Proc. 16(4), 1289–1299 (2019)
Jin, X., Hirakawa, K.: Analysis and processing of pixel binning for color image sensor. EURASIP Journal on Advances in Signal Processing 2012(125) (2012)
Lentaris, G., Maragos, K., Stratakos, I., Papadopoulos, L., Papanikolaou, O., Soudris, D., Lourakis, M., Zabulis, X., Gonzalez-Arjona, D., Furano, G.: High-performance embedded computing in space: Evaluation of platforms for vision-based navigation. J. Aerospace Inform Syst 15(4), 178–192 (2018)
Leon, V., Bezaitis, C., Lentaris, G., Soudris, D., Reisis, D., Papatheofanous, E.A., Kyriakos, A., Dunne, A., Samuelsson, A., Steenari, D.: FPGA & VPU Co-Processing in Space Applications: Development and Testing with DSP/AI Benchmarks. In: IEEE Int’l Conference on Electronics, Circuits, and Systems (ICECS), pp 1–5 (2021a)
Leon, V., Lentaris, G., Petrongonas, E., Soudris, D., Furano, G., Tavoularis, A., Moloney, D.: Improving Performance-Power-Programmability in Space Avionics with Edge Devices: VBN on Myriad2 SoC. ACM Trans Embedded Comput Syst 20(3), 1–23 (2021)
Leon, V., Stamoulias, I., Lentaris, G., Soudris, D., Domingo, R., Verdugo, M., Gonzalez-Arjona, D., Codinachs, D.M., Conway, I.: Systematic Evaluation of the European NG-LARGE FPGA & EDA Tools for On-Board Processing. In: European Workshop on On-Board Data Processing (OBDP), pp 1–8 (2021c)
Leon, V., Stamoulias, I., Lentaris, G., Soudris, D., Gonzalez-Arjona, D., Domingo, R., Codinachs, D.M., Conway, I.: Development and Testing on the European Space-Grade BRAVE FPGAs: Evaluation of NG-Large Using High-Performance DSP Benchmarks. IEEE Access 9, 131877–131892 (2021)
Leon, V., Lentaris, G., Soudris, D., Vellas, S., Bernou, M.: Towards Employing FPGA and ASIP Acceleration to Enable Onboard AI/ML in Space Applications. In: IFIP/IEEE International Conference on Very Large Scale Integration (VLSI-SoC), pp 1–4 (2022)
Liebe, C.: Accuracy Performance of Star Trackers - A Tutorial. IEEE Trans. Aerosp. Electron. Syst. 38(2), 587–599 (2002)
Maragos, K., Leon, V., Lentaris, G., Soudris, D., Gonzalez-Arjona, D., Domingo, R., Pastor., A, Codinachs, D.M., Conway, I.: Evaluation Methodology and Reconfiguration Tests on the New European NG-MEDIUM FPGA. In: NASA/ESA Conference on Adaptive Hardware and Systems (AHS), pp 127–134 (2018)
Marcelino, G., Schulz, V., Seman, L., Bezerra, E.: Centroid determination hardware algorithm for star trackers. International Journal of Sensor Networks 32 (2020)
Mortari, D., Samaan, M.A., Bruccoleri, C., Junkins, J.L.: The Pyramid Star Identification Technique. Annual Navig. 51(3), 171–183 (2004)
NASA-Solar System Exploration ((accessed March 2023)) Cassini Raw Images. URL https://solarsystem.nasa.gov/raw-images/cassini-raw-images/?order=earth_date+desc &per_page=50 &page=0
Pérez, A., Rodríguez, A., Otero, A., González-Arjona, D., Jiménez-Peralo, A., Verdugo, M.A., De La Torre, E.: Run-Time Reconfigurable MPSoC-Based On-Board Processor for Vision-Based Space Navigation. IEEE Access 8, 59891–59905 (2020)
Spratling, B., Mortari, D.: A survey on star identification algorithms. Algorithms 2 (2009)
Stone, R.C.: A comparison of digital centering algorithms. Astron. J. 97, 1227 (1989)
Wan, X., Wang, G., Wei, X., Li, J., Zhang, G.: Star Centroiding Based on Fast Gaussian Fitting for Star Sensors. MDPI Sensors 18, 2836 (2018)
Wang, H., Xu, E., Li, Z., Jingjin, L., Qin, T.: Gaussian analytic centroiding method of star image of star tracker. Advances in Space Research 56 (2015a)
Wang, X., Wei, X., Fan, Q., Li, J., Wang, G.: HW implementation of fast & robust star centroid extraction with low resource cost. IEEE Sensors J 15(9), 4857–4865 (2015)
Wei, X., Xu, J., Li, J., Yan, J., Zhang, G.: S-curve centroiding error correction for star sensor. Acta Astronaut. 99, 231–241 (2014)
von Wielligh, C.L.: Fast star tracker hardware implementation and algorithm optimisations on a system-on-a-chip device. Master’s thesis, Stellenbosch Univ (2019)
Wilson, C., George, A.: CSP Hybrid Space Computing. J. Aerospace Informa Syst. 15(4), 215–227 (2018)
Zhou, F., Zhao, J., Ye, T., Chen, L.: Fast star centroid extraction algorithm with sub-pixel accuracy based on fpga. J. Real-Time Image Proc. 12(3), 613–622 (2016)
Zhu, X., Wu, F., Xu, Q.: A Fast Star Image Extraction Algorithm for Autonomous Star Sensors. Optoelectronic Imag. Multimedia Tech II 8558, 443–451 (2012)
Funding
Open access funding provided by HEAL-Link Greece.
Author information
Authors and Affiliations
Contributions
V.P. and E.P. performed the SW & HW development, conducted the experimental analysis, and wrote the main manuscript text. V.L. managed the technical details, guided the development, and participated in the manuscript writing. D.S. organized the team and supervised the work. E.K. contributed to the system requirements analysis. G.L. supervised the work, guided the development and experimental evaluation, and provided technical clarifications. All the authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Panousopoulos, V., Papaloukas, E., Leon, V. et al. HW/SW co-design on embedded SoC FPGA for star tracking optimization in space applications. J Real-Time Image Proc 21, 16 (2024). https://doi.org/10.1007/s11554-023-01391-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11554-023-01391-8