
Abstract
Facial expression recognition (FER) is utilized in various fields that analyze facial expressions. FER is attracting increasing attention for its role in improving the convenience in human life. It is widely applied in human–computer interaction tasks. However, recently, FER tasks have encountered certain data and training issues. To address these issues in FER, few-shot learning (FSL) has been researched as a new approach. In this paper, we focus on analyzing FER techniques based on FSL and consider the computational complexity and processing time in these models. FSL has been researched as it can solve the problems of training with few datasets and generalizing in a wild-environmental condition. Based on our analysis, we describe certain existing challenges in the use of FSL in FER systems and suggest research directions to resolve these issues. FER using FSL can be time efficient and reduce the complexity in many other real-time processing tasks and is an important area for further research.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Facial expression is the most important factor for recognizing the emotions of a person. Whitehill et al. [1] proved that the human face is the most adaptive tool to judge engagement. Facial expression recognition (FER) has been widely researched in the field of human psychology [2]. FER has various applications such as human–computer intelligence interaction, e-learning systems, marketing, stress analysis, and different types of interactive services. Such services should be able to guarantee status updation in real time. Therefore, FER in real-time processing is a significant task in the computer vision field.
Meanwhile, convolutional neural network (CNN) model-based FER has attracted attention with the exploitation of large-scale datasets for deep learning. Several survey papers have presented the history of the development of FER techniques [3, 4]. Moreover, Deshmukh et al. [5] also surveyed real-time FER techniques. However, no survey papers are available on FER using few-shot learning (FSL) technology, as FSL is another learning strategy. This technique can address the current issues in deep learning.
In this paper, we discuss the recent FER systems using FSL, which can also solve the existing problems in FER. This work is organized as follows. In Sect. 2, we introduce various datasets used in FER tasks. Section 3 presents the general definitions in the fields of FER and FSL. With the provided information, we introduce certain current issues in FER and organize them according to the types of data and methods. Section 4 reviews FER using FSL, which is the primary section of this paper. In Sect. 5, we discuss the performance of each model by calculating the model parameters and time complexity. Section 6 presents a discussion and future work of FER with FSL. The last section concludes this review paper. The uniqueness of this work lies in the following aspects:
-
This is the first review paper on FER using FSL.
-
We provide a thorough review of the recent deep learning models on FER focusing on its issues by categorizing them into types of data problems and methods.
-
We investigate FER using FSL by comparing two different scenarios: generalization on novel data and domain adaptation.
-
We present the possibility that FER with FSL can be time efficient and reduce complexity in several real-time image processing tasks.
2 FER datasets used in FSL
Several facial expression datasets are available in the FER field. However, we introduce only a few datasets, particularly those that are applied for FER using FSL.
Acquiring the maximum possible data is a significant issue in deep learning-based FER. This is because facial images vary significantly based on age, sex, and race. Datasets can be classified as in-the-lab and in-the-wild datasets. An in-the-lab dataset usually provides clean and high-quality data [6] as well as fine-structured and careful annotations from emotions based on the Facial Action Code [7], which is system designed in a controlled environment. Conversely, an in-the-wild dataset usually contains spontaneous facial expressions that are captured in various environmental conditions [8].
FER datasets can be split into image- and video-based datasets. A video-based dataset includes sequences of emotions; consequently, more information can be collected when compared to an image containing one emotion.
With the commencement of the Emotion Recognition in the Wild Challenge (EmotiW) [9, 10], numerous unconstrained face images can currently be obtained from the Internet. However, FER tasks that are developed in a controlled environment degrade in terms of performance in the real world where spontaneous and sequence images exist. Consequently, deep learning-based models have been studied to exploit real-world datasets.
In this section, we discuss various datasets used in FSL-based FER tasks. The FER 2013 (FER2013) dataset [11], FER+ [12], AffectNet [8], and Real-world Affective Faces Database (RAF-DB) [13] provide images with six basic emotions (anger, disgust, fear, happiness, sadness, and surprise) with a neutral emotion; in contrast, the extended Cohn–Kanade (CK+) [6] provides seven basic emotions (anger, contempt, disgust, fear, happiness, sadness, and surprise). Moreover, FSL usually deals with the domain shift generalization problem, and most experiments involve training on datasets with basic emotions and testing of data with compound emotions. Therefore, we also discuss the RAF-DB and Compound Facial Expressions of Emotion (CFEE) dataset [14], which provide several compound emotions such as sadly surprised and fearfully angry. As shown in Fig. 1, datasets can be classified based on basic emotions, compound emotions, in-the-lab conditions, and in-the-wild conditions.
2.1 In-the-lab datasets
2.1.1 CK+ [6]
The CK+ database contains 593 sequences across 123 subjects with seven basic emotions, including the contempt emotion. Each sequence contains images from neutral to peak expression. It is the most widely used lab-controlled dataset for evaluating FER systems.
2.1.2 CFEE [14]
The CFEE dataset contains 21 distinct emotion categories. Compound emotions are composed of more than two basic component categories to create new ones such as happily surprised and angrily surprised. Images were collected from 230 humans and were analyzed based on the Facial Action Coding System. The production process of these 21 categories is different but consistent with the subordinate categories they represent (e.g., a happily surprised expression combines muscle movements observed in happiness and surprised emotions).

Distribution of facial expression datasets
2.2 In-the-wild datasets—image
2.2.1 FER2013 [11]
FER2013 is a large-scale database that was collected and preprocessed by the Google image search application programming interface and OpenCV [15] face recognition program. Face images were cropped from collected images using OpenCV, and human labelers removed the incorrectly labeled images. All images were resized to 48 \(\times\) 48 pixels and converted to gray scale. FER2013 contains 35,887 images with 6 basic expression labels and 1 neutral emotion label. Specifically, these images are divided into three groups (28,709 training images, 3589 validation images, and 3589 test images) for evaluation.
2.2.2 FER+ [12]
FER+ is improved from the original FER dataset by providing a set of new labels for standard emotions. FER+ also provides higher-quality ground truth for still image emotions as each image were labeled by 10 crowdsourced taggers. With 10 taggers for each image, researchers can estimate the probability distribution of an emotion for each face. In particular, this dataset can be used to construct algorithms that produce statistical distributions or multi-label outputs instead of the traditional single-label output.
2.2.3 EmotioNet [16]
EmotioNet is a large-scale database with 1 million facial expression images. The images in EmotioNet were collected from the Internet using an automatic action unit (AU) detection model, of which 950,000 images were annotated. However, 25,000 images could not be annotated with the AUs; therefore, they were manually annotated using 11 AUs.
2.2.4 AffectNet [8]
AffectNet contains more than 1,000,000 facial images and facial landmark points, which were obtained from the Internet by querying three major search engines using 1250 emotion-related keywords in six different languages. Of the retrieved images, 450,000 images were manually annotated for 8 basic expressions. AffectNet is the largest database that provides facial expressions in two different emotion models (categorical and dimensional models)
2.2.5 RAF-DB [13]
The RAF-DB is a real-world database providing both common expression perception and compound emotions in unconstrained environments. It is the first large-scale database that contains 29,672 significantly diverse facial images that were downloaded from the Internet. For evaluation, 12,271 training and 3068 testing samples are grouped in one basic emotion set from the total of 15,339 images.
2.3 In-the-wild datasets—video
2.3.1 AFEW [17]
Acted Facial Expression in the Wild (AFEW) is a video database collected from various movies, containing natural expressions, illuminations, occlusions, and head poses. Unlike controlled-condition emotion datasets, AFEW is sufficient for investigating the problem of FER analysis in a challenging environment condition. It contains 957 videos labeled with six basic expressions and the neutral expression.
3 Facial expression recognition: few-shot learnings
We introduce the specific definitions of FER and FSL in Sect. 3.1 Subsequently, we discuss certain issues of FER tasks in Sect. 3.2 In Sects. 3.2.1 and 3.2.2, we organize the various issues related to deep learning-based FER based on the data and methods to determine the increase in the contributions of FER using FSL.
3.1 Problem definition
As FER is a recognition task in the computer vision field, we describe the significance of FER and its applications in the field of human–computer interaction (HCI). As FSL is a branch of machine learning, a brief comparison between machine learning and the FSL strategy is provided.
3.1.1 FER
Facial expression is a basis of communication in human interactions [18] and is the most powerful, natural, and universal signal to understand human emotion [19, 20]. The usage of FER is prevalent in various fields, especially in HCI systems such as feedback for e-learning enhancement, driver fatigue surveillance, and robotics. Therefore, FER systems have been deeply explored in the field of computer vision and machine learning. The availability of large-scale datasets makes automatic facial expression analysis possible and these FER systems have been applied in various applications. According to Tian et al. [21], facial expressions are universal irrespective of the culture, and they can be classified into six basic emotions: anger, disgust, fear, happiness, sadness, and surprise. In addition, a neutral emotion was added and a total of seven emotion labels are used for classification tasks. Contempt was subsequently added as a basic emotion [22]. Although six basic emotions were dominant [23] in the FER field, studies have also been conducted on compound expression recognition with an idea that human emotional state consists of several emotions, and cannot be justified as just six basic emotions [24,25,26,27,28].
The three main modules in an FER system are as follows: face detection, feature extraction, and classification. Face detectors such as multi- task cascaded CNN (MTCNN) [29], Dlib [30], Retinaface [31], and frame attention network (FAN) [32] have been used to detect faces and align them from images. Then, facial expression features are captured using a feature extractor and these features are classified into specific categories via a well-designed classifier. Traditionally, texture in the image and shape of face played significant roles in FER. In previous works, histogram of oriented gradients [33], Gabor wavelet [34], local binary pattern (LBP) [35], local ternary pattern [36], and nonnegative matrix factorization [37] were used. Generally, these methods have been experimented on using lab-controlled datasets such as CK+, MMI [38], Oulu-CASIA [39], CFEE [14], and other constrained datasets [40, 41]. Features extracted via those algorithms were classified using support vector machine (SVM) [42], adaptive boosting [43], and other classification models. Especially, the combination of LBP, which extracts fine features regardless of overall brightness of the image, and SVM, which shows high classification performance from the extracted features, has been widely researched.
With the commencement of the EmotiW challenge, large-scale facial datasets can be obtained from the Internet, such as RAF-DB, AffectNet, and EmotioNet. With the degradation of training performance in large-scale unconstrained datasets and the advantage of CNNs [44], which can extract deeper and obtain more spatial inductive biases information, CNN-based models have been employed in FER tasks. Other approaches such as network ensemble, cascade network, and generative adversarial network (GAN)-based models have also been widely researched in FER tasks.
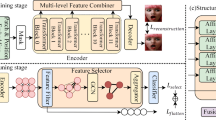
As shown in Fig. 2, recent FER processes have three stages: pre-processing, feature learning, and classification. In the pre-processing stage, face alignment, data augmentation, and normalization are proposed. However, depending on its necessity, certain models use alignment and augmentation without normalization. In the feature learning stage, various deep learning-based models such as CNN, deep CNN, and recurrent neural network have been used to extract effective features without losing prior information. The final step in FER is the classification of extracted features into an emotion category. However, in recent works, separation of feature extraction and feature classification in the pipeline has achieved end-to-end learning, from pre-processing to classification through deep networks. In addition, a loss function is added in the final stage to regularize learning.
Despite the promising results in the use of these models for FER tasks, still, limitations exist. Recent deep learning-based models have been designed for large-scale datasets such as ImageNet [45]. However, when compared to ImageNet (approximately 1.2 million images), RAF-DB (approximately 30 thousand images) and AffectNet (approximately 450 thousand images) result in overfitting problems. Consequently, although images are trained well, the accuracy of the algorithm declines for test images. Unfortunately, owing to privacy issues, obtaining facial expression images is difficult. One way to solve this issue is using pre-trained models that are trained on ImageNet or other large-scale datasets. Images in ImageNet are coarse-grained images, which includes several categories, such as dogs, cats, people, and objects. Conversely, facial expression images are fine-grained images. The examples of fine-grained images also include species of dogs and flowers. However, fine-grained images (facial expression images) have smaller variance than coarse-grained images (ImageNet); consequently, using pre-trained models may not be appropriate. Therefore, available datasets must be utilized and FSL can play a key role in overcoming this issue.

General pipeline of a facial expression recognition task
3.1.2 FSL
With the availability of large-scale resources and datasets (e.g., ImageNet dataset) and significant improvements in CNN-based models such as residual network (ResNet) [46] and long short-term memory network [47], which have reduced information loss, machine learning has shown significant and continuous improvement. However, despite these active studies on machine learning, certain unsolved issues exist. That is, when training is performed with only a few samples, the efficiency of the model reduces continuously and it converges rapidly. To alleviate problems using high-dimension data, deep learning models are becoming more complex.
Initial approaches for FSL are based on [48, 49]. Inspired by human learning [50], the idea of learning one example of a category for an inference on other examples of the same category has been researched by Fei-Fei et al. [48]. Prior knowledge helps a model when facing a new example under a new category [48, 51, 52]. Prior knowledge usually utilizes learned information. On the other hand, Fink [49] focused on the similarity between classes. Training a single example results in an overfitting problem because of the high-dimensional data. However, by reducing the within-class distance and increasing the neighbor class distances, classification schemes can achieve successful learning using only one example. Thus, it is possible to learn a few data efficiently.
The idea of constructing an algorithm that generalizes using only a few sample data is FSL. Various studies on FSL or its concept have been published after [49, 52] and the term “n-shot k-way learning” has been widely used for defining several learning strategies based on FSL [53,54,55].
One aim of FSL is achieving the best learning efficiency from less data. According to [56], FSL is defined as follows: a type of machine learning where a limited number of examples act as supervised information for the target. FSL has been researched in various fields such as computer vision, robotics, and natural language processing (NLP).
In the field of computer vision, only few datasets such as Omniglot [57] and miniImageNet [58] have been provided. The existing FSL models have achieved sufficiently high accuracy on these benchmark datasets. Moreover, FSL has been successfully used in various tasks in the computer vision field, such as image generation [59, 60], few-shot object detection [61,62,63], object tracking [64], few-shot image classification [65,66,67]), few-shot semantic segmentation [68,69,70], image retrieval [71], motion prediction [72], video classification [73], and 3D object reconstruction [74]. Moreover, research has progressed using the strategy of training in the robotics field in a manner similar to the human recognition process. To learn generalization from a few samples, FSL reinforcement learning has been primarily studied. FSL for NLP has also been studied for several tasks including text classification [75, 76], parsing [77], and translation [78]. Moreover, the release of a new benchmark dataset for FSL task in NLP, called few-shot relation classification dataset [79], has resulted in further improvements.
As FSL application is disseminated in various fields of machine learning tasks, its specific usage can be defined based on problems and solutions for specific scenarios. Three scenarios of FSL were defined by Wang et al. [56], which are subsequently elaborated.
-
1.
Scenario 1: simulating the process of human learning In this case, inspired by humans, for the learning, generation, classification, and detection of samples of novel data, pre-learned knowledge and relations are set as prior knowledge.
-
2.
Scenario 2: learning for rare cases In this case, similar data works as prior knowledge when training with insufficient examples.
-
3.
Scenario 3: alleviating the data gathering issue and computational cost In this case, a few labeled images for each class of the target and raw images of other classes or pre-trained models are set as prior knowledge.
FSL can also be defined by the number of datasets. Basically FSL is also known as n-way k-shot learning. Here, “n” denotes the number of classes (or categories) that the model will classify and “k” is the number of samples for each class. Therefore, training on an example of the data is called one-shot learning [48], and classification of unseen data without training examples is called zero-shot learning [80].
Since the FSL approach varies for different fields, it has been enhanced to provide solutions for each issue. FSL performance has been enhanced with data augmentation and improvement of the model and algorithm. Particularly, owing to the small amount of samples used for training, overfitting and generalization problems are big issues of FSL. Moreover, the use of prior knowledge is a key solution for addressing FSL issues. Three challenging aspects are observed when enhancing FSL using prior knowledge: data, model, and algorithm.
Unlike the perfect annotation with training data in supervised learning, augmentation of few samples is required to obtain prior knowledge from neighbor data to annotate weakly labeled or unlabeled dataset. Labeling methods [81,82,83] have been processed for weakly labeled and unlabeled datasets. Another labeling method that used similar datasets [84,85,86] was also proposed.
Refined models to enhance FSL are classified as follows: multi-task [87] and embedding learning methods. Multi-task learning is an approach involving inductive transfer to improve generalization using the domain information contained in the training signals of related tasks as an inductive bias. Multi-task learning for FSL [88, 89] was developed by sharing and tying parameters to create a smaller hypothesis space, which enhances its accuracy. Motiian et al. and Hu et al. [88, 90] researched multi-tasking with FSL and used the parameter tying method for regularization by comparing parameters from each training batch set for penalization [91, 92].
Conversely, embedding learning reduces the dimension, translating to a smaller hypothesis space that requires only a few training samples. It also learns from prior knowledge and obtains extra information from the training data [93,94,95,96]. Recently, a task-invariant embedding model, which uses a similarity metric to compare distances between the embedding of a training batch and a test sample was proposed. Using prototypical [55], matching [97], and relation networks [67], FSL has achieved a significant step forward; these three networks have been mainly used in FER tasks with FSL. A hybrid embedding model, which alleviates the problems that arise when applied to new tasks, learned from prior knowledge based on the task-specific information in the training dataset [98,99,100,101]. Moreover, in [54, 102], extra memory was used to train the model.
From the perspective of the algorithm, research on altering the search strategy based on prior knowledge has been studied. Therefore, regularizing by fine-tuning parameters, aggregating sets of parameters, and fine-tuning existing parameters with new parameters were proposed for refinement. Furthermore, the refining of meta-learned parameters or a learning optimizer was studied [103, 104] to determine the parameter that achieves the best hypothesis.
3.2 FER issues
To alleviate the limitation of the current FER research, as mentioned in Sect. 3.1.1, various methods have been proposed. In this paper, we review the recent FER research that show state-of-the-art performance in addressing the existing problems of facial expression datasets and the current methods for FER. As a CNN-based model extracts effective features from both in-the-lab and in-the-wild datasets, it has been widely used for FER tasks. However, deep learning does not always achieve the best performance for the FER problem. Therefore, in this section, we discuss various issues of deep learning-based FER pertaining to both data and method to understand why FSL is employed for FER. The FER issues related to the different datasets and methods are listed in Tables 1 and 2, respectively.
3.2.1 Data
In this section, we focus on various issues in each facial dataset. We review the different data-related issues and the studies that have addressed each problem. Facial expression datasets, particularly in-the-wild datasets include challenges from factors such as noise, occlusion, and differences in age and pose. Therefore, we discuss recent works dealing with the facial data problem and enhancement in FER tasks.
-
1.
FER+
As FER+ is an in-the-wild dataset, studies have focused on class imbalance, tiny variations in expressions, and noises in images that must be refined. Li et al. [105] focused on the following in-the-wild dataset issues: class imbalance and minor differences in muscle movements in the facial area. To address the class imbalance, they proposed adaptive re-weighting of feature differences. Minor differences exist in muscle movements; for example, anger and sadness, have similar muscle movements, which degrade learning accuracy. To solve this problem, the authors trained the model separately with coarse-grain and fine-grain features and used transfer learning to learn the similarities between the classes using cross-entropy. Conversely, Siqueira et al. [106] also determined that imbalanced label distribution with vast variations in intra-class features, rotations, and occlusions affected performance. However, with ensemble method, they could handle the problem and create a flexible and robust model. The model also showed fine prediction accuracy on an in-the-wild test dataset that was not used for training.
-
2.
RAF-DB
Several studies [107, 112, 113] focused on issues such as noise, occlusion, and pose variations in the RAF-DB. Facial expression images with noises usually exhibit large variances in the latent embedding spaces, which cause incorrect recognition [114]. Moreover, removing the subjectivity of the annotator and ambiguity of the facial expression is difficult, causing data uncertainty, which limits the improvement of FER performance [115]. In [107], relative uncertainty learning (RUL) was proposed to show robust performance on noisy data. RUL learns uncertainty through the relativity of two different samples using the uncertainties from input images as weights to mix two features of different labels. This method not only achieved a robust performance, but also training efficiency. Conversely, Wang et al. [112] determined that CNN methods often deteriorate significantly in occlusion and pose-variant environments, which are important factors in FER. While the direct application of CNN on an entire facial image ignores the features of occlusion and variant pose, inspired by [116], the authors proposed a region-based deep attention architecture for pose- and occlusion-robust FER that integrated visual evidence from small regions and entire faces. As facial images include fine-grain facial features, the input face image was cropped into random regions and re-scaled to the size of the original image to focus on a specific facial region.
-
3.
AffectNet
Vo et al. [109] analyzed both RAF-DB and AffectNet dataset and determined that the original input image size varies. The experimental result indicates that CNNs are sensitive to input image size while training. Focusing on this problem, they [109] proposed a pyramid with super-resolution network with several branches. Each of the branches worked on one level of the input scale. During training, the original images were resized and a super-resolution method was applied to up-scale low-resolution images.
-
4.
AFEW
An approach using the AFEW dataset in [110] identified its limitations that restricted the capability of generalization in deep learning models. Therefore, the network was trained with an additional dataset (Body Language Dataset [117]) with semi-supervised learning to overcome these limitations. Furthermore, to address the darkness of images in the AFEW dataset, they also used EnlightenGAN [118] to correct the illumination in the pre-processing stage. As AFEW is a video dataset, several pre-processing stages are required to extract frames from videos, which are input to CNN-based models. However, as the frames exhibit a spectrum of moving facial images, the importance of each frames varies. To define the weights of important frames, Meng et al. [111] proposed a FAN. With this mechanism, they attempted to maximize the advantages of using a video dataset.
3.2.2 Methods
As CNN-based models can extract deeper and obtain more information on spatial inductive biases, CNN-based models on FER tasks have been widely researched. As its utility has been proven, CNN-based learning and other strategies have been proposed including ensemble learning, uncertainty learning, and augmentation strategy. In this section, we discuss various methods used in FER tasks while highlighting the problem of the existing CNN-based FER.
-
Augmentation strategy
Focusing on the in-the-wild large-scale datasets, which often tend to overfit in deep neural networks, Psaroudakis and Kollias [113] proposed a new data augmentation strategy called MixAugment based on the Mixup [119] data augmentation technique. By increasing the diversity of available data by applying constrained transformations on the original data, the method achieved state-of-the-art performance. The MixAugment process can be briefly explained as follows: two different facial expressions with different head poses are mixed up to create a synthesized virtual image that is trained along with the original image. Figure 3 shows a sample operation of this technique.
-
Ensemble learning
Ensemble learning is a learning mechanism that helps in the development of existing deep learning-based FER. Ensemble learning is a learning strategy that combines multiple classifiers to provide the possibility of higher accuracy results than a single classifier [120]. However, ensemble networks exhibit high computational cost and redundancy while training; to address these issues, ensemble with shared representations (ESR) [106] was proposed. ESR comprises various networks for learning, where low- and mid-level feature learning is performed in the convolution layers. These informative features that are learned are shared with independent convolutional branches that constitute the ensemble.
-
Attention Mechanism
Attention mechanisms have been widely used in FER tasks. One issue of the attention mechanism for FER is that the model focuses on facial features without understanding facial expression images globally [124]. To address this problem, attention mechanisms or attention networks were proposed to capture the most relevant regions for identifying the facial expression and obtain significant information learned from facial images [112, 121,122,123]. Specifically, Wang et al. [112] proposed a novel region attention network to accurately capture the important facial regions for occlusion- and pose-robust FER. However, attention mechanisms usually use either a low-level feature extraction method or only one identical attention mechanism, which cannot easily achieve the best accuracy in CNN-based FER models. To solve this problem, Huang et al. [124] proposed a combination of two stages: low-level feature learning and high semantic representation stages. In the low-level feature learning stage, grid-wise attention could gather long-range dependencies among different regions in a facial image. In another approach [110], a three-level attention mechanism, which included spatial, channel, and frame attention mechanisms, was proposed to focus on each part of the face that is important for understanding human emotion. Spatial self-attention has been used in [130, 131] and even for FER tasks [125] as an instruction for feature extraction. Furthermore, this mechanism can identify significant local image features. To extract the different effects of facial expressions from upper and lower facial regions, Zeng et al. [126] used a combination of spatial self-attention and channel-attention mechanisms. In this model, group-based convolution architecture was employed to independently process the computation. First, spatial attention was focused on images of each facial part (lip and eye) and one-dimensional features from four residual blocks were concatenated to form one feature vector. This feature vector contains fine information of facial regions. For the feature vectors of each image, channel attention was used and an average feature was produced, which represented the attention feature of one frame. Further, the frame attention was used in the last stage of this mechanism. To alleviate the difficulty in learning from frames, Meng et al. [111] proposed a FAN to automatically highlight discriminative frames while learning. Using self-attention for each frame, relation attention is calculated by concurrently considering the features for each frame and global representation from self-attention weights. With this additional attention process, FAN obviously and aggressively emphasized significant features.
-
Loss function
Fard and Mahoor [128] introduced an Adaptive Correlation (Ad-Corre) loss to improve the discriminative power of the deep embedded feature vectors. As facial expressions have similar variations, the Ad-Corre loss alleviates this problem by ensuring a high correlation for intra-class vectors and low correlation for inter-class vectors during training using three different components: feature discriminator (FD), mean discriminator (MD), and embedding discriminator (ED). The correlation between two d-dimensional random variables X and Y is formulated as shown below. \({\bar{x}}\) and \({\bar{y}}\) are the mean of the X and Y vectors, respectively.
$$\begin{aligned} COR(X, Y ) = \frac{\sum ^{d}_{k=1} \left( X_{k} - {\hat{x}}\right) \left( Y_{k} - {\hat{y}}\right) }{\sqrt{\left( \sum ^{d}_{k=1} X_{k} - {\hat{x}}\right) \left( \sum ^{d}_{k=1} Y_{k} - {\hat{y}}\right) }}. \end{aligned}$$(1)Based on the above correlation equation, the final Ad-Corre loss is determined by combining the independently calculated losses from the aforementioned three different discriminators, that is, the losses of FD, MD, and ED. The equation is as shown as follows:
$$\begin{aligned} \textrm{Loss}_\mathrm{Ad-Corre}= \textrm{CE} + \lambda \left( \textrm{Loss}_\textrm{FD} +\textrm{Loss}_\textrm{MD} +\textrm{Loss}_\textrm{ED}\right) . \end{aligned}$$(2)Another approach to achieve robust optimization of the FER network is proposed in [127]:
$$\begin{aligned} L_{\theta } (X, y) = - log\left( W_{y} * softmax(z_{y}(X;\theta ))\right) . \end{aligned}$$(3)In Eq. (3), \(\theta\) indicates the weight vector of a neural network, X indicates the training image, y is its emotional label, \(z_y (X; \theta )\) is the y-th output of the penultimate (logits) layer of the CNN with input X, and softmax denotes the softmax activation function. Moreover, the proposed optimization task to incorporate robust data mining is formulated as follows:
$$\begin{aligned} \textrm{min}_{\theta } L_{\theta + \epsilon {\hat{\nabla }} L_{\theta }} (X, y). \end{aligned}$$(4) -
Other approaches
Recently, certain studies have been proposed to solve the uncertainty learning problem in the FER field [114, 115, 129]. Specifically, Wang et al. [115] designed attention weights that were extracted from each image for determining the cross-entropy loss to alleviate the adverse effects of noisy samples. In [132], the authors proposed the utilization of several branches to model the latent label distribution of facial expression images. To capture uncertain images, they used cosine similarity. Although the progress in uncertainty learning could be observed, degradation of the uncertainty learning branch still remained. To solve this problem, Zhang et al. [107] proposed learning uncertainty from the relative difficulty in learning two examples. Equation (5) shows an element-wise normalization of the uncertainty vectors to compare two features with each other. \({\hat{\sigma }}_{i}\) and \({\hat{\sigma }}_{j}\) are the uncertainty vectors for image i and its counterpart image j, which is sampled from the shuffled indexes, respectively; notably, they have different labels. This regulates the problem of learning uncertainty values, and also benefits the training process as extreme uncertainty values might destabilize the process or even result in a loss that cannot converge.
$$\begin{aligned} {\hat{\sigma }}_{i},{\hat{\sigma }}_{j} = \frac{\sigma _{i}}{\sigma _{i} + \sigma _{j}}, \frac{\sigma _{j}}{\sigma _{i} + \sigma _{j}}. \end{aligned}$$(5)Equation (6) shows the total loss function, which was designed to boost the uncertainty learning branch to learn different uncertainty values for different facial images, where \(y_i\), \(y_j\) denote \(label_i\), \(label_j\), respectively, \(W_c\) is the c-th classifier, and C indicates the total number of expression classes. When i is difficult to learn, j can be easily recognized. When j is difficult to learn, a large amount of the mixed feature \({\hat{\mu }}\) is required to ensure that the model can identify a useful feature for a small classification loss with label \(y_j\):
$$\begin{aligned} L_\textrm{total} = - \frac{1}{N}\sum ^{N}_{i,j}\left( \textrm{log} { \frac{e^{{W}_{{y}_{i}} {\hat{\mu }} } }{\sum ^{C}_{c}e^{{W}_{c}{\hat{\mu }} } } } + \textrm{log} { \frac{e^{{W}_{{y}_{j}}{\hat{\mu }}} }{\sum ^{C}_{c}e^{{W}_{c}{\hat{\mu }}}} }\right) . \end{aligned}$$(6)

Examples of Mixup technique
4 FER with FSL
As the solutions to FER problems aligned with FSL scenarios, Wang et al. and Psaroudakis and Dimitrios [56, 113] proposed that generalization on few datasets is required in future FER tasks. Therefore, the FSL technique can be reasonably applied for FER tasks.
In this section, we discuss an overview of FER systems using FSL with respect to generalization on novel data and domain adaptation. In a facial expression dataset, the data scarcity and sample numbers vary depending on the categories. Moreover, the domain shift problem for compound expression recognition tasks still remains [133].
FSL for FER has been implemented to reduce the inter-class distance and increase the intra-class distance to solve the existing problem. Therefore, as shown in Fig. 4, n-way k-shot episodic learning is usually implemented in FER tasks. The metric-based FSL learns a distance function to determine which class is closest to the query set (target).

Example of few-shot episodic learning
4.1 Generalization on novel data
Early FER tasks using FSL generally focused on two techniques: training with few examples and generalizing on a new dataset. Before the appearance of facial datasets that can be obtained from the Internet, early FER tasks generally suffered from the problem of less number of examples. Therefore, utilizing as few examples as possible for training and achieving reasonable performance were the main issues [134]. Another approach on generalization on new faces was studied. One problem is that there are insufficient examples of a specific person to model his or her emotion. To summarize, people have different faces with different expressions; satisfactorily generalizing faces is difficult if the model encounters a new face that has not been previously trained. This study also indicated the problem of insufficient examples. To address these issues, Cruz et al. [135] proposed a model that matches a face video to references of emotion without requiring fine registration. They [135] proposed one-shot emotion scores that can determine the similarity of a region-of-interest (ROI) of a given face to the reference of an emotion. The two primary score that are computed are as follows: one is to determine how similar the target (a query facial ROI) is to a reference of a characteristically expressed emotion, and the other is to determine how similar the target is to background emotions. With this approach, classification performance in inter-dataset experiments was improved over that of a baseline system, which was obtained by testing a different dataset that was not used in training.
Shome and Tejaswini [136] suggested a research that focused on the generalization problem to deploy a system in a real-world environment. They [136] proposed few-shot federated learning for FER (FedAffect), thus tackling the problem of generalization on unseen data. FedAffect is a novel federated learning framework that simultaneously trains two disjoint neural networks. The first neural network performs self-supervised representation learning from large-scale unlabeled facial images. The other one exploits the representation learner as a feature extractor. This enables the prediction of probability scores of the extracted features for robust FER in the FSL setting.
Zhu et al. [137] insisted that the poor performance in FER was due to class imbalance and great intra-class variation in facial datasets. Certain emotion categories including fear, disgust, and anger cannot meet the training needs of deep learning models owing to their scarcity when compared to other basic emotions such as surprise, happiness, and sadness. Inspired by [138], they considered the emotion classes with sufficient training samples as the training set, and the emotion classes with limited samples as the testing set. To address the problem of intra-class variation, they proposed a convolutional relation network (CRN) that included emotion similarity learning with salient discriminative feature learning. The complete architecture is shown in Fig. 5. The implementation setting is similar to that of k-shot n-way learning, where support and query sets are exploited as input for the relation network. Then, the feature extracted from the relation network is calculated with depth attention pooling and Jensen-Shannon (JS) divergence. The depth attention pooling and query vectors are concatenated, and then multiplied with the relation score. With this architecture, the intra-class distance is reduced and the inter-class distance is penalized.

Convolutional relation network architecture
4.2 Domain adaptation
Ciubotaru et al. [139] explored the generalization ability of few-shot classification algorithms in recognizing unseen categories with limited training examples. Various experiments were conducted on cross-domain shifts including large- and narrow-domain shifts, which opened the possibility that FSL can aid in cross-domain shift for FER tasks. Starting from a previous review study [139], several approaches for generalizing domain shift problem in FER have been studied, particularly related to compound emotion recognition.
Zou et al. [140] proposed emotion-guided similarity network (EGS-Net) for the recognition of compound emotions. EGS-Net consists of two branches: the emotion branch extracts features from all input images and similarity branch computes similarity between the support and query sets. During the training phase, the EGS-Net is progressively trained using a two-stage learning framework. In stage 1, joint learning of the two branches is performed in a multi-task fashion. In stage 2, alternate learning between the two branches is performed. During the testing phase, the performance was evaluated on a compound expression dataset based on the learned similarity branch. The joint learning prevents the model from overfitting to highly overlapped sampled base classes. Finally, the alternate learning stage can further improve the inference ability of the model for generalizing to the unseen task.
Although Zou et al. [140] used basic emotion datasets for training for compound expression recognition, Dai and Feng [133] used compound emotion datasets for both training and testing by proposing cross-domain FSL for micro-expression recognition. Typically, cross-domain FSL focuses on the data scarcity problem of the new task. Two methods (fine-tuning and metric-based FSL methods) are adopted to enable the model to acquire knowledge from datasets on other scenarios (source domain), and then transfer the knowledge to the scenario where it works (target domain), recognizing novel classes with only a few labeled samples. Furthermore, facial action units are utilized to leverage the scarcity issue and to enhance facial representation. Figure 6 shows the classification process with a prototypical network.

Classification process with a prototypical network
However, addressing the limitations of CRN and EGS-Net and highlighting the burden of collecting large-scale labeled data on compound expressions, Zou et al. [141] proposed a novel cascaded decomposition network (CDNet), which was trained to obtain a transferable expression feature region with cascaded learn-to-decompose modules with a shared parameter. The gathered transferable expression features were easily adapted to novel compound FER tasks. In particular, a partial regularization strategy was designed to completely exploit episodic training (using support and query sets) and batch training. Thus, CDNet could alleviate overfitting of highly overlapped viewed tasks owing to limited base categories. Unlike [140], CDNet was trained with basic expression datasets for compound expression recognition tasks.
5 Analysis of complexity and real-time performance
In this section, we analyze FSL for FER models that are based on CNN. We compare the number of parameters, floating-point operations per second (FLOPS), and time complexity of each model. We also discuss their performance. Generally, a few-shot training model is composed of a feature encoder and metric-based network. In Sect. 5.1, we discuss the number of parameters that are trainable in each model. In Sect. 5.2, we also discuss about FLOPS and the calculated time complexity. Finally, we suggest the prerequisites for FER to be applied in the real world in Sect. 5.3.
5.1 Parameters
Most of the FSL models for FER use ResNet [46] as their feature encoder (backbone) and only the number of layers are varied. They usually utilize ResNets with the number of layers ranging from 18 (ResNet-18) to 50 (ResNet-50) for the feature encoder. EGS-Net used ResNet-18 for both the emotion and similarity encoders. The prototypical network was used as the classification network. FedAffect used a Resnet-50V2 backbone without pre-trained weights. A relation network was used as the classification network. The Micro-Expression Recognition framework incorporating AUs (MERAU) applied a twin-cycle autoencoder (TCAE) as the encoder of the AU module and ResNet-18 was used for the optical flow module. TCAE and ResNet-18 are composed of 14.7 M and 11.4 M trainable parameters, respectively, resulting in a total of approximately 26.1 M, and has the deepest layers among the four models. Conversely, the CRN applied a CNN-based feature encoder, which is composed of four convolutional layers. As it has fewer layers, it is composed of 113,088 (0.1 M) parameters. A relation network was used as the classification network. Therefore, approximately 0.2 M parameters are trainable in the CRN.
We also included the model parameters of MTCNN because it was utilized in EGS-Net during training. MTCNN is composed of 495,850 parameters (0.5 M). However, the differences in the number of input images, dimensions, and channels cause changes in the number of parameters. We arbitrarily considered three channels and an input size of 64 images and then calculated the parameters for an appropriate comparison. The relation and prototypical networks are composed of approximately equal parameters; they are composed of 115,601 (0.1 M) and 148,224 (0.1 M) parameters, respectively. The matching network is composed of 212,928 (0.2 M) parameters. Therefore, MERAU is the heaviest and CRN is the lightest model among the FSL models for FER. The total number of trainable parameters for each model is listed in Table 3.
We determined that the backbone network is the main architecture that represents the number of parameters. Using an appropriate feature extractor is more important than choosing a classification metric to obtain a light model.
5.2 FLOPs and time complexity
The FLOPS is a measure of the computer performance in terms of the number of operations. According to Table 3, the number of FLOPS increases and decreases in proportion to the number of parameters. Therefore, a CNN model with the most parameters will have the highest computation cost and vice versa. Thus, we assume that MERAU has the greatest FLOPS followed by FedAffect, EGS-Net, and CRN.
Calculating the exact time complexity is not possible. Time complexity depends on GPU performance and resource power. However, we can presume time cost based on the parameters of the model and FLOPS.
We calculated the test time of each network with exactly identical resource specifications. The hardware and OS used for checking test time are illustrated in Table 4. We set the network architecture without pre-trained weight and chose one random RGB image from RAF-DB. The image was resized to 244 and given to each network.
From Table 3, we can observe that the GPU processing time is significantly faster than that of the CPU. However, the GPU requires a few seconds to load the given model. To address this problem, we calculated the average processing time for the same 1000 images.
FedAffect [136] required approximately 84 ms to infer a three-channel, 244 \(\times\) 244 image using a CPU. In contrast, it was 10 times faster using a GPU. However, determining the specific inference time of MERAU is challenging. Therefore, we presumed that MERAU is based on FedAffect [136]. We considered that it takes an equal or marginally more amount of time than FedAffect. As trainable parameters become smaller, its inference time also becomes smaller. Therefore, EGS-Net took 40 ms to test one image using the CPU and approximately 4.6 ms using the GPU. CRN [137] exhibited the fastest time complexity among the four models. It took 9 ms using the CPU and 0.9 ms using the GPU. Thus, we can reduce the time complexity using a GPU.
5.3 Discussion on performance
Based on the above analysis, we determined the prerequisite for FSL that must be satisfied for FER to adapt in a real-world situation. Initially, we expected FedAffect to exhibit a lesser time complexity because it was developed for direct application in the real world. However, it ranked as the second largest model. Based on the model architecture and assumed time complexity of FedAffect, we can interpret that at least ResNet-50 must be used as a feature encoder for FER. Selecting an appropriate feature encoder is critical as a negligible difference exists between metric-based networks. Conversely, the CRN showed relatively good performance in terms of accuracy while using few depth networks. However, this light model may have lower performance in the real world according to the shown result and computational complexity of FedAffect.
Moreover, we concluded that using FSL is time efficient in terms of both training and prediction. FSL trains on fewer datasets and can infer untrained categories. This implies that additional training time is not necessary for new users or a new environment. From this perspective, FER using FSL is worth observing not only because of its uniqueness but also in the aspect of real-time processing.
6 Discussion and future work
Deep learning has been extensively researched in the FER field. Cutting-edge technology has solved the problem of computing cost and the utilization of large-scale datasets; thus, deep learning models are the main solution for FER tasks. Moreover, using multiple GPUs has been a default implementation condition in FER with deep learning. However, simply depending on powerful computing resources hinders further research. Therefore, utilizing existing possible information and deriving reasonable performance in the real world are essential.
Sustainable and expandable research implies that the research focuses on task issues with a creative perspective. In this way, FSL is suitable for addressing the issues of training FER with state-of-the-art performance. Therefore, applying FSL on FER results in sustainable and expandable research. FSL deals with the problems of facial expression datasets, alleviates overfitting, and saves computing resources.
6.1 Reasons why FSL for FER tasks should be researched
We discussed that FSL can solve the overfitting problem of FER and the facial dataset problem due to class imbalance and noises. In this section, we discuss further reasons for focusing on FSL.
FSL is suitable for dealing with the problems of FER and its dataset. Recent FER model networks are expanding and using extra information for training. However, the performance is not increasing in proportion to the training complexity. This shows that datasets are easily overfitted in the training stage. The performance is unpredictable and using a larger amount of facial data will not result in better performance based on existing results [110, 142, 143].
FSL is a solution for the overfitting problem in FER tasks. With the learn-to-learn training strategy in FSL, FER generalizes well in the wild condition without overfitting. Another approach to capture fine differences between data is required in fine-grained training [144]. FSL with metric-based learning considers the relation between same- and different-class datasets to calculate the similarity. This method helps models to extract more detailed features between data. Many FER datasets including FER+, FER2013, and RAF-DB already exhibit 90\(\%\) more accuracy. However, if we develop a better distance algorithm focusing on the fine-grained attributes of the dataset, we can further improve the performance.
Furthermore, classification tasks based on close to real-world such as Static Facial Expressions in the Wild (SFEW) [145] and AFEW datasets is challenging. As the facial expressions captured in these datasets are similar to natural expressions, distinguishing between the emotions is challenging. Moreover, the performance using the SFEW dataset has not improved from 56\(\%\), whereas the performance using the AFEW dataset has not been able to reach an accuracy of 70\(\%\) even today. The CRN was designed using the new metric-based method that fine-tuned the FER tasks; however, this method shows the possibility of enhancement for SFEW and AFEW datasets using FSL. This proves that FSL can help in the application of FER tasks in real-world situations. Moreover, used FSL does not require huge computation costs and extra computing resources.
6.2 Open issues in FSL for FER
However, certain open issues exist in the application of FSL for FER. We have categorized this discussion according to two main fields of FSL for FER.
-
1.
Discussion on FSL for generalization on novel data FedAffect includes a novel federated learning framework using FSL for user device. However, the central server used two models (self-supervised representation learning and FSL model), which escalated computational cost. Therefore, to utilize the light-weight advantage of FSL, reducing computing complexity by decreasing parameters in the self-supervised learning model should be investigated. CRN could measure the effective similarity distances of each facial expression feature by designing depth attention pooling and JS-divergence loss function. Researchers have provided an upgraded version of the metric algorithm that is appropriate for identifying facial expression features and proved improved performance. However, the proposed function fit specific emotion categories as it considered 2–3 categories for inference. Therefore, a robust facial expression feature extractor must be developed.
-
2.
Discussion on FSL for domain adaptation In the domain adaptation field for FER, multiple training branches are usually used. Therefore, the main strategy is to identify an appropriate interaction training method for each models. Dai and Feng [133] proposed a combined model with AU-related features and general features extracted from optical flow. This model is called MERAU and is used for cross-domain few-shot micro-expression classification. Using an AU detector, they could enhance the ability for extracting salient facial features. However, when the AU detector was frozen, they simply implemented the FSL algorithm for the classification part. To maximize performance by fusing two models, implementing an AU detector and few-shot classification model that can interact together by sharing parameters or updating the loss must be further investigated. With the emotion classification loss, the AU detector may obtain significant information for extracting the salient region in a facial expression image. Conversely, EGS-Net was applied for full regularization of batch training to facilitate the entire training process. In this way, EGS-Net could prevent the overfitting to highly overlapped sampled base classes. Furthermore, it could exploit the global information of basic expressions with the models alternatively freezing to update each models during the training. However, when the number of base classes decreased, the performance of the FSL method completely dropped. Therefore, exploiting both batch and episodic trainings under limited base classes should be further researched.
In summary, computational cost must be alleviated in training processes that use more than two models. Even a single FSL model must be tested on sufficient number of emotion categories to observe its generalization. To maximize multi-training performance, designing of an appropriate regularization mechanism between FSL and batch learning must be further researched. FER tasks primarily focus on eyes and lips. Therefore, obtaining the loss by comparing specific regions may help in alleviating the loss. In addition, a strategy for composition of support set and metric algorithm that can adjust the distance between facial expression features is required. Designing a metric algorithm that is specific to facial expression is also needed and this can be improved by applying the attributes of facial emotions.
7 Conclusion
As facial expression recognition plays an important role in computer vision field, studies on FER are needed. Developing deep learning-based models by training with facial datasets has been researched on various FER tasks. Moreover, FSL has been used to solve the overfitting and generalization problems of FER.
In this paper, we elaborate on how FER can be improved using FSL. We first introduced facial expression datasets in FER. We defined FER and FSL, and discussed two aspects of the issues in recent FER tasks. By analyzing and separating the FER problems based on data and methods, we could identify appropriate approaches together with FSL for solving these issues. Subsequently, FER using FSL was analyzed to understand the limitations and improvements. To inspire future research for using FSL on FER, we discussed open issues in the recent FSL and provided various ways for improvement.
Data availability
CRN and its dataset was not opened. Authors described them in the paper. Therefore, we do not have any available data.
References
Whitehill, J., Serpell, Z., Lin, Y.-C., Foster, A., Movellan, J.R.: The faces of engagement: Automatic recognition of student engagement from facial expressions. IEEE Trans. Affect. Comput. 5(1), 86–98 (2014)
Jerritta, S., Murugappan, M., Nagarajan, R., Wan, K.: Physiological signals based human emotion recognition: a review. In: 2011 IEEE 7th International Colloquium on Signal Processing and Its Applications, pp. 410–415 . IEEE (2011)
Ekundayo, O.S., Viriri, S.: Facial expression recognition: a review of trends and techniques. Ieee Access 9, 136944–136973 (2021)
Li, S., Deng, W.: Deep facial expression recognition: a survey. IEEE Trans. Affect. Comput. (2020)
Deshmukh, S., Patwardhan, M., Mahajan, A.: Survey on real-time facial expression recognition techniques. Iet Biometrics 5(3), 155–163 (2016)
Lucey, P., Cohn, J.F., Kanade, T., Saragih, J., Ambadar, Z., Matthews, I.: The extended Cohn-Kanade dataset (ck+): a complete dataset for action unit and emotion-specified expression. In: 2010 Ieee Computer Society Conference on Computer Vision and Pattern Recognition-workshops, pp. 94–101 . IEEE (2010)
Ekman, P., Friesen, W.V.: Measuring facial movement. Environ. Psychol. Nonverb. Behav. 1(1), 56–75 (1976)
Mollahosseini, A., Hasani, B., Mahoor, M.H.: Affectnet: a database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 10(1), 18–31 (2017)
Dhall, A., Ramana Murthy, O., Goecke, R., Joshi, J., Gedeon, T.: Video and image based emotion recognition challenges in the wild: Emotiw 2015. In: Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, pp. 423–426 (2015)
Dhall, A., Goecke, R., Ghosh, S., Joshi, J., Hoey, J., Gedeon, T.: From individual to group-level emotion recognition: Emotiw 5.0. In: Proceedings of the 19th ACM International Conference on Multimodal Interaction, pp. 524–528 (2017)
Goodfellow, I.J., Erhan, D., Carrier, P.L., Courville, A., Mirza, M., Hamner, B., Cukierski, W., Tang, Y., Thaler, D., Lee, D.-H.,: Challenges in representation learning: a report on three machine learning contests. In: International Conference on Neural Information Processing, pp. 117–124. Springer (2013)
Barsoum, E., Zhang, C., Ferrer, C.C., Zhang, Z.: Training deep networks for facial expression recognition with crowd-sourced label distribution. In: Proceedings of the 18th ACM International Conference on Multimodal Interaction, pp. 279–283 (2016)
Li, S., Deng, W., Du, J.: Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2852–2861 (2017)
Du, S., Tao, Y., Martinez, A.M.: Compound facial expressions of emotion. Proc. Natl. Acad. Sci. 111(15), 1454–1462 (2014)
Bradski, G.: The opencv library. Dr. Dobb’s J. Softw. Tools Prof. Program. 25(11), 120–123 (2000)
Fabian Benitez-Quiroz, C., Srinivasan, R., Martinez, A.M.: Emotionet: an accurate, real-time algorithm for the automatic annotation of a million facial expressions in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5562–5570 (2016)
Dhall, A., Goecke, R., Lucey, S., Gedeon, T.: Collecting large, richly annotated facial-expression databases from movies. IEEE Multimed. 19(03), 34–41 (2012)
Zhou, J., Zhang, S., Mei, H., Wang, D.: A method of facial expression recognition based on Gabor and nmf. Pattern Recognit Image Anal. 26(1), 119–124 (2016)
Darwin, C., Prodger, P.: The Expression of the Emotions in Man and Animals. Oxford University Press, USA,??? (1998)
Zeng, J., Shan, S., Chen, X.: Facial expression recognition with inconsistently annotated datasets. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 222–237 (2018)
Tian, Y.-I., Kanade, T., Cohn, J.F.: Recognizing action units for facial expression analysis. IEEE Trans. Pattern Anal. Mach. Intell. 23(2), 97–115 (2001)
Matsumoto, D.: More evidence for the universality of a contempt expression. Motiv. Emot. 16(4), 363–368 (1992)
Ekman, P.: An argument for basic emotions. Cognit. Emot. 6(3–4), 169–200 (1992)
Jarraya, S.K., Masmoudi, M., Hammami, M.: Compound emotion recognition of autistic children during meltdown crisis based on deep spatio-temporal analysis of facial geometric features. IEEE Access 8, 69311–69326 (2020)
Guo, J., Lei, Z., Wan, J., Avots, E., Hajarolasvadi, N., Knyazev, B., Kuharenko, A., Junior, J.C.S.J., Baró, X., Demirel, H.: Dominant and complementary emotion recognition from still images of faces. IEEE Access 6, 26391–26403 (2018)
Haamer, R.E., Rusadze, E., Lsi, I., Ahmed, T., Escalera, S., Anbarjafari, G.: Review on emotion recognition databases. Hum. Robot Interact. Theor. Appl. 3, 39–63 (2017)
Slimani, K., Ruichek, Y., Messoussi, R.: Compound facial emotional expression recognition using cnn deep features. Eng. Lett. 30(4), 1402–1416 (2022)
Kamińska, D., Aktas, K., Rizhinashvili, D., Kuklyanov, D., Sham, A.H., Escalera, S., Nasrollahi, K., Moeslund, T.B., Anbarjafari, G.: Two-stage recognition and beyond for compound facial emotion recognition. Electronics 10(22), 2847 (2021)
Zhang, K., Zhang, Z., Li, Z., Qiao, Y.: Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 23(10), 1499–1503 (2016)
King, D.E.: Dlib-ml: a machine learning toolkit. J. Mach. Learn. Res. 10, 1755–1758 (2009)
Deng, J., Guo, J., Ververas, E., Kotsia, I., Zafeiriou, S.: Retinaface: Single-shot multi-level face localisation in the wild. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5203–5212 (2020)
Bulat, A., Tzimiropoulos, G.: How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks). In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1021–1030 (2017)
Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), vol. 1, pp. 886–893 . Ieee (2005)
Gabor, D.: Theory of communication. Part 1: the analysis of information. J. Inst. Electr. Eng.-Part III: Radio Commun. Eng. 93(26), 429–441 (1946)
Shan, C., Gong, S., McOwan, P.W.: Facial expression recognition based on local binary patterns: a comprehensive study. Image Vis. Comput. 27(6), 803–816 (2009)
Tan, X., Triggs, B.: Enhanced local texture feature sets for face recognition under difficult lighting conditions. IEEE Trans. Image Process. 19(6), 1635–1650 (2010)
Zhi, R., Flierl, M., Ruan, Q., Kleijn, W.B.: Graph-preserving sparse nonnegative matrix factorization with application to facial expression recognition. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 41(1), 38–52 (2010)
Valstar, M., Pantic, M.,: Induced disgust, happiness and surprise: an addition to the mmi facial expression database. In: Proc. 3rd Intern. Workshop on EMOTION (satellite of LREC): Corpora for Research on Emotion and Affect, p. 65 . Paris, France (2010)
Zhao, G., Huang, X., Taini, M., Li, S.Z., PietikäInen, M.: Facial expression recognition from near-infrared videos. Image Vis. Comput. 29(9), 607–619 (2011)
Kim, J.-H., Kim, B.-G., Roy, P.P., Jeong, D.-M.: Efficient facial expression recognition algorithm based on hierarchical deep neural network structure. IEEE Access 7, 41273–41285 (2019)
Park, S.-J., Kim, B.-G., Chilamkurti, N.: A robust facial expression recognition algorithm based on multi-rate feature fusion scheme. Sensors 21(21), 6954 (2021)
Cortes, C., Vapnik, V.: Support-vector networks. Mach. Learn. 20(3), 273–297 (1995)
Freund, Y., Schapire, R.E.: Experiments with a new boosting algorithm. In: Icml, vol. 96, pp. 148–156 . Citeseer (1996)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998)
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., Fei-Fei, L.: Imagenet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255 . Ieee (2009)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Fe-Fei, L.,: A Bayesian approach to unsupervised one-shot learning of object categories. In: Proceedings Ninth IEEE International Conference on Computer Vision, pp. 1134–1141 . IEEE (2003)
Fink, M.: Object classification from a single example utilizing class relevance metrics. Adv. Neural Inf. Process. Syst. 17 (2004)
Biederman, I.: Recognition-by-components: a theory of human image understanding. Psychol. Rev. 94(2), 115 (1987)
Fei-Fei, L., Fergus, R., Perona, P.: Learning generative visual models from few training examples: an incremental Bayesian approach tested on 101 object categories. In: 2004 Conference on Computer Vision and Pattern Recognition Workshop, pp. 178–178. IEEE (2004)
Fei-Fei, L., Fergus, R., Perona, P.: One-shot learning of object categories. IEEE Trans. Pattern Anal. Mach. Intell. 28(4), 594–611 (2006)
Finn, C., Abbeel, P., Levine, S.: Model-agnostic meta-learning for fast adaptation of deep networks. In: International Conference on Machine Learning, pp. 1126–1135. PMLR (2017)
Cai, Q., Pan, Y., Yao, T., Yan, C., Mei, T.: Memory matching networks for one-shot image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4080–4088 (2018)
Snell, J., Swersky, K., Zemel, R.: Prototypical networks for few-shot learning. Adv. Neural Inform. Process. Syst. 30 (2017)
Wang, Y., Yao, Q., Kwok, J.T., Ni, L.M.: Generalizing from a few examples: a survey on few-shot learning. ACM Comput. Surv. (csur) 53(3), 1–34 (2020)
Lake, B.M., Salakhutdinov, R., Tenenbaum, J.B.: Human-level concept learning through probabilistic program induction. Science 350(6266), 1332–1338 (2015)
Ravi, S., Larochelle, H.: Optimization as a model for few-shot learning (2016)
Reed, S., Chen, Y., Paine, T., Oord, A.v.d., Eslami, S., Rezende, D., Vinyals, O., de Freitas, N.: Few-shot autoregressive density estimation: Towards learning to learn distributions. arXiv preprint arXiv:1710.10304 (2017)
Rezende, D., Danihelka, I., Gregor, K., Wierstra, D.: One-shot generalization in deep generative models. In: International Conference on Machine Learning, pp. 1521–1529. PMLR (2016)
Wu, J., Liu, S., Huang, D., Wang, Y.: Multi-scale positive sample refinement for few-shot object detection. In: European Conference on Computer Vision, pp. 456–472 . Springer (2020)
Wang, X., Huang, T.E., Darrell, T., Gonzalez, J.E., Yu, F.: Frustratingly simple few-shot object detection. arXiv preprint arXiv:2003.06957 (2020)
Sun, B., Li, B., Cai, S., Yuan, Y., Zhang, C.: Fsce: Few-shot object detection via contrastive proposal encoding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7352–7362 (2021)
Jung, I., You, K., Noh, H., Cho, M., Han, B.: Real-time object tracking via meta-learning: efficient model adaptation and one-shot channel pruning. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 11205–11212 (2020)
Garcia, V., Bruna, J.: Few-shot learning with graph neural networks. arXiv preprint arXiv:1711.04043 (2017)
Yang, F.S.Y., Zhang, L., Xiang, T., Torr, P., Hospedales, T.M.: Learning to compare: Relation network for few-shot learning. In: CVPR, vol. 1, p. 6 (2018)
Sung, F., Yang, Y., Zhang, L., Xiang, T., Torr, P.H., Hospedales, T.M.: Learning to compare: Relation network for few-shot learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1199–1208 (2018)
Wang, K., Liew, J.H., Zou, Y., Zhou, D., Feng, J.: Panet: Few-shot image semantic segmentation with prototype alignment. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9197–9206 (2019)
Ouyang, C., Biffi, C., Chen, C., Kart, T., Qiu, H., Rueckert, D.: Self-supervision with superpixels: Training few-shot medical image segmentation without annotation. In: European Conference on Computer Vision, pp. 762–780 . Springer (2020)
Liu, Y., Zhang, X., Zhang, S., He, X.: Part-aware prototype network for few-shot semantic segmentation. In: European Conference on Computer Vision, pp. 142–158. Springer (2020)
Zhang, Z., Zhang, Y., Feng, R., Zhang, T., Fan, W.: Zero-shot sketch-based image retrieval via graph convolution network. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 12943–12950 (2020)
Gui, L.-Y., Wang, Y.-X., Ramanan, D., Moura, J.M.: Few-shot human motion prediction via meta-learning. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 432–450 (2018)
Xian, Y., Korbar, B., Douze, M., Schiele, B., Akata, Z., Torresani, L.: Generalized many-way few-shot video classification. In: European Conference on Computer Vision, pp. 111–127. Springer (2020)
Michalkiewicz, M., Parisot, S., Tsogkas, S., Baktashmotlagh, M., Eriksson, A., Belilovsky, E.: Few-shot single-view 3-d object reconstruction with compositional priors. In: European Conference on Computer Vision, pp. 614–630 . Springer (2020)
Yan, L., Zheng, Y., Cao, J.: Few-shot learning for short text classification. Multimed. Tools Appl. 77(22), 29799–29810 (2018)
Xu, J., Du, Q.: Learning transferable features in meta-learning for few-shot text classification. Pattern Recogn. Lett. 135, 271–278 (2020)
Kumar, N., Baghel, B.K.: Intent focused semantic parsing and zero-shot learning for out-of-domain detection in spoken language understanding. IEEE Access 9, 165786–165794 (2021)
Kaiser, Ł., Nachum, O., Roy, A., Bengio, S.: Learning to remember rare events. arXiv preprint arXiv:1703.03129 (2017)
Han, X., Zhu, H., Yu, P., Wang, Z., Yao, Y., Liu, Z., Sun, M.: Fewrel: a large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation. arXiv preprint arXiv:1810.10147 (2018)
Lampert, C.H., Nickisch, H., Harmeling, S.: Learning to detect unseen object classes by between-class attribute transfer. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 951–958. IEEE (2009)
Douze, M., Szlam, A., Hariharan, B., Jégou, H.: Low-shot learning with large-scale diffusion. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3349–3358 (2018)
Pfister, T., Charles, J., Zisserman, A.: Domain-adaptive discriminative one-shot learning of gestures. In: European Conference on Computer Vision, pp. 814–829 . Springer (2014)
Wu, Y., Lin, Y., Dong, X., Yan, Y., Ouyang, W., Yang, Y.: Exploit the unknown gradually: one-shot video-based person re-identification by stepwise learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5177–5186 (2018)
Tsai, Y.-H.H., Salakhutdinov, R.: Improving one-shot learning through fusing side information. arXiv preprint arXiv:1710.08347 (2017)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial networks. Commun. ACM 63(11), 139–144 (2020)
Gao, H., Shou, Z., Zareian, A., Zhang, H., Chang, S.-F.: Low-shot learning via covariance-preserving adversarial augmentation networks. Adv. Neural Inform. Process. Syst. 31 (2018)
Caruana, R.: Multitask learning. Mach. Learn. 28(1), 41–75 (1997)
Hu, Z., Li, X., Tu, C., Liu, Z., Sun, M.: Few-shot charge prediction with discriminative legal attributes. In: Proceedings of the 27th International Conference on Computational Linguistics, pp. 487–498 (2018)
Zhang, Y., Tang, H., Jia, K.: Fine-grained visual categorization using meta-learning optimization with sample selection of auxiliary data. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 233–248 (2018)
Motiian, S., Jones, Q., Iranmanesh, S., Doretto, G.: Few-shot adversarial domain adaptation. Adv. Neural Inform. Process. Syst. 30 (2017)
Yan, W., Yap, J., Mori, G.: Multi-task transfer methods to improve one-shot learning for multimedia event detection. In: BMVC, pp. 37–1 (2015)
Luo, Z., Zou, Y., Hoffman, J., Fei-Fei, L.F.: Label efficient learning of transferable representations acrosss domains and tasks. Adv. Neural Inform. Process. Syst. 30 (2017)
Bachman, P., Sordoni, A., Trischler, A.: Learning algorithms for active learning. In: International Conference on Machine Learning, pp. 301–310. PMLR (2017)
Altae-Tran, H., Ramsundar, B., Pappu, A.S., Pande, V.: Low data drug discovery with one-shot learning. ACS Cent. Sci. 3(4), 283–293 (2017)
Tang, K.D., Tappen, M.F., Sukthankar, R., Lampert, C.H.: Optimizing one-shot recognition with micro-set learning. In: 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 3027–3034. IEEE (2010)
Koch, G., Zemel, R., Salakhutdinov, R.,: Siamese neural networks for one-shot image recognition. In: ICML Deep Learning Workshop, vol. 2, p. 0 . Lille (2015)
Vinyals, O., Blundell, C., Lillicrap, T., Wierstra, D., et al.: Matching networks for one shot learning. Adv. Neural Inform. Process. Syst. 29 (2016)
Bertinetto, L., Henriques, J.F., Valmadre, J., Torr, P., Vedaldi, A.: Learning feed-forward one-shot learners. Adv. Neural Inform. Process. Syst. 29 (2016)
Bertinetto, L., Henriques, J.F., Torr, P.H., Vedaldi, A.: Meta-learning with differentiable closed-form solvers. arXiv preprint arXiv:1805.08136 (2018)
Oreshkin, B., Rodríguez López, P., Lacoste, A.: Tadam: Task dependent adaptive metric for improved few-shot learning. Advances in neural information processing systems 31 (2018)
Zhao, F., Zhao, J., Yan, S., Feng, J.: Dynamic conditional networks for few-shot learning. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 19–35 (2018)
Park, S., Chun, S., Cha, J., Lee, B., Shim, H.: Few-shot font generation with localized style representations and factorization. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 2393–2402 (2021)
Bottou, L., Bousquet, O.: The tradeoffs of large scale learning. Adv. Neural Inform. Process. Syst. 20 (2007)
Bottou, L., Curtis, F.E., Nocedal, J.: Optimization methods for large-scale machine learning. SIAM Rev. 60(2), 223–311 (2018)
Li, H., Wang, N., Ding, X., Yang, X., Gao, X.: Adaptively learning facial expression representation via cf labels and distillation. IEEE Trans. Image Process. 30, 2016–2028 (2021)
Siqueira, H., Magg, S., Wermter, S.: Efficient facial feature learning with wide ensemble-based convolutional neural networks. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 5800–5809 (2020)
Zhang, Y., Wang, C., Deng, W.: Relative uncertainty learning for facial expression recognition. Adv. Neural. Inf. Process. Syst. 34, 17616–17627 (2021)
Wang, K.: Peng: Region attention networks for pose and occlusion robust facial expression recognition. IEEE Trans. Image Process. 29, 4057–4069 (2020)
Vo, T.-H., Lee, G.-S., Yang, H.-J., Kim, S.-H.: Pyramid with super resolution for in-the-wild facial expression recognition. IEEE Access 8, 131988–132001 (2020)
Kumar, V., Rao, S., Yu, L.: Noisy student training using body language dataset improves facial expression recognition. In: European Conference on Computer Vision, pp. 756–773 . Springer (2020)
Meng, D., Peng, X., Wang, K., Qiao, Y.: Frame attention networks for facial expression recognition in videos. In: 2019 IEEE International Conference on Image Processing (ICIP), pp. 3866–3870. IEEE (2019)
Wang, K., Peng, X., Yang, J., Meng, D., Qiao, Y.: Region attention networks for pose and occlusion robust facial expression recognition. IEEE Trans. Image Process. 29, 4057–4069 (2020)
Psaroudakis, A., Kollias, D.: Mixaugment & mixup: augmentation methods for facial expression recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2367–2375 (2022)
Shi, Y., Jain, A.K.: Probabilistic face embeddings. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6902–6911 (2019)
Wang, K., Peng, X., Yang, J., Lu, S., Qiao, Y.: Suppressing uncertainties for large-scale facial expression recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6897–6906 (2020)
Yovel, G., Duchaine, B.: Specialized face perception mechanisms extract both part and spacing information: Evidence from developmental prosopagnosia. J. Cogn. Neurosci. 18(4), 580–593 (2006)
Luo, Y., Ye, J., Adams, R.B., Li, J., Newman, M.G., Wang, J.Z.: Arbee: towards automated recognition of bodily expression of emotion in the wild. Int. J. Comput. Vis. 128(1), 1–25 (2020)
Jiang, Y., Gong, X., Liu, D., Cheng, Y., Fang, C., Shen, X., Yang, J., Zhou, P., Wang, Z.: Enlightengan: deep light enhancement without paired supervision. IEEE Trans. Image Process. 30, 2340–2349 (2021)
Zhang, H., Cisse, M., Dauphin, Y.N., Lopez-Paz, D.: mixup: beyond empirical risk minimization. arXiv preprint arXiv:1710.09412 (2017)
Ju, C., Bibaut, A., van der Laan, M.: The relative performance of ensemble methods with deep convolutional neural networks for image classification. J. Appl. Stat. 45(15), 2800–2818 (2018)
Li, J., Jin, K., Zhou, D., Kubota, N., Ju, Z.: Attention mechanism-based cnn for facial expression recognition. Neurocomputing 411, 340–350 (2020)
Liu, Y., Peng, J., Zeng, J., Shan, S.: Pose-adaptive hierarchical attention network for facial expression recognition. arXiv preprint arXiv:1905.10059 (2019)
Minaee, S., Minaei, M., Abdolrashidi, A.: Deep-emotion: Facial expression recognition using attentional convolutional network. Sensors 21(9), 3046 (2021)
Huang, Q., Huang, C., Wang, X., Jiang, F.: Facial expression recognition with grid-wise attention and visual transformer. Inf. Sci. 580, 35–54 (2021)
Aminbeidokhti, M., Pedersoli, M., Cardinal, P., Granger, E.: Emotion recognition with spatial attention and temporal softmax pooling. In: International Conference on Image Analysis and Recognition, pp. 323–331 . Springer (2019)
Zeng, X., Wu, Q., Zhang, S., Liu, Z., Zhou, Q., Zhang, M.: A false trail to follow: differential effects of the facial feedback signals from the upper and lower face on the recognition of micro-expressions. Front. Psychol. 9, 2015 (2018)
Savchenko, A.V., Savchenko, L.V., Makarov, I.: Classifying emotions and engagement in online learning based on a single facial expression recognition neural network. IEEE Trans. Affect. Comput. 13(4), 2132–2143 (2022)
Fard, A.P., Mahoor, M.H.: Ad-corre: adaptive correlation-based loss for facial expression recognition in the wild. IEEE Access 10, 26756–26768 (2022)
Terhorst, P., Kolf, J.N., Damer, N., Kirchbuchner, F., Kuijper, A.: Ser-fiq: unsupervised estimation of face image quality based on stochastic embedding robustness. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5651–5660 (2020)
Fang, Y., Gao, J., Huang, C., Peng, H., Wu, R.: Self multi-head attention-based convolutional neural networks for fake news detection. PLoS One 14(9), 0222713 (2019)
Lin, Z., Feng, M., Santos, C.N.d., Yu, M., Xiang, B., Zhou, B., Bengio, Y.: A structured self-attentive sentence embedding. arXiv preprint arXiv:1703.03130 (2017)
She, J., Hu, Y., Shi, H., Wang, J., Shen, Q., Mei, T.: Dive into ambiguity: Latent distribution mining and pairwise uncertainty estimation for facial expression recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6248–6257 (2021)
Dai, Y., Feng, L.: Cross-domain few-shot micro-expression recognition incorporating action units. IEEE Access 9, 142071–142083 (2021)
Yang, Y., Saleemi, I., Shah, M.: Discovering motion primitives for unsupervised grouping and one-shot learning of human actions, gestures, and expressions. IEEE Trans. Pattern Anal. Mach. Intell. 35(7), 1635–1648 (2012)
Cruz, A.C., Bhanu, B., Thakoor, N.S.: One shot emotion scores for facial emotion recognition. In: 2014 IEEE International Conference on Image Processing (ICIP), pp. 1376–1380. IEEE (2014)
Shome, D., Kar, T.: Fedaffect: Few-shot federated learning for facial expression recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4168–4175 (2021)
Zhu, Q., Mao, Q., Jia, H., Noi, O.E.N., Tu, J.: Convolutional relation network for facial expression recognition in the wild with few-shot learning. Expert Syst. Appl. 189, 116046 (2022)
Ren, M., Triantafillou, E., Ravi, S., Snell, J., Swersky, K., Tenenbaum, J.B., Larochelle, H., Zemel, R.S.: Meta-learning for semi-supervised few-shot classification. arXiv preprint arXiv:1803.00676 (2018)
Ciubotaru, A.-N., Devos, A., Bozorgtabar, B., Thiran, J.-P., Gabrani, M.: Revisiting few-shot learning for facial expression recognition. arXiv preprint arXiv:1912.02751 (2019)
Zou, X., Yan, Y., Xue, J.-H., Chen, S., Wang, H.: When facial expression recognition meets few-shot learning: A joint and alternate learning framework. arXiv preprint arXiv:2201.06781 (2022)
Zou, X., Yan, Y., Xue, J.-H., Chen, S., Wang, H.: Learn-to-decompose: cascaded decomposition network for cross-domain few-shot facial expression recognition. In: European Conference on Computer Vision, pp. 683–700. Springer (2022)
Jiang, L., Zhou, Z., Leung, T., Li, L.-J., Fei-Fei, L.: Mentornet: learning data-driven curriculum for very deep neural networks on corrupted labels. In: International Conference on Machine Learning, pp. 2304–2313. PMLR (2018)
Arpit, D., Jastrzębski, S., Ballas, N., Krueger, D., Bengio, E., Kanwal, M.S., Maharaj, T., Fischer, A., Courville, A., Bengio, Y.,: A closer look at memorization in deep networks. In: International Conference on Machine Learning, pp. 233–242. PMLR (2017)
Wei, X.-S., Song, Y.-Z., Mac Aodha, O., Wu, J., Peng, Y., Tang, J., Yang, J., Belongie, S.: Fine-grained image analysis with deep learning: a survey. IEEE Trans. Pattern Anal. Mach. Intell. (2021) Query ID="Q5" text="Kindly provide the volume number and page range for the reference 4, 144"
Dhall, A., Goecke, R., Lucey, S., Gedeon, T.: Static facial expression analysis in tough conditions: Data, evaluation protocol and benchmark. In: 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), pp. 2106–2112 . IEEE (2011)
Author information
Authors and Affiliations
Contributions
B-GK supervised to make this research and C-LK collected all materials. C-LK wrote the draft of this manuscript and B-GK guided the direction and content description. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kim, CL., Kim, BG. Few-shot learning for facial expression recognition: a comprehensive survey. J Real-Time Image Proc 20, 52 (2023). https://doi.org/10.1007/s11554-023-01310-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11554-023-01310-x