
Abstract
Purpose
With the recent development of deep learning technologies, various neural networks have been proposed for fundus retinal vessel segmentation. Among them, the U-Net is regarded as one of the most successful architectures. In this work, we start with simplification of the U-Net, and explore the performance of few-parameter networks on this task.
Methods
We firstly modify the model with popular functional blocks and additional resolution levels, then we switch to exploring the limits for compression of the network architecture. Experiments are designed to simplify the network structure, decrease the number of trainable parameters, and reduce the amount of training data. Performance evaluation is carried out on four public databases, namely DRIVE, STARE, HRF and CHASE_DB1. In addition, the generalization ability of the few-parameter networks are compared against the state-of-the-art segmentation network.
Results
We demonstrate that the additive variants do not significantly improve the segmentation performance. The performance of the models are not severely harmed unless they are harshly degenerated: one level, or one filter in the input convolutional layer, or trained with one image. We also demonstrate that few-parameter networks have strong generalization ability.
Conclusion
It is counter-intuitive that the U-Net produces reasonably good segmentation predictions until reaching the mentioned limits. Our work has two main contributions. On the one hand, the importance of different elements of the U-Net is evaluated, and the minimal U-Net which is capable of the task is presented. On the other hand, our work demonstrates that retinal vessel segmentation can be tackled by surprisingly simple configurations of U-Net reaching almost state-of-the-art performance. We also show that the simple configurations have better generalization ability than state-of-the-art models with high model complexity. These observations seem to be in contradiction to the current trend of continued increase in model complexity and capacity for the task under consideration.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Retinal vessel segmentation from fundus images is an extensively studied field [14, 19, 40]. Analysis of the distribution, thickness and curvature of the retinal vessels assists the diagnosis, therapy planning, and treatment procedures of circulatory system-related eye diseases such as diabetic retinopathy (DR), glaucoma and age-related macular degeneration, which are the leading causes of blindness in the aging population [48]. Previous work on retinal vessel segmentation can be roughly divided into unsupervised and supervised categories, where supervised approaches often outperform the unsupervised ones. Unsupervised approaches do not require manual annotations, and are usually based on certain rules, such as template matching [4, 21, 45], vessel tracking [49, 54], region growing [35], multiscale analysis [3, 29, 51], and morphological processing [7]. Supervised approaches rely on ground truth annotations by expert ophthalmologists. In conventional machine learning-based methods, hand-crafted or learnt features are used as input for classifiers such as k-nearest neighbors (kNN) [46], support vector machine (SVM) [33], random forest (RF) [44], AdaBoost [8], Gaussian mixture model (GMM) [39], and the multilayer perceptron (MLP) [36]. With the recent advancements in deep learning-based technologies [27], convolutional neural networks (CNNs), which do not explicitly separate the feature extraction and the classification procedures, are employed in this field and have achieved great success [9, 25, 28]. Apart from models that are designed for high-performance, researchers have proposed to improve the interpretability of the constructed segmentation pipelines as well. For instance, the Frangi-Net [11], which is the CNN counterpart of the classical Frangi filter [6], has been proposed and combined with a preprocessing net [10] to reach the state-of-the-art performance.
Among the deep learning-based methods designed for biomedical image segmentation, U-Net [37] is one of the most successful models. Since published, U-Net and its variants have achieved remarkable performance in various applications and have been employed as the state-of-the-art method for segmentation tasks to compare with [23, 47, 52]. Isensee et al. [18] even draw an empirical conclusion that hyper-parameter tuning of the U-Net rather than new network architecture design is the key to high performance. Since the U-Net normally contains huge amounts of parameters, training and inference processes are resource-consuming. Compression of the network architecture has been tackled in previous work, such as the U-Net++ [55] by Zhou et al.. Additional convolutional layers are inserted in-between the skip connections to introduce self-similarity to the structure. This modification enables easy pruning in the testing phase, yet introduces parameters in the training phase. Besides, only one decisive structural factor, namely the number of levels, is considered.
This work is an extension of our previous publication [31], which focuses on degenerating the U-Net for retinal vessel segmentation on the DRIVE [41] database. The major differences comparing to [31] are as follows. Firstly, the U-Net variant with no skip connections is explored. Secondly, all experiments are conducted on three additional fundus databases besides the DRIVE [41], namely the STARE [15], the HRF [3], and the CHASE_DB1 [34]. Fourfold cross-validation is performed on these databases. Thirdly, parameter searching is conducted for training the default U-Net on the HRF database, which contains the largest number of fundus images, to explore how the hyperparameters affect the training process. Fourthly, a five-level U-Net is trained on the HRF database to explore how enlarging the model influences the performance. Lastly, the performance and generalization ability of our few-parameter nets are compared with that of the SSA-Net [32], which yields state-of-the-art performance on multiple fundus databases.

Default U-Net configuration. The dash box defines one U-Net block

Illustration of the dense block (a), residual block (b), and the side-output block (c)
We start with a default U-Net and firstly seek to enhance its performance by introducing additional resolution scales and substituting the vanilla U-Net blocks with commonly used functional blocks, namely the dense block [16], the residual block [13], the dilated convolution block [50], and the side-output block [9]. Due to the observation of no remarkable performance boost, we propose the assumption that the default U-Net alone is capable or even over-qualified for the task of retinal vessel segmentation. Thereafter, we turn our focus onto simplification of the network architecture, aiming for a minimized model which yields reasonably good performance. Different components of the default U-Net are explored independently using the “control variates” strategy, where only one factor is changed while the others are fixed at one time. The number of U-Net levels, the number of convolutional layers in each U-Net block, and the number of filters in the convolution layers are step-wise decreased; the nonlinear activation layers and skip connections are removed; and the size of training set is reduced. Analysis of the performance evaluation metrics yields unexpected conclusion; only under substantially harsh conditions does the U-Net degenerate. With one down-/upsampling step, or one convolutional layer in each U-Net block, or two filters in the input layer, the segmentation performance remain satisfactory, producing AUC scores above 0.97. Comparison to the SSA-Net [32], which is state-of-the-art retinal vessel segmentation network model, also reveals that the few-parameter networks have strong generalization ability. The contribution of this work is two-sided. On the one hand, the importance of different configuration components of the U-Net model is quantitatively assessed, and a minimized well-performing model is obtained. On the other hand, this work provides an exemplary reminder that the research behavior of pursuing marginal performance gain at the cost of massive resource consumption could be unworthy.
Materials and methods
Default U-Net configuration
The default U-Net configuration in this work is illustrated in Fig. 1. Likewise the original U-Net [37], each U-Net block consists of two consecutive convolutional layers with \(3\times 3\) filters. The number of filters doubles after each down-sampling, and halves after each up-sampling. Down-sampling is performed by the max-pooling operation. ReLU activation layers are employed to introduce nonlinearity into the model, and the concatenation operation is used as the skip connection to merge the localization and contextual information. In comparison to the original U-Net architecture, four major modifications are made. Firstly, our model is composed of three rather than five scale levels. Secondly, the number of filters in the first convolutional layer is set to 16 rather than 64. Thirdly, up-sampling is realized with an up-pooling layer followed by a \(1\times 1\) convolutional layer rather than the transposed convolutional layer. Lastly, batch normalization [17] layers are applied after all but the last ReLU [31] layers to stabilize the training process. The overall architecture contains 108,976 parameters.
Additive variants
Four structural additive modifications are applied on the vanilla U-Net architecture, namely the dense block [16], the residual block [13], the side-output block [9] (see Fig. 2), and the dilated convolution block [50]. These structural modifications are chosen due to their popularity in the U-Net-based medical image segmentation community [1, 5, 22, 23, 26, 30, 43, 53]. In the dense block, activation maps from all preceding layers are concatenated to all latter ones. Such connections create many additional channels and introduce a large amount of parameters. Due to computational resource limits, dense blocks replace the vanilla blocks only in the encoder path. In the residual block, two additional convolutional layers are inserted, where the activation maps from the first convolutional layer are added to those of the third layer. The residual blocks replace the vanilla U-Net blocks in the encoder, the bottleneck, as well as the decoder. The concatenation operations in dense blocks and the addition operations in residual blocks allow for better gradient backpropagation since preceding layers can receive more direct supervision from the loss function. In dilated convolution layers, the kernels are enlarged, creating holes in-between which are filled with zeros. No additional parameters are introduced, while the receptive field is enlarged. The dilated convolution block is employed in the bottleneck of the model. The side-output blocks are applied in the decoder path to provide step-wise deep supervision, where the output maps from the U-Net blocks are passed through a \(1\times 1\) convolutional layer, upsampled to the shape of the network input, and compared with the ground truth using a mean square error (MSE) loss. Besides, a U-Net with five scale levels is trained on the biggest fundus database, namely the HRF [3] database to explore how enlarged architecture influences the network performance.
Subtractive variants
The default U-Net in this study is configured as described in “Default U-Net configuration” section. Exploration of the limits of subtractive U-Net variants follows the “control variates” strategy, which means only one aspect of the model is changed from the default configuration at one time. Experiment series are designed as:
-
1.
Nonlinear activation functions, i.e., the ReLU layers, are removed.
-
2.
Skip connections between the encoder and the decoder are removed.
-
3.
The number of convolutional layers in each U-Net block is reduced to one.
-
4.
The number of filters in the first level is halved from sixteen down to one. Correspondingly, the number of filters in deep levels is proportionally decreased.
-
5.
The number of levels decreases step-wise to one, until the network degenerates into a chain of convolutional layers.
-
6.
The number of images for training the model is consecutively halved by a factor of two until only one image is used.
Parameter searching
In order to investigate on the importance of parameter tuning for the network performance, a random hyperparameter searching [2] experiment is carried out for the default U-Net configuration on the HRF [3] database which contains the largest number of annotated fundus images. Nine different hyperparameters which control the model architecture and the training process are considered. The optimum parameter combination is selected from 29 experiment roll-outs, and utilized to retrain the default U-Net. The experimental details for parameter searching are elaborated in the supplementary material.
Comparison to the state-of-the-art method
To compare the performance of our few-parameter networks with the state-of-the-art methods, we select the scale-space approximated network [32] (SSA-Net) which reaches the highest performance on various fundus databases as the target model. We firstly rerun the SSA-Net for five repetitive times to obtain the mean and standard deviation of the experiments rather than merely the optimum results as in [32]. Note that the SSA-Net is trained with the exactly same software and configuration as in [32]. Since the SSA-Net utilizes the backbone of ResNet34 [13] and contains more than 25 million trainable weights, it is natural to propose that the high performance of the model could be due to overfitting. Thereafter an experiment to investigate on the generalization ability of the network models is designed. Both our few-parameter networks and the SSA-Net are trained on the DRIVE database and transferred to the STARE [15] directly.
Database description
DRIVE
The digital retinal images for vessel extraction (DRIVE) [41] database contains 40 8-bit RGB fundus images with a resolution of \(565\times 584\) pixels. The database consists of 33 healthy cases and 7 cases with early signs of DR, and is evenly divided into one training and one testing set. In this work, a subset of four images is further separated from the training set for validation purpose. For all images, FOV masks and manually labeled annotations are provided. In the training process, each minibatch contains 50 image patches of size \(168\times 168\), which are randomly sampled from the training images.

Preprocessing pipeline
STARE
The structured analysis of the retina (STARE) database [15] contains 20 8-bit RGB fundus photographs of size \(605\times 700\) pixels. Half of the images are from healthy subjects, while the other half is corrupted with pathologies that affect the visibility of retinal vessels. Manually labeled vessel masks are available for all images. FOV masks are generated using a foreground / background separation technique named “GrabCut” [38]. Training and testing sets are not predefined. A fourfold cross-validation is performed, with five images for testing, eleven images for training and four images for validation in each experiment. During the training process, minibatches are constructed in the same way as for DRIVE.

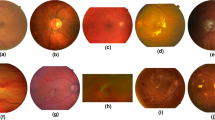
Probability predictions of U-Net variants with AUC scores presented on upper right corners. (f–i) are the additive variants of the U-Net. (j–m) denote U-Net with one level, U-Net with one filter in the initial convolutional layer, U-Net trained with one sample, and U-Net with one convolutional layer in each block. (n–p) correspond to U-Net without ReLU layers, three-level U-Net without skip connections, and five-level U-Net without skip connections
HRF
The high-resolution fundus (HRF) image database [3] consists of 45 8-bit RGB fundus photographs of size \(2336\times 3504\) pixels. It contains 15 images from healthy patients, 15 from DR patients, and 15 from glaucomatous patients. For each image, a manual annotation and an FOV mask are provided. Training and testing sets are not predefined, and a fourfold cross-validation is performed for evaluation. In each experiment, 34 images are used for training, seven for validation, and eleven/twelve for testing. In the training process, each minibatch contains 15 patches of size \(400\times 400\) pixels.
CHASE_DB1
The CHASE_DB1 [34] database contains 28 fundus images from both eyes of 14 pediatric subjects with a resolution of \(999\times 960\) pixels. Ground truth vessel maps are provided, yet FOV masks are created using the GrabCut algorithm. For evaluation, a fourfold cross-validation is performed. The 28 images are divided into a training set of 17 images, a validation set of four images, and testing set containing seven images in each experiment. For training, a minibatch contains 40 patches of shape \(200\times 200\) pixels.
Preprocessing pipeline
Before fed into network models, raw fundus photographs are preprocessed using the pipeline illustrated in Fig. 3. Firstly, the green channels of the RGB images, which exhibit the best contrast between the retinal vessels and the background, are extracted. Secondly, the CLAHE [56] algorithm, with a window size of \(8\times 8\) pixels and the max slope equals 3.0, is applied to equalize the local histogram in an adaptive manner and balance the illumination. The data range within the FOV masks is then normalized between 0.0 and 1.0, and a Gamma transform with \(\gamma = 0.8\) is applied to further lift the contrast in dark small vessel regions. Finally, the data range within the FOV mask is standardized between \(-1.0\) and 1.0 to generate input for the networks. Additionally for HRF and CHASE_DB1 databases, images are down-sampled with bilinear interpolation by a factor of 4 and 2, respectively, before fed into networks, and up-scaled after the network processing to restore their original shape.
The borders of FOV masks of all databases are inwardly eroded by four pixels to remove potential border effects and ensure meaningful comparison. In order to stress on the thin vessels during training, weight maps are generated and multiplied to the pixel-wise loss as in Eq. (1), where \(d_{x_i}\) is the vessel diameter in the manual label map of the given pixel \(x_i\):
Experimental details
The objective function in this work is a weighted sum of two parts, namely the segmentation loss and the regularization loss, i.e.,
where \(L_{\mathrm{focal}}(x_i)\) is the focal loss [24] for a given pixel \(x_i\), N is the overall number of pixels, and \(L_{{\ell }_2}\) is the regularizer loss representing the \(\ell _2\) norm of all network weights. For the focal loss, the focusing factor \(\gamma \) is set to 2.0 to differentiate between easy and hard cases, and a class-balancing factor \(\alpha \) is set to 0.9 to emphasize on the foreground pixels. The \(\ell _2\) loss is combined with the segmentation loss with a factor \(\lambda =0.2\) to prevent over-fitting. The Adam optimizer [20] with \(\beta _1 = 0.9, \beta _2=0.999\) is used for the training process. The learning rate decays by 10% after each 10,000 iterations. Different initial learning rates are tailored for different models to achieve smooth loss curves; the more weights in the model, the smaller the learning rate. Networks are trained until convergence is observed in the validation loss curve. Data augmentation techniques are utilized for better generalization, including rotation within 20 degrees, shearing within 30% of the linear patch size, zooming between 50% and 150% of the linear patch size, additive Gaussian noise and uniform intensity shifting within the range of 8% of the image intensities.
Experiments with each different configuration are repeated for five times to make sure that the conclusion is not dominated by certain specific initialization settings, and to evaluate the stability of the model. The models are trained on an NVIDIA GPU cluster. Projects are implemented in Python 3.6.8., using the framework TensorFlow 1.13.1.
Results
Commonly used performance evaluation metrics for semantic medical image segmentation, namely specificity, sensitivity, F1 score, accuracy and the AUC score [42], are employed in this work. Binarization of the prediction maps from a model is conducted by selecting a threshold which maximizes the average F1 score of the validation sets. The AUC score, which is threshold-independent, is chosen as the major performance indicator. The mean and standard deviation of the metric values on each testing image over the five experiment roll-outs are firstly computed individually. The average of these mean and standard deviation values over all the testing images are reported in Tables 1, 2, 3 and 4. The evaluation results to compare the generalization ability of our few-parameter networks with the SSA-Net are presented in Table 5. The significance analysis of predictions from different U-Net variants is presented in the supplementary material. The predicted probability maps from different network variants for one testing image in DRIVE are shown in Fig. 4a–o.
Performance evaluation of structural U-Net variants are presented in Table 1. For additive variants, we observe that comparing to the vanilla U-Net, the changes in AUC scores stay in reach of the standard deviations. This implies that the introduced functional blocks or the additional levels fail to incur the expected performance enhancement. As for the subtractive variants, the performance of U-Net with one convolutional layer in each block drops marginally and remains satisfactory. Removing skip connections barely harms the network performance; while eliminating the ReLU layer causes 0.01 decrease in the AUC scores. In Table 2, the evaluation metrics of the U-Nets with decreased number of filters in the initial convolutional layer are reported. A uniform performance decay is observed as the network shrinks. However, it is remarkable that the performance remains reasonable with AUC scores above 0.96 for all databases even for the model with a total of 451 parameters and with only one filter in the first convolutional layer. U-Nets with reduced number of levels are evaluated in Table 3. We notice that compared to the default three-level U-Net, the segmentation capability of the two-level U-Net is basically retained; and that even if the model degenerates into a chain of convolutional layers, the predictions remain plausible, reaching AUC scores above 0.96 for all databases. Experiment series of training the default U-Net with decreased amount of data in Table 4 show the generalization ability of the model. In accordance with expectation, a monotonous performance decline concurs with a decreasing number of samples in the training set. However, it is unexpected that the U-Nets trained with only two images achieve AUC scores above 0.96 in all databases.
Discussion and conclusion
In this work, we firstly attempt to improve the capability of U-Net on the retinal vessel segmentation task by introducing functional blocks or additional scale levels to the model. Although the modified models accommodate more parameters, their performance does not improve considerably. To investigate on the impact of hyperparameters on the network performance, a parameter searching experiment is carried out for the default U-Net on the HRF database. However, the optimum set of parameters also fails to introduce significant improvement. Thereafter, we turn our research direction into exploring the minimum configurations of the U-Net by removing or reducing certain characteristics from a default U-Net configuration. It is proved that ReLU layers have larger impact on the model functionality than the amount of parameters. Linear U-Nets with no ReLU activation levels arrive at the lowest segmentation performance among all structural variants on all four databases. In the DRIVE database, the default U-Net achieves an AUC score of 0.9756, the U-Net with two filters in the input layer achieves an AUC score of 0.9719, while U-Net without ReLU layers yields an AUC score of 0.9643, as presented in Tables 1, 2. One interesting observation is that when skip connections are absent, the high performance is maintained. A possible explanation is that the detail loss due to resampling is limited in three-level models and that the missing details can still be successfully encoded in the bottleneck. In other words, for this specific task, skip connections are not necessary when the network is shallow. The assumption is confirmed by evaluating the segmentation performance on a five-level U-Net without skip connections. Comparing the prediction of the five-level linear U-Net in Fig. 4p and that of the three-level linear U-Net in Fig. 4o, we observe that qualitatively not only are thin vessels neglected, but adjacent big vessels get blended as well; and that quantitatively the AUC score drastically drops from 0.9819 to 0.9689 as exhibited on the upper right corners of corresponding image tiles.
The segmentation performance of U-Net-based few-parameter networks are compared with the state-of-the-art retinal vessel segmentation model SSA-Net. Although their model performance is significantly better than ours, the differences are on the third digit. Besides, the generalization ability is another issue. When trained on the DRIVE database and directly transferred to the STARE database, our few parameter models exhibit much stronger generalization ability than the SSA-Net. The AUC scores yielded from our models are all above 0.96, while that from the SSA-Net is around 0.94 as presented in Table 5. The poor generalization ability could be explained by overfitting since the SSA-Net contains more than 25 million trainable parameters which is over 250 times more than that of our default U-Net.
The observation that U-Net produces pleasing segmentation predictions even under extreme configuration conditions is unanticipated and intriguing. Small networks save both memory and computational resource, and allow for agile usage on mobile devices. Given the fundamental network architecture, the performance gain caused by increasing the amount of parameters or training data becomes marginal once the corresponding conditions, namely the minimal number of levels, number of filters, and number of convolutional layer in each block, are sufficiently satisfied. On the one hand, this observation could be explained by the simplicity of the task and the similarity among fundus photographs; on the other hand, it raises the question whether trading immense resource cost with minor performance increase is worthwhile. As future work, the same “control variates” methodology could be applied on alternative tasks for compression. Smart rather than bulky design should be the preferred research direction.
References
Alom MZ, Hasan M, Yakopcic C, Taha TM, Asari VK (2018) Recurrent residual convolutional neural network based on u-net (r2u-net) for medical image segmentation. arXiv preprint arXiv:1802.06955
Bergstra J, Bengio Y (2012) Random search for hyper-parameter optimization. Journal of Machine Learning Research 13(1):281–305
Budai A, Bock R, Maier A, Hornegger J, Michelson G (2013) Robust vessel segmentation in fundus images. Int J Biomed Imaging, vol 2013
Chaudhuri S, Chatterjee S, Katz N, Nelson M, Goldbaum M (1989) Detection of blood vessels in retinal images using two-dimensional matched filters. IEEE Trans Med Imaging 8(3):263–269
Dolz J, Ayed IB, Desrosiers C (2018) Dense multi-path U-Net for ischemic stroke lesion segmentation in multiple image modalities. In: International MICCAI Brainlesion workshop. Springer, Cham, pp 271–282
Frangi AF, Niessen WJ, Vincken KL, Viergever MA (1998) Multiscale vessel enhancement filtering. In: International conference on medical image computing and computer-assisted intervention. Springer, Berlin, Heidelberg, pp 130–137
Fraz MM, Basit A, Barman S (2013) Application of morphological bit planes in retinal blood vessel extraction. J Digital Imaging 26(2):274–286
Fraz MM, Rudnicka AR, Owen CG, Barman SA (2014) Delineation of blood vessels in pediatric retinal images using decision trees-based ensemble classification. Int J Comput Assisted Radiol Surgery 9(5):795–811
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Fu W, Breininger K, Schaffert R, Ravikumar N, Maier A (2019) A divide-and-conquer approach towards understanding deep networks. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, Cham, pp 183–191
Fu W, Breininger K, Schaffert R, Ravikumar N, Würfl T, Fujimoto J, Moult E, Maier A (2018) Frangi-net: a neural network approach to vessel segmentation. In: Bildverarbeitung für die Medizin 2018. Springer Vieweg, Berlin, Heidelberg, pp 341–346
Fu W, Breininger K, Pan Z, Maier A (2020) Degenerating U-Net on retinal vessel segmentation. In: Bildverarbeitung für die Medizin. Springer, pp 33–38
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Honale SS, Kapse VS (2012) A review of methods for blood vessel segmentation in retinal images. Int J Eng Res Technol 1:1–4
Hoover A, Goldbaum M (2003) Locating the optic nerve in a retinal image using the fuzzy convergence of the blood vessels. IEEE Trans Med Imaging 22(8):951–958
Huang G, Liu Z, Van Der Maaten L, Weinberger KQ (2017) Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4700–4708
Ioffe S, Szegedy C (2015) Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167
Isensee F, Petersen J, Klein A, Zimmerer D, Jaeger FP, Kohl S, Wasserthal J, Köhler G, Norajitra T, Wirkert S, Maier-Hein HK (2018) nnU-Net: self-adapting framework for U-Net-based medical image segmentation. Nat Methods 18(2):203–211
Khan MI, Shaikh H, Mansuri AM, Soni P (2011) A review of retinal vessel segmentation techniques and algorithms. Int J Comput Technol Appl 2(5):1140–1144
Kingma DP, Ba J (2014) Adam: a method for stochastic optimization. arXiv:1412.6980
Kovács G, Hajdu A (2016) A self-calibrating approach for the segmentation of retinal vessels by template matching and contour reconstruction. Med Image Anal 29:24–46
Li S, Chen Y, Yang S, Luo W (2019) Cascade dense-unet for prostate segmentation in mr images. In: International conference on intelligent computing. Springer, pp 481–490
Li X, Chen H, Qi X, Dou Q, Fu CW, Heng PA (2018) H-DenseUNet: hybrid densely connected UNet for liver and tumor segmentation from CT volumes. IEEE Trans Med Imaging 37(12):266–2674
Lin TY, Goyal P, Girshick R, He K, Dollár P (2017) Focal loss for dense object detection. In: Proceedings of the IEEE international conference on computer vision, pp 2980–2988
Liskowski P, Krawiec K (2016) Segmenting retinal blood vessels with deep neural networks. IEEE Trans Med Imaging 35(11): 2369–2380
Liu W, Sun Y, Ji Q (2020) Mdan-unet: multi-scale and dual attention enhanced nested u-net architecture for segmentation of optical coherence tomography images. Algorithms 13(3):60
Maier A, Syben C, Lasser T, Riess C (2019) A gentle introduction to deep learning in medical image processing. Zeitschrift für Medizinische Physik 29(2):86–101
Maninis KK, Pont-Tuset J, Arbeláez P, Van Gool L (2016) Deep retinal image understanding. In: International conference on medical image computing and computer-assisted intervention. Springer, Cham, pp 140–148
Moghimirad E, Rezatofighi SH, Soltanian-Zadeh H (2012) Retinal vessel segmentation using a multi-scale medialness function. Comput Biol Med 42(1):50–60
Moradi S, Oghli MG, Alizadehasl A, Shiri I, Oveisi N, Oveisi M, Maleki M, Dhooge J (2019) Mfp-unet: a novel deep learning based approach for left ventricle segmentation in echocardiography. Phys Med 67:58–69
Nair V, Hinton G (2010) Rectified linear units improve restricted boltzmann machines vinod nair. Proceedings of the 27th International Conference on International Conference on Machine Learning, pp 807–814
Noh KJ, Park SJ, Lee S (2019) Scale-space approximated convolutional neural networks for retinal vessel segmentation. Comput Methods Programs Biomed 178:237–246
Orlando JI, Prokofyeva E, Blaschko MB (2016) A discriminatively trained fully connected conditional random field model for blood vessel segmentation in fundus images. IEEE Trans Biomed Eng 64(1):16–27
Owen CG, Rudnicka AR, Mullen R, Barman SA, Monekosso D, Whincup PH, Ng J, Paterson C (2009) Measuring retinal vessel tortuosity in 10-year-old children: validation of the computer-assisted image analysis of the retina (CAIAR) program. Invest Ophthalmol Vis Sci 50(5):2004–2010
Palomera-Pérez MA, Martinez-Perez ME, Benítez-Pérez H, Ortega-Arjona JL (2009) Parallel multiscale feature extraction and region growing: application in retinal blood vessel detection. IEEE Trans Information Technol Biomed 14(2):500–506
Rahebi J, Hardalaç F (2014) Retinal blood vessel segmentation with neural network by using gray-level co-occurrence matrix-based features. J Med Syst 38(8):1–12
Ronneberger O, Fischer P, Brox T (2015) U-Net: convolutional networks for biomedical image segmentation. In: International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, pp 234–241
Rother C, Kolmogorov V, Blake A (2004) “GrabCut” interactive foreground extraction using iterated graph cuts. ACM Trans Graph (TOG) 23(3):309–314
Roychowdhury S, Koozekanani DD, Parhi KK (2014) Blood vessel segmentation of fundus images by major vessel extraction and subimage classification. IEEE Journal Biomed Health Info 19(3):1118–1128
Srinidhi CL, Aparna P, Rajan J (2017) Recent advancements in retinal vessel segmentation. J Med Syst 41(4):70
Staal J, Abràmoff MD, Niemeijer M, Viergever MA, Van Ginneken B (2004) Ridge-based vessel segmentation in color images of the retina. TMI
Taha AA, Hanbury A (2015) Metrics for evaluating 3-D medical image segmentation: analysis, selection, and tool. BMC Med Imaging 15(1):1–28
Venkatesh G, Naresh Y, Little S, O’Connor NE (2018) A deep residual architecture for skin lesion segmentation. In: OR 2.0 context-aware operating theaters, computer assisted robotic endoscopy, clinical image-based procedures, and skin image analysis. Springer, pp 277–284
Wang S, Yin Y, Cao G, Wei B, Zheng Y, Yang G (2015) Hierarchical retinal blood vessel segmentation based on feature and ensemble learning. Neurocomputing 149:708–717
Wang Y, Ji G, Lin P, Trucco E (2013) Retinal vessel segmentation using multiwavelet kernels and multiscale hierarchical decomposition. Pattern Recognit 46(8):2117–2133
Wu A, Xu Z, Gao M, Buty M, Mollura DJ (2016) Deep vessel tracking: a generalized probabilistic approach via deep learning. In: 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI). IEEE, pp 1363–1367
Xiao X, Lian S, Luo Z, Li S (2018) Weighted Res-Unet for high-quality retina vessel segmentation. In: 2018 9th international conference on information technology in medicine and education (ITME). IEEE. pp 327–331
Yau JW, Rogers SL, Kawasaki R, Lamoureux EL, Kowalski JW, Bek T, Chen SJ, Dekker JM, Fletcher A, Grauslund J, Haffner S, Hamman FR, Kamran MI, Kayama T, Klein EB, Klein R, Krishnaiah S, Mayurasakorn K, O’hare PJ, Orchard JT, Porta M, Rema M, Roy SM, Sharma T, Shaw J, Taylor H, Tielsch MJ, Varma R, Wang J, Wang N, West S, Xu L, Yasuda M, Zhang X, Mitchell P, Wong YT (2012) Global prevalence and major risk factors of diabetic retinopathy. Diabetes Care 35(3):556–564
Yin Y, Adel M, Bourennane S (2012) Retinal vessel segmentation using a probabilistic tracking method. Pattern Recognit 45(4):1235–1244
Yu F, Koltun V (2015) Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122
Yu H, Barriga S, Agurto C, Zamora G, Bauman W, Soliz P (2012) Fast vessel segmentation in retinal images using multi-scale enhancement and second-order local entropy. In: Medical imaging 2012: computer-aided diagnosis, vol 8315, p. 83151B. International Society for Optics and Photonics
Zeng Z, Xie W, Zhang Y, Lu Y (2019) Ric-Unet: an improved neural network based on Unet for nuclei segmentation in histology images. IEEE Access 7:21420–21428
Zhang J, Jin Y, Xu J, Xu X, Zhang Y (2018) Mdu-net: multi-scale densely connected u-net for biomedical image segmentation. arXiv preprint arXiv:1812.00352
Zhang J, Li H, Nie Q, Cheng L (2014) A retinal vessel boundary tracking method based on bayesian theory and multi-scale line detection. Comput Med Imaging Graph 38(6):517–525
Zhou Z, Siddiquee MMR, Tajbakhsh N, Liang J (2018) Unet++: a nested U-Net architecture for medical image segmentation. In: Deep learning in medical image analysis and multimodal learning for clinical decision support. Springer, Cham, pp 3–11
Zuiderveld K (1994) Contrast limited adaptive histogram equalization. In: Graphics gems. Academic Press, pp 474–485
Funding
Open Access funding enabled and organized by Projekt DEAL. The research leading to these results has received funding from the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (ERC Grant No. 810316).
Author information
Authors and Affiliations
Contributions
W.F. is the main author of the paper. She designed the experiments, conducted the experiments and evaluation, and wrote the main part of the manuscript. K.B., R.S., Z.P., and A.M. contributed to the experimental design and the writing of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Code availability
Not available.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed consent
Informed consent was obtained from all individual participants included in the original study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fu, W., Breininger, K., Schaffert, R. et al. “Keep it simple, scholar”: an experimental analysis of few-parameter segmentation networks for retinal vessels in fundus imaging. Int J CARS 16, 967–978 (2021). https://doi.org/10.1007/s11548-021-02340-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11548-021-02340-1