
Abstract
This paper explores an approach to root and stem allomorphy that does not make use of context sensitive rules (i.e., secondary exponence) and relies on primary exponence only. In such a system, each feature is referenced by realisation rules only once and multiple exponence is eliminated. The study applies this system to the phenomenon of root and stem allomorphy in declension systems (McFadden in Glossa 3:8.1-36, 2018, Christopoulos & Zompì in Natural Language & Linguistic Theory 1–31, 2022). The paper argues that in this domain, the theory makes different empirical predictions than models based on context-sensitive rules. Specifically, the current model allows for an account of special nominative singular forms and the so-called pseudo-ABA patterns (Middleton in Morphology 31:329–354, 2021, Davis in Glossa 6, 2021). The proposal relies on the Nanosyntax model of grammar, using phrasal lexicalisation and lexicalisation-driven movements (Starke in Exploring nanosyntax, Oxford University Press, Oxford, pp. 239–249, 2018), though alternative implementations of this idea are conceivable.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
This article deals with multiple exponence in the domain of irregular (suppletive) roots and stems (Bobaljik, 2012; Moskal, 2015; McFadden, 2018; Smith et al., 2019; Christopoulos & Zompì, 2022; Vanden Wyngaerd et al., 2021). From the perspective of multiple exponence, examples with suppletive roots/stems fall into two (descriptive) classes. In some cases, suppletive bases are accompanied by regular suffixes, as in (1a). Other times, the special form of the root lacks the regular suffix, as in (1b).
-
(1)
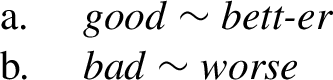
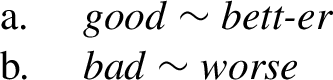
The pair in (1b) would traditionally fall under the label cumulative exponence: the morpheme worse conveys both the conceptual meaning of good and the grammatical meaning of a comparative. On the other hand, forms that exhibit root suppletion along with regular affixal marking (such as (1a)) can be considered instances of multiple exponence. That is because the comparative meaning seems to be reflected twice in bett-er: once by the suffix, and also by the special shape of the root bett-.
In current Late-Insertion theories such as Distributed Morphology (Halle & Marantz, 1993), multiple exponence is standardly implemented via ‘context specification.’ In this approach, the example (1a) can be accounted for by the rules in (2) (from Bobaljik 2012, 8, see also Smith et al. 2019, 1035).
-
(2)


The rule (2b), inserting the suppletive root, includes a context specification after the slash, which means that it only applies in the context of a comparative feature. Given that the cmpr meaning is then also realised by -er (due to (2c)), the comparative meaning is referenced twice: once by the context sensitive rule and for the second time by the primary exponent -er. The result of lexicalisation using these rules is shown in (3a,b) for the positive and the comparative degree respectively.Footnote 1
-
(3)


It is relevant to note at this point that the pair bad ∼ worse can be treated similarly. This can be achieved by the rules in (4).
-
(4)
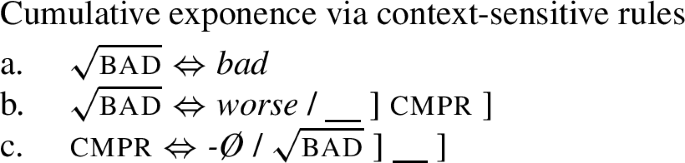
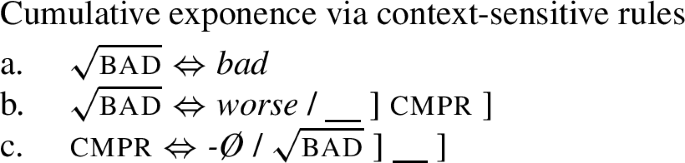
The suppletive root worse is again introduced by a context-sensitive rule, see (4b). In addition, the comparative marker is zero in the context of the root \(\sqrt{\text{\textsc{bad}}}\), (4c). This leads to the result shown in (5).Footnote 2
-
(5)


The interest of this analysis is that it allows for a unified approach to all root suppletion, using just a single mechanism (namely context-sensitive rules). From a theoretical perspective, this is clearly attractive.
This paper follows a similar idea (attempting to unify all suppletion), but it investigates the merits of the opposite logical possibility, which is that root and stem suppletion (including pairs such as good ∼ bett-er) can be analysed in terms of cumulative exponence. In this approach, allomorphic variation does not arise due to contextual specification; it arises as a result of the fact that the two different roots (or stems) realise different features.
To see how this works, consider first an analysis of bad ∼ worse in terms of cumulative exponence. This is shown schematically in Table (6).
-
(6)
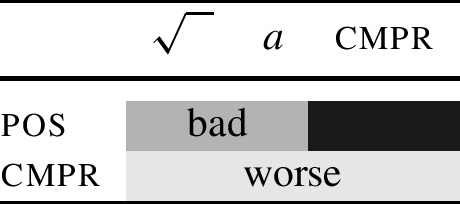

In this table, the forms bad ∼ worse realise the relevant features as indicated by the shading. The positive-degree bad realises the \(\sqrt{ \phantom{ll} }\) and a (the absence of cmpr in the positive is indicated by the black colouring under cmpr). The comparative worse realises the cmpr meaning in addition. The two roots do not differ by their context, they differ because each of them realises a different set of features.
This paper implements portmanteau morphology by means of phrasal lexicalisation (Starke, 2009 et seq.), using rules of exponence such as those in (7).
-
(7)


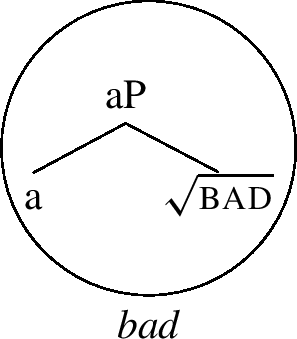
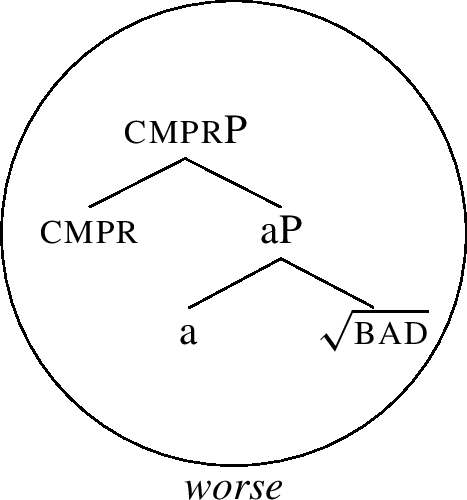
The rule (7a) says that the constituent corresponding to the positive is lexicalised as bad, see (8). When the cmpr feature is added, the whole constituent is realised as worse due to (7b), see (9).
-
(8)

-
(9)

Regardless of these details, the gist of the approach is that bad and worse do not realise the same feature(s). Rather, they realise different (even if overlapping) feature sets. As a consequence of this, context specification is not needed, and multiple exponence is not involved. During insertion, no feature is referenced twice in either form.
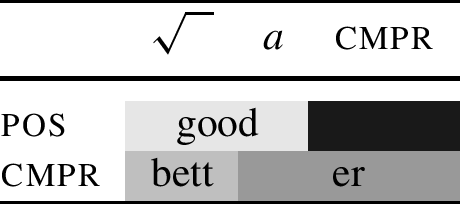
Let me now turn to the question of how we can extend this type of account to good ∼ bett-er. One possible implementation of this idea is in (10) (cf. Caha et al. 2019).
-
(10)
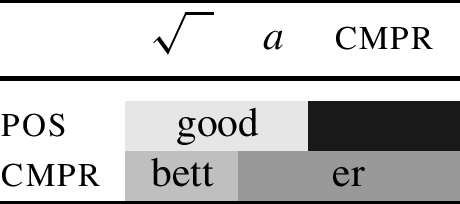

The analysis depicted in (10) says that in the positive degree, the features \(\sqrt{ \phantom{ll} }\) and a are realised by the root good. In the comparative, the cmpr feature must be lexicalised. However, in the case of this particular root, the lexicon lacks a portmanteau for all the features. This is why -er must appear, and the three features of the comparative will have to be divided between the root and the suffix. The idea depicted in Table (10) is that -er lexicalises both cmpr and a. This leaves only the \(\sqrt{ \phantom{ll} }\) feature to be lexicalised by the root. Since this is a different feature set from the one realised by the root good in the positive, a different root (bett) may appear in the comparative without the need for context specification.Footnote 3
The lexical items that give rise to the lexicalisation in Table (10) are provided in (11).
-
(11)


Importantly, no rule in (11) includes any context specification; the application of each rule realises a given feature and prevents other lexical items from targeting the same feature again. For ease of reference, I will call this an NME system (for No Multiple Exponence).Footnote 4
One of the goals of this paper is to provide an algorithmic implementation of this idea using the lexicalisation algorithm of Nanosyntax (Starke, 2018). The second goal is to show that in certain well-defined contexts, the NME approach is able to generate patterns of suppletion that an approach based on context-sensitive rules cannot. Since these patterns are attested in natural languages, this establishes the empirical need for an approach along these lines.
The organisation of the article is as follows. Section 2 introduces the phenomenon of special nom.sg stems (building on the facts and insights offered in McFadden, 2018). The section also describe the so-called cumulative case decomposition (Caha, 2009), which serves as an important background for the overall analysis. Section 3 demonstrates that context-sensitive rules cannot generate special nom.sg stems if the cumulative decomposition is adopted (drawing on Christopoulos & Zompì, 2022). Section 4 shows that special nom.sg stems can be modeled in a system that adheres to ‘no multiple exponence.’ Sect. 5 introduces a Nanosyntactic formalisation of the NME approach (drawing on Starke, 2018). Section 6 turns to additional patterns of root suppletion that can be captured in the NME system, but cannot be accounted for by context-sensitive rules. Section 7 investigates the implications of this analysis for the so-called pseudo-ABA patterns. Section 8 concludes.
2 Special nominatives
The empirical discussion in this paper revolves around case paradigms such as the one in Table (12). The table shows the declension of the Latin noun senec-s ‘old man,’ compared to the noun rēg-s ‘king.’Footnote 5
-
(12)
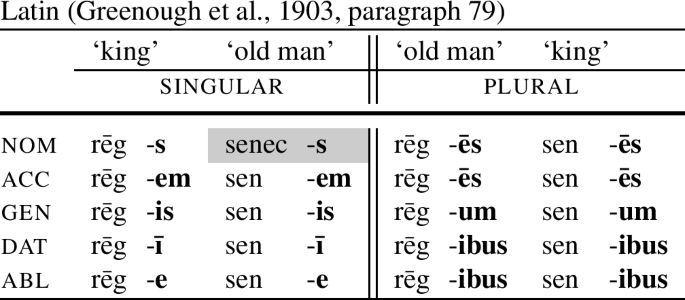

We can see that the two nouns have exactly the same endings both in the singular (on the left in the table) and in the plural (on the right). The identity of the endings is highlighted by boldface. The noun senec-s ‘old man’ differs from the noun rēg-s ‘king’ in that it has a special form of the root in the nominative singular (senec), which differs from the base in all other forms (sen).
As to whether the base for ‘old man’ in (12) should be split into two separate morphemes (sen-ec) or not (senec) is orthogonal to the main point. The form is not segmented in (12), but even if it were, one would still need to account for the presence of -ec in the nominative singular and its absence in all other cases, which is the same distribution as the alternation between senec and sen.
There are reasons to think that the distribution of the special stem (nom.sg vs. the rest) is conditioned by morphosyntax. In principle, looking at the paradigms in Table (12), it could be the case that the form senec- appears before consonants, and sen- before vowels. However, the existence of forms such as senec-iō ‘old man’ suggests that such a phonological explanation is most likely not on the right track (because senec may appear before vowels).
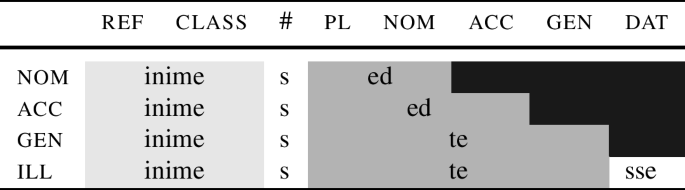
The paradigm in Table (12) – with a special nominative singular differentiated from all other cases – is representative of a larger class of cases. McFadden (2018) notes that a pattern like this is also found in Finnish. Table (13) provides an analogous example from Estonian.
-
(13)
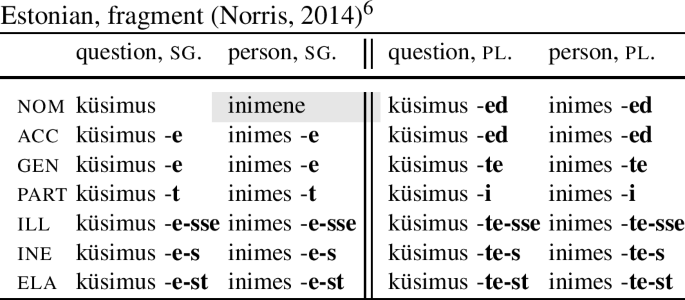

We can see that the nouns ‘question’ and ‘person’ inflect alike in all cases. However, in nom.sg, the noun ‘question’ has the same stem as in all the other cases, but the noun ‘person’ has an irregular stem inimene (instead of the expected *inimes). The pattern of distribution (nom.sg vs. the rest) is the same type of distribution as that exhibited by senec.
Christopoulos and Zompì (2022) bring up additional examples from pronominal declensions. Table (14) illustrates the existence of a special nom.sg stem by the feminine forms of the Doric Greek definite determiner.
-
(14)
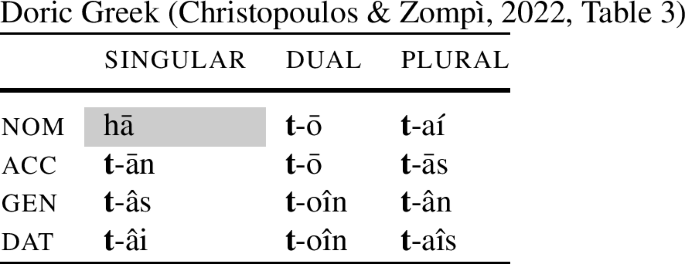

Having established the existence of special forms in nom.sg, let me turn to their theoretical implications. There are two points that I am going to argue for in this paper. The first point is that under certain assumptions concerning case features, the special nom.sg forms cannot be derived by context-sensitive rules (as pointed out by Christopoulos and Zompì 2022). The second point is that under the same decomposition, there are NME systems that can generate such paradigm. The two claims are summarised in (15).
-
(15)
The argument based on (15) is of course not a direct argument in favour of NME. For it to be one, we have to independently prove that D is correct, a point to be returned to in Sects. 6 and 7. However, regardless of the (in)correctness of D, we can still conclude something about the generative power of the NME system in comparison with context sensitive rules. Namely, it follows from (15) that NME can generate some paradigms that context-sensitive rules cannot.
This conclusion brings some nuance to the common understanding in the literature, which is that context-sensitive rules have a greater generative capacity than NME systems. This is correct in one sense, namely with respect to locality: NME systems are strictly local, and allomorphy can only be triggered under adjacency. To see this, recall the core idea of an NME system, which is that the specific allomorph of the root is determined by how many features it lexicalises. In the model to be developed, the amount of features lexicalised by the root can only be influenced by the neighbouring morpheme. We saw this in Table (10), repeated for convenience in (16). In the table, -er lexicalises a, which prevents the root from doing so (yielding a different root allomorph from positive). Crucially, such an interaction between morphemes proceeds locally, and cannot skip across a morpheme. This is going to be formalised in Sect. 5.
-
(16)

Such a strictly local nature of the interaction does not follow from the formalism of context sensitive rules. This is not to say that such theories are unconstrained by locality: most theories based on context-sensitive rules do impose some locality requirements on how local the trigger must be (some even independently adopt morpheme adjacency, e.g., Bobaljik 2012, Embick 2015, Merchant 2015). However, the point is that this is not an inherent property of the formalism. As a result, some authors use context-sensitive rules to model apparent cases of non-local allomorphy. For example, Choi and Harley (2019, 1320) argue that “[t]o derive the realization of suppletive Korean verbs, [...] it is necessary to allow conditioning by hierarchically and linearly nonlocal nodes [...].” This in turn leads them to “refut[e] alternative theories of locality constraints on suppletion” (see also Moskal and Smith 2016).
Whether non-local allomorphy exists is, however, a debated issue. Specifically, some of the literature argues that non-local allomorphy in the relevant cases is only apparent, and that the actual facts can be analysed using strictly local processes.Footnote 6
If this is so (and non-local allomorphy does not exist), the ability of context-sensitive rules to model non-local allomorphy may be, in fact, a disadvantage. This follows from the idea that, in the ideal case, the formalism we use for a particular process not only allows us to capture the relevant phenomenon (allomorphy), but also correctly delineates the restrictions that the phenomenon is subject to.
Regardless of how this issue is resolved, this article makes a complementary point: it argues that when we consider locally conditioned allomorphy (which is allowed by both approaches), special nominatives represent a phenomenon that can be generated by an NME approach, but cannot be captured by context-sensitive rules (assuming a particular decomposition D). By showing this, the article aims to establish the fact that context-sensitive rules do not represent a theory with an unlimited empirical coverage, which we can simply fall back on in response to apparent cases of non-local allomorphy, as the quote from Choi and Harley (2019) seems to imply.
With the issues surrounding generative power clarified, let us now come back to the main point in (15), namely, that under a particular case decomposition D, context-sensitive rules cannot derive paradigms with special nom.sg forms, while at least some NME models can. I start the discussion by describing the properties of the decomposition D, which is used in the argument.
The relevant type of decomposition will be referred to as ‘cumulative’ decomposition. In this decomposition (pioneered in the work by Bobaljik 2012), the feature structures of individual paradigm cells are related by containment. In the literature, such a decomposition has also been proposed for case (see Caha 2009, 2013, Zompì 2017, McFadden 2018, Smith et al. 2019). Specifically, the literature argues that the nominative is characterised by just a single feature, called f1 in Table (17). The accusative has the feature f1 plus one more feature, which I call simply f2. Oblique cases (genitive, dative and so on) add additional features on top of f1 and f2.
-
(17)


For the purpose of this article, I follow works such as Smith et al. (2019) or Christopoulos and Zompì (2022) and conflate all the obliques into just one cell. This is because for the argument, the fine distinctions among various oblique cases are irrelevant.Footnote 7 I also use the privative feature pl to capture the difference between the singular and plural. However, nothing hinges on this and any approach to number is compatible with the argument made here.
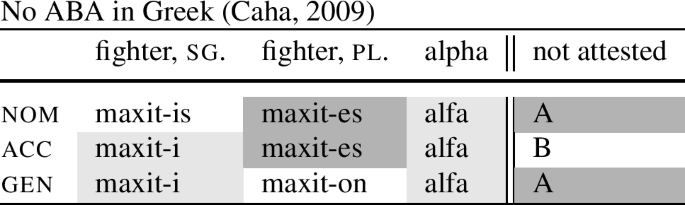
Now the reason why the cumulative decomposition has been proposed is that it disallows the generation of the so-called ABA syncretism patterns, where the nominative and an oblique case would be the same, with the accusative different. This is desirable, since the empirical work by Baerman et al. (2005, 49), Caha (2009), Zompì (2019) and others has established that such syncretisms are indeed (virtually) unattested.
An illustration of the typological gap is provided in (18) using paradigms from Greek. We can see that we only get syncretisms that are adjacent in the sequence nom–acc–obl. There is no skipping across a case, so a paradigm like to one on the right is not found.
-
(18)

The cumulative decomposition in Table (17) allows us to derive the absence of ABA patterns. This is achieved by relying on the notion of a natural class definable over the features in Table (17). The only trait that nom and obl share is the presence of f1. However, the natural class defined by the presence of f1 also includes acc. Therefore, there is no way of defining a natural class comprised of nom and obl to the exclusion of acc.Footnote 8
Following much of the literature, I refer to the absence of ABA patterns of syncretism as *ABA. However, it must be pointed out that the term *ABA is currently used to refer to two different subtypes of *ABA. The first subtype of *ABA pertains to full forms. *ABA in this sense means that there is no paradigm where the nom as a whole looks the same as the oblique, with the accusative different. I will refer to this subtype of *ABA as Full *ABA.Footnote 9
In the second sense, *ABA refers to the relationship between roots or stems. This is how the term *ABA has been used in the seminal work on adjectives by Bobaljik (2012). This latter use has been also used in works dealing with roots and stems in case paradigms, such as McFadden (2018), Smith et al. (2019) or Christopoulos and Zompì (2022). I will refer to this second sense of *ABA as Base *ABA.
To see the difference between the two senses, consider the singular paradigm of ‘fighter’ in (18). All the forms are derived from the same base, so from the perspective of the base, this is an AAA pattern. However, from the perspective of the full form, this is an ABB pattern (nom≠acc=gen).
Some authors argue that both senses should be theoretically unified (e.g., Zompì, 2017). This desideratum stems from an observation that domains where Full *ABA holds are often also domains where Base *ABA holds and vice versa. However, there is also some work arguing that domains where Full *ABA is observed may contain Base *ABA violations (Middleton, 2021). I return to this issue in Sect. 7; the point for now is that we need to keep the two notions apart.
Summarising, this section has introduced the phenomenon of special nom.sg stems. I have further introduced the main claim, which is that if the cumulative decomposition is adopted, special nom.sg stems cannot be modelled by context-sensitive rules, while they can be modelled in NME approaches. I have also introduced the cumulative decomposition, which has been used in the literature to model the absence of ABA patterns (*ABA). The final thing to keep in mind is that the term *ABA has two different subtypes, which will be referred to as the Full *ABA and the Base *ABA.
3 Context-sensitive rules cannot derive special nominatives
This section shows why, if cumulative decomposition is adopted, context-sensitive rules cannot capture special nominative forms. The discussion in its essence repeats the conclusions reached in Christopoulos and Zompì (2022).
Let me begin by showing how context sensitive rules operate in a system with cumulative decomposition. In order to demonstrate this, I introduce here the gist of the work done in Bobaljik (2012).
Bobaljik investigates bases in the three canonical adjectival degrees, i.e., in the positive, comparative and superlative. One of his core observations is that in addition to regular Base AAA cases such as (19a), we also find Base ABB triplets such as (19b) or Base ABC triplets such as (19c); but one rarely (if ever) finds Base ABA patterns, illustrated by the unattested sequence in (19d).Footnote 10
-
(19)

Bobaljik (2012, 2) states the absence of the Base ABA pattern as follows (slightly modified):
-
(20)
The Comparative-Superlative Generalization
If the comparative degree of an adjective is suppletive, then the superlative is also suppletive (i.e., with respect to the positive).
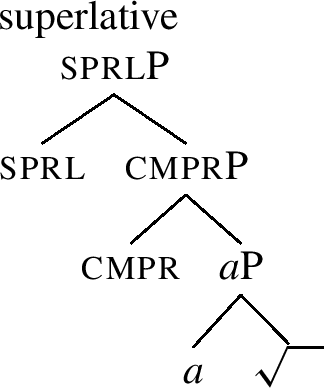
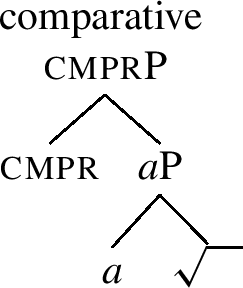
Bobaljik (2012) proposes an account of (20) terms of cumulative nesting structures, such as those given in (21)-(23).
-
(21)

-
(22)

-
(23)
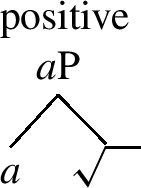

The positive in (23) is the simplest structure. The comparative in (22) contains the positive and adds cmpr. The superlative contains the comparative, adding sprl.
The reasoning that brings us from the structures to the *ABA generalisation is based on context-sensitive rules. Under this view, if the adjective has a special root in the comparative, this is because it is inserted by a rule sensitive to cmpr; see (24a,b), repeated from (2).
-
(24)


Now since the superlative in (21) contains the cmpr node, the conditions for the application of the rule (24b) are also met in the superlative, yielding be(tt)-st. That is why, if the comparative has a suppletive root, the superlative cannot ‘fall back on’ the root of the positive degree.Footnote 11
The combination of context-sensitive rules and cumulative decomposition is thus successful in both allowing for root suppletion, and, at the same time, deriving also the restrictions that suppletion is subject to. The question I turn to now is why it is impossible to extend this model to the case facts discussed above.
To explain this, let me turn to the work by McFadden (2018). In his article, McFadden investigates root and stem suppletion in declensional paradigms. He observes that root suppletion in case paradigms is restricted by the generalisation (25).Footnote 12
-
(25)
Nominative Stem-Allomorphy Generalization (NSAG)
When there is (noun) stem allomorphy conditioned by case, it distinguishes the nominative from all other cases.
This generalisation is rather similar to Bobaljik’s *ABA generalisation. To see that, suppose that we are looking at a nominative-accusative language. In such a language, if (25) is correct, (26) is also necessarily correct:
-
(26)
The Accusative-Oblique Generalization
If the accusative case of a noun is suppletive, then the oblique is also suppletive (i.e., with respect to the nominative).
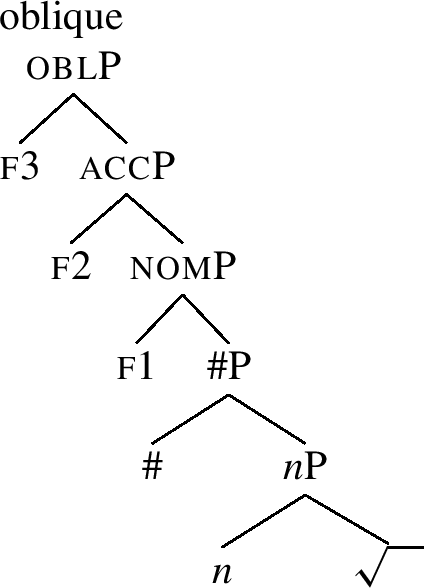
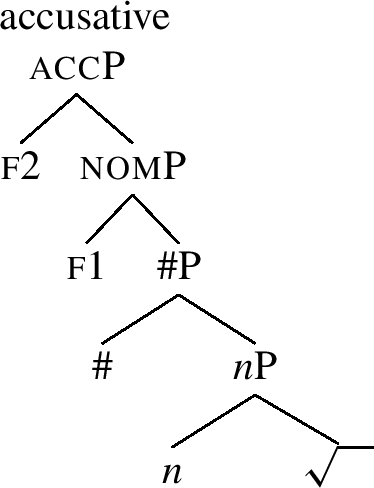
McFadden (2018) explains the generalisation (25) (and thereby also (26)) by proposing an account which uses Bobaljik’s work as a model. First of all, McFadden relies on nested case structures like the ones in (27)-(29).
-
(27)

-
(28)

-
(29)
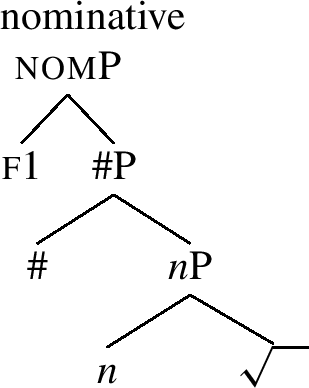

The nominative structure is under (29). It contains the root feature and the little n head (traditionally hosting gender). The head # represents the singular number, on top of which we see the nominative case feature f1. The accusative in (28) adds the feature f2 on top of the nominative, etc. Once these structures are adopted, it seems that we can model the special nominative forms using an approach based on vanilla-flavour context-sensitive rules. This is presented in (30) (drawing on McFadden 2018, ex. 13).
-
(30)
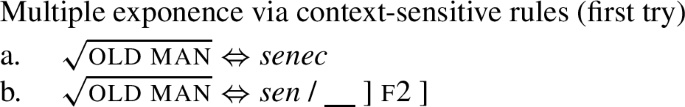
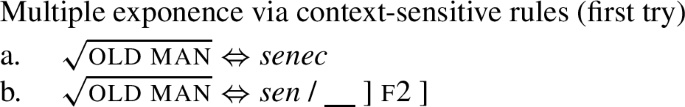
Specifically, the root senec- would be a default form of the root, see (30a) (just like good in the positive is the unmarked form of the adjectival root). The root sen would be sensitive to the presence of f2, see (30b). Since this feature is also found in all the oblique cases, the root sen- appears here as well.Footnote 13
This correctly generates the singular, repeated in Table (31) for convenience.
-
(31)


However, this approach fails in the plural (regardless of how plural number is grammatically encoded). This is because the rule (30b) (inserting sen-) only applies in the presence of the ‘accusative’ feature f2. However, the f2 feature is obviously missing in the nominative plural. Thus, as things currently stand, we would expect the root senec- in nom.pl, contrary to fact.
Given this problem, we must therefore change the rules in one way or another. The intuition that one would like to encode is that the root sen- is not a form that would be bound to a special case (which is what the problematic rule (31b) says); instead, sen- appears to be an ‘elsewhere’ form, which applies whenever the more specific rule inserting senec- fails to apply.
This latter intuition entails that senec- must be lexically coded for a specific context of insertion: the nominative singular. However, under the cumulative decomposition, the nominative case only has the f1 feature, and no other case feature. Therefore, the only way we could formulate an entry for senec would be as in (32), where (#) indicates that we could also specify this rule for the singular context.
-
(32)
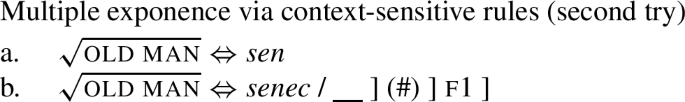
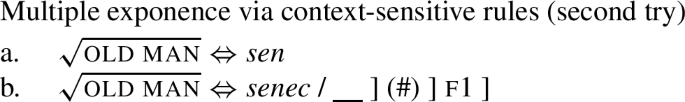
But this does not work either, because under cumulative decomposition, the nom feature f1 is found in all cases. This has the effect that specifying senec- for f1 incorrectly leads to senec- in all cases (minimally in the singular). But this is obviously the wrong result. So the conclusion is that under cumulative decomposition, it is impossible to model the distribution of the two stem allomorphs, sen and senec.
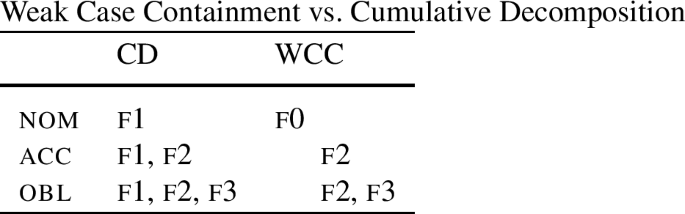
Given this result, Christopoulos and Zompì (2022) draw the conclusion that cumulative decomposition must be abandoned. To make sure that senec- is able to refer specifically to the nominative, they propose a new type of decomposition, which they call ‘Weak Case Containment’ (WCC). According to this proposal, the accusative is still contained in all oblique cases, but it does not contain the nominative. The nominative case has a feature that is not contained in the accusative, or any other case. This feature will be called f0.
Table (33) compares the Cumulative Decomposition (CD) with Weak Case Containment (WCC). We can see that there is no containment between nom and acc in the latter.
-
(33)
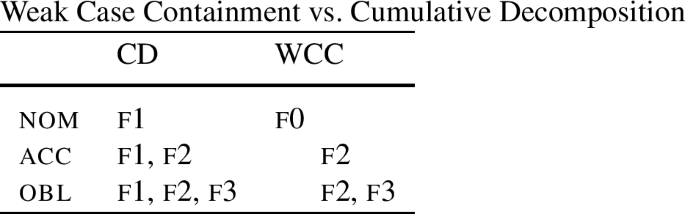

Once such a decomposition is adopted, it becomes possible to single out the nominative by specifying the context of insertion for senec as f0 (+ singular). The root sen is then the elsewhere form.
-
(34)
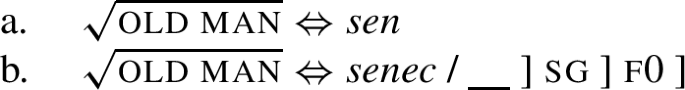
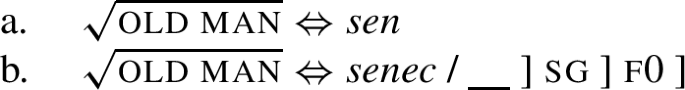
Concluding, context-sensitive rules cannot model paradigms with special nom.sg under cumulative decomposition. Given this result, we have two options: we either abandon cumulative decomposition, or context-sensitive rules. Christopoulos and Zompì (2022) suggest to abandon cumulative decomposition. In Sects. 4 and 5, I explore the second alternative, abandoning context-sensitive rules. I come back to the comparison of the two alternatives in Sects. 6 and 7.
4 NME can derive special nominatives
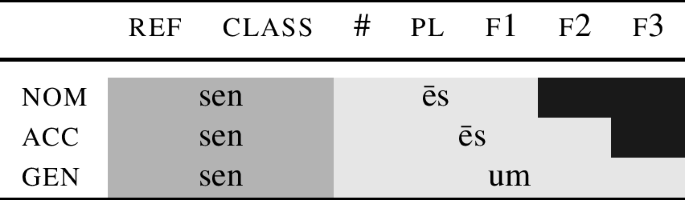
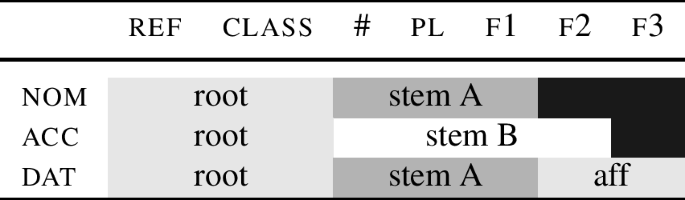
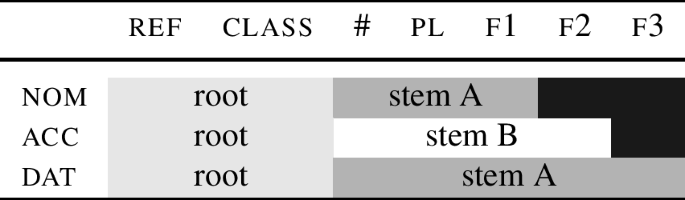
This section describes in an informal way how an NME system can model special nom.sg while maintaining cumulative decomposition. (An algorithmic implementation is offered in Sect. 5.) The proposal is depicted in the lexicalisation table (35). The core idea is that the roots senec and sen lexicalise different feature sets.
-
(35)


In the table, I switch the features \(\sqrt{ \phantom{bl} }\) and n for ref and class. These latter features originate in Harley and Ritter (2002). Ref indicates that nouns are referring expressions. Class is a gender-related head. Nothing hinges on this, but since I am switching from a DM-style analysis to a different model, I swap also these DM-specific labels.
Turning back to Table (35), we can see that the root senec lexicalises the features ref class and the number feature #.Footnote 14 In the nominative, the only remaining feature that needs to be spelled out is f1. According to the analysis in (35), this is the job of the nominative ending -s. The lexical entries are provided below. They associate phonological exponents to sets of features.
-
(36)
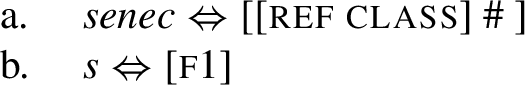
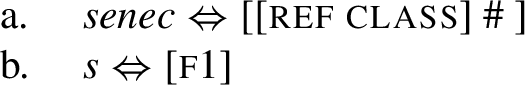
In the accusative, the feature f2 must be spelled out. This entails that we must find in the lexicon a lexical item that lexicalises f2. The analysis depicted in the table builds on the observation that Latin is a fusional language; this means that its case endings generally express both case and number.Footnote 15 Because of this, there is no ‘pure’ (agglutinative) accusative case ending that would lexicalise just f1+f2 regardless of number. As a result, to lexicalise f2, we can only use endings that also spell out #. The assumed lexical entry of the accusative -em is in (37).
-
(37)
em ⇔ [[[ #] f1 ] f2 ]
The consequence of the need to use the ending -em to spell out f2 is that in the accusative, # can be spelled out in two different ways: on the one hand, it can be realised by the root senec in (36a). In the other hand, it can be realised by the ending -em in (37).
In Nanosyntax (Starke, 2018), such conflicts are always resolved by ‘shrinking’ the root in a way that it only realises the lower features, leaving # to be lexicalised by the ending, see the accusative row in (35). Now as a result of the fact that the root no longer realises # in the accusative, it appears in a different form, namely sen-, with a lexical entry as in (38a).
-
(38)
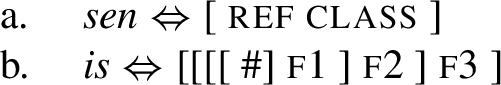
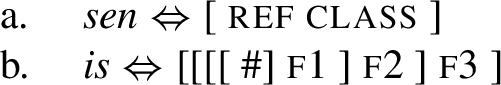
This root is then maintained throughout the declension, since all oblique case markers also lexicalise the number feature #. In (38b), this is illustrated by the genitive singular ending -is.
The analysis of the plural is shown in (39). The header of the table provides the grammatical features that need to be realised. The crucial addition here concerns the plural, which (I assume) contains an additional pl feature in between the # node and case.
-
(39)

In Table (39), all the features starting from ref and going all the way to case must be lexicalised. (40) provides the two items relevant for the analysis in (39).
-
(40)
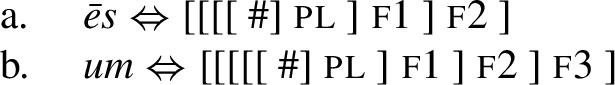
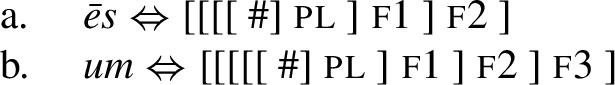
These endings spell out all the features starting at # and going across the plural all the way to case. This again leads to a situation where both the endings in (40) and the root senec in (36-a) can spell out #. This tension is again resolved by lexicalising # using the endings, which in turn leads to the emergence of the root sen.Footnote 16
In Table (39), -ēs is ambiguous between the accusative and the nominative. Similarly to other frameworks, Nanosyntax models this by allowing realisation rules to apply to multiple different feature representations. In Nanosyntax, the principle that defines the applicability of a lexical entry to a particular representation is the so-called Superset Principle. I give the technical wording in (41).
-
(41)
The Superset Principle, Starke (2009):
A lexically stored tree L matches a syntactic node S iff L contains the syntactic tree dominated by S as a subtree.
In non-technical terms, the Superset Principle says that a lexical item may realise any feature set that it contains. It can be easily seen that the structured representation of the nominative plural (given in (42b)) is literally contained within the lexical entry for -ēs repeated in (42a). Therefore, -ēs applies both in the accusative and nominative in (39), yielding syncretism between the two cases.
-
(42)
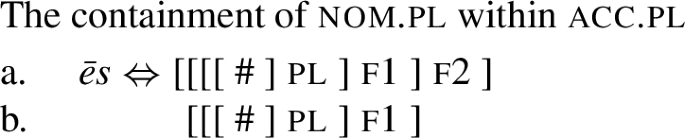
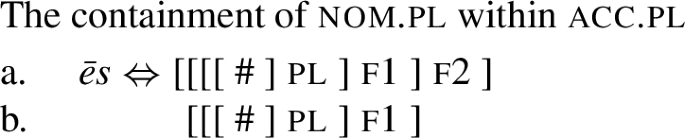
Once the Superset Principle is introduced, it must be pointed out that the genitive plural ending -um, with a lexical entry as in (43a), can also apply in the accusative plural (43b) and the nominative plural (43c). This is because the relevant feature sets are clearly contained in the lexical entry.
-
(43)


As a result, two lexical entries may apply in the accusative and nominative plural. The choice between them is decided by the Elsewhere Condition. The Elsewhere Condition (going back to Panini) basically says that whenever two rules may apply in a given environment, one should use the more specific rule. The following formulation (from Neeleman and Szendrői (2007)) brings out the intuition.
-
(44)
Elsewhere Condition (Neeleman & Szendrői, 2007)
Let R1 and R2 be competing rules that have D1 and D2 as their respective domains of application. If D1 is a proper subset of D2, then R1 blocks the application of R2 in D1.
According to this formulation, what we should do is compare the range of environments where R1 and R2 apply. In our specific case, we see that the range of environments where -ēs applies (see (42)) is a proper subset of the environments where -um does (see (43)). Therefore, where both rules apply, -ēs takes precedence over -um.
As a rule of thumb, we can decide between two rules by the amount of “superfluous features” (i.e., features found in the entry but not in the structure). Since -um has more superfluous features than -ēs in any context where they both apply, -ēs wins over -um.
The Superset Principle also leads to the competition among different root shapes. For example, assuming the Superset Principle, it is clear that the root senec in (45a) (repeated from (36-a)) also applies to the structure (45b). However, the structure (45b) is also associated to the phonology sen, see (45c), repeated from (38-a).
-
(45)
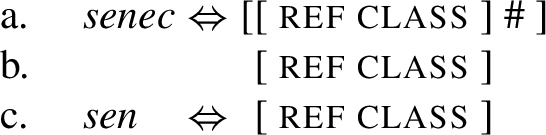
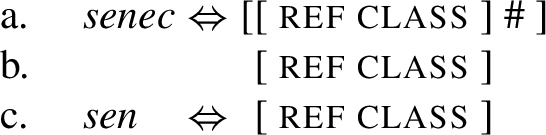
The consequence of having two root shapes as in (45a,c) is competition: when the root only spells out the features [ ref class ] given in (45b), both roots can apply, but sen wins due to the Elsewhere Condition, since it has fewer superfluous features.
Another consequence of the Superset Principle is that if a root has a lexical entry as in (45a) and no competitor, it will also realise the structure (45b). This consequence allows us to model the behaviour of regular roots belonging in the same declension as ‘old man.’ To see that, consider the lexical entry for rēg ‘king,’ given in (46).
-
(46)
rēg ⇔ [[ ref class ] # ]
This root is going to interact with the declension endings in the same way as the root for ‘old man.’ This means that in the nominative, it will spell out #, ref and class, see the first line in (47).
-
(47)
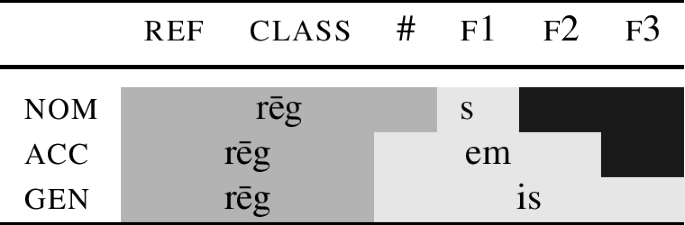

However, when f2 needs to be realised, the only ending that can spell it out must also realise #. As a result, the root is confined to realising the features [ ref class ], see the acc row in (47). In the case of the root ‘old man,’ this had an effect on form, leading to the change from senec- to sen-. However, the root ‘king’ only has one root shape for both structures, and we thus get ‘syncretism.’ The result is a ‘regular’ declension with the same shape of the root throughout.
Summarising, the main point of this section was to show how special nom.sg roots can be modelled by an NME account even if cumulative decomposition is assumed (this was impossible under context-sensitive rules). The crucial idea is that lexicalisation operates in a way that the root always spells out as many features as possible, given its lexical entry; but if a higher feature can only be spelled out by an ending that overlaps with the root/stem for some of the features, the root/stem ‘shrinks’ and realises only a subset of its maximal specification. In some cases, this leads to root allomorphy (when there are multiple entries for the same root). However, the same theory is also compatible with the existence of ‘regular’ paradigms with just a single root shape. In the next section, I shall provide an algorithmic implementation of the lexicalisation procedure that delivers lexicalisations as depicted in Tables (35), (39) or (47).
5 Technical implementation
This section implements the analysis described informally above within Nanosyntax (building on Starke (2018)). Readers who are not interested in the technicalities may proceed to Sect. 6.
Nanosyntax is a model with post-syntactic insertion of phonology. This means that syntax operates over abstract (phonology-free) building blocks and assembles them into morphosyntactic structures by the application of Merge. Phonology is introduced (by realisation rules) only after the relevant structure is created by Merge.
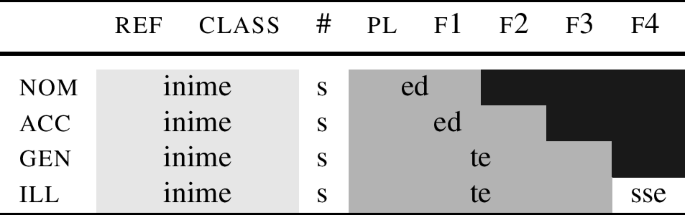
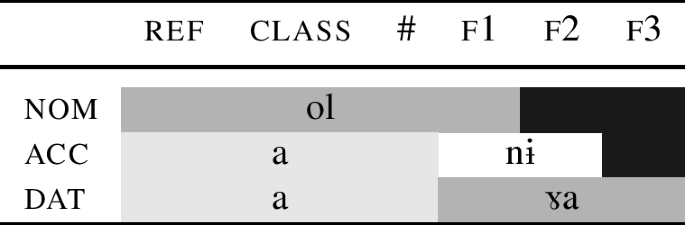
I will illustrate further details using a paradigm fragment from Estonian, discussed in (13), and repeated in (48) for convenience.
-
(48)


My goal is to show how the forms in the table are generated. Starting with the singular of the paradigm ‘person,’ the analysis I will be working towards is depicted in (49).
-
(49)
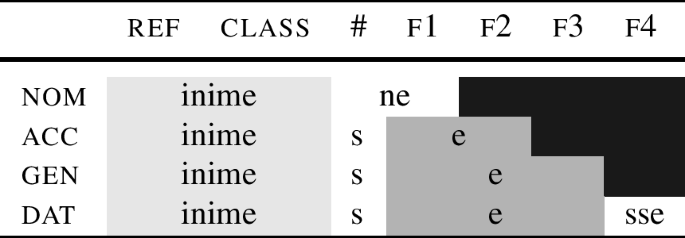

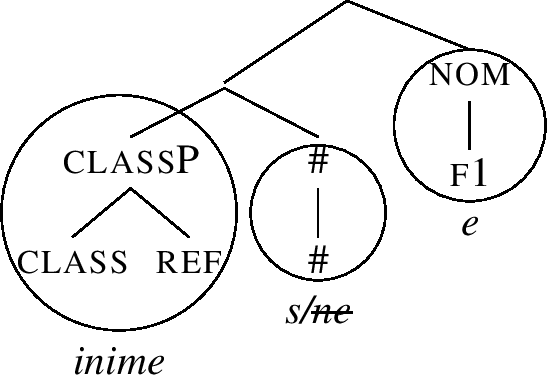
In (49), the root inime- ‘person’ spells out ref and class. The root is always followed by a stem marker. The stem marker lexicalises the features that cannot be realised by the root. Other than that, the gist of the analysis is the same as before: the stem marker tries to realise the maximum number of features allowed by its entry, spelling out # and f1 in the nominative. However, to lexicalise the acc feature f2, we need to use an additional ending (-e). This additional ending also lexicalises f1, which makes the stem marker ‘shrink’ in the same way as roots do, so that in the acc, the stem marker only realises #. The different feature sets realised by the stem marker ([#+f1] vs. [#]) are reflected by the different forms, i.e., -ne vs. -s. In Estonian, the genitive form (inime-s-e) then serves as the base for the addition of all oblique suffixes, as illustrated in (49) for the dative.Footnote 17
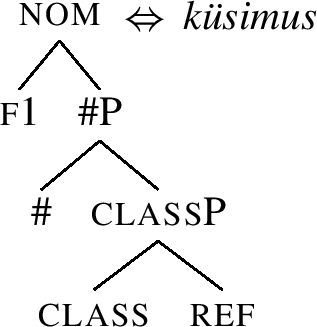
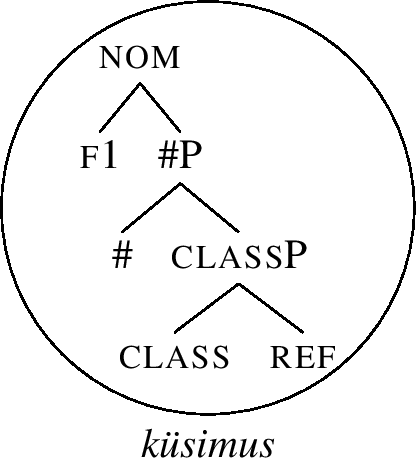
Let me now show in detail how the lexicalisation of the nominative inime-ne ‘person’ works. The first relevant thing is that in Nanosyntax, the elementary building blocks assembled by Merge are assumed to be atomic (non-decomposable) features (Fs). Therefore, all the features given in the header of Table (49) are merged one by one in a hierarcical structure like (50).
-
(50)
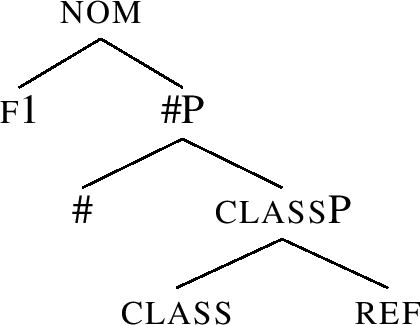

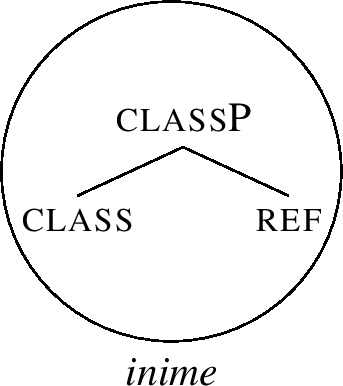
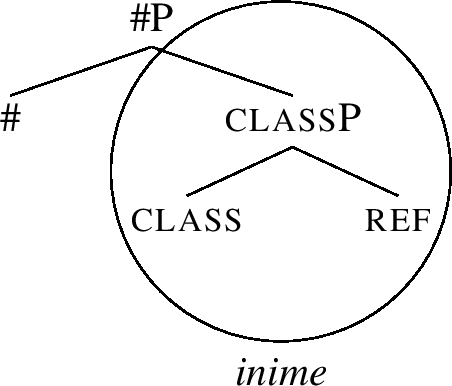
In order to model the idea that a single exponent may realise more than a single feature, lexicalisation is assumed to target phrasal nodes (FPs). For example, as proposed in Table (49), the root always spells out the ref and class features. Its lexical entry is then as in (51a). The entry links the relevant part of the structure (50) to a particular phonological representation: when syntax builds the structure given in (51a), the structure can be pronounced as inime.
-
(51)
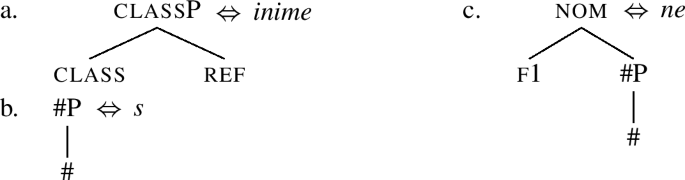
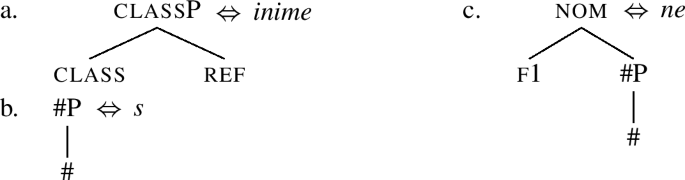
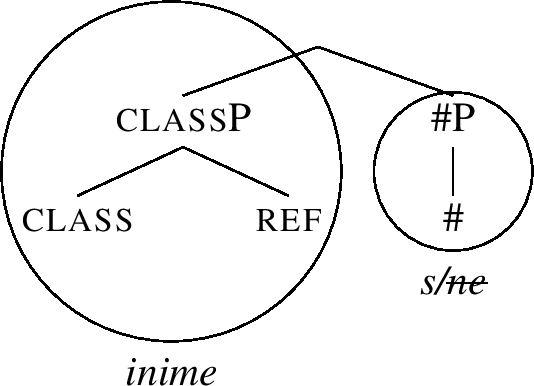
The special nominative stem marker -ne spells out # and f1 in Table (49). Its entry is therefore as in (51c): it realises a constituent that contains these two features. The entry corresponds to the residue of the structure (50), minus the part lexiclised by the root. In (51b), the entry for the stem marker -s is provided for completeness.
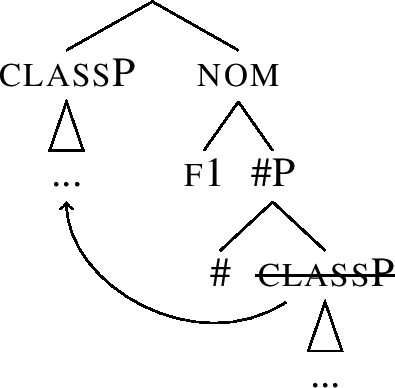
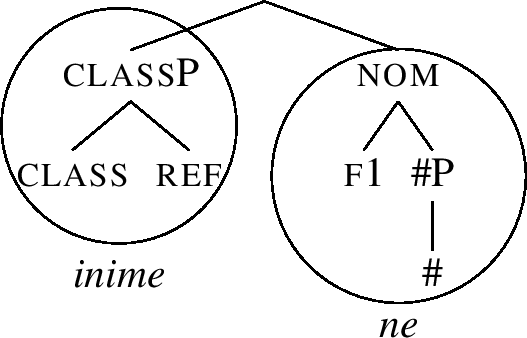
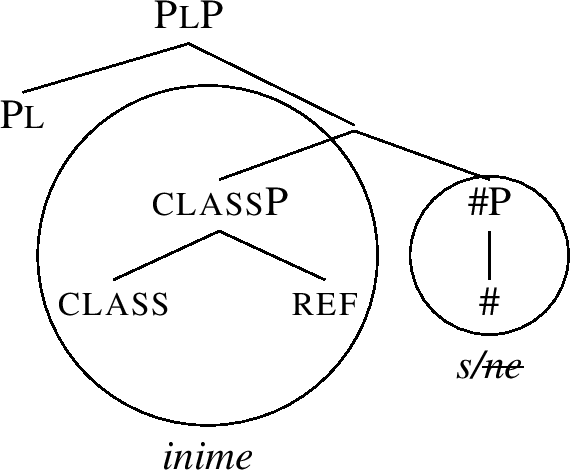
Note that the entries (51b,c) contain a unary branching phrasal node, namely #P. Since Merge in Nanosyntax is assumed to be binary (producing structures such as (50)), such entries can only be used if the other daughter of the #P node, namely classP, moves out of the whole constituent. This is schematically shown in (52) and (53). The idea depicted in (52) is that classP first moves to the top of the structure, which then creates the right type of configuration for -ne to lexicalise the nom constituent, as in (53).Footnote 18
-
(52)

-
(53)

In order to show how exactly such movements work, we need to look at the so-called lexicalisation algorithm (Starke, 2018). This algorithm is based on the idea that lexicalisation is cyclic. This means that whenever a new feature F is merged into the phrase marker, the newly formed FP must be lexicalised. This means that after every step of Merge F, the resulting structure is matched against the lexicon of a given language. If a matching lexical item is found (with matching governed by the Superset Principle), Merge F may continue. However, if syntax creates a structure that has no match in the lexicon, syntax must perform one in a series of repair operations, namely movements. The lexicalisation algorithm is given in (54). The first two lines of the algorithm describe the essence of the cyclic lexicalisation procedure: we merge a new feature (Merge F), producing an FP. When FP is produced, we must find a match for it in the lexicon; this is the content of (54a). (54b-d) then provide instructions for repair operations that must be performed if matching fails. I explain its working step-by-step in what follows.Footnote 19
-
(54)


Using the lexicalisation algorithm, the derivation of the nominative inime-ne proceeds as follows. First, the ref feature is merged with class, yielding the structure (55). Since Merge F has applied, forming classP, lexicalisation applies, as defined in (54-a).
-
(55)

Lexicalisation means that a matching item for the classP must be found (where matching item is one that contains a constituent identical to that structure, as per the Superset Principle (41)). Since the structure (55) is identical to the lexical entry of the root inime- in (51-a), lexicalisation succeeds. This is depicted in (56), where the relevant constituent is circled.
-
(56)

However, note that finding a matching item does not mean that the structure must be directly pronounced. Rather, the idea is that the interface only ‘checks’ the lexicon to make sure that the syntactic structure is ‘externalisable,’ but it does not immediately pronounce it. Pronunciation happens only at the end of a derivation.
Since matching suceeded, Merge F may continue and # is merged on top of (56), yielding (57). For clarity, I also include in (57) the information that classP has been matched by the root inime- ‘person.’
-
(57)
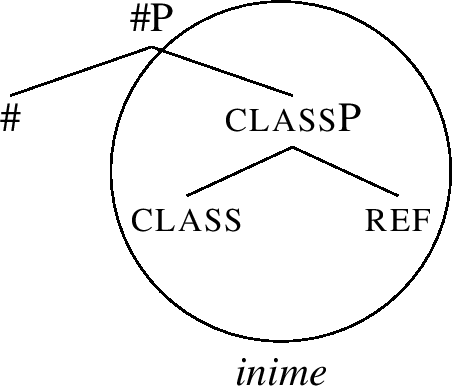

After merging #, the #P thus formed must be lexicalised (i.e., matched against a lexical entry), recall (54-a). However, the structure (57) cannot be matched by the root meaning ‘person,’ since the relevant root (inime-) does not contain the constituent #P, recall (51-a). Therefore, direct lexicalisation – required by (54-a) – fails in (57).
This means that other lexicalisation options of the algorithm are tried in the order as they are listed. The first repair strategy tried by the algorithm is to move the specifier of the complement and retry the lexicalisation of #P, recall (54-b). However, the structure (57) has no specifier and so this step is undefined. Since lexicalisation has still not succeeded, it proceeds to the next rescue strategy, which is complement movement, as stated in (54-c). This step is depicted in (58).
-
(58)
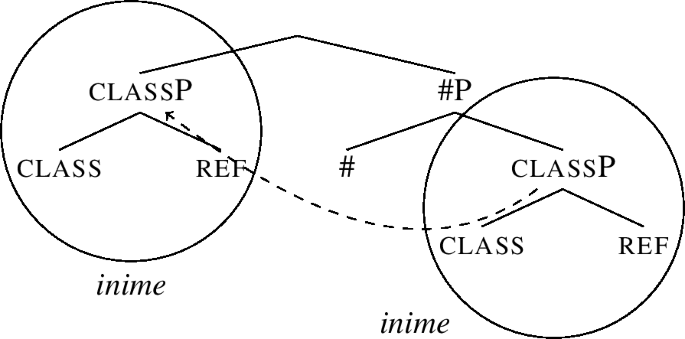

The structure resulting from complement movement is in (59), where the complement has been deleted in the original position. This is in line with the idea that movements triggered by the lexicalisation algorithm either do not leave a trace, or the trace is ignored by matching.
-
(59)
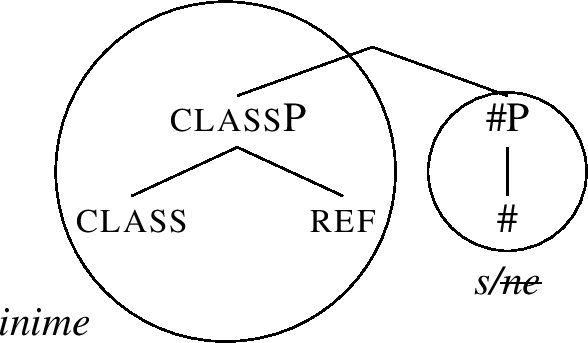

In this structure (resulting from complement movement), we again have to try spelling out the #P that has been formed by merging #. Two lexical entries match the relevant #P (because they contain a constituent identical to it): (51-c) and (51-b), inserting -ne and -s respectively. Since two items match, competition arises. The item inserting -ne loses in competition because it has a superfluous feature. The losing status of -ne is indicated in (59) by strikethrough.
The derivation now continues by merging the nominative feature f1 to (59). The result of the merger is in (60).
-
(60)
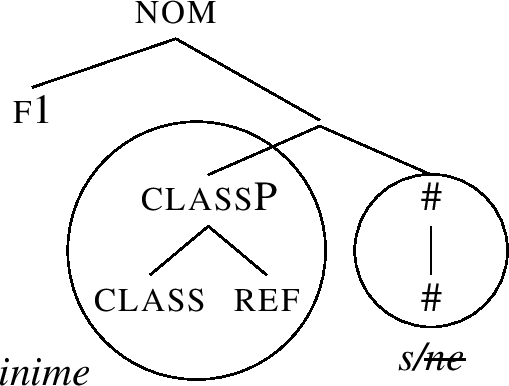

But there is no match for the nom constituent in (60) (as required by (54-a)), so rescue movements must be tried. The tree (61) shows the result of Spec-movement triggered by (54-b). The structure was formed by taking the Spec of f1’s complement in (60) and moving it across f1. The original position of the Spec is left out in (61), again in accordance with the idea that lexicalisation movements leave no trace.
-
(61)
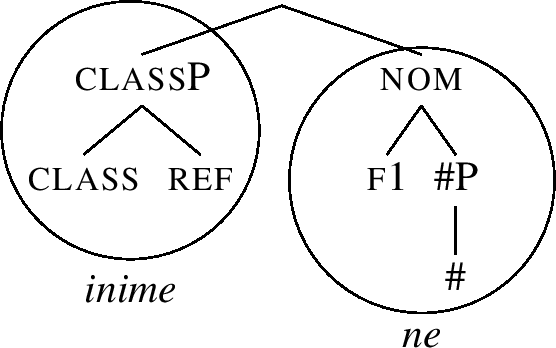

In this structure, f1 and # form a constituent, and lexicalisation successfully matches this constituent by -ne, recall (51-c). Note also that -s is no longer a match, since its lexical entry (51-b) does not contain f1. We have thus derived the correct nominative inime-ne.
It is important to realise that Spec movement in (61) leads to the effect that the stem marker realises as many features as possible. We will shortly see that complement movement would prevent the stem marker from realising f1 along with #: it is therefore important that Spec movement is preferred to complement movement. This is the part of the algorithm that makes sure that the realisation of features by stem markers is preferred to introducing additional suffixes.
Let me now show how the other case forms are produced. These will be formed by adding features on top of the nominative. Before we run the derivations, we must introduce the accusative/genitive suffix -e, which is associated to features from f1 to f3, see (62a). The entry again has a unary branching node at the bottom, and it will therefore only be usable as a suffix. Finally, in the illative/dative, we have an additional f4 feature spelled out by -sse, see (62b).
-
(62)
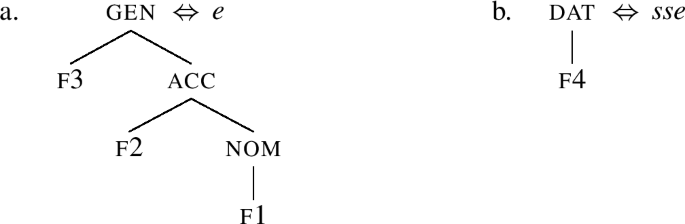

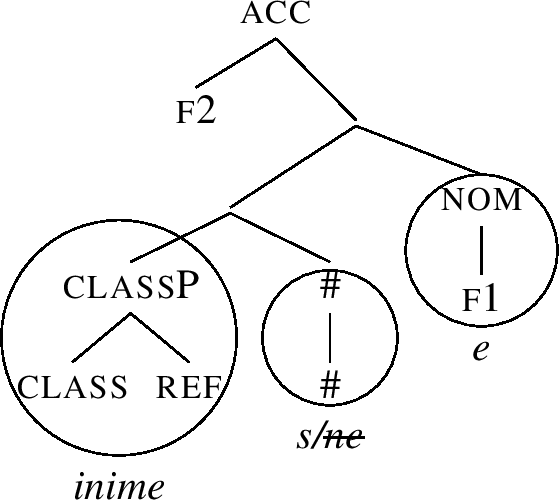
Let us now see how the accusative inime-s-e is produced. To derive it, we merge f2 on top of the nominative inime-ne, yielding (63).
-
(63)
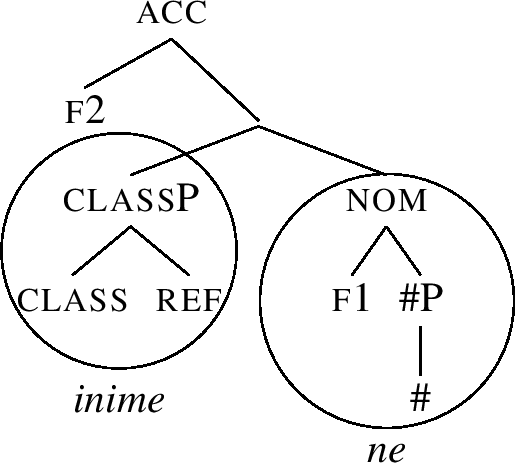

(63) finds no match in the lexicon, so we move the Spec of f2’s complement across f2, yielding (64).
-
(64)
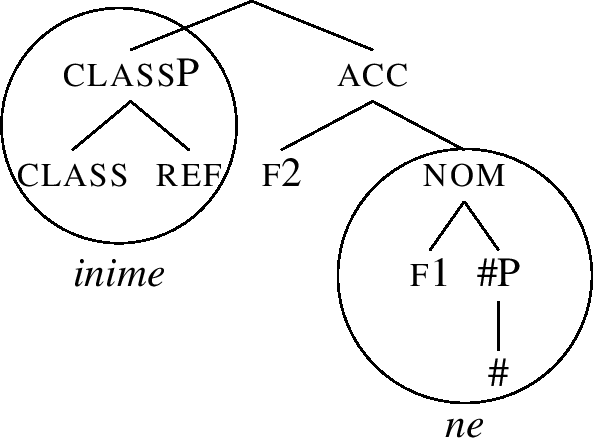

But there is still no match. So we go back to the structure (63), and try complement movement, producing the structure (65).
-
(65)
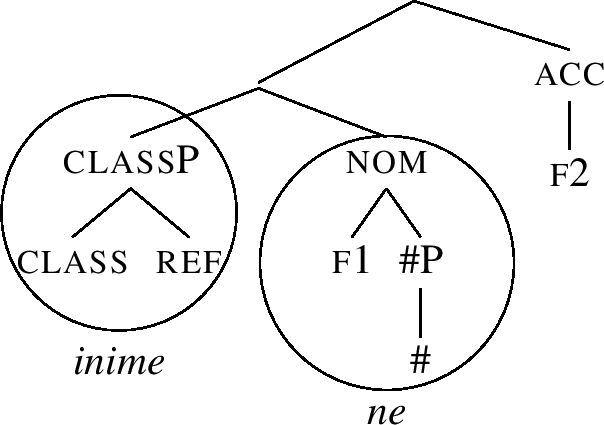

However, the acc node in (65) cannot be lexicalised either, since the acc constituent on the right in (65) is not a subconstituent of the lexical entry for the accusative ending -e, recall (62-a).
Therefore, we must activate the last clause of the lexicalisation algorithm, which is Backtracking, recall (54-d). This clause says that if complement movement failed, we should go back to the previous cycle and try the next lexicalisation option for that cycle. How does this work?
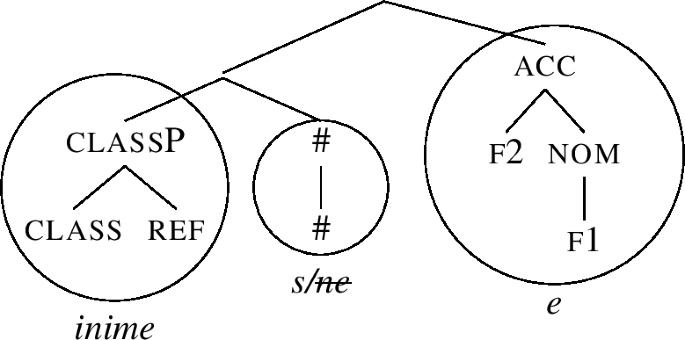
We first have to realise that the “current” cycle is defined by the external merge of f2. Going to the previous cycle therefore means going back to the f1 cycle, given in (66), repeated from (60).
-
(66)
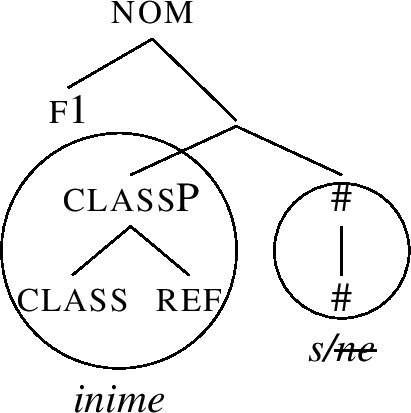

When we first tried to lexicalise this structure, we succeeded by moving the Spec inime-, recall (61). However, since that ultimately lead nowhere, the subsequent lexicalisation option in the algorithm must be pursued now, which is complement movement. Applying complement movement to (66) displaces the whole complement inime-s across f1. The result is in (67). Here, f1P can be spelled out as -e.
-
(67)

Note that as a result of backtracking, the ‘stem marker’ now shrinks and lexicalises only #, which leads to the emergence of -s. This stem will be found in all forms from now on.Footnote 20
The next thing to do is to merge f2 on top of (67), yielding (68). Recall that we had already introduced the accusative feature to the derivation before (to a base that contained the suffix -ne), but there was no match for this structure no matter what we tried. That is why backtracking was triggered, which led to the result that we are now adding the accusative feature to a different constituent (to a base that has the stem-suffix -s).
-
(68)

The acc node in (68) cannot be spelled out as is, and rescue movements are triggered. Spec movement produces (69), which spells out using the ambiguous acc/gen -e, recall (62-a). (69) is the correct direct-object form in Estonian.
-
(69)

Note that the algorithm interacts with the lexical entries in a way that the lexicalisation of the accusative feature f2 is only successful when the base contains an -s, as in (69). On the other hand, the lexicalisation of f2 was impossible when the base contained -ne, as in (65). This shows that the algorithm indeed produces outputs as drawn in the lexicalisation table. The logic is such that the stem marker lexicalises as many features as it can, given its entry: only when lexicalisation fails, backtracking leads to the shrinking of the stem/root.
It is also interesting to note that the stem marker -ne will never be able to reappear in the oblique cases. That is because -ne can only be inserted when the addition of f1 on top of #P is followed by Spec movement, as in (61). During the derivation of the accusative, however, we have been forced to backtrack from this derivational path, and the algorithm will never come back to it again, since it is a dead end, making the lexicalisation of f2 impossible.
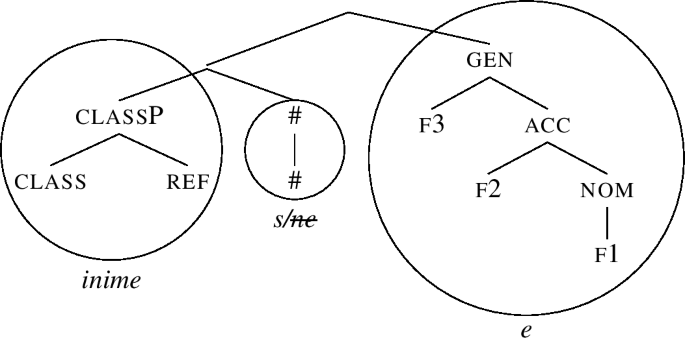
If we wanted to derive the accusative, the derivation would terminate as (69). If we want to form the genitive, the derivation continues by adding the genitive feature f3 to (69), yielding (70).
-
(70)
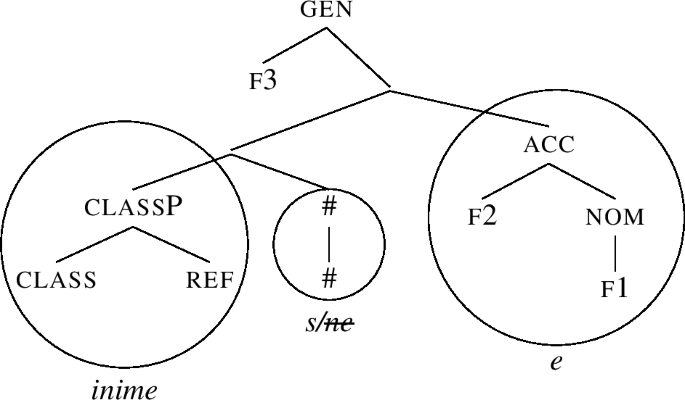

The gen constituent in (70) fails to be lexicalised. Therefore, the Spec inime-s is moved across f3, producing (71), where gen is successfully lexicalised using the lexical entry for -e in (62-a).
-
(71)

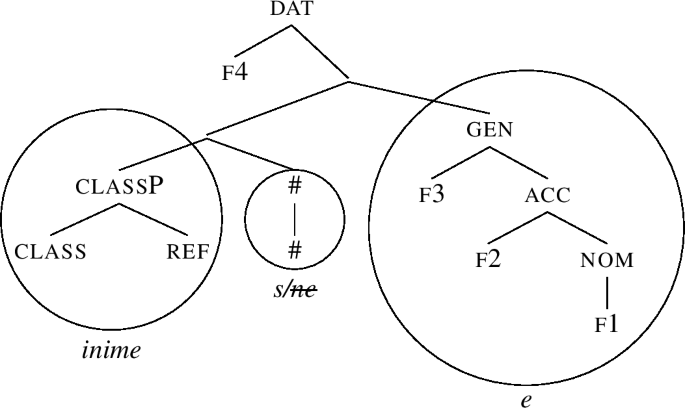
Should we aim for the genitive form, the derivation would terminate as (71). If the dative/illative structure is to be derived, Merge F adds the dative feature f4 to (71), yielding (72).
-
(72)

The dat node in (72) cannot be lexicalised (there is no match). Spec movement (not shown) produces a structure that leads to no match; therefore, complement movement is tried, yielding (73) (which arises by moving the complement of f4 in (72)).
-
(73)
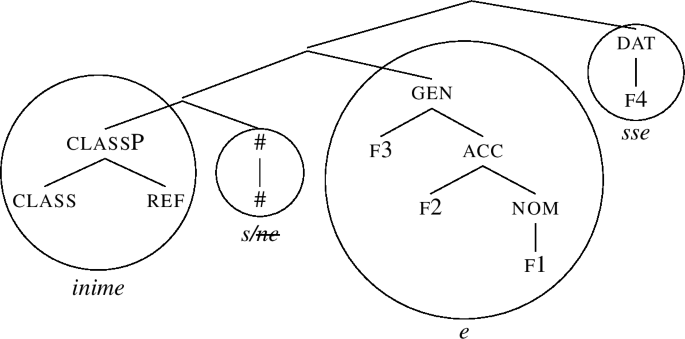

In this structure, the remnant dat node can be lexicalised as sse.
Summing up, we just saw that the lexicalisation algorithm interacts with the proposed lexical items in a way that the features relate to the affixes as shown in (74).
-
(74)
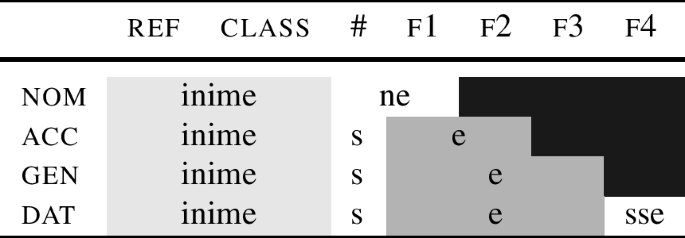

The derivation of the singular is a first step towards demonstrating that it is possible to propose a strictly local realisational theory with a generative power that is, in at least some domains, greater than that of a theory with context-sensitive rules. To complete this demonstration, we need to turn to the plural.
The analysis of the plural is shown in (75). The main idea here is that in order to spell out pl, we again have to use endings that restrict the stem marker to the realisation of #. As a result, the plural endings attach on top of the stem marker -s (compare (74)).
-
(75)

The most relevant point of the derivation arises after we derive the #P inime-s. Recall from (59) that this structure arises by merging #, as in (76), and moving the classP inime- across the # head, such that the remnant #P is lexicalised by -s, see (77).
-
(76)

-
(77)

Consider what happens when pl is added on top of (77), as in (78).
-
(78)

This structure cannot be lexicalised without movement and Spec movement fails too (there is no lexical item lexicalising pl jointly with #). Therefore, complement movement applies, yielding (79).
-
(79)
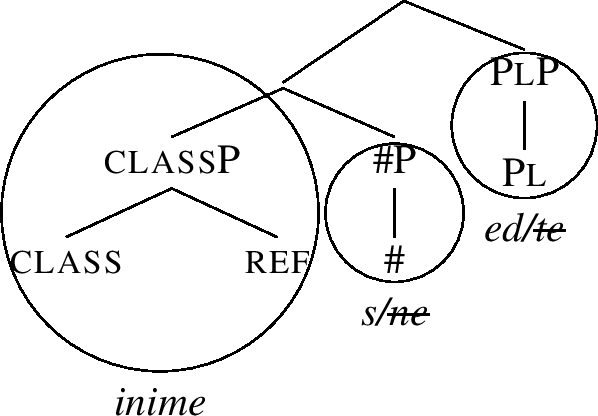

The remnant plP in (79) is lexicalised as -ed, whose entry is in (80a). The genitive ending -te, given in (80b), is also a candidate for realising plP, but it has more superfluous features.
-
(80)
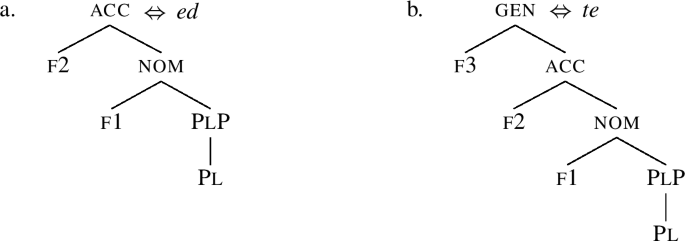
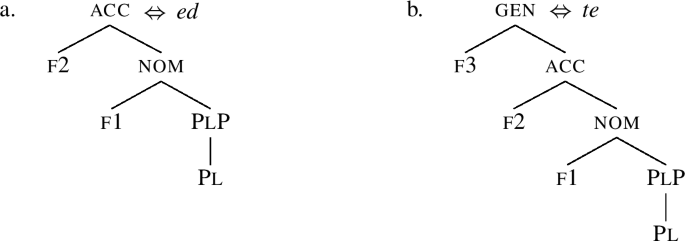
What is crucial, the structure in (79) shows that the pl endings attach to a base which corresponds to a #P, which is predicted to be realised as inime-s. This is the case regardless of how many case features are added on top of plP. For instance, the derivation of the nominative plural proceeds by merging f1 to (79), moving the Spec, and realising the remnant constituent as -ed again, see (81).
-
(81)
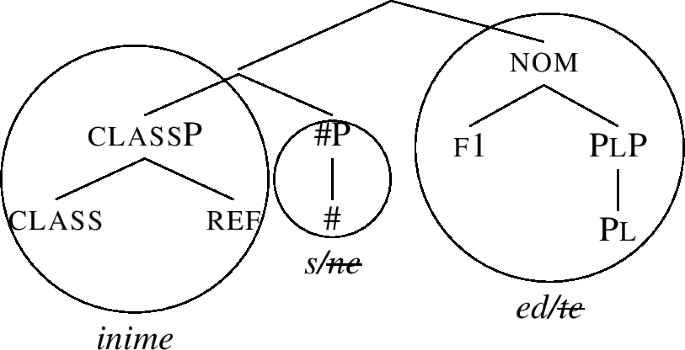

Analogous steps are available for the other case features, too, leading to the result that the nom/acc ending -ed and the genitive -te attach to the -s stem, as shown in the lexicalisation table (82).
-
(82)

The final point of this section is to show how single-stem nouns like küsimus ‘question’ are generated, producing the lexicalisation table (83). In the table, the root küsimus- is able to lexicalise all the features up to f1, which is why it needs no stem marker, see the first line in (83). In the accusative, the ending -e is needed to lexicalise f2. As a result, the root ‘shrinks’ to spell out just ref, class and #. However, since there is no competing item for these features, this leads to no change in form (we get syncretism).
-
(83)


We can see that the case suffixes (-e, -sse) are the same as with the noun inimene ‘person,’ so the only new lexical entry we need is that of the noun küsimus ‘question.’ The entry is provided in (84).
-
(84)

This entry leads to a derivation where we merge features one by one from ref to f1, and we are always able to successfully lexicalise the structure without movement, leading to (85) as the structure of the nominative.
-
(85)

Notice that the structure is different from the noun inime-ne ‘person:’ the latter root is unable to lexicalise all the features and needs the stem marker -ne, recall (61). However, since the root for ‘question’ can lexicalise all the features, this is always preferred, due to the ranking of the operations in the lexicalisation algorithm.
Let us now turn to the acc case. Its derivation starts by adding the accusative feature f2 to (85), yielding (86). However, (86) cannot be lexicalised without movement because there is no match: the structure is not contained in (84). Therefore, Spec movement should be tried. However, since there is no Spec in (86), this step is vacuous and we proceed to complement movement, yielding (87).
-
(86)
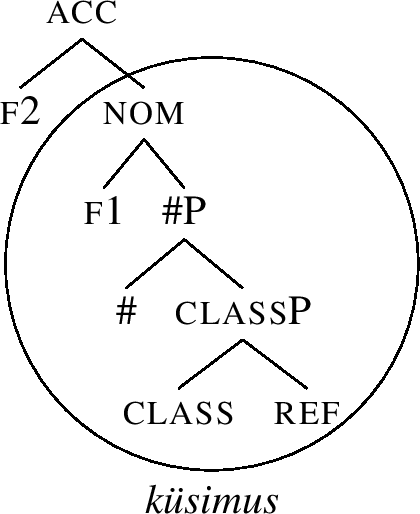

-
(87)
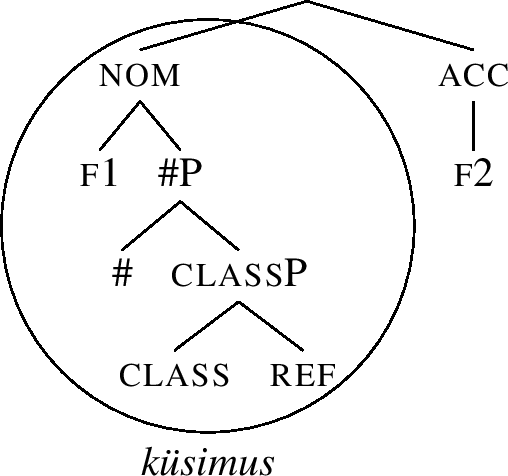

However, there is no match for (87), since the only entry capable of realising f2, namely -e, also lexicalises f1, recall (62-a). We therefore have to backtrack to the previous cycle, i.e., to the cycle when f1 was merged. At the first attempt, we realised the structure using the non-movement lexicalisation option, yielding (85). However, that led to a dead end when we added f2, so we must lexicalise f1P differently, using subsequent steps of the lexicalisation algorithm. The next step of the algorithm after non-movement lexicalisation is Spec movement; however, the structure (85) has no Spec. That is why we proceed to complement movement, yielding (88). Here, lexiclisation of nom succeeds, since -e in (62-a) is a match.
-
(88)
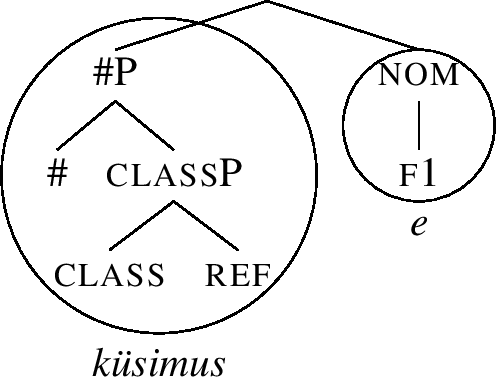

Note also that the root now only realises #P, as opposed to the nominative structure (85), where it lexicalised all the features of the nom case. This leads to no change in form, since küsimus (with the entry (84)) matches both structures, and it has no competitor for the realisation of #P.
When f2 is merged to (88), we get the structure (89).
-
(89)
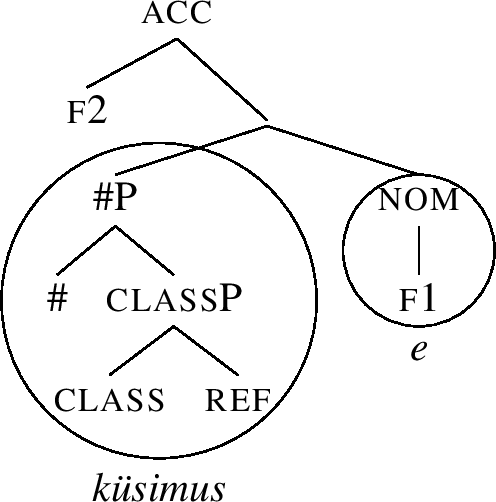

This structure cannot be lexicalised without movement, triggering the Spec-movement clause of the lexicalisation algorithm. When the #P Spec in (89) is moved across f2, we get the structure in (90), where the acc constituent is lexicalised by -e. (This is the same suffix as found in the accusative of inime-s-e ‘person.’)
-
(90)
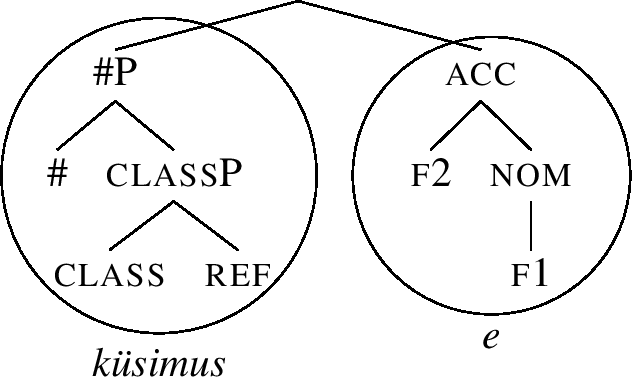

The derivation of the genitive and dative forms do not lead to any unexpected options, proceeding along steps analogous to those in (70)-(73). The result is that the same lexicalisation algorithm correctly delivers the lexicalisation Table (83).
Summarising, this section described an algorithmic procedure that can generate paradigms containing special nom.sg stems even under cumulative decomposition. All of this is achieved using a theory that eschews context-sensitivity and relies on portmanteau realisation only. Importantly, portmanteau realisation in this model is restricted by tight locality constraints, where the features that are lexicalised together must form a constituent. The right constituency arises by following the lexicalisation algorithm, which relies on two standard movement operations (Spec movement, complement movement) and backtracking.
The larger importance of this result is that tightening the locality constraints does not lead to a theory whose generative power is a subset of a non-local theory. As we just saw, there are cases where a strictly local theory like the current one allows for the generation of patterns that are impossible to generate by potentially unconstrained context-sensitive rules.
6 Base AAB patterns
As the discussion stands, we currently have two theories capable of deriving special nominatives. The theory described in the previous section maintains cumulative decomposition and models the phenomenon by cumulative exponence. The alternative theory, explored in Christopoulos and Zompì (2022), maintains context-sensitive rules and abandons cumulative decomposition instead. Their alternative feature decomposition is depicted in (91) (repeated from (33)). The main point is that the nominative is not contained in the accusative: this is what makes it possible to refer specifically to the nominative (singular) by a context-sensitive rule.
-
(91)

In this section, I show that even though both approaches can capture special nominatives, they make different predictions elsewhere. These different predictions concern paradigms where the nominative and the accusative singular have one stem, and all other forms have a different stem, as in (92).
-
(92)
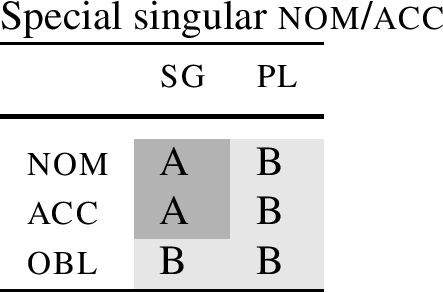

The goal of this section is to argue for the following points. (i) That a paradigm with the stem distribution as given in (92) cannot be derived by context sensitive rules, regardless of whether we use WCC or CD (Christopoulos & Zompì, 2022). (ii) That the NME theory introduced in the previous section can derive such paradigms under cumulative decomposition. And finally, (iii), that such paradigms exist. These three points considered together favour the NME approach over the one based on context sensitive rules, even when WCC is adopted instead of CD.
Let me begin by saying why the abstract form of the paradigm (92) is impossible to derive for context-sensitive rules. As a starting point, recall that in this approach, either the stem A or B must be conditioned by some feature. However, in Table (92), neither the stem A or B appears in a set of environments that is definable by some feature F, regardless of whether we assume WCC or CD. As a result, it is impossible to write a (non-disjunctive) rule that would insert one of the stems in the relevant environments.
To begin with, consider the stem B. This stem cannot be obviously conditioned by a specific number feature since it appears both in the singular and in the plural. It also cannot be conditioned by case. This is obvious from the plural, where, under WCC, there is no case feature common to all three cases. If we added one (analogous to f1 of CD), and made the rule inserting B sensitive to this generic case feature, the form B would then also appear in all the singular cases. The result is that the distribution of B cannot be linked to any specific feature. Let us therefore conclude that B must be the context-free elsewhere form.
This requires us to come up with a conditioning feature for the stem form A. However, regardless of whether we look at CD or WCC, there is no feature that puts nom and acc (singular) together against the oblique cases. Therefore, Christopoulos and Zompì (2022) take it as a prediction of the approach based on context-sensitivity that stem distributions such as the one in (91) will not be found. (If found, such a distribution would have to be governed by phonology.)
Let me now turn to the point (ii), which is that the NME theory described in the preceding section is able to generate an AAB pattern of stem distribution in the singular, alongside a BBB pattern in the plural, while at the same time maintaining the cumulative decomposition. One way in which this can be achieved is shown in (93).
-
(93)
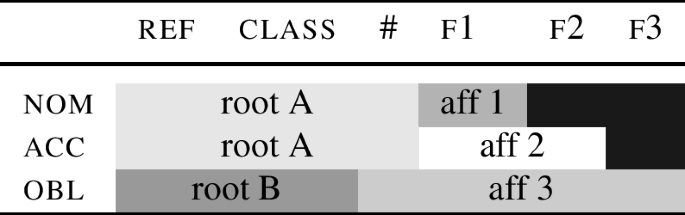

In this table, the root A spells out all the features up to #. In nominative and accusative, the endings spell out case features f1 and f1 and f2 respectively. In the oblique case(s), the ending spelling out f3 spells out also #. If this is the only ending capable of spelling out f3, the root will have to backtrack from spelling out #, and realise only features up to class. The fact that the root spells out different projections in nom/acc vs. obl allows for suppletion to take place.
If the plural endings in the relevant language start at the # feature, the plural base will also correspond to root B:
-
(94)
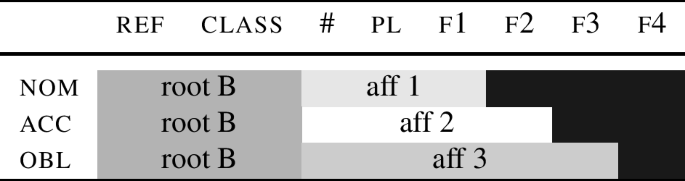

In effect, Tables (93) and (94) show that the NME system can generate an AAB pattern in the singular with the accompanying BBB pattern in the plural.
Such patterns can also be generated at the level of stems (i.e., when the base decomposes into two morphemes); this is shown in (95) for the singular.
-
(95)
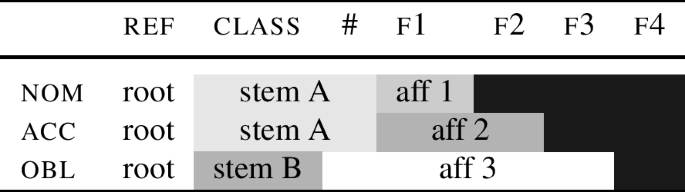

In this table, the stem marker alternates between two different forms due to the same ‘shrinking’ mechanism (i.e., backtracking) as just described for the roots. The plural is not shown, since its analysis runs in parallel to that in Table (94).
At this point, we can conclude that there is another difference between the NME system operating over cumulative decomposition and the system based on context-sensitive rules. While NME can generate an AAB pattern in the singular along with BBB in the plural, context-sensitive rules cannot do so, regardless of whether one adopts the cumulative decomposition or WCC.
Turning now to the empirical facts, Christopoulos and Zompì (2022) note that patterns of root/stem distributions that instantiate the relevant pattern are in fact attested (at least on the surface). As one example, they mention the Latin noun femur/femin ‘bone,’ with a partial paradigm in (96).
-
(96)
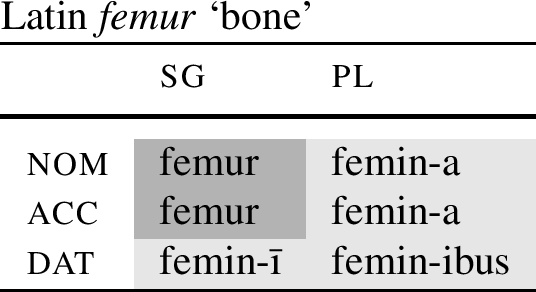

Since the WCC system cannot capture such a distribution, Christopoulos and Zompì (2022) remain skeptical as to what paradigms such as (96) actually show. Specifically, they point out that since there is no overt marker that would follow the root/stem fem(-)ur ‘bone,’ it may well be the case that the femur/femin (or -ur/-in alternation) is phonologically conditioned (word final vs. before a vowel). To avoid this confound, we need to find a Base AAB pattern where both bases are followed by an ending.
As a potential case in point, consider the paradigms in (97) from Slovene. What we see here is again a comparison of a regular noun (mest-o ‘city’) and an irregular noun (tel-o ‘body’). The accent sign indicates the position of stress. In the irregular declension, we find about 10 nouns, all with a similar alternation, e.g., črev-ó ‘intestine, nom.sg’ ∼ črevés-a gen.sg.
-
(97)


The segmentation of the nominative into a root tel- and an affix -o rests on the observation that both pieces exist independently. The bare root belonging to the nouns of this declension is found in some word-formation processes. For example, the noun slov-ó ‘farewell’ (gen slovés-a) is related to the verb po-slov-iti se ‘to bid farewell,’ where the derivational base is slov-. Similarly, for drev-ó ‘tree’ (genitive drevés-a), there is a related noun drev-ak ‘a canoe dugout from a tree trunk.’ Since the nouns in this declension contain an independent root (tel-), this entails that -o is an affix. Since this suffix is identical to the ending in the regular declension, it is analysed here as such. This analysis is supported by the fact that the declension of tel-o ‘body’ has always the same ending as in mest-o ‘city.’
If we adopt this reasoning, the distribution of the two different stem shapes (tel vs. telés) does not seem amenable to the same type of phonological explanation as provided by Christopoulos and Zompì (2022) for the Latin femur/femin ‘bone.’ In Slovene, both stem shapes (tel and telés) are found word-internally before vowels. Therefore, I submit that the paradigm (97) shows that we need to allow our theory of morphology to generate AAB patterns in the singular, along with the BBB pattern in the plural.Footnote 21
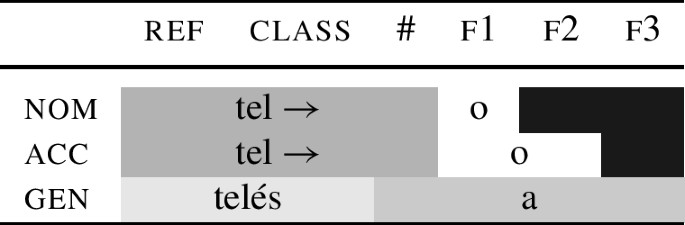
Let me now turn to the analysis of the paradigm in (97). One option is to not decompose the oblique base, and propose that we have two non-decomposable roots tel- and telés-. The root tel- would be postaccented, and the stress would therefore land on the ending; postaccentuation is marked by the → sign in (98). The root telés- would be accented, and therefore prevent the stress from being located on the ending (as in Melvold 1989).
-
(98)

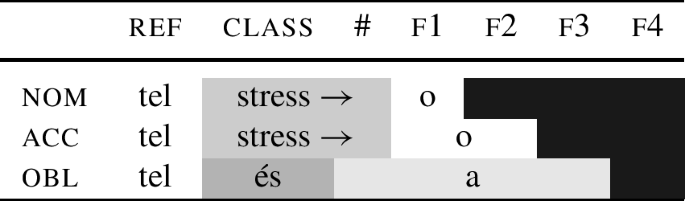
Another possibility is shown in (99), which is a concrete rendering of the abstract analysis in (95). In the table, I assume that in nom/acc, there is a stress-shifting stem marker ‘stress →’, which shifts the stress from the stem onto the ending.
-
(99)

Summarising, this section has explored the pattern of stem distributions with AAB in the singular, and BBB in the plural. The NME theory investigated here allows for such patterns, unlike any of its alternatives based on context-sensitive rules (Christopoulos & Zompì, 2022). I discussed the Slovenian paradigm ‘body’ as a paradigm that seems to exhibit such a distribution, thus confirming the predictions of the NME theory against theories based on context-sensitive rules.
7 Base ABA patterns
The last topic to be addressed is the issue of Base ABA patterns. Following the structure of the argument in the preceding section, I again want to show three things. (i) That context-sensitive rules cannot generate Base ABA (keeping all else constant). (ii) That the NME theory adopted here actually allows for the generation of Base ABA patterns, while disallowing Full ABA patterns. (iii) That there are reasons to think that Base ABA patterns are found both in the domain of case (Ganenkov, 2018; Davis, 2021) and elsewhere (Middleton, 2021; Sudo & Nevins, 2022).
Let me turn to the point (i), which is that under cumulative decomposition, context-sensitive rules fail to generate Base ABA (keeping all else constant). This has already been discussed in Sect. 3, which summarised the results achieved in Bobaljik (2012). The core idea is that when a context-sensitive rule introduces a suppletive root in the comparative, then the superlative cannot fall back on the positive base. This is because, as a defining feature of the cumulative decomposition, the superlative contains the comparative, and thereby also the feature cmpr. Since cmpr is present in the superlative, the elsewhere form (found in the positive) cannot be used.
The new thing to be added is that this result holds only if all else is kept constant between the comparative and the superlative form (as also argued for in Bobaljik (2012)). The starting point of the discussion is the fact that a couple of examples of Base ABAs are actually found in the domain of degree morphology, see (100).
-
(100)


In order to deal with these examples, Bobaljik suggests that the cmpr node, which triggers suppletion in the comparative form, may be removed from the local domain of the root in the superlative (e.g., due to upward head movement of cmpr to sprl). If the cmpr feature is contained in a different local domain (roughly: in a different word), it becomes incapable of triggering suppletion, despite its presence in the structure. As a side-effect of removing cmpr from the local domain of the root, cmpr and sprl should be realised as an independent word, see, e.g., samyj or ülen in the first two columns of Table (100).
Clearly, on this approach, much depends on our ability to independently establish what it means that cmpr is inside vs. outside a particular domain. In some of the examples in Table (100), these differences are not always easy to establish. For instance, the Bulgarian comparative and superlative morphemes po- and naj- seem to have the exact same status (both are phrasal prefixes), yet the root patterns differently in the comparative and in the superlative, suggesting that po- is inside the local domain, while naj- is not. Bobaljik discusses these issues in some detail, and, admitting the difficulty, he resolves the conundrum by postulating a zero suffix in the Bulgarian comparative.
Summarising, and keeping a number of details aside, the point is that if all else is kept constant, context-sensitive rules cannot generate Base ABA patterns. The only way to make an approach based on context-sensitive rules compatible with the existence of Base ABA patterns is to introduce additional factors (like varying the accessibility of the suppletion triggering feature).
This brings me to my point number (ii), which is that the introduction of such additional factors is not needed under the NME approach explored here; the system is capable of producing Base ABA patterns like those in Table (100) without any additions. There are a number of logical options how such a system may arise. Table (101) shows how a plural stem marker may exhibit a Base ABA.
-
(101)

In (101), the root always spells out ref and class. In the nominative, we see a stem marker A that can spell out all the features starting at # and going all the way up to the nominative feature f1. In the accusative, this stem marker is replaced by a different stem marker that fuses number and case. In the dative, the feature f3 must be spelled out. Table (101) assumes that the only case marker that can spell out f3 is also specified for f2. This makes the stem marker ‘shrink’ (via backtracking) and realise only the features from # to f1. This in turn leads to the resurfacing of the stem marker A, and so we get a Base ABA. As already mentioned, this differs from context-sensitive rules in that the Base ABA pattern is generated without invoking any additional factors.
A paradigm that seems to exemplify the lexicalisation in (101) is found in Barguzin Buryat (as discussed in Davis 2021). Specifically, we can see that the distribution of nuud vs.  creates an ABA pattern of the relevant sort.
creates an ABA pattern of the relevant sort.
-
(102)


Davis (2021) argues that the form  cannot be derived phonologically from an underlying
cannot be derived phonologically from an underlying  , and has to be treated as a suppletive version of the stem marker. If this is so, the paradigm exemplifies the type of lexicalisation given in (101).
, and has to be treated as a suppletive version of the stem marker. If this is so, the paradigm exemplifies the type of lexicalisation given in (101).
As always, there are caveats. First, as an anonymous reviewer points out, Poppe (1938, 52) actually treats the alternation between nʉʉʃɘ and nuud as phonological. Alternatively, one could suggest that the dative suffix is actually a postposition, where the feature that conditions suppletion in the accusative (i.e., f2) is actually outside of the local domain of the root in the dative (a strategy used in Smith et al. 2019, 1049 to explain a Base ABA pattern in Nen).
Both of these alternative analyses seem unavailable for the paradigm fragment (103) from Xakas, a Turkic language, pointed out to me by S. Zompì and discussed also in Smith et al. (2019, ftn. 28).
-
(103)


The table shows that the demonstrative pu ‘this’ has a suppletive form in the accusative (mɨnɨ). In the dative, there is the suffix

a, which attaches to the nominative form. The suffix

a is segmented because it also shows up with regular nouns; for instance, the dative of ton ‘fur coat’ is ton-

a. If the segmentation of the dative is correct, the proximal demonstrative pu represents a case of a Base ABA.Footnote 22
Furthermore, the distribution of the two root forms pu – mɨnɨ is not phonological, since both are attested word finally. (The same is true if we considered the stems to be pu and mɨ: both can be found word internally, namely in pu-

a and mɨ-nɨ.) Similarly, it seems unlikely that

a is a nominative-selecting postposition. The reason is that -

a is optionally present in the dative of the demonstrative ‘that,’ shown in the final column of Table (103). It is not clear what to make of that optionality, but the form clearly demonstrates that

a is not a postposition that attaches to the nominative form of the base.
Using the NME technology developed up to this point, the simplest analysis of the proximal demonstrative would be as given in Table (104). Here, the idea is that in nom/acc, we have a portmanteau realisation of all the features. The dative suffix triggers backtracking, and attaches to #P. In (104), #P is realised the same as the nominative, namely by pu; this is due to syncretism.
-
(104)


One possible analysis of the distal demonstrative is shown in (105). We could analyse the accusative form as a portmanteau, but it is also possible to analyse it compositionally, namely as involving a regular accusative suffix nɨ.
-
(105)

Summarising, this section has demonstrated that the NME system investigated here is capable of generating Base ABA patterns, while the system based on context-sensitive rules cannot do so, keeping all else equal. The ‘keeping all else equal’ clause is important, since basically all current work agrees that Base ABA patterns exist. The question is thus not whether – but rather how – these patterns should be generated (see Bobaljik 2012, Caha 2017, Davis 2021, Middleton 2021, Sudo and Nevins 2022). While the current system provides a rather straightforward way of generating Base ABAs, context-sensitive rules rely on additional factors, e.g., domain restrictions. This makes it harder to find data that decide between the two theories. However, it seems to me that the Xakas data presented in (104) (pointed out to me by S. Zompì) provide an instance of a Base ABA that may prove the benefits of the NME system investigated here.
Before I conclude, I would like to make it clear that there is a contrast between Base ABA patterns and Full ABA patterns. Specifically, while the version of the NME approach described in Sect. 5 can derive a Base ABA pattern, it cannot derive a Full ABA pattern like the one in Table (106).
-
(106)

The reason why (106) cannot be derived is the following: In order for stem marker A to spell out all the features from # to f3, as it does in dat, it would have to include all these features in its lexical entry. This would make it also a candidate in the accusative, since it contains the genitive as a proper subpart. The reason why it does not surface in the accusative is that the stem marker B only spells out features from # to f2. Such marker is therefore a better match for the accusative because the marker A has more superfluous features. But by this logic, the stem marker B would also be chosen in the nominative, so the lexicalisation in Table (106) is underivable.
8 Conclusions
This paper investigated the theoretical implications of root and stem suppletion for theories of multiple exponence. Root suppletion (as in bett-er) is standardly considered a special type of multiple exponence, modelled via context-sensitive rules. In this paper, I investigated the option that such examples do not involve multiple exponence at all, and that all the relevant facts can be explained by using cumulative exponence instead.
In the system I investigated here, every feature is referenced by realisation rules only once. On this account, root/stem suppletion is a consequence of the division of labour between roots, stems and suffixes. When a suffix is introduced to realise a particular element of meaning (like cmpr), this may affect the number of features realised by the root, with suppletion arising as a consequence of this. I have further shown that the lexicalisation algorithm (currently widely used in the Nanosyntax literature) allows for a relatively simple algorithmic implementation of this idea.
Finally, I have explored some of the empirical differences between context-sensitive rules and the NME model. It turns out that there exist quite a few patterns of root/stem suppletion that cannot be modelled via context sensitive rules under cumulative decomposition, as recently discussed by Christopoulos and Zompì (2022). All of these patterns can be generated in the NME system explored here.
A more general point which may feed into a further debate is the issue of generative power of various systems. In the debates related to non-local allomorphy (Moskal & Smith, 2016; Choi & Harley, 2019), it is sometimes proposed that the existence of non-local allomorphy forces us to abandon a strict version of locality, such as morpheme adjacency or feature constituency. An implicit assumption is that relaxing the locality conditions will automatically lead to a theory with a greater descriptive coverage (generative power). The empirical cases discussed here suggest that while the existence of (non-)local allomorphy is an important issue, the theoretical consequences of relaxing locality restrictions are more intricate than previously thought. Specifically, I have argued that a system based on context-sensitive rules may have the ability to capture non-local allomorphy, but runs into problems elsewhere. Setting up the right balance between these conflicting considerations remains a task for future research.
Notes
The structures are adapted from Smith et al. (2019, 1031). They include the root position and the categorising a head. The comparative has the cmpr head in addition.
With regular adjectives, the idea is that the form realising \(\sqrt{ \phantom{ll} }\) is syncretic with the form realising [\(\sqrt{ \phantom{ll} }\)+a] (just like you is syncretic between [addressee] and [addressee+others]).
An anonymous reviewer correctly points out that if the comparative only had two features (\(\sqrt{ \phantom{ll} }\) and cmpr), and the positive just a single feature (\(\sqrt{ \phantom{ll} }\)), the analysis depicted in Table (10) would not be possible because the root would then necessarily lexicalise the same \(\sqrt{ \phantom{ll} }\) node in the positive and in the comparative. One may then ask whether we find suppletion in such cases. However, I consider this a moot point, since it is not clear if one can find forms that correspond to a bare \(\sqrt{ \phantom{ll} }\) without the categorising head.
In the Latin orthography, the nouns are written as rex and senex. I chose a different spelling so as not to obscure the boundary between the base rēg-/senec- and the suffix -s.
The fine structure of the obliques is a matter of debate. Caha (2009) proposes that the smallest oblique case is the genitive, which is contained in the dative, which is in turn contained in the instrumental. However, there are reasons to think that the relation between the genitive and the dative is more complex (see Harðarson, 2016; Starke, 2017; Van Baal & Don, 2018). It has also been debated as to whether individual oblique cases stand in a containment relation at all (Zompì, 2017; Smith et al., 2019). However, all the works cited in this footnote agree on the containment relations as depicted in Table (17).
acc and obl can be unified due to the fact that they contain f2; nom and acc are a natural class due to the simultaneous presence of f1 and the lack of f3.
This subtype of *ABA has been investigated, e.g., in Caha (2009).
For completeness, let me mention that the exponents for the functional heads cmpr and sprl are introduced by the following set of rules (Bobaljik, 2012, 34-35):
-
(i)
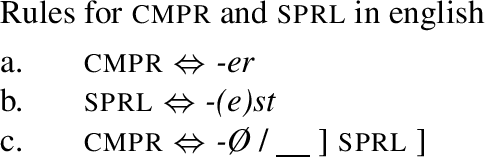
The rule (24a) makes sure that -er appears in the comparative, and (24b) introduces -(e)st under sprl in the superlative. Since in English, -er and -est do not combine, Bobaljik assumes that cmpr is zero in the context of sprl, see (24c).
-
(i)
McFadden has also identified some counterexamples. He discusses them in detail and sets them aside. I return to them in Sect. 6.
The endings would then be introduced by the rules in (31), modelled on the basis of Bobaljik’s approach to the comparative/superlative suffixes in English, recall 12.
-
(i)
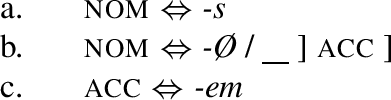
-
(i)
Bare # corresponds to a singular. The plural adds the pl feature.
The lexical item -s in (36-b) is an exception, since it only spells out case features. It does not appear in the plural for reasons that become clear as we proceed.
If the plural endings were not specified for #, but started at pl, they would attach to the nom.sg stem (spelling out ref, class and #). Such endings are found, for instance, in Tamil, where the plural forms are based on the nominative stem, rather than the oblique stem, as discussed in McFadden (2018).
The dative is traditionally called the illative in descriptions of Estonian. However, since one of its most prominent uses is to mark recipients in ditransitive constructions, I analyse it as a dative, keeping the traditional name in descriptive tables such as (48).
In (53), the original position of classP is left empty, reflecting the idea that certain kinds of movements (which produce these representations) do not leave a trace (see, e.g., Baunaz and Lander 2018, 38). These movements are referred to as lexicalisation-driven movements in Nanosyntax, and they will be discussed immediately below (53). The absence of a trace is only valid for lexicalisation movements; traditional feature-driven movements do leave a trace.
The trace-free nature of lexicalisation movements (while widely adopted in Nanosyntax) is not crucial: if one wanted to maintain that there is a trace present, one would simply need to update the lexical items (51-b) and (51-c). These would have to also include the trace as the second daughter inside their lowest non-terminal.
At the same time, note that if the Estonian lexicon contained no -s, the only candidate for realising the #P in (67) would be -ne, and we would thus get the same stem marker in nom and acc. So stem identity remains a logical option, it’s just not one that is chosen in this paradigm due to the existence of -s in the lexicon.
An anonymous reviewer points out that if -o in tel-o ‘body’ was analysed as a stem marker, rather than a case ending, we would get variation between stems tel-o (word finally) and tel-es (elsewhere), which then boils down to the same analysis as offered for the femur/femin paradigm discussed in (96). This is an important caveat to be kept in mind. At the same time, this alternative analysis relies on postulating an accidental homophony between two -o’s: a case marker and a stem marker, missing the generalisation that mest-o and tel-o always end in the same vowel (including no vowel, in gen.pl). One also suspects that if this type of analysis involving accidental homophony is allowed as an analytical tool in all similar cases, it can easily render all potential counterexamples to the context-sensitive theory irrelevant. By rendering counterexamples irrelevant, it also robs the theory of predictions.
I assume that the accusative form mɨnɨ is non-decomposable. Alternatively, it could also be segmented as mɨ-nɨ, but I ignore this here for simplicity. Whether the accusative form is segmented or not does not change the point that this is a case of a Base ABA.
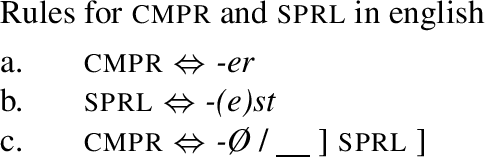
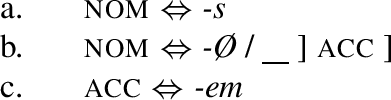
References
Anderson, G. (1998). Xakas. Munich: Lincom Europa.
Baerman, M., Brown, D., & Greville, G. C. (2005). The syntax-morphology interface. A study of syncretism. Cambridge: Cambridge University Press.
Baunaz, L., & Lander, E. (2018). Nanosyntax: The basics. In L. Baunaz, K. De Clercq, L. Haegeman, & E. Lander (Eds.), Exploring nanosyntax (pp. 3–56). Oxford: Oxford University Press.
Blevins, J. (2008). Declension classes in Estonian. Linguistica Uralica, 44(4), 241–267.
Bobaljik, J. (2012). Universals in comparative morphology. Cambridge: MIT Press.
Caha, P. (2009). The nanosyntax of case. PhD Dissertation, CASTL, University of Tromsø. Lingbuzz/000956.
Caha, P. (2013). Explaining the structure of case paradigms through the mechanisms of Nanosyntax. Natural Language and Linguistic Theory, 31, 1015–1066.
Caha, P. (2017). Suppletion and morpheme order: Are words special? Journal of Linguistics, 53(4), 865–896.
Caha, P., De Clercq, K., & Vanden Wyngaerd, G. (2019). The fine structure of the comparative. Studia Linguistica, 73(3), 470–521.
Choi, J., & Harley, H. (2019). Locality domains and morphological rules. Phases, heads, node-sprouting and suppletion in Korean honorification. Natural Language & Linguistic Theory, 37, 1319–1365.
Christopoulos, C., & Zompì, S. (2022). Taking the nominative (back) out of the accusative: Case features and the distribution of stems in Indo-European paradigms. Natural Language & Linguistic Theory, 1–31.
Davis, C. P. (2021). Case-sensitive plural suppletion in Barguzin Buryat: On case containment, suppletion typology, and competition in morphology. Glossa: A journal of general linguistics, 6(1).
Embick, D. (2015). The morpheme: A theoretical introduction (Vol. 31). Berlin: de Gruyter.
Embick, D., & Marantz, A. (2008). Architecture and blocking. Linguistic Inquiry, 39(1), 1–53.
Ganenkov, D. (2018). The ABA pattern in Nakh-Daghestanian pronominal inflection. Snippets, 11–13.
Greenough, J. B., Kitteredge, G. L., Howard, A. A., & D’Ooge, B. (Eds.) (1903). Allen and Greenough’s Latin grammar for schools and colleges. Boston: Ginn and Company.
Halle, M., & Marantz, A. (1993). Distributed morphology and the pieces of inflection. In K. Hale & J. Keyser (Eds.), The view from building 20 (pp. 111–176). Cambridge: MIT Press.
Harðarson, R. G. (2016). A case for a weak case contiguity hypothesis-a reply to Caha. Natural Language & Linguistic Theory, 34(4), 1329–1343.
Harley, H., & Ritter, E. (2002). Person and number in pronouns: A feature-geometric analysis. Language, 78(3), 482–526.
Herrity, P. (2000). Slovene: A comprehensive grammar. London: Routledge.
Kasenov, D. (2023). Revisiting Basque (Xe-)comparatives. Manuscript.
McFadden, T. (2018). *ABA in stem-allomorphy and the emptiness of the nominative. Glossa, 3(1), 8.1–36.
Melvold, L. J. (1989). Structure and stress in the phonology of Russian. PhD dissertation, MIT.
Merchant, J. (2015). How much context is enough? Two cases of span-conditioned stem allomorphy. Linguistic Inquiry, 46(2), 273–303.
Middleton, J. (2021). Pseudo-ABA patterns in pronominal morphology. Morphology, 31(4), 329–354.
Moskal, B. (2015). Limits on allomorphy: A case study in nominal suppletion. Linguistic Inquiry, 46(2), 363–376.
Moskal, B., & Smith, P. W. (2016). Towards a theory without adjacency: Hyper-contextual VI-rules. Morphology, 26(3), 295–312. https://doi.org/10.1007/s11525-015-9275-y.
Neeleman, A., & Szendrői, K. (2007). Radical pro drop and the morphology of pronouns. Linguistic Inquiry, 38(4), 671–714.
Norris, M. (2014). A theory of nominal Concord. PhD Dissertation, Univeristy of California, Santa Cruz.
Norris, M. (2018). Unmarked case in Estonian nominals. Natural Language & Linguistic Theory, 36(2), 523–562.
Poppe, N. N. (1938). Grammatika burjat-mongol’skogo jazyka [grammar of the Buryat-Mongolian language]. Moskva; Leningrad: Izdavatelstvo Akademii nauk SSSR [Publishing house of the USSR Academy of sciences].
Smith, P. W., Moskal, B., Xu, T., Kang, J., & Bobaljik, J. D. (2019). Case and number suppletion in pronouns. Natural Language & Linguistic Theory, 37(3), 1029–1101.
Starke, M. (2009). Nanosyntax: A short primer to a new approach to language. Nordlyd, 36, 1–6.
Starke, M. (2017). Resolving (DAT = ACC) ≠ GEN. Glossa, 2(1), 104.1-8. lingbuzz/003783.
Starke, M. (2018). Complex left branches, spellout, and prefixes. In L. Baunaz, K. De Clercq, L. Haegeman, & E. Lander (Eds.), Exploring nanosyntax (pp. 239–249). Oxford: Oxford University Press.
Sudo, Y., & Nevins, A. (2022). No ABA patterns with fractionals. In L. Stockall, L. Martí, D. Adger, I. Roy, & S. Ouwayda (Eds.), For Hagit: A celebration, (pp. 1–10). London: Queen Mary University.
Van Baal, Y., & Don, J. (2018). Universals in possessive morphology. Glossa, 3(1), 1–19.
Vanden Wyngaerd, G., Starke, M., De Clercq, K., & Caha, P. (2020). How to be positive. Glossa, 5(1), 1–34.
Vanden Wyngaerd, G., De Clercq, K., & Caha, P. (2021). Late insertion and root suppletion. Revista Virtual de Estudos da Linguagem - ReVEL, 19(18), 81–123.
Zompì, S. (2017). Case decomposition meets dependent-case theories. Pisa, Italy: Università di Pisa MA thesis. Lingbuzz/003421.
Zompì, S. (2019). Ergative is not inherent: Evidence from *ABA in suppletion and syncretism. Glossa, 4(1), 73.
Funding
Open access publishing supported by the National Technical Library in Prague. I acknowledge the support of the Czech Science Foundation (GAČR) grant GA24-10073S.
Author information
Authors and Affiliations
Ethics declarations
Competing Interests
The author has no competing interests to declare.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Caha, P. Root and stem allomorphy without multiple exponence: the case of special nominatives. Morphology (2024). https://doi.org/10.1007/s11525-024-09425-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11525-024-09425-y