
Abstract
Rock quality designation (RQD), as a well-accepted and appliable rock quality index, is crucial in geotechnical engineering. Current RQD estimation mainly relies on either manual statistics or the image binarisation method, while the former approach surrenders high labour intensity and low efficiency and the latter one is constrained by image acquisition. Considering the above-mentioned limitations in RQD estimation, this study proposed a novel convolutional neural network (CNN) approach to automatically perform core recognition and RQD cataloguing with significant improvement in accuracy and efficiency. Firstly, the proposed neural network automatically identified the prefabricated round markers to distinct drilling rounds. To maximumly strengthen the engineering capability of CNN without losing generality, we considered image inversion, rotation, noise addition, and RGB conversion of 200 core box samples in total. Secondly, replacing the unstable image binarisation method, the advanced YOLO V2 object detection model, a single-stage real-time object detection model, was adopted in this study. We also proposed the modified four-layer downsampling structure as our CNN, and then developed an automatic recognition approach for both cores and the round markers, resulting in a 93.1% accuracy according to the validation set. Thirdly, this study proposed an auto-ranking algorithm to sequence the core sample according to the confidence of core recognition by the CNN and row-scanning results for subsequent RQD cataloguing. In addition, the optimal scan width was proved to be 1.33 times larger than the average core width. Finally, a quick cataloguing platform for drill cores was developed. Compared with manual measurement and visual statistics, intelligent RQD cataloguing is characterised by its unparalleled accuracy and efficiency, which is merited by the low relative error (1.84%) and fast processing time (around 0.2 s). Moreover, the application presented in this paper is applicable to most geotechnical engineering scenarios. This is attributed to its low requirements in image acquisition, high efficiency, precise recognition, and robustness.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The Rock Quality Designation (RQD) [8,9,10, 35] is an index reflecting the integrity of rocks for rock quality classification. It is also a vital index in various rock mass classification systems [4, 11, 13, 19, 33], such as rock mass rating (RMR) [12, 13, 24], Q system [4, 12], the geological strength index (GSI) [23, 40, 45], and the basic quality system (BQ) [5, 39]. It is the most common assessment index of rock mass quality used in geological engineering, such as underground mining and tunnelling. There are currently two main methods to estimate RQD [2, 5, 28, 36]: the rock mass surface survey method, such as the scanning window method and the scanning line method [6, 43], and the method of geological drilling and statistically calculating the RQD index. Geological drilling is widely used in rock mass quality evaluation in hydropower engineering and mining operations [2, 16, 17, 20, 32]. RQD cataloguing based on geological drilling [26, 34, 37] is mainly measured manually, which is generally time-consuming and labour-intensive, with poor accuracy and low automation in data management. To improve work efficiency, many scholars propose core recognition and core fracture boundary reconstruction methods. These methods are primarily based on the analytical research of high-definition digital images, focussing on pixel analysis for automatic core extraction and length identification [7, 20, 25, 28, 32, 44]. Among them, Lemy [20] and Saricam’s [32] work got a good outcome in automatic core recognition. To some extent, Saricam [32] follows Lemy’s work [20]. Lemy [20] provided the basic idea and framework of automatic recognition and RQD cataloguing; proposed line scanning and boundary reconstruction algorithms based on high-definition and fixed-focus images; and finally, to a certain extent, realised automatic RQD cataloguing. However, the proposed method has many restrictions on image acquisition, such as requiring a high-resolution single-lens reflex (SLR) camera, fixed focal length (160 cm), and eliminating interference factors while taking a picture as much as possible. Due to unavoidable factors such as image shadows, the recognition is still poor with fragmented and multi-mineral cores (presents as non-single-colour), making it challenging to promote and apply in on-site practice. Then, Saricam [32] overcame technical weaknesses to improve the algorithm's accuracy. In detail, they proposed a core recognition and processing method using the shadow analysis algorithm through the colour gamut of high-resolution images. This method eliminates some interference factors, such as eliminating image shadow by three different directions of light sources. But indeed, this method also has many restrictions. However, it is still challenging to recognise cores in specific situations, such as containing multiple minerals (displayed as various colours), unexpected fractures, and overlapping cores (Fig. 1). Both image acquisition devices are complicated to manipulate and difficult to promote in on-site practice. The algorithm is susceptible to the shadow of external light sources, the complexity of core mineral composition, the core box's colour, and the core placement's regularity. As a result, automatic recognition and cataloguing still need improvements.

Existing binarisation method limitations (including recognition errors and ranking errors) [32]
Different from image recognition, Olson [25] proposed an algorithm to identify every single core through the fissure between cores based on 3D point cloud data. Combined with the centreline method, this method could automatically recognise the core length and complete the core catalogue. However, it is limited by the apparent fissures between cores. If the fissures are close, which means the Z coordinate difference of the point cloud data cannot be identified, then the recognition cannot be finalised. This is the primary error of this automatic identification and cataloguing strategy. Moreover, 3D point cloud data scanning equipment is also much more complicated and expensive. This application does not significantly reduce the time for cataloguing, and finally, the limitations make this scheme challenging to implement.
Therefore, this paper aims to summarise the above-mentioned issues and challenges in core box image-based core recognition and cataloguing, then propose a deep learning model-based high accuracy geological core recognition and automatic cataloguing model. Benefiting from the replaced round marker (Fig. 2b) and sufficient sample set, the final result shows that the model performs excellently on core recognition. The round marker is used to separate two adjacent drilling rounds, normally unable to be identified by models due to its tiny scale (Fig. 2a. Thus, we replace it while taking core box images to make round detection easier. As a result, the model can substantially reduce the workload of manual cataloguing process. Compared to the manual process, it is much faster and more applicable. Compared to current automatic recognition solution, due to the required equipment being simple, it is also easy to manipulate and promote on-site.

Round Marker: a regular paper round marker; b prefabricated round marker
2 Deep learning model development
2.1 Network structure adaption
The main goal of deep learning is to build a deep network to extract features [1, 15, 18, 27, 38, 42]. And the object detection algorithm based on deep learning aims to distinguish the object category and determine its position in the image by acquiring object characteristics. Therefore, this study uses a deep learning model to complete core recognition. The limitation of Lemy and Saricam’s [20, 32] work is that the core recognition features are artificially extracted in specific situations. And these features are constrained by environment status, which increases the pre-processing work and cannot adapt to complex on-site conditions.
This study constructs a sample set of cores and round markers, aiming to cover enough features of on-site cores and the core box. It deliberately includes interference factors, for example, light shadows, various core box styles, and many types of actual production factors such as gravel and powder deposition in the core box. The model automatically learns the shallow and deep features of the image and finally achieves the desired result.
The proposed model uses the YOLO series object detection algorithm constructed by a convolutional neural network [3, 21, 29,30,31, 41]. Based on the dataset, the core and round marker recognition model is developed. The most prominent feature of this series of algorithms is that all targets are detected only once, starting from the image directly and using convolutional neural network calculation to find image features. Compared with other convolutional network-based image recognition algorithms, it directly regresses the position and category of the detection frame in the output layer. It reduces the image recognition problem to a regression problem [30, 31].
The Darknet-19 network is a feature learning network for non-dense object detection tasks [1]. Most areas in the target image are background and do not contain the detection object. To reduce the influence of a large background area on feature extraction, large multiples of downsampling are usually used to extract the detection object features. This network uses five-layer downsampling. However, the core detection is a dense object detection task. The cores occupy almost all of the image, and the background area only occupies 5–8%. Therefore, large multiples of downsampling will make the output feature map too small. As a result, it may lose some core features, and the recall would perform poorly. This study adjusts the five-layer downsampling to a four-layer downsampling, which ensures the output feature map has a larger scale. After inputting a 416 × 416 tensor image, the model will output a 26 × 26 tensor feature map through the downsampling process. A maximum of 26 cores can be predicted in both horizontal and vertical directions. Statistics show that it is difficult to exceed 26 cores of each row, even in extremely fragmented core box images. The final results show that the four-layer downsampling has excellent recognition, as depicted in Fig. 3. The subfigure (a) shows the outcome of a origin Darknet-19, subfigure (b) shows the proposed four-layer model recognition result, and (c) shows the recognition errors under a three times sample expansion.

Example of extremely fragmented core box image and a the comparison of the origin Darknet-19 model, b proposed four-layer model outcome, and c recognition errors outcome
To prevent feature loss in the initial downsampling process, the network structure used in this study has the following features: the feature map, obtained from the end of the third downsampling layer, is merged with the feature map obtained by the 13th layer of the network; and the final feature map is produced after a six-layer convolution operation. The specific network structure is shown in Fig. 4.

Network structure
The convolution layer uses an equal filling method to ensure that the size of the feature map remains unchanged after the convolution operation, and it uses the ReLU function to perform the nonlinear conversion. The downsampling process uses a 2-stride pooling layer and a 2 × 2 max-pooling. The feature map size is going to be halved in each downsampling, and finally, the image is downsampled 16 times. The network structure, shown in Fig. 5, will output a 26 × 26 tensor feature map based on the 416 × 416 tensor input image. Each cell of the final output feature map is used as a prediction grid for output coordinates and categories. Each cell outputs five predictions, including the target centre point coordinates (x, y), width and height (W, H), confidence, and two categories. The final network output is a tensor of 26 × 26 × (5 × (5 + 2)), that is 26 × 26 × 35. The meaning of each part of the output is shown in Fig. 5.

Network output description
Given that directly regressing the target position may lead to output coordinates deviation and unstable, since the loss will not reflect the actual wireframe [14, 31], the pre-calculated prior bounding box is used to fix the output. The \(({t}_{x},{t}_{y},{t}_{h},{t}_{w})\) is the predicted coordinate of the network, and the \(({b}_{x},{b}_{y},{b}_{h},{b}_{w})\) is the target's actual coordinate relative to the image. The upper left corner coordinate of the cell is \(({C}_{x},{C}_{y})\), the prior bounding box size is \(({P}_{w},{P}_{h})\), and the output feature map size is \((W,H)\). The relationship is shown as follows:
where σ(∙) is the Sigmoid function.
The size of the prior bounding box comes from the K-means clustering [22] algorithm, which learns all the core and round marker frames in the sample set. This study applies the K-means algorithm to the core frame and the round marker frame and selects five cluster centre points as the length and width values of the prior bounding box, specifically (19,31), (37,25), (60,31), (25,8), (193,35). The first three represent the length–width ratio of the short cores and the round marker, while the latter two are for the long cores.
In prediction, the network output includes the confidence and category probability. The pre-set confidence threshold decides whether the prediction is valid or not. For the predicted category, take the largest value as the predicted category.
2.2 Sample set
2.2.1 Image acquisition
The image acquisition process especially focuses on cases such as light and shadow, various core sizes, complex mineral composition, core fragmentation, accumulation of dust and gravel, various core box styles, multiple drill rounds in one image, joint enriched cores, and partially filled core box. The image could be taken without any constraints, which means phone and normal digital cameras (normally resolution higher than 3088 × 2320 pixels) will be good enough rather than a professional camera in Lemy and Saricam’s [20, 32] study. And there are no unified standards for core box material, colour, size, core diameter, lithology, and mineral composition. The generalised acquisition could enrich the core box dataset and enhance the recognition's generalisation. Finally, the collected core box images include various core boxes, with core colours including white (Fig. 6a, c), light grey (Fig. 6d), black (Fig. 6e), reddish-brown (Fig. 6b)), and core diameter of 42 mm (Fig. 6c, e), 50 mm (Fig. 6a, d, f, h) and 60 mm (Fig. 6b). At the same time, in order to achieve the rapid and automatic cataloguing of RQD based on the recognition results, prefabricated round markers (Fig. 2b) with a fixed size and a specific shape were added into every core box, replacing the paper round marker (Fig. 2a). The sample image is shown in Fig. 6g. The replacement can help the model quickly identify the drill rounds and simplify the size transformation. Finally, the RQD and drilling rate calculation is finalised rapidly and efficiently. In particular, due to the output result is ranked based on descending threshold, it is different from the actual rank. It is necessary to guarantee calculation accuracy through the automatic data ranking algorithm. The data ranking algorithm is further discussed in Sect. 4.

List of generalised core box images included in the dataset: a partially filled core box; b large diameter core and gravel and powder deposition core box; c small diameter and fragmented core box; d low light source core box; e complex colour gamut core box; f long-core core box; g unique core box size; h high light source core box
A total of 200 core box image samples, which is around 20,000 core samples, were collected from around ten different mine sites, including solid light (Fig. 6h), low light (Fig. 6d), shadow environment (Fig. 6g), complex mineral composition (Fig. 6e), long cores (Fig. 6f), and various kinds of core boxes such as broken, jointed, dust accumulation, different styles (Fig. 6a–d, g), and partially filled core box (Fig. 6a), with around 20 core box image samples (around 2000 core samples) for each type.
2.2.2 Image expansion
The sample set is expanded based on the principle of data augmentation. This study uses four methods: flip, rotate, add noise, and RGB conversion. Flip operations are horizontal flip and vertical flip, using its symmetry axis as the flip axis to exchange the image content. Image rotation is 180° clockwise with the image centre point. Adding noise simulates the unstable operation of the imaging device, specifically adding black and white pixels to random locations in the image. The RGB transformation randomly transforms all the pixels of each channel of the image, and the adjusted image displays very differently in colour distribution. A random image expansion method is adopted for each original core box image. As a result, 400 core box images are obtained (around 40,000 core samples). The image expansion outcome is shown in Fig. 7.

Image expansion effect example: a original image; b flip horizontal; c rotation; d add noise; e RGB conversion
2.2.3 Sample annotation
The sample set is divided into a training set and a validation set at a ratio of 8:2 [27]. In terms of the division of training and validation dataset, as the samples collection has been tried to cover more practice scenarios of core boxes and cores, this paper utilise random split to process the dataset. Since a single core box image contains multiple cores, the final number of samples reaches around 20,000. The validation set has nearly 4000 samples. The training inputs include the relative coordinates and the pixel size (length and width) of the smallest outsourcing rectangle of both the core and the round marker. Every core box image will generate multiple data records according to the amount of labelled data. The format of each record is in the order of name, type, location, width, and height, where type is used to distinguish between core and round marker, and the value is core or marker. The annotation diagram is shown in Fig. 8.

One sample of the labelled core box image
2.3 Model training
The stochastic gradient descent (SGD) algorithm optimises the loss function and updates the network weight in the training process. The loss function is defined as the mean square error of the predicted value and the actual value, including the frame position loss, confidence loss, and classification loss. Given that the core to round marker ratio is around 37, the statistic shows that the objects are seriously unbalanced in quantity. In the network training process, the object with a larger quantity is much easier to optimise and reduce in the loss function. Therefore, disregarding this would make the core feature to be learned first, resulting in a low round marker recognition rate. However, accurate identification of the round marker is the prerequisite of intelligent RQD cataloguing. Thus, the network's total loss is divided into core loss and round marker loss to solve the issue caused by sample quantity imbalance. The parameter \(\alpha \) is introduced to balance the two types of losses. The test found that the network has a good learning ability to the round marker features when \(\alpha =0.2\). The equation is shown as follows:
The initial training parameters are 0.01 for learning rate, 32 for the batch size, and 2000 times training. Then the learning rate is set to 0.001 without changing the batch size. This time, the training process uses exponential decay to slowly reduce the learning rate, and finally accomplishes 1800 times training. Equation 6 is an exponential decay expression, where \({r}_{0}\) is the learning rate that starts to decay, and \({r}_{0}\)=0.001; \(\beta \) is the decay rate, and \(\beta \) =0.99; \(\mathrm{epoch}\) is the current training round, and \(r\) is the updated learning rate.
3 Model evaluation
In order to evaluate the prediction accuracy of the deep learning model, four indicators are used: precision, Recall, mAP (mean average precision), and F1-score. When calculating the core index, the core is the positive sample, the round marker is the negative sample, and vice versa.
-
(1)
Precision
The precision is the ratio of correctly predicted samples to all predicted samples, expressed as:
-
(2)
Recall
The recall is the proportion of samples correctly predicted to all samples, expressed as:
-
(3)
F1-score
F1-score is the harmonic mean of precision and recall of a certain category, expressed as:
The total F1-score of the model is the average of the F1-score of the two categories of core and round marker:
where TP is the number of correctly predicted positive samples; TN represents the number of correctly predicted negative samples; FP is the number of incorrectly predicted negative samples; and FN is the number of incorrectly predicted positive samples.
Evaluation is conducted on a validation dataset with 80 core box images (around 8000 core samples). Different confidence thresholds are used for calculating the recall and precision of cores and round markers. When the confidence threshold is small, the recall is high, but the precision is low, and the average F1-score value is low. When the confidence threshold is large, the precision is high, but the recall is low, and the average F1-score is low. The average confidence threshold and F1-score curves are drawn to determine the best confidence threshold and ensure that the recall and precision are both at a high level, as shown in Fig. 9. It is concluded that when the confidence threshold is 0.6, the highest F1-score is 0.903. The average precision of the two categories is 93.1%, and the average recall is 87.6%, as shown in Fig. 10.

Confidence threshold-F1 curve

The index value of each category (confidence threshold: 0.6)
The performance is shown in Fig. 11. The recognition result shows that this model can identify changes in core diameter and length (Fig. 11a–c) and accurately identify dense small-diameter cores (Fig. 11b, d). But an extremely fragmented core will be misidentified as a whole long core or just missed (Fig. 11c). The recognition under various light sources shows that high or low light source has no impact on the result (Fig. 11b, d). The recognition of partially filled core box (Fig. 11c) and complex material components (Fig. 11a) shows that this model detects the deep features of the core, rather than the shallow features, and finally achieves a reasonable accuracy. In general, the model has good recognition of various samples, indicating that the overall error of core recognition is approximately evenly distributed across the sample set rather than concentrated on some specific core box images.

Recognition effect of core box images (original on the left, and recognition labelled on the right): a larger diameter and fragmented core box; b regular core box; c partially filled core box; d high light source and irregular core box shape image
4 Automatic cataloguing
4.1 Obtain the actual core length
Based on the deep learning model, the following JSON data string is a sample of the core recognition result:
“results”: [
[“location”:[“height”:431.1408,”left”:498.2432,”top”:460.856,”width”:745.5818],”name”:”core”,”score”:0.942],
……
[“location”:[“height”:237.7177,”left”:3200.794,”top”:1701.291,”width”:81.71545],”name”:”marker”,”score”:0.895]]
Since the size in the result is based on pixel data, actual length mapping is needed for calculating RQD index. There are two steps in the traditional manual extraction scheme: (1) place a fixed size marker and (2) cut the core box image, scale the image to the corresponding size in the computer-aided design software (CAD), and directly measure and obtain the core size (Fig. 12). Different from the manual measurement, the image acquisition scheme proposed by Saricam [32] uses a fixed focal length (90 cm) to photograph to simplify the size mapping process. In fact, although fixed-focus shooting ensures that the mapping relationship between the image elements and the actual size is fixed, the shooting process becomes complicated. Fixed focal length shooting requires the camera, focal length, core box height and even core diameter to be fixed, which undoubtedly increases the complexity of image acquisition and operation, and also weakens the generalisation of the recognition model.

Schematic diagram of the on-site core box image-based cataloguing work
This study has customised a fixed-size round marker (Fig. 2b) with actual width of 6 cm. In the core box image, its pixel width is output by the detection network. The ratio of the object's actual width to the pixel length is called the Image Mapping Ratio. This value reflects the mapping relationship between the identified target pixel size and its actual size in a specific core box image. The actual core size calculation formulas are shown in Eqs. (11) and (12).
where \({\text{Map}}_{{{\text{marker}}}}\) is the Image Mapping Ratio; \(H_{{{\text{marker}}}}\) is the round marker pixel width; \(L_{{{\text{marker}}}}\) is the core length (cm); \(W_{{{\text{pixel}}}}\) is the core pixel length.
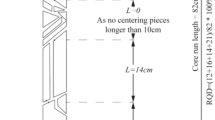
In order to evaluate the model performance in measuring the accrual core length, this study compared the model calculated core length to the CAD-based manual measured length, where the actual size is the benchmark. The relative error and the time used by each method are listed in Fig. 13 and Table 1. The average relative error of the automatic calculation method is 1.849%, and the manual measurement is 1.680%, indicating that both approaches have high measurement accuracy. In the subsequent RQD calculation based on the measurement results (Fig. 14 and Table 2), this accuracy deviation does not affect the rock mass quality classification result. In contrast, the time required for manual measurement and image-based manual measurement methods is more than 1800 times longer than the proposed automatic method in this study.

Comparison of error rate between manual and intelligent size recognition

RQD value and grading evaluation comparison
4.2 Automatic ranking algorithm
The output data based on the intelligent recognition model are the smallest outsourcing rectangle information of each core and round marker. The data are ranked according to the recognition quality, where recognition quality is defined as the reliability of the recognition results under the current threshold, and the data range is 0–1. It means the order of cores in each image is out of sequence. While core ranking is the prerequisite for RQD cataloguing, especially for those multi-round core box samples (such as Fig. 8). Correct and without omission of each drill round sequence contributes to the accuracy of RQD cataloguing. To perfect this, the recognition result needs to be ranked from left to right and top to bottom according to the actual position.
Based on the recognised rectangle, this study proposes an automatic ranking algorithm with three steps: (1) group samples by rows; (2) rank within each group; and (3) rank all samples in the core box row by row. The flow chart and diagram are shown in Figs. 15 and 16. In contrast to the conventional centreline scanning method [32], this automatic ranking algorithm uses area scanning. This method determines \(1.33\times {W}_{\mathrm{mean}}\) as the scanning area width, where the \({W}_{\mathrm{mean}}\) is the average width of the core outsourcing rectangle frame according to the recognition result of each core box image, and the centre point of the first recognised object of the upper left corner is the starting point of the scanning area. After completing the single-row area scan, the recognition results are ranked by the centre coordinate “x” value from small to large. The effect diagram of ranked core box images is shown in Fig. 17. Finally, multiple rows of ranked data are merged to get the whole ranking result of each core box, then the ranked data is automatically catalogued.

Flow chart of automatic ranking algorithm

Area scanning method diagram

The effect diagram of the labelled core box images based on the ranking algorithm: a usual core box image; b closely placed core box image; c partially filled core box image; d across row placement core box image
The ranking algorithm tests various scan widths, as shown in Table 3. Based on 129 images, \({W}_{\mathrm{mean}}\), \(0.67\times {W}_{\mathrm{mean}}\), \(1.33\times {W}_{\mathrm{mean}}\), and \(1.5\times {W}_{\mathrm{mean}}\) are tested as scan width. Data shows that \(1.33\times {W}_{\mathrm{mean}}\) achieves the best ranking accuracy. Specifically, the \({W}_{\mathrm{mean}}\) is dynamically changed in each recognition which will always keep the accuracy of ranking.
4.3 Cataloguing result analysis
The cores between every two round markers result in an RQD value. The calculation formula is shown as follows:
where \({L}_{\mathrm{core}}\) is the length of a single core, and \({L}_{\mathrm{round}}\) is the length of the drilling round. According to the actual production process, the length of one drill round is generally around 1.2–1.5 m. For one drilling round, sum the core lengths greater than 100 mm, and the ratio of this sum to the round length is the corresponding RQD value.
The error of the RQD cataloguing result is one of the indicators to evaluate the recognition model. As shown in Fig. 14, compared to manual calculation, the RQD error obtained by the intelligent cataloguing algorithm based on deep learning can be controlled within ± 2.5%, showing an excellent recognition result. At the same time, referring to the RQD value and its corresponding rock mass classification in Table 4, the RQD cataloguing error did not cause classification error. As a result, the model can meet on-site needs in RQD value calculation and rapid rock mass classification evaluation.
5 Discussion
5.1 Sample set limitation
In this paper, model generalisation in core recognition is crucial in model construction and validation. In Sect. 2.2, image expansion was applied to satisfy the sample volume requirement in deep learning model construction. Two times expansion was finalised based on model validation. Actually, image expansion has limitations on either less or over-expansion. In detail, less expansion will cause the recognition model to lose universality in on situ core samples, then induce recognition error, normally presenting as core omission or unstable recognition while facing unexpected noises. On the other hand, too much expansion will lead to model overfitting, normally shown as high accuracy in training and validation set but extremely low precision in practice. In addition, too much expansion will also cause recognition error, as depicted in Fig. 3c, overlapping core can be recognised more then once. The result indicates that two times of image expansion is certificated to be more balanced in core and round marker recognition.
5.2 Error analysis
5.2.1 Size mapping error
Actual size mapping is the main task before RQD cataloguing. This study attributes to the size-fixed round marker for accurate core size mapping. Four different shape markers have been tested (shown in Fig. 18). Firstly, cylinder markers (Fig. 18a,b) are good for size mapping. However, its diameter is difficult to be determined due to two main aspects: (1) a smaller cylinder is difficult to be identified and could be obfuscated with other objects while training the model; (2) the opposite is then challenging to place in such dense space of a core box. Moreover, the larger cylinder could cover neighbour cores and finally cause length error (Fig. 18d). Secondly, cubic markers (Fig. 18c) have the same concern in practice. Core box is always too dense to contain any big markers. Finally, we figured out a bench-like marker (Fig. 2b) to replace the paper round marker (Fig. 2a), ensuring the shape is easy to identify but does not fuse with cores.

Three other different round markers in core box
The size mapping error mainly comes from the improper placement of round markers. The placement of the round marker may be shown in Fig. 19a, forming an angle θ between the pixel width (\({L}_{ac}\)) of the outsourcing rectangle and the actual pixel length (\({L}_{ab}\)) of the round marker, and generally \({L}_{ac}\) is smaller than \({L}_{ab}\). This kind of placement will result in a larger \({\text{Map}}_{{{\text{marker}}}}\) and then a larger \(L_{{{\text{core}}}}\), which finally causes a larger RQD value. To avoid this error, it is necessary to ensure that the round markers are appropriately placed, as shown in Fig. 19b, where \(L_{ac} = L_{ab}\), and \({\text{Map}}_{{{\text{marker}}}}\) is the most accurate.

Example of the round marker placement: a irregular placement, b standard placement
To deal with irregular placement in Fig. 19a, this study proposes adjusting Eq. (12) to achieve data correction. The adjusted equation is shown as follows:
In the mapping process, Eq. (14) is used to make a correction and improve the recognition accuracy.
5.2.2 Core ranking error
The existing core recognition models usually adopt the snake-like path scanning method, for example, the centreline scanning method [6, 32], as shown in Fig. 20. In the snake-like method, the starting position is manually calibrated (the pink marker in the upper right corner in Fig. 20), and then scanning is done row by row from left to right, top to bottom, finally achieving the whole image ranking. This method does not consider the condition where one core box could have multiple drilling rounds. It also cannot be applied to different core boxes, such as the mismatched core size shown in Fig. 21. In addition, the centreline scanning method still relies on manual calibration and does not achieve automatic RQD cataloguing.

Snake-like path core ranking [32]

Examples of centreline scan error
Therefore, this study proposes an automatic ranking algorithm based on recognised coordinates. The algorithm has a low error rate at 0.78%. Compared to the ranking scheme, which requires manual intervention, the automatic ranking algorithm is more suitable for automatic RQD cataloguing and could improve efficiency.
5.2.3 Recognition error
Core fragmentation and irregular placement can affect the recognition result to a certain extent. These recognition error cases are shown in Fig. 22. There are three main reasons for the error: (1) the core stacking leads to the fusion of image pixels, that is, the core boundary is too blurred, and more than two cores are identified as one section (Fig. 22a); (2) the core fracture surface is complex, and the shape of the fracture surface is irregular, so one segment is recognised as two or more segments (Fig. 22b); or (3) the core is too long to be recognised as a sample (Fig. 22c).

Examples of recognition errors: a recognise two cores as one core; b recognise one core as two cores; c miss recognition of a long core
In response to those errors, the platform has a built-in complementary mechanism based on the interactive visualisation interface (Fig. 23). The complementary functions include: re-mark cores (Fig. 23a), re-mark fragmented zone (Fig. 23b), re-mark round marker (Fig. 23c), cancel operation (Fig. 23d), submit operation (Fig. 23e), and object dashboard (Fig. 23f), which are all easy manual corrections. At the same time, the poorly recognised images in the actual process could be added to the model sample set, and the sample set is regularly upgraded and trained to make up for the lack of actual samples. In addition, due to the zone scan method, a horizontal fracture could be recognised as two cores, which can cause a RQD error. Given the error can only occur in the scenario that the drilling core size is much smaller than the box line (as depicted in Fig. 21), the error is currently be avoid by the complementary mechanism. Considering the further update of recognition model, this error will be optimised in next version.

The interactive interface of the complementary mechanism: a re-mark cores; b re-mark Fragmented zone; c re-mark round marker; d cancel operation; e submit operation; f object dashboard
5.3 Platform development
5.3.1 Applicable on situ practice
Some previous work based on image recognition were burdened with complex image acquisition. For example, the fixed focal length shooting scheme is based on a specific device (Fig. 24). It requires various pieces of equipment to be set, such as the camera, focal length, the height of the core box, and even the core diameter. This increases the shooting and operation complexity, weakens the recognition model's generalisation, and loses precision in recognising different core sizes and core boxes.

a Core box image acquisition equipment and b Schematic diagram indicating positions of camera and light sources [32]
The deep learning model proposed in this study detected the deep features of the core. It adapts to actual images without specific restrictions and then achieves fast and accurate recognition. The future trend of this application is developing mobile applications that link to a robust database and target combining photo and parameter entry. Then core recognition and RQD cataloguing will reach a super high automatic.
5.3.2 Platform extension
With the abovementioned fragmentation marking in Sect. 5.2.3, the geological fault could be highlighted as a fragmented zone in the core box, shown in Fig. 25. Moreover, the location of the fragmented zone can be retrieved from the drilling coordinates, azimuth angle, and drilling round information.

Label for fragmented zone
The marked fragmented zone can provide a basis for determining the geological fault in the process of drilling visualisation. Then the trend of fault extension could be predicted based on multiple drilling fragmented zones, as shown in Fig. 26. This prediction is an essential part of the follow-up application.

Geological fault according to the mark of fragmented zones
6 Conclusions
This study developed a novel CNN model-based drill core recognition and intelligent RQD cataloguing platform. Considering those defects in RQD estimation via traditional methods, such as labour intensity, low accuracy, and complex prerequisites in image acquisition, we proposed an excellent, efficient CNN model and intelligent object ranking algorithm that brought significant outcomes, such as excellent mAP (90%), high average recognition precision (93.1%), outstanding average recall (87.6%), and unparalleled low core recognition error (within ± 4.5%). For on situ practice promotion, a web-based platform is developed. Moreover, the built-in recognition complementary function contributes to the correction of recognition errors. And for further concern, sample accumulation is available on the web platform to continuously upgrade the model.
However, even though we have collected samples from more than ten different mine sites, and it works well and gets excellent outcomes. It is not possible to cover all conditions in practice. That is the reason for the development of a web-based complementary function. A further study could upgrade and strengthen the recognition model in long-term learning and advancement. Continuous efforts would be needed to perfect this automatic core recognition and intelligent RQD cataloguing platform.
References
Al-Haija QA et al (2020) Identifying phasic dopamine releases using darknet-19 convolutional neural network. IEEE, New York
Azimian A (2016) A new method for improving the rqd determination of rock core in borehole. Rock Mech Rock Eng 49(4):1559–1566
Bai X-D et al (2021) A comparative study of different machine learning algorithms in predicting epb shield behaviour: a case study at the xi’an metro, china. Acta Geotech 16(12):4061–4080
Barton N et al (1974) Engineering classification of rock masses for the design of tunnel support. Rock Mech Felsmech Mécanique des Roches 6(4):189–236
Chen K et al (2021) Modification of the bq system based on the lugeon value and rqd: A case study from the maerdang hydropower station, china. Bull Eng Geol Env 80(4):2979–2990
Choi S, Park H (2004) Variation of rock quality designation (rqd) with scanline orientation and length: a case study in korea. Int J Rock Mech Min Sci 41(2):207–221
Crida R, De Jager G (1994) Rock recognition using feature classification. In: Proceedings of COMSIG'94–1994 South African symposium on communications and signal processing, IEEE
Deere, D. (1988) The rock quality designation (rqd) index in practice. In: Rock classification systems for engineering purposes, ASTM International.
Deere, D et al (1966) Design of surface and near-surface construction in rock. In: The 8th US symposium on rock mechanics (USRMS). OnePetro
Deere DU, Deere, DW (1989) Rock quality designation (rqd) after twenty years. Deere (Don U) Consultant Gainesville Fl
Dimitrov I (2020) Structural geological methods in the geotechnical practice—rock mass rating. Adv Probl Rat Methods. https://doi.org/10.52215/rev.bgs.2020.81.1.3
Fernández-Gutiérrez J et al (2017) Correlation between bieniawski's rmr index and barton's q index in fine-grained sedimentary rock formations. Informes de la construccion, 69(547)
Fernandez-Gutierrez JD et al (2021) Analysis of rock mass classifications for safer infrastructures. Transp Res Proc 58:606–613
Han X et al (2021) Real-time object detection based on yolo-v2 for tiny vehicle object. Proc Comput Sci 183:61–72
He K et al (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition
He M et al (2021) Deep convolutional neural network-based method for strength parameter prediction of jointed rock mass using drilling logging data. Int J Geomech 21(7):04021111
He M et al (2021) Prediction of fracture frequency and rqd for the fractured rock mass using drilling logging data. Bull Eng Geol Env 80(6):4547–4557
Hsiao C-H et al (2022) Performance of artificial neural network and convolutional neural network on slope failure prediction using data from the random finite element method. Acta Geotech 17(12):5801–5811
Khetwal A et al (2021) Understanding the effect of geology-related delays on performance of hard rock tbms. Acta Geotech 17(3):919–29
Lemy F et al (2001) Image analysis of drill core. Min Technol 110(3):172–177
Li L, Iskander M (2022) Use of machine learning for classification of sand particles. Acta Geotech 7(10):4739–59
Likas A et al (2003) The global k-means clustering algorithm. Pattern Recogn 36(2):451–461
Marinos P, Hoek E (2000) Gsi: a geologically friendly tool for rock mass strength estimation. In: ISRM international symposium. International Society for Rock Mechanics and Rock Engineering.
Naithani AK (2007) Rmr-a system for characterizing rock mass classification: a case study from Garhwal Himalaya, Uttarakhand. J Geol Soc India 70(4):627
Olson L et al (2015) 3-d laser imaging of drill core for fracture detection and rock quality designation. Int J Rock Mech Min Sci 73:156–164
Palmstrom A (2005) Measurements of and correlations between block size and rock quality designation (rqd). Tunn Undergr Space Technol 20(4):362–377
Pascual AD et al (2019) Autonomous and real time rock image classification using convolutional neural networks. The University of Western Ontario, London
Pells P et al (2017) Rock quality designation (rqd): time to rest in peace. Can Geotech J 54(6):825–834
Rajesh Kumar B et al (2013) Regression analysis and ann models to predict rock properties from sound levels produced during drilling. Int J Rock Mech Min Sci 58:61–72
Redmon J et al (2016) You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition
Redmon J, Farhadi A (2017) Yolo9000: better, faster, stronger. In: Proceedings of the IEEE conference on computer vision and pattern recognition
Saricam T, Ozturk H (2018) Estimation of rqd by digital image analysis using a shadow-based method. Int J Rock Mech Min Sci 112:253–265
Satria, J et al (2021) Rock mass classification for design of excavation method and support system of tunnel 1 sigli-aceh toll road, indonesia. In: IOP conference series: earth and environmental science. IOP Publishing
Schunnesson HJT, Technology US (1996) Rqd predictions based on drill performance parameters. Tunn Undergr Space Technol 11(3):345–351
Séguret SA, Moreno CG (2015) Geostatistical evaluation of rock-quality designation and its link with linear fracture frequency. In: The 17th annual conference international association for mathematics geosciences
Sonmez H et al (2022) A novel approach to structural anisotropy classification for jointed rock masses using theoretical rock quality designation formulation adjusted to joint spacing. J Rock Mech Geotech Eng 14(2):329–345
Vavro M et al (2015) Application of alternative methods for determination of rock quality designation (rqd) index: a case study from the rožná i uranium mine, strážek moldanubicum, bohemian massif, czech republic. Can Geotech J 52(10):1466–1476
Wan J et al (2014) Deep learning for content-based image retrieval: A comprehensive study. In: Proceedings of the 22nd ACM international conference on Multimedia, ACM
Wang M-N et al (2021) Support pressure assessment for deep buried railway tunnels using bq-index. J Central South Univ 28(1):247–263
Winn K (2020) Multi-approach geological strength index (gsi) determination for stratified sedimentary rock masses in singapore. Geotech Geol Eng 38(2):2351–2358
Yi X et al (2023) An efficient method for extracting and clustering rock mass discontinuities from 3d point clouds. Acta Geotech 18:3485–3503
Yin Z et al (2014) Deep learning and its new progress in object and behavior recognition. J Image Graph 19(2):175–184
Zhang W et al (2013) Size effect of rqd and generalized representative volume elements: A case study on an underground excavation in baihetan dam, southwest china. Tunn Undergr Space Technol 35:89–98
Zhang W et al (2016) Identification of structural domains considering the size effect of rock mass discontinuities: a case study of an underground excavation in baihetan dam, china. Tunn Undergr Space Technol 51:75–83
Zuo J, Shen J (2020) The geological strength index. Springer, Singapore, pp 85–104
Acknowledgements
This study was funded by the State Key Research Development Program of China (2018YFC0604400), the National Science Foundation of China (51874068, 52074062), the Fundamental Research Funds for the Central Universities (N180701016), and the 111 Project (B17009).
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xu, S., Ma, J., Liang, R. et al. Intelligent recognition of drill cores and automatic RQD analytics based on deep learning. Acta Geotech. 18, 6027–6050 (2023). https://doi.org/10.1007/s11440-023-02011-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11440-023-02011-2