
Abstract
Videos are an increasingly popular medium for supporting learning in various educational settings. Nowadays, newly designed video-based environments contain enhanced tools that allow for specific interactions with video materials (such as adding annotations and hyperlinks) which may well support generative learning and conceptual understanding. However, to exploit the potentials of such enhanced tools, we need to gain a deeper understanding on the learning processes and outcomes that go along with using these tools. Thus, we conducted a controlled laboratory experiment with 209 participants who were engaged in learning a complex topic by using different enhanced video tools (annotations vs. hyperlinks vs. control group) in different social learning settings (individual vs. collaborative learning in dyads). Findings revealed that participants who learned with hyperlinks and participants in collaborative settings created hypervideo products of higher quality than learners in other conditions. Participants who learned with annotations assessed their knowledge gain higher and had higher results in conceptual understanding when they experienced low cognitive load. With our study we contribute new original work to advance cognitive research on learning with enhanced video learning environments. Limitations and recommendations for future research are discussed.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
How can we support effective learning? Answering this question is of utmost practical and scientific interest, as it is key for successful educational and work performance. In times of digital transformation—recently boosted through the challenges occurring from the COVID-19 crisis—effective learning with digital tools and new digital classroom settings gained in importance (Marinoni et al., 2020; Yan et al., 2021). Especially digital videos were recognized by educational institutions to be a promising opportunity to tackle challenges of such settings since they can be provided asynchronously and remotely (Noetel et al., 2021) and have been shown to foster learning (e.g., Tiernan, 2015).
Nowadays, enhanced video-based environments provide video tools that allow learners not only to watch videos, but to interact with the video materials and re-structure them according to their own needs (e.g., Chambel et al., 2006; Zahn et al., 2005). In other words: videos can be used in more flexible and creative ways. For instance, learners can use annotations to place their own comments and remarks or self-written summaries into videos, or they can add hyperlinks to connect video objects to additional pieces of information thereby creating their own (new) information structures. Moreover, learners can not only work individually, but also collaboratively in such enhanced video-based environments – sharing their annotations and hyperlinks and discuss them with others (peers, colleagues, teachers) or edit the material in learning groups (e.g., Chambel et al., 2006; Goldman, 2007; Sauli et al., 2018; Zahn et al., 2012). In this sense, video tools can be seen as socio-cognitive tools for learning that afford advanced learning activities like “analyze”, “evaluate” or “create” according to Bloom`s taxonomy (Anderson & Krathwohl, 2001; Krathwohl, 2002). However, there is no consensus in the literature on whether and how enhanced tools really support individual and collaborative learning or are rather cognitively overwhelming (Evi-Colombo et al., 2020; Sauli et al., 2018). A holistic view on learning might shed light into this question. Situative approaches from cognitive research on learning and computer-supported collaborative learning (CSCL) suggest to study learning by a simultaneous consideration of different aspects that shape learning (Greeno & Engeström, 2014; Janssen & Kirschner, 2020): antecedents of learning, such as subjective conditions (individuals or groups), objects (topics and tasks learners work on), and resources (e.g., tools learners use to transform the object to a desired outcome), processes of learning, and consequences of learning. In Fig. 1, we adapted the model of the relationship between antecedents, processes, and consequences of collaboration by Janssen and Kirschner (2020, p.790) and integrated further concepts provided by Greeno and Engeström (2014, learning in activity), Wittrock (1992, generative learning) and Mayer (2009, multimedia learning). These concepts are explained in more detail below.

The relationship between antecedents, processes, and consequences of learning, based on situative approaches. Note. Explanations to supplement or clarify information in the image. Adapted from “Applying collaborative cognitive load theory to computer-supported collaborative learning: towards a research agenda” by J. Janssen and P. A. Kirschner, 2020, Educational Technology Research and Development, 68(2), p. 790. CC BY 4.0
In the present article, we report on our research systematically investigating in a controlled laboratory experiment how specific resources (video tools) and subjective conditions of learning (individual or collaborative setting) may interact and influence processes and consequences of learning. Precisely, the effects of different enhanced video tools (Tool-use: annotations vs. hyperlinks)—alongside with a control group (no Tool-use)—and different social learning Settings (individual vs. collaborative learning in dyads) on learning processes (i.e., learning activity and cognitive load) and outcomes (i.e., generative learning product and conceptual understanding) were analyzed. In the following sections, we introduce related research on enhanced video-based learning and on individual and collaborative learning. The introduction closes with the aims of the present work.
Literature review
From learning with videos to enhanced video tools
Videos have been used to support learning in many domains as they allow to depict objects, situations, and movements (also those that cannot easily be watched with naked eyes) and are able to visualize abstract information processes (Overbaugh, 1995). Even before the COVID-19 pandemic, the use of videos had a long tradition in educational institutions around the globe (for a review see Poquet et al., 2018). However, the rather passive viewing of videos—although it seems very easy (Salomon, 1984)—can result in little engagement, mental effort or reflection of learners, which may impede the construction of their own understanding of a topic (Shin et al., 2018). Thus, the possibility for learners to interact with the video material was emphasized to be of crucial importance (Hasler et al., 2007). For example, by using basic video control tools, such as play, pause, or rewind, learners are able to actively engage and interact with the material and, thus, to adapt the learning information to their own cognitive needs with positive effects for learning (e.g., Schwan & Riempp, 2004). Or, as another example, in-video quizzes afford that learners answer questions that directly appear during video watching (Cattaneo et al., 2018) and, thus, self-assess their own knowledge or discover still existing knowledge gaps (Panadero et al., 2017) with positive effects on learning performance (Haagsman et al., 2020; Rice et al., 2019), engagement (Cummins et al., 2016), and motivation (Leisner et al., 2020).
Today, enhanced video-based environments go beyond these types of interaction and instead allow learners to use enhanced video tools to actively create their own enriched information structures and thereby generate meaning (for an overview, see Schwartz & Hartman, 2007, for hypervideo see Chambel et al., 2006 and Zahn, 2017). According to Bloom’s taxonomy (Krathwohl, 2002), such an active creation of own learning structures is important, since knowledge acquisition is not only a product of “understanding”, but also of "creating" (see also learning through design approach: Kafai & Resnick, 1996). This is in line with Wittrock's (1992) model of generative learning and Mayer’s (2009) select-organize-integrate (SOI) model, suggesting that generative activity also promotes generative processing in the working memory, i.e., the organizing and integrating of new learning material with prior knowledge (see Fig. 1, cf. Fiorella & Mayer, 2016). More specifically, according to Fiorella and Mayer (2016, p. 717), “generative learning is the process of transforming incoming information (e.g., words and pictures) into usable knowledge (e.g., mental model schemas)” by making either internal or external connections. Learners make internal connections when they make links between different elements of the material to be learned and external connections when they link the material to be learned to existing knowledge.
Examples of supporting students' generative learning include classroom activities such as summarizing and mapping (for an overview, see Fiorella & Mayer, 2016). Summarizing asks students to select relevant new information and put it into their own words, relating this new information to their prior knowledge. Mapping involves linking content from different sources of information and making associations between related concepts. In order to prevent students from being cognitively overwhelmed, it is advisable to provide support tools (Fiorella & Mayer, 2016). Investigating different examples of such study activities have been shown to affect learning in different ways. For example, Ponce and Mayer, (2014) investigated the effects of note-taking and a graphic organizing tool and found different effects on reading comprehension.
In our research we compare different examples of how specific tools support generative learning activities in video-based learning: functions for diving on video that enable users to create own points of view onto a source video and comment on these e.g., for guided noticing (Pea, 2006; Pea et al., 2004) or annotations, i.e., self-written notes or summaries added to a video (Chiu et al., 2018), and hyperlinks, i.e., supplementary material that includes predefined texts or pictures (Meixner, 2017; Zahn, 2017; Zahn et al., 2005), which we understand as a graphical form of mapping.
Enhanced video tools have received a growing interest in education (Noetel et al., 2021) and research reported overall positive effects on learning (for a review, see Evi-Colombo et al., 2020). For example, learners were found to perform better on knowledge tests when they used annotations to learn about first aid (Chiu et al., 2018) or physics (Delen et al., 2014) than when they learned with common video material without enhanced tools. Moreover, rare existing research on hyperlinks (cf. Evi-Colombo et al., 2020) has shown that the creation of own hypervideo structures supports learning of complex history topics (Zahn, 2017; Zahn et al., 2005). Findings from these empirical studies reveal that digital design tasks with video tools were generally effective for learning and applicable to diverse regular in-class, face-to-face and online learning settings (cf. Zahn, 2017). Overall, students’ knowledge and skills significantly increased while significant tool effects were evidenced: An enhanced video tool with a selection function (diving = virtually cutting out video objects from a video sequence, see Pea et al., 2004) proved superior to a control condition (simple video player and text editing tool) concerning design performance, content learning and visual skills acquisition. Qualitative analyses illustrated how students used specific video tool functions for support of guided noticing and joint elaboration of specific content items. However, many studies also reported conflicting results (for an overview, see Sauli et al., 2018). Thomas et al. (2016), for instance, found that learners who used annotations to learn a history topic underperformed learners who learned with common videos. Merkt et al. (2011), who investigated the effects of a common video, an enhanced video with a table of contents, and an illustrated textbook, also found that learning with a common video was more useful to learn history topics than learning with an enhanced video. They argued that performing so-called micro-level activities (resulting from the use of basic video control tools) is unproblematic for learning, while performing macro-level activities (resulting from the use of enhanced tools) caused problems for learners.
From reviewing the empirical results, we assume that general statements about the effectiveness of enhanced tools are still difficult for the following reasons. First, video tools differ in how they support learning, which, in turn, is reflected in learning outcomes. For example, the act of writing promoted by annotation tools stimulates the cognitive processes of reflecting, organizing, and integrating of information (Lawson & Mayer, 2021), which, in turn, supports the understanding and evaluation of individual concepts and the creation of own (new) ideas (Zahn et al., 2012). Hyperlinks, in contrast, support the integration of related pieces of information and their re-structuring, which promotes the understanding of interrelations between concepts (Chambel et al., 2006; Rickley & Kemp, 2020; Stahl et al., 2006; Zahn, 2017). These examples illustrate the importance of considering different impacts on learning processes and outcomes when examining the effects of enhanced tools and their affordances for learning. Second, enhanced tools need to be clearly instructed and included as a necessary part of the learning task (Rice et al., 2019; Zahn et al., 2005). So far, however, enhanced tools have often been investigated rather as optional supporters for learning. Previous research suggests that learners may not develop appropriate learning strategies to use optional tools for learning (Merkt et al., 2011) and that they may cognitively overwhelm learners rather than support them in effective learning (Krauskopf et al., 2014).
In consequence, direct comparisons of enhanced video tools in systematic research are needed that could help to explain and predict how different tools might afford different learning activities under concrete learning conditions and in specific task contexts—with important implications for their use in educational practice (see also, Ponce & Mayer, 2014).
Concerning task context, Zahn (2017) developed a framework and new scope of using advanced video collaboration tools together with the paradigm of digital design for learning. The author explains the cognitive and collaborative processes involved in learning through designing one`s own information structures with video tools based on established cognitive and collaborative problem solving models (e.g., Goel & Pirolli, 1992; Lowry et al., 2004) and constructionism (cf. Kafai & Resnick, 1996).
Concrete learning conditions include both individual and collaborative learning—and video tools have been considered for both ways (e.g., Chambel et al., 2006; Pea, 2006; Zahn, 2017). The focus in these studies has been on specific functions that afford either cognitive activities in individual learning (e.g., relating concepts by annotations or cognitive maps, Chambel et al., 2006; Rich & Trip, 2011; Stahl et al., 2006) or socio-cognitive activities in collaborative knowledge building scenarios (e.g., sharing annotations and comments, jointly developing links, and discussing related contents, Pea et al., 2004; Stahl et al., 2006; Zahn, 2017; Zahn et al., 2010). The effects of such functions on learning outcomes have—to the knowledge of the authors—not been studied intensively empirically and comparatively—recent research has focused more on learning processes, such as cognitive load (Van Sebille et al., 2018), or intentions that determine when learners use such tools (Mirriahi et al., 2021). Here, tool effects were proven (for a summary, see Zahn, 2017) but more research is still needed.
In sum, we conclude that direct comparisons of different task-relevant usage of enhanced video tools in systematic research could provide new original results for better insights into the conditions under which they can effectively support learning. This research might also provide new knowledge about possible interactions between video tool functions and learning conditions which would have implications for educational practice. We further consider a simultaneous investigation of the effects of enhanced tools on learning processes and learning outcomes, following previous approaches (see Fig. 1, c, f. Greeno & Engeström, 2014; Janssen & Kirschner, 2020) crucial. Accordingly, incorporating investigations of learning processes help to understand (1) how learners use enhanced video tools for learning (i.e., micro- and macro-level learning activities, cf. Merkt et al., 2011) both individually or collaboratively and (2) how these tools influence learners’ cognitive load (Rice et al., 2019; Zahn, 2017). Furthermore, both generative learning (e.g., Fiorella & Mayer, 2016; Kafai & Resnick, 1996; Krathwohl, 2002) and conceptual understanding should be considered when developing measures to assess learning outcomes to account for different supportive roles of video tools and functions in the light of concrete learning goals (Stahl et al., 2006; Zahn et al., 2012).
Individual vs. collaborative video-based learning
Although computer-supported collaborative learning (CSCL) has received considerable attention in the last decades—especially in higher education (see e.g., Janssen & Kirschner, 2020; Jeong et al., 2019)—and research on video-supported collaborative learning was added to this scientific knowledge (Zahn, 2017; Zahn et al., 2010, 2012) it is still rare (Ramos et al., 2019). Especially, direct comparisons between different social conditions (i.e., individual and collaborative learners) would be important in the research field and for educational practice. Related research on learning with animations, for instance, did such comparisons and found that collaborative learning is superior to individual learning in problem solving (Kirschner et al., 2011; Retnowati et al., 2016), retention, interpretation, explanation (Bol et al., 2012), and transfer tasks (Rebetez et al., 2010). Rebetez et al. (2010) for example, examined the impact of different multimedia instructions that varied regarding their level of interactivity (static vs. animated material) on learning a science topic and found that participants who learned with animations were overall superior in retention tasks, but only collaborative learners benefited from animations in transfer tasks. In a study by Kirschner et al. (2011), the authors examined the impact of different instructional formats (worked examples vs. equivalent problem solving) on individual and collaborative learning outcomes in biology and could show that studying worked examples was better performed by individuals but problem solving tasks were easier for collaborative learners. A more recent study by Liao et al. (2019) further found that collaborative learning combined with instructional videos supports learning achievement and reduces extraneous load in a digital game-based learning context.
In sum, research on animations and game-based learning indicates that collaborative learning fosters learning outcomes for complex tasks with important implications for educational practice. Yet, the possible effects of individual and collaborative learning in enhanced video-based learning still have to be investigated. In the present work, we aim to fill this gap.
Aim of the present study
Given the high and still growing relevance of videos in educational institutions (Noetel et al., 2021), we aim to tackle the research gaps described above and contribute new original data. In doing so, we follow previous approaches (Greeno & Engeström, 2014; Janssen & Kirschner, 2020) and pursue a holistic approach by systematically and simultaneously examining different antecedents, processes, and consequences of learning in a co-located face-to-face context. According to the literature described above, we assume that different video tools can be used to foster different generative activities, which, in turn, should support learning and conceptual understanding in different ways in individual vs. collaborative learning situations and with possible interaction effects. We use two representative video tool functions (annotation and hyperlinks) that are common representatives of enhanced video-based learning environments in education (Cattaneo et al., 2018; Chambel et al., 2006; Rich & Trip, 2011; Stahl et al., 2006; Zahn, 2017; Zahn et al., 2005, 2010) and have been discussed with respect to their possible functions for learning before while the learning activities they could possibly afford were specified in detail (Chambel et al., 2006; Zahn, 2017; Zahn et al., 2010). We connect up to this research by investigating such possible effects.
For the purpose of the present study, we pursue the following research question: How does learning in different Tool-use (annotations vs. hyperlinks vs. control) and different Setting conditions (individual vs. collaborative learning in dyads) impact learning processes (H1), outcomes (H2), and their relations (H3)? The following hypotheses are derived from this: first, regarding the effects on learning processes, we expect (H1a) differences in Tool-use and (H1b) Setting. Second, regarding learning outcomes, we expect (H2a) an overall knowledge gain after learning over all conditions, (H2b) differences in Tool-use, and (H2c) a superiority of collaborative over individual learning (i.e., Setting). Third, we exploratory investigate (H3) if learning processes can function as possible mediators between the independent variables Tool-use and Setting and the dependent variables of learning outcome.
Methods
Participants and study design
Overall, 209 participants were part of this experiment (74.6% female, M = 24.30, SD = 6.7) which took place in a controlled laboratory setting at a Swiss University. Figure 2 includes detailed information on the study design and sample size. The ethical standards were met as is confirmed by the ethical review board of our institution. Each participant received either course credits or 20.- Swiss francs for participation. Participants were randomly assigned to the experimental conditions of a 3 × 2 study plan. The first factor (Tool-use) determined whether participants were allowed to use enhanced tools and/or which tools they were allowed to use to perform the task: annotations of self-written summaries, hyperlinks, or no option to use enhanced tools (no Tool-use = control group). The second factor concerned the social learning Setting: participants learned either alone (individual condition) or collaboratively in dyads (collaborative condition). We studied dyads rather than larger groups for four reasons: first, as participants were learning together in front of a desktop computer with one screen and one interaction device, we intended to ensure the best possible collaborative learning situation in terms of accessibility for interaction and visibility. This situation is close to natural settings often used in real educational school-based or higher education. Second, as we focused on comparing individual and collaborative learning, and as research on the effect of group size on learning outcomes is inconsistent here (Caulfield & Caroline, 2006; Kim et al., 2020), we started with dyads for reasons of feasibility in the present project. Knowing that collaborative processes in dyads vs. small groups of three or four are not always the same, we still expect our results to be extremely relevant for some settings and more importantly that they will provide a foundation for future investigation. Third, because of the nature of our task, which aims at learning about a natural science topic (cell biology) and not at learning to discuss conflicting or multiple perspectives (e.g., in politics) we do not assume that the results would have been largely different with larger groups. Last, studying dyads also facilitates methodological evaluation (e.g., in relation to video analysis and comparisons with previous related studies that were also conducted with dyads, see Zahn, 2017).

Study design and procedure
Procedure
The experimental procedure lasted approximately one and a half hours and followed four phases (see Fig. 2). In the pre-experimental phase, participants were welcomed and asked to complete questions about their demographics (gender, age, educational level), their prior experience with digital media for learning, prior self-assessed (what persons think they know) and objective knowledge (what persons actually know), and prior topic-related interest. Next, in the preparation phase, participants were instructed to their task to learn about synaptic plasticity for a post-experimental questionnaire either by using enhanced tools (Tool-use: annotations vs. hyperlinks) or without the possibility to use enhanced tools (control group) and were asked to familiarize themselves with the environment by a tutorial video. In the design phase, participants were then asked to accomplish the task either individually or in dyads working on a shared desktop computer (= Setting). Participants in the Tool-use conditions were additionally asked to use enhanced tools to create a high-quality hypervideo product that should also help other students to learn in the future. Participants in the collaborative settings were instructed to discuss the material carefully with their learning partner to learn the material and to fulfill their task (e.g., formulate summaries and insert them to appropriate video sequences). Participants in the control group were asked to watch the video considerately. The design phase took on average 35.04 min (SD = 16.8). Participants could invest as much time as they needed. This should ensure that they were able to fully understand the content, to compensate for effects of cognitive load, and to complete the given task. In the post-experimental phase participants were finally asked to complete the post-questionnaires before they were thanked and released.
Materials
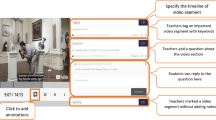
The exemplary video used as learning material for the experiment addressed the neuroscience topic synaptic plasticity of the human brain. It was originally produced as high-quality instructional learning material by the Max Planck Society and lasts 3:56 min. The video was embedded in the enhanced video-based environment FrameTrail (see Fig. 3). This environment additionally included topic-related in-depth information in form of prepared text snippets directly available below the video. These texts were developed together with an expert in the field of neurobiology. While participants in the annotation condition were asked to read these texts and then write own summaries (i.e., annotations) to add them into the video, participants in the hyperlinks condition could grab these text snippets and add them directly into the video at appropriate places (per drag and drop). In both conditions, the display time of the hyperlinks or annotations could be manually changed to adapt the additional learning material to the relevant part of the video. Participants in the control group were asked to simply watch the video and read the text snippets (i.e., common video learning).

Illustration of the enhanced video-based environment FrameTrail
Measures
Measures and scores of the dependent variables on learning processes and outcomes are summarized in Table 1.
To measure learning processes, we, on the one hand, collected participants’ learning activities by using log-file protocols provided by FrameTrail. These files included information about video interaction for each individual and dyad (i.e., actions such as clicking on the “play” button). According to previous research (Delen et al., 2014; Merkt et al., 2011), learning activity was measured by distinguishing between (1) micro- and (2) macro-actions. While micro-actions included logs of interactions with basic video control tools, i.e., play, pause, skipping forward and backward, macro-actions covered interactions with enhanced tools, i.e., adding or deleting hyperlinks or annotations, changes of the display time on the video timeline, and changes of self-written annotation texts. The fact that participants learned at their own pace was reflected in a spread of variance for both the absolute learning time (annotation: M = 47.46 min, SD = 16.2; hyperlinks: M = 35.51 min, SD = 11.6; control group: M = 21.85 min, SD = 11.2) and the absolute frequencies of performed micro- (annotations: M = 65.15, SD = 35.1; hyperlinks: M = 110.13, SD = 47.3; control group: M = 3.71, SD = 7.2) and macro-actions over all participants (annotations: M = 86.04, SD = 48.6; hyperlinks: M = 48.81, SD = 22.2; control group: no macro-actions according to the learning task). We thus considered relative values of these actions (absolute performed actions divided by total learning time in minutes) to take account of varying total learning times. Although analyses for both absolute and relative values were conducted, we focus on relative values hereafter. On the other hand, we measured cognitive load, according to previous definitions of the concept (De Jong, 2010; Paas, 1992), with the one-item scale “Please estimate how easy or how difficult you found the learning material” from 1 (very easy) to 7 (very difficult) according to Kalyuga et al. (1999). Note, we used this one-item scale as it does not only extensively measure subjective perceived task difficulty but is also widely and successfully used in research on cognitive load (Brünken et al., 2010; De Jong, 2010). We, moreover, refer to previous research on the effectiveness of one-item scales (Gogol et al., 2014).
To collect learning outcomes, we were guided by the above-mentioned literature (Fiorella & Mayer, 2016; Krathwohl, 2002; Wittrock, 1992) and investigated both (1) generative learning product, by measuring the quality of self-created hypervideo products, and (2) conceptual understanding of the topic. First, hypervideo product quality (HPQ) was measured by the ratings of two experts with 10% of the products rated by both experts (Cronbach’s alpha: 0.96). The experts evaluated several quality indicators based on a grading system developed for this study: (1) knowledge transformation (correctness of content and use of own words instead of “copy/paste”), (2) information structuring (correct placement the enhanced tools, completeness of content, meaningful change of display time), (3) formal criteria (text length, correct grammar, use of titles), and (4) knowledge development (additional information provided by the learners based on their prior knowledge). Additionally, experts rated (5) an overall impression of the products. To compare HPQ of the annotation and hyperlink condition, we developed a weighted grading system (total points achieved * 5 divided by max. score) from 1 (lowest grade) to 6 (top grade). Note, while all categories could be addressed in the annotation condition, the hyperlink condition could only be evaluated via (2) information structuring and (5) overall impression. Thus, we conducted separate analyses with “information structuring”, which was equally measured in both conditions. A maximum of 300 points could be scored (see Table 1).
Second, conceptual understanding was measured using a post-experimental questionnaire including eight questions that addressed ‘understanding of concepts’ (6 MC- and 2 short answer questions, e.g., “what are vesicles?” referring to understanding the concept of vesicles), eight questions that addressed ‘understanding of interrelations’ between concepts (6 MC- and 2 short answer questions, e.g., “what role do calcium ions play in synaptic transmission?” referring to an understanding of the interrelation of calcium ions and synaptic transmission), and four questions that addressed ‘transfer knowledge’ (3 MC- and 1 short answer questions intended to measure the ability to transfer learned information to other situations or circumstances, see Rebetez et al., 2010). Learners received one point for a correct and zero points for an incorrect answer. The Cronbach’s alpha of the full test was 0.76. Moreover, we randomly selected two questions each of ‘understanding of concepts’ and ‘understanding of interrelations’ and one ‘transfer knowledge’ question that we integrated in the pre-experimental questionnaire. These five questions were used to check for between-group comparisons and to measure objective knowledge gain.
Third, we collected self-assessed knowledge gain using a post-experimental one-item scale. Participants were asked to specify how much they think their knowledge about synaptic plasticity has improved after learning from 1 (not at all) to 5 (very much).
Data analysis
Regarding the data analysis of the present study, the following should be noted: the first focus of the present study relied on the impact of different enhanced tools on learning processes and outcomes. For this reason, we included measures that could not be collected for the control group (i.e., macro-actions and HPQ). Consequently, the control group was not considered in all analyses. Analyses that could be conducted with the control group were performed both with and without the control group. The second focus of this study relied on the impact of different social settings on learning processes and outcomes. Hence, 132 participants learned and performed the task in dyads on a shared desktop computer (= 66 dyadic settings). As a result, measures on learning activity and HPQ were only available at the group level while other measures were available at the individual level. Hence, to compare the different settings with analyses of variance, data from learners in groups were aggregated (by averaging group means). With this, we refer to previous research, suggesting interdependence of students working in one team (Kenny et al., 2006). Still, we additionally performed multilevel analyses by using HLM (Raudenbush & Bryk, 2002) and found similar effects. Moreover, standard deviations between individual and collaborative learners were found to be relatively similar (see Tables 2, 3, 4, 5). Therefore, we considered our measures to be independent.
To test our hypotheses, we used the following analyses. First, regarding H1 (learning processes), we conducted a two-way multivariate analysis of variance (MANOVA) with micro- and macro-actions (i.e., learning activity) as dependent variables. The control group was not considered. Moreover, a two-way analysis of variance (ANOVA) was conducted with cognitive load as dependent variable.
Second, regarding H2 (learning outcomes), we conducted a two-way repeated-measures ANOVA for objective knowledge gain (H2a). Furthermore, two similar two-way ANOVAs with either HPQ or information structuring as dependent variables were conducted (H2b, H2c). The control group was not considered. Also, a two-way MANOVA was performed with the variables ‘understanding of concepts’, ‘understanding of interrelations’, and ‘transfer knowledge’ (i.e., conceptual understanding) as dependent variables. Last, we conducted a two-way ANOVA with self-assessed knowledge gain as dependent variable.
Third, we intended to exploratory investigate effects of learning processes as pre-supposed mediators between the independent variables Tool-use and Setting and the dependent variables on learning outcomes in H3. Therefore, we checked for assumptions to conduct mediation analyses, on one hand, provided by the findings demonstrated in our analyses on learning processes (H1) and outcomes (H2), and, on the other hand, by running a series of bivariate correlations (Pearson) between the mediators and the dependent variables (Baron & Kenny, 1986). The assumption checks are discussed separately in the results section below. The mediation analyses were then conducted using the regression-based approach for conditional process modeling using the SPSS-macro PROCESS (Hayes et al., 2017). The control group was not considered in these analyses because no data on macro-actions and HPQ were available. For all analyses, requirements were checked in advance referring to relevant literature (e.g., Blanca et al., 2017; Finch, 2005; Kenny et al., 2006).
Results
Between-group comparisons and manipulation check
The analyses for gender (chi-square test), age, educational level, prior experience with digital media for learning, prior self-assessed knowledge, and prior interest in the learning topic (ANOVAs) yielded no significant differences in Tool-use (annotations vs. hyperlinks vs. control, p > 0.10) nor Setting (individual vs. collaborative, p > 0.10). Hence, groups were comparable on these variables. For manipulation check, the hypervideo products of the annotation and hyperlink condition were compared by an expert using log data of learners’ interaction to confirm that participants in the Tool-use conditions only performed the task they were assigned to. Results revealed that participants in the annotation condition only added annotations, participants in the hyperlink condition only hyperlinks, and that no enhanced tools were used in the control group.
Impact of Tool-use and Setting on learning processes (H1)
Learning activity (see Table 2): MANOVA revealed a statistically significant effect for Tool-use (as expected in H1a), F(2,88) = 41.709, p < 0.01, partial η2 = 0.487, Wilk’s Λ = 0.513. Additionally conducted post-hoc ANOVAs revealed that participants that learned with annotations performed significantly more macro-actions (annotation: M = 1.75, SD = 0.6; hyperlink: M = 1.45, SD = 0.7, F(1,89) = 1.978, p = 0.033, partial η2 = 0.050), and significantly fewer micro-actions than participants that learned with hyperlinks (annotation: M = 1.41, SD = 0.7; hyperlink: M = 3.22, SD = 1.3, F(1,89) = 74.116, p < 0.01, partial η2 = 0.440). No significant effect was found for Setting (H1b, p > 0.10).
Cognitive load (see Table 3): results yielded significance for Tool-use, F(1,92) = 9.000, p = 0.003, partial η2 = 0.089 (as expected in H1a), indicating that learners in the annotation condition perceived a significant lower cognitive load (M = 3.75, SD = 1.2) than learners in the hyperlink condition (M = 4.49, SD = 1.2). No effects were found for Setting (H1b, p > 0.10). A similar analysis that considered the control group revealed no additional significant results (p > 0.10).
Impact of Tool-use and Setting on learning outcome (H2)
Hypervideo product quality (see Table 4): results revealed a significant main effect for Tool-use (as expected in H2b), F(1,88) = 24.414, p < 0.01, partial η2 = 0.216, d = 1.01, indicating that learners in the hyperlink condition produced hypervideo products of higher quality (M = 4.96, SD = 0.4) than learners in the annotation condition (M = 4.47, SD = 0.5). Moreover, a marginal significant effect for Setting was found, F(1,88) = 3.605, p = 0.061, partial η2 = 0.039, d = 0.36, indicating that dyads (M = 4.82, SD = 0.6) slightly outperformed individuals (M = 4.63, SD = 0.5), as expected in H2c. An analysis with information structuring revealed similar results: a significant effect for Tool-use, F(1,88) = 52.36, p < 0.01, partial η2 = 0.373, d = 1.47, with a superiority of the hyperlink condition (hyperlink: M = 243.16, SD = 25.0; annotation: M = 199.99, SD = 33.3), and a marginally significant effect for Setting, F(1,88) = 3.485, p = 0.065, partial η2 = 0.038, d = 0.32, with higher scores for dyads (dyads: M = 228.16, SD = 38.5; individuals: M = 216.68, SD = 33.9). These results, too, confirm H2b and c.
Conceptual understanding (see Table 5): as expected in H2a, results yielded significance, F(1,93) = 119.47, p < 0.001, Wilks’ Lambda = 0.438 (Mprior = 2.44, SDprior = 1.3; Mpost = 3.91, SDpost = 1.0), indicating an objective knowledge gain after learning over all conditions. No significant differences were found between the conditions (all p > 0.10). An equal analysis considering the control group revealed similar results (knowledge gain: F(1,137) = 210.57, p < 0.001, Wilks’ Λ = 0.394; Mprior = 2.47, SDprior = 1.3; Mpost = 3.99, SDpost = 1.0; no differences between the conditions, all p > 0.10). Moreover, in contrast to our assumptions in H2b and H2c, no significance differences were found for Tool-use or Setting on the combined dependent variables ‘understanding of concepts’, ‘understanding of interrelations’, and ‘transfer knowledge’ (all p > 0.10). A similar analysis that considered the control group, however, yielded significance for Tool-use, F(6,270) = 2.87, p = 0.010, partial η2 = 0.060, Wilk’s Λ = 0.884. Post-hoc univariate ANOVAs revealed significance for the variables ‘understanding of interrelations’, F(2,137) = 6.530, p = 0.002, partial η2 = 0.087, and ‘transfer knowledge’, F(2,137) = 4.294, p = 0.016, partial η2 = 0.059, both indicating that the control group outperformed the two other conditions (Tukey post-hoc analyses: ‘understanding of interrelations’: control > annotation, p = 0.022 (Mdiff = 0.91, 95%-CI[0.11,1.71]); control > hyperlinks, p = 0.003 (Mdiff = 1.15, 95% CI[0.35,1.96]; ‘transfer knowledge’: control > annotation, p = 0.010 (Mdiff = 0.50, 95% CI[0.10,0.90])). Results on Setting were not significant (H2c, p > 0.10).
Self-assessed knowledge gain (see Table 5): a significant effect for Tool-use was found, F(1,93) = 5.907, p = 0.017, partial η2 = 0.60, indicating (as expected in H2b) that learners using annotations had experienced a higher knowledge gain (M = 3.83, SD = 0.8) than learners using hyperlinks (M = 3.50, SD = 0.6). No effects were found for Setting (H2c, p > 0.10). A similar analysis additionally considering the control group did not reveal further significant effects (p > 0.10).
Assumption checks for mediation analyses
Before conducting the mediation analyses, we, first, took a closer look at the results found for H1 and H2. The results showed that no or only marginal effects were found for the independent variable Setting. Thus, we subsequently focused on Tool-use as independent variable for the following mediation analyses. Second, Pearson correlations were performed with learning process variables (pre-supposed mediators) and variables relating to learning outcome (see Table 6). Significant correlations were found between learning activity and HPQ, information structuring, and self-assessed knowledge gain. Moreover, results revealed that cognitive load positively correlated with ‘understanding of concepts’, ‘understanding of interrelations’, and ‘transfer knowledge’. The analyses further revealed (1) that micro- and macro-actions did not correlate, which is why they were included as separate mediators in the following analyses, (2) that the three dependent variables on conceptual understanding correlated, whereas we combined these variables into the single variable “conceptual understanding” (by sum) for further analyses, and (3) significant correlation between macro-actions and cognitive load, indicating that the less macro-actions were performed by learners, the lower was perceived cognitive load.
In sum, based on the results found regarding H1 and H2 and the Pearson correlations, the following mediation analyses were conducted with Tool-use as independent variable: (1) learning activity (micro-, and macro-actions) as mediator for HPQ and information structuring, (2) learning activity as mediator for self-assessed knowledge gain, and (3) cognitive load as mediator for “conceptual understanding”.
Mediating effects of learning processes on learning outcomes (H3)
Learning activity, HPQ, and information structuring (see Figs. 4 and 5): the mediation analysis with HPQ as dependent variable revealed a significant c path, indicating a total effect of Tool-use on HPQ (β = 0.49, t = 4.78, p < 0.001). Moreover, both a paths of learning activity were significant, indicating an effect of Tool-use on the performance of micro- (β = 1.75, t = 8.25, p > 0.001) and macro-actions (β = − 0.34, t = − 2.56, p = 0.012). Moreover, while the b path from macro-actions to HPQ was significant (β = 0.19, t = 2.54, p = 0.013) the b path for micro-actions was not (p > 0.10). Last, the direct effect of Tool-use on HPQ controlling for learning activity was still significant (path c’; β = 0.61, t = 4.07, p < 0.001), suggesting a partial mediation. We found that the relationship between Tool-use and HPQ is mediated by the amount of less performed macro-actions, ab = − 0.119, 95% CI[− 0.294, − 0.011], but not by the amount of performed micro-actions, ab = − 0.091, 95% CI[− 0.389, 0.227]. A mediation analysis with information structuring as dependent variable revealed similar results (macro-actions: ab = − 4.381, 95% CI[− 10.115, -0.577]; micro-actions: ab = − 1.124, 95% CI[− 10.43, 8.429]).

Mediation analysis Tool-use, learning activities, and HPQ

Mediation analysis Tool-use, learning activities, and information structuring
Learning activity and self-assessed knowledge gain (see Fig. 6): the mediation analysis revealed a significant c path, indicating a total effect of Tool-use on self-assessed knowledge gain (β = − 0.42, t = − 3.24, p = 0.002). Furthermore, both a paths for learning activity were significant, indicating an effect of Tool-use on micro- (β = 1.81, t = 8.45, p > 0.001) and macro-actions (β = − 0.30, t = − 2.22, p = 0.03). However, the b paths and the c’ path were not significant (p > 0.10). This suggests that the relationship between Tool-use and self-assessed knowledge gain is not mediated by learning activity.

Mediation analysis Tool-use, learning activities, and self-assessed knowledge gain
Cognitive load and “conceptual understanding” (see Fig. 7): the mediation analysis revealed no significant c path, indicating that there was no total effect of Tool-use on “conceptual understanding” (β = − 0.083, t = − 0.13, p > 0.10). However, following previous approaches (Rucker et al., 2011; Zhao et al., 2010), we continued with the analysis. A significant a path was found, indicating an effect of Tool-use on cognitive load (β = 0.740, t = 3.05, p = 0.003). Moreover, the b path was found to be significant, indicating an effect of cognitive load on “conceptual understanding” (β = − 1.388, t = − 5.05, p < 0.001). Last, the relationship between Tool-use and “conceptual understanding” was found to be mediated by cognitive load, ab = − 1.027, 95% CI[-1.738, -0.391].

Mediation analysis Tool-use, learning activities, and “conceptual understanding”
Discussion
The present work aimed to close current research gaps to the question how different enhanced video-tools can support generative learning and conceptual understanding in individual and groups? We intended to provide new original findings on how learning with an interactive video in different Tool-use conditions (annotations vs. hyperlinks vs. no Tool-use: control group) and in different social Settings (individual vs. collaborative learning) impact learning processes (H1) and learning outcomes (H2) in a co-located face-to face-context. Since our results indicate a close association between learning processes and outcomes (H3), we discuss them, first, in terms of generative learning, followed by conceptual understanding. The discussion closes with limitations and recommendations for future work.
The impact of Tool-use and Setting on generative learning (HPQ)
Our results indicate (H2b) that the hypervideo products of learners who were asked to use hyperlinks were of better quality according to experts than of learners who were asked to use self-written annotations. To explain this result, we need to take a closer look at our instrument for measuring hypervideo product quality (HPQ). The instrument considered the different foci of the two Tool-use conditions: since learners of the hyperlink condition were asked to learn by expanding the video material with predefined text snippets, their focus was primarily on a meaningful structuring of the material. Therefore, they were primarily evaluated according to the quality of their information structuring. In contrast, learners of the annotation condition were additionally asked to expand the video material with self-written content. These learners were, thus, also evaluated according to the quality of their writing activities. The different focus between the conditions was also reflected in different learning activities: more micro-actions but less macro-actions were performed in the hyperlink compared to the annotation condition (H1a). From this we conclude the following: a high quality of information structuring seems to depend on a sparse but target-oriented use of enhanced tools that requires multiple interactions with basic control tools in advance. In other words: learners use basic video control tools (i.e., skipping forward and backward, pressing play and pause) to correctly place and adapt hyperlinks to relevant parts of the video. This is also reflected in our results, (1) indicating that the effect of Tool-use on HPQ was partially mediated by the performance of less macro-actions (H3) and (2) by a positive correlation of micro-actions with HPQ (see Table 6). Hence, it appears that learners in the hyperlink condition, who were able to focus more on information structuring, were able to create hypervideo products of higher quality, which is in line with previous research (Schwartz & Hartman, 2007; Zahn et al., 2005). In contrast, learners in the annotation condition did not seem to distribute their focus evenly between the two tasks information structuring and writing but focused mainly on the latter. This was reflected in more performed macro-actions and resulted in poorer hypervideo products. Our results further revealed that dyads (marginally) designed hypervideo products of higher quality than individuals (H2c). In line with previous research, we, thus, argue that enhanced environments support socio-cognitive processes (Schwartz & Hartman, 2007) and enable collaborative learners to jointly engage with the material (Sinha et al., 2015).
As stated by earlier approaches on learning though design (cf. Kafai & Resnick, 1996; Krathwohl, 2002) a high quality of own constructed learning material should also foster conceptual understanding, deep processing, and re-organizing of concepts (see also Rickley & Kemp, 2020; Wittrock, 1992). Hence, according to our results, it could be assumed that learners in the hyperlink condition and in collaborative settings should also have higher outcomes in conceptual understanding. However, our results suggest that this is not necessarily the case. This is discussed in the next section.
The impact of Tool-use and Setting on conceptual understanding
Our results indicate a general knowledge increase after learning with the enhanced video-based environment over all conditions (H2a). This is in line with previous research on video learning (Evi-Colombo et al., 2020; Poquet et al., 2018) and with research on collaborative learning (Janssen & Kirschner, 2020; Liao et al., 2019). However, we could not find differences in conceptual understanding for Tool-use (H2b) or Setting (H2c). Our results even demonstrate a superiority of the control group. This result could be explained by the fact that participants in the control group were able to focus exclusively on learning the topic. Thus, the capacity of their working memory may have been higher, leading to better results in conceptual understanding (cf. Baddeley, 2010; Maj, 2020). Moreover, in contrast to previous assumptions (e.g., Krathwohl, 2002; Rickley & Kemp, 2020), we could not show that successful information structuring (high-quality hypervideo products) led to deeper conceptual understanding. More precisely, we could not find a significant relationship between high-quality hypervideo products and conceptual understanding, and we found that learners in the hyperlink condition, who created hypervideo products of higher quality compared to learners in the annotation condition, did not achieve higher results in conceptual understanding. A possible explanation is that the present study focused on short-term memory effects. According to Kassymova et al. (2020), the usage of ‘e-tasks’ support the proper function of the brain’s limbic system that increase neuroplasticity of these parts in the brain that are responsible for long term memory (see also Zull, 2004). Therefore, the effect of constructing own information structures by using enhanced tools on knowledge acquisition could develop over time.
However, when additionally considering learning processes the following picture appears: our results indicate that not learners in the control group, but learners in the annotation condition perceived the lowest cognitive load (H1a). Lower cognitive load was further found to be related with higher outcomes in conceptual understanding and to mediate the effect of Tool-use on conceptual understanding (H3). Moreover, our results suggest that lower cognitive load is related to frequently performed macro-actions. Hence, we conclude that an active and frequent use of enhanced tools, which occurs more often in the annotation condition (H1a), can support conceptual understanding, but only when low cognitive load is perceived. In other words: if learners using annotations did not perceive the learning material too complex, annotations could help them build conceptual understanding. This assumption is underlined by the fact that participants in the annotation condition reported higher self-assessed knowledge gain compared to participants in other conditions.
Moreover, we found that collaborative learners did not perform better in conceptual understanding than individual learners (H2c), which is in contrast to related research (Kirschner et al., 2011; Retnowati et al., 2016). Results on learning processes revealed that learning activity and cognitive load appeared to be relatively similar between individuals and dyads (H1b). Thus, considering previous work (cf. Janssen & Kirschner, 2020), we conclude that the used environment supported learning in such a way that not only individuals, but also collaborative learners could benefit.
In sum, by considering different antecedents of learning and learning processes, as suggested by situative approaches (Greeno & Engeström, 2014; Janssen & Kirschner, 2020), we were able to gain a deeper understanding of how (individual and collaborative) learners use enhanced tools to learn (cf. Fiorella & Mayer, 2016) and found that enhanced tools impact learners’ focus on learning in enhanced video-based environment, leading to different strategies to use these tools for learning, which results in different learning outcomes.
Limitations and future work
This study has several limitations, which we will discuss here, along with recommendations for future research. First, to investigate our study goals, we conducted an experimental laboratory study in a co-located face-to-face context. Thus, high internal validity could be achieved because several disturbing variables could be excluded or controlled. However, especially regarding intrinsic and extrinsic motivation, learning in the laboratory cannot be compared with learning in everyday contexts (cf. motivational processes, Mayer, 2014). Hence, future research should conduct field studies as they allow for reasonable generalizations by implying high situational representativity and, thus, external validity (Rack & Christophersen, 2009). Second, the success of computer-supported (collaborative) learning depends on many different aspects (e.g., Janssen & Kirschner, 2020). Although we pursued a holistic approach by including different aspects that shape learning, many other variables play a decisive role: for example, student characteristics, such as the ability for self-regulated learning processes (Janssen & Kirschner, 2020). Future research should increasingly address such aspects and their mutual influence on learning processes and outcomes. Third, our results on learning outcomes (i.e., generative learning and conceptual understanding) suggest, on one hand, that investigating long-term effects of learning with enhanced video environments could provide new insights, which should be addressed in future work. On the other hand, further methods to measure quality of hypervideo products—for example by deeply considering text quality of annotation texts—are recommended for future research. Forth, concerning learning processes, we suggest addressing the close relationship between micro- and task-actions in future research, for example by conducting behavior sequence analyses (see for example, Sinha et al., 2014). Last, cognitive load should be considered by using measurements for intrinsic, extraneous, and germane load with validated instruments (e.g., Klepsch et al., 2017) and by focusing on collaborative load (e.g., Kontogiorgos & Gustafson, 2021).
Conclusion
Enhanced video-based environments could provide answers to the question of how we can support effective learning. In the present work, we aimed to tackle the conflicting results on whether enhanced tools support generative learning and conceptual understanding in individuals and groups. The scientific relevance of this study lied on a holistic approach to investigate learning. We systematically and simultaneously investigated the effects of different antecedents of learning (different enhanced tools: annotations vs. hyperlinks; different settings: individual vs. collaborative learning) on learning processes (i.e., learning activity and cognitive load), learning outcomes (i.e., hypervideo product quality and conceptual understanding), and their relations. Our results suggest that hyperlinks are more suited to create own information structures of the learning material (i.e., hypervideo products) compared to annotations. Results further indicate that this depends on a frequent use of basic video control tools (such as play, pause, and rewind). In contrast, annotations foster self-assessed knowledge gain and help learners to deepen their conceptual understanding of the learning material—but only when they perceive the learning material not too difficult. Moreover, we found a marginal superiority of collaborative over individual learnings in constructing hypervideo products, indicating that generative learning might be fostered through collaboration. Our study sheds light into the different aspects that shape learning and highlights the importance to investigate them holistically.
References
Anderson, L., & Krathwohl, D. A. (2001). Taxonomy for learning, teaching and assessing: A revision of Bloom’s Taxonomy of Educational Objectives. Longman.
Baddeley, A. D. (2010). Working memory. Current Biology, 20(4), R136–R140. https://doi.org/10.1016/j.cub.2009.12.014
Baron, R. M., & Kenny, D. A. (1986). The moderator–mediator variable distinction in social psychological research: Conceptual, strategic, and statistical considerations. Journal of Personality and Social Psychology, 51(6), 1173. https://doi.org/10.1037/0022-3514.51.6.1173
Blanca, M. J., Alarcón, R., Arnau, J., Bono, R., & Bendayan, R. (2017). Non-normal data: Is ANOVA still a valid option? Psicothema, 29(4), 552–557.
Bol, L., Hacker, D. J., Walck, C. C., & Nunnery, J. A. (2012). The effects of individual or group guidelines on the calibration accuracy and achievement of high school biology students. Contemporary Educational Psychology, 37(4), 280–287. https://doi.org/10.1016/j.cedpsych.2012.02.004
Brünken, R., Seufert, T., & Paas, F. (2010). Measuring cognitive load. In J. L. Plass, R. Moreno, & R. Brünken (Eds.), Cognitive load theory (pp. 181–202). Cambridge University Press.
Cattaneo, A. A. P., van der Meij, H., Aprea, C., Sauli, F., & Zahn, C. (2018). A model for designing hypervideo-based instructional scenarios. Interactive Learning Environments, 27(4), 508–529. https://doi.org/10.1080/10494820.2018.1486860
Caulfield, S. L., & Caroline, H. P. (2006). Teaching social science reasoning and quantitative literacy: The role of collaborative groups. Teaching Sociology, 34(1), 39–53. https://doi.org/10.1177/0092055X0603400104
Chambel, T., Zahn, C., & Finke, M. (2006). Hypervideo and Cognition: Designing Video-Based Hypermedia for Individual Learning and Collaborative Knowledge Building. In E. Alkhalifa (Ed.), Cognitively Informed Systems: Utilizing Practical Approaches to Enrich Information Presentation and Transfer (p. 24). Idea Group Publishing.
Chiu, P.-S., Chen, H.-C., Huang, Y.-M., Liu, C.-J., Liu, M.-C., & Shen, M.-H. (2018). A video annotation learning approach to improve the effects of video learning. Innovations in Education and Teaching International, 55(4), 459–469. https://doi.org/10.1080/14703297.2016.1213653
Cummins, S., Beresford, A. R., & Rice, A. (2016). Investigating engagement with in-video quiz questions in a programming course. IEEE Transactions on Learning Technologies, 9(1), 57–66. https://doi.org/10.1109/TLT.2015.2444374
De Jong, T. (2010). Cognitive load theory, educational research, and instructional design: Some food for thought. Instructional Science, 38(2), 105–134. https://doi.org/10.1007/s11251-009-9110-0
Delen, E., Liew, J., & Willson, V. (2014). Effects of interactivity and instructional scaffolding on learning: Self-regulation in online video-based environments. Computers and Education, 78, 312–320. https://doi.org/10.1016/j.compedu.2014.06.018
Evi-Colombo, A., Cattaneo, A., & Bétrancourt, M. (2020). Technical and pedagogical affordances of video annotation: A literature review. Journal of Educational Multimedia and Hypermedia, 29(3), 193–226.
Finch, H. (2005). Comparison of the performance of nonparametric and parametric MANOVA test statistics when assumptions are violated. Methodology, 1(1), 27–38. https://doi.org/10.1027/1614-1881.1.1.27
Fiorella, L., & Mayer, R. E. (2016). Eight ways to promote generative learning. Educational Psychology Review, 28(4), 717–741. https://doi.org/10.1007/s10648-015-9348-9
Goel, V., & Pirolli, P. (1992). The structure of design problem spaces. Cognitive Science, 16(3), 395–429. https://doi.org/10.1207/s15516709cog1603_3
Gogol, K., Brunner, M., Goetz, T., Martin, R., Ugen, S., Keller, U., Fischbach, A., & Preckel, F. (2014). “My questionnaire is too long!” The assessments of motivational-affective constructs with three-item and single-item measures. Contemporary Educational Psychology, 39(3), 188–205. https://doi.org/10.1016/j.cedpsych.2014.04.002
Goldman, R. (2007). Orion™, an online digital video analysis tool: Changing our perspectives as an interpretive community. In R. Goldman, R. Pea, B. Barron, & S. Derry (Eds.), Video research in the Learning Sciences (pp. 507–520). Lawrence Erlbaum Associates.
Greeno, J., & Engeström, Y. (2014). Learning in activity. In R. K. Sawyer (Ed.), Cambridge Handbook of the Learning Sciences (2nd ed., pp. 128–147). Cambridge University Press.
Haagsman, M. E., Scager, K., Boonstra, J., & Koster, M. C. (2020). Pop-up questions within educational videos: Effects on students’ learning. Journal of Science Education and Technology, 29(6), 713–724. https://doi.org/10.1007/s10956-020-09847-3
Hasler, B. S., Kersten, B., & Sweller, J. (2007). Learner control, cognitive load and instructional animation. Applied Cognitive Psychology, 21(6), 713–729. https://doi.org/10.1002/acp.1345
Hayes, A. F., Montoya, A. K., & Rockwood, N. J. (2017). The analysis of mechanisms and their contingencies: PROCESS versus structural equation modeling. Australasian Marketing Journal (AMJ), 25(1), 76–81. https://doi.org/10.1016/j.ausmj.2017.02.001
Janssen, J., & Kirschner, P. A. (2020). Applying collaborative cognitive load theory to computer-supported collaborative learning: Towards a research agenda. Educational Technology Research and Development, 68(2), 783–805. https://doi.org/10.1007/s11423-019-09729-5
Jeong, H., Hmelo-Silver, C. E., & Jo, K. (2019). Ten years of computer-supported collaborative learning: A meta-analysis of CSCL in STEM education during 2005–2014. Educational Research Review, 28, 100284. https://doi.org/10.1016/j.edurev.2019.100284
Kafai, Y. B., & Resnick, M. (1996). Constructionism in practice: Designing, thinking, and learning in a digital world. Lawrence Erlbaum Associates.
Kalyuga, S., Chandler, P., & Sweller, J. (1999). Managing split-attention and redundancy in multimedia instruction. Applied Cognitive Psychology, 13(4), 351–371. https://doi.org/10.1002/(sici)1099-0720(199908)13:4%3c351::aid-acp589%3e3.0.co;2-6
Kassymova, G., Bekalaeva, A., Yershimanova, D., Flindt, N., Gadirova, T., & Sh, D. (2020). E-learning environments and their connection to the human brain. International Journal of Advanced Science and Technology, 29(9), 947–954.
Kenny, D. A., Cook, W. L., & Kashy, D. A. (2006). The analysis of dyadic data. Guilford Press.
Kim, N. J., Belland, B. R., Lefler, M., Andreasen, L., Walker, A., & Axelrod, D. (2020). Computer-based scaffolding targeting individual versus groups in problem-centered instruction for STEM education: Meta-analysis. Educational Psychology Review, 32(2), 415–461. https://doi.org/10.1007/s10648-019-09502-3
Kirschner, F., Paas, F., Kirschner, P. A., & Janssen, J. (2011). Differential effects of problem-solving demands on individual and collaborative learning outcomes. Learning and Instruction, 21(4), 587–599. https://doi.org/10.1016/j.learninstruc.2011.01.001
Klepsch, M., Schmitz, F., & Seufert, T. (2017). Development and validation of two instruments measuring intrinsic, extraneous, and germane cognitive load. Frontiers in Psychology, 8, 1997. https://doi.org/10.3389/fpsyg.2017.01997
Kontogiorgos, D., & Gustafson, J. (2021). Measuring collaboration load with pupillary responses—implications for the design of instructions in task-oriented HRI. Frontiers in Psychology, 12, 623657. https://doi.org/10.3389/fpsyg.2021.623657
Krathwohl, D. R. (2002). A revision of bloom’s taxonomy. Theory into Practice, 41(4), 212–219. https://doi.org/10.1207/s15430421tip4104
Krauskopf, K., Zahn, C., Hesse, F., & Pea, R. (2014). Understanding video tools for teaching: Mental models of technology affordances as inhibitors and facilitators of lesson planning in history and language arts. Studies in Educational Evaluation, 43, 230–243. https://doi.org/10.1016/j.stueduc.2014.05.002
Lawson, A. P., & Mayer, R. E. (2021). Benefits of writing an explanation during pauses in multimedia lessons. Educational Psychology Review, 33, 1859–1885. https://doi.org/10.1007/s10648-021-09594-w
Leisner, D., Zahn, C., Ruf, A., & Cattaneo, A. (2020). Different ways of interacting with videos during learning in secondary physics lessons. In C. Stephanidis & M. Antona (Eds.), International Conference on Human-Computer Interaction (pp. 284–291). Springer International Publishing.
Liao, C.-W., Chen, C.-H., & Shih, S.-J. (2019). The interactivity of video and collaboration for learning achievement, intrinsic motivation, cognitive load, and behavior patterns in a digital game-based learning environment. Computers & Education, 133, 43–55. https://doi.org/10.1016/j.compedu.2019.01.013
Lowry, P. B., Curtis, A., & Lowry, M. R. (2004). Building a taxonomy and nomenclature of collaborative writing to improve interdisciplinary research and practice. The Journal of Business Communication, 41(1), 66–99.
Maj, P. S. (2020). Cognitive load optimization – a statistical evaluation for three STEM disciplines. 2020 IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE), 414–421. https://doi.org/10.1109/TALE48869.2020.9368430
Marinoni, G., Van’t Land, H., & Jensen, T. (2020). The impact of Covid-19 on higher education around the world. IAU Global Survey Report. https://www.iau-aiu.net/IMG/pdf/iau_covid19_and_he_survey_report_final_may_2020.pdf
Mayer, R. E. (2009). Multimedia learning (2nd ed.). Cambridge University Press.
Mayer, R. E. (2014). Introduction to multimedia learning. In R. E. Mayer (Ed.), The Cambridge Handbook of Multimedia Learning (pp. 1–24). Cambridge University Press.
Meixner, B. (2017). Hypervideos and interactive multimedia presentations. ACM Computing Surveys, 9, 1–34. https://doi.org/10.1145/3038925
Merkt, M., Weigand, S., Heier, A., & Schwan, S. (2011). Learning with videos vs. learning with print: The role of interactive features. Learning and Instruction, 21(6), 687–704. https://doi.org/10.1016/j.learninstruc.2011.03.004
Mirriahi, N., Jovanović, J., Lim, L.-A., & Lodge, J. M. (2021). Two sides of the same coin: Video annotations and in-video questions for active learning. Educational Technology Research and Development, 69, 2571–2588. https://doi.org/10.1007/s11423-021-10041-4
Noetel, M., Griffith, S., Delaney, O., Sanders, T., Parker, P., del Pozo Cruz, B., & Lonsdale, C. (2021). Video improves learning in higher education: A systematic review. Review of Educational Research, 91(2), 204–236. https://doi.org/10.3102/0034654321990713
Overbaugh, R. C. (1995). The efficacy of interactive video for teaching basic classroom management skills to pre-service teachers. Computers in Human Behavior, 11(3), 511–527. https://doi.org/10.1016/0747-5632(95)80014-Y
Paas, F. G. W. C. (1992). Training strategies for attaining transfer of problem-solving skill in statistics: A cognitive-load approach. Journal of Educational Psychology, 84(4), 429–434. https://doi.org/10.1037/0022-0663.84.4.429
Panadero, E., Jonsson, A., & Botella, J. (2017). Effects of self-assessment on self-regulated learning and self-efficacy: Four meta-analyses. Educational Research Review, 22, 74–98. https://doi.org/10.1016/j.edurev.2017.08.004
Pea, R. (2006). Video-as-Data and Digital Video Manipulation Techniques for Transforming Learning Sciences Research, Education, and Other Cultural Practices. In J. Weiss, J. Nolan, J. Hunsinger, & P. Trifonas (Eds.), The International Handbook of Virtual Learning Environments (pp. 1321–1393). Springer, Netherlands.
Pea, R., Mills, M., Rosen, J., Dauber, K., Effelsberg, W., & E., Hoffert. (2004). The DIVER™ project: Interactive digital video repurposing. IEEE Multimedia, 11(1), 54–61.
Ponce, H. R., & Mayer, R. E. (2014). Qualitatively different cognitive processing during online reading primed by different study activities. Computers in Human Behavior, 30, 121–130. https://doi.org/10.1016/j.chb.2013.07.054
Poquet, O., Lim, L., Mirriahi, N., & Dawson, S. (2018). Video and learning: a systematic review (2007–2017). Proceedings of the 8th International Conference on Learning Analytics and Knowledge, 151–160. https://doi.org/10.1145/3170358.3170376
Rack, O., & Christophersen, T. (2009). Experimente. In S. Albers, D. Klapper, U. Konradt, A. Walter, & J. Wolf (Eds.), Methodik der empirischen Forschung (pp. 17–32). Springer Gabler.
Ramos, J. L., de Jong, F. F., Laitinen-Väänänen, S., Cattaneo, A., Pedaste, M., Leijen, A., Lepp, L., Bent, M., Burns, E., Fialho, I., Evi-Colombo, A., Takkinen, T., Tiebosch. Nadja; Espadeiro, R., Boldrini, E., & Monginho, R. (2019). Video-supported collaborative learning: insights in the state of the art in everyday educational practice within the visual-project experiments. EAPRIL 2019 Conference Proceedings, 77–91.
Raudenbush, S. W., & Bryk, A. S. (2002). Hierarchical linear models (2nd ed.). Sage.
Rebetez, C., Bétrancourt, M., Sangin, M., & Dillenbourg, P. (2010). Learning from animation enabled by collaboration. Instructional Science, 38(5), 471–485. https://doi.org/10.1007/s11251-009-9117-6
Retnowati, E., Ayres, P., Sweller, J., Retnowati, E., Ayres, P., & Sweller, J. (2016). Can collaborative learning improve the effectiveness of worked examples in learning mathematics? Journal of Educational Psychology, 109(5), 666–679. https://doi.org/10.1037/edu0000167
Rice, P., Beeson, P., & Blackmore-Wright, J. (2019). Evaluating the impact of a quiz question within an educational video. TechTrends, 63(5), 522–532. https://doi.org/10.1007/s11528-019-00374-6
Rich, P. J., & Trip, T. (2011). Ten essential questions educators should ask when using video annotation tools. TechTrends, 55(6), 16–24. https://doi.org/10.1007/s11528-011-0537-1
Rickley, M., & Kemp, P. (2020). The effect of video lecture design and production quality on student outcomes: A quasi-experiment with implications for online teaching during the COVID-19 pandemic. The Electronic Journal of E-Learning, 19(3), 170–185. https://doi.org/10.34190/ejel.19.3.2297
Rucker, D. D., Preacher, K. J., Tormala, Z. L., & Petty, R. E. (2011). Mediation analysis in social psychology: Current practices and new recommendations. Social and Personality Psychology Compass, 5(6), 359–371. https://doi.org/10.1111/j.1751-9004.2011.00355.x
Salomon, G. (1984). Television is “easy” and print is “tough”: The differential investment of mental effort in learning as a function of perceptions and attributions. Journal of Educational Psychology, 76(4), 647–658. https://doi.org/10.1037/0022-0663.76.4.647
Sauli, F., Cattaneo, A., & van der Meij, H. (2018). Hypervideo for educational purposes: A literature review on a multifaceted technological tool. Technology, Pedagogy and Education, 27(1), 115–134. https://doi.org/10.1080/1475939X.2017.1407357
Schwan, S., & Riempp, R. (2004). The cognitive benefits of interactive videos: Learning to tie nautical knots. Learning and Instruction, 14(3), 293–305. https://doi.org/10.1016/j.learninstruc.2004.06.005
Schwartz, D. L., & Hartman, K. (2007). It is not television anymore: Designing digital video for learning and assessment. In Video research in the learning sciences (pp. 335–348).
Shin, Y., Kim, D., & Jung, J. (2018). The effects of representation tool (visible-annotation) types to support knowledge building in computer-supported collaborative learning. Journal of Educational Technology & Society, 21(2), 98–110.
Sinha, T., Jermann, P., Li, N., & Dillenbourg, P. (2014). Your click decides your fate: Inferring Information Processing and Attrition Behavior from MOOC Video Clickstream Interactions. Proceedings of the EMNLP’2014 Workshop, 3–14.
Sinha, S., Rogat, T. K., Adams-Wiggins, K. R., & Hmelo-Silver, C. E. (2015). Collaborative group engagement in a computer-supported inquiry learning environment. International Journal of Computer-Supported Collaborative Learning, 10(3), 273–307. https://doi.org/10.1007/s11412-015-9218-y
Stahl, E., Finke, M., & Zahn, C. (2006). Knowledge acquisition by hypervideo design: An instructional program for university courses. Journal of Educational Multimedia and Hypermedia, 15(3), 285–302.
Thomas, A. O., Antonenko, P. D., & Davis, R. (2016). Understanding metacomprehension accuracy within video annotation systems. Computers in Human Behavior, 58, 269–277. https://doi.org/10.1016/j.chb.2016.01.014
Tiernan, P. (2015). An inquiry into the current and future uses of digital video in University teaching. Education and Information Technologies, 20(1), 75–90.
Van Sebille, Y., Joksimovic, S., Kovanovic, V., Mirriahi, N., Stansborough, R., & Dawson, S. (2018). Extending video interactions to support self-regulated learning in an online course. In M. Campbell, J. Willems, C. Adachi, D. Blake, I. Doherty, S. Krishnan, S. Macfarlane, L. Ngo, M. O’Donnell, S. Palmer, L. Riddell, I. Story, H. Surif, & J. Tai (Eds.), Open Oceans Learning without borders (pp. 262–272). Rome: Proceedings ASCILITE 2018 Geelong.
Wittrock, M. C. (1992). Generative learning processes of the brain. Educational Psychologist, 27(4), 531–541. https://doi.org/10.1207/s15326985ep2704_8
Yan, Z., Gaspar, R., & Zhu, T. (2021). How humans behave with emerging technologies during the COVID-19 pandemic? Human Behavior and Emerging Technologies, 3(1), 5–7. https://doi.org/10.1002/hbe2.249
Zahn, C. (2017). Digital design and learning: Cognitive-constructivist perspectives. In S. Schwan & U. Cress (Eds.), The Psychology of Digital Learning: Constructing, Exchanging and Acquiring Knowledge with Digital Media (pp. 147–170). Springer International Publishing A.
Zahn, C., Hesse, F., Finke, M., Pea, R., Mills, M., & Rosen, J. (2005). Advanced digital video technologies to support collaborative learning in school education and beyond. CSCL ’05: Proceedings of Th 2005 Conference on Computer Support for Collaborative Learning: Learning 2005: The next 10 Years!, 737–742.
Zahn, C., Krauskopf, K., Hesse, F., & Pea, R. (2012). How to improve collaborative learning with video tools in the classroom? Social vs cognitive guidance for student teams. International Journal of Computer-Supported Collaborative Learning, 7(2), 259–284. https://doi.org/10.1007/s11412-012-9145-0
Zahn, C., Pea, R., Hesse, F., & Rosen, J. (2010). Comparing simple and advanced video tools as supports for complex collaborative design processes. Journal of the Learning Sciences, 19(3), 403–440. https://doi.org/10.1080/10508401003708399
Zhao, X., Lynch, J. G., & J., & Chen, Q. (2010). Reconsidering baron and kenny: Myths and truths about mediation analysis. Journal of Consumer Research, 37(2), 197–206. https://doi.org/10.1086/651257
Zull, J. E. (2004). The art of changing the brain. Educational Leadership, 62(1), 68–72.
Acknowledgements
This work was funded by the Swiss National Science Foundation (SNSF) under Grant 100014_176084. The authors acknowledge the financial support of the SNSF.
Funding
Open access funding provided by FHNW University of Applied Sciences and Arts Northwestern Switzerland. We report financial support was provided by Swiss National Science Foundation (SNSF). We confirm that we followed the ethical standards of the American Psychological Association in the treatment of our sample.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
We declare that we have no competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ruf, A., Zahn, C., Roos, AL. et al. How do enhanced videos support generative learning and conceptual understanding in individuals and groups?. Education Tech Research Dev 71, 2243–2269 (2023). https://doi.org/10.1007/s11423-023-10275-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11423-023-10275-4