
Abstract
Purpose
The rising of the sharing economy (SE) has lowered the barrier of purchase price to accessing many different products, thus changing the consumer decision paradigm. This paper addresses the challenge of assessing the life cycle impacts of SE systems in the context of this new consumer decision-making process. The paper proposes a methodological framework to integrate consumer preferences into the Dynamic Life Cycle Assessment (dynamic-LCA) of SE systems.
Methods
In the proposed consumer preference integrated dynamic-LCA (C-DLCA) methodological framework, system dynamics (SD) is used to combine consumer preference and the principal method, dynamic-LCA, which follows the ISO 14040 LCA framework. Choice-based conjoint analysis (CBCA) is chosen as the stated preference tool to measure consumer preference based on SE alternatives, attributes and attribute levels. CBCA integrates discrete choice experiments (DCE) and conjoint analysis features. Random utility theory is selected to interpret the CBCA results by employing multinomial logistics as the estimation procedure to derive the utilities. Derived utilities are connected in iterative modelling in the SD and LCA. Dynamic-LCA results are determined based on dynamic process inventory and DCE outcomes and then interpreted aligned with the SD policy scenarios.
Results and discussion
The C-DLCA framework is applied to assess the GHG changes of the transition to car-based shared mobility in roundtrips to work in the USA. Carpooling and ridesourcing are selected as the shared mobility alternatives based on different occupancy behaviours. Powertrain system and body style are employed as the fleet technology attributes and the latter as an endogenous variable. Dynamic-LCA results are generated considering the high battery electrical vehicle (BEV) adoption as the policy scenario, and results are measured against a service-based functional unit, passenger-kilometre. The model outcomes show a significant reduction in aggregated personal mobility-related dynamic-GHG emissions by transitioning to car-based shared mobility. In contrast to the use phase GHG emissions, the production phase emissions show an increase. The results highlight the importance of integrating consumer preference and temporality in the SE environmental assessments.
Conclusions
The proposed C-DLCA framework is the first approach to combine consumer preferences, SD and LCA in a single formulation. The structured and practical integration of conjoint analysis, SD and LCA methods added some standardisation to the dynamic-LCAs of the SE systems, and the applicability is demonstrated. The C-DLCA framework is a fundamental structure to connect consumer preferences and temporal effects in LCAs that is expandable based on research scope.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Sharing economy (SE) models such as book renting and shared mobility are becoming more prevalent in the current business context as a solution to economic and environmental considerations (Amasawa et al. 2020; Botsman 2015; Fernando et al. 2020a; Goedkoop et al. 1999). SE models provide access to products without owning them and feature differently to the linear economy model by changing from ownership to usership. The model primarily operates in the peer-to-peer market with similar opportunities in the business-to-consumer market. SE is defined as an economic model that shares the underutilised pool of existing assets among users for monetary or non-monetary benefits without changing the ownership (Botsman 2015; Gobble 2017). Product service system is defined as “a marketable set of products and services capable of jointly fulfilling a user’s need” (Goedkoop et al. 1999) and is a subset of the SE modes. Carsharing and common taxis are examples of product service systems that have existed for decades (Shaheen et al. 1998). Current market models such as ridesourcing (e.g., Uber and Lyft), Airbnb, book renting, garden tool renting and private parking space rental in city areas are typical collaborative consumption modes, which is another subset of the SE model. Ertz et al. (2016) have defined collaborative consumption as “set of resource circulation systems which enable consumers to both obtain and provide, temporarily or permanently, valuable resources or services through direct interaction with other consumers or through a mediator”. Some reports suggest the sharing economy value will reach 325 billion USD in 2025 (Yaraghi and Ravi 2017). Today, the majority of the SE models are facilitated and enhanced in their connection with internet-based platforms (Gobble 2017). These models reduce the upfront capital investment challenges to a variable expense through hiring/lending. This change of expenditure in SE models allows greater access to expensive high-tech products (Ajanovic 2015).
In SE systems, products reach their maximum longevity levels in a shorter time and provide accessibility to newer products than in conventional linear economy systems (take-make-use-waste) due to high levels of utilisation. For example, a taxi reaches its lifetime distance (the longevity level of a car) in a shorter period of time than a private car. The SE characteristics of accessing the high-tech products and changes in longevity influence the environmental impacts and the time they occur, compared to the linear economy system. Technology upgrades in SE system asset pools are faster than in the traditional ownership model. This trend is driven by the SE systems’ consumer behaviour (Hamari et al. 2016) and the SE mode operators (Uber 2020). The consumer gets the opportunity to access newer products in SE systems, with better technology. They are often more sustainably driven and cost-effective. An example is that the composition of hybrid-electric vehicles in the Uber fleet in the USA is six times more than the country’s average (Uber 2020). Also, the two giant ridesourcing companies, Uber and Lyft, have pledged to achieve a 100% battery electric vehicle (BEV) fleet by 2040 and 2030, respectively (Lyft 2020a; Uber 2020). These changes create challenges for calculating life cycle environmental impacts using conventional and static methods and highlight the importance of incorporating SE specific consumer influences and dynamic changes.
The consumer preferences in SE models differ from that of traditional linear economy systems. The upfront capital investment, longevity of the product and variable cost (maintenance and repair cost) are commonly considered in conventional purchase decision-making processes. However, in SE systems, consumer decision-making considers the cost of the service versus the cost of ownership (Weber 2015). As a result, capital expenditure and maintenance costs are less important than service reliability and availability (Priporas et al. 2017). SE models, therefore, more quickly reflect the changes in consumer preferences and behaviour, with faster market adoption (Eckhardt et al. 2019; Zervas et al. 2017). The faster fleet electrification plans of Uber and Lyft are examples of faster market adoptions (Lyft 2020b; Uber 2020). Hence, the SE consumer behaviour and preferences influence temporal characteristics of SE systems’ life cycle environmental assessments compared to linear economy modes.
Integrating temporal influences into the life cycle assessment (LCA) is required to achieve more credible environmental outcomes of SE systems (Kjaer et al. 2016). Changes such as achieving longevity, disposing of a product at an earlier point than within the conventional lifetime and accessing newer and technologically improved products require combining temporal aspects into the LCA calculations. Integration of these temporal changes throughout the life cycle, such as faster electrification and the end-of-life of BEV batteries in ridesourcing fleets, is essential to achieve a more reliable environmental impact outcome in SE systems.
To address the challenges of the environmental impact assessments of SE systems, this paper proposes a methodological approach that integrates consumer preferences and dynamic-LCA. The consumer preference analysis component determines the user preferences in the decision-making process and quantifies their importance. The dynamic-LCA method is proposed to determine the temporal environmental impacts based on its robustness in integrating temporal variables (Roux et al. 2017). In dynamic-LCA applications, the system dynamics (SD) method is commonly utilised (Onat et al. 2016; Stasinopoulos et al. 2012). The SD model interconnects the consumer preference component and the environmental dynamic-LCA. This work proposes a new methodology that combines consumer preference and dynamic-LCA to assess the impact of SE systems effectively.
The structure of this paper is as follows. Section 2 covers a background literature study. The proposed methodological approach follows this in Sect. 3. An illustrative case study is selected to apply the proposed methodology, and its applications are discussed in Sect. 4 by choosing a car-based shared mobility case study. In Sect. 5, the dynamic-LCA results are presented and discussed in Sect. 6. Section 7 provides the conclusions.
2 Background
Research has shown SE systems to be an alternative way to reduce environmental impacts (Amasawa et al. 2020; Fernando et al. 2020a; Harris et al. 2021). Conversely, LCA-based research has also highlighted that some SE modes are more damaging to the environment. Fernando et al. (2020b) and the Union of Concerned Scientists (2020a, b) have found that greenhouse gas (GHG) emissions are higher in carsharing and ridesourcing than in private cars, respectively. The faster technology adoption also influences the SE systems, which can be further changed based on consumer preferences. A literature review is carried out to understand the above aspects and presented in Sects. 2.1 to 2.4.
2.1 Life cycle environmental assessments in sharing economy systems
The LCA method was developed to assess goods and services (ISO 2006). Hence, the method has been employed to determine the environmental impacts of service systems that engage single or multiple products (goods) to offer SE services such as book sharing (Amasawa et al. 2020), Mobility as a Service (MaaS) (Fernando et al. 2020b), shared laundry facilities (Klint and Peters 2021) and clothes (Farrant et al. 2010).
The traditional product–based functional units are not suitable for SE systems’ LCA studies. As SE is not an ownership-driven system, the functional units of the SE models have to represent the exact functionality of the use of the service rather than considering the entire product lifespan. One kilogram of laundry and p.km are two applications of service-based functional units used in the SE system, instead of a washing cycle and use of a car that is typically measured in vehicle kilometres (v.km) in the linear economy system, respectively (Fernando et al. 2020a; ISO 2006; Klint and Peters 2021). These approaches support the measure of environmental impacts only for the particular service function and related wear and tear components. However, Goedkoop et al. (1999) have highlighted the importance of using a wider definition, such as the actual monthly transport activities of two persons. Their study further elaborates on the importance of equal levels of user satisfaction in those modes to use a wider definition. However, later studies on shared mobility have widely used occupancy-integrated functional units such as p.km to interpret the LCA outcomes of car-based MaaS modes (Aamas and Andrew 2020; Amatuni et al. 2020; California Air Resource Board, 2019; Dang et al. 2021; Ertz et al. 2016; Fernando et al. 2020a, b; Union of Concerned Scientists 2020b). The selection of passenger (occupancy) and distance integrated functional units provides a practical approach to communicating and interpreting results with fewer assumptions compared to wider definitions, such as transport during a month. Therefore, the selection of the functional unit that integrates occupancy, such as p.km, is more critical when comparing different service offerings and comparing linear (ownership) and SE systems with different consumer preference (satisfaction) levels (Chun and Lee 2017). It also enhances the ability to compare results, such as the transition between car-based personal mobility modes. However, the LCA method itself cannot incorporate the environmental impacts of systems, such as product-service-system, influenced by user behaviour changes (Kjaer et al. 2016).
The dynamic-LCA method integrates temporal effects that can interpret the SE results more robustly and structurally aligns with ISO 14040 framework. LCA is a static environmental assessment method that does not consider the temporal effects. Lueddeckens et al. (2020) have found that the precision of LCA outcomes is challenged by not addressing the whole range of temporal (dynamic) issues. Pinto et al. (2019) highlight the dependency of exogenous sources on future trends or behaviour as a threat to the LCA method. They also emphasise maximising endogenous dynamics. The dynamic-LCA has been utilised to overcome the above issues by integrating dynamic and endogenous variables and their feedback (causality) into the LCA applications (Stasinopoulos et al. 2012). Applying dynamic-LCA has shown insights in environmentally assessing those products with a longer life (Changsirivathanatahathamrong et al. 2001; Collinge et al. 2013; Halog and Manik 2011; Roux et al. 2017). The method has been used to assess different products such as mobile phones (Yao et al. 2018), steel (Pinto et al. 2019) and SE services such as public transport (Ercan et al. 2016).
2.2 System dynamics in sharing economy
The SD method has been used to understand the time-dependent variables and their causal relationships in SE systems. The method has also been utilised to quantify environmental impacts in different shared service models by integrating temporal feedbacks (Astegiano et al. 2019; Geum et al. 2014; Luna et al. 2020; Stasinopoulos et al. 2021; Wang et al. 2018; Wasserbaur et al. 2020). Esfandabadi et al. (2020) have found four shared mobility-related system thinking, mainly SD-based case studies, in their review. They found that the SD can be utilised to analyse policy (He and Li 2019) and environmental impacts (Astegiano et al. 2019) in SE-based mobility studies. Lee et al. (2012) have utilised the SD approach to measuring triple bottom line sustainability and developed integrated causality diagrams. The SD model also connects causality to the system, which provides a solution to break exogenous system dependency by combining the market (Geum et al. 2014) and consumer preferences elements.
The incorporation of the Bass diffusion model to analyse consumer preferences in the SE system is more applicable compared to other approaches. Past studies have also utilised agent-based modelling in analysing the sharing economy system behaviour (Querbes 2018). However, it was not employed to analyse temporal (dynamic) modelling connected with consumer preferences. Instead, the Bass diffusion model has been employed to integrate consumer preferences into the SD modelling (Jiang 2019; Wang et al. 2016). The model describes the behaviour for the diffusion of innovation in the early stages of innovation and assumes the total adoption rate in the early transition resulted from word-of-mouth (WoM) and advertising (Bass 1969; Sterman 2000). Many SE systems are still in their early stages of innovation. Hence, the Bass model can be applied to SE systems based on their early stage market status (which can also be modelled using agent-based modelling approach) and its historical use in SE systems. Zhang et al. (2020) adopted the Bass model in their one-way carsharing case study and proved its applicability in a SE system. The Bass model–derived methodological approaches have also been applied in SE systems (Franco 2019; Wasserbaur et al. 2020). This explanation also fits with SE models such as Airbnb, ride-hailing and jeans-sharing. In these models, the initial adoption is based on a higher advertising effect and later through the adoption from WoM.
2.3 Dynamic-LCA method—combining the temporal effect for LCA in SE
The dynamic-LCA has emerged as the most commonly used methodology to integrate temporal effect into LCA since 1991, and there have been 165 applications by 2016 (Sohn et al. 2020). Sohn et al. (2020) have also found the majority of the dynamic-LCA works (44 out of 55) have followed the ISO 14040 based LCA phases. The literature revealed that the SD method is used as the interface to integrate the dynamic and causal (feedback) effects into dynamic-LCA work (Stasinopoulos 2013; Stasinopoulos et al. 2021).
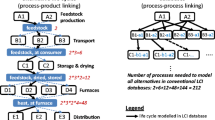
The SD method is used in integrating both temporal and causality effects into the LCAs. Two approaches that have been used in combining SD and LCA (or GHG/sustainability indicators) are shown in Fig. 1. Approach 1 was developed by Halog and Manik (2011) and is frequently used. It calculates the LCA/GHG results in the conventional approach and then feeds into an SD model to include the temporal and causality effects. In Approach 2, the temporal and causality effects considered SD outcomes are utilised to calculate the life cycle inventory (LCI) (Kumar et al. 2019). The existing research has revealed that SD is an effective method for combining temporal and causal effects in LCA, GHG and other sustainability assessments (McAvoy et al. 2021).

Two main approaches in combining SD and LCA/GHG/sustainability indicators (Sus, sustainability indicators). Modified based on (McAvoy et al. 2021)
There is limited research combining temporal effects into the LCAs of SE systems. Chen and Huang (2019) concluded the importance of establishing dynamic-LCA analysis in product service systems. Amasawa et al. (2020) have recognised the importance of the SE asset pool lifetime changes. However, they have not integrated the temporal or causality effects into their LCA calculations. Only two scenario-based case studies have been identified by the authors that utilised the dynamic-LCA method to assess the temporal environmental impacts of SE systems. These studies include shared-ownership autonomous vehicle fleets (Stasinopoulos et al. 2021) and pay-per-wash washing machine services (Sigüenza et al. 2021). Both studies used secondary literature for consumer adoption scenarios. These works confirm the ability to apply the dynamic-LCA method in SE systems. The findings also suggest that research on dynamic-LCA application in SE systems is still emerging.
The dynamic-LCA method has also been used for integrating the temporal and causal effects of the technology transitions into the environmental assessment of SE systems (Sigüenza et al. 2021; Stasinopoulos et al. 2021) and complies with the LCA methodology principles (Stasinopoulos 2013). Garcia et al. (2015) have applied dynamic-LCA to determine the GHG impacts in BEV transition. The technology changes in shared products (SE asset pool), such as the transition from internal combustion engine vehicles to BEVs in ridesourcing fleets (Uber 2020), produce significant differences throughout the life cycle, starting from production until the end-of-life. Querini and Benetto 2015 have highlighted the causality elements that influence the LCA modelling in their powertrain system-based LCA work to assess fleet electrification. However, they have not considered the temporality effects. Temporal technology changes in SE system asset pools significantly influence production and end-of-life impacts compared to the linear system. Shared products such as leased jeans, ridesourcing car fleets, shared books or pooled electrical machinery would reach their maximum product longevity in a shorter time period than an owned private product. Hence, the product cycle and upgrading to newer versions in SE systems are faster than owned private products. Therefore, a dynamic-LCA-based study is necessary to environmentally assess the changes of the impacts caused by SE systems.
Consumer decisions are significant factors influencing SE systems (Eckhardt et al. 2019; Xu 2020). The decisions are driven by peer-to-peer or consumer-to-consumer interactions in temporarily accessing under-utilised physical assets (Frenken 2017). As discussed in Sect. 2.2, according to the Bass model, the adoption is a function of advertising and WoM contributions. The Bass model is just a simplistic (yet powerful) representation of adoption (Jha et al. 2008). The consumer values can influence SE systems’ final decision-making (Piscicelli et al. 2015). Hence, identifying and integration of the consumer values that contribute to the model decisions is significant for accurate modelling.
2.4 Consumer preference integration
Conjoint analysis is a frequently used stated preference technique for predicting consumer preferences for multi-attribute alternative options of products or services. As products and services are a bundle of attributes and conjoint determines, the degree consumers value specific products, which leads to a purchase behaviour intention (Green and Srinivasan 1978). In contrast to traditional rating or ranking-based methods that simply capture consumer attitudes, conjoint analysis measures the constrained choices from a given conjoint block by making trade-offs. Consumer produces a rating of preferences and places the utility. Conjoint analysis results are interpreted using utility (or part-worth) values, defined as “attractiveness of an alternative expressed by a vector of attributes values reducible to a scalar” (Ben-Akiva and Lerman 1987).
Choice-based conjoint analysis (CBCA) integrates the features of both discrete choice experiment (DCE) and conjoint analysis (Cohen 1997). CBCA results derive utility of value from a consumer place on a product or service attributes. Trade-offs consumers are willing to make need to be made between attributes and attribute levels. Since the consumer’s choice is constrained, it simulates a real-life buying decision process. CBCA, also known as brand conjoint, allows for analysing the alternative product or services, an essential feature in SE case studies. Generally, SE modes have been compared against the most relevant linear economy case, such as a washing machine, in washing service-based SE studies (Amasawa et al. 2020; Sigüenza et al. 2021). In some instances, different SE alternatives are also included by providing multiple choices to the consumer preference experiment (Amasawa et al. 2020; König et al. 2018). Based on this study’s intentions, different technological scenarios of SE assets can also be considered attributes in these instances. CBCA simplify aspects of alternatives (also known as modes or brands), attributes and attribute levels to make the consumer decision whilst compatible with the DCE method (Ben-Akiva and Lerman 1987; Jiang 2019). Past work has integrated consumer preference and behaviour into the LCA calculation (Krystofik et al. 2014; Polizzi di Sorrentino et al. 2016; Querini and Benetto 2015; Shahmohammadi et al. 2018). Polizzi di Sorrentino et al. (2016) employed a similar approach to the stated preference technique to quantify LCA findings based on consumer preferences. Folkvord et al. (2020) and Shahmohammadi et al. (2018) have highlighted the importance of the attributes in the accuracy of consumer behaviour integrated LCA studies.
Standard and mixed logit models are the most prevalent modelling techniques in stated preference choice experiments (Ben-Akiva and Lerman 1987; Train 2009). Standard logit/multinomial logistics (MNL) is a commonly used discrete choice estimation procedure in conjoint analysis results analysis (Ben-Akiva and Atherton 1977). The conjoint analysis supported software employs the hierarchical Bayesian multinomial method estimation procedure (Conjoint.ly, n.d.). In particular, the hierarchical Bayesian model is capable of individual-level (preference) data analysis and is applicable in smaller sample sizes (Lenk et al. 1996). Hence, the method also supports determining the aggregated level preferences based on individual preferences beyond the typical conjoint analysis results of the importance of attributes.
There are three common approaches found in the previous research integrating conjoint analysis and SD to simulate the temporality, causality and influence of consumer preferences. They are (a) integrating the most responsive attribute using a logarithmic utility relationship (Wang et al. 2016; Wang and Lai 2020), (b) considering all or some of the attributes as exogenous (Jiang 2019; Schmidt and Gary 2002) and (c) consider the temporal variables using the “utility elasticity of the attribute” (Derwisch et al. 2016; Kopainsky et al. 2012). The latter is only reasonable when the part-worth utility curve is linear (Kubli 2020). The five-step iterative modelling process introduced by Sterman (2000) is a commonly used approach to combine conjoint analysis findings into the SD simulation (Schmidt and Gary 2002; Wang et al. 2016). Jiang (2019) has combined DCE based CBCA method and SD to model the influence of different powertrain types based on consumer preferences. Therefore, DCE and SD combined approach can be utilised to extend the integration of consumer preference into a more detailed analysis level, such as alternatives or brands.
Consumer preferences in SE systems are different from that of the traditional product economy. In a product economy, the consumer is critical in product-based–decision-making, considering ownership and capital investments. However, there is a low barrier to choosing SE models by the consumer compared to traditional product models. This convenience increases the SE consumers’ desire to demand newer high-tech products with improved service functionality. Hence, the integration of consumer preferences and temporal changes in the SE asset pool in environmental LCA analysis is crucial. Past studies have highlighted the importance of integrating consumer preferences into the LCA work for more practical interpretations of the results (Bartolozzi et al. 2013; MacLean and Lave 2003). Hicks and Theis 2014; Querini and Benetto 2015, 2014 have used agent-based modelling technique to integrate, mainly policy-based people behaviour inputs, with LCA modelling. Walzberg et al. 2019 have also utilised agent-based modelling and considered temporal changes for a short period. However, no previous studies have quantified the impact of combining measured (surveyed) consumer preference analysis, dynamic (technology) changes and their causal influence with an LCA study. A novel methodological approach is proposed in Sect. 3 to incorporate consumer preferences into dynamic-LCA to assess the environmental impacts of SE systems effectively.
3 Methodological framework
This work proposes a methodology to establish consumer preference incorporating dynamic-LCA to evaluate the environmental impacts of services offered in SE systems. Dynamic-LCA, which follows ISO 14040 LCA methodology, has been chosen as the key method in this proposed methodological approach. The following approach has been taken to develop the proposed methodology, inspired by the dynamic-LCA applications in SE systems. It starts by considering the SD method as the model interface in combining the outcome of DCE and LCA. Then, a structured methodological framework is introduced by integrating consumer preferences (measured by DCE), temporality and LCA. Finally, a detailed model integrating SD and LCA and DCE and SD is established. The methodological approach is discussed in Sects. 3.1 and 3.2 and is further elaborated in detail in Sects. 3.3 to 3.9.
3.1 Methodology approach—system dynamics as the interface of consumer preferences and dynamic-LCA
The ISO 14040 based LCA principles are followed in building the dynamic-LCA model in this methodological approach. The technical standard can be applied to both products and services (ISO 2006), which enables its use for SE systems. The proposed methodological approach defines the LCA goal and scope as the first process and ends with generating the life cycle impact assessment (LCIA) scenarios and interpretation (Fig. 2).

Methodology approach: consumer preference integrated dynamic life cycle assessment (C-DLCA) (based on Jiang 2019; Sohn et al. 2020; Stasinopoulos et al. 2012; Sterman 2000; Wang et al. 2016; Yao et al. 2018)). Legend: orange coloured—SD process steps; green coloured—LCA phases; blue coloured—consumer preference inputs
The SD method is selected to systematically and structurally combine consumer preferences with dynamic-LCA in the proposed methodological approach. Prior studies have employed the SD method in consumer preferences studies (Jiang 2019) and dynamic-LCA models (see Fig. 1). The widely used Sterman’s five-step iterative process (Sterman 2000) is selected as the SD modelling process in the proposed methodological approach shown in Fig. 2. This iterative process provides a systematic and straightforward approach to applying SD in a case study. It resembles a constant iterative process as the SD interface and excludes the limitation of applying the conventional LCA and SD integration approaches, as shown in Fig. 1. The proposed methodological approach features the feedback process, non-linear sequence steps and, notably, constant iteration. The approach also provides a solution to combine three methodological components: (a) consumer preferences effects measured by the DCE method, (b) consideration of temporal and causal feedback in SD modelling and (c) generating environmental life cycle assessment analysis, to quantify the integration of consumer preferences into the LCA. Therefore, the integration enables to perform a consumer preference integrated dynamic-LCA (C-DLCA).
A hybrid combination of Approach 1 and 2 in Fig. 1 is utilised in the methodological approach. After studying the applications in previous studies (Collinge et al. 2013; Stasinopoulos et al. 2012; Yao et al. 2018), a mixed approach is proposed to integrate LCA before and after SD modelling. The interactions between the SD and LCA components demonstrate a data feedback loop starting from the formulation and simulation process, LCI, LCIA, and end up in the formulation and simulation process. The process step “formulation and simulation” plays a pivotal role in the proposed approach. Its two outcomes are dynamic process inventory and dynamic system inventory, which add temporal effects to the conventional LCI.
The proposed methodological approach is employed to develop the detailed methodological framework in Sect. 3.2.
3.2 Proposed consumer preference integrated dynamic-LCA methodological framework of SE systems
A methodological framework is introduced to combine consumer behaviour and dynamic-LCA based on the introduced C-DLCA approach to assess SE systems. As highlighted in Sect. 2.4, integrating consumer preferences is critical to gathering information directly from stakeholders involved to understand the temporal effect in the SE system analysis. The C-DLCA approach utilises SD as the interface that integrates consumer preferences and the LCA model to represent the temporal and causal effects. This section presents a robust and structured C-DLCA methodological framework that uses SD, LCA and conjoint analysis methods, as presented in Fig. 3 and is consistent with the C-DLCA approach shown in Fig. 2.

Proposed C-DLCA methodological framework of SE systems. DPI, dynamic process inventory. (The red numbers in each process box propose the most practical sequence of the steps; ash and black arrows (hexagons) represent the feedback flows and data flows, respectively. Components represent in the framework: blue—DCE model and consumer preference data; yellow—system dynamic modelling interface (the star mark resembles the iteration characteristics of the chosen SD modelling framework (Sterman 2000)); green—LCA phases)
There are three critical stages in the proposed C-DLCA methodological framework resembling constant iterations. Stage 1 (S2, (C1, C2, C3), S3) connects the DCE and the SD models as explained in Sect. 3.1 by modifying the previous work (Jiang 2019; Wang et al. 2016). Its application is presented in Sect. 3.4. Stage 2 is the five-step iterative SD process model proposed by Sterman (2000). As shown in Fig. 3, the step formulation and simulation (S3) acts as the data and information exchange process step in the C-DLCA methodology framework. Its application is presented in Sect. 3.5. These steps help to understand the systems and the mental models of the real world. The interconnections indicated in the centre of the diagram represent the possibility of iteration occurrence. Each step starting from the problem articulation (boundary setting) is utilised to combine the information or data flow of DCE and LCA models. Stage 3 (L1 to S1, L2a to S3 and S3, L2, L3, S3 to S5, L4) represents part of the beginning and the end of the structured C-DLCA framework. It connects SD and LCA models and is presented in Sect. 3.3.
The proposed C-DLCA methodology framework has provided a structured combination of consumer preferences based on primary data from consumer preference surveys and the LCA by employing the SD method as the interface to integrate dynamic and causality characteristics. Its robustness is checked in a case study presented in Sect. 4, and the final dynamic-LCA results are presented in Sect. 5.
3.3 LCA and SD model design
In this section, the SD and LCA methods are integrated following the C-DLCA methodological approach and framework established in Sects. 3.1 and 3.2. In the C-DLCA, hybrid integration of SD and LCA methods is utilised instead of the conventional modelling approaches shown in Fig. 1. Hence, it is a combination of Approaches 1 and 2, shown in Fig. 1, with multiple iterations between SD and LCA models. The three connections identified in Stage 1 in Sect. 3.3 combine SD and LCA models, as shown in Fig. 3. They are connecting goal and scope (L1) with problem articulation (S1), dynamic-LCI (L2) and formulation and simulation (S3) and finally connecting LCIA and interpretation (L4) to policy scenarios (S5). These are discussed in Sects. 3.3.2, 3.3.4 and 3.4 and 3.7, respectively. The SD and LCA integration in the C-DLCA framework starts with the first step of the LCA methodology, as discussed in Sect. 3.3.1.
3.3.1 Setting up the LCA goal, scope and functional unit (L1)
The goal of the LCA is derived based on the specific research problem and relates to a transition to SE systems. The objective setting process of the LCA follows the conventional approach based on the identified research goal(s). The scope of the LCA is a comprehensive collection of both the SE assets (product) and business-as-usual (linear economy) products utilised or impacted in a transition to SE systems. As discussed in Sects. 2.1 and 3.1, extending the scope to production and end-of-life phases is more significant for SE systems. The proposed extension enables the integration of the temporal impacts of production and end-of-life phases of SE systems, considering typical technology upgrades and achieving maximum product longevity in a shorter lifespan. The scope must be decided case-by-case considering the goal, significance of the contribution to the model and resources.
Selecting a service-based functional unit is essential in interpreting the SE environmental impacts. Service-based functionality units such as p.km are more suitable than distance-based (v.km) to assess mobility servitisation modes (Fernando et al. 2020b; Union of Concerned Scientists 2020b). As discussed in Sect. 2.1, the service-based functional unit, p.km, fits this study and is proven with the wider application in quantitative environmental analysis in car-based shared economy studies (Fernando et al. Under review). Typical product-based references such as per metre square, per car and per machine neither effectively interpret the LCA results nor do they allow comparison between two different SE alternatives. Kjaer et al. (2016) have highlighted the challenges in defining the functional unit when conducting an LCA of a product service system. Hence, it is essential to check the ability to compare both the SE alternatives and the business-as-usual product (representing the linear economy) by employing the selected service-based functional unit.
3.3.2 Connecting LCA goal and scope (L1) with the SD problem articulation (S1)
The SD and LCA model integration starts with connecting the defined goal and the scope of the LCA (L1 in Fig. 3) with problem articulation (S1 in Fig. 3), the first of Sterman’s five steps (Sterman 2000). In this step, the problem is defined with key dynamic variables, boundary, the time horizon of the simulation and problem definition, including reference modes and historical behaviour (Richardson and Pugh III 1981; Sterman 2000). Hence, the defined goals and scope are direct inputs into SD system problem articulation (information flow from L1 to S1 in Fig. 3). It is crucial to map the relationship between the defined functional unit in the LCA and the dynamic problem definition, the reference modes. These synchronisation steps are significant in understanding the key variables of the SD model to develop a draft feedback structure.
3.3.3 Establishing the dynamic hypothesis (S2)
The dynamic hypothesis initiates the conceptualising of the consumer preference experiment. Richardson and Pugh III (1981) define it as “a statement of system structure that appears to have the potential to generate the problem behaviour”, and Sterman (2000) refers as “a working theory of how the potential problem arose”. Step two (S2 in Fig. 3) depends on the articulated problem in Sect. 4.1. In the process of dynamic hypothesis generation, endogenous consequences are identified to map causal structures that are typically presented using causal loop diagrams. Causal loop diagrams are utilised to explain the causal relationships in the dynamic-LCAs (Onat et al. 2016; Stasinopoulos et al. 2012). In the proposed C-DLCA method, the causal loop diagram process is extended to integrate the LCA-based environmental impact calculations in addition to identifying the contributing endogenous variables. This extended step helps to understand the requirements of the consumer preference experiment to generate the identified reference mode(s) of the SD model by considering the LCA model requirements. In the C-DLCA method, establishing the LCI framework is proposed before the formulation step and is discussed in Sect. 3.3.4.
3.3.4 Life cycle inventory considerations (L2a)
Establishing the LCI framework (L2a in Fig. 3) begins with a qualitatively hypothesised model based on the set goal and scope. The hypothesis process supports listing all input data fields required to calculate the LCI. Then, these fields are categorised according to the two following definitions. First is the source of data field: either within the system or exogenous based on external data sources (e.g., life cycle impact factors). Data within the system are endogenous and depend on the feedback from the SD system. The second classification is based on the dynamic-LCA good practises: data fields within dynamic process inventory or dynamic inventory analysis and dynamic system inventory (Sohn et al. 2020; Su et al. 2021). The dynamic system inventory process is not considered in the proposed methodology. Based on the set scope, dynamic process inventory fields can be either endogenous or exogenous (e.g., temporal energy production systems—fuels used in a MaaS fleet). The selection of the attributes and their integration in the dynamic-LCA calculations are discussed in Sects. 3.4.2 and 3.5.
Step L2, LCI calculation, is dependent on three data inputs. The formulation and simulation step outcomes (data flow D2 in Fig. 3) provide the SD system-generated data inputs (Sect. 3.4). The second data input is from LCA databases whilst using the LCA software to model the system. The third is directly from the outcomes of the consumer preference experiment (data flow D1b in Fig. 3) and is often used to calculate the functional unit.
3.4 Discrete choice experiment–based consumer preference survey (C1 to C3)
The DCE model provides the primary data that decides consumer preferences for the transition to the SE system. A market survey is designed (C1) as the first step within the DCE model. It has two key components. They define the sample and design the survey instrument. The selection of the sample for the market survey is crucial in determining the inputs to the C-DLCA framework. Hence, the LCA goal (L1) and SD model articulation (S1) are two key factors that define the survey sample. The survey instrument combines the DCE model integration (C2) and other descriptive questions that are required to analyse the sample’s characteristics. The DCE model integration and analysis are discussed in Sects. 3.4.1 to 3.4.3.
3.4.1 Stated preference method
The conjoint analysis technique (Green and Srinivasan 1978) is selected as the stated preference method in understanding SE consumer preferences. It is a widely used technique to assess the transition to different product technologies (Jiang 2019) and is also used to quantify SE systems such as shared mobility service attributes (König et al. 2018). The conjoint analysis technique is capable of quantifying constrained choice modelling. Hence, it provides more meaningful consumer preference results closer to the actual market. CBCA is selected as the most suitable conjoint analysis type for the proposed C-DLCA framework (Sect. 2.4). The selection is based on its ability to integrate the DCE model (Cohen 1997) and analyse the alternatives based on the importance of attributes and attribute levels (Jiang 2019; Wang et al. 2016). The attributes discussed in Sect. 3.3.4 that relate to the LCI framework have to be considered in the attributes of the DCE model. CBCA supports constrained-choice modelling, and alternatives (also known as brands, e.g., carpooling and ridesourcing in a shared mobility-based survey) can also be operationalised. The survey is the primary data source of the C-DLCA to quantify the attributes and is executed within the chosen population.
The most influential consumer decision-making attributes are chosen from the exploratory research. The compatibility of the selected attributes is checked with the formulation and simulation process (S3) before finalising the steps of survey design (C1) and the DCE model (C2). This extra step is introduced beyond the approaches represented by Jiang (2019) and Wang et al. (2016). This extra iterative process step ensures the synchronisation of the DCE results with the SD simulation. In the C-DLCA framework, the CBCA experiment is designed based on the dynamic hypothesis and the data requirements of the formulation and simulation model. The feedback flows from both problem articulation (S1) and formulation and simulation (S3) to the DCE model (C1-C3) in Fig. 3 are introduced, considering the nature of the SE systems by modifying (Jiang 2019; Wang et al. 2016).
3.4.2 Random utility theory and discrete choice experiment
Random utility theory–based DCE is selected to interpret the CBCA results. Step C3 represents this process in Fig. 3. DCE is a robust technique that has been shown to be useful for simulating customers’ actual market behaviour (Louviere et al. 2010). Random utility theory is also a method for interpreting the choice behaviour of humans (Louviere et al. 2010). As defined in Eq. (1) (Train 2009), random utility models represent a decision-maker (n) that faces a choice among J alternatives. The utility that decision maker n obtained from alternative j is Unj, j = 1,2,…, J,
where xnj is a vector of attributes relating to alternative j and person n; βn is a vector of partworth utilities for the attributes that depict a person n’s tastes associated with each of the observed variable (attribute in this case); εnj is an error term that is an independently and identically distributed standard normal distribution with mean 0 and standard deviation 1 (n (0, 1)).
3.4.3 Multinomial logistic (logit) model
The MNL/logit model is utilised in the C-DLCA framework. MNL is the most widely employed method to analyse DCEs (Ben-Akiva and Atherton 1977; Train 2009) and is utilised in SE consumer preference assessments to analyse the stated preference-based survey outcomes (Carroll et al. 2017; Malichová et al. 2020). The method is also used in the CBCA to assess the attributes at the aggregate level (Eisen-Hecht et al. 2004). The MNL model–based logit choice probability is expressed in Eq. (2) (Ben-Akiva and Atherton 1977; Train 2009). The probability that individual n would choose alternative j out of J alternatives (carpooling and ridesourcing in the case study) is given by
which is the exponential of the utility of alternative j divided by the sum of the exponentials of utility values of all alternatives in the choice set (in this study, j represents target SE system). SE system attractiveness (Ej) value for each alternative is derived by calculating the probability using the total of the (attribute) level utility values. The single attribute value, Ej, the scalar parameter for each alternative, is selected to represent the consumer preference attributes in the proposed C-DLCA methodology. The integration of Ej in modelling is discussed in Sect. 4.5.1. The calculations are based on the conjoint analysis outcomes of the survey. No specific statistical estimation procedure was selected to operationalise the MNL in the proposed methodology. However, the hierarchical Bayesian model is often used in conjoint analysis-supported survey software to calculate MNL.
3.5 Formulating the simulation model (S3)
The step formulation of the simulation (S3 in Fig. 3) is developed to cater for the identified temporal LCI inputs and dynamic process inventory. The consideration of the LCI framework in the C-DLCA method is an extended step beyond a typical SD case study. This process step is planned based on the listed variables in the LCI hypothesising process discussed in Sect. 3.3.4. In the case study, the technological changes (e.g., car body style) in the carpooling and ridesourcing fleets are considered to identify the inputs to calculate dynamic process inventory. Defining the SD model structure, decision rule specification, estimation of parameters and consistency test are the key components in this process step. The model structure is also designed to accommodate consumer preference findings (e.g., based on the car body styles and trip fare in the case study). Hence, the iterative process between the formulation and simulation process step and the consumer preference experiment is important.
The SD model step simulation and formulation (S3) represent the connecting interface of consumer preference survey outcomes and LCI results into the SD modelling. As presented in Fig. 3, in the C-DLCA framework, the process S3 enables the hybrid approach adopted in this research by connecting and functioning as the data exchange process to incorporate SD and LCA methods. As shown in Fig. 3, it links data from consumer preference (D1a), LCI input data (D2) and LCIA outcome data flow (D4) and finally connects them all with the step, testing (S4) via the data flow D5. Step S3 also facilitates information flow from the LCI framework with the consumer preference study. Hence, formulating the simulation modelling work is complex. Secondary data–based exogenous variables are also common in SD simulations. However, the exogenous relationships are not represented in the C-DCLA framework in Fig. 3 for simplicity and to ensure generic applicability.
3.6 Model optimisation (S4)
The dynamic model simulation starts with the model calibration step (also known as testing; see step S4 in Fig. 3). The calibration process supports reproducing the real-world behaviour in the SD model to achieve the goal of the model. Generally, the testing is performed by calibrating against the historical values of the reference mode(s). This step is critical for the constants, the precise values of which are difficult to gauge since most of these parameters are intangible. Model calibration is performed to estimate the values of these model constants to ensure the robustness of policies, specifically under extreme conditions and sensitivity analysis. An example is the high BEV adoption in ridesourcing (see Sect. 1). The calibration and optimisation step also supports assessing the SD model structure and model parameters based on their sensitivity to uncertainties (Sterman 2000). In a dynamic-LCA, the generated LCIA results can also be used to measure sensitivity. The sensitivity outcomes initiate the policy scenarios.
3.7 Policy scenario analysis (S5)
Step policy decision and evaluation (S5 in Fig. 3) is used to generate dynamic-LCIA scenarios and interpretations in the proposed C-DLCA framework. This is the last step in the SD model, which contains scenario specifications, policy designs and extended sensitivity analysis (data flow D7). Based on the testing outcomes, scenario specifications and policy designs are listed to improve the robustness of the SD outcomes, including the LCIA results.
Two types of policy scenarios are related to SE system dynamic-LCAs. They are based on consumer preferences and technological changes in SE assets. The effect of the changes in carpooling and ridesourcing modes’ fare structure is an example of a consumer behaviour–based policy scenario. Also, a fleet upgrade, such as introducing a BEV fleet, can generate a technology change based on potential policy scenarios. These policy scenarios are employed to explore the possible responses to problem articulation (S1 in Fig. 3). There are instances where independent system variables can also be utilised as scenarios. A change in the renewable component in an electric grid outside the SD scope is a typical example of an SD system-independent (exogenous) policy scenario.
3.8 Dynamic process inventory (L2) and dynamic-LCA results generation (L3)
The dynamic process inventory inputs are the outcome of the DCE results and SD simulation findings related to the LCA calculations. The data flows are represented in D1b and D2, respectively, in Fig. 3. The DCE model and the SD simulation outcomes have been used to calculate the LCI in past studies (Halog and Manik 2011; Onat et al. 2016; Pinto et al. 2019; Stasinopoulos 2013). The process step formulation and simulation (S3) functions as the central process step combining DCE model outcomes that are required to calculate the dynamic process inventory (L2) results in the C-DLCA framework introduced in Sect. 3.2. Data flow D1b also represents the DCE outcomes that were required to calculate the functional unit.
The step dynamic-LCA result (L3) is a function of the dynamic process inventory inputs and an LCA database. The LCA database is not illustrated in Fig. 3, as it is an external process. In the C-DLCA framework, the employing LCA data points from the external database are also required to represent the dynamically changing life cycle impacts responding to the temporal changes of the product/service. An example is a changing shared mobility fleet composition in a sharing economy system. Based on the powertrain type composition of the fleet, the data points sourced from the external LCA database have to be changed. Therefore, unlike conventional LCA work, the external LCA datasets are time-varying. In the above, the powertrain system composition is a result of the DCE and SD simulation process, which is endogenous. However, in the C-DLCA framework, the external database is assumed to be mutually exclusive from the system. These LCA data points are multiplied with the respective dynamic process inventory inputs to generate the dynamic-LCA results. In general, this step is executed using LCA software. The final step of the C-DLCA framework is presented in Sect. 3.9.
3.9 LCIA scenarios and interpretation (L4)
The LCIA calculation process has not deviated from the conventional approach. Selecting an LCIA method does not depend on the dynamic-LCA study and follows the conventional approach. The LCIA results are connected back to the formulation and simulation process (S3) (see data flow D5 in Fig. 3) to integrate the temporal simulations. Then, the temporal modelling is performed using the SD model until the set time horizon in the SD problem articulation (S1) step. The calculated impacts represent dynamic outcomes influenced by consumer preferences and the technological transformations of the SE assets. Finally, the LCIA results are re-analysed based on the derived policy scenarios discussed in Sect. 3.7 and undergo sensitivity analysis to demonstrate the robustness and minimise deviations from the actual system behaviour. Then, the results are interpreted based on the chosen functional unit. The LCIA scenario analysis concludes the proposed C-DLCA method.
Dynamic characterisation and dynamic normalisation factors are not considered in the C-DLCA framework to simplify the proposed methodology. Sohn et al. (2020) highlight only 23% of temporal LCA studies have integrated a dynamic characterisation process. The integration of the dynamic characterisation process requires background system expansion and manual modelling by considering the type of the LCA method, either consequential or attributional. Global warming and toxicity impacts commonly incorporate LCIA categories in the dynamic characterisation process (Su et al. 2021). However, it can be challenging to incorporate the dynamic characterisation process in commonly used LCA modelling software (Sohn et al. 2020). The dynamic normalisation factor is also rarely integrated into dynamic-LCAs (Su et al. 2021). Hence, dynamic characterisation and dynamic normalisation factors processes are not considered in the proposed methodology. Therefore, the step LCIA and interpretation (L4 in Fig. 3) does not deviate from the conventional method.
The proposed C-DLCA framework provides an approach to combining the consumer preferences linked with a dynamic-LCA of SE systems. It captures the temporal and causality influences in the life cycle environmental assessment in an SE system by integrating consumer-based and technological changes in SE assets. This section has elaborated on the application of the proposed C-DLCA framework representing the proposed process steps in Fig. 3. Section 4 explains a case study application and sets up the model to calculate the consumer preference integrated dynamic-LCA results employing the C-DLCA methodology framework.
4 Case study and the system dynamics model setting
In this section, the C-DLCA framework is applied to check its applicability and robustness. A shared mobility case study is chosen to demonstrate the application of the C-DLCA methodology framework in Sect. 4.1. A summary of the market survey and derived results is discussed in Sect. 4.2. The SD model structure is introduced in Sect. 4.3, and the user and fleet behaviour sub-model implementations and results are discussed in Sects. 4.5 and 4.6. This section ends by generating the dynamic process inventory and setting up the dynamic-LCA results sub-model.
4.1 Case study selection
A case study is chosen to represent the transition to car-based sharing economy modes to demonstrate the applicability of the C-DLCA methodology framework. Multiple factors are considered whilst selecting the case study. They are (a) significance of the journey type to conduct the market survey, (b) geographical location and market representation, (c) shared mobility modes, their availability and usage, (d) fleet technology changes and (e) the availability of the secondary data.
The roundtrip to work has been chosen as it is the most frequent person journey type in the USA other than non-regular journey types such as shopping and recreational trips (McGuckin and Fucci 2018). It represents the door-to-door journey from home to office and the return trip. The USA was selected as the geographical area of the study based on its significant changes in use patterns of car-based MaaS modes (McGuckin and Fucci 2018; Schneider 2021a; US Census Bureau 2020).
The drove-alone cohort for work increased from 64.4% in 1980 to 75.9% in 2019, and the number of daily commuting employees increased by 11 million from 2010 to 2019 (US Census Bureau 2020). The USA shared rides usage in commuting work, including carpooling, makes up 10.3% of total trips (US Census Bureau 2020). Hence, it is a case that demonstrates the current car-based MaaS practise. It is the only journey type that increased from 2009 to 2017, whilst total commuting trips have decreased by 11% in the USA (McGuckin and Fucci 2018). An average USA employee travels 20.6 km daily to/from work (McGuckin and Fucci 2018). The above journey characteristics represent the significance of the roundtrip to work and its contribution to the light-duty vehicle GHG emission that represents 57% of the USA transport sector GHG emissions (US EPA 2020).
Three car–based MaaS modes, (a) carpooling, (b) solo-ridesourcingFootnote 1 and (c) pooled-ridesourcing, are chosen to assess the transition of personal mobility in commuting to work in the USA carpooling (including informally organised trips) represents the highest car-based MaaS mode of commuting to work trips (US Census Bureau 2020). However, its usage reduced by 10% from 1980 to 9.8% in 2019 (Office of Energy Efficiency and Renewable Energy 2016; US Census Bureau 2020). On the other hand, solo-ridesourcing and pooled-ridesourcing have shown an increasing market share in a few USA cities, such as New York and Chicago, relative to taxis (Schneider 2021a, b). Also, those relatively new modes replace taxis in other USA cities demonstrating higher consumer choice (Rayle et al. 2016). Hence, taxis are not considered a car-based MaaS mode in this study as it reduces consumer interest in cities.
To simplify the system structure of the case study, vehicle body style and powertrain type are chosen as the only two fleet technology attributes. The global electric vehicle market share reached almost 10 million in 2020 from nearly zero in 2010 (International Energy Agency (IEA), 2021). The fleet electrification significantly depends on the government’s policy support (Qian et al. 2019) and the USA has set to achieve 50% BEV sales by 2030 (The White House, 2021). Shared mobility operators have adopted powertrain types such as hybrid electric vehicles (HEVs) and BEVs in their fleets. Uber has a more than five-fold higher HEV fleet than the private fleet (Uber 2020). Transport network companies also lead their fleet electrification goals beyond the state policies and demonstrate their environmental sustainability commitments. Two giant ridesourcing companies, Uber and Lyft, have pledged to achieve a 100% EV fleet by 2040 and 2030, respectively (Lyft 2020b; Uber 2020).
The transition to sports utility vehicles (SUVs) from sedan body style is widespread among personal mobility users. SUVs’ global share has increased from 16.5% in 2010 to 45.9% in 2021 (Cozzi and Apostolos 2021). In the last few decades, the transition to SUV body type in the USA auto market also aligned with the global trends (US EPA 2021). SUVs have increased from 6.9% in 1995 to 23.7% in 2017 in the USA household–based vehicle distribution (McGuckin and Fucci 2018). SUV adoption is higher in MaaS modes such as ridesourcing than the private vehicle fleets. The use of SUVs in pooled-ridesourcing modes is demanded by the modes’ nature to cater to many passengers compared to solo-ridesourcing. Transport network companies demand larger vehicles for pooled-ridesourcing compared to solo-ridesourcing (Uber 2021a).
The body style is identified as an endogenous attribute. This selection is based on the provisions in ridesourcing Apps to select vehicle body style and not the powertrain type (Uber 2021b). Hence, an information feedback loop activates and eventually controls the fleet body style composition in car-based shared mobility based on the customers’ selection. Likewise, the powertrain type is selected as an exogenous parameter. Considering the market trends, gasoline, HEV and BEV are chosen as the powertrain types. Sedans, SUVs and hatchbacks are chosen as the vehicle body style to analyse in this work (McGuckin and Fucci 2018; U.S. Energy Information Administration - EIA 2016, 2019, 2020, 2021; US EPA 2021, 2018a).
4.1.1 Policy scenarios
The high BEV adoption is selected as an extreme policy scenario against the baseline scenarios, aligned with the US president’s executive order on fleet electrification (The White House, 2021). The anticipated changes to the vehicle body styles are also integrated into these scenarios. The detailed policy scenarios can be found in Table 1.
4.1.2 Dynamic-LCA goal
The chosen case study to illustrate the C-DLCA framework represents a shift from a linear economy–based private vehicle (the business-as-usual scenario) to SE alternatives (in this work, carpooling, solo-ridesourcing and pooled-ridesourcing). Since there are two modes to assess in the roundtrip to work journey in the USA, (a) the private vehicle usage representing product-based linear economy and (b) car-based MaaS modes from SE systems, hence, the functional unit of the LCA has to be chosen to cater for both. As discussed in Sect. 2.1, passenger kilometre (p.km) is selected as the functional unit. The number of MaaS users is selected as the reference mode in the dynamic hypothesis. This selection is based on the chosen functional unit (p.km) and its connectivity with the number of passengers. Hence, the selected reference mode and the functional unit complement each other. In addition, the availability of resources, the required accuracy of the results and, notably, the client(s)/audience(s)’ interests are identified to determine the scope of the LCA objectively.
The goal of the dynamic-LCA work (step L1 in the C-DLCA framework) is defined as “analysing the GHG emissions changes of the transition from private car use to car-based sharing economy modes in an average roundtrip to/from work journey in the USA, considering the consumer preferences and the fleet technology changes”. Carpooling, solo-ride sourcing and pooled-ride sourcing have been chosen as the car-based sharing economy modes and using a private vehicle to work forms the business-as-usual (baseline) scenario. A full life cycle (cradle-to-grave) is selected as the scope of the chosen case study, including the identified vehicle body styles and powertrain types in the fleets. The time scope of the dynamic-LCA study is chosen from 2014 to 2050. The starting year 2014 represents the year that pooled-ridesourcing, the newest mode out of the three MaaS modes, is established in the market, and year 2050, to capture at least two product cycles from 2030, the year demands 50% new BEV sales in the USA. Section 4.2 presents the conducting of the market survey to capture consumer preferences.
4.2 DCE model set up and results (steps: C1, C2, C3)
The three market survey outcomes, (a) sampling and survey instrument (C1), (b) DCE model integration (C2) and (c) survey analysis (C3), are based on (Fernando et al. Under review). The survey objective was aligned with the goal and objective (L1) of the dynamic-LCA study and the chosen case study in Sect. 4.1. Hence, the sampling and survey instrument were designed to analyse the consumer preference attributes of the roundtrip to/from work in the USA, considering the use of the private vehicle as the baseline and carpooling, solo-ridesourcing and pooled-ridesourcing as the shared mobility modes.
Fernando et al. (Under review) have chosen two fleet technology attributes. They are (a) rapidly changing vehicle body style and (b) fleet electrification (McGuckin and Fucci 2018; U.S. Energy Information Administration - EIA 2021, 2020, 2019, 2016; US EPA 2021, 2018a). These are other than the most influential attributes based on the exploratory research, such as cost, time and number of passengers (Fernando et al. Under review). The attributes in the DCE model (process C2 in Fig. 3) are aligned with the identified data fields contributing to calculating dynamic-LCA in the formulation and simulation (S3) and dynamic process inventory framework (L2a) processes. The compatibility of the selected attributes is checked with the formulation and simulation process (S3) before finalising the DCE model integration (C2). This extra step is introduced beyond the approaches represented by Jiang (2019) and Wang et al. (2016) and ensures the synchronisation of the conjoint analysis results with the SD simulation. The outcomes of the DCE model are analysed employing MNL, and the results are presented in Table 2.
The above results show that users of the selected three modes have shown different consumer preferences on attributes. The results also demonstrate different utilities for the attribute levels of those modes. In the C-DLCA framework, the DCE is designed based on the dynamic hypothesis.
4.3 Adoption of the Bass diffusion model
The Bass diffusion model is selected to explain the consumer preferences and the dynamic hypothesis model, considering the generic nature of SE businesses (Zhang et al. 2020). It is a model employed to explain automobile technology changes (Santa-eulalia et al. 2011). A causal loop diagram that represents the transition from commuting by private vehicle to shared mobility modes is shown in Fig. 4 by adopting the Bass model. Bass (1969) found that the market depends on innovators and imitators. Typically, the innovators adopt based on WoM or other positive feedback sources. The imitators, instead, are driven by advertising (Sterman 2000). Two adoption sources WoM and advertising are assumed to be independent, and the total adoption rate is expressed in Eq. (3), based on (Sterman 2000).

Causal loop diagram—the transition to shared mobility modes. Note: adopted from (Bass 1969); variables in green—introduced to integrate the consumer preferences; WoM—word of mouth
In this equation, c, i, P, N, a and A denote the contact rate of SE adopters with potential adopters, SE adoption fraction, SE potential adopters, total population, advertising effectiveness and adopted population, respectively. The adoption from WoM is a function of the aforementioned five factors, and the adoption through advertising is of a and P. Though P is considered a stock in the Bass model, it is wholly determined by N and A and can be represented as an auxiliary variable (Sterman 2000). Hence, the variable P can be expressed as in Eq. (4).
The casual loop diagram in Fig. 4 represents the original stock: “Employees commuting by private vehicles” and the transitioning stock “Active MaaS users”. Two variables, “Adoption from WoM” and “Adoption from advertising”, represent the variables that influence the stock levels and the two feedback loops based on the Bass model (Bass 1969; Sterman 2000). The key feedback loops are marked as B1 and B2, representing the negative or balancing loops. The causal loop diagram supports the SD model articulation and formulation of the dynamic hypothesis (steps S1 and S2 in Fig. 3). The causal loop diagram in Fig. 4 also helps to understand the reference mode (the pattern, behaviour over time (Sterman 2000)) that ultimately leads to the dynamic hypothesis of the SD model. The number of individuals transferred to three car-based MaaS modes has been chosen as the reference mode for this illustrative case study, which can be dynamically hypothesised. The polarity symbol (+ / −) at the end of the arrow represents the influence of a particular variable.
The SD model implementation is discussed in Sects. 4.4 to 4.7.
4.4 System dynamics sub-model structure
The sub-models are utilised to explain the deeper information flows (Sterman 2000). They depend on the defined problem articulation and the model boundary in Sect. 3.3.2. Figure 5 presents a simplified sub-model to illustrate the data and information links associated with the chosen case study in Sect. 4.1. The sub-model arrangement also supports simplifying the formulation of the simulation model steps. The defined goal of the dynamic-LCA study and the problem articulation outcome of the SD model (see Sect. 4.1.2) are considered for deriving these sub-models. Hence, the identified three sub-models are (a) the transition to MaaS, (b) fleet behaviour and (c) the dynamic-LCA calculation. They explain the behaviour of the transition model by incorporating consumer preferences, changes in the fleet adoption based on the powertrain and body style changes and, subsequently, their combined influence on dynamic life cycle GHG emissions. They are aligned with the LCA and SD model design defined in Sect. 3.3, and the case study in Sect. 4.1. The detailed Stock and flow diagram that represents the sub-model structure can be found in Fig. 12 in Appendix. Thus, three sub-models support the execution of the formulation step aligned with the identified key stocks of the model.

Sub-model diagram for the SD stock and flow model of the transition to car-based MaaS on GHG emissions
4.5 Model implementation: sub-model—transition to MaaS
The model implementation of the transition to car-based MaaS modes by integrating the market survey–based DCE results is discussed in this section. Section 4.3 introduced the operationalising of the Bass model (Bass 1969; Sterman 2000), the chosen model to explain the dynamic hypothesis for the chosen case study. The feedback systems establishment and integration of the DCE result to calculate the SE system attractiveness variables are discussed in Sect. 4.5.1. Finally, the transition to MaaS user behaviour is determined in Sect. 4.5.2.
4.5.1 Integration of survey results and endogenous explanation
The additional feedback loop (MaaS mode attractiveness) beyond the typical Bass model illustrated in green colour in Fig. 4 represents the integration of consumer preference into the model formulation and simulation work. Consumer decision-making in the SE system does not depend on product acquisition but on its service functionality for temporary use. Hence, integrating consumer preference in the transition to active MaaS users is critical and relevant to the dynamic-LCA results. The additional feedback loop also represents the endogenous explanation (vehicle body style) introduced in Sect. 4.1. Therefore, vehicle body style explains the key endogenous feedback loop for considering the consumer preference inputs and is connected to SD modelling work by employing the variable MaaS mode attractiveness variable.
The product attractiveness concept is employed to integrate consumer preferences into the SD model. Schmidt and Gary (2002) have introduced the concept of product attractiveness and defined it as “the additive utilities of each individual product attribute”. They have also employed the product attractiveness concept in SD modelling (Schmidt and Gary 2002). In the proposed C-DLCA methodology, the product attractiveness conceptually resembles the variable “fraction willingness to adopt” as introduced by Sterman (2000). He further argues that the variable “potential adopters” in WoM is a multiplication of the fraction of willingness to adopt and the total population. Hence, Eq. (3) is reworked by introducing Eq. (4), considering the concepts of product attractiveness and fraction willingness to adopt and combining Eq. (4).
where, Ej denotes ‘mode attractiveness’ (j = carpooling, solo-ridesourcing and pooled-ridesourcing), the specific variable to represent product attractiveness in the C-DLCA method. The primary data collection process to determine the variable Ej is discussed in Sect. 4.2. The variable carpooling, solo-ridesourcing and pooled-ridesourcing mode attractiveness combine the consumer behaviour feedback with the adoption from WoM. As discussed earlier, the feedback from body style is the only endogenous feedback loop in this simulation.
4.5.2 Transition to MaaS behaviour
The user transition from private vehicles to car-based MaaS modes shows an increase based on the model results shown in Fig. 6. These findings are the outcomes of the formulation and simulation step (S3) of the sub-model transition to MaaS, the first of three sub-models (see Figs. 5 and 12 in Appendix). The user transition results show that carpooling is decreasing whilst solo-ridesourcing is significantly increasing. The model outcomes demonstrate a more noticeable decline among carpooling users from the mid-2020s in the high BEV adoption scenario. The highest adoption in the transition to MaaS for the chosen case study is seen in the low-occupancy-based solo-ridesourcing mode. The results are aligned with the current ridesourcing market trends of major cities in the USA (Schneider 2021a, b). The pooled-ridesourcing behaviour is not discussed separately since its contribution to the aggregated MaaS is less than 3% at the end of the modelling period. The increasing number of private vehicle-driven employees in the USA declined compared to the start of the modelling time.

User transition behaviour (PC, private vehicles; CP, carpooling; sRS, solo-ridesourcing)
The car-based MaaS users show an increase in the high BEV adoption scenario compared to the baseline. In contrast, to carpooling results, the model outcomes suggest the highest user uptake in the transition to car-based MaaS in low-occupancy-based solo-ridesourcing with the high BEV adoption scenario. The uptake can be further increased if the BEV utility values are favourable for the ridesourcing (see Table 2). Therefore, the model findings suggest that the high BEV adoption scenario attracts more car-based MaaS users than the baseline scenario in solo-ridesourcing. For private vehicle use, it works in the other way.
4.6 Model implementation: sub-model—fleet behaviour
The expected outcome of this sub-model is to determine the fleet behaviour of three MaaS modes extending to powertrain type and body style compositions by integrating the outcomes of the transition to MaaS sub-model discussed in Sect. 4.5. Hence, the reference mode of this sub-model is chosen as “fleet stock”. Fleet stock behaviour is modelled in two components: (a) MaaS fleet behaviour and (b) private vehicle fleet behaviour. The variables scrap rates are formulated based on the outcomes of the curve fitting exercises of the vehicle survival rates (Davis and Boundy 2021; Lu 2006). The detailed SD modelling work can be found in Fig. 11 in Appendix.
The stocks of MaaS fleets (carpooling, solo-ridesourcing and pooled-ridesourcing) connect the feedback loop between the transition to MaaS and consumer preference outcomes. This connection subsequently establishes a feedback loop (causal relationship) with the variables MaaS fleet body distribution, vehicle body style attractiveness and MaaS mode attractiveness (see the green loop in Fig. 4). The values for gross occupancy, an exogenous variable that determines the behaviour of the MaaS fleet, are sourced from the literature. They are: carpooling—2.18 calculated based on US Census Bureau (2020), solo-ridesourcing—1, pooled-ridesourcing—2.3, a conservative estimation based on previous studies (Henao and Marshall 2018; Uber 2020; Wilkes et al. 2021). PC to user ratio variable using the inverse of the occupancy rate of private vehicles to/from work journey, 1.18 (McGuckin and Fucci 2018). The variable cars per trip defines as the inverse of gross occupancy rates and distinguishes the vehicle requirements of MaaS modes. It was assumed that two trips could perform utilising a vehicle in ridesourcing fleets to cater to/from work trips that usually occur during peak hours. The temporal fleet technology changes are integrated through the variable MaaS fleet tech changes and are based on Table 1.
4.6.1 Fleet behaviour
According to the model results, the personal mobility fleet shows an increase (see Fig. 7). Carpooling has shown the largest fleet reduction, whilst solo-ridesourcing shows the highest fleet increase. The above observations are aligned with the user preferences results discussed in Sect. 4.5.2. Hence, the overall fleet stock results highlight that the solo-ridesourcing fleet dynamics can significantly influence the dynamic-LCA calculations based on the magnitude of the fleet increase and the changes in the fleet composition.

Fleet behaviour baseline scenario: a aggregated personal mobility fleet, b carpooling fleet and c solo-ridesourcing fleet
The fleet composition changes among mobility modes show different trends. A considerably larger gasoline fleet exists in carpooling at the end of the modelling time than in the other modes. The potential reasons are the increased automobile longevity based on the survival rates (Davis and Boundy 2021; Lu 2006), reduced user volumes and no market mechanism to limit the vehicle age like in ridesourcing modes. The highest fleet increase is seen in the transition to the SUV BEV fleet, whilst the largest reduction is in gasoline sedans. It also reflects the reinforced consumer preference for SUVs. Unsurprisingly, the SUV adoption is significant in solo-ridesourcing compared to sedans, which is also similar to the carpooling fleet behaviour. The SUVs represent almost a three-fold increase in 2050 compared to the 2014 solo-ridesourcing fleet. The fleet behaviour of hatchbacks is not presented in Fig. 7 and LCA results since the numbers are significantly lower compared to sedans and BEVs. This behaviour aligns with the outcomes presented in Tables 1 and 2. The modelling results also suggest a significantly higher BEV uptake in the solo-ridesourcing fleet from the mid-2020s onwards whilst flattening and diminishing the gasoline fleet trajectory. The high BEV adoption scenario predicts a more considerable uptake of BEVs in all modes and a larger fleet size. This trend is largely dominated by the solo-ridesourcing fleet, which is more frequently replaced to meet the transport network company requirements than carpooling and private vehicles.
The above observation highlights the importance of considering the powertrain type and body style in the car-based MaaS fleet behaviour analysis integrating the consumer preference in the dynamic-LCA calculations. The total fleet size, powertrain type and body style factors are unique to the car-based MaaS mode, with the highest contribution from solo-ridesourcing out of the three chosen modes. Figure 13 in the Appendix shows the stock behaviours of the high BEV adoption scenario.
4.7 Model implementation: sub-model—dynamic-LCA calculation
The sub-model fleet behaviour (Sect. 4.6) and dynamic process inventory are combined in this sub-model to generate the final dynamic-LCA results (L3). The results are a combination of four components: (a) GHG emissions from private vehicles, (b) GHG emissions from MaaS, (c) the functional unit calculations for p.km and distance-based v.km units and (d) GHG emissions results component. Components (a) and (b) are depended on the dynamic process inventory, which is the temporal version of a (static) LCI in conventional LCA studies.
4.7.1 Establishing the dynamic process inventory
The dynamic process inventory for this work is generated by combining the (static) LCI data inputs sourced from the GREET model (Wang et al. 2021). The LCI inputs are extracted from the GREET model for the chosen fleet technologies established in Sect. 4.6 based on the introduced temporal changes in Sect. 4.1.1. This approach produces a dynamic-LCI profile instead of a conventional static approach (Sohn et al. 2020). Two vehicle body styles—sedan and SUVs-related GREET model data—are employed, and 90% of sedan impacts are assumed for hatch body style. Passenger car type number one from the GREET model for sedan and SUV is chosen for this study’s modelling work. Three powertrain types, (a) gasoline driven, b) HEV and c) BEV data, are also sourced from the GREET model. In addition, the GREET model-based vehicle lightweighting factors are also integrated into the dynamic process inventory, as introduced in Table 1.
The dynamic process inventory is created considering the three key life cycle phases. The secondary data obtained from the GREET model for raw materials, production energy and vehicle lightweighting are utilised to calculate the dynamic process inventory inputs for the production phase. The derived vehicle weight values align with the policy scenarios introduced in Sect. 4.1.1 and are presented in Table 3. The production phase GHG values and vehicle lightweighting scenarios are integrated into the production dynamic process inventory calculations.
The use phase dynamic process inventory changes consist of three GHG emission components. They are (a) combustion emissions in gasoline and HEV fleets, (b) secondary emission sources such as refinery emissions and electric grid and (c) fleet maintenance. Components (a) and (c) are derived from the GREET model. For component (b), the USA electricity grid GHG emissions changes are integrated into the use phase dynamic process inventory calculations (U.S. Energy Information Administration - EIA 2021, 2019, 2016). The energy required to treat a vehicle at the end-of-life and battery recycling impacts are considered in the dynamic process inventory establishment for the end-of-life phase. The recycled material impacts are not considered since the GREET model follows the secondary material approach, and those impacts are already captured in the production phase (Wang et al. 2021).
5 Dynamic-LCA results
This section presents dynamic-LCA outcomes of the transition to MaaS from private vehicles for roundtrips to work in the US. GHG is chosen as the life cycle impact category aligning with the previous research on shared mobility (Doka and Ökobilanzen 2001; Fernando et al. 2020b; Greenblatt and Saxena 2015; Nurhadi et al. 2017). The GREET model is selected as the life cycle database considering a US-based system and specialising in automobile-related GHG emissions (Wang et al. 2021). The outcomes of two of the three sub-sections in the C-DLCA methodology framework application were already discussed in Sects. 4.5 and 4.6. They are combined to generate the dynamic-LCA results in this section following the implementation steps established in Sect. 4.7 and the dynamic process inventory introduced in Sect. 4.7.1. The objective, goal and scope setting of the dynamic-LCA were introduced in Sect. 4.1.2, and p.km was selected as the functional unit of the study. The C-DLCA methodology framework ends with the LCIA scenario and interpretation component, ensuring that it follows the ISO14040 principles. The final results are presented in Fig. 8 in three forms. They are (a) absolute GHG emissions, (b, c) specific GHG emissions related to the functional unit p.km and (d) the number of p.km.

Dynamic-GHG results: a absolute GHG emissions, b specific GHG emissions compared to p.km – aggregated fleets, c specific GHG emissions compared to p.km—individual modes and d p.km
The model outcomes show a significant reduction in aggregated personal mobility-related dynamic-GHG emissions for the roundtrip to work in the USA by transitioning to car-based MaaS at the end of modelling compared to the beginning in both scenarios (see Fig. 8a). The dynamic-GHG results also reflect the influence of final results based on the user preferences and fleet composition findings presented in Sects. 4.5 and 4.6. The steep decline in absolute GHG emissions starting from the mid-2020s represent the influence of fleet electrification based on the policy scenarios introduced in Sect. 4.1.1. The high BEV adoption scenario shows an increase starting from 2022 and gradually declining. This trajectory represents the contribution of higher production emissions during the aggressive fleet electrification to achieve 100% BEV sales in 2030 (the life cycle phase implications are discussed in detail in Sect. 5.1). Hence, this observation demonstrates that the model responds to the established policy scenarios in Sect. 4.1.1.
The overall GHG emission reduction in the high BEV adoption scenario compared to the baseline is significant. Still, it does not provide a complete solution to the personal mobility-related GHG emissions for the chosen case study (see Fig. 8a). These outcomes are against the expectations of the transport network companies (Lyft 2020b; Uber 2020) that only consider fleet technology changes such as electrification. However, the integration of consumer preferences reflects the influence of market response in the dynamic-LCA results. Therefore, it is worthwhile to analyse the dynamic-GHG emissions of mobility modes.
As shown in Fig. 8a, carpooling mode predicts significant GHG emissions savings at the end of modelling compared to the beginning. It also shows higher GHG emissions savings in the high BEV adoption scenario than in the baseline. Unsurprisingly, the high BEV adoption scenario carpooling shows the least specific GHG emissions in the transition to car-based MaaS modes supported by the higher p.km volumes based on the highest occupancy rate. Hence, this result highlights the importance of promoting high occupancy shared mobility modes in reducing GHG emissions in personal mobility. The model results also show the overall carpooling p.km units decreased at the end of the modelling period compared to the beginning. The above finding aligns with the declining user behaviour discussed in Sect. 4.5.2.
Model results suggest a significant increase in the absolute GHG emissions in the solo-ridesourcing mode in both scenarios. Interestingly, the absolute GHG emissions of solo-ridesourcing of the high BEV adoption scenario are larger than the baseline scenario. This trend can be explained based on the higher utility values for BEVs in solo-ridesourcing fleets (see Table 2) and resulting in a larger fleet in the high BEV adoption scenario compared to the baseline scenario (see Fig. 7c). Both faster fleet replacement rates and higher electrification rates to satisfy the transport network company requirements significantly change the GHG emissions trajectory of solo-ridesourcing fleets. However, the reduction is significantly steeper than the other modes in specific GHG results (see Fig. 8c). The above observation demonstrates the significance of fleet technology changes in reducing specific GHG reduction. Due to the highest user transition (see Fig. 6), the p.km volumes of solo-ridesourcing record a higher number. Hence, further optimisation of p.km can bring down the specific GHG emission reductions. The above results reinforce the importance of optimising the occupancy rate to achieve better GHG results in car-based shared mobility modes. The results also confirm the choosing p.km as an effective functional unit to compare against the modes. Pooled-ridesourcing also shows similar behaviour to solo-ridesourcing with a significantly lower magnitude. Hence, its variations are not discussed explicitly.
Figure 8(a) also shows that the absolute GHG emissions of the aggregated MaaS modes increased significantly, at least threefold, from 2014 to 2050. The aggregated MaaS GHG emissions per p.km in 2050 do not show a reduction in both scenarios compared to 2014 (Fig. 8b). The shift to the higher specific GHG emitting solo-ridesourcing mode and the reduction of lower-specific GHG emitting carpooling users contribute to the increasing GHG emission per p.km. The emissions changes are also supported by the transition to the dominant SUV fleets, especially in two ridesourcing modes. Two modes’ occupancy rates also conversely contributed to the emission changes. Revealing these findings would not have been possible if the consumer preferences and temporal changes were not integrated. In all mobility modes, both aggregated and individual, the high BEV adoption scenario shows lower GHG emissions compared to the baseline scenario. Hence, the specific GHG results show the importance of fleet electrification in the overall transition to the car-based MaaS from private vehicles. However, it is not providing a complete solution to the GHG emissions for personal mobility in roundtrips to work in the USA.
5.1 Results in life cycle phases
As shown in Fig. 9c, the model predicts a significant GHG reduction in the use phase and a little more reduction in the high BEV adoption scenario compared to the baseline scenario at the end of the modelling period compared to 2014. The historical steady increase started to decline in the mid-2020s when the BEV transition was activated. The further reduction in the mid to later modelling period is supported by vehicle lightweighting and the USA electric grid GHG emissions reductions. Altogether, by 2050, the use phase GHG emission contribution is around half of the overall GHG emissions. The private vehicle fleet contributes the highest GHG emission in the use phase (see Fig. 9d), nearly 90%. However, a significant observation towards the end of the modelling period is reducing the contribution of the private vehicle fleet to the use phase GHG emissions.

Dynamic-GHG results—life cycle phases in the baseline scenario. a Production phase—aggregated emissions, b production phase—individual modes, c use phase—aggregated emissions and d use phase—individual modes
In contrast, the solo-ridesourcing use phase GHG fraction increased significantly, reaching nearly one-fifth at the end of the modelling period, which was initially insignificant. The use phase GHG emissions of the carpooling mode reduced by the end of the modelling. These observations align with the user preference trends discussed in Sect. 4.5.2 and subsequent fleet behaviour in Sect. 4.6.1. A key factor for the GHG emissions changes in solo-ridesourcing and carpooling modes is the gross occupancy rates and the deadheading factors (Fernando et al. 2020b, 2020b; Henao and Marshall 2018; Union of Concerned Scientists 2020b). The gross occupancy rates of solo-ridesourcing are significantly lower than carpooling, and the mode records the highest deadheading among the chosen car-based mobility modes (Henao and Marshall 2018; Union of Concerned Scientists 2020a). Hence, the aggregated car-based MaaS modes contribute to a higher use phase GHG emission fractions at the end of the modelling time, mainly dominated by the solo-ridesourcing mode.
In contrast to the use phase GHG emissions, the production phase emissions show an increase (see Fig. 9a). In the high BEV adoption scenario, the production GHG emissions show an increase from 2022, the year that starts replacing gasoline vehicles rapidly, to achieve 100% BEV purchase by 2030 (see Sect. 4.1.1). The higher GHG emissions from the BEV raw material composition compared to internal combustion engine vehicles, especially from the battery, is a key reason for this increase (Wang et al. 2021). The fleet purchasing behaviour and the vehicle production GHG emission rates determine the production phase GHG emissions. The composition of private vehicle purchases significantly changes from gasoline sedans and SUVs to more BEV-driven vehicles, particularly SUVs, in the late 2030s (see Fig. 14 in Appendix). The higher GHG emissions in the production phase due to fleet electrification can be seen by comparing graphs (a) and (b) in Fig. 9. The highest production phase GHG emissions are recorded when the complete transition to BEVs with a higher composition of SUVs, demonstrating a node by the end of the 2030s. The consumer preferences determine the vehicle purchasing composition (based on the derived utility values in Sect. 4.2), and the results of the SD sub-model transition to MaaS and replacements for the scrappages are also determining factors in fleet purchasing.
As shown in Fig. 9b, other than private vehicles, the highest GHG contribution is from the solo-ridesourcing fleet. In the solo-ridesourcing production phase GHG emissions are increased because of the higher purchasing and scrappage rates to maintain the vehicle age restrictions enforced by the transport network companies (Uber 2021a). The combination of larger BEV and SUV fractions in the ridesourcing modes is another explanation for the rise of production phase GHG emissions. Both BEVs and SUVs generate larger production phase GHG emissions than internal combustion engine vehicles and body styles such as sedans (Wang et al. 2021).
The model results predict the significance of the production phase GHG emissions in the future. It is contributed by several factors such as raw material embodied emissions due to lightweighting and fleet electrification, transition to SUVs from sedans, and consumer preference-influenced changes in the user compositions in car-based mobility fleets. This explanation highlights the importance of integrating consumer preferences, technology changes, temporality, and their causal interactions in the sharing economy systems in assessing GHG emissions.
6 Discussion
6.1 The C-DLCA model application summary
The C-DLCA framework has provided a structured and practical approach to integrating consumer preference outcomes into the SD model, considering the dynamic-LCA calculation as the end goal. The framework effectively facilitated the integration of inputs and outputs of the three models: (a) consumer preference measured by DCE, (b) temporality and causality integrated using SD as the interface and (c) environmental impact assessment by employing LCA. The complex handling of the process step formulation and simulation (S3 in Fig. 3) would have been impossible without such a simplified and straightforward framework. The step S3 itself, handled four data flows (D1a, D2, D4 and D5). The methodology framework demonstrates its robustness by the effectual application in the selected complex case study.
Based on the chosen case study, the established C-DLCA feedback flows were well utilised and demonstrated the model’s capability to determine the life cycle GHG emissions of the transition to car-based MaaS modes of the roundtrip to work journey in the US. As shown in Fig. 5, the sub-model diagram and the derived causal loop diagram based on the Baas diffusion model (see Fig. 4) combine consumer preference and fleet technology feedback in the systems modelling. The selected shared mobility-based case study is complex in terms of considering several shared mobility modes and their fleet technology implications. The technology consideration is further extended to the changes in automobile production aspects. They are lightweighting and extended longevity (based on the survival rates). Indirect influences such as the electric grid GHG emissions changes are also considered in the dynamic-LCA calculations. Hence, applying the C-DLCA framework in the chosen case study is closer to the market reality. The application of the framework in the case study also indicates the replicability of the C-DLCA in other SE systems. It highlights the importance of integrating consumer preference and temporality in the environmental evaluations of SE systems.
Though the C-DLCA methodology framework is designed for SE systems, with brief customisations, it can also apply to environmentally evaluate the linear economy systems. The only foreseen difference is the changes in the DCE model to change the attributes to represent linear economy-centric consumer preferences.
6.2 Effect of consumer preference
A significant gap can be seen in the dynamic-GHG results in the two conditions: (a) considering consumer preference and (b) not considering. In a typical dynamic-LCA work, only the temporal changes influence the results compared to a conventional, static LCA (Sohn et al. 2020). Figure 10 shows the generated results combining consumer preference in dynamic-GHG emissions (as discussed in Sect. 5) and the conventional dynamic-LCA approach without considering consumer preferences. The graphical representation of “not considering consumer preference” is generated by simplifying the sub-model transition to MaaS introduced in Sect. 4.5. A simple, linear formulation is introduced to car-based MaaS modes instead of the Bass diffusion model-driven causality explanation. Hence, the results “not considering consumer preference” shown in Fig. 10 only characterise the temporal fleet technological attributes (powertrain type and vehicle body style compositions, lightweighting and longevity improvements, and the USA electric grid GHG changes) as introduced in Sect. 4.1.1. Therefore, a significant GHG emission gap is determined between the integrated DCE results (i.e., consumer preference combined, as in this work) findings versus the typical approach of not considering them.

Consumer preference integrated dynamic-LCA results versus not combining it (the baseline scenario results)
Figure 10 shows a significant deviation in GHG emissions considering consumer preferences against those not considering. The expected GHG reduction, considering only the fleet technology changes, shows a significantly higher GHG emission reduction in personal mobility compared to the results shown in Sect. 5. The difference in GHG emissions outcomes highlights the significance of consumer preference integration in the environmental consequences of the technology changes. Hence, the results show the importance of combining consumer preference in the dynamic-LCAs in the transition to car-based sharing economy modes. A GHG emission reduction is expected without consumer preference integration, considering the anticipated fleet technology changes introduced in Sect. 4.1.1. However, consumer preference integration significantly changes the car-based MaaS composition considering the fleet-technology offerings. Another observation is that only the technology-based uncertainties would have been analysed if consumer preference were not integrated into the analysis. Hence, the sensitivity of the uncertainty associated with consumer preferences and other sensitivity elements is limited if not applying the C-DLCA framework and assessing by only employing the dynamic-LCA approach. These findings also align with the outcomes of Sects. 4.5 and 4.6, particularly the consumer preferences in different MaaS modes. In this work, the vehicle body style was only chosen as the endogenous explanation (see Sect. 4.3). Therefore, the above results highlight the significance of combining consumer preference in dynamic-LCA analysis in SE systems, and the practical and robust application of the C-DLCA methodology framework.
7 Conclusion
This paper presented a new methodology framework to integrate consumer preferences into the dynamic-LCA of sharing economy systems. The life cycle environmental impact assessments of SE systems required a robust method to integrate consumer-based decisions and temporal technological changes in their asset pools. The influence of consumer preferences in SE systems is significant compared to linear economy systems. This paper explored consumer preferences and its dynamic and causal influences in the life cycle environmental assessments of SE systems compared to linear economy models. The C-DLCA framework is proposed to assess SE systems, combining the technological changes in asset pools. The full life cycle scope is chosen to determine the differences in SE asset pools to integrate the features: achieving product longevity within a shorter period, adopting newer technologies, and different production and disposal patterns. Selecting a service-based functional unit (i.e., p.km in this study) is identified as a must in effectively interpreting the dynamic-LCA results of an SE system and for effective comparison against the respective linear economy system.
The SD method is used as the interface to combine consumer preference dynamics and the LCA method. Sterman’s five process steps (Sterman 2000) is selected as the SD approach, and its iterative characteristics are integrated with the proposed methodology. Previous research has not combined consumer preferences, SD model and LCA to assess the systems through SD models (Jiang 2019; Wang et al. 2016), and SD and LCA modes (Stasinopoulos et al. 2012) were conducted separately. A novel methodology approach and structured framework, C-DLCA, is introduced to connect the consumer preference integrated SD model with the LCA method. The proposed methodology has provided a step-based approach connecting the different phases of the three methods (DCE, SD and LCA) and established the feedback and data loops. In the C-DLCA framework, the step “formulation and simulation” combines the conjoint analysis-based DCE results, LCI and LCIA outcomes into the SD model. This connectivity added temporal and causal influences to the dynamic process inventory inputs for the LCI and then derived the LCIA results. The testing and policy scenarios steps of the SD approach generate the LCIA scenarios to be re-evaluated.
This is the first study that quantified the combined impacts of consumer preferences, technology changes and their causal influences on the life cycle environmental impacts. The outcomes of the case-study-based C-DLCA methodology framework demonstrate the significance of integrating SE consumer preferences into a dynamic-LCA. In SE, integrating consumer preference is critical to gathering information directly from stakeholders (consumers specifically) to understand the temporal effect in the analysis. The proposed C-DLCA framework has provided a solution to integrate consumer preferences, technological changes in SE assets and their dynamics into the life cycle environmental impact assessments of SE systems in a single formulation. The Bass model (Bass 1969) is adopted to simulate the transition to SE systems. MNL model-based, logit choice probability results are utilised to represent the SE mode attractiveness as a probabilistic function. The most influential attributes are incorporated into the consumer preferences study and are classified as either endogenous or exogenous based on the scope of the study. The vehicle body style is chosen as the endogenous variable in this work based on the chosen case study. A robust and structured integration of utilising the SD interface has also added some standardisation to the dynamic-LCAs of the SE systems. The above capabilities of the proposed C-DLCA framework have been proven with the illustrated complex case study on the transition to car-based shared mobility modes of the roundtrip to work journey in the US. Hence, the C-DLCA framework is suitable for environmentally assessing the SE modes.
The attribute powertrain type was not considered endogenous since consumers do not have the choice option to select it in current shared mobility Apps. However, with the BEV promotion in the ridesourcing fleet, the option to select the powertrain type would be generic in the future. Therefore, the powertrain type can be considered an endogenous attribute identified as a potential future work. It can add increased research value with the speed of changes in the electrification of the personal mobility fleet Fig. 11, 12, 13, and 14.
Data availability
None.
Notes
Solo-ridesourcing term is employed to highlight the usage of the ridesourcing mode in non-shared trips.
References
Aamas B, Andrew R (2020) Estimating effects on emissions of sharing (No. 2020:03). CICERO Center for International Climate Research, Oslo
Ajanovic A (2015) The future of electric vehicles: prospects and impediments. Wires Energy Environ 4:521–536. https://doi.org/10.1002/wene.160
Amasawa E, Shibata T, Sugiyama H, Hirao M (2020) Environmental potential of reusing, renting, and sharing consumer products: systematic analysis approach. J Clean Prod 242:118487. https://doi.org/10.1016/j.jclepro.2019.118487
Amatuni L, Ottelin J, Steubing B, Mogollón JM (2020) Does car sharing reduce greenhouse gas emissions? Assessing the modal shift and lifetime shift rebound effects from a life cycle perspective. J Clean Prod 266:121869. https://doi.org/10.1016/j.jclepro.2020.121869
Astegiano P, Fermi F, Martino A (2019) Investigating the impact of e-bikes on modal share and greenhouse emissions: a system dynamic approach. Transp Res Procedia 37:163–170. https://doi.org/10.1016/j.trpro.2018.12.179
Bartolozzi I, Rizzi F, Frey M (2013) Comparison between hydrogen and electric vehicles by life cycle assessment: a case study in Tuscany, Italy. Appl Energy, Sustainable Development of Energy, Water and Environment Systems 101:103–111. https://doi.org/10.1016/j.apenergy.2012.03.021
Bass FM (1969) A new product growth for model consumer durables. Manag Sci 15:215–227. https://doi.org/10.1287/mnsc.15.5.215
Ben-Akiva M, Atherton TJ (1977) Methodology for short-range travel demand predictions: analysis of carpooling incentives. J Transp Econ Policy 11:224–261
Ben-Akiva M, Lerman SR (1987) Discrete Choice Analysis. The MIT Press, Massachusetts, Theory and Application to Travel Demand
Botsman R (2015) Defining The Sharing Economy: What Is Collaborative Consumption–And What Isn’t? [WWW Document]. Fast Co. https://www.fastcompany.com/3046119/defining-the-sharing-economy-what-is-collaborative-consumption-and-what-isnt. (Accessed July 14, 2021)
California Air Resource Board (2019) SB 1014 Clean Miles Standard 2018 Base-year Emissions Inventory Report (No. SB 1014)
Carroll P, Caulfield B (Brian), Ahern A (2017) Encouraging sustainable commuting behaviour through smart policy provision: a stated preference mode-choice experiment in the Greater Dublin Area. Presented at the Irish Transport Research Network Conference 2017, University College Dublin, Ireland, 31 August -1 September 2017, Irish Transport Research Network
Changsirivathanatahathamrong A, Moore S, Linard K (2001) Integrating system dynamics with life cycle assessment: a framework for improved policy formulation and analysis. Int Congr Model Simul 2001(3):1213–1218
Chen Z, Huang L (2019) Application review of LCA (Life Cycle Assessment) in circular economy: from the perspective of PSS (Product Service System). Procedia CIRP 83:210–217. https://doi.org/10.1016/j.procir.2019.04.141
Chun Y, Lee K (2017) Environmental impacts of the rental business model compared to the conventional business model: a Korean case of water purifier for home use. Int J Life Cycle Assess Dordr 22:1096–1108. https://doi.org/10.1007/s11367-016-1227-1
Cohen SH (1997) Perfect union. Mark Res 9:12–17
Collinge WO, Landis AE, Jones AK, Schaefer LA, Bilec MM (2013) Dynamic life cycle assessment: framework and application to an institutional building. Int J Life Cycle Assess 18:538–552. https://doi.org/10.1007/s11367-012-0528-2
Conjoint.ly (n.d.) Technical points on DCE with Conjoint.ly [WWW Document]. Tech. Points DCE Conjointly. https://conjointly.com/guides/conjoint-technical-notes/. (Accessed May 11, 2021)
Cozzi L, Apostolos P (2021) Global SUV sales set another record in 2021, setting back efforts to reduce emissions – analysis [WWW Document]. IEA. https://www.iea.org/commentaries/global-suv-sales-set-another-record-in-2021-setting-back-efforts-to-reduce-emissions. (Accessed February 14, 2022)
Dang L, von Arx W, Frölicher J (2021) The impact of on-demand collective transport services on sustainability: a comparison of various service options in a rural and an urban area of Switzerland. Sustainability 13:3091. https://doi.org/10.3390/su13063091
Davis SC, Boundy RG (2021) Transportation Energy Data Book (Edition 39 No. ORNL/TM-2020/1770 (Edition 39 of ORNL-5198)). Office of Energy Efficiency and Renewable Energy U.S. Department of Energy, Oak Ridge, USA
Derwisch S, Morone P, Tröger K, Kopainsky B (2016) Investigating the drivers of innovation diffusion in a low income country context. The case of adoption of improved maize seed in Malawi. Futures, Modelling and Simulation in Futures Studies 81:161–175. https://doi.org/10.1016/j.futures.2015.08.011
Doka G, Ökobilanzen D (2001) Complete Life Cycle Assessment for Vehicle Models of the Mobility CarSharing Fleet Switzerland 14
Eckhardt GM, Houston MB, Jiang B, Lamberton C, Rindfleisch A, Zervas G (2019) Marketing in the sharing economy. J Mark 83:5–27. https://doi.org/10.1177/0022242919861929
Eisen-Hecht JI, Kramer RA, Huber J (2004) A hierarchical Bayes approach to modeling choice data: a study of wetland restoration programs, in: AgEcon Search. Presented at the American Agricultural Economics Association Annual Meeting, Denver, Colorado. https://doi.org/10.22004/ag.econ.20253
Ercan T, Onat NC, Tatari O (2016) Investigating carbon footprint reduction potential of public transportation in United States: a system dynamics approach. J Clean Prod 133:1260–1276. https://doi.org/10.1016/j.jclepro.2016.06.051
Ertz M, Durif F, Arcand M (2016). Collaborative Consumption: Conceptual Snapshot at a Buzzword. https://doi.org/10.2139/ssrn.2799884
Esfandabadi ZS, Ravina M, Diana M, Zanetti MC (2020) Conceptualizing environmental effects of carsharing services: a system thinking approach. Sci Total Environ 745:141169. https://doi.org/10.1016/j.scitotenv.2020.141169
Farrant L, Olsen SI, Wangel A (2010) Environmental benefits from reusing clothes. Int J Life Cycle Assess 15:726–736. https://doi.org/10.1007/s11367-010-0197-y
Fernando C, Buttriss G, Yoon H-J, Soo VK, Compston P, Kim HC, De Kleine R, Doolan M Under review. Characterising the consumer preferences of car-based mobility for a roundtrip to work. J Consum Behav
Fernando C, Soo VK, Compston P, Doolan M (Under review) The impact of car-based shared mobility on greenhouse gas emissions: a review. Transp Saf Environ
Fernando C, Soo VK, Compston P, Kim HC, De Kleine R, Weigl D, Keith DR, Doolan M (2020a) Life cycle environmental assessment of a transition to mobility servitization. Procedia CIRP, 27th CIRP Life Cycle Engineering Conference (LCE2020a)Advancing Life Cycle Engineering : from technological eco-efficiency to technology that supports a world that meets the development goals and the absolute sustainability 90:238–243. https://doi.org/10.1016/j.procir.2020.01.098
Fernando C, Soo VK, Doolan M (2020b) Life cycle assessment for servitization: a case study on current mobility services. Procedia Manuf., Sustainable Manufacturing - Hand in Hand to Sustainability on Globe: Proceedings of the 17th Global Conference on Sustainable Manufacturing 43:72–79. https://doi.org/10.1016/j.promfg.2020.02.112
Folkvord F, Veltri GA, Lupiáñez-Villanueva F, Tornese P, Codagnone C, Gaskell G (2020) The effects of ecolabels on environmentally- and health-friendly cars: an online survey and two experimental studies. Int J Life Cycle Assess 25:883–899. https://doi.org/10.1007/s11367-019-01644-4
Franco MA (2019) A system dynamics approach to product design and business model strategies for the circular economy. J Clean Prod 241:118327. https://doi.org/10.1016/j.jclepro.2019.118327
Frenken K (2017) Political economies and environmental futures for the sharing economy. Philos Trans r Soc Math Phys Eng Sci 375:20160367. https://doi.org/10.1098/rsta.2016.0367
Garcia R, Gregory J, Freire F (2015) Dynamic fleet-based life-cycle greenhouse gas assessment of the introduction of electric vehicles in the Portuguese light-duty fleet. Int J Life Cycle Assess 20:1287–1299. https://doi.org/10.1007/s11367-015-0921-8
Geum Y, Lee S, Park Y (2014) Combining technology roadmap and system dynamics simulation to support scenario-planning: a case of car-sharing service. Comput Ind Eng 71:37–49. https://doi.org/10.1016/j.cie.2014.02.007
Gobble MM (2017) Defining the sharing economy. Res-Technol Manag 60:59–63. https://doi.org/10.1080/08956308.2017.1276393
Goedkoop MJ, van Halen CJG, te Riele HRM, Rommens PJM (1999) Product Service systems, Ecological and Economic Basics. Ministry of Housing, Spatial Planning and the Environment
Green PE, Srinivasan V (1978) Conjoint analysis in consumer research: issues and outlook. J Consum Res 5:103–123
Greenblatt JB, Saxena S (2015) Autonomous taxis could greatly reduce greenhouse-gas emissions of US light-duty vehicles. Nat Clim Change Lond 5:860–863. https://doi.org/10.1038/nclimate2685
Halog A, Manik Y (2011) Advancing integrated systems modelling framework for life cycle sustainability assessment. Sustainability 3:469–499. https://doi.org/10.3390/su3020469
Hamari J, Sjöklint M, Ukkonen A (2016) The sharing economy: Why people participate in collaborative consumption. J Assoc Inf Sci Technol 67:2047–2059. https://doi.org/10.1002/asi.23552
Harris S, Mata É, Plepys A, Katzeff C (2021) Sharing is daring, but is it sustainable? An assessment of sharing cars, electric tools and offices in Sweden. Resour Conserv Recycl 170:105583. https://doi.org/10.1016/j.resconrec.2021.105583
He S, Li J (2019) A Study of Urban City Traffic Congestion Governance Effectiveness Based on System Dynamics Simulation. Int Refereed J Eng Sci IRJES 1(8):37–47
Henao A, Marshall WE (2018) The impact of ride-hailing on vehicle miles traveled. Transportation. https://doi.org/10.1007/s11116-018-9923-2
Hicks AL, Theis TL (2014) An agent based approach to the potential for rebound resulting from evolution of residential lighting technologies. Int J Life Cycle Assess 19:370–376. https://doi.org/10.1007/s11367-013-0643-8
International Energy Agency (IEA) (2021) Global electric vehicle stock by transport mode, 2010–2020 – Charts – Data & Statistics [WWW Document]. IEA. https://www.iea.org/data-and-statistics/charts/global-electric-vehicle-stock-by-transport-mode-2010-2020. (Accessed February 14, 2022)
ISO (2006) Environmental management -Life cycle assessment - Principles and framework (No. ISO 14040:2006). International Organization for Standardization, Zurich
Jha PC, Gupta A, Kapur PK (2008) Bass model revisited. J Stat Manag Syst 11:413–437. https://doi.org/10.1080/09720510.2008.10701320
Jiang Y (2019) Implications of Changes in Consumer Attitudes and Preferences on Alternative Fuel Vehicle Adoption: A System Dynamics and Choice Modelling Approach. Australian National University, Canberra
Kjaer LL, Pagoropoulos A, Schmidt JH, McAloone TC (2016) Challenges when evaluating product/service-systems through life cycle assessment. J Clean Prod 120:95–104. https://doi.org/10.1016/j.jclepro.2016.01.048
Klint E, Peters G (2021) Sharing is caring - the importance of capital goods when assessing environmental impacts from private and shared laundry systems in Sweden. Int J Life Cycle Assess 26:1085–1099. https://doi.org/10.1007/s11367-021-01890-5
König A, Bonus T, Grippenkoven J (2018) Analyzing urban residents’ appraisal of ridepooling service attributes with conjoint analysis. Sustainability 10:3711. https://doi.org/10.3390/su10103711
Kopainsky B, Tröger K, Derwisch S, Ulli-Beer S (2012) Designing sustainable food security policies in sub-Saharan African countries: how social dynamics over-ride utility evaluations for good and bad. Syst Res Behav Sci 29:575–589. https://doi.org/10.1002/sres.2140
Krystofik M, Babbitt CW, Gaustad G (2014) When consumer behavior dictates life cycle performance beyond the use phase: case study of inkjet cartridge end-of-life management. Int J Life Cycle Assess 19:1129–1145. https://doi.org/10.1007/s11367-014-0713-6
Kubli M (2020) Navigating through the unknown: how conjoint analysis reduces uncertainty in energy consumer modelling. Syst Res Behav Sci 37:880–885. https://doi.org/10.1002/sres.2756
Kumar VV, Hoadley A, Shastri Y (2019) Dynamic impact assessment of resource depletion: a case study of natural gas in New Zealand. Sustain Prod Consum 18:165–178. https://doi.org/10.1016/j.spc.2019.01.002
Lee S, Geum Y, Lee H, Park Y (2012) Dynamic and multidimensional measurement of product-service system (PSS) sustainability: a triple bottom line (TBL)-based system dynamics approach. J Clean Prod 32:173–182. https://doi.org/10.1016/j.jclepro.2012.03.032
Lenk PJ, DeSarbo WS, Green PE, Young MR (1996) Hierarchical Bayes conjoint analysis: recovery of Partworth heterogeneity from reduced experimental designs. Mark Sci 15:173–191. https://doi.org/10.1287/mksc.15.2.173
Louviere JJ, Flynn TN, Carson RT (2010) Discrete choice experiments are not conjoint analysis. J Choice Model 3:57–72. https://doi.org/10.1016/S1755-5345(13)70014-9
Lu S (2006) Vehicle Survivability and Travel Mileage Schedules (No. DOT HS 809 952), NHTSA Technical Report. National Center for Statistics and Analysis Regulatory Analysis and Evaluation Division National Highway Traffic Safety Administration, Washington DC
Lueddeckens S, Saling P, Guenther E (2020) Temporal issues in life cycle assessment—a systematic review. Int J Life Cycle Assess 25:1385–1401. https://doi.org/10.1007/s11367-020-01757-1
Luna TF, Uriona-Maldonado M, Silva ME, Vaz CR (2020) The influence of e-carsharing schemes on electric vehicle adoption and carbon emissions: An emerging economy study. Transp Res Part Transp Environ 79:102226. https://doi.org/10.1016/j.trd.2020.102226
Lyft (2020a) Leading the Transition to Zero Emissions: Our Commitment to 100% Electric Vehicles by 2030 [WWW Document]. https://www.lyft.com/blog/posts/leading-the-transition-to-zero-emissions. Accessed December 18, 2020
Lyft (2020b) Leading the Transition to Zero Emissions: Our Commitment to 100% Electric Vehicles by 2030 [WWW Document]. Lyft. https://www.lyft.com/blog/posts/leading-the-transition-to-zero-emissions (Accessed January 6, 2021)
MacLean HL, Lave LB (2003) Life cycle assessment of automobile/fuel options. Environ Sci Technol 37:5445–5452. https://doi.org/10.1021/es034574q
Malichová E, Pourhashem G, Kováčiková T, Hudák M (2020) Users’ perception of value of travel time and value of ridesharing impacts on Europeans’ ridesharing participation intention: a case study based on MoTiV European-wide mobility and behavioral pattern dataset. Sustainability 12:4118. https://doi.org/10.3390/su12104118
McAvoy S, Grant T, Smith C, Bontinck P (2021) Combining life cycle assessment and system dynamics to improve impact assessment: a systematic review. J Clean Prod 315:128060. https://doi.org/10.1016/j.jclepro.2021.128060
McGuckin N, Fucci A (2018) Summary of travel trends 2017 national household travel survey (No. FHWA-PL-18–019). Federal Highway Administration, Washington, DC. https://doi.org/10.2172/885762
Nurhadi L, Borén S, Ny H, Larsson T (2017) Competitiveness and sustainability effects of cars and their business models in Swedish small town regions. J. Clean. Prod. Systematic Leadership towards Sustainability 140:333–348. https://doi.org/10.1016/j.jclepro.2016.04.045
Office of Energy Efficiency and Renewable Energy (2016) Fact #946: October 10, 2016 Driving Alone in a Private Vehicle is the Most Common Means of Transportation to Work [WWW Document]. Energy.gov. https://www.energy.gov/eere/vehicles/fact-946-october-10-2016-driving-alone-private-vehicle-most-common-means. (Accessed September 23, 2021)
Onat NC, Kucukvar M, Tatari O, Egilmez G (2016) Integration of system dynamics approach toward deepening and broadening the life cycle sustainability assessment framework: a case for electric vehicles. Int J Life Cycle Assess Dordr 21:1009–1034. https://doi.org/10.1007/s11367-016-1070-4
Pinto JTM, Sverdrup HU, Diemer A (2019) Integrating life cycle analysis into system dynamics: the case of steel in Europe. Environ Syst Res 8:15. https://doi.org/10.1186/s40068-019-0144-2
Piscicelli L, Cooper T, Fisher T (2015) The role of values in collaborative consumption: insights from a product-service system for lending and borrowing in the UK. J. Clean. Prod., Special Volume: Why have ‘Sustainable Product-Service Systems’ not been widely implemented? 97:21–29. https://doi.org/10.1016/j.jclepro.2014.07.032
Polizzi di Sorrentino E, Woelbert E, Sala S (2016) Consumers and their behavior: state of the art in behavioral science supporting use phase modeling in LCA and ecodesign. Int J Life Cycle Assess 21:237–251. https://doi.org/10.1007/s11367-015-1016-2
Priporas C-V, Stylos N, Rahimi R, Vedanthachari LN (2017) Unraveling the diverse nature of service quality in a sharing economy: a social exchange theory perspective of Airbnb accommodation. Int J Contemp Hosp Manag 29:2279–2301. https://doi.org/10.1108/IJCHM-08-2016-0420
Qian L, Grisolía JM, Soopramanien D (2019) The impact of service and government-policy attributes on consumer preferences for electric vehicles in China. Transp Res Part Policy Pract 122:70–84. https://doi.org/10.1016/j.tra.2019.02.008
Querbes A (2018) Banned from the sharing economy: an agent-based model of a peer-to-peer marketplace for consumer goods and services. J Evol Econ 28:633–665. https://doi.org/10.1007/s00191-017-0548-y
Querini F, Benetto E (2015) Combining agent-based modeling and life cycle assessment for the evaluation of mobility policies. Environ Sci Technol 49:1744–1751. https://doi.org/10.1021/es5060868
Querini F, Benetto E (2014) Agent-based modelling for assessing hybrid and electric cars deployment policies in Luxembourg and Lorraine. Transp Res Part Policy Pract 70:149–161. https://doi.org/10.1016/j.tra.2014.10.017
Rayle L, Dai D, Chan N, Cervero R, Shaheen S (2016) Just a better taxi? A survey-based comparison of taxis, transit, and ridesourcing services in San Francisco. Transp Policy 45:168–178. https://doi.org/10.1016/j.tranpol.2015.10.004
Richardson GP, Pugh AL III (1981) Introduction to System Dynamics Modeling with DYNAMO. MIT Press
Roux C, Schalbart P, Peuportier B (2017) Development of an electricity system model allowing dynamic and marginal approaches in LCA—tested in the French context of space heating in buildings. Int J Life Cycle Assess 22:1177–1190. https://doi.org/10.1007/s11367-016-1229-z
Santa-eulalia LAD, Gestion ÉE, Neumann D, Klasen J, Baden EE, Ag W (2011) A Simulation-Based Innovation Forecasting Approach Combining the Bass Diffusion Model, the Discrete Choice Model and System Dynamics An Application in the German Market for Electric Cars. Presented at the The Third International Conference on Advances in System Simulation
Schmidt MJ, Gary MS (2002) Combining system dynamics and conjoint analysis for strategic decision making with an automotive high-tech SME. Syst Dyn Rev 18:359–379. https://doi.org/10.1002/sdr.257
Schneider T (2021a) Taxi and Ridehailing App Usage in New York City [WWW Document]. toddwschneider.com. https://toddwschneider.com/dashboards/nyc-taxi-ridehailing-uber-lyft-data/. (Accessed September 23, 2021)
Schneider T (2021b) Taxi and Ridehailing App Usage in Chicago [WWW Document]. toddwschneider.comhttps://toddwschneider.com/dashboards/chicago-taxi-ridehailing/. (Accessed September 23, 2021)
Shaheen S, Sperling D, Wagner C (1998) Carsharing in Europe and North American: Past, Present, and Future (No. UCTC No 467). The University of CatiformaTransportation CenterUl~iversiEr of California, Berkeley
Shahmohammadi S, Steinmann Z, Clavreul J, Hendrickx H, King H, Huijbregts MAJ (2018) Quantifying drivers of variability in life cycle greenhouse gas emissions of consumer products—a case study on laundry washing in Europe. Int J Life Cycle Assess 23:1940–1949. https://doi.org/10.1007/s11367-017-1426-4
Sigüenza CP, Cucurachi S, Tukker A (2021) Circular business models of washing machines in the Netherlands: material and climate change implications toward 2050. Sustain Prod Consum 26:1084–1098. https://doi.org/10.1016/j.spc.2021.01.011
Sohn J, Kalbar P, Goldstein B, Birkved M (2020) Defining temporally dynamic life cycle assessment: a review. Integr Environ Assess Manag 16:314–323. https://doi.org/10.1002/ieam.4235
Stasinopoulos P (2013) A system dynamics approach to life cycle assessment
Stasinopoulos P, Compston P, Newell B, Jones HM (2012) A system dynamics approach in LCA to account for temporal effects--a consequential energy LCI of car body-in-whites. Int J Life Cycle Assess Dordr 17:199–207. https://doi.org/10.1007/s11367-011-0344-0
Stasinopoulos P, Shiwakoti N, Beining M (2021) Use-stage life cycle greenhouse gas emissions of the transition to an autonomous vehicle fleet: a system dynamics approach. J Clean Prod 278:123447. https://doi.org/10.1016/j.jclepro.2020.123447
Sterman JD (2000) Business dynamics: Systems thinking and modeling for a complex world. Irwin/McGraw-Hill, Boston
Su S, Li X, Zhu C, Lu Y, Lee HW (2021) Dynamic life cycle assessment: a review of research for temporal variations in life cycle assessment studies. Environ Eng Sci. https://doi.org/10.1089/ees.2021.0052
The White House (2021) FACT SHEET: President Biden Announces Steps to Drive American Leadership Forward on Clean Cars and Trucks [WWW Document]. White House. https://www.whitehouse.gov/briefing-room/statements-releases/2021/08/05/fact-sheet-president-biden-announces-steps-to-drive-american-leadership-forward-on-clean-cars-and-trucks/. (Accessed August 25, 2021)
Train KE (2009) Discrete Choice Methods with Simulation. Cambridge University Press
Uber (2021a) Eligible-Vehicles | Drive | Uber New York City [WWW Document]. Uber. https://www.uber.com/us/en/drive/new-york/get-started/eligible-vehicles/. (Accessed September 29, 2021)
Uber (2021b) Uber Services and Types of Rides [WWW Document]. Uber. https://www.uber.com/us/en/ride/ride-options/. (Accessed January 6, 2021)
Uber, 2021c. Vehicle Requirements | Uber Los Angeles [WWW Document]. Uber. https://www.uber.com/us/en/drive/los-angeles/vehicle-requirements/. (Accessed August 26, 2021)
Uber (2020) Climate Assessment and Performance Report
Union of Concerned Scientists (2020a) Ride-Hailing Climate Risks, Steering a Growing Industry toward a Clean Transportation Future. Union of Concerned Scientists, Cambridge MA
Union of Concerned Scientists (2020b) Ride-Hailing Climate Risks (Methodology), Steering a Growing Industry toward a Clean Transportation Future. Union of Concerned Scientists, Cambridge MA
US Census Bureau (2020) Census - Table Results [WWW Document]. Commut. Charatersitics Sex S0801. https://data.census.gov/cedsci/table?q=s0801&tid=ACSST1Y2019.S0801&hidePreview=false. (Accessed April 21, 2021)
U.S. Energy Information Administration - EIA (2021) Annual Energy Outlook 2021 [WWW Document]. Indep. Stat. Anal. US Energy Inf. Adm. https://www.eia.gov/outlooks/aeo/data/browser/#/?id=17-AEO2021&cases=ref2021&sourcekey=0. (Accessed January 29, 2022)
U.S. Energy Information Administration - EIA, 2020. Annual Energy Outlook 2020 Table 39. Light-Duty Vehicle Stock by Technology Type [WWW Document]. https://www.eia.gov/outlooks/aeo/data/browser/#/?id=49-AEO2020&cases=ref2020&sourcekey=0. (Accessed September 12, 2021)
U.S. Energy Information Administration - EIA, 2019. Annual Energy Outlook 2019 [WWW Document]. US Energy Inf Adm - EIA - Indep Stat. Anal. https://www.eia.gov/outlooks/aeo/data/browser/#/?id=17-AEO2019®ion=1-0&cases=ref2019&start=2017&end=2019&f=A&linechart=ref2019-d111618a.33-17-AEO2019.1-0&map=ref2019-d111618a.4-17-AEO2019.1-0&ctype=linechart&sourcekey=0. (Accessed January 29, 2022)
U.S. Energy Information Administration - EIA (2016) Annual Energy Outlook 2016 [WWW Document]. US Energy Inf Adm - EIA - Indep Stat Anal. https://www.eia.gov/outlooks/aeo/data/browser/#/?id=8-AEO2016®ion=0-0&cases=ref2016&start=2013&end=2040&f=A&linechart=ref2016-d032416a.21-8-AEO2016&map=&ctype=linechart&sourcekey=0. (Accessed January 29, 2022)
US EPA (2021) The 2020 EPA Automotive Trends Report (No. EPA-420-R-21–003), Greenhouse Gas Emissions, Fuel Economy, and Technology since 1975
US EPA (2020) Sources of Greenhouse Gas Emissions [WWW Document]. https://www.epa.gov/ghgemissions/sources-greenhouse-gas-emissions. (Accessed June 19, 2022)
US EPA (2018a) Explore the Automotive Trends Data [WWW Document]. https://www.epa.gov/automotive-trends/explore-automotive-trends-data. (Accessed March 4, 2022)
US EPA (2018b) Explore the Automotive Trends Data [WWW Document]. https://www.epa.gov/automotive-trends/explore-automotive-trends-data. (Accessed August 23, 2021)
Walzberg J, Dandres T, Merveille N, Cheriet M, Samson R (2019) Assessing behavioural change with agent-based life cycle assessment: application to smart homes. Renew Sustain Energy Rev 111:365–376. https://doi.org/10.1016/j.rser.2019.05.038
Wang H, Zhang K, Chen J, Wang Z, Li G, Yang Y (2018) System dynamics model of taxi management in metropolises: economic and environmental implications for Beijing. J Environ Manage 213:555–565. https://doi.org/10.1016/j.jenvman.2018.02.026
Wang J, Lai J-Y (2020) Exploring innovation diffusion of two-sided mobile payment platforms: a system dynamics approach. Technol Forecast Soc Change 157:120088. https://doi.org/10.1016/j.techfore.2020.120088
Wang J, Lai J-Y, Chang C-H (2016) Modeling and analysis for mobile application services: the perspective of mobile network operators. Technol Forecast Soc Change 111:146–163. https://doi.org/10.1016/j.techfore.2016.06.020
Wang M, Elgowainy A, Lee U, Befana A, Benavides P, Burnham A, Cai H, Dai Q, Gracia-Alvarez U, Hawkins T, Jaquez P, Kelly J, Kwon H, Lu Z, Liu X, Ou L, Sun P, Winjobi O, Xu H, Yoo E, Zaimes G, Zang G (2021) Summary of Expansions and Updates in GREET® 2020 (No. ANL/ESD-20/9). Systems Assessment Center, Energy Systems Division, Argonne National Laboratory, Oak Ridge, TN 37831–0062
Wasserbaur R, Sakao T, Ljunggren Söderman M, Plepys A, Dalhammar C (2020) What if everyone becomes a sharer? A quantification of the environmental impact of access-based consumption for household laundry activities. Resour Conserv Recycl 158:104780. https://doi.org/10.1016/j.resconrec.2020.104780
Weber TA (2015) The question of ownership in a sharing economy, in: 2015 48th Hawaii International Conference on System Sciences. Presented at the 2015 48th Hawaii International Conference on System Sciences 4874–4883. https://doi.org/10.1109/HICSS.2015.578
Wilkes G, Briem L, Heilig M, Hilgert T, Kagerbauer M, Vortisch P (2021) Determining service provider and transport system related effects of ridesourcing services by simulation within the travel demand model mobiTopp. Eur Transp Res Rev 13:34. https://doi.org/10.1186/s12544-021-00493-3
Xu X (2020) How do consumers in the sharing economy value sharing? Evidence from online reviews. Decis Support Syst 128:113162. https://doi.org/10.1016/j.dss.2019.113162
Yao L, Liu T, Chen X, Mahdi M, Ni J (2018) An integrated method of life-cycle assessment and system dynamics for waste mobile phone management and recycling in China. J Clean Prod 187:852–862. https://doi.org/10.1016/j.jclepro.2018.03.195
Yaraghi N, Ravi S (2017) The Current and Future State of the Sharing Economy. SSRN Electron J Impact Series. https://doi.org/10.2139/ssrn.3041207
Zervas G, Proserpio D, Byers JW (2017) The rise of the sharing economy: estimating the impact of Airbnb on the hotel industry. J Mark Res 54:687–705. https://doi.org/10.1509/jmr.15.0204
Zhang C, Schmöcker J-D, Kuwahara M, Nakamura T, Uno N (2020) A diffusion model for estimating adoption patterns of a one-way carsharing system in its initial years. Transp Res Part Policy Pract 136:135–150. https://doi.org/10.1016/j.tra.2020.03.027
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions. This study is supported by the ARC Training Centre in Lightweight Automotive Structure (project number IC160100032) and the Australian National University and is funded by the Australian Government. The authors sincerely appreciate valuable comments and suggestions from the reviewers that helped to improve the manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
None.
Additional information
Communicated by Yi Yang.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix

Calculated cumulative vehicle scrappage rates. Note: a sedan and hatch—carpooling and private fleets, b SUVs—carpooling and private fleets, c sedan and hatch—ridesourcing and d SUVs—ridesourcing; assuming the vehicle was purchased in 2014, based on the vehicle survival data (Davis and Boundy (2021, pp. 3–20) and (Lu (2006, p. 8); for c, d, assuming the maximum age of a vehicle in a ridesourcing fleet is 15 years (Uber 2021c) and no second life

Stock flow diagram of the transition to MaaS dynamic-GHG. Notes: key to colour codes

Fleet behaviour high BEV adoption scenario: a aggregated personal mobility fleet, b carpooling fleet and c solo-ridesourcing fleet

Private vehicles—production phase. a Dynamic-GHG emission results based on fleet technology composition—baseline scenario and b private vehicle purchasing trends based on the key fleet technology composition—baseline scenario. The yellow highlighted area represents the complete transition to BEVs
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fernando, C., Buttriss, G., Yoon, HJ. et al. Integration of consumer preferences into dynamic life cycle assessment for the sharing economy: methodology and case study for shared mobility. Int J Life Cycle Assess 28, 429–461 (2023). https://doi.org/10.1007/s11367-023-02148-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11367-023-02148-y