
Abstract
The greenhouse gases cause global warming on Earth. The cement production industry is one of the largest sectors producing greenhouse gases. The geopolymer is produced with synthesized by the reaction of an alkaline solution and the waste materials such as slag and fly ash. The use of eco-friendly geopolymer concrete decreases energy consumption and greenhouse gases. In this study, the fc (compressive strength) of eco-friendly geopolymer concrete was predicted by the deep long short-term memory (LSTM) network model. Moreover, the support vector regression (SVR), least squares boosting ensemble (LSBoost), and multiple linear regression (MLR) models were devised to compare the forecast results of the deep LSTM algorithm. The input variables of the models were used as the mole ratio, the alkaline solution concentration, the curing temperature, the curing days, and the liquid-to-fly ash mass ratio. The output variable of the proposed models was chosen as the compressive strength (fc). Furthermore, the effects of the input variable on the fc of eco-friendly geopolymer concrete were determined by the sensitivity analysis. The fc of eco-friendly geopolymer concrete was predicted by the deep LSTM, LSBoost, SVR, and MLR models with 99.23%, 98.08%, 78.57%, and 88.03% accuracy, respectively. The deep LSTM model forecasted the fc of eco-friendly geopolymer concrete with higher accuracy than the SVR, LSBoost, and MLR models. The sensitivity analysis obtained that the curing temperature was the most important experimental variable that affected the fc of geopolymer concrete.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The most used material in the world is water. The second most used material in the world is concrete. Furthermore, cement production consumes between 12 and 15% of the total industrial energy in the world (Ali et al. 2011). When a ton of cement is produced, 600–800 kg of carbon dioxide arises (Huntzinger and Eatmon 2009; Li et al. 2011; Peng et al. 2013). Today, cement production has a carbon dioxide emission of between 4 and 7% in the world. It is predicted that this emission value in cement production will increase by up to 15% in the next decade (Mahasenan et al. 2003). The geopolymer was first mentioned by Davidovits in 1979 (Davidovits 1979, 1988b, a, 1991). He used kaolinite (Al2Si2O5(OH)) and alkali activators in the main reaction of geopolymerization (Ryu et al. 2013). The carbon dioxide emission of the geopolymer is 60 to 80% less than comparable to Portland cement (Duxson et al. 2007). The geopolymer can be produced using fly ash, slag, metakaolin, red mud, etc. materials. Fly ash (FA) is both a cheap and easily obtainable material (Xu and Deventer 2000; Meesala et al. 2020). So, FA is a good raw material for geopolymer concrete or mortar because fly ash contains high amounts of silicon and aluminum (Zhao et al. 2019). According to conventional concrete, the geopolymer concrete produced using FA has less shrinkage, better performance against sulfate and acid attack, higher chloride ingress resistance, higher freeze–thaw resistance, less alkali-aggregate reaction, and higher resistance under temperature (García-Lodeiro et al. 2007; Tanyildizi and Yonar 2016; Gunasekara et al. 2016; Zhao et al. 2019; Meesala et al. 2020). Also, many factors, including material composition and curing conditions, impact the performance of geopolymer composites (Wang et al. 2024). Ersoy and Çavuş (2023) studied the properties of foam geopolymer composites under different curing conditions. They stated that the high curing temperature increased both the physical and strength qualities of the specimens. Zailani et al. (2024) investigated the effect of the binder/sand ratio on the strength features of geopolymer composites. They found that choosing a binder/sand ratio of 1/2 was optimum in terms of mechanical properties. El-Mir et al. (2023) examined the usability of waste perlite powder in geopolymer composite. They indicated that the 25% replacement of waste perlite powder in the geopolymer composite was optimum. Rohit et al. (2024) researched the strength properties of geopolymer composites containing construction demolition waste. They stated that the use of more than 10% waste material in the samples caused a decrease in the strength properties. Raza et al. (2024) studied the strength properties of geopolymer and cement-based composites. They found that the optimum for building applications was a hybrid cement mortar containing 35% OPC and 5% sodium hydroxide. Thakur and Bawa (2023) investigated the effect of dolomite and ground-granulated blast furnace slag on the mechanical properties of geopolymer composites. They found that using 10% dolomite and ground-granulated blast furnace slag was more cost-effective and showed better strength properties.
Artificial intelligence has been used to forecast the performance of geopolymer or concrete in the last years (Karahan et al. 2008; Nazari and Sanjayan 2015; Lahoti et al. 2017; Tanyildizi 2017, 2018; Soleimani et al. 2018; Akyuncu et al. 2019; Alkroosh and Sarker 2019; Rifaai et al. 2019; Lau et al. 2019; Maleki and Emami 2019; Dao et al. 2019; Ling et al. 2019; Nguyen et al. 2020; Nagajothi and Elavenil 2020; Zhang et al. 2020; Shahmansouri et al. 2021; Kina et al. 2023). Because it is time-consuming and costly to determine the fc of eco-friendly geopolymer concrete using an experimental program, the use of artificial intelligence models might speed up the procedure. Kina et al. (2023) prepared the machine learning approaches to guess the fc of geopolymer composite. They found that the least-squares boosting model predicted the fc of the geopolymer concrete with high accuracy. Eftekhar Afzali et al. (2024) used machine learning algorithms to examine the features of geopolymer concrete. They indicated that machine learning algorithms will help to advance the development of sustainable building materials by facilitating experimental activities, reducing labor and material requirements, and enhancing time efficiency. Latif (2021a) proposed the support vector machine and boosted decision tree regression models to forecast the fc of eco-friendly concrete. He found that the support vector machine model had better performance than the boosted decision tree regression model. Tran et al. (2024) tried the fc of geopolymer composite by machine learning. They found that the proposed model guessed the fc with high accuracy. Lahoti et al. (2017) did a study to forecast the fc of metakaolin-based geopolymer concrete. They selected the Naïve Bayes, random forests, and k-nn classifier methods for estimation. They expressed that the k-nn classifier method estimated the fc with 83% accuracy. Nazari and Sanjayan (2015) selected the support vector regression (SVR) approach to forecasting the fc of geopolymers. They emphasized that the proposed model can forecast the fc with 86.91% accuracy. Deep learning modeling has become very popular in recent years (Deng et al. 2018; Jang et al. 2019; Narloch et al. 2019; Abuodeh et al. 2020; Latif 2021b; Tanyildizi 2021, 2024; Chen et al. 2022; Yin et al. 2023). Narloch et al. (2019) tried estimating the fc of cement-stabilized rammed Earth with the microstructure images by deep learning. The 4284 images were used in the proposed algorithm. They stated that the deep learning model guessed fc with 84% accuracy. Latif (2021b) tried to predict the fc of concrete by deep long short-term memory (LSTM) and SVR models. He found that the deep LSTM algorithm predicted the fc with higher accuracy than the SVR algorithm. Yin et al. (2023) proposed deep learning models forecasting the fc of concrete with waste-rock backfill. They stated that the combined use of the genetic algorithm and deep LSTM forecasted the fc of concrete with higher accuracy than the deep LSTM model. Tanyildizi (2024) proposed machine and deep learning hybrid models for guessing the fc of engineering cementitious composites. He found that the hybrid deep learning algorithms were better than the machine learning models. Kumar et al. (2024) carried out the comparisons of machine learning and deep learning models in forecasting the fc of geopolymer composite. They stated that the performance of the deep learning model was superior to machine learning models. Yao et al. (2024) guessed the carbon emission using deep learning and machine learning algorithms. They stated that the deep learning algorithm made forecasts with higher accuracy.
There is no study estimating the fc of eco-friendly geopolymer concrete using the deep LSTM model. So, this present study was made. This study aims to forecast the fc of eco-friendly geopolymer concrete using the deep LSTM model. Also, the estimation results of the deep LSTM algorithm were compared to the estimation results of the LSBoost, SVR, and multiple linear regression (MLR) models.
Data and prediction methodology
Data
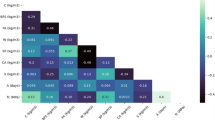
In this study, the fc results of eco-friendly geopolymer concrete were taken from the literature (Ling et al. 2019). The database is tabulated in Table 1. It can be seen from Table 1 that the database consisted of the results of 273 specimens for fc of eco-friendly geopolymer concrete. The inputs of the models used in forecasting the fc of eco-friendly geopolymer concrete were used as the liquid-to-fly ash mass ratio, the mole ratio, the curing temperature, the alkaline solution concentration, and the curing days. The fc of the geopolymer concrete is obtained as the output variable. In the literature, descriptive statistical values were given for input and output values (Ibrahim et al. 2023; Golafshani et al. 2024). They are standard deviation, minimum, average, maximum, coefficient of variation, skewness, and kurtosis. The descriptive statistics of inputs and outputs are given in Table 2. Also, Fig. 1. displays a correlation matrix graph of data.

Correlation matrix graph of data
The methodology of long short-term memory network
The deep LSTM was recommended by Hochreiter and Schmidhuber (Hochreiter and Schmidhuber 1997). The LSTM that occurs input (a sequence input layer feeds data into the neural network in the form of a sequence or time series), forget (the forget determines which information is important and which may be disregarded), and output (the value of the next hidden state is calculated by the output; this state includes data from earlier inputs) is a Recurrent Neural Networks. The illustration of LSTM structure is illustrated in Fig. 2.

The illustration of the LSTM structure
Figure 2 displays the data flow at time step t. Also, this graphic displays how the gates forget, update, and output cell and hidden states. The LSTM occurred in three steps. Firstly, it is calculated which information to delete by x(t) and h(t-1). This is determined by Eq. 1.
- t:
-
timestep
- ft:
-
forget get at t
- W:
-
the weights
- x(t):
-
input at time t
- h(t-1):
-
the output of the previous state
- bf:
-
the biases
Secondly, the input layer for the new information is activated. The information is restructured using the sigmoid function in Eq. 2. Following, the candidate information, which occurs with the new information, is obtained by the tanh function in Eq. 3.
Then, the new information is formed using Eq. 4.
Lastly, the output is determined by Eqs. 5 and 6.
where
- Ct:
-
value produced by tanh,
- it:
-
input gate at t,
- b:
-
bias vector,
- Wc:
-
weight matrix of tanh operator between cell state information and network output,
- Wo:
-
weight matrix of output gate,
- O(t):
-
output gate at t, and
- h(t):
-
LSTM output.
Then, bias parameters (b) and weight parameters (W) are learned by the model in a way that minimizes the difference between the actual training values and the LSTM output values (Hochreiter and Schmidhuber 1997; Gers et al. 2003; Liu et al. 2019).
The methodology of support vector regression
The SVR was recommended by Vapnik (2000). The non-linear SVR tries to find a regression function in hyperspace stated by f (x) = w Tϕ (x) + b. The eq. is calculated by the “ϵ-insensitive” loss function. The below equations are expressed non-linear SVR.
where
- C:
-
a predetermined parameter. Also, it is an adjustment factor that offers the balance between the adaptation of errors and the flatness of the regression function,
- E:
-
the unit vector,
- ξ and ξ*:
-
slack variables that specify whether specimens entered the ϵ-tube or not.
When using the Lagrange multipliers α and α*, the below Eqs. 10–12 are used.
lastly
where
α and α* = Lagrange multipliers,
A = the input of the training,
Y = the output of the training,
b = bias parameters,
K(xi, x) = Kernel function, and
f(x) = the SVR equation (Burges 1998; İNCE et al. 2016).
Multiple linear regression
The method of expressing the linear relationship between a dependent variable (y) and an independent single variable x by a mathematical formula is known as simple linear regression. MLR is a method used to express the relationship between more than one independent variable (xn) and the dependent variable (y) (Cohen 2013). The mathematical model showing the relationship in multivariate regression analysis was expressed with the following equation for m independent variables.
where
- Y:
-
The dependent variable,
- X:
-
The independent variable,
- h0:
-
The y-axis intercept of the regression curve,
- m:
-
The number of input parameters,
- hmxm:
-
The regression coefficient of the independent variable, and
- t:
-
The error term.
Least squares boosting ensemble
The gradient-boosting ensemble method includes a restricted collection of frail learners and a meta-learner that gives weights to each learner and then aggregates their estimator findings by voting techniques to obtain a higher forecast result. Least-squares boosting (LSBoost) is a method that uses least squares as its loss criterion (Alajmi and Almeshal 2021). The LSBoost method was first used by Friedman (2001). Friedman suggested using the following equations for the LSBoost method. Friedman (2001) stated that explainable variables (xi and yi) and the number of iterations (H) should be defined. Then, the training set, a loss function, and a regression function are defined using the following equations, respectively.
Initialize \({F}_{0}\left(x\right)=\overline{y }\); lastly, it is estimated using the following equations.
where
xi and yi = explainable variables,
H = the number of iterations,
\({\left\{({x}_{i}\left.,{y}_{i}\right\}\right.}_{i=1}^{n}\)= the training set,
L(y, F) = a loss function,
Fm(x) = the regression function,
h = activation function,
α = a sequence of pseudo-random U ([0; 1]) numbers, and
ρ = learning rate (0< \(\rho\) <1).
Sensitivity analysis
Sensitivity analysis is a good method to find the effect of experimental variables on the experimental result (Yang and Zhang 1997). The cosine amplitude method in the sensitivity analysis of this study was used. Ross (2010) stated that the cosine amplitude method is a good method to define the effect of experimental parameters on the result. It has a collection of data specimens using n data specimens.
Each of the elements, xi, in the data array X is itself a vector of length m.
xj and xi are the dependent and the independent variables in the data. Thus, the following equation is used to determine the similarity of each element (Khandelwal and Singh 2007)
Assessments of forecast models
Performance metrics are used to establish the performance of machine learning and deep learning models in the literature (Botchkarev 2018; Solhmirzaei et al. 2020; Steurer et al. 2021; Imik Tanyildizi and Tanyildizi 2022; Plevris et al. 2022; Kina et al. 2022; Naser and Alavi 2023; Turk et al. 2023). In this study, performance metrics were utilized to assess the prediction abilities of deep learning and machine learning models. These metrics are mean square error (MSE), root-mean-square-error (RMSE), the peak signal-to-noise ratio (PSNR), mean absolute percentage error (MAPE), and normalized root-mean-square error (NRMSE). The mathematical expressions of these metrics are given in Eqs. 23–28.
In Eqs. 23–28, \(n\) is the whole number of datasets. Also, \({y}_{f}\) and \({y}_{r}\) are the forecasted and actual results, respectively.
Results
The results of the deep LSTM model
In this present section, the deep LSTM model was developed to forecast the fc of eco-friendly geopolymer concrete. In this study, one output and five inputs for fc were selected in the deep LSTM model. Ninety percent of all data was used for training in the model. Ten percent of all data was selected for testing. The fully connected layer, the output size of the bidirectional LSTM layer, the gradient threshold, and the mini-batch size were 1, 200, 1.2, and 30, respectively. The training technique used the “adam.” The learning rate and the initial learning rate were selected with a dropped factor of 0.000001 during the training with 100 epoch periods and 0.1. The selected parameters of the proposed algorithm were obtained by an empirical approach. The deep LSTM forecast results and the training progress for the fc of geopolymer concrete are given in Figs. 3 and 4.

The training and testing results of the deep LSTM model. a Training. b Testing

The training process of the deep LSTM model
It was shown in Fig. 3 that the deep LSTM algorithm guessed the fc of eco-friendly geopolymer with 99.84% and 99.23% accuracy for training and testing. Ling et al. (2019) designed an artificial neural network (ANN) algorithm estimating the same data. They found that the proposed ANN algorithm guessed the fc of eco-friendly geopolymer concrete with 96.1% accuracy. Moreover, MSE, RMSE, PSNR, MAPE, and NRMSE were selected to identify the performance of the deep LSTM model. MSE and RMSE are also the most commonly used statistical tools to find the difference between the real and forecasted values. The lower these values are, the performance of the model is considered better than other models. NRMSE analyzes the difference between the forecasted values by a mode and the real values. The lower this value, the performance of the model is considered better than other models. MAPE is the relative average vertical distance between target and output values in percentage. The lower this distance, the performance of the model the better than other models. PSNR is the ratio between the maximum possible power of a signal and the power of noise that influences the quality. The larger this ratio, the better the performance of the model than the other models. R squared (R2) symbolizes the proportion of the variance for the dependent variable y that is explained by the independent variables. If the R2 of a model is 1, then 100% of the observed variation can be explained by the model’s specifications. Therefore, it is desired to be close to 1. It must be the higher PSNR, lower MSE, NRMSE, lower RMSE, and lower MAPE that the model has good performance. The MSE, the PSNR, the RMSE, the NRMSE, and MAPE values for the training of fc of eco-friendly geopolymer concrete were obtained 0.7042, 46.65, 0.8392, 0.0112, and 5.2378, respectively.
The PSNR, MSE, NRMSE, RMSE, and MAPE values for the testing phase were 44.5864, 2.2617, 0.0283, 1.5039, and 224874, respectively. There are very few articles predicting the fc of concrete by deep learning methods. Jang et al. (2019) developed a deep learning algorithm forecasting the fc of concrete. They used microscope images of concrete in the estimation model. They mentioned that these images could be used to predict fc. Abuodeh et al. (2020) chose the deep learning technique to guess the fc of concrete with high strength. They used the results of 110 samples in the model. They found that the fc can be guessed with 80.1% accuracy. Chen et al. (2022) used the deep LSTM and SVR models to guess the mechanical features of concrete. They emphasized that the deep LSTM algorithm forecasted the strength features of concrete with higher accuracy (99.7%) than the SVR algorithm. In this study, the deep LSTM algorithm was proposed to forecast the fc of eco-friendly geopolymer concrete with high accuracy.
The results of the support vector regression model
In this study, the fc of eco-friendly geopolymer concrete was predicted by the SVR algorithm. Similar to the deep LSTM algorithm, the same inputs and outputs were selected in the SVR algorithm. The 10% and 90% of all data were used for testing and training in the model. This study used hyperparameter optimization in the SVR model. As a result of hyperparameter optimization used in SVR, the box constraint, kernel scale, and epsilon values were found to be 0.0042986, 0.0025956, and 2.1922. The Box constraint optimizable hyperparameter combines the preset SVM models’ Box constraint mode and Manual box constraint advanced options. The Kernel scale optimizable hyperparameter includes the preset SVM models’ Kernel scale mode and Manual kernel scale advanced options (MATLAB 2019). The SVR results and the minimum objective number of function evaluations for the fc of eco-friendly geopolymer concrete are given in Figs. 5 and 6.

The training and testing results of the SVR model. a Training. b Testing

The minimum objective number of function evaluations of the SVR model
As can be shown in Fig. 5, the SVR model forecasted the fc of eco-friendly geopolymer concrete with 78.22% and 78.57% accuracy for training and testing, respectively. Similar to the deep LSTM, the MSE, MAPE, NRMSE, RMSE, and PSNR were used to evaluate the SVR model. The MAPE, RMSE, PSNR, NRMSE, and MSE values for the training of fc of eco-friendly geopolymer concrete were obtained as 76.6235, 7.9593, 30.1133, 0.1064, and 63.3505, respectively. The MAPE, RMSE, PSNR, NRMSE, and MSE values for the testing phase were 99.6202, 7.6908, 30.4114, 0.1446, and 59.1481, respectively. When these results of the SVR algorithm are compared to the deep LSTM algorithm, the deep LSTM can be found to be superior. Ling et al. (2019) forecasted the same fc of eco-friendly geopolymer concrete with 96.1% accuracy. The proposed SVR model guessed the fc with lower accuracy than the ANN model. Rahmati and Toufigh (2022) used the SVR and ANN models to guess the fc of geopolymer concrete subjected to high temperatures. They stated that the SVR model predicted better the experimental results than the ANN model. Maleki and Emami (2019) developed an SVR model estimating the fc of fly ash-based geopolymer concrete. They stated that the model forecasted the fc with 84% accuracy. Wu et al. (2023) evaluated the performance of the SVR algorithm and experimental results of geopolymer mortar exposed to seawater. They mentioned that SVR had a higher performance than ANN in predicting experimental results of geopolymer mortar exposed to seawater.
The results of the multiple linear regression model
In the present section, multiple linear regression (MLR) was used to estimate the fc of eco-friendly geopolymer concrete. The equations obtained from the MLR were given below.
where
- fc:
-
The compressive strength,
- M:
-
The mole ratio,
- T:
-
The curing temperature,
- L:
-
The liquid-to-fly ash mass ratio,
- A:
-
The alkaline solution concentration, and
- C:
-
The curing days.
The MLR model results are given in Fig. 7. Figure 7 shows that the MLR model forecasted the fc of eco-friendly geopolymer concrete with 88.03% accuracy. The MLR model forecasted the results with less accuracy than the SVR and deep LSTM models. Amin and Nasier (2018) statistically examined the properties of fly ash-based geopolymer concrete. They devised the stepwise multiple linear regression model for fc. They said that the water-to-powder ratio affected the fc by 90%. Kazemian et al. (2015) used an MLR model to forecast the fc of geopolymer mortar. They stated that the model guessed the fc with 82.36% accuracy. Demir and Derun (2019) investigated the properties of gold mine waste-based geopolymer. Furthermore, they devised an MLR model for the reaction degree. They mentioned that the accuracy of their model was 80.94%. Lee et al. (Lee and Lee 2020) suggested a model predicting the setting time and fc of concrete using ultrasonic pulse velocity. They said that the proposed MLR model could be found in the experimental results with a 10% error. In the literature, the accuracy of MLR models has been found to be between 90 and 80%. In this study, it was found to be 88.03%, similar to the results in the literature.

The results of the MLR model
The results of the LSBoost model
In this current study, the LSBoost model predicted the fc of eco-friendly geopolymer concrete. The automatic hyperparameter optimization in the LSBoost model was used. The number of ensemble learning cycles, learning rate, and the maximum number of splits resulting from hyperparameter optimization were obtained as 498, 0.10478, and 24, respectively. The guess results of the LSBoost algorithm, the minimum objective number of function evaluations, and the tree view for the fc are shown in Figs. 8, 9, and 10.

The training and testing results of the LSBoost model. a Training. b Testing

The minimum objective number of function evaluations of the LSBoost model

Tree view of LSBoost model
As can be seen in Fig. 8, the LSBoost model in the training and testing phase estimated the fc with 99.94% and 98.08%, respectively. As in other algorithms, the NRMSE, MSE, PSNR, MAPE, and RMSE were used in assessing the LSBoost model. The MSE, PSNR, RMSE, NRMSE, and MAPE values in the training phase were obtained as 0.1594, 56.1057, 0.3993, 0.0053, and 2.3980, respectively. The MSE, PSNR, RMSE, NRMSE, and MAPE values for the testing phase were computed 5.5103, 40.7190, 2.3474, 0.0441, and 19.5143, respectively. The minimum objective number of function evaluations of the LSBoost model is displayed in Fig. 9. It can be seen from Fig. 9 that the min. observed objective was closer to the estimated min. objective. Also, the tree view of the LSBoost model is shown in Fig. 10. Although the LSBoost model guessed the fc with higher accuracy than the SVR and MLR algorithms, it estimated the fc with lower accuracy than the deep learning model. Zhang and Xu (2022) carried out a study to forecast the elastic modulus of concrete using the LSBoost model. They used the results of normal and high-strength concrete. They found that the recommended model forecasted the normal and high-strength concrete with 97.59% and 97.395 accuracy, respectively. Adamu et al. (2022) used the SVR, Gaussian Process Regression, MLR, and LSboost models to guess the flexural strength of concrete incorporating the calcium carbide and nano-silica. They expressed that the GPR model was superior to other models in the prediction of flexural strength. The comparison of all models is given in Fig. 11.

The comparison of all models for training and testing. a Training. b Testing
It can be seen from Fig. 11 that the LSTM approach was closer to the real fc values than other algorithms in both the testing and training stages. Thus, it can be said that the LSTM approach had a better predictive ability. The radar chart comparisons of prediction metrics of all models are given in Fig. 12. Figure 12a shows that the LSBoost model carried out a better performance than the LSTM and SVR algorithms because the lower MAPE, the higher R-value, the lower MSE, the lower RMSE values, the lower NRMSE, and the higher PSNR were obtained from the LSBoost model. Also, the metrics of the LSTM and LSBoost models are very close to each other. Figure 12b shows that the higher PSNR, the higher R-value, the lower MAPE, the lower NRMSE, the lower RMSE, and the lower MSE values were obtained from the LSTM model in the testing phase. So, the LSTM model showed better performance than the LSBoost and SVR models. Figure 13 illustrates the Taylor diagram for the training and testing phase. When the Taylor diagram is examined, the best predictor model in the testing phase was the LSTM model. Also, the best predictive model in the training stage was the LSboost model, but the LSboost model and LSTM model made very close estimations during the training phase.

The radar chart comparisons of all metrics of the models. a Training. b Testing

Taylor diagrams of the models. a Training. b Testing
The results of sensitivity analysis
This study applied a sensitivity analysis to calculate the influence of the input variables. The sensitivity analysis (rij) results for the fc of eco-friendly geopolymer concrete are given in Fig. 13.
It is shown in Fig. 14 that the curing temperature (0.82) was the most important variable on the fc of eco-friendly geopolymer concrete. Tanyildizi and Yonar (2016) examined the effect of the curing temperature on the properties of fly ash-based geopolymer concrete with PVA fiber after being subjected to high temperatures. They kept the samples at 60, 80, and 100 °C. They said that the curing temperature was effective on compressive strength, and 60 °C was the best temperature. Abdullah et al. (2011) studied the differences in the alkaline solution concentration, the curing temperature, the liquid-to-fly ash mass ratio, and the mole ratio on the mechanical features of fly ash-based geopolymer concrete. They stated that the curing temperature had a major effect on the fc. Bai et al. (2023) studied the effect of curing temperature on eco-friendly geopolymer concrete. They stated that changing the curing temperature affects the fc of the composite. They also stated that the fc increased as it prevented crack formation in the geopolymer composite due to maintaining a certain moisture level during curing. Saludung et al. (2023) studied the effect of curing conditions on geopolymer composites. They showed that the curing condition has a substantial effect on the characteristics of the unexposed geopolymer composite. Gopalakrishna and Dinakar (2023) examined the fc of geopolymer composites under different curing temperatures. They reported that as thermal curing conditions increase, the polymerization of the geopolymer composite accelerates, and thus the fc increases. In this current study, results similar to the results in the literature were obtained.

The sensitivity analysis results
Conclusions
This study estimated the fc of eco-friendly geopolymer concrete using the SVR, deep LSTM, LSBoost, and MLR models. Furthermore, the effect of the input variables in the algorithms was identified by the sensitivity analysis. The results of the fc of eco-friendly geopolymer concrete were obtained from the literature. The results of 273 samples for fc were used in the algorithms. The results obtained from this current study are given as follows:
-
The deep LSTM model forecasted the fc of eco-friendly geopolymer concrete with 99.23% accuracy, while the fc of eco-friendly geopolymer concrete was forecasted using the SVR, LSBoost, and MLR models with 78.22%, 98.08%, and 88.03% accuracy, respectively. Furthermore, an ANN model in the literature estimated the same data with 96.1% accuracy, respectively. According to these results, the deep LSTM model forecasted the fc of eco-friendly geopolymer concrete with higher accuracy than the LSBoost, SVR, MLR, and ANN models.
-
The sensitivity analysis found that the most important input variable for the fc of eco-friendly geopolymer concrete was the curing temperature.
-
As a result of the results obtained in this research, guessing the compressive strength of geopolymer concrete with high accuracy using the deep LSTM model better serves the practical construction needs regarding the strength design of concrete. Also, it is thought that the application of deep learning-based approaches as a user-friendly interface to directly predict the mixture ratios required to obtain the desired compressive strength in structures will be useful for the construction industry. Thus, it will help develop sustainable and eco-friendly structures without time-consuming and costly experiments. Because of this superiority of the deep LSTM model, it can be recommended to be used in forecasting the properties of eco-friendly concrete or mortar.
Data availability
There are no repository data, and all data are present in the paper.
References
Abdullah MMA, Kamarudin H, Mohammed H, et al (2011) The relationship of NaOH molarity, Na2SiO3/NaOH ratio, fly ash/alkaline activator ratio, and curing temperature to the strength of fly ash-based geopolymer. Adv Mater Res 328–330:1475–1482. https://doi.org/10.4028/www.scientific.net/amr.328-330.1475
Abuodeh OR, Abdalla JA, Hawileh RA (2020) Assessment of compressive strength of ultra-high performance concrete using deep machine learning techniques. Appl Soft Comput J 95:106552. https://doi.org/10.1016/j.asoc.2020.106552
Adamu M, Umar IK, Haruna SI et al (2022) A soft computing technique for predicting flexural strength of concrete containing nano-silica and calcium carbide residue. Case Stud Constr Mater 17:e01288. https://doi.org/10.1016/J.CSCM.2022.E01288
Akyuncu V, Uysal M, Tanyildizi H, Sumer M (2019) Modeling the weight and length changes of the concrete exposed to sulfate using artificial neural network. Rev La Constr 17:337–353. https://doi.org/10.7764/RDLC.17.3.337
Alajmi MS, Almeshal AM (2021) Least squares boosting ensemble and quantum-behaved particle swarm optimization for predicting the surface roughness in face milling process of aluminum material. Appl Sci 11:2126. https://doi.org/10.3390/app11052126
Ali MB, Saidur R, Hossain MS (2011) A review on emission analysis in cement industries. Renew Sustain Energy Rev 15:2252–2261
Alkroosh IS, Sarker PK (2019) Prediction of the compressive strength of fly ash geopolymer concrete using gene expression programming. Comput Concr 24:295–302. https://doi.org/10.12989/cac.2019.24.4.295
Amin M, Nasier S (2018) Experimental evaluation of eco-friendly no-fines geo-polymer concrete for sustainable pavement applications. Indian J Sci Technol 11. https://doi.org/10.17485/ijst/2018/v11i26/130573
Bai B, Bai F, Nie Q, Jia X (2023) A high-strength red mud–fly ash geopolymer and the implications of curing temperature. Powder Technol 416:118242. https://doi.org/10.1016/j.powtec.2023.118242
Botchkarev A (2018) Performance metrics (error measures) in machine learning regression, forecasting and prognostics: properties and typology. arXiv arXiv:1809.03006. https://doi.org/10.48550/ARXIV.1809.03006
Burges CJC (1998) A tutorial on support vector machines for pattern recognition. Data Min Knowl Discov 2:121–167. https://doi.org/10.1023/A:1009715923555
Chen H, Li X, Wu Y et al (2022) Compressive strength prediction of high-strength concrete using long short-term memory and machine learning algorithms. Buildings 12:302. https://doi.org/10.3390/BUILDINGS12030302
Cohen (2013) Applied multiple regression/correlation analysis for the behavioral sciences. Routledge
Dao D, Ly H-B, Trinh S et al (2019) Artificial intelligence approaches for prediction of compressive strength of geopolymer concrete. Materials (basel) 12:983. https://doi.org/10.3390/ma12060983
Davidovits J (1991) Geopolymers - inorganic polymeric new materials. J Therm Anal 37:1633–1656. https://doi.org/10.1007/BF01912193
Davidovits J (1979) Synthesis of new high-temperature geo-polymers for reinforced plastics/composites. pp 151–154
Davidovits J (1988a) Geopolymer chemistry and properties
Davidovits J (1988b) Soft mineralurgy and geopolymers. France, pp 19–23
Demir F, Derun EM (2019) Modelling and optimization of gold mine tailings based geopolymer by using response surface method and its application in Pb2+ removal. J Clean Prod 237:117766. https://doi.org/10.1016/j.jclepro.2019.117766
Deng F, He Y, Zhou S et al (2018) Compressive strength prediction of recycled concrete based on deep learning. Constr Build Mater 175:562–569. https://doi.org/10.1016/j.conbuildmat.2018.04.169
Duxson P, Provis JL, Lukey GC, van Deventer JSJ (2007) The role of inorganic polymer technology in the development of “green concrete.” Cem Concr Res 37:1590–1597. https://doi.org/10.1016/j.cemconres.2007.08.018
Eftekhar Afzali SA, Shayanfar MA, Ghanooni-Bagha M et al (2024) The use of machine learning techniques to investigate the properties of metakaolin-based geopolymer concrete. J Clean Prod 446:141305. https://doi.org/10.1016/j.jclepro.2024.141305
El-Mir A, Hwalla J, El-Hassan H et al (2023) Valorization of waste perlite powder in geopolymer composites. Constr Build Mater 368:130491. https://doi.org/10.1016/j.conbuildmat.2023.130491
Ersoy H, Çavuş M (2023) Thermomechanical properties of environmentally friendly slag-based geopolymer foam composites in different curing conditions. Environ Sci Pollut Res 30:58813–58826. https://doi.org/10.1007/s11356-023-26663-5
Friedman JH (2001) Greedy function approximation: a gradient boosting machine. Ann Stat 29:1189–1232. https://doi.org/10.1214/aos/1013203451
García-Lodeiro I, Palomo A, Fernández-Jiménez A (2007) Alkali-aggregate reaction in activated fly ash systems. Cem Concr Res 37:175–183. https://doi.org/10.1016/j.cemconres.2006.11.002
Gers FA, Schraudolph NN, Schmidhuber J (2003) Learning precise timing with LSTM recurrent networks. J Mach Learn Res 3:115–143. https://doi.org/10.1162/153244303768966139
Golafshani E, Khodadadi N, Ngo T et al (2024) Modelling the compressive strength of geopolymer recycled aggregate concrete using ensemble machine learning. Adv Eng Softw 191:103611. https://doi.org/10.1016/j.advengsoft.2024.103611
Gopalakrishna B, Dinakar P (2023) The study on various temperature condition of fly ash based geopolymer mortar. Mater Today Proc 93:234–238. https://doi.org/10.1016/j.matpr.2023.07.176
Gunasekara C, Law DW, Setunge S (2016) Long term permeation properties of different fly ash geopolymer concretes. Constr Build Mater 124:352–362. https://doi.org/10.1016/j.conbuildmat.2016.07.121
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9:1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
Huntzinger DN, Eatmon TD (2009) A life-cycle assessment of Portland cement manufacturing: comparing the traditional process with alternative technologies. J Clean Prod 17:668–675. https://doi.org/10.1016/j.jclepro.2008.04.007
Ibrahim SM, Ansari SS, Hasan SD (2023) Towards white box modeling of compressive strength of sustainable ternary cement concrete using explainable artificial intelligence (XAI). Appl Soft Comput 149:110997. https://doi.org/10.1016/j.asoc.2023.110997
Imik Tanyildizi N, Tanyildizi H (2022) Estimation of voting behavior in election using support vector machine, extreme learning machine and deep learning. Neural Comput Appl 34:17329–17342. https://doi.org/10.1007/s00521-022-07395-y
İnce H, İnce H, İmamoğlu SZ (2016) Supplier selection with support vector regression and twin support vector regression. Doğuş Univ J 17:241–253
Jang Y, Ahn Y, Kim HY (2019) Estimating compressive strength of concrete using deep convolutional neural networks with digital microscope images. J Comput Civ Eng 33:4019018. https://doi.org/10.1061/(asce)cp.1943-5487.0000837
Karahan O, Tanyildizi H, Atis CD (2008) An artificial neural network approach for prediction of long-term strength properties of steel fiber reinforced concrete containing fly ash. J Zhejiang Univ Sci A 9:1514–1523. https://doi.org/10.1631/jzus.A0720136
Kazemian A, Vayghan AG, Rajabipour F (2015) Quantitative assessment of parameters that affect strength development in alkali activated fly ash binders. Constr Build Mater 93:869–876. https://doi.org/10.1016/j.conbuildmat.2015.05.078
Khandelwal M, Singh TN (2007) Evaluation of blast-induced ground vibration predictors. Soil Dyn Earthq Eng 27:116–125. https://doi.org/10.1016/j.soildyn.2006.06.004
Kina C, Turk K, Tanyildizi H (2022) Deep learning and machine learning-based prediction of capillary water absorption of hybrid fiber reinforced self-compacting concrete. Struct Concr 23:3331–3358. https://doi.org/10.1002/suco.202100756
Kina C, Tanyildizi H, Turk K (2023) Forecasting the compressive strength of GGBFS-based geopolymer concrete via ensemble predictive models. Constr Build Mater 405:133299. https://doi.org/10.1016/j.conbuildmat.2023.133299
Kumar P, Pratap B, Sharma S, Kumar I (2024) Compressive strength prediction of fly ash and blast furnace slag-based geopolymer concrete using convolutional neural network. Asian J Civ Eng 25:1561–1569. https://doi.org/10.1007/s42107-023-00861-5
Lahoti M, Narang P, Tan KH, Yang E-H (2017) Mix design factors and strength prediction of metakaolin-based geopolymer A R T I C L E I N F O.https://doi.org/10.1016/j.ceramint.2017.06.006
Latif SD (2021a) Developing a boosted decision tree regression prediction model as a sustainable tool for compressive strength of environmentally friendly concrete. Environ Sci Pollut Res 28:65935–65944. https://doi.org/10.1007/s11356-021-15662-z
Latif SD (2021b) Concrete compressive strength prediction modeling utilizing deep learning long short-term memory algorithm for a sustainable environment. Environ Sci Pollut Res 1–9. https://doi.org/10.1007/s11356-021-12877-y
Lau CK, Lee H, Vimonsatit V et al (2019) Abrasion resistance behaviour of fly ash based geopolymer using nanoindentation and artificial neural network. Constr Build Mater 212:635–644. https://doi.org/10.1016/j.conbuildmat.2019.04.021
Lee T, Lee J (2020) Setting time and compressive strength prediction model of concrete by nondestructive ultrasonic pulse velocity testing at early age. Constr Build Mater 252:119027. https://doi.org/10.1016/j.conbuildmat.2020.119027
Li C, Gong X, Cui S et al (2011) CO2 emissions due to cement manufacture. In: Materials Science Forum. Trans Tech Publications Ltd, pp 181–187
Ling Y, Wang K, Wang X, Li W (2019) Prediction of engineering properties of fly ash-based geopolymer using artificial neural networks. Neural Comput Appl 1–21. https://doi.org/10.1007/s00521-019-04662-3
Liu Y, Qin Y, Guo J et al (2019) Short-term forecasting of rail transit passenger flow based on long short-term memory neural network. In: 2018 International Conference on Intelligent Rail Transportation, ICIRT 2018. Institute of Electrical and Electronics Engineers Inc.
Mahasenan N, Smith S, Humphreys K (2003) The Cement Industry and Global Climate ChangeCurrent and Potential Future Cement Industry CO2 Emissions. Greenh Gas Control Technol - 6th Int Conf 995–1000
Maleki MA, Emami M (2019) Application of SVM for investigation of factors affecting compressive strength and consistency of geopolymer concretes. J Civ Eng MaterApp 3:101–107. https://doi.org/10.22034/jcema.2019.92507
MATLAB (2019) Hyperparameter Optimization in Regression Learner App - MATLAB & Simulink - MathWorks United Kingdom. https://www.mathworks.com/help/stats/hyperparameter-optimization-in-regression-learner-app.html. Accessed 5 Oct 2023
Meesala CR, Verma NK, Kumar S (2020) Critical review on fly-ash based geopolymer concrete. Struct Concr 21:1013–1028. https://doi.org/10.1002/suco.201900326
Nagajothi S, Elavenil S (2020) Influence of aluminosilicate for the prediction of mechanical properties of geopolymer concrete – artificial neural network. SILICON 12:1011–1021. https://doi.org/10.1007/s12633-019-00203-8
Narloch P, Hassanat A, Tarawneh AS et al (2019) Predicting compressive strength of cement-stabilized rammed earth based on SEM images using computer vision and deep learning. Appl Sci 9:5131. https://doi.org/10.3390/app9235131
Naser MZ, Alavi AH (2023) Error metrics and performance fitness indicators for artificial intelligence and machine learning in engineering and sciences. Archit Struct Constr 3:499–517. https://doi.org/10.1007/s44150-021-00015-8
Nazari A, Sanjayan JG (2015) Modelling of compressive strength of geopolymer paste, mortar and concrete by optimized support vector machine. Ceram Int 41:12164–12177. https://doi.org/10.1016/j.ceramint.2015.06.037
Nguyen KT, Nguyen QD, Le TA et al (2020) Analyzing the compressive strength of green fly ash based geopolymer concrete using experiment and machine learning approaches. Constr Build Mater 247:118581. https://doi.org/10.1016/j.conbuildmat.2020.118581
Peng J, Huang L, Zhao Y et al (2013) Modeling of carbon dioxide measurement on cement plants. In: Advanced Materials Research. Trans Tech Publications Ltd, pp 2120–2128
Plevris V, Solorzano G, Bakas N, Ben Seghier M (2022) Investigation of performance metrics in regression analysis and machine learning-based prediction models. In: 8th European Congress on Computational Methods in Applied Sciences and Engineering. CIMNE
Rahmati M, Toufigh V (2022) Evaluation of geopolymer concrete at high temperatures: an experimental study using machine learning. J Clean Prod 372:133608. https://doi.org/10.1016/j.jclepro.2022.133608
Raza MH, Khan M, Zhong RY (2024) Strength, porosity and life cycle analysis of geopolymer and hybrid cement mortars for sustainable construction. Sci Total Environ 907:167839. https://doi.org/10.1016/j.scitotenv.2023.167839
Rifaai Y, Yahia A, Mostafa A et al (2019) Rheology of fly ash-based geopolymer: effect of NaOH concentration. Constr Build Mater 223:583–594. https://doi.org/10.1016/j.conbuildmat.2019.07.028
Rohit P, Gunneswara Rao TD, Chandrasekhar M (2024) Effect of construction demolition waste as fine aggregate and NaOH molarity on strength and fracture parameters of slag based geopolymer mortars. J Eng Appl Sci 71:37. https://doi.org/10.1186/s44147-024-00373-2
Ross TJ (2010) Fuzzy logic with engineering applications. Wiley
Ryu GS, Lee YB, Koh KT, Chung YS (2013) The mechanical properties of fly ash-based geopolymer concrete with alkaline activators. Constr Build Mater 47:409–418. https://doi.org/10.1016/j.conbuildmat.2013.05.069
Saludung A, Azeyanagi T, Ogawa Y, Kawai K (2023) Mechanical and microstructural evolutions of fly ash/slag-based geopolymer at high temperatures: effect of curing conditions. Ceram Int 49:2091–2101. https://doi.org/10.1016/j.ceramint.2022.09.175
Shahmansouri AA, Yazdani M, Ghanbari S et al (2021) Artificial neural network model to predict the compressive strength of eco-friendly geopolymer concrete incorporating silica fume and natural zeolite. J Clean Prod 279:123697. https://doi.org/10.1016/j.jclepro.2020.123697
Soleimani S, Rajaei S, Jiao P et al (2018) New prediction models for unconfined compressive strength of geopolymer stabilized soil using multi-gen genetic programming. Meas J Int Meas Confed 113:99–107. https://doi.org/10.1016/j.measurement.2017.08.043
Solhmirzaei R, Salehi H, Kodur V, Naser MZ (2020) Machine learning framework for predicting failure mode and shear capacity of ultra high performance concrete beams. Eng Struct 224:111221. https://doi.org/10.1016/j.engstruct.2020.111221
Steurer M, Hill RJ, Pfeifer N (2021) Metrics for evaluating the performance of machine learning based automated valuation models. J Prop Res 38:99–129. https://doi.org/10.1080/09599916.2020.1858937
Tanyildizi H (2017) Prediction of compressive strength of lightweight mortar exposed to sulfate attack. Comput Concr 19:217–226. https://doi.org/10.12989/cac.2017.19.2.217
Tanyildizi H (2021) Predicting the geopolymerization process of fly ash-based geopolymer using deep long short-term memory and machine learning. Cem Concr Compos 123:104177. https://doi.org/10.1016/J.CEMCONCOMP.2021.104177
Tanyildizi H (2024) Prediction of compressive strength of nano-silica modified engineering cementitious composites exposed to high temperatures using hybrid deep learning models. Expert Syst Appl 241:122474. https://doi.org/10.1016/j.eswa.2023.122474
Tanyildizi H, Yonar Y (2016) Mechanical properties of geopolymer concrete containing polyvinyl alcohol fiber exposed to high temperature. Constr Build Mater 126:381–387. https://doi.org/10.1016/j.conbuildmat.2016.09.001
Tanyildizi H (2018) Prediction of the strength properties of carbon fiber-reinforced lightweight concrete exposed to the high temperature using artificial neural network and support vector machine. Adv Civ Eng 2018. https://doi.org/10.1155/2018/5140610
Thakur M, Bawa S (2023) Evaluation of strength and durability properties of fly ash-based geopolymer concrete containing GGBS and dolomite. Energy, Ecol Environ. https://doi.org/10.1007/s40974-023-00309-1
Tran NT, Nguyen DH, Tran QT et al (2024) Experimental and machine learning based study of compressive strength of geopolymer concrete. Mag Concr Res 1–15. https://doi.org/10.1680/jmacr.23.00144
Turk K, Kina C, Tanyildizi H (2023) Extreme learning machine for estimation of the engineering properties of self-compacting mortar with high-volume mineral admixtures. Iran J Sci Technol Trans Civ Eng. https://doi.org/10.1007/s40996-023-01153-3
Vapnik VN (2000) The Nature of Statistical Learning Theory. Springer New York, New York
Wang S, Chen K, Liu J et al (2024) Multi-performance optimization of low-carbon geopolymer considering mechanical, cost, and CO2 emission based on experiment and interpretable learning. Constr Build Mater 425:136013. https://doi.org/10.1016/j.conbuildmat.2024.136013
Wu Y, Du K, Wu C et al (2023) Time-varying pattern and prediction model for geopolymer mortar performance under seawater immersion. Materials (Basel) 16
Xu H, van Deventer JSJ (2000) The geopolymerisation of alumino-silicate minerals. Int J Miner Process 59:247–266. https://doi.org/10.1016/S0301-7516(99)00074-5
Yang Y, Zhang Q (1997) A hierarchical analysis for rock engineering using artificial neural networks. Rock Mech Rock Eng 30:207–222. https://doi.org/10.1007/BF01045717
Yao X, Zhang H, Wang X et al (2024) Which model is more efficient in carbon emission prediction research? A comparative study of deep learning models, machine learning models, and econometric models. Environ Sci Pollut Res 31:19500–19515. https://doi.org/10.1007/s11356-024-32083-w
Yin S, Yan Z, Chen X et al (2023) Mechanical properties of cemented tailings and waste-rock backfill (CTWB) materials: laboratory tests and deep learning modeling. Constr Build Mater 369:130610. https://doi.org/10.1016/J.CONBUILDMAT.2023.130610
Zailani WWA, Apandi NM, Adesina A et al (2024) Physico-mechanical properties of geopolymer mortars for repair applications: impact of binder to sand ratio. Constr Build Mater 412:134721. https://doi.org/10.1016/j.conbuildmat.2023.134721
Zhang Y, Xu X (2022) Modulus of elasticity predictions through LSBoost for concrete of normal and high strength. Mater Chem Phys 283:126007. https://doi.org/10.1016/J.MATCHEMPHYS.2022.126007
Zhang P, Wang K, Wang J et al (2020) Mechanical properties and prediction of fracture parameters of geopolymer/alkali-activated mortar modified with PVA fiber and nano-SiO2. Ceram Int 46:20027–20037. https://doi.org/10.1016/j.ceramint.2020.05.074
Zhao R, Yuan Y, Cheng Z et al (2019) Freeze-thaw resistance of Class F fly ash-based geopolymer concrete. Constr Build Mater 222:474–483. https://doi.org/10.1016/j.conbuildmat.2019.06.166
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK).
Author information
Authors and Affiliations
Contributions
The study was performed by Harun TANYILDIZI.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The author declares no competing interests.
Additional information
Responsible Editor: José Dinis Silvestre
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tanyildizi, H. Deep learning–based prediction of compressive strength of eco-friendly geopolymer concrete. Environ Sci Pollut Res 31, 41246–41266 (2024). https://doi.org/10.1007/s11356-024-33853-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11356-024-33853-2