
Abstract
In practice, it is common that a best fitting structural equation model (SEM) is selected from a set of candidate SEMs and inference is conducted conditional on the selected model. Such post-selection inference ignores the model selection uncertainty and yields too optimistic inference. Using the largest candidate model avoids model selection uncertainty but introduces a large variation. Jin and Ankargren (Psychometrika 84:84–104, 2019) proposed to use frequentist model averaging in SEM with continuous data as a compromise between model selection and the full model. They assumed that the true values of the parameters depend on \(n^{-1/2}\) with n being the sample size, which is known as a local asymptotic framework. This paper shows that their results are not directly applicable to SEM with ordinal data. To address this issue, we prove consistency and asymptotic normality of the polychoric correlation estimators under the local asymptotic framework. Then, we propose a new frequentist model averaging estimator and a valid confidence interval that are suitable for ordinal data. Goodness-of-fit test statistics for the model averaging estimator are also derived.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Structural equation models (SEMs) with ordinal data are widely used in social and behavioral sciences. As many other statistical models, a common practice is to choose an optimal model from a number of candidate models according to some criteria. A long-standing critique of model selection is that the post-selection inference is often conducted in such a way that model selection was never present. Because of the randomness in the data, the model selection step is also stochastic and ignoring such uncertainty yields too optimal inference. The reader is directed to Preacher and Merkle (2012) and Lubke et al. (2017) for discussions on the consequences of ignoring model selection uncertainty within SEM.
A well-known remedy to acknowledge the contribution of all candidate models is Bayesian model averaging. Instead of purely relying on the optimal model, Bayesian model averaging combines different candidate models together by a weighted average (Hoeting et al., 1999; Madigan & Raftery, 1994). In the past decades, the interest on frequentist model averaging (FMA) has grown exponentially in the statistics literature. The reader is directed to Fletcher (2018) for a long list of FMA related references.
The main purpose of the paper is to generalize the FMA principle to SEMs with ordinal data. Jin and Ankargren (2019) have applied the FMA technique to SEMs with continuous data, using the likelihood-based FMA machinery developed by Hjort and Claeskens (2003a). Similar to FMA in the other context, they showed that FMA tends to produce a mean squared error (MSE) that is lower than that of the full model if the population parameter value is small and is lower than that of model selection if the population value is moderate. Hence, the FMA estimator is a robust compromise between model selection and the full model in the SEM context. Since ordinal data are often encountered in practice, it is of interest to extend the FMA technique for SEM with continuous data to SEM with ordinal data. As we shall see in the later sections, some results in Jin and Ankargren (2019) need to be revised for ordinal data.
The rest of the paper is organized as follows. First, the results in Jin and Ankargren (2019) are briefly reviewed. Second, the necessary modifications for the FMA estimator in ordinal SEM are presented. Third, a simulation study is conducted to investigate the small sample properties of the FMA technique. Fourth, FMA is applied to an empirical example as an illustration. A discussion ends the paper.
1 Background
Consider the SEM
where \(\varvec{x}^{*}\) (\(p_x \times 1\)) and \(\varvec{y}^{*}\) (\(p_y \times 1\)) are the vectors of continuous indicators, \(\varvec{\xi }\) and \(\varvec{\eta }\) are the latent variables, \(\varvec{\delta }_{x}\), \(\varvec{\delta }_{y}\), and \(\varvec{\varepsilon }\) are the error terms. Here, \(\varvec{\Lambda }_{x}\) and \(\varvec{\Lambda }_{y}\) are the loading matrices, \(\varvec{B}\) contains the linear effects among \(\varvec{\eta }\), and \(\varvec{\Gamma }\) contains linear effects of \(\varvec{\xi }\) on \(\varvec{\eta }\). The joint distribution of \(\varvec{x}^{*}\) and \(\varvec{y}^{*}\) is assumed to be multivariate normal. Throughout the paper, \(\varvec{\Sigma }\) is used to denote the model-implied covariance of the SEM, \(\varvec{\sigma }\) the vector of unique entries in \(\varvec{\Sigma }\), and \(\varvec{\beta }\) the vector of all free parameters needed to determine \(\varvec{\Sigma }\) (i.e., free parameters in \(\varvec{\Lambda }_{x}\), \(\varvec{\Lambda }_{y}\), \(\varvec{B}\), \(\varvec{\Gamma }\), \(\text {var}(\varvec{\xi })\), \(\text {var}(\varvec{\delta }_{x})\), \(\text {var}(\varvec{\delta }_{y})\), \(\text {cov}(\varvec{\delta }_{x},\varvec{\delta }_{y}^T)\), and \(\text {var}(\varvec{\varepsilon })\)).
1.1 Brief Review of Jin and Ankargren (2019)
Jin and Ankargren (2019) investigated FMA in SEM where \(\varvec{x}^{*}\) and \(\varvec{y}^{*}\) are observed. In order to clarify the modifications needed for ordinal SEM, their results are briefly reviewed in this subsection. Suppose that there exist a number of candidate SEMs, indexed by s, in which a full model that nests all other models and a narrow model that is nested in all other models are well-defined. The vector \(\varvec{\beta }\) is partitioned into \(\varvec{\beta }^{T}=\left( \varvec{\theta }^{T},\varvec{\gamma }^{T}\right) \), where \(\varvec{\theta }\) is contained in all candidate models and \(\varvec{\gamma }=\varvec{\gamma }_0\) is known in the narrow model. For candidate model s, the elements in \(\varvec{\gamma }\) to be estimated are \(\varvec{\gamma }_{s}=\varvec{\pi }_{s}\varvec{\gamma }\), where \(\varvec{\pi }_{s}\) is a selection matrix. The candidate models are fitted by maximum likelihood, i.e., minimizing \(F_{ML}(\varvec{\beta }) = n\log \left| \varvec{\Sigma }\right| + n \text {tr}\left\{ \varvec{S}\varvec{\Sigma }^{-1}\right\} - n\log \left| \varvec{S}\right| - n\left( p_x + p_y \right) \), where n is the sample size, \(\varvec{S}\) is the sample covariance matrix, and \(\text {tr} \left\{ \right\} \) is the matrix trace of the enclosed matrix. Suppose that the parameter vector of interest is \(\varvec{\mu }=\varvec{\mu }\left( \varvec{\theta },\varvec{\gamma }\right) \), which is continuously differentiable in \(\varvec{\theta }\) and \(\varvec{\gamma }\). The FMA estimator of \(\varvec{\mu }\) is \(\bar{\varvec{\mu }} \left( \varvec{c} \right) = \sum _{s}c_{s}\hat{\varvec{\mu }}_{s}\), where \(\hat{\varvec{\mu }}_{s}\) is the estimator of \(\varvec{\mu }\) in the candidate model s and the model weight vector \(\varvec{c} = \left\{ c_{s}\right\} \) lies in the unit simplex \(\{ c_{s}:\sum _{s}c_{s}=1,\,0\le c_{s}\le 1 \}\).
Jin and Ankargren (2019) assumed that \(\varvec{\beta }_{true} = \left( \varvec{\theta }_{0}^T,\varvec{\gamma }_{0}^T+\varvec{\delta }^T/\sqrt{n}\right) ^T\) is the true value of \(\varvec{\beta }\), where \(\varvec{\theta }_{0}\) is the true value of \(\varvec{\theta }\), \(\varvec{\gamma }_{0}+\varvec{\delta }/\sqrt{n}\) is the true value of \(\varvec{\gamma }\), and \(\varvec{\delta }\) is the local parameter. Hence, the true values of \(\varvec{\sigma }\) and \(\varvec{\mu }\) are \(\varvec{\sigma }_{true} = \varvec{\sigma }\left( \varvec{\beta }_{true}\right) \) and \(\varvec{\mu }_{true} = \varvec{\mu }\left( \varvec{\beta }_{true} \right) \), respectively. The framework that the true value is drifted in a \(n^{-1/2}\) neighborhood is known as the local asymptotic framework. In contrast, the standard asymptotic framework refers to the case where all true values are free of n. The local asymptotic framework is a popular choice to study FMA. The reader is directed to Hjort and Claeskens (2003b) for the reasons of using the local asymptotic framework.
Suppose that \(n^{-1} \partial ^{2}F_{ML}\left( \varvec{\beta }_{0}\right) / \partial \varvec{\beta }\partial \varvec{\beta }^{T}\) converges in probability to \(2\varvec{J}_{full}\), where \(\varvec{\beta }_{0} = \left( \varvec{\theta }_{0}^T,\varvec{\gamma }_{0}^T\right) ^T\) and \(\varvec{J}_{full}\) can be partitioned to
Let \(\varvec{M}\) and \(\varvec{N}\) be the random variables such that
For fixed weights, Jin and Ankargren (2019) derived that
where \(\varvec{\mu }_{0} = \varvec{\mu }\left( \varvec{\theta }_{0},\varvec{\gamma }_{0}\right) \), \(\varvec{W}= \frac{\partial \varvec{\mu }_{0}}{\partial \varvec{\theta }^{T}}\varvec{J}_{\theta \theta }^{-1}\varvec{J}_{\theta \gamma }-\frac{\partial \varvec{\mu }_{0}}{\partial \varvec{\gamma }^{T}}\), \(\varvec{K}^{-1}=\varvec{J}_{\gamma \gamma }-\varvec{J}_{\theta \gamma }^{T}\varvec{J}_{\theta \theta }^{-1}\varvec{J}_{\theta \gamma }\), \(\varvec{K}_{s}=\left( \varvec{\pi }_{s}\varvec{K}^{-1}\varvec{\pi }_{s}^{T}\right) ^{-1}\), \(\varvec{K}^{(s)} = \varvec{\pi }_{s}^{T}\varvec{K}_{s}\varvec{\pi }_{s}\), and \(\varvec{D}= \varvec{\delta }-\varvec{K}\varvec{J}_{\theta \gamma }^{T}\varvec{J}_{\theta \theta }^{-1}\varvec{M}+\varvec{K}\varvec{N}\)Footnote 1. To estimate \(\varvec{c}\), the limit of \(nE\left( \bar{\varvec{\mu }}-\varvec{\mu }_{true}\right) ^{T}\left( \bar{\varvec{\mu }}-\varvec{\mu }_{true}\right) \) is minimized, which is equivalent to minimizing
subject to the unit simplex, where \(\varvec{\Delta }_1 = -\varvec{W}\varvec{\delta }\varvec{\delta }^{T}\varvec{K}^{-1}\), and \(\varvec{\Delta }_2 = \varvec{K}^{-1} + \varvec{K}^{-1}\varvec{\delta }\varvec{\delta }^{T}\varvec{K}^{-1}\).
In the spirit of Hjort and Claeskens (2003a) and Liu (2015), Jin and Ankargren (2019) also proposed a confidence interval for \(\mu _{i}\), the ith entry in \(\varvec{\mu }\), which is given by
where \({\hat{u}}_{i}\) is the ith entry of the vector \(\hat{\varvec{W}}\left( \hat{\varvec{\delta }} - \tilde{\varvec{\delta }} \right) \) with \(\tilde{\varvec{\delta }} = \sum _{s}{\hat{c}}_{s} \hat{\varvec{K}}^{(s)} \hat{\varvec{K}}^{-1}\hat{\varvec{\delta }}\), \(z_{1-\alpha /2}\) is the \(1-\alpha /2\) quantile of the standard normal distribution, and \(\kappa _{i}\) is (i, i)th entry of the covariance matrix of \(\frac{\partial \varvec{\mu }_{0}}{\partial \varvec{\theta }^{T}}\varvec{J}_{\theta \theta }^{-1}\varvec{M}-\varvec{W}\varvec{D}\) with \({\hat{\kappa }}_i\) being its estimator.
1.2 Ordinal Data Model
In the ordinal SEM, the ordinal counterparts \(\varvec{x}\) and \(\varvec{y}\) are observed, which are obtained by discretizing \(\varvec{x}^{*}\) and \(\varvec{y}^{*}\). In the ordinal data model, the diagonal entries in \(\varvec{\Sigma }\) are assumed to be 1. Accordingly, \(\varvec{\Sigma }\) is a polychoric correlation matrix. In practice, a multi-step procedure is commonly used to fit an ordinal SEM. First, the polychoric correlation matrix and its asymptotic covariance matrix are estimated. Second, the least squares fit function \(F_{LS}\left( \varvec{\beta }\right) = n\left( \hat{\varvec{\rho }}-\varvec{\sigma }\left( \varvec{\beta }\right) \right) ^{T} \hat{\varvec{V}} \left( \hat{\varvec{\rho }}-\varvec{\sigma }\left( \varvec{\beta }\right) \right) \) is minimized, where \(\varvec{\rho }\) is the vector of unique polychoric correlation coefficients and \(\varvec{V}\) is some weight matrix.
In the current study, we will extend Jin and Ankargren (2019) to SEM with ordinal data. Since both \(F_{ML}\) and \(F_{LS}\) can be viewed as distance functions between \(\varvec{\rho }\) and \(\varvec{\sigma }\), many results from Jin and Ankargren (2019) still hold. However, as we shall explain in the next section, some modifications are also needed, due to the choice of \(\varvec{V}\).
2 Frequentist Model Averaging Estimator
2.1 Polychoric Correlation Estimation
Throughout the paper, we estimate the polychoric correlation coefficients using the two-step procedure of Olsson (1979). First, the thresholds are estimated from the univariate standard normal distribution. Second, the correlation coefficient is estimated conditional on the estimated thresholds. Estimation of the polychoric correlation matrix and its asymptotic covariance matrix has been extensively studied (e.g., Jin & Yang-Wallentin, 2017; Jöreskog, 1994; Monroe, 2017; Muthén, 1984) within the standard asymptotic framework. For example, Jöreskog (1994) showed that
where \(\varvec{\sigma }_0=\varvec{\sigma }\left( \varvec{\beta }_0 \right) \) and \(\varvec{\Upsilon }\) is the asymptotic covariance matrix.
We still assume that the thresholds are not locally drifted. However, the true values of the polychoric correlation coefficients depend on n. To the best of our knowledge, none of the above mentioned studies on polychoric correlations are conducted under the local asymptotic framework. Further, the polychoric correlation estimator from the two-step procedure is a pseudo-maximum likelihood estimator (Gong & Samaniego, 1981), making the results in Hjort and Claeskens (2003a) not directly applicable. For these reasons, we establish consistency and asymptotic normality of the polychoric correlation estimators in this subsection. For ease of presentation, all regularity conditions and mathematical proofs are placed in the online appendix.
Theorem 1
Under the regularity conditions stated in the online appendix, \(\hat{\varvec{\rho }} \overset{p}{\rightarrow } \varvec{\sigma }_{0}\).
Theorem 1 shows that \(\hat{\varvec{\rho }}\) remains a consistent estimator of \(\varvec{\sigma }_{0}\) under the local asymptotic framework. The following theorem shows asymptotic normality.
Theorem 2
Under the regularity conditions stated in the online appendix, \(\sqrt{n}\left( \hat{\varvec{\rho }}-\varvec{\sigma }_{true}\right) \overset{d}{\rightarrow }N\left( \varvec{0},\varvec{\Upsilon }\right) \), where \(\varvec{\Upsilon }\) is the same as the covariance matrix in (4).
Theorem 2 shows that the estimator of the asymptotic covariance matrix under the standard asymptotic framework is also valid under the local asymptotic framework. The implication is that the estimated asymptotic covariance matrix can simply be extracted from the standard SEM packages. Theorem 2 also shows that the mean of the limiting distribution of \(\sqrt{n}\left( \hat{\varvec{\rho }}-\varvec{\sigma }_{0}\right) \) is nonzero under the local asymptotic framework. In contrast, the mean of the limiting distribution of \(\sqrt{n}\left( \hat{\varvec{\rho }}-\varvec{\sigma }_{0}\right) \) is zero under the standard asymptotic framework.
2.2 Frequentist Model Averaging: From Continuous Data to Ordinal Data
Since both \(F_{LS}\) and \(F_{ML}\) can be viewed as distance functions between \(\varvec{\rho }\) and \(\varvec{\sigma }\), the expansion (1) still holds if \(F_{ML}\) is replaced by \(F_{LS}\) when obtaining \(\varvec{J}_{full}\), \(\varvec{M}\), and \(\varvec{N}\). However, Jin and Ankargren (2019) derived the weight estimation criterion (2) and the confidence interval (3) under the assumption that \(\varvec{M}\) and \(\varvec{D}\) are independent, which holds for observed multivariate normal data. Regarding ordinal SEM, it is shown in the appendix that the joint distribution of \(\varvec{M}\) and \(\varvec{N}\) is multivariate normal with mean \(\varvec{0}\) and covariance matrix
Consequently,
which depends on the choice of \(\varvec{V}\). Commonly used \(\varvec{V}\) includes \(\varvec{V}=\varvec{I}\) in unweighted least squares (ULS; Muthén, 1978), the inverse of diagonal elements of \(\varvec{\Upsilon }\) in diagonally weighted least squares (DWLS; Muthén et al., 1997), and \(\varvec{V}=\varvec{\Upsilon }^{-1}\) in weighted least squares (WLS; Browne, 1984). If WLS is used, then \(\text {cov}\left( \varvec{M},\varvec{D}^{T}\right) = \varvec{0}\) and the results in Jin and Ankargren (2019) remain applicable. However, if ULS or DWLS is used, \(\varvec{M}\) and \(\varvec{D}\) are not necessarily independent. Consequently, modifications are needed.
2.3 Weight Estimation
It is shown in the online appendix that, in the context of ordinal SEM, minimizing the limit of \(nE\left( \bar{\varvec{\mu }}-\varvec{\mu }_{true}\right) ^{T}\left( \bar{\varvec{\mu }}-\varvec{\mu }_{true}\right) \) is equivalent to minimizing \(Q\left( \varvec{c}\right) \) given in (2), but with modified \(\varvec{\Delta }_1\) and \(\varvec{\Delta }_2\) as
where the covariance matrix of \(\varvec{M}\) and \(\varvec{N}\) is shown in (5).
In practice, the unknown population values (e.g., \(\varvec{\Delta }_{1}\), \(\varvec{\Delta }_{2}\), \(\varvec{K}^{(s)}\), and \(\varvec{W}\)) are replaced by their estimators from the candidate models, yielding the estimator \({\hat{Q}}\left( \varvec{c}\right) \) of \(Q\left( \varvec{c}\right) \). Then, \(\hat{\varvec{c}}\), the estimator of \(\varvec{c}\), is obtained by minimizing \({\hat{Q}}\left( \varvec{c}\right) \). Similar to Jin and Ankargren (2019), the unknown population values can be consistently estimated from the full model, except \(\varvec{\delta }\). Hjort and Claeskens (2003a) and Liu (2015) showed that \(\varvec{\delta }\) can only be asymptotically unbiasedly estimated and suggested to estimate it from the full model as \(\hat{\varvec{\delta }}=\sqrt{n}\left( \hat{\varvec{\gamma }}_{full}-\varvec{\gamma }_{0}\right) \), where \(\hat{\varvec{\gamma }}_{full}\) is the estimator of \(\varvec{\gamma }\) from the full model. It is an unbiased estimator of \(\varvec{\delta }\) but a biased estimator of \(\varvec{\delta }\varvec{\delta }^{T}\). Jin and Ankargren (2019) showed that, for SEM with continuous data, \(\hat{\varvec{\delta }}\) remains an unbiased estimator of \(\varvec{\delta }\) and \(\hat{\varvec{\delta }}\hat{\varvec{\delta }}^{T} -\varvec{K}\) is an unbiased estimator of \(\varvec{\delta }\varvec{\delta }^{T}\). It is shown in the online appendix that, for SEM with ordinal data, \(\hat{\varvec{\delta }}\) is still an unbiased estimator of \(\varvec{\delta }\), but an unbiased estimator of \(\varvec{\delta }\varvec{\delta }^{T}\) becomes \(\hat{\varvec{\delta }}\hat{\varvec{\delta }}^{T} - \hat{\varvec{G}} \hat{\varvec{H}} \hat{\varvec{G}} ^T\), where \(\varvec{G} = \begin{pmatrix}-\varvec{K}\varvec{J}_{\theta \gamma }^{T}\varvec{J}_{\theta \theta }^{-1}&\varvec{K}\end{pmatrix}\).
2.4 Model Averaging Confidence Interval
In the spirit of Hjort and Claeskens (2003a) and Liu (2015), we conjecture that there is joint convergence in distribution of \(\hat{\varvec{c}}\) and all \(\hat{\varvec{\mu }}_s\) such that
The reader is directed to the online appendix for a heuristic proof of the joint convergence. From (7), the FMA confidence interval for \(\mu _i\) is still of the form (3) for SEM with ordinal data. In Jin and Ankargren (2019),
In an ordinal SEM, the covariance matrix of \(\frac{\partial \varvec{\mu }_{0}}{\partial \varvec{\theta }^{T}}\varvec{J}_{\theta \theta }^{-1}\varvec{M}-\varvec{W}\varvec{D}\) should be computed using (6), due to nonzero \(\text {cov}(\varvec{M},\varvec{D}^{T})\). Similar to weight estimation, the confidence interval in Jin and Ankargren (2019) remains applicable if WLS is used.
If (7) holds, the interval (3) that accounts for \(\text {cov}(\varvec{M},\varvec{D}^{T})\) attains the nominal level asymptotically. Another valid confidence interval is the one from the full model, given by \(\left[ {\hat{\mu }}_{i,full} - z_{1-\alpha /2} {\hat{\kappa }}_{i} / \sqrt{n}, \, {\hat{\mu }}_{i,full} + z_{1-\alpha /2} {\hat{\kappa }}_{i} / \sqrt{n}\right] \), where \({\hat{\mu }}_{i,full}\) is the estimator of \(\mu _i\) from the full model. Various studies (e.g., Ankargren & Jin, 2018; Kabaila & Leeb, 2006; Wang & Zhou, 2013) have shown that the FMA confidence intervals of the form (3) can be asymptotically equivalent to the confidence interval from the full model. In the likelihood context, Wang and Zhou (2013) proved that
and showed that the equivalence holds for all FMA confidence intervals suggested by Hjort and Claeskens (2003a). Since least squares are used in SEM with ordinal data, their results cannot be directly applied here. Nevertheless, it is shown in the online appendix that (8) still holds in ordinal SEM. Hence, the FMA confidence interval (3) remains asymptotically equivalent to the full model interval. The implication is that the small sample realizations of (3) may be different from the full model interval, but they will be similar to each other when the sample size is large.
2.5 Goodness-of-fit Test
Consider the case where \(\varvec{\mu }=\varvec{\beta }\), i.e., we want all parameters (expect the thresholds) to be accurately estimated. In practice, it is often of interest to test the overall fit of a hypothesized model. The full model goodness-of-fit test can be interpreted as testing whether the full model decomposition of the population covariance matrix evaluated at the full model estimator fits the data well. Since FMA aims to combine different models, the population covariance matrix is generally decomposed according to the full model, but evaluated at the FMA estimator. Hence, it is important to test whether the full model evaluated at the FMA estimators fits the data well (Jin & Ankargren, 2019). For this reason, a goodness-of-fit test for model averaged SEM with ordinal data is proposed here.
A residual-based test statistic is
where \(\bar{\varvec{\sigma }}=\varvec{\sigma }\left( \bar{\varvec{\mu }}\left( \hat{\varvec{c}}\right) \right) \). The asymptotic property of \(T_{FMA}\) is shown in following theorem.
Theorem 3
Let \(\varvec{\mu }=\varvec{\beta }\). Suppose that the regularity conditions in the online appendix hold. Then, \(T_{FMA}=T_{full}+o_{\text {P}}\left( 1\right) \), where \(T_{full}= n\left( \hat{\varvec{\rho }}-\hat{\varvec{\sigma }}_{full}\right) ^{T} \hat{\varvec{V}} \left( \hat{\varvec{\rho }}-\hat{\varvec{\sigma }}_{full}\right) \) is the test statistic for the full model.
The assumption that \(\varvec{\mu }=\varvec{\beta }\) plays an important role in the proof of the theorem. It is certainly the case that some applications may be only interested in a subset of \(\varvec{\beta }\). In such a case, Theorem 3 is not guaranteed to be applicable. A different test statistic is proposed by Jin and Ankargren (2019) for SEM with continuous data. Both test statistics adjust the fit function (\(F_{ML}\) or \(F_{LS}\)), but with different adjustments. The adjustment \(\frac{\partial \varvec{\sigma }_{full}}{\partial \varvec{\beta }^{T}}\varvec{W}\left( \hat{\varvec{\delta }}-\tilde{\varvec{\delta }} \right) \) is used in \(T_{FMA}\), since \(\varvec{W}\left( \hat{\varvec{\delta }}-\tilde{\varvec{\delta }} \right) \) is also the adjustment term in the FMA confidence interval (3).
Since \(T_{FMA}\) is asymptotically equivalent to \(T_{full}\), we can define the Satorra and Bentler (1994) mean-scaled statistic and mean-variance adjusted statistic as
respectively, where r is the difference between the number of unique polychoric correlation coefficients and the number of parameters and
with
\(T_{FMA-SB-m}\) can be approximated by a Chi-square distribution with r degrees of freedom and \(T_{FMA-SB-mv}\) can be approximated by a Chi-square distribution with \(\left[ \text {tr} \left( \hat{\varvec{\Xi }}_{FMA}\right) \right] ^{2}/ \text {tr} \left( \hat{\varvec{\Xi }}_{FMA}^{2}\right) \) degrees of freedom. The fit indices such as robust RMSEA, CFI, and TLI (Brosseau-Liard & Savalei, 2014; Brosseau-Liard et al., 2012) can also be defined accordingly.
3 Simulation Study
In this section, a simulation study is conducted to compare the finite sample properties of FMA with the full model estimation and model selection.
3.1 Simulation Design
The population model is a four-factor SEM, where
Under the local asymptotic framework, we let \(\gamma _{12}=\gamma _{0}+\delta /\sqrt{n}\), \(\gamma _{21}=\gamma _{0}+0.75\cdot \delta /\sqrt{n}\), and \(b_{21}=\gamma _{0}+0.5\cdot \delta /\sqrt{n}\), where \(\gamma _{0}=0\) and \(\delta =150^{1/2}\zeta \), with \(\zeta \) being seven equidistant values between 0 and 0.30 at the step size 0.05. The covariance matrices of \(\varvec{\delta }_{x}\) and \(\varvec{\delta }_{y}\) are set to be diagonal, of which the diagonal elements make the marginal variances of \(\varvec{x}^{*}\) and \(\varvec{y}^{*}\) be 1. The distribution of \(\varvec{x}^{*}\) and \(\varvec{y}^{*}\) is assumed to follow a multivariate normal distribution. These population models are similar to those of Jin and Ankargren (2019), with minor changes of the true values. \(\text {var}(\varvec{\varepsilon })\) is set to be a diagonal matrix, and its diagonal elements are 0.45 and 0.5 if the narrow model is the data generation process (\(\zeta =0\)). For other values of \(\zeta \), the diagonal elements are chosen such that the reliability of the measurement models remains the same as the \(\zeta =0\).
We fix the number of categories to be five and consider two sets of threshold values. In the first set, the probabilities of belonging to each category are 0.24, 0.41, 0.22, 0.1, and 0.03, which is the moderate asymmetry setting in Rhemtulla et al. (2012). In the second set, the probabilities of belonging to each category are 0.52, 0.15, 0.13, 0.11, and 0.09, which is the extreme asymmetry setting in Rhemtulla et al. (2012). We also take the sample sizes that are used in Rhemtulla et al. (2012), i.e., \(n=150\), 350, and \(n=600\). The number of replications is set to 10, 000.
Four candidate models are considered in the current study, corresponding to the free parameters in \(\varvec{B}\) and \(\varvec{\Gamma }\). Model 1, the narrow model, assumes \(b_{21}=\gamma _{12}=\gamma _{21}=0\). Model 2 frees \(\gamma _{12}\) but assumes \(b_{21}=\gamma _{21}=0\). Model 3 freely estimates \(\gamma _{12}\) and \(\gamma _{21}\), but assumes \(b_{21}=0\). Model 4, the full model, freely estimates \(b_{21}\), \(\gamma _{12}\) and \(\gamma _{21}\). Hence, only the full model is the true model if \(\zeta \ne 0\). To estimate the local parameter \(\varvec{\delta }\), the unbiased estimator \(\hat{\varvec{\delta }}=\sqrt{n}\left( \hat{\varvec{\gamma }}_{full}-\varvec{\gamma }_{0}\right) \) is used for simplicity. The parameter of interest is defined to be the vector of free parameters in the full model, excluding the thresholds.
In order to examine the effects of the local asymptotic framework, data are also generated from the standard asymptotic framework, where \(\gamma _{12}=\zeta \), \(\gamma _{21}=0.75\zeta \), and \(b_{21}=0.5\zeta \). The local asymptotic framework coincides with the standard asymptotic framework when \(n=150\) but is different when \(n=350\) and \(n=600\).
The methods considered here include FMA, full model, and model selection. Three implementations of FMA will be considered. The first implementation, denoted by FMAord, is the ordinal data FMA proposed in the current study by accounting for \(\text {cov}(\varvec{M},\varvec{D}^T)\). The second implementation, denoted by FMAordcont, uses the weight estimation method and confidence interval from Jin and Ankargren (2019) (i.e., treating \(\text {cov}(\varvec{M},\varvec{D}^T) = \varvec{0}\)), but ordinal data are still treated as ordinal. Comparing FMAord with FMAordcont allows us to examine the consequence of ignoring a nonzero \(\text {cov}(\varvec{M},\varvec{D}^T)\). It is of interest to see whether ordinal data can be treated as continuous in the context of FMA, since it is common that the applied researchers treat ordinal data as continuous. Hence, the third implementation, denoted by FMAcont, treats ordinal data as continuous and directly uses the results from Jin and Ankargren (2019). Since least-squares are used, information criterion is not used for model selection. Rather, we start with whether the narrow model fits the data well by the robust RMSEA (Brosseau-Liard et al., 2012) from lavaan (Rosseel, 2012). In the current simulation, an RMSEA no higher than 0.05 is an indication of a good fit. If the narrow model does not fit the data well, Model 2 is under investigation. If Model 2 does not fit the data well, Model 3 is under investigation. If Model 3 does not fit the data well, the full model is chosen.
All candidate models are estimated in lavaan (Rosseel, 2012) using DWLS. The FMA estimator, confidence interval, and test statistics are programmed in R Core Team (2020). The code can be retrieved from the online appendix.
3.2 Simulation Results
It is likely to encounter non-convergence or Heywood cases when estimating the candidate models. The candidate models that are not converged or have non-positive definite covariance matrices are regarded as inadmissible. The inadmissible candidate models are removed from further analysis. If either the narrow model or full model are inadmissible, the corresponding FMA replication is also considered as inadmissible. Further, outliers are encountered in the current simulation. For simplicity, replications with MSE values that are twice higher than the \(99\%\) sample percentile are considered as possible outliers and are removed from further analysis. When \(n=150\), at most \(0.4\%\) and \(1.2\%\) replications are removed if the thresholds are moderately asymmetric and extremely asymmetric, respectively. When \(n=600\), at most \(0.02\%\) replications are removed. Hence, the percentage of inadmissible solutions are not tabulated here.
To compare the finite sample performance of FMA with model selection and the full model, we compute the normalized MSE, defined as the average of MSE of some method relative to the infeasible minimum MSE across all candidate models, i.e.,
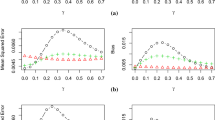
with R being the number of replications. We also compute the average of absolute bias \(p^{-1}\sum _{i=1}^{p} | \text {median of } \left\{ {\hat{\mu }}_{i,r} - \mu _{i,true}; \, r = 1, \cdots R \right\} |\), where \({\hat{\mu }}_{i,r}\) is the estimate of \(\mu _i\) at iteration r, \(\mu _{i,true}\) is the ith entry in \(\varvec{\mu }_{true}\), and p is the number of parameters. Both the normalized MSE and the averaged bias for moderately asymmetric thresholds are illustrated in Fig. 1. The pattern when \(n=600\) is similar to \(n=350\) and the pattern for extremely asymmetric thresholds is similar to that for moderately asymmetric thresholds. Hence, they are not reported here due to space limitation. The conclusions that we can draw from Fig. 1 are similar to those in Jin and Ankargren (2019). FMAord tends to yield a lower normalized MSE than the full model, especially when the parameter value is small. Model selection performs well with the lowest normalized MSE when the parameter value is low, whereas it performs the worst when the parameter value is large. This is due to the fact that RMSEA often picks the correct model if the narrow model is the true model, and that RMSEA often implies that a too simple model fits the data well enough. As expected, the cost of MSE reduction is the inclusion of bias. Nevertheless, the induced averaged bias is generally low (Fig. 1), comparing with model selection. It is also seen from Fig. 1 that FMAord tends to have a slightly lower normalized MSE but a higher absolute bias than FMAordcont. A lower normalized MSE is in line with our expectation, since FMAord aims to minimize the correctly derived asymptotic MSE. Further, FMAcont has a higher normalized MSE and a higher absolute bias than FMAord and FMAordcont. Results not presented here show that the normalized MSE and the absolute bias of FMAcont are even higher when the thresholds are extremely asymmetric.

Normalized mean squared error (MSE) and averaged absolute bias of model selection (black square), the full model (red dot), FMAord (green triangle), FMAordcont (blue diamond), and FMAcont (cyan dot) (Color figure online).
To investigate the coverage probability, the probability of covering \(\gamma _{11}=0.5\) when the thresholds are moderately asymmetric is used as an illustration in Table 1. It is seen that the model selection interval is generally accurate when the narrow model is the true model, but is greatly undercovered when the full model is the true model. It is also seen that the FMAord interval performs similar to the full model interval, which is close to the nominal coverage probability \(95\%\). These observations are also in line with the findings in Jin and Ankargren (2019). Further, FMAordcont yields a lower coverage probability than FMAord, suggesting that it is important to account for the correlation between \(\varvec{M}\) and \(\varvec{D}\) when constructing confidence intervals. It is interesting to see that the coverage probability of the FMAcont interval is close to \(95\%\) when the thresholds are moderately asymmetric. However, the coverage probability of the FMAcont interval tends to be lower than \(95\%\) when the thresholds are extremely asymmetric.
Regarding the goodness-of-fit tests, we only consider the full model, FMAord, and FMAordcont. FMAcont is not considered since the Chi-square test derived in Jin and Ankargren (2019) requires normally distributed data and no robust corrections are derived yet. Table 2 tabulates the empirical rejection rate of the mean-scaled statistic and the mean-and-variance adjusted statistic at the significance level 0.05 when the thresholds are moderately asymmetric. Results for extremely asymmetric thresholds show similar patterns. Hence, they are not reported here. Since the full model is correctly specified, we expect the empirical rejection rate to be approximately 0.05. It is seen that the FMA goodness-of-fit test statistic performs similar to the goodness-of-fit test statistic of the full model, which is in line with Theorem 3 that the goodness-of-fit test statistics are asymptotically equivalent. Comparing the mean-scaled statistic with the mean-and-variance adjusted statistic, the latter tends to have a better size. It is also seen that FMAord and FMAordcont often yield similar empirical sizes, indicating that the effect of \(\text {cov}(\varvec{M},\varvec{D}^T)\) is minor when it comes to the goodness-of-fit tests.
4 Empirical Example
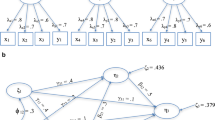
In this section, an empirical example is analyzed as an illustration. In order to study the supplier–customer relationship, Selnes and Sallis (2003) sampled 780 Scandinavian companies that have more than 50 employees. A total of 665 of them participated in the study. A total of 315 dyads in the sense of supplier and customer are identified. Selnes and Sallis (2003) used a subset of this data set to study how the learning capacity of supplier–customer relationship can be promoted by management. Recently, Sallis (2018) used another subset with 303 dyads to study the effect of relationship flexibility to relationship performance. Two five-factor models under consideration are shown in Fig. 2, which are simplified from Sallis (2018). The narrow model omits the paths from Goal congruence to Relationship performance and Environmental uncertainty to Relationship performance, whereas the full model also estimates such two paths. The sample size remained after deleting missing values is \(n=266\). All indicators are measured on the 7-point Likert scale. They are aggregated into a 3-point Likert scale that is close to the 3-category extreme asymmetry setting in Rhemtulla et al. (2012). The focus parameter is defined to be the vector of all free parameters needed for the model-implied covariance matrix.
Table 3 tabulates the estimated effects of Goal congruence and Environmental uncertainty on Relationship performance, Coordination effort, and Flexibility. Model selection chooses the narrow model, since it yields satisfactory fit indices. Nevertheless, all FMA implementations assign non-ignorable weights to the full model, which can be seen from the estimates of the path Goal congruence to Relationship performance: 0.33 (=0.027/0.083) for FMAord, 0.42 (=0.034/0.083) for FMAordcont, and 0.70 (=0.067/0.083) for FMAcont. FMAord and FMAordcont produce similar point estimates, which can be largely different from those produced by FMAcont. This is in line with our observations from Fig. 1 in the simulation study that FMAcont can be much more biased than FMAord and FMAordcont. Despite similar point estimates, it is also seen that the FMAordcont intervals are generally nested in the FMAord interval, which may lead to a lower coverage probability that we observed in the simulation study. Further, the fit indices and the confidence intervals of the full model are similar to those of FMAord, which is in line with our theoretical results.

Path diagonal of the seller example. The dashed lines are present in the full model but is omitted in the narrow model.
5 Conclusion and Discussion
In this study, FMA is generalized to the SEM with ordinal indicators. We showed that one assumption in Jin and Ankargren (2019), namely \(\text {cov}(\varvec{M},\varvec{D}^T) = \varvec{0}\), is violated in SEM with ordinal data. Hence, the results in Jin and Ankargren (2019) for SEM with continuous data need to be revised for SEM with ordinal data. To this end, we derived the correct criterion function for weight estimation, and the valid confidence interval for SEM with ordinal data. To evaluate the global fit, a mean-scaled test statistic and a mean-variance adjusted test statistic are proposed. In the simulation study, we showed that the ordinal data cannot always be treated as continuous, since FMAcont can yield much more biased estimators. We also showed that FMAordcont generally yields similar point estimators to FMAord. However, the FMAordcont interval can be undercovered. Hence, FMAord is still preferred.
Similar to FMA for SEM with continuous indicators, FMA does not uniformly dominate model selection nor the full model in our simulation. The same phenomenon has also been observed in various other models (e.g., Wan et al., 2014; Wang and Zou, 2012; Yang, 2003). This is a general issue for FMA, which is closely related with the combination puzzle (Claeskens et al., 2016) in the forecasting literature. The asymptotic MSE that we aim to minimize is derived under the assumption that the weights are fixed. However, the weights are generally random, if they are estimated from data. Since the uncertainty in the random weights is not accounted for when computing the asymptotic MSE, there is no guarantee that the FMA estimator will be dominating (Claeskens et al., 2016). Nevertheless, as Jin and Ankargren (2019) suggested in the context of SEM with continuous indicators, FMA is a robust compromise between model selection and the full model. Estimators followed by model selection can be unstable (Breiman, 1996) and neither the bias nor the MSE are necessarily bounded (Leeb & Pötscher, 2005). The full model estimator is often unstable (Hjort & Claeskens, 2003a) due to the presence of small parameters. FMA, on the other hand, tends to produce a robust MSE also for SEM with ordinal indicators. Future research is needed to provide guidelines on this matter.
The confidence interval considered in this paper is the Hjort and Claeskens (2003a) type, which is asymptotically equivalent to the full model confidence interval. Various other model-averaging confidence interval have also emerged in the literature, such as (Fletcher and Dillingham (2011), Fletcher and Turek (2011), and Turek and Fletcher (2012)). Their properties have been investigated by Kabaila et al. (2016), Kabaila et al. (2017), and Kabaila (2018). Nevertheless, it is difficult to outperform the full model confidence interval (Kabaila et al., 2016). Wang and Zou (2012) suggested the use of the full model interval since it is computationally easy and the FMA interval does not offer a major improvement. Following these suggestions, both the full model interval and the FMA interval will offer valid inference in practice. Even if the point estimator is taken from one candidate model, Jin and Ankargren (2019) still suggested to use the full model interval or the FMA interval to take the selection uncertainty into consideration. The same suggestion applies to the SEM with ordinal data.
One limitation of the proposed goodness-of-fit statistic is that the focus parameter \(\varvec{\mu }\) ought to be the vector of all free parameters in \(\varvec{\Sigma }\), an assumption needed for Theorem 3. If \(\varvec{\mu } \ne \varvec{\beta }\) such as \(\varvec{\mu }=(\varvec{I} - \varvec{B} )^{-1} \varvec{\Gamma }\), we can still obtain valid FMA estimate \(\bar{\varvec{\mu }}\) and construct valid confidence intervals for \(\varvec{\mu }\). However, the proposed test statistic is not guaranteed to be asymptotically equivalent to the full model test statistic. Further studies will be devoted to the model evaluation for a general parameter vector of interest.
References
Ankargren, S., & Jin, S. (2018). On the least squares model averaging interval estimator. Communications in Statistics: Theory and Methods, 47, 118–132.
Breiman, L. (1996). Heuristics of instability and stabilization in model selection. The Annals of Statistics, 24, 2350–2383.
Brosseau-Liard, P. E., & Savalei, V. (2014). Adjusting incremental fit indices for nonnormality. Multivariate Behavioral Research, 49, 460–470.
Brosseau-Liard, P. E., Savalei, V., & Li, L. (2012). An investigation of the sample performance of two nonnormality corrections for RMSEA. Multivariate Behavioral Research, 47, 904–930.
Browne, M. W. (1984). Asymptotically distribution-free methods in the analysis of covariance structures. British Journal of Mathematical and Statistical Psychology, 37, 62–83.
Claeskens, G., Magnus, J., Vasnev, A. L., & Wang, W. (2016). The Forecast Combination Puzzle: A Simple Theoretical Explanation. International Journal of Forecasting, 32, 754–762.
Fletcher, D. (2018). Model averaging. Berlin, Germany: Springer.
Fletcher, D., & Dillingham, P. W. (2011). Model-averaged confidence intervals for factorial experiments. Computational Statistics and Data Analysis, 55, 3041–3048.
Fletcher, D., & Turek, D. (2011). Model-averaged profile likelihood intervals. Journal of Agricultural, Biological and Environmental Statistics, 17, 38–51.
Gong, G., & Samaniego, F. J. (1981). Pseudo maximum likelihood estimation: theory and applications. The Annals of Statistics, 9, 861–869.
Hjort, N. L., & Claeskens, G. (2003). Frequentist model average estimators. Journal of the American Statistical Association, 98, 879–899.
Hjort, N. L., & Claeskens, G. (2003). Rejoinder. Journal of the American Statistical Association, 98, 938–945.
Hoeting, J. A., Madigan, D., Raftery, A. E., & Volinsky, C. T. (1999). Bayesian model averaging: a tutorial (with discussion). Statistical Science, 14, 382–417.
Jin, S., & Ankargren, S. (2019). Frequentist model averaging in structural equation modeling. Psychometrika, 84, 84–104.
Jin, S., & Yang-Wallentin, F. (2017). Asymptotic robustnesss study of the polychoric correlation estimation. Psychometrika, 82, 67–85.
Jöreskog, K. G. (1994). On the estimation of polychoric correlations and their asymptotic covariance matrix. Psychometrika, 59, 381–389.
Kabaila, P. (2018). On the minimum coverage probability of model averaged tail area confidence intervals. The Canadian Journal of Statistics, 46, 279–297.
Kabaila, P., & Leeb, H. (2006). On the large-sample minimal coverage probability of confidence intervals after model selection. Journal of the American Statistical Association, 101, 619–629.
Kabaila, P., Welsh, A. H., & Abeysekera, W. (2016). Model-averaged confidence intervals. Scandinavian Journal of Statistics, 43, 35–48.
Kabaila, P., Welsh, A. H., & Mainzer, R. (2017). The performance of model averaged tail area confidence intervals. Communications in Statistics - Theory and Methods, 46, 10718–10732.
Leeb, H., & Pötscher, B. M. (2005). Model selection and inference: Facts and fiction. Econometric Theory, 21(1), 21–59.
Liu, C.-A. (2015). Distribution theory of the least squares averaging estimator. Journal of Econometrics, 186, 142–159.
Lubke, G. H., Campbell, I., McArtor, D., Miller, P., Luningham, J., & van den Berg, S. M. (2017). Assissing model selection uncertainty using a bootstrap approach: an update. Structural Equation Modeling: A Multidisciplinary Journal, 24, 230–245.
Madigan, D., & Raftery, A. E. (1994). Model selection and accounting for model uncertainty in graphical models using Occam’s window. Journal of the American Statistical Association, 89, 1535–1546.
Monroe, S. (2017). Contributions to estimation of polychoric correlation estimation. Multivariate Behavioral Research, 53, 247–266.
Muthén, B. (1978). Contributions to factor analysis of dichotomous variables. Psychometrika, 43, 551–560.
Muthén, B. (1984). A general structural equation model with dichotomous ordered categorical and continuous latent indicators. Psychometrika, 49, 115–132.
Muthén, B., du Toit, S. H. C., & Spisic, D. (1997). Robust inference using weighted least squares and quadratic estimating equations in latent variable modeling with categorical and continuous outcomes. Retrieved from https://www.statmodel.com/download/Article$_075$.pdf. Accessed by 2013-09-12.
Olsson, U. (1979). Maximum likelihood estimation of the polychoric correlation coefficient. Psychometrika, 44, 443–460.
Preacher, K. J., & Merkle, E. C. (2012). The problem of model selection uncertainty in structural equation modeling. Psychological Methods, 17, 1–14.
R Core Team. (2020). R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing.
Rhemtulla, M., Brosseau-Liard, P. E., & Savalei, V. (2012). When can categorical variables be treated as continuous? A comparison of robust continuous and categorical sem estimation methods under suboptimal conditions. Psychological Methods, 17, 354–373.
Rosseel, Y. (2012). lavaan: an R package for structural equation modeling. Journal of Statistical Software, 48, 1–36.
Sallis, J. (2018). Relationship flexibility in buyer-seller partnerships. Unpublished manuscript, Department of Business Studies, Uppsala University.
Satorra, A., & Bentler, P. M. (1994). Corrections to test statistics and standard errors in covariance structure analysis. In A. V. Eye & C. C. Clogg (Eds.), Latent variables analysis: Applications for developmental research (pp. 399–419). Thousand Oaks, CA, US: SAGE Publications.
Selnes, F., & Sallis, J. (2003). Promoting relationship learning. Journal of Marketing, 67, 80–95.
Turek, D., & Fletcher, D. (2012). Model-averaged Wald confidence intervals. Computational Statistics and Data Analysis, 56, 2809–2815.
Wan, A. T. K., Zhang, X., & Wang, S. (2014). Frequentist model averaging for multinomial and ordered logit models. International Journal of Forecasting, 30, 118–128.
Wang, H., & Zhou, S. Z. F. (2013). Interval estimation by frequentist model averaging. Communications in Statistics: Theory and Methods, 42, 4342–4356.
Wang, H., & Zou, G. (2012). Model averaging for varying-coefficient partially linear measurement error models. Electronic Journal of Statistics, 6, 1017–1039.
Yang, Y. (2003). Regression with multiple candidate models: selecting or mixing? Statistica Sinica, 13, 783–809.
Acknowledgements
We are grateful for the valuable comments from the associate editor and the reviewers to improve the work. We also would like to thank Professor James Sallis for sharing the empirical data set. The project is supported by Vetenskapsrådet (Swedish Research Council) under the contract 2017-01175.
Funding
Open access funding provided by Uppsala University.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
We are grateful for the valuable comments from the associate editor and the reviewers to improve the work. We also would like to thank Professor James Sallis for sharing the empirical data set. The project is supported by Vetenskapsrådet (Swedish Research Council) under the contract 2017-01175.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Jin, S. Frequentist Model Averaging in Structure Equation Model With Ordinal Data. Psychometrika 87, 1130–1145 (2022). https://doi.org/10.1007/s11336-021-09837-3
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11336-021-09837-3