
Abstract
Artificial intelligence (AI) has made remarkable progress in the past decade. Despite the plethora of AI research, we lack an accrued overview of the extent to which management research uses AI algorithms. The context, purpose, and type of AI used in previous work remain unknown, though this information is critical to coordinating, extending, and strengthening the use of AI. We address this knowledge gap with a systematic literature review (SLR), focusing on 12 leading information systems (IS) journals and leveraging a customized generative pre-trained transformer (GPT) in our analyses. We propose a conceptual framework comprising eight dimensions to categorize our findings in terms of application areas, methods, and algorithms of applied AI, mitigating the lack of a concise AI taxonomy. Thus, we identify and discuss trends, outline underrepresented algorithms with significant potential, and derive research avenues. We extend the literature with a conceptual overview that may serve as a building block for theory building and further exploration of the evolving AI research domain.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Based on exponentially increasing computing power (Schaller 1997; Shalf 2020) and big data availability, artificial intelligence (AI) has gained substantial traction in recent years (Haenlein and Kaplan 2019). In 2016, AlphaGo, a deep reinforcement learning algorithm developed by Google, was able to beat Lee Sedol, arguably one of the most renowned players of the board game “Go”, which is considered to be multiple times more complex than chess (Haenlein and Kaplan 2019; Padmanabhan et al. 2022; Silver et al. 2017). With the introduction of ChatGPT, AI has made its way to a broad common perception, raising promising expectations about impactful AI use cases in business research and practice.
The potential of AI has aroused the attention of management research (Zhang et al. 2022). This has resulted in a compound annual growth rate of more than 35% in AI referencesFootnote 1 between 2015 and 2019 (Fosso Wamba et al. 2021). Especially for the 2020s, we observe a steep increase in AI-related publications in top-tier management journalsFootnote 2 and expect even higher yields in the post-generative AI era.
Although AI-related literature is rich (Padmanabhan et al. 2022), we currently lack a comprehensive understanding of the use of AI algorithms. The absence of a concise AI definition and taxonomy in business (Collins et al. 2021; Samoili et al. 2020; Wirtz et al. 2019) results in a dispersed knowledge base, which has two critical implications. First, it currently seems challenging to assess the extent to which management research has exploited the potential of AI algorithms. Second, an overview of current trends as well as future potentials of applied AI remains opaque.
To further coordinate, extend, and strengthen the use of AI, researchers need to understand in what context, for what purpose, and which types of AI have been used in previous work. With only a few reviews investigating the overall topic from a sociotechnical lens (e.g., Abdel-Karim et al. 2021; Collins et al. 2021), we see a knowledge gap regarding the extent of applied AI algorithms, leaving the following questions unanswered: Do specific use cases or application areas foster the use of AI algorithms in management research? For which purposes do management researchers leverage AI algorithms? Which data type is commonly processed? And which algorithms are most popular?
We argue that answering these questions is critical to compiling a holistic overview of AI applications in management research. Likewise, for identifying gaps between the use of AI algorithms and their potential, and discovering avenues for research. We refer to several scholars calling for research in this area. For example, Raisch and Krakowski (2021) point out the need for more interdisciplinary efforts in AI research. They encourage melding perspectives of management research and computer science scholars to “embrace the topic of AI in management” (Raisch and Krakowski 2021, p. 33).
AI affects a broad scope of management research communities, and the field of information systems (IS) accounts for a large share of AI-related publications.Footnote 3 IS, at the intersection of computer science and management, encompasses the social and technical aspects of AI, and consequently, it plays a pioneering role in fostering the settlement of AI in management research (Berente et al. 2021). Therefore, we narrow the scope of this study to IS. In doing so, we align with the research call of Raisch and Krakowski (2021) to combine perspectives from computer science and management research. This study poses the following research question (RQ):
Rq
What is the current state of applied AI algorithms in IS, and how can extant research be synthesized?
By answering this RQ, we build a basis for profound research on the use of AI in IS and provide valuable insights transferrable to the general management research domain. We conduct a systematic literature review (SLR) of AI-related articles published between January 2016 and March 2024 in leading IS journals to identify, structure, and synthesize the use of AI in IS research. According to Rowe (2014, p. 242), literature reviews can build a foundation for research landscaping to “evolve more rapidly towards a more comprehensive and effective research genre’s spectrum”.
To improve the understanding of the use of AI, we propose a conceptual framework covering eight dimensions within the application areas, methods, and algorithms of applied AI. In detail, we categorize the application area into (1) the industry sector and (2) the functional area and dissect the technical aspects of AI applications into (3) AI categories, (4) input data, (5) learning behavior, (6) whether deep learning (DL) is applied, (7) whether explainable AI (xAI) is addressed, and (8) the algorithm used. We draw on a customized generative pre-trained transformer (GPT) based on OpenAI’s GPT-4, along with manual coding to verify its suggestions. Using this hybrid approach, we evaluate the articles of our literature population in terms of these eight dimensions. Overall, we aim to provide a well-developed, organized knowledge base to serve as a foundation for researchers to further explore the field of applied AI algorithms in management research.
Our main findings reveal that the number of AI publications per year and the relative share of articles per year addressing DL and xAI sharply increase within our observation period, and the use of AI falls into distinct topic clusters regarding the functional area and industry sector. Particularly, a large share of articles discusses topics related to the functional area of marketing and sales as well as the industry sectors of information, health care and social assistance, retail trade, and finance and insurance. Furthermore, supervised algorithms that process numerical or text data for predictive purposes constitute most of the applied AI we find in our literature population, and generative AI, reinforcement learning, and semi-supervised learning techniques occur seldom, although they offer vast potential for management research.
Our contribution to the literature is threefold. First, we conduct an in-depth analysis of the use of AI in IS research regarding its application areas, methods, and algorithms. We fully enclose our coding methodology and its results for each article within our literature population. We thereby create transparency in the complex landscape of AI in IS on both a general and specific level. This helps researchers understand the overall dynamics in the field of applied AI as well as specific characteristics on the level of a journal, topic, or article. As such, the overview of the applied AI landscape elucidates the convergence of the areas of computer science and management research within IS.
Second, we propose a conceptual framework of eight dimensions to structure our review, allowing for improved tangibility and increased transparency of AI applications. We use the framework within the field of IS, although its structure is applicable to other management research domains. Such transferability can guide future research conducting structured analyses of applied AI. Our framework aims to disaggregate the evolving research domain and provides a starting point for theory building for management scholars (Rowe 2014; Templier and Paré 2015).
Third, we review IS literature to inform about recent developments in the AI landscape and provide insights that may be transferrable to the broader management research domain. We identify topics that have gained increasing attention as well as underrepresented AI algorithms that show potential for future research. Our study invites scholars to identify gaps in the field of applied AI and further extend and strengthen the use of AI in both IS and the broader management research domain.
The remainder of the article is organized as follows. First, we introduce the research background of our conceptual framework. Next, we describe our research method, then summarize the findings of our SLR. Finally, we suggest avenues for research and discuss the limitations of our approach.
2 Conceptual Framework
Management research lacks clarity about and in-depth analyses of the use of AI algorithms. With neither a universally accepted AI definition (e.g., Collins et al. 2021; Wirtz et al. 2019) nor a mutually exclusive way to categorize AI algorithms (Samoili et al. 2020) in business, we must invent an appropriate structure to systematically evaluate the use of AI.
To derive a conceptual framework for our SLR, we use the European AI expert group’s schematic depiction of AI systems as a starting point, which describes that AI systems perceive information from their environment, process that information to allow decision-making, and react with some kind of action (The European Commission’s High Level Expert Group on Artificial Intelligence, 2018). Accordingly, an AI system comprises its environment, various forms of input, a processing unit, and various forms of output. We use these categories as a foundation to derive the dimensions of our conceptual framework. We divide an AI system’s environment into the dimensions of the industry sector and functional area. Regarding the input and output of an AI system, we introduce the dimensions of AI category and input data. We categorize the processing unit of an AI system according to the dimensions of learning behaviors, DL, xAI, and AI algorithms. The following sections elaborate on each dimension in detail. Our conceptual framework is illustrated in Fig. 1.

Conceptual framework
AI category: While artificial general intelligence—the ultimate vision of AI research—is multi-versatile, today’s state-of-the-art AI applications are mainly specialized to fulfill one specific purpose (Haenlein and Kaplan 2019). We include the following differentiations in our conceptual framework’s dimension of “AI categories”: descriptive, predictive, prescriptive, and generative.
Descriptive AI refers to the analysis of data from the past to extract insights and detect hidden patterns (Roy et al. 2022). For example, clustering identifies groups of related data points without prior knowledge of relationships (Han et al. 2012; Sarker 2021). In addition to pure clustering tasks, topic modeling detects similarities of data points in the latent space and is therefore commonly used to identify the relevant content of text data (Blei 2012; Vayansky and Kumar 2020). Another text-based AI task is sentiment analysis, the computational evaluation of authors’ opinions and emotions toward other individuals, events, or topics (Feldman 2013; Medhat et al. 2014).
Predictive AI learns from past data to reveal unknown information or forecast future events (Roy et al. 2022). For example, classification assigns a discrete class label to a given input with an unknown class label (Han et al. 2012). Reminiscent of this definition, regression predicts a continuous variable based on a given input (Sarker 2021).
Prescriptive AI builds on prediction to recommend the best action to achieve a desired objective or outcome (Roy et al. 2022). Among others, prescriptive systems are used for recommender systems (e.g., Luo et al. 2019; Wei et al. 2023), or healthcare applications (e.g., Wang et al. 2023; Yu et al. 2023).
While the previously discussed tasks extract knowledge from data, generative AI refers to the ability to create content from a learned probability distribution (Goodfellow et al. 2020). For example, large language models, such as GPT4, can create pictures from users’ descriptions.
Input data: In addition to numerical data, AI can process various other inputs, including text (e.g., Adamopoulos et al. 2018), images (e.g., Wang et al. 2022a, b; Zhang and Ram 2020), and sensor data (e.g., Tofangchi et al. 2021; Zhu et al. 2020). We add the dimension “input data” to our framework and distinguish between numerical, text, audio and signal, and image data.
The type of input data is closely related to different AI fields. Wang et al. (2021, p. 2) state that “AI branches out into closely related fields of computer vision, natural language processing, speech recognition, and machine learning”. Computer vision generally refers to a computer’s ability to perceive objects (Russell and Norvig 2010). Natural language processing (NLP) encompasses “systems and algorithms able to interact through human language” (Lauriola et al. 2022, p. 1). Speech recognition revolves around the conversion of “speech signal to a sequence of words” (Gaikwad et al. 2010, p. 16). Machine learning (ML) is a technique that enables “computer systems to improve with experience and data” (Goodfellow et al. 2016, p. 8). Text data and NLP have a close connection; likewise, image data and computer vision, and audio data and speech recognition.
We stress that none of these categorizations are mutually exclusive. First, speech recognition is broadly related to NLP. Second, ML, especially DL, plays a central role in various AI fields. For example, researchers frequently use ML algorithms in NLP (Lauriola et al. 2022; Li 2017), computer vision (Voulodimos et al. 2018), and speech recognition (Nassif et al. 2019).
Learning behavior: Currently, AI is mainly driven by ML algorithms (Jordan and Mitchell 2015). Goodfellow et al. (2016, p. 8) contend that “machine learning is the only viable approach to building AI systems that can operate in complicated, real-world environments”. Hence, we expect to see many ML applications in our SLR, and thus consider it necessary to make more granular distinctions between ML methods. Researchers generally categorize ML algorithms’ learning behavior into supervised, unsupervised, semi-supervised, and reinforcement learning (Jordan and Mitchell 2015; Mohammed et al. 2016).
We integrate the dimension of “learning behavior” into our framework and explain the categories as follows. Supervised learning algorithms perform tasks like classification and regression (Han et al. 2012; Sarker 2021) by processing labeled training data to infer mappings from an input to an output (Mahesh 2020; Mohammed et al. 2016). Unsupervised learning algorithms process unlabeled data to identify underlying patterns (Mohammed et al. 2016), as in clustering (Han et al. 2012; Sarker 2021). Labeled data can be a bottleneck in AI projects or take high manual effort and significant cost (Goodfellow et al. 2020; Roh et al. 2021). Therefore, semi-supervised learning, operating on partially labeled data sets (Han et al. 2012), aims to provide better results than unsupervised learning while requiring less labeled data than supervised methods (Sarker 2021). In contrast to the aforementioned closely related learning behaviors, reinforcement learning refers to agents that improve decision-making by adapting to feedback from the environment in which they operate (Ma and Sun 2020).
Deep learning: Major recent AI achievements and breakthroughs have been associated with DL (Jordan and Mitchell 2015). Deep learning is a particular type of ML (Goodfellow et al. 2016) typically based on artificial neural network architectures with several hidden layers (Ma and Sun 2020). We add the dimension of “deep learning” to our framework and distinguish whether DL is applied.
Explainable AI: With the evolvement of AI towards ML and especially DL, which often comprises black-box systems in such a way that users cannot understand the resulting model predictions, there is a need for more transparency in AI systems (Confalonieri et al. 2021). Explainable AI addresses this challenge by integrating explanation mechanisms into AI models (Doran et al. 2017). Researchers have access to several well-known methods to enhance AI algorithm interpretability. For example, the Shapley additive explanation outlines the contributions of explanatory variables to a given output (Gramegna and Giudici 2021). Locally interpretable model agnostic explanations use explainable, local models as proxies for black-box models (Gramegna and Giudici 2021). We include the dimension of “explainable AI” in our conceptual framework and distinguish whether xAI is addressed.
AI algorithms: AI encompasses various algorithms. For our framework’s dimension “AI algorithms”, we initially consider a selection of algorithms and inductively include others if necessary. Explaining each algorithm is out of the scope of this article, so we refer to the literature for more detail. We include the supervised ML algorithms Bayesian learning, logistic regression (LR), k-nearest neighbors (kNN), support vector machines (SVM), decision trees (DT) and random forests (RF), boosting (for an overview, see Sarker 2021), and autoencoder (Goodfellow et al. 2016). For unsupervised ML algorithms, we include k-means (Sarker 2021) and latent Dirichlet allocation (LDA) (Blei et al. 2003). For DL, we consider the multilayer perceptron (MLP), also known as artificial neural network (Goodfellow et al. 2016), convolutional neural networks (CNN), recurrent neural networks (RNN), including long-short memory cells (for an overview, see Sarker 2021), and generative adversarial networks (GAN) (Goodfellow et al. 2020). Lastly, we include reinforcement learning (Ma and Sun 2020) and (large) language models (Vaswani et al. 2017).
2.1 Industry sector
Padmanabhan et al. (2022) expect AI to evolve from a technique that companies at the forefront of innovation have developed and applied into a common tool for all organizations. However, innovation adoption speed may vary between industries (Lee and Xia 2006; Porter and Millar 1985). Some industries may lead in integrating AI algorithms or offer more potential for applied AI use cases. As research points to the path for practice, we ask whether the literature focuses on specific industry sectors that use AI algorithms. We use the dimension “industry sector” in our framework to evaluate the distribution of AI use cases in IS research. We use the North American Industry Classification System (NAICS), which is known for its cohesive industry distinction (Krishnan and Press 2003).
2.2 Functional area
The distribution of applied AI may vary not only between industries but also within a company. We integrate the dimension “functional area” into our framework to allocate AI use cases to a specific function in a company. We follow the functional area classification of Cannella et al. (2008), referencing Michel and Hambrick (1992) and Carpenter and Fredrickson (2001), consisting of Production-operations, R&D and Engineering, Accounting and Finance, Management and Administration, Marketing and Sales, Law, and Personnel and Labor Relations. Since we expect many studies to fall under an information technology-related background, we add a new category, IT.
3 Methodology
Thorough literature reviews represent a “trustworthy account of past research that other researchers might seek out for inspiration and use to position their own studies” (Templier and Paré 2015, p. 113). Therefore, a review must systematically identify relevant literature and be executed with methodological rigor, in line with its research objectives (Kitchenham et al. 2009; Rowe 2014; Templier and Paré 2015). To assure methodological rigor, we follow the framework proposed by Templier and Paré (2015) for guiding IS literature reviews. This framework consists of six steps (Templier and Paré 2015): (1) problem formulation, (2) literature search, (3) screening for inclusion, (4) quality assessment, (5) data extraction, and (6) analysis and synthesis. Table 1 illustrates our approach. The following sections detail each step.
Step 1—Problem formulation: According to Rowe (2014), literature reviews should not only summarize previous work in the field of interest but also identify knowledge gaps to guide future research directions. Understanding a review’s objectives governs later decisions and matters for the outcome (Kitchenham and Charters 2007). We define the objectives of this study in three ways: (1) Its justification as a standalone literature review, (2) the SLR’s purpose, and (3) the outline of the intended analyses’ core constructs (Templier and Paré 2015). We refer to the introduction regarding the justification and purpose of our standalone review. The core construct of our analysis is to evaluate IS research’s use of AI algorithms in terms of the eight dimensions of our framework.
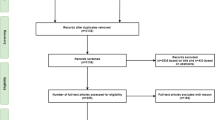
Step 2—Literature search: The literature search involves selecting sources, i.e., databases to search, and choosing search terms (Rowe 2014). To assemble our initial literature population, we searched the online databases EBSCOhost, Scopus, and Web of Science. The broad scope of online databases results in duplicates, but yields a more reliable selection of relevant work.
We restrict our search to leading IS journals, targeting the intersection of information technology and business research. We draw on the Association for Information Systems’ Senior Scholars’ List of Premier Journals with three modifications. We exclude the journal Decision Support Systems due to its technical scope and include Business and Information Systems Engineering (BISE) as well as Electronic Markets (EM). Both are well-cited journals outside of the list of premier journals and complement our literature corpus. Our final selection comprises the following twelve journals: BISE, EM, European Journal of Information Systems (EJIS), Information and Management (I&M), Information and Organization (I and O), Information Systems Journal (ISJ), Information Systems Research (ISR), Journal of the Association of Information Systems (JAIS), Journal of Information Technology (JIT), Journal of Management Information Systems (JMIS), Journal of Strategic Information Systems (JSIS), and Management Information Systems Quarterly (MISQ). In general, we agree with the critique by Larsen et al. (2019) that restricting a literature search to top journals might exclude relevant work. However, for our purpose, we argue that the selected journals cover the appropriate spectrum of applied AI algorithms we want to investigate, given their position at the intersection of computer science and management within IS.
We closely align the selection of our search terms to our research question (Kitchenham and Charters 2007). We want to extract articles that proactively use AI algorithms. To that end, our search terms include AI abbreviations, synonyms, closely related terms (e.g., ML), and, most importantly, a list of concrete AI algorithms. By dispensing with generic search terms like “robot” or “automation,” which occur in related work (e.g., Collins et al. 2021; Mariani et al. 2022), we propose an approach more focused toward applied AI. We use the following search terms: artificial intelligence, AI, machine learning, ML, deep learning, DL, *supervised learning, reinforcement learning, pattern recognition, neural network, decision tree, random forest, support vector, natural language processing, computer vision, machine vision, expert systems, speech recognition, predictive analytics, generative adversarial networks, generative artificial intelligence, large language models, transformer model, diffusion model, ChatGPT, GPT-4, and zero-shot learning.
With the defined set of search terms, we conducted a title-abstract-keyword search on the databases until March 2024 and received 1299 hits: 347 on EBSCOhost, 377 on Scopus, and 575 on Web of Science.
Step 3—Screening for inclusion: According to Templier and Paré (2018), we define criteria to guide the decision of which studies to include in subsequent steps. We distinguish formal from informal criteria. Formal criteria include document type, language, and publication date. We restrict our results to peer-reviewed articles in English. In light of a surge of interest in AI following the AlphaGo milestone (Haenlein and Kaplan 2019; Zhang et al. 2022), we choose articles published from 2016 on. We have already applied the formal inclusion criteria in Step 2, leading to the initial literature population of 1,299 articles. After removing duplicates, 695 articles remain. Our informal inclusion criterion is that the content of a study has to do with applied AI. Eligible studies use at least one AI algorithm, either to solve the research question or for illustrative purposes. We use a hybrid approach to screen the literature population. First, we use OpenAI’s GPT-4 to screen the studies’ abstracts and recommend whether to include or exclude an article. Then, we manually confirm or revise the AI’s suggestion based on the abstract and full paper reading. After excluding all studies that lack a dedicated use of AI algorithms, the remaining population consists of 143 studies. Table 2 presents this literature population categorized according to the publishing journals.
Step 4—Quality assessment: Assessing quality refers to screening the research design and methods used in the literature population for methodological rigor (Templier and Paré 2015). However, this step is not required in every form of literature review. According to Rowe (2014), reviews in IS can be placed into four categories: describing, understanding, explaining, and theory-testing. While explaining and theory-testing reviews include a quality assessment, describing and understanding reviews do not (Templier and Paré 2018). Since we aim to describe and understand the use of AI algorithms in IS research, not to explain and theory-test, we exclude quality assessment from our approach.
Two other arguments support our decision. First, excluding articles that use AI (referring to Step 3) but may have methodological areas of improvement would bias our analysis. Second, due to the restriction to leading IS journals, we expect a high standard of methodological rigor. These journals are highly competitive, and publications are often iteratively refined in review. We confirm these high standards after the reading stage of the previous step (Screening for Inclusion).
Step 5—Data extraction: We apply a hybrid coding approach to extract relevant data for further investigation. First, using a customized GPT, we leverage generative AI to screen the articles of our literature population for the eight dimensions of our framework. Next, we manually review the recommendations to decide how to code each article. For the first step, we use OpenAI’s GPT-4 to build a custom GPT named “Lit Review Analyzer”. After initialization, we proceed with manual coding examples for studies in our literature population. As a result, the Lit Review Analyzer processes PDF articles to output a table of recommendations for each framework dimension, for example, suggesting the best-fitting industry sector or functional area. We provide details on the set-up of the custom GPT in Table 3.
EBSCOhost provides a NAICS-based industry sector classification for some articles. If available, we adopt this classification. Otherwise, we apply our hybrid coding procedure. For the dimension of AI algorithms, we differentiate between those that address the core research question and those used as a benchmark, baseline, or other form of comparison.
Importantly, the entries of each dimension of our framework are not mutually exclusive, so a study can be assigned to more than one in each dimension. For example, a study may be assigned to both text data and image data in the dimension of input data. To resolve ambiguity, we conducted discussions within our research team and iteratively refined our coding approach. The results of our coding scheme are summarized in the “6.” of this study.
Step 6—Analysis and synthesis: In this step, we investigate the absolute frequency and the rank of items within each of the eight dimensions.
4 Findings And Discussion
4.1 Literature Population
The literature population consists of 143 studies. Table 4 presents the distribution of the studies over the journals and years of publication. We highlight three observations. First, ISR, MISQ, and JMIS account for 65% of the articles in our literature population. Specifically, 93 of 143 articles are published by these journals, with 36, 32, and 25 publications for ISR, MISQ, and JMIS, respectively. Second, EJIS, I and O, ISJ, JIT, and JSIS barely publish studies that use AI algorithms, with three or fewer studies each. Third, we notice an increase in articles that use AI over time, with more than 100 articles published between 2020 and 2023.
The significant increase in publications in our literature population shows that AI algorithms have recently gained substantial traction in the field of IS. However, we think that the establishment of applied AI in IS has just started to rise. We expect to see growing attention paid to AI algorithms in the future, further fueled by the introduction of generative AI.
4.2 Dimensions Of The Conceptual Framework
4.2.1 Industry Sector
Within the reviewed literature, the preceding industry sector is 51: Information. We count 60 articles assigned to the category, which equals a relative frequencyFootnote 4 of more than 35%. With 23 studies assigned to its category, 62: Health Care and Social Assistance is the second most frequent industry sector, followed by 44–45: Retail Trade (16), 52: Finance and Insurance (11), 92: Public Administration (8), 31–33: Manufacturing (6), and 48–49: Transportation and Warehousing (5). Other NAICS categories have two or fewer studies assigned. We also find 23 that cannot be assigned to any industry sector. Table 5 presents the distribution of our literature population over the industry sectors.
We attribute the prevalence of the industry sector 51: Information to two main reasons. First, since IS research, by definition, investigates information management, we expect information to be particularly relevant. Second, many studies in our population address research questions regarding social media (e.g., Ghiassi et al. 2016; Guo et al. 2018), product reviews (e.g., Liu et al. 2021; Mejia et al. 2019), cybersecurity (e.g., Ebrahimi et al. 2020; Li et al. 2016), or mobile apps (e.g., He et al. 2019; Lee et al. 2020), which commonly relate to the industry sector of information.
We attribute the prevalence of healthcare-related publications in our literature population to research questions on the intersection of healthcare and IS. For example, several studies process sensor data of home observation systems that improve older adult care. Zhu et al. (2020) propose a deep transfer learning approach to meet the challenges of sensor-based home activities of daily living monitoring systems. In a later study, they use deep learning for a multiphase activities of daily living recognition model (Zhu et al. 2021). Other studies source data from social media to advance knowledge on health-related issues, such as research by Xie et al. (2021) who use deep learning to understand opioid use disorder. Mousavi et al. (2020) use ML to evaluate content quality on health-related question-and-answer forums.
The high prevalence of the industry sector 44–45: Retail Trade mainly relates to studies addressing e-commerce research questions. For example, Luo et al. (2019) investigate e-commerce cart targeting and “simulate the treatment effects for every combination of individual demographics and purchase history and, thus, provide e-retailers with an optimal targeting scheme” (Luo et al. 2019, p. 17). Another study uses artificial neural networks to “predict consumers’ future path-to-purchase journeys based on their historical omnichannel behaviors” (Sun et al. 2022, p. 429).
4.2.2 Functional Area
Regarding the functional areas, Marketing and Sales comes in first, with 39 studies assigned to it, followed by IT (15), Accounting and Finance (14), Management and Administration (14), Law (14), R&D and Engineering (10), Production-operations (8), and Personnel and Labor Relations (5). We also report 45 studies that cannot be assigned to any functional area. Table 6 presents the absolute frequencies and the rank of assigned functional areas.
We find two main reasons to explain the frequent assignment of studies in our literature population to the functional area of marketing and sales. First, we see a close link between marketing and sales and the studies assigned to the retail trade industry sector. Fifteen of 16 studies related to this industry sector are also associated with marketing and sales. Second, we identify several studies addressing research questions regarding consumer reviews, which strongly link to marketing and sales. For example, Kumar et al. (2018, p. 351) “propose a novel hierarchical supervised-learning approach to increase the likelihood of detecting anomalies” in consumer reviews. Gunarathne et al. (2022) use CNNs to identify business-to-customer bias in social media-based customer service. Heightened interest in generative AI and its strong base of potential use cases in marketing, e.g., the AI-assisted development of advertising slogans, indicates that AI will be used even more frequently in marketing in the future.
4.2.3 Ai Category
Of the 157 articles assigned to the AI category, the subcategory of predictive AI leads with 106 articles, followed by descriptive (27), prescriptive (19), and generative AI (5). The prevalence of predictive AI fulfills our expectations, since classification and regression tasks, which use predictive algorithms, address a variety of problem domains.
The use of descriptive AI in our literature population is closely related to text analysis (21 of 27 articles process text data) and topic modeling, such as LDA. Another common use case for descriptive AI is clustering, an effective for finding patterns in unlabeled data, but not necessarily requiring AI. Hence, researchers may rely on legacy algorithms that do not qualify as AI to address clustering tasks. We see this as the reason for the few clustering AI algorithms in top IS research. We do not expect significant changes to this observation in the future.
In our literature population, prescriptive AI relates to ML tasks that process numerical data (14 of 19 articles) and DL algorithms (11 of 19 articles) that address recommendations. For example, He et al. (2019) propose a method for personalized mobile app recommendation and Liebman et al. (2019) develop a music playlist recommendation algorithm that integrates the emotional context of the listener.
Despite the rise of large language models in 2023, generative AI is underrepresented in our literature population, with only five studies assigned to this category. Importantly, generative AI has great potential for intensified use by future research. First, generative algorithms, comparable to semi-supervised and reinforcement learning, allow learning without requiring extensively labeled training data (Goodfellow et al. 2020). Second, generating content may reveal new use cases for business research and practice. To date, many applications of generative algorithms, especially GANs, focus on images (Creswell et al. 2018), but the application area may broaden to other use cases. For example, Krahe et al. (2020) use GANs to process 3D objects represented as point clouds for automated product design. With the increasing possibilities of transformers and large language models, we expect a sharp increase in the generation of use cases soon.
4.2.4 Input Data
Of the 179 total articles assigned to the input data dimension, 73 are assigned to the subcategory of numerical data, 75 to text data, 11 to audio and signal, and 11 to images. We also find nine studies we cannot assign to any of the subcategories of input data, five of which process graph-based data.
The prevalence of text data and the prevalence of NLP in IS research are linked, which reflects a significant interest in the research community. We attribute this to two main reasons. First, NLP can process unstructured data like text. This is a valuable information source for IS research, especially in the age of social media. Second, recent advancements in DL have increased the capabilities of NLP techniques and reinforced interest in ML research (Lauriola et al. 2022). In the literature population, 49 out of the 75 studies assigned to text data show the application of DL techniques. We see this trend confirmed by the recent developments of generative AI tools like ChatGPT that further boost NLP’s capabilities. For example, Drori and Te'eni (2023) discuss the use of large language models for peer-reviewing purposes in academia.
Conversely, the use of images and audio and signal data related to computer vision and speech recognition falls short in our SLR. However, computer vision, especially in the image recognition field, is used more frequently in other research communities, e.g., medicine (Esteva et al. 2021). For example, CNNs are applied for image-based cancer detection (e.g., Haenssle et al. 2018). Within our literature population, two studies in which image data is processed with AI address health-related issues (Pfeuffer et al. 2023; Zhang and Ram 2020). Another field that provides interesting use cases for computer vision is social media. Shin et al. (2020) use, among others, social media images to predict post popularity.
Therefore, we expect image processing to grow in future IS research based on two arguments. First, computer vision, especially image analysis, yields high maturity. For example, CNNs achieve superhuman performances in image classification tasks (Haenssle et al. 2018). Second, our SLR shows that many IS publications that use AI algorithms tackle health care and social media-related research questions. Both of these fields embrace use cases related to images.
In the broader management research scope, audio and signal data processing draws less attention. Based on this observation, we make two main arguments. First, the input data format, such as voice recordings, is unusual for management research issues and impractical to handle. Second, even if audio and signal data are required to process voice recordings, researchers can use established software tools to create transcripts and then process them via NLP. Hence, IS researchers may see fewer opportunities to contribute to the field of speech recognition.
4.2.5 Learning Behavior
Goodfellow et al. (2020) state that most of today’s AI approaches are based on supervised ML. We confirm this with our SLR by counting, of 175 assignments in total, 112 to supervised learning, 10 to semi-supervised learning, 47 to unsupervised learning, and six to reinforcement learning.
Semi-supervised and reinforcement learning algorithms, rarer than supervised and unsupervised ones, allow learning with fewer data amounts or even without labeled data. For example, Ebrahimi et al. (2020) present a semi-supervised learning approach to identify cyber threats on dark net marketplaces. They address the fact that data obtained from web platforms is usually unlabeled, and manual labeling “requires expensive human labor and expertise” (Ebrahimi et al. 2020, p. 696). Liebman et al. (2019) entirely bypass the need for labeled training data. Based on real-time interaction with the listener, they use reinforcement learning to adapt music playlist generation, since personal music preferences can vary for the same person under different circumstances (Liebman et al. 2019). Given the maturity and corresponding achievements in research and practice of semi-supervised and reinforcement learning, we see them as areas with great potential for future IS and management research. Semi-supervised learning allows the use of ML, though labeled data may be sparse. Reinforcement learning allows the integration of real-time feedback within an agent’s environment. Furthermore, it has significantly contributed to AI milestones, i.e., AlphaGo in 2016 (Haenlein and Kaplan 2019).
4.2.6 Deep Learning
We find that 92 of our 143 studies use advanced DL algorithms. Deep learning is associated with major breakthroughs in AI (Jordan and Mitchell 2015) in all branches, i.e., NLP (Lauriola et al. 2022; Li 2017), computer vision (Voulodimos et al. 2018), speech recognition (Nassif et al. 2019), and ML (Sarker 2021). The strong presence of DL in our literature population confirms that IS effectively uses the advantages of DL algorithms. However, we see a large increase in DL studies in the 2020s. In studies of our SLR published between 2016 and 2019, approximately every fourth one uses DL. Deep learning studies published in the 2020s come in at greater than 75%. We illustrate the relative share of DL within our literature population over time in Fig. 2. Based on this finding and since DL advances rapidly, embracing new use cases and opportunities, we expect the share of DL in AI-related IS research to stay high.

Relative share of DL articles by time
4.2.7 Explainable Ai
Our results show that 16 articles explicitly address xAI. Comparable to DL, xAI use increased within our literature population over the years: between 2016 and 2019, no study addresses xAI. With one article in 2020, two articles in 2021, six articles in 2022, and seven articles in 2023, the topic of xAI becomes increasingly relevant in later publication dates. Given the importance of transparency in AI recommendations, we expect the share of xAI-related articles to continue to grow.
4.2.8 Ai Algorithms
Table 7 shows the absolute frequency of AI algorithms within the literature population. In the following, we highlight the most frequently used algorithms. Artificial neural networks are particularly present. Sixty-one studies use MLPs, 51 use CNNs, 59 use RNNs, and eight use GANs. Regarding legacy ML algorithms, 69 studies use SVMs, and 56 use either DTs or RFs or both. Latent Dirichlet allocation (LDA) is applied in 28 studies. While reviewing our literature population, we found 84 algorithms that are not included in our framework. Particularly present are graph-based learning algorithms and hidden Markov models, with nine and four articles, respectively. Due to the specialization of the remaining algorithms, we refrain from discussing them in more detail. We reference our coding results in the “6.” of this study, which provides details on the algorithms of our SLR.
Comparable to the section input data, the distribution of AI algorithms applied in the reviewed literature supports previous findings. For example, the prevalence of artificial neural networks, i.e., MLPs, CNNs, RNNs, and GANs, reinforces the prevalence of DL in IS research, since these algorithms all belong to the field of DL.
Besides advanced DL algorithms, we find legacy ML algorithms widely applied in the reviewed literature, especially for benchmarking. For example, SVM, the most frequently applied algorithm in our study, was introduced in the early 1990s (Zoppis et al. 2019), DTs in the 1980s (Russell and Norvig 2010), and LDA in the early 2000s (Blei et al. 2003).
We have already outlined the potential of generative and reinforcement methods in previous sections. The sparse applications of GANs and reinforcement learning algorithms we found support our impression that generative and reinforcement algorithms are underrepresented in IS research. This is in spite of the current cultural and media attention paid to generative AI and its underlying language models. However, we expect a steep increase in research on generative AI over the next few years.
5 Outlook, Contribution, And Limitations
5.1 Avenues For Research
Computer vision, semi-supervised learning, reinforcement learning, and generative algorithms fall short in the reviewed studies, although they show great potential for IS. Computer vision is a branch of AI that deals with a computer’s ability to perceive objects. Especially in the field of image recognition, the literature and use cases offer established algorithms and examples of high-performance implementation. Because of the unstructured data represented in images, researchers using traditional approaches often disregard images as information sources. We encourage IS researchers to benefit from the capabilities of computer vision algorithms. For example, social media is a thriving research topic in IS, offering access to large amounts of content-rich image data. Researchers may use computer vision to exploit research questions primarily based on image information. They could also enrich other approaches with additional information gained through image analysis. Convolutional neural networks represent the most common DL image recognition algorithm and offer a well-described starting point (e.g., Voulodimos et al. 2018) for future research with several sample IS use cases (e.g., Shin et al. 2020; Zhang and Ram 2020).
Semi-supervised learning lets partially labeled data sets be processed. Thus, it provides a workaround if large amounts of labeled training data are unavailable or too costly. Hence, we see potential for semi-supervised learning algorithms to advance IS research. For example, many researchers in our SLR investigate data from social media or the internet. Both offer nearly inexhaustible amounts of unlabeled data. Semi-supervised learning may let research gaps in these fields be exploited by processing data with ML while keeping the underlying labeling effort manageable. Researchers may consider examples of semi-supervised learning in our literature population as a starting point for future research (e.g., Ebrahimi et al. 2020; Zhang and Ram 2020).
Instead of learning from historical data, reinforcement learning adapts to real-time feedback from an agent’s environment. As previously noted, we attribute the potential of reinforcement learning to past achievements that prove the capabilities of this methodology. We find many potential use cases for reinforcement learning in management research areas. These offer qualified environments for feedback-based adaption. For example, many studies in our SLR address research questions in the fields of e-commerce and social media. These may offer opportunities to receive feedback from buyers or users. With the example of Liebman et al. (2019) in our SLR, we encourage researchers to pursue opportunities to leverage the advantages of reinforcement learning in future studies.
Lastly, generative algorithms may help researchers explore new use cases and research questions. Generative algorithms embrace creativity within AI and give high-quality outputs if trained accordingly. For management research use cases, generative algorithms may create marketing and social media content or simulate cyber-attacks to test and improve cybersecurity. One of the most renowned generative algorithms is GAN, explicated by Goodfellow et al. (2020), and represented in our literature population (Ebrahimi et al. 2022; Golovianko et al. 2022). Moreover, since language models have gained so much attention as an underlying technique for the generative AI breakthrough in 2023, we expect them to represent many AI use cases in research going forward.
5.2 Contribution
We contribute to the literature in several ways. First, we conduct an SLR to analyze the application areas, methods, and algorithms of applied AI in leading IS journals. Our work extends existing literature and improves the transparency of the opaque landscape of applied AI. For every article we review, we include our coding methodology and results on both an aggregate and a granular level to shed light on the use of AI in IS. In doing so, we aim to provide a knowledge base for the overall dynamics as well as the specific characteristics of applied AI on a more detailed level. For example, our results allow researchers to analyze how the use of AI algorithms relates to certain journals, publication dates, industry sectors, or functional areas. Furthermore, the overview of the applied AI landscape in IS elucidates the convergence of the areas of computer science and management research within IS.
Second, we introduce a conceptual framework of eight dimensions that disaggregates the evolving research domain of applied AI, improving tangibility and providing a practicable structure. We use the framework within the field of IS, but its structure is transferrable to other management research domains. Considering the absence of a concise AI definition and taxonomy in business (Collins et al. 2021; Samoili et al. 2020; Wirtz et al. 2019), our framework may guide future analyses of AI in management research and stimulate theory building (Rowe 2014; Templier and Paré 2015).
Third, we use IS literature to inform the research community about recent developments in the AI landscape and provide insights that may be transferrable to the broader management research domain. We identify topics that have gained increasing attention, e.g., xAI, as well as underrepresented AI algorithms that hold potential for future research, such as generative algorithms and reinforcement learning. Hence, our study enables scholars to identify gaps in the field of applied AI and to further extend and strengthen its use in IS and the broader management research domain.
5.3 Limitations
As with any study, there are some limitations to our review. First, we limit our literature search to a selection of leading IS journals. While we believe that the literature selection suits our purpose, this restriction may exclude relevant work.
Second, we structure the review according to the framework we have introduced here, which increases transparency and tangibility in using AI in IS research. However, we stress that our conceptual framework is not mutually exclusive or collectively exhaustive. Other possibilities for structuring an SLR to address our research question may exist.
Third, the SLR’s spectrum of application areas, methods, and algorithms appears broad. Future studies could focus on specific dimensions of our conceptual framework or specific AI algorithms to evaluate findings even more granularly.
Fourth, we consider AI a highly dynamic and continuously evolving field of research. We see this in the drastic shift of attention towards AI algorithms after the introduction of ChatGPT. We expect significant changes in the kind of algorithms used in research and practice in the future. Therefore, the findings of this SLR must be continuously monitored and updated to allow for a real-time perspective on this research field in flux.
6 Conclusion
This study conducts an SLR to answer the research question “What is the current state of applied AI algorithms in IS, and how can extant research be synthesized?”. To break down the research question for analysis, we propose a conceptual framework to increase transparency about the application areas, methods, and algorithms of applied AI in IS research. We analyze 143 articles from leading IS journals, finding that the number of AI publications per year, and the relative share of articles per year addressing DL and xAI, significantly increase within our SLR’s observation period. The use of AI falls into distinct topic clusters regarding the functional area and industry sector. Supervised algorithms predictively using numerical or text data dominate our literature population. Furthermore, our SLR shows that only a few studies use computer vision, semi-supervised learning, reinforcement learning, and generative algorithms. These algorithm types have potential for use cases in IS and management research in general. Therefore, we identify them as underrepresented and suggest that they offer promising fields for research avenues.
Notes
In the area of operations research and management science.
According to the number of publications between January 2016 and June 2022 in the following top-tier management research journals with “artificial intelligence,” “machine learning”, or “deep learning” in their title, abstract, or keywords, found on EBSCO host: Academy of Management Review, Information Systems Research, International Journal of Research in Marketing, Journal of Economic Behavior & Organization, Journal of Marketing Research, Journal of Management Information Systems, Journal of Service Research, Journal of the Academy of Marketing Science, Journal of Marketing, Management Science, Marketing Science, MIS Quarterly, Organization Science, Production and Operations Management, Research Policy, Strategic Management Journal.
IS journals account for more than 25% of AI-related publications of our EBSCOhost search explained in footnote 2.
Assignment of more than one industry sector per study is permitted. The relative frequency is calculated by the number of assignments per industry sector divided by the sum of assignments.
References
Abbasi A, Li JJ, Adjeroh D, Abate M, Zheng WH (2019) Don’t mention it? Analyzing user-generated content signals for early adverse event warnings. Inf Syst Res 30(3):1007–1028. https://doi.org/10.1287/isre.2019.0847
Abbasi A, Dobolyl D, Vance A, Zahedi FM (2021) The phishing funnel model: a design artifact to predict user susceptibility to phishing websites. Inf Syst Res 32(2):410–436. https://doi.org/10.1287/isre.2020.0973
Abdel-Karim BM, Pfeuffer N, Hinz O (2021) Machine learning in information systems—a bibliographic review and open research issues. Electron Mark 31(3):643–670. https://doi.org/10.1007/s12525-021-00459-2
Adamopoulos P, Ghose A, Todri V (2018) The impact of user personality traits on word of mouth: text-mining social media platforms. Inf Syst Res 29(3):612–640. https://doi.org/10.1287/isre.2017.0768
Adamopoulos P, Ghose A, Tuzhilin A (2022) Heterogeneous demand effects of recommendation strategies in a mobile application: evidence frome conometric models and machine-learning instruments. MIS Quart 46(1):101–150. https://doi.org/10.25300/misq/2021/15611
Ampel BM, Samtani S, Zhu H, Chen H (2024a) Creating proactive cyber threat intelligence with hacker exploit labels: a deep transfer learning approach. MIS Quart 48(1):137–166. https://doi.org/10.25300/MISQ/2023/17316
Ampel BM, Samtani S, Zhu HY, Chen HC, Nunamaker JF (2024b) Improving threat mitigation through a cybersecurity risk management framework: a computational design science approach. J Manag Inf Syst 41(1):236–265. https://doi.org/10.1080/07421222.2023.2301178
Balster A, Hansen O, Friedrich H, Ludwig A (2020) An ETA prediction model for intermodal transport networks based on machine learning. Bus Inf Syst Eng 62(5):403–416. https://doi.org/10.1007/s12599-020-00653-0
Bartelheimer C, de Heiden P, Lüttenberg H, Beverungen D (2022) Systematizing the lexicon of platforms in information systems: a data-driven study. Electron Mark 32(1):375–396. https://doi.org/10.1007/s12525-022-00530-6
Ben-Assuli O, Padman R (2020) Trajectories of repeated readmissions of chronic disease patients: risk stratification, profiling and prediction. MIS Quart 44(1):201–226. https://doi.org/10.25300/misq/2020/15101
Benjamin V, Raghu TS (2022) Augmenting social bot detection with crowd-generated labels. Inf Syst Res. https://doi.org/10.1287/isre.2022.1136
Berente N, Bin G, Recker J, Santhanam R (2021) Managing artificial intelligence. MIS Quart 45(3):1433–1450. https://doi.org/10.25300/MISQ/2021/16274
Binder M, Heinrich B, Hopf M, Schiller A (2022) Global reconstruction of language models with linguistic rules—explainable AI for online consumer reviews. Electron Mark 32(4):2123–2138. https://doi.org/10.1007/s12525-022-00612-5
Blei DM (2012) Probabilistic topic models. Commun ACM 55(4):77–84. https://doi.org/10.1145/2133806.2133826
Blei DM, Ng AY, Jordan MI, Lafferty J (2003) Latent Dirichlet allocation. J Mach Learn Res 3(4/5):993–1022
Brusch I (2022) Identification of travel styles by learning from consumer-generated images in online travel communities. Inf Manag 59(6):103682. https://doi.org/10.1016/j.im.2022.103682
Cannella AA, Park J, Lee H (2008) Top management team functional background diversity and firm performance: examining the roles of team member colocation and environmental uncertainty. Acad Manag J 51(4):768–784. https://doi.org/10.5465/amr.2008.33665310
Carpenter MA, Fredrickson JW (2001) Top management teams, global strategic posture, and the moderating role of uncertainty. Acad Manag J 44(3):533–545. https://doi.org/10.2307/3069368
Chai Y, Liu H, Zhu H, Pan Y, Zhou A, Liu H, Liu J, Qian Y (2024) A profile similarity-based personalized federated learning method for wearable sensor-based human activity recognition. Inf Manag. https://doi.org/10.1016/j.im.2024.103922
Chang YC, Ku CH, Nguyen DDL (2022) Predicting aspect-based sentiment using deep learning and information visualization: the impact of COVID-19 on the airline industry. Inf Manag 59(2):103587. https://doi.org/10.1016/j.im.2021.103587
Chatterjee S, Byun J, Dutta K, Pedersen RU, Pottathil A, Xie H (2018) Designing an internet-of-things (IoT) and sensor-based in-home monitoring system for assisting diabetes patients: iterative learning from two case studies. Eur J Inf Syst 27(6):670–685. https://doi.org/10.1080/0960085x.2018.1485619
Chau M, Li TMH, Wong PWC, Xu JJ, Yip PSF, Chen H (2020) Finding people with emotional distress in online social media: a design combining machine learning and rule-based classification. MIS Quart 44(2):933–955. https://doi.org/10.25300/misq/2020/14110
Chen C, Walker D (2022) A bitter pill to swallow? The consequences of patient evaluation in online health question-and-answer platforms. Inf Syst Res 34(3):811–1319. https://doi.org/10.1287/isre.2022.1158
Chen G, Xiao S, Zhang C, Zhao H (2023) A theory-driven deep learning method for voice chat-based customer response prediction. Inf Syst Res 34(4):1513–1532. https://doi.org/10.1287/isre.2022.1196
Clark K, Luong MT, Le QV, Manning CD (2020) Electra: pre-training text encoders as discriminators rather than generators. Inf Syst Res. https://doi.org/10.48550/arXiv.2003.10555
Clarke J, Chen HL, Du D, Hu YJ (2021) Fake news, investor attention, and market reaction. Inf Syst Res 32(1):35–52. https://doi.org/10.1287/isre.2019.0910
Collins C, Dennehy D, Conboy K, Mikalef P (2021) Artificial intelligence in information systems research: a systematic literature review and research agenda. Int J Inf Manag 60:102383. https://doi.org/10.1016/j.ijinfomgt.2021.102383
Confalonieri R, Coba L, Wagner B, Besold TR (2021) A historical perspective of explainable artificial intelligence. Wires Data Min Knowl Discov 11(1):e1391. https://doi.org/10.1002/widm.1391
Creswell A, White T, Dumoulin V, Arulkumaran K, Sengupta B, Bharath AA (2018) Generative adversarial networks: an overview. IEEE Signal Process Mag 35:53–65. https://doi.org/10.1109/msp.2017.2765202
Dong W, Liao SY, Zhang ZJ (2018) Leveraging financial social media data for corporate fraud detection. J Manag Inf Syst 35(2):461–487. https://doi.org/10.1080/07421222.2018.1451954
Doran D, Schulz S, Besold TR (2017) What does explainable AI really mean? A new conceptualization of perspectives. arXiv preprint arXiv:1710.00794. https://doi.org/10.48550/arXiv.1710.00794
Drori I, Te’eni D (2023) Human-in-the-loop AI reviewing: feasibility, opportunities, and risks. J Assoc Inf Syst 25(1):98–109. https://doi.org/10.17705/1jais.00867
Ebrahimi M, Nunamaker JF, Chen HC (2020) Semi-supervised cyber threat identification in dark net markets: a transductive and deep learning approach. J Manag Inf Syst 37(3):694–722. https://doi.org/10.1080/07421222.2020.1790186
Ebrahimi M, Chai YD, Samtani S, Chen H (2022) Cross-lingual cybersecurity analytics in the international dark web with adversarial deep representation learning. MIS Quart 46(2):1209–1226. https://doi.org/10.25300/misq/2022/16618
Esmeli R, Bader-El-Den M, Abdullahi H (2021) Towards early purchase intention prediction in online session based retailing systems. Electron Mark 31(3):697–715. https://doi.org/10.1007/s12525-020-00448-x
Esteva A, Chou K, Yeung S, Naik N, Madani A, Mottaghi A, Liu Y, Topol E, Dean J, Socher R (2021) Deep learning-enabled medical computer vision. Npj Digit Med 4(1):5. https://doi.org/10.1038/s41746-020-00376-2
Fang X, Hu PJH (2018) Top persuader prediction for social networks. MIS Quart 42(1):63. https://doi.org/10.25300/misq/2018/13211
Feldman R (2013) Techniques and applications for sentiment analysis. Commun ACM 56(4):82–89. https://doi.org/10.1145/2436256.2436274
Folino F, Folino G, Guarascio M, Pontieri L (2022) Semi-supervised discovery of DNN-based outcome predictors from scarcely-labeled process logs. Bus Inf Syst Eng 64(6):729–749. https://doi.org/10.1007/s12599-022-00749-9
Fosso Wamba S, Bawack RE, Guthrie C, Queiroz MM, Carillo KDA (2021) Are we preparing for a good AI society? A bibliometric review and research agenda. Technol Forecast Soc Change 164:120482. https://doi.org/10.1016/j.techfore.2020.120482
Fu RS, Huang Y, Singh PV (2021) Crowds, lending, machine, and bias. Inf Syst Res 32(1):72–92. https://doi.org/10.1287/isre.2020.0990
Gaikwad SK, Gawali BW, Yannawar P (2010) A review on speech recognition technique. Int J Comput Appl 10(3):16–24. https://doi.org/10.5120/1462-1976
Ghiassi M, Zimbra D, Lee S (2016) Targeted Twitter sentiment analysis for brands using supervised feature engineering and the dynamic architecture for artificial neural networks. J Manag Inf Syst 33(4):1034–1058. https://doi.org/10.1080/07421222.2016.1267526
Gleue C, Eilers D, von Mettenheim HJ, Breitner MH (2019) Decision support for the automotive industry forecasting residual values using artificial neural networks. Bus Inf Syst Eng 61(4):385–397. https://doi.org/10.1007/s12599-018-0527-3
Golovianko M, Gryshko S, Terziyan V, Tuunanen T (2022) Responsible cognitive digital clones as decision-makers:a design science research study. Eur J Inf Syst. https://doi.org/10.1080/0960085x.2022.2073278
Gong J, Abhishek V, Li BB (2018) Examining the impact of keyword ambiguity on search advertising performance: a topic model approach. MIS Quart 42(3):805. https://doi.org/10.25300/misq/2018/14042
Goodfellow I, Bengio Y, Courville A (2016) Deep learning. MIT Press, Cambridge
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2020) Generative adversarial networks. Commun ACM 63(11):139–144. https://doi.org/10.1145/3422622
Gramegna A, Giudici P (2021) SHAP and LIME: an evaluation of discriminative power in credit risk. Front Artif Intell. https://doi.org/10.3389/frai.2021.752558
Groeneveld J, Herrmann J, Mollenhauer N, Dreessen L, Bessin N, Tast JS, Kastius A, Huegle J, Schlosser R (2023) Self-learning agents for recommerce markets. Bus Inf Syst Eng. https://doi.org/10.1007/s12599-023-00841-8
Guan C, Hung YC, Liu W (2022) Cultural differences in hospitality service evaluations: mining insights of user generated content. Electron Mark 32(3):1061–1081. https://doi.org/10.1007/s12525-022-00545-z
Gunarathne P, Rui HX, Seidmann A (2022) Racial bias in customer service: evidence from Twitter. Inf Syst Res 33(1):43–54. https://doi.org/10.1287/isre.2021.1058
Guo J, Zhang W, Fan W, Li W (2018) Combining geographical and social influences with deep learning for personalized point-of-interest recommendation. J Manag Inf Syst 35(4):1121–1153. https://doi.org/10.1080/07421222.2018.1523564
Haenlein M, Kaplan A (2019) A brief history of artificial intelligence: on the past, present, and future of artificial intelligence. Calif Manag Rev 61(4):5–14. https://doi.org/10.1177/0008125619864925
Haenssle HA, Fink C, Schneiderbauer R, Toberer F, Buhl T, Blum A, Kalloo A, Hassen ABH, Thomas L, Enk A, Uhlmann L, Alt C, Arenbergerova M, Bakos R, Baltzer A, Bertlich I, Blum A, Bokor-Billmann T, Bowling J, Braghiroli N, Braun R, Buder-Bakhaya K, Buhl T, Cabo H, Cabrijan L, Cevic N, Classen A, Deltgen D, Fink C, Georgieva I, Hakim-Meibodi L-E, Hanner S, Hartmann F, Hartmann J, Haus G, Hoxha E, Karls R, Koga H, Kreusch J, Lallas A, Majenka P, Marghoob A, Massone C, Mekokishvili L, Mestel D, Meyer V, Neuberger A, Nielsen K, Oliviero M, Pampena R, Paoli J, Pawlik E, Rao B, Rendon A, Russo T, Sadek A, Samhaber K, Schneiderbauer R, Schweizer A, Toberer F, Trennheuser L, Vlahova L, Wald A, Winkler J, Wölbing P, Zalaudek I (2018) Man against machine: diagnostic performance of a deep learning convolutional neural network for dermoscopic melanoma recognition in comparison to 58 dermatologists. Ann Oncol 29(8):1836–1842. https://doi.org/10.1093/annonc/mdy166
Han J, Pei J, Tong H (2012) Data mining: concepts and techniques, 3rd edn. Morgan Kaufmann Publishers
Han X, Wang LY, Fan WG (2021) Is hidden safe? Location protection against machine-learning prediction attacks in social networks. MIS Quart 45(2):821–858. https://doi.org/10.25300/misq/2021/16266
He JN, Fang X, Liu HY, Li XD (2019) Mobile App recommendation: an involvement-enhanced approach. MIS Quart 43(3):827. https://doi.org/10.25300/misq/2019/15049
Hirt R, Kühl N, Satzger G (2019) Cognitive computing for customer profiling: meta classification for gender prediction. Electron Mark 29(1):93–106. https://doi.org/10.1007/s12525-019-00336-z
Hou JR, Zhang J, Zhang KP (2023) Pictures that are worth a thousand donations: how emotions in project images drive the success of online charity fundraising campaigns? An image design perspective. MIS Quart 47(2):535–583. https://doi.org/10.25300/misq/2022/17164
Johnson M, Murthy D, Robertson BW, Smith WR, Stephens KK (2023) Moving emergency response forward: leveraging machine-learning classification of disaster-related images posted on social media. J Manag Inf Syst 40(1):163–182. https://doi.org/10.1080/07421222.2023.2172778
Jordan MI, Mitchell TM (2015) Machine learning: trends, perspectives, and prospects. Science 349(6245):255–260. https://doi.org/10.1126/science.aaa8415
Kalgotra P, Sharda R (2021) When will I get out of the hospital? Modeling length of stay using comorbidity networks. J Manag Inf Syst 38(4):1150–1184. https://doi.org/10.1080/07421222.2021.1990618
Kannan K, Pamuru V, Rosokha Y (2023) Analyzing frictions in generalized second-price auction markets. Inf Syst Res 34(4):1437–1454. https://doi.org/10.1287/isre.2022.1187
Karanam SA, Agarwal A, Barua A (2022) Design for social sharing: the case of mobile apps. Inf Syst Res. https://doi.org/10.1287/isre.2022.1151
Kim B, Srinivasan K, Kong SH, Kim JH, Shin CS, Ram S (2023) Rolex: a novel method for interpretable machine learning using robust local explanations. MIS Quart 47(3):1303–1332. https://doi.org/10.25300/misq/2022/17141
King KK, Wang B, Escobari D, Oraby T (2021) Dynamic effects of falsehoods and corrections on social media: a theoretical modeling and empirical evidence. J Manag Inf Syst 38(4):989–1010. https://doi.org/10.1080/07421222.2021.1990611
Kitchenham B, Pearl Brereton O, Budgen D, Turner M, Bailey J, Linkman S (2009) Systematic literature reviews in software engineering—a systematic literature review. Inf Softw Technol 51(1):7–15. https://doi.org/10.1016/j.infsof.2008.09.009
Kitchenham B, Charters S (2007) Guidelines for performing Systematic literature reviews in software engineering. Retrieved December 28, 2022, from https://www.elsevier.com/__data/promis_misc/525444systematicreviewsguide.pdf
Kitchens B, Dobolyi D, Li JJ, Abbasi A (2018) Advanced customer analytics: strategic value through integration of relationship-oriented big data. J Manag Inf Syst 35(2):540–574. https://doi.org/10.1080/07421222.2018.1451957
Kokkodis M (2021) Dynamic, multidimensional, and skillset-specific reputation systems for online work. Inf Syst Res 32(3):688–712. https://doi.org/10.1287/isre.2020.0972
Kokkodis M, Lappas T, Ransbotham S (2020) From lurkers to workers: predicting voluntary contribution and community welfare. Inf Syst Res 31(2):607–626. https://doi.org/10.1287/ISRE.2019.0905
Krahe C, Bräunche A, Jacob A, Stricker N, Lanza G (2020) Deep learning for automated product design. Proc CIRP 91:3–8. https://doi.org/10.1016/j.procir.2020.01.135
Kratsch W, Manderscheid J, Röglinger M, Seyfried J (2021) Machine learning in business process monitoring: a comparison of deep learning and classical approaches used for outcome prediction. Bus Inf Syst Eng 63(3):261–276. https://doi.org/10.1007/s12599-020-00645-0
Krishnan J, Press E (2003) The North American industry classification system and its implications for accounting research. Contemp Account Res 20(4):685–717. https://doi.org/10.1506/N57L-0462-856V-7144
Kuehl N, Muehlthaler M, Goutier M (2020) Supporting customer-oriented marketing with artificial intelligence: automatically quantifying customer needs from social media. Electron Mark 30(2):351–367. https://doi.org/10.1007/s12525-019-00351-0
Kumar N, Venugopal D, Qiu L, Kumar S (2018) Detecting review manipulation on online platforms with hierarchical supervised learning. J Manag Inf Syst 35(1):350–380. https://doi.org/10.1080/07421222.2018.1440758
Kumar N, Venugopal D, Qiu LF, Kumar S (2019) Detecting anomalous online reviewers: an unsupervised approach using mixture models. J Manag Inf Syst 36(4):1313–1346. https://doi.org/10.1080/07421222.2019.1661089
Kwark Y, Lee GM, Pavlou PA, Qiu LF (2021) On the spillover effects of online product reviews on purchases: evidence from clickstream data. Inf Syst Res 32(3):895–913. https://doi.org/10.1287/isre.2021.0998
Landwehr JP, Kühl N, Walk J, Gnädig M (2022) Design knowledge for deep-learning-enabled image-based decision support systems: evidence from power line maintenance decision-making. Bus Inf Syst Eng 64(6):707–728. https://doi.org/10.1007/s12599-022-00745-z
Larsen KR, Bong CH (2016) A tool for addressing construct identity in literature reviews and meta-analyses. MIS Quart 40(3):529–551. https://doi.org/10.25300/MISQ/2016/40.3.01
Larsen KR, Hovorka DS, Dennis AR, West JD (2019) Understanding the elephant: the discourse approach to boundary identification and corpus construction for theory review articles. J Assoc Inf Syst 20(7):887–927. https://doi.org/10.17705/1jais.00556
Lash MT, Zhao K (2016) Early predictions of movie success: the who, what, and when of profitability. J Manag Inf Syst 33(3):874–903. https://doi.org/10.1080/07421222.2016.1243969
Lauriola I, Lavelli A, Aiolli F (2022) An introduction to deep learning in natural language processing: models, techniques, and tools. Neurocomputing 470:443–456. https://doi.org/10.1016/j.neucom.2021.05.103
Lausen J, Clapham B, Siering M, Gomber P (2020) Who is the next “wolf of wall street”? Detection of financial intermediary misconduct. J Assoc Inf Syst 21(5):1153–1190. https://doi.org/10.17705/1jais.00633
Lee Y (2022) Identifying competitive attributes based on an ensemble of explainable artificial intelligence. Bus Inf Syst Eng 64(4):407–419. https://doi.org/10.1007/s12599-021-00737-5
Lee G, Xia W (2006) Organizational size and IT innovation adoption: a meta-analysis. Inf Manag 43(8):975–985. https://doi.org/10.1016/j.im.2006.09.003
Lee GM, Qiu LF, Whinston AB (2016) A friend like me: modeling network formation in a location-based social network. J Manag Inf Syst 33(4):1008–1033. https://doi.org/10.1080/07421222.2016.1267523
Lee GM, He S, Lee J, Whinston AB (2020) Matching mobile applications for cross-promotion. Inf Syst Res 31(3):865–891. https://doi.org/10.1287/isre.2020.0921
Li H (2017) Deep learning for natural language processing: advantages and challenges. Natl Sci Rev 5(1):24–26. https://doi.org/10.1093/nsr/nwx110
Li WF, Chen HC, Nunamaker JF (2016) Identifying and profiling key sellers in cyber carding community: AZSecure text mining system. J Manag Inf Syst 33(4):1059–1086. https://doi.org/10.1080/07421222.2016.1267528
Li T, van Dalen J, van Rees PJ (2018) More than just noise? Examining the information content of stock microblogs on financial markets. J Inf Technol 33(1):50–69. https://doi.org/10.1057/s41265-016-0034-2
Li ZP, Ge Y, Bai X (2021) What will be popular next? Predicting hotspots in two-mode social networks. MIS Quart 45(2):925–966. https://doi.org/10.25300/misq/2021/15365
Liébana-Cabanillas F, Kalinic Z, Muñoz-Leiva F, Higueras-Castillo E (2024) Biometric m-payment systems: a multi-analytical approach to determining use intention. Inf Manag 61(2):103907. https://doi.org/10.1016/j.im.2023.103907
Liebman E, Saar-Tsechansky M, Stone P (2019) The right music at the right time: adaptive personalized playlists based on sequence modeling. MIS Quart 43(3):765. https://doi.org/10.25300/misq/2019/14750
Lin YK, Fang X (2021) First, do no harm: predictive analytics to reduce in-hospital adverse events. J Manag Inf Syst 38(4):1122–1149. https://doi.org/10.1080/07421222.2021.1990619
Lin YK, Chen HC, Brown RA, Li SH, Yang HJ (2017) Healthcare predictive analytics for risk profiling in chronic care: a bayesian multitask learning approach. MIS Quart 41(2):473. https://doi.org/10.25300/misq/2017/41.2.07
Liu R, Mai F, Shan Z, Wu Y (2020a) Predicting shareholder litigation on insider trading from financial text: an interpretable deep learning approach. Inf Manag 57(8):103387. https://doi.org/10.1016/j.im.2020.103387
Liu X, Zhang B, Susarla A, Padman R (2020b) Go to youtube and call me in the morning: use of social media for chronic conditions. MIS Quart 44(1):257–283. https://doi.org/10.25300/misq/2020/15107
Liu YY, Pant G, Sheng ORL (2020c) Predicting labor market competition: leveraging interfirm network and employee skills. Inf Syst Res 31(4):1443–1466. https://doi.org/10.1287/isre.2020.0954
Liu AX, Li Y, Xu SX (2021) Assessing the unacquainted: inferred reviewer personality and review helpfulness. MIS Quart 45(3):1113–1148. https://doi.org/10.25300/MISQ/2021/14375
Lukyanenko R, Parsons J, Wiersma YF, Maddah M (2019) Expecting the unexpected: effects of data collection design choices on the quality of crowdsourced user-generated content. MIS Quart 43(2):623. https://doi.org/10.25300/misq/2019/14439
Luo XM, Lu XH, Li J (2019) When and how to leverage e-commerce cart targeting: the relative and moderated effects of scarcity and price incentives with a two-stage field experiment and causal forest optimization. Inf Syst Res 30(4):1203–1227. https://doi.org/10.1287/isre.2019.0859
Lycett M, Radwan O (2019) Developing a quality of experience (QoE) model for web applications. Inf Syst J 29(1):175–199. https://doi.org/10.1111/isj.12192
Ma L, Sun B (2020) Machine learning and AI in marketing—connecting computing power to human insights. Int J Res Mark 37(3):481–504. https://doi.org/10.1016/j.ijresmar.2020.04.005
Mahesh B (2020) Machine learning algorithms-a review. Int J Sci Res 9:381–386. https://doi.org/10.21275/ART20203995
Malik N, Singh PV, Srinivasan K (2023) When does beauty pay? A large-scale image-based appearance analysis on career transitions. Inf Syst Res. https://doi.org/10.1287/isre.2021.0559
Mariani MM, Perez-Vega R, Wirtz J (2022) AI in marketing, consumer research and psychology: a systematic literature review and research agenda. Psychol Mark 39(4):755–776. https://doi.org/10.1002/mar.21619
McFowland E, Gangarapu S, Bapna R, Sun TS (2021) A prescriptive analytics framework for optimal policy deployment using heterogeneous treatment effects. MIS Quart 45(4):1807–1832. https://doi.org/10.25300/misq/2021/15684
Medhat W, Hassan A, Korashy H (2014) Sentiment analysis algorithms and applications: a survey. Ain Shams Eng J 5(4):1093–1113. https://doi.org/10.1016/j.asej.2014.04.011
Mehdiyev N, Evermann J, Fettke P (2020) A novel business process prediction model using a deep learning method. Bus Inf Syst Eng 62(2):143–157. https://doi.org/10.1007/s12599-018-0551-3
Mejia J, Mankad S, Gopal A (2019) A for effort? Using the crowd to identify moral hazard in New York City restaurant hygiene inspections. Inf Syst Res 30(4):1363–1386. https://doi.org/10.1287/isre.2019.0866
Michel JG, Hambrick DC (1992) Diversification posture and top management team characteristics. Acad Manag J 35(1):9–37. https://doi.org/10.2307/256471
Mohammed M, Khan M, Bashier E (2016) Machine learning: algorithms and applications, vol 1. CRC Press. https://doi.org/10.1201/9781315371658
Mousavi R, Raghu TS, Frey K (2020) Harnessing artificial intelligence to improve the quality of answers in online question-answering health forums. J Manag Inf Syst 37(4):1073–1098. https://doi.org/10.1080/07421222.2020.1831775
Muller O, Junglas I, vom Brocke J, Debortoli S (2016) Utilizing big data analytics for information systems research: challenges, promises and guidelines. Eur J Inf Syst 25(4):289–302. https://doi.org/10.1057/ejis.2016.2
Nasir M, Dag A, Simsek S, Ivanov A, Oztekin A (2022) Improving imbalanced machine learning with neighborhood-informed synthetic sample placement. J Manag Inf Syst 39(4):1116–1145. https://doi.org/10.1080/07421222.2022.2127453
Nassif AB, Shahin I, Attili I, Azzeh M, Shaalan K (2019) Speech recognition using deep neural networks: a systematic review. IEEE Access 7:19143–19165. https://doi.org/10.1109/ACCESS.2019.2896880
Padmanabhan B, Xiao F, Sahoo N, Burton-Jones A (2022) Machine learning in information systems research. MIS Quart 46(1):3–18. https://doi.org/10.1007/s12525-021-00459-2
Pfeiffer J, Pfeiffer T, Meissner M, Weiss E (2020) Eye-tracking-based classification of information search behavior using machine learning: evidence from experiments in physical shops and virtual reality shopping environments. Inf Syst Res 31(3):675–691. https://doi.org/10.1287/isre.2019.0907
Pfeuffer N, Baum L, Stammer W, Abdel-Karim BM, Schramowski P, Bucher AM, Hügel C, Rohde G, Kersting K, Hinz O (2023) Explanatory interactive machine learning: establishing an action design research process for machine learning projects. Bus Inf Syst Eng 65(6):677–701. https://doi.org/10.1007/s12599-023-00806-x
Pocher N, Zichichi M, Merizzi F, Shafiq MZ, Ferretti S (2023) Detecting anomalous cryptocurrency transactions: an AML/CFT application of machine learning-based forensics. Electron Mark 33(1):37. https://doi.org/10.1007/s12525-023-00654-3
Porter ME, Millar VE (1985) How information gives you competitive advantage. Harv Bus Rev 63(4):149–160
Ptaszynski M, Lempa P, Masui F, Kimura Y, Rzepka R, Araki K, Wroczynski M, Leliwa G (2019) Brute-force sentence pattern extortion from harmful messages for cyberbullying detection. J Assoc Inf Syst 20(8):1075–1127. https://doi.org/10.17705/1jais.00562
Qamar U, Niza R, Bashir S, Khan FH (2016) A majority vote based classifier ensemble for web service classification. Bus Inf Syst Eng 58(4):249–259. https://doi.org/10.1007/s12599-015-0407-z
Raisch S, Krakowski S (2021) Artificial intelligence and management: the automation–augmentation paradox. Acad Manag Rev 46(1):192–210. https://doi.org/10.5465/amr.2018.0072
Ravenda D, Valencia-Silva MM, Argiles-Bosch JM, García-Blandón J (2022) The strategic usage of Facebook by local governments: a structural topic modelling analysis. Inf Manag 59(8):103704. https://doi.org/10.1016/j.im.2022.103704
Ravichandran T, Deng C (2023) Effects of managerial response to negative reviews on future review valence and complaints. Inf Syst Res 34(1):319–341. https://doi.org/10.1287/isre.2022.1122
Roh Y, Heo G, Whang SE (2021) A survey on data collection for machine learning: a big data—AI integration perspective. IEEE Trans Knowl Data Eng 33(4):1328–1347. https://doi.org/10.1109/TKDE.2019.2946162
Rowe F (2014) What literature review is not: diversity, boundaries and recommendations. Eur J Inf Syst 23(3):241–255. https://doi.org/10.1057/ejis.2014.7
Roy D, Srivastava R, Jat M, Karaca MS (2022) A complete overview of analytics techniques: descriptive, predictive, and prescriptive. In: Jeyanthi PM, Choudhury T, Hack-Polay D, Singh TP, Abujar S (eds) Decision intelligence analytics and the implementation of strategic business management. Springer, New York, pp 15–30. https://doi.org/10.1007/978-3-030-82763-2_2
Russell SJ, Norvig P (2010) Artificial intelligence: a modern approach, 3rd edn. Prentice Hall
Ryoba MJ, Qu S, Zhou Y (2021) Feature subset selection for predicting the success of crowdfunding project campaigns. Electron Mark 31(3):671–684. https://doi.org/10.1007/s12525-020-00398-4
Salovaara A, Upreti BR, Nykänen JI, Merikivi J (2020) Building on shaky foundations? Lack of falsification and knowledge contestation in IS theories, methods, and practices. Eur J Inf Syst 29(1):65–83. https://doi.org/10.1080/0960085X.2019.1685737
Samoili S, López Cobo M, Gómez E, De Prato G, Martínez-Plumed F, Delipetrev B (2020) AI watch: defining artificial intelligence: towards an operational definition and taxonomy of artificial intelligence. Publications Office of the European Union. Retrieved December 28, 2022, from https://data.europa.eu/doi/10.2760/382730
Samtani S, Chai YD, Chen HC (2022) Linking exploits from the dark web to known vulnerabilities for proactive cyber threat intelligence: an attention-based deep structured semantic model. MIS Quart 46(2):911–946. https://doi.org/10.25300/misq/2022/15392
Sarker IH (2021) Machine learning: algorithms, real-world applications and research directions. SN Comput Sci 2(3):160. https://doi.org/10.1007/s42979-021-00592-x
Schaller RR (1997) Moore’s law: past, present and future. IEEE Spectr 34(6):52–59. https://doi.org/10.1109/6.591665
See-To EWK, Yang Y (2017) Market sentiment dispersion and its effects on stock return and volatility. Electron Mark 27(3):283–296. https://doi.org/10.1007/s12525-017-0254-5
Shajalal M, Boden A, Stevens G (2022) Explainable product backorder prediction exploiting CNN: introducing explainable models in businesses. Electron Mark 32(4):2107–2122. https://doi.org/10.1007/s12525-022-00599-z
Shalf J (2020) The future of computing beyond Moore’s Law. Philos Trans Roy Soc A Math Phys Eng Sci 378(2166):20190061. https://doi.org/10.1098/rsta.2019.0061
Shen RP, Liu D, Wei X, Zhang M (2022) Your posts betray you: detecting influencer-generated sponsored posts by finding the right clues. Inf Manag 59(8):103719. https://doi.org/10.1016/j.im.2022.103719
Shin D, He S, Lee GM, Whinston AB, Cetintas S, Lee KC (2020) Enhancing social media analysis with visual data analytics: a deep learning approach. MIS Quart 44(4):1459–1492. https://doi.org/10.25300/misq/2020/14870
Shuo Y, Yidong C, Hsinchun C, Sherman SJ (2022) Wearable sensor-based chronic condition severity assessment: an adversarial attention-based deep multisource multitask learning approach. MIS Quart 46(3):1355–1394. https://doi.org/10.25300/MISQ/2022/15763
Siering M, Muntermann J, Grcar M (2021) Design principles for robust fraud detection: the case of stock market manipulations. J Assoc Inf Syst 22(1):156–178. https://doi.org/10.17705/1jais.00657
Silver D, Schrittwieser J, Simonyan K, Antonoglou I, Huang A, Guez A, Hubert T, Baker L, Lai M, Bolton A, Chen Y, Lillicrap T, Hui F, Sifre L, van den Driessche G, Graepel T, Hassabis D (2017) Mastering the game of Go without human knowledge. Nature 550(7676):354–359. https://doi.org/10.1038/nature24270
Sun CS, Adamopoulos P, Ghose A, Luo XM (2022) Predicting stages in omnichannel path to purchase: a deep learning model. Inf Syst Res 33(2):429–445. https://doi.org/10.1287/isre.2021.1071
Syed R, Silva L (2023) Social movement sustainability on social media: an analysis of the women’s march movement on Twitter. J Assoc Inf Syst 24(1):249–293. https://doi.org/10.17705/1jais.00776
Templier M, Paré G (2015) A framework for guiding and evaluating literature reviews. Commun Assoc Inf Syst 37:112–137. https://doi.org/10.17705/1CAIS.03706
Templier M, Paré G (2018) Transparency in literature reviews: an assessment of reporting practices across review types and genres in top IS journals. Eur J Inf Syst 27(5):503–550. https://doi.org/10.1080/0960085X.2017.1398880
The European Commission’s High Level Expert Group on Artificial Intelligence (2018) A definition of AI: main capabilities and disciplines. European Commission. Retrieved December 28, 2022, from https://ec.europa.eu/futurium/en/system/files/ged/ai_hleg_definition_of_ai_18_december_1.pdf
Thirumuruganathan S, Al Emadi N, Jung SG, Salminen J, Robillos DR, Jansen BJ (2023) Will they take this offer? A machine learning price elasticity model for predicting upselling acceptance of premium airline seating. Inf Manag 60(3):103759. https://doi.org/10.1016/j.im.2023.103759
Tofangchi S, Hanelt A, Marz D, Kolbe LM (2021) Handling the efficiency-personalization trade-off in service robotics: a machine-learning approach. J Manag Inf Syst 38(1):246–276. https://doi.org/10.1080/07421222.2021.1870391
Vargas KL, Runge J, Zhang R (2022) Algorithmic assortative matching on a digital social medium. Inf Syst Res 33(4):1138–1156. https://doi.org/10.1287/isre.2022.1135
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. Adv Neural Inf Process Syst 30:1. https://doi.org/10.48550/arXiv.1706.03762
Vayansky I, Kumar SAP (2020) A review of topic modeling methods. Inf Syst 94:101582. https://doi.org/10.1016/j.is.2020.101582
Venkatesan S, Valecha R, Yaraghi N, Oh O, Rao HR (2021) Influence in social media: an investigation of tweets spanning the 2011 Egyptian revolution. MIS Quart 45(4):1679–1714. https://doi.org/10.25300/MISQ/2021/15297
Voulodimos A, Doulamis N, Doulamis A, Protopapadakis E (2018) Deep learning for computer vision: a brief review. Comput Intell Neurosci 2018:7068349. https://doi.org/10.1155/2018/7068349
Wang N, Sun SW, OuYang DT (2018a) Business process modeling abstraction based on semi-supervised clustering analysis. Bus Inf Syst Eng 60(6):525–542. https://doi.org/10.1007/s12599-016-0457-x
Wang Q, Li B, Singh PV (2018b) Copycats versus original mobile apps: a machine learning copycat-detection method and empirical analysis. Inf Syst Res 29(2):273–291. https://doi.org/10.1287/isre.2017.0735
Wang J, Ma Y, Huang Z, Xue R, Zhao R (2019) Performance analysis and enhancement of deep convolutional neural network: application to gearbox condition monitoring. Bus Inf Syst Eng 61(3):311–326. https://doi.org/10.1007/s12599-019-00593-4
Wang X, Ryoo JH, Bendle N, Kopalle PK (2021) The role of machine learning analytics and metrics in retailing research. J Retail 97(4):658–675. https://doi.org/10.1016/j.jretai.2020.12.001
Wang T, He C, Jin FJ, Hu YJ (2022a) Evaluating the effectiveness of marketing campaigns for malls using a novel interpretable machine learning model. Inf Syst Res 33(2):659–677. https://doi.org/10.1287/isre.2021.1078
Wang Y, Currim F, Ram S (2022b) Deep learning of spatiotemporal patterns for urban mobility prediction using big data. Inf Syst Res 33(2):579–598. https://doi.org/10.1287/isre.2021.1072
Wang YF, Yahav I, Padmanabhan B (2023) Smart testing with vaccination: a bandit algorithm for active sampling for managing COVID-19. Inf Syst Res. https://doi.org/10.1287/isre.2023.1215
Wei Q, Mu Y, Guo XH, Jiang WJ, Chen GQ (2023) Dynamic bayesian network-based product recommendation considering consumers’ multistage shopping journeys: a marketing funnel perspective. Inf Syst Res. https://doi.org/10.1287/isre.2020.0277
Wenninger S, Wiethe C (2021) Benchmarking energy quantification methods to predict heating energy performance of residential buildings in Germany. Bus Inf Syst Eng 63(3):223–242. https://doi.org/10.1007/s12599-021-00691-2
Wirtz BW, Weyerer JC, Geyer C (2019) Artificial intelligence and the public sector—applications and challenges. Int J Public Adm 42(7):596–615. https://doi.org/10.1080/01900692.2018.1498103
Wu J, Zheng ZQ, Zhao JL (2021) FairPlay: detecting and deterring online customer misbehavior. Inf Syst Res 32(4):1323–1346. https://doi.org/10.1287/isre.2021.1035
Xie JH, Zhang Z, Liu X, Zeng D (2021) Unveiling the hidden truth of drug addiction: a social media approach using similarity network-based deep learning. J Manag Inf Syst 38(1):166–195. https://doi.org/10.1080/07421222.2021.1870388
Xie JH, Liu X, Zeng DDJ, Fang X (2022) Understanding medication nonadherence from social media: a sentiment-enriched deep learning approach. MIS Quart 46(1):341–372. https://doi.org/10.25300/misq/2022/15336
Xie J, Chai Y, Liu X (2023) Unbox the black-box: predict and interpret youtube viewership using deep learning. J Manag Inf Syst 40(2):541–579. https://doi.org/10.1080/07421222.2023.2196780
Xiong J, Yu L, Zhang D, Leng Y (2021) DNCP: an attention-based deep learning approach enhanced with attractiveness and timeliness of news for online news click prediction. Inf Manag 58(2):103428. https://doi.org/10.1016/j.im.2021.103428
Xu JJ, Dongyu C, Chau M, Liting L, Haichao Z (2022) Peer-to-peer loan fraud detection: constructing features from transaction data. MIS Quart 46(3):1777–1792. https://doi.org/10.25300/MISQ/2022/16103
Xu D, Hu PJH, Fang X (2023a) Deep learning-based imputation method to enhance crowdsourced data on online business directory platforms for improved services. J Manag Inf Syst 40(2):624–654. https://doi.org/10.1080/07421222.2023.2196770
Xu R, Chen H, Zhao JL (2023b) SocioLink: leveraging relational information in knowledge graphs for startup recommendations. J Manag Inf Syst 40(2):655–682. https://doi.org/10.1080/07421222.2023.2196771
Xuan W, Zhu Z, Mingyue Z, Weiyun C, Dajun Zeng D (2022) Combining crowd and machine intelligence to detect false news on social media. MIS Quart 46(2):977–1008. https://doi.org/10.25300/MISQ/2022/16526
Yan B, Mai F, Wu CJ, Chen R, Li XL (2023) A computational framework for understanding firm communication during disasters. Inf Syst Res. https://doi.org/10.1287/isre.2022.0128
Yang K, Lau RYK, Abbasi A (2022a) Getting personal: a deep learning artifact for text-based measurement of personality. Inf Syst Res 30:24. https://doi.org/10.1287/isre.2022.1111
Yang Y, Zhang KP, Fan YY (2022b) sDTM: a supervised bayesian deep topic model for text analytics. Inf Syst Res. https://doi.org/10.1287/isre.2022.1124
Yang Y, Qin Y, Fan Y, Zhang Z (2023) Unlocking the power of voice for financial risk prediction: a theory-driven deep learning design approach. MIS Quart 47(1):63–96. https://doi.org/10.25300/MISQ/2022/17062
Yi Y, Subramanyam R (2023) Extracting actionable insights from text data: a stable topic model approach. MIS Quart 47(3):923–954. https://doi.org/10.25300/MISQ/2022/16957
Yin HHS, Langenheldt K, Harlev M, Mukkamala RR, Vatrapu R (2019) Regulating cryptocurrencies: a supervised machine learning approach to de-anonymizing the bitcoin blockchain. J Manag Inf Syst 36(1):37–73. https://doi.org/10.1080/07421222.2018.1550550
Yu S, Chai YD, Chen SC, Brown RA, Sherman SJ, Nunamaker JF (2021) Fall detection with wearable sensors: a hierarchical attention-based convolutional neural network approach. J Manag Inf Syst 38(4):1095–1121. https://doi.org/10.1080/07421222.2021.1990617
Yu S, Chai YD, Samtani S, Liu HY, Chen HC (2023) Motion sensor-based fall prevention for senior care: a hidden markov model with generative adversarial network approach. Inf Syst Res. https://doi.org/10.1287/isre.2023.1203
Zhang W, Ram S (2020) A comprehensive analysis of triggers and risk factors for asthma based on machine learning and large heterogeneous data sources. MIS Quart 44(1):305–349. https://doi.org/10.25300/MISQ/2020/15106
Zhang J, Wang L, Wang K (2021a) Identifying comparable entities from online question-answering contents. Inf Manag 58(3):103449. https://doi.org/10.1016/j.im.2021.103449
Zhang Z, Wei X, Zheng X, Zeng DD (2021b) Predicting product adoption intentions: an integrated behavioral model-inspired multiview learning approach. Inf Manag 58(7):103484. https://doi.org/10.1016/j.im.2021.103484
Zhang W, Wang Y, Chen L, Yuan Y, Zeng X, Xu L, Zhao H (2024) Dynamic circular network-based federated dual-view learning for multivariate time series anomaly detection. Bus Inf Syst Eng 66(1):19–42. https://doi.org/10.1007/s12599-023-00825-8
Zhang D, Maslej N, Brynjolfsson E, Etchemendy J, Lyons T, Manyika J, Ngo H, Niebles JC, Sellitto M, Sakhaee E, Shoham, Y, Clark J, Perrault R (2022) The AI index 2022 annual report. Retrieved December 28, 2022, from https://arxiv.org/abs/2205.03468
Zhao X, Fang X, He J, Huang L (2023) Exploiting expert knowledge for assigning firms to industries: a novel deep learning method. MIS Quart 47(3):1147–1176. https://doi.org/10.25300/MISQ/2022/17171
Zheng JY, Qi ZL, Dou YF, Tan Y (2019) How mega is the mega? Exploring the spillover effects of wechat using graphical model. Inf Syst Res 30(4):1343–1362. https://doi.org/10.1287/isre.2019.0865
Zhou J, Zhang Q, Zhou S, Li X, Zhang X (2023a) Unintended emotional effects of online health communities: a text mining-supported empirical study. MIS Quart 47(1):195–226. https://doi.org/10.25300/MISQ/2022/17018
Zhou T, Wang Y, Yan L, Tan Y (2023b) Spoiled for choice? Personalized recommendation for healthcare decisions: a multiarmed bandit approach. Inf Syst Res 34(4):1493–1512. https://doi.org/10.1287/isre.2022.1191
Zhu HY, Samtani S, Chen HC, Nunamaker JF (2020) Human identification for activities of daily living: a deep transfer learning approach. J Manag Inf Syst 37(2):457–483. https://doi.org/10.1080/07421222.2020.1759961
Zhu H, Samtani S, Brown RA, Chen H (2021) A deep learning approach for recognizing activity of daily living (adl) for senior care: exploiting interaction dependency and temporal patterns. MIS Quart 45:2. https://doi.org/10.25300/MISQ/2021/15574
Zhu Q, Zhang F, Liu S, Li Y (2022) An anticrime information support system design: application of K-means-VMD-BiGRU in the city of Chicago. Inf Manag 59(5):103247. https://doi.org/10.1016/j.im.2019.103247
Zolbanin HM, Davazdahemami B, Delen D, Zadeh AH (2022) Data analytics for the sustainable use of resources in hospitals: predicting the length of stay for patients with chronic diseases. Inf Manag 59(5):103282. https://doi.org/10.1016/j.im.2020.103282
Zoppis I, Mauri G, Dondi R (2019) Kernel methods: support vector machines. In: Ranganathan S, Gribskov M, Nakai K, Schönbach C (eds) Encyclopedia of bioinformatics and computational biology. Academic Press, pp 503–510
Zschech P, Heinrich K, Bink R, Neufeld JS (2019) Prognostic model development with missing labels: a condition-based maintenance approach using machine learning. Bus Inf Syst Eng 61(3):327–343. https://doi.org/10.1007/s12599-019-00596-1
Zschech P, Horn R, Höschele D, Janiesch C, Heinrich K (2020) Intelligent user assistance for automated data mining method selection. Bus Inf Syst Eng 62(3):227–247. https://doi.org/10.1007/s12599-020-00642-3
Acknowledgements
We would like to thank the State of North Rhine-Westphalia’s Ministry of Economic Affairs, Industry, Climate Action and Energy as well as the Exzellenz Start-up Center.NRW program at the REACH – EUREGIO Start-Up Center for their kind support of our work. We would like to thank Prof. Dr. Fabian Gieseke for his valuable feedback on our conceptual framework.
Funding
Open Access funding enabled and organized by Projekt DEAL. Funding is provided by ESC.NRW and Ministry of Economic Affairs, Industry, Climate Action and Energy NRW.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict Of Interest
The authors report that there are no competing interests to declare.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: Summary Of The Coding Approach
Appendix: Summary Of The Coding Approach
Author(s) | Journal | Industry sector | Functional area | AI category | Input data | Learning behavior | DL/xAI | AI algorithm (b = benchmark) |
|---|---|---|---|---|---|---|---|---|
Adamopoulos et al. (2018) | ISR | 51: Information | Marketing and Sales | Descriptive | Numerical, text | Unsupervised | Yes/No | LDA, other (graph-based) |
Wang et al. (2018b) | ISR | Not applicable | Marketing and Sales, Law | Predictive | Numerical, text, images | Unsupervised | No/No | Other (Markov clustering), LDAb |
Luo et al. (2019) | ISR | 44–45: Retail Trade | Marketing and Sales | Prescriptive | Numerical | Supervised | No/No | DT/RF |
Abbasi et al. (2019) | ISR | 51: Information, 62: Health Care and Social Assistance | Marketing and Sales | Predictive | Numerical, text | Supervised | No/No | Other (genetic algorithm), SVMb, DT/RFb, otherb (Markov, graph-based, other) |
Clark et al. (2020) | ISR | 51: Information | Not applicable | Predictive | Text | Supervised | Yes/No | Autoencoder, language model, language modelb |
Zheng et al. (2019) | ISR | 51: Information | Not applicable | Descriptive | Numerical | Unsupervised | No/No | Other (graph-based) |
Mejia et al. (2019) | ISR | 23: Construction, 72: Accomod. and Food Services | Not applicable | Descriptive | Numerical, text | Supervised | No/No | Bayesian, LR, SVM |
Liu et al. (2020c) | ISR | Not applicable | Personnel and Labor Relations | Predictive | Numerical, text | Supervised, Unsupervised | Yes/No | LR, kNN, SVM, DT/RF, LDA, CNN, RNN, other (bagging) |
Pfeiffer et al. (2020) | ISR | 44–45: Retail Trade | Marketing and Sales | Predictive | Signals/audio | Supervised | No/No | LR, SVM, DT/RF |
Lee et al. (2020) | ISR | Not applicable | Marketing and Sales | Descriptive | Numerical, text | Supervised, Unsupervised | Yes/No | LR, kNN, SVM, LDA, MLP, CNN, other (Lasso) |
Kokkodis et al. (2020) | ISR | 51: Information | Not applicable | Predictive | Numerical | Supervised, Unsupervised | Yes/No | kNN, SVM, boosting, other (hidden Markov, ARIMAX), LRb, DT/RFb, boostingb, otherb (hidden Markov) |
Fu et al. (2021) | ISR | 31–33: Manufacturing | Accounting and Finance | Predictive | Numerical | Supervised | No/No | Boosting |
Kwark et al. (2021) | ISR | 44–45: Retail Trade | Marketing and Sales | Descriptive, predictive | Numerical, text | Supervised, Unsupervised | Yes/No | LR, kNN, SVM, DT/RF, LDA, MLP, CNN, other (Lasso) |
Abbasi et al. (2021) | ISR | 51: Information | Law, IT | Predictive | Numerical | Supervised | No/No | SVM, other, Bayesianb, SVMb, otherb |
Clarke et al. (2021) | ISR | 51: Information, 92: Public Administration | Accounting and Finance | Predictive | Numerical, text | Supervised | Yes/No | Bayesian, LR, SVM, DT/RF, boosting, MLP |
Wu et al. (2021) | ISR | 51: Information | Law | Prescriptive | Numerical, text | Supervised, Unsupervised | Yes/No | LR, SVM, DT/RF, LDA, CNN, RNN, other, boostingb, MLPb |
Kokkodis (2021) | ISR | Not applicable | Personnel and Labor Relations | Prescriptive | Numerical, text | Unsupervised | Yes/No | MLP, other (hidden Markov), SVMb, boostingb, RNNb |
Gunarathne et al. (2022) | ISR | 48–49: Transport. and Warehousing, 51: Information | Management and Administration | Predictive | Text | Supervised | Yes/No | CNN |
Vargas et al. (2022) | ISR | 51: Information | Personnel and Labor Relations | Prescriptive | Numerical | Supervised | No/No | Boosting, DT/RFb |
Sun et al. (2022) | ISR | 44–45: Retail Trade | Marketing and Sales | Predictive | Numerical | Supervised | Yes/No | MLP, other, Bayesianb, LRb, DT/RFb, boostingb, MLPb |
Wang et al. (2022a) | ISR | 44–45: Retail Trade | Marketing and Sales | Predictive | Numerical | Supervised | Yes/Yes | GAN, other (generalized additive model), otherb (generalized additive model) |
Wang et al. (2022b) | ISR | 48–49: Transport. and Warehousing | R&D and Engineering | Predictive | Numerical, other (graph-based) | Supervised | Yes/No | k-means, MLP, CNN, RNN, SVMb, MLPb, otherb |
Benjamin and Raghu (2022) | ISR | 51: Information | Not applicable | Predictive | Text | Supervised | Yes/No | Language model, SVMb, RNNb |
Chen and Walker (2022) | ISR | 51: Information, 62: Health Care and Social Assistance | Not applicable | Predictive | Numerical, text | Supervised | Yes/Yes | MLP |
Karanam et al. (2022) | ISR | 51: Information | Marketing and Sales, IT | Descriptive | Text | Supervised, unsupervised | Yes/No | RNN, other (conditional random field) |
Yang et al. (2022a) | ISR | Not applicable | Not applicable | Predictive | Text | Semi-supervised | Yes/No | CNN, RNN, other, kNNb, SVMb, boostingb, CNNb, RNNb, language modelb, otherb (graph-based) |
Yang et al. (2022b) | ISR | Not applicable | Not applicable | Predictive | Numerical, text | Supervised | Yes/No | Autoencoder, RNN, SVMb, LDAb, CNNb |
Yan et al. (2023) | ISR | 51: Information | Not applicable | Descriptive | Not applicable | Supervised, unsupervised | Yes/Yes | Language model |
Chen et al. (2023) | ISR | 44–45: Retail Trade | Marketing and Sales | Predictive | Text, signals/audio | Supervised | Yes/No | MLP, RNN, Language model, SVMb, DT/RFb, boostingb, Autoencoderb, MLPb |
Kannan et al. (2023) | ISR | 44–45: Retail Trade | Marketing and Sales | Predictive | Numerical | Reinforcement | No/No | Reinforcement learning |
Malik et al. (2023) | ISR | Not applicable | Personnel and Labor Relations | Descriptive, predictive, generative | Images | Supervised | Yes/No | SVM, CNN, GAN |
Ravichandran and Deng (2023) | ISR | 51: Information | Marketing and Sales | Descriptive, predictive | Not applicable | Supervised | Yes/No | CNN |
Wang et al. (2023) | ISR | 62: Health Care and Social Assistance, 92: Public Administration | Not applicable | Prescriptive | Numerical | Reinforcement | No/No | kNN, reinforcement learning, other (graph-based) |
Wei et al. (2023) | ISR | 44–45: Retail Trade | Marketing and Sales | Prescriptive | Numerical | Supervised | No/No | Bayesian, MLP, boostingb, autoencoderb, MLPb, otherb (hidden Markov) |
Yu et al. (2023) | ISR | 62: Health Care and Social Assistance | R&D and Engineering | Prescriptive, generative | Signals/audio | Supervised, semi-supervised | Yes/No | GAN, other (hidden Markov), Bayesianb, LRb, SVMb, DT/RFb, boostingb, LDAb, CNNb, RNNb |
Zhou et al. (2023b) | ISR | 62: Health Care and Social Assistance | Not applicable | Prescriptive | Numerical | Reinforcement | Yes/No | RNN, reinforcement learning, other, MLPb, CNNb, RNNb, reinforcement learningb, otherb |
Larsen and Bong (2016) | MISQ | Not applicable | Not applicable | Predictive | Text | Unsupervised | No/No | LDA, other (latent semantic analysis), otherb (knowledge-based models) |
Lin et al. (2017) | MISQ | 62: Health Care and Social Assistance | Not applicable | Predictive | Numerical | Supervised | No/No | Bayesian, LR, DT/RFb, MLPb, otherb |
Gong et al. (2018) | MISQ | 44–45: Retail Trade | Marketing and Sales | Descriptive | Text | Unsupervised | No/No | LDA |
Fang and Hu (2018) | MISQ | 62: Health Care and Social Assistance | Not applicable | Predictive | Numerical | Supervised | No/No | DT/RF |
Lukyanenko et al. (2019) | MISQ | 51: Information | IT | Predictive | Numerical | Supervised | Yes/No | Bayesian, SVM, DT/RF, boosting, MLP |
Liebman et al. (2019) | MISQ | 51: Information | R&D and Engineering | Prescriptive | Not applicable | Reinforcement | No/No | Reinforcement learning |
He et al. (2019) | MISQ | Not applicable | R&D and Engineering, Marketing and Sales | Prescriptive | Numerical | Unsupervised | No/No | Other (graph-based), Bayesianb, kNNb, LDAb |
Shin et al. (2020) | MISQ | Not Information | Marketing and Sales | Descriptive | Text | Supervised | Yes/No | LDA, MLP, CNN |
Chau et al. (2020) | MISQ | 51: Information | Not applicable | Descriptive, predictive | Text | Supervised | No/No | SVM, other (genetic algorithm), SVMb |
Liu et al. (2020b) | MISQ | 51: Information, 62: Health Care and Social Assistance | Not applicable | Descriptive | Text | Supervised, unsupervised | Yes/No | LR, MLP, RNN, other, otherb (conditional random field) |
Ben-Assuli and Padman (2020) | MISQ | 62: Health Care and Social Assistance | Management and Administration | Predictive | Numerical | Supervised, unsupervised | No/No | LR, DT/RF, boosting, other, otherb (hidden Markov, latent models) |
Zhang and Ram (2020) | MISQ | 51: Information, 62: Health Care and Social Assistance | R&D and Engineering | Predictive | Numerical, text, images | Supervised, semi-supervised | Yes/No | DT/RF, CNN, other (sequential pattern mining), LRb, otherb (generative additive model) |
Zhu et al. (2021) | MISQ | Not applicable | Not applicable | Predictive | Signals/audio | Supervised | Yes/No | CNN, kNNb, SVMb, RNNb, otherb (hidden Markov) |
Li et al. (2021) | MISQ | 51: Information, 92: Public Administration | Management and Administration, Marketing and Sales | Predictive | Other (graph-based) | Reinforcement | No/No | Reinforcement learning, otherb |
McFowland et al. (2021) | MISQ | Not applicable | Management and Administration | Prescriptive | Numerical | Supervised | No/No | DT/RF |
Liu et al. (2021) | MISQ | 51: Information | Marketing and Sales | Predictive | Numerical, text | Supervised, unsupervised | Yes/No | Bayesian, SVM, DT/RF, boosting, MLP, CNN |
Venkatesan et al. (2021) | MISQ | 51: Information | Not applicable | Predictive | Text | Supervised | No/No | DT/RF |
Han et al. (2021) | MISQ | 51: Information | IT | Prescriptive | Numerical | Supervised | Yes/No | LR, DT/RF, boosting, MLP, kNNb, MLPb, otherb (graph-based) |
Adamopoulos et al. (2022) | MISQ | 51: Information | Marketing and Sales | Predictive | Text | Supervised | Yes/No | MLP |
Ebrahimi et al. (2022) | MISQ | 51: Information | Law, IT | Predictive | Text | Supervised | Yes/No | RNN, GAN, Bayesianb, SVMb, DT/RFb, CNNb, RNNb |
Xie et al. (2022) | MISQ | 92: Public Administration | R&D and Engineering | Predictive | Text | Supervised, unsupervised | Yes/No | CNN, RNN, other, kNNb, SVMb, MLPb, CNNb, RNNb, otherb |
Samtani et al. (2022) | MISQ | 51: Information | Law, IT | Predictive | Text | Supervised | Yes/Yes | RNN, LDAb, MLPb, CNNb, RNNb, otherb |
Shuo et al. (2022) | MISQ | 62: Health Care and Social Assistance | R&D and Engineering | Predictive | Numerical | Supervised | Yes/Yes | CNN, RNN, other, kNNb, SVMb, DT/RFb, boostingb, otherb |
Xu et al. (2022) | MISQ | 52: Finance and Insurance | Accounting and Finance | Predictive | Numerical, text | Supervised | Yes/No | DT/RF, boosting, MLP, RNN |
Xuan et al. (2022) | MISQ | 51: Information | Not applicable | Predictive | Numerical, text | Supervised, unsupervised | Yes/No | Bayesian, SVMb, CNNb, RNNb, language modelb |
Kim et al. (2023) | MISQ | 62: Health Care and Social Assistance | Not applicable | Predictive | Numerical | Supervised | Yes/Yes | DT/RF, boosting, MLP |
Hou et al. (2023) | MISQ | 52: Finance and Insurance | Accounting and Finance | Predictive | Images | Supervised | Yes/No | CNN, SVMb, DT/RFb, boostingb, CNNb |
Zhou et al. (2023a) | MISQ | 62: Health Care and Social Assistance | Not applicable | Descriptive, predictive | Text | Supervised | Yes/No | RNN, SVMb, CNNb, RNNb, otherb (graph-based) |
Zhao et al. (2023) | MISQ | Not applicable | Not applicable | Predictive | Text | Supervised | Yes/No | Langugage model, SVMb, MLPb, language modelb, otherb |
Yi and Subramanyam (2023) | MISQ | Not applicable | Not applicable | Descriptive | Text | Unsupervised | Yes/Yes | kNN, LDA, MLP, LDAb |
Yang et al. (2023) | MISQ | 52: Finance and Insurance | Accounting and Finance | Predictive | Text, images | Supervised | Yes/No | SVM, RNN, SVMb, boostingb, RNNb, language modelb |
Ampel et al. (2024a) | MISQ | 51: Information | Law, IT | Predictive | Text | Semi-supervised | Yes/No | CNN, RNN, Bayesianb, LRb, SVMb, boostingb, CNNb, RNNb |
Lee et al. (2016) | JMIS | 51: Information | Not applicable | Descriptive, predictive | Text, other | Unsupervised | No/No | LDA, other |
Lash and Zhao (2016) | JMIS | 51: Information | Management and Administration | Predictive | Numerical, text | Supervised, unsupervised | Yes/No | Bayesian, LR, DT/RF, boosting, LDA, MLP |
Ghiassi et al. (2016) | JMIS | 51: Information | Marketing and Sales | Predictive | Numerical, text | Supervised | Yes/No | MLP, SVMb |
Li et al. (2016) | JMIS | 51: Information | Not applicable | Predictive | Numerical, text | Supervised, unsupervised | Yes/No | LDA, RNN, other, Bayesianb, kNNb, SVMb |
Kitchens et al. (2018) | JMIS | Not applicable | Marketing and Sales, IT | Predictive | Numerical | Supervised | No/No | SVM, LRb, DT/RFb, MLPb, otherb |
Dong et al. (2018) | JMIS | 51: Information | Accounting and Finance, Law | Predictive | Text | Supervised, unsupervised | No/No | SVM, LDA, other, LRb, DT/RFb, MLPb |
Guo et al. (2018) | JMIS | 51: Information, 62: Health Care and Social Assistance | Not applicable | Predictive | Numerical | Unsupervised | Yes/No | Autoencoder, other (Boltzmann machine), otherb |
Kumar et al. (2018) | JMIS | 44–45: Retail Trade, 51: Information | Marketing and Sales, Law | Predictive | Numerical | Supervised | No/No | Bayesian, LR, kNN, SVM, DT/RF, boosting |
Yin et al. (2019) | JMIS | 51: Information | Law, IT | Predictive | Numerical | Supervised | No/No | kNN, DT/RF, boosting, other (bagging) |
Kumar et al. (2019) | JMIS | 51: Information | Marketing and Sales, Law | Descriptive | Numerical, text | Unsupervised | No/No | Other (finite mixture model), SVMb, otherb (Gaussian mixture model) |
Ebrahimi et al. (2020) | JMIS | 44–45: Retail Trade | IT | Predictive | Text | Semi-supervised | Yes/No | SVM, RNN, LRb, kNNb, SVMb, CNNb, RNNb |
Zhu et al. (2020) | JMIS | 62: Health Care and Social Assistance | R&D and Engineering | Predictive | Signals/audio | Supervised | Yes/No | CNN, kNNb, SVMb, CNNb |
Mousavi et al. (2020) | JMIS | 51: Information | Not applicable | Predictive | Numerical, text | Supervised, unsupervised | No/No | Bayesian, LDA, language model |
Yu et al. (2021) | JMIS | 62: Health Care and Social Assistance | R&D and Engineering | Predictive | Signals/audio | Supervised | Yes/Yes | CNN, Bayesianb, LRb, kNNb, SVMb, DT/RFb, boostingb, MLPb, CNNb, RNNb |
Xie et al. (2021) | JMIS | 51: Information, 62: Health Care and Social Assistance | IT | Predictive | Text | Supervised, unsupervised | Yes/No | k-means, MLP, RNN, Bayesianb, LRb, SVMb, otherb |
Tofangchi et al. (2021) | JMIS | 31–33: Manufacturing | Production-operations | Prescriptive | Signals/audio | Supervised | Yes/No | RNN, DT/RFb, MLPb, RNNb |
Kalgotra and Sharda (2021) | JMIS | 62: Health Care and Social Assistance | Management and Administration | Predictive | Numerical | Supervised | Yes/No | MLP, RNN |
King et al. (2021) | JMIS | 92: Public Administration | Not applicable | Predictive | Text | Unsupervised | No/No | LDA |
Lin and Fang (2021) | JMIS | Not applicable | Not applicable | Predictive | Text | Not applicable | No/No | Other, Bayesianb, DT/RFb, MLPb, otherb |
Nasir et al. (2022) | JMIS | Not applicable | Not applicable | Predictive | Numerical | Supervised | Yes/No | Other, LRb, SVMb, DT/RFb, MLPb |
Johnson et al. (2023) | JMIS | 92: Public Administration | Not applicable | Predictive | Images | Supervised | Yes/No | MLP, CNN |
Xie et al. (2023) | JMIS | 51: Information | Marketing and Sales | Predictive, generative | Images, other (video) | Semi-supervised | Yes/Yes | CNN, RNN, GAN,, LRb, kNNb, SVMb, DT/RFb, MLPb, CNNb, RNNb |
Xu et al. (2023a) | JMIS | 51: Information | Not applicable | Predictive | Numerical, text | Supervised, unsupervised | Yes/No | Autoencoder, MLP, kNNb, Autoencoderb, k-meansb, MLPb |
Xu et al. (2023b) | JMIS | 52: Finance and Insurance | Accounting and Finance | Predictive | Other (graph-based) | Supervised | Yes/No | Other (graph-based), kNNb, otherb |
Ampel et al. (2024b) | JMIS | 51: Information | IT | Prescriptive | Numerical, text | Supervised | Yes/No | Language model, Bayesianb, LRb, SVMb, DT/RFb, RNNb, language modelb |
Qamar et al. (2016) | BISE | 51: Information | Not applicable | Predictive | Text | Supervised | No/No | Bayesian, SVM, DT/RF, other |
Wang et al. (2018a) | BISE | 51: Information | Not applicable | Descriptive | Other (process model data) | Semi-supervised | No/No | k-means, other |
Gleue et al. (2019) | BISE | 31–33: Manufacturing | Accounting and Finance | Predictive | Numerical | Supervised | Yes/No | MLP |
Wang et al. (2019) | BISE | 31–33: Manufacturing | Production-operations | Predictive | Signals/audio | Supervised | Yes/No | CNN, Autoencoderb, MLPb |
Zschech et al. (2019) | BISE | 31–33: Manufacturing | Production-operations | Prescriptive | Numerical, signals/audio | Supervised, semi-supervised, unsupervised | Yes//No | k-means, RNN |
Balster et al. (2020) | BISE | 48–49: Transport. and Warehousing | Management and Administration | Predictive | Numerical | Supervised | No/No | DT/RF, boosting |
Mehdiyev et al. (2020) | BISE | 51: Information | Management and Administration | Predictive | Numerical | Supervised, unsupervised | Yes/No | Autoencoder, MLP, other, Bayesianb, LRb, SVMb, DT/RFb, RNNb |
Zschech et al. (2020) | BISE | Not applicable | Management and Administration | Predictive, prescriptive | Text | Supervised, unsupervised | Yes/No | kNN, SVM, LDA, MLP, RNN |
Wenninger and Wiethe (2021) | BISE | 22: Utilities, 53: Real Estate and Leasing | Not applicable | Predictive | Numerical | Supervised | Yes/No | SVM, DT/RF, boosting, MLP, other, |
Lee (2022) | BISE | Not applicable | Management and Administration, Marketing and Sales | Descriptive | Text | Supervised | Yes/No | LR, CNN, RNN, other |
Folino et al. (2022) | BISE | 51: Information | Production-operations, Management and Administration | Predictive | Numerical | Semi-supervised | Yes/No | RNN |
Pfeuffer et al. (2023) | BISE | 62: Health Care and Social Assistance | Not applicable | Predictive | Images | Supervised | Yes/No | CNN |
Groeneveld et al. (2023) | BISE | 44–45: Retail Trade | Marketing and Sales | Prescriptive | Numerical | Reinforcement | No/No | Reinforcement learning |
Zhang et al. (2024) | BISE | Not applicable | Management and Administration | Predictive | Numerical | Supervised, semi-supervised | Yes/No | Other (graph-based)) Bayesianb, kNNb, DT/RFb, Autoencoderb, MLPb, GANb, otherb (graph-based) |
Kratsch et al. (2021) | BISE | 51: Information | Production-operations, Management and Administration | Predictive | Numerical | Supervised | Yes/No | SVM, DT/RF, MLP, RNN |
Landwehr et al. (2022) | BISE | 22: Utilities | Production-operations, Management and Administration | Predictive | Images | Supervised | Yes/No | CNN |
Liu et al. (2020a) | I&M | 52: Finance and Insurance | Law | Predictive | Text | Supervised | Yes/Yes | RNN, other (graph-based), Bayesianb, LRb, SVMb, DT/RFb, MLPb, CNNb, otherb |
Xiong et al. (2021) | I&M | 51: Information | Marketing and Sales | Predictive | Numerical, text | Supervised | Yes/Yes | LDA, RNN, other, SVMb, MLPb, CNNb, RNNb |
Zhang et al. (2021a) | I&M | 51: Information | Not applicable | Predictive | Text | Supervised, unsupervised | Yes/No | LR, RNN |
Zhang et al. (2021b) | I&M | 51: Information | Marketing and Sales | Predictive | Text, other | Supervised | Yes/No | CNN, RNN, other (graph-based), Bayesianb, LRb, SVMb, DT/RFb, boostingb, CNNb, RNNb |
Zhu et al. (2022) | I&M | 92: Public Administration | Law | Predictive | Numerical | Supervised, unsupervised | Yes/No | k-means, RNN, other |
Zolbanin et al. (2022) | I&M | 62: Health Care and Social Assistance | Management and Administration | Predictive | Numerical | Supervised | Yes/No | MLP, |
Brusch (2022) | I&M | 51: Information | Marketing and Sales | Predictive | Images | Supervised, unsupervised | Yes/No | SVM, CNN, other |
Chang et al. (2022) | I&M | 48–49: Transport. and Warehousing | Marketing and Sales | Predictive | Text | Supervised | Yes/No | Language model, kNNb, DT/RFb, CNNb |
Ravenda et al. (2022) | I&M | 92: Public Administration | Not applicable | Descriptive | Text | Unsupervised | No/No | Topic model, LDAb |
Shen et al. (2022) | I&M | 51: Information | Not applicable | Descriptive | Text | Supervised | Yes/No | LDA, CNN, RNN, SVMb, CNNb, RNNb, GANb |
Thirumuruganathan et al. (2023) | I&M | 48–49: Transport. and Warehousing | Marketing and Sales | Prescriptive | Numerical | Supervised, unsupervised | Yes/No | LR, SVM, DT/RF, Autoencoder, k-means, MLP, GAN, otherb |
Liébana-Cabanillas et al. (2024) | I&M | 52: Finance and Insurance | Not applicable | Predictive | Numerical | Supervised | Yes/No | MLP |
Chai et al. (2024) | I&M | 62: Health Care and Social Assistance | Not applicable | Predictive | Signals/audio | Supervised | Yes/No | CNN, RNN, CNNb, RNNb |
See-To and Yang (2017) | EM | 52: Finance and Insurance | Accounting and Finance | Predictive | Text | Supervised | No/No | Bayesian, SVM |
Hirt et al. (2019) | EM | 51: Information | Marketing and Sales | Predictive | Numerical, text | Supervised | No/No | Bayesian, SVM, DT/RF, boosting |
Kuehl et al. (2020) | EM | 51: Information | Marketing and Sales | Predictive | Text | Supervised | No/No | SVM, DT/RF |
Ryoba et al. (2021) | EM | 52: Finance and Insurance | Not applicable | Predictive | Numerical, text | Supervised | No/No | kNN |
Esmeli et al. (2021) | EM | 44–45: Retail Trade | Marketing and Sales | Predictive | Numerical | Supervised | No/No | Bayesian, kNN, DT/RF, other (bagging) |
Guan et al. (2022) | EM | 72: Accomod. and Food Services | Marketing and Sales | Descriptive, predictive | Text | Unsupervised | No/No | LDA, language model |
Shajalal et al. (2022) | EM | 31–33: Manufacturing | Production-operations | Predictive | Numerical | Supervised | Yes/Yes | CNN, Bayesianb, kNNb, SVMb, DT/RFb, boostingb |
Binder et al. (2022) | EM | 44–45: Retail Trade | Marketing and Sales | Predictive | Text | Supervised, unsupervised | Yes/Yes | Language model |
Bartelheimer et al. (2022) | EM | Not applicable | Not applicable | Descriptive | Text | Unsupervised | No/No | k-means, MLP |
Pocher et al. (2023) | EM | 52: Finance and Insurance | Accounting and Finance | Predictive | Other (graph-based) | Supervised | Yes/Yes | CNN, other (graph-based), LRb, kNNb, SVMb, DT/RFb, boostingb, MLPb |
Ptaszynski et al. (2019) | JAIS | 51: Information | Law, personnel and labor relations, IT | Not applicable | Text | Not applicable | No/No | Other, Bayesianb, kNNb, SVMb, DT/RFb, otherb |
Larsen et al. (2019) | JAIS | Not applicable | Not applicable | Descriptive | Numerical | Supervised | No/No | Bayesian |
Lausen et al. (2020) | JAIS | 51: Information | Law | Predictive | Numerical, text | Supervised | Yes/No | Bayesian, LR, SVM DT/RF, MLP |
Siering et al. (2021) | JAIS | 52: Finance and Insurance | Accounting and Finance | Predictive | Text | Supervised | No/No | SVM, other |
Drori and Te'eni (2023) | JAIS | Not applicable | Not applicable | Prescriptive, generative | Text | Not applicable | Yes/No | Language model |
Syed and Silva (2023) | JAIS | 51: Information | Not applicable | Descriptive, predictive | Text | Unsupervised | No/No | LDA |
Muller et al. (2016) | EJIS | 44–45: Retail Trade | Marketing and Sales | Predictive | Numerical, text | Supervised, unsupervised | No/No | DT/RF, LDA |
Chatterjee et al. (2018) | EJIS | 62: Health Care and Social Assistance | R&D and Engineering | Predictive | Numerical | Supervised, unsupervised | Yes/No | k-means, MLP |
Salovaara et al. (2020) | EJIS | Not applicable | Not applicable | Predictive | Numerical, text | Supervised, unsupervised | No/No | SVM, LRb |
Li et al. (2018) | JIT | 51: Information, 52: Finance and Insurance | Accounting and Finance | Predictive | Text | Supervised | No/No | Bayesian |
Lycett and Radwan (2019) | ISJ | Not applicable | Marketing and Sales, IT | Predictive | Numerical | Supervised | No/No | Bayesian, DT/RF, other |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bendig, D., Bräunche, A. The role of artificial intelligence algorithms in information systems research: a conceptual overview and avenues for research. Manag Rev Q (2024). https://doi.org/10.1007/s11301-024-00451-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11301-024-00451-y