
Abstract
This paper reviews literature in the domain of information overload in accounting. The underlying psychological concepts of information load (as applied in accounting research) are summarized, and a framework to discuss findings in a structured way is proposed. This framework serves to make causes, consequences, and countermeasures transparent. Variables are further clustered into major categories from information processing research: input, process, and output. The main variables investigated are the characteristics of the information set, especially the number of information cues as an input variable; the experience of the decision-maker, the decision time, decision rule, and cue usage as process variables; and measures related to decision quality (i.e., accuracy, consensus, consistency) and related to selfinsight (calibration, confidence, feeling of overload) as output variables. The contexts of the respective research papers are described, and the operationalization of variables detailed and compared. We employ the method of stylized facts to evaluate the strength of the links between variables (number of links, direction and significance of relationship). The findings can be summarized as follows: most articles focus on individual decision-making in the domain of external accounting, with financial distress predictions constituting a large part of these. Most papers focus on input and output variables with the underlying information processing receiving less attention. The effects observed are dependent on the type of information input and the task employed. Decision accuracy is likely to decrease once information load passes a certain threshold, while decision time and a feeling of overload increase with increasing information load. While experience increases decision accuracy, the results on decision time and consensus are conflicting. Most articles have not established a significant link between changes in information load and changes in decision confidence. Relative cue usage, consensus, consistency, and calibration decline with increasing information load. Available time has a rather positive effect on decision accuracy and consensus. Based on these findings, implications for practice and future research are derived.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Information overload is a widely accepted phenomenon that has been researched across a number of disciplines. This article aims to conduct an in-depth review of information overload research in accounting. Eppler and Mengis (2004) and Roetzel (2019) have conducted comprehensive literature reviews in the field of management science. In addition, several research articles include extensive literature reviews, for example Schick et al. (1990) and Hirsch and Volnhals (2012), which focus primarily on accounting-related topics. Nevertheless, a review of the current state of research into information overload in accounting is warranted as it allows to take a narrower stance on the literature to be included and also to go into greater detail with regards to the causes and effects of information overload. In this vein, our review aims to expand and detail the work done by Eppler and Mengis (2004) on accounting by including accounting-related literature that has been published since 2003 and accounting-related literature that was not included in their review. Inclusion of literature published later is beneficial as several changes have taken place. For example, new technologies have shaped the accounting landscape (e.g., web-based reporting; Kelton and Murthy 2016), and over the last few years, the amount of data to be processed has increased (e.g., Brown-Liburd et al. 2015). The problem of information overload is therefore also likely to have increased. On the other hand, new methods for dealing with higher information loads may have been developed or new research methodologies may have shed further light on the subject of information overload.
Reviewing the literature on information overload, it is apparent that concepts and variables are not always operationalized in a standardized way, for example with regards to what “information” means. In this regard, a framework that clusters and defines the relevant variables and their interactions as presented in this paper—building primarily on Eppler and Mengis (2004) and Libby and Lewis (1977)—is therefore beneficial for future research in the field of information overload. A narrow focus as well as a more detailed framework allow the derivation of more specific implications for practice and implications for future research than it was the case in previous review articles. In addition, by employing the methodology of stylized facts (e.g., Weißenberger and Löhr 2008), based on the number of papers finding significant relationships for the variables investigated, this review highlights the potential strength of the links proposed in the framework and therefore also allows the identification of gaps and ambiguous relationships. This literature review focuses on research more narrowly related to the topic of information overload in accounting, and not on information processing in accounting in general. However, models of information processing in accounting form the basis for the framework presented later.
Following the line of thought in Hartmann (2022), we argue that findings on how information overload impacts human decision-making will continue to be relevant even with algorithm-based decision-making becoming increasingly relevant. For example, nowadays many business models are using data as the principal production factor. Furthermore, data also enhance understanding of customers and markets or are the basis for improved business processes (Henke et al. 2016). As a consequence, integration of innovative and external data becomes more and more important for corporate performance management (Mahlendorf et al. 2022; Simons and Masamvu 2014). Overall, the information environment used in business is thus not only growing, but also becoming increasingly opaque, driven by the so-called VUCA-world, “an acronym, which describes a volatile, uncertain, complex and ambiguous world” (Minciu et al. 2020, p. 237). In addition, disclosure requirements continue to increase, e.g., in the field of sustainability reporting (e.g., Velte 2022).
At the same time, accounting-based decision-making is changing in a significant way (e.g., Richins et al. 2017), as new technologies are being applied allowing for, e.g., increases in data storage, more powerful business intelligence systems, and growing opportunities for automated decision-making by applying artificial intelligence and utilizing big data (e.g., Kelton and Murthy 2016; Rikhardsson and Yigitbasioglu 2018). Analyzing the susceptibility to automation of several professions, Frey and Osborne (2017) put forward the assumption that the occupation “Accountants and Auditors” is highly automatable (probability of 94%). Richins et al. (2017) point out that accounting professionals’ skills are an ideal basis and will be complemented by new analytical methods and supported by the necessary tools, even though this trend is in some cases hampered by so-called “algorithm aversion”, i.e., the lack of adoption of algorithmic decision-making even if models are known to outperform human decision-making (Mahmud et al. 2022).
In the future, human decision-makers will need to interact more with the results generated by algorithms compared to manually generating these results themselves (e.g., Richins et al. 2017). As a consequence, the problem of information overload shifts to another level when the output of one or several human and algorithm-based decision models need to be reconciled. In addition, decision-making might be impacted by the way big-data based information output is presented to the decision-maker (Holt and Loraas 2021). As a consequence, even though findings will need to be applied to different decision-environments, the phenomenon of information overload will remain relevant.
To address these issues, the next section of our literature review describes the main concepts of information overload referred to in accounting literature. The main research topics in accounting on information overload as well as the methodology employed to identify the articles included in this review are outlined in Sects. 3 to 4. In Sect. 5, the conceptual framework for our analysis is described. The findings are then presented in Sect. 6 and matched to the respective parts of the framework, which serves as the basis for deriving implications for practice in Sect. 7 and directions for future research in Sect. 8. Section 9 concludes our review with a brief summary of our main findings.
2 The concepts of information overload in accounting research
As summarized by Bonner (1999), important judgments and decisions are made based on accounting information. This happens in a system where producing, using, and auditing (including its evaluation) of accounting information are closely linked and where changes in one factor influence the behavior and decision outcomes of other actors, for example the outlooks given by financial analysts (Bonner 1999). Furthermore, accounting information “constructs reality”, as, e.g., accounting for revenues or evaluating assets “constructs” their values (Hines 1988). Therefore, accounting information plays an important role in the functioning of organizations and the economy. However, judgments and decision-making based on accounting information may be flawed, sometimes leading to a systematic deviation from optimal decisions (Bonner 1999; Schipper 1991). Decreases in decision-making effectiveness and efficiency may be triggered by information overload, for example if the amount of information makes decision-makers process information in a sub-optimal way (e.g., Schroder et al. 1967).
In more detail, information overload can be summarized as the (negative) consequences on either the process of information use and subsequent integration, and/or the objective or subjective judgment/decision/prediction quality, caused by a supply of too many information or data cues and/or limited time available. Data cues refer here to cues that are irrelevant to the decision at hand. When using the term “information load” or “information overload” in a general sense in this article, it is meant to encompass consequences that are caused by information or data cues, independent of their characteristics as relevant, irrelevant, or redundant for the decision problem at hand, as this is also the case in most research articles. For clarification, the terms and their implicit meanings are further discussed when describing the causes, particularly the information set (see 6.1.1).
In accounting research, two related concepts are applied to make predictions regarding the effects of increases in information load. The first concept primarily relates to individuals’ processing capacity (e.g., Schroder et al. 1967), while the second highlights the time available for the information processing task (Schick et al. 1990). Both concepts are closely related. As noted by Tuttle and Burton (1999), the most prominent model is that of Schroder et al. (1967), describing the influence of increases in environmental complexity on information processing. In short, information processing reaches an optimal state at a certain point of environmental complexity and then declines when environmental complexity increases beyond that point, resulting in the famous inverted U-curve for the level of information integration exemplified in Fig. 1. In a different vein, Schick et al. (1990) describe information overload as strictly related to the time at hand, occurring when “the demands on an entity for information processing time exceed its supply of time” (Schick et al. 1990, p. 215). Information load is thus measured as the time needed to process the information, while information processing capacity refers to the time available. In addition, the definition of information load is broadened by not only referring to information cues but also to all other input that individuals receive. Schick et al. (1990) split the necessary capacity to process such input into “processing demands on an individual’s actual time to interact with others and perform internal calculations” (Schick et al. 1990, p. 204).

Number of Integrations Under Different Information Load Conditions. Note Reprinted from “Conceptual structure, environmental complexity and task performance” by Streufert, S., and Schroder, H. M., 1965, Journal of Experimental Research in Personality, 1(2), p. 135
According to Schroder et al. (1967), levels of information processing refer to the abilities of groups or individuals to integrate the information cues at hand, where information processing is clustered into low (termed “concrete conceptual levels”) or high integration structures (termed “abstract conceptual levels”). The latter can deal with complex patterns by differentiating, combining, and comparing information dimensions and adapting and developing new structures of information processing. Environmental complexity relates to properties of the environment, namely, considering the complexity of the information set, “information load, information diversity, and rate of information change” as so-called “primary properties” (Schroder et al. 1967, p. 31) or “secondary properties” such as rewards (“eucity”) or threats (“noxity”) associated with the task (Schroder et al. 1967, p. 32).
Focusing on the question of whether optimal information load differs between groups as suggested by Miller (1972), Wilson (1973) highlights the findings from Streufert and Schroder (1965). Figure 1 is based on Wilson (1973) and Streufert and Schroder (1965); it shows the levels of information integration for concrete and abstract conceptual levels for changing levels of information load. In Streufert and Schroder (1965)’s experiment, groups were formed of individuals who had achieved either very low or very high scores on tests to identify levels of conceptual abstractness. These groups were tasked with playing a tactical game (making decisions in relation to invasion of an island) receiving differing numbers of information cues. The graph depicts the number of integrations in task performance on the y-axis, depending on the information load (x-axis) for groups of people with concrete (lower curve), as well as abstract (higher curve) conceptual structures (Streufert and Schroder 1965). Information integration is described as the number of decisions that are based upon each other. While groups or individuals with concrete conceptual levels only reach lower levels of information integration, both curves reach an optimum at the same level of information load (Streufert and Schroder 1965; Wilson 1973). Schroder et al. (1967, p. 153) summarize their main finding (see Fig. 1) as follows: “… for concrete and abstract structures, the optimal environment … is the same.“ Therefore, although individuals have different levels of conceptual abstractness, the level of environmental complexity that leads to the specific maximum level of information integration seems to be the same (Schroder et al. 1967; Streufert and Schroder 1965; Wilson 1973).
It is important to highlight that, without further knowledge of the characteristics of the information to be integrated, there is no definite link between the level of information integration and decision quality. The model suggests that individuals become better at creating more links and incorporating more information with increasing environmental complexity. However, if environmental complexity increases and the predictive value of the information stays the same, then individuals’ information processing might be at a higher level, but without further benefit to decision effectiveness—even with the highest level of information integration, irrelevant or redundant information added cannot increase decision quality. Vice versa, decision quality is not necessarily low when the number of information cues is low, if one considers the maximum possible decision quality that can be reached with the information at hand (see also Iselin 1996). To illustrate the link between increases in the number of information cues and decision quality, he depicts the link for three different information characteristics: the impact of relevant information cues on uncertainty reduction (I), relevant information cues (not yet considering their impact in reducing uncertainty for the problem at hand) (II), and irrelevant information (III).
Considering the effect of relevant information cues on reducing uncertainty, decision quality should increase gradually, at some point reaching a plateau as additional cues only contribute incrementally to increased decision quality (Fig. 2, I). Only considering relevant information cues without their effect on uncertainty reduction, decision quality declines after a certain point when the maximum information processing capacity is reached (Fig. 2, II). Finally, increases in the number of irrelevant information cues leads to a decline in decision quality from the first irrelevant information cue, as it must be filtered out and thus requires additional processing capacity (see Fig. 2, III). Iselin (1996) summarizes the trade-off as follows: While decision-makers should not be given irrelevant information, provision of relevant information cues needs to consider the trade-off between the associated increase in decision quality attributable to uncertainty reduction and the negative impact on decision quality due to the increasing number of information cues that need to be integrated in the decision.

Effects of changes in the number of information cues. Note Reprinted from “Accounting information and the quality of financial managerial decisions,” by Iselin, E. R., 1996, Journal of Information Science, 22(4), p. 149–151
The model by Schroder et al. (1967) therefore is the basis for claiming that decision performance will decline beyond a certain point of environmental complexity. However, even the most elaborate information processing structures are of no use for increasing decision quality if the input to be processed is irrelevant or additional information is redundant with regards to the information cues already at hand. A potential missing link between information integration and decision quality is similarly addressed by Snowball (1979, p. 26), who refers to the relationship between the “level of processing” and the “effectiveness of processing”. Also relying on Schroder et al. (1967), Miller and Gordon (1975) argue that individuals can adapt their conceptual level and that higher environmental complexity can have a training effect in the long term. As such, in the long term a decision-maker may move to a more abstract curve (i.e., the top curve in Fig. 1). Miller and Gordon (1975, p. 262), referring to Schroder et al. (1967) and to Harvey et al. (1961) state that “the key long-run training variables which influence conceptual level are the diversity (complexity) and conflict induced over extended periods in the learning situation” and highlight that more abstract conceptual levels are not superior to more concrete conceptual levels as there are decision problems for which less abstract conceptual levels are better suited.
Models that address humans’ limited information processing capacity make similar predictions with regards to information processing performance declining beyond a certain point of input, for example as highlighted by Tuttle and Burton (1999); Newell and Simon (1972); and the landmark article, “The magical number seven, plus or minus two,” by Miller (1956). Such predictions are also made by models that assume a certain medium level of stress or arousal to be necessary to reach optimal performance (e.g., Eysenck 1982; Berlyne 1960). The latter models posit that when stress is too low, performance might suffer (Iselin 1988). Citing Berlyne (1960), Iselin (1988, p. 151) calls the reduced performance when performing simple tasks the “boredom effect”. Relating to the optimal amount of stress, both remaining below the optimal level and surpassing the optimal level can harm performance (e.g., Baumeister 1984). In the field of behavioral economics, Ariely et al. (2009) demonstrate how high performance-based incentives can lead to decreases in performance. The other models named above (Miller 1956; Newell and Simon 1972; Schroder et al. 1967) do not explicitly state that a lack of stress in itself leads to inferior performance.
Finally, it has to be noted that the concepts of information overload are closely related to models of task complexity (e.g., Wood 1986) or cognitive load (e.g., Sweller 1988). This is particularly relevant when interaction with further variables is investigated, for example in decision aid research (e.g., Rose and Wolfe 2000; Rose 2005).
3 Main topics and literature
Information overload research in the accounting domain was first triggered by the question of how reporting of more (detailed) information in external reporting would affect users of this information; this was partially triggered by early initiatives to expand the information reported in external financial reports (e.g., as summarized by Snowball 1979). The first conceptual papers were therefore concerned with applying research in psychology (notably the model by Schroder et al. 1967) to the accounting domain and describing how changes in information load might affect the readers of external reports (Fertakis 1969; Miller 1972; Revsine 1970; Wilson 1973). Researchers then continued to broaden the conceptual research to managerial decision-making (e.g., Ashton 1974; Miller and Gordon 1975).
The first empirical papers addressed the influence of aggregated vs. disaggregated data in the analysis of cost variances (Barefield 1972), financial distress prediction (Abdel-Khalik 1973), and operational management (Chervany and Dickson 1974). Most empirical papers have addressed so-called “bankruptcy prediction tasks” or “financial distress prediction tasks”, in which subjects are tasked with assessing a firm’s financial health by analyzing financial ratios, statements, or further financial information (e.g., footnotes). Bankruptcy prediction has received important research attention in the past. However, decision-models have become increasingly advanced. Decision-makers still need to deal with the output of these models—while they do not need to “run” the calculation based on the input factors themselves, they likely need to act based on the recommendations generated by the decision models. Human decision-making will continue to be relevant, e.g., as long as not all decision-making is fully replaced with decision models. In addition, algorithm aversion is likely to lead to an incomplete reliance on automated decision-making (e.g., Mahmud et al. 2022). Even if bankruptcy prediction that is not assisted by advanced, algorithm-based decision models has lost relevance, the mechanisms that are at work (e.g., role of group decision-making, role of structured vs. unstructured tasks) can also be applied to other decision-making settings. A number of papers have also investigated the information search process by applying methodologies to track subjects’ information acquisition processes, either in the analysis of performance reports (Shields 1980, 1983) or in the capital budgeting domain (Swain and Haka 2000). More recently, new technological developments have triggered additional research, notably addressing how new interactive presentation formats affect decision-making (Kelton and Murthy 2016) or how “big data” influences decision-making in auditing (Brown-Liburd et al. 2015).
Table 8 in the supplementary material provides an overview of the research included in this literature review in chronological order, stating the context analyzed in each paper and whether it is a conceptual or empirical article (similar to Schick et al. 1990). For further analysis, all papers can be organized into the following four categories.Footnote 1
-
1.
The first category represents research that is concerned with how changes in external financial reporting affect users of financial statements (“external financial reporting”). A number of papers address external financial reporting in general; these are largely conceptual papers that analyze the extent to which more detailed external reporting might influence financial statement users’ decision-making. Others have more specifically investigated topics like, e.g., the quality of cash flow predictions dependent on varying information load in the footnotes of annual reports (Snowball 1980), stock price predictions based on a varying number of information cues (Tuttle and Burton 1999), the effectiveness of graphs in mitigating the effects of increases in information load when predicting future operating margins based on historical data (Chan 2001), or the effects of changes in the number of available options in a retirement contribution plan on choice behavior (Agnew and Szykman 2005).
-
2.
The second category comprises research that has investigated how changes in information load affect financial distress or bankruptcy predictions (“financial distress prediction”). Papers in this section typically investigated subjects’ judgment quality in making predictions on bankruptcy or financial distress for several firms, manipulating the number of financial indicators the subjects received to make their predictions.
-
3.
The third category comprises research in the field of management accounting (“management accounting”). This covers several areas, including managerial decision-making, e.g., the effect of increases in information load on search patterns (Swain and Haka 2000) or on judgment accuracy (Shields 1983), the impact of financial incentives on a mood congruency bias under two different levels of information load (Ding and Beaulieu 2011) or the relation of organizational performance to multi-perspective performance reporting (Iselin et al. 2009).
-
4.
The fourth category comprises research addressing how auditing is affected (“auditing” or “internal auditing”), covering also different topics, like e.g., whether experience can mitigate bias under high information load in a going concern and an insolvency setting (Arnold et al. 2000), how big data, including potential information overload effects, could impact auditing (Brown-Liburd et al. 2015) or internal audit tasks (Blocher et al. 1986; Davis and Davis 1996).
Most research has addressed individual decision-making. Unsurprisingly, the most common research methodology is experimental research, experiments being the most powerful tool in investigating cause and effect relationships (e.g., summary in Sprinkle 2003).
4 Methodology of analysis
To identify research articles that address information overload in accounting, a methodology similar to that applied by Eppler and Mengis (2004), who based their methodology on Webster and Watson (2002), was used. Webster and Watson (2002) propose identifying the relevant literature to be included by starting with a set of relevant papers and looking at references cited as well as forward-citations. This technique, also called ‘snowballing’ (Wohlin 2014) begins with defining a valid start set. In the field of accounting, Eppler and Mengis (2004) and Schick et al. (1990) provide very helpful starting points for the compilation of the landmark articles for the time periods from 1970 to 2003. To further advance completeness, similar to Eppler and Mengis (2004), the Business Source Premier database within EBSCO was used. Also following Eppler and Mengis (2004), an initial broad selection was made by searching for papers that included either “information load,” “information overload,” “cognitive load,” or “cognitive overload” in either title or abstract, restricted to only include peer-reviewed journals. The papers identified were then screened to determine whether information overload related to accounting, i.e., focusing on any form of interaction with accounting information, was the main topic of the article (similar to Eppler and Mengis 2004). As a result, our review includes papers in the realm of financial and management accounting, auditing, tax, individual investment decisions (stock markets), or capital budgeting decisions.
In a second step, so-called “iterations”, further papers are identified by backward- and forward snowballing, i.e., analyzing the reference list of the respective paper and checking if there are any relevant articles that cite the respective research paper. This results in an additional set of papers that is then in turn analyzed and either included or excluded. Iterations are run until no additional papers are identified (Wohlin 2014). Following this procedure, our analysis resulted in a total of 57 articles that have been reviewed for this article, excluding those articles that rather describe underlying psychological mechanisms, such as Schroder et al. (1967), and also those dealing with overarching models of task performance (e.g., Bonner et al. 2000; Bonner and Sprinkle 2002). As suggested by Webster and Watson (2002), we neither focus on a specific region or time period, nor on a pre-specified selection of journals, but rather attempt to attain completeness by including peer-reviewed scientific articles that address the concept of information overload in the accounting domain. Still, we deviate from the procedure outlined in Wohlin (2014) in one aspect, as we include a paper if it is relevant, even if the original article in which it was cited, is later on excluded.
While the literature on information processing in accounting is vast, the set of articles dealing with the effects of information overload is narrower. Therefore, not all articles that relate to the topic of information processing have been included. In addition, the focus is on information overload and its impact on individual or group decision making. Therefore, articles that focus rather on the role of information in mechanisms in aggregate capital markets have not been included. In summary, for a paper to be included, an overload situation needs to be present, the research needs to deal with accounting, and individual or group decision-making needs to be in focus. Especially the field of disaggregation of accounting information and the “tables vs. graphs” literature can be considered fields with some overlaps with the literature considered in this review. Papers from these two fields have only been included when they were broadly linked to the topic of information overload. Papers that focus more narrowly on the benefits of providing graphs vs. tables (even if these graphs constitute additional information) or how information processing in graphs can be achieved in an optimal manner, were not included (e.g., Hirsch et al. 2015; Tan 1994). The same is true for papers focusing on disaggregation of accounting information in a broader sense, such as its effect on audit fees (e.g., Shan et al. 2021).
As will be seen later in this review, not all variables have been investigated with similar intensity. While some links have received considerable attention, others have been investigated less frequently. In addition, some links are rather unambiguous with similar cause-effect relationships in the papers reviewed, while for other links, results point in differing directions. What has come to be known as the replication dilemma (e.g., Schooler 2014) also seems to apply for research in the information overload context.
To account for the different levels of empirical validation, the methodology of “stylized facts” was applied. Stylized facts can be considered a common ground based on current empirical knowledge: “Stylized facts are broad, but not necessarily universal generalizations of empirical observations and describe essential characteristics of a phenomenon that call for an explanation” (Heine et al. 2007, p. 583). Loos et al. (2011) summarize the methodology of stylized facts, which was initially coined by Kaldor (1961) as lying between a review and meta-analysis. Unlike a literature review, it includes only empirical findings. Unlike a meta-analysis, it is less restrictive with regards to similarity of content of the studies or empirical methodology employed and therefore allows for a broader consideration of the subject. Based on Weißenberger and Löhr (2008), Schwerin (2001), and Oppenländer (1991), Loos et al. (2011) summarize three requirements for the formulation of stylized facts: (1) Stylized facts must be important for the research question at hand; (2) they should hold irrelevant of the underlying theory or research methodology; and (3) they should not only be based on one observation, but should rely on findings that are observable multiple times. As there is no generally agreed threshold for classification of a finding as a stylized fact (Weißenberger and Löhr 2008), there is an element of subjectivity that makes it especially important to make the process of generating the stylized facts transparent (e.g., Heine et al. 2007; Weißenberger and Löhr 2008). For this review we use the following clusters, only considering effects that have been analyzed by a minimum of two articles:
-
1.
+ + : clear positive link: dominance of positive, significant relationships
-
2.
+ : rather positive link (e.g., one positive, one insignificant)
-
3.
O: tested, but no significant results
-
4.
?: contradictory results
-
5.
-: rather negative link (e.g., one negative, one insignificant)
-
6.
--: clear negative link: dominance of negative, significant relationships
5 Framework for analysis
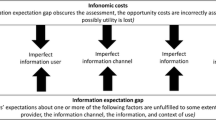
To effectively analyze the literature and formulate well-structured implications, a framework serves to cluster the variables and their respective interactions encountered in the research reviewed. The framework combines relevant elements from the framework proposed by Eppler and Mengis (2004), research on information processing in accounting (Libby and Lewis 1977), and the model on task performance by Bonner et al. (2000) and Bonner and Sprinkle (2002). Figure 3 below illustrates the framework that will be used in this review to categorize the findings on information overload effects in accounting-based decision-making.

Framework for Analysis of Information Overload
The overarching structure is borrowed from Eppler and Mengis (2004). They focus their synthesis around the three elements “causes,” “consequences” (termed “symptoms” by Eppler and Mengis 2004), and “countermeasures,” highlighting the fact that it is not a one-dimensional or one-directional relationship—changing one of the elements (e.g., applying a countermeasure) might affect other elements in the relationship. Eppler and Mengis (2004)’s approach resembles that of Bonner (1999), as it establishes a framework around causes, consequences (or “deficiencies” in Bonner 1999), and countermeasures (or “remedies” in Bonner 1999). Generally speaking, causes are the independent variables investigated, while consequences are the dependent variables. Countermeasures can either be directly researched as independent variables or are implied in the discussion section of the articles. Countermeasures can be effective when addressing the causes of information load, and their analysis is thus structured in the same way as the causes for information overload (Eppler and Mengis 2004).
Libby and Lewis (1977)’s model is very useful for further structuring the relevant variables that are used to investigate the described causes, consequences, and countermeasures. They categorize the parameters of their model into input, process, and output parameters, where input variables of interest consist of the information set that is being used. The process then describes the characteristics of the “judge”, differentiating between judge characteristics and characteristics of the decision rule. The judge refers to the person or “mechanical” judge making the decision. The concept of a mechanical judge is only relevant for few papers reviewed here (Gadenne and Iselin 2000; Iselin 1991; Keasey and Watson 1986; Simnett 1996) but is of potential interest for future considerations of the automation of decision-making. Instead of “judge,” the term “decision-maker” will be used here. The output variables in Libby and Lewis (1977) refer to “judgment—prediction—decision,” whereby the variables of interest are “qualities of the judgment” and “self-insight.”
Input parameters appear as “causes” in the framework and are clustered into characteristics of the information set, further task characteristics, and environmental variables. Process parameters are relevant to both the “causes” and the “consequences” section. Decision-maker characteristics, such as experience, are considered to be potential causes, whereas decision time, cue usage, and the decision rule applied are considered consequences of increases in information load for the purposes of this review. In her commentary on judgment and decision-making research in accounting, Bonner (1999) also categorizes the variables of interest referring to input, process, and output variables. The categorization of the respective parameters differs slightly from that of Libby and Lewis (1977), however. One example is the following: While Libby and Lewis (1977) consider person variables, such as the knowledge the decision-maker applies a parameter that refers to the “process,” Bonner (1999) considers this to be an input parameter. The categorization employed here, that sees decision-maker characteristics as a cause (even if related to the process), aligns with the view that person variables are “input” or independent variables, as described by Bonner (1999).
Consequences of information load can be measured both on an objective and subjective level, for example via self-reports by subjects. Libby and Lewis (1977) term these “self-insight.” Self-insight can also relate to perceptions of the information set. With regards to process variables, in the research reviewed here, decision time and decision rules employed have been measured objectively.Footnote 2 Cue usage can be measured on both an objective and a subjective level. Accuracy, consistency, and consensus are measured on an objective level, while decision confidence and the feeling of overload are subjective measures. Calibration is measured by combining objective measures (in general, accuracy) with subjective measures (in general, confidence).
Eppler and Mengis (2004) equally organize causes and countermeasures by “personal factors,” “information characteristics” and “task and process parameters.” However, they add “organizational design” and “information technology.” Information overload research on decision-making in accounting, with few exceptions (see Table 8 in the supplementary material), mainly addresses individual decision-making, for which an organizational setting would set the frame. We therefore include organizational design under the cluster “environment.” Similarly, in the papers reviewed, “information technology” either changes the task or the presentation format and thus is included under these clusters respectively (e.g., Kelton and Murthy 2016). Eppler and Mengis (2004) categorize consequences of information overload into the following clusters: “limited information search and retrieval strategies,” “arbitrary information analysis and organization,” and “suboptimal decisions.” According to Libby and Lewis (1977), suboptimal decisions are a consequence of the input and process variables. As such, “limited information search and retrieval strategies” and “arbitrary information analysis and organization” would be considered variables that describe the process and then possibly entail suboptimal decisions in the framework described above.
In our analysis, we concentrate on the main variables that are investigated. The framework serves as a schematic overview covering the main aspects and does not claim completeness, neither of all possible variables, nor of all interactions between variables (which are described in detail in the analysis Sect. 6). We also deviate from Libby and Lewis (1977)’s model by assigning decision time to “process,” whereas Libby and Lewis (1977) consider decision time an attribute of decision quality. Benbasat and Dexter (1979) note that there is often a trade-off between decision quality and decision time, for example in Chervany and Dickson (1974). For the purpose of investigating information overload, it makes sense to consider decision time as an antecedent to output variables such as accuracy, consistency, and consensus. As explained below, decision time can in turn influence output variables. The placement of the decision rule to be employed also needs some further explanation: While Libby and Lewis (1977) consider the decision rule a personal characteristic, we prefer to describe the decision rule separately: although it is clearly related to the person, it does not need to be considered as invariable. Whereas available time is to be considered as a cause, decision time is a consequence.
The variable “feeling of overload” or a similar concept has been investigated in a number of articles (Agnew and Szykman 2005; Gadenne and Iselin 2000; Hirsch and Volnhals 2012; Iselin 1993; Kelton and Murthy 2016). It is not addressed by Libby and Lewis (1977) directly, but it can be considered a sub-aspect of self-insight. Libby and Lewis (1977) describe task characteristics as “context” of the information set. As the task at hand plays an important role in the effects of increases in information load, “further task characteristics” are considered a separate category in the framework employed here.
Although the main objective of Bonner et al. (2000) and Bonner and Sprinkle (2002) was to build a conceptual framework to explain how monetary incentives effect task performance, the general parameters in their framework can serve as an addition to the variables already described above and help further classify research on information load. The following section summarizes the main findings from the papers reviewed.
6 Analysis of the literature
6.1 Causes of information overload
6.1.1 Information set
Naturally, the most obvious cause of information overload is an increase in the amount of “information.” However, what is understood by “information” must be further defined. As will be seen in this review, an increase in the number of “information cues” can lead to a variety of consequences, both at the processing stage and at the output stage, depending on what the characteristics of the information set (among other factors) are.
In the model proposed by Libby and Lewis (1977), the characteristics of the information set are categorized into several clusters. The aspects that are especially relevant for describing the information set in the context of this literature review are summarized below (Fig. 4). Some characteristics of the Libby and Lewis (1977) model have not been explicitly investigated in the articles dealing with information load and therefore are not included in Fig. 4; these characteristics are “scaling characteristics of individual cues,” for example whether a cue’s measurement is ordinal or nominal. Rather than being considered within the “information set” section, for this review, the characteristics mentioned for the context of the information set (“physical viewing conditions,” “instructions,” and “feedback”) are considered in the “environment” section (see 6.1.3) while “task characteristics” are described in the “further task characteristics” section (see 6.1.2).

Characteristics of the Information Set. Note Parts are adapted from “Human information processing in accounting: The state of the art,” by Libby, R. and Lewis, B. L., 1977, Accounting, Organizations and Society, 2(3), p. 247
Research into information load has typically investigated a combination of the characteristics (Libby and Lewis 1977), for example changing the number of cues by presenting either aggregated or disaggregated data, or increasing the number of cues when the cues are uncorrelated with those already present (“relationship to criterion”). Not all studies explicitly describe which elements are changed; in this case, they are inferred from the description in the articles where possible. In addition, manipulating one aspect sometimes affects other aspects as well, for example, data aggregation is likely to affect the information content. This section aims to present the major clusters.
I: Statistical properties of the information set
I.a. Looking at the statistical properties of the information set, the most evident element in information load research is the number of cues. A change in the number of cues is of interest in all research articles dealing with information load. An exception are the articles that imply information overload to be present (e.g., Kelton and Murthy 2016, or the second experiment in Ding and Beaulieu 2011, and Henderson 2019) or those that trigger information overload effects by restricting the time (Davis and Davis 1996; Hirsch and Volnhals 2012; Snowball 1980). Conducting a questionnaire-based study, Iselin et al. (2009) also do not manipulate information load, but rather analyze the perceived level of information (or data) load.
I.b. Distributional characteristics are most often termed “uncertainty.” Iselin (1990) manipulated uncertainty by changing the variability of the data over time periods. Ragland and Reck (2016) manipulated the volatility of the variable of interest to induce increased task complexity. Uncertainty, as best described by variability, is to be differentiated from a cue’s potential to reduce environmental uncertainty (see “relationship to criterion” below).
I.c. Interrelationship of cues is referred to by Libby and Lewis (1977) more narrowly as redundancy. In this review, redundancy is described in detail, together with “relationship to criterion” (to explain the link to relevance, see II.c). In a wider sense, similarity can be considered an aspect of interrelationship of cues—Agnew and Szykman (2005) analyzed the effect of similarity of investment options on the feeling of information overload.
I.d. Underlying dimensionality is operationalized in several ways. A similar term used in this context is “information diversity” (e.g., Iselin 1988, 1989). Studies applying the model by Schroder et al. (1967) to accounting have highlighted that the amount and diversity of information may lead to an increase in environmental complexity (Fertakis 1969; Revsine 1970). Iselin (1988, 1989) investigated the effects of increasing information diversity, defining information diversity as the number of different dimensions in an information set. Adding an additional performance indicator (e.g., adding information for earnings before interest and taxes to the information set that might until then consist of net sales and gross profit) is thus defined as adding a new dimension, whereas the value of that performance indicator for another time period (e.g., not only looking at net sales for the years 2000–2005 but for the years 2000–2006) is called a “repeated dimension.” Shields (1980, 1983) differentiated between adding organizational units or performance indicators to the information set. Similarly, Swain and Haka (2000) differentiated between adding investment alternatives and adding additional performance indicators, which they term dimensions. Iselin et al. (2009) apply the term dimensions to performance indicators used within a Balanced Scorecard perspective.
II: Information content
II.a., II.b.: Two elements of information content, namely bias (systematic error; Libby and Lewis 1977) and reliability (random error; Libby and Lewis 1977) in the data set are not of interest in the research of information overload in accounting—there are no research papers that have manipulated these characteristics.
II.c. The most important aspect of the information content cluster is the aspect “relationship to criterion.” This refers to the predictive ability of the cue with regards to a specific event. Summaries can be found in Libby and Lewis (1977) and Belkaoui (1984).
Relevance and redundancy are the two key terms when it comes to describing the relationship to criterion within information load research. Relevance refers to the predictive ability of a cue. Cues that have no predictive ability for the respective event are irrelevant. Relevance is typically measured by looking at the significance of coefficients in a regression model (e.g., Gadenne and Iselin 2000) or based on expert judgments (Casey 1980).
Redundancy refers to the cue’s correlation with other cues in the information set. It therefore describes both a form of interrelationship of cues (Libby and Lewis 1977) and relationship to criterion. As summarized by Rakoto (2005), redundancy can thus only be determined by considering at least two cues in conjunction. If a cue added to the information set is (highly) correlated with another cue, it is considered redundant. The predictive ability of the information set therefore does not increase when redundant cues are added. Redundancy is typically measured by the correlation coefficients between cues (e.g., Belkaoui 1984; Rakoto 2005). It is important to note that the concepts of relevance and redundancy are independent: a cue can be relevant and redundant at the same time (or neither of the two). However, if a cue is redundant with regards to another relevant cue, it is also relevant.
Often, the term “data load” is used to describe irrelevant data (e.g., Iselin 1993). Gadenne and Iselin (2000) define data load as the total number of cues minus the number of the relevant cues, considering a cue irrelevant that does not have any predictive ability with regards to the event to be predicted. Iselin (1993) considers a cue as data load when the correlation with another cue is larger or equal to 0.85, indicating redundancy. This article focuses on the terms “relevance” and “redundancy” to ensure unambiguous wording.
A term that is related to relevance is the term “uncertainty”, meaning the cue’s potential to reduce uncertainty with regards to the decision at hand. Only relevant information can objectively reduce uncertainty. Uncertainty is then measured by “one minus the coefficient of environmental predictability” (Iselin 1993, p. 258). Iselin (1993) and Gadenne and Iselin (2000) explicitly investigated changes in uncertainty. As noted above, uncertainty refers to the uncertainty around predicting an outcome, not to uncertainty in the variability of information cues (see “distributional characteristics” above).
Most studies address an increase in relevant information. This is true for most financial distress prediction studiesFootnote 3 and for studies that have employed a highly structured decision task requiring the inclusion of all cues presented to attain the optimal solution (e.g., Iselin 1988; Tuttle and Burton 1999; Hirsch and Volnhals 2012). Effects of increases in redundant data have been explicitly investigated by Barefield (1972), Belkaoui (1984) and Rakoto (2005). In a questionnaire-based study, Iselin et al. (2009) consider perceived (over-)load of redundant data. Referring to the conceptual model by Schroder et al. (1967), the differentiation between relevant, irrelevant, and redundant data can be considered as creating a link between increased information integration and increased decision quality: Adding redundant or irrelevant cues may increase information integration, but, as the information content does not increase, the decision quality will only increase as much as is warranted by integration of relevant cues already present.
Increases in the amount of irrelevant data have been investigated by Gadenne and Iselin (2000), Iselin (1993), Iselin et al. (2009), and Rakoto (2005). Some researchers argue that a lack of significant effects of increased information load is due to the addition of redundant data or subjects perceiving the data as redundant or irrelevant (Snowball 1980). In the context of Balanced Scorecard evaluations, Hioki et al. (2020) argue that indicators related to the internal business processes- and learning and growth-dimensions are more ambiguous with regards to financial performance, thereby also referring to the “relationship to criterion” aspect, even if not explicitly mentioning relevance.
III: Method of presentation
III.a. With regards to the “format” of information presented, most studies have used numerical data. However, some financial distress prediction studies have used “top 1/3 of the industry”, for example Chewning and Harrell (1990) or Stocks and Tuttle (1998) or use verbal characteristics such as “weak” or “favorable” (Tuttle and Burton 1999). The paper by Snowball (1980), who adds footnotes, the paper by Henderson (2019), who analyzes the perception of notes in financial reporting (thus primarily focusing on verbal cues), the paper by Keasey and Watson (1986) who include verbal bank statements, as well as the papers by Umanath and Vessey (1994), Blocher et al. (1986), and Chan (2001) who investigate numerical (tables) vs. graphical presentation are further examples of differing methods of presentation. Relying on archival data, Impink et al. (2021) use an index based on the appearance of certain key words in the companies’ filings to reflect regulation-based increases in information load, combining increases in numerical and verbal data.
III.b. “Sequence” has not been explicitly investigated in the articles analyzed for this review.
III.c. Aggregated or disaggregated data are also termed a “precombination of data” by Libby and Lewis (1977). The precombination of data (or the contrary, decomposition of data) was the focus of early conceptual papers (e.g., Fertakis 1969; Miller and Gordon 1975; Revsine 1970) and a number of empirical studies (e.g., Abdel-Khalik 1973; Barefield 1972; Chervany and Dickson 1974; Dong et al. 2017; Eberhartinger et al. 2020; Elliott et al. 2011; Hirst et al. 2007; Kelton and Murthy 2016; Otley and Dias 1982, Ragland and Reck 2016). It is important to note that the methods of aggregation and disaggregation differ markedly between the papers, for example calculating variances (Barefield 1972), adding up data (Abdel-Khalik 1973; Kelton and Murthy 2016; Otley and Dias 1982), and calculating statistical measures (mean, variation coefficient, range, maximum value; Chervany and Dickson 1974). Swain and Haka (2000) aimed to add performance indicators by disaggregating data without changing information content. Different aggregation methods are likely to influence information content; the method of aggregation therefore must be taken into account when interpreting the resulting effects. As will be seen in Sect. 6.2, the consequences of varying the number of information cues by aggregating or disaggregating differ notably from simply increasing or reducing the number of information cues.
6.1.2 Further task characteristics
One way to investigate the influence of task characteristics is to compare different tasks against each other, making a change in task characteristics the independent variable. An example could be comparing performance in a structured decision-making task with performance in an unstructured decision-making task (more details regarding structured and unstructured decision-making can be found below). While such a setting cannot be found among the articles reviewed here, it can be argued that some aspects of manipulations in an experimental design implicitly lead to changes in task characteristics. Even if task characteristics are not explicitly manipulated in the literature reviewed, it is still important to consider the nature of the task being investigated—task characteristics, especially task complexity, are likely to influence how changes in further variables (e.g., possible reduction of the effect of experience or learning) affect task performance (Bonner et al. 2000; Bonner and Sprinkle 2002). Thus, considering task characteristics is essential when analyzing and comparing results.
According to Wood (1986), task complexity consists of three components: component complexity, which depends on the amount of information and steps needed to perform a task; coordinative complexity, which describes the relationship between input and output of a task; and dynamic complexity, which is present when the form of the relationship between input and output changes. While the former two dimensions are relevant in the context of information overload research, dynamic complexity is less important—in experiments, the relationship between task input and task output rarely changes (Bonner et al. 2000). Research that considers the effects of aggregation or disaggregation of accounting information and therefore implicitly changes information load (e.g., Barefield 1972) is likely to result in changes in task complexity. Otley and Dias (1982) manipulate task complexity by having subjects estimate either overall (low complexity) or marginal contribution (high complexity) to profit.
As Iselin (1988), referring to Mason and Mitroff (1973), highlights, an important aspect is the divide between structured and unstructured decision-making. Gorry and Scott Morton (1971, p. 60; referring to Simon 1960) describe the difference as follows: “in the unstructured case the human decision-maker must provide judgment and evaluation as well as insights into problem definition. In a structured situation, much if not all of the decision-making process can be automated.” Simon (1960, p. 6) explains that the distinction between the two types is not clear-cut, but typical management decisions should be positioned on a “continuum” from highly structured to highly unstructured.Footnote 4 As task structure increases, task complexity decreases (e.g., Bonner and Sprinkle 2002; Wood 1986). Most research reviewed in this article is concerned with unstructured decision-making, which is a task where “there is no unique correct decision and no algorithmic decision procedure” (Iselin 1989, p. 164). Iselin (1988), Otley and Dias (1982), Tuttle and Burton (1999), and Hirsch and Volnhals (2012) investigated structured decision-making. They investigated tasks that, when employing an adequate algorithm, could be solved unambiguously. Task characteristics also played a role in early conceptual papers. Fertakis (1969) describes tasks or information needs as relating to three broad areas: internal organization of the firm, information regarding the firm’s external relationships, and the firm in its social or political role. According to Fertakis (1969), individuals do not have the capacity to select the relevant information for their specific purposes when provided with all information relevant to the above areas, so there must be a fit between information provision and task requirements. Miller and Gordon (1975) introduce the task aspect more explicitly, stating that the optimum conceptual level depends on the task at hand. Less abstract conceptual levels might be beneficial for simpler tasks.
6.1.3 Environment
Environmental characteristics have the potential to influence task outcomes (e.g., Bonner and Sprinkle 2002). Environmental variables of primary relevance to information load research in accounting are available time and incentives.
Snowball (1980), Davis and Davis (1996), and Hirsch and Volnhals (2012) operationalized increases in information load (partly) by restricting the time available to perform the task. Similarly, as mentioned above, in their conceptual paper, Schick et al. (1990) explicitly describe the concept of information overload as relating to the time available. Snowball (1980) notes that in the Schroder et al. (1967) model, the time available is explicitly considered. While a certain number of studies tracked (decision) time, for example Abdel-Khalik (1973), Barefield (1972), and Chervany and Dickson (1974), besides the articles mentioned above, no other study has explicitly claimed to have restricted decision time. Impink et al. (2021) investigate whether the number of firms that analysts follow have an impact on their reaction to increases in information load, a variable that can be interpreted as available time.
Tuttle and Burton (1999) and Ding and Beaulieu (2011) investigated the influence of a performance-based monetary incentive as an independent variable. Even if not explicitly part of the experimental manipulation, whether subjects received some sort of incentive to participate in the study might influence performance (Bonner and Sprinkle 2002). In the following studies, subjects received (only) a monetary base payment, and/or course credit, and/or opportunity to participate in a draw: Agnew and Szykman (2005), Casey (1980), Chervany and Dickson (1974), Davis and Davis (1996), Ding and Beaulieu (2011), Otley and Dias (1982), Rose et al. (2004), Swain and Haka (2000), Stocks and Tuttle (1998), and Tuttle and Burton (1999)—for the groups that were not part of the incentives manipulation described above. In some studies, subjects received a performance-based payment (the following list also includes those that received performance-based incentives in addition to a base payment): Barefield (1972), Benbasat and Dexter (1979), Chervany and Dickson (1974), Davis and Davis (1996), Rose et al. (2004), Swain and Haka (2000), and Umanath and Vessey (1994). Other studies used the opportunity to learn, receive feedback, or the results as an incentive for participation: Casey (1980), Iselin (1991), and Iselin (1993). The remaining articles reviewed are silent with regards to incentives of any kind or did not include incentives.
Further environmental variables include feedback and viewing conditions. Feedback during the task is described by Libby and Lewis (1977) as a context variable. Although not analyzed explicitly as an independent variable, feedback is likely to impact learning and motivation—see Bonner and Sprinkle (2002) for a summary. Otley and Dias (1982) and Tuttle and Burton (1999) provided feedback to the subjects after each decision. Impink et al. (2021) consider the size of the brokerage house (as a proxy for resources available to the analyst) an additional factor when analyzing analyst forecasts. Libby and Lewis (1977) name “physical viewing conditions” as another context variable. In the 1970s, interactive drilldowns (Kelton and Murthy 2016) or multiscreen presentations (Rose et al. 2004) did not play a role in accounting-based decision-making; nevertheless, these variations can be included under further environmental variables.
6.1.4 Decision-maker
The structure proposed by Libby and Lewis (1977) is useful for describing variables that refer to the decision-maker. Their first characteristic refers to whether decisions were taken by humans or a decision rule. Gadenne and Iselin (2000), Iselin (1991), Keasey and Watson (1986), and Simnett (1996) investigated human performance compared to that of a mechanical rule; other research reviewed here has exclusively addressed human decision-making. Libby and Lewis (1977)’s second differentiation refers to the number of decision-makers. As described above, except for Iselin (1991) and Stocks and Harrell (1995), most empirical research has addressed individual decision-making as opposed to group decision-making.
Libby and Lewis (1977) further describe personal characteristics and task related characteristics of the decision-maker as relevant clusters. With regards to personal characteristics, early conceptual papers mostly addressed individuals’ level of conceptual abstractness—this is a prominent component of the Schroder et al. (1967) model. Personal characteristics were empirically investigated by Abdel-Khalik (1973), who investigated risk preference, and Ding and Beaulieu (2011), who investigated the effects of moods. Benbasat and Dexter (1979) and Otley and Dias (1982) compared the performance of high and low analytic subjects. In a similar vein, Hioki et al. (2020) compare outcomes by splitting the group into high and low Need for Cognition (NFC; see e.g., Epstein et al. 1996) subjects.
Task-related characteristics of the decision-maker have been more frequently investigated than personal characteristics, most often as experience (Abdel-Khalik 1973; Impink et al 2021; Iselin 1988—students vs. practical decision-making experience; Iselin 1989, 1990; Keasey and Watson 1986; Simnett 1996; Snowball 1980; Swain and Haka 2000) or knowledge, based on a test taken by subjects (Agnew and Szykman 2005). Task learning (Iselin 1988, 1989, 1990, 1991; Otley and Dias 1982) is another aspect that may be counted within task-related characteristics of the decision-maker. However, because of the way it is operationalized (measuring how performance changes over a number of trials), it is not used to analyze different personal characteristics, but rather to analyze if there is a learning effect in general.
6.2 Consequences of information overload
The following section synthesizes the consequences triggered by a change in the variables described above, focusing solely on empirical articles. With the exception of the effects on decision rules and cue usage, where variables are too diverse to be clustered in a tabular format, each section contains a tabular overview of the effects encountered. While the main effects studied that did not yield any significant effects are also included, only significant interaction effects are presented in the tables; the reason being, besides brevity, that the articles’ authors most often restrict the discussion to significant interactions. The tables give an overview, especially conflicting results and the potential underlying reasons are discussed in more detail. Findings are summarized as stylized facts.
6.2.1 Decision time
Decision time, or the time used to complete the task, is generally considered an (opportunity) cost for decision-making (Abdel-Khalik 1973; Benbasat and Dexter 1979; Iselin 1988). This is similar to using time as a measurement for effort duration, as in models of task performance, for example Bonner and Sprinkle (2002). Time can either be self-reported by subjects (e.g., Abdel-Khalik 1973), recorded by the experimenter (e.g., Iselin 1988), or tracked automatically when using computer-based technology (e.g., Chervany and Dickson 1974; Swain and Haka 2000). Impink et al. (2021) measure the delay in analyst forecasts, which can be interpreted as decision time in a broader sense. As noted above, time can be explicitly limited to induce information overload and is then considered a characteristic of the environment. This section focuses on decision time as a dependent variable.
Table 1 gives an overview of the factors affecting decision time, using the classification described in Sect. 4 to categorize the stylized facts drawn from the reviewed papers.
First, providing more cues (even if they are redundant) tends to increase decision time (++), as does an increase in information diversity and uncertainty. For increases in information load that are due to disaggregating measures, the relationship is less clear. While Benbasat and Dexter (1979) observed an increase in decision time, Chervany and Dickson (1974) found a decrease in decision time for disaggregated data, that is, more information cues. Abdel-Khalik (1973) and Otley and Dias (1982) find no significant effect (?). A tentative interpretation could be that aggregating measures as statistical measures (as is the case in Chervany and Dickson 1974) reduces information cues, but makes the task more difficult, leading to increased decision times.
The effect of experience is unclear. While Swain and Haka (2000) found experience to increase decision time, Impink et al. (2021), Iselin (1988). and Iselin (1989) found experienced subjects to (sometimes) spend less time on the task, and Iselin (1990) found no significant effect on decision time (?). A reason could be the different tasks employed—while Swain and Haka (2000) used an unstructured task, Iselin (1988) employed a structured decision-making task. However, this does not explain the opposite effects between Swain and Haka (2000) and Iselin (1989), whose experiment also employs an unstructured decision-making task. Task learning seems to decrease decision time (--).
6.2.2 Decision Rule
In the articles reviewed, decision rules used by subjects refer to either the way of weighing alternatives against each other, the use of heuristics, or the tendency for biases when making judgments or decisions. Having subjects choose between alternatives, Shields (1980) and Swain and Haka (2000) investigated cue usage patterns (see following section) to derive assumptions as to which decision rule might have been used by subjects. As will be described also in the “Cue usage” section, Swain and Haka (2000) found that with increasing information load, the relative amount of information searched decreased, the variability of the search process increased, and subjects switched from an intradimensional to interdimensional search strategy—which is interpreted as a switch to a less systematic, more satisficing search strategy. However, the last finding was not robust to different measurements of search strategy employed. Shields (1980) implies that his findings regarding the increased variability of search patterns with increasing information load indicate the use of non-compensatory decision strategies. Unlike compensatory decision strategies, which incorporate all information and require exact weights on the different attributes, non-compensatory strategies are assumed to require less cognitive capacity, for example by identifying the most important attributes and only taking those into account (see Luft and Shields 2010).
With regards to heuristics, within the context of balanced scorecard-based performance ratings, Ding and Beaulieu (2011) found incentives to be unsuccessful at correcting a mood congruency bias (performance evaluations influenced by either an induced positive or negative mood) when information load was too high. Kelton and Murthy (2016) found that an earnings fixation effect in an information overload setting was reduced by providing interactive drilldown possibilities; this was not the case when using footnotes to present the additional information. Elliott et al. (2011) found an earnings fixation effect to be reduced when subjects were provided with disaggregated earnings information. In a similar context, Hirst et al. (2007) found disaggregated earnings forecasts to be judged more credible, countering impacts of high management incentives. However, in a multi-period setting, Dong et al. (2017) found stronger negative reactions to earnings surprises for disaggregated vs. aggregated forecasts. Eberhartinger et al. (2020) found additional disaggregated tax disclosure information to only affect judgment when it significantly deviated from an initial anchor. Rose et al. (2004) provide evidence that memory reconstruction effects to match an affective state induced (e.g., having a tendency of recalling rather positive performance indicators after a decision when a positive mood was induced) decreased when information load or cognitive load was reduced.
Agnew and Szykman (2005) investigated whether increases in information load made subjects choose a default option more frequently, which could be interpreted as using a heuristic decision rule. They found an interaction effect between knowledge and number of options—high knowledge individuals chose the default option more often when the number of options increased, while low knowledge individuals chose the default option less often. Arnold et al. (2000) found that the assumption for experience to mitigate biases proposed by the belief adjustment model did not hold for complex (high information load) environments. Roetzel et al. (2020) investigate the effect of increases in information load in the context of escalating commitment. They found a U-shaped relationship, with increases in information load mitigating escalation tendencies up to a certain point (in the context of negative feedback) but leading to increased escalation of commitment beyond that point. Furthermore, they found increases in information load to reduce self-justification to a certain extent (in the context of negative feedback).
In the context of individual investment decisions, Ewe et al. (2018) found that inducing a certain regulatory focus (prevention vs. promotion-focus) by showing subjects a corresponding visualization is not effective when financial information is provided in addition. Blocher et al. (1986) investigated whether internal auditors systematically rate reports as high (or low) risk. They found increases in information load to be associated with a tendency to classify reports as high risk, pointing out that there is a strong interaction effect (tabular format—high information load and graphical format—low information load combinations both yielded the highest tendency for biased decision-making). Due to the differing definitions and the limited number of articles investigating decision rules, no stylized facts can be derived.
6.2.3 Cue usage
Similar to the previous section, this section addresses how the information set is used. This can be either the search pattern applied or the extent to which the cues are incorporated in the respective judgment. As information demand is the necessary—if not sufficient—condition for information use, this aspect is also considered in this section. As described in the framework (Sect. 5), cue usage can be measured either objectively or subjectively.
Objective measurement is possible via regression (Chewning and Harrell 1990; Stocks and Harrell 1995; Stocks and Tuttle 1998; Tuttle and Burton 1999) or process tracing (Shields 1980, 1983; Swain and Haka 2000). Process tracing allows the tracking of which information cues have been selected or viewed by the decision-maker. It is important to note that selecting a cue does not necessarily equal integration of that cue into the respective decision (e.g., Reisen and Hoffrage 2008). Hioki et al. (2020) and Ragland and Reck (2016) use successful recall as a proxy for cue usage. Subjective measurement refers to self-reports by subjects, sometimes used in addition to objective measurement (e.g., Chewning and Harrell 1990; Henderson 2019; Stocks and Tuttle 1998).
Stocks and Tuttle (1998) found increased information load and numerical (vs. categorical) data to negatively impact relative cue usage (measured by significant betas in the regression model). In addition, subjects in the high information load condition reported subjectively integrating significantly more information cues in their judgments, while this perception was not influenced by the type of information presented. Furthermore, the low information load group and the categorical data group showed higher self-insight, measured by the correlation between subjective cue weights and weights objectively determined by the regression model. Tuttle and Burton (1999) also found a decline in relative cue usage with increasing information load.
Shields (1983) found that absolute frequency of information selection increased with increasing information load, while relative frequency declined. Chewning and Harrell (1990) and Stocks and Harrell (1995) measured cue usage utilizing a regression model, with significant beta weights as indicators for cues used. Chewning and Harrell (1990) split subjects into two groups based on their absolute cue usage. For the group impacted by information overload, cue usage declined significantly from the six- to eight-cue level, while it significantly increased for all information load levels for the group not affected by information overload. However, individuals were not aware of the decline in cue usage. In addition, they observed significant differences between different information load levels (within subjects). Stocks and Harrell (1995) found that groups increased their cue usage with increasing information load levels, while individuals did not incorporate more cues (significant interaction effect).
In a qualitative study, Henderson (2019) found an indication of a decline in cue usage but does not specify whether this relates to relative or absolute cue usage.
Hioki et al. (2020) observed a decline in relative cue usage. They also found subjects’ NFC to affect cue usage. In addition, they analyzed whether the type of measure (financial vs. non-financial) had an impact on their usage. They found that low NFC subjects focused on financial measures while high NFC subjects tried to integrate non-financial measures—however, failing when information load increased beyond a threshold. Ragland and Reck (2016) found information use (measured by the ability to recall the information) to increase when information was presented in a disaggregated way.
The effect of increases in information load on the search patterns employed are not clear. Shields (1980) used search patterns as the dependent variable and found that variability increased (per unit) when the number of units to be analyzed increased. There was no significant switch to a more “processing-by-parameter” search (switch to intradimensional search) when the number of units increased. As mentioned in the previous section, Swain and Haka (2000) found the relative amount of information searched to decrease with increasing information load, while the variability of the search increased. Subjects seemed to switch from an intradimensional to interdimensional search strategy. As mentioned above, the switch to interdimensional search was not robust to different ways of measuring search strategy.
As described above, information demand is related to cue usage. Benbasat and Dexter (1979) found that information demand varied with psychological type and information provision. While using an aggregate reporting system, low-analytic-type subjects requested more reports. Under the detailed reporting system, high-analytic types asked for longer time series of historical data than low-analytic types, although there was no significant difference in report demand.
Overall, one stylized fact that can be derived is a decline in relative information use (--) as shown by Shields (1983), Stocks and Tuttle (1998), Swain and Haka (2000), Tuttle and Burton (1999), and Hioki et al. (2020).
6.2.4 Accuracy
Measuring decision accuracy requires the task at hand to have a correct solution against which judgment and decision outcomes can be measured. An unambiguous solution can in most cases be found in highly structured tasks, which allows the unambiguous measurement of accuracy (e.g., Hirsch and Volnhals 2012; Iselin 1993; Tuttle and Burton 1999). Snowball (1980), among others, indicates that measuring decision accuracy is harder to implement when subjects are supposed to engage in unstructured decision-making. However, researchers have resorted to several approaches to overcome this issue: the most common case when measuring accuracy is to use historical data and then compare judgments and decisions to the real event. In most cases, this is the bankruptcy / no bankruptcy of a firm to be analyzed (see Hwang and Lin 1999, for an overview). Another option is to compare outcomes with expert judgments (e.g., Shields 1983) or the results of a statistical model (Rakoto 2005). Another measure of accuracy is attaining low production costs (Chervany and Dickson 1974), higher profit (Iselin 1989, 1990) in a simulation task, or providing accurate earnings forecasts (Impink et al. 2021).
Difficulty arises when both decision accuracy and cue usage should be measured using a regression model, as cues must be uncorrelated to measure cue usage. It is therefore not possible to use real firm data and the real default event: Chewning and Harrell (1990), for example, describe the trade-off between measuring cue usage and measuring decision accuracy (hypothetical, uncorrelated cues vs. real firms).
Table 2 provides an overview of the effects of increases in information cues on accuracy; stylized facts are summarized in Fig. 6. Although some studies have found the predicted decline of decision accuracy when the number of cues surpasses a certain threshold, this is not the case for all research articles reviewed here. The first studies that investigated data aggregation are among these: Barefield (1972) did not find a significant effect of data aggregation on decision quality (applying the optimal decision criterion); Chervany and Dickson (1974) found provision of aggregated data to be associated with higher decision quality, but the difference was not significant. Iselin (1993) did not study the effect of information load further as there was no significant difference between the subjective measurement for both conditions. Only data load (considered as irrelevant data in the article) was further investigated.
Abdel-Khalik (1973) found that disaggregated data, which technically constituted an increase in the number of information cues, led to higher decision accuracy. However, the reason for this is unclear as users indicated in a questionnaire that they found the same data important (the aggregated measures that were provided to both groups). One possible reason proposed by Abdel-Khalik (1973) was that users of disaggregated data felt more comfortable. Furthermore, he investigated whether experience affected accuracy; the effect was not significant. Otley and Dias (1982) found disaggregate data to be associated with lower decision accuracy.
Operationalized as predictive accuracy, Casey (1980) found an increase in predictive accuracy when supplementing financial ratios with balance sheet and income statement, but no further increase when adding the notes as well.
The effect of adding redundant cues to the information set is also ambivalent. While Belkaoui (1984) found an increase in decision accuracy, Rakoto (2005) found a decline. A reason for the differing result could be the task employed in the experiment. While Belkaoui (1984) operationalized the increase in information load by adding further financial ratios, Rakoto (2005) added financial statements to increase information load. Furthermore, the number of ratios provided was lower in Belkaoui (1984). Einhorn et al. (1979) summarize the possible positive (e.g., limited search effort) and negative effects (e.g., attention paid to cues that have little predictive value) of redundant information clues. A tentative interpretation of the different outcomes is that these effects worked differently or with differing strength due to the differences in task design.
Iselin et al. (2009), in a questionnaire-based study, do not directly measure decision accuracy but ask for the perception of organizational performance that they associate with managerial decision quality. They hypothesize organizational performance to be associated with increases in information load to a certain point. In contrast to most experimental studies, they only find partial evidence for overload of relevant, redundant, or irrelevant information to negatively affect organizational performance. As decision accuracy is not explicitly measured, results are not included in the stylized facts formulated below.
To derive stylized facts, papers that found limited effects (Casey 1980) or where effects were only observable for a sub-set of cases (Abdel-Khalik 1973) were not included in the analysis. Summarizing the effects, increases in information load (excluding increases caused by disaggregation) above a certain level rather reduce decision accuracy (-). There is little or no effect of increases in information load caused by disaggregating information (O). Experience seems to have a rather positive effect on decision accuracy (+) as well as task learning (++). Available time has a rather positive effect on accuracy (+). With regards to interaction effects, increasing cognitive load further harms task performance (Rose et al. 2004). In addition, Benbasat and Dexter (1979) found an interaction between psychological type and format of data provision.
As a measurement of decision accuracy cannot be implemented in all cases (e.g., when there is no “correct” solution to the task), researchers have resorted to measuring further aspects of the outcome that are sometimes also called quality-indicators, such as consensus or consistency. These variables are analyzed in the subsequent sections.
6.2.5 Consensus
In the research papers reviewed, decision consensus typically refers to the distribution of judgments or decisions across several individuals (Abdel-Khalik 1973; Chewning and Harrell 1990; Impink et al. 2021; Shields 1983; Snowball 1980; Stocks and Harrell 1995) or of several groups of individuals (Stocks and Harrell 1995). It is measured by comparing variances between experimental groups (Abdel-Khalik 1973; Snowball 1980) or the average degree of correlation between individuals’ decisions (Chewning and Harrell 1990; Stocks and Harrell 1995). Similarly, Shields (1983) used a non-parametric equivalent (coefficient of concordance).
As mentioned above, consensus is often used as proxy for decision quality when decision accuracy cannot be measured (e.g., Ashton 1985; Stocks and Harrell 1995; Stocks and Tuttle 1998; Wright 1988). Consensus being a major variable of interest, especially in the auditing context, Ashton (1985) found a significant correlation between consensus and decision accuracy in a prediction task. This supports the assumption of consensus being a proxy for decision accuracy.
While Snowball (1980) found experience to negatively affect consensus, the effect of a reduction in processing time only approached significance—an operationalization of information load similar to that defined by Schick et al. (1990). A possible reason mentioned is that the more detailed footnotes used in the experiment may not have added any informational value. Impink et al. (2021) found experience and available time to positively affect consensus.
Table 3 gives an overview of the effects on consensus. There is some support for increases in information load to have either no effect (one article) or to negatively affect decision consensus (four articles). As a stylized fact, we summarize this as “(--)”. The effect of available time on consensus is rather positive (+), while the effect of experience on consensus is ambiguous (?). In addition, Stocks and Harrell (1995) found an interaction effect between increases in the number of cues and the judgments made by individuals vs. groups, with consensus decreasing more for individuals then it did for groups when information load was at the highest level. Further interaction effects were observed between available time and expertise (Snowball 1980); the level of information load and type of group (affected vs. not affected by information load; Chewning and Harrell 1990); and changes in information load and data format (numerical vs. categorical; Stocks and Tuttle 1998).
6.2.6 Consistency
Consistency refers to the stability of subjects’ judgments and decisions, either over several judgments in a repeated measure design (e.g., Barefield 1972), or by comparing different measures of decision outcomes to each other (e.g., lending decision and estimate of default probability; Abdel-Khalik 1973). The findings for the effects of an increase in the number of information cues on consistency are ambiguous, see Table 4. Again, the studies on data aggregation/disaggregation are an exception to the general tendency, finding increased decision consistency for disaggregated data (Abdel-Khalik 1973; Barefield 1972). In contrast, Stocks and Harrell (1995) and Stocks and Tuttle (1998), who did not operationalize increases in information load via disaggregation, found negative effects.
Blocher et al. (1986) find consistency to be negatively impacted by increases in information load. Applying the experimental task used in Blocher et al. (1986), Davis and Davis (1996) found no effect of increases in information load per se, and, surprisingly, higher consistency when measuring increased information load per unit of time (U-curve).
The different findings can most likely be attributed to differences in the task at hand (e.g., a clear decision rule in Tuttle and Burton 1999; while others have employed unstructured decision tasks) and different measurements for decision consistency: Barefield (1972) defines consistency as the consequent use of the decision model chosen by the subject. Chewning and Harrell (1990), Stocks and Harrell (1995), Stocks and Tuttle (1998), and Tuttle and Burton (1999) used the adjusted R2 of subjects’ regression models. To summarize, increases in information load not caused by disaggregating data seem to affect consistency rather negatively (-).
6.2.7 Confidence
Confidence is measured by having subjects indicate their confidence or certainty with the decision or judgment made (Agnew and Szykman 2005; Chervany and Dickson 1974; Hirsch and Volnhals 2012; Keasey and Watson 1986). Agnew and Szykman (2005) measured confidence as an item in an overall satisfaction score. In contrast, in Snowball (1980)’s study, subjects were asked to indicate a confidence interval, in addition to a confidence interval assumed for experts or under complete information provision, which then served as a reference point. Another set of papers had subjects estimate the probability of their answer being correct (Belkaoui 1984; Simnett 1996). Belkaoui (1984) measured confidence in reporting under- and overconfidence (among others) but did not report confidence separately; results are therefore not included in Table 5.
The effect of increased information load on decision confidence is not clear—most studies (except for the second experiment in Agnew and Szykman 2005) have found no effect, disaggregating data also seems to not affect decision confidence (Chervany and Dickson 1974). Not considering studies using disaggregation to increase information load, most papers analyzed have not found an impact of increases in information load on decision confidence (O).
6.2.8 Calibration
Calibration refers to “accuracy of confidence” Simnett (1996, p. 700), thus describing the extent to which subjects realistically estimate the quality of their decisions. Calibration is measured by comparing confidence judgments to decision accuracy. Hirsch and Volnhals (2012) did not compare confidence to accuracy but rather compared perceived overload with objective overload. A limited number of studies have investigated the effects on calibration; the effects of increases in the number of information cues are insignificant or negative (-), see Table 6.
6.2.9 Feeling of overload
Several research articles have investigated subjects’ self-insight with regards to their perception of information load or cognitive load (Agnew and Szykman 2005; Gadenne and Iselin 2000; Hirsch and Volnhals 2012; Iselin 1993; Kelton and Murthy 2016). Measurement is typically done via a questionnaire during or after the experimental task. As described above, it is thus a self-reported measure.
While some research articles have focused more on the judgments of subjects regarding effort needed for completion (e.g., Kelton and Murthy 2016) or make use of a measure containing several items to determine subjective information overload (Agnew and Szykman 2005), others have asked participants directly for an estimate of information load (Iselin 1993).
The findings are ambiguous. Iselin (1993) neither found an increase in subjective information load, formulated in the questionnaire as “relevant information,” nor in subjective uncertainty, but only subjective data load (worded as “irrelevant data” in the questionnaire). Using a similar set of measures, Gadenne and Iselin (2000) found a significant effect of increases in number of cues on subjective data load and uncertainty reduction, but also not on subjective information load. Using a questionnaire-based approach, Iselin et al. (2009) use perceived information (over)load as an independent variable in their model of organizational performance, as they do not manipulate the number of information cues.
Agnew and Szykman (2005) found a significant main effect of an increase in the number of options on perceived overload. They also found an interaction effect between financial knowledge and perceived information load (approaching significance at p < 0.10) in their first experiment: Individuals with low scores on financial knowledge had high scores on the perceived overload measure, independent of the level of information load received, while perceived information load was reduced for high financial knowledge subjects in the low information load condition.
Kelton and Murthy (2016) found diverging effects for the use of an interactive drilldown functionality: while the reported cognitive load increased when using a drill-down functionality for subjects in the group for which the utility of disaggregating data was low, it decreased for subjects in the group for which the utility of disaggregating the data was high. Hirsch and Volnhals (2012) provide evidence that subjects’ perceptions of feeling overloaded increased from the group with few information cues to the group with an optimal number of information cues. However, it did not significantly increase from “optimal” information load to the “high information load” group.
In summary, although objective increases in information load are not always fully reflected in subjective judgments of information load, there seems to be a slightly positive link between increases in the number of information cues and the subjective information or data load reported (+) (Table 7).
6.3 Countermeasures against information overload
Looking at possible countermeasures, it is important to distinguish countermeasures named as potential mitigations for information overload effects in the discussion or conclusion of a paper, and countermeasures that were the direct focus of the paper and have been tested empirically. Furthermore, some possible countermeasures, in addition to those named in the articles reviewed, can be derived by analyzing the causes identified in the previous sections. Investigating possible countermeasures has high relevance for practice, as recommendations can be made regarding possible actions to take to mitigate the negative effects of information overload.
As highlighted in the framework for analysis, countermeasures should try to address the causes for information overload phenomena (see also Eppler and Mengis 2004). This section therefore clusters possible countermeasures by following the categories in the “causes” section of the framework, also naming countermeasures that have not been effective. An overview of potential countermeasures described in more detail in the following sections is illustrated in Fig. 5.

Potential countermeasures to mitigate information overload
6.3.1 Information set
The most immediately evident possible countermeasure is changing the characteristics of the information set. One measure is to fit the information set to the task at hand, as discussed in the conceptual paper of Fertakis (1969), supplying only the information cues that are necessary for the decision to be taken. Considering the negative effects that even redundant and irrelevant information cues can have on decision outcomes, the information set should be limited to relevant information cues (e.g., Iselin 1996; Rakoto 2005). Given that the decision is taken repeatedly, relevance of information cues can be determined by analyzing the information cues’ predictive ability, for example, via regression models as in Gadenne and Iselin (2000). Redundant cues that correlate highly with the relevant information set in use should be excluded. Another possibility, as discussed by Iselin (1989), is “exception reporting,” which focuses on reporting relevant deviations only (e.g., Judd et al. 1981). With regards to information presentation, Chan (2001) did not find graphical presentation to be effective in mitigating information overload effects, Blocher et al. (1986) found mixed results. Umanath and Vessey (1994) also did not find an effect on decision accuracy, but did find increases in information load to increase decision time for subjects provided with tabular data, but not for subjects provided with graphical data or data in the form of schematic faces. However, generalization beyond the task analyzed should be done with caution. More research is necessary to determine whether graphical representations can help mitigate information overload effects. Interactive drilldowns have been shown by Kelton and Murthy (2016) to reduce perceived cognitive load and an earnings fixation effect for data disaggregation when the utility of the disaggregated data is high. This indicates possibilities for improving decision-making by giving the decision-maker more control over how to approach the information set. Presentation of additional information in footnotes has not been shown to have an effect similar to interactive drilldowns (Kelton and Murthy 2016).
A question that can be raised is whether personalization of information provision might be beneficial, meaning that personal characteristics are considered when selecting the amount and characteristics of information cues to be provided. Fitting the information set to the decision at hand (and therefore implicitly to a person’s role within or outside of the organization, e.g., Fertakis 1969) is beneficial. However, even though Hioki et al. (2020) suggest considering decision-makers level of NFC, the arguments for fitting an information set to personal characteristics are less promising: decision-makers are probably more similar than they are different. Although the number of cues integrated into a decision might differ between decision-makers, the maximum level of integration is reached at a similar degree of environmental complexity (see Sect. 2 for more details), indicating that the optimal number of information cues does not differ between individuals, even if some individuals perform better than others at this optimal level of information load (Schroder et al. 1967; Streufert and Schroder 1965; Wilson 1973). Personalization is also difficult to implement, as information users’ individual decision models would need to be transparent to the designer of the information system (Revsine 1970). In addition, learning has been shown to be possible: Wilson (1973) highlights Streufert and Schroder (1965)’s findings, indicating that individuals’ conceptual levels are not fixed but can develop. In addition, task learning has been shown to positively affect decision accuracy and reduce decision time (e.g., Iselin 1988, 1989, 1990). Another potential drawback when considering fitting the information set to personal characteristics becomes apparent when considering interaction around accounting numbers in an organization. A certain standardization is necessary in order to facilitate efficient discussions within and across departments. Iselin (1989) discusses aggregation as a possible remedy; however, as described in the section dealing with consequences of increased information load (6.2), the effects of data aggregation on decision performance are ambiguous at best.
As highlighted by Snowball (1979), to be able to provide decision-makers with a pre-selected information set, knowledge on the specific requirements of the decision problem and process at hand is critical. Therefore, asking the decision-makers for their information requirements could solve this issue. However, decision-makers tend to demand more information than is useful for effective decision-making, thus risking information overload and reduced decision quality (e.g., Snowball 1979). In addition, self-insight with regards to information use and relevance is rather limited (e.g., Stocks and Tuttle 1998).
6.3.2 Further task characteristics
Task characteristics other than the number of information cues provided can further improve or deteriorate decision performance. Reducing cognitive load associated with the task, supplying decision aids, or changing the task structure are potential remedies to mitigate effects of increases in information load. Changes in cognitive load resulting from a change in task characteristics imply changes in the total processing capacity needed (e.g., Schick et al. 1990) to accomplish the task at hand. Therefore, these changes are likely to influence individuals’ information processing capabilities. Rose et al. (2004) indicate that variations in information load should be investigated along with increases in cognitive load, as cognitive load is a factor that is influenceable by the way a task is set up. Although Rose et al. (2004)’s experiments were not designed to investigate interaction effects between information load and cognitive load, the findings showed that increases in cognitive load negatively impacted recall and led subjects to rely more heavily on reconstruction matching affects.
Discussing their results, Chewning and Harrell (1990) and Rakoto (2005) indicate that making decision-makers use a decision model might be a solution to the information overload problem when reducing the number of information cues is not an option. However, as Rose et al. (2004) indicate, increases in cognitive load must be considered when providing individuals with a decision aid.
As outlined by Richins et al. (2017), a new skill set is needed in order to benefit from more advanced decision models that rely on big data. (Management) accountants and auditors therefore need to be provided with respective trainings and teams need to be complemented by new roles, e.g., data scientists. As described by Brown-Liburd et al. (2015) for the audit setting, the use of big data and the associated technologies comes with a specific set of concerns that need to be mitigated—such as a potential increase in ambiguity when using unstructured data, increased difficulty in identifying relevant information or the need for training to recognize patterns in the data.
The latter countermeasures, in the more radical form, imply replacing the person with a statistical model (one step further than providing a decision aid to the decision-maker). While offering the potential for more effective and efficient decision-making, the introduction of algorithm-based decision models is not always successful, partially due to limited adoption driven by a hesitancy to rely on the respective models, even if they are known to outperform human decision-makers (Mahmud et al. 2022).
Benbasat and Dexter (1979) argue that, depending on the structure of the task, information should be provided structured and aggregated for more structured, programmable tasks, and less so for tasks that require more flexible information use. However, there is no empirical evidence that verifies this assumption. Although not directly investigated by the research reviewed for this article, task complexity (e.g., Wood 1986) is likely to interact with the information set. Increases in information load might have a stronger effect in more complex (e.g., less structured) tasks than in simpler or more structured tasks. Reducing task complexity (notably coordinative and dynamic complexity, as component complexity is determined by the number of cues—Wood 1986) is therefore likely to mitigate information overload effects.
6.3.3 Characteristics of the environment
Characteristics of the decision-making environment (such as time available or incentives) can help or harm information processing. One of the most evident countermeasures is to increase the time available for information processing for an individual decision-maker or within an organization (Schick et al. 1990; Snowball 1980). Another option is to incentivize task performance (Ding and Beaulieu 2011; Tuttle and Burton 1999). However, as shown by Ding and Beaulieu (2011) and also pointed out by Bonner and Sprinkle (2002), there is a limit to the effect incentives have on task performance. If information load increases beyond a certain level, even incentives cannot mitigate the negative effects on decision performance (as shown by Ding and Beaulieu 2011). When deciding which countermeasures to implement, a cost–benefit calculation is advisable as some countermeasures might be costly—either with regards to additional decision time due to longer time needed for individual decision processes or discussion and coordination in teams; or for defining relevant information, decision models, implementing information systems, training, and more.
6.3.4 Decision-maker characteristics
Several articles discuss measures that deal broadly with the characteristics of the decision-maker (task-related and person-related). Countermeasures can be categorized into countermeasures that help change certain task-related characteristics and those that relate to a replacement of the decision-maker. The former countermeasures encompass measures such as training. Task learning has been shown to positively affect task performance (e.g., Iselin 1988, 1989, 1990). In these articles, the task was not changed, so it seems reasonable to assume that the learning effects represent an upper limit and should be lower in tasks that are less standardized. In addition, experience has been shown to improve decision-making performance in selected experiments (e.g., Iselin 1988). However, not all measures improve with experience: Snowball (1980) found less consensus for experienced subjects. Experience has also been associated with longer decision times (Swain and Haka 2000). The latter countermeasures, in the more radical form, imply replacing the person with a statistical model (one step further than providing a decision aid to the decision-maker).
A further measure (not directly linked to task performance but necessary nonetheless) is to create awareness around the phenomenon of information overload—decision-makers are often unaware they are overloaded (Hirsch and Volnhals 2012) or that their cue usage deteriorates (Chewning and Harrell 1990). In some cases, this can lead to overconfidence on the side of the decision-maker (e.g., Abdel-Khalik 1973) and potentially to harmful decisions. If decision-makers are aware of the potential detrimental effects of information overload on decision-making performance, they might stop requesting too many information cues or know when to ask for help or use a decision model.
Chewning and Harrell (1990) found that certain subjects’ cue usage was not affected by increases in information load, leading to the question of whether a person who is not or is less affected by information overload should be the one to make decisions. However, there is a limit to the number of information cues humans can handle. Therefore, as described by Brown-Liburd et al. (2015), employing statistical models and teaching (human) decision-makers how to engage with the output of these decision models seems a more fruitful middle ground when the information set cannot be kept to a level that does not generate information overload effects. Another aspect relates to the person-task fit. Miller and Gordon (1975) argue that people with less abstract conceptual structures are better at simple tasks. Benbasat and Dexter (1979) found that high-analytic-type subjects performed better with a pre-structured, aggregate report, while low-analytic-type subjects performed better with a database inquiry system. The evidence on finding a person-task fit, however, is rather scarce. While Iselin (1991) does not find groups to be able to better cope with increases in information load, Stocks and Harrell (1995) do find group decision-making to improve performance; having more complex decisions taken by groups might therefore help to improve decision-making performance.
7 Summary of findings and recommendations
Summarizing the main findings is no easy task, as for some variables, there is no consistent picture with regards to the effects on the dependent variables investigated. The stylized facts which have been derived for each of the potential consequences in Sect. 6.2 are summarized in Fig. 6. In addition, the number of articles analyzing the respective variable have been added.

Overview framework with stylized facts
In a nutshell, our analysis resulted in the following key findings:
-
1.
Not all information cues are equal: it is important to distinguish between relevant, irrelevant, and redundant information. Depending on information characteristics, effects of increased information load on decision accuracy are likely to have different effects. In particular, disaggregating information does not have the same impact as providing additional information cues. Management accountants as providers of information must therefore be aware of the type of information they provide to decision-makers. While redundant or irrelevant information should never be provided, the trade-off between increased decision accuracy and the risk of information overload should be considered for relevant information cues. In addition, they must be aware of the effects that aggregating or disaggregating information has on the decision-maker.
-
2.
Do not give decision-makers what they want: while a “feeling of overload” seems to increase with additional information, self-insight into decision quality (as measured by calibration) seems to decrease when information load increases. Increasing information load does not impact decision confidence in the same way that it does decision accuracy. Complying with decision-makers’ demands for additional information is therefore likely to increase information overload. This is especially relevant when considering initiatives for increased self-service reporting. Users must be effectively trained or at least made aware of the pitfalls associated with making decisions based on reports that contain a high number of information cues.
-
3.
Consider the trade-offs: while providing decision-makers with more (relevant) information can increase decision accuracy up to a certain point, decision time is likely to increase. The same is true for implementing countermeasures that might be costly.
-
4.
Experience is not always a good thing: while it is likely to increase decision accuracy, the effect on decision time is not clear.
-
5.
There is more to a task than just information input: While this is not immediately visible from the summary of stylized facts as there are only few papers which have investigated the issue, depending on the task (e.g., structured vs. unstructured), increases in information load are likely to have differing effects. Increasing information load past an optimal level in an unstructured task is likely to have a more negative effect than increasing information load in a structured task. Tuttle and Burton (1999), for example, did not find increases in information load to negatively impact consistency or accuracy when a specific decision model should be applied. In addition, further task characteristics, for example viewing conditions or incentives, are likely to further impact or at least interact with information load in influencing decision-making performance.
8 Opportunities for future research
The high number of articles included in this review on information overload research in accounting underlines the interest in the topic. However, some aspects have been researched in more detail than others. The framework presented in Sect. 5 and the main topics researched as described in Sect. 3 serve as a basis for categorizing opportunities for future research. In addition, the stylized facts summarized in Fig. 6 can be used to identify fields in which additional research is warranted (Loos et al. 2011; Winter 2009).
The first aspect that becomes apparent are the domains that are being researched. Much research concentrates on financial distress prediction. This focus is understandable, considering the combination of a high relevance for practice and the unique benefits of being able to analyze an unstructured decision-making task that allows researchers to investigate either decision accuracy or cue usage conveniently. Other areas, such as the field of management accounting, have received less attention and thus offer potential for new findings.
The next aspect considers the categories of variables researched, that is, causes, consequences, and countermeasures. Most research addresses the link between causes and consequences. Although possible countermeasures are discussed by the authors and in some cases investigated in the course of the experiment (see Sect. 6.3), further direct empirical investigation of possible countermeasures might offer valuable insights for practice.
Another aspect refers to the distinction between input, process, and output variables. Most research addresses how changes in input variables affect output variables, such as decision accuracy or decision confidence. Fewer papers have investigated process variables, such as the information acquisition process or decision rules applied, especially not in conjunction with decision accuracy as a measure for decision quality. Gaining more insight into the decision process might provide valuable insights into how information use and decision rules influence decision performance.
As described above, most empirical research on information overload in accounting (with the exception of Iselin 1991, and Stocks and Harrell 1995) is concerned with individual decision-making. This fact has already been highlighted by Birnberg (2011) for the domain of behavioral accounting research in general. However, it is likely that major decisions are not taken by individuals, but rather by groups. Investigating how groups manage increases in accounting information load is therefore warranted.
Currently, new technological developments are reshaping the accounting landscape; big data is just one example. Decision models (that have been considered in few articles) will become more important, and as highlighted by Brown-Liburd et al. (2015), it is not yet clear how decision-makers will deal with the output of these models. In addition, algorithm aversion (Mahmud et al. 2022) could pose a barrier.
With regards to research methodology, some suggestions can be derived from the literature reviewed. Experiments are the dominant method when it comes to researching information overload in the accounting domain as experiments are an excellent tool for showing cause and effect relationships. Nevertheless, other methods, such as surveys or case studies, can complement these findings with evidence from practice. With the exception of Henderson (2019), no qualitative studies have been identified for this literature review and Iselin et al. (2009) is the only study applying a questionnaire-based approach to study information overload effects in an organizational setting. As discussed above (Sect. 6.1.1), manipulations of the information set can be operationalized in a variety of ways, the effects on decision performance differing markedly depending on the change investigated. It is therefore necessary to clearly define which aspects of the information set have been manipulated and whether relevant, redundant, or irrelevant information is being investigated. The same applies to the manipulation of further variables (e.g., task variables) and the measurement of dependent variables.
In general, designing the perfect information overload research project is no easy task, starting with, as described above, the limitations when it comes to measuring decision accuracy in unstructured decision-making. A clear focus is therefore necessary. As noted already by Eppler and Mengis (2004), the field still lacks integration: while most of the research articles are based upon the same theory, the settings in which increases in information load are investigated differ. While it is beneficial to investigate different task settings, it makes comparison of results difficult. As summarized by Loos et al. (2011), stylized facts, as formulated in this review article, can contribute to putting a focus on the key links within the information overload model that might need further clarification.
9 Conclusion
This literature review synthesizes accounting-related information load literature. It provides a framework for analysis and clusters the major variables researched and their operationalization, presenting the relationships between causes and effects of changes in information load. In addition to giving an overview of the fields that have been researched, summarizing the development of research over the years, and presenting some methodological advice, this literature review suggests opportunities for future research. With regards to practice, useful implications can be derived, especially with regards to possible countermeasures. The strength of this literature review, focusing on accounting related topics and therefore allowing an exploration of the mechanisms at work in greater detail—for example allowing for the discussion of contradictory findings—is also a limitation: there might be findings from other disciplines that are helpful in deriving further recommendations.
With major technological changes currently occurring and data analysis and decision-making becoming increasingly automated, the role of the human decision-maker will change and most likely shift from structuring and analyzing data to dealing with the output of an algorithm. This shift is unlikely to make human decision-making irrelevant in the near to mid-term. Algorithm aversion (Mahmud et al. 2022) might contribute to a limited adoption in the field. In the future, unless decision-making is completely automated, even the output of an algorithm will need to be managed by human decision-makers (e.g., Richins et al. 2017). The effects and relationships between variables discussed here are therefore relevant even in a more automated decision-making environment.
Data availability
All data generated or analysed during this study are included in this published article (and its supplementary information files).
Notes
The examples used in each category describe typical research settings for illustration purposes.
In theory, decision time and decision rules could also be investigated by subjective measures. As this is not the case for most papers reviewed here, the two variables are included in “objective measurement.”
Simon (1960, p. 6) uses the terms “programmed decisions” and “nonprogrammed decisions”.
References
Abdel-Khalik AR (1973) The effect of aggregating accounting reports on the quality of the lending decision: An empirical investigation. J Account Res 11:104–138
Agnew JR, Szykman LR (2005) Asset allocation and information overload: The influence of information display, asset choice, and investor experience. J Behav Financ 6(2):57–70
Ariely D, Gneezy U, Loewenstein G, Mazar N (2009) Large stakes and big mistakes. Rev Econ Stud 76(2):451–469
Arnold V, Collier PA, Leech SA, Sutton SG (2000) The effect of experience and complexity on order and recency bias in decision making by professional accountants. Accounting and Finance 40(2):109–134
Ashton RH (1974) Behavioral implications of information overload in managerial accounting reports. Cost Manag 48:37–40
Ashton AH (1985) Does consensus imply accuracy in accounting studies of decision making? Account Rev 60(2):173–185
Barefield RM (1972) The effect of aggregation on decision making success: a laboratory study. J Account Res 10(2):229–242
Baumeister RF (1984) Choking under pressure: Self-consciousness and paradoxical effects of incentives on skillful performance. J Pers Soc Psychol 46(3):610–620
Belkaoui A (1984) The effects of diagnostic and redundant information on loan officers’ predictions. Account Bus Res 14(55):249–256
Benbasat I, Dexter AS (1979) Value and events approaches to accounting: an experimental evaluation. Account Rev 54(4):735–749
Berlyne DE (1960) Conflict, arousal, and curiosity. McGraw-Hill Book Company, New York
Birnberg JG (2011) A proposed framework for behavioral accounting research. Behav Res Account 23(1):1–43
Blocher E, Moffie RP, Zmud RW (1986) Report format and task complexity: interaction in risk judgments. Acc Organ Soc 11(6):457–470
Bonner SE (1999) Judgment and decision-making research in accounting. Account Horiz 13(4):385–398
Bonner SE, Sprinkle GB (2002) The effects of monetary incentives on effort and task performance: theories, evidence, and a framework for research. Acc Organ Soc 27(4–5):303–345
Bonner SE, Hastie R, Sprinkle GB, Young SM (2000) A review of the effects of financial incentives on performance in laboratory tasks: Implications for management accounting. J Manag Account Res 12(1):19–64
Brown-Liburd H, Issa H, Lombardi D (2015) Behavioral implications of big data’s impact on audit judgment and decision making and future research directions. Account Horiz 29(2):451–468
Casey CJ (1980) Variation in accounting information load: The effect on loan officers’ predictions of bankruptcy. Account Rev 55(1):36–49
Chan SY (2001) The use of graphs as decision aids in relation to information overload and managerial decision quality. J Inf Sci 27(6):417–425
Chervany NL, Dickson GW (1974) An experimental evaluation of information overload in a production environment. Manage Sci 20(10):1335–1344
Chewning EG, Harrell AM (1990) The effect of information load on decision makers’ cue utilization levels and decision quality in a financial distress decision task. Acc Organ Soc 15(6):527–542
Davis CE, Davis EB (1996) Information load and consistency of decisions. Psychol Rep 79(1):279–288
Ding S, Beaulieu PR (2011) The role of financial incentives in balanced scorecard-based performance evaluations: Correcting mood congruency biases. J Account Res 49(5):1223–1247
Dong L, Lui G, Wong-On-Wing B (2017) Unintended consequences of forecast disaggregation: a multi-period perspective. Contemp Account Res 34(3):1580–1595
Eberhartinger E, Genest N, Lee S (2020) Financial statement users’ judgment and disaggregated tax disclosure. J Int Account Audit Tax 41:100351
Einhorn HJ, Kleinmuntz DN, Kleinmuntz B (1979) Linear regression and process-tracing models of judgment. Psychol Rev 86(5):465–485
Elliott WB, Hobson JL, Jackson KE (2011) Disaggregating management forecasts to reduce investors’ susceptibility to earnings fixation. Account Rev 86(1):185–208
Eppler MJ, Mengis J (2004) The concept of information overload: a review of literature from organization science, accounting, marketing, MIS, and related disciplines. Inf Soc 20(5):325–344
Epstein S, Pacini R, Denes-Raj V, Heier H (1996) Individual differences in intuitive–experiential and analytical–rational thinking styles. J Pers Soc Psychol 71(2):390–405
Ewe SY, Gul FA, Lee CKC, Yang CY (2018) The role of regulatory focus and information in investment choice: some evidence using visual cues to frame regulatory focus. J Behav Financ 19(1):89–100
Eysenck MW (1982) Attention and arousal, cognition and performance. Springer, Heidelberg
Fertakis JP (1969) On communication, understanding, and relevance in accounting reporting. Account Rev 44(4):680–691
Frey CB, Osborne MA (2017) The future of employment: How susceptible are jobs to computerisation? Technol Forecast Soc Chang 114:254–280
Gadenne D, Iselin ER (2000) Properties of accounting and finance information and their effects on the performance of bankers and models in predicting company failure. J Bus Financ Acc 27(1–2):155–193
Gorry GA, Scott Morton MS (1971) A framework for management information systems. Sloan Manag Rev 13(1):55–70
Hartmann M (2022) Accounting-based decision-making under information overload: consequences and potential remedies. Universitäts- und Landesbibliothek der Heinrich-Heine-Universität Düsseldorf, Düsseldorf
Harvey O, Hunt DE, Schroder HM (1961) Conceptual systems and personality organization. Wiley, Hoboken
Heine B-O, Meyer M, Strangfeld O (2007) Das Konzept der stilisierten Fakten zur Messung und Bewertung wissenschaftlichen Fortschritts. Die Betriebswirtschaft 67(5):583–601
Henderson E (2019) Users’ perceptions of usefulness and relevance of financial statement note disclosures and information overload. Int J Bus Account Finance 13(1):41–56
Henke N, Bughin J, Chui M, Manyka J, Saleh T, Wiseman B, Sethupathy G (2016) The age of analytics: competing in a data-driven world
Hines RD (1988) Financial accounting: in communicating reality, we construct reality. Acc Organ Soc 13(3):251–261
Hioki K, Suematsu E, Miya H (2020) The interaction effect of quantity and characteristics of accounting measures on performance evaluation. Pac Account Rev 32(3):305–321
Hirsch B, Volnhals M (2012) Information Overload im betrieblichen Berichtswesen—ein unterschätztes Phänomen. Die Betriebswirtschaft 72(1):23–55
Hirsch B, Seubert A, Sohn M (2015) Visualisation of data in management accounting reports. J Appl Acc Res 16(2):221–239
Hirst DE, Koonce L, Venkataraman S (2007) How disaggregation enhances the credibility of management earnings forecasts. J Account Res 45(4):811–837
Holt TP, Loraas TM (2021) A potential unintended consequence of big data: Does information structure lead to suboptimal auditor judgment and decision-making? Account Horiz 35(3):161–186
Hwang MI, Lin JW (1999) Information dimension, information overload and decision quality. J Inf Sci 25(3):213–218
Impink J, Paananen M, Renders A (2021) Regulation-induced disclosures: evidence of information overload? Abacus 58:432–478
Iselin ER (1988) The effects of information load and information diversity on decision quality in a structured decision task. Acc Organ Soc 13(2):147–164
Iselin ER (1989) The impact of information diversity on information overload effects in unstructured managerial decision making. J Inf Sci 15(3):163–173
Iselin ER (1990) Information, uncertainty and managerial decision quality: an experimental investigation. J Inf Sci 16(4):239–248
Iselin ER (1991) Individual versus group decision-making performance: a further investigation of two theories in a bankruptcy prediction task. J Bus Financ Acc 18(2):191–208
Iselin ER (1993) The effects of the information and data properties of financial ratios and statements on managerial decision quality. J Bus Financ Acc 20(2):249–266
Iselin ER (1996) Accounting information and the quality of financial managerial decisions. J Inf Sci 22(2):147–153
Iselin ER, Mia L, Sands J (2009) Multi-perspective performance reporting and organisational performance: the impact of information, data and redundant cue load. Int J Account Audit Perform Eval 6(1):1–27
Judd P, Paddock C, Wetherbe J (1981) Decision impelling differences: an investigation of management by exception reporting. Inf Manag 4(5):259–267
Kaldor N (1961) Capital accumulation and economic growth. In: Lutz FA, Hague DC (eds) The theory of capital. Palgrave Macmillan UK, London, pp 177–222
Keasey K, Watson R (1986) The prediction of small company failure: some behavioural evidence for the UK. Account Bus Res 17(65):49–57
Kelton AS, Murthy US (2016) The effects of information disaggregation and financial statement interactivity on judgments and decisions of nonprofessional investors. J Inf Syst 30(3):99–118
Libby R, Lewis BL (1977) Human information processing research in accounting: the state of the art. Acc Organ Soc 2(3):245–268
Loos P, Fettke P, Weißenberger BE, Zelewski S, Heinzl A, Frank U, Iivari J (2011) What in fact is the role of stylized facts in fundamental research of business and information systems engineering? Bus Inf Syst Eng 3(2):107–125
Luft J, Shields MD (2010) Psychology models of management accounting. Found Trends in Account 4(3–4):199–345
Mahlendorf MD, Martin MA, Smith DA (2022) Editorial: Innovative data—use-cases in management accounting research and practice. Eur Account Rev (forthcoming), Available at SSRN (https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4297954).
Mahmud H, Islam AN, Ahmed SI, Smolander K (2022) What influences algorithmic decision-making? A systematic literature review on algorithm aversion. Technol Forecast Soc Chang 175:121390
Mason RO, Mitroff II (1973) A program for research on management information systems. Manage Sci 19(5):475–487
Miller GA (1956) The magical number seven, plus or minus two: some limits on our capacity for processing information. Psychol Rev 63(2):81–97
Miller H (1972) Environmental complexity and financial reports. Account Rev 47(1):31–37
Miller D, Gordon LA (1975) Conceptual levels and the design of accounting information systems. Decis Sci 6(2):259–269
Minciu M, Berar F-A, Dobrea RC (2020) New decision systems in the VUCA world. Manag Market 15(2):236–254
Newell A, Simon HA (1972) Human problem solving. Prentice-Hall, Englewood Cliffs
Oppenländer K-H (1991) Stilisierte Fakten des Innovationsprozeßes und ihre Analyse. Ifo Studien: Zeitschrift Für Empirische Wirtschaftsforschung 37(2):151–158
Otley DT, Dias FJB (1982) Accounting aggregation and decision-making performance: an experimental investigation. J Account Res 20(1):171
Ragland L, Reck JL (2016) The effects of the method used to present a complex item on the face of a financial statement on nonprofessional investors’ judgments. Adv Account 34:77–89
Rakoto P (2005) Caractéristiques de l’information, surcharge d’information et qualité de la prédiction. Comptabilité - Contrôle - Audit 11(1):23
Reisen N, Hoffrage UMFW (2008) Identifying decision strategies in a consumer choice situation. Judgm Decis Mak 3(8):641–658
Revsine L (1970) Data expansion and conceptual structure. Account Rev 45(4):704–711
Richins G, Stapleton A, Stratopoulos TC, Wong C (2017) Big data analytics: opportunity or threat for the accounting profession? J Inf Syst 31(3):63–79
Rikhardsson P, Yigitbasioglu O (2018) Business intelligence and analytics in management accounting research: Status and future focus. Int J Account Inf Syst 29:37–58
Roetzel PG (2019) Information overload in the information age: a review of the literature from business administration, business psychology, and related disciplines with a bibliometric approach and framework development. Bus Res 12(2):479–522
Roetzel PG, Pedell B, Groninger D (2020) Information load in escalation situations: combustive agent or counteractive measure? J Bus Econ 90(5):757–786
Rose JM (2005) Decision aids and experiential learning. Behav Res Account 17(1):175–189
Rose JM, Wolfe CJ (2000) The effects of system design alternatives on the acquisition of tax knowledge from a computerized tax decision aid. Acc Organ Soc 25(3):285–306
Rose JM, Roberts F, Rose AM (2004) Affective responses to financial data and multimedia: the effects of information load and cognitive load. Int J Account Inf Syst 5(1):5–24
Schick AG, Gordon LA, Haka S (1990) Information overload: A temporal approach. Acc Organ Soc 15(3):199–220
Schipper K (1991) On analysts’ forecasts. Account Horiz 5(4):105–121
Schooler JW (2014) Metascience could rescue the ‘replication crisis.’ Nature 515(7525):9
Schroder H, Driver M, Streufert S (1967) Human information processing. Holt, Rinehard and Winston, New York
Schwerin J (2001) Wachstumsdynamik in Transformationsökonomien: Strukturähnlichkeiten seit der Industriellen Revolution und ihre Bedeutung für Theorie und Politik. Böhlau, Köln
Shan L, San Z, Tsang A (2021) Management earnings forecasts disaggregation and audit fees: international evidence. Int J Auditing 25(2):408–425
Shields MD (1980) Some effects on information load on search patterns used to analyze performance reports. Acc Organ Soc 5(4):429–442
Shields MD (1983) Effects of information supply and demand on judgment accuracy: evidence from corporate managers. Account Rev 58(2):284–303
Simnett R (1996) The effect of information selection, information processing and task complexity on predictive accuracy of auditors. Acc Organ Soc 21(7–8):699–719
Simon HA (1960) The new science of management decision: the Ford distinguished lectures, 3rd edn. Harper, New York
Simons P, Masamvu T (2014) Readying business for the big data revolution (CGMA Briefing)
Snowball D (1979) Information load and accounting reports: too much, too little or just right? Cost Manag 15(3):22–28
Snowball D (1980) Some effects of accounting expertise and information load: an empirical study. Acc Organ Soc 5(3):323–338
Sprinkle GB (2003) Perspectives on experimental research in managerial accounting. Acc Organ Soc 28(2–3):287–318
Stocks MH, Harrell A (1995) The impact of an increase in accounting information level on the judgment quality of individuals and groups. Acc Organ Soc 20(7–8):685–700
Stocks MH, Tuttle B (1998) An examination of information presentation effects on financial distress predictions. In: Sutton SG (ed) Advances in accounting information systems, 6th edn. JAI Press, Stamford, pp 107–128
Streufert S, Schroder HM (1965) Conceptual structure, environmental complexity and task performance. J Exp Res Pers 1(2):132–137
Swain MR, Haka SF (2000) Effects of information load on capital budgeting decisions. Behav Res Account 12:171–198
Sweller J (1988) Cognitive load during problem solving: effects on learning. Cogn Sci 12(2):257–285
Tan JK (1994) Human processing of two-dimensional graphics: Information-volume concepts and effects in graph-task fit anchoring frameworks. Int J Hum-Comput Interact 6(4):414–456
Tuttle B, Burton F (1999) The effects of a modest incentive on information overload in an investment analysis task. Acc Organ Soc 24(8):673–687
Umanath NS, Vessey I (1994) Multiattribute data presentation and human judgment: a cognitive fit perspective. Decis Sci 25(5–6):795–824
Velte P (2022) Meta-analyses on corporate social responsibility (CSR): a literature review. Manag Rev Q 72(3):627–675
Webster J, Watson RT (2002) Analyzing the past to prepare for the future: writing a literature review. Manag Inf Syst Q 26(2):8–13
Weißenberger BE, Löhr B (2008) Planung und Unternehmenserfolg: Stylized Facts aus der empirischen Controllingforschung im deutschsprachigen Raum von 1990–2007. Zeitschrift Für Planung and Unternehmenssteuerung 18(4):335–363
Wilson DA (1973) A note on “environmental complexity and financial reports.” Account Rev 48(3):586–588
Winter R (2009) What in fact is fundamental research in business and information systems engineering? Bus Inf Syst Eng 1(2):192–199
Wohlin C (2014) Guidelines for snowballing in systematic literature studies and a replication in software engineering. In M: Shepperd T, Hall, Myrtveit I (eds), Proceedings of the 18th international conference on evaluation and assessment in software engineering—EASE ’14, pp. 1–10. ACM Press, New York
Wood RE (1986) Task complexity: definition of the construct. Organ Behav Hum Decis Process 37(1):60–82
Wright WF (1988) Audit judgment consensus and experience. In: Ferris K (ed) Behavioral accounting research: a critical analysis. Century VII Publishing Company, Bloomington, pp 305–328
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hartmann, M., Weißenberger, B.E. Information overload research in accounting: a systematic review of the literature. Manag Rev Q 74, 1619–1667 (2024). https://doi.org/10.1007/s11301-023-00343-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11301-023-00343-7