
Abstract
Objectives
A comprehensive scoping review, followed by visual analyses of results, was conducted to understand the overall money laundering threat landscape.
Methods
A PRSIMA-ScR-compliant review of 105 money laundering ‘typologies and trends’ reports was conducted, coding different components of money laundering and addressing the often-inconsistent nature of typologies reporting.
Results
The review identified 16 typologies, over 200 value instruments, over 200 actors/entities and 2565 red-flag indicators relevant to money laundering. Results were visualised to identify aggregate trends, including the suspicious activities with which these actors/entities and value instruments are typically involved.
Conclusion
The review suggests that a more holistic and cross-typological approach to reporting money laundering-related financial intelligence can assist in fostering better data sharing and cooperation across jurisdictions. Implications are drawn for how ‘typologies’ can be reported and articulated across relevant stakeholders in a more standardised and effective manner to improve prevention measures.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
From Chinese merchants hiding wealth from officials in 2000 BC to the Pandora Papers leak of 2021 (ICIJ, 2021; Seagrave, 1995), money laundering (ML) has been an enabler for organised criminal activity through millennia. Taking advantage of technological and financial developments, criminals have exploited certain industries (such as banking or real estate), instruments of value (such as cash or virtual assets) or financial processes (such as trade or crowdfunding) to legitimise their illicit proceeds. In response, international organisations have collated and analysed case studies in ‘typologies and trends’ reports to inform stakeholders of their money laundering vulnerabilities (the specific vectors by which launderers can exploit them) and risks (the likelihood of those vectors being exploited).
However, as laundering possibilities have increased and more case studies have become known, the dissemination of ‘typologies’ (the definition of which is explored further below) has struggled to scale uniformly. Different reports and agencies sometimes contradict, rather than contribute to, each other (examples will be discussed in due course). The result has been a muddied understanding of the overall ML threat landscape (Gilmour, 2021), which has caused inconsistencies in how financial intelligence has been collected, reported and shared across relevant stakeholders seeking to counter money laundering. This has implications on the effectiveness of anti-money laundering (AML) regimes more generally.
The problem and implications of non-standardised financial intelligence
As a crime that often transcends international borders, the effective pursuit of laundered funds and the perpetrators thereof routinely relies on data exchange and collaboration across jurisdictions — a process that has been associated with lower money laundering to a statistically significant degree (Ferwerda, 2009). In addition, as a crime that involves numerous financial, non-financial and governmental institutions in its prevention, effective data sharing requires not just co-operation across jurisdictions but effective public–private partnerships within them (Lassalle & Vogel, 2023).
Despite the heavy dependence of anti-money laundering efforts on international and domestic co-operation, many issues currently restrict the efficiency of collaborative initiatives. Existing literature has discussed issues including cultural or language differences (Unger, 2023), international relations (Sultan & Mohamed, 2022; Tsingou, 2010), lack of resources (FATF, 2021a), differing legal systems (OECD, 2015) and data privacy (Mouzakiti, 2020). Numerous attempts have been made at devising solutions for these issues, with varying degrees of success. For data privacy issues, machine learning or distributed ledger technology-based solutions have been developed to share data without compromising personal details (Caffarone, 2019; FATF, 2021b; Zand et al., 2020). For issues relating to international relations, the rise of the Financial Action Task Force (FATF), INTERPOL and the Edgmont Group are just some initiatives that have aimed to foster better global communication between both law enforcement agencies and financial intelligence units, respectively (Graycar, 2010; Sandhu, 2000).
However, no matter how effective these resolutions are, the data sharing they facilitate will still be hindered if there are inconsistencies in how that data is recorded in the first place. It is arguable, therefore, that the problem of data standardisation is a common denominator to all these issues. This has, arguably, been recognised across institutions such as INTERPOL, raising the likelihood that, as an organisation aiming to itself facilitate international co-operation, it has observed these issues out of the direct experience. In the field of cybercrime, INTERPOL (2022) and the Australian Institute of Technology has launched the ‘DW-VA’ (Dark Web and Virtual Assets) taxonomy, which was founded on the basis that stakeholders and solution providers needed a common language and some communication protocols for automated data exchange and interoperability. The taxonomy contains standardised descriptions and terms to discuss concepts, such as ‘dark web’, that commonly comprise intelligence and data collection activities by cybersecurity stakeholders.
Not considering the fundamental issue of taxonomy harmonisation has arguably harmed the effectiveness of some cross-border initiatives. The 2015 Fourth European Union Anti-Money Laundering Directive, which aimed to streamline legal frameworks across EU member states, highlighted this in two ways. Firstly, it has been argued that the Directive required the collection and processing of an immense amount of data (Bourton, 2020), causing issues with administrative processing and sharing between EU member states. This is exacerbated by the inconsistencies in how data is collected by each member; for example, the unique way in which the Italian financial intelligence unit collects statistics on suspicious activity reports rendered its figures incomparable to the rest of the EU in Europol’s (2017) assessment of the continent’s anti-money laundering efforts.
Secondly, Gerbrands et al. (2022) found that the use of non-EU individuals and corporate structures for money laundering increased notably after the Directive was announced, strengthening the need for cross-jurisdictional collaboration with nations of even less legal, linguistic and cultural uniformity than those within the EU. This is a process known as displacement — where criminals shift their crimes, often to less detectable ways of committing them, to avoid prevention measures (Johnson et al., 2014).
The standardisation of financial intelligence collection, therefore, can be considered a fundamental initial step for streamlining and upscaling international anti-money laundering co-operation. Especially given the rise in big data, artificial intelligence and automated solutions in facilitating data sharing, it is becoming ever more important to ensure that financial intelligence (or ‘FININT’) is compatible and uniform across institutions and jurisdictions to begin with, such that their efficient (and even automated) exchange at scale can be facilitated effectively. This is especially relevant for money laundering, which both involves a wide range of stakeholders and is also especially dependent on cross-jurisdictional co-operation to counter effectively.
Considering these issues, the purpose of this study is to navigate through the large volume of typologies literature, ‘de-muddy’ the waters, and shine a comparatively clearer and holistic lens on the ML threat landscape — including the actors, entities and value instruments involved. It aims to motivate this approach as a step towards a wider global standardisation of ML-related financial intelligence, such that new insights of criminal methods can be reported, visualised, articulated, analysed and appended to existing intelligence in a more effective and efficient manner. The next section explores the main anti-money laundering provisions and institutions in place today, followed by a discussion on the state of the art of ML ‘typologies’ reporting.
Anti-money laundering and the FATF
The FATF and regional bodies
The issue of money laundering was first addressed internationally by the 1988 UN Vienna Convention, which called for all parties (191 countries as of 2024) to criminalise and prevent the laundering of drug trafficking proceeds (Bell, 2002). This led to the establishment of the Financial Action Task Force (FATF) as a global standard-setter for anti-money laundering (AML) policies in 1989. In 1990, the FATF released 40 recommendations for the prevention of money laundering, which became the basis for the prevailing global AML framework.Footnote 1 These recommendations, also covering counter-terrorist financing since 2001, include guidance on topics such as risk assessments, implementation of regulations, entity-specific obligations and international co-operation.
The FATF has 39 members, though also has nine associated regional bodies (called FATF-style regional bodies or ‘FSRBs’) that seek to further its aims in specific geographic regions (Alexander, 2001; Holder, 2003).
The fundamentals of anti-money laundering
The AML framework underpinned by the FATF and its FSRBs requires financial institutions (such as banks and securities intermediaries) and designated non-financial businesses and professionals (DNFBPs, such as lawyers and casinos) to understand customer risk profiles through a verification process called ‘know-your-customer’ (KYC) (McLaughlin & Pavelka, 2013), often at the account-opening stage. KYC involves the collection of financial intelligence such as identity, income, affiliates and occupation (Thony, 1996), all of which are then verified for authenticity through customer due diligence (CDD) checks (Roberge, 2007).
These ‘obliged entities’ (financial institutions and DNFBPs) then compare this information to customers’ transaction patterns to identify suspicious activity. Often, machine learning algorithms are used to flag such activity, followed by manual checks by money laundering reporting officers (Naheem, 2018). Transactions deemed suspicious are then compiled into a suspicious activity report and submitted to the designated financial intelligence unit (FIU) of the jurisdiction. FIUs, which can be independent government bodies or affixed to finance ministries or law enforcement agencies (Egmont Group, n.d.), then assess whether to refer the case to law enforcement (Gottselig & Underwood, 2004).Footnote 2 The process is summarised in Fig. 1 (European Commission, 2018).

The prevailing AML framework
Enhancements and critical approaches to AML
The effectiveness of the prevailing AML framework in capturing laundered money has been criticised for its low success rate (Pol, 2018). Critiques have often been coupled with disagreements on how to conceptualise the underlying processes and concepts that underpin money laundering, and therefore motivate how it is detected and disseminated through suspicious activity reports. Of note is the ‘placement, layering and integration’ model, arguably the most popular model to generalise the ML process. It splits the process of ML into the three stages of (1) introducing (placing) illicit funds into the financial system, (2) conducting a series of transactions (layering) to distance it from its illicit source and (3) re-integrating it back into the economy (FATF, n.d.). The model has been criticised for being outdated (Koningsveld, 2013), too complex (Soudijn, 2016) and inapplicable to certain types of ML, such as trade-based ML (Gilmour & Hicks, 2023), which is discussed in due course.
Various literature has sought to enhance AML frameworks and bridge these gaps. Tiwari et al. (2023) focus on understanding money launderers’ decision-making and why they choose specific techniques, culminating in a framework that factors in the (1) actors involved, (2) predicate offences, (3) purpose of laundering and (4) technological innovations used (APPT). Hetzel (2023) approaches the issue from a different perspective, looking also at physical activities that occur during ML activities, such as driving vehicles filled with cash, and communicating via phone with accomplices, increasing the three-stage ‘placement-layering-integration’ model into an 11-stage one. Such contributions all have the value of exploring different aspects of ML schemes, therefore serving to paint a holistic picture that can assist with detection and prevention. To be compatible with each other or other frameworks, however, all of these proposed enhancements would need to operate on the same standardised foundation of ML-related terms and concepts — again emphasising the contribution of the current study.
Informing obliged entities on money laundering risks
To adapt to financial and technological developments since the 1990s, the FATF’s AML framework has been modified over time. One modification was the introduction of the ‘risk-based approach’, which encourages obliged entities to prioritise ML risks increased by geopolitical factors or the nature of their services/products (FATF, 2007a).
To aid this, the FATF and FSRBs routinely undertake studies into new ‘typologies’ of ML. Often, these involve questionnaires being completed by FIUs of member states, which provide details of trends and case studies they have recently observed. Results are then analysed and discussed at workshops attended by delegates from states and obliged entities. These often culminate in the publication of ‘typologies reports’, which share the latest ML methods, techniques and indicators identified. As a means of collating and disseminating such information to several jurisdictions and stakeholders, this is arguably where standardising the reporting of financial intelligence should begin. However, competing aims and interests in the dissemination of typologies has caused a number of obstacles to these efforts thus far. These will now be discussed in detail.
Typologies: the state of the art
What are typologies?
Incidentally, typologies reports are often vague about what a ‘typology’ denotes or how they are formulated. Shortly after typologies workshops became mainstream, the Council of Europe defined them in 2000 rather obscurely as ‘a classification of a phenomenon in such a way as to illustrate the similarities within the “type” and differences between types’ (Levi, 2000, p. 2). The Asia–Pacific Group (APG), the FSRB for its stated geographical region, simply defines them as the study of [ML] methods and trends (APG, n.d.). The Government of Jersey identifies the purpose of typologies as below (JFCSG, 2015).
-
‘Inform relevant persons about the various methods and techniques criminals may employ to launder the proceeds of their illicit activity;
-
identify areas that require further attention and help relevant persons to identify higher risk activities that necessitate monitoring or enhanced monitoring; and
-
more generally, assist with the prevention and detection of money laundering’.
FATF/FSRB typologies reports appear to focus either on specific industries (e.g. the securities industry), a specific category of value instrument (such as virtual assets) or specific financial processes (such as trade). These focus points are all relevant due to certain ML vulnerabilities arising from their specific circumstances, such as a common criminogenic feature they share or a particularly anonymous service they provide. These reports investigate these vulnerabilities by assessing cases of ML and clustering them into similar ‘typologies’. Essentially, a typology (insofar as the term applies within these reports) can be defined as a common way of exploiting a certain industry, value instrument or financial process for the purpose of laundering money, based on observations from one or more similar real-world case studies.
The state of the art of typologies reporting
Arguably the first major endeavour of using typologies as a basis of standardising the reporting of ML financial intelligence dates back to a 2005 workshop with experts in Moscow, where the FATF (2005) developed a hierarchical framework for categorising money laundering trends. The terms created were ‘scheme’, ‘typology’, ‘method’, ‘technique’, ‘mechanism’ and ‘instrument’. Several techniques, mechanisms and instruments can be present per method, and several methods can be present per typology. Definitions (left) and examples of each term (right) are shown in Fig. 2, which shows the developed framework in flowchart form as shown in two FATF reports (FATF, 2007b, pp. 32–33, 2013b, p. 92).

Adaptation of the FATF money laundering and terrorist financing framework
Additionally, the word ‘scheme’ represents a collection of ML methods and is defined below.
‘An ML scheme is the particular ML/TF process that combines various methods (techniques, mechanisms and instruments) into a unique operation.’
(FATF, 2005, p. 89)
Typologies vs. standardisation
As Fig. 2 shows, typologies are relevant to the current study as they represent a drive for a degree of standardisation by one of the most prominent institutions in the anti-money laundering scene. However, as subsequent sections will show, the framework in Fig. 2 has seldom been applied uniformly throughout typologies reports, which, to the extent that standardisation is concerned, have a range of inconsistencies both within and between them.
This can be attributed to a disconnect between the endeavour for standardisation and the purposes of typologies as stated above, for example by the Government of Jersey. As those purposes suggest, typologies are intended to make specific stakeholders aware of ML/TF trends relevant to them — an aim that does not necessarily require cross-publication standardisation or a large scope. Typologies reports are not necessarily intended to be academically robust, holistic, consistent or mutually exclusive. Furthermore, as some industries may be subject to common risks, it is also natural that different reports can consider the same ML/TF typology/method/technique but from different perspectives, each time tailored towards the audience industry, which may use different terminologies or concepts to others. Terminologies or concepts may also adapt throughout the years to account for technological advances or new regulations.
Additionally, typologies reports face a trade-off between (a) being highly generalised and thus accounting for a large portion of the phenomenon that is ‘money laundering’, or (b) honing into a specific aspect (e.g. a value instrument or specific actor/entity) thereof in detail but not accounting for how said aspect may be influenced or related to other aspects. This trade-off is necessitated by the sheer volume of ML-related financial intelligence that exists; a single holistic report considering both the micro and macro aspects of all forms of ML would potentially span thousands of pages and end up being of little use due to cognitive overload.
This trade-off matters due to the implications on how relevant stakeholders, such as law enforcement, can make use of the insights from these reports. There are, naturally, benefits for understanding granular processes, for example, the concept of ‘refining’ (the conversion of lower-denomination banknotes to higher-denomination ones to reduce the physical size of bundles). Such a micro-level insight provides banks and cash exchangers a specific red flag indicator to watch out for, and regulators an issue for consideration. However, in doing so, the wider context may be lost. In this case, the wider context is that ‘refining’ is a process that typically takes place before cash couriering (the physical transport of cash across borders) to reduce the load of cash a courier needs to conceal on their person or luggage during border checks. Thus, banks close to border crossings are at elevated risk, and indeed, reports indicate that bank branches on the U.S.-Mexico border have closed due to such concerns (US GAO, 2018). However, of the four FATF typologies reports identified that mention ‘refining’ (FATF, 2009, 2010, 2013a), only one (FATF, 2010) mentions the association between it and cash couriering. This emphasises the disconnect between two relevant ML issues arising due to the macro–micro trade-off, which can therefore result in stakeholders being under-informed or misinformed about the full scope and context of their ML risks.
Standardisation can address these issues and broaden the level of relevant financial intelligence that can be communicated to relevant stakeholders in an accessible and scalable manner. For example, were ‘refining’ and ‘cash couriering’ activity reported in a standardised way across jurisdictions and industries, said association would become naturally evident through data sharing. Furthermore, the standardised reporting thereof could lend itself to more efficient typologies generation and dissemination, in a manner that accessibly incorporates both micro and macro aspects of ML, thereby communicating risks more effectively. As subsequent sections of this paper will show, standardising concepts can also assist in the generation of visuals that can depict both macro- and micro- issues at scale, surmounting this trade-off to an extent.
Using typologies as a basis for standardisation
Typologies reports have nevertheless provided a foundational basis for a standardisation framework, namely the ‘typology-method-technique’ (hereon ‘TMT’) hierarchy shown in Fig. 2. Given that this framework is devised and adopted by the global standard-setter for AML, it is arguable that the road to standardisation begins with navigating these typologies reports from a TMT lens, extracting commonalities, ensuring conceptual consistency and identifying a way of linking relevant concepts within them holistically.
This paper therefore adopts this framework as a foundation for devising an understanding of what these typologies, methods, techniques, mechanisms and instruments are. Due to the reasons discussed previously, however, these reports do not lend themselves to simple data extraction in line with such constructs. From the perspective of standardisation, the reports contain a number of common inconsistencies, which can be categorised into inconsistencies of (1) framework adherence, (2) conceptualisation, (3) scope, (4) detail and (5) completeness. The sections below will discuss these inconsistencies in more depth, as they are both a factor for consideration during data collection and a further motivation for the issues that standardisation can resolve without voiding typologies of their purpose as described above.
Inconsistencies in framework adherence
The first inconsistency is, simply, the lack of adherence to the TMT framework throughout typologies reports. The odd reality remains, for example, that even the report that put forward this flowchart itself does not seem to adhere to it (FATF, 2007b). Instead of referring to methods or typologies, it refers directly to techniques and rarely ever makes any reference to mechanisms or instruments.
In some cases, the report denotes instruments as methods or techniques (the ‘or’ demonstrating the ambiguity) as synonymous with one another. For example, ‘cash’ and ‘checks and wire transfers’ are listed as a method or technique of ML (again with the ‘or’ demonstrating the ambiguity), although they would actually be an ‘instrument’ according to the definitions above. Other reports have similar issues, with the terms present in Fig. 2 being used selectively, interchangeably and/or not at all.
The implication of this is twofold. Firstly, for the purpose of data collection, it means no easy data extraction can occur, as the classification for insights both within and across reports are inconsistent. Secondly, there is a cognitive aspect to the lack of framework adherence, as the reference to similar concepts in different ways may lead to misleading interpretations that impact decisions by readers of these reports (Van der Waldt, 2020). This is particularly the case if there is a standardised framework present to govern the dissemination of concepts (which there ostensibly is, in the form of the TMT framework), as this lends to the assumption that insights would be reported in conformity to it.
Inconsistencies in conceptualisation
Often, concepts will be defined differently across reports (or even within the same report). For example, of the two major reports released by the FATF on hawala remittance businesses, one uses the term ‘Hawala or other similar service providers’ (HOSSPs) and defines them as designated non-financial businesses (FATF, 2013c). The other uses the term ‘money remittance/currency exchange’ (MR/CE) to define a similar set of services and designates them as financial institutions (FATF, 2010). Other terms, such as ‘money service businesses’ (MSBs) and ‘money or value transfer services’ (MVTSs), have also been used (FATF, 2016).
Furthermore, different reports may report the same methods under different typologies. For example, one of the FATF’s trade-based money laundering reports, published in 2006, describes a method involving the invoicing of non-existent services between sham corporations to justify illicit financial flows (2006, p. 6). This bears striking resemblance to the concept of ‘proxy networks’ in the FATF’s (2018, pp. 26–27) professional ML report, which essentially describes a network of such sham corporations trading with each other. Both these concepts are also synonymous with the concept of ‘services-based money laundering’ (SBML) discussed in the FATF’s more recent 2020 TBML report, which actually contradicts its earlier publication by calling it a totally different form of money laundering to TBML (FATF & Egmont Group, 2020, pp. 16, 35). Essentially, a very similar ML method has been conceptualised by three different reports in three different ways — once as a method within the TBML typology, once as ‘proxy networks’ and once (SBML) as a distinct typology/method/technique.
This inconsistency has the same implications as those for framework adherence — data collection will need to adapt to the same/similar concepts being mentioned in different ways, while readers of reports may be subject to increased confusion or omission of important information due to the lack of consistency.
Inconsistencies in scope
Inconsistencies in scope arise from reports typically only discussing one aspect of ML/TF in depth without acknowledging how it may relate to other aspects. This mainly becomes a problem since ML/TF schemes can transcend multiple typologies, meaning that reports seldom paint a full and representative picture of actual cases (Gilmour, 2021).
A scheme that begins by laundering funds through casino chips, for example, need not stick to only the casino and gaming sector in later parts of the scheme. To illustrate how typologies are often mixed and matched by launderers, the following case study included in the FATF’s, 2018 ‘professional money laundering’ report can be taken as an example (FATF, 2018, p. 22).
…The criminals’ modus operandi involved the use of cash couriers traveling by car to pick up dirty cash all over Europe. This was followed by [TBML] techniques to transmit the value to the Middle East, primarily through the shipment of second-hand cars; heavy machinery and construction equipment purchased in Germany and exported to Iraq, where the goods were ultimately resold in exchange for clean cash. The [organised crime group] was then able to make use of [money value transfer services] and unregulated financial channels (the hawala system) to integrate and further transfer funds into the regulated financial system. This left virtually no paper trail for law enforcement. Professional service providers, such as solicitors, accountants and company formation agents, provided the skills and knowledge of financial procedures necessary to operate this scheme…
Based on one’s understanding of ‘typologies’ (there is no standardised list or creation criteria), it can be argued that at least four are present in the above scheme. These are:
-
1.
Cash couriering,
-
2.
Trade-based money laundering
-
3.
The use of money value transfer services, and
-
4.
The use of professional services (solicitors, accountants, etc.).
Launderers can, additionally, use the same typology at different segments (e.g. the start and the end) of the scheme. The FATF acknowledges this interchangeability in several reports, though does not address it; the 2006 TBML report, for example, suggested that TBML techniques are frequently used in combination with other money laundering techniques to further obscure the money trail (FATF, 2006).
As mentioned previously, it is neither feasible nor even ideal for reports to address inconsistencies of scope in individual reports, as such a report would likely be extensive in length. However, from a standardisation point of view, not acknowledging such inter-typological links can risk providing incomplete information to stakeholders. For example, a customs official at a border crossing may be more incentivised to monitor nearby banks or currency exchanges for refining activity should they be aware of its relation to cross-border cash couriering.
Inconsistencies in detail
Similar to inconsistencies in scope are inconsistencies in the detail provided by reports when discussing different trends. To illustrate, the FATF (2007b) real estate report titled one of its typologies as ‘manipulation of the Appraisal or Valuation of a Property’, and another as ‘concealing money generated by illicit activities’. The former ‘typology’ (which, per the FATF’s framework should actually be a ‘method’) represents a concise and specific form of ML risk, while the latter is so broad that it is synonymous with the definition of ML itself. This demonstrates the lack of consistent typology/method/technique creation or reporting criteria, which affects the granularity of insights and the ability to consider them in comparison with each other.
Similarly, some reports might mention certain activities in a trivial manner, while others may be devoted to discussing that same activity far more extensively. An example of this is banking cash. While some reports go little further than suggesting that ‘cash is banked’ at a certain stage of an ML scheme, others will provide several insights into structuring techniques (splitting the funds into smaller denominations and over several transactions) that launderers may use while banking that cash — effectively generating an entire ‘typology’ out of a process that other reports summarise in a few words. This can result in the omission of insights potentially crucial for devising detection capabilities or interventions.
Inconsistencies in reported information
Reports often do not provide a complete account of how a typology, method or technique typically takes place. For example, the FATF’s (2009) casino report discusses that launderers may sell casino chips to legitimate gamblers for clean funds as a means of obscuring the illicit origin of the chips. However, as part of this method/technique, the report does not mention how the launderer would have acquired those casino chips in the first place, as casino chips are not a medium that illicit funds typically originate in. The initial stages of this method/technique are thus unclear, and the implication is that — per inconsistencies of scope — the launderer used some activities described in a separate typology/method/technique to acquire chips in the first place. Such details are crucial for generating a complete picture of what actions a scheme involves, generating risk assessments and narrowing down the indicators (in this case cash-related ones) that might apply.
Study aims
It is evident that, encompassing hundreds of reports, the ML threat landscape is large, complex and transcends numerous industries. There are benefits, therefore, to overcoming the inconsistencies in typologies reporting to improve the articulation of emerging trends and financial intelligence to relevant stakeholders. These benefits include connecting macro- and micro- insights together in an accessible manner to provide a more holistic understanding of ML trends and facilitating data standardisation for more effective cooperation. The opportunities unlocked through standardisation are further expanded in the discussion.
The following scoping review extracts a number of insights of relevance from typologies and trends reports. By doing so, it serves two aims. Firstly, it helps build a picture of the ML threat landscape at-large, cutting through the large swathes of often-inconsistent literature, to provide a holistic-lens view of the overall phenomenon that is ML. Secondly and synonymously, it formulates a standardised, hierarchical dataset that overcomes the discussed inconsistencies as much as possible (limitations will be discussed in due course). This not only allows for a holistic understanding of the ML threat landscape but also offers a more enhanced alternative approach to future typologies reporting across stakeholders.
Given the aim of capturing the state of money laundering holistically, this study aims to encompass all sub-categories thereof, including professional money laundering, self-laundering, and other terms that have often been applied to label specific methods, such as ‘cyber laundering’ (Filipkowski, 2008). As the methodology section will discuss, reports with foci ranging from ‘Professional Money Laundering’ to ‘New Payment Methods’ are reviewed in this paper in support of this objective.
Methodology
About scoping reviews
Focusing on broader issues in comparison to systematic reviews, scoping reviews involve reviewing existing literature to gather evidence on a subject. Their uses include identifying research gaps, summarising evidence for policymakers, categorising concepts and uncovering new trends (Arksey & O’Malley, 2005; Peters et al., 2015). All these uses are relevant to the study aims. A typical scoping review involves systematic approaches to identify relevant studies, code selected data points relevant to the research question, synthesise said data and draw conclusions in an aggregated manner.
Scoping reviews are predominantly used in the nursing profession to synthesise evidence on new treatments, though a few applications exist in crime-related issues.Footnote 3 The Enhancing the Quality and Transparency of Health Research Network (EQUATOR) has issued standards for conducting effective scoping reviews, named the Preferred Reporting Items for Systematic reviews and Meta-Analyses extension for Scoping Reviews (PRISMA-ScR).Footnote 4 PRISMA-ScR defines how relevant studies for ‘scoping’ should be identified, selected, coded and reported. This review complies with PRISMA-ScR (see supplementary material for a filled checklist).
Identifying relevant studies
This paper will consider reports specifically originating from the FATF and its constituent FSRBs (with one exception, namely Australia’s FIU AUSTRAC, discussed below). This determination was made for four reasons. First, the FATF (and its constituent FSRBs) are considered the international standard-setters for AML and are at the forefront of fostering international co-operation and workshops to identify ML insights and trends. This makes their outputs particularly relevant to the aims of this study, which aims to contribute to fostering international co-operation. Second, it is the FATF that, per Fig. 2, has attempted to standardise the dissemination of said insights, which is the basis on which the data collection exercise in the current study will be conducted. Third, other literature often derives typology discussions from FATF/FSRB reports, thus raising the risk of double-counting insights. Fourth, many alternative (e.g. private sector) reports are comparatively specialist and build on the foundations of the concepts identified across generic typologies reports. Reports specialising in the laundering of cryptocurrency, for example, allude to trends widely discussed in existing reports, such as structuring and gambling (Carlisle, 2022). By considering the more foundational literature, the output of this paper hopes to provide the basis for comparatively more specialist work. There are, naturally, limitations to only considering FATF/FSRB reports, which will be discussed in due course.
Typologies reports can be downloaded from FATF/FSRB websites. Table 1 shows the URL and number of retrieved reports from each entity. In addition to the FATF and nine FSRBs, one FIU (Australia’s AUSTRAC) was also included, as their reports are frequently cited by Asia–Pacific Group (APG) FSRB reports. Other FIUs, as well as compliance firms, also produce typologies reports. However, these are not included due to time and feasibility considerations.
Downloads are current as of September 2021 (for the FATF/APG) and December 2019 for the others. The timeliness aspect of this review, which may seem outdated due to these dates, is addressed further in the limitations. However, it should be recalled here that the fundamental aim of this review is more abstract in nature and largely uninfluenced by issues of recency.
Study selection
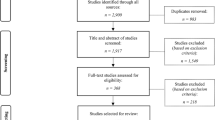
Any report jointly published by multiple entities (two FATF/GIABA and one FATF/MENAFATF) were deleted per criterion B for the secondary entity and included in the primary author’s tally (FATF). The final three stages excluded reports based on content relevancy. If reports only focused on terrorist/proliferation financing and had no relevance to ML, they were excluded per criterion C. Reports of irrelevant perspective (such as country risk assessments or legal guidelines) were excluded per criterion D. Figure 3 visualises the process as a flow chart.

Report exclusion process
Finally, reports with no codable insights (following full-text review) were excluded per criterion E. These were mainly predicate offence-based reports, which often did not discuss ML extensively. Table 2 shows the number of reports remaining following the application of the exclusion criteria, grouped by perspective.
A total of 105 relevant reports published between 2000 and 2021 met the inclusion criteria. The topics covered ranged from laundering illicit motor vehicle smuggling proceeds in Africa to using intellectual property for ML. Well-known ML risks such as trade, remittance services and securities were covered by numerous reports and FSRBs, ensuring comprehensive data for the main trends. A full list of the reports included is available, per PRISMA-ScR guidelines, in the supplementary material.
Data coding
Data collection involves analysing individual publications and extracting insights that are relevant to the study aims. For the current study, these were influenced by the FATF’s TMT framework. However, given the inconsistencies in framework adherence, the term ‘mechanism’ was swapped for a new synonymous construct named ‘actors/entities’, accounting for the numerous instances of the term ‘mechanism’ being applied selectively throughout reports. Per similar considerations, the term ‘instrument’ was clarified as ‘value instrument.’ Overall, the insights for which data was coded wereFootnote 5:
-
a)
Typologies, methods and techniques (TMTs), per the FATF’s framework
-
b)
Actors/entities that can undertake or facilitate ML (such as ‘cash couriers’ or ‘banks’ respectively)
-
c)
Value instruments (VIs) that illicit funds can take the form of (such as ‘cash’ or ‘casino chips’)
-
d)
Risk indicators (such as client refuses to provide ID to open an account)
Typically, the best practice is to code insights objectively, exactly as presented in reports. However, as previously discussed, inconsistencies forced numerous judgement calls throughout the coding process. To emphasise this, Table 3 shows the frequency of each inconsistency when coding the 38 FATF reports. The ‘count’ denotes every occasion where a subjective decision was made due to that inconsistency.
Coding was guided by thematic analysis (Braun & Clarke, 2012; Terry et al., 2017), with strict guidelines to minimise the effect of the above inconsistencies. The TMT framework guided the coding of data. Coding order for institutions was determined by report count, meaning FATF reports were coded first, followed by the APG, and so on. Reports with more comprehensive analyses of certain industries and financial processes were coded first to give a foundational set of insights that were then built on by subsequent reports with less extensive discussions. Only original insights were coded; case study examples were ignored. Figure 4 shows how reports were coded using the FATF’s (2009) Casino-based ML report as an example.

Data coding process example
As discussed per inconsistencies in scope in the conceptual framework chapter, reports mentioned insights with varying detail. For example, where one went no deeper than ‘professional services’, others would mention sub-categories such as accountants, lawyers, notaries, company services (etc.). This was addressed by coding actors/entities and VIs in a hierarchical structure as they emerged. In this case, therefore, professional services would be listed as a sub-category of designated non-financial businesses and professionals (DNFBPs), while accountants (etc.) would be coded as a second-order sub-sub-category thereof. The more specific the insight, the lower down the hierarchy it was coded. The same applied for VIs, for example, ‘cash’ (category), ‘banknotes’ (sub-category) and ‘high/low-denomination banknotes’ (sub-sub-categories). Figure 5 shows an (incomplete) example of this hierarchical process.

An (incomplete) example of hierarchical coding of actors/entities and value instruments
If an indicator was found to be relevant to an actor/entity or value instrument, it was also deemed relevant for all sub-category actors/entities or value instruments lower down their respective hierarchy. For example, an indicator concerning securities intermediaries was also deemed relevant for insurance providers, broker-dealers, and so on. However, an indicator specific to broker-dealers was attributed to broker-dealers only (and any subsequent sub-categories), not for any other entity at the same hierarchy level or above.
Where inconsistencies in conceptualisation existed (e.g. ML TMTs being categorised or described differently), the coding strategy was decided by (a) by consensus, i.e., the conceptualisation adopted by the most reports or, if no such consensus existed, (b) the conceptualisation adopted in the most recent report.
As mentioned previously, the coding experience lent itself to a thorough practical exercise exploring the applicability of the FATF’s typologies-methods-techniques classification for recording data. Some proposed modifications arose from this process. For example, while conducting full-text reviews, it became evident that the concept of ‘typologies’ had to be distinguished between (a) core strategies for ML and (b) additional but optional measures to further conceal ML. A recurring example of (b) is structuring, namely splitting cash into smaller denominations across several transactions to reduce suspicion when depositing it into an institution. Structuring is not necessarily an ML typology, as it can be utilised (optionally) wherever there is a financial interaction with an obliged entity, and may therefore be utilised as a part of any other typology where such an interaction is required. Other examples include using free-trade zones rather than standard jurisdictions to take advantage of lax regulations. These ‘concealment enhancers’ (CEs) are coded separately to typologies, though follow the same coding structure (concealment enhancer typology-method-technique).
Collating and reporting results
Results for actors/entities, VIs and ML/CE typologies are first presented in summary chart form, to show the number of reports (out of 105) that contained any mentions of them. For actors/entities and VIs, the number of times they were mentioned in total is also shown. This number was extracted through a text search of reports and was considered a good indicator of how relevant they are in the context of ML due to their frequency of appearance within relevant discussions. For ML/CE typologies, the ‘number of mentions’ were not retrieved as they were often custom named and effectively equal to the number of mentioning reports.
Identified red-flag indicators were grouped through thematic analysis into a more manageable number of categories, sub-categories and sub-sub-categories and are presented in tables. For each indicator, the relevant actors/entities and value instruments they involved were coded to allow for further analysis. This process will be expanded on in due course.
Due to the large number of insights collected (N = 3282), presenting them in greater depth was not feasible in the body of this article without producing tables spanning several pages. Therefore, more comprehensive breakdowns of results are available in the data supplement, which lists the constituent methods and techniques per typology along with brief descriptions for all insights collected.
The purpose of the statistics reported here is to provide an overview of the typologies, actors/entities, value instruments and red-flag indicators that ML can entail, in a manner that (a) provides a holistic overview of the components that comprise the phenomenon of ML and (b) significantly reduces the inconsistencies in their reporting. This therefore provides an overview of ML as a phenomenon (per the first study aim) and motivates how a standardised approach to terminology is a comparatively better approach to the current state of the art (per the second study aim).
Results
Review statistics
The total number of insights collected concerned 226 actors/entities, 212 VIs, 2565 red-flag indicators (including 757 duplicates that were effectively identical in idea to other indicators), 15 ML ‘typologies’ (with 62 methods and 96 techniques), and six concealment enhancer (CE) typologies (with 25 methods and 36 techniques). Figures 6 and 7 show the number of insights collected per publishing entity.

Number of Actors/entities, VIs and indicators collected per publishing entity

ML/CE typologies, methods and techniques collected per publishing entity
Actors and entities
The emerging categories for actors/entities were criminals, financial institutions, designated non-financial businesses and professionals (DNFBPs), corporate structures, cyber-actors, and state actors. In terms of specific sub-categories, banks were the most frequently mentioned entity of concern, with shell corporations and related front structures the next most mentioned. Cyber-actors were mentioned relatively infrequently, as there were few reports on these issues in the timeframe covered. However, it should be noted that as of January 2024, the FATF has since released two new reports on virtual assets.
Figure 8 shows the total number of mentions and reports for these categories. Figure 9 shows a breakdown of mentions and the number of reports for the first-order sub-categories contained within each.

Actors/entities by number of mentions and number of mentioning reports

Number of mentions and number of mentioning reports for each actor/entity first order sub-category
Value instruments
The emerging categories for VIs were cash, electronic funds accounts, tangible goods, financial securities, bearer-negotiable instruments, non-negotiable instruments, stored-value cards, and intangible assets.
The most and second most mentioned VIs were precious stones and real estate respectively, both under the ‘tangible assets’ category. Other frequently mentioned VIs included cheques, insurance products, transferrable securities, and financial institution-issued (i.e., credit or debit) cards.
Figure 10 shows the total number of mentions and reports for these categories. Figure 11 shows a breakdown of mentions and number of reports for the sub-categories contained within each.

VIs by number of mentions and number of mentioning reports

Number of mentions and number of mentioning reports for each VI category
ML typologies, methods and techniques
Emerging typologies are shown in Fig. 12. Full breakdowns of the methods and techniques within each are available in the data supplement with brief descriptions. Trade-based ML was the most frequently mentioned typology and will be discussed in depth in due course.

Number of reports and constituent methods/techniques for each ML typology
Concealment enhancers
The identified concealment enhancers (CEs) contain optional actions, undertaken before, during or after the ML TMTs above. Their aim is to further obfuscate ML activities. Some techniques are relevant to specific ML typologies. For example, ‘regularly switching casino tables’ was a technique coded under the ‘structuring’ typology, which is only relevant to gambling-based ML. The vast number of mentions for structuring (which exceeded even the most frequently mentioned ML typology) was unsurprising, given the applicability of this CE across most ML activities.
Figure 13 shows the CE typologies identified. As with ML TMTs, a full list of constituent methods/techniques are available in the data supplement with descriptions.

Number of mentions in reports and constituent methods/techniques for each CE typology
Risk indicators
To recall, risk indicators are suspicious activities that can potentially be indicative of an ML scheme taking place. The 2565 risk indicators identified throughout reports could be categorised, at the base level, into three groups; indicators relating to the (a) suspicious transaction, (b) suspicious actor/entity and/or (c) actor/entity being exploited/interacted with.
These are shown in Tables 4, 5 and 6 along with examples, the number of mentions and number of reports mentioning indicators within each category. Of the 105 reports, only 68 contained indicators. Again, some were highly specific to a certain typology (e.g. ‘suspect regularly cashes out casino chips at routine intervals’) while others were more generic (e.g. ‘suspect appears uncomfortable when asked to disclose personal identification details’).
Reviewing the results in context
This section has provided, per the first research aim, a general overview of the ML threat landscape by standardising and visualising different components of ML, including actors/entities, value instruments and red flag indicators. By placing these in the context of mentions and the frequency of mentioning reports, it has also aimed to provide a general understanding of ML priorities and levels of threat.
Per the second research aim, this section has recorded data in a standardised hierarchical manner, which can contribute to forming the basis of how ML-related financial intelligence is collected. It has, however, concurrently highlighted issues with the existing TMT framework, which despite being used as a foundation for data coding in this review, has made apparent a number of flaws in terms of wider standardisation efforts. These will be discussed next.
Implications for the TMT framework
Besides the presence of the inconsistencies discussed previously, the results suggest that the FATF’s ‘typology-method-technique’ framework is limited in a number of ways. First, the coding process stressed the need for the distinction between actual typologies and concealment enhancers. Second, it is important to note that the average ML and CE typology was mentioned by 9 and 18 reports (8.5% and 17%) of the total consulted, respectively. This suggests that ‘typologies’ and their constituent methods/techniques are relevant for a range of predicate offences, timespans, industries and value instruments. They are, therefore, interchangeable across contexts, and per inconsistencies of scope, may play varying parts in uniquely constructed ML schemes. To not acknowledge this causes issues for standardisation and risks mis- or under-informing readers.
One can, therefore, essentially consider ML as a sequence of (mandatory and optional) actions. Figure 4, which includes an excerpt of the FATF’s casino ML report, underscores this by providing a sequence of actions in prose, which it ultimately combines into ‘techniques’ and ‘methods’. Actions are, essentially, the fundamental building block of typologies, methods and techniques — which are themselves essentially commonly observed sequences of individual actions. One can effectively characterise this, as the ‘TMTA’ framework, where ‘actions’ are the building blocks of ‘techniques’. However, the abundance of overlap between reports underscores that actions themselves need not be confined to a specific TMT, and can be sequenced together to formulate custom ML schemes.
Going forward, this paper will therefore adopt the more granular approach of considering the ML threat landscape as an interconnected web of individual actions, rather than assuming their place in distinct and neat typologies, methods or techniques. This allows data to be standardised and disseminated without being constrained or prejudiced by TMTs created in inconsistent manners in the past. The next section discusses how the devised standardised hierarchical dataset, and in particular red-flag indicators, can serve to attain this goal.
Indicator analysis
The large number of indicators identified throughout this review, as well as the information they contain, makes them an ideal means of understanding the prevailing money laundering scene. This is because they combine all the previously discussed insights (actors/entities, value instruments, ML/CE typologies) into a data value with context. Figure 14 shows the number of indicators, per the three main categories (transaction-based, offender-based, facilitator-based), released by year across the 68 coded reports with indicators.

Number of indicators released by reports per year. No reports were coded from 2016 or 2019
To recall, ‘actions’ are motivated as the fundamental building block of ML schemes, which are essentially themselves a sequence of actions. In a field where substantive real-world case data is not easily obtainable and has a high prevalence of false positives (discussed further in the limitations section), there exists a particular utility to considering transaction-based indicators, which essentially describe a suspicious action (i.e. a transfer and/or an exchange of illicit funds) that is, crucially, observable to the intermediary facilitating it. Therefore, to consider them equates to considering the most valuable of ML data to regulated entities and law enforcement — the points at which criminals are at their most vulnerable to being detected. Table 7 shows the application of transaction-based indicators to represent transfers and/or exchange actions.
For each transaction-based indicator (N = 1365) that involved a transfer or exchange (or both), the input, facilitator and output actor/entity and value instruments can be coded. Facilitators (i.e. any intermediary facilitating a transfer or any temporary medium of funds during an exchange) were only coded if any were mentioned. All actors/entities and value instruments (VIs) were derived from the hierarchical insights presented in the results. The more detailed the indicators were, the more granular the coding of actors/entities and VIs was. Table 8 shows three examples.
Coding all transfer/exchange indicators in this way gives the ability to visualise ML from a macro perspective. Figure 15 shows the number of actors/entities and VIs, respectively, identified across indicators in any capacity (i.e. input, output, facilitator, other ways). Figure 16, meanwhile, shows the distribution of the different actor/entity and value instrument categories identified by year.

Actor/entity categories (left) and value instrument categories (right) by frequency of appearance in indicators in any capacity

Actors/entities (left) and value instruments (right) mentioned by transaction-based indicators as a percentage of total mentions for each year (2016, 2019 and ‘non-negotiable instruments’ are removed due to a lack of data)
The charts suggest that financial services, state actors and DNFBPs (actors/entities) and cash, tangible goods and electronic account funds (VIs) have recurringly been the focus of AML across 15 years of typologies reporting. Virtual assets and cyber-entities became a VI of interest in 2020, as cryptocurrency fraud rose during the COVID-19 pandemic — though little other change in priorities is observed. Since 2021, the FATF has released two reports regarding virtual assets, suggesting that an update would show this trend continuing.
Another metric of importance is the role that each of these actors/entities and VIs play in an ML transaction – namely whether they are the input, facilitator or output. For example, per Table 8, if an indicator read money mule converts cash to cryptoassets via a bank, then cash would be the ‘input’ VI, bank accounts would be the ‘facilitator’ VI and cryptoassets would be the ‘output’ VI. Since this is an example of an exchange (no change in actor/entity), both the input and output actor/entity would be ‘money mule’ with ‘bank’ and ‘crypto exchange’ as facilitators. Several VIs were also mentioned in a unique or unknown capacity. These included insurance policies (financial securities) being used to justify fraudulent claims, or tangible goods used as decoys for sham trade invoicing.
Figure 17 shows the role(s) that each actor/entity and VI, respectively, took when identified as relevant to an indicator.

Roles of actors/entities (left) and value instruments (right) as mentioned in transaction-based indicators
The analysis suggests, unsurprisingly, that actors/entities are distinctly divided into set roles: criminals and corporate fronts initiate ML as either ‘inputs’ or ‘outputs’, while financial services, DNFBPs, cyber and state entities typically facilitate ML. VIs were all observed in input/output roles at similar levels, though electronic funds were also occasionally mentioned as facilitators. Typically, this was by indicators that identified criminals depositing cash into bank accounts and facilitating another transaction (such as the previous money mule cash-to-crypto example) soon after.
The analyses of the visualisations thus far may be unsurprising. It is not unexpected, for example, that criminals are initiators and banks are (complicit or unwitting) facilitators of ML. However, the benefit of quantifying and visualising this (as made possible through the standardised hierarchical manner of coding scoping review insights) is that more thorough policy assessments now become possible. For example, knowing the extent to which banks facilitate (rather than initiate) ML can lead to algorithmic and predictive solutions that incorporate this data into suspicious activity detection mechanisms. It can also provide a statistical foundation for a better understanding of the extent to which policies should tackle the problem of, for example, banks being complicit and initiating ML, versus them inadvertently facilitating ML. This study seeks to provide the foundation upon which such possibilities may be built. In this light, the following sections further explore how policy-relevant quantitative insights can be gained and visualised from transaction-based indicators.
Visualising money laundering through transaction-based indicators
Taking transaction-based indicators as synonymous with transfers/exchanges, the specific transactions they indicate can be visualised on Sankey diagrams as shown in Fig. 18. These diagrams show the input, facilitator (if any) and output actor/entity (left) and value instrument (right) as identified within each indicator (see example raw data in Table 8).

Sankey diagrams of indicator-observed transfers between actor/entities (left) and exchanges between value instruments (right)
While these diagrams do not show how frequently these transactions occur in ML overall (though it may be indicative of it), they do show how often an indicator for these transactions has been identified and reported by the FATF/FSRBs, which itself is an indicator of what their priorities entail and what trends are being more commonly observed. This further emphasises the trade-based money laundering (TBML) and traditional banking-centric nature of the risks discussed in these reports, as these processes are mentioned in the most indicators. The emphasis on TBML is evident from the volume of observed transfers occurring between corporate vehicles. Meanwhile, typical financial transactions, such as exchanges between cash and bank accounts, or between different types of electronic accounts, are the most indicated exchange transactions.
Other transactions have comparably lower emphasis, with the next most common transfer being those facilitated to or from securities intermediaries (a form of financial service) by launderers purchasing insurance products.
Breakdown of actors/entities and value instruments across indicators
To recall, the developed dataset of actors/entities and VIs is hierarchical — namely, the top-level categories such as ‘financial services’ are broken down into several more specific sub-categories (such as ‘banks’, ‘securities intermediaries’), and so on. The Sankey diagram in Fig. 18 accounts only for top-level categories. More granular insights can, therefore, be gained by visualising transfers and exchanges between more specifically-defined actors/entities and VIs.
The tree maps in Figs. 19 and 20 show sub-categories of actors/entities and VIs, with their colours corresponding to their parent categories (per their colours in Fig. 15). The sizes of their segments represent the number of indicators for which they were coded in at least one capacity (input, facilitator, output or ‘relevant in other ways’). The capacity in which they appear is not distinguished. Larger segments, therefore, denote actors/entities or VIs that are more frequently involved in observable ML activities. Only actors/entities or VIs with a frequency of two or above are shown.

Tree map of second-order actors/entities by frequency of appearance in indicator parameters. IVTS, informal value transfer systems; SOCs, state-owned companies; OGCs, organised crime groups; FTZs, free-trade zones; C, charities; S, social media/communications services; H, hospitality sector; PML, professional money launderers, TH, transport hubs; LE, law enforcement; A, alternative banking systems; P, pre-paid card issuers; T, trade finance companies; F, financial intelligence units

Tree-map of second-order value instruments by frequency of appearance in indicator parameters. CIUs, collective investment units; B, winning betting tickets; IP, intellectual property; BoEs, bills of exchange; V, vehicles; PPC, pre-paid cards; BA, gold bullion accounts; S, services
These tree maps do not provide unexpected observations. Indicators covering financial services were split almost equally into those discussing securities intermediaries, banks and money value services. Due to the emphasis on TBML, the largest state entity discussed were customs agencies, while the largest corporate vehicle discussed were trade companies. For DNFBPs, a broadly even split was observed between high-value goods traders, casinos and professional services. This is likely to reflect the fact that all three of these areas have been covered by substantial reports looking exclusively into their exploitation. For virtual asset services, this is also the case, as they have largely only been referenced exclusively by one FATF report (and, to a smaller extent, by some FSRB reports) at the time of analysis.
Meanwhile, bank accounts and cheques were the most prevalent value instruments – demonstrating the cross-typology use cases for both. Note that cash is not included as it is not a sub-category. Other major value instruments, such as insurance policies, cryptoassets, precious metals, casino value instruments and real estate, also featured prominently largely due to dedicated comprehensive reports covering their misuse. One notable observation here is that ‘traded goods’ is not hugely observed among the VIs shown, despite a large emphasis on TBML among indicators. This is mainly due to most TBML-related indicators focusing on the financial transactions occurring between sham trade companies, rather than the physical shipment of goods between them (Innab, 2021). In many cases, TBML arises from trade fraud itself, therefore often being intertwined with the predicate offence, and per ‘services-based money laundering’ (SBML), some goods/services may not be traded at all. The goods/services ostensibly being traded on paper are therefore not the primary value instrument through which illicit funds are transferred, but rather the financial payments they falsely offer justification for.
However, in the minority of TBML-related indicators that did concern goods, it was often the case that subsequent sales of traded goods by the recipient entity were being discussed, though the specific type of good was not specified in detail (meaning no specific sub-category of ‘tangible goods’, a parent category of VI, was coded). Typical goods traded for the purpose of fraud or TBML include items where the quantity, quality or weight can easily be manipulated, for example, vehicles, precious metals, electronics, textiles and clothes — representing 70% of TBML casework according to the US Department of Homeland Security (US GAO, 2020).
Visualising the ML threat landscape holistically
So far, this article has presented a number of visualisations showing the prevalence of different actors/entities and value instruments in instances of identified suspicious activity. The aim has been to provide a general holistic view of the components of ML. The Sankey diagram in Fig. 18 gives an overview of how and to what extent these components interact with each other.
This section motivates a means of viewing the ML threat landscape that incorporates all these variables and interactions into one visualisation — namely chord diagrams. Though seemingly complex at first, these diagrams (when the interpretation is understood) provide an instant snapshot of the key takeaways of 105 comprehensive reports holistically — all the while overcoming the five inconsistencies discussed previously through utilising the standardised hierarchical dataset developed during the review.
The chord diagrams in Figs. 21 and 22 show the beneficiaries and senders of illicit funds and the input/output value instruments in illicit transactions respectively. Their segments are formed of either parent or sub-categories depending on which visualisation provides the most information (based on the frequency of occurrence). These diagrams were computed using the circlize package in R (Gu et al., 2014). Given the visual complexity of visualising these diagrams, which is often discouraged in graphical visualisations (Tufte, 2001), a walkthrough is provided for each chord diagram.

Chord diagram showing the senders and beneficiaries according to transaction-based indicators

Chord diagram showing the input and output value instruments in illicit transactions
For Fig. 21, each coloured part of the chord shows an actor/entity, split between where they send and receive funds (inputs and outputs, respectively). Of the two outer rings, the inner one closest to the diagram shows what actors/entities are used to facilitate these transfers. The outer chord shows the nature of the VI that these transfers occur with. Numbers indicate the number of red-flag indicators that mention these transfers. Though complex, such visualisations are an effective holistic overview of general ML transaction trends. For example, going clockwise, the first actor/entity shown is that of trade companies (marked with an ‘A’). Looking at indicators where trade companies are the ‘input’, roughly 50% (approximately 108 indicators) suggest that illicit funds originating from such companies are sent to generic launderers, while the other 50% suggest transfers to other trade companies. Looking at the thin inner ring outside the diagram, it appears that most of these transfers involve state entities as a facilitator, while a smaller number involve financial services and DNFBPs. Looking at the outer ring, most of these transfers appear to be in tangible goods, with a smaller amount in electronic funds.
Figure 22 can be read in the same way, though this time it shows how VIs change during transactions. In this case, the inner ring outside the diagram shows any intermediary value instruments used for the shown transactions, while the outer ring shows the actors/entities that facilitate them. Going clockwise, roughly 500 indicators described transactions that began with cash. The fate of this cash is rather varied, with a plurality just staying as cash (no exchange), and the rest being converted into either electronic funds accounts or other VIs. Looking at the inner ring outside the diagram, these transactions rarely involve intermediary VIs, though the ones that do tend to be in electronic funds. Looking at the outer ring, the actor/entity that facilitates the sending of this cash appears overwhelmingly to be generic launderers.
The diagrams again demonstrate a clear emphasis on TBML and cash-electronic funds conversions. Indicators covering actors/entities and/or VIs outside these main trends were scarce. Both diagrams suggest that ML transactions occur typically between the same categories of actor/entity or VI. Cash-to-electronic funds exchanges and transfers between generic launderers, securities intermediaries, DNFBPs and front/straw persons were the main exceptions to this trend.
The complexity of these diagrams is justified by the specialised nature of their intended audience (namely AML/compliance), which already requires experience in specialised data interpretation (e.g. transaction monitoring) techniques. Furthermore, it is argued that they are still comparatively more simplistic than 105 substantial reports that often convey information inconsistently. Besides visualising typological insights using red-flag indicators, the variety of visualisations provided here also seeks to present ways in which ML trends can be visualised in a manner that can be beneficial to relevant stakeholders. Sankey, chord or tree-map diagrams may all be useful in different contexts to understand various aspects of the overall ML threat landscape.
It should be noted that the chord diagrams here convey data according to the prevalence of indicators, rather than actual ML cases – an issue further discussed in the limitations section. However, were data from actual ML cases available, there is no reason why the same type of chord diagrams – or indeed Sankey diagrams or tree maps – could not be compatible with such data.
Visualising cross-typology ML schemes
One of the main contentions of this chapter and the one before it is that ML activities need not remain within the same typology, (per inconsistencies of scope). Now with the ability to use transaction-based indicators as synonymous with ML actions, it becomes possible to demonstrate this visually. The network in Fig. 23 clusters all indicators into nodes depending on which typology they were identified for within their respective report. For example, the indicator criminal cancels insurance policy early would be considered an exchange transaction (generic launderer converting an insurance policy into cash) clustered under the ‘misuse of insurance’ typology.

A directed typologies network map (left) and the number of connections (or ‘edges’) involving each typology (right). The colours on the right double as a key for the network on the left, where circles indicate ML typologies and diamonds indicate concealment enhancers. Numbers in the chart are the sum of all identified edges in both directions (i.e. where an action within that typology is at the start or receiving end of an edge). Edge thickness is adjusted to reflect more frequently observed connections. The sole node without connections is ‘misuse of intellectual property rights’, for which no indicators were identified
Consequently, links are generated between typologies depending on whether any transactions clustered within them can feasibly be followed on with a transaction identified as part of another typology. For example, a courier carries cash overseas can be followed on with depositing cash into a casino account — two transaction-based indicators from the ‘physical overseas transport’ and ‘misuse of casinos/gambling’ typologies, respectively. The assumption used to generate these links is as follows: any transaction that results in a certain value instrument A, held by a certain actor/entity B, can be followed on by any transaction that requires value instrument A held by actor/entity B to begin with. This condition can be likened to dominos — an action with a certain set of output parameters can be followed with an action with the same set of input parameters.
Each time this condition was met counts as one edge between the typology clusters of each action; the total number of links, both incoming and outgoing, for each typology (many of which were repeatedly observed) are shown in the bar chart key in Fig. 23.
Assuming all 22 typologies and CEs were linked to each other at least once, there would be 484 (222) possible combinations in Fig. 23. Incidentally, 371 — or 77 percent of all these possible combinations — were observed at varying frequencies. Particularly interconnected were actions relating to the securities sector, new payment methods, TBML, money value services and casinos. Theoretically, an ML scheme could involve all these typologies on multiple occasions, possibly swapping typology on a transaction-by-transaction basis — if it contributes to ultimately laundering the funds. Less interconnected were actions involving high-value goods, loans, legal services or physical overseas transport of VIs (e.g. cash couriering).
This exercise demonstrates that transactions undertaken as part of nearly all typologies can be followed on with other transactions from other typologies. The implication is that it is imperative to understand ML trends holistically, without limiting the scope of typological investigations. This is not to discount the value of observing commonalities between different ML cases and disseminating them to relevant parties. Rather, this exercise showcases how standardisation can help this aim and is crucial for gauging an accurate picture of the prevailing threat landscape. ML activity discussed in a report about ML in the real estate sector, for example, may be just one transaction removed from ML activity involving the securities sector. This may be crucial for stakeholders to consider when devising risk and prevention strategies, but would not necessarily be obvious given the inconsistencies in scope within compartmentalised reports. It is also a further justification for cross-stakeholder data sharing, as ML schemes may closely involve stakeholders in, ostensibly, completely irrelevant industries.
Discussion: expanding the case for standardisation
Standardising how concepts are reported and understood has long been an endeavour across a wide range of industries, ranging from managing smart sustainable cities to agreeing on a universal definition of terrorism (Carlile, 2007). Standardisation efforts aim to ensure that data collection, analysis, reporting and sharing across different agencies occurs in a consistent manner. Global entities such as the International Organisation for Standards (ISO) have emerged to devise and encourage the uniform adoption of standards, working also to counter biases and partiality in different fields (Dror & Pierce, 2020). Failure to standardise can lead to significant problems — the lack of international agreement on a definition of terrorism has arguably undermined the response from entities such as the United Nations (Levitt, 1986).
From an academic perspective, researching the same crime problems while using inconsistent statistics (such as different poverty metrics) can lead to similar studies yielding widely different results (Groeneveld & Breetzke, 2022). This harms the ability of studies to be replicated, the ability to test theories in different jurisdictions and, ultimately, the ability for researchers and practitioners to provide concrete solutions to contemporary problems. The utility of standardisation, therefore, is to ensure that the data is reported in a way that is comparable, efficient, compatible across entities and can thus appropriately influence policy.
Under a standardised means of reporting typologies and trends, all relevant stakeholders will have a common understanding of what is meant by specific terms that refer, for example, to criminal actors/entities, value instruments and red-flag indicators of ML/TF. There would be no ambiguity, for example, on what is meant by ‘money remittance businesses’, and alternative terminologies previously used (such as ‘MR/CE’ or ‘HOSSP’) and all specific actors/entities they incorporate would be standardised into one consistent term. Terms describing concepts of varying specificity are now acknowledged through a hierarchical structure. Stakeholders will also have a common understanding of how these insights can interact with each other, allowing them to better understand and process ML-related financial intelligence. It is acknowledged that the current study presents an initial (rather than a complete) endeavour to build a standardised hierarchical dataset to support this objective. More data, going beyond publicly available FATF/FSRB reports and potentially also including actual cases, will be needed for consideration. This study has motivated efficiencies for future expansions of this work, for example by suggesting modifications to the TMT framework to enhance data collection.
This in turn unlocks further benefits. Firstly, no stakeholder responsible for reporting or investigating ML, be it a bank, cryptocurrency exchange, law enforcement agency, casino or otherwise, has in itself a complete picture of what the phenomenon of money laundering looks like, as their financial intelligence will be limited to only capturing suspicious activities within specific jurisdictions or contexts. Therefore, as different stakeholders contribute different observations, a more complete holistic understanding of the overall ML/TF threat landscape can be pieced together. Not only would this include the fullest possible understanding of overall risk and criminal methods, but it could also make possible statistical analyses of the severity of risks. These may include the popularity of certain ML/TF activities or geographic distribution of popular methods — all of which are crucial for policy and resource allocation. The development and brief discussions of the previous visualisations indicate that policy-relevant insights can be gained from a standardised holistic approach. Even predictive or timescale analyses can be run to understand how the threat landscape is evolving and what methods might be more popular in the future. All these possibilities are motivations for further research.
Although the findings presented here appear predominantly relevant to the financial sector, the incorporation of a range of insights (actors/entities, value instruments, actions and indicators) is also beneficial to other stakeholders. For example, law enforcement and regulators can use standardisation-enabled visualisations such as the tree-maps or chord diagrams to understand priority threats for focus. Regulatory technology (RegTech) firms, which may provide analytics or intelligent anomaly detection tools tailored to specific industries, can make use of these findings to inform their algorithms. Given the relative abundance of findings relating to TBML, customs agencies and trade-focused businesses can also benefit from this standardisation effort.
It is crucial to stress that the realisation of all these benefits is only possible because the underlying data is standardised and reported consistently. This short discussion of benefits also emphasises that the advantages of standardisation are by no means surface level, and that they can be both wide-ranging and significant. The piecing together of a standardised hierarchical dataset of relevant concepts, namely actors/entities, value instruments, red-flag indicators and so on, is the first step that builds the foundations of these possible next steps, while addressing the inconsistencies in current typologies and trends reporting.
Limitations
Some limitations of the scoping review process warrant acknowledgement. Due to the extensive and time-consuming nature of data collection (spanning 2018–2021), a second coder did not validate the review process or the subsequent indicator coding exercise. Given the lack of inter-rater reliability and the subjective considerations required to overcome encountered inconsistencies, it should be emphasised that the review results present one way of coding insights and does not claim to be the only or best way. Using multiple raters, or artificial intelligence (AI) tools to scan reports, may improve both the speed and quality of the results. Despite the large number of judgement calls, the results are still not entirely void of inconsistencies — similar methods duplicated under different typologies (e.g. proxy networks and sham invoicing) can still be observed. Nevertheless, this study has demonstrated the need for such an exercise and contends to offer one way to conduct it.
The same challenges also relate to the latest reports included in the review being from 2021, which predates the release of a number of years’ worth of more recent reports. The extensiveness of the review process as described in the methodology makes producing more timely reviews a challenge. However, this by no means invalidates the results, for two reasons. First, most of the findings in this review are not time-limited, and where they are (e.g. when discussing virtual assets), it has been acknowledged. Second, a quick application of the report exclusion criteria to FATF publications between October 2021 and May 2024 identified only six reports that may be of codable value, which given the existing sample size of 105 reports is not notable to the extent that it invalidates existing findings. Of these reports, three focus on predicate offences rather than actual typologies (migrant smuggling, cyber-enabled fraud and fentanyl trafficking). Of the other three, one focused on art and antiquities (i.e. high-value goods) and two on virtual assets.
Additionally, non-FATF/FSRB typologies reports (of which there are many) were not consulted. Numerous private compliance firms and national FIUs produce reports on ML typologies and could have, in this case, aided topics where the coded reports were lacking (for example cryptocurrency-based laundering). Additionally, confidential versions of reports (released to governments and obliged entities only) were not obtainable. Future iterations of this review will benefit from including resources from a wider range of sources to ensure that the concepts considered are as wide ranging and applicable throughout the holistic ML threat landscape as possible.
A final limitation relates to the visualisations using indicator data. It should be noted here that these do not represent actual ML cases — but rather abstract indicators thereof. This is unlikely to be representative of the full picture, as it is dependent on the assumption that stated red-flag indicators (and their frequencies) are representative of actual observations. In this sense, however, it must also be acknowledged that even if actual ML data were available, it would still be unrepresentative given the low detection rates and false positives that arise in other data sources, such as suspicious activity reports (SARs) filed by obliged entities to FIUs. In 2018, 95% of SARs filed in the United States were reported to be false positives (Fruth, 2018). Alternative data sources such as court cases and case studies may have similar issues, with Bright et al. (2021) highlighting the issue of incomplete information and inaccessibility of court documents in many jurisdictions. This demonstrates the importance of consulting a wide range of data sources going forward, thus ensuring a well-rounded utilisation of insights that can address these common issues.
Future trends: opportunities and challenges
With the rise of technologies such as artificial intelligence that have the capability of streamlining the processing of data, work on creating privacy-preserving protocols for cross-border intelligence sharing is on the rise. Furthermore, machine learning and AI tools raise the potential for such data to not only be shared, but itself collected at scale in an automated manner. In the age of growing automation and digitisation, however, a standardised basis that guides such processes will inevitably be necessary to avoid data compatibility issues in the future. This emphasises the importance of endeavours for standardisation as an important step in motivating further international collaboration against money laundering.
Throughout this process, there will inevitably be challenges, and standardisation is not an all-encompassing answer to fostering cross-jurisdictional AML collaboration. Creating a unified taxonomy of concepts, for example, leaves little room for interpretation or multiple ‘truths’ when classifying a concept. This has the risk of standardised protocols being inevitably incompatible with innovation. For example, should one jurisdiction classify money remittance providers as financial institutions while another considers them to be a designated non-financial business, standardisation protocols may struggle to accommodate both approaches at once while remaining meaningful. Legal and regulatory differences are particularly observable in the face of new technologies, with cryptoassets yet to be regulated by many jurisdictions. In the jurisdictions that do, cryptoassets are often classified differently; for example, the United States classifies bitcoin as a commodity (US CFTC, 2019), El Salvador classifies it as legal tender currency (Alvarez et al., 2022) and China has adopted a strict ban on all cryptocurrencies (Chen & Liu, 2022). Though this is not an immediate issue for the initial standardised hierarchical dataset developed here, it highlights the challenges yet to come should standardisation efforts gain traction in the future.
Conclusion
This scoping review has produced a comprehensive breakdown of the different typologies, constituent actors/entities and value instruments that can be involved within money laundering schemes. In doing so, it makes several contributions. Firstly, it has generated a dataset that is more uniform and standardised than the fractured nature of the resources it initially consulted. This has helped provide a fundamental understanding of the types and extent to which different actors/entities and value instruments are involved in money laundering, and in what role.
Secondly, it has identified a method of breaking down ML typologies into constituent actions using red-flag indicator data. It has also visualised the ML threat landscape in numerous different ways that can assist in policy considerations and overcome inconsistencies in current articulations of typologies — again using indicator data to do so. The analytical advantages of using indicator data have been motivated through discussions of the different trends that the devised visualisations appear to show. The review has also exemplified the process crime nature of ML and the significant issues that inconsistencies within existing literature — particularly inconsistencies in scope — can pose to the effective articulation of ML risks.
The paper motivates the standardised hierarchical dataset devised here as a foundation for a consistent and more insightful approach to collecting, sharing, visualising and articulating ML-related financial intelligence. It argues that the standardised and hierarchical nature of this dataset unlocks numerous benefits — ranging from better data sharing to being able to analyse the ML threat landscape holistically — that can ultimately benefit the policies and practices of a range of stakeholders, including FIUs, law enforcement, financial services and international AML organisations.
Data Availability
The corresponding data is available in the supplementary material.
Notes
See this link for a list of FIUs by country: https://aml-cft.net/library/list-financial-intelligence-units-fius/
When the term insights is used in the current study, it refers collectively to these four data categories.
References
Alexander, K. (2001). The international anti-money-laundering regime: The role of the financial action task force. Journal of Money Laundering Control, 4(3), 231–248. https://doi.org/10.1108/eb027276
Alvarez, F. E., Argente, D., & Van Patten, D. (2022). Are cryptocurrencies currencies? Bitcoin as legal tender in El Salvador (Working Paper 29968; Working Paper Series). National Bureau of Economic Research. https://doi.org/10.3386/w29968
APG. (n.d.). Methods and trends: Introduction to APG typologies. The Asia-Pacific Group (APG) on Money Laundering. Retrieved 3 January 2022, from http://www.apgml.org/methods-and-trends/page.aspx?p=a4a11dca-75f2-4dae-9c25-6215103e56da
Arksey, H., & O’Malley, L. (2005). Scoping studies: Towards a methodological framework. International Journal of Social Research Methodology, 8(1), 19–32. https://doi.org/10.1080/1364557032000119616
Bell, R. E. (2002). Abolishing the concept of ʽpredicate offence’. Journal of Money Laundering Control, 6(2), 137–140. https://doi.org/10.1108/13685200310809482
Bourton, S. (2020). Too much information? Evaluating the financial intelligence gathering provisions of the Fourth European Union Anti-Money Laundering Directive and the Common Reporting Standard in combatting tax evasion. In K. Benson, C. King, & C. Walker (Eds.), Assets, Crimes and the State. Routledge.
Bowles, R., Akpokodje, J., & Tigere, E. (2005). Evidence-based approaches to crime prevention in developing countries. European Journal on Criminal Policy and Research, 11(3), 347–377. https://doi.org/10.1007/s10610-005-9001-0
Braun, V., & Clarke, V. (2012). Thematic analysis. In APA handbook of research methods in psychology, Vol 2: Research designs: Quantitative, qualitative, neuropsychological, and biological (pp. 57–71). American Psychological Association. https://doi.org/10.1037/13620-004
Bright, D., Brewer, R., & Morselli, C. (2021). Using social network analysis to study crime: Navigating the challenges of criminal justice records. Social Networks, 66, 50–64. https://doi.org/10.1016/j.socnet.2021.01.006
Caffarone, A. (2019). The non-data sharing data-sharing network: One anti-money laundering innovation requires a closer look (SSRN Scholarly Paper 3368437). https://doi.org/10.2139/ssrn.3368437
Carlile, A. (2007). The Definition of Terrorism (p. 48). UK Home Office.
Carlisle, D. (2022). Preventing financial crime in crypto: Typologies Report 2022. Elliptic. https://www.elliptic.co/resources/typologies-report-2022
Chen, C., & Liu, L. (2022). How effective is China’s cryptocurrency trading ban? Finance Research Letters, 46, 102429. https://doi.org/10.1016/j.frl.2021.102429
Dror, I. E., & Pierce, M. L. (2020). ISO standards addressing issues of bias and impartiality in forensic work. Journal of Forensic Sciences, 65(3), 800–808. https://doi.org/10.1111/1556-4029.14265
Egmont Group. (n.d.). Financial Intelligence Units (FIUs). Egmont Group. Retrieved 3 December 2021, from https://egmontgroup.org/en/content/financial-intelligence-units-fius
European Commission. (2018). Preventing money laundering and terrorist financing across the EU - How does it work in practice? https://ec.europa.eu/info/sites/info/files/diagram_aml_2018.07_ok.pdf
EUROPOL. (2017). From Suspicion to Action. EUROPOL. https://www.europol.europa.eu/publications-documents/suspicion-to-action-converting-financial-intelligence-greater-operational-impact
FATF. (2005). Money Laundering & Terrorist Financing Typlogies 2004–2005. http://www.fatf-gafi.org/media/fatf/documents/reports/2004_2005_ML_Typologies_ENG.pdf
FATF. (2006). Trade Based Money Laundering. Financial Action Task Force. https://www.fatf-gafi.org/media/fatf/documents/reports/Trade%20Based%20Money%20Laundering.pdf
FATF. (2007a). Guidance on the Risk-Based Approach to combating Money Laundering and Terrorist Financing. Financial Action Task Force. http://www.fatf-gafi.org/media/fatf/documents/reports/High%20Level%20Principles%20and%20Procedures.pdf
FATF. (2007b). Money laundering & Terrorist Financing through the Real Estate Sector. Financial Action Task Force. http://www.fatf-gafi.org/media/fatf/documents/reports/ML%20and%20TF%20through%20the%20Real%20Estate%20Sector.pdf
FATF. (2009). Vulnerabilities of Casinos and Gaming Sector. Financial Action Task Force. https://www.fatf-gafi.org/media/fatf/documents/reports/Vulnerabilities%20of%20Casinos%20and%20Gaming%20Sector.pdf
FATF. (2010). Money Laundering through Money Remittance and Currency Exchange Providers. Financial Action Task Force. https://www.fatf-gafi.org/fr/publications/methodesettendances/documents/moneylaunderingthroughmoneyremittanceandcurrencyexchangeproviders.html?hf=10&b=0&s=desc(fatf_releasedate)
FATF. (2013a). Money Laundering and Terrorist Financing Related to Counterfeiting of Currency (p. 86). Financial Action Task Force. https://www.fatf-gafi.org/media/fatf/documents/reports/money-laundering-terrorist-financing-related-to-counterfeit-currency.pdf
FATF. (2013b). Money Laundering and Terrorist Financing Vulnerabilities of Legal Professionals (p. 148). Financial Action Task Force. https://www.fatf-gafi.org/media/fatf/documents/reports/ML%20and%20TF%20vulnerabilities%20legal%20professionals.pdf
FATF. (2013c). The Role of Hawala and other Similar Service Providers in Money Laundering and Terrorist Financing. Financial Action Task Force. https://www.fatf-gafi.org/media/fatf/documents/reports/Role-of-hawala-and-similar-in-ml-tf.pdf
FATF. (2016). Guidance for a Risk-Based Approach for Money or Value Transfer Services. Financial Action Task Force. https://www.fatf-gafi.org/en/publications/Fatfrecommendations/Rba-money-or-value-transfer.html
FATF. (2018). Professional Money Laundering (p. 53). Financial Action Task Force. http://www.fatf-gafi.org/media/fatf/documents/Professional-Money-Laundering.pdf
FATF. (2021a). Opportunities and Challenges of New Technologies for AML/CFT. Financial Action Task Force.
FATF. (2021b). Stocktake on Data Pooling, Collaborative Analytics and Data Protection. Financial Action Task Force. https://www.fatf-gafi.org/en/publications/digitaltransformation/documents/data-pooling-collaborative-analytics-data-protection.html?hf=10&b=0&s=desc(fatf_releasedate)
FATF. (n.d.). Frequently Asked Questions - Money Laundering. Financial Action Task Force. https://www.fatf-gafi.org/en/pages/frequently-asked-questions.html#tabs-36503a8663-item-6ff811783c-tab
FATF, & Egmont Group. (2020). Trade-based Money Laundering. Financial Action Task Force. https://www.fatf-gafi.org/publications/methodsandtrends/documents/trade-based-money-laundering-trends-and-developments.html
Ferwerda, J. (2009). The economics of crime and money laundering: Does anti-money laundering policy reduce crime? Review of Law & Economics, 5(2), 903–929. https://doi.org/10.2202/1555-5879.1421
Filipkowski, W. (2008). Cyber laundering: An analysis of typology and techniques. International Journal of Criminal Justice Systems, 3(1), 15–27.
Fruth, J. (2018, March 14). Anti-money laundering controls failing to detect terrorists, cartels, and sanctioned states. Reuters. https://www.reuters.com/article/bc-finreg-laundering-detecting-idUSKCN1GP2NV
Gerbrands, P., Unger, B., Getzner, M., & Ferwerda, J. (2022). The effect of anti-money laundering policies: An empirical network analysis. EPJ Data Science, 11(1), Article 1. https://doi.org/10.1140/epjds/s13688-022-00328-8
Gilmour, N. (2021). Crime scripting the criminal activities of money laundering – holistically. Journal of Money Laundering Control, ahead-of-print(ahead-of-print). https://doi.org/10.1108/JMLC-09-2020-0109
Gilmour, N., & Hicks, T. (2023). The war on dirty money. Policy Press.
Gottselig, G., & Underwood, S. (2004). Financial intelligence units: An overview. International Monetary Fund & World Bank.
Graycar, A. (2010). International cooperation to combat money laundering. In M. Natarajan (Ed.), International Crime and Justice. Cambridge University Press.
Groeneveld, G., & Breetzke, G. D. (2022). The vagaries of variables: Towards a standardised approach for variable selection in spatial crime research. Methodological Innovations, 20597991221091513. https://doi.org/10.1177/20597991221091513
Gu, Z., Gu, L., Eils, R., Schlesner, M., & Brors, B. (2014). Circlize implements and enhances circular visualization in R. Bioinformatics (oxford, England), 30(19), 2811–2812. https://doi.org/10.1093/bioinformatics/btu393
Hetzel, F. (2023). A classification of money laundering incidents [University College London (UCL)]. https://discovery.ucl.ac.uk/id/eprint/10175664/
Holder, W. E. (2003). The International Monetary Fund’s involvement in combating money laundering and the financing of terrorism. Journal of Money Laundering Control, 6(4), 383–387. https://doi.org/10.1108/13685200310809716
ICIJ. (2021, October 3). International Consortium of Investigative Journalists. Offshore Havens and Hidden Riches of World Leaders and Billionaires Exposed in Unprecedented Leak. https://www.icij.org/investigations/pandora-papers/global-investigation-tax-havens-offshore/
Innab, D. (2021, June 14). How trade-based money laundering works and its impact on world finances. World Economic Forum. https://www.weforum.org/agenda/2021/06/trade-based-money-laundering/
INTERPOL. (2022). INTERPOL Dark Web and Virtual Assets Taxonomy. INTERPOL Darknet and Cryptocurrencies Working Group. https://interpol-innovation-centre.github.io/DW-VA-Taxonomy/
JFCSG. (2015). Money Laundering Typologies and Trends. Jersey Financial Crime Strategy Group. https://www.gov.je/SiteCollectionDocuments/Crime%20and%20justice/R%20Money%20laundering%20typologies%20and%20trends%20Jersey%2020150115%20LB.pdf
Johnson, S. D., Guerette, R. T., & Bowers, K. (2014). Crime displacement: What we know, what we don’t know, and what it means for crime reduction. Journal of Experimental Criminology, 10(4), 549–571. https://doi.org/10.1007/s11292-014-9209-4
Koningsveld, J. van. (2013). Money laundering – ‘You don’t see it, until you understand it’: Rethinking the stages of the money laundering process to make enforcement more effective. In D. van der Linde & B. Unger (Eds.), Research Handbook on Money Laundering. Edward Elgar. https://www.elgaronline.com/view/edcoll/9780857933997/9780857933997.00044.xml
Lassalle, M., & Vogel, B. (2023). Developing public-private information sharing to strengthen the fight against money laundering and terrorism financing: Recommendations for the European Union. Max Planck Institute for the Study of Crime, Security and Law. https://doi.org/10.30709/eucrim-2023-031
Levi, M. (2000). Conclusions of the Second Typologies Exercise on the Links between Organised Crime and Money Laundering (PC-R-EV (2000)2). Council of Europe, European Committee on Crime Problems (CDPC).
Levitt, G. (1986). Is terrorism worth defining. Ohio Northern University Law Review, 13(1), 97–116.
McLaughlin, J. S., & Pavelka, D. (2013). The use of customer due dilligence to combat money laundering. Accountancy Business and the Public Interest, 12, 57–84.
Mouzakiti, F. (2020). Cooperation between financial intelligence units in the EU: Challenges for the rights to privacy and data protection. In K. Benson, C. King, & C. Walker (Eds.), Assets, Crimes and the State. Routledge.
Naheem, M. A. (2018). TBML suspicious activity reports – A financial intelligence unit perspective. Journal of Financial Crime, 25(3), 721–733. https://doi.org/10.1108/JFC-10-2016-0064
OECD. (2015). Improving Co-operation Between Tax and Anti-Money Laundering Authorities. Organisation for Economic Co-operation and Development. https://www.oecd.org/ctp/crime/report-improving-cooperation-between-tax-anti-money-laundering-authorities.pdf
Peters, M. D. J., Godfrey, C. M., Khalil, H., McInerney, P., Parker, D., & Soares, C. B. (2015). Guidance for conducting systematic scoping reviews. International Journal of Evidence-Based Healthcare, 13(3), 141–146. https://doi.org/10.1097/XEB.0000000000000050
Pol, R. F. (2018). Uncomfortable truths? ML=BS and AML= BS2. Journal of Financial Crime, 25(2), 294–308. https://doi.org/10.1108/JFC-08-2017-0071
Roberge, I. (2007). Misguided policies in the war on terror? The case for disentangling terrorist financing from money laundering. Politics, 27(3), 196–203. https://doi.org/10.1111/j.1467-9256.2007.00300.x
Rummens, A., Hardyns, W., & Pauwel, L. (2017). A scoping review of predictive analysis techniques for predicting criminal events. In G. Vermeulen & E. Lievens (Eds.), Data Protection and Privacy under Pressure (pp. 253–292). Maklu.
Sandhu, H. S. (2000). The global detection and deterrence of money laundering. Journal of Money Laundering Control, 3(4), 336–344. https://doi.org/10.1108/eb027247
Seagrave, S. (1995). Lords of the Rim. Bantam Press.
Soudijn, M. R. J. (2016). Rethinking money laundering and drug trafficking: Some implications for investigators, policy makers and researchers. Journal of Money Laundering Control, 19(3), 298–310. https://doi.org/10.1108/JMLC-07-2015-0028
Sultan, N., & Mohamed, N. (2022). The role of information sharing in combating money laundering: The importance and challenges of mutual legal assistance for developing jurisdictions like Pakistan. Journal of Money Laundering Control, 26(6), 1242–1260. https://doi.org/10.1108/JMLC-09-2022-0128
Terry, G., Hayfield, N., Clarke, V., & Braun, V. (2017). Thematic analysis. In C. Willig & W. S. Rogers (Eds.), The SAGE Handbook of Qualitative Research in Psychology. SAGE.
Thony, J.-F. (1996). Processing financial information in money laundering matters: The financial intelligence units research note. European Journal of Crime, Criminal Law and Criminal Justice, 4(3), 257–282.
Tiwari, M., Ferrill, J., Gepp, A., & Kumar, K. (2023). Factors influencing the choice of technique to launder funds: The APPT framework. Journal of Economic Criminology, 1, 100006. https://doi.org/10.1016/j.jeconc.2023.100006
Tsingou, E. (2010). Global financial governance and the developing anti-money laundering regime: What lessons for International Political Economy? International Politics, 47(6), 617–637. https://doi.org/10.1057/ip.2010.32
Tufte, E. R. (2001). The Visual Display of Quantitative Information, 2nd Ed. (2nd edition). Graphics Pr.
Unger, B. (2023). Project ‘ECOLEF’ The Economic and Legal Effectiveness of AntiMoney Laundering and Combating Terrorist Financing Policy. Utrecht University. http://www2.econ.uu.nl/users/unger/ecolef_files/Final%20ECOLEF%20report%20(digital%20version).pdf
US CFTC. (2019). Bitcoin Basics. U.S. Commodity Futures Trading Commission. https://www.cftc.gov/sites/default/files/2019-12/oceo_bitcoinbasics0218.pdf
US GAO. (2018). Bank Secrecy Act: Derisking along the Southwest Border Highlights Need for Regulators to Enhance Retrospective Reviews. United States Government Accountability Office (GAO). https://www.gao.gov/assets/700/690310.pdf.
US GAO. (2020). Trade-Based Money Laundering: U.S. Government Has Worked with Partners to Combat the Threat, but Could Strengthen Its Efforts (Report to Congressional Requesters GAO-20–333). U.S. Government Accountability Office (GAO). https://www.gao.gov/assets/gao-20-333.pdf
Van der Waldt, G. (2020). Constructing conceptual frameworks in social science research. TD : THe Journal for Transdisciplinary Research in Southern Africa, 16(1), 1–9. https://doi.org/10.4102/td.v16i1.758
Zand, A., Orwell, J., & Pfluegel, E. (2020). A secure framework for anti-money-laundering using machine learning and secret sharing. International Conference on Cyber Security and Protection of Digital Services (cyber Security), 2020, 1–7. https://doi.org/10.1109/CyberSecurity49315.2020.9138889
Funding
Open access publishing enabled by City University of Hong Kong Library's agreement with Springer Nature This study was funded by the Dawes Centre for Future Crime at UCL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Akartuna, E.A., Johnson, S.D. & Thornton, A. Motivating a standardised approach to financial intelligence: a typological scoping review of money laundering methods and trends. J Exp Criminol (2024). https://doi.org/10.1007/s11292-024-09623-y
Accepted:
Published:
DOI: https://doi.org/10.1007/s11292-024-09623-y