
Abstract
Recommendation algorithms are data filtering tools that make use of algorithms and data to recommend the most relevant items to a particular user. The algorithm-driven recommenders become indispensable and supersede search engines as the most important information dissemination channel. On one hand, it becomes an integral component in the existing social media, e.g. Weibo, Twitter, etc. On the other hand, news aggregators and recommenders have proliferated and gained an increasing market share. As a result, the previous studies usually study the “filter bubbles” phenomenon in the context where the social filtering dominates the dissemination of information. However, less attention is paid to the news aggregators and recommenders where algorithm-driven technological filtering dominates. Therefore, in the previous research, “filter bubbles” are usually equated with the community structure, but lack of the detailed analysis of the content agglomeration through the users’ interaction with the platforms. Based on these concerns, we propose a four-phase (“Selection”, “Setup”, “Link”, and “Evaluation”) skeletal solution framework targeted at exploiting the filter bubble effect of the personalized news aggregation and recommendation system. Furthermore, we illustrate the effectiveness of the proposed framework with a case study in three top Chinese news aggregators, i.e. Toutiao, Baidu News, and Tencent News. The results show that the users are narrowed into one or a limited number of topics over time. The phenomenon of the narrowed topics is deemed as the emergence of the “filter bubbles”. We also observe that the filter bubbles demonstrate different convergence degrees as user’s individual preference varies.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The emergence of “self-media” has resulted in a flood of information generation, and thus the main body of information communication becomes more complex [41]. To help the end users deal with the information overload problem, the news aggregators and recommenders use recommendation algorithms to learn the user’s preferences and behavioral patterns, and recommend the content catering for the user’s preference. The news aggregators and recommenders built upon recommendation algorithms can achieve a fine recommendation result based on user segmentation and neighbor discovery on a hyper-dimensional basis [7, 20, 24], and learn with cross-references to what each user is interested in. Despite the ease of access to information, there are mounting concerns about the recommendation algorithms providing the audience with the filtered channels of information [3, 9, 15]. The goal of the platform is to design those algorithms which maximize the time that users spend on the platforms in order to maximize the profits generated through advertising [13, 37]. This predefined optimization goal is usually criticized as “bias” embedded in those information filtering algorithms [5, 12], and those biases may have unintended consequences. Reliance on the homogeneity signals may lead to an entrenchment of the established sources at the expense of novel sources [4, 28]. This “homogeneity bias” is also termed as “filter bubble” in the media theories [27]. The filter bubble has become one of today’s most urgent issues for social media. Extensive research efforts have been devoted to this area [6, 10, 11, 17, 26, 27, 32]. However, existing research suffers from the following limitations.
Firstly, the previous studies usually study the “filter bubbles” phenomenon in the context where the social filtering mechanism and the algorithm-driven technological filtering effect co-exist [40]. This is in line with the fact that the recommendation engine comes to be an integral component in the existing social media, e.g. Weibo, Twitter, and etc. On the other hand, we note that due to the exponential increase in the available contents online and the technological development in the field of recommendation technologies, recommendation algorithm-driven news aggregators and recommenders have played an increasing important role. However, less attention is paid to the news aggregators and recommenders where the information dissemination is dominated by the algorithm-driven technological filtering. Secondly, the previous studies usually equate the filter bubbles with community structures and emphasize this exogenous isolation effect. There is however a lack of the full discussion of the internal organization of filter bubbles [25]. In [25], the authors studied the endogenetic structure of filter bubbles in social networks. However, a detailed understanding of the endogenetic news composition, w.r.t topic distribution, is missing.
In the industrial real-world recommenders, such as ToutiaoFootnote 1, the recommendation system is designed in a way where tens of millions of customers and millions of items are discretized into the one-hot representation [7, 20, 24]. The feature size after discretization and the feature crossing can easily reach millions or even billions [7, 20]. The internal hyper-parameter mechanics of the algorithm design suffers from a significant lack of explainability, which makes it a major analysis barrier to evaluate the impact of recommenders in a “white-box” way (i.e. the algorithm design is given) through directly analyzing the algorithmic design.
In this paper, we consider the filter bubble effect problem of the personalized recommenders and develop a four-phase Select-Setup-Link-Evaluate (SSLE) framework to exploit in a “black-box” way (i.e. the algorithm design is unknown) for the problem.
We outline the procedures in applying SSLE to address the filter bubble effect evaluation problem. Further, we propose the impact evaluation metrics of news aggregation and recommendation systems, and expand the traditional user satisfaction and the accuracy-oriented evaluation metrics of recommenders. We illustrate the effectiveness of the SSLE framework with empirical studies on Toutiao, Baidu News, and Tencent News, which are the top three news aggregators and recommenders.
Our main contributions are listed as follows:
-
1.
A four-phase skeletal solution framework is proposed to target at exploiting the filter bubble effect on the information receiver’s exposure to the recommended news at the joint influence of individual filter and technological filter. This solution framework does not rely on the design of the recommendation function, and thus, is a black-box and lightweight solution.
-
2.
We present an empirical analysis of the filter bubbles on three real-world news recommenders, including Toutiao, Baidu News, and Tencent News, which are the top three news aggregator apps in China, by illustrating the effectiveness of the proposed solution framework.
-
3.
We find that the news recommenders interactively filter out the users’ uninterested content and filter in the content that caters for the user’s interests, and thus, the users are narrowed into one or a limited number of topics over about 7-day period. The phenomenon of the narrowed topics is deemed as the emergence of the “filter bubbles”.
-
4.
We also observe that the filter bubbles demonstrate different convergence degrees as user’s individual preference varies, with users interested in “Society” facing with several converged topics as the users are also interested in several other topics as well, while users interested in “Entertainment” topic facing with one big converged topic. With the same reason, the converged topics differ with different user groups. Furthermore, the technological filter reflects and strengthens the individual filter. With the proliferation of “self-media” and users’ growth of interest of UGC over PGC, there is a corresponding increment of UGC over PGC recommended by the news aggregator and recommender, with the highest percentage of UGC recommended reaching around 83%, and the lowest reaching about 50%.
We survey related work in Section 2. This is followed by a concrete outline of the problem statement and the solution framework in Sections 3.1 and 3.2, respectively. Section 4 details our experiment processes using the Select-Setup-Link-Evaluate (SSLE) solution framework. This followed by our empirical evaluation in Section 5 and conclusions in Section 6.
2 Related work
In this Section, we present previous works related to our study. First the concept of filter bubble and the empirical investigation on social media is briefly presented in order to introduce the reader into the world of network evolution. After that recommendation engines that enable the information spread in an algorithm-driven way are discussed. Finally, we present the state-of-the-arts of the evaluation metrics of recommenders.
2.1 Filter bubble and social media
The filter bubble is an intermediate structure formed in online digital space constraining an individual’s exposure to a full spectrum of news and other information on the internet. Online media providers, such as Google or Facebook, compete for user attention. The goal is to maximize the time users spend on their respective sites, thus to maximize profits generated through advertising. Therefore, the information provided on online media is selectively filtered through the available flood of information, according to the algorithmically assumed individual users’ wants and needs. In [13], the authors proposes the triple filter theory, namely, individual filter, social filter, technological filter [13] in the formation of filter bubbles. Individual filter refers to the filtering of content caused by users’ own preferences, tastes, interests. Social filter refers to the filtering of content by pushing the content that is posted, retweeted, and favored by the user’s online social connections, whether it is bilateral friendship relation as in Facebook, or unilateral following relation as in Twitter. Technological filter refers to the filtering of content caused by algorithmically selecting and tailoring the content that suits the user’s tastes or excluding content that does not, examples include pagerank, recommendation algorithms [4], etc.
Previous studies usually study the “filter bubbles” phenomenon in the context where social filtering mechanism and algorithm-driven technological filtering effect coexist. This is in line with the fact that the recommendation engine comes to be an integral component in existing social media, e.g. Weibo, Twitter, etc. On the other hand, we note that due to the exponential increase in available content online and technological development in the field of recommendation technologies, recommendation algorithm-driven news aggregators and recommenders have proliferated and gained an increasing market share. However, less attention is paid to the news aggregators and recommenders where the information dissemination is dominated by algorithm-driven technological filtering.
2.2 Recommendation engines and its filtering mechanisms
Recommendation engines (REs) enable the web platforms to elicit the interests or preferences of individual users for the items, either explicitly or implicitly. Recommendation engines have been used in different areas, including e-commerce, news media, and education since its invention [35]. To the end users, the degree to which the recommendation engines understand them and are personalized for them are key factors in the adoption of the web platforms [36]. Therefore, a vast amount of research [7, 20, 23, 38] has been devoted to design and develop underlying algorithms to generate the personalized recommendations.
Recommendation engines essentially are data filtering tools designed to understand the individual needs of particular users and fetch the most relevant items to a particular user. Broadly speaking, there are three categories of the filtering mechanisms: (i) collaborative filtering, where recommendation engines recommend content based on user neighbourhood information and give recommendations by combing the neighbors’ previously selected content; (ii) content-based filtering, where recommendation engines recommend content based on similarities of properties and characteristics between previously chosen and available content; (iii) hybrid filtering, where recommendation engines combine both approaches [36]. Of these three mechanisms, we can see that the “relevancy” of the items to the end users are determined based on “similarity”, whether it is similarity between users or item or a combination of both. The technological filtering effect driven by recommendation is criticized as “homogeneity bias” [4, 31], with the concern that people are exposed to similar minds and discuss similar views with like-minded peers [4, 31].
2.3 Evaluation metrics of recommenders
Prior research on REs evaluations [1, 18, 21, 22, 29] has focused mostly on accuracy metrics, such as accuracy, Root Mean Square Error, roc curve, ranking score, and Precision@N and recall@N for top\(-k\) recommendations, where N represents the size of the recommendation list [16]. Silveira’s work [34] categorizes the evaluation metrics of recommendation quality into two groups: (i) base metrics, including “utility” (i.e. accuracy metrics), “novelty” (the extent to which the items are unknown to a user), “diversity” (variety of items in recommendation lists), “coverage” (the extent of items that a recommender is capable of working with), and (ii) compound metrics, including “unexpectedness” (divergence from the history of a user, related to “diversity”, “coverage”), “serendipity” (a lucky finding or a satisfying surprise, related to “accuracy”, “novelty”, and “diversity”). Other work [33] further adds “context compatibility” (referring to whether or not the recommendations consider general or personal context requirements, e.g. users’ current mood, different occasions for watching the movie, etc.) to the category of recommendation quality.
However, these evaluation metrics largely focus on the satisfaction or improving the user experience. Little is known about the social impact that these systems have on the audiences. Take “novelty” as an example, the concept of“novelty” involves three levels: (i) life level novelty, the extent to which the items are never consumed or known in the users’ lifetime, (ii) system level novelty, the popularity of items in the list, (iii) recommendation list level novelty, the extent to which the items are not repeatedly recommended [34]. To put it briefly, the optimization goal of recommenders is to improve the customer retention rate, thus it will inevitably lead to the negligence of its potential cocoon effect and other impacts on the audiences/information receivers [2].
Here, we approach the impact evaluation problem from an information receiver’s perspective, while existing research approaches from an information sender’s perspective, e.g. opinion leader [40] and his/her social status (usually in terms of follower count and the position in the network structure). In our previous work [39], we proposed the impact evaluation metrics of the personalized news recommenders that approach from an information receiver’s perspective. In this paper, we further generalize the evaluation process into a four-phase framework, and and dive into the differences of the filter bubbles formed under different topics.
Note that there are certain evaluation aspects of recommender systems that are out of the scope of this paper. In particular, we have decided to avoid the general usability evaluation of the interface, including the perceived usefulness and perceived ease of use of recommender systems, and the large area of marketing-inspired evaluation, as these are well covered in research and practition literature [19, 33]. We also do not consider the emerging robustness and explainability discussions of recommender algorithms, as substantially more solid work needs to occur.
3 Problem statement and solution framework
We now outline the problem statement more formally and introduce the solution framework.
3.1 Problem statement
Given a recommender engine RE and the demographic profile of a user group UG that is of interest to the analysts, the problem is defined as to evaluate to what extent a user \(u\in UG\) receives content from a narrow set of information sources. The recommendation function itself is external to the task. It may be noted that we do not presume availability of usage data (e.g., query logs) in addressing the RE evaluation tasks. However, apriori-knowledge \(A = <F_B, F_I, F_E>\) comprising of behavioral feature \(F_B\), interests feature \(F_I\) and environmental feature \(F_E\) is presumed as available.
3.2 Solution framework
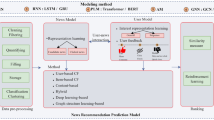
We now outline our four-phase skeletal framework for receiver-centric impact evaluation of personalized news aggregator and recommender. An overview is given in Figure 1. The four phases are as follows:

Solution framework
-
1.
Selection: Different user groups bear different interests and preferences, thus may lead to different topic convergence distributions over time. To shed light on the influence of users’ preferences on the technological algorithm-driven filters of the news aggregator and recommender, we select four user groups that are of interest, that is, white-collar, blue-collar, cyber-celebrity, and students.
-
2.
Setup: This phase sets up the bots that mimic the selected user group’s online behavior based on the apriori-knowledge \(A = <F_I, F_B, F_E>\). The bots simulation outline is shown in Fig. 2. To be more specific, the simulation comprises of the following steps:
-
(a)
Log-on Behavior Simulation based on \(F_B\). The behavioral feature \(F_B = <F_{IF}, F_{ITL}, F_{OTS}>\) comprises of interaction frequency (clicks per 100 articles), interaction time length per day, and online timeslots. For each avatar user u, first we get the randomized online time length tl within the intervals specified in the apriori domain knowledge based \(F_B\) template, and the randomized log-on times l. When l =1, it indicates a continuous activity within time slot i. When l>1, in indicates consecutive activities, l is no more than the number of hours of time slot i. Then, we get the randomized online time lengths \(tl_i'\) within each subdivided online time slot \(i'\) (\(\sum {tl_i'}=tl_i\),\(\sum {tl_i}=tl\)). Let \(tsl_i'\) denote the length of time slot \(i'\), the user will log on within the subdivided time slot \(i'\) with starting time no later than \(tsl_i' - tl_i'\).
-
(b)
News Reading Behavior Simulation based on \(F_I\). The initial topic features \(F_I = <F_T,F_{P}>\), \(F_T=<T,W,D>\) is the topic-keyword feature set, where \(T = \{t_j\}\) is the topic set, \(W = \bigcup W_j\) is the keyword set, and \(D={f(T,W)}\) is the topic-key distribution feature, f(T, W) is the mapping function between T and W, \(F_{P}\) is the topic preference feature. Thus, using the top few terms in D relevant to topics in \(F_P\) are capable of eliciting news relevant to users’ interests on RE. To simulate a user u’s news reading behavior, firstly, we get the randomized values of the simulated interaction frequency f. Then, the simulator decide on whether the avatar clicks to read the news or not based on the topic preference distribution \(F_P\), and the keywords in the keywords topic distribution feature D. If the article falls within \(W^u_P\) (the set of keywords of the preferred topics)Footnote 2, the articles will be clicked at the simulated clicked frequency within the subdivided online time slot \(i'\). The recommendation page is simulated to slide till the \(ts_i'\) ends.
-
(c)
Log-on Environment Simulation based on \(F_E\). The environmental feature \(F_E = <F_{CellBrand}, F_{CellOS}, F_{NetworkOperator}, F_{GPS}, F_{IP}>\), of which \(F_{CellBrand}\) is defined as \(F_{CellBrand}=<F_{AccessDistribution(CellCate}\) \(_{gory)}\), \(F_{SalesDistribution(CellBrand)}>\), where CellBrand = \(\{\)Huaiwei, Apple, Oppo, Vivo, Xiaomi, Oneplus, ...\(\}\), and CellCategory = \(\{\)“Economy (\(\le\)1500 RMB)”, “Normal (1500-5000 RMB)”, “Flagship (\(\ge\)5000 RMB)”, “Special (limited editions, and hunger marketing)”\(\}\) is a partition of CellBrand, \(F_{AccessDistribution(CellCateg}\) \(_{ory)}\) is the social media access distribution w.r.t cell categories in CellCategory, and \(F_{SalesDistribution}\) \(_{(CellBrand)}\) is the sales distribution of cell brands within each category. We simulated cellbrand feature based on \(F_{CellBrand}\) and then \(F_{CellOS}\) can be directly derived from \(F_{CellBrand}\).
-
(d)
Update User Profile and Model Adjustment. For each topic, it may happen that topic keyword distribution shifts over a certain time period. That is, \(F_I\) of the simulation model is adjusted. Let \(W_t\) denote the set of the top m (m=3 in the experiment) keywords extracted for each article using TF-IDF method for the time interval t. Considering the recency effect, we segment the keyword set \(W_t\) (t is set weekly in the experiment) into recent past keyword set \(W^R_t\) (keywords of articles read in the past 7 days) and further past keyword set \(W^F_t\) (keywords of articles read in more than 7 days ago), and we have \(W = W^R_t \cup W^F_t\), \(W^R_t \cap W^F_t\ne \emptyset\). \(W_{t+1}\) is adjusted as follows,
-
For the keyword \(w_j \notin W^R_t\) and \(w_j \notin W^F_t\), \(w_j \in W_{t+1}\)
-
For the keyword \(w_j \notin W^R_t\) and \(w_j \in W^F_t\) and \(w_j \notin W^H_t = \{w_j|w_j \notin W^R_{t-1} and w_j \in W^F_{t-1}\}\), \(w_j \in W_{t+1}\)
-
For the keyword \(w_j \in W_R\), \(w_j \in W_{t+1}\)
In addition, we note that users’ interests shift may also happen as time goes by, the interest shift is adjusted as follows. First, we apply CNN-based neural network to learn and predict to which topics the articles fall withinFootnote 3. Then, for each user, we sort the topics by its count of articles, and get the top \(n^u_t\) topic categories. If it is not identical to the set of topic categories defined in \(F_P\), update \(F^u_P\) and \(W^u_P\). Initially, the keywords are assigned with weights \(w_k\) as defined in D. As the simulator runs, we assign weights \(w_k = w_k + w_c\) to the keywords belonging to the articles clicked to read, and weights \(w_k = w_k + w_r\) to the keywords simply belonging to the articles recommended (in the experiment, \(w_c\)=2, \(w_r\)=0.5). The weights are then normalized to [0,1].
-
-
(a)
-
3.
Link: This phase involves linking the news recommended to the receiver to topics. To achieve this, we make use of Latent Dirichlet Allocation based topic modeling (LDA)Footnote 4.
-
4.
Evaluation: This phase involves analyzing the topic distribution over time of the news recommended to the receiver and evaluate whether the topic distribution tends to form filter bubbles. The topic distribution might vary with different user groups due to user’s preference and interaction. Thus, differences in the previous phase across the user group entail consequent differences in the number and composition of the filter bubbles. The analysis consists of:
-
(a)
longitudinal analysis. If the topics change over time from an evenly-distributed state to a skewed distributed state, the head several topics that take up the most percentage of the topic distribution is deemed as the filter bubbles for the users on the personalized news aggregator and recommender. Also the differentiation effect of topics on filter bubbles was investigated in order to find out the characteristics of filter bubbles formed under the joint influence of individual filter and technological filter.
-
(b)
microscopic per interaction analysis. The technological filtering w.r.t user’s individual preference is analysed at a per interaction micro-scopic view. Firstly, the recommender’s topic-wide reaction after a user’s click was analyzed for all the users, whether it increases the news within the same topic category of user’s clicked news. Secondly, the recommender’s reaction w.r.t news generation type (user generated content(UGC) and professionally generated content(PGC)) after a user’s click was analyzed for all the users, whether it increases the news within the same topic generation type category of user’s clicked news.
-
(a)

Simulation Outline
4 Experiments
The research methodology employed in this work is outlined in Figure 3. The building blocks of the methodology are: (i) data collection and preparation process, (ii) characteristics of recommended news distribution at the receiver’s end.

Research Methodology
4.1 Data collection
An overview of data collection is given in Figure 4. We have distributed 15 cellphones and deployed 100 bots (that is, \(N_1\) = 15, \(N_2\) =100 in Figure 4) in 2019.12\(\sim\)2020.05 to collect the news recommended to the users (white-collar, blue collar, cyber celebrity, students) on Toutiao, Baidu News, and Tencent News. The bot mimics the user’s reading behavior by clicking the news containing information of relevance to the topics of interest specified in the user group’s profile Section 3.2. The parameters setting are as follows: For behavior features \(F_B\), examples are given in Table 1. For interests features \(F_I\), top 20 key words distribution of selective topic categories are shown in Table 2. For environmental feature \(F_E\), the \(F_{AccessDistribution(CellCategory)}\) and \(F_{SalesDistribution(CellBrand)}\) are given in Table 3 and 4. The GPS locations and IP addresses are set in Nanyang in Henan province, China. The responses of the recommender per user’s click was collected. The behavioral statistics is shown in Table 5.

Overview of data collection
Bot validation To perform the effectiveness evaluation of the setup bot avator, we utilize two metrics to evaluate the compatibility of the avatar simulator and real users, with corrected conditional entropy (CCE) for temporality compatibility and Kullback-Leibler divergence [14] for interests compatibility. Note that the lower value for these metrics indicates the better performance.
Temporality compatibility The corrected conditional entropy (CCE) [8] evaluates whether the complexity of the avatar users’ online behavior is compatible with that of the real users’.
where the first part is the conditional term CE, and the second part is the corrective term, \(X_m\) represents the online click times sequence within the time slots. A lower value of CCE indicates periodic or regular timing of tweeting behavior, while a higher value implies irregular behavior. Simply put, a lower value of CCE can be seen as a sign of automation, while a higher value can be seen as a sign of human participation.
Interests compatibility Kullback-Leibler divergence evaluates the difference between the probability distributions of topics read (on a weekly basis) for real user \(u_r\) and avatar user \(u_a\), and is defined as:
where i denotes topic index, \(H(u_r,u_a)\) is the cross-entropy, and \(H(u_r)\) is the entropy of real user. A smaller value of Kullback-Leibler divergence indicates a closer interest distribution.
The results of behavior temporality verification is shown in Table 6.The results of interests compatibility verification is shown in Table 7. For each real user \(u_r\), we get the minimum value of \(KL(u_r,u_a)\), i.e. the closest interests distribution of avatar users to \(u_r\). Note that the average topic read on Toutiao per week is 10.5, while the number for Baidu News is 8.4.
4.2 Data preparation
In preparing the data for evaluation analysis, the affect valence of an article is obtained using Naive Bayes classification models, see Figure 5. In the training phase, the news and comments are labelled as “positive” and “negative”, with examples shown in Table 8 and 9. The model learns the affect valence of each tokenized word based on the probability of its appearance in the positive and negative corpus, and predict the affect valence of testing news and comments.

Sentiment Classification
4.3 Characteristics of the recommended news to the information receivers
An overview is given in Table 10. The evaluation of the filter bubble effect is based on the concentration of the topic groups reflected in the recommended news w.r.t each individual user, corresponding to the “Information Cocoon” and “Convergence Factor” in Table 10. If a user reads a large number of articles belonging to one single topic category, the risk of falling into the information cocoon is relatively large; otherwise, if a user’s reading interest is relatively scattered in the topics categories, the risk of falling into the information cocoon house is relatively low. As given in Table 10, the metric can be calculated w.r.t time interval or number of clicks. The latter enables a finer view as the number of news a user reads per day differs with each person. Further, to shed light on the filter bubble effect and polarization, we zoom into the concentration of the affects reflected in the recommended news w.r.t polarized groups of users, corresponding to the “Affect Cocoon” and “Affect Valence” in Table 10.
5 Experiment analysis and discussion
5.1 Longitudinal analysis
In this section, to evaluate the filter bubbles effect on information receivers, we analyze (i) the topic convergence trend over time, (ii) the time length it takes for the topics to get converged.
5.1.1 Impact evaluation of personalized news aggregators & recommenders
Figure 6 reports the evaluation of new recommenders w.r.t the constructs given in Table 10Footnote 5. The measurement of “information cocoon” concerns about the concentration of the topics covered in the recommended news as a user’s online time (or a user’s clicks) increases, see the first and the third curve in Figure 6 A. In addition, we are also interested in its convergence factor, i.e. the time (or the clicks) it takes for the news recommended to get concentrated, see the second and the fourth curve in Figure 6 A. The cocoon factor reflects the convergence degree of the topics of the news recommended to the end user. if the recommender recommends a large number of articles belonging to one single topic category to the end user, the risk of falling into the information cocoon is relatively large; otherwise, if the news recommended to the user is relatively scattered in the topics categories, the risk of falling into the information cocoon house is relatively low. As mentioned earlier, the metric can be calculated w.r.t time interval or number of clicks. The latter enables a finer view as the number of news a user reads per day differs with each person. The convergence factor characterizes the length of the interval that the news recommended to a user gets converged. We can observe from Figure 6 that it takes around 7 days or 300 clicks for the recommender to get converged.

Impact evaluation of Toutiao, Baidu News and Tencent News over time. A. Information cocoon and convergence evaluation. B. Affect cocoon and affect valence evaluation. The users are classified into three groups, positive, negative, and neutral. The classification for positive/negative group is with average percentage of positive/neutral clicked articles > 50%, the remaining group of users is neutral group
Table 11 shows the highest information cocoon factor that the four group of users could achieve. We can see that the information cocoon factor the students and blue-collar group are the highest, the information cocoon factor for the white-collar group is the lowest. The cyber celebrity group is second to the lowest. This is in line with the observation that the capability in information retrieval and the diversity of information acquisition channels for the white-collar group is better, and the interests for the cyber celebrity group are relatively more diverse than the others.
As for the affect cocoon evaluation, the affect cocoon result is given in the top part in Figure 6 B. We can see that there is no significant trend of the affect cocoon curve. Therefore, to shed light on the affect distribution within the news recommended to the end users, we classify the users into three groups, positive, negative, and neutralFootnote 6. The results of affect distribution within each user group is shown as the bottom part in Figure 6 B. We observe that unlike user information cocoon, the affect distribution is distinctly related with the user group. The affect distribution for the positive and neutral user group is similar, with a skewed distribution towards the positive news category. The affect for the negative user group is more evenly distributed.
5.1.2 Differentiation effect of topics on filter bubbles
Figure 7 shows the topic distribution of the news recommended to a particular user, where the node size is correlated with the number of news within a topic, the color of the node varies from warm color to cold color with the node size as well, with a warmer color indicating a larger topic size, the blue nodes surrounding the topic node represent the keywords, a keyword may connect to multiple topics. Figure 7 (a) illustrates the changes in the topic distribution of the news recommended to user \(u_1\) focusing on “Society” topics before and after the topic converges. The two points are selected at the beginning and the end of the experiment period. Figure 7 (b) illustrates the changes in the topic distribution of the news recommended to user \(u_2\) focusing on “Entertainment” topics.

Filter Bubbles – the converged topics as a user’s online time and interaction with the recommender increases
The results show that the topic distribution demonstrates different convergence degrees as user’s preference varies. For the users interested in “Society” topics, the news will turn into several converged topics (see Figure 7 (a)). For the users interested in “Entertainment”, the news will turn into one big converged topic (see Figure 7 (b)). This indicates the users interested in “Society” topics may also be interested in other topics, e.g. “Finance”, etc. While the users interested in “Entertainment” topic are solely interested in “Entertainment” topic, which indicates a certain degree of addictiveness. Table 12 shows the converged topics distribution w.r.t the four groups on Toutiao. We can see that the topics converged for white-collar group are “Finance”, “Society”, “World”, and “Current Affairs”, the topics converged for blue-collar group are “Society”, “World”, and “Current Affairs”, the topics converged for cyber celebrities are “Society”, “Current Affairs”, “Fashion”, the topics converged for students are “Society”, and “Education”. The results on Baidu News and Tencent News demonstrate similar convergence distribution.
5.2 Micro analysis
5.2.1 Interactive adjustment of recommenders w.r.t topic preference
Figure 8 shows the topic distribution of the recommended news and the topic distribution of the read news. We can see that for the topics that take up the most percentage, there exists a high overlapping degree. Furthermore, we zoom into the topic-wide news increment w.r.t top 5 keywords of users’ read news at each interaction (see Table 13). We can see that the keywords belonging to the topics that a user previously clicked on the recommenders tend to bring an increment in the recommender’s responses. This explains the previous observation that the topics tend to converge in the long-run. Note that the decrement indicates a shift of keywords. This is in line with our daily experience and the emergence of new hot topics from time to time.

Topic distribution of recommended news and read news on Toutiao, Baidu News, and Tencent News
5.2.2 Interactive adjustment of recommenders w.r.t news generation type preference
Table 14 illustrates the cultivation between recommender and users w.r.t news generation type, i.e PGC and UGC. We can clearly see from the table that there is a significant decrement trend in the recommended PGC, in particular, there are three notably significant periods, i.e. 2020.01.05-2020.01.09, 2020.01.13-2020.01.20, and 2020.01.21-2020.01.27, with the highest reaching around 40%, and the lowest reaching about 16%. Correspondingly, there is a significant increment trend in the recommended UGC, with the highest percentage of UGC recommended reaching around 83%, and the lowest reaching about 50%.
In the meanwhile, we can see that there is a similar trend in the read PGC and UGC on the recommender. However, the read news distribution w.r.t PGC and UGC is skewer than the recommended new distribution w.r.t PGC and UGC. The lowest point for the read PGC with the decrement trend could go even lower, around 11.11%, and the highest point for the read UGC with the increment trend could achieve even higher, 88.89%. This explains the increment in the recommended PGC news and decrement in the recommended UGC news.
The above experiments on Toutiao, Baidu News, and Tencent News illustrate that all three applications demonstrate a periodic topic convergence trend over about 7-day time interval, indicating the formation of “filter bubble” effect on the information receivers. Zooming into the topic-wide news increment at each interaction gives us a fine insight with the keywords belonging to the topics that a user previously clicked on the recommenders tending to bring an increment in the recommender’s responses. The topic distribution demonstrates different convergence degrees as user’s preference varies. For the users interested in “Society” topics, the news will turn into several converged topics. For the users interested in “Entertainment”, the news will turn into one big converged topic. The technological filter brings the individual preference to surface with the help of algorithms. The users interested in “Society” topics may also be interested in other topics. While the users interested in “Entertainment” topic are solely interested in “Entertainment” topic, and the recommender captures the preference, assimilates similar content and feeds back to the user at the per interaction, which indicates a certain degree of addictiveness over the long run. From this sense, the technological filter reflects and strengthens the individual filter. Furthermore, a similar strengthening effect can be observed that at the influence of individual preference of UGC over PGC, there is a corresponding increment of UGC over PGC recommended by the news aggregator and recommender.
6 Conclusion and future work
This paper proposes a four phase solution framework of evaluating the impact of personalized news aggregation and recommendation system on the information receivers. The introduced framework starts from an information-receiver perspective and focuses on exploiting the filter bubble effect at the joint influence of individual filter and technological filter. Further, we provide empirical evidence of this “partial information blindness” of filter bubble effects on personalized news aggregation and recommendation applications, with experiments on Toutiao, Baidu News, and Tencent News, the top three news aggregator apps in China. The results show that it demonstrates a periodic information cocoon of about 7-day time interval with the news recommenders interactively filters out the users’ uninterested content and filter in the content that caters to the user’s interests. Thus, the users are narrowed into one or a limited number of topics over time. The phenomenon of the narrowed topics is deemed as the emergence of the “filter bubbles”. In addition, we also observe that the filter bubbles demonstrate different convergence degrees as user’s individual preference varies. Although limited in scope, our findings may be of interest to those who are working to reduce political polarization in applied settings.
As for the generalization, the proposed solution framework approaches from a “black-box” way, and thus has wide applicability irrespective of the internal mechanics. One future direction is to extend the solution framework by incorporating the social filtering into the evaluation design. Another direction is to investigate the correlation between the triple-filtering mechanisms with the user retention rate, and social media addiction.
Notes
https://www.toutiao.com/
Note that \(|W_P|\)=\(a*n^u_t\), \(n^u_t\) is the number of topics a user is interested in, \(a=3\) indicating that for each topic the top 3 most weighted keywords are kept).
In the experiment, we use K-fold (K=10) cross validation for the hyperparameter optimization. That is, Layer number=\(2^n\) (n=3,4,5,6), Layer size=\(2^m\) (m=6,7,8), filter size: \(L*H\) (L=3,4,5, H=1,2,3), with the best parameters Layer number = 32 (n=5), Layer size = 128 (m=7), filter size = 9 (L=3, H=3).
In the experiment, the initial parameters are set as alpha = 50/k, k is the topic number (k=26 in the experiment), beta = 0.01. In hyperparameter tuning, alpha = 50/k +|- n*(50/k)*0.2 (n=1,2,3,4,5), beta = 0.01 +|- n*0.01*0.2 (n=1,2,3,4,5).
The continuous affect valence within [0,1] is segmented into A categories, in the experiment we have A=3, with [0-0.35] as “Negative”, [0.35-0.75] as “Neutral”, and [0.75-1] as “Positive”.
The classification for positive/negative group is with average percentage of positive/neutral clicked articles > 50%, the remaining group of users is neutral group
References
Adomavicius, G., Kwon, Y.: Improving aggregate recommendation diversity using ranking-based techniques. IEEE Transactions on Knowledge and Data Engineering 24(5), 896–911 (2012)
Alkan, O., Daly, E. M., Botea, A.: An evaluation framework for interactive recommender systems. In: Proceeding UMAP’19 Adjunct Publication of the 27th Conference on User Modeling, Adaptation and Personalization(UMAP), pp. 217–218 (2019)
Bail, C.A., Argyle, L.P., Brown, T.W., Bumpus, J.P., Chen, H., Hunzaker, M.B.F., Lee, J., Mann, M., Merhout, F., Volfovsky, A.: Exposure to opposing views on social media can increase political polarization. Proceedings of the National Academy of Sciences 115(37), 9216–9221 (2018)
Bakshy, E., Messing, S., Adamic, L.A.: Exposure to ideologically diverse news and opinion on facebook. Science 348(6239), 1130–1132 (2015)
Beam, M.A.: Automating the news: How personalized news recommender system design choices impact news reception. Communication Research 14(8), 1019–1041 (2014)
Borgesius, F.J.Z., Trilling, D., Möller, J., Bodó, B., de Vreese, C.H., Helberger, N.: Should we worry about filter bubbles. Internet Policy Review 5(1), 1–16 (2016)
Chen, C., Zhao, P., Li, L., Zhou, J., Li, X., Qiu, M.: Locally connected deep learning framework for industrial-scale recommender systems. In: The World Wide Web Conference (WWW), pp. 769–770 (2017)
Chu, Z., Gianvecchio, S., Wang, H., Jajodia, S.: Detecting automation of twitter accounts: are you a human, bot, or cyborg? IEEE Transactions on Dependable and Secure Computing 9(6), 811–824 (2012)
Dandekar, P., Goel, A., Leec, D.T.: Biased assimilation, homophily, and the dynamics of polarization. PNAS 110, 5791–5796 (2013)
Flaxman, S., Goel, S., Rao, J.M.: Filter bubbles, echo chambers, and online news consumption. Public Opinion Quarterly 80, 298–320 (2016)
Fletcher, R., Nielsen, R.K.: Are news audiences increasingly fragmented? a cross-national comparative analysis of cross-platform news audience fragmentation and duplication. Journal of Communication 67(4), 476–498 (2017)
Garimella, K., Gionis, A., Parotsidis, N., Tatti, N.: Balancing information exposure in social networks. In: Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), pp. 4663–4671 (2017)
Geschke, D., Lorenz, J., Holtz, P.: The triple-filter bubble: Using agent-based modelling to test a meta-theoretical framework for the emergence of filter bubbles and echo chambers. British Journal of Social Psychology 58(1), 129–149 (2019)
Goodfellow, I., Bengio, Y., Courville, A.: Deep learning (Vol.1). Cambridge: MIT Press, pp. 71–73 (2016)
Guerra, P.H.C., Meira, W., Cardie, C., Kleinberg, R.: A measure of polarization on social media networks based on community boundaries. In: Proceedings of the 7th International AAAI Conference on Weblogs and Social Media(AAAI), pp. 215–224 (2013)
Gunawardana, A., Shani, G.: A survey of accuracy evaluation metrics of recommendation tasks. Journal of Machine Learning Research 10, 2935–2962 (2009)
Haim, M., Graefe, A., Brosius, H.: Burst of the Filter Bubble? Effects of personalization on the diversity of Google News. Digital Journalism 6(3), 330–343 (2018)
Hayes, C., Massa, P., Avesani, P., Cunningham, P.: An on-line evaluation framework for recommender systems. In: Proceedings of the ACM RecSys 2010 Workshop on User-Centric Evaluation of Recommender Systems and Their Interfaces (2010)
Herlocker, J.L., Konstan, J.A., Terveen, L.G., Riedl, J.: Evaluating collaborative filtering recommender systems. ACM Transactions on Information Systems 22(1), 5–53 (2004)
Hu, Y., Yu, Y., Tu, W., Yang, Q., Chen, Y., Dai, W.: Multi-fidelity automatic hyper-parameter tuning via transfer series expansion. In: Proceedings of the 33rd AAAI Conference on Artificial Intelligence(AAAI), pp. 3846–3853 (2019)
Knijnenburg, B., Meesters, L., Marrow, P., Bouwhuis, D.: User-centric evaluation framework for multimedia recommender systems. User Centric Media, pp. 366–369, Springer Berlin Heidelberg (2009)
Krohn-Grimberghe, A., Nanopoulos, A., Schmidt-Thieme, L.: A novel multidimensional framework for evaluating recommender systems. In: Proceedings of the ACM RecSys 2010 Workshop on User-Centric Evaluation of Recommender Systems and Their Interfaces (2010)
Liu, D., Bai, T., Lian, J., Sun, G., Zhao, W., Wen, J., Xie, X.: News graph: an enhanced knowledge graph for news recommendation. In: Proceedings of 2nd Workshop on Knowledge-Aware Recommender Systems (KARS) (2019)
Luo, Y., Wang, M., Zhou, H., Yao, Q., Tu, W., Chen, Y., Yang, Q., Dai, W.: AutoCross: automatic feature crossing for tabular data in real-world applications. In: KDD, pp. 1936–1945 (2019)
Min, Y., Jiang, T., Jin, C., Li, Q., Jin, X.: Endogenetic structure of filter bubble in social networks. Royal Society Open Science 6(11), 190868 (2019)
Möller, J., Trilling, D., Helberger, N., van Es, B.: Do not blame it on the algorithm: An empirical assessment of multiple recommender systems and their impact on content diversity. Information, Communication & Society 21(7), 959–977 (2018)
Nikolov, D., Oliveira, D.F.M., Flammini, A., Menczer, F.: Measuring online social bubbles. PeerJ Computer Science 1, e38 (2015)
Nikolov, D., Lalmas, M., Flammini, A., Menczer, F.: Quantifying biases in online information exposure. JASIST 20(3), 218–229 (2019)
Olmo, F.H.D., Gaudioso, E.: Evaluation of recommender systems: A new approach. Expert Systems with Applications 35(3), 790–804 (2008)
Paramythis, A., Weibelzahl, S., Masthoff, J.: Layered evaluation of interactive adaptive systems: framework and formative methods. User Modeling and User-Adaptation Interaction 20(5), 383–453 (2010)
Pariser, E.: The filter bubble: how the new personalized web is changing what we read and how we think. Penguin, New York (2011)
Pariser, E.: The filter bubble: What the internet is hiding from you. Penguin UK, London, UK (2011)
Pu, P., Chen, L., Hu, R.: A user-centric evaluation framework of recommender systems. In: RecSys (2011)
Silveira, T., Zhang, M., Lin, X., Liu, Y., Ma, S.: How good your recommender system is? A survey on evaluations in recommendation. International Journal of Machine Learning and Cybernetics 10, 813–831 (2019)
Terveen, L., Hill, W. (eds.): Beyond recommender systems: helping people help each other. Addison-Wesley, New York (2001)
Xiao, B., Benbasat, I.: E-commerce product recommendation agents: use, characteristics, and impact. MIS Quarterly 31(1), 137–209 (2007)
Zhang, Y., Yin, H., Huang, Z., Du, X., Yang, G., Lian, D.: Discrete deep learning for fast content-aware recommendation. In: Proceedings of the 11th ACM International Conference on Web Search and Data Mining (WSDM), pp. 709–717 (2018)
Zhang, Y., Yin, H., Huang, Z., Du, X., Yang, G., Lian, D.: Discrete deep learning for fast content-aware recommendation. In: WSDM, pp. 709–717 (2018)
Zhao, Y., Wang, C., Han, H., Shu, M., Wang, W.: An impact evaluation framework of personalized news aggregation and recommendation systems. In: Proceedings of the 2020 IEEE/WIC/ACM International Joint Conference on Web Intelligence and Intelligent Agent Technology (WI-IAT), pp. 893-900 (2020)
Zhao, H., Xu, X., Song, Y., Lee, D.L., Chen, Z., Gao, H.: Ranking users in social networks with higher-order structures. In: Proceedings of the 32nd AAAI Conference on Artificial Intelligence(AAAI), pp. 232–239 (2018)
Zhou, X., Feng, H.: Research on the prevention and control of the internet rumor from the perspective of the self-media. Journal of Computer and Communications 7, 1–7 (2019)
Acknowledgements
The authors would like to thank all the people who have contributed to the data preparation for their selfless work. We also thank the anonymous reviewers for their valuable feedback and constructive criticism that have helped us to revise the manuscript. The work is supported by the National Key R&D Program of China (NO.2019YFC1509402 and NO.2018YFB0804204).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare that they have no conflict of interest.
Additional information
This article belongs to the Topical Collection: Special Issue on Web Intelligence = Artificial Intelligence in the Connected World
Guest Editors: Yuefeng Li, Amit Sheth, Athena Vakali, and Xiaohui Tao
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Han, H., Wang, C., Zhao, Y. et al. SSLE: A framework for evaluating the “Filter Bubble” effect on the news aggregator and recommenders. World Wide Web 25, 1169–1195 (2022). https://doi.org/10.1007/s11280-022-01031-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11280-022-01031-4