
Abstract
With the development of various mobile social applications, video data has already occupied a dominant proportion of mobile Internet traffic, and is still growing rapidly, which not only brings economic pressure to users, but also causes traffic explosion on Internet. Data delivery through mobile opportunistic networks is regarded as an efficient way to deal with this problem. But, due to the characteristics of video data and the mode of multi-copy routing, video opportunistic delivery will consume large amount of network resources, resulting in excessive transmission overhead and lower delivery quality. Fortunately, the strong aggregation of human activity gives us some inspiration, which can provide more space of deep optimization on video opportunistic transmission. Thus, in this paper, taking fully advantage of the connectivity of cluster formed by the gathering crowds, we propose a Video Opportunistic Replication scheme based on multi-player cooperative games, named VideoOR, which can achieve the double optimizations of transmission overhead and video delivery quality by scheduling the replication and forwarding of video packets under the guidance of Nash Equilibrium solution. Extensive simulations have been done based on the synthetic and real mobility traces, and the results show that our scheme can maximize the quality of reconstructed video and minimize the average replication times of each video packet.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The past decade has witnessed the rapid development of mobile Internet all over the world, which has reached into every corner of our daily life. For common users, benefiting from the seamless access to mobile Internet, everyone can perceive the physical world anytime and anywhere, share the interesting information instantly with others through the social platforms, such as Twitter and Facebook, and have voice or video conversations with their family, friends or colleagues conveniently. For the governments and enterprises, with the help of mobile Internet, they can manage the city more effectively and provide more convenient services to the public. On the one hand, the mobile Internet makes our life more informative and the production more efficient, and ordinary people are not only passive consumers of information, but also active producers of information. On the other hand, although wireless communication technology has made huge progress in recent years, the mobile Internet is still unable to withstand the pressure brought by the rapid growth of data. Massive amounts of data generated by large scale mobile users transmitting on mobile Internet brings serious problem, known as data explosion, which decreases the performance of mobile networks greatly and puts the network operators in a very embarrassing position [1].
Video data has always been a perfect information carrier due to its readability and the content richness. With the development of wireless communication technologies and the emergence of various mobile social applications and platforms, services based on live video streaming on mobile Internet, such as video conversation, video conference, online movies, and live TV, are becoming more and more popular. Therefore, video traffic is growing much faster than other data types, and has become the dominant part on the mobile Internet. According to forecast data of Cisco, the proportion of video data is 75%, and will eventually increase to 84% by 2020 [2]. Thus, the huge growth of video data is the main factor of traffic explosion on mobile Internet, and the key to deal with the issue of traffic explosion is to reduce video data traffic as much as possible.

The illustration of mobile video traffic offloading through opportunistic transmission
Mobile data offloading is regarded by academia as the most ideal and effective way to solve the above problems [3, 4], which utilizes the complementary wireless network technologies to deliver data originally targeted to mobile cellular networks, such as 3G/4G, LTE, and the incoming 5G. Among the complementary wireless communication technologies, Wi-Fi is the commonly used one to provide service of mobile data access to Internet other than mobile cellular networks [5, 6]. However, due to the factors of technologies and costs, it is hard to build fully covered Wi-Fi networks which can support mobile user’s handover among different access points. Thus, up to now, mobile traffic transmission still depends on the mobile cellular networks, and how to offload mobile video data efficiently and cheaply is still an urgent problem to be solved for academic and industrial communities [7,8,9,10]. On the other hand, with the activities of human, mobile intelligent terminals, which are resource redundant in storage and computing, and have the ability of device-to-device communication, are spread all over the urban area, but ignored and not fully utilized. Therefore, inspired by this, in this paper, we fully utilize the ubiquitousness and aggregation of mobile users, and propose to achieve mobile data offloading by the means of mobile opportunistic communications among mobile devices which deliver data directly through short-range wireless communication interface when they encounter with each other. Figure1 illustrates a intuitive scenario sample, in which user A delivers a video clip to user B by a sequence of device-to-device communications among opportunistically encountered mobile users other than through mobile cellular networks. Thus, video data transmission is accomplished through the mode of wireless multi-hop, and mobile traffic is successfully offloaded from the cellular networks correspondingly.
Although the idea proposed above looks very promising, there are still some challenges that need to be addressed before it is implemented. Opportunistic communication has been extensively studied in mobile opportunistic networks, however these efforts just focus on the delivery of general data, such as periodic measurements, temperature, and humidity [11, 12]. If opportunistic communication is utilized to offload video data, it will be another different story. The first reason is that, for opportunistic delivery of video data, the construction of objective function and the guarantee of performance indexes are far more complicated. High delivery rate and small transmission delay are the main metrics for general data transmission, and can be counted directly from the packets delivered. But the metric which can evaluate the opportunistic delivery quality of video data involves more factors including data itself and the network, and must be carefully elaborated. Furthermore, the construction of objective function which can guarantee the video delivery quality is also very challenging. The other main reason is that, for opportunistic delivery of video data, the transmission overhead and resource consumption are excessively high. Due to the uncertainty of user contact, to increase the delivery rate and decrease the transmission delay, multi-copy routing schemes are usually used, in which a packet will be replicated many times and all the copies will be transmitted over the network simultaneously until one of them is successfully delivered. For regular scalar data transmission, such as the measurements of periodic sampling, multi-copy schemes can bring significant performance improvements. But for video data, due to its persistence and volume, the huge number of copies of video packets will exhaust the network resources (such as nodal memory and bandwidth), congest the network, and on the contrary decrease the video delivery quality. Thus, how to maximize the opportunistic delivery quality of video data while minimizing the average number of copies is the key to the successful offloading of mobile video data by the means of opportunistic communication.
Therefore, in view of the above problems, in this paper we investigate the issue from the perspective of data diffusion, and propose an optimal Video packet Opportunistic Replication scheme for video transmission based on multi-player cooperative game, namely VideoOR, which can optimally determine the process of video packet replications among encountered mobile users under the guide of Nash Equilibrium solution. More specifically, in our scheme, all the encountered mobile users are regarded as a fully connected subnetwork, each user in the subnetwork is regarded as a player, and the process of video packet replication and forwarding among them is modeled as a cooperative game. Based on the maximization of utility function which is designed on the purpose to optimize the opportunistic delivery quality of video data, the Nash Equilibrium solution of the cooperative game can be achieved. And then, the replication and forwarding of the video packets in the subnetwork are all scheduled uniformly according to the solution. Thus, in each cluster of mobile users at any time during video data transmission, the replication scheme proposed can minimize the average copy number of video packets while maximizing the video delivery quality. Due to that the video data offloading is achieved through a sequence of opportunistic communications among different subnetworks, the video delivery quality is optimized perfectly.
In summary, the main contributions of our work in this article can be described as follows:
-
Fully utilizing the aggregation of mobile users, we regard the cluster of encountered uses as a subnetwork and propose to optimize the data diffusion among them as a whole to achieve further performance improvements;
-
Fully considering the characteristics of video data itself and networks, we elaborate a novel model for opportunistic transmission of video data, by which the expected contribution of each video packet to the video delivery quality can be quantified when they are replicated or forwarded;
-
Based on the above model, we propose a replication scheme VideoOR, which regards the process of data replication and forwarding among the users in a subnetwork as a multi-player cooperative game, and use Nash Equilibrium solution to schedule the video packet in subnetwork so as to achieve the optimization of video data diffusion;
-
We evaluate the performance of VideoOR through extensive simulations, and prove its usefulness and efficiency by comparison with other schemes.
The rest of the paper is organized as follows. A brief survey of the related works is given in Sect. 2. The network model and problem formulation are introduced in Sect. 3, and the process of model formulation for reconstructed video quality is detailed in Sect. 4. Next, the replication scheme is described in Sect. 5. The simulation setting and evaluation are introduced in Sect. 6, followed by the conclusion in Sect. 7.
2 Related Works
Mobile opportunistic transmission which achieves the end-to-end data delivery through a sequence of device-to-device communications among pairs of encountered mobile users with short wireless interface, has been extensively studied in Delay Tolerant Networks and opportunistic networks over the last two decades. Generally speaking, the research on this transmission mode has gone through two stages. The first one is called single-copy opportunistic transmission, in which the data will not be replicated and there is no copy delivered other than the message itself during its transmission. The typical works belonging to this category are [13,14,15]. Because there is no redundant data in network, the resource assumption and network cost are very small, and the only key problem in this state is to find the appropriate intermediate nodes which can relay data to its destination with high efficiency. Due to the uncertainty of contacts among mobile users, it is hard to greatly improve the delivery quality only depending on the relay node selection. Thus, the research on mobile opportunistic transmission has entered into the second stage, namely multi-copy opportunistic transmission.
During multi-copy opportunistic transmission, each data can be replicated, thus there will be more than one copies for each of them in the network, and if one of the copies is transmitted to its destination, the data is regarded delivered successfully. Multiple copies and their independent transmission bring great improvement of network performance, but performance growth comes at the expense of network and equipment resources. The large amount of redundant data is saved and transmitted in the network, which consumes the buffer and bandwidth, and even worse, congests the networks and reduces the network performance instead. The typical example is Epidemic [16], which utilizes the pattern like infectious disease spreading to transmit data in the network, and gives no restrictions on data replication. Thus, in this stage, how to design replication scheme to control the data reproduction so as to decrease the transmission overhead is the key problem. As for the existed works related with replication schemes, they can be divided into the following two categories.
Pre-determined Replication Schemes In this category of replication schemes, in order to increase the delivery ratio and decrease the transmission cost, before the data delivery, the maximum number of the copies for each piece of data is defined in advance. The only difference among them is how to replicate their data before the number of copies reaching to their thresholds respectively. The works of [17,18,19] are typical ones in this category. The authors of [17] proposed the Spray-and-Wait scheme, which combines the diffusion speed of Epidemic and the simplicity of direct transmission, and reduces the overhead of blooding-based schemes by the means of predefining the total number of nodes that data can be forwarded to. The authors of [18] proposed a improved one named Spray-and-Focus based on Spray-and-Wait. The two schemes have the same spray phase. but the difference between them is that, in the focus phase of Spray-and-Focus, the node carrying data only selects the contacted node which has a bigger utility value than that if itself as relay node. The authors of [19] proposed the scheme of OPF, on the purpose to maximize the expected delivery rate while satisfying a certain constant on the number of forwardings per message. In addition to these, there are many replication schemes belonging to this category, such as [20, 21].
Adaptive Replication Schemes If there is too much redundant data in the network, the performance of data delivery will be degraded due to network congestion; on the other hand, if the number of replicas in the network is too small, the network performance can not be optimized. In other words, there should be a best value for the number of copies, and this value will also change with the progress of data transmission due to the dynamic of the networks. Therefore, it is obvious that the pre-determined replication schemes can not achieve the optimal delivery quality, and the category of adaptive replication schemes are proposed, in which the number of copies can be adaptively adjusted dynamically according to the optimization progress of data delivery. The scheme of Delegation Forwarding proposed in [22] is the typical one in this class, which makes timely replication decisions based on optimal stopping theory to achieve the optimizations of transmission overhead and delivery quality. The scheme of OPPO proposed in [23] spray data copies based on the transient contact ratio of nodes so as to optimize the delivery delay. The scheme of GameR proposed in [24] models the data forwarding among nodes as a bargaining game, and uses Nash solution to guide the data replication.
Consideration from the comprehensive performance, the kind of adaptive replication schemes is more suitable for data transmission in opportunistic networks, but the existing schemes can hardly satisfy the requirements of video data transmission in opportunistic networks. The first reason, which has been mentioned, is that the formulations of the metric to quantify the delivery quality and the utility function to guarantee the optimization of the metric are complex. The other reason is that, there is strong correlation among video packets during video reconstruction, and different video packets should have different priorities in transmission, which complicates the the first reason further. However, these factors are not considered in above schemes which were designed for opportunistic transmission of general data.
3 System Model and Problem Formalization
In this section, we will firstly give the system model in which our replication scheme works, and then formalize the problem that we want to resolve.
3.1 System Model Description
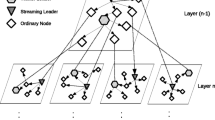
In order to offload video data from mobile Internet, the video clips which are originally targeted to the mobile cellular networks are transmitted through s sequence of direct device-to-device communications among mobile users. From the perspective of data transmission, the mobile users form an opportunistic network unconsciously, which is usually called mobile opportunistic network. Thus, the contacts among mobile users are the opportunities to transmit data. Due to the human aggregation, in urban area, multi-user contacts are more common than two-user encounters. The multi-contacting users form a cluster, which can be regarded as a fully connected subnetwork, and during opportunistic transmission of video data, the entire opportunistic network is composed of many such clusters in each snapshot. In each cluster, every mobile user must know which video packet carried by itself needs to be replicated and which one in cluster the copy should be transmitted to so as to optimize the metric desired. In other words, multi-user meeting gives better opportunity to data transmission, which also makes the data diffusion more complex. Thus, the replication scheme is needed.
Figure 2 gives the system model of a specific application scenario of video data offloading, which is composed of platform side and user side. The platform can be regarded as a server which can communicate with mobile users through cellular base station and is mainly responsible for video request management, and packet information collection. Each user have two wireless interfaces, one of which is for device-to-device communication and the latter is for cellular networks. On the purpose to accurately compute the utility of video packets in real time, each mobile user must report and acquire video information to or from the platform through cellular networks, which is usually called “control messages” and used to assist video transmission through opportunistic networks. Video data offloading in this scenario is illustrated by the following steps. A mobile user wants a video clip, and firstly sends a requesting message to the platform through cellular networks ( the steps : \(\textcircled {1}-\textcircled {2}\)). Then, the platform informs the user who has the video clip ( the steps: \(\textcircled {3}-\textcircled {4}\)). Finally, the user sends video clip to its requester by a sequence of opportunistic device-to-device communication (the step: \(\textcircled {5}\)).
During the modeling, the accurate information such as the number of replicas the nodes carrying them is needed, thus after each contact, all the nodes participating in data forwarding much report the change of video packets in their buffers through cellular networks immediately. In addition, during our modeling, it is assumed that the contact between two mobile nodes, \({u_i}\) and \({u_j}\), can be regarded as a homogeneous Poisson process with a contact frequency of \({\lambda _{ij}}\). This assumption is the theoretical basis of our formulations, and has been validated in [26].

The system model of video data offloading from cellular networks (dotted line with arrows denotes transmission through cellular base station, while solid line with arrows denotes video offloading through opportunistic communication)
3.2 Problem Formulation
The multi-meeting users form a fully connected subnetworks or cluster, in which each one can replicate or forward the video packets in his buffer to any other mobile user if he want to do so. In other words, a subnetwork or cluster provides a excellent opportunity for video data transmission. However, uncontrolled data diffusion cannot bring good network performance, and the actions of each mobile users must be done under the unified guidance. In our replication scheme, the decisions on whether a video packet should be replicated or forwarded and which user a video packet should be replicated or forwarded to are based on the following optimization criteria: maximizing the quality of recovered video data and minimizing the network costs.
On the purpose to formulize the problem, some assumptions are given as follows. There are N mobile users in a subnetwork at time t, and they totally carry M video packets. The packets are from X video clips which are transmitted concurrently by the means of opportunistic communication. The vector \({s_i} = ({s_{i,1}},{s_{i,2}},\ldots ,{s_{i,m}},\ldots {s_{i,M}})\) denotes the packet information in the buffer of user i, in which each element is a binary number, and indicates whether a particular video packet is in this buffer. For example, if \(s_{i,m}\) is equal to 1, the m-th packet of M video packets is in the buffer of user i. Thus, we can use the vector \(s = ({s_1},{s_2},\ldots ,{s_n},\ldots ,{s_N})\) to indicate the distribution of video packets in the cluster or subnetwork. Each video packet has an expected contribution on the quality of recovered video data if it is not successfully delivered yet. The contribution is called Marginal Gain, which is denoted by G, and determined by the number of copies and the mobile users carrying them. Our purpose is to optimize the delivery quality and cost, thus we hope the actions of mobile users in the subnetwork can maximize the sum of marginal gains of all the video packets while increase the number of replications as much as possible. Therefore, our problem can be formulized as the following formula:
where, \({G_n} = ({G_{n,1}},{G_{n,2}},\ldots ,{G_{n,m}},\ldots ,{G_{n,M}})\) is a vector, which denotes the values of marginal gains of video packets in the buffer of user n after replications, and \({{{\overline{G} }_n}}\) is the marginal gain vector of user n before replications. \({S_n}\) and \({{{\overline{S} }_n}}\) are the packet vector of user n after and before replications respectively. Therefore, the main task in our work is to find the optimal packet vector \(S^*\), and schedule the replications of video packets among mobile users in the subnetwork according to the vector \(S^*\).
4 Modelling of Marginal Gain for Video Packets
From the problem formulization above, it is known that, we must be able to accurately calculate the packets’ expected contributions on the recovered video data, namely marginal gains if we want to find the best packet vector \(S^*\) to guide the replications of video packets. Thus, in this section, we show how to construct the model of marginal gain for video packets during their opportunistic transmissions.
4.1 Preliminary Knowledge of Video Data
According to [25], any video clip can be divided into a sequence of GoPs (Group of Pictures), and all the GoPs in the same video clip have the same structure. Each Gop consists of I-frames, B-frames, P-frames which are arranged in a specific order, and the numbers of I-frames, B-frames, P-frames are all fixed. Figure 3 gives a structure example of GoP, in which there are totally 9 frames. Actually, the number of frames in a GoP can be other positive integer, but for convenience, in the following derivation, we assume that all the GoPs have the same structure as shown in the figure. Furthermore, to describe them easily, we identify each frame as \({I_1}\), \({B_1}\), \({B_2}\), \({P_1}\), \({B_3}\), \({B_4}\), \({P_2}\), \({B_5}\), \({B_6}\) consequently. For convenience of preservation and transmission, compression coding technology is used in video data, which makes strong local correlation among frames in a GoP. Due to the correlation, the frames must be decoded in the side of receiver in a particular order as shown in Fig. 3. Specifically, the I-frame in the structure is used as a reference frame, and can be decoded independently. P-frame is the term used to define the forward Predicted pictures, and its decoding depends on the successfully decoding of the previous I-frame or P-frame. B-frame is the term for bidirectionally predicted pictures, and its decoding depends on not only the the previous I-frame or P-frame, but also the following I-frame or P-frame. Thus, due to the decoding dependence, different frames in the GoP have the different importance on the video data construction. For example, the decoding of frame \(P_2\) depends on the successfully decoding of \(P_1\), while the decoding of \(B_2\) depends on the \(I_1\) and \(P_1\).

The frame structure of a GoP (group of pictures)
4.2 Derivation of Reconstructed Video Quality
When a video clip is transmitted in network, each frame of it must be fragmented into pieces which are encapsulated into many video packets and injected into network. With the transmission going on, more and more video packets will be received by the receiving end, and intuitionally the quality of video reconstruction will be better and better. In order to compute the marginal gain of these video packets in transmitting, we must be able to calculate the quality of the reconstructed video during video data transmission. Up to now, the metric which be used to accurately quantify the quality of video data is PSNR (Peak Signal to Noise Ratio), but it cannot be used in opportunistic transmission. The reason is that, PSNR is based on the level of video frame, and the evaluated video data must be recovered. In our scenario, the evaluation must be based on the level of video packet, and the transmission is ongoing. Therefore, we use the Frame Delivery Rate to quantify the reconstructed video quality, which is denoted by \(R_F\) and defined as the number of frames that can be rebuilt successfully at destination node to the number of all the frames transmitted.
On the purpose to calculate the frame delivery ratio of video clip, the following assumptions are given. The symbol \(Q_G\) denotes the number of GoPs in the video clip. The symbols of \(Q_I\), \(Q_B\), and \(Q_P\) denote the expected number of I-frames, B-frames, and P-frames which can be decoded in receiver side respectively. Each I-frame, B-frame, and P-frame can be fragmented into \({M_I}\) I-packets, \({M_B}\) B-packets, and \({M_P}\) P-packets on average, respectively. \(p_I\), \(p_B\), and \(p_P\) are the successful delivery probability of I-packets, B-packets, and P-packets, respectively. Thus, according to the decoding dependence among frames, we can derive the following expressions:
Thus, the metric of FDR can be calculated as following:
When video data is transmitted, the parameters of \({M_I}\), \({M_B}\), and \({M_P}\) are all known, thus the equation above can be abbreviated as the following function:
Thus, the variables of \({p_I}\), \({p_P}\), and \({p_B}\) should be specified. Next, taking \({p_I}\) as an example, we give the derivation process in detail.
During the opportunistic transmission of the video clip, we assume that, there are \({K_{I}}(t)\) distinct I-packets totally at time t in the whole network, and all the packets have the same lifetime LT. For an I-packet \(i \in [1,{} {} {} {} {K_{I}(t)}]\), we use \({T_{I,i}}(t)\) to denote the time it has been in the network at time t, use \({S_{I,i}(t)}\) to denote the time to survive. \({M_{I,i}}({T_{I,i}(t)})\) denotes the number of users which received a copy of this video packet at one time (excluding the source user), and \({N_{I,i}}({T_{I,i}(t)})\) is the number of users which still have a copy of this video packet at time t. Additionally, \(U_T\) is the total number of mobile users in the whole network. According to [26, 27], the inter-contact time follows exponential distribution with \(\lambda\), thus the probability that the I-packet i can be delivered successfully before its expiration, which is denoted by \({P_{I,i}}\), can be derived as following:
Thus, the average delivery probability of I-packets in the whole network at time t can be computed as following:
In the same way, we can calculate the \({p_P}\), and \({p_B}\) respectively as follows:
where, the symbols with subscript P and B are the parameters related with P-packets and B-packets respectively, and have the same meanings with the symbols in Eq. (8).
4.3 Calculation for Marginal Gain
As mentioned above, for a video clip in delivery, each video packet which has not been received will have a contribution to the video quality if it is received at the receiver side. From Eqs. (6), (8), (9) and (10), it is can be seen that, the expected quality of a delivered video \(R_F\) is a function of the copies of each video packets \({N_{I,i}}({T_{I,i}(t)})\), and the number of mobile users that the packets have traversed \({M_{I,i}}({T_{I,i}(t)})\). Thus, for video packet, if the replication occurs at time t, the number of its copies will change, then the value of \(R_F\) will change also. Therefore, the amount of change of \(R_F\) can be regarded as the marginal gain of each copy of this video packet, which can be computed by partial derivative and discretization. Due to the dynamic of network, the copies of each video packets will change, thus the values of marginal gains of them will change over time. Thus, for the i-th I-packet in the network, its marginal gain \(G_{I,i}\) at time t can be calculated as following:
Similarly, we can get marginal gain \(G_{B,i}\) and \(G_{P,i}\) for a B-packet i and P-packet i as follows:
5 Replication Scheduling Based on Multi-play Cooperative Game
In a subnetwork at a snapshot, on the purpose to maximize the opportunistic transmission quality of video data while maximizing the transmission overhead, which video packet should be replicated or forwarded to which mobile users is the key problem to be resolved. Because each mobile user will receive a certain amount of revenue which is quantified by the marginal gains of the video packets he/she transmits after delivery of the video data, thus they will not to replicate or forward video packets to others for free. In other words, all the users in the subnetwork have the same goal, but compete with each other. To deal with this paradoxical situation, we model the video packet replications among mobile user in a subnetwork as multi-player cooperative game, and seek help from Nash Pareto-optimal theory.
5.1 Introduction to Multi-player Cooperative Game
The multi-play cooperative game is a non-zero-sum game, and the players participating in the game are selfish but rational. Conflicts of interest exist among all the players, but agreement can be reached through compromise. All the players participating in the game are denoted by a set \(H = \{ 1,2,\cdots i\,\cdots N\}\). All the possible strategies taken by player i consist of its strategy space denoted by \({s_i}\). Thus, \(S = {s_1} \times {s_2} \times \cdots \times {s_N}\) is the joint strategy set of the N players. In addition, each player in the game has a gain function denoted by \({F_i}\) which will change if different strategy is taken. Each player wants to take the strategy which can maximize its gain function, thus they will come to an equilibrium through compromise and there is no other possible agreement that allows each player to have the high gain simultaneously [28]. Thus, we have the following theorem:
Theorem 1
Nash Theorem [28]: The solution for multi-player cooperative game, which satisfies four axioms: invariance, symmetry, independence, and Pareto optimality, is given by Eq. (14).
where \((U_1^*,U_2^*, \cdots U_n^*)\) is the optimal gain space, which is also called Nash Equilibrium Solution; \(U_i^*\) is the gain of player i in Nash Equilibrium Solution; \(U_i^0\) is the status quo point, which is usually defined as the utility gain of no cooperation, and the expression of \(\arg \max \prod \limits _{i \in H} {({U_i} - U_i^0)}\) is called Nash Product.
5.2 Utility Function for Replication Scheduling Strategy
During the opportunistic delivery of video clips, data transmission is done based on the contact among mobile users, thus a subnetwork formed by some encountered users provides a excellent opportunity to transmit video packets. Thus, to formalize our problem, the variable N is used to denote the number of mobile users in the subnetwork at time t, and M is the total number of all the distinct video packets in the subnetwork. The symbol V is the number of video clips transmitted concurrently, and each of them has its different destination user. As mentioned, each video packet which is not received yet has a expected contribution to the quality of recovered video clip, thus the marginal gain be be used to design utility function for mobile users. Because different video packet has different destination, and each mobile user in the subnetwork has different contacting probability with the destination of each video packet, thus the utility function for mobile user is constructed as following:
where \({{G_{v,m}}}\) denotes the marginal gain of the m-th of M video packets in the subnetwork (the video packet from video clip v), and \(Pr_{n,v}\) is the contacting probability between mobile user n and the destination of video clip v. \({s_{n,m}}\) is the m-th element of \(s_n\), which should be 0 or 1.
Due to some incentive scheme, all the mobile users participating in the opportunistic transmission of video data want to increase their contribution to the quality of recovered video clips as much as possible, thus every one want to maximize their contribution increments in every contact with others. Thus, in the subnetwork, the purpose of any user denoted as n is to maximize the value of \(({U_n} - \overline{{U_n}} )\), in which \({U_n}\) and \(\overline{{U_n}}\) are the utility values of user n after and before data replications respectively. However, if a video packet is replicated to others, the number of its copies will increase, and the marginal gain \(G_n\) of each copy will decrease. Then, as a result, the utility value of the mobile use who carries the video packet before replication will decrease. Similarly, data forwarding can lead to the same result. In other words, the mobile users in the subnetwork conflict with each other in interests, but have the same goal to maximize the video delivery quality. Thus, the replication among them can be regarded modeled as multi-player cooperative game, and the key problem is to find a equilibrium which can make the sum of utility increments of all the users to achieve maximum. Therefore, according to Theorem 1, we have the following formulation:
where \({{G_{v,m}}}\) and \({\overline{{G_{v,m}}} }\) denote the marginal gains of the m-th of M video packets after and before replications, respectively; \({s_{n,m}}\) and \(\overline{{s_{n,m}}}\) are the values of the m-th element in \(s_n\) and \(\overline{s_n}\), respectively.
In the equation above, \(S^*= ({s^*_1},{s^*_2},\ldots ,{s^*_n},\ldots ,{s^*_N})\) is the optimal packet vector which indicates the distribution of video packets among all the users in the subnetwork when the replications are completed. In other words, which each video packet should be replicated or forwarded to whom is decided by \({S^*}\), and all the actions of users is guided by the optimal strategy to maximize the video delivery quality. However, the equation above just gives the requirement that the optimal solution should satisfy, and does not show how to find it. Next, we will show to achieve the solution \({S^*}\) efficiently.
5.3 Solution Based on Geometrical Spatial Representation
The cooperative game is actually a bargaining problem in essence, and can be resolved by the means of traversing all the possible strategy sets if the computational complexity is not taken into account. However, the method of traversal is unrealistic because its computation will increase exponentially with the increase of the number of video packets M. Fortunately, the authors of [29] proposed an efficient method of Geometrical Spatial Representation to deal with such kind problems, in which, the utility of item to the player is modeled as a distance in geometric space, and the principle of leverage balance is used to allocate the items among players. The detailed steps are given as follows.
Step 1: Utility-Distance Calculation. Specific to our model, due to that each video packet m has a utility to any mobile user n in the subnetwork, thus we use a distance to a player to denote the utility value of this packet to the player, which is named as Utility-Distance and denoted by \(d_{n,m}\). According to [29], the smaller the distance, the closer the packet is to the player. Thus, the distance is defined as a decreasing function of the utility, and the inverse proportionality function is usually used for simplicity. As mentioned, the utility of a video packet to some mobile user can be defined as the product between the marginal gain of this packet and contacting probability of the user with packet’s destination. Then, we have the formula used to computing the Utility-Distance which is normalized as following:
in which, \({u_{n,m}} = {Pr_{n,v}}{G_{v,m}}\) is the utility value of video packet m to the mobile user n, and N is the number of users in the subnetwork.
Step 2: Video Packet Sorting From the formula of utility distance, it can be seen that, the larger the utility value of the packet to the mobile user, the shorter the utility distance between the packet and the user, which means that this video packet has a bigger priority to this user during allocations. Thus, for each node n participating in the game, we can have a packet list \(L_n\), in which the total M video packets are arranged in increasing order in terms of their utility distances to the mobile user, as following:
Step 3: Utility-Distance Product According to [29], the authors regard the equilibrium of the Pareto-optimality as a balance of leverage, and assigning a video packet which has a slightly too high or too low utility to a player can break the balance and shift the equilibrium away from the Pareto-optimality. Assignment by traversing these video packets from the highest priority to the lowest one can solve this problem, but computational complexity is what we want. To deal with this problem, the authors introduced the concept of Utility-Distance Product. Specifically, in our model, the Utility-Distance Product for an video packet m to mobile user n, denoted by \(ud{p_{n,m}}\), can be computed as following:
Step 4: Equilibrium Condition Decision For the formula of utility-distance product, we can see that, every video packet has the same Utility-Distance Product for each mobile user. Thus, according to [29], for user n, to achieve the equilibrium of the Pareto-optimality, the sum of utility-distances of video packets which are allocated to him, should satisfy the following requirement:
where, M is the total number of video packets in the subnetwork, and \({D_n}\) is used to determine the video packet which corresponds to the pivot location.
Step 5: Video Packet Allocation The sum of utility-distances of video packets, denoted by \({D_n}\), is known, thus, we can assign the video packets in the list \(L_n\) to the mobile user n one by one in increasing order in terms of their utility distances until the k video packets allocated satisfy the following requirement:
where, \(d_j\) is the utility distance of the j-th video packet of list \(L_n\) to node n. According to the assignment, each mobile user n can select video packets from the M ones, and construct packet vector \({s^*}_n\). In other words, according the steps above, we can get the \(S^*= ({s^*_1},{s^*_2},\ldots ,{s^*_n},\ldots ,{s^*_N})\), which is utilized to schedule the video packet replications among mobile users in a subnetwork.
Please note that, it is possible that a video packet is assigned to several users, thus, the video packet must be replicated to these mobile users and the exact number of replications of this video packet is determined by the solution \(S^*\). On the other hand, it is also possible that, a video packet with low utility is placed at the bottom of each user’s list, then it will be dropped and not assigned to any user any more.
6 Simulation and Evaluation
Because there is very little work on the issue of video data transmission in mobile opportunistic networks, thus research on the replication schemes for video data is even more limited. Although some works claim that they can be used to control data diffusion for video, the characteristics of video data are not fully considered during their design, and they can not achieve the optimal performance. The closest work to ours is the scheme of GameR proposed in [24], which also considers the scenario of multi-node meeting during data diffusion, but is designed for common data. Another work is the scheme of CbR proposed in [30], which also considers the data replication in a cluster, but is also designed for common data. To verify the effectiveness of optimization, we also compare our scheme VideoOR with its variant VideoOR-v which only considers the video data replication between two contacting users other than the situation of multi-user meeting. In addition, to evaluate the adaptive replication of video packets, we also compare our scheme with Epidemic.
6.1 Simulation Environment Setup
On the purpose to evaluate the performance of the scheme proposed, we integrate the tool of myEvalvid [31] into network simulator NS-2, and setup a simulation framework, in which the simulation can be driven by synthetic mobility datasets and real-life mobility datasets. The number of mobile nodes is same with the number of mobile users in the dataset. During simulations, each node can communicate with others using 802.11b, and the communication range is 100 meters; each node has two queues to save video packets, and the first one is used to store the video packets generated by itself, and the other one is used to cache the video packets received from other nodes. The two queues have the same length, which can store up to 128 video packets. In order to simulate the transmission of video data, we use the the standard video sequence of “foreman qcif” as source data. With the help of myEvalvid, the source data can be easily divided into 659 video packets and injected into the network strictly according to their location and time interval in the original video sequence. Thus, based on the received video packets at the destination node, the video data can be constructed, and the evaluation can be done.

Comparisons of performance Based on synthetics dataset (a Average FDR, b Average PSNR)
6.2 Performance Evaluation Based on Synthetic Mobility Traces
The synthetic mobility traces are generated based on the mobility model of Random Waypoint, which consist of 60 mobile nodes moving in the region of \(1000\,\times \,1000\,\text{ m}^2\). For each nodes, its maximal speed is 10m/s, and the waiting time is 0s. During each time of simulation, all the video packets have the same TTL (Time-to-Live). During our simulations, we also change the value of TTL as as to obtain extensive comparison results. In each simulation, the pair of source and destination nodes is selected randomly.
Figure 4 gives the simulation results of the five schemes in terms of FDR and PSNR. Specifically, it can be seen in Fig. 4a that: (1) with the change of TTL, the scheme of Epidemic always has the lowest FDR, and our scheme VideoOR has the biggest one among the five schemes; (2) although the performance of CbR is better than that of Epidemic, it is worse than that of GameR; (3) the performances of VideoOR and VideoOR-v are obviously better than the performances of Epidemic, CbR, and GameR; (4) the FDRs of all the schemes increase with the increase of TTL. The reasons are as follows. Due to the unlimited replication, Epidemic exhausts the resource quickly, and many video packets are dropped during video delivery, which results in the worst performance. The schemes of CbR and GameR have strict controls on the process of data replication, but they are designed for general data delivery, and the characteristics of video data are not considered. Thus, it is not surprising that the performances of VideoOR and VideoOR-v are better than the performances of CbR and GameR. As for the performance gap between VideoOR and VideoOR-v, the main reason is that, the replication process in a subnetwork has much more optimization space than that between two mobile users. On the purpose to show the performance difference among them more intuitive, the comparison results of PSNR of reconstructed video clips are also given in in Fig. 4b. It can be seen that, the performances of the five schemes in term of PSNR have the same tendency with the ones illustrated in Fig. 4a.
6.3 Performance Evaluation Based on Real-life Mobility Traces
On the purpose to validate our scheme’s practicability, we also do simulations based on real-life mobility traces of KAIST [32], which are collected by the 92 mobile students in the region of \(10{,}000\,\times \,10{,}000\,\text{ m}^2\). The total duration time is one week, and we just extract the mobility traces of one day.

FDR comparisons based on real-life dataset (a the number of video clips is 1; b the number of video clips is 5)
The simulation results based on real-life traces are illustrated in Figs. 5 and 6. In these simulations, on the purpose to observe the effect of concurrent video transmission to the performance of replication schemes, the number of video clips transmitted concurrently is set to 1, 5, and 10, respectively. From these figures, we can find the same results as observed in Fig. 4. In addition to these, we can also find that the replication schemes have different extensibility to concurrent video transmissions. More specifically, when the number of concurrent video clips is changed from 1 to 10, all the five schemes have a performance drop, but the drop of CbR, GameR, VideoOR-v, and VideoOR are slight, is about 0.05 and 0.8dB in terms of FDR and PSNR, respectively, while that of Epidemic is about 0.08 and 2.5dB respectively. This phenomenon can be explained as follows. With the increase of the concurrent video clips, the storage resources of the network are becoming more and more scarce, the network can not accommodate the unlimited replicas of Epidemic, and more video packets are dropped due to the overflow of nodal buffer, which will certainly reduce its performance. However, the other four schemes have strict control on the replication of video packets, thus the influence of concurrent transmissions on them is not very obvious.
On the purpose to compare the resource consumptions of the five schemes more intuitively, Fig. 7 illustrates the the statistics of the average maximum number of replications for each of them. It can be observed that, the maximum number of replications for Epidemic is close to 80 times on average, the values of GameR and VideoOR are 13 and 15 respectively, and the values of CbR and VideoOR-v are 21 and 24 respectively. Thus, the simulation result is in line with our expectation of the five schemes.

PSNR comparisons based on real-life dataset (a the number of video clips is 1; b the number of video clips is 5; c the number of video clips is 10)

The average maximum number of replication based on real-life dataset
6.4 Performance Evaluation Based on Mobility Traces with Different Characteristics
In order to further investigate the influence of mobility traces with different characteristic on the performance of VideoOR, we generate two sets of mobility traces based on the mobility models of TVCM and Random Waypoint, namely TVCM and RandomWay, respectively. The two synthetic datasets have the same parameters, such as the number of nodes, moving speed, moving region, and communication range, with the real-life mobility traces KAIST. We firstly give an analysis on the characteristics of the three datasets, and then do a set of simulations using VideoOR based on the them. The comparison results are illustrated in Fig. 8.
Figure 8a is the comparison of meeting times among different nodes in the the datasets. We extract the data of 3600 s, then count the number of node encounters every 30 s, and then accumulate the number of encounters according to the different number of meeting nodes. The X-axis represents the number of nodes that meet, and the Y-axis represents the total number of times that x nodes meet. Due to the large different of meeting times, in order to better render, the lg operation is done on the y. From the figure, it can be seen that, as the number of nodes increases, the total number of contacts decreases, but the rates of decline are different, which means that, the nodal aggregation of KAIST is better than TVCM, and TVCM is better than RandomWay. For example, the numbers of encounters among 3, and 4 nodes are 372 and 119, respectively; while the numbers for TVCM are 120 and 38, and for RandomWay are 49 and 18. Figure 8b, c give the comparisons of average PSNR and average maximum number of replications based on the the datasets. In each simulation, the duration is 3600 s, and number of video clips transmitted concurrently is 5. The values of average PSNR for KAIST, TVCM, and RandomWay are 31.45 dB, 30.41 dB, and 28 dB, respectively, and the values of average maximum number of replications are 12.1, 14.9, and 16.4. From these results, we can see that: (1) the characteristics have great influence on the performance of our scheme VideoOR; (2) the stronger the aggregation of nodes, the better their indicators will be, and vice versa. But in the same dataset, our scheme has the best performance than the others, which means that the scheme of VideoOR has better adaptability than the other ones when video data is transmitted.

Performance comparison of VideoOR based on different datasets (a the meeting times among different nodes; b the comparison of PSNR; c the comparison of average maximum number of replication
7 Conclusions
Opportunistic transmission is regarded as an ideal way to achieve mobile data offloading, but also faces many challenges. To deal with the resource overconsumption incurred by too many copies, we propose a quality oriented replication scheme named VideoOR for video transmission in mobile opportunistic networks, which models the replication among mobile users as a double optimization problem, and use the multi-player cooperative game to find optimal solution. The decision of whether a video packet should be replicated or forwarded to which nodes is made entirely based on the solution. Therefore, the scheme can maximize the video delivery quality of video data while minimizing the delivery cost. The performance of VideoOR is validated through extensive simulations driven by the synthetic and real-life mobility traces.
References
Chen, B. X. (2012). Carriers Jain1984FairMeawarn of crisis in mobile spectrum. New York Times.
Han, B., Hui, P., Kumar, V. S. A., Marathe, M. V., Shao, J., & Srinivasan, A. (2011). Mobile data offloading through opportunistic communications and social participation. IEEE Transactions on Mobile Computing, 11(5), 821–834.
Rebecchi, F., De Amorim, M. D., Conan, V., Passarella, A., Bruno, R., & Conti, M. (2014). Data offloading techniques in cellular networks: A survey. IEEE Communications Surveys and Tutorials, 17(2), 580–603.
Lee, K., Lee, J., Yi, Y., Rhee, I., & Chong, S. (2013). Mobile data offloading: How much can wifi delivery. IEEE ACM Transactions on Networking, 21(2), 536–550.
Cheng, R., Huang, C., & Pan, S. (2018). WiFi offloading using the device-to-device (D2D) communication paradigm based on the software defined network (SDN) architecture. Journal of Network and Computer Applications, 112, 18–28.
Cheng, F., Zhang, S., Li, Z., Chen, Y., Zhao, N., Yu, F. R., et al. (2018). UAV trajectory optimization for data offloading at the edge of multiple cells. IEEE Transactions on Vehicular Technology, 67(7), 6732–6736.
Wu, Y., He, Y., Qian, L., Huang, J., & Shen, X. (2018). Optimal resource allocations for mobile data offloading via dual-connectivity. IEEE Transactions on Mobile Computing, 17(10), 2349–2365.
Wu, H., Liu, L., Zhang, X., & Ma, H. (2019). Vbargain: A market-driven quality oriented incentive for mobile video offloading. IEEE Transactions on Mobile Computing, 18(9), 2203–2216.
Belouanas, S., Thai, K., Spathis, P., & de Amorim, M. D. (2019). Mobility-assisted offloading in centrally-coordinated cellular networks. Journal of Network and Computer Applications, 128, 1–10.
Ma, H., Zhao, D., & Yuan, P. (2014). Opportunities in mobile crowd sensing. IEEE Communications Magazine, 52(8), 29–35.
Yuan, Y., Ma, H., & Fu, H. (2015). Hotspot-entropy based data forwarding in opportunistic social networks. Pervasive and Mobile Computing, 16, 136–154.
Shah, R. C., Roy, S., Jain, S., & Brunette, W. (2003). Data mules: Modeling and analysis of a three-tier architecture for sparse sensor networks. Ad Hoc Networks, 1(2–3), 215–233.
Jain, S., Fall, K., & Patra, R. (2004). Routing in a delay tolerant network. ACM, 34, 4.
Yuan, Q., Cardei, I., & Wu, J. (2011). An efficient prediction-based routing in disruption-tolerant networks. IEEE Transactions on Parallel and Distributed Systems, 23(1), 19–31.
Vahdat, A., & Becker, D., et al. (2000). Epidemic routing for partially connected ad hoc networks. Technical Report CS-200006, Duke University.
Spyropoulos, T., Psounis, K., & Raghavendra, C. S. (2005). Spray and wait: An efficient routing scheme for intermittently connected mobile networks. In Proceedings of the 2005 ACM SIGCOMM workshop on Delay-tolerant networking (pp. 252–259). ACM.
Spyropoulos, T., Psounis, K., & Raghavendra, C. S. (2008). Efficient routing in intermittently connected mobile networks: The multiple-copy case. IEEE ACM Transactions on Networking (ToN), 16(1), 77–90.
Liu, C., & Wu, J. (2009). An optimal probabilistic forwarding protocolin delay tolerant networks. In Proceedings of the tenth ACM international symposium on Mobile ad hoc networking and computing (pp. 105–114). ACM.
Nelson, S. C., Bakht, M., & Kravets, R. (2009). Encounter-based routing in DTNs. In IEEE INFOCOM 2009 (pp. 846–854). IEEE.
Costa, P., Mascolo, C., Musolesi, M., & Mirco, G. P. (2008). Socially-aware routing for publish-subscribe in delay-tolerant mobile ad hoc networks. IEEE Journal on selected areas in communications, 26(5), 748–760.
Erramilli, V., Crovella, M., Chaintreau, A., & Diot, C. (2008). Delegation forwarding. In Proceedings of the 9th ACM international symposium on Mobile ad hoc networking and computing (pp. 251–260). ACM.
Yuan, P., & Wang, C. (2018). OPPO: An optimal copy allocation scheme in mobile opportunistic networks. Peer-to-Peer Networking and Applications, 11(1), 102–109.
Li, L., Qin, Y., & Zhong, X. (2015). A novel routing scheme for resource-constraint opportunistic networks: A cooperative multiplayer bargaining game approach. IEEE Transactions on Vehicular Technology, 65(8), 6547–6561.
Richardson, I. E. (2004). H. 264 and MPEG-4 video compression: Video coding for next-generation multimedia. New York: Wiley.
Gao, W., Li, Q., Zhao, B., & Cao, G. (2009). Multicasting in delay tolerant networks: A social network perspective. In Proceedings of the tenth ACM international symposium on Mobile ad hoc networking and computing (pp. 299–308). ACM.
Conan, V., Leguay, J., & Friedman, T. (2007). Characterizing pairwise inter-contact patterns in delay tolerant networks. In Proceedings of the 1st international conference on autonomic computing and communication systems (p. 19). (ICST) Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering.
Peters, H. J. (2013). Axiomatic bargaining game theory (p. 9). Berlin: Springer.
Wong, K. K. L. (2010). A geometrical perspective for the bargaining problem. PLOS ONE, 5(4), e10331.
Papapetrou, E., & Likas, A. (2018). Cluster-based Replication: A forwarding strategy for mobile opportunistic networks. In 2018 IEEE 19th international symposium on“ a world of wireless, mobile and multimedia networks” (WoWMoM) (pp. 14–19). IEEE.
Funding
This work is supported by the National Natural Science Foundation of China (Nos. 61772175, 61771185, 62072158); the China Postdoctoral Science Foundation under Grant 2018M632772; the Key Science and Research Program in the University of Henan Province under Grant 21A510001.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declares that they have no conflict of interest.
Availability of data and material
Yes.
Code availability
Yes.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ma, H., Wu, H., Xing, L. et al. VideoOR: A Quality Oriented Replication Scheme for Video Opportunistic Transmission. Wireless Pers Commun 118, 2941–2963 (2021). https://doi.org/10.1007/s11277-021-08163-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-021-08163-2