
Abstract
Wireless sensor network has special features and many applications, which have attracted attention of many scientists. High energy consumption of these networks, as a drawback, can be reduced by a hierarchical routing algorithm. The proposed algorithm is based on the Low Energy Adaptive Clustering Hierarchy (LEACH) and Quadrant Cluster based LEACH (Q-LEACH) protocols. To reduce energy consumption and provide a more appropriate coverage, the network was divided into several regions and clusters were formed within each region. In selecting the cluster head (CH) in each round, the amount of residual energy and the distance from the center of each node were calculated by the base station (including the location and residual energy of each node) for all living nodes in each region. In this regard, the node with the largest value had the highest priority to be selected as the CH in each network region. The base station calculates the CH due to the lack of energy constraints and is also responsible for informing it throughout the network, which reduces the load consumption and tasks of nodes in the network. The information transfer steps in this protocol are similar to the LEACH protocol stages. To better evaluate the results, the proposed method was implemented with LEACH LEACH-SWDN, and Q-LEACH protocols using MATLAB software. The results showed better performance of the proposed method in network lifetime, first node death time, and the last node death time.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The wireless sensor network (WSN) contains a number of sensor nodes, which are capable of sensing, processing, and transmitting small-scale information. Considering the growth of electronic technology, self-organization of the WSNs, as well as the small size and high performance of nodes, WSNs have been used in many technologies, such as environmental monitoring, systems controlling, tracking, and military/security applications. The WSN with its own distinct design has been widely investigated by researchers [1].
These networks collect data and information from the environment, process them, and send them to the base station. In other words, these networks perform two important tasks of collecting data from the environment and transmitting the information.
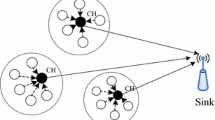
Given the small size of the sensor, its computational and processing capabilities are limited and its battery is tiny. Smaller battery causes early energy drain and loss of sensor node, which affects the function and application of WSN. As a result, ‘energy consumption’ is considered as one of the challenges of this network. Transmission of information is a critical task in WSN, which consumes energy more than other sensor node tasks, including sensing, processing, and storing data. Therefore, different routing protocols were categorized in these networks, which can be broadly classified into flat and hierarchical protocols. In flat protocols, all nodes have the same role, are connected with neighboring nodes within their range, and transmit data packets to the final destination. In hierarchical protocols, the nodes have different roles; the normal nodes send their data to the cluster head (CH) node, which sends the information to the final destination after aggregating and compressing. The CH node consumes energy more than other nodes due to its greater functions (Fig. 1) [2, 3].

Wireless sensor clustering [2]
In the hierarchical routing algorithm, CHs are initially formed using selected parameters and then clusters are formed after other nodes join. Cluster members collect the data and send them to their CH. Later, the CH sends this information to the base station (BS) after a series of processes.
The aims of this study were to:
-
Introduce the Low Energy Adaptive Clustering Hierarchy (LEACH) protocol and several other protocols along with their advantages and disadvantages.
-
Determine the role of selecting a CH and investigate the effect of considering residual
-
Energy criteria and node distance on reducing energy consumption.
-
Study the network zoning and its role in selecting the CH.
-
Present the proposed algorithm and introduce its advantages and disadvantages.
-
Simulate the proposed algorithm and compare it with LEACH, Quadrant-LEACH (Q- LEACH), LEACH with Sliding Window and Dynamic Number of Nodes (LEACH-SWDN) protocols.
-
Discuss about the results and make conclusions.
2 Background
The LEACH protocol, designed by Heinzelman et al., is considered as one of the most popular hierarchical protocols. In LEACH, nodes are based on the threshold formula and randomly selected as the CH. Node selection, as a CH or non- CH, is done by the node itself. The LEACH reduces CH energy consumption by decreasing rotation in the CH selection process among nodes.
The CH node introduces itself to other non-CH nodes and the nodes select their CH based on the strength of the received signal. Later, the cluster is formed after nodes inform themselves to the CH. The CH is responsible for collecting data from its member nodes under the specified schedule, processing and compressing data, as well as transmitting the data into the BS.
Since the CH node in LEACH has higher energy consumption, designers attempted to balance energy consumption among nodes by selecting the CH on a rotating and random basis. This protocol does not have a communication load or a complex control mechanism. It also does not include different criteria for selecting a CH (such as node residual energy, distance, etc.), moving nodes, scaling, and reliability. Therefore, these issues should be considered in designing new protocols [4, 5].
The LEACH-SWDN is another algorithm developed from LEACH. This algorithm has paid attention to the issue of CH selection to reduce energy consumption. In LEACH-SWDN, the number of living nodes in each round was used to calculate the optimal number of CH nodes. Furthermore, in the threshold formula of this algorithm, residual energy of the node and node initial energy are considered, which cause a better CH selection in each round of the algorithm. One of the disadvantages of this method is lack of load balancing monitoring in the network and more energy consumption of the CH due to the additional work load [6].
The Q-LEACH algorithm, as one of the developed protocols of LEACH, divides the network environment into regions, where CHs are selected. Although the proposed protocol has relative improvement compared to the LEACH protocol, it has some disadvantages: in each region, CH selection is based on the initial LEACH. In other words, CH is selected randomly and based on the threshold formula, so that residual energy of the nodes is not considered. As a result, problems of LEACH remain in CH selection and data transfer [7].
The FL-LEACH protocol uses the concept of a fuzzy logic based clustering algorithm to select a super CH by choosing appropriate fuzzy descriptors. These descriptors include remaining battery power, centrality of the clusters, and mobility of the BS, which represents sending a message to the mobile BS. The idea of BS mobility along with fuzzy logic increases the network life dramatically. In this protocol, the fuzzy inference engine (Mamdani’s rule) is used to select the chance of a super CH [3, 8].
The distance-based low-energy adaptive clustering (DISCPLN) protocol was introduced to increase the network lifetime and reduce the packet latency. This protocol divides the network into several regions (three vertical and two horizontal planes) containing equal number of nodes to create a better network coverage and cause proper distribution of CHs in homogeneous and heterogeneous sensor networks. In central regions of the network, nodes send their information to the base station directly. In other regions, according to the LEACH protocol, only one CH is selected from each region and then information is collected from all nodes of the region and sent to the base station [9].
Another improved LEACH protocol is the MMR-LEACH (Multi-tier Multi-hop Routing in LEACH) Protocol. This protocol uses CH layering in the network by selecting two CHs. The BS divides the entire network into several multi-tiers. The main CH is responsible for collecting, compressing, and transmitting data to the BS as well as selecting the vice CH based on the residual energy. In the process of data transmission, the vice CH acts as an interface between the main CHs of the network bottom layers and the BS. This protocol operates in three phases of clustering with two CHs, cluster layering by BS, and scheduling [10].
Basu et al. introduced a hierarchical algorithm to extend the life of wireless networks using the clustering technique. In this algorithm, another phase, called segmentation phase is added to the set-up and steady state phases of the LEACH algorithm, which is calculated before the other two phases in the network. In this hierarchical algorithm, the base station is aware of the location of all network nodes and the number of network regions is determined by the user (by trial and error experiments). Each node exchanges information only with members of its regions. Any addition or removal of nodes is noted by the base station. In selecting the CH, a new threshold formula is introduced according to the number of living nodes and information transfer such as LEACH algorithm. The findings showed that the proposed method had a longer lifespan and lower energy consumption compared to the game theory model algorithm [11].
Anzola et al. proposed a hierarchical routing protocol based on the k-d tree algorithm that uses network segmentation to organize nodes and clusters. This protocol divides the network into k parts and creates clusters within each region. The k-d tree creates a two-hop hierarchical network, based on which the corresponding tree is constructed according to the position of each node to transfer data to the base station. The results show an improvement in network latency and performance [12].
In the EESRA (Energy-Efficient Scalable Routing Algorithm) routing protocol, the goal is to extend the network’s lifetime and increase its size. In this protocol, the randomly selected CH adopts a three-layer hierarchical routing to minimize the CH load and uses multi-hop transmissions for intra-cluster transmission.
Furthermore, each CH selects one or more eligible nodes to act as cluster congregation. These cluster congregations are responsible for retrieving and collecting the measured data from their cluster members and transmitting them to the CH using the hybrid MAC protocol, which includes sleep and collision avoidance mechanisms for sensing data [13].
Fragkos et al. introduced a new evacuation planning mechanism to support the distributed and autonomous evacuation process in operation of a public safety system. The proposed system of Evacuation Strategy through Clustering and Autonomous Operation in Public Safety Systems (ESCAPE) is operated based on the principles of reinforcement learning and game theory in two layers of decision making. As stochastic learning automata, evacuees initially select a path for evacuation and model to move according to the past decisions during the current evacuation. As a result, a cluster of evacuees is created in each evacuation path and the evacuators decide whether to evacuate through the specific evacuation path in the current time memory. The evacuees’ competitive behavior is modeled as a minority game in each specific evacuation path. The second layer determines whether the evacuators of each cluster move towards the selected initial evacuation path or not. In this process, the evacuees’ mobility during the evacuation process is considered by taking into account the evacuation rate along the selected evacuation path. The proposed ESCAPE algorithm was introduced for evacuation with low complexity that is distributed to implement both above-mentioned layers of decision making. The proposed framework, evaluated by three scenarios of 1) Minority game, 2) Reinforcement learning, and 3) Benefits of learning, shows better performance in a process [14].
3 The proposed algorithm
As mentioned earlier, energy consumption is an important problem in the hierarchical routing algorithm. Therefore, different solutions have been proposed to reduce energy consumption. In routing methods, CH has different responsibilities (such as clustering, collecting and aggregating the data, contacting with the BS for sending information); consequently, its energy consumption is higher than normal nodes. Therefore, the problem of selecting the CH has been met in the proposed algorithm by considering some criteria, such as node residual energy, node distance, number of active nodes per round, and node location [15]. In the proposed algorithm, CH selection is performed in regions where the network is divided. Moreover, to reduce the energy consumption of normal nodes and CH, the task of selecting the CH is assigned to the BS.
Considering that the proposed algorithm was developed from the LEACH algorithm, more attempts were made to compare it with an important and similar algorithm. In this regard, the Q-LEACH and LEACH-SWDN algorithms were considered, since they are among the most important and effective known methods in this area. The reason for choosing these two methods is due to the special feature of each of the algorithms. The LEACH-SWDN algorithm takes into account the optimal number of the CH in a dynamic environment, which is also mentioned in various studies [16,17,18,19].
The Q- LEACH algorithm pays special attention to the better network coverage parameter, as shown by various studies [16, 19, 21,22,23].
Of course, both methods have disadvantages. In the proposed method, we tried to use these two important parameters (selecting the CH and network coverage) to increase the life of the network. The proposed method also has disadvantages (single hop, scalability, etc.). Which will be discussed in future studies.
3.1 Methodology
In the proposed algorithm, the network is divided into several regions and the nodes are randomly assigned to the network. The BS is aware of the location of each node and the coordinates of each region. After locating the nodes in each region, BS informs each node to select CH and form cluster in each region.
In the proposed algorithm, the environment of 100 by 100 square meters is considered to be divided into 4 regions (a1, a2, a3, a4), which can be seen in Fig. 2.

The network regions [20]
The general relationship of regions is represented in Eq. 1:
The coordinates for 4 regions, where 100 nodes exist in the network, are represented in Eqs. 2 to 5 [7, 24].
Like LEACH, this algorithm consists of several rounds and each round has two phases of ‘set up’ and ‘steady state’. The set up phase contains selecting CHs, getting membership of CHs, clustering, as well as timing for sending data. In the steady state phase, information is transmitted from the CH to the BS based on the cluster created in the set up phase [4].
Different criteria can affect CH selection, such as maximum residual energy, minimum distance to gravity center of the cluster, and minimum distance to BS. According to previous studies, the two criteria of maximum energy and minimum distance had a greater impact on reducing energy consumption, which was considered in the proposed algorithm.
3.1.1 Set up phase
After zoning the network and informing each node about the region and center, the process of CH selection begins. In the proposed algorithm, unlike the LEACH protocol, the BS selects and informs the CH and notifies to nodes of each area. The BS selects CH in each region based on the threshold Eq. 6.
where Ei-current is the residual energy of the node and Di-current is the distance of each node from the center of the region; Di-current has a constant value since the nodes are static.
In LEACH protocol, variable K is defined as K = P*N; in which, N is the total number of nodes in network and P is the predetermined number of CHs.
In order to obtain the optimal number of CHs in the proposed algorithm, N was used as the active nodes in each region, which has led to dynamic and better selection of CHs. The BS calculates K, determines the threshold value of the nodes in each region, and selects K number of the highest values as the CH [25, 26].
This study was designed in the small simulation environment. In order to consider large and real environments, the distance from each sensor to region center was measured by each node based on that regions and network range were determined from Euclidean distance Eq. 7
where CAj is the coordinate of each center region in the network, i is the coordinate of each node and j = 1,2,3,4.
The location of each sensor in region is determined according to the closest distance (minimum distance) to each center. Considering that the node computing process consumes lower energy than information exchange of the sensor nodes with the base station or the sensors with Global Positioning System (GPS), the computing process by node resulted in optimal energy consumption. It should be noted that after formation of the first round, location information is sent to the CH at the last allotted time slot of the sensor. Followed by data aggregation, CH transfers locations of all its members to the base station at the last time slot. Consequently, at the end of the first round, base station is also aware of the location of nodes and their regions. In the second round and after that, selection of the CH s is done by the base station based on the threshold Eq. 6.
For example, if 14 nodes exist in a region and P is considered .05, then, K will be 14 * .05 = .75; in which rounded upper and 1 CH is selected. This algorithm guarantees the existence of a CH in each region until the last node is activated. It also avoids direct connection of the normal nodes to BS in absence of a CH, reduces energy consumption, and increases the network lifetime.
Later, BS informs the nodes of each region about CH advertisement and its location, so that both the CH and other normal nodes are aware of the CH node and its location. Like the LEACH protocol, normal nodes select and inform their CH based on the received signal strength and distance.
Once the members of each CH are identified, the clusters are formed and CH transmits the data based on the number of member nodes and the time division multiple access schedule.
3.1.2 Steady state phase
Once the cluster is formed and members of each cluster are identified, information transmission begins. Each CH receives the data from member nodes based on the number of members and the time division multiple access schedule. Each normal node sends the data to its CH only in its allotted time and goes to sleep until beginning of the next time slots. However, CH is fully active and sends the collected, aggregated, and compressed data to BS based on its time schedule.
At the end of each round, each node sends its residual energy to the CH at the last allocated time slot and the CH sends it to the BS after being aggregated as the latest information. This information is used for updating values, selecting CH, and regulating the set up phase.
In the first round, all nodes have the same energy; so, the closest node to the region center has a higher priority to be selected as the CH. However, in the second round onwards, residual energy and distance affect CH selection based on the threshold Eq. 6.
Given the high cost and complexity of designing WSN, especially on large scales with a large number of nodes, simulation of networks seem necessary before evaluating, testing, and validating protocols as well as establishing the proposed algorithms prior to their real time. The aim of simulation is to explore new ideas more quickly and under different conditions. In this study, received signal strength indication (RSSI) was used to estimate the distance and formation of clusters as well as membership of the CH. The RSSI method is more appropriate in WSN, due to the limited power of nodes, communication overhead, lower price, as well as less complexity in operation and signal disorder. It also considers the RSSI in information transfer from normal nodes to CHs and to base station. The energy consumption of nodes and network is calculated according to the distance, type, and power of information transfer and energy model.
Data were transferred between member nodes of a cluster according to the time division multiple access schedule, in which each node transfers data to its CH at the allotted time and the node is only sensing the environment with no data transfer at the non-allotted times. Considering some sensors’ proximity and overlap of the covered regions, they may send similar information to the CH, which is transmitted to the base station after aggregation and compression by the CH. The energy consumption required for this aggregation and compression process was considered in our simulation.
It is worth noting that some rounds may consume more energy due to the lack of replacement of the CH in consecutive rounds, but in general, the simulation results showed better performance of the proposed method than the other three algorithms. This can be explained by mentioning that the balance of energy consumption and better stability in the network were achieved by network zoning.
3.1.3 Communication model
Due to the lack of radio spectrum, full communication without interference is not possible. Other radio devices or networks may cause interference using similar radio frequency bands. In the case of having a proper and accurate channel model between the transmitter and receiver, the input signal can be reconstructed. Sometimes, interference of other radio devices is very hard and even impossible due to the limited radio limitation. These problems are more apparent in real environments considering application type of the sensor networks as well as in large-scale networks, where the number and distance of the sensor nodes are greater. The channel model plays an essential role in reducing the received signal strength. In this study, single-hop transmission was used and multi-hop complexity was neglected due to the small space of the network. According to the RSSI in this study, the amount of RSSI reduces by increase of distance between the transmitter end and the receiver end (d).
Loss of the channel path is calculated and generated using RSSI values. Therefore, the quality of connection is calculated using the Eq. 8
where Pr (d) (dBm) is the receiver power at distance (d) and the value of calculation formula for losing the channel path PL (d) is according to Eq. 9
where Pt is the transmitter power, Gt (dBi) is the transmitter antenna gain, and Gr (dBi) is the antenna receiver gain.
In the real world, calculation of the remaining energy depends on various factors such as the sensor type, battery voltage, sensor manufacturer, environment in which the sensor network is located, and etc. Moreover, accurate calculation of energy and battery consumption in these networks is a function of paying attention to the sensor nodes’ facilities and application type of these networks. Due to financial constraints and other issues in sensor preparation, we used the simulation method similar to many other studies. In this study, the energy consuming processes were considered, such as: determining the head cluster and its membership, transferring information from node to CH and from CH to base station according to the type and distance of transmission, aggregating information by the head cluster, and etc. Later, energy consumption of each node was calculated according to its role in the network (a CH or a normal node). The result was subtracted from the initial energy and the remaining energy was obtained. Considering that the radio unit consumes more energy, an energy model should be provided.
The energy model used in the proposed protocol is represented in Fig. 3.

Energy model [25]
In this model, free-space factor εfs and multi-path factor εmp are used. If the distance is less than the threshold, the free space factor is used; otherwise, the multi-path factor is utilized. Equations 10 and 11 represent the amount of energy consumed by the nodes.
In Eq. 11, Eelec is the amount of energy consumed in electronic sending/receiving, K is the message size in terms of the number of bits, d is the distance between the receiver and transmitter, and d0 is the distance threshold. In the case that the distance between transmitter and receiver is greater than the threshold, εmp will be used; otherwise, εfs will be utilized to send to close distance. Distance threshold value is obtained from Eq. 12.
The energy consumption for receiving k bits data is calculated by Eq. 13.
4 Simulation
In order to analyze, the proposed algorithm was simulated by LEACH [6], LEACH-SWDN and Q-LEACH protocols using MATLAB software under the same conditions. In the simulation, all the sensors are homogeneous and a fixed location is considered. The used parameters are shown in Table 1. The reason for comparing the proposed method with the two algorithms of Q-LEACH and LEACH-SWDN was their Similarity and close relationship with the proposed protocol. In this study, we attempted to examine the advantages or disadvantages of the two common algorithms, considering their alterations and problems. As mentioned in the research background, the network is divided into several regions and clustered in the Q-LEACH algorithm, while the remaining energy in the energy threshold formula and the number of living nodes for the head cluster were noted in the LEACH-SWDN algorithm. The following criteria were considered for the analysis of protocols:
-
Death time of the first node: That is the round number in which the first node died.
-
Half node death: The round number in which half of the network nodes died due to power outage.
-
The last node death: The round number in which the last node in the network died due to power outage.
Based on the criterion “death time of the first node”, the network is more stable and better results are achieved in later death time of the first node; since node death may destroy part of the information and network coverage may be disrupted. As Fig. 4 reveals, LEACH protocol causes premature death of nodes and loss of network due to random selection of the CH and lack of a proper mechanism. In LEACH-SWDN protocol, use of node residual energy.

Simulation results based on network lifetime
Criterion in CH selection leads to energy consumption reduction. The Q-LEACH protocol had better results by zoning and rotating CH selections in each region compared to the two above-mentioned protocols. For a better representation and analysis of the results, a comparison of the proposed algorithm and the three protocols is presented in Table 2.
The proposed algorithm improved by 74%, 60%, and 40% in terms of “death time of the first node” compared to LEACH, LEACH-SWDN, and LEACH algorithms, respectively. This indicates stability and lifetime of the network. Moreover, the proposed algorithm for the criteria “half node death” and “the last node death” improved by 95% and 84% compared to LEACH algorithm, by 24% and 35% compared with LEACH-SWDN, and by 22% and 15% compared to Q-LEACH, respectively.
4.1 About CH number
Simulation results of the proposed algorithm, compared to the other three protocols, in terms of “CH number” are represented in Fig. 5. In LEACH protocol, no specific rule exists for the number of CH, which is based on probability. In Q-LEACH protocol, the number of CH is higher than LEACH protocol due to zoning. The LEACH-SWDN protocol performs better than Q-LEACH and LEACH protocols in terms of the number of CH using of the new threshold formula, residual energy of the nodes, and sliding window for random number selection. However, in Q-LEACH protocol, the LEACH protocol selection process is used, which does not include the node residual energy mechanism.

Results of the proposed algorithm compared to the other three protocols in terms of CH number
The results are better in the proposed algorithm compared with the other three protocols considering using of residual energy, node distance, and network zoning. As Fig. 5 illustrates, the beginning of reduction in the CH number occurred during the round 840 in the proposed algorithm. This can be justified by stepped energy consumption of the nodes. The number of CHs decreases in the proposed algorithm because it guarantees one CH in each region. In the round 1354, the number of CHs was decreased to 3, which indicates that the nodes of one region were completely lost (all were dead). The simulation results may be different at each simulation run due to the random distribution of nodes and the number of nodes in each region.
5 Results and discussion
In the proposed method, the number of CH nodes was determined based on the number of living nodes in each round. The number of CH nodes may be the same in different rounds, but based on the threshold Eq. 6, the CH node is changing and rotating based on the residual energy of the node and distance of each node from the center of its region. Considering the limitations (purchasing sensors, etc.), we had to use the simulation environment using the MATLAB software. In order to have a better simulation of the real environment, the location of nodes was randomly determined, which made the simulator to represent different results after each run.
In the proposed algorithm, a better network coverage was created and death time of the first node was extended due to network zoning and CH selection within each region. The number of CHs improved in each region due to the number of active nodes at each round in K equation. Considering the new threshold formula in addition to the residual energy criterion, the node distance was considered.
Unlike the LEACH protocol, the BS selects the CH and informs each node of its status (whether it is a CH or a normal node) due to the lack of energy limitation for the BS and high processing power.
In the proposed algorithm, although the “death time of the first node” was improved, the gap between “death time of the first node” and “death of the last node” criteria increased. This may affect network coverage or environmental data collection, which may necessitate further investigations.
6 Conclusion
Hierarchical routing algorithm is one of the solutions that reduces energy consumption in WSN and has been considered by many researchers.
The proposed algorithm, developed from LEACH and Q-LEACH protocols, introduces a new threshold formula in which CH is selected based on the residual energy of the node and distance criteria. Moreover, the number of active nodes in each round was used for the number of in each region, which caused unstable number of CHs and was calculated based on the number of active nodes. Network zoning and forming clusters within the region led to a better network coverage across different regions of the network. Furthermore, the process of CH selecting and informing the nodes is done by the BS, which reduces the workload on nodes to select the CHs and reduce energy consumption of the sensor.
The simulation results show that the proposed algorithm performs better than the other three protocols in terms of the “first death node” criterion. In the proposed algorithm, this criterion was improved by 74%, 60%, and 40% compared to LEACH, LEACH-SWDN, and Q-LEACH protocols, respectively.
The proposed algorithm does not include other parameters such as nodes’ load and quality assurance criteria, which can be addressed in the future studies.
References
Chen, Y., & Zhao, Q. (2005). On the lifetime of wireless sensor networks. IEEE Communications Letters, 9(11), 976–978.
Bhatia, T., et al. (2016). A genetic algorithm based distance-aware routing protocol for wireless sensor networks. Computers & Electrical Engineering, 56, 441–455.
Singh, S. K., Kumar, P., & Singh, J. P. (2017). A survey on successors of LEACH protocol. IEEE Access, 5, 4298–4328.
Heinzelman, W. R., Chandrakasan, A., & Balakrishnan, H. (2000). Energy-efficient communication protocol for wireless microsensor networks. In Proceedings of the 33rd annual Hawaii international conference on system sciences. IEEE.
Tan, N. D., et al. (2012). An improved LEACH routing protocol for energy-efficiency of wireless sensor networks. SmartCR, 2(5), 360–369.
Wang, A., Yang, D., & Sun, D. (2012). A clustering algorithm based on energy information and cluster heads expectation for wireless sensor networks. Computers & Electrical Engineering, 38(3), 662–671.
Deepa, S., Marimuthu, C., & Dhanvanthri, V. (2015). Enhanced Q-LEACH routing protocol for wireless sensor networks. ARPN Journal of Engineering and Applied Sciences, 10(9), 4036–4041.
Nayak, P., & Devulapalli, A. (2015). A fuzzy logic-based clustering algorithm for WSN to extend the network lifetime. IEEE Sensors Journal, 16(1), 137–144.
Liaqat, M., et al. (2016). Distance-based and low energy adaptive clustering protocol for wireless sensor networks. PLoS ONE, 11(9), e0161340.
Aghera, K., Pambhar, H., & Tada, N. (2017). MMR-LEACH: Multi-tier multi-hop routing in LEACH protocol. In Proceedings of international conference on communication and networks. Berlin: Springer.
Basu, S. V., et al. (2017). Improving the network lifetime of a wireless sensor network using clustering techniques. In 2017 2nd IEEE international conference on recent trends in electronics, information & communication technology (RTEICT). IEEE.
Anzola, J., et al. (2018). A clustering WSN routing protocol based on kd tree algorithm. Sensors, 18(9), 2899.
Elsmany, E. F. A., et al. (2019). EESRA: Energy efficient scalable routing algorithm for wireless sensor networks. IEEE Access, 7, 96974–96983.
Fragkos, G., Apostolopoulos, P. A., & Tsiropoulou, E. E. (2019). ESCAPE: Evacuation strategy through clustering and autonomous operation in public safety systems. Future Internet, 11(1), 20.
Aghda, S. A. F., & Mirfakhraei, M. (2019). An improved cluster routing protocol to increase the lifetime of wireless sensor network (WSN). Wireless Personal Communications, 109(3), 2067–2075.
Fanian, F., & Rafsanjani, M. K. (2019). Cluster-based routing protocols in wireless sensor networks: A survey based on methodology. Journal of Network and Computer Applications, 142, 111–142.
Chan, L., et al. (2020). Hierarchical routing protocols for wireless sensor network: A compressive survey. Wireless Networks, 26, 1–24.
Kang, S. H. (2019). Energy optimization in cluster-based routing protocols for large-area wireless sensor networks. Symmetry, 11(1), 37.
Guleria, K., & Verma, A. K. (2019). Comprehensive review for energy efficient hierarchical routing protocols on wireless sensor networks. Wireless Networks, 25(3), 1159–1183.
Manzoor, B., et al. (2013). Q-LEACH: A new routing protocol for WSNs. arXiv preprint arXiv:1303.5240.
Shahraki, A., et al. (2020). Clustering objectives in wireless sensor networks: A survey and research direction analysis. Computer Networks, 180, 107376.
Khan, M. K. U., & Ramesh K. (2019). A modified LEACH algorithm for WSN: MODLEACH. In International conference on e-business and telecommunications. Berlin: Springer.
Randhawa, S., & Jain, S. (2019). MLBC: Multi-objective load balancing clustering technique in wireless sensor networks. Applied Soft Computing, 74, 66–89.
Wang, H., Chen, Y., & Dong, S. (2016). Research on efficient-efficient routing protocol for WSNs based on improved artificial bee colony algorithm. IET Wireless Sensor Systems, 7(1), 15–20.
Heinzelman, W. B., Chandrakasan, A. P., & Balakrishnan, H. (2002). An application-specific protocol architecture for wireless microsensor networks. IEEE Transactions on Wireless Communications, 1(4), 660–670.
Heinzelman, W. B. (2000). Application-specific protocol architectures for wireless networks. Cambridge: Massachusetts Institute of Technology.
Acknowledgements
The authors would like to thank Prof. M.-H. Ehrampoush.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Farahzadi, H.R., Langarizadeh, M., Mirhosseini, M. et al. An improved cluster formation process in wireless sensor network to decrease energy consumption. Wireless Netw 27, 1077–1087 (2021). https://doi.org/10.1007/s11276-020-02485-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11276-020-02485-y