
Abstract
Accurate estimation of flood-damaged zones in a watershed is prominent in guiding a framework for developing sustainable strategies. For these purposes, several flood conditioning factor values at flooded and non-flooded points are extracted, and those points are analyzed using decision tree algorithms and eight novel information fusion techniques to get more reliable flood susceptibility mapping. The belief function values of flood susceptibility values at leaf nodes of the tree are fused by several techniques named Dempster-Shafer (DS), Fuzzy Gamma Overlay (FGO), Hesitant Fuzzy Weighted Averaging (HFWA), Hesitant Fuzzy Weighted Geometric (HFWG), Hesitant Fuzzy Weighted Ordered Averaging (HFWOA), HFWOG, Closeness coefficient (Cc) using Euclidean and Manhattan distances. The flood susceptibility values are extracted from the generated maps and are validated by receiver operating characteristics (ROC) curve parameters, and the seed cell area index (SCAI) of classified flood levels. The area under ROC (AUROC) values of training process are 0.997 for DS, HFWA, HFWOA, and Cc-Euclidean, 0.996 for Cc-Manhattan, 0.995 for FGO and 0.994 for HFWG and HFWOG. The AUROC values of the testing process are 0.951 for DS, HFWA, HFWOA, Cc-Euclidean, and Cc-Manhattan, 0.945 for FGO, 0.943 for HFWG, and 0.941 for HFWOG. True Skill Statistics values are 0.962 and 0.870 for training and testing processes. Although these techniques present excellent performance, the SCAI values versus flood susceptibility classes are fitted to assess the prediction capabilities of the techniques further. HFWA and HFWOG have the first- and second-best performances on the estimations. Hence, information fusion paradigm can be employed to combine flood conditioning factors based on a robust classification method to get reliable predictions of flood potential levels and utilize them for land use and construction planning and management.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In recent years, there has been a growing number of flash flood events recorded worldwide due to the triggering effects of climate change, increasing intensity of rainfall patterns with growing frequency, uncontrolled deforestation, unplanned land use changes, and other unpredictable anthropogenic factors (Costache et al. 2022). Decision makers have challenging tasks to provide sustainable landscapes and habitats by managing and combating flash floods regarding policy-making, strategy development to mitigate risks, environmental protection with limited soil and water resources, and overcoming the special needs of disadvantaged groups.
Accurately estimating flood locations is the most fundamental step to overcoming the flood management strategy (Zhao et al. 2018). The flood susceptibility mapping studies, which are the first stage for combatting the impacts of flash floods, may help decision-makers determine the least and most flood-vulnerable zones for land use planning and meeting human needs. The bivariate and multivariate statistical methods and multi-criteria decision-making models were explored to document the assessment of spatial variation of flood susceptibility by various researchers (Akay 2021a; Sahraei et al. 2022; Solaimani et al. 2023). These methods were compared and found to be preliminary attempts or efficient hybridization tools to estimate spatial variation of flood susceptibility (Akay 2022; Rana and Mahanta 2023). Recent research is coherent with developments in technology focusing on preparing flood susceptibility maps with increasing prediction capability. It achieves sustainable development goals related to flood risk mitigation, supported by an efficient management approach to detect highly susceptible zones to floods. Standalone machine learning models facilitate to achieve the challenges of determination of highly susceptible zones to flooding. Researchers adapted several machine learning models and found the results more accurate (Rahman et al. 2019; Avand et al. 2022). Since researchers cannot reach a general conclusion on an exact method for accurate prediction of flood susceptibility modeling results, hybrid or ensemble models of bivariate statistics, machine learning, and multi-criteria decision-making techniques are combined to improve the results (Adnan et al. 2023; Hasan et al. 2023). Similar endeavors are held to catch more accurate predictions by adapting new classification algorithms (Al-Areeq et al. 2023; Ghobadi and Ahmadipari 2024).
Besides ensemble and hybrid machine learning models, fusion or combining techniques of information from several sources may be preferred to generate more accurate flood susceptibility maps. Collected values of flood occurrence information of effective triggering factors might be combined into a single value as a new set of information based on algorithms, methods, mathematical operations, and procedures for data combination towards reducing vagueness and redundancy (Torra and Narukawa 2007). Information related to factors triggering flood occurrence, fuzzy number representation of information, and mathematical processes of information fusion directly affect flood susceptibility maps.
Order weighting averaging (OWA) and weighted OWA methods as a decision-making model, proposed by Yager (1988), are found to be applicable in the detection of flood-prone zones and flood vulnerability mapping studies using various hydrological data (Tang et al. 2018; Xiao et al. 2018). Malczewski et al. (2003) developed OWA module using various orness values to present pessimistic or optimistic strategies in GIS environment for watershed rehabilitation projects. Chen (2022) overlapped flood conditioning factors by OWA and two other MCDM models. On the other hand, the Dempster-Shafer rule and hesitant fuzzy sets played an important role in the generation of snow avalanche susceptibility depicted by combinations of triggering attributes based on binary classification of decision tree-based algorithms (Akay 2021b, 2022). Simple but efficient tree-based classification algorithms applying various fusion rules at leaf nodes lead to quantitative and qualitative results and concluding remarks on developing risk perception levels.
In this study, various techniques are proposed to predict the flood susceptibility map of the Kocanaz watershed, where flood events are exposed frequently. It is acknowledged that most of the models are examined and employed for flood susceptibility estimations. However, the author could not find a study on flood susceptibility predictions employing a novel information fusion paradigm coupled with a decision tree-based classification study. Eight information fusion techniques, such as aggregation operators, overlay functions, compromising solutions, etc., are utilized to test the predictions' enhancements by combinations of flood occurrence classification using the decision tree algorithm. The prediction capabilities of the proposed novel techniques are tested using a robust validation methodology. Seed cell area index versus flood potential classes are fitted and proposed to be used as an assessment criterion. A qualitative and quantitative assessment is provided by discussing the outcomes and shortfalls of the proposed techniques to present solid recommendations for stakeholders in land use planning and management and taking required actions.
2 Materials and Methods
2.1 Study Area
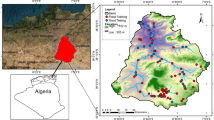
Kocanaz Creek watershed which is located between 435,135 – 471,964 X and 4,571,883 – 4,609,400 Y UTM coordinates is a sub-basin of Bartın Creek sub-basin of the Western Black Sea basin of Türkiye (Fig. 1). The watershed has a drainage area of approximately 650 km2, perimeter of 202.4 km and mainstream length of 60.7 km. The elevations of the drainage area vary between 10 m, and 1755 m with a median elevation of 1340 m, and has an average slope of 34%. Kocanaz watershed takes a large amount of precipitation annually, and the average curve number is approximately 79, pointing out that most of the rainfall transforms to runoff due to topographical and hydrological factors. In addition to meteorological factors, unfavorable factors such as rapid urbanization and deforestation due to uncontrolled land use changes inevitably result in flash floods every year and cause significant economic losses in the watershed. In the last five years, the watershed experienced substantial increases in precipitation trends that caused catastrophic disasters.

Study area and inventory data
2.2 Method
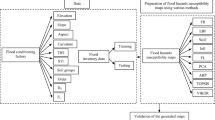
Generation of a flood susceptibility map of the Kocanaz watershed consists of the following steps. (1) Data preparation: flood conditioning factors and inventory data, (2) pre-processing: extraction of knowledge based on prepared data in ArcGIS environment, (3) processing: analyzing knowledge by decision tree-based classification algorithms, (4) synthesis: combination of attributes rendered by decision tree nodes by information fusion or compromising solutions, (5) post-processing: assigning values computed in step (4) for attributes defined in step (3) and generation of susceptibility map in ArcGIS environment.
2.3 Data
2.3.1 Flood Conditioning Factors
Flood triggering factors, as significant independent variables that are not strongly inter-correlated, are used for processing in the generation of susceptibility maps. Topographical, meteorological, geological, physiographic, hydrological, climatic, etc., conditions are assessed to be dominantly the main driving factors in flood susceptibility by many researchers worldwide. Rainfall amount is the key input parameter for flood occurrence. Since the Kocanaz watershed is scarcely gauged and small, spatiotemporal variation of rainfall amount may not be significant in estimating flood susceptibility (Akay 2021a).
Elevation is the principal factor in floods, where rainfall tends to drain from hillslopes at higher altitudes and concentrate on stream banks and floodplains at lower altitudes. Elevation is processed from the topographic maps, and the digital elevation model (DEM) of the watershed with a cell size of 10 m is created in ArcGIS (Fig. 2a). Slope, aspect, and curvature calculated using DEM considering points and their surroundings are the other crucial factors which have essential impulsive, inertial and resistance forces effects of water column on flow conditions, runoff and seepage (Fig. 2b, Fig. 2c, Fig. 2d). Water depth at low slopes cause inundation and accumulation of debris. Curvature of the surface is classified based on the flatness, convexity, and concavity of the terrain. Aspect factor is associated with flatness and the principal and quadrant directions and is categorized into nine classes with 45° increments.


Flood conditioning factors of Kocanaz watershed (a) elevation, (b) slope, (c) aspect, (d) curvature, (e) TWI, (f) SPI, (g) distance to stream, (h) Dd, (i) HSG, (j) CN
As a result of the cooperation of the slope with flow accumulation, the inertia effect of flow and erosion sensitivity of soil is enhanced. Topographic wetness index (TWI) and stream power index (SPI) are processed as a function of values of flow accumulation and slope of the pixels using raster calculator in ArcGIS. TWI and SPI are used for classifying the contributions of physiographic, hydrometric, and hydrologic processes and tendency of susceptibility to flooding and erosion in the watershed (Fig. 2e, Fig. 2f).
Stream network directly relates to climate, infiltration, and surface texture characteristics of the watershed. So, stream network-related parameters are commonly considered for assessing flash flood susceptibility. The distance to the stream is created by measuring the Euclidean distance to the stream raster and may be embodied as critical buffer zones for flooding (Fig. 2g). The closer the distance to the stream, the more susceptible it is to flooding. Drainage density expressed as the length of drainage line per unit drainage area and generated by line density function in ArcGIS is the fundamental factor for assessing susceptible zones to flooding (Fig. 2h). Drainage density with higher values is considered more susceptible to flooding.
Land use and soil type may affect disturbance of imperviousness and drainage characteristics of the watershed. Therefore, they are commonly used for the assessment of flood-prone zones. Hydrologic soil groups (HSG) are classified based on the ultimate infiltration capacity of the soil at saturated levels. The A, B, C, and D HSG are ordered regarding decreasing infiltration capacity and increasing in runoff capacity, respectively (Fig. 2i). Curve number (CN) is assigned based on land use and soil data and an efficient parameter in determining runoff depths (Fig. 2j). Hence, HSG and CN are utilized separately in spatial modeling of flood susceptibility considering of importance of anthropogenic and natural characteristics of the watershed in this study.
The aspect, curvature, and HSG are classified based on supervised classification, while the rest of the factors are classified into five groups based on the natural break method. Factors explaining flood susceptibility are hybridized by belief function so that it is simplified to classify and avoid the multicollinearity problem.
2.3.2 Flood Inventory Data
The study area is as hapless as the other residential areas in the Western Black Sea basin since it is subjected to torrential rainfall resulting in devastating flash floods yearly. The population is concentrated in Bartın city center and Hasankadı, Kumluca, and Kozcağız towns, but a considerable amount of people stays in villages sited near streams and uplands. Hence, disaster hazards are reported to be scattered across the watershed in damage assessment conducted by authorities, which are mainly concentrated by mainstream channel sides and zones with gentle slopes.
76 flooded (coded as 1) and 76 non-flooded (coded as 0) points are randomly selected to model the flood susceptibility of the Kocanaz watershed. Flooded points are collected from frequently reported flash flood damages that occurred in different years. 53 of them, corresponding to 70% for flooded and non-flooded points, are used for training of data by decision tree algorithms and generating the flood susceptibility map by information fusion techniques of classified data, while the rest of the data is used for testing the model estimations (Fig. 1).
2.4 Decision Tree
In this study, the decision tree (DT) method is employed because of its efficiency and simplicity in classifying non-occurrence and occurrence of flood. J48 algorithm is applied to construct a tree-based decision model by splitting conditioning factors considering their attributes of information gained at each node from root to leaf (Quinlan 1993). Flooded and non-flooded points are depicted at leaf nodes as 0 or 1 and tested using 10 folds cross-validation. Internal nodes of the tree represent the class of the conditioning factors. The confidence factor is adjusted as 0.95 in this study so that the structure of the tree is exposed to less pruning.
2.5 Information Fusion
Information fusion is a process of getting a single value by combining data from different sources. A single source may not be adequate to represent a system. In complex systems such as natural disaster susceptibility mapping, transforming a single value by transferring multiple attributes from different sources may be more accurate and reliable. DT models enable the production of efficient information by building a well-established architecture from root nodes to leaves. In DT, nodes are split by branches to generate sub-nodes or leaves. At the process till the leaf node, new factors are branched by internal nodes, and new information is thus provided. This analogy may be set by combining multiple attributes via information fusion techniques. Information fusion techniques employed in this study may be a new paradigm to re-assess multiple conditioning factors by assigning a single value of the intersections of the attributes based on a classification-type learning system. If the leaf node is classified as non-flooded, the information fusion technique is not employed, and the susceptibility value is assigned as 0. The main assumption in generating the susceptibility map is that the class value of the intersection of the multi-attributes computed by the information fusion technique is constant throughout the study area.
Information on flood occurrence obtained from training data based on the DT model is fused at each leaf node based on various information fusion techniques by combining a class of conditioning factors into a single value considering the architecture of the DT model. Processing information from different sources without leading to vagueness is as important as achieving the information. In the study, information is provided by belief functions of the classes of the conditioning factors.
2.6 Information Fusion Techniques
In the study, Dempster – Shafer, fuzzy overlay, hesitant fuzzy aggregation operators, and distance-based closeness coefficient are employed for processing information fusion (IF) techniques considering the DT classification.
2.6.1 Dempster – Shafer Rule
Dempster–Shafer (DS) rule is an evidential belief function theory based on a bivariate statistical method. DS consists of four functions, two of which (belief and plausibility) are the minimum and maximum probability limits of a conditioning factor. Disbelief (Dis) function is the probability of non-occurrence of the conditioning factor. Uncertainty (Unc) is considered complementary to Bel and Dis functions since the total probability of an event is unity. Two factors (A and B) are handled and can be combined in pairs using Eqs. 1–3.
2.6.2 Fuzzy gamma overlay
Bel values enable the presentation of membership values of the factors varying between 0 and 1 so that the flood susceptibility at the Decision Tree (DT) leaves can be overlaid in ArcGIS. ArcGIS provides fuzzy overlaying of multiple sources based on robust functions such as or, and, product, sum, and gamma. In the study, gamma type overlay function (Γ) is preferred since it has extensive usage in similar studies and predicts more realistic values (Eq. 4). Γ value typically varies between 0 and 1 and is set as 0.9 in most studies. N is the number of classified parameters regarding the DT model.
2.6.3 Hesitant fuzzy sets
Hesitant fuzzy sets (HFS) are one of the most popular extensions of fuzzy sets proposed by Torra (2010). Hesitant fuzzy element (HFE) and hesitant fuzzy information (HFI) are crucial components of the HFS. Flood conditioning factors are introduced as HFE, while the Bel values are represented as hesitant fuzzy information. HFE is expressed by hesitancy regarding HFI considering the uncertainty effect on flood susceptibility. Hence, subsets of the HFE, considering the constraints of the DT model, are elements of the flood susceptibility map. If an HFE has been placed at sub-trees from nodes to leaves, the Bel values of the classes are considered. Otherwise, HFI is taken as a neutral element. In the study, hesitant fuzzy weighted averaging (HFWA), hesitant fuzzy weighted geometric (HFWG), hesitant fuzzy ordered weighted averaging (HFOWA), and hesitant fuzzy ordered weighted geometric (HFOWG) operators are used for aggregating information (Eqs. 5–8). These operators enable to have neutral judgments in the assessment of the elements.
where σ sub-index represents information of the corresponding largest element, and wi denotes the aggregation weights. Information gain ratio (IGR) values of the factors are normalized by satisfying the criterion of summation, which is one and is accounted for in wi.
2.6.4 Closeness Coefficient
Closeness coefficient (Cc) used for the assessment of alternatives in the TOPSIS method proposed by Hwang and Yoon (1981) handles the alternatives by examining the relative positive and negative distances to the ideal solution of criteria (Eq. 9). In the study, flood susceptibility is expressed in terms of various conditioning factors on which have different effects. Hence, a compromising solution compatible with information fusion techniques is obtained by combining the Bel values.
where Si− and Si+ are the distances to the negative and positive ideal solutions, respectively. Negative and positive ideal solutions are measured based on the values of the class of a conditioning factor to the minimum and maximum values of that conditioning factor, respectively. The ideal solutions are summed up, starting from the root nodes and moving to the leaves. Euclidean and Manhattan distances are adopted to determine Cc in this study.
2.7 Validation of the Predictions
The calculated results adapting the information fusion techniques are assigned to the flood susceptibility value of the intersection of the classes of attributes. Raster of these values in the study area are merged and processed in ArcGIS. The prediction capability of the information fusion techniques is validated using the receiver operating characteristics (ROC) method by extracting flood susceptibility values from the generated raster map for training and testing processes. In the ROC curve, the false positive fraction (horizontal axis) versus the true positive fractions (vertical axis) corresponding to cutoff values are plotted. Area under ROC curve (AUROC) and the true skill statistics (TSS) (Eq. 10) in terms of the number of true and false predictions of flood occurrence (TP, FP) and non-occurrence (TN, FN) are computed. As the values of AUROC and TSS increase, the accuracy of the predicted results is found to be improved (Allouche et al. 2006).
It may not be sufficient to assess the ROC parameters alone in predictions of flood susceptibility maps, although most of the researchers evaluate their model results using these parameters. Flood susceptibility values are extracted by classification using the natural break method using the five risk perceptron (Very Low, VL, Low, L, Medium, M, High, H, and Very High, VH). Variations of potentials of flood susceptibility throughout the Kocanaz watershed in percentages and percentages of flooded points at potential classes are prominent in the accuracy of predictions. As flood susceptibility class increases, the areal percentage of the classes should decrease. The percentages of H and VH classes are even expected to be lower than those of the other classes. Moreover, flood pixels should concentrate on very high susceptibility classes. The seed cell area index (SCAI) is defined as the ratio of the areal class percentage and the flooded point percentage in the class. SCAI in accurate predictions is expected to decrease as the risk class increases. In the study, the power equation relationship of the outcomes of the predicted maps versus risk class is presented, and the results are interpreted accordingly.
3 Results and Discussions
In this study, the flood susceptibility map of the Kocanaz watershed is predicted using flood conditioning factors, which are elevation, slope, aspect, curvature, topographic wetness index (TWI), stream power index (SPI), distance to stream, drainage density (Dd), hydrologic soil groups (HSG), and curve number (CN). The Bel values calculated from flood conditioning factors and training dataset are given in Table 1 and are constant throughout the class ranges.
Class values of the flood conditioning factors are introduced as the Bel values, which enable easier classification, minimize multi-collinearity problems, and reduce computational efforts by satisfying equivalent quantification. However, absolute classification ranges require a lump evaluation of the class values, and the class boundaries may cause uncertainty problems, as in the whole classification methods. Following similar classification techniques of the results may tolerate this concern. Floods in the watershed damage mostly at lower elevations with flat and gentle slopes at confluent streams with high drainage density and close to the stream. It can be inferred from Table 1 that floods are not common at elevations greater than 509.49 m, slope greater than 15.75°, TWI less than 4.97, Dd less than 0.00032, and distance to stream greater than 3033.92 m. flood susceptibility map is prepared by decision tree classification using the extracted values of conditioning factors at flooded and non-flooded points.
There are some common problems faced by researchers in flood susceptibility assessment. Flood susceptibility values are sensitive to data sources, training, and validation processes. The randomness of inventory data and accumulation of data at a class of a conditioning factor may not cause dominant scattering exhibitions during the classification process. Moreover, this leads to memorizing problems and superiority differentiation of factors. Synergism created among decision tree classification coupled with information fusion techniques is assessed quantitatively in flood susceptibility to achieve the issues. A new Bel value is assigned to the intersection of attributes based on information fusion techniques such that the calculated Bel value is characterized as a part of the domain. Computed results of the decision tree-based information fusion techniques may reveal understanding model advantages/disadvantages by an in-depth analysis. Information fusion techniques may gain new insight by tolerating the classification errors or shortfalls aroused by decision tree algorithms.
Flood conditioning factors are assessed by quantifying the Information Gain Ratio (IGR) values regarding sub-classes. The corresponding IGR values are as follows for the factors: slope (0.569), TWI (0.513), distance to stream (0.388), HSG (0.380), SPI (0.365), Dd (0.247), CN (0.233), curvature (0.210), elevation (0.190) and aspect (0.175). The slope and TWI are the most influential factors, whereas the aspect is the least affecting factor. The IGR values denote that slope contributed to the growth of the tree by branches regarding the number of classes. Aggregation weights, considered in hesitant fuzzy sets' operators, are predicted by normalization of the IGR values. The superiority of the factors was considered in terms of the mean and standard deviation of the Bel values of the classes. Curvature and aspect have the most and least superiority since they have minimum and maximum class numbers, respectively. Factors with an equal average value are ordered inversely, considering the standard deviation values (Liao et al. 2014). Dd and slope are the most and least superior among the factors having five classes. Superiority of the factors that do not affect flood susceptibility and are not located at internal nodes of the tree is ignored, and the Bel values are then treated as neutral elements.
The research question in this study is to estimate the flood susceptibility value with different Bel values. For example, what is flood susceptibility value if it is required to combine intersections of the attributes of elevation values varying within 249.44–509.49 m, flat curvature, and B hydrologic soil group as pointed out by the decision tree? The corresponding Bel values of the class of factors are 0.23, 0.82, and 0.15, respectively. Hence, some information fusion techniques named Dempster-Shafer (DS), fuzzy gamma overlay (FGO), Hesitant Fuzzy Weighted Averaging (HFWA), Hesitant Fuzzy Weighted Geometric (HFWG), Hesitant Fuzzy Weighted Ordered Averaging (HFWOA), HFWOG, Closeness coefficient using Euclidian and Manhattan distances (Cc-Euclidean and Cc-Manhattan) are examined. The flood susceptibility value is computed considering the decision tree starting from the root node to the leaves. Moreover, this value is assigned to intersections of the classes of three factors and processed in ArcGIS. Flood susceptibility maps are classified into five groups by natural break method, indicating very low (VL), low (L), medium (M), high (H), and very high (VH) (Fig. 3).


Flood susceptibility maps processed using (a) DS rule, (b) FGO, (c) HFWA, (d) HFWG, (e) HFWOA, (f) HFWOG, (g) Cc-Euclidean distance, (h) Cc-Manhattan distance
DS, FGO, HFWA, HFWG, HFWOA, HFWOG, Cc-Euclidean and Cc-Manhattan techniques predicted the VL and L flood potential classes 87.5%, 92.3%, 92.3%, 91.6%, 89.4%, 91.6%, 89.4% and 89.4% of Kocanaz watershed and 4, 5, 5, 3, 6, 3, 6 and 6 flooded points in those classes, respectively. They predicted the H and VH flood potential classes 10.6%, 6.4%, 7%, 5.6%, 5.1%, 6.4%, 4.9% and 4.5% of Kocanaz watershed and 70, 67, 70, 57, 66, 67, 63 and 63 flooded points in those classes, respectively.
Validation of the results gains a quantitative measure to reach a qualitative assessment. Estimated flood susceptibility maps are validated by receiver operating characteristics (ROC) curve method using extracted flood susceptibility values for both training and testing data (Fig. 4). In this study, seed cell area index (SCAI), as well as ROC parameters, has a prominent role for validation of the results and judgment of the predictions in contrary to most of the researchers since the ROC parameters may not be sufficient to provide in-depth accurate predictions. The area under ROC curve (AUROC) values of training process are 0.997 for DS, HFWA, HFWOA, and Cc-Euclidean, 0.996 for Cc-Manhattan, 0.995 for FGO and 0.994 for HFWG and HFWOG. The AUROC values of the testing process are 0.951 for DS, HFWA, HFWOA, Cc-Euclidean, and Cc-Manhattan, 0.945 for FGO, 0.943 for HFWG, and 0.941 for HFWOG. Information fusion techniques presented excellent performance in the training and testing processes. True skill statistics (TSS) values indicate the same constant values throughout training and testing, independent of information fusion techniques. TSS value is 0.962 for the training process and 0.870 for the testing process. This arises from the outcome of the decision tree classification algorithm that predicts the same number of true and false positives.

Validation of the estimated flood susceptibility maps by extraction values of (a) training, (b) testing processes
The seed cell area index (SCAI) is a crucial criterion that determines the goodness of the predictions. SCAI enables distinguishing a well-predicted flood susceptibility map with the same ROC values. SCAI values are fitted with the classes (from 1 referring to VL to 5 referring to VH) flood potential classes (Fig. 5). SCAI is sensitive to the classification methods. The natural break method considers the ranges of flood susceptibility values and relative variation of interclasses and limits the boundaries accordingly. However, this issue may be suppressed since the natural break method is adapted for classifying flood susceptibility maps produced from all the information fusion techniques. From the point of view of the areal percentages of flood susceptibility classes, they are not regularly ordered. The shortcomings of the decision tree model are noticed to dominate the disordered variation of areal percentages of the classes for the whole method. The reason why the DS method overestimates flood susceptibility is reflected in excessive numbers of the H and VH class pixels. Suppression capability of the information fusion techniques may also be tested to overcome this challenge.

SCAI values versus flood potential classes (from 1 referring to VL to 5 referring to VH) for (a) DS, (b) FGO, (c) HFWA, (d) HFWG, (e) HFWOA, (f) HFWOG, (g) Cc-Euclidean distance, (h) Cc-Manhattan distance
An ideally estimated flood susceptibility map with the highest accuracy should involve lesser areal percentage and the whole flooded points at H and VH classes. SCAI value should have a value of infinity at VH class and zero value at VL class. SCAI values are fitted with VL to VH flood potential classes of the predicted maps. SCAI phenomena may be idealized as asymptotic lines at vertical and horizontal axes. However, SCAI versus flood potential classes may be simulated as an exponential tendency and should exhibit a decreasing trend as the flood potential increases. The coefficient of determination (R2) is greater than 0.9, except for DS and HFWOA, indicating very good estimations. FGO, HFWA, and HFWOG follow this pattern of relation. HFWOA, HFWG, Cc-Euclidean, and Cc-Manhattan techniques do not comfort this relationship despite their high R2 values. SCAI and flood susceptibility class of HFWA outperform the best, while DS performs the worst. HFWOG also exhibits a similar manner as HFWA. Interpretation of the difference in outcomes points out the inherent uncertainty of information fusion techniques. Hence, these techniques are understood to have an outcome to cover the shortcomings of decision tree classifications promisingly.
4 Conclusion
Floods because of climate change impact are assessed as the most important environmental and ecological threatening factor. Hence, new policies are required to manage environmental challenges and adapt environmental management strategies to overcome the fragility of humans, the environment, and ecology. Flood susceptibility mapping studies have an increasing trend to provide and afford a guide for the sustainability of environmental protection. Flood susceptibility mapping studies are the first stage in getting a great motivation for combating and highlighting human needs. Hence, this study proposes a novel and reliable methodology to provide a more accurate flood susceptibility map.
This paper examines the effects of information fusion techniques on decision tree classification-based flood susceptibility mapping of Kocanaz watershed to get more reliable predictions. The Bel function values are an efficient tool for hybridizing flood conditioning factors. Information of the Bel values of the conditioning factors is fused to get a unique value at leaf nodes as an intersection of the classes of the factors. Akay (2021b) and Akay (2022) employed the Bel values using the Dempster-Shafer rule and HFWOA aggregation operators to combine the factors based on various decision tree-based learning models to estimate snow avalanche susceptibility. However, in this study, various methods to enable reaching a consensus and getting a relatively compromising solution, such as DS, fuzzy gamma overlay, HFWA, HFWG, HFWOA, HFWOG, Cc-Euclidean distance, and Cc-Manhattan, are adapted. The predicted results are validated by adapting the ROC and SCAI analyses and discussed in detail. The TSS results and percentages of flood potential areas reveal the decision tree classification model's weakness. ROC parameters point out very good estimation, but spatial variation of flood potentials differ. A very good performance indicating the ROC parameters may be avoided in spatial variation of flood potentials. DS overestimates the H and VH flood potentials and exhibits weakness in the relation between SCAI and flood potentials. Generated maps via geographic information system software tools point out the inherent uncertainty effects of the information fusion techniques. However, the improvement effects of information fusion techniques can be visible in the estimations. HFWA and HFWOG lead a good SCAI and flood potential, and they all have very good ROC parameters. Information fusion techniques employed in this study may be a new paradigm for re-assessing multiple conditioning factors by assigning a single value of the intersections of the attributes based on a classification-type learning system. New construction facilities and land use controls may be promoted with the outcomes of the flood susceptibility maps.
On the other hand, various hybridization tools using bivariate statistical techniques may be tested, and flood susceptibility may be classified using different algorithms to get classification method-independent results and avoid inherent uncertainty.
Data Availability
Limited data is available upon request.
References
Adnan MSG et al (2023) A novel framework for addressing uncertainties in machine learning-based geospatial approaches for flood prediction. J Environ Manage 326:116813
Akay H (2021a) Flood hazards susceptibility mapping using statistical, fuzzy logic, and MCDM methods. Soft Comput 25(14):9325–9346
Akay H (2021b) Spatial modeling of snow avalanche susceptibility using hybrid and ensemble machine learning techniques. CATENA 206:105524
Akay H (2022) Towards linking the sustainable development goals and a novel-proposed snow avalanche susceptibility mapping. Water Resour Manage 36(15):6205–6222
Al-Areeq AM et al (2023) Flood subsidence susceptibility mapping using elastic-net classifier: new approach. Water Resour Manage 37:4985–5006
Allouche O, Tsoar A, Kadmon R (2006) Assessing the accuracy of species distribution models: Prevalence, kappa and the true skill statistic (TSS). J Appl Ecol 43:1223–1232
Avand M, Kuriqi A, Khazaei M, Ghorbanzadeh O (2022) DEM resolution effects on machine learning performance for flood probability mapping. J Hydro-Environ Res 40:1–16
Chen Y (2022) Flood hazard zone mapping incorporating geographic information system (GIS) and multi-criteria analysis (MCA) techniques. J Hydrol 612:128268
Costache R et al (2022) Flood susceptibility evaluation through deep learning optimizer ensembles and GIS techniques. J Environ Manage 316:115316
Ghobadi M, Ahmadipari M (2024) Enhancing Flood Susceptibility Modeling: a Hybrid Deep Neural Network with Statistical Learning Algorithms for Predicting Flood Prone Areas. Water Resour Manage 38:2687–2710
Hasan MH, Ahmed A, Nafee KM, Hossen MA (2023) Use of machine learning algorithms to assess flood susceptibility in the coastal area of Bangladesh. Ocean Coast Manage 236:106503
Hwang CL, Yoon K (1981) Multiple attribute decision making: methods and application. Springer, New York
Liao HC, Xu ZS, Xia MM (2014) Multiplicative consistency on hesitant fuzzy preference relation and the application on group decision making. Int J Inf Tech Decis 13:47–76
Malczewski J et al (2003) GIS-multicriteria evaluation with ordered weighted averaging (OWA): a case study of developing watershed management strategies. Environ Plann A 35:1769–1784
Quinlan JR (1993) C4.5: Programs for Machine Learning. San Mateo, CA
Rahman M et al (2019) Flood susceptibility assessment in Bangladesh using machine learning and multi-criteria decision analysis. Earth Syst Environ 3:585–601
Rana MS, Mahanta C (2023) Spatial prediction of flash flood susceptible areas using novel ensemble of bivariate statistics and machine learning techniques for ungauged region. Nat Hazards 115:947–969
Sahraei R et al (2022) A novel hybrid GIS‐based multi‐criteria decision‐making approach for flood susceptibility analysis in large ungauged watersheds. J Flood Risk Manag 16:e12879
Solaimani K, Shokrian F, Darvishi S (2023) An assessment of the integrated multi-criteria and new models efficiency in watershed flood mapping. Water Resour Manage 37:403–425
Tang Z, Zhang H, Yi S, Xiao Y (2018) Assessment of flood susceptible areas using spatially explicit, probabilistic multi-criteria decision analysis. J Hydrol 558:144–158
Torra V (2010) Hesitant fuzzy sets. Int J Intell Syst 25(6):529–539
Torra V, Narukawa Y (2007) Modeling decisions: information fusion and aggregation operators. Springer Science & Business Media, Berlin, Heidelberg
Xiao Y, Yi S, Tang ZA (2018) Spatially Explicit Multi-Criteria Analysis Method on Solving Spatial Heterogeneity Problems for Flood Hazard Assessment. Water Resour Manage 32:3317–3335
Yager RR (1988) On ordered weighted averaging aggregation operators in multi-criteria decision making. IEEE T Syst Man Cyb 18:183–190
Zhao G et al (2018) Mapping flood susceptibility in mountainous areas on a national scale in China. Sci Total Environ 615:1133–1142
Acknowledgements
The author would like to thank the Scientific and Technological Research Council of Türkiye (TÜBİTAK) for providing a digital elevation model, land use, and soil map (Project No. 114M292).
Funding
Open access funding provided by the Scientific and Technological Research Council of Türkiye (TÜBİTAK). The author gives many thanks to TÜBİTAK for data and technical support.
Author information
Authors and Affiliations
Contributions
All steps in the manuscript were implemented by Hüseyin Akay.
Corresponding author
Ethics declarations
Consent to Participate
Author consent to participate in this research /publication.
Consent to Publish
This research does not have any consent to publish.
Conflict of Interest
The author declares that they have no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Akay, H. Flood Susceptibility Mapping Using Information Fusion Paradigm Integrated with Decision Trees. Water Resour Manage (2024). https://doi.org/10.1007/s11269-024-03918-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11269-024-03918-5