
Abstract
Precipitation is the most important element of the water cycle and an indispensable element of water resources management. This paper’s aim is to model the monthly precipitation in 8 precipitation observation stations in the province of Hamadan, Iran. The effects and role of different feature weights pre-processing methods (Weight by deviation, Weight by PCA, Weight by correlation and Weight by Support Vector Machine) on artificial intelligence modeling were investigated. Deep learning method based on a multi-layer feed-forward artificial neural network that is trained with Stochastic Gradient Descent using back-propagation (DL-SGD) and Convolutional Neural Networks (CNN) modelling were applied. The precipitation of each station is modeled using the precipitation values of the other stations. The best result, among all scenarios, at the Vasaj station according to the DL-SGD method (CC = 0.9845, NS = 0.9543 and RMSE = 10.4169 mm) and at the Varayineh station according to the CNN method (CC = 0.9679, NS = 0.9362 and RMSE = 16.0988 mm) were estimated.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Water resources fed by precipitation are globally becoming increasingly important, in terms of both environment and socio-economic aspects. Global warming, climate change and droughts, on the one hand, and unsuccessful water resources management policies, on the other hand, adversely affect the environment and people’s lives (Sattari et al. 2012; Inan 2021). Precipitation has a random and stochastic nature. Precipitation is in a complex and non-linear relationship with other meteorological variables (Zhu et al. 2022). As a matter of fact, precipitation levels in a basin and neighbouring precipitation stations in the same climate are also in connection with each other. There are different statistical models for the estimation of precipitation levels. However, in recent years, it is seen that data-based models that can make predictions by using only observed data from past periods, without caring about the physics of the event, have expanded in all branches of science. Measured or observed historical data are the basis of models such as data mining, data-driven models, black box, artificial intelligence, machine learning and deep learning.
Various studies use data-driven methods in modeling precipitation (Xie et al. 2021). Nourani et al. (2017) estimated the maximum precipitation in Iran using decision tree and association rules models. In this study, along with meteorological variables, the Black, Mediterranean and Red Seas, sea surface temperature values were used as model inputs. The estimated measures attest to the suggested hybrid data mining method's dependability in predicting extreme precipitation events while taking higher threshold values into account. Chen et al. (2020) used the Deep Learning-based multilayer perceptron (MLP) method to predict precipitation. In the study, high quality precipitation products from the ground radar network were used as target tags to train the MLP model. Apaydin and Sattari (2020) used a hybrid approach of deep learning and geographic information system based on spatio-temporal variables to model the amount of precipitation on the Turkish coastline. Spatial variables such as latitude, longitude, altitude, distance to the sea and the change in monthly precipitation were considered as temporal variables. Yan et al. (2021) successfully predicted precipitation using 5-year meteorological data from 26 stations in the Beijing-Tianjin-Hebei region of China, with a new Attentive Interpretable Tabular Learning Neural network (TabNet) approach using machine learning to monitor and method precipitation with the help of satellite system. Kassem and Gökçeku (2021) estimated monthly precipitation in Nigeria using artificial intelligence and mathematical models. They used a multilayer feedforward neural network, graded feedforward neural network and radial basis neural network models together with quadratic and Poisson regression models.
With the help of cutting-edge soft computing methods including multivariate adaptive regression splines (MARS), classification and regression trees (CART), and gene expression programming (GEP), Chaplot (2021) sought to concentrate on the rainfall prediction in India's Udaipur district, which receives 631 mm of annual rainfall. Diriba and Debusho (2021) used a multivariate conditional modeling approach to analyze the behavior of common precipitation events in South Africa to explore the co-dependence of extreme precipitation events. Vathsala and Koolagudi (2021) used a combination of data mining and neuro-fuzzy inference system to predict precipitation in India. Precipitation levels were successfully estimated with the if–then rules derived according to the proposed method in the study. Ahi et al. (2023) aimed to predict evaporation in the Karaidemir Reservoir in Turkey using ANN and 30 years of daily meteorological data. Afshari Nia et al. (2023) combined the deep learning model with ANN to predict monthly precipitation in the Kashan plain of Iran. Three different models were developed to compare the results of the study. That the literature review showcases how artificial intelligence and machine learning techniques consistently make effective and accurate predictions worldwide (Lin et al. 2021; Ng et al. 2021; Tabatabaei et al. 2021; Roslan et al. 2021).
The aim of this research is modelling the monthly precipitation of the neighbouring station in the Hamadan region by deep learning method based on a multi-layer feed-forward artificial neural network that is trained with Stochastic Gradient Descent using back-propagation (DL-SGD) and Convolutional Neural Networks (CNN). The methods used in the study to forecast precipitation at the neighbouring stations are well-known, but it is unclear which stations should be included in the model to estimate the data of each station. This study considered how the weights should be taken into account in order to use the least number of neighboring station data. The novelty of the research consists in applying the Simple Additive Weighted (SAW) technique, then designing and applying three types of scenarios when choosing the correlated sources based on the computed aggregated weights (AW): (1) ALL scenario – no selection of correlated sources, (2) W1 scenario – all sources having AW > 1, (3) W2 scenario – all sources having AW > 2. In addition, our study seeks to improve the precipitation forecast by using data from fewer stations by using four different feature weights pre-processing (Weight by deviation, Weight by PCA, Weight by correlation and Weight by SVM) method and to investigate the effects of stations on one another.
2 Material and Methods
2.1 Case Study
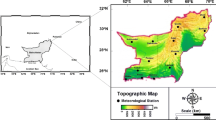
Hamadan province is located in the Western part of Iran and is characterized by its mountainous topography. The region has moderate temperatures in summer and very cold in winter (Baaghideh et al. 2017). The input data came from 8 stations: Varayineh, Kheyirabad, Sarabi, Khosroabad, Namileh, Pihan, Vasaj (Fig. 1). For each of these locations the information available was the value for the rainfall. The available data was collected for 300 months. The monthly precipitation data of 8 precipitation observation stations between 1995–2019 water year were used. The geographical location of these stations and the statistical properties of precipitation amounts are given in Table 1.

Study locations
As can be seen in Table 1, Varayineh is the station with the highest rainfall with a mean annual precipitation of 557.64 mm (monthly mean average of 46.47 mm) and Namileh has the least mean annual precipitation with 322.44 mm (26.87 mm monthly mean precipitation). At the same time, according to Table 1, it is seen that the study area is rugged and mountainous with an altitude of at least 1525 m (Khosroabad) and at most 1925 m (Sarabi).
When the monthly precipitation levels are examined (Fig. 2 and Table 2), it is seen that the averages fall below 50 mm, and the extreme precipitations levels are below 200 mm with the exception of Varayineh and Babapirali stations. Unprecedented precipitation occurred in the region in April 2019 (295th month) in last 70 years (Sinamet 2018), and the highest values observed in all stations were measured in this event. The driest months in the region are July–August with the wettest occurring in April.

Distribution of monthly precipitation and extreme values
According to Fig. 3, where the precipitation time series is given, the water years of 1999 and 2008 are the driest; The water years of 1995, 2016 and 2019 were the wettest periods. Varayineh was the station with the most rainfall, while Namileh and Pihan had the least rainfall.

Yearly time series of precipitation
2.2 Methods
The purpose of the research is to determine the best approach for predicting the rainfall of a specific location, when also having the input of other stations in the proximity. Various combinations and scenarios have been determined using different model inputs. In addition, various feature weights were taken into account in the selection of scenarios. To compute the relevance of the attributes (correlated sources) for each location, additional methods were used, described as follows.
2.2.1 Feature Weights, Selection and Scenarios
Weight by Deviation
Computes the weight of attributes with respect to the predicted attribute based on the (normalized) standard deviation of the attributes. It is only applicable to numerical predictions.
Weight by PCA (Principal Component Analysis)
Uses an orthogonal transformation to transform an initial (correlated) set of data into an equal or smaller set of so called principal components (a new set of uncorrelated attributes).
Weight by Correlation
Computes the correlation between each attribute in the initial data set and the attribute predicted. The value returned is the absolute or squared value of the resulted correlation for each attribute.
Weight by SVM
Calculates the relevance of the attributes by computing for each attribute of the initial data set, the weight with respect to the predicted attribute. The coefficients of a hyperplane calculated by an SVM are set as attribute weights.
The attributes with the highest weights are considered to have the highest relevance for all the above methods.
Each of the eight available locations was considered as predicted target and the values of the proposed weights were computed for all the other locations with respect to the predicted one. Once the results were obtained, the next step was to normalize the weights value, since these were in different ranges. According to Schowe (2011) there are three possibilities to combine the resulted weights: (1) by counting the number of times a feature was selected among top k features – the k features with the highest count are considered; (2) by defining a minimum number of iterations that a feature has to be selected; (3) by accumulating weights. In the present research, the third option was considered and the sum of the featured weights was computed for each location. It is also known as SAW (Prasetiyo and Baroroh 2016; Kaliszewski and Podkopaev 2016; Setyawan et al. 2017).
In the scenario creation phase, 3 alternatives were determined. In the first alternative (Called Scenario All), all stations surrounding a station participated in the modeling. In the second scenario (Scenario W2), stations providing the condition of the locations with a scored sum of weights > = 2 were included in the modeling. In the third scenario (Scenario W1), stations providing the condition of the locations with a scored sum of weights > = 1 were included in the modeling.
2.2.2 Deep Learning Based on a Multi-Layer Feed-Forward Artificial Neural Network
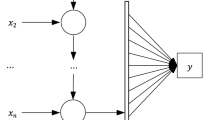
Deep Learning models was performed using RapidMiner. This algorithm is based on a multi-layer feed-forward artificial neural network, trained with stochastic gradient descent using back-propagation. The RapidMiner operator starts a 1-node local H2O cluster and runs the algorithm on it. In the implemented scenarios, it attempts to minimize the network error by using the gradient descent method, more specific, by moving down the gradient of the error curve (Alsmadi et al. 2009).
Parameter Optimization
The network can have multiple hidden layers of neurons, with the activation functions being Tanh, Rectifier or Maxout (Neamt et al. 2017). Before running the final experiment, we needed to know what the best combination of parameter inputs for the algorithm is. For this purpose, the following combinations of parameters were considered:
-
Activation: Tanh, Rectifier, Maxout, ExpRectifier;
-
Epochs: 10, 20, 30, 40, 50;
-
Learning rate: 0.1 to 1 with a step of 0.1.
The best combination of parameters was chosen by looking at the results that produced the lowest Root Mean Squared Error (RMSE) per scenario (more than 2000 combinations per each feature weight scenario). Overall, the best results have been obtained for the ExpRectified activation function, 10 as number of epochs and learning rate different by case.
After the optimal values for the parameters were determined, the process described in Avram et al. (2020) has been applied to the input data in order to obtain the results for the predicted location (Fig. 4). The 300 months of input data were split into 70% data for learning the model and 30% data for testing it.

Schematic example of the methods exemplified for the Pihan station
2.2.3 Convolutional Neural Networks (CNN) in Python
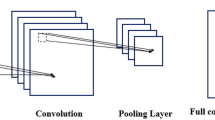
CNN were developed and inspired by biological processes in that the connection model between neurons resembles the organization of the animal visual cortex, and was first presented at the Neural Information Processing Workshop in 1987. CNN are deep artificial neural networks mainly used for classifying images, clustering similarities, and object identification. CNN is very successful in revealing the features of the data. A basic CNN network architecture usually has a ReLU layer as the activation function, followed by hidden layers such as fully connected layers, normalization layers, and pooling layers. Inputs and outputs are masked by the activation function.
Python programming language and its libraries were used for CNN modelling (https://github.com/Hapaydin/Hamadan/). The alternative Learning Rate (LR), Activation function, Decay (DE) and epochs of the models are determined using the grid search algorithm. In the initial stage LR, 0.1 to 1 with a step of 0.1 was used but produced worse results. Instead, 1e−1, 1e−2, 1e−3, 1e−4 and 1–5 were chosen. ReLU, Tanh and Sigmoid chosen as activation function. Decay from 1e−1 to 1e−5, and 5, 10, 50, 100, 500 and 1000 epochs have been tried.
The assumption that data collected for the study is unbiased and that there is no error during the collection of measurements was taken into account. In addition, in the preparation of the experiments and parameter optimization phase, since the number of combinations might be infinite and the resources limited, we based the selection of the best option by looking at the RMSE and the overall results of about 2000 combinations per scenario.
2.3 Evaluation Metrics
More well-known metrics such as Pearson correlation coefficient (r), Nash–Sutcliffe coefficient (NS), Willmott index of agreement (WI), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE) were computed in the evaluation of the models (Hyndman and Koehler 2006).
3 Results
3.1 Feature Selection
In this study, firstly, a station was selected as the target station and the weights of the other stations were calculated according to the feature weights algorithms. Then this process was applied for each station. For the purpose of comparison between the calculated weights, Table 3 presents the summary of the obtained aggregated feature weights results, ordered by descending value, for each predicted location.
As can be seen from Table 3, the weights vary between 0 and 3.6195. Three alternatives were considered for the formation of the scenarios. To predict the target station; i) All stations as input (w = > 0), ii) Stations with resulted sum of weights > = 2 and, iii) Stations with resulted sum of weights > = 1 were considered as model input and scenarios were selected as in Table 4.
In this case, either all stations or stations with a value greater than 1 or 2 according to the degree of weights were taken into account in order to estimate the precipitation of the target station. Naturally, the accuracy rate will increase when all stations are considered as model inputs, but it is aimed to avoid the size and complexity of the model by modeling with the least number of stations. In this context, the performance of each scenario in each station and method was evaluated separately.
3.2 Results of DL-SGD Method
The results obtained according to the deep learning based on a multi-layer feed-forward artificial neural network (DL-SGD) method are given in Table 5. The DL-SGD method predicted monthly precipitation at all stations with great success. In general, the results of all 3 scenarios follow each other with very little difference. At this stage, the results of each target station were discussed one by one.
-
1.
Babapirali: In this station, the best result was obtained as CC = 0.9626 and RMSE = 15.2109 mm in the test phase according to the W1 scenario (Vrayyineh, Sarabi, Vasaj, Khosroabad and Kheyirabad). As can be seen here, Namileh and Pihan stations did not have an effect on the forecast of Babapirali station precipitation. As can be seen from the map in Fig. 1, Namileh and Pihan stations are located at a far distance from Babapirali station, and in this case, it is logical that these two stations have little or no physical effect on Babapirali precipitation.
-
2.
Kheyirabad: In this station, although the CC value of the All scenario is slightly higher, the RMSE value is 1 mm lower, so it was chosen as the best alternative (CC = 0.9779 and RMSE = 16.6576 mm) in the testing phase compared to the W1 scenario (Sarabi, Varayineh, Vasaj, Babapirali and Namileh). As can be seen here, Khosroabad and Pihan stations had no effect on the forecasting of precipitation at Kheyirabad station. As can be seen from the map in Fig. 1, Khosroabad station is located at a far distance from Kheyirabad station and also Pihan station is 100 m higher than Kheyirabad station. In this case, it is thought that these two stations have no effect on Kheyirabad precipitations.
-
3.
Khosroabad: At this station, the best result (CC = 0.9285 and RMSE = 18.9193 mm) was determined in the test phase according to the W2 scenario (Vrayyineh, Sarabi, Babapirali and Vasaj). As can be seen here, Kheyirabad, Namileh and Pihan stations did not have an effect on the forecast of Khosroabad station precipitation. As can be seen from the map in Fig. 1, Khosroabad station is located at a far distance from Kheyirabad, Namileh and Pihan stations. In this case, it is thought that these three stations will not have any effect on Khosroabad precipitation.
-
4.
Namileh: In this station, the best result was determined as CC = 0.9477 and RMSE = 15.2309 mm in the test phase according to the All scenario (all stations).
-
5.
Pihan: In this station, the best result CC = 0.9707 and RMSE = 14.7623 mm was determined in the test phase according to the All scenario (all stations).
-
6.
Sarabi: At this station, the best result (CC = 0.9840 and RMSE = 13.5916 mm) was determined during the test phase according to the All scenario (all stations). As can be seen from the map in Fig. 1, Sarabi station is located in the approximate center of the study area. From this point of view, it is expected that the All scenario and all stations are effective for precipitation estimation.
-
7.
Varayineh: At this station, the best result (CC = 0.9670 and RMSE = 20.6893 mm) was determined during the test phase according to the All scenario (all stations).
-
8.
Vasaj: At this station, the best result (CC = 0.9845 and RMSE = 10.4169 mm) was determined during the test phase according to the All scenario (all stations). As can be seen from the map in Fig. 1, Vasaj station is also located in the relatively central position of the study area. From this point of view, it is expected that the All scenario and all stations will be effective for precipitation prediction.
Considering the results of all 8 stations, the DL-SGD method successfully predicted monthly precipitation levels at Vasaj station with the highest accuracy rate and the least error according to the evaluation criteria.
In order to make a better visual evaluation and comparison, the time series and scatter plot graphics of all 8 stations according to the DL-SGD method are given in Fig. 5. As can be seen from Fig. 5, the precipitation levels of all stations in general have been estimated at an acceptable level according to all 3 scenarios. At the same time, smaller levels of precipitation are better predicted than medium and high levels. It is seen that the elevation of the stations and their positions relative to the other stations are affected by the estimation values. In general, it was concluded that the DL-SGD method was effective at estimating monthly precipitation.




Time series and scatter plots of the DL-SGD method
3.3 Results of CNN Method
The results obtained according to the CNN method are given in Table 6. Table 6 shows that when precipitation is calculated at all stations and in all 3 scenarios according to the CNN method, the CC value is high, but the amount of error is high at other stations with the exception of the Babapirali and Varyaneh stations. All 8 stations were evaluated separately, taking into account the evaluation criteria given in Table 6.
-
1.
Babapirali: At this station, the best results (CC = 0.9615 and RMSE = 15.6860 mm) were obtained in the W1 scenario (Varayineh, Sarabi, Vasaj, Khosroabad and Kheyirabad) during the test phase. As can be seen, the Namileh and Pihan stations had no effect on the forecasting of precipitation at Babapirali station. As explained in the same DL-SGD method, the map in Fig. 1 shows that the Namileh and Pihan stations are located at a remote distance from the Babapirali station, and it is logical that these two stations have no physical effect on the Babapirali precipitation levels. Thus, we can see that DL-SGD and CNN methods provide similar results at Babapirali station.
-
2.
Kheyirabad: At this station, the best result (CC = 0.9665 and RMSE = 10.0270 mm) was obtained from the All scenario (all stations). Considering the CC and RMSE values obtained here, it cannot be said clearly which of the CNN and DL-SGD methods is more effective.
-
3.
Khosroabad: According to the W2 scenario (Varayineh, Sarabi, Babapirali and Vasaj) at this station, the best result in the test phase was determined as CC = 0.8720 and RMSE = 18.5460 mm. The Kheyirabad, Namileh and Pihan stations did not have an effect on the prediction of precipitation at the Khosroabad station. While the RMSE values of the DL-SGD and CNN methods are close to each other, the CC value of the DL-SGD method is higher.
-
4.
Namileh: According to the All scenario (all stations) at this station, the best result was determined as CC = 0.9421 and RMSE = 11.3406 mm during the test phase. While the CC values of the DL-SGD and CNN methods are close to each other, the RMSE value of the CNN method is lower.
-
5.
Pihan: At this station, the best results (CC = 0.9430 and RMSE = 11.1221 mm) were obtained in the All scenario (all stations). Considering the CC and RMSE values obtained here, it cannot be said clearly which of the CNN and DL-SGD methods is more successful.
-
6.
Sarabi: In this station, the best result was obtained as CC = 0.9753 and RMSE = 8.5302 mm in the test phase according to the W2 scenario (Varayineh, Vasaj, Kheyirabad and Babapirali). While the CC values of the DL-SGD and CNN methods are close to each other, the RMSE value of the CNN method is lower.
-
7.
Varayineh: In this station, the best result in the All scenario (all stations) alternative was determined as CC = 0.9679 and RMSE = 16.0988 mm. While the CC values of the DL-SGD and CNN methods are close to each other, the RMSE value of the CNN method is lower.
-
8.
Vasaj: At this station, the best result (CC = 0.9700 and RMSE = 8.4304 mm) was obtained in the W1 scenario (Sarabi, Varayineh, Kheyirabad, Babapirali and Khosroabad). While the CC values of the DL-SGD and CNN methods are close to each other, the RMSE value of the CNN method is lower.
When the results of these 8 stations are examined, it is seen that the estimation results of the CNN method are quite accurate in other stations except for Khosroabad station. Considering the RMSE values, CNN gave more accurate results than the DL-SGD method. Considering the CC and NS values, a definite superiority cannot be determined. In order to make a more effective evaluation and comparison visually, the time series and scatter plot graphics of all 8 stations according to the CNN method are given in Fig. 6.




Time series and scatter plots based on feauture selection methods for all stations on CNN method
As can be seen in Fig. 6, the precipitations of all stations are generally estimated at an acceptable level based on the CC and RMSE values for each of the 3 scenarios. However, when we consider the margins of error, only the Babapirali and Varayineh stations have made really accurate estimations. When we look at the scatter plots here, it is seen that the points are sparse and scattered to the far points of the diagonal line, and, consequently, it is inevitable that the error value increases.
4 Discussion and Conclusions
In this study, the monthly precipitation levels of 8 precipitation observation stations were estimated according to the precipitation levels of neighbouring stations and based on the principle that precipitation events between neighbouring stations may be similar. This was done by applying the Stochastic Gradient Descent using back-propagation (DL-SGD) and Convolutional Neural Networks (CNN). The novelty proposed in the paper is designing scenarios by reducing the number of sources based on the computed AW (aggregated weights).
Four feature selection algorithms were used in evaluating the available data sources (Weight by deviation, Weight by PCA, Weight by correlation and Weight by SVM) and SAW technique was used to combine the results. Three distinct scenarios, involving a different number of sources, based on the value of the aggregated weights, were proposed, and applied using the DL-SGD and CNN methods. The following conclusions were reached after analysing the outcome:
-
In the selection of the scenarios, it was observed that the weight values were compatible with the station locations and the distance between the stations.
-
The CNN model predicted precipitation at other stations with low error values, with the exception of one station. It can be stated that the CNN method provided better results overall, since all the scenarios produced results closer to the observed value than when applying the DL-SGD method.
-
Since this study was conducted in a semi-arid and mountainous region, the results may not yield similar results in all climates and regions. This may be considered as a disadvantage of the study.
-
All three proposed scenarios produced similar results in estimating the monthly precipitations, hence the SAW technique can be used to reduce the number of correlated sources.
-
Another enhancement that could be done is expanding the list of machine learning algorithms applied and extending the research to different areas while addressing other practical prediction problems.
One of the main limitations of the study is that it refers only to a certain selected areal (province of Hamadan, Iran) and because of its specificity, the extracted conclusions cannot be generalized. However, the proposed approach of considering only a subset of the correlated sources, by applying the SAW technique is a procedure that could be further enhanced by exploring the limit of this value that would still allow for accurate predictions.
Data Availability
Data are available on request due to privacy or other restrictions.
Code Availability
Rapidminer (educational license) was used. Python code are available on https://github.com/Hapaydin/Hamadan.
References
Afshari Nia M, Panahi F, Ehteram M (2023) Convolutional neural network- ANN- E (Tanh): A new deep learning model for predicting rainfall. Water Resour Manag 37:1785–1810. https://doi.org/10.1007/s11269-023-03454-8
Ahi Y, Coşkun Dilcan Ç, Köksal DD (2023) Reservoir evaporation forecasting based on climate change scenarios using ANN. Water Resour Manag 37:2607–2624. https://doi.org/10.1007/s11269-022-03365-0
Alsmadi MKS, Omar K, Noah SA (2009) Back propagation algorithm: The best algorithm among the multi-layer perceptron algorithm. Int J Comput Sci Netw Secur 378–383
Apaydin H, Sattari MT (2020) Deep-learning GIS hybrid approach in precipitation modeling based on spatio-temporal variables in the coastal zone of Turkey. Climate Res 9:81. https://doi.org/10.3354/cr01612
Avram A, Matei O, Pintea C, Anton C (2020) Innovative platform for designing hybrid collaborative & context-aware data mining scenarios. Mathematics 5:8. https://doi.org/10.3390/math8050684
Baaghideh M, Fallah Ghalhari G, Hajimohammadi H, Rezaei H (2017) Investigating the role of irregularities in the formation of regions and sub-regions of Hamadan Province. Quart Geogr Data 26(103):109–122. https://doi.org/10.22131/sepehr.2017.28897
Chaplot B (2021) Prediction of rainfall time series using soft computing techniques. Environ Monit Assess 193:721. https://doi.org/10.1007/s10661-021-09388-1
Chen H, Chandrasekar V, Cifelli R, Xie P (2020) A machine learning system for precipitation estimation using satellite and ground radar network observations. IEEE Trans Geosci Remote Sens 2:58. https://doi.org/10.1109/TGRS.2019.2942280
Diriba TA, Debusho LA (2021) Statistical modelling of extreme rainfall indices using multivariate extreme value distributions. Environ Model Assess 8:26. https://doi.org/10.1007/s10666-021-09766-6
Hyndman RJ, Koehler AB (2006) Another look at measures of forecast accuracy. Int J Forecast 22:679–688. https://doi.org/10.1016/j.ijforecast.2006.03.001
Inan HI (2021) Spatial data model for rural planning and land management in Turkey. J Agric Sci 27(3):254–266. https://doi.org/10.15832/ankutbd.983096
Kaliszewski I, Podkopaev D (2016) Simple additive weighting—A metamodel for multiple criteria decision analysis methods. Expert Syst Appl 7:54. https://doi.org/10.1016/j.eswa.2016.01.042
Kassem Y, Gökçekuş H (2021) Do quadratic and Poisson regression models help to predict monthly rainfall? Desalin Water Treat 215. https://doi.org/10.5004/dwt.2021.26397
Lin K, Zhou J, Liang R, Hu X, Lan T, Liu M, Gao X, Yan D (2021) Identifying rainfall threshold of flash flood using entropy decision approach and hydrological model method. Nat Hazards 9:108. https://doi.org/10.1007/s11069-021-04739-0
Neamt L, Matei O, Chiver O (2017) Finite element method combined with neural networks for power system grounding investigation. Int J Adv Comput Sci Appl 8(2):187–192
Ng CWW, Liu ZQ, Kwan JSH, Yang B (2021) Spatiotemporal modelling of rainfall-induced landslides using machine learning. Landslides 7:18. https://doi.org/10.1007/s10346-021-01662-0
Nourani V, Sattari MT, Molajou A (2017) Threshold-based hybrid data mining method for long-term maximum precipitation forecasting. Water Resour Manag 7:31. https://doi.org/10.1007/s11269-017-1649-y
Prasetiyo B, Baroroh N (2016) Fuzzy simple additive weighting method in the decision making of human resource recruitment. Lontar Komputer: Jurnal Ilmiah Teknologi Informasi 12. https://doi.org/10.24843/LKJITI.2016.v07.i03.p05
Roslan N, Md Reba MN, Sharoni SMH, Hossain MS (2021) The 3D neural network for improving radar-rainfall estimation in monsoon climate. Atmosphere 5:12. https://doi.org/10.3390/atmos12050634
Sattari MT, Apaydin H, Ozturk F, Baykal N (2012) Application of a data mining approach to derive operating rules for the Eleviyan irrigation reservoir. Lake Reservoir Manag 28(2):142–152. https://doi.org/10.1080/07438141.2012.678927
Schowe B (2011) Feature selection for high-dimensional data with RapidMiner. Proceedings of the 2nd RapidMiner Community Meeting and Conference (RCOMM 2011), Aachen
Setyawan A, Akhlis I, Arini FY (2017) Comparative analysis of simple additive weighting method and weighted product method to new employee recruitment decision support system (DSS) at PT. Warta Media Nusantara. Sci J Inform 5:4. https://doi.org/10.15294/sji.v4i1.8458
Sinamet (2018) Analysis of unprecedented rainfall in April 2018 in Hamedan province. Ministry of Roads and Urban Development, National Meteorological Organization, General Directorate of Meteorology. Access date: 06 Jun 2023. http://www.sinamet.ir/data/prsinamet/pr/baresh%20bi%20sabegheh.pdf
Tabatabaei SM, Hamraz BS, Nazeri Tahroudi M (2021) Comparison of the performances of GEP, ANFIS, and SVM artificial intelligence models in rainfall simulation. Időjárás 125. https://doi.org/10.28974/idojaras.2021.2.2
Vathsala H, Koolagudi SG (2021) Neuro-fuzzy model for quantified rainfall prediction using data mining and soft computing approaches. IETE J Res 4. https://doi.org/10.1080/03772063.2021.1912648
Xie X, Xie B, Cheng J, Chu Q, Dooling T (2021) A simple Monte Carlo method for estimating the chance of a cyclone impact. Nat Hazards 107(3):2573–2582. https://doi.org/10.1007/s11069-021-04505-2
Yan J, Xu T, Yu Y, Xu H (2021) Rainfall forecast model based on the TabNet model. Water 4:13. https://doi.org/10.3390/w13091272
Zhu X, Xu Z, Liu Z, Liu M, Yin Z, Yin L, Zheng W (2022) Impact of dam construction on precipitation: a regional perspective. Mar Freshw Res 74:877–890. https://doi.org/10.1071/MF22135
Acknowledgements
This work was supported by the project “Collaborative Framework for Smart Agriculture” – COSA that received funding from Romania’s National Recovery and Resilience Plan PNRR-III-C9-2022-I8, under grant agreement 760070.
Author information
Authors and Affiliations
Contributions
Mohammad Taghi Sattari performed conceptualization, methodology, validation, writing—original draft preparation and supervision phases. Anca Avram performed methodology, software, validation, formal analysis, writing—original draft preparation and visualization stages. Halit Apaydin performed software, validation, data curation and visualization stages. O Oliviu Matei performed conceptualization, writing—review and editing, supervision phases. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Ethics Approval
No need/Not applicable.
Consent to Participate
No need/Not applicable.
Consent for Publication
No need/Not applicable.
Conflict of Interest/Competing Interests
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sattari, M.T., Avram, A., Apaydin, H. et al. Evaluation of Feature Selection Methods in Estimation of Precipitation Based on Deep Learning Artificial Neural Networks. Water Resour Manage 37, 5871–5891 (2023). https://doi.org/10.1007/s11269-023-03563-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-023-03563-4