
Abstract
The gap filling is common practice to complete hydrological data series without missing values for environmental simulations and water resources modeling in a changing climate. However, gap filling processes are often cumbersome because physical constraints, such as complex terrain and density of weather stations, often limit the ability to improve the performance. Although several studies of gap filling methods have been developed and improved by researchers, it is still challenging to find the best gap filling method for broad applications. This research explores a gap filling method to improve climate data estimates (e.g., daily precipitation) using gamma distribution function with statistical correlation (GSC) in conjunction with cluster analysis (CA). The daily dataset at the source stations (SSs) is utilized to estimate missing values at the target stations (TSs) in the study area. Three standard gap filling methods, including Inverse Distance Weight (IDW), Ordinary Kriging (OK), and Gauge Mean Estimator (GME) are evaluated along with cluster analysis based on statistical measures (RMSE, MAE, R) and skill scores (HSS, PSS, CSI). The result indicates that cluster analysis can improve estimation performances regardless of the gap filling methods used. However, the GSC method associated with cluster analysis, in particular, outperformed other methods when the performance comparison task was conducted under rain and no-rain conditions in the study area. The proposed method, GSC, therefore, will be used as a case toward advancing gap filling methods in the field.





Similar content being viewed by others
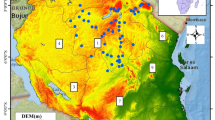

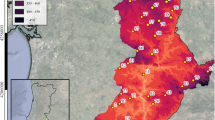
References
Adhikary SK, Muttil N, Yilmaz AG (2015) Genetic programming-based ordinary kriging for spatial interpolation of rainfall. J Hydrol Eng. doi:10.1061/(ASCE)HE.1943-5584.0001300, 04015062
Ahrens B (2006) Distance in spatial interpolation of daily rain gauge data. Hydrol Earth Syst Sci 20:197–208
ASCE (1996) Hydrology handbook, 2nd edn. American Society of Civil Engineers ASCE, New York
Barry RG, Chorley RJ (1987) Atmosphere, weather and climate, 5th edn. Routledge, London
Breiger RL, Boorman SA, Arabie P (1975) An algorithm for clustering relation data with applications to social network analysis and comparison with multidimensional scaling. J Math Psychol 12(3):328–384
Bunkers MJ, Miller JR, Degaetano AT (1996) Definition of climate regions in the northern plains using an objective cluster modification technique. J Climatol 9:130–146
Chang KT (2009) Introduction to geographic information systems. McGraw Hill, New York
Chen MS, Han J, Yu PS (1996) Data mining: an overview from a database perspective. IEEE Trans Knowl Data Eng 8(6):866–883
Chmielewski MS, Grzymala-Busse JW (1996) Global discretization of continuous attributes as preprocessing for machine learning. Int J Approx Reason 15(4):319–331
Davis JC (2002) Statistics and data analysis in geology. Wiley, New York
Eisen MB, Spellman PT, Brown PO, Botstein D (1998) Cluster analysis and display of genome-wide expression patterns. Proc Natl Acad Sci U S A 95:14863–14868
Faloutsos C, Oard DW (1998) A survey of information retrieval and filtering methods. Technical Report of the Computer Science Department, University of Maryland, No. CS-TR-3514
Garcia BIL, Sentelhas PC, Tapia L, Sparovek G (2006) Filling in missing rainfall data in the Andes region of Venezuela, based on a cluster analysis approach. Rev Bras Agrometeorologia 14(2):225–233
Gardner JW (1991) Detection of vapours and odours from a multisensory array using pattern recognition Part 1. Principal and component and cluster analysis. Sens Actuators B 4:109–115
Hansen P, Jaumard B (1997) Cluster analysis and mathematical programming. Math Program 79(1):191–215
Hasan MM, Croke BFW (2013) “Filling gaps in daily rainfall data: a statistical approach.” 20th International Congress on Modeling and Simulation, Adelaide, Australia, 1-6 December 2013
Hruschka ER, Ebecken NF (2003) A genetic algorithm for cluster analysis. Intell Data Anal 7(1):15–25
Isaake HE, Srivastava RM (1989) An introduction to applied geostatistics. Oxford University Press, Oxford
Journel AG, Huijbregts CJ (1978) Mining Geostatistics Academic, New York
Kanevski M, Maignan M (2004) Analysis and modeling of spatial environmental data. EPEL Press, Italy
Kim JJ, Ryu JH (2015) Quantifying a threshold of missing values for gap filling processes in daily precipitation series. Water Resour Manag 29(11):4173–4184
Kumar CNS, Ramulu VS, Reddy KS, Kotha S, Kumar CM (2012) Spatial data mining using cluster analysis. Int J Comput Sci Inf Technol (IJCSIT) 4(4):71–77
Llyod CD (2005) Assessing the effect of integrating elevation data into the estimation of monthly precipitation in Great Britain. J Hydrol 308:128–150
Lu GY, Wong DW (2008) An adaptive inverse-distance weighting spatial interpolation technique. Comput Geosci 34(9):1044–1055
Lund R, Li B (2010) Revisiting climate region definitions via clustering. J Climatol 22:1787–1800
Maarek YS, Berry DM, Kaiser GE (1991) An information retrieval approach for automatically constructing software libraries. IEEE Trans Softw Eng 17(8):800–813
MacQueen JB (1967) “Some methods for classification and analysis of multivariate observation.” Proceedings of 5-th Berkeley symposium on mathematical statistics and probability. University of California Press, Berkeley, pp 281–297
Mair A, Fares A (2011) Comparison of rainfall interpolation methods in a mountainous region of a tropical island. J Hydrol Eng 16(4):371–383
McCuen RH (1998) Hydrologic analysis and design. Prentice-Hall, NJ
Pan W, Lin J, Le CT (2002) Model-based cluster analysis of microarray gene-expression data. Genome Biol 3(2):1–8
Pedrycz W (1990) Fuzzy sets in pattern recognition: methodology and methods. Pattern Recogn 23(1):121–146
Ryu J, Palmer R, Matthew W, Jeong S (2009) Mid-range streamflow forecasts based on climate modeling-Statistical correction and evaluation. J Am Water Resour Assoc 45(2):355–368
Simanton JR, Osborn HB (1980) Reciprocal-distance estimate of point rainfall. J Hydraul Eng 106:1242–1246
Simolo C, Brunetti M, Maugeri M, Nanni T (2010) Improving estimation of missing values in daily precipitation series by a probability density function-preserving approach. Int J Climatol 30(10):1564–1576
Teegavarapu RSV (2007) Use of universal function approximation in variance-dependent surface interpolation method: An application in hydrology. J Hydrol 332(1–2):16–29
Teegavarapu RSV (2012) Spatial interpolation using nonlinear mathematical programming models for estimation of missing precipitation records. Hydrol Sci 57(3):383–406
Teegavarapu RSV (2014a) Statistical corrections of spatially interpolated missing precipitation data estimates. Hydrol Process 28:3789–3808
Teegavarapu RSV (2014b) Missing precipitation data estimating using optimal proximity metric-based imputation, nearest-neighbor classification and cluster-based interpolation methods. Hydrol Sci J 59(11):2009–2026
Teegavarapu RSV, Chandramouli V (2005) Improved weighting methods, deterministic and stochastic data-driven models for estimation of missing precipitation records. J Hydrol 312:191–206
Teegavarapu RSV, Tufail M, Irmsbee L (2009) Optimal functional forms for estimation of missing precipitation records. J Hydrol 374:106–115
Teegavarapu RSV, Meskele T, Pathak CS (2012) Geo-spatial grid-based transformations of precipitation estimates using spatial interpolation methods. Comput Geosci 40(1):28–39
Turkes M, Tatli H (2011) Use of the spectral clustering to determine coherent precipitation regions in Turkey for the period 1929–2007. J Climatol 31:2055–2067
Vieux BE (2001) Distributed Hydrologic Modeling using GIS. Water Science and Technology Library. Kluwer Academic Publishers
Watson DF, Philip GM (1985) A refinement of inverse distance weighted interpolation. Geo-Processing 2:315–327
Westerberg I, Walther A, Guerrero JL, Coello Z, Halldin S, Xu CY, Chen D, Lundin LC (2010) Precipitation data in a mountainous catchemnt in Honduras: quality assessment and spatiotemporal characteristics. Theor Appl Climatol 101:381–396
Wilks DS (1995) Statistical methods in the atmospheric sciences. Academic Press
Xia Y, Fabian P, Stohl A, Winterhalter M (1999) Forest climatology: estimation of missing values for Bavaria, Germany. Agr Forest Meteorol 96:131–144
Acknowledgments
This research is supported partially by the National Institute of Food and Agriculture, United States Department of Agriculture, under ID01507. Any opinions, findings, conclusions, or recommendations expressed in this publication are those of the authors and do not necessarily reflect the view of the United States Department of Agriculture.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1.1 Gauge Mean Estimator (GME)
The Gauge Mean Estimator (GME) is to use an arithmetic average of all SSs. It is a special case of Inverse Distance Weighting (IDW) and it is a similar method being used for the average precipitation estimation method presented by McCuen (1998). The estimation of missing precipitation is given by
Where, Xm = estimated value at the TSm, n = the number of stations, Xi = the observed value at SSi, Nm and Ni = the average monthly precipitation at TSm and SSi, respectively.
1.2 Inverse Distance Weighting (IDW) Method
As proposed by Simanton and Osborn (1980), the Inverse Distance Weighting (IDW) is used to estimate the missing precipitation values and it is implemented by Watson and Philip (1985). IDW has been commonly used to fill the missing values. It is also widely used many water resources applications (ASCE 1996). For the precipitation estimation at TSs, IDW provides weighting values inversely depending on the distance between TS and SS. The missing values at TSs can be computed by Eq. (12).
Where, m = the selected TS, Xm = the estimated value at the TS m; n is the number of stations, Xi = the observed value at SS I, dmi = the distance from the station i to station m, and k = referred to as friction distance (Vieux 2001) that ranges from 1.0 to 6.0. In this study, k = 2 is used (Teegavarapu et al. 2009).
1.3 Ordinary Kriging (OK) Method
The Ordinary Kriging (OK) is the standard approach for surface interpolation method based on scalar measurement at different locations (Journel and Huijbregts 1978; Isaake and Srivastava 1989). OK is spatially dependent variance (Vieux 2001). The degree of spatial dependence in OK method can be determined using a semivariogram. The weights of OK are based on the distance between SS and TS as well as. The equations for OK method to estimate missing values include Eqs. (13) – (15).
where, δ = the weight obtained from the fitted simivariogram, τ = the gamm matrix, which is the model semivariance for all sampled pairs, γ(d) = the semivariance which is defined over observations X i and X j lagged successively by distance d, n(d) = the number of distinct pairs in n(d), X i and X j = data values at spatial location I and j, respectively.
1.4 RMSE, MAE, and R
where, PQi = the observed precipitation data at time step I, PSi = the estimated precipitation data, \( {\overline{P}}_{Qi}\kern0.5em and\ {\overline{P}}_{Si} \) = the mean of the observed and estimated precipitation data, respectively; N = the number of sample sizes.
Rights and permissions
About this article

Cite this article
Kim, J., Ryu, J.H. A Heuristic Gap Filling Method for Daily Precipitation Series. Water Resour Manage 30, 2275–2294 (2016). https://doi.org/10.1007/s11269-016-1284-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-016-1284-z