
Abstract
This paper studies the convergence performance of the transform domain normalized least mean square (TDNLMS) algorithm with general nonlinearity and the transform domain normalized least mean M-estimate (TDNLMM) algorithm in Gaussian inputs and additive Gaussian and impulsive noise environment. The TDNLMM algorithm, which is derived from robust M-estimation, has the advantage of improved performance over the conventional TDNLMS algorithm in combating impulsive noises. Using Price’s theorem and its extension, the above algorithms can be treated in a single framework respectively for Gaussian and impulsive noise environments. Further, by introducing new special integral functions, related expectations can be evaluated so as to obtain decoupled difference equations which describe the mean and mean square behaviors of the TDNLMS and TDNLMM algorithms. These analytical results reveal the advantages of the TDNLMM algorithm in impulsive noise environment, and are in good agreement with computer simulation results.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Adaptive filters are widely used for filtering problems in which the statistics of the underlying signals are either unknown a priori, or in some cases, slowly-varying. Many adaptive filtering algorithms have been proposed and they are usually variants of the well known least mean square (LMS) [1] and the recursive least squares (RLS) [2] algorithms. An important variant of the LMS algorithm is the normalized least mean square (NLMS) algorithm [3], where the step size is normalized with respect to the energy of the input vector. Due to the numerical stability and computational simplicity of the LMS and the NLMS algorithms, they have been widely used in various applications [4, 5].
An important class of NLMS is the transform domain NLMS (TDNLMS) algorithms [6–11] where unitary transformations such as the discrete Fourier transform (DFT), the discrete cosine transform (DCT), and the wavelet transform (WT) are employed to pre-whiten the input signal. Prewhitening and element-wise normalization usually help to reduce the eigenvalue spread of the input autocorrelation matrix and hence significantly improve the convergence speed. Driven by the practical advantages of the TDNLMS family, there is also considerable interest in the performance analysis of these algorithms [8, 9]. Results concerning the performance behaviors of the TDNLMS algorithm were studied in [6–11].
In this paper, we study a more general TDNLMS algorithm, the TDNLMS algorithm with general error nonlinearity. The convergence performance of this algorithm in Gaussian inputs and additive Gaussian and impulsive noise environments are studied. The main novelty lies in handling the normalization, evaluating the expectations specific to this algorithm and dealing with the error nonlinearity. We study with particular emphasis on two special cases of this algorithm: the conventional TDNLMS algorithm with no nonlinearity, and the transform domain normalized least mean M-estimate (TDNLMM) algorithm [12], which is based on robust M-estimation [13, 14] and adaptive threshold selection (ATS) [12, 15]. These techniques have been successfully employed in the LMM [12], the recursive least M-estimate (RLM) [15] and the normalized LMM (NLMM) [16] algorithms for robust filtering in impulsive noise environment. The motivation of studying this algorithm is that the performance of the TDNLMS algorithm, which is based on LS estimation as in the LMS algorithm, will deteriorate considerably when the desired or the input signal is corrupted by impulsive noise. The mean and mean square convergence analysis for the TDNLMS algorithm with general error nonlinearity is treated in a single framework using the Price’s theorem [17] for Gaussian case and its extension [18] for contaminated Gaussian (CG) case. The finally obtained decoupled difference equations clearly interpret the convergence performance of all the studied algorithms. The validity of the analytical results is verified through extensive simulations and they are in good agreement with each other. The rest of this paper is organized as follows: In section 2, the TDNLMS and TDNLMM algorithms are reviewed and the TDNLMS algorithm with general error nonlinearity is formulated. Their convergence performance analysis is given in section 3. Computer simulations are conducted in section 4. Finally, conclusions are drawn in section 5.
2 TDNLMS Algorithm with General Error Nonlinearity and TDNLMM Algorithm
2.1 The TDNLMS Algorithm
Consider the adaptive system identification problem in Fig. 1 where an input signal x(n) is applied simultaneously to an adaptive transversal filter of order L with weight vector \( W(n) = {\left[ {{w_1}(n),{w_2}(n), \cdots, {w_L}(n)} \right]^T} \) and an unknown system to be identified with an impulse response \( W* = {\left[ {{w_1},{w_2}, \cdots, {w_L}} \right]^T} \). \( X(n) = {\left[ {x(n),x\left( {n - 1} \right), \cdots, x\left( {n - L + 1} \right)} \right]^T} \) is the input vector and the superscript T denotes the transpose of a vector or a matrix. e(n) is the estimation error and d(n) is the desired signal of the adaptive filter, which may be corrupted by an additive noise η o (n). Hence

Adaptive system identification.
The update equations for the TDNLMS algorithm can be written as:
where μ is a constant step size parameter controlling the convergence rate and steady state error of the algorithm. \( {X_C}(n) = CX(n) = {\left[ {{X_{C,1}}(n),{X_{C,2}}(n), \cdots, {X_{C,L}}(n)} \right]^T} \) is the transformed signal vector. C is an L × L transform matrix such as (DFT) or (DCT). \( \Lambda_C^{ - 1} = {\hbox{diag}}\left[ {\varepsilon_1^{ - 1}(n),\varepsilon_2^{ - 1}(n), \cdots, \varepsilon_L^{ - 1}(n)} \right] \) which is an element-wise normalization matrix with ε i (n) being the estimated power of the i-th signal component after transformation. Common methods for choosing ε i (n) include \( {\varepsilon_i} + X_{C,i}^2(n) \) and \( {\varepsilon_i}(n) = \left( {1 - {\alpha_\varepsilon }} \right){\varepsilon_i}\left( {n - 1} \right) + {\alpha_\varepsilon }X_{C,i}^2(n) \), where \( {\alpha_\varepsilon } \) is a positive forgetting factor smaller than one. ε i is a small positive value used to avoid division by zero or it can be chosen as certain prior power estimate of the corresponding component. In the analysis to be presented in section 3, a form \( {\varepsilon_i} + {\alpha_\varepsilon }X_{C,i}^2(n) \) similar to the above two choices will be chosen. In the simulation section, we shall introduce a method to approximately analyze the effect of this choice.
2.2 The TDNLMM Algorithm and TDNLMS Algorithm with General Error Nonlinearity
Many techniques have been proposed to combat the adverse effect of impulsive noise on adaptive filters. They include the median-filtering algorithms [19, 20], the nonlinear clipping approaches [21, 22], and approaches based on robust statistics [12, 15, 16]. The LMM [12] and the RLM [15] algorithms are two effective algorithms derived from robust M-estimation and their improved robustness in impulsive noise and performance comparison with other relevant algorithms were thoroughly discussed in [12] and [15].
In the TDNLMM algorithm [12], an M-estimate distortion measure \( {J_\rho } = E\left[ {\rho \left( {e(n)} \right)} \right] \) is minimized, where ρ(e), as illustrated in Fig. 2 (a), is chosen as the modified Huber (MH) function:
ξ is a threshold parameter used to suppress the effect of outlier when the estimation error e is very large. Other M-estimate function such as the Hampel’s three-part redescending function [14] can also be used. Notice that when \( \rho (e) = {e^2}/2 \) it reduces to the conventional mean square error (MSE) criterion. Like the LMS algorithm, \( {J_\rho } \) is minimized by updating W(n) in the negative direction of the instantaneous gradient vector \( {\hat{\nabla }_{{\mathbf{W}}\rho }} \). Therefore, the gradient vector, \( {\nabla_{\mathbf{W}}}\left( {{J_\rho }} \right) \), is approximated by \( {\hat{\nabla }_{{\mathbf{W}}\rho }} = - \partial \rho \left( {e(n)} \right)/\partial \mathbf{W} = - \psi \left( {e(n)} \right)\mathbf{X}(n) \), where \( \psi (e) = \partial \rho (e)/\partial e \) is the score function, which is depicted in Fig. 2 (b). The following LMM algorithm can be obtained:

a The MH function ρ(e); bψ(e), the MH score function of ρ(e).
It can be seen that when e(n) is smaller than ξ, ψ(e(n)) is equal to e(n) and (5) becomes identical to the LMS algorithm. When \( \left| {e(n)} \right| > 1 \), ψ(e(n)) will become zero. Thus the LMM algorithm can effectively reduce the adverse effect of large estimation error on updating the filter coefficients. In the adaptive threshold selection (ATS) method used in [12, 15], e(n) is assumed to be Gaussian distributed except being corrupted occasionally by additive impulsive noise and the following robust variance estimate is proposed
where \( {\lambda_\sigma } \) is a forgetting factor close to but smaller than one, c 1 = 2.13 is the finite sample correction factor and N w is the length of the data set. med(·) is the median operator and \( {A_e}(n) = \left[ {{e^2}(n), \cdots, {e^2}\left( {n - {N_w} + 1} \right)} \right] \). Using (6), the following adaptive threshold ξ can be obtained:
\( {k_\xi } \) is a constant used to control the suppression of impulsive interference. A reasonable value of \( {k_\xi } \) is 2.576 and the window length N w is usually chosen between 5 and 9 [12, 15].
If the step sizes for updating the coefficients are normalized according to the power of the corresponding transform signal components as in the TDNLMS algorithm, the following TDNLMM algorithm can be obtained from (5) [12]:
The convergence performance of the LMS algorithm with other nonlinearity than MH function can be found in literature. The LMS algorithm with error function nonlinearity was studied in [23]. A related algorithm is the dual-sign LMS [24] algorithm. The former concluded that the nonlinearity will slow down the convergence rate, while the latter is mainly introduced to reduce the implementation complexity. The robustness of this class of algorithms to impulsive outliers was later studied by Koike in [22, 25, 26], and in [21] using the clipping nonlinearity. On the contrary, in [12, 15] the threshold parameter ξ in the MH function is continuously updated as in (7), which greatly improves the convergence speed and steady state error.
3 Mean and Mean Square Convergence Analysis
In this section, the convergence performance analysis of the TDNLMS algorithm with general nonlinearity and particularly the TDNLMS and TDNLMM algorithms will be studied. The main contributions of the analysis include: i) the use of the Price’s theorem [17] to handle the nonlinearity for Gaussian noise case and its extension [18] for the CG noise case, and ii) introduction of new special functions and the evaluation of related expectations in order to obtain decoupled difference equations describing the mean and mean square behaviors of the algorithms. To simplify the analysis, we make the following assumptions:
Assumption 1
The input signal x(n) is an ergodic process which is Gaussian distributed with zero mean and autocorrelation matrix \( {\mathbf{R}_{XX}} = E\left[ {\mathbf{X}(n){\mathbf{X}^T}(n)} \right] \).
Assumption 2
The additive noise η o (n) is assumed to be a Gaussian noise (\( {\eta_o}(n) = {\eta_g}(n) \)) for the analysis in section 3.1 below. For the analysis in section 3.2 below, η o (n) is modeled as a CG noise [27] which is a frequently used model for analyzing impulsive noise. More precisely, it is given by:
where η g (n) and η w (n) are both independent and identically distributed (i.i.d.) zero mean Gaussian sequences with respective variance \( \sigma_g^2 \) and \( \sigma_w^2 \). b(n) is an i.i.d. Bernoulli random sequence whose value at any time instant is either zero or one, with occurrence probabilities \( {P_r}\left( {b(n) = 1} \right) = {p_r} \) and \( {P_r}\left( {b(n) = 0} \right) = 1 - {p_r} \). The variances of the random processes η im (n) and η o (n) are then given by \( \sigma_{im}^2 = {p_r}\sigma_w^2 \) and \( \sigma_{{\eta_o}}^2 = \sigma_g^2 + \sigma_{im}^2 = \sigma_g^2 + {p_r}\sigma_w^2 \). The ratio \( {r_{im}} = \sigma_{im}^2/\sigma_g^2 = {p_r}\sigma_w^2/\sigma_g^2 \) is a measure of the impulsive characteristic of the CG noise. Accordingly, the probability distribution function (PDF) of this CG distribution is given by
Assumption 3
W(n), x(n) and η o (n) are statistically independent (the independent assumption [1]). Although this assumption is not completely valid in general applications, it is a good approximation for large value of L and is commonly used to simplify the convergence analysis of adaptive filtering algorithms. Moreover, we denote \( \mathbf{W}* = R_{{X_C}{X_C}}^{ - 1}{P_{d{X_C}}} \), where \( {P_{d{X_C}}} = E\left[ {d(n){\mathbf{X}_C}(n)} \right] \) is the ensemble-averaged cross-correlation vector between X C (n) and d(n). W* is related to the optimal Wiener solution \( {\mathbf{W}_{\rm{OPT}}} = \mathbf{R}_{XX}^{ - 1}{\mathbf{P}_{dX}} \) by WOPT = CW*.
3.1 Mean and Mean Square Convergence Behaviors in Gaussian noise
3.1.1 Mean Behavior
From (9), the weight-error vector \( {\mathbf{v}}(n) = \mathbf{W}* - \mathbf{W}(n) \) for the TDNLMS algorithm with general nonlinearity can be written as
where W* is the transformed optimal weight vector defined above and ψ(e(n)) is a general nonlinearity. When it is equal to e(n), (12) reduces to the conventional TDNLMS algorithm. Taking expectation over {v, X C , η g } on both sides of (12), one gets
where E[·] denotes the expectation over {v(n), X C (n), η g (n)} (also written as \( {E_{\left\{ {{\mathbf{v}},{{\mathbf{X}}_C},{\eta_g}} \right\}}}\left[ \cdot \right] \) for clarity), and \( H = {E_{\left\{ {{\mathbf{v}},{{\mathbf{X}}_C},{\eta_g}} \right\}}}\left[ {\Lambda_C^{ - 1}\psi \left( {e(n)} \right){X_C}(n)} \right] \). By dropping the time index of X C (n), e(n), and η g (n), one gets
where \( {H_1} = {E_{\left\{ {{X_C},{\eta_g}} \right\}}}\left[ {\Lambda_C^{ - 1}\psi (e){X_C}\left| v \right.} \right] \) and the second equation is obtained from the independence assumption of η g (n), W(n) and x(n) in Assumption 3.
The i-th component of H 1 is evaluated in Appendix A to be
where \( \sigma_e^2(n) = E\left[ {{v^T}(n){R_{{X_C}{X_C}}}v(n)} \right] + \sigma_g^2 \), \( \overline {\psi \prime } \left( {\sigma_e^2} \right) = \int_{ - \infty }^\infty {\frac{{\psi \prime (e)}}{{\sqrt {{2\pi }} {\sigma_e}}}\exp \left( { - \frac{{{e^2}}}{{2\sigma_e^2}}} \right)de} \), \( {\alpha_i} = \int_0^\infty {\exp \left( { - \beta {\varepsilon_i}} \right){{\left( {{g_i}\left( {\tilde{\beta }} \right)} \right)}^{ - 3/2}}d\beta } \), \( {g_i}\left( {\tilde{\beta }} \right) = \left( {1 + 2\tilde{\beta }{R_{{X_C}{X_C}_ i,i}}} \right) \), \( {R_{{X_C}{X_{C\_i,j}}}} \) is the (i, j)-th element of \( {R_{{X_C}{X_C}}} \), e i is a column vector with the i-th element equal to one and zero elsewhere. For a given ψ(e), \( \overline {\psi \prime } \left( {\sigma_e^2} \right) \) can be evaluated analytically or numerically. Substituting (14), (15) into (13), the following mean weight-error vector update equation is obtained:
where \( {D_\alpha } = {\hbox{diag}}\left( {{\alpha_1}, \ldots, {\alpha_L}} \right) \) is a diagonal matrix. For notation convenience, we write \( \overline {\psi \prime } \left( {\sigma_e^2(n)} \right) \) as \( {A_\psi }\left( {\sigma_e^2(n)} \right) \) and use \( \sigma_e^2(n) \) and \( \sigma_e^2 \) interchangeably. Also we replace the approximate sign in (16) by the equality sign. Let \( V(n) = D_\alpha^{ - 1/2}v(n) \), (16) can be simplified to
where \( {R_{{X_D}{X_D}}} = D_\alpha^{1/2}{R_{{X_C}{X_C}}}D_\alpha^{1/2} \) is the correlation matrix of a scaled input vector \( {X_D} = D_\alpha^{1/2}{X_C} \). Since it is symmetric, it can be written as the following eigenvalue decomposition (EVD): \( {R_{{X_D}{X_D}}} = {U_{{X_D}}}{\Lambda_{{X_D}}}U_{{X_D}}^T \), where \( {U_{{X_D}}} \) is certain orthogonal matrix and \( {\Lambda_{{X_D}}}{\hbox{ = diag}}\left( {\lambda_1^\prime, \lambda_2^\prime, \cdots, \lambda_L^\prime } \right) \) contains the corresponding eigenvalues. Pre-multiplying both sides of (17) with \( U_{{X_D}}^T \) gives
where \( E\left[ {{V_D}(n)} \right] = U_{{X_D}}^TE\left[ {V(n)} \right] \). This is equivalent to the following L scalar first order finite difference equations:
where \( E{\left[ {{V_D}(n)} \right]_i} \) is the i-th element of the vector \( E\left[ {{V_D}(n)} \right] \) for \( i = 1,2, \cdots, L \).
Remarks
-
(R-A1):
The TDNLMS algorithm
For conventional TDNLMS algorithm, ψ(e) = e and \( \overline {\psi \prime } \left( {\sigma_e^2} \right) = {A_\psi }\left( {\sigma_e^2} \right) = 1 \). The algorithm will converge if
where \( \lambda_i^\prime \) is the i-th eigenvalue of \( {R_{{X_D}{X_D}}} \). The corresponding maximum step size for convergence should satisfy
where \( \lambda_{\max }^\prime \) is the maximum eigenvalue of \( {R_{{X_D}{X_D}}} \). Let us examine the eigenvalues of \( {R_{{X_D}{X_D}}} \). We note that \( {R_{{X_D}{X_D}}} = D_\alpha^{1/2}\left( {C{R_{XX}}{C^T}} \right)D_\alpha^{1/2} \). It can be shown that \( {\alpha_i} = \frac{1}{{2{\alpha_\varepsilon }{R_{{X_C}{X_C}_ i,i}}}}\exp \left( {\frac{1}{2}{\varepsilon_i}\alpha_\varepsilon^{ - 1}R_{{X_C}{X_C}_ i,i}^{ - 1}} \right) \cdot {E_{3/2}}\left( {\frac{1}{2}{\varepsilon_i}\alpha_\varepsilon^{ - 1}R_{{X_C}{X_C}_ i,i}^{ - 1}} \right), \)where \( {E_n}(x) = \int_1^\infty {\frac{{\exp \left( { - \beta x} \right)}}{{{\beta^n}}}d\beta } \). The i-th diagonal element of \( {R_{{X_D}{X_D}}} \) is
It can be seen that \( {R_{{X_D}{X_D}_ i,i}} \) has the same order as \( {R_{{X_C}{X_C}_ i,i}} \). Therefore, the order of the elements in \( {R_{{X_C}{X_C}}} \) after scaling, i.e. \( {D_\alpha }{R_{{X_C}{X_C}}}{D_\alpha } \), is preserved. If ε i is simply chosen as \( R_{{X_C}{X_C}_ i,i}^{ - 1} \) with \( {\alpha_\varepsilon } = 0 \), i.e. perfect power estimation, then \( {\alpha_i} = R_{{X_C}{X_C}_ i,i}^{ - 1} \), and hence \( {\hat{\lambda }_i} = 1 \) for all i.
If C diagonalizes R XX , then \( {R_{{X_D}{X_D}}} \) becomes the identity matrix. The eigenvalue spread is equal to one and it will significantly speed up the convergence of the algorithm, especially for situations with large eigenvalue spread.
Usually C only approximately diagonalizes R XX and the detailed analysis becomes rather difficult. Here we try to study the eigenvalue and obtain bounds for their values using the Gershgorin circle theorem (GCT). For orthogonal transformation, the eigenvalues of R XX and \( {R_{{X_C}{X_C}}} = C{R_{XX}}{C^T} \) are the same. From the GCT, we have
where \( {\rho_{{X_C}{X_C}_ i,j}} \) is the normalized correlation coefficients. Similarly, the eigenvalues of \( {R_{{X_D}{X_D}}} \) satisfy
Since \( {\alpha_i} = {\left( {{R_{{X_C}{X_C}_ i,i}}} \right)^{ - 1}}{\hat{\lambda }_i} \), we have \( \left| {\lambda_i^\prime - {{\hat{\lambda }}_i}} \right| \leqslant \sum\limits_{1 \leqslant j \ne i \leqslant L} {\left| {{{\left( {\frac{{{{\hat{\lambda }}_i}{{\hat{\lambda }}_j}}}{{{R_{{X_C}{X_C}_ i,i}}{R_{{X_C}{X_C}_ j,j}}}}} \right)}^{ - 1/2}}{R_{{X_C}{X_C}_ i,j}}} \right|} \). If \( {R_{{X_C}{X_C}}} \) is diagonal-dominant, then the off-diagonal elements \( {\rho_{XX_ i,j}} \), i ≠ j will be small and all the eigenvalues of \( {R_{{X_D}{X_D}}} \) will be close to one with a tight bound. \( {\hat{\lambda }_i} \) can therefore be viewed as the estimated eigenvalues of \( {R_{{X_D}{X_D}}} \). The corresponding estimated eigenvalue spread for diagonal-dominant \( {R_{{X_C}{X_C}}} \) is
which is close to one for a relatively wide range of \( {R_{{X_C}{X_C}_ i,i}} \) and \( {R_{{X_C}{X_C}_ j,j}} \). This explains the speed-up in convergence rate of the TDNLMS algorithm even if sub-optimal transformations are used. It was also shown that [9], pp.219] the performance of the TDNLMS algorithm can never be worse than its conventional LMS counterpart and the degree of improvement achieved depends on the distribution of the signal powers at transformed outputs.
-
(R-A2):
TDNLMS algorithm with general nonlinearity and the TDNLMM algorithm
For general nonlinearity other than ψ(e) = e, (18) or (19) becomes a set of nonlinear difference equations. A general solution is rather difficult to obtain because the term \( {A_\psi }\left( {\sigma_e^2} \right) \) is dependent on MSE.
For \( C = {D_\alpha } = I \), we obtain the LMS algorithm with general nonlinearity. (19) agrees with the result for the LMS algorithm with dual-sign nonlinearity [23]. (18) also agrees with the result in [22] for the LMS algorithm with error function nonlinearity. The case for LMS and NLMM algorithms with general nonlinearity was studied in [30]. For most M-estimate functions, ψ(e) = q(e)e, where q(e) is equal to 1 when |e| is less than a certain threshold ξ and will gradually decrease to reduce its sensitivity to impulses with large amplitude. Hence, \( 0 \leqslant \psi \prime (e) \leqslant 1 \) and ψ′(e) ≈ 1 when |e| < ξ. For MH nonlinearity, it can be shown that \( {A_{\rm{MH}}}\left( {\sigma_e^2} \right) = {A_{\rm{MH}}}\left( {\sigma_e^2} \right) = \frac{2}{{\sqrt {{2\pi }} }}\int_0^{\xi /{\sigma_e}} {\exp \left( { - \frac{{{u^2}}}{2}} \right)du} - \frac{{2\xi }}{{\sqrt {{2\pi }} {\sigma_e}}}\exp \left( { - \frac{{{\xi^2}}}{{2\sigma_e^2}}} \right) \) with \( \mathop {{\lim }}\limits_{\sigma_e^2 \to 0} {A_{\rm{MH}}}\left( {\sigma_e^2} \right) \to 1 \) and \( \mathop {{\lim }}\limits_{\sigma_e^2 \to \infty } {A_{\rm{MH}}}\left( {\sigma_e^2} \right) \to 0 \). For sufficiently small step size μ, the algorithm will converge and \( \sigma_e^2 \) will decrease. If \( {A_{\rm{MH}}}\left( {\sigma_e^2} \right) \) is not made adaptive, an inappropriately chosen ξ may suppress the signal component, instead of the outliers. This will cause \( {A_{\rm{MH}}}\left( {\sigma_e^2} \right) \) to increase gradually and lead to slow adaptation. For the TDNLMS algorithm, ξ is chosen as a multiple of the estimated σ e as shown in (7). This helps to maintain a fairly stationary \( {A_{\rm{MH}}}\left( {\sigma_e^2} \right) \) so as to avoid significant signal suppression since \( {A_{\rm{MH}}}\left( {\sigma_e^2} \right) \approx {\hbox{erf}}\left( {\frac{{{k_\xi }}}{{\sqrt {2} }}} \right) = {A_{\rm{C}}} \) (if \( \hat{\sigma }_e^2 \approx \sigma_e^2 \)) is approximately constant and slightly less than one. The degradation in convergence over its TDNLMS counterpart is therefore minimal. Though the maximum possible step size is in general difficult to obtain, a sufficient condition for the algorithm to converge is \( \left| {1 - \mu {A_\psi }\left( {\sigma_e^2} \right)\lambda_i^\prime } \right| < 1 \), for all i. If \( \overline {\psi \prime } \left( {\sigma_e^2} \right) \) is bounded above by a constant \( {A_{\psi \_\max }} \), then a conservative maximum step size is
which yields good estimates in practical algorithms. \( {A_\psi }\left( {\sigma_e^2} \right) \) for some commonly used error nonlinearities are summarized in Table 1.
3.1.2 Mean Square Behavior
Post-multiplying (12) by its transpose and taking expectation over {v, X C , η g } gives
where \( \Xi (n) = E\left[ {v(n){v^T}(n)} \right] \),
and
where \( {s_3} = {E_{\left\{ {X,{\eta_g}} \right\}}}\left[ {{\psi^2}(e)\Lambda_C^{ - 1}{X_C}X_C^T\Lambda_C^{ - 1}\left| v \right.} \right] \). Note, the final expressions in (26) and (27) are obtained by using our previous result in (15). The (i, j)-th element of s 3 is evaluated in Appendix B to be:
where
where \( \alpha_i^{(k)} = \int_0^\infty {\int_0^\infty {{{\left( {\tilde{\beta }} \right)}^k}{{\left( {{g_i}\left( {\tilde{\beta }} \right)} \right)}^{ - \left( {2k + 3} \right)/2}}\exp \left( { - \beta {\varepsilon_i}} \right)d\beta } } \), \( \alpha_i^{\left( {m,n} \right)} = \int_0^\infty {{{\tilde{\beta }}^m}\exp \left( { - \beta {\varepsilon_i}} \right)/{{\left( {1 + 2\tilde{\beta }{R_{{X_C}{X_C}_ i,i}}} \right)}^n}} d\beta \),\( {B_\psi }\left( {\sigma_e^2} \right) = \int_{ - \infty }^\infty {\frac{{{\psi^2}(e)}}{{\sqrt {{2\pi }} {\sigma_e}}}\exp \left( {\frac{{ - {e^2}}}{{2\sigma_e^2}}} \right)de} \), \( {C_\psi }\left( {\sigma_e^2} \right) = \frac{d}{{d\sigma_e^2}}E\left[ {{\psi^2}(e)} \right] \), and \( {\left( {{r_{{X_C}{X_C}_ i}}} \right)^T} \) is the i-th row of \( {R_{{X_C}{X_C}}} \). For a given nonlinearity ψ(e), the above two integrals can be computed analytically or numerically.
Substituting (26–29) into (25) gives
where \( {D_\sigma } \) is a diagonal matrix with its i-th element \( {\left[ {{D_\sigma }} \right]_{i,i}} = {\left( {{r_{{X_C}{X_C}_ i}}} \right)^T}\Xi (n){r_{{X_C}{X_C}_ i}} \), \( {\left[ {{S^{(k)}}} \right]_{i,j}} = s_{ij}^{(k)} \) and \( {\left[ {{\Gamma_\alpha }} \right]_{ij}} = \sum\limits_{m = 0}^\infty {\alpha_{i,j}^{(m)}\left( {{4^m}} \right)} \left( {\begin{array}{*{20}{c}} { - \frac{3}{2} + m - 1} \\m \\\end{array} } \right)R_{{X_C}{X_C}_ i,j}^{\left( {2m + 1} \right)}. \)
Let \( \Phi (n) = D_\alpha^{ - 1/2}\Xi (n)D_\alpha^{ - 1/2} \), (30) can be further simplified to
where \( {\left[ {{D_\sigma }} \right]_{i,i}} = {\left( {D_\alpha^{1/2}{r_{{X_C}{X_C}_ i}}} \right)^T}\Phi (n)\left( {D_\alpha^{1/2}{r_{{X_C}{X_C}_ i}}} \right) \).
Since \( D_\alpha^{1/2}{R_{{X_C}{X_C}}}D_\alpha^{1/2} \) is symmetric, it can be diagonalized as \( {U_{{X_D}}}{\Lambda_{{X_D}}}U_{{X_D}}^T \). Again, let \( \Psi (n) = U_{{X_D}}^T\Phi (n){U_{{X_D}}} \), (31) yields
Since \( {\left[ {{D_\sigma }} \right]_{i,i}} = {\left( {D_\alpha^{1/2}{r_{{X_C}{X_C}_ i}}} \right)^T}{U_{{X_D}}}\Psi (n)U_{{X_D}}^T\left( {D_\alpha^{1/2}{r_{{X_C}{X_C}_ i}}} \right) \) is a scalar, after taking the vec(·) operation we have the following:
Hence,
where the \( \left[ {\left( {i - 1} \right)L + i} \right] - {\hbox{th}} \) row of Δ is equal to Δ i and zero elsewhere. Let \( \Theta (n) = {\hbox{vec}}\left( {\Psi (n)} \right) \). (32) can be rewritten as
where \( {\Gamma_1}(n) = I - \mu {A_\psi }\left( {\sigma_e^2} \right)\left( {{\mathbf{I}} \otimes {\Lambda_{{X_D}}}} \right) - \mu {A_\psi }\left( {\sigma_e^2} \right)\left( {{\Lambda_{{X_D}}} \otimes {\mathbf{I}}} \right) + {\mu^2}{C_\psi }\left( {\sigma_e^2} \right)\left\{ {\left( {U_{{X_D}}^T \otimes U_{{X_D}}^T} \right)\left( {{S^{(0) + (3)}}} \right)\left[ {\left( {D_\alpha^{ - 1}{U_{{X_D}}}} \right) \otimes \left( {D_\alpha^{ - 1}{U_{{X_D}}}} \right)} \right] \cdot \left( {{\Lambda_{{X_D}}} \otimes {\Lambda_{{X_D}}}} \right) + \left( {U_{{X_D}}^T \otimes U_{{X_D}}^T} \right)\left[ {I \otimes \left( {D_\alpha^{ - 1/2}S_D^{(1)}D_\alpha^{ - 1/2}} \right) + \left( {D_\alpha^{ - 1/2}S_D^{(2)T}D_\alpha^{ - 1/2}} \right) \otimes I} \right]\Delta } \right\} \), \( {\Gamma_2}(n) = {\mu^2}{B_\psi }\left( {\sigma_e^2} \right){\hbox{vec}}\left( {U_{{X_D}}^TD_\alpha^{ - 1/2}{\Gamma_\alpha }D_\alpha^{ - 1/2}{U_{{X_D}}}} \right) \), and \( {S^{(0) + (3)}} = {\hbox{diag}}\left( {{S^{(0)}} + {S^{(3)}}} \right) \).
The algorithm will converge if \( {\left\| {I - {\Gamma_1}(n)} \right\|_2} < 1 \). Using triangular inequality, we have
where \( \alpha \prime = s_{\max }^{(0) + (3)} + {\left( {\lambda_{\max }^\prime } \right)^{ - 2}}\left( {s_{\max }^{(2)} + s_{\max }^{(1)}} \right){\Delta_{\max }} \).
Therefore the algorithm converges if
where \( r_{0,1}^\prime = \lambda_{\max }^\prime \left( {{A_\psi }\left( {\sigma_e^2} \right)\pm \sqrt {{A_\psi^2\left( {\sigma_e^2} \right) - {C_\psi }\left( {\sigma_e^2} \right)\alpha \prime }} } \right) \). Hence, the maximum possible step size for mean square convergence is
If the algorithm converges, we have from (34)
The excess mean square error (EMSE) at time instant n is \( {\hbox{EMSE}}(n) = {\hbox{Tr}}\left( {\Xi (n){R_{{X_C}{X_C}}}} \right) = {\hbox{Tr}}\left( {\Psi (n){\Lambda_{{X_D}}}} \right) \). Hence
where vec−1(·) is the inverse vec(·) operator. (35) is rather difficult to further simplify in general. We shall analyze the cases with small step size and uncorrelated transform output below.
Small step sizes
If μ is small enough, then we can drop the terms involving Ψ(n) and μ 2, and (32) becomes
where \( {\hat{\Gamma }_{{\rm{UD}}_ \alpha }} = U_{{X_D}}^TD_\alpha^{ - 1/2}{\Gamma_\alpha }D_\alpha^{ - 1/2}{U_{{X_D}}} \). Let D diag(K) be an operator which retains only the diagonal values of a square matrix K and setting the others to zero. When the algorithm converges, we have
Hence, (35) reduces to
Uncorrelated Case
If \( {R_{{X_C}{X_C}}} \) is diagonal, then it can be shown that \( {I_{1,i,i}} = 2{\left( {{v_i}{\lambda_i}} \right)^2}\tilde{\alpha }_i^{\left( { - 5/2} \right)} \), \( {I_{2,i,i}} = {\lambda_i}\tilde{\alpha }_i^{\left( { - 3/2} \right)} \), and zero otherwise, where \( \tilde{\alpha }_i^{(k)} = \int_0^\infty {\int_0^\infty {\exp \left( { - \left( {{\beta_1} + {\beta_2}} \right){\varepsilon_i}} \right){g_i}{{\left( {{{\tilde{\beta }}_1} + {{\tilde{\beta }}_2}} \right)}^{ - k}}d{\beta_2}d{\beta_1}} } \) and \( {\lambda_i} = {R_{{X_C}{X_C}_ i,i}} \). Hence, (30) reduces to
which is equivalent to the following set of scalar equations:
Assuming the difference equation converges, the corresponding steady state value of \( {\Xi_{i,i}}\left( \infty \right) \) can be obtained from (39) as
The EMSE is then given by
Remarks
-
(R-A3):
TDNLMS algorithm
In this case, \( {A_\psi }\left( {\sigma_e^2} \right) = {C_\psi }\left( {\sigma_e^2} \right) = 1 \), \( {B_\psi }\left( {\sigma_e^2} \right) = \sigma_e^2 \). Since \( \sigma_e^2(n) = {\hbox{EMS}}{{\hbox{E}}_{\rm{TDNLMS}}}(n) + \sigma_g^2 \), the EMSE from the small step size result in (38) is
where \( {\phi_{\rm{TDNLMS}}} = Tr\left( {{\Gamma_\alpha }D_\alpha^{ - 1}} \right) \). Particularly, for the LMS algorithm, C = I, \( {D_\alpha } = I \), and \( {\Gamma_\alpha } = {R_{XX}} \). (42) will reduce to
which agrees with the conventional result for the LMS algorithm.
For the uncorrelated case,
where \( {\phi _{{\text{TDNLMS\_U}}}} = \sum\limits_{i = 1}^L {\frac{{\tilde{\alpha }_i^{\left( { - 3/2} \right)}{\lambda _i}}}{{\alpha {}_i - \mu {\lambda _i}\tilde{\alpha }_i^{\left( { - 5/2} \right)}}}} \). For perfect power estimation, \( {\varepsilon_i} = \sigma_{{X_C}_ i}^2 \) and \( {\alpha_\varepsilon } = 0 \), α i = ε i −1, \( \tilde{\alpha }_i^{\left( { - 3/2} \right)} = \tilde{\alpha }_i^{\left( { - 5/2} \right)} = \varepsilon_i^{ - 2} \) and \( \mu {\varphi_{{\rm{TDNLMS_ U}}}} = \sum\limits_{i = 1}^L {\frac{{\left( {\mu /{\varepsilon_i}} \right){\lambda_i}}}{{1 - \left( {\mu /{\varepsilon_i}} \right){\lambda_i}}}} = \frac{{\mu L}}{{1 - \mu }} \), which reduces to the classical result of the LMS algorithm with an exact power normalized step size (μ/ε i ). For stability, EMSE(∞) should be a finite quality and it gives the following two conditions on μ for stability:
Following the approach in [30], one gets the approximate stepsize bound as
where \( {c_i} = \frac{1}{{{\alpha_i}}}{\lambda_i}\tilde{\alpha }_i^{\left( { - 3/2} \right)} \) and \( {d_i} = \frac{1}{{{\alpha_i}}}\mu {\lambda_i}\tilde{\alpha }_i^{\left( { - 5/2} \right)} \).
-
(R-A4):
The TDNLMS algorithm with general nonlinearity and the TDNLMM algorithm
For the TDNLMS algorithms with general nonlinearity, (38) or (42) is a nonlinear equation in EMSE(∞) since \( \sigma_{\rm{e}}^2\left( \infty \right) = {\hbox{EMSE}}\left( \infty \right) + \sigma_{\rm{g}}^2 \), general solution is difficult to obtain. In contrast, for the TDNLMM algorithm using MH nonlinearity and ATS, \( {A_{\rm{MH}}}\left( {\sigma_e^2} \right) \approx {\hbox{erf}}\left( {\frac{{{k_\xi }}}{{\sqrt {2} }}} \right) - \frac{{2{k_\xi }}}{{\sqrt {{2\pi }} }}\exp \left( { - \frac{{k_\xi^2}}{2}} \right) = {A_{\rm{c}}} \), \( {B_{\rm{MH}}}\left( {\sigma_e^2} \right) \approx \left( {{\hbox{erf}}\left( {\frac{{{k_\xi }}}{{\sqrt {2} }}} \right) - \frac{{2{k_\xi }}}{{\sqrt {{2\pi }} }}\exp \left( { - \frac{{k_\xi^2}}{2}} \right)} \right)\sigma_e^2 = {A_c}\sigma_e^2 \), \( {C_{\rm{MH}}}\left( {\sigma_e^2} \right) \approx {A_{\rm{c}}} - \left( {\frac{{k_\xi^3}}{{\sqrt {{2\pi }} }}} \right)\exp \left( { - \frac{{k_\xi^2}}{2}} \right) \cdot {\hbox{EMS}}{{\hbox{E}}_{\rm{TDNLMM}}}\left( \infty \right) \approx \frac{1}{2}\mu \sigma_e^2{\hbox{Tr}}\left( {{\Gamma_\alpha }D_\alpha^{ - 1}} \right) \). Solving for EMSETDNLMM(∞) gives
where ϕ TDNLMM = ϕ TDNLMS.
For the LMM algorithm with MH nonlinearity, C = I, D R = I, and \( {\Gamma_\alpha } = {R_{XX}} \). (41) will reduce to
which agrees with the result in [16] and is close to their LMS counterpart. \( {B_\psi }\left( {\sigma_e^2} \right) \) and \( {C_\psi }\left( {\sigma_e^2} \right) \) for some related algorithms are summarized in Table 1.
3.2 Convergence Behaviors in CG Noise
We now study the mean and mean square behaviors of the TDNLMS algorithm with general nonlinearity and particularly the TDNLMS and TDNLMM algorithms in CG noise environment. For most M-estimate functions which suppress outliers with large amplitude, the convergence rate will only be slightly impaired after employing ATS. We shall employ an extension of the Price’s theorem to Gaussian mixtures [18]. This extension was employed in the analysis of the LMS and NLMS algorithms with MH nonlinearity and CG noise in [16]. Similar techniques were also employed in analyzing the RLM and other related algorithms [15] for the MH nonlinearity. We shall show in the following that with the use of M-estimate function and ATS, the impulsive noise can be effectively suppressed and the EMSE is similar to the case where only Gaussian noise is present. On the other hand, the EMSE of the LMS-based algorithms will be substantially affected by the impulsive CG noise.
3.2.1 Mean Behavior
Since η o is now a CG noise as defined in (11), it is a Gaussian mixture consisting of two components η o_1 and η o_2, each with zero mean and variance \( \sigma_1^2 = \sigma_g^2 \) and \( \sigma_2^2 = \sigma_\Sigma^2 \), respectively. The occurrence probability of the impulsive noise is p r . Accordingly,
where \( f\left( {X(n),e(n)} \right) \) is an arbitrary quantity whose statistical average is to be evaluated. Since X(n), η o_1, and η o_2 are Gaussian distributed, each of the expectation on the right hand side can be evaluated using the Price’s theorem. Consequently, the results in section A can be carried forward to the CG noise case by firstly changing the noise power respectively to \( \sigma_g^2 \) and \( \sigma_\Sigma^2 \), and then combining the two results using (48).
Recall the relation of the mean weight-error vector in (13):
where \( H\prime = {E_{\left\{ {v,{X_C},{\eta_o}} \right\}}}\left[ {\Lambda_C^{ - 1}\psi \left( {e(n)} \right){X_C}(n)} \right] = \left( {1 - {p_r}} \right)H_1^\prime + {p_r}H_2^\prime \), \( H_1^\prime \) and \( H_2^\prime \) are respectively the expectation of the term inside the brackets above with respect to {v, X C , η o_1}, and {v, X C , η o_2}. From (16) and (17), we have \( H_i^\prime \approx \overline {\psi \prime } \left( {\sigma_{{e_i}}^2} \right){D_\alpha }{R_{{X_C}{X_C}}}v\left( {n} \right) \), i = 1,2, where \( \sigma_{{e_1}}^2(n) = \sigma_{{e_g}}^2(n) = E\left[ {{v^T}(n){R_{{X_C}{X_C}}}v(n)} \right] + \sigma_g^2 \), \( \sigma_{{e_2}}^2(n) = \sigma_{{e_\Sigma }}^2(n) = E\left[ {{v^T}(n){R_{{X_C}{X_C}}}v(n)} \right] + \sigma_\Sigma^2 \). Hence
where \( {\tilde{A}_\psi }(n) = \left( {1 - {p_r}} \right)\overline {\psi \prime } \left( {\sigma_{{e_g}}^2(n)} \right) + {p_r}\overline {\psi \prime } \left( {\sigma_{{e_\Sigma }}^2(n)} \right) \). Substituting (50) into (49) and using the transformation \( {V_D}(n) = U_{{X_D}}^TD_\alpha^{ - 1/2}v(n) \), one gets
For simplicity, we have replaced the approximate symbol by the equality symbol. This yields the same form as (18), except for \( {\tilde{A}_\psi }(n) \). Similar argument regarding the mean convergence in section 3.1 also applies to (51). A sufficient condition for the algorithm to converge is \( \left| {1 - \mu {{\tilde{A}}_\psi }(n)\lambda_i^\prime } \right| < 1 \), for all i. If \( \overline {\psi \prime } \left( {\sigma_e^2} \right) \) is upper bounded and so is \( {\tilde{A}_\psi }(n) \), say by \( {\tilde{A}_{\psi \_\max }} \), then following the argument in part 3.1, the following conservative maximum step size is obtained:
Remarks:
-
(R-B1):
TDNLMS algorithm
In this case, \( {\tilde{A}_\psi }(n) = 1 \). Compared with the Gaussian case, the convergence rate remains unchanged. All the conclusions in (R-A1) apply.
-
(R-B2):
TDNLMS algorithm with general nonlinearity and TDNLMM algorithm:
For general nonlinearity without ATS, both \( \sigma_{{e_g}}^2 \) and \( \sigma_{{e_\Sigma }}^2 \) can be very large due to the large value of \( \sigma_{{e_\Sigma }}^2 \) and the slow decay of the EMSE \( E\left[ {{v^T}(n){R_{{X_C}{X_C}}}v(n)} \right] \), as the gain \( {\tilde{A}_\psi }(n) = \left( {1 - {p_r}} \right)\overline {\psi \prime } \left( {\sigma_{{e_g}}^2(n)} \right) + {p_r}\overline {\psi \prime } \left( {\sigma_{{e_\Sigma }}^2(n)} \right)\) can be very small initially. This leads to nonlinear adaptation and slow convergence. Near convergence, \( E\left[ {{v^T}(n){R_{XX}}v(n)} \right] \) and \( {\tilde{A}_\psi }(n) \) will become stable. The convergence is exponential and the convergence rate of the i-th mode is approximately \( 1 - \mu {\tilde{A}_\psi }\left( \infty \right)\lambda_i^\prime \), where \( {\tilde{A}_\psi }\left( \infty \right) \) is the steady state value of \( {\tilde{A}_\psi }(n) \). Normally, the second term \( {p_r}\overline {\psi \prime } \left( {\sigma_{{e_\Sigma }}^2(n)} \right) \) will be much smaller than the first one due to the clipping property of the nonlinearity and the large variance of the impulsive noise \( \sigma_\Sigma^2 \). For the TDNLMM algorithm with ATS, the degradation in convergence rate is not so serious since if \( \sigma_{{e_g}}^2 < < \sigma_{{e_\Sigma }}^2 \), \( {\tilde{A}_{\rm{MH}}} \approx \left( {1 - {p_r}} \right){A_c} \) is a constant close to one if p r is not too large.
3.2.2 Mean Square Behavior
Using a similar approach, it can be shown that
where \( {\tilde{C}_\psi }(n) = \left( {1 - {p_r}} \right){C_\psi }\left( {\sigma_{{e_g}}^2(n)} \right) + {p_r}{C_\psi }\left( {\sigma_{{e_g}}^2(n)} \right) \) and \( {\tilde{B}_\psi }(n) = \left( {1 - {p_r}} \right){B_\psi }\left( {\sigma_{{e_g}}^2(n)} \right) + {p_r}{B_\psi }\left( {\sigma_{{e_g}}^2(n)} \right) \).
Due to page limitation, we only summarize the result for the small step size case as:
-
(R-B3):
TDNLMS algorithm
In these cases, \( {\tilde{A}_\psi }(n) = {\tilde{C}_\psi }(n) = 1 \), and \( {\tilde{B}_\psi }(n) = \left( {1 - {p_r}} \right)\left( {\sigma_{\rm{excess}}^2(n) + \sigma_g^2} \right) + {p_r}\left( {\sigma_{\rm{excess}}^2(n) + \sigma_\Sigma^2} \right) = \sigma_{\rm{excess}}^2(n) + \sigma_{{\eta_o}}^2 \) where \( \sigma_{{\eta_o}}^2 = \left( {1 - {p_r}} \right)\sigma_g^2 + {p_r}\sigma_\Sigma^2 \), \( \sigma_{\rm{excess}}^2(n) = E\left[ {{v^T}(n){R_{{X_C}{X_C}}}v(n)} \right] \) is the EMSE. Hence
which gives
It can be seen that the EMSE will be considerably increased over the Gaussian case by \( {p_r}\mu \sigma_w^2{\phi_{\rm{TDNLMS}}}/\left( {1 - \mu {\phi_{\rm{TDNLMS}}}} \right) \), which increases with the probability of occurrence of the impulses and the difference in power between the impulsive and Gaussian components.
For the TDNLMM algorithm with MH nonlinearity and ATS, \( {\tilde{A}_{\rm{MH}}}\left( \infty \right) \approx \left( {1 - {p_r}} \right){A_c} \), \( {\tilde{B}_{\rm{MH}}}\left( \infty \right) \approx \left( {1 - {p_r}} \right)\sigma_{{e_g}}^2{\hbox{erf}}\left( {\frac{{{k_\xi }}}{{\sqrt {2} }}} \right) = \left( {1 - {p_r}} \right)\sigma_{{e_g}}^2{A_c} \), \( {\tilde{C}_{\rm{MH}}}\left( \infty \right) \approx {\tilde{A}_{\rm{MH}}}\left( \infty \right) - \left( {1 - {p_r}} \right)\left( {\frac{{k_\xi^3}}{{\sqrt {{2\pi }} }}} \right)\exp \left( { - \frac{{k_\xi^2}}{2}} \right) \)
which is identical to the case with Gaussian noise only. This illustrates the robustness of the TDNLMM algorithm to impulsive noise.
For the LMM algorithm with the MH nonlinearity, D R = I, and \( {\Gamma_\alpha } = {R_{XX}} \). (55) will reduce to
which is also similar to its conventional LMS counterpart when the additive noise is Gaussian. This illustrates the robustness of the M-estimation based algorithms to impulsive noise.
4 Simulation Results
In this section, computer simulations on the system identification problem shown in Fig. 1 are conducted to evaluate the analytical results for the TDNLMS and TDNLMM algorithms obtained in section 3. The unknown system W* is a FIR filter with L = 8. Its coefficients are randomly generated and normalized to unit energy. The input signal x(n) is generated as a first-order AR process
where v(n) is a white Gaussian noise sequence with zero mean and variance \( \sigma_v^2 \). 0 < a < 1 is the correlation coefficient and in our experiment it is set to be 0, 0.5 and 0.9. DCT is employed due to its wide usage and efficiency in practice. The simulation results are averaged over K = 200 independent runs. Only impulses in the desired signal are considered. The locations of impulses are not fixed for each independent run and their amplitudes are varying. For the CG impulsive noise, we test p r = 0.005, 0.01 and 0.02; r im = 50, 100 and 200. \( {\lambda_\sigma } = 0.95 \), N w = 9, \( {k_\xi } = 2.576 \). For mean convergence, the norm of the mean square weight-error vector
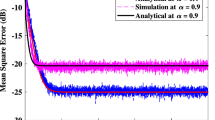
is used as the performance measure. \( {\hbox{EMSE}}(n) = {\hbox{Tr}}\left( {\Xi (n){R_{XX}}} \right) = {\hbox{Tr}}\left( {\Phi (n)\Lambda } \right) \) is adopted as the mean square performance measure. The integrals α i defined in (A-9b), \( \alpha_i^{(k)} \) in (B-9) and \( \alpha_i^{\left( {m,n} \right)} \) in (B-10) are evaluated numerically [28]. Figures 3 and 4 respectively depict the mean and mean square performance of the TDNLMS algorithm in Gaussian noise and the TDNLMM algorithm with CG noise. The theoretical results are computed respectively from (19), (30) and (51), (52). Different values of a, μ, \( \sigma_g^2 \), r im and p r are used as specified in respective figure caption. All these figures show a satisfactory agreement between the theoretical and simulation results. Since the results for the TDNLMM algorithm in Gaussian noise is similar to those in CG noise, they are omitted to save space. For the TDNLMS algorithm in CG noise, the mean weight vector can be considerably affected by the impulsive noise and the independent assumption in assumption 3 becomes less accurate. Since this case is of little interest, the simulation result is also omitted.

The mean and mean square convergence performance of the TDNLMS algorithm with Gaussian noise: a, b: α = 0, \( \sigma_g^2 = {10^{ - 4}} \), c, d: α = 0.5, \( \sigma_g^2 = {10^{ - 3}} \), e, f: α = 0.9, \( \sigma_g^2 = {10^{ - 5}} \); Three step sizes are used: (1) μ = 0.01, (2) μ = 0.004, (3) μ = 0.002.

The mean and mean square convergence performance of the TDNLMM algorithm with CG noise: a, b: a = 0, \( \sigma_g^2 = {10^{ - 4}} \), r im = 200, p r = 0.02. c, d: a = 0.5, \( \sigma_g^2 = {10^{ - 3}} \), r im = 100, p r = 0.01. (e), (f): a = 0.9, \( \sigma_g^2 = {10^{ - 5}} \), r im = 100, p r = 0.005; Three step sizes are used: (1) μ = 0.01, (2) μ = 0.004, (3) μ = 0.002.
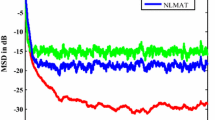
To study the effect of the recursive power estimation of the signal components in the normalization part of the TDNLMS algorithm, \( {\varepsilon_i}(n) = \left( {1 - {\alpha_\varepsilon }} \right)\sigma_{{X_{C_ i}}}^2 + {\alpha_\varepsilon }X_{C,i}^2(n) \) is used, which allows us to approximately model the effect of prior knowledge of the signal power on the algorithms. This is valid when the recursive estimation of the signal power converges. The value of \( \sigma_{{X_{C_ i}}}^2 \) can be obtained from calculation or offline estimation. In our experiment, it is derived from (57) plus DCT operation and known parameters. Figure 5 illustrates that with the increase of \( {\alpha_\varepsilon } \), the estimation accuracy slightly deteriorates. This verifies the efficiency of power normalization in TDNLMS algorithm.

Test of the effect of a priori knowledge of signal power in normalization part of the TDNLMS algorithm. μ = 0.01. (1) \( {\alpha_\varepsilon } = 0.01 \), \( \sigma_g^2 = {10^{ - 3}} \), (2) \( {\alpha_\varepsilon } = 0.25 \), \( \sigma_g^2 = {10^{ - 4}} \), (3) \( {\alpha_\varepsilon } = 0.5 \), \( \sigma_g^2 = {10^{ - 5}} \), (4) \( {\alpha_\varepsilon } = 0.75 \), \( \sigma_g^2 = {10^{ - 6}} \).
5 Conclusions
The convergence performance of the TDNLMS algorithm and its TDNLMM generalizations with Gaussian inputs and additive Gaussian and contaminated Gaussian noises is presented. Difference equations describing the mean and mean square convergence behaviors for these algorithms are derived. The analytical results reveal the advantages of the TDNLMM algorithms in impulsive noise environment, and they are shown to be in good agreement with computer simulation results.
References
Widrow, B., McCool, J., Larimore, M. G., & Johnson, C. R., Jr. (1976). Stationary and nonstationary learning characteristics of the LMS adaptive filter. Proceedings of IEEE, 64, 1151–1162.
Plackett, R. L. (1972). The discovery of the method of least-squares. Biometrika, 59(2), 239–251.
Nagumo, J. I., & Noda, A. (1967). A learning method for system identification. IEEE Transactions on Automatic Control, AC-12, 282–287.
Sayed, A. H. (2003). Fundamentals of adaptive filtering. NY: Wiley.
Haykin, S. (2001). Adaptive filter theory, 4th edn. Prentice Hall Press.
Narayan, S., Peterson, A. M., & Narasimha, M. J. (1983). Transform domain LMS algorithm. IEEE Transactions on Acoustics, Speech, and Signal Processing, ASSP-31, 609–615.
Lee, J. C., & Un, C. K. (1986). Performance of transform-domain LMS adaptive digital filters. IEEE Transactions on Acoustics, Speech, and Signal Processing, 34(3), 499–510.
Boroujeny, B. F., & Gazor, S. (1992). Selection of orthonormal transforms for improving the performance of the transform domain normalized LMS algorithm. IEE Proceedings. Radar and Signal Processing, 139(5), 327–335.
Boroujeny, B. F. (1998). Adaptive filters: theory and applications. John Wiley & Sons.
Pei, S. C., & Tseng, C. C. (1996). Transform domain adaptive linear phase filter. IEEE Transactions on Signal Processing, 44(12), 3142–3146.
Marshall, D. F., Jenkins, W. K., & Murphy, J. J. (1989). The use of orthogonal transforms for improving performance of adaptive filters. IEEE Transactions on Circuits and Systems, 36(4), 474–484.
Zou, Y., Chan, S. C., & Ng, T. S. (2000). Least mean M-estimate algorithms for robust adaptive filtering in impulsive noise. IEEE Transactions on Circuits and Systems II, 47, 1564–1569.
Huber, P. J. (1981). Robust statistics. New York: John Wiley.
Hampel, F. R., Ronchetti, E. M., Rousseeuw, P. J., & Stahel, W. A. (2005). Robust statistics: the approach based on influence functions. New York: Wiley.
Chan, S. C., & Zou, Y. (2004). A recursive least M-estimate algorithm for robust adaptive filtering in impulsive noise: fast algorithm and convergence performance analysis. IEEE Transactions on Signal Processing, 52(4), 975–991.
Chan, S. C., & Zhou, Y. (2007). On the convergence analysis of the normalized LMS and the normalized least mean M-estimate algorithms. In: Proc. IEEE Int. Symp. Signal Processing and Information Technology (pp. 1059–1065).
Price, R. (1958). A useful theorem for nonlinear devices having Gaussian inputs. IEEE Transactions on Information Theory, 4(2), 69–72.
Price, R. (1964). Comment on: ’A useful theorem for nonlinear devices having Gaussian inputs’. IEEE Transactions on Information Theory, IT-10, 171.
Haweel, T. I., & Clarkson, P. M. (1992). A class of order statistic LMS algorithms. IEEE Transactions on Signal Processing, 40(1), 44–53.
Settineri, R., Najim, M., & Ottaviani, D. (1996). Order statistic fast Kalman filter. Proceedings of IEEE International Symposium on Circuits and Systems, 2, 116–119.
Weng, J. F., & Leung, S. H. (1997). Adaptive nonlinear RLS algorithm for robust filtering in impulsive noise. Proceedings of IEEE International Symposium on Circuits and Systems, 4, 2337–2340.
Koike, S. (1997). Adaptive threshold nonlinear algorithm for adaptive filters with robustness against impulsive noise. IEEE Transactions on Signal Processing, 45(9), 2391–2395.
Bershad, N. J. (1988). On error-saturation nonlinearities in LMS adaptation. IEEE Transactions on Acoustics, Speech, and Signal Processing, ASSP-36(4), 440–452.
Mathews, V. J. (1991). Performance analysis of adaptive filters equipped with the dual sign algorithm. IEEE Transactions on Signal Processing, 39, 85–91.
Koike, S. (2006). Performance analysis of the normalized LMS algorithm for complex-domain adaptive filters in the presence of impulse noise at filter input. IEICE Transactions on Fundamentals of Electronics, Communications and Computer Science, E89-A(9), 2422–2428.
Koike, S. (2006). Convergence analysis of adaptive filters using normalized sign-sign algorithm. IEICE Transactions on Fundamentals of Electronics, Communications and Computer Science, E88-A(11), 3218–3224.
Tukey, J. W. (1960). A survey of sampling from contaminated distributions in contributions to probability and statistics: I. In: Olkin (Ed.) Stanford University Press.
Recktenwald, G. (2000). Numerical methods with MATLAB: implementations and applications. Englewood Cliffs: Prentice-Hall.
Bershad, N. J. (1986). Analysis of the normalized LMS algorithm with Gaussian inputs. IEEE Transactions on Acoustics, Speech, and Signal Processing, ASSP-34, 793–806.
Zhou, Y. (2006). Improved analysis and design of efficient adaptive transversal filtering algorithms with particular emphasis on noise, input and channel modeling. Ph. D. Dissertation, The Univ. Hong Kong, Hong Kong.
Chan, S. C., & Zhou, Y. (Dec. 2008). On the convergence analysis of the transform domain normalized LMS and related M-estimate algorithms. Proc. IEEE APCCAS 2008, 205–208.
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A
In this Appendix, \( {H_1} = {E_{\left\{ {{X_C},{\eta_g}} \right\}}}\left[ {\Lambda_C^{ - 1}\psi \left( {e(n){X_C}(n)} \right)\left| v \right.} \right] \) is evaluated. For notational convenience, we shall drop the subscript C in X C . An approach similar to [15, 29] is employed to evaluate this expectation. As η g (n) and x(n) are assumed to be statistically independent, and X are jointly Gaussian with covariance matrix \( {R_{{X_C}{X_C}}} \), the i-th element of the vector H 1 is
where \( {C_R} = {\left( {2\pi } \right)^{ - L/2}}{\left| {{R_{{X_C}{X_C}}}} \right|^{ - 1/2}} \) and \( {f_{{\eta_g}}}\left( {{\eta_g}} \right) \) is the PDF of the Gaussian noise η g . |·| denotes the determinant of a matrix. Similar to [17], let us consider the integral
It can be seen that H 1,i = F i (0). Differentiating (A-2) with respect to β, one gets
where \( {B_i} = {\left( {2\tilde{\beta }{e_i}e_i^T + R_{{X_C}{X_C}}^{ - 1}} \right)^{ - 1}} \), \( \tilde{\beta } = {\alpha_\varepsilon }\beta \) and e i is a column vector with its i-th element equal to one and zero elsewhere. Using the matrix inversion lemma, we get
where \( {G_i} = \left( {{\mathbf{I}} - 2\tilde{\beta }{{\left( {{g_i}\left( {\tilde{\beta }} \right)} \right)}^{ - 1}}{E_i}} \right) \), \( {g_i}\left( {\tilde{\beta }} \right) = 1 + 2\tilde{\beta }{R_{{X_C}{X_C}_ i,i}} \), \( {R_{{X_C}{X_C}_ i,j}} \) is the (i, j)-th element of \( {R_{{X_C}{X_C}}} \) and \( {E_i} = {e_i}r_{{X_C}{X_C}_ i}^T \). \( r_{{X_C}{X_C}_ i}^T \) is the i-th row of \( {R_{{X_C}{X_C}}} \). The determinant of B i is \( \left| {{B_i}} \right| = \left| {{R_{{X_C}{X_C}}}} \right|\left| {{G_i}} \right| = \left| {{R_{{X_C}{X_C}}}} \right|{\left( {{g_i}\left( {\tilde{\beta }} \right)} \right)^{ - 1}} \). (A-3) can be rewritten as follows
where \( {C_{{B_i}}} = {\left( {2\pi } \right)^{ - L/2}}{\left| {{B_i}} \right|^{ - 1/2}} \),\( {\gamma_i}\left( \beta \right) = \exp \left( { - \beta {\varepsilon_i}} \right){\left( {{g_i}\left( {\tilde{\beta }} \right)} \right)^{ - 1/2}} \), and \( {L_{2,i}} = {E_{\left\{ {X,{\eta_g}} \right\}}}\left[ {\psi (e){X_i}\left| v \right.} \right]\left| {_{E\left[ {X{X^T}} \right] = {B_i}}} \right. \) is the expectation of ψ(e)X i conditioned on v when X i , X j ∈ X are jointly Gaussian with covariance matrix B i . Since X and e are assumed to be jointly Gaussian in Assumption 3, the Price’s theorem [18] for X and e can be invoked to obtain the following,
b i is the i-th column of B i . Inserting (A-6) into (A-5) and integrating with respect to β yields
where \( \overline {\psi \prime } \left( {\sigma_e^2} \right) = \int_{ - \infty }^\infty {\frac{{\psi \prime (e)}}{{\sqrt {{2\pi }} \sigma_e}}\exp \left( { - \frac{{{e^2}}}{{2\sigma_e^2}}} \right)de} \), \( {\rm I}_i^T\left( \beta \right) = - \int^\beta {{\gamma_i}\left( \beta \right)b_i^Td\beta } \), and the constant of integration is equal to zero because of the boundary condition F i (∞) = 0. Here, we have assumed that \( \sigma_e^2(v) \) depends weakly on β and can be taken outside of the integral. This is a good approximation if the variation of \( \overline {\psi \prime } \left( {\sigma_e^2} \right) \) is limited, such as in the TDNLMM algorithm with adaptive threshold selection or at the steady state of the algorithm. To evaluate \( {\rm I}_i^T\left( \beta \right) \), we note from (A-4) that
Hence,
and
where \( {\alpha_i} = \int_0^\infty {\exp \left( { - \beta {\varepsilon_i}} \right){{\left( {{g_i}\left( {\tilde{\beta }} \right)} \right)}^{ - 3/2}}d\beta } \). Combining, we have the desired result
Appendix B
In this appendix, \( {s_3} = {E_{\left\{ {{X_C},{\eta_g}} \right\}}}\left[ {{\psi^2}(e)\Lambda_C^{ - 1}{X_C}X_C^T\Lambda_C^{ - 1}\left| v \right.} \right] \) is evaluated. Similar to deriving H i in Appendix A, the (i, j)-th element of s 3 is given by
Let us define
It can be seen that \( {s_{3,i,j}} = {\overline F_{i,j}}\left( {0,0} \right). \) To evaluate \( {\overline F_{i,j}}\left( {{\beta_1},{\beta_2}} \right) \), let’s differentiate (B-2) twice with respect to β 1 and β 2:
where \( {L_{3,i,j}} = {E_{\left\{ {X,{\eta_g}} \right\}}}{\left. {\left[ {{\psi^2}(e){X_i}{X_j}\left| v \right.} \right]} \right|_{E\left[ {X{X^T}} \right] = {B_{i,j}}}} \), \( {B_{i,j}} = {\left( {2{{\tilde{\beta }}_1}{e_i}e_i^T + 2{{\tilde{\beta }}_2}{e_j}e_j^T + R_{{X_C}{X_C}}^{ - 1}} \right)^{ - 1}} \), \( {\gamma_{i,j}}\left( {{\beta_1},{\beta_2}} \right) = \exp \left( { - \left( {{\beta_1}{\varepsilon_i} + {\beta_2}{\varepsilon_j}} \right)} \right){\left| {{B_{i,j}}} \right|^{1/2}}{\left| {{R_{{X_C}{X_C}}}} \right|^{ - 1/2}} \), and \( {C_{{B_{i,j}}}} = {\left( {2\pi } \right)^{ - L/2}}{\left| {{B_{i,j}}} \right|^{ - 1/2}} \).
Using the matrix inversion formula, it can be shown that [30] the determinant of B i,j and its (i, k)-th and (k, j)-th elements are respectively given by
where \( {u_{i,j}}\left( {{{\tilde{\beta }}_1},{{\tilde{\beta }}_2}} \right) = {g_i}\left( {{{\tilde{\beta }}_1}} \right){g_j}\left( {{{\tilde{\beta }}_2}} \right) - 4{\tilde{\beta }_1}{\tilde{\beta }_2}R_{{X_C}{X_C}_ j,i}^2 \), \( {\phi_{i,j,i,k}}\left( {{{\tilde{\beta }}_2}} \right) = \left[ {{R_{{X_C}{X_C}_ i,k}} + 2{{\tilde{\beta }}_2}\left( {{R_{{X_C}{X_C}_ j,j}}{R_{{X_C}{X_C}_ i,k}}{\kern 1pt} - {R_{{X_C}{X_C}_ i,j}}{R_{{X_C}{X_C}_ j,k}}} \right)} \right] \), \( {\phi_{i,j,k,j}}\left( {{{\tilde{\beta }}_1}} \right) = \left[ {{R_{{X_C}{X_C}_ k,j}} + 2{{\tilde{\beta }}_1}\left( {{R_{{X_C}{X_C}_ k,j}}{R_{{X_C}{X_C}_ i,i}} - {R_{{X_C}{X_C}_ i,j}}{R_{{X_C}{X_C}_ k,i}}} \right)} \right] \), and
Using (B-4), γ i,j (β 1, β 2) is determined as follows
Using the Price’s theorem, L 3,i,j is evaluated to be [30]
where b i,j is the (i,j)-th element of B i and \( {\mathbf{}}{B_\psi }\left( {\sigma_e^2} \right) = E[{\psi^2}(e)] = \tfrac{1}{{\sqrt {{2\pi }} \sigma_e}}\int_{ - \infty }^\infty {{\psi^2}(e)\exp \left( { - \frac{{{e^2}}}{{2\sigma_e^2}}} \right)de} \), \( {C_\psi }\left( {\sigma_e^2} \right) = \frac{d}{{d\sigma_e^2}}E\left[ {{\psi^2}(e)} \right] \). From (B-3) and (B-6), we have
Integrating (B-7) with respect to β 1 and β 2 yields
where \( {I_{1,i,j}} = \int_0^\infty {\int_0^\infty {2{\gamma_{i,j}}\left( {{\beta_1},{\beta_2}} \right)b_i^Tv{v^T}{b_j}d{\beta_2}d{\beta_1}} } \) and \( {I_{2,i,j}} = \int_0^\infty {\int_0^\infty {{\gamma_{i,j}}\left( {{\beta_1},{\beta_2}} \right){b_{i,j}}d{\beta_2}d{\beta_1}} } \).
To simplify the analysis, we shall assume that \( \sigma_e^2 \) depends weakly on β and is taken outside the integral (mean value theorem). Like \( {A_\psi }\left( {\sigma_e^2} \right) \), this is a good approximation if the variations of \( {B_\psi }\left( {\sigma_e^2} \right) \) and \( {C_\psi }\left( {\sigma_e^2} \right) \) are limited. The integrals are evaluated below.
Evaluation of I 2,i,j .
where \( \alpha_{i,j}^{(k)} = \int_0^\infty {\int_0^\infty {{{\left( {{{\tilde{\beta }}_1}{{\tilde{\beta }}_2}} \right)}^k}{{\left( {{g_i}\left( {{{\tilde{\beta }}_1}} \right){g_j}\left( {{{\tilde{\beta }}_2}} \right)} \right)}^{ - \left( {2k + 3} \right)/2}}} } \cdot \exp \left( { - \left( {{\beta_1}{\varepsilon_i} + {\beta_2}{\varepsilon_j}} \right)} \right)d{\beta_2}d{\beta_1} = \alpha_i^{(k)}\alpha_j^{(k)} \), and \( \alpha_i^{(k)} = \int_0^\infty {\int_0^\infty {{{\left( {\tilde{\beta }} \right)}^k}{{\left( {{g_i}\left( {\tilde{\beta }} \right)} \right)}^{ - \left( {2k + 3} \right)/2}}\exp \left( { - \beta {\varepsilon_i}} \right)d\beta } } \).
Evaluation of I 1,i,j .
Similarly from (B-5) and (B-8), we get
where we have assumed that the matrix \( {R_{{X_C}{X_C}}} \) is diagonal-dominant so that we can employ the binomial expansion and
In matrix form, we have
where
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License (https://creativecommons.org/licenses/by-nc/2.0), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Chan, S.C., Zhou, Y. On the Performance Analysis of a Class of Transform-domain NLMS Algorithms with Gaussian Inputs and Mixture Gaussian Additive Noise Environment. J Sign Process Syst 64, 429–445 (2011). https://doi.org/10.1007/s11265-010-0494-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11265-010-0494-5