
Abstract
This paper studies a new learning paradigm for noisy labels, i.e., noisy correspondence (NC). Unlike the well-studied noisy labels that consider the errors in the category annotation of a sample, the NC refers to the errors in the alignment relationship of two data points. Although such false positive pairs are common especially in the data harvested from the Internet, which however are neglected by most existing works. By taking cross-modal retrieval as a showcase, we propose a method called learning with noisy correspondence (LNC). In brief, the LNC first roughly obtains the clean and noisy subsets from the original data and then rectifies the false positive pairs by using a novel adaptive prediction function. Finally, the LNC adopts a novel triplet loss with soft margins to endow cross-modal retrieval the robustness to the NC. To verify the effectiveness of the proposed LNC, we conduct experiments on six benchmark datasets in image-text and video-text retrieval tasks. Besides the effectiveness of the LNC, the experimental results show the necessity of the explicit solution to the NC faced by not only the standard model training paradigm but also the pre-training and fine-tuning paradigms.










Similar content being viewed by others


References
Anderson, P., He, X., Buehler, C., Teney, D., Johnson, M., Gould, S., & Zhang, L. (2018). Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 6077–6086).
Arazo, E., Ortego, D., Albert, P., O’Connor, N., & McGuinness, K. (2019). Unsupervised label noise modeling and loss correction. In International conference on machine learning, PMLR (pp. 312–321).
Arpit, D., Jastrzebski, S., Ballas, N., Krueger, D., Bengio, E., Kanwal, M. S., Maharaj, T., Fischer, A., Courville, A., Bengio, Y., & Lacoste-Julien, S. (2017). A closer look at memorization in deep networks. In International Conference on Machine Learning, PMLR (pp. 233–242).
Bai, Y., Yang, E., Han, B., Yang, Y., Li, J., Mao, Y., Niu, G., & Liu, T. (2021). Understanding and improving early stopping for learning with noisy labels. Advances in Neural Information Processing Systems, 34, 24392–24403.
Berthelot, D., Carlini, N., Goodfellow, I., Papernot, N., Oliver, A. & Raffel, C. A. (2019). MixMatch: A holistic approach to semi-supervised learning. arXiv preprint arXiv:1905.02249.
Carreira, J., & Zisserman, A. (2017). Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 6299–6308).
Chen, H., Ding, G., Liu, X., Liu J., & Han J. (2020). Imram: Iterative matching with recurrent attention memory for cross-modal image-text retrieval. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 12,655–12,663).
Deng, C., Chen, Z., Liu, X., Gao, X., & Tao, D. (2018). Triplet-based deep hashing network for cross-modal retrieval. IEEE Transactions on Image Processing, 27(8), 3893–3903.
Diao, H., Zhang, Y., Ma, L., & Lu, H. (2021). Similarity reasoning and filtration for image-text matching. In AAAI.
Faghri, F., Fleet, D. J., Kiros, J. R., & Fidler, S. (2017). VSE++: Improving visual-semantic embeddings with hard negatives. arXiv preprint arXiv:1707.05612.
Feng, L., & An, B. (2019). Partial label learning with self-guided retraining. In Proceedings of the AAAI conference on artificial intelligence (pp. 3542–3549).
Han, B., Yao, Q., Yu, X., Niu, G., Xu, M., Hu, W., Tsang, I., & Sugiyama, M. (2018). Co-teaching: Robust training of deep neural networks with extremely noisy labels. arXiv preprint arXiv:1804.06872.
Han, J., Luo, P., & Wang, X. (2019). Deep self-learning from noisy labels. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 5138–5147).
Hara, K., Kataoka, H., & Satoh, Y. (2018). Can spatiotemporal 3D CNNs retrace the history of 2D CNNs and imagenet? In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 6546–6555).
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 770–778).
Huang, Z., Niu, G., Liu, X., Ding, W., Xiao, X., Wu, H. & Peng, X. (2021). Learning with noisy correspondence for cross-modal matching. In Thirty-Fifth conference on neural information processing systems.
Jia, C., Yang, Y., Xia, Y., Chen, Y. T., Parekh, Z., Pham, H., Le, Q., Sung, Y. H., Li, Z., & Duerig, T. (2021). Scaling up visual and vision-language representation learning with noisy text supervision. arXiv preprint arXiv:2102.05918.
Kaufman, D., Levi, G., Hassner, T., & Wolf, L. (2017). Temporal tessellation: A unified approach for video analysis. In Proceedings of the IEEE international conference on computer vision (pp. 94–104).
Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Kiros, R., Salakhutdinov, R., & Zemel, R. S. (2014). Unifying visual-semantic embeddings with multimodal neural language models. arXiv preprint arXiv:1411.2539.
Kuang, Z., Gao, Y., Li, G., Luo, P., Chen, Y., Lin, L., & Zhang, W., (2019). Fashion retrieval via graph reasoning networks on a similarity pyramid. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 3066–3075).
Lee, K. H., Chen, X., Hua, G., Hu, H., & He, X., (2018). Stacked cross attention for image-text matching. In Proceedings of the European conference on computer vision (ECCV) (pp. 201–216).
Li, J., Socher, R., & Hoi, S. C. (2020). DivideMix: Learning with noisy labels as semi-supervised learning. arXiv preprint arXiv:2002.07394.
Li, K., Zhang, Y., Li, K., & Fu, Y. (2019a). Visual semantic reasoning for image-text matching. In ICCV.
Li, S., Tao, Z., Li, K., & Fu, Y. (2019). Visual to text: Survey of image and video captioning. IEEE Transactions on Emerging Topics in Computational Intelligence, 3(4), 297–312.
Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., & Zitnick, C. L. (2014). Microsoft COCO: Common objects in context. In European conference on computer vision (pp. 740–755). Springer.
Liu, T., & Tao, D. (2015). Classification with noisy labels by importance reweighting. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38(3), 447–461.
Miech, A., Laptev, I., & Sivic, J. (2018). Learning a text-video embedding from incomplete and heterogeneous data. arXiv preprint arXiv:1804.02516.
Miech, A., Zhukov, D., Alayrac, J. B., Tapaswi, M., Laptev, I., & Sivic, J. (2019). Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 2630–2640).
Mikolov, T., Chen, K., Corrado, G., & Dean J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
Patrini, G., Rozza, A., Krishna Menon, A., Nock, R., & Qu, L. (2017). Making deep neural networks robust to label noise: A loss correction approach. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1944–1952).
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., & Krueger, G. (2021). Learning transferable visual models from natural language supervision. arXiv preprint arXiv:2103.00020.
Reed, S., Lee, H., Anguelov, D., Szegedy, C., Erhan, D., & Rabinovich, A. (2014). Training deep neural networks on noisy labels with bootstrapping. arXiv preprint arXiv:1412.6596.
Ren, S., He, K., Girshick, R. B., & Sun, J. (2015). Faster R-CNN: Towards real-time object detection with region proposal networks. In NIPS.
Rohrbach, A., Torabi, A., Rohrbach, M., Tandon, N., Pal, C., Larochelle, H., Courville, A., & Schiele, B. (2017). Movie description. International Journal of Computer Vision, 123(1), 94–120.
Schuster, M., & Paliwal, K. K. (1997). Bidirectional recurrent neural networks. IEEE Transactions on Signal Processing, 45(11), 2673–2681.
Sharma, P., Ding, N., Goodman, S., & Soricut, R. (2018). Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th annual meeting of the association for computational linguistics (Volume 1: Long Papers, pp. 2556–2565).
Shekhar, R., Pezzelle, S., Klimovich, Y., Herbelot, A., Nabi, M., Sangineto, E., & Bernardi, R. (2017). Foil it! find one mismatch between image and language caption. arXiv preprint arXiv:1705.01359.
Song, H., Kim, M., Park, D., Shin, Y., & Lee, J. G. (2020). Learning from noisy labels with deep neural networks: A survey. arXiv preprint arXiv:2007.08199.
Torabi, A., Tandon, N., & Sigal, L. (2016). Learning language-visual embedding for movie understanding with natural-language. arXiv preprint arXiv:1609.08124.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., & Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. arXiv preprint arXiv:1706.03762.
Wang, L., Li, Y., & Lazebnik, S. (2016). Learning deep structure-preserving image-text embeddings. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5005–5013).
Wu, Q., Shen, C., Wang, P., Dick, A., & Van Den Hengel, A. (2017). Image captioning and visual question answering based on attributes and external knowledge. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(6), 1367–1381.
Wu, Q., Teney, D., Wang, P., Shen, C., Dick, A., & Van Den Hengel, A. (2017). Visual question answering: A survey of methods and datasets. Computer Vision and Image Understanding, 163, 21–40.
Xu, J., Mei, T., Yao, T., & Rui, Y. (2016). MSR-VTT: A large video description dataset for bridging video and language. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5288–5296).
Xu, X., Shen, F., Yang, Y., Shen, H. T., & Li, X. (2017). Learning discriminative binary codes for large-scale cross-modal retrieval. IEEE Transactions on Image Processing, 26(5), 2494–2507.
Yang, E., Deng, C., Liu, W., Tao, D., & Gao, X. (2017). Pairwise relationship guided deep hashing for cross-modal retrieval. In Proceedings of the AAAI conference on artificial intelligence.
Ye, M., Shen, J., Lin, G., Xiang, T., Shao, L., & Hoi, S. C. (2021). Deep learning for person re-identification: A survey and outlook. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44, 2872–2893.
Young, P., Lai, A., Hodosh, M., & Hockenmaier, J. (2014). From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2, 67–78.
Yu, X., Han, B., Yao, J., Niu, G., Tsang, I., & Sugiyama, M. (2019). How does disagreement help generalization against label corruption? In International conference on machine learning, PMLR (pp. 7164–7173).
Yu, Y., Ko, H., Choi, J., & Kim, G. (2017). End-to-end concept word detection for video captioning, retrieval, and question answering. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3165–3173).
Yu, Y., Kim, J., & Kim, G. (2018). A joint sequence fusion model for video question answering and retrieval. In Proceedings of the European conference on computer vision (ECCV) (pp. 471–487).
Zhao, Z., Yang, Q., Cai, D., He, X., & Zhuang, Y. (2017). Video question answering via hierarchical spatio-temporal attention networks. In IJCAI (pp. 3518–3524).
Zheng, W. S., Gong, S., & Xiang, T. (2012). Reidentification by relative distance comparison. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(3), 653–668.
Zhou, L., Xu, C., & Corso, J. J. (2018). Towards automatic learning of procedures from web instructional videos. In Thirty-second AAAI conference on artificial intelligence.
Acknowledgements
The authors would like to thank the associate editor and reviewers for the constructive comments and valuable suggestions that remarkably improve this study. This work was supported in part by NSFC under Grant U21B2040, 62176171; and in part by the Fundamental Research Funds for the Central Universities under Grant CJ202303.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Gang Hua.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Exactly Matched Element (EME)
To quantify the noise in the correspondence, here we introduce the exactly matched element (EME) score which evaluates the similarity of image and text pairs based on how many elements they share in common. Formally,
where \(e_i\) and \(e_t\) are meaningful elements extracted from the image I and the text T respectively, \(N_I\) and \(N_T\) are the number of elements in I and T respectively, the function \(E(e_i, T)\) is an indicator function that outputs 1 if the element \(e_i\) is accurately described in T, and 0 otherwise. Similarly, \(E(e_t, I)\) is an indicator function that outputs 1 if the element \(e_t\) is depicted in I, and 0 otherwise. EME could be considered as the correspondence label of cross modal pairs. To obtain EME score, we have two main approaches. Firstly, we can compute the EME score with human annotations to ensure accuracy. Alternatively, we can leverage advanced techniques such as semantic segmentation or object detection on images to extract all visual elements, and employ text segmentation methods on text to extract all textual elements. Subsequently, we can calculate EME by utilizing a visual-language model as the indicator (i.e., the function \(E(e_i, T)\) and \(E(e_t, I)\)), such as CLIP. Such an indicator helps identify whether the extracted elements from one modality are described in the other modality.
The EME degree ranges from 0 to 1, where higher values indicate higher similarity between image and text pairs. For example, if an image and a text are completely unrelated, their EME degree will be 0. If they are partially related, their EME degree will be between 0 and 1. If they are fully related, their EME degree will be 1. A toy example is illustrated in Fig. 10 to show how to calculate the EME score of an image-text pair. Note that, the calculation of EME is contingent upon the quantity of shared content across various modalities. Thus EME score primarily estimates the level of cross-modal semantic completeness and lacks the capability to assess other intricate relationships, such as contradictions or complements.
Appendix B: Algorithm
Here we provide the detail algorithm of LNC in Algorithm 1.

Appendix C: Additional Experiments
1.1 C.1 Evaluation on the MS-COCO 5K Testing Set
Here we provide the additional comparison results on the 5K testing set of MS-COCO. As shown in Table 10, LNC achieves SOTA results in the non-noise case. In the cases with noisy correspondence, LNC remarkably outperforms all the baselines. Specifically, in the noisy setting, LNC improves R@1 by 3.9%, 2.7%, 3.7%, and 3.1% in text and image retrieval compared to the best baseline SGR-C.
1.2 C.2 Case Study
In this section, we show some qualitative results of LNC. The example image-text retrieval results are shown in Fig. 11 and Fig. 12. As shown in Fig. 11 (1)–(4) and Fig. 11 (1)–(5), LNC could successfully retrieve the corresponding samples with given queries. Moreover, we provide some failure cases from LNC in Fig. 11 (5)–(6) and Fig. 12 (6). Interestingly, the retrieved image from LNC is fit to the query compared to the ground truth in Fig. 12 (6).

Some retrieved images by the LNC from CC152K. The left images are the ground truth while the right are the retrieved ones. The successfully retrieved images and the failure cases are highlighted by green dashed boxes and red dashed boxes, respectively (Color figure online)

Some retrieved captions by the LNC from CC152K. The top sentence is the ground truth while the rest are the retrieved top 3 captions. The successfully retrieved images and the failure cases are highlighted by  and
and  , respectively
, respectively

a The visualization of loss distribution and GMM fitting results from LNC. b The visualization of the rectified correspondence from LNC
1.3 C.3 Co-divide and Co-rectify from LNC
In this section, we conduct analysis experiments to further study the influence of co-divide and co-rectify modules. First, we provide the visualization on co-divide and co-rectify from LNC in Fig. 13. As one could observe, the noisy and clean pairs are well divided and rectified by our method.
Besides, to evaluate the impact of our confidence estimation, we performed an ablation study by setting \(w_i\) to 1 for clean samples and 0 for noisy samples, based on the ground truth labels. We denote this method as LNC (\(w^c_i=1, w^n_i=0\)). The results are shown in Table 11. Interestingly, our LNC achieved better results than LNC (\(w^c_i=1, w^n_i=0\)), despite the latter having access to the ground truth labels. This indicates that our confidence estimation can effectively capture the uncertainty of data correspondence, including fully-matched, partially-matched, and unmatched image-text pairs, and thus improve the cross-modal matching performance.
Appendix D: Implementation Detail
1.1 D.1 Image-text Retrieval
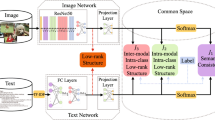
Here we detail how LNC adopts SGR for cross-modal retrieval.
Specifically, for images, the visual features of K local regions are extracted by the Faster R-CNN (Ren et al., 2015). Then we obtain the local embeddings \(\{{\textbf{v}}_1,\ldots ,{\textbf{v}}_K\}\) by embedding the above visual features by a fully connected layer f. The global embeddings are obtained via the self-attention mechanism (Vaswani et al., 2017). Moreover specifically, we aggregate all the local embeddings to obtain global embedding \(\hat{{\textbf{v}}}\) by treating the average local embeddings as query. For captions, the caption is spited into L words and are further represented by the 300-dimensional features with word embedding technique. Then the 1024-dimensional local embeddings \(\{{\textbf{t}}_1,\ldots ,{\textbf{t}}_L\}\) are obtained by a Bi-GRU (Schuster & Paliwal, 1997) g(T). The global embeddings \(\hat{{\textbf{t}}}\) of captions are computed similar to the image.
With the extracted visual and textual embeddings, we compute the similarity vector for given pairs. In detail, the similarity vector is computed by:
where \({\textbf{W}}\) denotes a learnable matrix. Then we compute the similarity of global visual and textual embeddings as:
and the similarity of local visual and textual embeddings:
where \({\textbf{a}}^v_j\) denotes aggregated embeddings, \(\alpha _{ij}\) denotes the attention coefficient:
where \({\hat{c}}_{ij}\) denotes the cosine similarity between the i-th image region and j-th word in a given image-text pair.
Once the similarity vectors \({\mathcal {N}} = \{{\textbf{s}}_1^l, {\textbf{s}}_2^l, \cdots , {\textbf{s}}_K^l\}\) are obtained, we treat them as the similarity graph nodes and compute the graph edges as:
where \({\textbf{W}}_{in}\) and \({\textbf{W}}_{out}\) are the learnable matrixes to transform the incoming and outgoing similarity. Finally, we aggregate all the similarities by updating the similarity of nodes and edges by
where \({\textbf{W}}_{in}^n\), \({\textbf{W}}_{out}^n\) and \({\textbf{W}}_{r}^n\) are learnable matrixes, \({\textbf{s}}_p^0\) and \({\textbf{s}}_q^0\) are the initial nodes from \({\mathcal {N}}\) at step \(n = 0\). Specifically, it iteratively updates the similarity for N steps, and treats the global node as the reasoned similarity. Finally, we use a fully connected layer to compute the final similarity as S(I, T) in LNC.
Here we provide the used parameters for training LNC in Table 12 including the number of epochs for warmup, the number of epochs for training, the number of learning rate update intervals (LR Update) and batch size.
1.2 D.2 Video-Text Retrieval
In the video-text retrieval experiment, we take the model proposed by Miech et al. (2019) as an example and extend it to be robust again noisy correspondence. Specifically, with the given video clip and caption \(({\textbf{v}}, {\textbf{t}})\), we adopt the class of non-linear embedding functions to obtain the visual and textual features, i.e.,
where \(W_1^v\), \(W_1^t\), \(W_2^v\), and \(W_2^t\) are the learnable weight, \(b_1^v\), \(b_1^t\), \(b_2^v\), and \(b_2^t\) are the learnable bias vectors, \(\sigma \) is an element-wise sigmoid activation and \(\circ \) is the element-wise multiplication. In all experiments, we embed the clip and caption into 4096-dimensional space.
For all video-text experiments, we adopt the Adam optimizer with a learning rate of 0.0001 and set the batch size to 256. For the pre-training on HowTo100M data, we follow the default settings in Miech et al. (2019). The number of warmup epochs is fixed to 3 for all video datasets.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Huang, Z., Hu, P., Niu, G. et al. Learning with Noisy Correspondence. Int J Comput Vis (2024). https://doi.org/10.1007/s11263-024-02064-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11263-024-02064-0