
Abstract
This work addresses the problem of recognizing action categories in videos when no training examples are available. The current state-of-the-art enables such a zero-shot recognition by learning universal mappings from videos to a semantic space, either trained on large-scale seen actions or on objects. While effective, we find that universal action and object mappings are biased to specific regions in the semantic space. These biases lead to a fundamental problem: many unseen action categories are simply never inferred during testing. For example on UCF-101, a quarter of the unseen actions are out of reach with a state-of-the-art universal action model. To that end, this paper introduces universal prototype transport for zero-shot action recognition. The main idea is to re-position the semantic prototypes of unseen actions by matching them to the distribution of all test videos. For universal action models, we propose to match distributions through a hyperspherical optimal transport from unseen action prototypes to the set of all projected test videos. The resulting transport couplings in turn determine the target prototype for each unseen action. Rather than directly using the target prototype as final result, we re-position unseen action prototypes along the geodesic spanned by the original and target prototypes as a form of semantic regularization. For universal object models, we outline a variant that defines target prototypes based on an optimal transport between unseen action prototypes and object prototypes. Empirically, we show that universal prototype transport diminishes the biased selection of unseen action prototypes and boosts both universal action and object models for zero-shot classification and spatio-temporal localization.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
This paper addresses the problem of recognizing actions in videos. Foundational deep network approaches performed action recognition through frame-level fusion (Karpathy et al., 2014), two-stream networks (Simonyan & Zisserman, 2014; Feichtenhofer et al., 2016), and 3D convolutional networks (Carreira & Zisserman, 2017). Building upon these approaches, recent works have shown great recognition capabilities through e.g., slow-fast architectures (Feichtenhofer et al., 2019), separated 3D convolutions (Tran et al., 2019), and video transformers (Arnab et al., 2021). Such deep networks require large amounts of video material for training and efforts have been made to meet those video demands, such as ActivityNet (Caba Heilbron et al., 2015), EPIC Kitchens (Damen et al., 2018), Kinetics (Carreira & Zisserman, 2017), HowTo100M (Miech et al., 2019), and EGO4D (Grauman et al., 2022) to name a few. While such datasets increase the coverage of the action space, we seek to recognize actions even when no examples are available during training.
In zero-shot action recognition, many works have outlined approaches that mirror successes in the image domain, for example by using attributes (Liu et al., 2011; Gan et al., 2016b) or feature synthesis (Mishra et al., 2020) to transfer knowledge from seen to unseen actions. More recently, state-of-the-art results have been achieved by taking a universal learning perspective, where large-scale models are trained to map input videos to a shared semantic space occupied by both seen and unseen categories. In the first universal perspective, large-scale networks train a mapping from videos to a semantic space on hundreds of seen actions from e.g., ActivityNet (Zhu et al., 2018) or Kinetics (Brattoli et al., 2020; Pu et al., 2022). For a target dataset with unseen actions, zero-shot inference is directly possible through a nearest neighbour search between the video mappings and the embeddings of unseen actions. In the second perspective, networks are trained on thousands of objects (Jain et al., 2015; Mettes et al., 2021), where inference becomes a function of the object likelihoods in test videos and the semantic relation between objects and actions.

Predicted and ground truth action distributions for an example universal action model. The distributions are out of alignment, with a quarter of the actions never predicted altogether, severely limiting the upper bound for zero-shot action recognition. We seek to overcome this misalignment by matching the distributions of unseen actions and test videos
While effective, both universal perspectives share a common limitation: they are strongly biased to subsets of the unseen actions. Compounding biases in (i) the mapping of videos to seen categories and (ii) in the matching between seen and unseen categories result in a mismatch between the prototypes of unseen actions and projected test videos. A significant part of the actions are as a result simply never selected, disrupting progress in zero-shot action recognition. This is a direct result of their inductive nature, where each test video is individually evaluated. Figure 1 illustrates this problem on UCF-101 for example with the recent universal action model of Brattoli et al. (2020). Here, 23% (!) of the unseen actions are simply never selected for any test video in the first place, placing hard upper bounds on the accuracy in zero-shot recognition. We seek to address this limitation by enriching universal models with an optimal transport transductive perspective.
We introduce universal prototype transport for zero-shot action recognition with universal models. The main idea is to re-position the prototypes of unseen actions in the shared semantic space to better align with the test videos. For universal action models, we first find an optimal mapping from action prototypes to test videos on the hypersphere. We then define a target prototype for each unseen action as a weighted Fréchet mean based on the coupling matrix from the optimal transport. Rather than doing a nearest neighbor search directly on the target prototypes for zero-shot recognition, we re-position the prototypes through interpolation along the geodesic spanned by the original and target prototypes. The intuition behind the interpolation is to maintain a form of semantic regularization for the target prototypes from their original semantic representation. For universal object models, we follow a similar setup, but replace the test videos with object prototypes during the optimal transport mapping. Beyond action recognition, we show that our approach is also helpful for zero-shot spatio-temporal action localization due to an improved ranking of tubes from different test videos to unseen actions.
We perform empirical evaluations on four action datasets for two tasks: zero-shot action recognition and zero-shot spatio-temporal action localization. The experiments confirm that universal prototype transport diminishes the biased selection of unseen actions in universal models, resulting in better recognition performance. By combining inductive universal action and object models, we are able to improve both zero-shot action recognition and spatio-temporal action localization in videos. Our approach is general in nature and can be used on top of any existing approach. The code is available on https://github.com/psmmettes/upt.
2 Related work
2.1 Zero-shot action recognition
Zero-shot action recognition refers to the task of assigning an action label to a test video given a pool of actions not observed during training. A common approach is to learn and transfer a shared representation on seen actions with training examples to be able to perform inference on unseen actions. A well-known shared space is given by attributes (Gan et al., 2016b; Liu et al., 2011; Zhang et al., 2015). By projecting test videos to an attribute space, inference is possible through a neighbour search with unseen actions manually defined in the same space. Since attributes require manual annotations for every action, other works prefer to use word embeddings (Bishay et al., 2019; Gan et al., 2016a, 2016; Li et al., 2016), video captions (Estevam et al., 2021a), or action hierarchies (Long et al., 2020) to provide a shared space for seen and unseen actions.
State-of-the-art zero-shot action recognition solutions take a universal learning perspective with semantic word embeddings as the shared space for knowledge transfer. Rather than relying on a small set of seen actions from the same dataset, large-scale models are trained on hundreds or thousands of seen categories to learn a direct mapping from videos to the shared space. The first universal learning direction relies on large-scale actions with training videos. Zhu et al. (2018) were the first to propose a large-scale universal action perspective by learning a video network on 200 actions from ActivityNet (Caba Heilbron et al., 2015). Brattoli et al. (2020) have obtained high performance in zero-shot action recognition by scaling this perspective to 664 actions from Kinetics (Carreira & Zisserman, 2017). Pu et al. (2022) have subsequently shown that incorporating alignment, uniformity, and feature synthesis further improve recognition. Due to the large amount of seen actions, care needs to be taken to avoid (near) duplicates between seen and unseen actions, as also noted by Roitberg et al. (2018). These universal models share a similar fate, where the predicted and ground truth action distributions are mis-aligned due to biased training. We show that our proposed prototype transport improves the current state-of-the-art action-based models for zero-shot recognition.
Next to universal action models, several works have shown competitive results by taking a universal object perspective. Large-scale networks are trained in the image domain on thousands of object labels (Jain et al., 2015; Liu et al., 2019; Mettes & Snoek, 2017; Mettes et al., 2021; Wu et al., 2016). Once trained any action can be inferred based on the object likelihoods in test video and the semantic similarities between objects and unseen actions. For example, Bretti and Mettes (2021) show that actions like skateboarding are easy to recognize as its corresponding action embedding is close to object embeddings like skateboard and roller skates. Similar to universal action models, we show that the object-based perspective also benefits from our proposed approach.
By operating on the entire test distribution, we take a transductive view, a common setting in zero-shot action recognition as noted by Estevam et al. (2021). Where inductive reasoning requires solving a general problem and applying them to individual samples, transduction is about reasoning from observed training cases to observed test cases. It is hence commonly seen as a more direct way to solve inference problems (Vapnik, 2006) with direct implications for zero-shot learning, semi-supervised learning, transfer learning, and more (Arnold et al., 2007). In practical settings, inference is often performed on video collections, for example for recommendation or searching in large databases, making transductive learning a viable learning setting. Rohrbach et al. (2013) provide a foundation for transduction in zero-shot context by exploiting the inter-sample similarity over the test set. In similar spirit, several works have proposed transductive extensions for zero-shot action recognition (Alexiou et al., 2016; Fu et al., 2014; Gao et al., 2019; Kodirov et al., 2015; Mandal et al., 2019; Xu et al., 2017, 2020; Zhuo et al., 2022). Transductive learning performs inference over the entire video batch, rather than each video individually. Different from existing approaches, we use the test video distribution to improve the unseen action embeddings in the shared space of universal models by building on optimal transport. Moreover, our approach can switch between inductive and transductive settings, as only the positions of unseen action prototypes are updated.
Wang et al. (2021) have also investigated optimal transport in the context of zero-shot learning. In their work, optimal transport is used to match distributions of generated and real features in their generative learning. Wu et al. (2021) consider optimal transport to align batches of unpaired images and textual descriptions for self-supervised learning with zero-shot learning as down-stream task. In our work, we outline a hyperspherical optimal transport to align distributions of unseen action labels to videos and objects in shared semantic spaces for zero-shot recognition in videos.
2.2 Zero-shot action localization
Beyond recognition, a number of works have researched action localization in zero-shot settings. In the temporal domain, zero-shot localization has been investigated by aligning temporal proposals with label embeddings (Zhang et al., 2020, 2022), by training models on trimmed seen actions followed by a knowledge transfer to unseen actions (Jain et al., 2020), or by taking an open-set perspective (Bao et al., 2022).
In the spatio-temporal domain, Jain et al. (2015) were the first to investigate zero-shot spatio-temporal action localization with a universal object perspective by computing object likelihoods for spatio-temporal proposals, followed by a semantic transfer to unseen actions. This direction has been expanded by incorporating knowledge about spatial relations between actors and objects (Mettes & Snoek, 2017) and by taking into account semantic priors about objects (Mettes et al., 2021). We build upon these works and improve the ranking of action tubes from different videos through our universal prototype transport.
Soomro and Shah (2017) have previously performed unsupervised spatio-temporal action localization, while Yang et al. (2022) have recently enabled a similar localization by performing a self-shot learning to automatically find relevant common videos from an unlabelled video pool to help the optimization. Different from these works, we seek to perform zero-shot spatio-temporal localization by assigning semantic labels to action tubes, rather than unsupervised or common action localization.
3 Background
This paper builds upon optimal transport to improve zero-shot recognition. The background section provides the background for the general problem and the common task to be solved in optimal transport, following the formulation of Peyré and Cuturi (2019). Optimal transport is the problem of moving one distribution of mass to another with minimal effort, with piles of dirt and multiple holes as a classical practical example.
More formally, optimal transport is a minimization problem over discrete measures, where a discrete measure is defined as:
with \(\delta _{x_{i}}\) the Dirac position of the \(i^{th}\) element and \(\textbf{a}_i \in \Sigma _n\) denotes probability vector and element of the probability simplex:
Optimal transport is concerned with finding an optimal assignment between two discrete measures. If we assume that two discrete measures are of equal size and want to find a one-to-one mapping between the elements of the two measures, we arrive at the Monge problem (Monge, 1781):
with \(\textbf{C}_{i,j}\) a precomputed cost matrix between two discrete measures and Perm\((\cdot )\) the set of all possible permuations. Here, we are interested in optimal assignment between discrete measures of different sizes and distributing mass from any point in one discrete measure to multiple points in the other discrete measure. We will therefore focus on the Kantorovich relaxation of the Monge problem (Kantorovich, 1942). In this relaxation, the permutation operation is replaced by a coupling matrix \(\textbf{P} \in \mathbb {R}^{n \times m}_{+}\), where \(\textbf{P}_{i,j}\) denotes the amount of mass that is distributed from point i to point j. The minimization problem is in turn given as:
with \(\textbf{a}_1\) and \(\textbf{a}_2\) two discrete measures and \(\textbf{U}(\textbf{a}_1, \textbf{a}_2)\) the set of possible admissible couplings. With \(\textbf{a}_1\), \(\textbf{a}_2\), and \(\textbf{C}\) known, the goal is to find the optimal coupling matrix. We will extensively rely on optimal transport on the hypersphere and on the coupling matrix of the Kantorovich relaxation in the context of zero-shot actions. For a full foundation on optimal transport, we recommend the work of Peyré and Cuturi (2019).

Overview of universal prototype transport. First, we find an optimal mapping from unseen action prototypes to the projected test videos when building on universal action models. For universal object models, the test videos are replaced by object prototypes. Second, we define the target prototype for each unseen action as the weighted Fréchet mean over the transport couplings. Third, we re-position unseen action prototypes along the geodesic spanned by the original and target prototypes
4 Universal prototype transport
For the problem of zero-shot action recognition, we are given a set of test videos \(\mathcal {V}_u\) and a set of labels \(L_u\) denoting actions which have not been observed during training. We seek to assign a label \(l \in L_u\) to each test video. We start from two state-of-the-art universal learning directions in zero-shot action recognition, namely by transferring knowledge from large-scale seen actions and from objects. Below, we first introduce transductive universal transport for the transfer from seen to unseen actions. Second, we extend our approach for re-positioning unseen action embeddings based on universal object models.
4.1 Transporting universal action models
Universal action models are centered around a semantic space that should be shared by both videos and action labels. This requires two transformation functions: a function \(\omega \) that maps a label to a prototype in the semantic embedding space and a function \(\phi \) that maps a video to the same embedding space. The function \(\omega \) is given by a pre-trained word embedding model (Mikolov et al., 2013b), where embeddings are \(\ell _2\)-normalized and optimized with the cosine distance. The mapping function \(\phi \) is learned on a set of training videos \(\mathcal {V}_s\) with seen action labels \(L_s\), with its loss given as:
with \(l_v \in L_s\) the action label for video v. Once such a network is optimized for a set of seen actions with training videos, zero-shot learning can be enabled for a test video simply through a nearest neighbor search with a set of unseen action prototypes in the shared semantic space. This paper argues that that since \(\phi \) is trained on actions not used during inference, the projected videos and unseen action prototypes are not well aligned. We propose to improve zero-shot action recognition by re-positioning unseen action prototypes with optimal transport.
The main idea here is to find an optimal mapping between the set of unseen action prototypes and the set of projected test videos in the shared semantic space. We then want to utilize the optimal mapping to improve the location of unseen action prototypes in the shared space, to improve the zero-shot nearest neighbor inference. Figure 2 provides an overview of our approach. To be able to find the optimal mapping between unseen actions and test videos, we first need to redefine them as discrete measures in order to solve the corresponding optimal transport problem. For the unseen actions, the definition is given as:
Definition 1 (Actions as a discrete measure). The set of unseen actions is represented as a measure as:
where \(w_{l_u} \in \textbf{w}_u\) denotes the set of weights for the action, such that \(\textbf{w}_u \in \Sigma _{|L_u|}\) is on the probability simplex, and \(l_u\) denotes the label of unseen action u.
The unseen actions are given by a weighted combination of their word embeddings in the shared semantic space. The definition of the projected test videos is given as:
Definition 2 (Videos as a discrete measure). The set of projected test videos is given as a measure as:
with \(w_c \in \textbf{w}_c \in \Sigma _k\) akin to Definition 1, where \(C^k\) denotes a k-component cluster aggregation over the set of videos, and where \(a(\mathcal {V}_u; c)\) denotes the set of videos assigned to cluster c.
Rather than using all test videos as individual points in the discrete measure, we first cluster the test videos and define the measure over the cluster centers. The idea behind Definition 2 is to make the discrete measure robust to outliers and to increase the focus on high-density regions of projected videos.
With the unseen action labels and videos defined as discrete measures in the same space, we are able to compute an optimal transport mapping between the two. By operating over the entire distribution of test videos rather than performing inference for each video independently, we view this as a transductive form of optimal transport. We seek to obtain a coupling matrix \(\textbf{P}^u\) with the minimization objection given in Equation 4. To that end, let \(\textbf{C}^u\) denote the required cost matrix, with \(C_{ij}^u\) defined as the cosine distance between unseen action i and video cluster j. Then the hyperspherical optimal transport from \(\mu _u\) to \(\mu _v\) is as:
with \(P^u_{ij}\) a single coupling value, where the minimization is solved using the Lagrangian approach of Bonneel et al. (2011). This results in a coupling matrix \(\textbf{P}^u\). When working with universal action models, we set the weights \(\textbf{w}_u\) and \(\textbf{w}_v\) uniformly. The overall step of finding an optimal mapping from unseen actions to test videos is shown in Figure 2 as step (1) in the universal prototype transport.
Given the optimal transport mapping, we propose to condense the corresponding coupling into a single target prototype per unseen action. Since the semantic space on which we operate is a hypersphere, we define the target prototype for unseen action i as the weighted Fréchet mean (Lou et al., 2020; Miolane et al., 2020) based on normalized coupling values:
with d the cosine similarity and s the obtained mean. Determining the target prototype of each unseen action is visualized in Figure 2 as step (2). We opt for a hyperspherical optimal transport formulation because we rely on word embeddings for actions and objects, which are hyperspherical in nature as they are optimized with cosine distances (Mikolov et al., 2013b) and they are state-of-the-art for zero-shot action recognition (Brattoli et al., 2020; Pu et al., 2022; Zhuo et al., 2022). The target provides a new prototype in embedding space for each unseen action, guided by the distribution of mapped and clustered test videos. While we can directly use the new embeddings for inference, we want to avoid big changes in embedding space since that relates with losing the original semantic interpretation of the action. We therefore dictate that the final prototype of each unseen action is positioned along the geodesic spanned by the original and target prototypes, modelled through spherical interpolation:
where \(\lambda \) denotes the interpolation ratio between the extremes. In this manner, we move each unseen action towards its proposed target prototype, with the interpolation acting as a regularization pulling the action towards the original semantic prototype, visualized as step (3) in Figure 2. Zero-shot inference is performed the same as in existing universal action models, by means of a nearest neighbour search between video v and each unseen action label l as
after which the action label with the highest similarity is selected.
4.2 Transporting universal object models
Universal object models for zero-shot action recognition suffer from the same bias in the assignment of unseen action labels to test videos. We therefore also seek to transport unseen action prototypes in this setting. We start by redefining objects as discrete measures to make them suitable in the context of optimal transport:
Definition 3 (Objects as a discrete measure). The set of objects are given as a measure as :
with \(w_o \in \textbf{o}_c\) and where p(o|v) denotes the likelihood of object o occurring in video v.
Unique in this definition, the discrete measure for objects is based on a subset \(\mathcal {O}_s \in \mathcal {O}\), i.e., we define a degenerate distribution over objects. The subset is determined by again taking a transductive view; we exclude any object which does not have a likelihood over a low threshold \(\tau \) in any test video. The idea behind this is simple: we want to avoid a bias in the optimal transport to objects which do not actually occur in videos.
In the universal object context, the optimal transport mapping is now given between the unseen action measure and the object measure. Moreover, we set non-uniform weights for both the actions and objects. The objects are weighted according to their transductive maximum score,
with \(\mathcal {Z}_o\) a normalization constant over all objects in \(\mathcal {O}_s\). The unseen action weights are given as
with \(\mathcal {Z}_a\) a normalization constant over all actions. The intuition behind the object weights is to focus the attention of the transductive universal transport on objects with a higher visual likelihood. The weights for the unseen actions are given as the inverse over the maximum word embedding similarity with respect to the objects, under the notion that actions without obvious relations to objects should have a more prominent spot in the transport coupling. With the optimal transport computed between unseen actions and objects, action prototypes are again interpolated following Equations 9 and 10, with the updated prototype for action label l now denoted as \(\omega ^{\ddagger }(l)\).
For the final zero-shot action inference from objects, we follow the same setup as current object-based approaches, where the score for each action label l in video v is determined based on the top relevant objects for that action (Jain et al., 2015; Mettes et al., 2021):
with \(\mathcal {O}_l\) the set of most semantically similar objects for action label l. Finally, the transductive action-based and object-based scores from respectively Equations 11 and 15 can also be fused as \(s_{\text {fusion}}(l | v) = \epsilon \cdot s_{\text {action}}(l | v) + (1 - \epsilon ) \cdot s_{\text {object}}(l | v)\).
Summarized, our approach formulated for universal object models differs in three ways from its formulation to universal action models: the mapping is performed towards object embeddings rather than video embeddings, the object measure only includes objects that actually occur in any of the test videos, and the object measure is weighted based on video likelihood, where as the video measure is unweighted.
5 Experimental setup
5.1 Datasets
Source datasets. We employ two source datasets for universal representation learning, namely Kinetics-700 for actions and ImageNet for objects. For Kinetics-700, we follow Brattoli et al. (2020) and use a subset with 664 action categories to avoid any overlap with action categories in datasets used for zero-shot action recognition. For ImageNet, we follow Mettes et al. (2021) and use the reorganized variant containing 12,988 object categories (Mettes et al., 2020).
Target datasets. The classification evaluation is performed on the two datasets used most often in zero-shot action recognition: UCF-101 and HMDB51. The UCF-101 dataset consists of 13,320 videos covering 101 action categories. Next to 101-way zero-shot evaluation, we also evaluate on settings with 20 and 50 test actions. For these settings, we rerun our approach on 10 runs with randomly selected actions and we report the mean and standard deviation over the runs. We note that in the 20- and 50-way zero-shot recognition, we do not use the other actions for training, they are simply not used in our approach. The HMDB51 dataset consists of 6,766 videos covering 51 action categories. Next to 51-way evaluation, we also investigate 10- and 25-way zero-shot recognition.

Evaluating universal prototype transport from seen actions on UCF-101. Left: The effect of the number of clusters and the interpolation ratio on the recognition performance. An interpolation rate of 1 denotes the baseline with the original unseen action prototypes. We find that re-positioning the prototypes directly boosts zero-shot performance given sufficient clusters, with a further boost by interpolating between the original and target prototypes, see the highest overall score for 1,000 clusters and interpolation ratio 0.5. Right: Intuition behind our improved results. Using the original unseen action prototypes results in large biases during zero-shot inference. With our approach, this imbalance is reduced, as indicated by the more even action distributions in the plot and the corresponding higher entropy scores in brackets in the legend
We also investigate the potential of our approach for zero-shot spatio-temporal action localization on UCF Sports and J-HMDB. UCF Sports consists of 150 videos with 10 actions and J-HMDB consists of 928 videos with 21 actions. For the evaluation, we follow Jain et al. (2015) and report results with the AUC metric across five overlap thresholds.
5.2 Implementation details
We consider two universal action networks \(\phi \). First, we employ the R(2+1)D network (Tran et al., 2018) as given by Brattoli et al. (2020), pre-trained on 664 Kinetics categories. For each video, we obtain its corresponding video embedding by randomly selecting a 16 frame shot and passing the shot through \(\phi \). For a fair comparison to Brattoli et al. (2020), we also use the same word embedding \(\omega \), namely a word2vec model (Mikolov et al., 2013a), resulting in a 300-dimensional representation per word. For any action or object with more than one word, the word representations are averaged. Second, we employ the network of Pu et al. (2022) with 25 splits per video, which is based on the same word embedding and Kinetics splits as the first action model. For both approaches, we rely on author-provided code to obtain action and video embeddings. For the universal object model, the object scores in a video are obtained following the protocol of Mettes et al. (2021), where two frames per second are sampled, each fed to the pre-trained ImageNet model, and with the object probabilities averaged over the sampled frames.
For the clustering of the video embeddings, we use k-means clustering along with \(\ell _2\)-normalization, akin to Banerjee et al. (2005). For the optimal transport, we employ the Lagrangian approach of Bonneel et al. (2011) as implemented in (Flamary et al., 2021). Specifically, we set the cosine distance matrix as loss matrix, run for a maximum of 100,000 iterations if there has been no convergence and with the dual potential centered in the optimization. Unless specified otherwise, accuracy denotes the top 1 accuracy. Lastly for spatio-temporal localization, we start from the tubes made available by Mettes et al. (2021). To each tube, we add the corresponding video-level action scores from our approach to improve the ranking of the action tubes over the entire dataset. The universal transport takes roughly 36 seconds CPU time for 13,320 videos, 101 actions, and 1000 clusters on UCF-101 on an Intel Xeon CPU. Once the action prototypes are re-positioned, no additional computational effort is required for zero-shot inference. All code will be made publicly available.
6 Experimental results
We focus on five experiments: (i) evaluations on universal action models; (ii) evaluations on universal object models; (iii) integrating and fusing our approach with recent methods; (iv) state-of-the-art comparison for zero-shot action recognition and zero-shot spatio-temporal action localization; (v) qualitative analyses.
6.1 Universal transport from seen actions
Setup. For the first experiment, we evaluate on UCF-101 using all 101 actions for classification. We investigate the two variables that come with our approach in the context of universal action models, namely the granularity of the cluster aggregation over all test videos and the interpolation ratio between the original and target prototypes of the unseen actions. We use the universal action model of Brattoli et al. (2020) throughout this experiment.
Results. The results for five cluster sizes and three interpolation ratios are shown in Figure 3a. An interpolation rate of 1 denotes the baseline using only the original action prototypes and 0 denotes the setting using the target prototypes. With the original semantic prototypes, we obtain an accuracy of 39.2%. Using the target prototypes directly boosts the classification accuracy when using sufficiently many clusters. Using only few clusters results in a coarse approximation of the distribution of test videos, which leads to lower performance. The best performance is obtained by positioning the unseen actions halfway along the geodesic between the original and target embeddings. With 1,000 clusters the accuracy becomes 42.4%, compared to 40.1% when using the target prototypes directly. We will use 1,000 clusters and an interpolation ratio of 0.5 for all other experiments involving universal action models.
Analysis. An explanation for our obtained improvements is shown in Figure 3b. We show the distributions of selected actions across all three interpolation ratios when using 1,000 clusters. With the original unseen action embeddings, this distribution is highly uneven, with 23% of the actions never being selected, naturally leading to zero accuracy for these actions. With our approach, the distributions become more uniform, highlighting the bias reduction. This is also reflected in the entropy of the action selection distributions in the top right of 3b, which increases when employing universal prototype transport, confirming that the distribution becomes more uniform.

Per-class improvements as a function of the number of times an action is selected prior to universal prototype transport on UCF-101. Our approach improves especially those classes that are rarely selected in a stand-alone universal action model

Confusion matrices on UCF-101 before (left) and after (right) performing universal prototype transport on the model by Brattoli et al. (2020), sorted by selection frequency in the base model. For the baseline, the entire right side of the matrix is dark blue, since those actions are never selected by any test video. After performing our approach, the confusion matrix is more uniform and highlights a better performance for actions ignored by the baseline
In Figure 4, we show the per-class performance gains as a function of selection frequency before our transport. The figure shows that our approach improves especially those classes that were not frequently occurring in a stand-alone universal model. This result highlights that our improvements are due to a better alignment between unseen action prototypes and projected test videos in semantic space. Examples of most improved actions include sky diving (accuracy from 8.2% to 80.9%), hammering (from <0.1% to 65.0%), and cricket bowling (from 0.0% to 55.4%). Figure 5 provides dives deeper into the observation by highlighting the improved alignment based on the entire confusion matrix.
As an extra test, we investigate the effect of class imbalance in the test set for universal prototype transport. Following the long-tailed literature (Cui et al., 2019), we sample UCF-101 with exponential decays of factors 0.1 and 0.01. The average per-class accuracy on standard UCF-101 is 42.0% and remains stable (42.4% at imbalance ratio 0.1 and 41.6% at imbalance ratio 0.01), highlighting that our approach is stable to test-time class imbalance.
6.2 Universal transport from objects
Setup. Second, we investigate our approach on universal object models. We again use UCF-101 with all 101 actions for evaluation, with the interpolation ratio fixed to 0.5. We evaluate three threshold levels that come with the definition of objects as discrete measure, along with the universal object model itself and a vanilla uniformly-weighted optimal transport using all objects as baselines.
Results. In Table 1, we show the zero-shot action results for our approach when maintaining the top 2,500, 1,000, and 500 objects according to their transductive maximum likelihoods over all test videos. We first find that using a baseline optimal transport approach akin to the setup for seen actions provides only a marginal boost from 29.9% to 30.1%. In contrast, using the proposed weights for the unseen actions and objects, combined with a filtering of objects never present in a test video, provides a boost to 31.6% with the top 1,000 objects. We find that as long as the threshold is not set too strictly (e.g., keeping 1,000 objects or more) provides stable zero-shot results.
In Table 2, we show that the proposed weighting matters. For this Table we keep the top 1,000 objects and investigate all four combinations of uniform and proposed weighting. With uniform weights for both unseen actions and objects, the results are similar to the baseline object-based setup, while the results improve when incorporating either or both of the weight vectors to the proposed setup. We conclude that in the universal object-based model for zero-shot action recognition, the proposed transport is also beneficial.

Fusing action and object information for zero-shot recognition on UCF-101 and HMDB51. Combining universal action and object information benefits zero-shot recognition, with universal prototype transport preferred across all fusion proportion between both sources
6.3 Transporting multiple universal models
Setup. Third, we investigate how universal prototype transport operates across and in combination with multiple universal models. We focus on two results: providing an overview of our approach on multiple state-of-the-art universal models and combining action and object models with universal transport.
Results. In Table 3, we provide an overview of our approach on top of recent universal action and object models. For the universal action models of Brattoli et al. (2020) and Pu et al. (2022), we use the pre-trained models provided by the authors to compute video embeddings and add our universal prototype transport on top. For the universal object model of Mettes et al. (2021), we take the author-provided pre-trained object network and directly use the conventional object-to-action formulation of Equation 15 to obtain zero-shot predictions. We find that across multiple models, the results of both the top 1 and top 5 accuracy are improved. For action models, the top 5 improvements are even higher than the top 1 improvements, highlighting the better overall alignment between unseen actions and test videos. We conclude form this Table that our approach is generic and can be plugged in new methods to obtain better zero-shot results.
Beyond individual universal models, we also investigate the potential of combining action with object models for zero-shot action recognition. Intuitively, both types of methods bring different perspectives and rely on different sources for generalizing to actions without training examples. Hence their predictions can be of a complementary nature. In Figure 6, we show the effect of combining both perspectives on UCF-101 and HMDB51. We fuse the action model of Brattoli et al. (2020) with the object model of Mettes et al. (2021) and leave the final fusion with the model of Pu et al. (2022) for the state-of-the-art comparison.
On UCF-101, we find that fusing both approaches has a clear, positive effect. Our results improve from 42.4% (universal actions) and 31.6% (universal objects) to 47.9% when balancing both equally. When setting the fusion proportion to 0.3, the results can even be further improved to 48.9. Due to the zero-shot nature of our approach, we stick to an a priori equal balance between both setups. Averaged over all fusion ratios, our approach provides a boost of 3.0 percent point compared to the baseline fusion. On HMDB51 with universal action models, adding our approach improves the results from 24.9% to 28.1%. The results are further improved to 29.4% when fusing with universal object models. We conclude that both perspectives are complementary for zero-shot action recognition and their fusion benefits from our proposed transport.

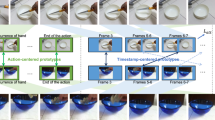
Qualitative examples from UCF-101. Columns 1-3: Success and failure cases of our approach on the universal action model of Brattoli et al. (2020). Our approach can help to better align videos with unseen actions, as shown in the skydiving and nunchuck videos, but can fail for actions such as front crawl due to confusion with a similar action like breast stroke. Columns 4-5: Qualitative examples from the fusion of universal action and object models in our approach. In both cases, we are better able to classify fine-grained unseen actions by transferring dynamic knowledge about other actions and static knowledge about the objects used to perform these actions
6.4 Comparison to state-of-the-art
Zero-shot recognition. In Table 4, we compare our results on UCF-101 and HMDB51 to the state-of-the-art in zero-shot action recognition. Similar to other universal approaches, in the scenarios with random sub-selection of the test actions (20 and 50 for UCF-101, 10 and 25 for HMDB51) we do not use the remaining actions and their videos for network training. On both datasets, the current state-of-the-art is given by Lin et al. (2022) and Pu et al. (2022). For the action number of our approach, we add our universal transport on top of the two action models used in Table 3. We note that when reproducing the results of Pu et al. (2022), we obtained an average accuracy of 55.3% on UCF-101 with 50 actions and 46.3% with 101 actions. Our approach boosts these reproduced numbers to 57.3% for 50 actions and 49.4% for 101 actions. Across both datasets and dataset splits, we find that integrating universal prototype transport on both action and object models is important for zero-shot action recognition. On UCF-101 with 101 test actions, we obtain an accuracy of 51.4%, the first result over the 50% threshold in literature. On HMDB51 with 51 action we improve the results from 33.4% to 33.9%. We conclude that universal prototype transport is effective for zero-shot action recognition.
Table 4 details comparisons with both complete testsets and smaller subsets. Averaged over the multiple runs, our approach is effective for both small and large dataset sizes. Compared to the baseline models used as starting point in our method, we find that the larger the testset, the higher the relative improvement, indicating that our approach benefits from richer semantics.
Zero-shot localization. We also showcase the potential of our approach for zero-shot spatio-temporal action localization. Since our approach operates over entire videos, we start from the spatio-temporal tubes made publicly available by Mettes et al. (2021). For each tube, we simply add the score for each action from the entire video as given by our approach. In Table 5, we report the AUC scores for UCF Sports and J-HMDB. Across datasets and overlap thresholds, we find that the global scores from our approach boosts spatio-temporal localization. This is because the scores of our approach help to distinguish and rank tubes from different videos as they encode contextual information.
In conclusion, we find that for both zero-shot classification and spatio-temporal localization on all datasets, our approach provides consistent improvements, highlighting that universal prototype transport is effective across different collections of unseen actions.
6.5 Qualitative analysis
In Figure 7, we show success and failure cases for our approach when applied to the universal action model of Brattoli et al. (2020) and its fusion with the universal object model of Mettes et al. (2021). Theses results reiterate the potential of combining action and object perspectives in zero-shot action recognition and the role of universal prototype transport in combining both views.
7 Conclusions
In this work, we investigate a persistent limitation in current universal learning models for zero-shot action recognition, namely selection biases in the assignment of unseen actions to test videos. We introduce universal prototype transport to alleviate this limitation. Our approach consists of three stages: (i) finding an optimal transport mapping from unseen action prototypes to the projected test videos (in universal action models) or to object prototypes (in universal object models); (ii) obtaining a target prototype for each unseen action using the couplings from the hyperspherical optimal transport; and (iii) re-positioning the unseen actions along the geodesic spanned by the original and target prototypes. Empirical evaluation on four datasets shows the effectiveness of our approach for debiasing action assignments and for improving zero-shot recognition and localization as a result. Our approach is general and can be used to improve any universal model.
Data availability statement
The pre-trained networks and meta-data of the universal action and object models are publicly available on the repos of Brattoli et al. (2020)(github.com/bbrattoli/ZeroShotVideoClassification) and Mettes et al. (2020)(github.com/psmmettes/shuffled-imagenet-bank). All experiments are performed on publicly available datasets: UCF-101(www.crcv.ucf.edu/data/UCF101.php), HMDB51(serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/), UCF Sports (www.crcv.ucf.edu/research/data-sets/ucf-sports-action/), and J-HMDB (jhmdb.is.tue.mpg.de/). The code for this paper will be made available on github.
References
Alexiou, I., Xiang, T., & Gong, S., (2016). Exploring synonyms as context in zero-shot action recognition. In: 2016 IEEE International Conference on Image Processing (ICIP), IEEE, pp 4190–4194
Arnab, A., Dehghani, M., Heigold, G., Sun, C., Lučić, M., & Schmid, C., (2021). Vivit: A video vision transformer. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 6836–6846
Arnold, A., Nallapati, R., & Cohen, WW., (2007). A comparative study of methods for transductive transfer learning. In: Seventh IEEE international conference on data mining workshops (ICDMW 2007), IEEE, pp 77–82
Banerjee, A., Dhillon, IS., Ghosh, J., Sra, S., & Ridgeway, G., (2005). Clustering on the unit hypersphere using von mises-fisher distributions. Journal of Machine Learning Research 6(9)
Bao, W., Yu, Q., & Kong, Y., (2022). Opental: Towards open set temporal action localization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 2979–2989
Bishay, M., Zoumpourlis, G., & Patras, I., (2019). Tarn: Temporal attentive relation network for few-shot and zero-shot action recognition. In: British Machine Vision Conference
Bonneel, N., Van De Panne, M., Paris, S., & Heidrich, W., (2011). Displacement interpolation using lagrangian mass transport. In: Proceedings of the 2011 SIGGRAPH Asia conference, pp 1–12
Brattoli, B., Tighe, J., Zhdanov, F., Perona, P., & Chalupka, K., (2020) Rethinking zero-shot video classification: End-to-end training for realistic applications. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 4613–4623
Bretti, C., & Mettes, P., (2021). Zero-shot action recognition from diverse object-scene compositions. British Machine Vision Conference
Caba Heilbron, F., Escorcia, V., Ghanem, B., & Carlos Niebles, J., (2015) Activitynet: A large-scale video benchmark for human activity understanding. In: Proceedings of the ieee conference on computer vision and pattern recognition, pp 961–970
Carreira, J., & Zisserman, A., (2017) Quo vadis, action recognition? a new model and the kinetics dataset. In: proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 6299–6308
Chen, S., & Huang, D., (2021). Elaborative rehearsal for zero-shot action recognition. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp 13638–13647
Cui, Y., Jia, M., Lin, TY., Song, Y., & Belongie, S., (2019) Class-balanced loss based on effective number of samples. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 9268–9277
Damen, D., Doughty, H., Farinella, GM., Fidler, S., Furnari, A., Kazakos, E., Moltisanti, D., Munro, J., Perrett, T., & Price, W., et al (2018). Scaling egocentric vision: The epic-kitchens dataset. In: European Conference on Computer Vision, pp 720–736
Estevam, V., Laroca, R., Menotti, D., & Pedrini, H., (2021a) Tell me what you see: A zero-shot action recognition method based on natural language descriptions. CoRR
Estevam, V., Pedrini, H., & Menotti, D. (2021). Zero-shot action recognition in videos: A survey. Neurocomputing, 439, 159–175.
Feichtenhofer, C., Pinz, A., & Zisserman, A., (2016). Convolutional two-stream network fusion for video action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1933–1941
Feichtenhofer, C., Fan, H., Malik, J., & He, K., (2019). Slowfast networks for video recognition. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 6202–6211
Flamary, R., Courty, N., Gramfort, A., Alaya, M. Z., Boisbunon, A., Chambon, S., Chapel, L., Corenflos, A., Fatras, K., Fournier, N., et al. (2021). Pot: Python optimal transport. The Journal of Machine Learning Research, 22(1), 3571–3578.
Fu, Y., Hospedales, TM., Xiang, T., Fu, Z., & Gong, S., (2014). Transductive multi-view embedding for zero-shot recognition and annotation. In: European Conference on Computer Vision, Springer, pp 584–599
Gan, C., Lin, M., Yang, Y., Melo, G., & Hauptmann, AG., (2016a). Concepts not alone: Exploring pairwise relationships for zero-shot video activity recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 30
Gan, C., Yang, T., & Gong, B., (2016b). Learning attributes equals multi-source domain generalization. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 87–97
Gan, C., Yang, Y., Zhu, L., Zhao, D., & Zhuang, Y. (2016). Recognizing an action using its name: A knowledge-based approach. International Journal of Computer Vision, 120, 61–77.
Gao, J., Zhang, T., & Xu, C., (2019). I know the relationships: Zero-shot action recognition via two-stream graph convolutional networks and knowledge graphs. In: Proceedings of the AAAI conference on artificial intelligence, vol 33
Grauman, K., Westbury, A., Byrne, E., Chavis, Z., Furnari, A., Girdhar, R., Hamburger, J., Jiang, H., Liu, M., & Liu, X., et al (2022). Ego4d: Around the world in 3,000 hours of egocentric video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 18995–19012
Hahn, M., Silva, A., & Rehg, JM., (2019). Action2vec: A crossmodal embedding approach to action learning. In: Computer Vision and Pattern Recognition workshops
Jain, M., Van Gemert, JC., Mensink, T., & Snoek, CG., (2015). Objects2action: Classifying and localizing actions without any video example. In: Proceedings of the IEEE international conference on computer vision, pp 4588–4596
Jain, M., Ghodrati, A., & Snoek, CGM., (2020). Actionbytes: Learning from trimmed videos to localize actions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 1171–1180
Kantorovich, L. V. (1942). On the translocation of masses. Dokl. Akad. Nauk. USSR (NS), 37, 199–201.
Karpathy, A., Toderici , G., Shetty, S., Leung, T., Sukthankar, R., & Fei-Fei, L., (2014). Large-scale video classification with convolutional neural networks. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp 1725–1732
Kerrigan, A., Duarte, K., Rawat, Y., & Shah, M. (2021). Reformulating zero-shot action recognition for multi-label actions. Advances in Neural Information Processing Systems, 34, 25566–25577.
Kim, T. S., Jones, J., Peven, M., Xiao, Z., Bai, J., Zhang, Y., Qiu, W., Yuille, A., & Hager, G. D. (2021). Daszl: Dynamic action signatures for zero-shot learning. Proceedings of the AAAI conference on artificial intelligence, 35, 1817–1826.
Kodirov, E., Xiang, T., Fu, Z., Gong, S., (2015). Unsupervised domain adaptation for zero-shot learning. In: Proceedings of the IEEE international conference on computer vision, pp 2452–2460
Li, Y., Hu, Sh., & Li, B., (2016). Recognizing unseen actions in a domain-adapted embedding space. In: 2016 IEEE International Conference on Image Processing (ICIP), IEEE, pp 4195–4199
Lin, CC., Lin, K., Wang, L., Liu, Z., & Li, L., (2022). Cross-modal representation learning for zero-shot action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 19978–19988
Liu, J., Kuipers, B., & Savarese, S., (2011). Recognizing human actions by attributes. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3337–3344
Liu, K., Liu, W., Ma, H., Huang, W., & Dong, X. (2019). Generalized zero-shot learning for action recognition with web-scale video data. World Wide Web, 22(2), 807–824.
Long, T., Mettes, P., Shen, HT., & Snoek, CGM., (2020). Searching for actions on the hyperbole. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 1141–1150
Lou, A., Katsman, I., Jiang, Q., Belongie, S., Lim, SN., & De Sa, C., (2020). Differentiating through the fréchet mean. In: International Conference on Machine Learning, PMLR, pp 6393–6403
Mandal, D., Narayan, S., Dwivedi, SK., Gupta, V., Ahmed, S., Khan, FS., & Shao, L., (2019) Out-of-distribution detection for generalized zero-shot action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 9985–9993
Mettes, P., & Snoek, CGM., (2017). Spatial-aware object embeddings for zero-shot localization and classification of actions. In: Proceedings of the IEEE international conference on computer vision, pp 4443–4452
Mettes, P., Koelma, D. C., & Snoek, C. G. (2020). Shuffled imagenet banks for video event detection and search. ACM Transactions on Multimedia Computing, Communications, and Applications, 16(2), 1–21.
Mettes, P., Thong, W., & Snoek, C. G. M. (2021). Object priors for classifying and localizing unseen actions. International Journal of Computer Vision, 129, 1954–1971.
Miech, A., Zhukov, D., Alayrac, JB., Tapaswi, M., Laptev, I., & Sivic, J., (2019). Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 2630–2640
Mikolov, T., Chen, K., Corrado, G., & Dean, J., (2013a). Efficient estimation of word representations in vector space. In: International Conference on Learning Representations workshops
Mikolov, T., Sutskever, I., Chen, K., Corrado, GS., & Dean, J., (2013b). Distributed representations of words and phrases and their compositionality. In: Advances in neural information processing systems, vol 26
Miolane, N., Guigui, N., Le Brigant, A., Mathe, J., Hou, B., Thanwerdas, Y., Heyder, S., Peltre, O., Koep, N., Zaatiti, H., et al. (2020). Geomstats: A python package for riemannian geometry in machine learning. The Journal of Machine Learning Research, 21(1), 9203–9211.
Mishra, A., Pandey, A., & Murthy, H. A. (2020). Zero-shot learning for action recognition using synthesized features. Neurocomputing, 390, 117–130.
Monge, G., (1781). Mémoire sur la théorie des déblais et des remblais. Mem Math Phys Acad Royale Sci pp 666–704
Peyré, G., & Cuturi, M., et al (2019). Computational optimal transport: With applications to data science. Foundations and Trends® in Machine Learning 11(5-6):355–607
Pu, S., Zhao, K., & Zheng, M., (2022). Alignment-uniformity aware representation learning for zero-shot video classification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 19968–19977
Rohrbach, M., Ebert, & S., Schiele, B., (2013). Transfer learning in a transductive setting. Advances in neural information processing systems 26
Roitberg, A., Martinez, M., Haurilet, M., & Stiefelhagen, R., (2018). Towards a fair evaluation of zero-shot action recognition using external data. In: European Conference on Computer Vision workshops
Simonyan, K., & Zisserman, A., (2014). Two-stream convolutional networks for action recognition in videos. In: Advances in neural information processing systems, vol 27
Soomro, K., & Shah, M., (2017). Unsupervised action discovery and localization in videos. In: Proceedings of the IEEE International Conference on Computer Vision, pp 696–705
Tran, D., Wang, H., Torresani, L., Ray, J., LeCun, Y., & Paluri, M., (2018). A closer look at spatiotemporal convolutions for action recognition. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp 6450–6459
Tran, D., Wang, H., Torresani, L., & Feiszli, M., (2019). Video classification with channel-separated convolutional networks. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 5552–5561
Vapnik, V., (2006). Estimation of dependences based on empirical data. Springer Science & Business Media
Wang, W., Xu, H., Wang, G., Wang, W., & Carin, L., (2021). Zero-shot recognition via optimal transport. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp 3471–3481
Wu, B., Cheng, R., Zhang, P., Vajda, P., & Gonzalez, JE., (2021). Data efficient language-supervised zero-shot recognition with optimal transport distillation. In: International Conference on Learning Representations
Wu, Z., Fu, Y., Jiang, YG., & Sigal, L., (2016). Harnessing object and scene semantics for large-scale video understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 3112–3121
Xu, X., Hospedales, T., & Gong, S. (2017). Transductive zero-shot action recognition by word-vector embedding. International Journal of Computer Vision, 123, 309–333.
Xu, Y., Han, C., Qin, J., Xu, X., Han, G., & He, S. (2020). Transductive zero-shot action recognition via visually connected graph convolutional networks. IEEE Transactions on Neural Networks and Learning Systems, 32(8), 3761–3769.
Yang, P., Asano, YM., Mettes, P., & Snoek, CG., (2022). Less than few: Self-shot video instance segmentation. In: European Conference on Computer Vision, Springer, pp 449–466
Zhang, L., Chang, X., Liu, J., Luo, M., Wang, S., Ge, Z., & Hauptmann, A., (2020). Zstad: Zero-shot temporal activity detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 879–888
Zhang, L., Chang, X., Liu, J., Luo, M., Li, Z., Yao, L., & Hauptmann, A. (2022). Tn-zstad: Transferable network for zero-shot temporal activity detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(3), 3848–3861.
Zhang, Z., Wang, C., Xiao, B., Zhou, W., & Liu, S. (2015). Robust relative attributes for human action recognition. Pattern Analysis and Applications, 18, 157–171.
Zhu, Y., Long, Y., Guan, Y., Newsam, S., & Shao, L., (2018). Towards universal representation for unseen action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 9436–9445
Zhuo, J., Zhu, Y., Cui, S., Wang, S., MA, B., Huang, Q., Wei, X., & Wei, X., (2022). Zero-shot video classification with appropriate web and task knowledge transfer. In: Proceedings of the 30th ACM International Conference on Multimedia, pp 5761–5772
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Dima Damen.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mettes, P. Universal Prototype Transport for Zero-Shot Action Recognition and Localization. Int J Comput Vis 131, 3060–3073 (2023). https://doi.org/10.1007/s11263-023-01846-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-023-01846-2