
Abstract
So far, the most prominent measure for actual truthlikeness, i.e. the likeness of a theory to the actual truth, is Ilkka Niiniluoto’s minsum definition, which is purely based on distances. A competing definition is the average distance measure proposed by Pavel Tichy and Graham Oddie. We will define three related, distance and size based, measures for actual truthlikeness and compare them with the two well-known options. However, we will start, Sect. 2, from a trio of such measures for nomic truthlikeness. The nomic truth, or the true theory, here refers to what is nomically, e.g. physically, possible. In a nomic (and factual) context there are two basic kinds of theories, viz. either based on an exclusion claim or on an inclusion claim. Two-sided theories combine these claims, with the maximal claim as extreme special case. We will base truthlikeness measures for exclusion, inclusion, two-sided, and hence maximal, nomic theories on two similarity measures, one in terms of distances between conceptual possibilities and the other in terms of sizes of sets of such possibilities. In Sect. 3 we will treat actual truthlikeness as extreme special case of nomic truthlikeness, viz. assuming that there is just one nomic possibility, the actual one. Next we will compare the resulting measures mutually and with the above mentioned measures of Niiniluoto and Tichy & Oddie. Finally, in Sect. 4, we will sum up the results and explore five questions for further research.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
So far, the most prominent measure for actual truthlikeness, i.e. the likeness of a theory to the actual truth, is Ilkka Niiniluoto’s (1987, 2020) minsum definition, which is purely based on distances. A competing definition is the average distance measure proposed by Pavel Tichy (1978) and Graham Oddie (1981, 1986, 2013, 2016). We will define three related, distance and size based, measures for actual truthlikeness and compare them with the two well-known options. However, we will start, Sect. 2, from a trio of such measures for nomic truthlikeness. The nomic truth, or the true theory, here refers to what is nomically, e.g. physically, possible. In a nomic (and factual) context there are two basic kinds of theories, viz. either based on an exclusion claim or on an inclusion claim. Two-sided theories combine these claims, with the maximal claim as extreme special case. We will base truthlikeness measures for exclusion, inclusion, two-sided, and hence maximal, nomic theories on two similarity measures, one in terms of distances between conceptual possibilities and the other in terms of sizes of sets of such possibilities. In Sect. 3 we will treat actual truthlikeness as extreme special case of nomic truthlikeness, viz. assuming that there is just one nomic possibility, the actual one. Next we will compare the resulting measures mutually and with the above mentioned measures of Niiniluoto and Tichy & Oddie. Finally, in Sect. 4, we will sum up the results and explore five questions for further research.
2 Nomic truthlikeness
2.1 Basic notions
In this section the main distance and size based definitions of nomic truthlikeness will be given. We will present them in Niiniluoto’s cognitive problem terms, but for the rest in our favorite set-theoretical way. There are two cognitive problems to be considered, the actual and the nomic, both with corresponding partial and complete answers. The cognitive problems are:
What is the actual or factual truth?
What is the nomic truth?
Here, the nomic truth is the truth about what is e.g. physically, biologically, economically possible. It turns out to be practical to start with the nomic truth problem.
Our basic universe is a set of mutually exclusive and together exhaustive conceptual possibilities at a certain occasion in a certain fixed context. One conceptual possibility will be the (f)actual one at a certain moment and a specific subset will contain the nomic possibilities on each occasion, the other ones are nomically impossible. Apart from the assumption that all subsets to be considered are finite, it will be a very general approach.
We will use the following symbolizations throughout the paper.
-
U: universe, the set of elementary conceptual possibilities in a given domain, constituting the (mutually exclusive and together exhaustive) complete answers to the (f)actual cognitive problem: what is (f)actually the case? These possibilities can be of any kind, e.g. the natural or the real numbers, the possible states or trajectories of a system, the constituents of a language, the (local) possible worlds, the elementary outcomes of an experiment, or the possible kinds of systems.
-
x, y, t, x1, x2, …xk: elements of U, complete answers to the cognitive problem of the actual truth. Singleton sets {x} will also be simply indicated by x in set-theoretically isolated contexts
-
-
d(x, y): a given, logically or mathematically well founded, underlying normalized symmetric non-trivial distance function, that is,
-
0 ≤ d(x, y) ≤ 1, d(x, y) = 0 iff x = y, d(x, y) = d(y, x)
-
d(x, y) is a (normalized) metric if it satisfies in addition the triangle inequality: d(x, y) ≤ d(x, z) + d(z, y)
-
d is non-trivial, where d is (discrete or) trivial means that d(x, y) = 0 if x = y, otherwise d(x, y) = 1.
-
s(x, y) = df 1 − d(x, y), the similarity of x and yFootnote 1
-
-
X, Y, T: finite subsets of U (non-empty, except when otherwise stated), representing partial or complete answers to the cognitive problem of the nomic and the actual truth (to be characterized). (Finiteness of subsets: to be generalized).
-
|X|: the size (or measure) of X;|{x}| =|x|= 1
-
t ∈ U: the actual or factual truth
-
tl(x, t) = s(x, t) = 1 − d(x, t): the underlying truthlikeness measure
-
T ⊆ U: if |T|> 1, T represents the nomic truth, i.e. the set of nomic, e.g. physical, biological, or economic possibilities; if |T|= 1, T represents the (singleton) actual truth {t}.
The nomic cognitive problem reads: Which of the subsets of U is the set of nomic possibilities T? In Kuipers (2019, Ch. 4) I present my basic theory of qualitative (symmetric difference based) nomic truthlikeness in terms of claims of theories.Footnote 2 The three possible claims of ‘theory X’ are:
Exclusion claimFootnote 3 | T ⊆ X (⇔ cX ⊆ cT) | All excluded possibilities are nomic impossibilities (X is a law following from T) |
Inclusion claim | X ⊆ T | All included possibilities are nomic possibilities (all members of X are models of T) |
Combined claim | X ⊆ T ⊆ X (⇔ X = T) | the maximal claim,Footnote 4,Footnote 5 |
These theories will may be called exclusion (E-), inclusion (I-), and maximal theories, respectively.
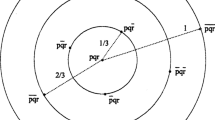
Figure 1 depicts the first two claims. The third claim represents of course a complete answer to the nomic cognitive problem. The first two claims represent partial answers. The exclusion claim ‘T ⊆ X’ can be reconstructed as the disjunction of complete answers for all subsets Y of X (Y ⊆ X) with the claim ‘Y = T’. The inclusion claim ‘X ⊆ T’ can be reconstructed as the disjunction of complete answers for all supersets Y of X (X ⊆ Y) with the claim ‘Y = T’.

The exclusion and inclusion claim
A theory X is called E-true (or, an E-theory is true) when its exclusion claim is true (T − X = ∅), it is E-false (or, an E-theory is false) otherwise (T − X ≠ ∅). A theory X is called strongly E-false (or, an E-theory is strongly false) when X and T do not even overlap (T − X = T or equivalently, X − T = X). Note that the exclusion claim has due to the equivalence T ⊆ X ⇔ cX ⊆ cT a Popperian flavor, the complement of X, cX, is its empirical content, i.e. what X excludes, by this claim, to be or to happen.
Similarly, with similar (but not mentioned) alternative formulations, a theory X is called I-true when its inclusion claim is true (X − T = ∅), it is I-false otherwise (X − T ≠ ∅). It is called strongly I-false when X and T do not even overlap (X − T = X). Of course, X is strongly I-false iff X is strongly E-false.
In many contexts it will be possible to give a syntactical formulation of the three kinds of claims, as well as examples of true and false claims. Let L5 indicate an interpreted propositional language of five atomic propositions p1, p2, p3, p4, and q, representing a connected electric circuit with 4 switches that are on (pi) or off (¬pi), and one bulb that may give light (q) or not (¬q). Let T be the, as yet unknown, L5-proposition representing precisely all physically possible states of affairs of the circuit, that is, the nomic truth (one of which will be the (f)actual truth at a certain occasion). Let S be some L5-proposition. Then T → S is an exclusion claim, viz. claiming that ‘¬S-states’ are excluded from T, and S → T is an inclusion claim, claiming that all S-states are included in T, in the sense that they are compatible with T. Finally, combined maximal claims are of the form T ↔ S. Let, for a specific circuit (represented in Kuipers, 2019, p. 24, but easy to reconstruct) T amount to: T = df q ↔ (((p1∧p2)∨p3)∧p4). Since T → (q → p4) is valid, T → (q → p4) is a true exclusion claim, whereas T → (p4 → q) is a false one. Similarly, ((q∧p1∧p2∧p4) ∨ (q∧p3∧p4)) → T is a true inclusion claim and ((q∧p1∨p2∧p4) ∨ (q∧p3∧p4)) → T is a false one. Finally, replacing ín all examples ‘ → ’ by ‘ ↔ ’ leads to false maximal claims; T ↔ T is the only true maximal claim. By the way, it would be possible to continue the bold / non-bold distinction (T / T), but as a rule it will be clear which ‘T’ is intended, the unknown or the specified one.
The above example deals with the conceptually and nomically possible states of a system. An example dealing with conceptually and nomically possible (kinds) of systems is the following. Let U represent the conceptually possible (stable) molecules, each consisting of a selection of (stable) chemical elements. Let T represent the subset of chemically possible (stable) molecules. As we know, specifying T will be a matter of fitting chemical valences and the like. Of course, the actual truth can be represented as some member of T.
It turns out to be useful (Kuipers, 2019) to introduce separate symbols for E- and I-theories: P represents a postulate (or a conjunction of postulates) that is supposed to include all nomic possibilities (T ⊆ P) and M represents a set of (tentative) models that are supposed to be nomic possibilities (M ⊆ T). Combining them, we get two-sided theories < M, P > with the (combined) claim ‘M ⊆ T ⊆ P’. An < M. P > theory is (EI-) true if both claims are true, false otherwise. Note that a quasi two-sided theory of the form < ∅, P > is just an exclusion theory, and of the form < M, U > it is just an inclusion theory.
In Kuipers (2019) it is still assumed, as a matter of course, that M should be a subset of P. However, on second thoughts this is not self-evident. In an early stage of research one may have rather separate ideas about both M and P such that M is not (yet) a subset of P. But, if so, it is clear, in view of the inconsistency of the combined claim ‘M ⊆ T ⊆ P’, that at least one of them should be revised. Ultimately, one will aim at a pair satisfying the subset relation. As a kind of intermediate, one may assume that at least |M| ≤|P|, the size condition, should hold.
Finally, an < M, P > -theory is maximal if M = P = df X, and hence with the claim ‘X ⊆ T ⊆ X’, that is, X = T. It is (EI-) true if X = T, false otherwise.
2.2 Truthlikeness of nomic exclusion theories
In this subsection we focus on an exclusion theory P, hence with the exclusion claim ‘T ⊆ P’. Recall that P can be seen as the conjunction of tentative postulates satisfied by T. We define the (normalized distance based) exclusion similarity of P as the average maximal similarity of T relative to P, where smax(z, P) = 1 − dmin(z, P) = 1 − min{d(z, x)| x ∈ P}Footnote 6:
Note that if P is E-true, i.e. T ⊆ P, EST(P) = 1.
EST(P) is a prima facie plausible definition of exclusion truthlikeness of P. However, several different P-theories can have the same average maximal similarity. What also matters is the size of P, |P|, in comparison with that of T, |T|. In (Manuscript, 2023) we argue for a general definition of the similarity of two quantities, leading in the present context to the following definition of the relative size or the similarity in size of X and YFootnote 7:
For now it is important to know that d*(X, Y) = df 1 – s*(X, Y) is a genuine normalized metric:
Moreover, s*(X, Y) has two especially desirable general properties:
Scale invariance:
For any positive real number a, if |X’|= a|X| and |Y’|= a|Y|, then s*(X’, Y’) = s*(X, Y).
Translation convergence:
For variable set X and constant set C, s*(|X|, |X| +|C|) monotone increases to 1 if |X| goes to ∞.Footnote 8
Translation convergence seems plausible enough.Footnote 9 However, if one has doubts about the desirability of scale invariance, e.g., in terms of (size) numbers, s*(1, 2) = s*(100, 200), one should realize that if one is inclined to make a difference in this case, one is almost forced to make also differences from the beginning, i.e. between s(1, 2), s(2, 4), s(3, 6),….
We list some special values of s*(X, Y), where U corresponds to a tautology and ∅ to a contradiction:
Now we define the exclusion truthlikeness of P as the productFootnote 10 of the size based similarity of P and T and the ‘normalized distance based average maximal similarity’, henceforth simply, distance based similarity of T relative to PFootnote 11:
If P is E-true, i.e. T ⊆ P, EST(P) = 1, and hence ETL(P; T) =|T|/|P|. In a noteFootnote 12 we specify some special values that may be interesting.
It is easy to check that ETL(P; T) has the following general properties:
\({\mathcal{TL}}\).1 | Normalized (i.e. unit interval) range | 0 ≤ ETL(P; T) ≤ 1 |
\({\mathcal{TL}}\)2 | Unique target | ETL(P; T) = 1 iff P = T |
\({\mathcal{TL}}\).3 | (Conceptual) continuity | ETL(x. t) = s(x, t) = df tl(x, t) |
A frequently subscribed or critically discussed condition of adequacy (Popper, 1963; Niiniluoto 1987, 2020; Oddie 2013, 2016; & Cevolani & Festa, 2020)Footnote 13 is that among true statements, in the sense of E-true statements, truthlikeness covaries with logical strength, here called E-conditional covariance. In our terms, the principle amounts for P-theories to the claim that if T ⊂ P’ ⊂ P the truthlikeness should increase when going from P to P’.
\({\mathcal{TL}}\)E.4 | E-conditional covariance | If T ⊂ P’ ⊂ P, ETL(P’; T) > ETL(P; T)Footnote 14 |
Whereas the first three properties can be seen as general conditions of adequacy, whatever the truth claim is, conditional covariance can only be seen as such if the truthlikeness of exclusion (E-)claims is concerned (i.e. \({\mathcal{TL}}\)E.4).
Finally, it is important to note again that ETL(P; L) need not be symmetric: ETL(P; T) = ETL(T; P) does not hold in general.
2.3 Truthlikeness of nomic inclusion theories
Now we turn our attention to the inclusion claim ‘M ⊆ T’, or equivalently, cT ⊆ cM, of inclusion theory M. Recall that M can be seen as a set of tentative models of T. We define the distance based inclusion similarity of M as the average maximal similarity of M relative to T:
Note that if M is I-true, i.e. M ⊆ T, IST(M) = 1.
Again, several different I-theories can have the same average maximal similarity of M relative to T. Hence, what also matters is the size of M, |M|, in comparison with that of T, |T|. It is plausible to use also here the same definition of the size similarity between M and T:
Recall that s*(,) is based on the metric d*(,) = (1 − s*(,)) and has two especially desirable general properties: scale invariance and translation convergence.
Now we define the inclusion truthlikeness of inclusion theory M of course as the product of the size based similarity of M and T and the distance based similarity of M relative to T:
If M is I-true, i.e. M ⊆ T, ISM(T) = 1, and hence ITL(M; T) =|M|/|T|. Some more sp cial values are listed in the note.Footnote 15
Again it is easy to check that ITL(M; T) has the following general properties.
\({\mathcal{TL}}\).1 | Normalized range | 0 ≤ ITL(M; T) ≤ 1 |
\({\mathcal{TL}}\).2 | Unique target | ITL(M; T) = 1 iff M = T |
\({\mathcal{TL}}\).3 | Continuity | ITL(x. t) = s(x, t) = tl(x, t) |
Moreover, among true inclusion (I-true) claims, truthlikeness covaries again with the logical strength between the claims. In our terms, the principle amounts here to the claim that if M ⊂ M’ ⊂ T the inclusion truthlikeness should increase when going from M to M’:
\({\mathcal{TL_{I}}}\).4 | I-conditional covariance | If M ⊂ M’ ⊂ T, then ITL (M’; T) > ITL(M; T) |
Hence, it is a kind of mirror version of (E-)conditional covariance of ETL. The proof is similar.
Finally, it is important to note again that, like, ETL(P; L), ITL(M; T) need not be symmetric: ITL(M; T) = ITL(T; M) does not hold in general. However, it is easy to check that ITL(X; T) = ETL(T; X),Footnote 16 where the latter formula expresses the exclusion truthlikeness of T relative to X, i.e. when X would be the truth and T would be an E-theory, a property that might be called crosswise equality of ITL and ETL.
2.4 Truthlikeness of two-sided and maximal theories
2.4.1 Two-sided theories
The following general schematic definition for the combined truthlikeness of two-sided theories < M, P > , with the combined claim ‘M ⊆ X ⊆ P’, is now plausible, viz. the weighted sum of ETL(P; T) and ITL(M; T), where the weights are determined by a parameter α, 0 ≤ α ≤ 1:
Note that CTLα(< M, P > ; T) reduces to ETL(P; T) and ITL(M; T) when α is assigned the value 1 or 0, respectively.
So far, I do not see convincing reasons to assign to α another value than ½. One could be inclined to argue for objective reasons to let α and (1 − α) account for different values of the relevant size similarities, but this is already done by the relevant factors in ETL(P; T) and ITL(M; T). However, to keep room for convincing reasons, I will continue with the weights α and (1 − α), with 1/2 as preferred value.
Assuming the general definition, if theory < M, P > is (EI-) true, i.e. M ⊆ T ⊆ P, and hence s*(M, T) =|M|/|T| and s*(P, T) =|T|/|P|, we get:
This formula shows clearly that CTLα(< M, P > ; T) takes care of the fact that a genuine two-sided theory (M ≠ P), even if true, cannot reach the maximal value of 1. If, for example, M ⊆ T ⊆ P and α = ½, |T|= 2|M|= ½ |P|, we get CTL(< M, P > ; T) = 1/2, in our view an intuitively plausible value for this special case.
Another interesting special case is the following. If < M, P > is such that |M| =|P| =|T|, hence if the sizes are already correct, hence s*(P, T) = s*(M, T) = 1, we get:
If we take α = 1/2, this amounts to just taking the average of the exclusion and inclusion (distance based) similarity.
CTLα has the following general properties:
\({\mathcal{TL}}\).1 | Normalized range | 0 ≤ CTLα(< M, P > ; T) ≤ 1 |
\({\mathcal{TL}}\).2 | Unique target | CTLα(< M, P > ; T) = 1 iff M = T = P |
\({\mathcal{TL}}\).3 | Continuity | CTLα(< x, x} > , t) = s(x, t)) = tl(x, t) |
\({\mathcal{TL}}\)EI.4 | EI-conditional covariance: | if M ⊂ M’ ⊂ T ⊂ P’ ⊂ P, then CTLα(< M’, P’ > ; T) > CTLα (< M, P > ; T) |
2.4.2 Maximal theories
For maximal theories X, i. e., a theory < M, P > with M = P = X, hence with the claim ‘X = T’, we define TLα(X; T) = df CTLα(< X; X > ; T), and get:
Hence, TLα(X; T) is the product of the size similarity of X and T and the weighted average of the exclusion and inclusion (distance based) similarity.Footnote 17 If maximal theory X is (EI-) true, i.e. X = T, we get of course TLα(X; T) = 1.
For maximal theories there seems a plausible objective value of α other than 1/2: α+ =|T|/(|T| +|X|). Then we getFootnote 18:
Hence, TL+(X; T) is now the product of the size based similarity of X and T and the average of the sum of the distance based similarities in both directions.Footnote 19
Returning to TLα(X; T), or ‘α-truthlikeness’, it has the following properties:
\({\mathcal{TL}}\).1 | Normalized range | 0 ≤ TLα(X; T) ≤ 1 |
\({\mathcal{TL}}\).2 | Unique target | TLα(X; T) = 1 iff X = T |
\({\mathcal{TL}}\).3 | Continuity | TLα(x, t) = s(x, t) = tl(x, t) |
\({\mathcal{TL}}\)EI.4 | EI-conditional covariance | not applicableFootnote 20 |
In this section we have introduced a coherent trio of distance and size based measures of nomic truthlikeness, guided by the three different claims that a theory may make: nomic truthlikeness of exclusion, inclusion, and maximal theories, ETL(P; T), ITL(M; T), and TLα(X; T). For the last one we introduced first two-sided theories < M, P > , combining the first two claims, and their truthlikeness CTLα(< M, P > ; T), introducing a parameter α. The truthlikeness of maximal theories (M = P = X), TLα(X; T), was obtained from CTLα(< M, P > , T) by replacing M and P by X. All four measures are finite subsets of UFootnote 21 and satisfy the plausible conditions of a normalized range (\({\mathcal{TL}}\).1), a unique target (\({\mathcal{TL}}\).2), conceptual continuity with the underlying (distance based) truthlikeness measure (\({\mathcal{TL}}\).3), and the relevant kind of conditional covariance (\({\mathcal{TL}}\).4), as far as applicable.Footnote 22 ETL(P; T) and ITL(M; T) are the product of the relevant size based similarity and the relevant distance based similarity. CTLα(< M, P > , T) and TLα(X; T) are the weighted sums of the relevant terms, where α = (1 − α) = ½ is, for the time being, our favorite value. In general, the more similar the size of a theory is to the size of that of the nomic truth, the more the distance based similarities are valued.
To be sure, the direct practical value of these measures is limited as long as one does not know the nomic truth, respectively. But this paper is about the logical problem of truthlikeness, leaving the epistemological problem for a later occasion.Footnote 23 However, if one would know the nomic (or actual truth, see below), the measures clearly indicate which revisions of theories bring us closer to the truth and each measure suggests, besides adjusting size, its own focus for attempts to truth approximation: ETL on increasing the exclusion similarity, ITL suggests to focus on increasing the inclusion similarity, and CTLα (hence TLα) on both.
Hence we have good reasons to assume that, even without knowing the truth, all three measures provide meaningful guidelines for nomic and actual truth approximation, but also that ETL and ITL have their own risks of detours, whereas CTLα (hence TLα) is more cautious in both respects. However, the latter needs a parameter, be it with a plausible role.
3 Actual truthlikeness and the comparison with the minsum and the average definition
3.1 Actual truthlikeness as extreme special case of nomic truthlikeness and as average maximal similarity (Tichy & Oddie)
Most discussions about truthlikeness measures deal mainly, or even only, with actual truthlikeness. At first sight it may seem that the only complete answers to the cognitive problem of the actual truth are factual claims of the form ‘x = t’, with distance measure d(x, t) and truthlikeness measure tl(x, t) = 1 − d(x, t). Moreover, factual claims of the form ‘{t} ⊆ X’, i.e. ‘t ∈ X’, seem typically partial answers, and it is plausible to apply ETL.Footnote 24 However, formally nothing prevents us to take a more general outlook, and to apply the other ‘nomic’ definitions, ITL and TLα, in case of a factual claim of the form ‘X ⊆ {t}’Footnote 25 (formally also being a partial answer), or ‘X = {t}’, respectively. That is, doing so, even though knowing that the corresponding theories are false as soon as X has more than one element, whether or not including t. One could even argue that, if t is the only nomic possibility, this approach is the appropriate one. However, if t is just one of more nomic possibilities, one could perhaps argue for a different approach.
We assume non-empty subsets P, M, X, except when otherwise stated and replace everywhere T by {t} or, more practically, by t. Note that s*(X, t) = 1/|X|.
We turn first to actual truthlikeness of the exclusion type, i.e. ETL(P; t). Of course, we have now that P is X-true if t ∈ P holds, and E-false otherwise. Note that in the case of the actual truth, there is no distinction between being merely E-false and being strongly E-false, for being merely E-false implies the non-overlap of {t} and X. We getFootnote 26:
If P is E-true, i.e. t ∈ P, ETL(P; t) = 1/|P|.
Turning to actual truthlikeness of the inclusion type, i.e. ITL(M, t), recall that M is assumed to be non-empty. Hence, M being I-true is a very special case: M = {t}. But the formal definition of ITL(M; t) makes perfect sense:
If M is I-true, hence M = {t}, ITL(t; t) = 1/|{t}|= 1.
Note that e.g. ∑x ∈ M dmin(x, t) could now be replaced by ∑x ∈ M d(x, t) and hence that the second factor in the ‘d-version’ of ITL(M; t) amounts to “1 minus the average distance from M to t”, which is the so-called average distance definition of truthlikeness of Pavel Tichy (1978) and Graham Oddie (1981, 1986, 2013, 2016), recently defended by Cevolani and Festa (2020). From our perspective the size factor (1/|M|) is a crucial refinement of that definition.
For actual truthlikeness from the two-sided perspective we get:
Again, if (< M, P > is (E- and I-)true, viz. just in one case, M = P = {t}, the CTLα-value is 1.
CTLα(< M, P > ; t) may not be that interesting, except for maximal theories: if M = X = P, we get:
If X is E-true, i.e. t ∈ X, smax(t, X) = 1, and hence
If X is I-true, hence X = {t}, for X is assumed to be non-empty, we get, TLα(X; t) = 1. Similarly, if X is E-true and I-true (EI-true), i.e. X ⊆ {t} ⊆ X, hence X = {t}, we get, TLα(X; t) = 1.
If X = {x} we get TLα(x; t) = αs(t, x)) + (1 − α) s(x, t)) = s(x, t) = 1 − d(x, t), i.e. conceptual continuity of ‘actual truthlikeness’.
For the special value α+ =|T|/(|T| +|X|), TLα(X; T) was indicated by TL+(X; T), and we get:
When X is E-true, t ∈ X, this becomes:
TL+(X; t) remains of course 1 when X is I-true or, in the present context equivalently, when X is EI-true, X = {t}.
Regarding the principles of a normalized range (\({\mathcal{TL}}\).1), a unique target (\({\mathcal{TL}}\).2), conceptual continuity (\({\mathcal{TL}}\).3) to the underlying (distance based) truthlikeness measure, and the relevant kind of conditional covariance (\({\mathcal{TL}}\).4), it is easy to check that the first three remain to hold straightforwardly in the case of actual truthlikeness. However, it is worthwhile to look in detail to (\({\mathcal{TL}}\).4), for the situation is here more complicated.
E-conditional covariance (\({\mathcal{TL}}\)E.4) now amounts to: if t ∈ P’ ⊂ P, ETL(P’; t) > ETL(P; t). This is precisely the version of the covariation principle as it is discussed in the literature. I-conditional covariance (\({\mathcal{TL}}\)I.4) now amounts to: if M ⊂ M’ ⊂ {t}, then ITL (M’; t) > ITL(M; t). Hence, even if M might be empty, the antecedence cannot be satisfied in the case of inclusion theories. Finally, EI-conditional covariance (\({\mathcal{TL}}\)EI.4) was already not applicable to nomic maximal theories (TLα(X; T)), hence certainly not in the context of actual truthlikeness.
Regarding inclusion and maximal theories it is perhaps more important to remark that among E-true of such theories, covariation between (actual) truthlikeness and logical strength (in the sense in which the exclusion claim of a proper subset of a set is stronger than that of that set) is certainly not valid. We illustrate this for inclusion theories, for which: ITL(M; t) = (1/|M|) × (1 − ∑x ∈ M d(x, t)/|M|). Here it is evident that if t ∈ M’ ⊂ M, i.e. both are E-true, the average similarity (1 − ∑x ∈ M’ d(x, t)/|M’|) may decrease so much that it is not compensated by the increase of the size factor (1/|M’|.
In sum, formally derived from the nomic definitions, we have now three different ways of measuring actual truthlikeness, based on size based similarity and distance based similarity, viz., replacing P and M by X, ETL(X; t), ITL(X; t), TLα(X; t). Here ITL(M; t) is a size sensitive refined version of the ‘average minimal distance’, or better, ‘average maximal similarity’ definition of Tichy and Oddie, and TLα(X; t) will turn out to be formally a bit similar to Niiniluoto’s minsum measure: both are based on weighted sums of terms related to ETL(X; t) and ITL(X; t).
It will be useful to formulate the definition of Tichy and Oddie explicitly:
If X is I-true, hence X = {t}, TO(t; t) = 1.
It is easy to check that TO(X; t) satisfies the principles of a normalized range (\({\mathcal{TL}}\).1), a unique target (\({\mathcal{TL}}\).2),Footnote 27 and conceptual continuity (\({\mathcal{TL}}\).3) to the underlying truthlikeness measure. The inclusion kind of conditional covariance (\({\mathcal{TL}}\)I.4), if X ⊂ X’ ⊂ {t}, then TO (X’; {t}) > TO(X; {t}), is not applicable, like in the case of ITL(X; t). The exclusion kind is just not generally valid.
3.2 Actual truthlikeness according to the minsum definition of Niiniluoto
Niiniluoto’s minsum (ms-) definition of actual truthlikeness is evidently guided by an exclusion claim of the form ‘t ∈ X’, because a theory is supposed to be true, when this claim is true. But size considerations play, indirectly, also a role. Note that, if X’ ⊂ X, the (E-) theory X’ is stronger than (E-) theory X. For the comparison of our trio of definitions with Niiniluoto’s ms-definition of actual truthlikeness we first specify the relevant components (see Niiniluoto, 1987, (44) p. 216, (40) p. 214, (85) p. 228)Footnote 28:
Assuming positive parameters γ and γ’ such that γ + γ’ ≤ 1,Footnote 29 the crucial definition is:
Some critical remarks are already in order. Note first that, despite the suggestive notation, dsum is of a different order than dmin. The latter is a normalized distance and the former a ratio of (summations of) such distances. Hence, \({\text{d}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; t) adds two terms of a different order, which seems conceptually problematic.
Note also that there is no straightforward continuity connection to the underlying distance function:
is not in general equal to d(x, t), i.e. \({\mathcal{TL}}\).3 is not generally valid. As Niiniluoto (1987, p. 299) shows, this expression equals d(x, t) in case of a balanced distance function (∑x∈U d(x, y)/m(U) = ½) and the (very) special relation between the parameters: γ + 2γ’/m(U) = 1. Although a balanced distance function is plausible, the special relation does not seem to have a conceptual backing other than getting the desired consequence. However, as a reviewer noted, \({\text{d}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (x, t) is proportional to d(x, t) and hence order equivalent with d(x, t) in the sense that \({\text{d}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (x, t) < \({\text{d}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (y, t) iff d(x, t) < d(y, t). Be this as it may, in my view is conceptual continuity still to be preferred.
The resulting definition of actual truthlikeness is of course:
Note the similarity in form with our TLα(X; t), for this can be written as:
Both are based on weighted sums of terms related to ETL and ITL. But, of course, they are substantially different and have a substantially different conceptual background. Despite some similarity with TLα(X; t) in form, for conceptual reasons, \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; t) can best be compared with ETL(X; t) = (1 − dmin(t, X))/|X|, for Niiniluoto is focusing, in our terms, on the exclusion claim ‘t ∈ X’, i.e. ‘t ∉ U − X’.
It is easy to check that \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; t) satisfies the principles of a normalized range (\({\mathcal{TL}}\).1) and a unique target (\({\mathcal{TL}}\).2). Naturally, again there is no simple continuity connection (\({\mathcal{TL}}\).3) to the underlying truthlikeness measure: \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (x, t) ≠ 1 − d(x, t), but it is order equivalent (M6, below), though it is now not proportional to 1 − d(x, t) = s(x, t).Footnote 30
It is important to note that although, apart from the parameters, only underlying distances occur in \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; t), it is indirectly, via dsum, also substantially based on content or strength, hence size, considerations.
If X is true, i.e. E-true in our terms, i.e. t ∈ X, hence dmin(t, X) = 0, we get:
Now it is easy to see that Niiniluoto’s definition satisfies the E-conditional covariation principle for E-true claims, TLE.4 above (and M4 below), i.e. \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; t) increases when X shrinks but remains including t, i.e., E-true. This is simply because dsum(X; t) gets smaller whenever X shrinks in view of its size-independent normalization denominator. The construction seems an ingenious but also somewhat ad hoc way to get the principle satisfied. Moreover, as said before, the construction is conceptually problematic for, in contrast to dmin, dsum is not a normalized distance, but as a ratio of such distances.
3.3 Comparisons
For the comparison of Niiniluoto’s definition and our triple of definitions we take Niiniluoto’s total set of conditions of adequacy for actual truthlikeness (Niiniluoto, 1987, p. 232/3) as point of departure, of course in his favorite logico-linguistic terms, for which reason we also quote the introductory sentences of his survey as well:
“Our previous discussion in Chapters 5 and 6 has suggested a number of adequacy conditions which an explicate of the concept of truthlikeness should satisfy. We shall state these conditions for a measure Tr(g, h*): D(B) x B → IR for a statement g ∈ D(B) relative to the target h* ∈ B. Further, a non-trivial distance function Δ: B x B → ℜ between the elements of B is assumed to be given.
- (M1):
-
(Range) 0 ≤ Tr(g, h*) ≤ 1.
- (M2):
-
(Target) Tr(g, h*) = 1 iff g = h*
- (M3):
-
(Non-triviality) All true statements do not have the same degree of truthlikeness; all false statements do not have the same degree of truthlikeness.
- (M4):
-
(Truth and logical strength) Among true statements, truthlikeness covaries with logically strength.
-
(a)
If g and g’ are true statements and g |– g’, then Tr(g’, h*) ≤ Tr(g, h*).
-
(b)
If g and g’ are true statements and g |– g’ and g’ |-/- g, then Tr(g’, h*) < Tr(g, h*).
-
(a)
- (M5):
-
(Falsity and logical strength) Among false statements, truthlikeness does not covary with logical strength: there are false statements g and g’ such that g |-- g’ but Tr(g, h*) < Tr(g’, h*).
- (M6):
-
(Similarity) Tr(hi, h*) > = < Tr(hj, h*) iff [Δ(h*, hi) =] Δ*i > = < Δ*j for all hi and hj ∈ B.
- (M7):
-
(Truth content) If g is a false statement, then Tr(h* ∨ g, h*) > Tr(g, h*).
- (M8):
-
(Closeness to the truth) Assume j ∉ Ig [the index set of g]. Then Tr(g ∨ hj, h*) > Tr(g, h*) iff Δ*j < Δmin(h*, g).
- (M9):
-
(Distance from the truth) Let Δ*1 < Δ*i. Then Tr(h1 ∨ hi, h*) decreases when Δ*i increases.
- (M10):
-
(Falsity may be better than truth) Some false statements may be more truthlike than some true statements.
- (M11):
-
(Thin better than fat) If Δ*i = Δ*j > 0, i ≠ j, then Tr(hi ∨ hj, h*) < Tr(hi, h*).
- (M12):
-
(Ovate better than obovate) If Δ*1 < Δ*i <Δ*2, then Tr(h1 ∨ hi ∨ h2, h*) increases when Δ*i decreases.
- (M13):
-
(Δ-complementFootnote 31) Tr(g, h*) is minimal if g consists of the Δ-complements of h*.”
On p. 234, Niiniluoto lists the scoring of his definition on these conditions and a couple of other definitions, with the result that his definition scores the best. Among the other candidates is the average measure of Tichy and Oddie, indicated by Niiniluoto as Mav,Footnote 32 here as TO, amounting to TO(X; t) = (1 − ∑x ∈ X d(x, t)/|X|). We will translate Niiniluoto’s conditions in our set-theoretic terms and present the scores of his measure \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; t) = (1 − \({\text{d}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; t)) and those of ETL(X; t), ITL(X; t), and TLα(X; t).Footnote 33 In the ITL column we also list, between brackets, the scores of TO(X; t). Finally, recall that we assume that X is non-empty and that d is non-trivial in all cases. Note that the conditions M1 and M2 directly correspond to our \({\mathcal{TL}}\).1 and \({\mathcal{TL}}\).2, respectively, as applied to the case T = {t}. Connections between M-conditions and \({\mathcal{TL}}\).3 and \({\mathcal{TL}}\).4 will be indicated at the spot.
In the first table we list the relevant definitions and in the second table their scores on Niiniluoto’s conditions of adequacy, M1 – M13. In Table 1 we prefer to list the ‘distance versions’ of the five definitions. We also list the (most plausible) underlying claim and the result when X is E-true, i.e., t ∈ X.
We like to start with a global comparison of these five measures, viz. in terms of their plausible sufficient conditions for increasing actual truthlikeness. The crucial terms are |X|, dmin(t, X), and dav (X; t) (= df ∑x ∈ X d(x, t)/|X|). To increase TO(X; t) it is (necessary and) sufficient that dav(X; t) decreases. To increase ETL(X; t) it is enough that |X| and dmin(t,X) do not increase, and at least one of them decreases. To increase ITL(X; t) it is enough that |X| and dav(t,X) do not increase, and at least one of them decreases. Finally, both TLα(X; t) and \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; t) increase when all three terms |X|, dmin(t,X), and dav(X; t) do not increase and at least one of them decreases.
The technical way in which they guarantee these sufficient conditions, is rather different. In view of its nomic background, TLα(X; t) is a rather plausible construction, with a clear role of the parameter, whereas \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; t) is a rather complicated construction, with parameters without a clear conceptual backgroundFootnote 34 and based on (1 −) the sum of two terms of a different order.Footnote 35 For this reason, we prima facie prefer TLα(X; t) relative to \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; t). However, ETL(X; t) and ITL(X; t) are also plausible, and are parameter free. Finally, TO(X, t) can get a similar plausible background by the nomic generalization of it, TO(X; T) = df 1 − ∑z ∈ X dmin(z, T)/|X|, but compared to ITL(X; t), it fails to take the size factor into account.
In view of the fact that all measures, except TO(X; t), satisfy the target condition \({\mathcal{TL}}\).2, viz. Tr(X; t) = 1 iff X = {t}, see below, one might say that all (these four) roads lead to the truth, as all roads lead to Rome (which was in fact the case in the Roman Empire!). Compared to both \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; t) and TLα(X; t), the other measures may be seen as less cautious, they run the risk of detours as measured by the two more demanding measures.Footnote 36
So far for the global comparison. In Table 2 we evaluate the five measures in terms of Niiniluoto’s 13 conditions of adequacy. Besides the conditions of Niiniluoto, we have inserted rows for \({\mathcal{TL}}\).3, below M6, and some substitution versions of Niiniluoto’s conditions, viz. M7 and M8.
Overviewing the scores of the five measures with respect to the conditions M1-M13, we may draw some general comparative conclusions.
Comparing TO and ITL, the main differences concern M8 and above all M11. Regarding M8, TO scores half positive and ITL just negative. However, the at least as plausible substitution version of M8, M8#, is straightforwardly satisfied by both. The score difference with respect to M11 illustrates that sets of different sizes may well have the same average distance to t. For precisely this reason, ITL takes also size differences into account. For both it may remain strange that they have the underlying claim ‘X ⊆ {t}’ (and hence ‘X = {t}’, because X is non-empty). However, this type of claim is in the context of nomic truthlikeness conceptually very plausible: ‘X ⊆ T’.
So, let us focus on the comparison of \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) and our trio. In view of the apparently underlying claim of \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\), viz. ‘t ∈ X’, Niiniluoto’s definition should primarily be compared with ETL, but in view of the size related term dsum also with TLα. In all cases the validity of a principle may need some restriction on a parameter or on some other value. However, as far as the scores of \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) and ETL differ, viz. regarding M9 and M12, these principles seem irrelevant for the supposedly underlying (exclusion or maximal) claim. Although I do not see a good reason to claim that \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) in fact presupposes the maximal claim ‘X = {t}’, in view of the technical definition there is good reason to also compare \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) with TLα. Apart from M4, they largely share the other principles, now including M9 and M12. In two cases, M7 and M8, TLα satisfies plausible substitution versions. In case of M13, TLα satisfies it under a plausible condition, which need not be assumed if there is at least one x such that d(x, t) is maximal (1).
Comparing \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) with ITL, the scores regarding M4, M6, M7, and M8 need some clarification. Recall that there is a straightforward nomic mirror version of M4 (\({\mathcal{TL}}\)E.4) satisfied by ITL. That the relevant condition happens to be inapplicable in the factual case, is of course not a genuine negative point of ITL. Regarding M6, although both score positive, it is in my view to be preferred that the stronger version, M6# (conceptual continuity), is satisfied. Regarding M7, which is a mixture of a distance and a size condition and which is only conditionally satisfied by ITL, the at least as plausible substitution version M7# is straightforwardly satisfied by all four measures. Regarding M8, again a mixture of a distance and a size condition, the substitution version M8# assumes a plausible purely distance condition and is again satisfied by all four measures. Finally, in general, whereas ITL satisfies all (if relevant, substitution versions of) conditions without restriction, \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) has parameter restrictions with respect to three conditions, viz. M5, M8,Footnote 37 and M13.
In sum, in the comparison of \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) with our triple of definitions, the technical difference may not clearly be in favor of one of the two. However, our main claim is that our three definitions are conceptually more balanced and simpler constructions than Niiniluoto’s definition. The distance measure underlying the latter, i.e. \({\text{d}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; t), though technically serving its purposes, is a conceptually strange sum of two terms of a different order. Finally, in contrast to the triple of definitions (and TO), \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) does not straightforwardly satisfy the continuity principle (see M6 and M6# = \({\mathcal{TL}}\).3 in Table 2), which is conceptually unsatisfactory.
4 Conclusion and questions for further research
4.1 Conclusion
In this paper we have introduced a coherent trio of distance and size based normalized measures of nomic truthlikeness, guided by the three different claims that a theory may make: truthlikeness of exclusion, inclusion, and combined (maximal two-sided) theories, ETL, ITL, and TLα, respectively. The measures can formally also be used as measures for actual truthlikeness by assuming the extreme special case in which the set op nomic possibilities is the singleton of the actual possibility. The direct practical value of these measures is limited as long as one does not know the nomic and the actual truth, respectively. However, if one would know them they clearly indicate which revisions of theories bring us closer to the truth and each measure suggests its own focus for attempts to truth approximation. Hence we may at least conclude, as we did at the end of Sects. 2.4 and 3.1, that we have good reasons to assume that, even without knowing the truth, all three measures provide meaningful guidelines for nomic and actual truth approximation, but also that ETL and ITL have their own risk of detours, whereas TLα (and more generally, CTLα) is more cautious in both respects. However, the latter need a parameter, be it with a plausible role. Hence, we have no clear preference.
Comparing the main quantitative definitions of actual truthlikeness in the literature, Niiniluoto’s minsum definition and Tichy and Oddie’s average definition, with our trio, we may conclude, in view of the scores with respect to Niiniluoto’s 13 conditions, the reasons behind the deviations and the alternative ways to deal with them, that the technical difference may not clearly be in favor of one the two. However, in view of simplicity, it is already defensible to prefer ETL and TLα above Niiniluoto’s minsum definition \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) of the truthlikeness of claims of the form ‘t ∈ X’ and ‘X = {t}’, respectively. Moreover, ITL provides a size sensitive refined version of the ‘average minimal distance’ definition TO of Tichy and Oddie, and can compete very well with \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\).
There are important extra reasons to favor, depending on the claim, the relevant member of our trio, that is, ETL, ITL, or TLα. They have some very attractive exclusive properties: 1) they cover actual as well as nomic truthlikeness, the latter even for two-sided theories, 2) they not only satisfy (like \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) and TO) the unit range and the target condition, but also the conceptual continuity principle, that is, in contrast to Mγγms, but like TO, they reduce straightforwardly to the underlying distance based truthlikeness measure for singleton theories, and finally 3) \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) is a rather complicated construction, with puzzling parameters and based on (1 −) the sum of two terms of a different order, whereas ETL, ITL, and TLα are conceptually transparent and simple constructions. Only TLα needs a parameter, however with a plausible role.
4.2 Questions for further research
-
(1)
In a note about the definition of ‘exclusion similarity’ we suggested already that another route was possible for defining ‘exclusion truthlikeness’ due to the equivalence of the claims ‘T ⊆ X’ and ‘cX ⊆ cT’. This leads to the following two possibilities, the one in the text, ETL(X; T), and the complement variant, ETLc(X; T):
$${\text{ETL}}\left( {{\text{X}};{\text{ T}}} \right) \; = \;\frac{{{\text{min}}\left( {\left| {\text{X}} \right|, \, |{\text{T}}|} \right)}}{{{\text{max}}\left( {\left| {\text{X}} \right|, \, |{\text{T}}|} \right)}} \times ({1} - \sum_{{{\text{x}} \in {\text{X}}}} {\text{d}}_{{{\text{min}}}} \left( {{\text{x}},{\text{ T}}} \right))/\left| {\text{X}} \right|)$$$${\text{ETL}}^{{\text{c}}} \left( {{\text{X}};{\text{ T}}} \right) \; = \;\frac{{{\text{min}}\left( {\left| {{\text{cX}}} \right|,\;|{\text{cT}}|} \right)}}{{{\text{max}}\left( {\left| {{\text{cX}}} \right|,\;|{\text{cT}}|} \right)}} \times \left( {{1} - \sum_{{{\text{x}} \in {\text{cX}}}} {\text{d}}_{{{\text{min}}}} \left( {{\text{x}},{\text{ cT}}} \right)/\left| {{\text{cX}}} \right|} \right)$$
As is easy to see, ETLc(X; T) presupposes a finite universe for the size factor is undefined in case of an infinite universe and the denominator in the summation, |cX| =|U − X| =|U| −|X|, needs to be finite.
Against the first, ‘direct version’, ETL(X; T), one may object that it is conceptually problematic in comparison with ITL, for there seems no good reason to treat the complement version of the exclusion claim, i.e. ‘cX ⊆ cT’, formally different from the inclusion claim ‘X ⊆ T’. Treating this complement version, ‘cX ⊆ cT’, formally like the inclusion claim leads to the second, complement variant of exclusion truthlikeness, ETLc(X; T). It is easy to check that both versions satisfy the unit range condition (\({\mathcal{TL}}\).1), 0 ≤ ETL(c)(X; T) ≤ 1, the unique target condition (\({\mathcal{TL}}\).2), E(c) TL(X; T) = 1 iff X = T, and the exclusion version of conditional covariance (\({\mathcal{TL}}\)E.4), if T ⊂ X’ ⊂ X, then ETL(c)(X’; T) > ETL(c)(X; T). However, whereas the direct version satisfies conceptual continuity (\({\mathcal{TL}}\).3), ETL(x. t) = s(x, t) = tl(x, t), ETLc does not, as is easy to check, for we get, using |c{x}| =|c{t}| =|U|− 1,
In fact, ETLc(x; t) is not even order equivalent with tl (x, t) = 1 − d(x, t).
In sum, despite the formal objection, the need of assuming a finite universe and the lack of conceptual continuity seem enough reason to favor ETL above ETLc. However this may be, by combining ETLc with ITL and using a parameter like α one can get also a truthlikeness measure for two-sided and hence maximal theories, i.e. theories with the claim ‘X = T’. Further comparative evaluation of the two alternatives is needed.
-
(2)
This paper is restricted to the logical problem of actual and nomic truthlikeness. For the epistemic or epistemological problem, that is, not knowing the truth aiming at actual and nomic truth approximation in the face of evidence, we may focus on a definition of quantitative success guided by our measures and for the rest remain in line with my previous publications (Kuipers, 2000, 2019). For nomic truth approximation, the latter goes in terms of a set of experimentally realized possibilities, R, and, on their basis, induced laws, where S indicates the strongest law. Note that cS is the set of induced impossibilities. Assuming we made no mistakes, a strong assumption indeed, we get R ⊆ T ⊆ S,Footnote 38 whatever T is. This leads to the, for the realist-instrumentalist debate, challenging question to what extent a ‘success theorem’ holds, that is, to what extent does ‘quantitatively more truthlike’ predict ‘quantitatively more successful’.
It seems plausible to define, in line with ETL and ITL, the (empirical) exclusion success as s*(S, X) × (∑x ∈ X smax(x, S))/|X| and the inclusion success as s*(R, X) × (∑y ∈ R smax(y, X))/|R|, and for the combined success the α-weighted sum. Note that all three success notions are, though suggested by, not laden with the corresponding truthlikeness definitions, hence perhaps acceptable for instrumentalists. The following is easy to prove: if R has no counterexamples to X (R ⊆ X), the inclusion success reduces to s*(R, X), and if X explains, or at least entails, S, (X ⊆ S), the exclusion success reduces to s*(S, X). However, to what extent the three corresponding success theorems can be proved is not easy to determine.
To be sure, for the epistemological problem, we may also focus, in line with Niiniluoto (1987), on probabilistically estimating the truthlikeness of theories on the basis of the available evidence. Inevitably, such evaluations of theories by empirical results are explicitly laden with the presupposed definition of truthlikeness.
-
(3)
A number of topics in (Kuipers, 2019), in particular with respect to nomic truthlikeness, ask for extension and comparison (Chapters refer to that book).
-
(a)
Ch. 1 and 4 explore and defend the (qualitative) symmetric difference definition of more truthlikeness: Y is more truthlike than X iff YΔT is a proper subset of XΔT. The Δ-definition was first proposed for actual truthlikeness by David Miller (1978) and independently for theoretical or nomic truthlikeness by myself (Kuipers, 1982), and further developed in (Kuipers, 2000, 2019). It will be interesting to compare this definition with our trio, in particular assuming that the distance function is trivial: d(x, y) = 0 if x = y, otherwise d(x, y) = 1.Footnote 39 Moreover, it is interesting to investigate to what extent the ‘trivial’ trio measures are susceptible to the so-calledFootnote 40 child’s play objection of Pavel Tichy (1978) and Graham Oddie (1981, 1986, 2016) against the Δ-definition. Finally, it would be interesting to evaluate the (trivial and non-trivial) trio in the light of Zwart’s (2001) distinction, emphasized by Niiniluoto (2003), between content (e.g. Miller, 1978, Kuipers, 2000, 2019) and likeness (e.g. Niiniluoto, 1987; Oddie, 1986) approaches to truthlikeness.
-
(b)
Ch. 6 deals with a ‘refined’ qualitative (two-sided) approach, in which the ternary notion of structurelikeness (possibility y is more similar to z than x) plays a crucial role. In the present setup it is plausible to interpret this relation in terms of (non-trivial) distances (d(y, z) < d(x, z)), and the question is how refined truthlikeness relates to our trio.
-
(c)
Ch. 5 deals with a quantitative version of the qualitative approach in terms of symmetric differences in Ch, 4. The interesting question is whether this version also coheres with TLα, viz. as an extreme case for trivial d?
-
(d)
Finally, Ch. 7 deals with a (observational—theoretical) stratified version of the symmetric difference approach. Assuming a (reduction or) projection function π from the theoretical level to the observational level, and an order preserving relation between the underlying distance measures, the plausible relational questions are: to what extent does e.g. ETL(Y; T) > ETL(X; T) entail ETL(πY; πT) > ETL(πX; πT)?
-
(4)
Niiniluoto’s minsum definition asks for a generalization that is also applicable for the nomic truth T. Such a generalization is not only interesting in itself, but also for the comparison with other proposals that work for t and T, such as our trio. Besides some related ways in Ch. 11, Niiniluoto (1987) has defined (Ch. 10, (121), p. 248) a distance measure between statements, of which he points out that it gives his minsum measure as a (very) special case, when one of the statements is the true constituent.
Our tentative proposal for a straightforward generalization of \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; t) to nomic truthlikeness in Niiniluoto’s style of defining actual truthlikeness of (exclusion) theories is, assuming positive parameters γ and γ’ such that γ + γ’ ≤ 1:
Note that \({\text{d}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X, t) is straightforwardly the special case of \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; T) when T = {t}. Note also that dmin(T, X) = 0, and hence \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; T) = 1 − γ’dsum(X, T), if X is E-true, that is, if T ⊆ X.
\({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; T) = df 1 − \({\text{d}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X, T) satisfies at least the following principles:
- M1::
-
(Generalized Range) 0 ≤ Tr(X; T) ≤ 1.
- M2::
-
(Generalized Target) Tr(X; T) = 1 iff X = T.
- M3::
-
(Generalized Non-triviality).
For (E-)true ((E-)false) statements / claims, i.e., T ⊆ X (T − Y ≠ ∅),
Tr(X; T) (Tr(Y; T)) has not always the same value for varying X (Y)
- M4::
-
(Generalized Truth and logical strength).
-
(a)
If T ⊆ Y ⊆ X then Tr(X; T) ≤ Tr(Y; T)
-
(b)
If T ⊂ Y ⊂ X then Tr(X; T) < Tr(Y; T)
-
(a)
It would be interesting to also generalize M5 – M13 as plausible as possible and to compare \({\text{M}}_{{{\text{ms}}}}^{{\gamma \gamma^{\prime}}}\) (X; T), with our trio, in particular ETL(X; T) and TL(X; T), and with Niiniluoto’s distance measure between statements referred to at the beginning, and finally with Leg(D(X), C(T)) below.
There is still another way to deal with nomic truthlikeness in the style of Niiniluoto’s treatment of actual truthlikeness, viz. a kind of transformation in terms of ‘propositional nomic constituents’. As a reviewer remarked, a maximal theory “X = T” can be seen as a kind of constituent. Let C(X) = df “X = T”, where bold T indicates that T has not yet been characterized in the ‘language of U’. That is, C(X) can be seen as the propositional nomic constituent: ∀x ∈ X x ∈ T & ∀x ∉ X x ∉ T.Footnote 41 Of course, just one of them is true, to be indicated by C(T) = “T = T”, where the non-bold T is a characterization of T in the language of U. Now we can define nomic truthlikeness of a nomic exclusion theory X, (claiming ‘T ⊆ X’), i.e., a disjunction or set of nomic constituents, D(X) = {C(Y) / Y ⊆ X}, relative to the true nomic constituent, in Niiniluoto’s style. It corresponds to his discussion of legisimilitude (Niiniluoto, 1987, pp. 376–380), in particular by the definition of ‘leg3’ ((7), p. 377). However, he deals with monadic nomic constituents, i,e, conjunctions of the form &i( ±)⋄(∃x)Qi(x), which we do not consider. In terms of our propositional nomic constituents, we first need a plausible (normalized symmetric) distance function between constituents, δ(C(X), C(Y)). This function may or may not be (relative) size dependent but will almost certainly be based on some underlying (normalized symmetric) distance function d(x, y).Footnote 42 The crucial definition then is, again assuming positive parameters γ and γ’ such that γ + γ’ ≤ 1:
where
So far for the generalization, respectively transformation, of Niiniluoto’s minsum definition of actual truthlikeness (in)to nomic truthlikeness.
-
(5)
So far we assumed that all considered subsets of the universe are finite. Plausible challenges are extending the measures to denumerable infinite and continuous subsets. The latter problem brings us, among other, to the topic of the truthlikeness of an interval hypothesis relative to the actual truth (Festa, 1986). Surprisingly enough, our measures are easy to extend to the nomic truthlikeness of such an hypothesis. Let U be the set of real numbers, or the non-negative ones, with a suitable normalized distance function d(x, y) and s(x, y) = 1 − d(x, y). Let X and T be closed intervals. Then e.g. our combined measure TLα can directly be applied, replacing sums by integrals.
$$\begin{aligned} {\text{TL}}^{\alpha } \left( {{\text{X}};{\text{ T}}} \right)& = \;{\text{s}}^{*} \left( {{\text{X}},{\text{ T}}} \right) \, [\alpha {\text{ES}}_{{\text{T}}} \left( {\text{X}} \right) \, + \, ({1} - \alpha ){\text{IS}}_{{\text{X}}} \left( {\text{T}} \right)] \hfill \\ &\quad =_{{{\text{df}}}} {\text{s}}^{*} \left( {{\text{X}},{\text{ T}}} \right)\left[ {\alpha \int\limits_{{\text{T}}} {{\text{s}}_{{{\text{max}}}} \left( {{\text{z}},{\text{ X}}} \right)dz/ \, \left| {\text{T}} \right|} \; + \;({1} - \alpha )\int\limits_{{\text{X}}} {{\text{s}}_{{{\text{max}}}} } \left( {{\text{z}},{\text{ T}}} \right)dz/|{\text{X}})} \right] \hfill \\ & \quad ={\text{s}}^{*} \left( {{\text{X}},{\text{ T}}} \right) \, [\alpha ({1} - \int\limits_{{\text{T}}} {{\text{d}}_{{{\text{min}}}} \left( {{\text{z}},{\text{ X}}} \right)dz/ \, \left| {\text{T}} \right|)} \\ &\quad + \;({1} - \alpha )\;({1} - \int\limits_{{\text{X}}} {{\text{d}}_{{{\text{min}}}} } \left( {{\text{z}},{\text{ T}}} \right)dz/\left| {\text{X}} \right|)] \hfill \\ \end{aligned}$$
Here we assume:
For the underlying distance function d(x, y) we can use the normalized geometric distance if the reals are the universe: d(x, y) =|x − y| / (|x − y| + 1). If we are dealing with genuine quantities, i.e. a ratio scale on the non-negative reals, we would use of course d*(x, y) = 1 − s*(x, y) = 1 − min(x, y)/max(x, y) =|x − y| / max(x, y) (Sect. 2.2, and Manuscript, 2023).
Note, finally, that TL1/2(X; T) with α =1/2 and TL+(X; T) with α =|T|/(|T| +|X|) make perfect sense.
Unfortunately, it is now impossible to treat actual truthlikeness just as the extreme special case in which T = [t, t] = {t}. For, since |{t}|= 0, s*(X, {t}) = 0, which makes TLα(X; T) uniformly equal to 0. Perhaps one may defend to set s*(X, {t}) = 1/(1 +|X|) or to restrict actual truthlikeness to the second factor. In the second case, it is perfectly possible that d(x, y) is such that ∫Tdmin(z, X)dz / |T| goes to dmin(t, X) if T = [t, t + x] and x goes to 0. If so, we get:
-
(1)
$$\alpha ({1} - {\text{d}}_{{{\text{min}}}} \left( {{\text{t}},{\text{ X}}} \right)) \, + \, ({1} - \alpha ) \, \left( {{1} - \int\limits_{{\text{X}}} {{\text{d}}\left( {{\text{z}},{\text{ t}}} \right)dz/ \, \left| {\text{X}} \right|} } \right)$$
Note that the second factor of the second term, i.e., (1 − ∫X d(z, t)dz / |X)), is a straightforward generalization of the average measure of Tichy and Oddie. Note also that (1) reduces to this term when α = α+ =|[t, t]|/(|[t, t]| +|X|) = 0 for |[t, t]|= 0. We leave the detailed comparison of (1) with the definition of Festa (1986) as an interesting question for further research.
In conclusion, the proposed trio of truthlikeness measures, raises a number of challenging questions for further research.
Notes
Note that s(x, y), and hence the underlying truthlikeness measure tl(x, t) below, may be the primarily defined function and be based on ‘deeper’ underlying distance and size considerations, similar to the main topic of this paper. However, if so, we assume in this paper that the resulting d(x, y) = 1 − s(x, y) is a metric.
For the comparison of the trio of measures introduced in this paper with the symmetric difference definition in Kuipers (2001, 2019), see some specifications in Sect. 4.2 issue 3.
It is important to keep in mind that these claims are not just referring to set-theoretic relations. Crucial is that T refers to the set of (un-)known nomic possibilities. Moreover, ‘T ⊆ X’ gets its name due to the equivalence with cX ⊆ cT). Similarly for inclusion and inclusion theory, similarity, and truthlikeness.
So named in (Kuipers, 2019), leaving room for so-called two-sided theories, see below.
As a referee remarked, if U is the set of constituents C1, …, Ck (I = {1, 2,…, k}) of a finite (propositional or monadic) language (i.e. conjunctions of the form &i(±)pi and &i(±)(∃x)Qi(x), respectively), a maximal claim corresponds, assuming I(X) as the index set for X, to a modal claim of the form ∀i ∈ I (±)◊Ci, with ‘+’ when i ∈ I(X) and ‘–’ otherwise, or, equivalently, ∀i ∈ I(X)◊Ci & \(\square\) ∃i ∈ I(X)Ci (Niiniluoto, 1987, (100) resp. (101), p. 96). Note that this is in an important sense much stronger than the so called monadic nomic constituents, being of the form ∀j ∈ I ◊ ∃x Qj(x) & ∀j∉I \(\square\) ¬∃x Qj(x), where I is the index set of some subset of Q-predicates (Niiniluoto, 1987, (96), (97), p. 94), as the former entails that some existence claims are physically necessary.
Here we could take another route, viz. by defining the exclusion similarity of P as
EScP(cT) = df ∑z ∈ cP smax(z, cT)/|cP| = 1 − ∑z ∈ cP dmin(z, cT)/|cP|. However, this leads to a measure without conceptual continuity and it would force us to assume that the universe is finite, see Sect. 4.2 issue 1). As will be shown in this section, it is perfectly possible to avoid these shortcomings.
There is at least one other definition which satisfies the 3 properties below (see also Manuscript, 2023): (1 − s(x, y)) being a normalized metric, s(x, y) and (1 – s(x, y)), being scale invariant and translation convergent, viz. s#(X, Y) = s#(|X|, |Y|) = 2 min (|X|, |Y|)/(|X| +|Y|).
Or, equivalently, for any positive real number b such that |X’| = |X| + b and |Y’| = |Y| + b, hence ||X’| − |Y’|| = ||X| − |Y||, then s*(X’, Y’) > s*(X, Y) and goes to 1 if b goes to. Note that the ‘outside’ bars are used to indicate the absolute difference between |X| and |Y|.
Note that any definition solely as a function of the absolute difference, ||X| − |Y||, leads to equal similarity e.g., in (size) numbers, s(1, 2) = s(1000, 1001), which seems absurd.
Since both factors are conceived of as (the only) relevant factors and both are normalized on the unit interval, taking the product seems the plausible way to take both into account.
Note that ETL(P; T) is defined such that the order matters, due to the second factor. Note also that we could introduce a distance or difference measure DTL(X, T) simply as 1 − ETL(X, T).
Special values:
P = U, hence T ⊆ P, i.e. I-true, assuming U finite: ITL(U; T) = s*(U, T) × EST(U) =|T|/ |U|.
P = \(\varnothing\): EST(\(\varnothing\)) is undefined, however ITL(\(\varnothing\); T) = 0, for s*(\(\varnothing\), T) = |\(\varnothing\)|/|T|= 0, whatever value for EST(\(\varnothing\)) from the unit range is chosen.
P = {x}: ITL(x; T) = (1/|T|) × (∑z∈ T s(z, x)/|T|).
Niiniluoto calls it ‘truth and logical strength’ (M4, below), Oddie calls it ‘the value of content for truths’.
Proof:
- from T ⊂ P’ and T ⊂ P follows: EST(P’) = EST(P) = 1,
- from P’⊂ P follows |P| > |P’| and hence ITL(P; T) = |T|/|P| <|T|/|P’| = ITL(P’; T).
Special values:
M = U:assuming U finite, ISU(T) = ∑x ∈ U−T smax(x, T)/|U|, ETL(U, T) = s*(U, T) ISU(T) = (|T|/|U|) ISU(T).
M = \({\varnothing}\): IS\(_{\varnothing}\)(T) is undefined, however ETL(∅; T) = 0, for s(\({\varnothing}\), T) =|\({\varnothing}\)|/|T|= 0, whatever value for IS\(_{\varnothing}\)(T) from the unit range is chosen.
M = {x}: ISx(T) = smax(x, T). ETL(x, T) = (1/|T|) × smax(x, T) (= 1/|T| if x is E-true, i.e. x∈T).
For IST(X) = EST(X) and s(X, T) is symmetric.
It is interesting to note that if = ½ the second (distance based) factor in the corresponding TL1/2(X; T), i.e. the one between [], essentially corresponds to Niiniluoto’s (1987, (124), p. 249) generalized distance measure between two statements, i.e. the factor is 1 minus this distance.
Note that the second factor is equivalent to the distance measure between statements which Niiniluoto (1987, (126) p. 250) has formulated. He rejected the definition in passing for it does not satisfy the covariation principle of truthlikeness and strength for true claims. However, he also presented an almost similar definition, weighted symmetric difference (Niiniluoto, 1987, (7), p. 317), for the distance between monadic constituents. If U is the set of constituents of a monadic language, the normalized form certainly is a plausible distance measure in the present context.
Unfortunately, we do not yet see a plausible way to generalize this to weights for genuine two-sided theories.
Because X ⊂ X’ ⊂ T ⊂ X’ ⊂ X is an impossible condition.
For a continuous version of TL, see Sect. 4.2 issue 5), where the actual truthlikeness of an interval hypothesis is explored.
Note that TL1/2 (and only TL1/2) is symmetric: TL1/2(X; T) = TL1/2(T; X).
See Sect. 4.2 issue 2) for some provisional remarks.
The claim ‘t ∈ X’ can now better be paraphrased as ‘no excluded possibility is the actual(ized)’ or ‘X includes the actual(ized) possibility’.
Though formally just a set-theoretic claim, it is difficult to give a meaningful paraphrase.
The measure 1 − dmin(t, P) has been proposed as a measure of the degree of truth or degree of approximate truth (Niiniluoto, 1987, pp. 218–219; Niiniluoto, 1998, p. 6). Since ITL(P, t) is defined as (1/|P|) × (1 − dmin(t, P)), this kind of truthlikeness may be seen as the degree of (approximate) truth weighed by size.
Note however that the generalized version of TO(X; T), i.e. 1 − ∑z ∈ X dmin(z, T)/|X|, does not satisfy the principle, for TO(X; T) = 1 as soon as X is a subset of T. The size factor prevents this for ITL(X; T).
Note first that this formulation of dsum(X, t) presupposes a finite universe, but Niiniluoto (1987) presents also continuous versions.
Note also that dsum(X, t) can be written as the product of a quotient of averages and a quotient of sizes:
$$\frac{{\sum _{{{\text{x}} \in {\text{X}}}} {\text{d}}\left( {{\text{x}},{\text{ t}}} \right)/\left| {\text{X}} \right|}}{{\sum _{{{\text{x}} \in {\text{U}}}} {\text{d}}\left( {{\text{x}},{\text{ t}}} \right)/\left| {\text{U}} \right|}} \times {\left|{\text{X}}\right|\over \left|{\text{U}}\right|}$$and that the numerator of the first quotient corresponds to the crucial average distance of Tichy and Oddie, also occurring in ETL(X, t) and TL(X, t). The second quotient is in fact the size similarity s*(X, U).
Niiniluoto requires that the two parameters individually do not exceed 1, but this is too weak to get the result within [0, 1]. To see this, it is important to note that although the min and the sum term fall already in the interval [0, 1], the weighted sum γdmin(t, X) + γ’dsum(X, t) may exceed 1 for sufficiently high values of the parameters.
It is proportional to (1 − \({\upbeta}\)d(x, t)), where \({\upbeta}\)= γ + γ’/∑x∈U d(x, t).
“An element hj of B is called a \(\Delta\)-complement of hi, if \(\Delta\)ij = max \(\Delta\)ik, k ∈ I [the index set of B]” (Niiniluoto, 1987, p. 210).
The symbolization in Niiniluoto’s table also includes the superscript γ, but this must be a mistake, for TO has no parameters.
Note that for simplicity we have replaced here P in ITL and M in ETL by X.
See Sect. 4.2 issue 4) for the generalization, respectively transformation, of Niiniluoto’s minsum definition of actual truthlikeness (in)to nomic truthlikeness.
To avoid this, a product variant might be considered: (1 − dmin)(1 − dsum). It is parameter free and satisfies at least \({\mathcal{TL}}\).1, \({\mathcal{TL}}\).2, and the relevant version of \({\mathcal{TL}}\).4, but still fails to satisfy \({\mathcal{TL}}\).3.
We can even extend the analysis by taking a third term into account: dmax(t, X). Note first that similarity measure TLmax(X, t) = df (1 − dmax(t, X))/|X| satisfies unit range, target, and continuity. Hence, a revision where |X| and dmax(X, t) do not increase and one of them decreases is a plausible kind of increasing truthlikeness. In this way we get that if |X| does not increase, decreasing one or two or all three of dmin(t,X), dav (X; t), and dmax(X, t) can be seen as ways of truth approximation. Together with decreasing |X| and not decreasing the three other terms, we get in total 8 ways of truth approximation.
As to the possible nomic background of dmax(X, t), we may define ∑y∈T dmax(y, X)/|T| and ∑x∈X dmax(x, T)/|X|. Now it is easy to check that, for T = {t}, the first term reduces to dmax(t, X), and the second to ∑x∈X d(x, T)/|X|= dav(X; t), that is, the term we already got from ∑x∈X dmin(x, T)/|X| for T = {t}. However, we do not yet see a way to link the two nomic summations to the two nomic claims such that the sums are zero when the corresponding claim is true.
But it satisfies the substitution version M8# straightforwardly.
This may be paraphrased as: all realized possibilities are nomic possibilities and all induced impossibilities are nomic impossibilities.
As is easy to check, it is a genuine normalized metric.
This corresponds to the way in which nomic constituents are defined in (Cevolani, et al., 2013), where they are used to define a qualitative comparative notion of ‘closer to the nomic truth’, in fact a translation of Kuipers’s (2000, 2019) set-theoretic definition into the terms of ‘nomic conjunctive theories’.
If is only based on the trivial distance function, it leads to \(\delta\)(C(X), C(Y)) = |X\(\Delta\)Y|/|U|.
References
Cevolani, G., & Festa, R. (2020). A partial consequence account of truthlikeness. Synthese, 197(4), 1627–1646.
Gustavo, C., Festa, R., & Kuipers, T. (2013). Verisimilitude and belief change for nomic conjunctive theories. Synthese, 190(16), 3307–3324.
Festa, R. (1986). A measure for the distance between an interval hypothesis and the truth. Synthese, 67, 273–320.
Kuipers, T. (1982). Approaching descriptive and theoretical truth. Erkenntnis, 18(3), 343–378.
Kuipers, T. (2000). From instrumentalism to constructive realism. Synthese Library 287, Kluwer AP, Dordrecht (NL).
Kuipers, T. (2019). Nomic truth approximation revisited. Synthese Library 399, Springer.
Manuscript. Kuipers, T. (2023). Truthlikeness and the number of planets.
Miller, D., et al. (1978). On distance from the truth as a true distance. In J. Hintikka (Ed.), Essays on mathematical and philosophical logic (pp. 415–435). Reidel.
Niiniluoto, I. (1987). Truthlikeness, Synthese Library 185, Reidel.
Niiniluoto, I. (1998). Verisimilitude: The Third Period, BJPS 49.
Niiniluoto, I. (2003). Content and likeness definitions of truthlikeness. In J. Hintikka, T. Czarnecki, K. Kijania-Placek, T. Placek, & A. Rojszczak (Eds.), Philosophy and logic: In search of the Polish tradition. Kluwer.
Niiniluoto, I. (2020). Truthlikeness: Old and new debates. Synthese, 197, 1581–1599.
Oddie, G. (1981). Verisimilitude reviewed. The British Journal for the Philosophy of Science, 32, 237–265.
Oddie, G. (1986). Likeness to truth (Vol. 30). The University of Western Ontario Series in Philosophy of Science. Reidel.
Oddie, G. (2013). The content, consequence and likeness approaches to verisimilitude: Compatibility, trivialization, and underdetermination. Synthese, 190, 1647–1687.
Oddie, G. (2016). Truthlikeness. The Stanford Encyclopedia of Philosophy (Winter 2016 Edition), Edward N. Zalta (ed.). https://plato.stanford.edu/archives/win2016/entries/truthlikeness/.
Popper, K. R. (1963). Conjectures and refutations. Routledge and Kegan Paul.
Tichy, P. (1978). Verisimilitude revisited. Synthese, 38, 175–196.
Zwart, S. (2001). Refined verisimilitude. Synthese Library 307, Kluwer AP, Dordrecht.
Acknowledgements
I would like to thank David Atkinson for his great help and Alfonso Garcia—Lapena for his stimulating remarks. I am also very grateful to the two anonymous referees for their useful comments and who have strengthened my plan to drastically reorganize the first version.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
I see no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kuipers, T.A.F. A coherent trio of, distance and size based, measures for nomic and actual truthlikeness. Synthese 201, 68 (2023). https://doi.org/10.1007/s11229-022-03977-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11229-022-03977-4