
Abstract
Hardware/software (HW/SW) partitioning is a vital aspect of HW/SW co-design. With the development of the design complexity in heterogeneous computing systems, existing partitioning algorithms have demonstrated inadequate performance in addressing problems relating to large-scale task nodes. This paper presents a novel HW/SW partitioning algorithm based on node resource attributes hovering swarm particle swarm optimization (HSPSO). First, the system task graph is initialized via the node resource urgency partitioning algorithm; then, the iterative solution produced by HSPSO algorithm yields the partitioning result. We present new initialization by combining node resource attribute information and introduce two improvements to the learning strategy of HSPSO algorithm. For the main swarm, a directed sample set and the addition of perturbation particles are designed to direct the main swarm’s particle search process. For the secondary swarm, a dynamic particle update equation is formulated. Iterative updates are performed based on previous rounds’ prior information using adaptive inertia weight. The experimental results illustrate that, in large-scale systems task graph partitioning with more than 400 nodes, when compared with mainstream partitioning algorithms, the proposed algorithm improves partitioning performance by no less than 10% for compute-intensive task graphs and no <5% for communication-intensive task graphs, with higher solution stability.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
As Moore’s Law gradually loses its effectiveness and reaches its bottleneck [1, 2], information processing systems confront an ever-growing demand for big data processing. Currently, designers adopt a range of heterogeneous resource collaborative computing architectures to fulfill the requirements of high-performance computing [3]. Through the collaborative computation of diverse architectural units, corresponding instruction sets are invoked to execute calculations; types of prevalent calculation units encompass CPUs, GPUs, FPGAs, DSPs, etc. Depending on the characteristics of the application scenario, fully utilizing the performance of these heterogeneous computing resources can yield greater utilization benefits. A simple schematic diagram of a heterogeneous computing system is shown in Fig. 1.

Overview of heterogeneous computing system
In heterogeneous systems, numerous task modules can be implemented either through hardware or software resources. The key issue that HW/SW partitioning algorithms need to solve is how to achieve the optimal combination of task module implementation methods while satisfying all design constraints of the system [4, 5]. HW/SW partitioning algorithms determine the implementation method for each task module, guide the design and configuration of computing resources [6, 7], reduce overall power consumption of the system and achieve performance optimization and improvement. Therefore, HW/SW partitioning represents a crucial technology in HW/SW co-design and its results directly affect the performance of heterogeneous computing systems.
HW/SW partitioning algorithms can choose optimization objectives according to different application requirements, such as system power consumption, hardware area and time cost. At present, the HW/SW partitioning problem can be divided into two categories [8], a small part of which uses dynamic programming [9, 10], integer linear programming and other exact algorithms [11]. The early hardware and software partitioning had a small scale, and only dozens of system components were tested [12], which could solve the problem in polynomial time and obtain accurate results. However, with the increase in the number of nodes in the solution task, most partitioning problems are NP-hard problems [13]. Exact algorithms are easily affected by combinatorial explosion and often cannot solve problems to obtain results. Therefore, heuristic search algorithms are widely used in HW/SW partitioning problems.
Heuristic algorithms can be divided into two categories: local search and guided search. Local search methods generally determine the direction of the next stage of the search based on the gradient of the objective function, such as Newton’s method, conjugate gradient method and variable scale method. Their disadvantage is that they search according to the direction of change of the objective function’s gradient, which is easy to fall into local optimal solutions. For some complex problems, especially multi-objective optimization problems, it is difficult to give an objective function and cannot perform gradient calculation. Guided search methods use some search rules to guide the search for good solutions in the entire solution space, such as genetic algorithms [14,15,16,17], taboo search [18, 19], particle swarm optimization [20, 21]. There are also many fusion algorithms, such as combining greedy algorithms and simulated annealing algorithms [22]. These heuristic algorithms all have their own characteristics, but as the problem size increases and the computation becomes more intensive, it is difficult to obtain high-quality solutions in effective time.
In recent years, particle swarm optimization(PSO) and its variants have achieved good results in solving HW/SW partitioning problems due to their high design space search rate and short execution time [20]. In [23], it is revealed that the performance of PSO superior to genetic algorithm in both cost function and execution time when solving HW/SW partitioning problems. In order to avoid premature convergence, an improved reactivation PSO method was proposed in [24] to solve software-hardware partitioning problems. In [25], it was found that PSO performs better than integer linear programming(ILP), genetic algorithm(GA), ant colony optimization(ACO) algorithms in solving HW/SW partitioning problems. In [26], the authors proposed a discrete PSO and B &R algorithm to solve HW/SW partitioning problems and used it to improve the solution speed. In [27], it increased the diversity of search by simulating squirrel behavior and proposed a new initialization strategy to obtain better performance than other algorithms. However, these algorithms focus on optimizing the solution time and speeding up the entire search process for large-scale partitioning problems, and the improvement of solution quality is not high.
This article proposes a HW/SW partitioning algorithm based on the node resource attributes of the HSPSO algorithm for the large-scale HW/SW partitioning problem and obtains the final partitioning results by initializing the HSPSO population and alternating iterative processes of the main and secondary populations according to different learning strategies, and the final experimental results show that the solution quality of its algorithm is better than several other types of partitioning algorithms.
The rest of the paper is organized as follows: Sect. 2 briefly introduces the definitions related to the HW/SW partitioning model and system task graph used in this paper. The proposed node resource urgency partition(NRUP) algorithm and the HSPSO partitioning algorithm are introduced in Sect. 3. For Sect. 4, the performance of the algorithms is experimentally verified and compared with several types of algorithms cited. Section 5, a summary and outlook are provided.
2 Problem description
2.1 Task graph model
Currently, there are many system description models in the field of heterogeneous computing system design [28,29,30], such as discrete-event systems [31, 32], finite state machines [33, 34], control/data flow graphs [35, 36], task graphs [37, 38] and Petri nets [39, 40]. Each of these models has different structural characteristics and application scenarios. As the research object of this paper, system task graph modules have characteristics such as data dependency and time constraints. Therefore, choosing a task graph to describe the system can effectively represent a complete heterogeneous computing system.
Formally, the system task graph is defined as a weighted directed acyclic graph(DAG) \(G=(V, E)\), where V represents the various task nodes, E represents the set of edges between nodes, |V| represents the number of task nodes, and |E| is the number of edges. Each node in the set V represents a task \(v_i\), the edge \(e_{i j}=\left( v_i, v_j\right) \in E\) represents the data dependency relationship between task nodes \(v_i\) and \(v_j\), i.e., task \(v_i\) is the predecessor of \(v_j\), and \(v_j\) is called the successor node of \(v_i\). The node without precursor is called source node, and the node without successor is called sink node. At the same time, the node \(v_i\) also contains information about the hardware and software execution time of the task node and other attributes, which are recorded as \(v_i=\left\{ s t_i, h t_i, s a_i, h a_i\right\} \), a summary of the main symbols is shown in Table 1
2.2 Problem definition
In the given system task graph G and under the constraints of system power consumption costs, the main goal of HW/SW partitioning is to reasonably plan the implementation forms of various task modules to achieve optimal overall system performance. The objective is to minimize time cost. Its mathematical model can be expressed in the following equation:
where \(x=(x_1,x_2,\ldots ,x_n)\) indicates a solution of HW/SW partitioning scheme for a system implementation. \(x_i=1(x_i=0)\) denotes that the task node is partitioned to software(hardware). \(s_i\) and \(h_i\) represent the software and hardware costs of task node \(v_i\), respectively. \(C(x_i)\) indicates the communication cost between different nodes, including read/write, storage, and delay of data. R is the constraint condition of the system.
3 Algorithm for HW/SW partition problem
3.1 Overall framework of HW/SW partitioning algorithm
For the HW/SW partitioning problem, first, the NRUP algorithm is used to preprocess the system task graph, and the NRUP partitioning result is used as the initial solution of the two subswarms of HSPSO. Secondly, two subswarms use different learning strategies for algorithm solving and finally, obtain the partitioning result. For the main swarm, an efficient directed sample set(DSS) is proposed to guide the main swarm particles to approach the search area of the optimal solution in the search direction and ensure the diversity of the population. Different from the search method of constructing formula in the main swarm, the secondary swarm adopts a dynamically adjusted learning strategy and improves the update equation. According to the prior information of the previous round, it dynamically adjusts the inertia weight coefficient. When the evaluation index value is improved, it speeds up the search speed and increases a small part of random search ability. When the evaluation index does not improve, it slows down the search speed and increases other search ranges for solution areas. The two subswarms alternate in solving the entire system until termination conditions are met. The complete HSPSO algorithm process is shown in Fig. 2.

Overview of heterogeneous computing system
According to the specific application scenarios of the HW/SW partitioning problem, corresponding objective functions and constraints are set. For example, if the minimum time cost is set as the partitioning target; then, the system time cost is used as the population fitness evaluation value in the corresponding main swarm and secondary swarm for each iteration result evaluation. Although the search process between the main swarm and secondary swarm alternates during the entire algorithm process without involving re-grouping, there is still an information exchange process between the two subswarms. For example, when an individual member of the secondary swarm is closer to the global optimal position, it can provide useful information to construct DSS to guide the search process of the main swarm. In addition, when the main swarm obtains a better solution in the previous round of iteration, it can speed up the search speed of the secondary swarm.
3.2 Node resource urgency partition algorithm
When the number of task nodes in the HW/SW partitioning problem is too large, directly using the solution algorithm to iteratively explore the solution space will result in a long search time and poor result effect. Therefore, this paper designs a node partitioning algorithm based on local resource attributes, which combines the attribute information and objective function of nodes in the system task graph to quickly and efficiently obtain the initial partitioning results of nodes.
3.2.1 Node resource attribute classification
Different task nodes have different structural characteristics due to the variability of their attributes, for example, some nodes require a relatively large area for hardware implementation, while choosing software implementation takes only a relatively short time. Experiments have shown [41] that the attribute characteristics of nodes have a large impact on the classification results, so it is helpful to classify nodes to represent their attribute characteristics for subsequent classification operations, and in this paper, nodes are classified into normal node and extreme node.
An extreme node refers to a task node where the resources consumed by one implementation method are much higher than those consumed by another implementation method. For example, if a node takes up a large area when implemented in hardware but consumes fewer resources when implemented in software, it is called an extreme node. An extremity measure is defined to measure the attributes of a node. The steps for determining extreme nodes and calculating the extremity measure are as follows:
-
1.
Calculate the histogram of software execution time \(s t_i\) and hardware area \(h a_i\) for all nodes of the system task graph.
-
2.
Determine the values of parameters \(\alpha \) and \(\beta \) and calculate their corresponding values \(st(\alpha )\) and \(h\alpha (\beta )\) taken in the histogram.
-
3.
Classify all of the task nodes according to the values of \(st(\alpha )\) and \(ha(\beta )\). If the execution time of node \(v_i\) is bigger than \(st(\alpha )\) and the hardware area is less than \(ha(\beta )\), then, \(v_i\) belongs to the software extreme node, which is recorded as \(v_i\in EX_s\). If the hardware area of node \(v_i\) is bigger than \(ha(\beta )\) and the software execution time is less than \(st(\alpha )\), then, \(v_i\) belongs to the hardware extreme node, which is recorded as \(v_i\in EX_h\). Figure 3 illustrates the judgment process of extreme nodes.
In Fig. 3, The parameters \(\alpha \) and \(\beta \) indicate the percentage of the area of the graph on the left side below the curve to the whole graph. If a node is located to the right of \(st(\alpha )\) in the st histogram and to the left of \(\beta \) in the ha histogram, this node dimension software extreme node, the red curve \(EX_s\) denotes the region of software extreme nodes that satisfy the condition, and similarly \(EX_h\) is the region of hardware extreme nodes that satisfy the condition. The experimental results show that when \(\alpha ,\beta \in \begin{bmatrix}0.5,0.75\end{bmatrix}\), the extreme attributes of the nodes are more pronounced and can be effectively differentiated from ordinary nodes, while nodes beyond this range show that there is not much difference between the soft and hard implementations and can be treated as ordinary nodes.
-
4.
Calculate the extremity measure \(E_i\) of extreme nodes, first determine whether the extreme node is a software extreme node or a hardware extreme node, if \(v_i\in EX_s\), then, \(E_i=\dfrac{st_i/ts_{\text {max}}}{ha_i/ha_{\text {max}}}\), otherwise \(E_i=\dfrac{ha_i/ha_{\text {max}}}{st_i/ts_{\text {max}}}\), and the normalize it:
$$\begin{aligned} E_i&=-0.5\times \dfrac{E_i-E_{\max }}{E_{\max }-E_{\min }},-0.5\le E_i\le 0\left( v_i\in EX_s\right) \nonumber \\ E_i&=0.5\times \dfrac{E_i-E_{\min }}{E_{\max }-E_{\min }},0\le E_i\le 0.5\left( \nu _i\in EX_{h}\right) \end{aligned}$$(2)where \(E_{\textrm{max}}\) and \(E_{\textrm{min}}\) denote the maximum and minimum values of the extremity measure in the set of extreme nodes to which \(v_i\) belongs, respectively.

Judgment of extreme nodes
3.2.2 Node resource urgency
During the hardware and software partitioning process, the mapping domain of nodes is determined according to the objective function of system implementation. Commonly used objective functions are usually the shortest execution time or the lowest system cost. Choosing the shortest execution time as the objective function results in a partition with the least execution time but possibly higher system costs. Choosing the lowest system cost as the objective function may result in time constraints not being met. Therefore, it is necessary to dynamically adjust the objective function and select an appropriate mapping target for each task node according to the resource status under the current state of the system in order to obtain a compromise design scheme for time and cost and overcome the shortcomings of fixed partitioning objectives.
The system objective function is usually related to the execution time and HW/SW area in the constraint conditions. Therefore, this paper defines Global Time Criticality (GTC), Hardware Area Criticality (HAC), and Software Area Criticality (SAC), which represent the degree of tension of system time and hardware and software area resources, respectively. \(V_u\) represents the set of unpartitioned nodes, \(AH_{remain}\) represents the remaining available hardware area that can be dominated, and \(AS_{remain}\) represents the remaining available software area that can be dominated. Their definitions are as follows:
The GTC is calculated as follows:
-
1.
Calculate the remaining available time \(T_{remain}\) under the condition of satisfying the system time constraints.
-
2.
Map all unpartitioned nodes to the software domain to obtain the final completion time \(T^S_{finish}\) of the system.
-
3.
Compare the values of \(T^S_{finish}\) and \(T_remain\). If \(T^S_{finish}>T_{remain}\), some nodes need to be moved to the hardware domain. All unpartitioned nodes are sorted in descending order according to the ratio of \({st_i}/{ht_i}\). Nodes with larger ratios are moved to the hardware domain first. The nodes that are moved from the software domain to the hardware domain are denoted as \(V_{SH}\) so that \(T^S_{finish}<T_{remain}\) is satisfied.
The calculation process of HAC and SAC is similar to that of GTC. According to the above methods of resource urgency and node classification, for the entire system task graph inputted, define the set of unpartitioned nodes as \(V_U\) and the set of partitioned nodes as \(V_M\). The set of nodes in \(V_U\) hat are successors of all nodes in \(V_M\) is denoted as the ready node set \(V_R\). \(M_i\) is defined as the mapping domain of node \(v_i\). When \(M_i=0\), it means that the node is mapped to the hardware domain. \(t_i\) represents the start time of node \(v_i\). The initial value of \(V_U\) is V, the initial value of \(V_M\) is \(\emptyset \), and the initial value of \(V_R\) is the source node. The Node resource urgency partition algorithm process is given as follows.

In the entire algorithm process, how to select the nodes that need to be mapped from the ready node set has an important impact on the final partitioning result. In order to meet the time constraint conditions, select the ready nodes on the longest path in sequence for partitioning. Specifically, it is represented as a path from the source node to the sink node in the task graph. The length of the path is the sum of all node running times on the path. Step 3 calculates the effective execution time of nodes in preparation for step 4’s calculation of the longest path of system task graph. The longest path contains both mapped and unmapped nodes. For unmapped nodes, their value is taken as the average of software and hardware execution times.
The key is how to adjust the mapping target of nodes using resource urgency and local attributes. The most important constraint condition for the partitioning problem in this paper is time constraint. Therefore, when the algorithm performs node mapping, it needs to compare GTC with a threshold TH. If \(GTC>TH\), it means that the remaining time resources of the system are tight and choose the shortest time as the objective function. Otherwise, choose the minimum hardware area occupation as the objective function. At the same time, it is necessary to determine whether the current node is an extreme node and modify the threshold according to the attribute properties of nodes rather than being unchanged. Therefore, step 10 adjusts TH based on extreme attribute values of current nodes.
3.3 Improved HSPSO learning strategy
3.3.1 Overview of proposed HSPSO partition algorithm
To address the issue of unsatisfactory results in solving large-scale system task graph partitioning problems, this paper proposes an improved HSPSO partitioning algorithm. On the one hand, DSS is constructed by introducing perturbed particles to improve the update equation for the main swarm’s learning strategy. On the other hand, the learning strategy for the sub-swarm is adjusted based on the information obtained from the iterative results.
3.3.2 Improved main swarm learning strategies
Based on the framework of HSPSO [42], an improved method for the main swarm learning strategy was proposed to enhance the population diversity of HSPSO. Some existing variants of PSO are prone to premature convergence due to slow updates of individual particles and historical best positions of populations during iteration. This paper proposes a new method for constructing a directed sample set to optimize the main swarm search process. Unlike some existing methods [43,44,45] that select most candidate results as a sample set for construction, DSS selects two particles closest to the historical best position and one randomly perturbed particle to construct directed sample set \(E^U\). The positional information of these two particles contains more directional search information than other particles and improves search efficiency. Adding random perturbation particles can increase global search capabilities and prevent falling into local optima.
Suppose there are n particles in the original population of HSPSO searching for the optimal solution in the D-dimensional target search space, the velocity of the i-th particle is \(V_i=\{v_{i1},v_{i2},\ldots ,v_{iD}\}\), its current position is \(X_i=\{x_{i1},x_{i2},\ldots ,x_{iD}\}\), and its best experienced position is \(P_i=\{p_{i1},p_{i2},\ldots ,p_{iD}\}\), the set \(\chi =\{\chi _1,\chi _2,\ldots ,\chi _n\}\) is defined as the Euclidean distance between all particles and their optimal positions. The distance calculation is shown in Eq. (4):
After obtaining the Euclidean distance of all particles by Eq. (4), the set \(\chi \) is sorted in ascending order to obtain the sorted set \(\chi _{sort}=\{\chi _{sort1},\chi _{sort2},\ldots ,\chi _{sortD}\}\). Let \(\lambda ^1\) and \(\lambda ^2\) represent the particle index sequences of \(\chi _{sort1}\) and \(\chi _{sort2}\), respectively, that is \(\lambda _i=\left\{ \chi _{sorti}\in \chi _{xort}|i\in [1,2]\right\} \). Let \(\lambda ^3\) denote a randomly perturbed particle with its position information denoted as \(P_{\lambda ^3}\). The expression for the directed sample set \(E_d^U\) in the d-th dimension is as follows:
where \(p_{\lambda ^{i}d}(i=1,2)\) denotes the direction information of the two particles closest to the best position about the d-th dimension, \(r_{\lambda ^i}\in \begin{bmatrix}0,1\end{bmatrix}\begin{pmatrix}i=1,2\end{pmatrix}\) and \(r_{\lambda ^3}\in \begin{bmatrix}0,0.5\end{bmatrix}\) belong to the weight coefficients controlling the three key particles, and the effective search direction of \(E_d^U\) is closely related to the first two weight coefficients, and the global search capability can be improved by adjusting the third weight coefficient to prevent the search process from falling into the local optimal solution situation.
In addition, compared to the traditional method of updating particle velocity and position based on the global best position of the particle swarm, this paper proposes a new method for updating particle velocity and position based on a directed sample set to guide the search process of the main swarm particles in HSPSO. For the i-th individual in the particle swarm, the d-th dimensional component of its velocity and position update equation is as follows:
where \(\partial \) is a constraint factor to prevent particle population explosion, \(r\in \begin{bmatrix}0,1\end{bmatrix}\) is a random uniformly distributed weight factor, k is the number of iterations, and the main swarm searching algorithm as follows:

In the entire algorithmic process, the position information of the particles must first be discretized to meet the requirements of HW/SW partitioning. After each iteration updates the particle velocity and position information, the particles are judged according to the constraint conditions of the system task graph. If they meet the constraint conditions, they continue to update and define \(f(X_i)\) as the individual fitness of particle i. In each iteration process, compare new results with individual optimal positions and global optimal positions, if the former solution is better, update and replace it, at the same time, a new dynamic learning strategy is introduced to update particle velocity and position information. By adjusting weight coefficients to explore solution space, if \(r_{\lambda ^3}\) is set relatively large, it focuses more on global solution space exploration capabilities, and vice versa, it explores surrounding solution space based on \(P_g\).
3.4 Improved sub-swarm learning strategy
Different from the main swarm which adopts the DSS method to guide particle search in the iterative process, the sub-swarm uses an adaptive and dynamically adjusting learning strategy. Based on the previous iteration results and search status, the inertia weight in the update equation of all particles is adjusted, making their search more precise and efficient.
Compared with the main swarm, the learning strategy of the secondary swarm pays more attention to the dependence on the global optimal position. Define state variable \(\delta \in \{0,1\}\) for the result of previous iteration. When \(\delta =1\), it means that \(f(P_g)\) and \(P_g\) were optimized in previous iteration. It is only necessary to prevent all HSPSO particles from searching in same search range. Therefore, an inertia weight is added to improve exploration ability of secondary swarm in solution space. For each particle in secondary swarm at i-th generation, its velocity update equation for d-th dimension is as follows:
With respect to the added inertia weights \(c_0\), defining \(c_{max}\) and \(c_{min}\) as the maximum and minimum inertia weight values for all secondary swarm particles, respectively, \(P_{gd}\) denotes the optimal position of the particle in d-th dimension. \(\varepsilon _{min}\) and \(\varepsilon _{max}\) are, respectively, the maximum and minimum fitness evaluation numbers allocated for the HSPSO; \(c_0\) is defined as follows:
When \(\delta =1\), it means that no optimization was achieved in previous iteration. It may have fallen into local optimum. In order to prevent other particles from continuing to search in this area during subsequent iteration process, inertia coefficient weight in particle velocity update equation can be reduced linearly [46, 47]. At the same time, in order to reduce the impact of unoptimized results on subsequent secondary swarm particles, according to reference [48, 49], let \(c_1=c_2=1\), then, update equation and newly added inertia weight expression are as follows:
From Eq. (10), it can be analyzed that the decrease in inertia weights \(c_0\) and \(c_1\) reduces the dependence of subsequent particles on their own best position \(P_i\) and global best position \(P_g\) during search process. This avoids the impact of falling into local optimum and increases the range of selectable search. At the same time, the decrease in \(c_0\) weight reduces particle search speed to prevent the premature fitting and provide more opportunities for search. The algorithm process of the entire sub-swarm is shown in the Algorithm 3.

4 Results and discussion
4.1 Introduction of experiment
The algorithm proposed in this paper is compared with several heuristic partitioning algorithms currently proposed [27, 50]. These include the position disturbed particle swarm optimization (PDPSO) algorithm that simulates animal behavior to improve particle swarm search and a heuristic memory-reinforced tabu search algorithm with critical path awareness(HAMTS). Traditional PSO and GA algorithms are used as benchmark algorithms in the HW/SW partitioning domain. Most comparisons are generated through task graph for free(TGFF) tool to produce random task graphs with specified parameter ranges [51]. In order to make a fair comparison, the experiment uses the same type of task graph as used in [52]. The experimental environment is: CPU: i5-7300HQ @ 2.50 GHz; physical memory: 8GB; software: PyCharm 2021.
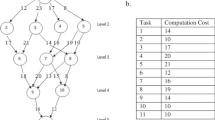
In the experiment, the system task graph was generated using the open-source tool TGFF. Parameters such as the number of nodes in the system task graph, software execution time, hardware execution time, communication overhead and hardware area need to be set in the experiment. Figure 4 shows a simple schematic diagram with 11 tasks.

Overview of heterogeneous computing system
Each node contains three pieces of information, which are hardware execution time, software execution time and hardware area, and the weight on the connection between two adjacent nodes is the communication overhead. This experiment uses the same HW/SW partitioning parameters as in the literature [50], which are shown in the following Table 2.
In the task graph, the hardware and software execution time of each node follows a random uniform distribution within the value range. According to the communication-to-computation ratio (CCR), the value range of (A) is the computation-intensive task, denoted as CCR_L. The value range of (B) is the communication-intensive task, denoted as CCR_H. Experiments were conducted on the proposed algorithm based on two different types of system task graphs.
Considering that the hardware resources in the system are limited, it is necessary to constrain the hardware area. Assuming that the hardware area required by a task node i is \(\alpha _i\), let A be the total area of all task nodes executing in hardware in the hardware/software partitioning. Considering the constraint of hardware area, let \(A=\beta \cdot \sum \alpha _i\). The coefficient \(\beta \in \begin{bmatrix}0,100\%\end{bmatrix}\) can be adjusted to simulate the constraint of hardware area in practical applications.
In order to compare the test performance of different HW/SW partitioning algorithms, the algorithm acceleration ratio (AR) and improvement degree (IMP) are usually chosen as two indicators to measure the quality of the algorithm. Assuming that all tasks in the system are implemented by software and the initial solution is \(x=[1,1,\ldots ,1]\), and the optimal solution obtained by the algorithm is denoted as \(x_{best}=[x_1,x_2,\ldots ,x_D]\). The acceleration ratio of the algorithm is the ratio of the maximum time overhead of the system to the total time of tasks under a given partitioning label by a partitioning algorithm. The specific expression is shown in Eq. (11).
Defining A and B as two HW/SW partitioning algorithms, respectively, the IMP of algorithm A with respect to algorithm B can be defined as follows:
4.2 Experiment result
Firstly, tests were conducted on computation-intensive and communication-intensive task graphs. The hardware constraint coefficient \(\beta \) was set to 0.7. The inertia coefficient \(\omega \) of the PSO was set to 1.2, with a learning factor of \(c_1=c_2=1\). The population size of the GA was initially set to 100, the crossover probability \(P_c\) was set to 0.6, and the mutation probability \(P_m\) was set to 0.01. The parameters for the PDPSO were set as follows: \(c_1=c_2=1.5\), \(c_3=0.75\), \(epsx=1\). The number of iterations for HAMTS was chosen to be 600. The parameters for the proposed algorithm in this paper were set as \(\alpha =\beta =0.6\), \(\sigma =0.7\), \(r_{\lambda ^1}=r_{\lambda ^2}=1\), \(r_{\lambda ^3}=0.3\). The experimental results are shown in the following figure:

Comparison of AR
Figure 5 shows the test results in an average of 100 instances of different algorithms; it can be seen that in the computation-intensive system task graph, when the number of task nodes is small; the AR results of other algorithms except for the GA are relatively close. This indicates that they can almost all search for the global optimal solution. As the number of nodes in the system task graph increases, the AR of the other four types of algorithms gradually decreases and their global search capabilities deteriorate. However, the HSPSO can still maintain good global search capabilities even as problem size increases and keep its AR stable at around 1.8. Its AR results are significantly better than other algorithms.
When the system task graph type is communication-intensive, it indicates that data take more time to pass between nodes and less time to be processed at nodes, communication overhead between nodes significantly affects overall time cost and communication time between different nodes also has a direct impact on final AR results. From Fig. 5, it can be seen that all algorithm’s AR results have decreased significantly.
The basic principle of the HSPSO in this paper is derived from the PSO algorithm, so this paper uses the PSO as the benchmark test algorithm to compare the degree of improvement of the PDPSO and HAMTS for the original PSO algorithm on two types of task graph data sets, and also to test the improvement effect of the algorithm after initialization with the NRUP algorithm, the specific experimental results are shown in Fig. 6.

The comparison of IMP
In Fig. 6, As the scale of node tasks increases, the IMP of HSPSO algorithm over the original PSO algorithm becomes greater. When the number of nodes exceeds 400, the IMP of HSPSO stabilizes at around 23.6\(\%\). The IMP for PDPSO is around 10\(\%\), and for HAMTS algorithm, it is around 5\(\%\). In Fig. 6b, Due to the influence of communication overhead between nodes, when there are fewer nodes, the proportion of communication overhead will be larger. Therefore, when node count is less than 200, the IMP over baseline algorithms is less than 10\(\%\). As node count increases and proportion occupied by communication overhead decreases, improved HSPSO’s IMP over original PSO algorithm can stabilize at around 15\(\%\), higher than other two improved algorithms. After using NRUP for initialization, HSPSO performance has been significantly improved in both types of system task graph models. This indicates that initial solution from NRUP combined with DSS construction method can improve particle swarm’s exploration ability toward optimal solution area and effectively guide particle swarm’s search direction.
In addition to the influence of system task graph type on algorithm performance, hardware area constraints will also directly affect algorithm’s solution results. For proposed HSPSO, the IMP comparison experiments were conducted according to different hardware area constraint coefficients. Specific experimental results are shown in Fig. 7.

Comparison of hardware constraint coefficient
As shown in Fig. 7, with the number of task nodes increases, algorithm’s IMP under any hardware area constraint condition generally tends to stabilize. When \(\beta =0.1\) and \(\beta =0.9\), algorithm’s IMP in both sets of experimental results is significantly lower than other constraint conditions. This is because when constraint conditions are too extreme, solution space range also significantly shrinks and baseline algorithms can also find optimal or suboptimal solutions. Therefore, when node count is low, the IMP is only 6–8%. As node count increases, algorithm’s IMP also increases. When value of \(\beta \) makes ratio between software and hardware choices close, solution space increases and HSPSO’s global search capability can be reflected.
In order to explore the improvement of the initialization of NRUP algorithm on the search time of HSPSO, the hardware area constraint factor is set to 0.7, and the comparison experiments are conducted for the solution time of HSPSO without initialized solution and HSPSO algorithm with increased initialization result of NRUP for different number of nodes, and the experimental results are shown in Fig. 8.

Comparison of search time
In Fig. 8, when system task graph has fewer nodes, NRUP algorithm providing initial solution does not significantly shorten HSPSO’s search time. This indicates that when solution space is small, algorithm itself has efficient and fast search capability. On one hand, DSS method reduces search time loss brought by many invalid direction information and on the other hand, global search capability is improved due to different learning strategies and information sharing between main swarm and secondary swarm. After node count exceeds 200, algorithm’s search time after NRUP initialization is significantly less than uninitialized time. This indicates that after solution space, range becomes larger an effective initial solution can shorten search time. It is also not difficult to see that system task graph type does not have significant impact on algorithm’s search time.
5 Conclusions and future work
To address the issue of inefficiency of existing partitioning algorithms in large-scale HW/SW partitioning, this paper proposed an HSPSO partitioning algorithm based on node resource attributes. The NRUP algorithm serves to initialize the main and secondary swarms of particles in HSPSO, while different learning strategies are adopted to iteratively optimize and derive the final partitioning outcome. An initialization approach that amalgamates node attribute information is designed to facilitate the preliminary partitioning of system task graph nodes. Based on this, distinct learning strategies are employed for the main and secondary swarms. A novel sample construction method is proposed for the main swarm, and it selects the optimum particle position information to guide all designated particles toward the anticipated region, while random particles are introduced to prevent falling into local optimal solutions. In the secondary swarm, a fresh inertia weight and velocity update equation are formulated based on the information outcomes from preceding rounds of iteration. According to the experimental results, when the number of nodes exceeds 400, the NRUP initialization algorithm efficaciously saves the partitioning timeframe of the entire algorithm while enhancing performance by at least 5% compared to uninitialized algorithms. Furthermore, when dealing with large-scale issues, the proposed algorithm exhibits significantly greater AR and IMP than mainstream algorithms. Additionally, its partitioning solutions prove to be more stable, providing effective solutions for increasingly complex system designs and augmenting the efficiency of HW/SW co-design.
Although good partitioning results have been achieved compared to some current partitioning algorithms, there are still several areas worth further research. Firstly, for partitioning algorithm search acceleration problem, this paper’s algorithm can be improved by combining parallel acceleration ideas to further shorten optimization when data scale expands. Secondly, with the proposal and widespread application of many optimization methods in other fields, this paper’s algorithm can be combined with time scheduling methods to be extended and applied in more complex HW/SW partitioning problems such as multi-processor system-on-a-chip(MPSoC) and High-level-synthesis(HLS).
References
Becker S, Cevher V, et al (2014) Convex optimization for big data. IEEE Signal Processing Magazine
Shalf J (2020) The future of computing beyond Moore’s law. Philos Trans R Soc A: Math Phys Eng Sci, 1–15
Silva TW, Morais et al (2018) Environment for integration of distributed heterogeneous computing systems. J Internet Serv Appl 1
Trappey, CAJ, Shen W, et al (2016) Special issue editorial on advances in collaborative systems engineering for product design, production and service network(editorial). J Syst Sci Syst Eng, 139–141
Yan X, He F, Hou N, et al (2017) An efficient particle swarm optimization for large-scale hardware/software co-design system. Int J Cooperative Inf Syst, 1792001
Jiang G, Wu J, Lam SK et al (2015) Algorithmic aspects of graph reduction for hardware/software partitioning. J Supercomput 71:2251–2274
Wu J, Sun Q, Srikanthan T (2012) Algorithmic aspects for multiple-choice hardware/software partitioning. Comput Oper Res 39(12):3281–3292
Arató P, Mann ZA, Orbán A (2005) Algorithmic aspects of hardware/software partitioning. ACM Trans Des Autom Electron Syst 10(1):136–156
Wu J, Srikanthan T (2006) Low-complex dynamic programming algorithm for hardware/software partitioning. Inf Process Lett 98(2):41–46
Zhu F et al (2015) Computing model and dynamic programming algorithm for multiple-choice hardware/software partitioning on MPSoC. Comput Eng Sci 37(04):641
Zhai Q, He Y, Wang G et al (2021) A general approach to solving hardware and software partitioning problem based on evolutionary algorithms. Adv Eng Softw 159:102998
Mourad K, Boudour R (2021) A modified binary firefly algorithm to solve hardware/software partitioning problem. Informatica 45(7)
Song S, Varshika ML, Das A, et al (2021) A design flow for mapping spiking neural networks to many-core neuromorphic hardware. In: 2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD), IEEE, pp 1–9
Wiangtong T, Cheung PY, Luk W (2002) Comparing three heuristic search methods for functional partitioning in hardware-software codesign. Des Autom Embed Syst 6:425–449
Purnaprajna M, Reformat M, Pedrycz W (2007) Genetic algorithms for hardware-software partitioning and optimal resource allocation. J Syst Architect 53(7):339–354
Halim ZA, Babu BS, Mustaffa M (2020) Hardware software partitioning using four levels hybrid algorithm technique. In: 2020 IEEE 10th Symposium on Computer Applications and Industrial Electronics (ISCAIE), IEEE, pp 42–47
Li SG, Feng FJ, Hu HJ et al (2014) Hardware/software partitioning algorithm based on genetic algorithm. J Comput 9(6):1309–1315
Hou N, He F, Zhou Y et al (2017) A gpu-based tabu search for very large hardware/software partitioning with limited resource usage. J Adv Mech Des Syst Manuf 11(5):JAMDSM0060–JAMDSM0060
Hou N, He F, Zhou Y et al (2020) An efficient gpu-based parallel tabu search algorithm for hardware/software co-design. Front Comput Sci 14:1–18
Abdelhalim MB, Habib SED (2011) An integrated high-level hardware/software partitioning methodology. Des Autom Embed Syst 15:19–50
Rahamneh S, Fong A, Sawalha L (2021) A comparison of different optimization algorithms for hw/sw partitioning using a high-performance cluster. In: 2021 IEEE/ACS 18th International Conference on Computer Systems and Applications (AICCSA), IEEE, pp 1–8
Jing Y, Kuang J, Du J, et al (2014) Application of improved simulated annealing optimization algorithms in hardware/software partitioning of the reconfigurable system-on-chip. In: Parallel Computational Fluid Dynamics: 25th International Conference, ParCFD 2013, Changsha, China, May 20–24, 2013. Revised Selected Papers 25, Springer, pp 532–540
Abdelhalim M, Salama A, Habib SD (2006a) Hardware software partitioning using particle swarm optimization technique. In: 2006 6th International Workshop on System on Chip for Real Time Applications, IEEE, pp 189–194
Abdelhalim M, Salama A, Habib SD (2006b) Hardware software partitioning using particle swarm optimization technique. In: 2006 6th International Workshop on System on Chip for Real Time Applications, IEEE, pp 189–194
Bhattacharya A, Konar A, Das S, et al (2008) Hardware software partitioning problem in embedded system design using particle swarm optimization algorithm. In: 2008 International Conference on Complex, Intelligent and Software Intensive Systems, IEEE, pp 171–176
Eimuri T, Salehi S (2010) Using dpso and b &b algorithms for hardware/software partitioning in co-design. In: 2010 Second International Conference on Computer Research and Development, IEEE, pp 416–420
Yan XH, He FZ, Chen YL (2017) A novel hardware/software partitioning method based on position disturbed particle swarm optimization with invasive weed optimization. J Comput Sci Technol 32:340–355
López-Vallejo M, López JC (2003) On the hardware-software partitioning problem: system modeling and partitioning techniques. ACM Trans Des Autom Electron Syst 8(3):269–297
Baumgart A, Reinkemeier P, Rettberg A, et al (2010) A model—based design methodology with contracts to enhance the development process of safety–critical systems. In: Software Technologies for Embedded and Ubiquitous Systems: 8th IFIP WG 10.2 International Workshop, SEUS 2010, Waidhofen/Ybbs, Austria, October 13–15, 2010. Proceedings 8, Springer, pp 59–70
Gamatié A, Gautier T, Guernic PL et al (2007) Polychronous design of embedded real-time applications. ACM Trans Softw Eng Methodol 16(2):9-es
Lee EA, et al (2001) Computing for embedded systems. In: IEEE Instrumentation and Measurement Technology Conference Proceedings, IEEE; 1999, pp 1830–1837
Mao J, Cassandras CG (2009) Optimal control of multi-stage discrete event systems with real-time constraints. IEEE Trans Autom Control 54(1):108–123
Dunbar C, Qu G (2014) Designing trusted embedded systems from finite state machines. ACM Trans Embed Comput Syst 13(5s):1–20
Ben-Ari M, Mondada F, Ben-Ari M, et al (2018) Finite state machines. Elements of Robotics, 55–61
Asghari SA, Marvasti MB, Daneshtalab M (2020) A software implemented comprehensive soft error detection method for embedded systems. Microprocess Microsyst 77:103161
Varea M, Al-Hashimi BM, Cortés LA et al (2006) Dual flow nets: modeling the control/data-flow relation in embedded systems. ACM Trans Embed Comput Syst 5(1):54–81
Xie Y, Wolf W (2001) Allocation and scheduling of conditional task graph in hardware/software co-synthesis. In: Proceedings Design, Automation and Test in Europe. Conference and Exhibition 2001, IEEE, pp 620–625
Khan MA (2012) Scheduling for heterogeneous systems using constrained critical paths. Parallel Comput 38(4–5):175–193
Zhijun W, Haolin M, Meng Y (2021) Reliability assessment model of IMA partition software using stochastic Petri nets. IEEE Access 9:25219–25232
Xia C, Li C (2020) Property preservation of petri synthesis net based representation for embedded systems. IEEE/CAA J Autom Sin 8(4):905–915
Kalavade AP (1995) System-level codesign of mixed hardware-software systems. PhD thesis, University of California, Berkeley
Karim AA, Isa NAM, Lim WH (2021) Hovering swarm particle swarm optimization. IEEE Access 9:115719–115749
Zhao X, Zhou Y, Xiang Y (2019) A grouping particle swarm optimizer. Appl Intell 49:2862–2873
Roshanzamir M, Balafar MA, Razavi SN (2020) A new hierarchical multi group particle swarm optimization with different task allocations inspired by holonic multi agent systems. Expert Syst Appl 149:113292
Xu G, Cui Q, Shi X et al (2019) Particle swarm optimization based on dimensional learning strategy. Swarm Evol Comput 45:33–51
Xia X, Gui L, He G et al (2020) An expanded particle swarm optimization based on multi-exemplar and forgetting ability. Inf Sci 508:105–120
Damaj I, Elshafei M, El-Abd M et al (2020) An analytical framework for high-speed hardware particle swarm optimization. Microprocess Microsyst 72:102949
Juang CF, Chang YC (2011) Evolutionary-group-based particle-swarm-optimized fuzzy controller with application to mobile-robot navigation in unknown environments. IEEE Trans Fuzzy Syst 19(2):379–392
Juang CF (2004) A hybrid of genetic algorithm and particle swarm optimization for recurrent network design. IEEE Trans Syst Man Cybern Part B (Cybernetics) 34(2):997–1006
Guo Z, Zhang X, Zhao B (2019) A memory-reinforced tabu search algorithm with critical path awareness for hw/sw partitioning on reconfigurable mpsocs. IEEE Access 7:112448–112458
Dick RP, Rhodes DL, Wolf W (1998) Tgff: task graphs for free. In: Proceedings of the Sixth International Workshop on Hardware/Software Codesign.(CODES/CASHE’98), IEEE, pp 97–101
Jigang W, Srikanthan T, Jiao T (2008) Algorithmic aspects for functional partitioning and scheduling in hardware/software co-design. Des Autom Embed Syst 12:345–375
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Contributions
S.D. was contributed to conceptualization, methodology, software, writing—original draft preparation, writing—review and editing. S.X. was contributed to conceptualization, data curation, supervision, software, writing—review and editing. Q.D. was contributed to formal analysis, investigation, writing—review and editing. H.L. was contributed to validation, writing—review and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interests to this work.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Deng, S., Xiao, S., Deng, Q. et al. A hovering swarm particle swarm optimization algorithm based on node resource attributes for hardware/software partitioning. J Supercomput 80, 4625–4647 (2024). https://doi.org/10.1007/s11227-023-05603-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-023-05603-7