
Abstract
In many fields, it is a common practice to collect large amounts of data characterized by a high number of features. These datasets are at the core of modern applications of supervised machine learning, where the goal is to create an automatic classifier for newly presented data. However, it is well known that the presence of irrelevant features in a dataset can make the learning phase harder and, most importantly, can lead to suboptimal classifiers. Consequently, it is becoming increasingly important to be able to select the right subset of features. Traditionally, optimization metaheuristics have been used with success in the task of feature selection. However, many of the approaches presented in the literature are not applicable to datasets with thousands of features because of the poor scalability of optimization algorithms. In this article, we address the problem using a cooperative coevolutionary approach based on differential evolution. In the proposed algorithm, parallelized for execution on shared-memory architectures, a suitable strategy for reducing the dimensionality of the search space and adjusting the population size during the optimization results in significant performance improvements. A numerical investigation on some high-dimensional and medium-dimensional datasets shows that, in most cases, the proposed approach can achieve higher classification performance than other state-of-the-art methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the current Big Data era, large datasets containing a high number of samples and features describing phenomena of interest are common in a variety of fields and applications, including health care, cybersecurity, social media and online purchases, satellite and earth observations, vehicle sensors for urban traffic monitoring, crowd monitoring, smart buildings, and a multitude of Internet of Things applications.
The availability of huge amount of data and sampled features, along with the increased research efforts in data science, has resulted in the recent remarkable advances in supervised machine learning (ML), with several well-known successful applications in the commercial and industrial arenas. Roughly speaking, the purpose of supervised ML is to automatically construct a model from a set of labeled data, i.e., from samples in which inputs (representing relevant features of the phenomenon being observed) match with the desired outputs. After a learning phase, the ML model can perform predictive tasks, that is, predict the correct output based on an input sample.
In the increasingly frequent cases of datasets characterized by thousands of features, the learning phase can be negatively influenced by the presence of numerous irrelevant features, that is, features that are not useful to the construction of the model but that rather slow down the learning, sometimes leading to results that are less satisfactory than one could expect and to a potential waste of computational resources, both in terms of training time, which inevitably increases as the feature space dimensionality increases, and storage space.
In addition, it is important to mention the negative impact that a large number of irrelevant features can have on the interpretability of ML models. Sometimes, in fact, the objective is not only to predict accurately, but also to gain information on the mechanisms affecting the outcome. In these cases, a simpler model can be much more appealing, as it provides a smaller set of features that can be the object of further investigation.
For the reasons outlined above, a preprocessing phase of Feature Selection (FS) is typically carried out to find a subset of the available features that maximize one or more performance measures (e.g., classification accuracy). In practice, FS is a hard combinatorial optimization problem given that the number of non-empty subsets of a set of n features is \(2^n-1\). This makes unfeasible to select the optimal features using an exhaustive method for a high-dimensional dataset.
According to the literature, a wide variety of search algorithms have been successfully used for tackling the FS problem [19,20,21, 42, 43, 47]. However, most of the ordinary optimization approaches are characterized by a rapid deterioration of the search efficiency as the dimensionality of the search space increases. This represents a serious issue considering that the typical number of features characterizing some of the recent datasets can easily exceed many thousands. For this reason, it is worth investigating optimization metaheuristics that proved particularly effective in case of large-scale optimization, trying to tailor them for the specific task of FS. Cooperative coevolution (CC) [32], a well-known divide-and-conquer strategy, is one of the approaches often adopted for large-scale optimization and has been already investigated in some FS applications [2, 9, 10, 37, 38]. In a CC algorithm, the search space is decomposed into lower dimensional subcomponents, and the optimization problem is solved individually within each of them. During the process, each subcomponent collaborates to build a complete solution in the original search space [33]. According to the literature, several design details, such as the collaboration method and the strategy used for decomposing the problem, can have a significant impact on the performance of a CC optimizer [8, 49]. Interestingly, the CC technique enables a natural data-parallel approach, given that the subcomponents can be evolved independently with only periodical exchange of information [7].
In this paper, we present a CC algorithm, based on an adaptive version of differential evolution (DE), and equipped with some specific adaptive strategies that enhance its effectiveness for the FS task. As shown in the following, in the proposed approach, both the dimensionality of the search space and the population size of each subcomponent are adapted during the search process by automatically considering the characteristics of the specific FS problem at hand. In addition, the devised FS algorithm includes a local search (LS) phase, which has proven effective in several large-scale optimization algorithms proposed in the literature [27]. Besides discussing the results of the proposed framework in some well-known benchmark datasets, we investigate the scalability of a data-parallel implementation for shared-memory architectures, based on OpenMP and C++. In brief, the key contributions of the article are:
-
introduction and empirical investigation of a CC algorithm for FS in high-dimensional datasets, based on an adaptive DE endowed with a LS phase;
-
development of an adaptive strategy for both the dimensionality of the search space and the population size of each subcomponent, to enhance the algorithm effectiveness;
-
investigation of the scalability of a data-parallel implementation for shared-memory architectures based on OpenMP and C++;
This article is an extension of the conference paper [11], in comparison with which a more effective search space adaptation strategy, a local search strategy, a much more extended empirical study, and a more effective parallelisation are proposed.
The source code of the developed framework is available for further experiments at: https://github.com/lsgo-metaheuristics/ACCFS.
The article is organized as follows: Sect. 2 frames the proposed contribution in the literature. Section 3 presents the algorithm in detail, including its parallel implementation. Section 4 illustrates the results obtained on two groups of datasets, discussing their comparison with some baseline results from the literature. Finally, Sect. 5 concludes the paper with some comments and hypotheses for future work.
2 Literature review
Every FS process includes a generation procedure, which is basically a search algorithm, and an evaluation function that evaluates the quality of the generated subsets of features in order to guide the search [6, 54]. The typical direct aim of the FS process is to maximize the classification accuracy while minimizing the number of involved features. On the basis of the adopted evaluation function, FS algorithms are traditionally categorized into filter and wrapper approaches [15]. In the first case, only the intrinsic characteristic of training data is exploited, regardless of the machine learning algorithm that will be used with that data. In the second category, learning algorithms are explicitly involved in the evaluation function.
By explicitly involving the target learning algorithm, wrapper methods tend to perform better than filter methods at the cost of greater computational requirements. On the other hand, filter methods can be considered more general, being independent from a particular type of classifier, and less computational demanding. Therefore, it is not surprising that in the literature, also some examples of hybrid approaches have been investigated [17, 47].
It is also worth noting that some researchers consider the further FS category of embedded methods, in which the selection of the best subset of features is performed during the training of classifiers [54].
As for the generation procedure, according to the literature, a variety of heuristic search techniques have been applied to FS. Among the most well-known methods, there are the sequential forward selection (SFS) [50] and backward FS methods [24]. A major problem with such methods is the fact that once added/removed, a feature is not further considered for removal/addition in spite of the fact that feature interaction is very common for many applications. However, search techniques dealing with this issue have been developed, such as the sequential forward floating selection and sequential backward floating selection [35].
Not surprisingly, given the nature of the problem that can give rise to large and complex search spaces, the use of population-based optimization metaheuristics for tackling FS has been also extensively investigated. Among the many such studies, there are applications based on genetic algorithms (GA) [19, 43], ant colony optimization [20, 42], particle swarm optimization (PSO) [22, 23, 48], differential evolution (DE) [21, 45], and several others. However, in spite of the relevance of the problem, only recently metaheuristics have been applied with some success to FS for high-dimensional datasets [13, 14, 37, 38, 46,47,48]. Among the most recent works addressing high-dimensional datasets with population-based metaheuristics, it is worth mentioning the use of PSO in [22], where a strategy for gradually reducing the search space during the evolutionary process was adopted. The approach consisted of periodically eliminating from the search space all the features not used at that moment by the personal bests in the swarm. Another relevant recent work on high-dimensional FS was presented in [48], where a variable-length PSO representation enabled the use of smaller search space and, therefore, improved the search performance. Some other work used the CC approach. For example in [38], the authors studied a variable-size CC PSO algorithm for FS based on a space division strategy based on the feature importance along with an adaptive adjustment mechanism of subswarm size with the purpose of saving computational cost. Another recent FS algorithm based on the CC approach was recently presented in [37]. In this case, the authors used a GA and some variants of the random grouping approach [57, 58] for dynamically decomposing the search space during the process.
As shown in the following, compared with the approaches mentioned above, the framework proposed in this article enables an effective synergy between search space reduction, population reduction, and the space decomposition characterizing the CC approach, potentially resulting into solutions of better quality. Moreover, we propose a parallel implementation that, depending on the available hardware, can lead to significantly reduced computational costs.
3 The Proposed framework
We formulate the feature selection problem as the maximization of a fitness function \(f(\textbf{x})\) where \(\textbf{x}\) is a bit vector of length n, being n the number of available features. For each bit in \(\textbf{x}\), 1 and 0 denote that the corresponding feature is or is not selected, respectively.
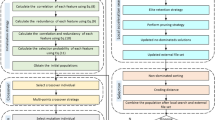
The proposed optimization procedure is based on the divide-and-conquer CC technique proposed by Potter and De Jong in [32], according to which an n-dimensional optimization problem is tackled trough a decomposition into lower dimensional subcomponents. Typically, candidate solutions in each subcomponent are separately evolved using a standard iterative algorithm and fixed values for the variables not included within that subcomponent. Periodically, the fixed values are updated by the subcomponent they represent. In more details, a n-dimensional optimization problem is tackled using the CC approach by partitioning the n-dimensional set of search directions \({G}=\{1,2,\dots ,n\}\) into k sets \(G_1 \dots G_k\), where each group \(G_i\) of directions defines a subcomponent (see Fig. 1). A peculiarity of the approach proposed in this article is that the subcomponents are not constrained to be of equal size as in some other CC optimizers proposed in the literature. Moreover, the size of the optimization problem, the number of subcomponents and the population size are suitably modified during the process.
Typically, the exchange of information between subcomponents is implemented through a common n-dimensional context vector \(\textbf{b}\), which is built using a representative individual provided by each subcomponent. Then, before its evaluation, each candidate solution is complemented through the appropriate elements of \(\textbf{b}\). In this study, the current best individual in each subcomponent is used to represent a subcomponent in the context vector.

Scheme of a decomposition into subcomponents with different sizes. Each row corresponds to an individual. All subcomponents operate on sub-populations with the same number \(n_{ind}\) of individuals. The individuals used for contributing to the context vector are shaded
When applying a CC optimizer, it should be considered that if interdependent variables are statically assigned to different subcomponents, it is more difficult to correctly adjust their values relying only on a periodical access to the context vector [51]. For this reason, in the latest years, suitable decomposition algorithms have been developed for dealing with the case of partially separable and partially overlapping problems [18, 25, 30, 31, 39,40,41, 56], that is, problems in which subsets of interacting variables can be recognized and grouped together. However, such a static decomposition requires a certain level of separability which is often missing in the FS problem, the difficulty of which is related not only to the size of the search space but also to feature interactions (or epistasis [26]) typical of many datasets [15]. In practice, when used together with other complementary features, a feature that seems weakly relevant can improve the classification accuracy significantly. However, it can also happen the opposite, i.e., when used in conjunction with other features, an individually relevant feature may not contribute significantly to the classification accuracy. In the adopted CC optimizer, we use a typical approach to cope with the possible epistatic interaction between variables belonging to different subcomponents, that is, the dynamic grouping strategy called Random Grouping (RG) [57, 58]. The latter consists of a periodic random regrouping of the problem variables into the CC subcomponents, so as to increase the probability of having grouped together two dependent variables during the optimization process [29, 57].
In this study, the evolutionary search algorithm within each subcomponent is based on the Success-History based Adaptive Differential Evolution (SHADE) [44], an adaptive version of the differential evolution (DE) algorithm. More in detail, since SHADE has been designed for continuous optimization, in order to evaluate the corresponding fitness, we use a threshold parameter to convert each individual \(\textbf{y} \in [0,\,1]^n\) of the SHADE population into a bit vector \(\textbf{x}\) (i.e., in this paper, if \(y_j \ge 0.5\) then \(x_j=1\), otherwise \(x_j=0\)).
In order to make the optimization process more efficient, we progressively reduce the size of the search space by eliminating those features that have been persistently excluded from the current candidate solution (i.e., the context vector). In particular, each feature is associated with a counter that is incremented at each CC cycle when that feature is excluded from the current solution, while it is set to zero if the corresponding feature is included. When the counter of a certain feature reaches a fixed threshold that feature is candidate to be permanently removed from the search space for the next CC cycles. In this way, the search algorithm can operate with increasing efficiency during the process due to the reduced size of the search space.
Note that the proposed strategy is similar to the search space reduction strategy named dynamic bits masking recently proposed in [22] for enhancing PSO. However, in the application of the present study, the search space reduction has the additional beneficial effect of increasing the probability of interacting features to be grouped in the same subcomponent, with a consequent better exploitation of the CC approach and related improvement of the convergence speed. Moreover, as detailed later, in order to avoid the risk of eliminating by chance a feature that may result useful in the subsequent stages of the optimization, we take two precautions.
-
The first is to avoid permanently excluding features that have a Permutation Feature Importance (PFI) [3, 12] above a certain threshold. PFI is defined as the deterioration in performance of the classifier when the corresponding feature value is randomly shuffled in the dataset. In the present study, we compute before the FS process a vector \(\textbf{pfi}\), the i-th component of which is the difference between the fitness \(f_0\) based on the original set of training instances \(\mathcal{D}_{tr}\), using a threefold cross-validation scheme, and the fitness \(\hat{f}_i\) determined after a random shuffling of the i-th feature in \(\mathcal{D}_{tr}\). Note that, due to the fact that PFI reflects how potentially relevant a feature is for the used model (KNN in this study), it is also employed in the proposed algorithm to bias the LS phase, as detailed below.
-
The second is to check, before a permanent exclusion, that the feature cannot increase the fitness of the current solution.
In this way, the search space reduction strategy is more conservative than that proposed in other recent works and, according to our experiments, leads to more stable and better quality solutions for some datasets. It is worth noting that not deleting a feature from the search space does not imply that it will actually be included in the final solution.

The CC FS procedure adopted in this study is outlined in Algorithm 1. The fitness of each candidate solution is computed by the function f using the already mentioned set \(\mathcal{D}_{tr}\) of training instances with features normalized in [0, 1]. Besides some algorithm parameters, another relevant input is represented by the \(\textbf{pfi}\) vector, each component of which represents a precomputed value of PFI.
As shown in Algorithm 1, after initializing the initial set \(\mathcal V\) of coordinates, the next steps consist of randomly initializing the population P, the initial decomposition, and a context vector \(\textbf{b}\). In particular, the initial space decomposition performed at line 3 by the function decomposition gives a set \(\mathcal G\) of subcomponents from the set \(\mathcal V\) of coordinates. Each individual in P has initial dimension \(num\_f\) and components in \([0,\,1]\), being \(num\_f\) the total number of features characterizing the problem. Typically, \(\textbf{b}\) is selected as a random element of P.
As mentioned above, the optimizer operates on a set \(\mathcal V\), initially containing all the available features (line 1). Subsequently, during the search process, some of the features can be permanently excluded from the search leading to a smaller set \(\mathcal V\). In order to determine the features to be excluded, a counter \(\textbf{c}[i]\) initialized to zero, is associated to each of the features (line 6). Since, for the purpose of fitness evaluation, each active search variable in the current \(\mathcal V\) has to be converted into the corresponding feature index in \([1,\dots ,num\_f]\), we use the array \(\textbf{cf}\), which is initialized at line 7 of the algorithm.

The optimization is organized in cycles (lines 10-33 of Algorithm 1). Every \(ls\_freq\) cycles, a LS procedure is undertaken according to the function localSearch outlined in Algorithm 3. The LS is designed so that it can be parallelized efficiently. For a number of iterations \(ite\_ls\), the algorithm randomly drawn \(p\_ls\) features. Then, each of them is activated/deactivated in the current solution. The latter is updated, together with the best fitness, if a fitness improvement is obtained. In order to increase the probability of success, the random selection of the features to be tested is biased based on their PFI. This is accomplished by a roulette wheel algorithm by simply assuming that the probability of a feature to be selected is proportional to the corresponding PFI.
The search space is redefined every \(adapt\_freq\) cycles by the function adaptDim, which is outlined in Algorithm 2 and implements the strategy of search space reduction, already explained above, based on the two thresholds \(th\_b\) and \(th\_p\). The former defines the minimum number of inactivity cycles for a feature to be excluded, and the latter represents a value of PFI above which the feature cannot be excluded but remains available for being potentially part of the final solution. Note that, after the set \(\mathcal V\) is updated, also both the array \(\textbf{cf}\), associating active search variables to features in the original search space, and the context vector \(\textbf{b}\) are updated by removing their components corresponding to excluded features.
Since the number of active search directions can be decreased during the process, also the number of subcomponents can be automatically reduced keeping almost constant the size \(subs\_size\) of subcomponents as long as they are more than one (function adaptiveDecomp). It is worth noting that the optimizer can operate with subcomponents of different sizes in such a way as to appropriately handle the frequent case in which the size of \(\mathcal V\) is not divisible by \(subs\_size\). Moreover, together with the the decomposition, at line 16 the population P is incremented with a suitable number of individuals. In fact, the population size is typically kept small at the beginning, when a high number of individuals multiplied by the number of subcomponents would correspond to a too high number of fitness evaluations per cycle, but is increased along the search in order to almost evenly distribute the number of fitness function evaluations among the CC cycles. In other words, we ensure that \(\vert P\vert \times \vert \mathcal{V}\vert /{subs\_size}\) is almost kept constant with a maximum of individuals given by the parameter \(n\_ind_{\max }\).
Once the subcomponents are generated, the coordinates are randomly shuffled (line 17), and the optimizers are activated in a round-robin fashion for the different subcomponents (lines 18-22). Each optimizer is executed for \(num\_{ite}\) iterations at each cycle. Note that the fitness function f passed to the optimizers operates on the training set \(\mathcal{D}_{tr}\). Before the next cycle, the context vector is updated using the current best individual of each sub-population (lines 23-24).
Then, in Algorithm 1, the bit vector \(\textbf{x}\), representing the current solution of dimension \(num\_f\), is computed from the context vector \(\textbf{b}\), and the inactivity counter of each feature included among the current search space is updated by considering the corresponding value in the bit vector \(\textbf{x}\) (lines 25-33).
For simplicity, the CC cycles in Algorithm 1 terminate when the number of fitness evaluations reaches the value max_fe. However, more complex termination conditions can obviously be implemented (e.g., termination after a certain number of cycles without improvement of fitness as done in our experiments).
3.1 Fitness function
The fitness of each candidate individual is computed using the already mentioned subset \(\mathcal{D}_{tr}\). We use a fitness function with the main objective of maximizing the balanced accuracy based on a k-nearest neighbors classifier (KNN). However, especially in the early stages of the optimization algorithm and in case of high-dimensional datasets, the accuracy can be insensitive to a small variation of the set of included features. This generates fitness landscapes with wide flat regions that would significantly slow down the search. For this reason, we define the fitness as a three-objective function that, besides maximizing the balanced accuracy, tries to minimize the average distance between the instances and their neighbors with the same label, and to maximize the average distance between the instances and their neighbors with a different label. More in detail, we evaluate each potential candidate solution using:
where \(w_1+w_2+w_3=1\). The balanced accuracy \(f_1\) is defined as:
where \(n_c\) is the number of classes, while \(m^{(i)}_{\text{ corr }}\) and \(m^{(i)}_{\text{ tot }}\) are the correctly identified instances in \(\mathcal{D}_{tr}\) belonging to class i and the total number of instances in \(\mathcal{D}_{tr}\) belonging to class i, respectively. The functions \(f_{dc}\) and \(f_{sc}\) are defined as:
where \(\delta _{ij}\) is the distance between the \(j^{th}\) instance of \(\mathcal{D}_{tr}\) and its \(i^{th}\) neighbor, \(n_v\) is the current number of features in the individual under evaluation, \(n_{dc}\) is the total number of neighbors with a different label, and \(n_{sc}\) is the total number of neighbors with the same label.

3.2 Parallel implementation
In order to cope with the high execution times required by FS in case of high-dimensional datasets, we developed a parallel implementation of the proposed algorithm for multi-threaded execution on shared-memory architectures. To this end, we suitably exploited the problem decomposition provided by the CC approach as outlined in Algorithm 4.
After a sequential initialization (lines 1-9), the search is organized in cycles, which are executed by the main thread except for some specific tasks that are executed in parallel. In particular, at each cycle, the LS procedure (lines 13-14) is carried out by the function localSearchInParallel, obtained from Algorithm 3 by parallelizing the cycle starting at line 9, which includes the computationally expensive fitness function evaluation. Also, the search space dimensionality reduction (line 16), is executed by the function adaptDimInParallel, obtained from Algorithm 2 by parallelizing the cycle starting at line 3. It is worth noting that, in the presented version of the algorithm, we avoided parallelizing the random shuffle of the coordinates, given that the parallel version was advantageous only for very high sizes of the corresponding vector. As for the activation of optimizers (lines 19-23), it is also executed in parallel by exploiting the dynamic scheduling feature of OpenMP. In fact, the optimizers for subcomponents may run for different durations because evaluating the fitness may be more or less computationally expensive depending on the number of features in the candidate solution under evaluation. A parallel reduction is used for accumulating the number of fitness evaluations into fe. Furthermore, using the function syncUpdateContextVector, the update of context vector \(\textbf{b}\) (line 25) is executed in parallel by each subcomponent. In fact, each of the latter is responsible of a specific segment of \(\textbf{b}\). However, since the update is executed only if it determines an actual improvement of the fitness, the actual replacement of each segment is protected by an OpenMP critical section in order to avoid race conditions. Finally, a parallelized cycle on the current size of the search space (line 27-23) is used for building the current bit vector representing the optimal solution and for updating the inactivity counters \(\textbf{c}[i]\) corresponding to the search directions.

4 Results and discussion
In this section, we present two sets of results. The first group concerns high-dimensional datasets, and the second is characterized by a lower number of features. The goal is to evaluate the proposed algorithm on a variety of dataset sizes and number of classes.
4.1 Results on high-dimensional datasets
We first discuss the results based on ten gene expression datasets having thousands of features and already used in [5]. The main characteristics of the adopted datasets are shown in Table 1.
As for the parameters adopted in the experiments, they are reported in Table 2. In order to perform a fair comparison with the results reported in [5], we adopted the same protocol based on a tenfold cross-validation procedure and neighborhood size \(K=1\) in KNN. In particular, for each experiment, we partitioned the original dataset into tenfold. Each fold has been used as test set after the FS process which was based on the remaining ninefold. Each FS experiment was composed of ten FS runs and was repeated 30 times to account for the random nature of the search algorithm. The t-test with a significance level of 0.05 was used to compare the proposed method with each of the other methods considered. Note that the optimization was carried out until the fitness did not improve for 20 CC cycles.

Convergence plots for the first group of datasets
Figure 2 shows the convergence plots obtained during the FS process. Both the fitness and the number of subcomponents as a function of the number of fitness evaluations are depicted. The plots show how the proposed algorithm adapts the search space dimensionality and, consequently, the decomposition into subcomponents of maximum size of 100 (see Table 2), up to the final CC cycle in which few subcomponents are optimized, depending on the problem.
In Tables 3 and 4, we first compare the accuracy obtained with the full set of features with the average and best accuracy obtained by applying the proposed ACCFS algorithm. Moreover, we show in the same table a comparison with the results reported in [5] and concerning the following algorithms: PSO-EMT (particle swarm optimization-evolutionary multitasking) [5], variable-length PSO (VLPSO) [48], CFS [16], FCBF [59], and SBMLR (sparsity based) [4].
As can be seen, compared with the use of the full set of features, we always obtained an improvement in the classifier accuracy ranging from 1.3% for the 'Lung Cancer' dataset to 102.6% for the '9 Tumor' dataset. Interestingly, although not as relevant as the average result, ACCFS achieved a best accuracy of 100% in half of the test cases.
In the case of 'Leukemia 1' dataset, ACCFS led to an improvement of 20% and performed better than the other algorithms under comparison, although statistically equivalent to VLPSO and CFS. The average number of selected features was 92.30, which is considerably lower than the original size of the problem. It is worth noting that although we are using accuracy here to compare the results of different algorithms, in some application cases, a trade-off between accuracy and number of selected features may be more appropriate. For example, in the case of 'Leuk. 1,' the VLPSO algorithm gives a reasonable accuracy of 0.9331 but with the much lower average number of features of 54.70. For 'DLBCL,' the best performing algorithm was PSO-EMT that provided an average accuracy of 0.9376 and and average number of involved features of 263.09. Although the ACCFS framework was able to improve the accuracy compared to the use of the full set of features, with respect to the remaining algorithms under comparison, it performed worse or equivalently. For the '9 Tumor' test case, the proposed algorithm resulted the best although statistically equivalent to PSO-EMT. Also, compared with the full set of 5726 features, ACCFS was able, on average, to improve by 103%, the average classification accuracy using only 256.5 features. For the 'Brain 1' dataset ACCSF, PSO-EMT and CFS achieved a statistically equivalent average result, which was also the best among those provided by the involved algorithms and corresponded to a relatively small improvement of about 2.4% over the full set of features. However, ACCFS achieved such result with much fewer features than PSO-EMT (i.e., 98.1 vs. 351.21). In the FS process for the 'Prostate Tumor' dataset, the best performing algorithm was SBMLR that provided an average accuracy of 0.9509 with the very low number of feature of 32. As for the three metaheuristic-based wrapper FS algorithms under comparison, the proposed algorithm ACCFS provided the best result on average, although statistically equivalent to PSO-EMT and with a higher number of selected features. In the case of 'Leukemia 2' dataset, ACCFS achieved the best result with an improvement of about 15.7% over using the full set of features and an average number of 85.6 features. Also in the case of 'Brain 2' dataset, ACCFS provided a significantly superior average accuracy with an improvement of about 8.18% over the full set of 10,367 features and an average number of 246.10 features. For the 'Leukemia 3' test case, all the involved algorithms are statistically equivalent to ACCFS. However, while the best average accuracy was provided by PSO-EMT, the proposed algorithm led to a much lower number of features on average (92.3 vs. 268.08). In the '11 Tumor,' ACCFS performed worse than PSO-EMT but better or equivalently to the remaining algorithms. In the 'Lung Cancer' dataset, characterized by 12600 features, the best performing algorithm was the proposed ACCFS. Noteworthy, while the improvement in terms of average accuracy was not particularly relevant (i.e., 1.3%), selecting only 261 features among the original 12,600 was a remarkable result.
One aspect that is interesting to discuss is the contrast between the convergence curves of the 'DLBCL' and 'LEUKEMIA 3' datasets, which reach the highest level of fitness, and the results on the test set of the corresponding classifiers, which provided an average accuracy of 0.91 and 0.94, respectively. This can be due to two factors. First, the fitness function defined by Eq. 2 does not only consider accuracy. Second, due to the well-known overfitting problem that can affect wrapper-type FS methods, if the training set is not sufficiently representative of the test set, a strong optimization capability of the search algorithm does not help to achieve better results. In order to mitigate this effect, however, k-fold cross-validation approaches can be used to compute the fitness with a consequent computational cost overhead.
Overall, according to the presented results in terms of average accuracy, the proposed algorithm was the best, or statistically equivalent to the best, in seven out of the ten high-dimensional datasets under consideration. The numerical investigation presented above suggests that the approach presented in this study can be very competitive with other state-of-the-art FS methods in case of high-dimensional datasets.
4.2 Results on medium-sized dataset
In addition to the numerical investigation concerning high-dimensional datasets presented above, we have also assessed the effectiveness of the proposed approach in the case of datasets having a lower number of features. The datasets used for that purpose are shown in Table 5, which were chosen from the UCI Machine Learning Repository [1] and already used in [55] for testing a new self-adaptive particle swarm optimization algorithm for feature selection (SaPSO). The dataset are available at http://archive.ics.uci.edu/ml/index.php and are identified as Grammatical Facial Expression (GFE), Semeion Handwritten Digit (SHD), Isolet5, Multiple Features Digit (MFD), HAPT, Har, UJIIndoorLoc, MadelonValid, Optical Recognition of Handwritten (ORH), Connectionist Bench Data (CBD), WDBC, and LungCancer. Note that, in order to compare the results with those reported in [55], we used the version of the datset made available by the authors where for Isolet5, MFD, HAPT, Har, UJIIndoorLoc, and ORH, the instances were randomly reduced for saving experimental time.

Convergence plots for the second group of datasets (see Table 5). Note that for the last four datasets, we plot the number of active features instead of the number of subcomponents
Relying on the results published in [55], we compared the proposed approach with five different FS approaches, including two self-adaptive algorithms, namely, SaPSO presented in [55] and SaDE presented in [36], a standard PSO algorithm already used for FS in the literature [52, 53] and two classical search-based FS algorithms, namely, the sequential floating forward selection (SFFS) and the sequential floating backward selection (SBFS) [34].
Also in this case, in order to perform a fair comparison, we used the same setting described in [55]. More in detail, each dataset was divided into two partitions: One was used as a training set, formed by randomly selecting 70% of the examples from the original dataset. The other partition was used as a test set, and it consists of the remaining examples. The adopted value of the number of neighbors in the KNN method, used in both the fitness function and for testing, was K = 3. Moreover, in KNN, threefold cross-validation is used to measure the classification accuracy. Each algorithm was run 30 times on each dataset. The remaining parameters adopted for the proposed method are those listed in Table 2.
Figure 3 shows the convergence plots in terms of both fitness and number of subcomponents as a function of the number of fitness evaluations. For the last four datasets, the dimension of which is below 100, we use a single subcomponent, performing a standard non-CC search. Therefore, for them, we plot the number of active features instead of the number of subcomponents. Compared with the previous group of datasets, characterized by a higher number of features, we can observe that in most cases, there was a lower room for fitness improvements by FS.
The numerical results of the comparison are reported in Tables 6 and 7, where a t-test with a significance level of 0.05 has been used to compare the proposed method with the others. Also in this case, the symbols '+'/'-' indicate when the results of ACCFS algorithm in terms of achieved accuracy are better/worse than the corresponding algorithm with a significant difference, and '=' indicates that there is no significant difference between ACCFS and the corresponding algorithm.
Looking at the results in detail, it can be seen that the proposed ACCFS provided the best average accuracy in all 12 test cases but three, namely, 'UJIIndoorLoc,' 'MadelonValid,' and 'LungCancer.' However, in the 'UJIIndoorLoc' and 'LungCancer' datasets, ACCFS was statistically equivalent to the best performing algorithm, which was SBFS. Comparing with the remaining metaheuristic-based FS algorithms, namely, SaPSO, SaDE ,and Std. PSO, the ACCFS algorithm performed always better or was statistically equivalent.
As can be observed in Tables 6 and 7, sometimes, when the provided accuracy was better, ACCFS generally did require a slightly higher average size of the optimal set of features compared to the other algorithms. For example in the 'GFE' dataset, the average accuracy of ACCFS was 0.8849 with 132.1 features, whereas the runner-up Std. PSO provided an average accuracy of 0.8507 with 121.0 features. Also, in the case of 'MFD,' ACCFS provided an average accuracy of 0.9737 with 160.6 features, whereas the runner-up SaPSO provided an average accuracy of 0.9388 with 147.4 features. This is not surprising because the fitness function adopted in ACCFS did not explicitly considered the number of selected features but privileged the accuracy that the KNN classifier could provide after the FS process. Overall, the ACCFS algorithms were remarkably superior in achieving his goal in terms of accuracy of the resulting classifier for the 12 datasets and five alternative algorithms under consideration.
4.3 Parallel efficiency
The parallel implementation was developed in C++ and OpenMP [28]. The program was compiled with Intel Compiler 2023 and run in three workstations: (i) The first one equipped with an Intel i9-7940X 14-Core CPU (3.10GHz), (ii) the second equipped with a single Intel i7-8750 H 6-Core CPU (2.20GHz), and (iii) the third one with two Intel Xeon X5660 (2.80 GHz) 6-Core CPUs (12 cores in total).
The results described in the following refer to the average run time obtained in ten repetitions of 40 CC cycles of optimization for the 'Brain Tumor 1' dataset (5920 features, 81 samples used during training) and for the MFD dataset (649 features, 700 samples used during training).
Since the used CPUs are endowed with Hyper-threading Intel's proprietary technology that associates two logical cores to each processor core physically present, we studied the elapsed time of each optimization up to 28, 24, and 12 threads, respectively. Moreover, for the scalability experiments, we exploited the Thread Affinity Interface of the Intel runtime library to bind OpenMP threads to specific physical processing units. By setting the thread affinity, we could: (i) prevent a thread from migrating between cores during experiments, which can reduce the measured performance and (ii) ensure that when the number of threads is not greater than the number of physical cores, each thread is executed by a different core.
In Fig. 4, we plot, as a function of the number of threads, both the average elapsed time and the achieved parallel efficiency (i.e., the ratio between single-thread and multi-thread execution divided by the number of threads).

Timing and parallel efficiency as a function of the number of threads
On the i9 workstation, a single-thread FS for 'Brain Tumor 1' dataset took 852 s on average, which could be reduced to the minimum value of 72 s using 27 threads, corresponding to a speedup of 11.9. As a reference value, in [5] is reported an elapsed time of 926 s for PSO-EMT algorithm that provided a result statistically equivalent to that given by proposed algorithm, although with different hardware and termination conditions. Note that in the i9 workstation, using a number of threads beyond the number of physical cores resulted in a modest gain of computing time. As shown in the following, this is a behavior observed also with the other experiments and can be motivated by the memory-bound nature of the computation resulting from the developed parallelization, which cannot take significant advantages from having additional threads belonging to the same physical core. With the i7 CPU, the FS procedure applied to the 'Brain Tumor 1' dataset required 920 s using one thread and a minimum of 173 s with 12 threads (corresponding to a speedup of 5.3). In the Xeon workstation, we obtained for the 'Brain Tumor 1' dataset a minimum elapsed time of 139 s with 20 threads and a maximum speedup of 10.1. A further increase in the number of threads provided no advantages. In the case of 'MFD' dataset, on the i9 workstation, a single-thread FS took 452 s on average, which could be reduced to the minimum value of 42 s using 24 threads with a speedup of 10.8. Using the i7 CPU with the same dataset required 510 s for the single-thread execution and a minimum of 106 s with 12 threads, which corresponds to a speedup of 4.8. In the Xeon workstation, we obtained for the 'MFD' dataset a minimum elapsed time of 88 s with 24 threads and a maximum speedup of 10.7.
According to Fig. 4, for the 'Brain Tumor 1' test case, within the number of available physical CPU cores, the parallel efficiency was always above 80%. In contrast, for the the 'MFD' dataset, we observed a small decline of the parallel efficiency that, within the number of available physical cores, ranged between 70% and 80%, depending on the workstation. As mentioned, the phenomenon was likely due to the significanlty higher number of training samples that characterize the 'MFD' dataset and the consequent more memory-intensive computation.
Table 8 summarizes the achieved parallel speedups. Overall, considering the nature of the computational problem, involving irregular computation due to the path-dependent computational demands of CC subcomponent, need for information exchange between subcomponents during the process, and memory-related aspects, the results are satisfactory. Interestingly, the older Xeon architecture was able to better cope with the higher number of samples characterizing the 'MFD' dataset, better exploiting hyperthreading.
5 Conclusions and future work
We have presented a new FS algorithm based on cooperative coevolution and differential evolution, in which the search space, the decomposition, and the population size are adapted during the optimization process. Then, we have discussed a comprehensive numerical investigation involving a variety of datasets from different fields. According to the presented results, the proposed parallelization enables relatively fast FS on a standard workstation equipped with multicore CPUs. Moreover, the results on the test cases considered, including both high-dimensional and medium-dimensional datasets, suggested that the proposed approach can be very competitive with other state-of-the-art FS methods.
Several research directions can be pursued to develop a more efficient and effective version of the proposed framework. In particular, a natural and appealing extension would be a multi-objective version of the ACCFS algorithm, in which in addition to a quality measure in terms of classification, the fitness function would also explicitly consider the number of selected features. There are studies in the literature that employ a CC approach for multi-objective evolutionary algorithms that could be integrated with the ideas proposed in this study as well as implemented in a parallel environment.
Data availability
Data and source code will be available in an open repository.
References
Bache K, Lichman M (2016) UCI machine learning repository. http://archive.ics.uci.edu/ml/index.php
Bhanu B, Krawiec K (2002) Coevolutionary construction of features for transformation of representation in machine learning. In: Proceedings of Genetic and Evolutionary Computation Conference (Workshop on Coevolution), pp 249–254
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Cawley GC, Talbot NL, Girolami M (2007) Sparse multinomial logistic regression via Bayesian l1 regularisation. Adv Neural Inf Process Syst 19:209
Chen K, Xue B, Zhang M et al (2020) An evolutionary multitasking-based feature selection method for high-dimensional classification. IEEE Trans Cyber 52(7):7172–7186
Dash M, Liu H (1997) Feature selection for classification. Intell Data Anal 1:131–156
De Falco I, Della Cioppa A, Trunfio GA (2017) Large scale optimization of computationally expensive functions: An approach based on parallel cooperative coevolution and fitness metamodeling. Association for Computing Machinery, New York, NY, USA, GECCO '17, pp 1788–1795
De Falco I, Della Cioppa A, Trunfio GA (2019) Investigating surrogate-assisted cooperative coevolution for large-scale global optimization. Inf Sci 482:1–26
Derrac J, GarcÃa S, Herrera F (2010) Ifs-coco: Instance and feature selection based on cooperative coevolution with nearest neighbor rule. Pattern Recogn 43(6):2082–2105
Ebrahimpour MK, Nezamabadi-Pour H, Eftekhari M (2018) CCFS: a cooperating coevolution technique for large scale feature selection on microarray datasets. Comput Biol Chem 73:171–178
Firouznia M, Trunfio GA (2022) An adaptive cooperative coevolutionary algorithm for parallel feature selection in high-dimensional datasets. In: González-Escribano A, GarcÃa JD, Torquati M, et al (eds.) 30th Euromicro International Conference on Parallel, Distributed and Network-based Processing, PDP 2022, Valladolid, Spain, March 9-11, 2022. IEEE, pp 211–218
Fisher A, Rudin C, Dominici F (2019) All models are wrong, but many are useful: learning a variable's importance by studying an entire class of prediction models simultaneously. J Mach Learn Res 20(177):1–81
Fong S, Wong R, Vasilakos AV (2016) Accelerated PSO swarm search feature selection for data stream mining big data. IEEE Trans Serv Comput 9(1):33–45
Gu S, Cheng R, Jin Y (2018) Feature selection for high-dimensional classification using a competitive swarm optimizer. Soft Comput 22(3):811–822
Guyon I, Elisseeff A (2003) An introduction to variable and feature selection. J Mach Learn Res 3:1157–1182
Hall MA, Smith LA (1999) Feature selection for machine learning: comparing a correlation-based filter approach to the wrapper. In: FLAIRS Conference, pp 235–239
Hsu HH, Hsieh CW, Lu MD (2011) Hybrid feature selection by combining filters and wrappers. Expert Syst Appl 38(7):8144–8150
Hu XM, He FL, Chen WN et al (2017) Cooperation coevolution with fast interdependency identification for large scale optimization. Inf Sci 381:142–160
Huang J, Cai Y, Xu X (2007) A hybrid genetic algorithm for feature selection wrapper based on mutual information. Pattern Recogn Lett 28(13):1825–1844
Kabir MM, Shahjahan M, Murase K (2012) A new hybrid ant colony optimization algorithm for feature selection. Expert Syst Appl 39(3):3747–3763
Khushaba RN, Al-Ani A, Al-Jumaily A (2011) Feature subset selection using differential evolution and a statistical repair mechanism. Expert Syst Appl 38(9):11515–11526
Li AD, Xue B, Zhang M (2021) Improved binary particle swarm optimization for feature selection with new initialization and search space reduction strategies. Appl Soft Comput 106(107):302
Liu Y, Wang G, Chen H et al (2011) An improved particle swarm optimization for feature selection. J Bionic Eng 8(2):191–200
Marill T, Green D (1963) On the effectiveness of receptors in recognition systems. IEEE Trans Inf Theory 9(1):11–17
Mei Y, Omidvar MN, Li X et al (2016) A competitive divide-and-conquer algorithm for unconstrained large-scale black-box optimization. ACM Trans Math Softw 42(2):1–24
Mitchell M (1998) An introduction to genetic algorithms. MIT press, Cambridge
Molina D, LaTorre A, Herrera F (2018) Shade with iterative local search for large-scale global optimization. In: 2018 IEEE Congress on evolutionary computation (CEC), pp 1–8, 10.1109/CEC.2018.8477755
Oliverio M, Spataro W, D'Ambrosio D et al (2011) OpenMP parallelization of the SCIARA cellular automata lava flow model: performance analysis on shared-memory computers. Proce Comput Sci 4:271–280
Omidvar MN, Li X, Yang Z, et al (2010) Cooperative co-evolution for large scale optimization through more frequent random grouping. In: IEEE congress on evolutionary computation. IEEE, pp 1–8
Omidvar MN, Li X, Mei Y et al (2014) Cooperative co-evolution with differential grouping for large scale optimization. IEEE Trans Evol Comp 18(3):378–393
Omidvar MN, Yang M, Mei Y et al (2017) DG2: a faster and more accurate differential grouping for large-scale black-box optimization. IEEE Trans Evol Comput 21(6):929–942
Potter MA, De Jong KA (1994) A cooperative coevolutionary approach to function optimization. In: Parallel problem solving from nature - PPSN III, LNCS, vol 866. Springer-Verlag, pp 249–257
Potter MA, De Jong KA (2000) Cooperative coevolution: an architecture for evolving coadapted subcomponents. Evol Comput 8(1):1–29
Pudil P, Novoviˇcov´a J, Kittler J (1994) Floating search methods in feature selection. Pattern Recogn Lett 15(11):1119–1125
Pudil P, Novoviˇcov´a J, Kittler J (1994) Floating search methods in feature selection. Pattern Recogn Lett 15(11):1119–1125
Qin AK, Huang VL, Suganthan PN (2009) Differential evolution algorithm with strategy adaptation for global numerical optimization. IEEE Trans Evol Comput 13(2):398–417
Rashid AB, Ahmed M, Sikos LF et al (2020) Cooperative co-evolution for feature selection in big data with random feature grouping. J Big Data 7(1):1–42
Song XF, Zhang Y, Guo YN et al (2020) Variable-size cooperative coevolutionary particle swarm optimization for feature selection on high-dimensional data. IEEE Trans Evol Comput 24(5):882–895
Sun Y, Kirley M, Halgamuge SK (2018) A recursive decomposition method for large scale continuous optimization. Trans Evol Comp 22(5):647–661
Sun Y, Li X, Ernst A, et al (2019a) Decomposition for large-scale optimization problems with overlapping components. In: 2019 IEEE congress on evolutionary computation (CEC), IEEE, pp 326–333
Sun Y, Li X, Ernst AT, et al (2019b) Decomposition for large-scale optimization problems with overlapping components. In: IEEE congress on evolutionary computation, CEC 2019, Wellington, New Zealand, June 10-13, 2019. IEEE, pp 326–333
Tabakhi S, Moradi P, Akhlaghian F (2014) An unsupervised feature selection algorithm based on ant colony optimization. Eng Appl Artif Intell 32:112–123
Tan F, Fu X, Zhang Y et al (2008) A genetic algorithm-based method for feature subset selection. Soft Comput 12(2):111–120
Tanabe R, Fukunaga A (2013) Success-history based parameter adaptation for differential evolution. In: 2013 IEEE congress on evolutionary computation, pp 71–78
Tarkhaneh O, Nguyen TT, Mazaheri S (2021) A novel wrapper-based feature subset selection method using modified binary differential evolution algorithm. Inf Sci 565:278–305
Tran B, Xue B, Zhang M (2016a) Bare-bone particle swarm optimisation for simultaneously discretising and selecting features for high-dimensional classification. In: European Conference on the Applications of Evolutionary Computation, Springer, pp 701–718
Tran B, Zhang M, Xue B (2016b) A PSO based hybrid feature selection algorithm for high-dimensional classification. In: 2016 IEEE congress on evolutionary computation (CEC), IEEE, pp 3801–3808
Tran B, Xue B, Zhang M (2019) Variable-length particle swarm optimization for feature selection on high-dimensional classification. IEEE Trans Evol Comput 23(3):473–487
Trunfio GA, Topa P, Was J (2016) A new algorithm for adapting the configuration of subcomponents in large-scale optimization with cooperative coevolution. Inf Sci 372:773–795
Whitney A (1971) A direct method of nonparametric measurement selection. IEEE Trans Comput C 20(9):1100–1103
Wiegand RP, Liles WC, De Jong KA (2002) The effects of representational bias on collaboration methods in cooperative coevolution. Springer, Berlin Heidelberg, pp 257–268
Xu R, Anagnostopoulos GC, Wunsch DC (2007) Multiclass cancer classification using semisupervised ellipsoid artmap and particle swarm optimization with gene expression data. IEEE/ACM Trans Comput Biol Bioinf 4(1):65–77
Xue B, Zhang M, Browne WN (2014) Particle swarm optimisation for feature selection in classification: Novel initialisation and updating mechanisms. Appl Soft Comput 18:261–276
Xue B, Zhang M, Browne WN et al (2015) A survey on evolutionary computation approaches to feature selection. IEEE Trans Evol Comput 20(4):606–626
Xue Y, Xue B, Zhang M (2019) Self-adaptive particle swarm optimization for large-scale feature selection in classification. ACM Trans Knowl Discov Data 13(5):1–27
Yang M, Zhou A, Li C et al (2021) An efficient recursive differential grouping for large-scale continuous problems. IEEE Trans Evol Comput 25(1):159–171
Yang Z, Tang K, Yao X (2008) Large scale evolutionary optimization using cooperative coevolution. Inform Sci 178(15):2985–2999
Yang Z, Tang K, Yao X (2008b) Multilevel cooperative coevolution for large scale optimization. In: IEEE Congress on evolutionary computation. IEEE, pp 1663–1670
Yu L, Liu H (2003) Feature selection for high-dimensional data: A fast correlation-based filter solution. In: Proceedings of the 20th International Conference on Machine Learning (ICML-03), pp 856–863
Acknowledgements
Not applicable.
Funding
Open access funding provided by Università degli Studi di Sassari within the CRUI-CARE Agreement. This work was partially funded by the University of Sassari through the program 'Fondo di Ateneo per la ricerca 2020.'
Author information
Authors and Affiliations
Contributions
The authors contributed equally.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Firouznia, M., Ruiu, P. & Trunfio, G.A. Adaptive cooperative coevolutionary differential evolution for parallel feature selection in high-dimensional datasets. J Supercomput 79, 15215–15244 (2023). https://doi.org/10.1007/s11227-023-05226-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-023-05226-y