
Abstract
Feature selection plays a very significant role for the success of pattern recognition and data mining. Based on the maximal relevance and minimal redundancy (mRMR) method, combined with feature subset, this paper proposes an improved maximal relevance and minimal redundancy (ImRMR) feature selection method based on feature subset. In ImRMR, the Pearson correlation coefficient and mutual information are first used to measure the relevance of a single feature to the sample category, and a factor is introduced to adjust the weights of the two measurement criteria. And an equal grouping method is exploited to generate candidate feature subsets according to the ranking features. Then, the relevance and redundancy of candidate feature subsets are calculated and the ordered sequence of these feature subsets is gained by incremental search method. Finally, the final optimal feature subset is obtained from these feature subsets by combining the sequence forward search method and the classification learning algorithm. Experiments are conducted on seven datasets. The results show that ImRMR can effectively remove irrelevant and redundant features, which can not only reduce the dimension of sample features and time of model training and prediction, but also improve the classification performance.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
With the development of machine learning and artificial intelligence, more and more rich information is obtained from research objects, but some irrelevant and redundant features are added, which leads to higher feature dimensions. For the classification learning, the good learning samples are the key to train the classifier. The irrelevant or redundant information of the samples will increase the complexity of the classification algorithm as well as the time of training and prediction, and directly affect the classification performance. Therefore, it is necessary to select the optimal features that can best represent the characteristic of object, and eliminate irrelevant and redundant features to improve the efficiency of the classifier [1].
Feature selection is the process of selecting the optimal feature subset from the raw feature set to reduce the dimension of the feature space [2]. Its purpose is to simplify the data structure, interpret the data information, and improve the robustness, stability and identification of the model. According to whether the evaluation criteria of feature subset are related to classifier, feature selection methods are divided into three ways: filter, wrapper and embedded [3]. Filter method relies on the properties of the feature space itself, based on feature metrics to maximize data representation information. The feature selection and training classifier are two independent processes. For example, Zhao et al. [4] applied constraint score method to score audio features in environmental sound classification and select the optimal feature subset to improve the classification performance. Saqlain et al. [5] used fisher score method to select feature subsets, and transferred selected feature subsets to the RBF kernel-based SVM for diagnosing heart disease. Yong et al. [6] divided features into three levels: strong correlation, sub-strong correlation and other features, based on the measurement criterion of mutual information and the correlation between the feature and the label. Then the features are simplified. Wrapper method relies on preselected classifiers, takes the performance of the classifier as an evaluation criterion for feature subset, and removes features that negatively affect the classification performance. For example, Ye et al. [7] proposed a multimodal wrapper feature selection method based on effective distance, which considered the global relationship between samples. Mafarja et al. [8] wrapped the whale optimization algorithm into the classifier, and used the crossover and mutation characteristics of the optimization algorithm to enhance the speed and accuracy of feature search. In order to improve the classification performance of the financial credit scoring model, Jadhav et al. [9] proposed an information gain directed feature selection algorithm, and propagated the top m features through the genetic algorithm wrapper. The embedded method puts the feature selection process into the learning algorithm, which is a compromise between the filter method and the wrapper method. For example, Xu et al. [10] proposed a joint intra-class variation coefficient and inter-class mutual information, constructed a joint index to evaluate the feature contribution, and combined the embedded method for feature selection. Maldonado et al. penalized the cardinality of feature sets through the scale factor technology, and used SVM as the embedded base classifier for feature selection. This method was applied to high-dimensional datasets with extremely uneven categories [11]. Liu et al. [12] proposed an unsupervised adaptive neighborhood embedded feature selection method, which mainly captures the internal geometric structure of the data based on the K-nearest neighbor method. Because both the wrapper and embedded methods have certain dependencies on the classification learning algorithm, and are prone to problems such as overfitting and low efficiency. The filter method has high efficiency and is suitable for various data types. The method has strong versatility and low algorithm complexity.
In the filter method, the feature metric is the key factor. That the maximal relevance and minimal redundancy (mRMR) criterion is a filter feature metric for pattern recognition [13], it aims to select the feature subset with the maximal dependency, maximal relevance and the minimal redundancy from the raw feature set. However, mRMR only considered the contribution of a single feature. The feature with the maximum contribution from the raw feature set are selected and added to form the optimal feature subset. In this way, the relevance between features will be ignored, and the joint contribution of multiple features to the classification will not be considered enough, resulting in the selected feature subset may not be optimal. There is still a certain room for improvement in the selection of the optimal feature subset. Therefore, based on the mRMR method, in this paper, the ImRMR (Improved mRMR) method is proposed. First, the relevance between each feature and the class is calculated through the Pearson correlation coefficient and mutual information, and tradeoff the two metrics to rank the features. Secondly, candidate feature subsets are generated with the proposed equal grouping method (EGM) according to the ranking features. The joint contribution of feature subset is evaluated by the relevance and redundancy of feature subset, and the ranking of feature subsets is found by incremental search method. Finally, the final optimal feature subset is obtained by combining the sequence forward search method (SFS). The experiments are conducted on seven datasets to verify the effectiveness of the ImRMR.
This paper adopts a supervised learning method to perform feature selection on these datasets through ImRMR, and uses advanced machine learning classification algorithm (random forest) to classify these features. In this study, 70% of each dataset was randomly selected for the training dataset, and the remaining 30% was used for the test dataset. We conduct extensive experiments and evaluate on various performance metrics (accuracy, dimensionality reduction rate, comprehensive rate, precision, recall and F-measure) to determine the effectiveness of the proposed method. Experiments show that the proposed feature selection method on random forest classifier outperforms the original mRMR and other methods.
The rest of this paper is organized as follows: Sect. 2 lists the related work done by various authors. Section 3 describes the mRMR method. Section 4 presents the proposed ImRMR method in detail. Then, the experiments and results are analyzed in Sect. 5. Finally, we give limitations and conclusion.
2 Related work
Based on the mRMR, Lu et al. extracted the key information most relevant to the fault location in traditional transmission line faults. By mining the implicit relationship between key features and fault location, the fault location result is obtained by synthesizing multiple feature information. This method has better fault location accuracy and better adaptability to transient components that appear after the fault [14]. Billah and Waheed [15] effectively reduced the dimensionality of the extracted features of endoscopic video frames with mRMR. Toaar et al. used the mRMR to select the features of the lung X-ray images for the diagnosis of pneumonia extracted by three deep models, and combined them to form an efficient feature set. The selected feature set provided robust and consistent features for pneumonia detection, and the mRMR can effectively reduce the dimension of the feature set [16]. Gu et al. calculated the relevance between power transformer fault feature quantities and the redundancy between feature quantities and fault types based on the mRMR, the optimal transformer fault feature set was obtained. Experiments show that the optimal feature set is more efficient than the traditional feature set in transformer fault diagnosis [17]. Erolu et al. [18] used the mRMR to select the features of breast ultrasound image extracted by the hybrid CNN structure, and achieved good results in classification and recognition. Fan et al. [19] used mRMR to select important lead-rhythm features extracted from electroencephalogram recordings to build a predictive model to predict the prognostic effect of acupuncture on depression. Tuncer et al. [20] used the discrete wavelet transform to decompose the electroencephalogram signal, and then used the mRMR to select the most discriminant feature from the texture features generated by the decomposed discrete wavelet transform subband, and used SVM classifier to classify the selected features. In the study of COVID-19 disease classification using supervised optimization machine learning technology, Sharma et al. [21] used the mRMR to remove irrelevant and misleading features in the high-dimensional data of COVID-19 to reduce the size of the search space of the cuckoo search algorithm and improve the learning efficiency. Baliarsingh et al. employed mRMR to select relevant subsets of genes from the microarray dataset. Then, simulated annealing is hybridized with Rao algorithm to improve the solution quality after each iteration of Rao algorithm. The discriminant genes selected on the SRBCT dataset have high classification accuracy [22].
In addition, many scholars have improved the mRMR to obtain better feature selection results. Feng and Zhang improved the mRMR by using conditional mutual information formula and three-dimensional calculation to determine the candidate connection of each attribute node in Bayesian network classifier. The method enhanced the reliability and robustness of small sample calculation [23]. Yao et al. introduced mRMR into the particle swarm optimization algorithm search process to select feature subset. The feasibility and effectiveness of the proposed algorithm were verified on the UCI dataset with SVM as the classifier [24]. Li and Wang [25] proposed a new mRMR method to use a variety of different evaluation criteria to measure the redundancy between features and the relevance between features and categories, and an indicator vector λ was introduced to describe the actual data dimension requirements of users. Wang et al. [26] improved the mRMR by merging relevance measurement coefficients to obtain a primary feature subset, and binary-coded the feature subset, and then combined the genetic algorithm to search for the optimal or suboptimal feature subset. Jo et al. [27] used the Pearson correlation coefficient as the redundancy metric and the R value as the relevance metric to improve the mRMR. Ahmed et al. put forward an enhanced mRMR (EmRMR) filtering method to remove the noise features in ransomware, and selected the most relevant feature subset to characterize the real behavior of ransomware. EmRMR requires only a small amount of evaluation, avoiding unnecessary calculations inherent in the original mRMR [28]. Combines EmRMR with term frequency-inverse document frequency (TF-IDF), a weighted mRMR (WmRMR) technology was proposed to filter out runtime noise behavior according to the weight calculated by TF-IDF. Compared with the mRMR, WmRMR has low-dimensional complexity and less evaluation times, and better estimates the feature significance in the data captured in the early stage of ransomware attacks [29].
The existing improved methods for mRMR are based on the calculation of correlation and redundancy of a single feature, they ignore the joint contribution of multiple features, and do not take into account the calculation of redundancy and correlation between feature subsets. We propose an improve mRMR (ImRMR) based on feature subsets. The proposed method and performance evaluation will be discussed in the following sections.
3 mRMR feature selection
3.1 mRMR definition
Maximal relevance and minimal redundancy (mRMR) is a filter feature measurement criterion, which calculates the redundancy between features and the correlation between features and class based on mutual information \(I\left( {x;y} \right)\). It selects the features that are most relevant to the category and have the least redundancy with other features from the raw feature set.
The mutual information \(I\left( {x;y } \right)\) is defined as Eq. 1.
where \(p\left( {x,y} \right)\) is the joint probability density of random variables \(x\) and \(y\), and \(p\left( x \right)\) and \(p\left( y \right)\) are the marginal probability densities of \(x\) and \(y\), respectively.
Given a sample feature set \(S = \{ f_{1} ,f_{2} , \ldots f_{n} \}\) and a sample class \(c\). The relevance between \(S\) and \(c\) is the mean of all mutual information between each feature \(f_{i}\) and class \(c\). It is shown in Eq. 2.
where \(\left| S \right|\) is the number of features in \(S\), and \(I\left( {f_{i} ;c} \right)\) is the mutual information between the feature \(f_{i}\) and the class \(c\).
The redundancy of all features in \(S\) is the mean of all mutual information between feature \(f_{i}\) and feature \(f_{j}\). It is shown in Eq. 3.
The mRMR method seeks the optimal features of the samples with maximal relevance \(D\left( {S,c} \right)\) and minimal redundancy \(R\left( S \right)\). So the criterion of feature measurement for mRMR can be as shown in Eq. 4.
3.2 Incremental search method
Incremental search is used to quickly and efficiently select the optimal feature set. Given the raw feature set \(X\), if the optimal feature \(S_{m - 1}\) has been selected, then it will continue to search for the optimal feature in the remaining feature space \(X - S_{m - 1}\). Equation 4 can be illustrated as Eq. 5.
4 Improved mRMR based on feature subset
The mRMR method measures the contribution of feature by calculating the relevance and redundancy of individual feature. The joint contribution of multiple features is ignored. Relevance and redundancy are only based on mutual information measures. Therefore, to obtain the optimal feature subset, from the perspective of feature subset, this paper uses two measurement criteria, Pearson correlation coefficient and mutual information to evaluate the relevance and redundancy of the feature subsets. A weight factor is introduced to tradeoff the two measurement criteria.
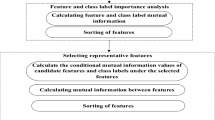
The whole process of proposed ImRMR is shown in Fig. 1. Firstly, we adopt equal grouping method (EGM) to initially divide the candidate feature subsets. Then the contribution of each candidate feature subset is calculated with the correlation and redundancy according to the Pearson correlation coefficient and mutual information. Finally, we convert the ranking of the feature subsets into the feature ranking and combine the SFS search strategy to obtain the final preferred subset. Mapping the optimal feature subset to the raw sample set can carry out classification and recognition.

The follow chart of feature selection with ImRMR method
4.1 Initialize the candidate feature subsets with EGM
Given a sample set of \(N*M\), \(N\) represents the number of samples, and \(M\) refers to the feature dimension. The base decision tree in the random forest includes the feature number \(\log_{2} \left( M \right)\) as the candidate feature subsets [30]. The relevance between each feature and the class is calculated by the Pearson correlation coefficient and mutual information, and α is introduced to adjust the weight of the two indicators. The features are ranked on relevance. The relevance \(Ic\left( {f_{i} ;c} \right)\) between a single feature and the sample class is calculated as shown in Eqs. 6 and 7.
where \(\alpha \in \left[ {0.1,1} \right]\), with a step size of 0.1, \(I\left( {f_{i} ;\,c} \right)\) represents the mutual information between each feature and class, and \({\text{corr}}\left( {f_{i} ;\,c} \right)\) refers to the Pearson correlation coefficient between each feature and class.
The range of feature subsets \(r\) is shown in Eqs. 8 and 9.
where \(Fc\) is the number of features in the feature subset.
This paper exploits an equal grouping method (EGM) to generate candidate feature subsets. According to the ranking features with relevance, each feature is assigned to a group one by one. When the first-round assignation has finished, the feature will be assigned to a group reversely till the end of the round, and keep going the assignation and swapping directions until all the features assigned to the groups.
For example, suppose the number of features \(M\) = 20, then \(Fc\) = 4, and the range of feature subsets \(r\) = 5, the feature subsets generation process is shown in Fig. 2.

Generate feature subsets with equal grouping method
4.2 Generate ranking feature subsets sequence
By calculating the contribution of each candidate feature subset, the ranking sequence of these feature subsets is obtained. It is mainly divided into the following three steps.
-
1.
Calculate the relevance of all individual features in each candidate feature subset according to Eq. 6, and accumulate them to obtain the contribution of the candidate feature subset. The candidate feature subset with the largest contribution is taken as the first selected feature subset \(F_{y}\);
-
2.
Calculate the relevance \(D\left( {F_{x} ;\,c} \right)\) and redundancy \(R\left( {F_{x} ;\,F_{y} } \right)\) of the remaining candidate feature subsets according to Eqs. 10 and 12, respectively;
-
3.
Combined with Eq. 14, the incremental search method is used to select feature subset. Then, contribution ranking of all feature subsets is obtained.
$$D\left( {F_{x} ;\,c} \right) = \beta *I\left( {F_{x} ;\,c} \right) + \left( {1 - \beta } \right)*{\text{corr}}\left( {F_{x} ;\,c} \right)$$(10)$$I\left( {F_{x} ;\,c} \right) = \mathop \sum \limits_{i = 1}^{Fc} I\left( {f_{i} ;\,c} \right),{\text{corr}}\left( {F_{x} ;\,c} \right) = \mathop \sum \limits_{i = 1}^{Fc} {\text{corr}}\left( {f_{i} ;\,c} \right)$$(11)$$R\left( {F_{x} ;\,F_{y} } \right) = \frac{1}{m - 1}\mathop \sum \limits_{{F_{y} \in S_{m - 1} }} \left( {\beta *I\left( {F_{x} ;\,F_{y} } \right) + \left( {1 - \beta } \right)*{\text{corr}}\left( {F_{x} ;\,F_{y} } \right)} \right)$$(12)$$I\left( {F_{x} ;\,F_{y} } \right) = \mathop \sum \limits_{i,j = 1}^{Fc} I\left( {f_{i} ;\,f_{j} } \right), {\text{corr}}\left( {F_{x} ;\,F_{y} } \right) = \mathop \sum \limits_{i,j = 1}^{Fc} {\text{corr}}\left( {f_{i} ;\,f_{j} } \right)$$(13)$${\text{ImRMR}} = \mathop {\max }\limits_{{F_{x} \in X - S_{m - 1} }} \left[ {D\left( {F_{x} ;\,c} \right) - R\left( {F_{x} ;\,F_{y} } \right)} \right]$$(14)where \(\beta \in \left[ {0.1,1} \right]\), with a step size of 0.1.
4.3 Acquisition of optimal feature subset
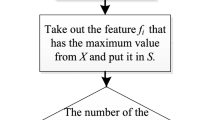
Take out the features of the feature subsets sequence in turn to find features sequence. The optimal feature subset is obtained according to the ranking features sequence and the SFS search strategy.
The feature selection algorithm based on ImRMR and SFS is descripted as follows.

In addition, for the ImRMR algorithm, the same \(\alpha\) and different \(\beta\) settings make the sample set generate different feature subset when calculating the contribution of feature subset according to Eq. 14. Therefore, the different feature subsets \(b_{1} ,b_{2} , \ldots ,b_{m}\) can be obtained, and \(m\) represents the number of settings \(\beta\), where the feature subset \(b_{\max }\) with the highest accuracy is selected as the optimal feature subset for the current \(\alpha\).
Different \(\alpha\) settings make the sample set generate different optimal feature subset such as \(CS_{1} ,CS_{2} , \ldots ,CS_{n}\), \(n\) represents the number of settings \(\alpha\). The feature subset \(CS^{*}\) with the highest accuracy among these \(n\) feature subsets is selected as the final optimal feature subset.
5 Experiment and result analysis
5.1 Experimental environment
The hardware platform is a laptop computer with 16G RAM and 11th Gen Intel(R) Core(TM) i7-11370H @ 3.30 GHz CPU. The operating system is Windows 10 64-bit. MATLAB 2018b is the data processing, programming and running platform as well WEKA 3.8.5.
5.2 Experimental datasets
Seven datasets were involved in experiments. Five of them are provided by the UCI Machine Learning Repository [31]: Musk dataset (Musk), Urban land cover dataset (Urban), Glass dataset (Glass), Libras Movement dataset (Movement) and Ionosphere dataset (Ionosphere). One dataset is the commonly used hyperspectral dataset Pavia University (PU) [32]. And the other one is crane songs dataset (Crane).
Each dataset is divided into training set and test set as the ratio of 7:3. The information of datasets are listed in Table 1.
5.3 The design of experiments
Two groups experimental scheme are designed. One group compared the proposed method of EGM with the method of randomly selecting features to generate candidate feature subsets. And the other compared the ImRMR with other feature selection methods, such as mRMR, InfoGain (IG) [33], Symmetrical Uncert (SU) [34], GainRatio (GR) [35] and ReliefF (RfF) [36].
The four feature selection methods of IG, SU, GR RfF and the classification method of random forest involved in the experiment are all built-in methods in WEKA 3.8.5, which are implemented by MATLAB 2018b calling the interface of WEKA 3.8.5, and the parameters of each feature selection method are default parameters. The mRMR method has no parameter settings, and \(\alpha \;{\text{and}}\;\beta\) in ImRMR are set in \(\left[ {0.1,1} \right]\).
Random forest is an ensemble learning method based on bagging, which can handle classification problems and regression problems well, and is one of the most widely used machine learning methods at present. To verify effectiveness of the proposed ImRMR feature selection method, the random forest classifier is adopted to obtain classification results of the selected optimal feature subset. Each experiment is repeated 30 times independently, and the average of the experimental results is taken as the final result. The evaluation indicators include accuracy rate, dimensionality reduction rate, comprehensive rate, precision, recall and F-measure.
The accuracy rate is used to evaluate the proportion of correctly identified samples to the total number of samples in the prediction results. Its calculation is shown in Eq. 15.
where \(P_{a}\) is the number of the correctly classified samples, and \(N\) represents the number of all samples.
The dimensionality reduction rate as an evaluation indictor is introduced, as shown in Eq. 16.
where \(Sc\) is the number of selected features, and \(Oc\) represents the number of raw features. The larger the \(Dr\) value, the stronger the ability to reduce dimensions.
The comprehensive rate considers the accuracy rate and the dimensionality reduction rate, as shown in Eq. 17.
where \(Z\) is the comprehensive rate, \({\text{Acc}}\) is the accuracy rate, \(Dr\) is the dimensionality reduction rate. The \(\theta\) is the tradeoff factor. In experiments, the value of \(\theta\) is 0.5.
The precision is used to evaluate the proportion of all predicted correct samples that contain actual correct samples. Its calculation is shown in Eq. 18.
where TP is the sum of the number of correctly classified samples and FP is the number of samples predicted to be correct that are actually wrong.
The recall rate is the percentage of in all samples where the correct sample is predicted to be correct. Its calculation is shown in Eq. 19.
where TP is the sum of the number of correctly classified samples and FN is the number of samples that are actually correct but predicted to be wrong.
F-measure is precision and recall weighted harmonic mean. F-measure calculation is shown in Eq. 20.
5.4 Result analysis
5.4.1 Comparison of EGM with random grouping
In this group experiments, EGM and the method of random grouping are, respectively, applied to the generating candidate feature subsets part of ImRMR, namely ImRMR-EGM and ImRMR-RS. The random grouping method is different from EGM only in that the features of its grouping are randomly assigned, and other parts are consistent with EGM.
Using SFS search strategy, by recording the dimensionality reduction rate, the accuracy rate, precision, recall, F-measure and the comprehensive rate when the classification accuracy obtained by the ImRMR-EGM and ImRMR-RS feature selection of the seven datasets reached the maximum value, the performances of the two methods are compared. The experimental results are shown in Table 2 and Fig. 3.

Performance of ImRMR-EGM and ImRMR-RS
Seen from Table 2 and Fig. 3, ImRMR-EGM has good effects on the seven datasets. The dimensionality reduction rate reaches 55.56–90.96%, and the classification accuracy is 2.34–18.75% higher than that of the raw feature. ImRMR-EGM not only effectively reduces the dimension of the dataset and but also improves the classification accuracy.
In seven datasets, the comprehensive rate of ImRMR-EGM is higher than that of ImRMR-RS by 0.14–5.42%. And in most cases, the accuracy, precision, recall and F-measure of ImRMR-EGM are higher than ImRMR-RS. Therefore, the EGM has achieved good results in generating candidate feature subsets, which outperforms the random grouping method.
5.4.2 Comparison of ImRMR with other feature selection methods
Experiments with ImRMR and other five feature selection methods are conducted on seven datasets. Combine SFS search strategy, the results of various feature selection methods are classified by random forest. Their performances are compared with the evaluation indices including dimensionality reduction rate, accuracy rate, precision, recall, F-measure and comprehensive rate when the classification accuracy reaches the maximum.
The experimental results are shown in Table 3 and Fig. 4. And the abscissa labels 1, 2, 3, 4, 5, 6, and 7 in Fig. 4 represent raw feature and six feature selection method of ImRMR, mRMR, IG, SU, GR, and RfF, respectively.

Performance of ImRMR with other methods
Seen from Table 3 and Fig. 4, ImRMR outperforms five methods (mRMR, IG, SU, GR, and RfF) on seven datasets of Musk, Urban, Ionosphere, Glass, PU, Movement, and Crane. Among them, the comprehensive rate of ImRMR is 1.27–3.82%, 6.34–24.48%, 3.8–6.94%, 4.75–20.36% and 0.83–6% higher than the five methods on the five datasets of Urban, Glass, Movement, PU and Crane, respectively; for the Musk dataset, the comprehensive rate of ImRMR is only 0.6% lower than that of mRMR, and 2.67–4.18% higher than that of the other four methods; for the Ionosphere dataset, the comprehensive rate of ImRMR is only 0.99% and 0.04% lower than mRMR and SU, respectively, and 1.95–6.36% higher than the other three methods. The accuracy of ImRMR on six datasets (Urban, Ionosphere, Glass, PU, Movement and Crane) is higher than these five feature selection methods, and the accuracy on Musk datasets is the same as mRMR and better than the other four feature selection methods. In addition, in most cases, ImRMR is superior to the other five feature selection methods in terms of recall, F-measure and precision on seven sets of datasets. Therefore, from a comprehensive comparison, the ImRMR feature selection method is superior to the five feature selection methods.
From the above comparative experiments, experimental results show that the proposed ImRMR method can effectively remove irrelevant and redundant features, which can not only reduce the dimension of sample features, but also achieve better classification and recognition results.
5.4.3 Comparison with state-of-the-art methods
Recently, various researchers have analyzed various feature selection methods due to improved accuracy results. Table 4 shows the comparative analysis of the proposed method with other methods using the same dataset. It can be noticed that the proposed method shows higher accuracy (Acc) and comprehensive rate (Z) in feature selection compared to other methods using the same dataset.
5.5 Discussion of using SFSFs for ranking feature subsets sequence
To further explore the effectiveness of the feature subset selected by the ImRMR, the sequence forward selection feature subset method (SFSFs) is used for the ranking feature subsets sequence to verify the pros and cons of the feature subset.
The steps of the SFSFs are as below.
-
1.
The optimal feature subset starts with an empty set;
-
2.
The first feature subset in the ordered feature subset set is added for the first time, and then the feature subset is added iteratively according to the order, which is combined with the selected feature subset to form a new feature subset;
-
3.
This process continues until the classification accuracy of the newly mapped training set is greater than or equal to the raw classification accuracy, and the corresponding feature subset is the selected optimal feature subset.
The feature selection method based on SFSFs is shown in Fig. 5. Combine the SFSFs search strategy to get the final preferred subset and mapping the optimal feature subset to the raw sample set can carry out classification and recognition. The effects of ImRMR and other five feature selection methods are compared by the dimensionality reduction rate, accuracy, comprehensive rate, recall, F-measure and precision when the classification accuracy with feature selection is greater than or equal to that of the raw datasets.

Feature selection method based on SFSFs
The experimental results are shown in Table 5 and Fig. 6. And the abscissa labels 1, 2, 3, 4, 5, 6, and 7 in Fig. 6 represent raw feature and six feature selection method of ImRMR, mRMR, IG, SU, GR, and RfF, respectively.

Comparison of the effects of six methods
From Table 5 and Fig. 6, the performance of ImRMR based on SFSFs is better than five feature selection methods including mRMR, IG, SU, GR, and RfF in seven datasets. Among them, the comprehensive rate of ImRMR is 5.32–26.46%, 15.64–24.39%, 21.57–31.02%, 9.39–30.21%, 11.33–29.33% higher than the five feature selection methods on the five datasets of Musk, Urban, Movement, PU and Crane, respectively; the comprehensive rate of ImRMR on Ionosphere was only 0.52% lower than mRMR, and 0.48–23.01% higher than the other four methods; the comprehensive rate of ImRMR on Glass is 3.3% and 8.08% lower than that of RfF and mRMR, respectively, and 1.47–12.58% higher than the other three methods. The accuracy of ImRMR on six datasets including Musk, Urban, Ionosphere, Glass, Movement and PU is higher than the five feature selection methods, and the accuracy on Crane dataset is the same as the five feature selection methods. Furthermore, ImRMR outperforms the other five feature selection methods in recall, F-measure and precision on the seven datasets in most cases. Therefore, in a comprehensive comparison, with SFSFs the ImRMR feature selection method is superior to the five feature selection methods such as mRMR, IG, SU, GR, and RfF, and can effectively measure the contribution of feature subset to obtain an effective ranking feature subsets sequence.
6 Limitations and future scope
This paper improves mRMR based on feature subsets, and proposes the ImRMR method, which is used to select efficient feature sets, reduce the dimension of feature sets, and improve the classification performance of samples. There still exists more issues to carry out in the future work, and some of the most important points are listed below:
-
Extend the method to more datasets.
-
This study currently proposes EGM to divide candidate feature subsets. Other more feature subset division methods are needed to be explored to improve the quality of candidate feature subsets.
-
This study only uses Pearson correlation coefficient and mutual information to measure correlation and redundancy. In the next work, we will try to explore other measurement criteria to improve the effectiveness of the selected features.
7 Conclusion
In this paper, considering the joint contribution between multiple features, the proposed ImRMR method expands the feature selection process based on feature subset.
EGM is used to divide the raw feature set into multiple different candidate feature subsets. Two criteria of Pearson’s correlation coefficient and mutual information are used to calculate the correlation and redundancy of candidate feature subsets, and weights are introduced to tradeoff both criteria. Then the SFS search strategy is combined for the ranking feature subsets sequence to obtain the optimal feature subset. Compared with five methods, including mRMR, InfoGain, Symmetrical Uncert, GainRatio, and ReliefF, experimental results verified the effectiveness on seven datasets. In most cases, ImRMR outperforms the other methods, and can effectively obtain the optimal feature subset and improve the performance of the classification.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Hall MA (1999) Correlation-based feature selection for machine learning. Doctoral Dissertation, Univ Waikato
Liu H, Motoda H (1999) Feature extraction, construction and selection: a data mining perspective. J Am Stat Assoc. https://doi.org/10.2307/2669967
Guyon I, Elisseeff A (2003) An introduction to variable and feature selection. J Mach Learn Res 3:1157–1182. https://doi.org/10.1162/153244303322753616
Zhao S, Zhang Y, Xu HF, Han T (2019) Ensemble classification based on feature selection for environmental sound recognition. Math Probl Eng. https://doi.org/10.1155/2019/4318463
Saqlain SM, Sher M, Shah FA, Khan I, Ashraf MU, Awais M, Ghani A (2019) Fisher score and Matthews correlation coefficient-based feature subset selection for heart disease diagnosis using support vector machines. Knowl Inf Syst 58:139–167. https://doi.org/10.1007/s10115-018-1185-y
Yong JY, Zhou ZM (2020) Multi-level feature selection algorithm based on mutual information. J Comput Appl 40:3478–3484
Ye TT, Liu MX, Zhang DQ (2016) Effective distance based multi-modality feature selection. Pattern Recognit Artif Intell 29:658–664
Mafarja M, Mirjalili S (2018) Whale optimization approaches for wrapper feature selection. Appl Soft Comput 62:441–453. https://doi.org/10.1016/j.asoc.2017.11.006
Jadhav S, He H, Jenkins K (2018) Information gain directed genetic algorithm wrapper feature selection for credit rating. Appl Soft Comput 69:541–553. https://doi.org/10.1016/j.asoc.2018.04.033
Xu HF, Zhang Y, Liu J, Lv DJ (2021) Feature selection method based on coefficient of variation and maximum feature tree. J Nanjing Norm Univ (Nat Sci Ed) 44:111–118
Maldonado S, López J (2018) Dealing with high-dimensional class-imbalanced datasets: embedded feature selection for SVM classification. Appl Soft Comput 67:94–105. https://doi.org/10.1016/j.asoc.2018.02.051
Liu YF, Li WB, Gao Y (2020) Adaptive neighborhood embedding based unsupervised feature selection. J Comput Res Dev 57:1639–1649. https://doi.org/10.7544/issn1000-1239.2020.20200219
Peng H, Long F, Ding C (2005) Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans Pattern Anal Mach Intell 27:1226–1238. https://doi.org/10.1109/tpami.2005.159
Lu SH, Sun M, Xie JH, Guo J, Jia WK, Su DY (2020) Fault location method of transmission line based on the maximum correlation-minimum redundancy algorithm. Electr Meas Instrum 57:79–85
Billah M, Waheed S (2020) Minimum redundancy maximum relevance (mRMR) based feature selection from endoscopic images for automatic gastrointestinal polyp detection. Multimed Tools Appl 79:23633–23643. https://doi.org/10.1007/s11042-020-09151-7
Toaar M, Ergen B, Cmert Z (2019) A deep feature learning model for pneumonia detection applying acombination of mRMR feature selection and machine learning models. IRBM 41:212–222. https://doi.org/10.1016/j.irbm.2019.10.006
Gu C, Yang Y, Zhang XX, Jin M, Zhou SY (2018) Feature selection for transformer fault diagnosis based on maximal relevance and minimal redundancy criterion. Adv Technol Electr Eng Energy 37:6
Erolu Y, Yildirim M, Inar A (2021) Convolutional neural networks based classification of breast ultrasonography images by hybrid method with respect to benign, malignant, and normal using mRMR. Comput Biol Med 133:104407. https://doi.org/10.1016/j.compbiomed.2021.104407
Fan X, Huang X, Zhao Y, Wang L, Yu H, Zhao G (2022) Predicting prognostic effects of acupuncture for depression using the electroencephalogram. Evid Based Complement Alternat Med 2022:1381683. https://doi.org/10.1155/2022/1381683
Tuncer T, Dogan S, Baygin M, Rajendra Acharya U (2022) Tetromino pattern based accurate EEG emotion classification model. Artif Intell Med 123:102210. https://doi.org/10.1016/j.artmed.2021.102210
Sharma DK, Subramanian M, Malyadri P, Reddy BS, Sharma M, Tahreem M (2022) Classification of COVID-19 by using supervised optimized machine learning technique. Mater Today Proc 56:2058–2062. https://doi.org/10.1016/j.matpr.2021.11.388
Baliarsingh SK, Muhammad K, Bakshi S (2021) SARA: a memetic algorithm for high-dimensional biomedical data. Appl Soft Comput 101:107009. https://doi.org/10.1016/j.asoc.2020.107009
Feng YJ, Zhang FB (2014) Max-relevance min-redundancy restrictive BAN classifier learning algorithm. J Chongqing Univ (Nat Sci Ed) 37:71–77
Yao X, Wang XD, Zhang YX, Quan W (2013) A maximum relevance minimum redundancy hybrid feature selection algorithm based on particle swarm optimization. Control Desicion 28:413-417+423
Li SY, Wang GB (2021) New MRMR feature selection algorithm. CAAI Trans Intell Syst 16:649–661
Wang HH, Huang L, Zhou YW, Zhao YK (2019) Application of improved mRMR feature selection in human activity recognition. J Chongqing Univ Posts Tel-ecommun (Nat Sci Ed) 31:261–269
Jo I, Lee S, Oh S (2019) Improved measures of redundancy and relevance for mRMR feature selection. Compututers 8:42. https://doi.org/10.3390/computers8020042
Ahmed YA, Koer B, Huda S, Al-rimy B (2020) A system call refinement-based enhanced Minimum Redundancy Maximum Relevance method for ransomware early detection. J Netw Comput Appl 167:102753. https://doi.org/10.1016/j.jnca.2020.102753
Ahmed YA, Huda S, Al-Rimy B, Alharbi N, Saeed F, Ghaleb FA, Ali IM (2022) A weighted minimum redundancy maximum relevance technique for ransomware early detection in industrial IoT. Sustainability (Basel) 14:1–15
Breiman L (2001) Random forests. Mach Learn 45:5–32. https://doi.org/10.1023/A:1010933404324
UCI Machine Learning Repository. https://archive-beta.ics.uci.edu/ml/datasets. Accessed 1 Nov 2021
Grupo De Inteligencia Computacional. http://www.ehu.eus/ccwintco/index.php/. Accessed 1 Nov 2021
Liu QH, Liang ZY (2011) Optimized approach of feature selection based on information gain. Comput Eng Appl 47:130-132+136
Kannan SS, Ramaraj N (2010) A novel hybrid feature selection via symmetrical uncertainty ranking based local memetic search algorithm. Knowl-Based Syst 23:580–585. https://doi.org/10.1016/j.knosys.2010.03.016
Modinat M, Abimbola A, Abdullateef B, Opeyemi A (2015) Gain ratio and decision tree classifier for intrusion detection. Int J Comput Appl 126:975–8887. https://doi.org/10.5120/ijca2015905983
Kononenko I (1994) Estimating attributes: analysis and extensions of RELIEF. In: Proceedings of European Conference on Machine Learning Catania, Italy, April 6–8. https://doi.org/10.1007/3-540-57868-4_57
Mafarja M, Aljarah I, Faris H, Hammouri AI, Al-Zoubi AM, Mirjalili S (2019) Binary grasshopper optimisation algorithm approaches for feature selection problems. Expert Syst Appl 117:267–286. https://doi.org/10.1016/j.eswa.2018.09.015
Du ZG, Pan JS, Chu SC, Chiu YJ (2020) Improved binary symbiotic organism search algorithm with transfer functions for feature selection. IEEE Access 8:225730–225744. https://doi.org/10.1109/ACCESS.2020.3045043
Ghosh KK, Singh PK, Hong J, Geem ZW, Sarkar R (2020) Binary social mimic optimization algorithm with x-shaped transfer function for feature selection. IEEE Access 8:97890–97906. https://doi.org/10.1109/ACCESS.2020.2996611
Han F, Chen WT, Ling QH, Han H (2021) Multi-objective particle swarm optimization with adaptive strategies for feature selection. Swarm Evol Comput 62:100847. https://doi.org/10.1016/j.swevo.2021.100847
Kang Y, Wang HN, Tao L, Yang HX, Yang XK, Wang F, Li H (2022) Hybrid improved flower pollination algorithm and gray wolf algorithm for feature selection. Comput Sci 49:125–132. https://doi.org/10.11896/jsjkx.210600135
Zhang L, Wang C (2018) Multi-label feature selection algorithm based on joint mutual information of max-relevance and min-redundancy. J Commun 39:111–122. https://doi.org/10.11959/j.issn.1000-436x.2018082
Chen JT, Yuan SH, Lv DD, Xiang Y (2021) A novel self-learning feature selection approach based on feature attributions. Expert Syst Appl 183:115219. https://doi.org/10.1016/j.eswa.2021.115219
Acknowledgements
This study was supported by the National Natural Science Foundation of China under Grant No. 61462078 and under Grant No. 31860332, the Yunnan Provincial Science and Technology Department under Grant No. 202002AA10007, the Yunnan Provincial Department of Education under Grant No. 2022Y558.
Author information
Authors and Affiliations
Contributions
Conceptualization, SSX and YZ; Data curation, JL and JL; Funding acquisition, YZ, DJL and SSX; Investigation, JL and JL; Methodology, SSX and YZ; Resources, JL and JL; Supervision, YZ and XC; Validation, SSX, DJL and XC; Writing—original draft, SSX; Writing—review & editing, YZ, DJL and XC. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The author(s) declare no competing interests.
Ethical statement
In this paper, the experiments did not use live cranes.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xie, S., Zhang, Y., Lv, D. et al. A new improved maximal relevance and minimal redundancy method based on feature subset. J Supercomput 79, 3157–3180 (2023). https://doi.org/10.1007/s11227-022-04763-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-022-04763-2