
Abstract
Because of the increasing complexities of systems and applications, the performance of many traditional HPC benchmarks, such as HPL or HPCG, no longer correlates strongly with the actual performance of real applications. To address the discrepancy between simple benchmarks and real applications, and to better understand the application performance of systems, some metrics use a set of either real applications or mini applications. In particular, the Sustained System Performance (SSP) metric Kramer et al. (The NERSC sustained system performance (SSP) metric. Tech Rep LBNL-58868, 2005), which indicates the expected throughput of different applications executing with different datasets, is widely used. Whereas such a metric should lead to direct insights on the actual performance of real applications, sometimes more effort is necessary to port and evaluate complex applications. In this study, to obtain the approximate performance of SSP representing real applications, without running real applications, we propose a metric called the Simplified Sustained System Performance (SSSP) metric, which is computed based on several benchmark scores and their respective weighting factors, and we construct a method evaluating the SSSP metric of a system. The weighting factors are obtained by minimizing the gap between the SSP and SSSP scores based on a small set of reference systems. We evaluated the applicability of the SSSP method using eight systems and demonstrated that our proposed SSSP metrics produce appropriate performance projections of the SSP metrics of these systems, even when we adopted a simple method for computing the weighting factors. Additionally, the robustness of our SSSP metric was confirmed via computation of the weighting factors based on a smaller set of reference systems and computation of the SSSP metrics of other systems.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Benchmarks play important roles in various stages of system life cycles, including design, development, implementation and maintenance, where they are used to estimate, evaluate, and ensure the effectiveness of a system. The High-Performance Linpack (HPL) kernel benchmark [14, 29] is one of the most widely used benchmarks in the world of high-performance computing. Linpack solves a dense linear system of equations, such as \(\varvec{y}=A\varvec{x}\). Because Linpack uses lower–upper (LU) factorization, its dominant computations are double-precision general matrix multiplications, which are relatively easy to tune to achieve the theoretical peak performance of processors. However, because of the increasing complexities of modern systems and applications, HPL performance no longer correlates strongly with the actual performance of real applications [13]. To address the discrepancy between HPL and real applications at performance levels, new benchmarks such as the High-Performance Conjugate Gradient (HPCG) [13] have been proposed. HPCG performance is known to be strongly influenced by memory bandwidth. Meanwhile, some systems with relatively few bytes per flop (B/F) also work efficiently for real applications.
Another approach to understanding system performance is to use a set of real applications, or real applications represented by mini applications. Several sets of mini applications, most of which are combinations of applications with different characteristics from different scientific fields [9, 17, 18, 23, 25, 32, 38], have been proposed. These sets of mini applications have not been provided with a single metric for system performance, to enable easy comparison between these systems. In response, Kramer et al. proposed the Sustained System Performance (SSP) metric, which is a system performance metric based on the time to solution and is able to accommodate any number of application areas [22]. In contrast to simple kernel benchmarks, these application metrics can lead to direct insights on the performance of systems in terms of their real workloads. However, execution of mini or real applications requires more time and effort than those required for the execution of simple kernel benchmarks. Furthermore, whereas methods for optimizing simple kernel benchmarks are well known, optimization of an application must be determined almost completely, without reliance on pre-existing methods.
In this paper, we propose a new system performance metric for application executions that is characterized by the ease of use of simple benchmarks, and the practicality of application sets. The proposed metric, which we refer to as the Simplified Sustained System Performance (SSSP) metric, is an extension of the SSP metric. Whereas the SSP metric focuses on the performance of systems based on actual executions of target applications, the SSSP metric focuses on the performance of applications based on the execution of simple benchmarks. SSSP uses a suite of simplified kernel benchmarks to produce performance projections for a suite of real applications. For the projection, we calculate a set of weighting factors that allow us to approximate the SSP metrics, which are computed over a set of applications using a set of simple benchmarks.
We performed experiments to investigate the applicability of the proposed metric. First, we executed a set of applications and a set of benchmarks on eight different systems. In this case, we considered relatively small-scale applications and benchmarks. From the results of the benchmarks, the SSSP metric for each system was computed and compared with the corresponding SSP metric. The experiments demonstrated that the SSSP metric produced appropriate performance projections of the SSP metric, especially when we introduced weighting factors into the benchmarks in the approximation of the SSP. Therefore, if we applied both the applications and benchmarks on a few reference systems to obtain the weighting factors, then we could approximate the SSP metric using the SSSP metric in other systems, i.e., we could obtain the SSP metric by executing only benchmarks and calculating the weighted sum of the benchmark scores. Secondly, we executed the set of applications and set of benchmarks on two large systems. Whereas using benchmark scores from a large-scale system and weighting factors from small-scale experiments could be used to approximate the SSP metric of the large system, the result was less precise than for the same-scale cases.
We summarize the contributions of this paper as follows:
-
A new performance metric called the SSSP metric, which can lead to appropriate insights on the application performance of systems without the need for actual execution of full scale, long running real applications,
-
A method for constructing SSSP metrics based on weighting factors on simple kernel benchmarks,
-
Experiments on eight different systems reveal that most well-known benchmarks cannot provide an appropriate performance metric on the application performance of systems.
The rest of this paper is structured as follows. In Sect. 2, we describe the Sustained System Performance (SSP) metric, which can be approximated using the proposed metric. Section 3 presents the Simplified System Performance (SSSP) metric, and Sect. 4 evaluates, via numerical experiments, how the SSSP metric can be used to approximate the SSP metric through numerical experiments. Sections 5 and 6 discuss the study, specifically its results, and examine related works. Lastly, Sect. 7 presents the conclusion of the study and discusses possible avenues for future research.
2 Background: Sustained System Performance (SSP)
In this section, we describe the SSP metric [22], which can be approximated using the proposed metric.
2.1 Overview of SSP metric
To evaluate high-performance computing (HPC) systems and compare different systems in terms of system effectiveness on sets of applications intended for use, the US National Energy Research Scientific Computing Center (NERSC) proposed a metric called the Sustained System Performance (SSP) metric[22]. NERSC has used SSP for their procurement process and on-going system evaluations since 1998. Aside from system comparison, the purpose of the SSP method was to provide the following guidelines throughout the lifetime of a system and to facilitate the design of future systems [20]:
-
Evaluating and/or selecting a system from among its competitors,
-
Validating the selected system once it is built and deployed,
-
Assuring the system performance remains as expected throughout the lifetime of the system,
-
Helping guide future system designs.
Moreover, the SSP metric takes the following attributes of good metrics, as described in [24, 35] into account:
-
proportionality
-
reliability
-
consistency
-
independence
-
ease of use
-
repeatability
-
avoid misleading conclusions
The objective of this paper is to propose a metric that leads to appropriate insights on the application performance of systems without the need for actual execution of real applications while maintaining all the attributes of good metrics. We construct our metric by approximating the SSP metric using a set of simplified benchmarks. We adapt the SSP metric as the approximation target of the proposed method, because the SSP metric is clearly defined, easy to apply, and is already being used for the procurement of several systems.
2.2 Definition of SSP metric
Here, we briefly describe how to compute the SSP metric. For more detail, please refer to Kramer et. al [21, 22].
Table 1 summarizes the notation used in defining the SSP metric.
Let I be a set of target applications i, and \(J_i\) be the data set for application i, where \(1\le i \le |I|\). Let the total reference operation count of application i executing data set j be \(f_{i,j}\). The reference operation count is determined once for each application–data combination. The determination can be performed either via static analysis of source code or using performance counters on a reference system. Let \(m_{i,j}\) be the concurrency of application i executing data set j. The amount of work for each processor for application i working on data set j, \(m_{i,j}\), is then calculated as follows:
If the time to completion of application i executed on data set j is \(t_{i,j}\), then the per-processor performance (PPP) \(p_{i,j}\) is calculated as follows
Note that, sometimes, we use \(p_{i,j}^s\) to indicate the per-processor performance of (i, j) on a system s.
The SSP metric for system s is obtained via multiplication of the sum of the PPPs over all applications for all data sets by the number of processors N in the system. Therefore, the SSP metric is calculated as follows:
As shown in Eq. 4, the SSP metric is defined as the expected throughput of different applications, multiple data sets, and various concurrences.
For more details on the SSP metric please refer [7, 20, 27]. As an instance of the SSP metric, the Sustained Petascale Performance (SPP) metric and the set of applications used in the SPP metric have been presented at [39].
3 Simplified Sustained System Performance (SSSP) Metric
In this section, we present a new metric called the Simplified Sustained System Performance (SSSP) metric, which we designed to produce performance projections for applications without the need to evaluate the full-scale applications based on actual execution. The proposed SSSP metric is a correlated simplification of the already existing SSP metric. Whereas the SSP metric is computed over a set of applications, the SSSP metric, for ease of use, is applied to a set of simplified benchmarks. To approximate the SSP metric accurately, weighting factors for the benchmarks are computed to in such a way as minimize the differences between the SSP and SSSP metrics. Firstly, both the applications and benchmarks must be executed on several systems to optimize the weighting factors. After we obtain the weighting factors, we can approximate the SSP metric using simple benchmark results and the weighting factors without having to run any applications. Therefore, the advantage of the SSSP metric compared to the SSP metric is that the SSSP metric is able to produce an approximated score to the SSP metric without requiring the actual execution of applications, unlike when the SSP metric itself is used.
3.1 Concept of the SSSP metric

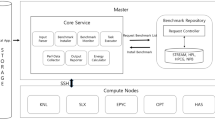
Overview of the Simplified Sustained System Performance (SSSP) metric, which estimates the performance of benchmarks to produce performance projections for real applications. The SSP metric is computed based on sets of applications for various fields of interest, such as astrophysics and life-sciences, whereas the SSSP metric is computed based on sets of benchmarks such as HPL and conjugate gradient method. Use of weighting factors on benchmarks allows SSSP metric to produce performance projections for applications
As described in Sect. 2, the SSP metric assigns a score to each system, indicating system performance with regard to its execution of applications. Because it is based on a wide variety of applications, the SSP metric can directly show the performance and time to solution of real workloads. However, we have to expend significantly much effort to port and optimize full applications to evolving architectures to compute SSP metric. Thus, initially, we have to better understand the working of the applications, prepare appropriate versions of libraries and compilers, and identify and eliminate bottlenecks as much as possible. To compare two or more systems, we will have to repeat these steps multiple times.
In this study, we extend the SSP metric to overcome its complexity. The new metric, which we have called the Simplified Sustained System Performance (SSSP) metric, replaces the set of applications used in the SSP metric with a set of simple benchmarks. In addition, we introduce weighting factors to adjust the impact of different benchmarks and to approximate the SSP metric using the SSSP metric. Therefore, the SSSP metric takes advantage of the benefits of simple benchmarks, such as ease of use, while also producing a performance projection of the application metric. With the SSSP metric, we aim to calculate performance projections for real applications by appropriately combining various benchmarks as shown in Fig. 1. The SSP metric is computed based on sets of applications for various fields of interest, such as astrophysics and life-sciences, whereas the SSSP metric is computed based on sets of benchmarks such as HPL and conjugate gradient method. Use of weighting factors on benchmarks allows SSSP metric to produce performance projections for applications.
3.2 Definition of the SSSP metric
The definition of the SSSP metric is very simple and is almost the same as that of the SSP:
where N is the number of nodes, \(I'\) is a set of benchmarks, \(J_i\) is a data set for each of the benchmarks, \(p_{i,j}\) is the per-processor performance which has been defined in (2), and \(w_{i,j}\) is the weighting factor, which will be defined to approximate \(\hbox {SSP}(s)\) using \(\hbox {SSSP}(s)\).
To ensure that the SSSP metric will be able to properly represent the performance of applications computed using the SSP metric, the SSSP metric must satisfy the following proportionality:
where S is a set of different systems. This indicates that if a system s is better than another system \(s'\) based on the SSSP metric, then system s must also be better than system \(s'\) on the basis of the SSP metric.
Additionally, by assigning appropriate weighting factors \({\varvec{w}}\), we aim to produce an accurate approximation of the SSP metric using the SSSP metric:
The weighting factors should be provided determined on the SSP and SSSP metrics of a set of reference systems.
4 Experiments
In this section, we investigate the applicability of the proposed metric.
4.1 Experimental procedure and environment
To validate the proposed metric, for the sake of simplicity, we focus on the per-processor performance (PPP) of the systems, rather than the SSP and SSSP metrics themselves:
where I is a set of applications, and \(P_{\hbox {ssp}}(s)\) is the PPP metric of a system s based on I, \(I'\) is a set of benchmarks, and \(P_{\hbox {sssp}}(s)\) is the PPP metric of a system s based on \(I'\).
The weighting factors \(w_{i,j}\in {\varvec{w}}\) are introduced for the approximation of \(P_{\hbox {ssp}}(s)\) based on \(P_{\hbox {sssp}}(s)\); In some cases, we do not consider the weighting factors by assuming \(w_{i,j}=1\) for all pairs of (i, j). The weighting factors are computed to minimize the difference between the \(P_{\hbox {ssp}}(s)\) and \(P_{\hbox {sssp}}(s)\) scores of a subset of systems;
while \(w_{i,j}>0\) for all pairs of (i, j), where \(S'\) is a partial set of systems. With the obtained weighting factors, \(P_{\hbox {sssp}}(s)\) are computed for the rest of the systems, to be compared with \(P_{\hbox {ssp}}(s)\). If the gap between \(P_{\hbox {sssp}}(s)\) and \(P_{\hbox {ssp}}(s)\) is small, this indicates that we can approximate the performance of applications, \(P_{\hbox {ssp}}(s)\), based only on the benchmark tests.
The overall procedure of the experiments is as follows:
-
1.
Execute applications I (shown in sect. 4.2) and benchmarks \(I'\) (shown in sect. 4.3) on the eight systems \(s\in S\) listed in Table 2 to obtain \(p_{i,j}^s\).
-
2.
Compute the weighting factors \(w_{i,j}\) based on eq. 10.
-
3.
Check how \(P_{\hbox {SSSP}}(s)\) is able to approximate \(P_{\hbox {SSP}}(s)\) for 2 cases:
-
when \(w_{i,j}=1\), and
-
when the weighting factors obtained at (2) are used.
-
4.
Check the robustness of the proposed method by computing the weighting factors over 8 subsets of the 8 systems. Each subset consists of 7 systems, one of the 8 systems is excluded.
-
Check how \(P_{\hbox {SSSP}}(s)\) with the aforementioned weighting factors can be used to approximate \(P_{\hbox {SSP}}(s)\).
-
Compare the sets of weighting factors computed from different sets of systems.
-
5.
To examine the scalability of the proposed method, execute applications I and benchmarks J on two large-scale systems.
-
6.
Compute the weighting factors \(w_{i,j}\) from the results at (5).
-
7.
Check how \(P_{\hbox {SSSP}}(s)\) can be used to approximate \(P_{\hbox {SSP}}(s)\) for 2 cases:
-
if the weighting factors obtained at (2) were used, and
-
if the weighting factors obtained at (6) were used.
As listed previously, we consider two types of experiments: small-scale experiments and large-scale experiments. Table 2 outlines the systems used in our experiments. Whereas we use all 8 systems for the small-scale experiments, we consider 2 systems (K, OFP) for the large-scale experiments. As shown in the table, the systems used in our experiments are of a wide range of varieties. For example, from the viewpoint of processor architectures, there are 3 Intel processors, 3 SPARC processors, 1 AMD processor, and 1 Arm processor.
4.2 Fiber miniapp suite
The Fiber Miniapp Suite [25] is used to evaluate \(P_{\hbox {ssp}}(s)\) for comparison with \(P_{\hbox {sssp}}(s)\). Table 3 lists the applications included in the Fiber Miniapp Suite. The Fiber Miniapp Suite is a set of mini applications that are extracted from real applications and retain the essential characteristics of their parent applications. From among the different sets of applications and mini applications designed to evaluate different systems, as discussed earlier, we selected the Fiber Miniapp Suite because this set covers a variety of social and scientific challenges and a wide range of computational characteristics, as shown in Table 3 [26]. Moreover, because the Fiber Miniapp Suite includes relatively “traditional” HPC workloads, we would be able to understand the experimental results and the relationship between applications and benchmarks easily.
CCS-QCD [8] is a lattice quantum chromodynamics (QCD) clover-fermion solver, which is used in quantum field theory. FFVC-MINI is a Navier-Stokes solver for the 3-dimensional unsteady thermal flow of incompressible fluid, and is used to assist practical design in industrial fields. NICAM-DC-MINI [37] is derived from the Non-hydrostatic ICosahedral Atmospheric Model (NICAM), which is used for weather forecasting. mVMC-MINI analyzes the physical characteristics of strongly correlated electron systems, by configuring variational wave functions that closely represent the ground state of such electron systems. NGS Analyzer-MINI analyzes data generated from a next-generation sequencer to identify genomic variation, mutation, etc. This application is regarded as an I/O-intensive application. NTChem-MINI calculates the molecular electronic structure based on an ab initio quantum chemistry method. NTChem performs dense–dense matrix multiplications. FrontFlow/blue (FFB)-MINI is based on a general-purpose thermal-flow simulation program.
4.3 Benchmarks
For a preliminary example of a set of benchmarks, we consider HPL, Fast Fourier Transform in the East (FFTE), HPCG, Stream-Triad, and NPB-BT-IO, which may cover different characteristics of systems, such as computation, memory, I/O, and networks. Please note that we used reference implementations without any modification in these experiments, and thus the benchmark efficiencies are different from those presented previously in Top 500 reports and other announcements.
HPL, which is one of the most widely used benchmarks, solves a dense linear system of equations via LU factorization. FFTE is a package for computing discrete Fourier transforms of 1-, 2-, or 3-dimensional sequences. The performance of FFTE is affected to a large degree by the memory and network bandwidth. HPCG solves a sparse linear system using the conjugate gradient method and is designed to implement computational and data access patterns that more closely match a different and broad set of important applications [3, 13]. The performance of HPCG is known to be influenced by memory system performance. Stream-Triad is one of the Stream benchmarks that evaluate memory performance, whereas NPB-BT-IO is from a NAS parallel benchmark (NPB) and repeats MPI-IO to evaluate network and IO performance.
4.4 How to obtain weighting factors

Algorithm to obtain the weighting factors
According to equations (9, 10), weighting factors are introduced to minimize the gap between SSP and SSSP metrics. These weighting factors result from the simple learning algorithm, shown in Fig. 2, which is almost the same as the learning algorithm used to compute weighting factors in single layer perceptron in machine learning. However, unlike in the perceptron algorithm, we adopt a simple constant value of d to update the weighting factors. Furthermore, we do not use a sigmoid function, which is generally used in many perceptron systems. The maximum number of iterations \(n_{\hbox {iter}}\) and the threshold t of the errors between \(P_{\hbox {SSP}}(s)\) and \(P_{\hbox {SSSP}}(s)\) must be assigned by user.
For the optimization of \(w_{i,j}\), it is possible to adopt more complicated algorithms, as discussed later.
4.5 Parameters
We performed two sets of experiments: (1) small-scale experiments using eight systems, and (2) large-scale experiments using two large systems. For the former, applications and benchmarks were executed on the eight systems listed in Table 2. For the latter, the K and OFP systems identified in Table 2 were used. Tables 4, 5, 6 show the numbers of nodes, MPI processes, and OpenMP threads per MPI process for the applications and benchmarks, respectively, for the small-scale (Tables 4, 5) and large-scale (Table 6) experiments.
For the parameters used for the algorithm shown in Sect. 4.4, we have adopted \(d=1.0e^{-26}\), \(n_{\hbox {iter}}=50000000\), and \(t=0\), i.e., small thresholds and the large number of iterations, because at least one of the weighting factors becomes zero before the convergence. Note that because each iteration of the algorithm finishes very quickly, the weighting factors are computed in less than 1 min.
4.6 Results for small systems
Tables 7 and 8 show the \(p_{i,j}^s\) for each application/benchmark i and data set j running on a system s. From the \(p_{i,j}^s\), we compute the \(P_{\hbox {SSP}}(s)\) and \(P_{\hbox {SSSP}}(s)\).

PPPs for SSP, SSSP, HPL, FFTE, HPCG, Stream, and BT-IO obtained from 8 systems, averaged over data set. Note that the \(P_{\hbox {SSSP}}(s)\) does not consider weighting factors. The Y-axis is set as log scale, and it does not start from 0.0
Figure 3 visualizes the \(P_{\hbox {SSP}}(s)\), \(P_{\hbox {SSSP}}(s)\), and the PPPs for benchmarks. The scores are averaged over data set. Note that in the figure, \(P_{\hbox {SSSP}}(s)\) does not consider any distinct weighting factors, i.e., \(w_{i,j}=1\) for all pairs of (i, j). Furthermore, note that the Y-axis is set to a log scale and does not start from 0.0, where as the X-axis is labeled with the names of systems arranged in order of the \(P_{\hbox {SSP}}(s)\). According to the figure, the performance rankings of the systems in terms of HPCG, Stream, and BT-IO are shuffled two or three times. For example, whereas SKL is better than TX2 in terms of \(P_{\hbox {SSP}}(s)\), TX2 is better than SKL in terms of HPCG, and although OFP is better than FX100 in terms of \(P_{\hbox {SSP}}(s)\), FX100 is better than FX100 in terms of HPCG. On the other hand, the performance rankings of systems in terms of \(P_{\hbox {SSSP}}(s)\), HPL, and FFTE are shuffled only once. The swap TX2\(\leftrightarrow \)SKL is observed for FFTE, and the swap OFP\(\leftrightarrow \)TX2 is observed for \(P_{\hbox {SSSP}}(s)\) and HPL. Moreover, the PPP for HPL is fairly larger than the \(P_{\hbox {SSP}}(s)\), and the PPP for FFTE is smaller than the \(P_{\hbox {SSP}}(s)\). It is obvious that HPL overestimates the performance of the OFP system. Because \(P_{\hbox {SSSP}}(s)\) averages several benchmark scores, including HPL, it seems reasonable for a swap between OFP and TX2 for both \(P_{\hbox {SSSP}}(s)\) and HPL. Gaps between \(P_{\hbox {SSP}}(s)\) and \(P_{\hbox {SSSP}}(s)\) without weighting factors are also observed, i.e., \(P_{\hbox {SSSP}}(s)\) without weighting factors always overestimate system performance. The reason for the gap is that the simple sum of benchmarks scores is increased by HPL, which generally results in high theoretical peak performance ratio.

PPPs for SSP, SSSP without weighting factors and SSSP using weighting factors, computed from application and benchmark results for eight systems. Note that Y-axis is set to log scale and does not start from 0.0
Figure 4 shows the \(P_{\hbox {SSP}}(s)\), \(P_{\hbox {SSSP}}(s)\) without weighting factors, and \(P_{\hbox {SSSP}}(s)\) using weighting factors. Note that the Y-axis is set to log scale and does not start from 0.0. In the figure, it is obvious that the \(P_{\hbox {SSSP}}(s)\) using weighting factors was able to result in an appropriate performance projection of the \(P_{\hbox {SSP}}(s)\). Although we still observe the swap between OFP and TX2 for \(P_{\hbox {SSSP}}(s)\) with weighting factors, the difference between the \(P_{\hbox {SSP}}(s)\) and \(P_{\hbox {SSSP}}(s)\) with weighting factors is smaller than that between \(P_{\hbox {SSP}}(s)\) and \(P_{\hbox {SSSP}}(s)\) without weighting factors.
Table 9 lists the weighting factors for the benchmarks and data sets. This result shows that if we assign a lower weight to HPL, a higher weight to BT-IO, and weights close to unity in the remaining cases, the \(P_{\hbox {SSSP}}(s)\) provides a more precise approximation of \(P_{\hbox {SSP}}(s)\). The result also suggests that we do not have to evaluate all the benchmarks for the approximation of the SSP metric, and that we would be able to omit HPL from the calculation. However, if the requirements for a target set of applications for a system are unclear, it is recommended to consider a set of benchmarks that cover the different characteristics of systems to construct the SSSP metric.

PPPs for SSP, SSSP (\(w_{i,j}=1\)), SSSP using weights obtained from eight systems, and SSSP using weights obtained from seven systems (all except TX2 cluster). Y-axis is set to log scale and does not start from 0.0

Sum of differences between \(P_{\hbox {SSP}(s)}\) and \(P_{\hbox {SSSP}}(s)\) over all systems \(s\in S\). Sets of weighting factors for \(P_{\hbox {SSSP}}(s)\) are computed using 8 systems (SSSP w/ weight), using all systems without K (SSSP w/o K), using all systems without FX10 (SSSP w/o FX10), etc. For reference, the sum of differences between \(P_{\hbox {SSP}(s)}\) and \(P_{\hbox {SSSP}}(s)\) without weighting factors (SSSP w/o weight) is also shown. Note that Y-axis is not log scale
To validate the robustness of the SSSP metric with weighting factors, we also compute the weighting factors in such a way as to minimize equation (10) for seven systems by excluding one of the eight systems from the computation of weighting factors. As an example of the robustness checks for our proposed method, Figure 5 compares the \(P_{\hbox {SSSP}}(s)\) using weighting factors obtained from all eight systems and the \(P_{\hbox {SSSP}}(s)\) using weighting factors obtained from seven systems, where the TX2 cluster has been omitted. As shown in the figure, the \(P_{\hbox {SSSP}}(s)\) based on the seven systems also approximated the \(P_{\hbox {SSP}}(s)\) for the TX2 system, which had been excluded in the computation of the weighting factors. Moreover, the \(P_{\hbox {SSSP}}(s)\) scores for the weights of the seven systems are similar to those for the weights of the eight systems. This indicates the robustness of the proposed method against different systems.
Figure 6 shows the sum of the differences between \(P_{\hbox {SSP}}(s)\) and \(P_{\hbox {SSSP}}(s)\) over all systems \(s\in S\), shown in equation (7). The X-axis is labeled with the sets of weighting factors used to compute \(P_{\hbox {SSSP}}(s)\). “SSSP w/o weight” indicates \(w_{i,j}=1\) for all pairs of benchmarks and data sets, whereas “SSSP w/ weight” indicates the use of the weighting factors obtained based on \(p_{i,j}\) for applications and benchmarks over all systems. On the other hand, “SSSP w/o K” indicates the use of the weighting factors obtained based on \(p_{i,j}\) from all systems except K; calculations of weighting factors excluding the other systems are identified in similar ways. As shown in the figure, it is obvious that using the weighting factors can reduce the gap between the SSP metric and the SSSP metric. It is also shown that the sum of the differences can be reduced successfully even if we omit a system in the computation of the weighting factors. Note that because we stopped the optimization of the weighting factors when at least one of the weighting factors becomes zero, \(w_{i,j}\le 0\), the sum of the differences does not converge to the threshold.

Weighting factors computed over all systems, and 7 systems in the absence of each system
Figure 7 shows the weighting factors for the benchmarks, computed via minimization of the equation (10) over all eight systems, and over each of the eight combinations of seven of the systems. As shown in the figure, we can obtain similar weights for the same benchmarks even when any one of the systems is excluded from the computation. It also indicates the robustness and applicability of the SSSP metric. For BT-IO, the weighting factor becomes higher than those of the other benchmarks when we omit TX2 in the computation of the weighting factors because TX2 demonstrates its most salient performance in terms of BT-IO, as shown in Figure 3 and Table 8. Nonetheless, the \(P_{\hbox {SSSP}}(s)\) obtained using the weighting factors computed by all systems except TX2 accord closely with the \(P_{\hbox {SSSP}}(s)\) obtained using the weighting factors computed by all systems, as already shown in Fig. 5.
4.7 Results for large systems
In Sect. 4.6, we discussed the experimental results for relatively small numbers of nodes. Here, we consider the results for large systems of up to 8192 nodes. Unfortunately, we were able to perform large-scale experiments for only two systems because of the sizes of the available systems. These two large systems are K and OFP, which are also used in Sect. 4.6. In addition, we had to omit I/O-intensive benchmarks and applications such as BT-IO and NGSAnalyzer because of the disk quota limits in these systems.
Tables 10 and 11 outline the PPPs for applications and benchmarks, respectively. We compute
-
(1)
\(P_{\hbox {SSP}}(s)\) using \(p_{i,j}\) in Table 10,
-
(2)
\(P_{\hbox {SSSP}}(s)\) using \(p_{i,j}\) in Table 11,
-
(3)
\(P_{\hbox {SSSP}}(s)\) using \(p_{i,j}\) in Table 11 and weighting factors obtained by minimizing gap between (1) and (2),
-
(4)
\(P_{\hbox {SSSP}}(s)\) using \(p_{i,j}\) shown in Table 11 and weighting factors obtained using the 8 small systems (shown in Fig. 9).

PPPs for SSP, SSSP (w/o weighting factors), SSSP (w/ weighting factors computed from small systems), SSSP (w/ weighting factors computed from large systems) in K and OFP (Left). The ratio of PPPs for SSSP (w/o weighting factors) and SSSP (w/ weighting factors computed from small systems), and the ratio of PPPs for SSSP (w/o weighting factors) and SSSP (w/ weighting factors computed from large systems) (Right)
Figure 8 (left) shows the \(P_{\hbox {SSP}}(s)\) and \(P_{\hbox {SSSP}}(s)\) for the K and OFP systems. As shown in the figure, the \(P_{\hbox {SSSP}}(s)\) metrics computed using the weighting factors obtained based on the small systems are less precise than those using the weighting factors obtained based on the large systems, but still lead to appropriate insights on the application performance of the systems.
Figure 8 (right) shows the ratios of \(P_{\hbox {SSSP}}(s)\) (without weighting factors) and \(P_{\hbox {SSSP}}(s)\) (with weighting factors computed based on small systems), and those of \(P_{\hbox {SSSP}}(s)\) (without weighting factors) and \(P_{\hbox {SSSP}}(s)\) (with weighting factors computed based on large systems), i.e.,
These ratios illustrate a strong need to modify the PPPs for the original SSSPs in favor of the PPPs for the weighted SSSPs. As shown in the figure, the modification ratios based on the sets of weighting factors computed from the two system sets are ranged from 0.42 to 0.48 for OFP and from 0.48 to 0.55 for K. Moreover, both sets of weighting factors consistently demonstrate a stronger need to use weighting factors for K than for OFP.
4.8 Execution times

Execution times of applications and benchmarks on 8 systems for small-scale applications and benchmarks. The execution times for HPCG are always 2000 due to its regulation. While the average execution time over applications is ranged from 216 (SKL) to 472 (BW) seconds, average execution times over benchmarks is ranged from 491 (SKL) to 1004 (BW) seconds

Execution times of applications and benchmarks on K and OFP for large-scale applications and benchmarks. The execution times for HPCG are always 2000 due to its regulation. While the average execution time over applications is ranged from 841 (K) to 3563 (OFP) seconds, average execution time over benchmarks is ranged from 692 (OFP) to 741 (K) seconds
Figures 9 and 10 show the execution times of instances for the SSP and SSSP metrics. Note that we adopt log scales for the y-axes in these figures, because of the executions of some of applications and benchmarks finished really quickly. For the small-scale cases, whereas the average execution times over applications ranged from 216 (SKL) to 472 (BW) seconds, the average execution times over benchmarks ranged from 491 (SKL) to 1004 (BW) seconds. This is mainly due to the fixed execution time of HPGC and relatively long execution time of HPL. Because it is recommended to set the execution time for HPCG to be more than 1,800 seconds (30 minutes), we have set the maximum execution time for HPCG to be 2,000 seconds for all systems and problem sizes. However, the maximum execution time can be reduced to a few minutes if the result does not have to be submitted to the HPCG ranking competition. If we ignore the execution time of HPCG, the average execution time over benchmarks can be reduced from 114 seconds to 756 seconds, which is comparable with that over applications. For the large-scale performance evaluations, whereas the average execution times over applications ranged from 841 (K) to 3563 (OFP) seconds, the average execution times over benchmarks ranged from 692 (OFP) to 741 (K) seconds even though the execution time for HPCG remains fixed to 2,000 seconds. On the other hand, some of the SSP metric instances require more than a few hours—for example, the NICAM-gl09rl04z80pe2560 on OFP requires approximately 6 hours—the maximum execution time for the SSSP metric except the HPCG, is only 1054 seconds (18 minutes). Therefore, the SSSP metric is demonstrated to be able to provide its score more easily and quickly than the SSP metric is able to do for large-scale systems. Because the performance of simple benchmarks, such as Stream and HPL, can be expected based on system specifications, not all benchmarks will have to be executed.
5 Discussion
We have presented the SSSP metric and the method for constructing the metric. The SSSP metric is computed using the results of simple benchmarks and the weighting factors for these benchmarks. Because the weighting factors are obtained using the SSSP metric for the approximation of the SSP metric, the SSSP metric is guaranteed to be able to quantify the performance of systems at executing applications. Therefore, the SSSP metric can accomplish the general characteristics of simple benchmarks, such as ease of use, while providing a more practical score than those of simple benchmarks.
Our experiments in Sect. 4 suggested that we should assign the smallest weighting factor to HPL in the approximation of the performance of systems at executing applications, because HPL is more likely to overestimate the performance of systems at executing applications and to mislead the expectations of application developers. By contrast, the SSSP metric can discount the HPL score based on the relationship between benchmarks and applications.
In our experiments, we did not include accelerator-based systems because some of the applications are not written for such systems. However, according to the results of our experiments, which were executed over a wide variety of different processor architectures, and the results of the robustness checks, we expect that the SSSP metric and the method developed for the computation of the SSSP metric can be applied to accelerator-based systems. Nonetheless, experiments on accelerator-based systems would be necessary to update the SSSP metric such that it would be able to approximate different sets of applications, including artificial intelligence applications, in the future.
During the design phase of a system, where we have to use performance estimation tools and several simulators, more time is required to estimate the performance of the system than to estimate using a real system. In that case, the SSSP metric has an advantage that complex applications will not have to be executed on the simulators. Sometimes, the calculated weighting factors for the benchmarks for a set of target applications may suggest the architectural characteristics that require enhancement. For example, if a memory-intensive benchmark has a high weighting factor, increasing the memory bandwidth should enhance the performance of the system at executing the target applications.
Another advantage of the SSSP metric over a simple set of applications or benchmarks is that the end result is very simple: a single value for a single system. Various methods have been developed for evaluating a system not only from a single view-point, such as the HPL score, but also from diversified standpoints. For example, the HPC Challenge benchmarks consist of seven different benchmarks, including HPL and Stream [2, 15]. Moreover, as discussed earlier, several sets of mini applications have been proposed for investigating the performance of systems at executing applications easily [9, 17, 18, 23, 25, 32, 38]. Whereas the results of these applications and benchmarks provide a radar chart for understanding a system, the SSSP metric provides a single score concentrating the radar chart to a single value.
In addition to the general purposes of benchmarks, such as selecting a system or confirming its performance, the simplicity and flexibility of the proposed method for constructing the SSSP allow us to better understand a set of applications or single application. For example, if a specific application is approximated based on a set of benchmarks and weighting factors, then the best system for the application from among different systems can be suggested based on the benchmark results and weighting factors. Moreover, since the SSSP metric can be approximated to the SSP metric instances of various workload sets, it can be used to evaluate various middleware, system software, virtual environments, and tools such as failure detection and fault tolerance in distributed systems [16], error correction in a virtual environment[19], and so on.
6 Related works
Although we have already discussed some of related works, such as HPL and HPCG, in the previous sections, we discuss more about the related works in greater detail in this section.
The HPC Challenge (HPCC) benchmark consists of seven different benchmarks including HPL and Stream [2]. The NAS parallel benchmarks [6, 28] are a set of benchmarks designed to help evaluate the performance of parallel supercomputers. The NAS parallel benchmarks are derived from computational fluid dynamics (CFD) applications and include kernels, pseudoapplications, OpenMP+MPI hybrid codes, and I/O tests. The Scalable HeterOgeneous Computing (SHOC) benchmark suite, which is designed for evaluating the performance of scalable heterogeneous systems [11] is a set of kernels and mini applications implemented in OpenCL and CUDA. Unlike the SSSP metric, these collections of benchmarks do not provide a single value for a single system.
The Standard Performance Evaluation Corporation (SPEC) [12, 36] provides sets of benchmarks and suites of applications for evaluating different aspects of systems, such as CPU, communication, and storage. The score of a target system for a set is computed based on the geometric mean of normalized performance ratios of the reference system. Although some of the SPEC benchmarks, such as SPEC HPC 2002, focus on real-application sets, these real application sets are not as easy to run as simple benchmarks [5]. Additionally, some of the SPEC benchmarks, such as the SPECint, consist of simple kernel benchmarks, which are designed to evaluate a specific aspect of a system.
To evaluate the performance of systems at executing applications, there are several suites of mini-, proxy-, or real applications. ESIF-HPC-2 [10] is a benchmark suite that collects kernels and applications to measure computational and I/O performance for systems and parts of systems ranging from single nodes to full HPC systems. The ESIF-HPC-2 has been designed to cover the specific needs of the energy research community. The Exascale Computing Project (ECP) proxy applications [1, 31], which are developed as part of the ECP, are a collection of small, simplified codes that allow application developers to share important features of large applications without forcing collaborators to assimilate large and complex code bases. Most application suites do not provide their own method for computing a single value as a quantitative performance discriminator. Although we can compute the SSP metric over these application suites, tuning and porting applications remains inconvenient and costly to perform.
Although we have focused on the correspondence between simple kernel benchmarks and mini-applications, there are several works which consider the correspondence proxy applications and their parental real applications, and the correspondence between simple kernel benchmarks and mini-applications. Aaziz et. al. [4] proposed a method for characterizing the relationship between real and proxy applications in the ECP application using collection of runtime data such as instructions per cycle, and cache miss ratio and analyzing them. Sharkawi et al. [34] also used hardware performance counter data for the HPC applications and SPEC CFP 2006 benchmark sets from a single base system to model the behavior of the HPC applications as a function of the benchmarks. A genetic algorithm was used to identify the “best” group of benchmarks that explain each HPC application. SWAPP [33], which was proposed by the same authors, applies the same scheme to project the performance of the MPI communication of HPC applications. Whereas they consider a single system in constructing the performance projection function, we constructed the performance projection function over several different systems. Additionally, unlike these methods, our method does not require any information from hardware counters.
Summarizing the above and benchmarks discussed in Sect. 1, most existing benchmarks, metrics, sets of benchmarks, and sets of applications have one or more of the following drawbacks:
-
does not consider the application performance of systems;
-
does involve complicated processes in the execution of real-world applications, such as porting and tuning;
-
does not provide a single value metric for the easy understanding and comparison of systems; and/or
-
requires more detailed information, such as hardware counters.
7 Conclusion
In this paper, we proposed a new performance metric, called the Simplified Sustained System Performance (SSSP) metric. The SSSP metric provides an easy approximation of the Sustained System Performance (SSP) metric, which indicates the performance of systems at executing applications. Whereas the SSP metric leads to direct insights on the performance of systems, it requires porting and evaluation of complex applications, which require significant amounts of effort. On the other hand, the SSSP metric can be computed via the performance evaluation of simple benchmarks and a set of weighting factors for the benchmarks. The weighting factors should be obtained by minimizing the differences between the SSP and SSSP metrics on a small set of reference systems. As demonstrated in the experiments, the SSSP metric was able to approximate the SSP metric more closely than any other single benchmark, such as HPL or HPCG. One of important future works is how exactly to approximate the SSP metric with respect to the SSSP metric. Although we have adopted a relatively simple learning algorithm in this paper, many algorithms have been developed for the computation of the weighting factors to minimize the equation (7). For example, we have confirmed that the CVXOPT [30], which is a software package for convex optimization, provides appropriate approximations. The Deep Learning/Machine Learning (DL/ML) algorithms have also been used in various optimization fields and should be strong candidates for our approximation.
References
ECP proxy applications. https://proxyapps.exascaleproject.org/
HPC challenge. http://www.hpcchallenge.org/
Hpcg benchmark. http://www.hpcg-benchmark.org/
Aaziz O, Cook J, Cook J, Juedeman T, Richards D, Vaugha C (2018)A methodology for characterizing the correspondence between real and proxy applications. In: Proceedings of 2018 IEEE International Conference on Cluster Computing (CSTER). IEEE
Armstrong B, Bae H, Eigenmann R, Saied F, Sayeed M, Zheng Y (2006) Hpc benchmarking and performance evaluation with realistic applications. In: The SPEC Benchmark Workshop, pp. 1–11
Bailey D, Harris T, Saphir W, van der Wijngaart R, Woo A, Yarrow M (1995) The nas parallel benchmarks 2.0. Tech. Rep. NAS Technical Report NAS-95-020
Bauer G, Hoefler T, Kramer W, Fiedler R (2012) Analyses and modeling of applications used to demonstrate sustained petascale performance on blue waters. In: Proceedings of the annual meeting of the cray users groups CUG-2012
Boku T, Ishikawa K, Minami K, Nakamura Y, Shoji F, Takahasi D, Terai M, Ukawa A, Yosie T (2012) Multi-block/multi-core SSOR preconditioner for the QCD quark solver for K computer. In: Proceedings of The 30th International Symposium on Lattice Field Theory
Center for exascale simulation of combustion in turbulence: ExaCT. http://exactcodesign.org/
Change CH, Carpenter IL, Jones WB (2020)The ESIF-HPC-2 benchmark suite. In: Proceedings of the Principles and Practice of Parallel Programming (PPoPP) 2020
Danalis A, Marin G, McCurdy C, Meredith J, Roth P, Spafford K, Tipparaju V, Vetter J (2010) The scalable heterogeneous computing (shoc) benchmark suite. In: Proceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems-ASPLOS . https://doi.org/10.1145/1735688.1735702
Dixit KM (1991) The spec benchmarks. Parallel Computing 17:1195–1209
Dongarra J, Heroux MA (2013) Toward a new metric for ranking high performance computing systems. Tech. Rep. SAND2013-4744, Sandia National Laboratories
Dongarra J, Bunch CMJ, Stewart GW (1979) LINPACK user’s guide. SIAM, Philadelphia
Dongarra J, Luszczek P (2013) HPC challenge: design, history, and implementation highlights. In: Contemporary high performance computing: from petascale toward exascale. Taylor and Francis
Ghosh S (2014) Distributed systems: an algorithmic approach, 2nd edn. Chapman and Hall/CRC
Heroux MA, Doerfler DW, Crozier PS, Willenbring JM, Edwards HC, Williams A, Rajan M, Keiter ER, Thorn-quist HK, Numrich RW (2009) Improving performance viamini-applications. Tech Rep SAND2009-5574, Sandia National Laboratories
Karlin I, Bhatele A, Keasler J, Chamberlain BL, Cohen J, DeVito Z, Haque R, Laney D, Luke E, Wang F, Richards D, Schulz M, Still C (2013) Exploring traditional and emerging parallel programming models using a proxy application. In: 27th IEEE International Parallel and Distributed Processing Symposium (IEEE IPDPS 2013)
Kononenko K (2016) An approach to error correction in program code using dynamic optimization in a virtual execution environment. J Supercomputing 72:845–873. https://doi.org/10.1007/s11227-015-1616-4
Kramer WTC (2013) Measuring sustained performance on blue waters with the SPP metric. In: Proceedings of the Annual Meeting of the Cray Users Groups CUG-2013
Kramer WT (2008) Percu: a holistic method for evaluating high performance computing systems. Ph D thesis, EECS Department, University of California, Berkeley . http://www.eecs.berkeley.edu/Pubs/TechRpts/2008/EECS-2008-143.html
Kramer WT, Shalf J, Strohmaier E (2005) The NERSC sustained system performance (SSP) metric. Tech Rep LBNL-58868
Lawrence Livermore National Lab: LULESH. https://codesign.llnl.gov/lulesh.php
Lilja DJ (2000) Measuring computer performance a practitioner’s guide. Cambridge University Press, New York
Maruyama N (2013) Mini-app effort in Japan. In: SC13 BoF: Library of mini-applications for exascale component-based performance modeling (Presentation)
Maruyama N (2014) Miniapps for enabling architecture-application co-design for exascale supercomputing. In: 19th Workshop on sustained simulation performance (Presentation)
Mendes CL, Bode B, Bauer GH, Enos J, Cristina Beldica WTK (2015) Deployment and testing of the sustained petascale blue waters system. J Comput Sci 10:327–337
NAS parallel benchmarks: http://www.nas.nasa.gov/ publications/npb.html
Petitet A, Whaley RC, Dongarra J, Cleary A HPL-a portable implementation of the high-performance linpack benchmark for distributed-memory computers. http://www.netlib.org/benchmark/hpl/
Python Software for Convex Optimization. CVXOPT. https://cvxopt.org/
Richards D, Bhatele1 A, Aaziz O, Cook J, Finkel H, Homerding B, McCorquodale P, Mintz T, Moore S, Pavel R (2018) FY18 proxy app suite release, milestone report for the ecp proxy app project. Tech Rep LLNL-TR-760903, Exascale computing project
Sandia National Laboratories: Mantevo project. https://mantevo.org/
Sharkawi S, DeSota D, Panda R, Stevens S, Taylor V, Wu X (2012) SWAPP: a framework for performance projections of hpc applications using benchmarks. In: Proceedings of the 2012 IEEE 26th International Parallel and Distributed Processing Symposium Workshops and PhD Forum, pp. 1722–1731. IEEE
Sharkawi S, DeSota D, Panda R, Indukuru R, Stevens S, Taylor V, Wu X (2009) Performance projection of hpc applications using spec cfp2006 benchmarks. In: Proceedings of the 23rd IEEE International Symposium on Parallel and Distributed Processing (IPDPS 2009), pp. 1–12. IEEE
Smith JE (1988) Characterizing computer performance with a single number. Commun ACM 31(10):1202–1206
Standard performance evaluation corporation: standard performance evaluation corporation. https://www.spec.org/
Terai M, Yashiro H, Sakamoto K, ichi Iga S, Tomita H, Satoh M, Minami K (2014) Performance optimization and evaluation of a global climate application using a 440m horizontal mesh on the K computer. In: Proceedings of 2014 International Conference for High Performance Computing, Networking, Storage and Analysis (SC 2014)
University of Illinois: Charm++:MiniApps. http://charmplusplus.org/miniApps/
William TC (2013) Kramer: blue waters and the future of @scale computing and analysis, 4th AICS Workshop
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tsuji, M., Kramer, W.T.C., Weill, JC. et al. A new sustained system performance metric for scientific performance evaluation. J Supercomput 77, 6476–6504 (2021). https://doi.org/10.1007/s11227-020-03545-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-020-03545-y