
Abstract
The problem of best subset selection in linear regression is considered with the aim to find a fixed size subset of features that best fits the response. This is particularly challenging when the total available number of features is very large compared to the number of data samples. Existing optimal methods for solving this problem tend to be slow while fast methods tend to have low accuracy. Ideally, new methods perform best subset selection faster than existing optimal methods but with comparable accuracy, or, being more accurate than methods of comparable computational speed. Here, we propose a novel continuous optimization method that identifies a subset solution path, a small set of models of varying size, that consists of candidates for the single best subset of features, that is optimal in a specific sense in linear regression. Our method turns out to be fast, making the best subset selection possible when the number of features is well in excess of thousands. Because of the outstanding overall performance, framing the best subset selection challenge as a continuous optimization problem opens new research directions for feature extraction for a large variety of regression models.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Recent developments in information technology have enabled the collection of high-dimensional complex data in engineering, economics, finance, biology, health sciences and other fields (Fan and Li 2006). In high-dimensional data, the number of features is large and often far higher than the number of collected data samples. In many applications, it is desirable to find a parsimonious best subset of predictors so that the resulting model has desirable prediction accuracy (Müller and Welsh 2010; Fan and Lv 2010; Miller 2019). This article is recasting the challenge of best subset selection in linear regression as a novel continuous optimization problem. We show that this reframing has enormous potential and substantially advances research into larger dimensional and exhaustive feature selection in regression, making available technology that can reliably and exhaustively select variables when the total number of variables is well in excess of thousands.
Here, we aim to develop a method that performs best subset selection and an approach that is faster than existing exhaustive methods while having comparable accuracy, or, that is more accurate than other methods of comparable computational speed.
Consider the linear regression model of the form \(\mathbf {y = X {\varvec{\beta }}+ \varvec{\epsilon },}\) where \(\textbf{y} = (y_1, \dots , y_n)^\top \) is an n-dimensional known response vector, X is a known design matrix of dimension \(n\times p\) with \(x_{i, j}\) indicating the ith observation of the jth explanatory variable, \({\varvec{\beta }}= (\beta _1, \dots , \beta _p)^\top \) is the p-dimensional vector of unknown regression coefficients, and \(\varvec{\epsilon }= (\epsilon _1, \dots , \epsilon _n)^{\top }\) is a vector of unknown errors, unless otherwise specified, assumed to be independent and identically distributed. Best subset selection is a classical problem that aims to first find a so-called best subset solution path (e.g. see Müller and Welsh 2010; Hui et al. 2017, ) by solving,
for a given k, where \(\Vert \cdot \Vert _2\) is the \(\mathcal {L}_2\)-norm, \(\Vert {\varvec{\beta }}\Vert _0 = \sum _{j = 1}^p { \mathbb {I}}(\beta _j \ne 0)\) is the number of non-zero elements in \({\varvec{\beta }}\), and \({ \mathbb {I}}(\cdot )\) is the indicator function, and the best subset solution path is the collection of the best subsets as k varies from 1 to p. For ease of presentation, we assume that all columns of X are subject to selection, but generalizations are immediate (see Remark 2 for more details).
Exact methods for solving (1) are typically executed by first writing solutions for low-dimensional problems and then selecting the best solution over these. To see this, for any binary vector \(\textbf{s} = (s_1, \dots , s_p)^\top \in \{0,1 \}^p\), let \(X_{[\mathbf {{s}}]}\) be the matrix of size \(n \times |\mathbf {{s}} |\) created by keeping only columns j of X for which \(s_{j} = 1\), where \(j =1,\ldots ,p\). Then, for any k, in the exact best subset selection, an optimal \(\mathbf {{s}}\) can be found by solving the problem,
where \(\widehat{\varvec{\beta }}_{[\textbf{s}]}\) is a low-dimensional least squares estimate of elements of \({\varvec{\beta }}\) with indices corresponding to non-zero elements of \(\textbf{s}\), given by
where \(A^{\dagger }\) denotes the pseudo-inverse of a matrix A. Both (1) and (2) are essentially solving the same problem, because \(\widehat{\varvec{\beta }}_{[\textbf{s}]}\) is the least squares solution when constrained so that \({\mathbb {I}}(\beta _{j} \ne 0) = s_j\) for all \(j = 1, \dots , p\).
It is well-known that solving the exact optimization problem (1) is in general non-deterministic polynomial-time hard (Natarajan 1995). For instance, a popular exact method called leaps-and-bounds (Furnival and Wilson 2000) is currently practically useful only for values of p smaller than 30 (Tarr et al. 2018). To overcome this difficulty, the relatively recent method by Bertsimas et al. (2016) elegantly reformulates the best subset selection problem (1) as a mixed integer optimization and demonstrates that the problem can be solved for p much larger than 30 using modern mixed integer optimization solvers such as in the commercial software Gurobi (Gurobi Optimization, limited liability company 2022) (which is not freely available except for an initial short period). As the name suggests, the formulation of mixed integer optimization has both continuous and discrete constraints. Although, the mixed integer optimization approach is faster than the exact methods for large p, its implementation via Gurobi remains slow from a practical point of view (Hazimeh and Mazumder 2020).
Due to computational constraints of mixed integer optimization, other popular existing methods for best subset selection are still very common in practice, these include forward stepwise selection, the least absolute shrinkage and selection operator (generally known as the Lasso), and their variants. Forward stepwise selection follows a greedy approach, starting with an empty model (or intercept-only model), and iteratively adding the variable that is most suitable for inclusion (Efroymson 1966; Hocking and Leslie 1967). On the other hand, the Lasso (Tibshirani 1996) solves a convex relaxation of the highly non-convex best subset selection problem by replacing the discrete \(\mathcal {L}_0\)-norm \(\Vert {\varvec{\beta }}\Vert _0\) in (1) with the \(\mathcal {L}_1\)-norm \(\Vert {\varvec{\beta }}\Vert _1\). This clever relaxation makes the Lasso fast, significantly faster than mixed-integer optimization solvers. However, it is important to note that Lasso solutions typically do not yield the best subset solution (Hazimeh and Mazumder 2020; Zhu et al. 2020) and in essence solves a different problem than exhaustive best subset selection approaches. In summary, there exists a trade-off between speed and accuracy when selecting an existing best subset selection method.
With the aim to develop a method that performs best subset selection as fast as the existing fast methods without compromising the accuracy, in this paper, we design COMBSS, a novel continuous optimization method towards best subset selection.

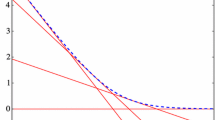
Illustration of the workings of COMBSS for an example data with \(p = 2\). Plot a shows the objective function of the exact method (2) for \(\textbf{s} \in \{0,1\}^2\). Observe that the best subsets correspond to \(k =0\), \(k =1\), and \(k =2\) are \((1,1)^\top \), \((1, 0)^\top \), and \((0,0)^\top \), respectively. Plots b–d show the objective function of our optimization method (4) for different values of the parameter \(\lambda \). In each of these three plots, the curve (in red) shows the execution of a basic gradient descent algorithm that, starting at the initial point \(\textbf{t}_{\mathsf init} = (0.5, 0.5)^\top \), converges towards the best subsets of sizes 0, 1, and 2, respectively. (colour figure online)
Our continuous optimization method can be described as follows. Instead of the binary vector space \(\{0,1\}^p\) as in the exact methods, we consider the whole hyper-cube \([0, 1]^p\) and for each \(\textbf{t} \in [0,1]^p\), we consider a new estimate \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) (defined later in Sect. 2) so that we have the following well-defined continuous extension of the exact problem (2):
where \(X_{\textbf{t}}\) is obtained from X by multiplying the jth column of X by \(t_j\) for each \(j = 1,\dots , p\), and the tuning parameter \(\lambda \) controls the sparsity of the solution obtained, analogous to selecting the best k in the exact optimization. Our construction of \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) guarantees that \(\Vert \textbf{y} - X_{\textbf{s}} \widetilde{\varvec{\beta }}_{\textbf{s}} \Vert _2 = \Vert \textbf{y} - {X}_{[\textbf{s}]} \widehat{\varvec{\beta }}_{[\textbf{s}]} \Vert _2\) at the corner points \(\textbf{s}\) of the hypercube \([0,1]^p\), and the new objective function \(\Vert \textbf{y} - X_{\textbf{t}} \widetilde{\varvec{\beta }}_{\textbf{t}} \Vert _2^2\) is smooth over the hypercube.
While COMBSS aims to find sets of models that are candidates for the best subset of variables, an important property is that it has no discrete constraints, unlike the exact optimization problem (2) or the mixed integer optimization formulation. As a consequence, our method can take advantage of standard continuous optimization methods, such as gradient descent methods, by starting at an interior point on the hypercube \([0,1]^p\) and iteratively moving towards a corner that minimizes the objective function. See Fig. 1 for an illustration of our method. In the implementation, we move the box constrained problem (4) to an equivalent unconstrained problem so that the gradient descent method can run without experiencing boundary issues.
The rest of the paper is organized as follows: In Sect. 2, we describe the mathematical framework of the proposed method COMBSS. In Sect. 3, we first establish the continuity of the objective functions involved in COMBSS, and then we derive expressions for their gradients, which are exploited for conducting continuous optimization. Complete details of COMBSS algorithm are presented in Sect. 4. In Sect. 5, we discuss roles of the tuning parameters that control the surface shape of the objective functions and the sparsity of the solutions obtained. Section 6 provides steps for efficient implementation of COMBSS using some popular linear algebra techniques. Simulation results comparing COMBSS with existing popular methods are presented in Sect. 7. We conclude the paper with some brief remarks in Sect. 8. Proofs of all our theoretical results are provided in Appendix A.
2 Continuous extension of best subset selection problem
To see our continuous extension of the exact best subset selection optimization problem (2), for \(\textbf{t} = (t_1, \dots , t_p)^\top \in [0,1]^{p}\), define \(T_{\textbf{t}} = \textsf{Diag}(\textbf{t})\), the diagonal matrix with the diagonal elements being \(t_1, \dots , t_p\), and let \( X_{\textbf{t}} = X T_{\textbf{t}}. \) With I denoting the identity matrix of an appropriate dimension, for a fixed constant \(\delta > 0\), define
where we suppress \(\delta \) for ease of reading. Intuitively, \(L_{\textbf{t}}\) can be seen as a ‘convex combination’ of the matrices \((X^\top X)/n\) and \(\delta I/n\), because \(X_{\textbf{t}}^\top X_{\textbf{t}} = T_{\textbf{t}} {X^\top X} T_{\textbf{t}}\) and thus
Using this notation, now define
We need \(L_{\textbf{t}}^{\dagger }\) in (7) so that \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) is defined for all \(\textbf{t} \in [0, 1]^p\). However, from the way we conduct optimization, we need to compute \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) only for \(\textbf{t} \in [0, 1)^p\). We later show in Theorem 1 that for all \(\textbf{t} \in [0,1 )^p\), \(L_{\textbf{t}}\) is invertible and thus in the implementation of our method, \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) always takes the form \({\widetilde{\varvec{\beta }}_{\textbf{t}} = L_{\textbf{t}}^{-1} X_{\textbf{t}}^\top \textbf{y}/n}\), eliminating the need to compute any computationally expensive pseudo-inverse.
With the support of these observations, an immediate well-defined generalization of the best subset selection problem (1) is
Instead of solving the constrained problem (8), by defining a Lagrangian function
for a tunable parameter \(\lambda > 0\), we aim to solve
By defining \(g_{\lambda }(\textbf{w}) = f_{\lambda }\left(\textbf{t}(\textbf{w})\right)\), we reformulate the box constrained problem (10) into an equivalent unconstrained problem,
where the mapping \(\textbf{t} = \textbf{t}(\textbf{w})\) is
The unconstrained problem (11) is equivalent to the box constrained problem (10), because \(1 - \exp (-u^2)< 1 - \exp (-v^2) \ \text {if and only if}\ u^2 < v^2\), for any \(u, v \in \mathbb {R}\).
Remark 1
The non-zero parameter \(\delta \) is important in the expression of the proposed estimator \(\widetilde{\varvec{\beta }}_{\textbf{t}}\), as in (7), not only to make \(L_{\textbf{t}}\) invertible for \(\textbf{t} \in [0,1)^p\), but also to make the surface of \(f_\lambda (\textbf{t})\) to have smooth transitions from one corner to another over the hypercube. For example consider a situation where \(X^\top X\) is invertible. Then, for any interior point \(\textbf{t} \in (0, 1)^p\), since \(T_{\textbf{t}}^{-1}\) exists, the optimal solution to \({\min _{{\varvec{\beta }}}\Vert y - X_{\textbf{t}} {\varvec{\beta }}\Vert _2^2/n}\) after some simplification is \(T_{\textbf{t}}^{-1} (X^\top X)X^\top y\). As a result, the corresponding minimum loss is \({\Vert y - X (X^\top X)X^\top y\Vert _2^2/n}\), which is a constant for all \(\textbf{t}\) over the interior of the hypercube. Hence, the surface of the loss function would have jumps at the borders while being flat over the interior of the hypercube. Clearly, such a loss function is not useful for conducting continuous optimization.
Remark 2
The proposed method and the corresponding theoretical results presented in this paper easily extend to linear models with intercept term. More generally, if we want to keep some features in the model, say features \(j =1, 2\), and 4, then we enforce \(t_j = 1\) for \(j = 1, 2, 4\), and conduct subset selection only over the remaining features by taking \(\textbf{t} = (1, 1, t_3, 1, t_5, \dots , t_p)^\top \) and optimize over \(t_3, t_5, \dots , t_p\).
Remark 3
From the definition, for any \(\textbf{t}\), we can observe that \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) is the solution of

which can be seen as the well-known Thikonov regression. Since the solution \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) does not change, even if the penalty \(\lambda \sum _{j = 1}^p t_j\) is added to the objective function above, with

in the future, we can consider the optimization problem

as an alternative to (10). This formulation allows us to use block coordinate descent, an iterative method, where in each iteration the optimal value of \({\varvec{\beta }}\) is obtained given \(\textbf{t}\) using (7) and an optimal value of \(\textbf{t}\) is obtained given that \({\varvec{\beta }}\) value.
3 Continuity and gradients of the objective function
In this section, we first prove that the objective function \(g_{\lambda }(\textbf{w})\) of the unconstrained optimization problem (11) is continuous on \(\mathbb {R}^p\) and then we derive its gradients. En-route, we also establish the relationship between \(\widehat{\varvec{\beta }}_{[\textbf{s}]}\) and \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) which are respectively defined by (3) and (7). This relationship is useful in understanding the relationship between our method and the exact optimization (2).
Theorem 1 shows that for all \(\textbf{t} \in [0,1)^p\), the matrix \(L_{\textbf{t}}\), which is defined in (5), is symmetric positive-definite and hence invertible.
Theorem 1
For any \(\textbf{t} \in [0, 1)^p\), \(L_{\textbf{t}}\) is symmetric positive-definite and \({\widetilde{\varvec{\beta }}_{\textbf{t}} = L_{\textbf{t}}^{-1} X_{\textbf{t}}^\top \textbf{y}/n}\).
Theorem 2 establishes a relationship between \(\widetilde{\varvec{\beta }}_{\textbf{s}}\) and \(\widehat{\varvec{\beta }}_{[\textbf{s}]}\) at all the corner points \(\textbf{s} \in \{0,1\}^p\). Towards this, for any point \(\textbf{s} \in \{0,1\}^p\) and a vector \(\textbf{u}\in \mathbb {R}^p\), we write \((\textbf{u})_{\scriptscriptstyle {+}}\) (respectively, \((\textbf{u})_{0}\)) to denote the sliced vector of dimension \(|\textbf{s} |\) (respectively, \(p - |\textbf{s} |\)) created from \(\textbf{u}\) by removing all its elements with the indices j where \(s_j = 0\) (respectively, \(s_j > 0\)). For instance, if \(\textbf{u}= (2,3,4,5)^\top \) and \(\textbf{s} = (1,0,1,0)^\top \), then \((\textbf{u})_+ = (2,4)\) and \((\textbf{u})_0 = (3, 5)\).
Theorem 2
For any \(\textbf{s} \in \{0,1\}^p\), \((\widetilde{\varvec{\beta }}_{\textbf{s}})_+ = \widehat{\varvec{\beta }}_{[\textbf{s}]}\) and \(( \widetilde{\varvec{\beta }}_{[\textbf{s}]} )_0 = \textbf{0}\). Furthermore, we have \( X_{[\textbf{s}]}\widehat{\varvec{\beta }}_{[\textbf{s}]} = X_{\textbf{s}}\widetilde{\varvec{\beta }}_{\textbf{s}}. \)
As an immediate consequence of Theorem 2, we have \(\Vert \textbf{y} - X_{[\textbf{s}]} \widehat{\varvec{\beta }}_{[\textbf{s}]} \Vert _2^2 = \Vert \textbf{y} - X_{\textbf{s}}\widetilde{\varvec{\beta }}_{\textbf{s}} \Vert _2^2\). Therefore, the objective function of the exact optimization problem (2) is identical to the objective function of its extended optimization problem (8) (with \({\lambda = 0}\)) at the corner points \(\textbf{s} \in \{0,1\}^p\).
Our next result, Theorem 3, shows that \(f_{\lambda }(\textbf{t})\) is a continuous function on \([0, 1]^p\).
Theorem 3
The function \(f_{\lambda }(\textbf{t})\) defined in (9) is continuous over \([0, 1]^p\) in the sense that for any sequence \(\textbf{t}^{(1)}, \textbf{t}^{(2)}, \dots \in [0, 1)^p\) converging to \(\textbf{t} \in [0, 1]^p\), the limit \(\lim _{l \rightarrow \infty } f_{\lambda }(\textbf{t}^{(l)})\) exists and
Corollary 1 establishes the continuity of \(g_\lambda \) on \(\mathbb {R}^p\). This is a simple consequence of Theorem 3, because from the definition, \(g_{\lambda }(\textbf{w}) = f_\lambda \left(\textbf{t}(\textbf{w})\right)\) with \(\textbf{t}(\textbf{w}) = \textbf{1 }- \exp (-\textbf{w} \odot \textbf{w})\). Here and afterwards, in an expression with vectors, \(\textbf{1}\) denotes a vector of all ones of appropriate dimension, \(\odot \) denotes the element-wise (or, Hadamard) product of two vectors, and the exponential function, \(\exp (\cdot )\), is also applied element-wise.
Corollary 1
The objective function \(g_{\lambda }(\textbf{w})\) is continuous at every point \(\textbf{w} \in \mathbb {R}^p\).
As mentioned earlier, our continuous optimization method uses a gradient descent method to solve the problem (11). Towards that we need to obtain the gradients of \(g_{\lambda }(\textbf{w})\). Theorem 4 provides an expression of the gradient \(\nabla g_{\lambda }(\textbf{w})\).
Theorem 4
For every \(\textbf{w} \in \mathbb {R}^p\), with \(\textbf{t} = \textbf{t}(\textbf{w})\) is defined by (12),
and, for \(\textbf{w} \in \mathbb {R}^p\),
where
with
Fig. 2 illustrates the typical convergence behavior of \(\textbf{t}\) for an example dataset during the execution of a basic gradient descent algorithm for minimizing \(g_\lambda (\textbf{w})\) using the gradient \(\nabla g_{\lambda }\) given in Theorem 4. Here, \(\textbf{w}\) is mapped to \(\textbf{t}\) using (12) at each iteration.

Convergence of \(\textbf{t}\) for a high-dimensional dataset during the execution of basic gradient descent. Solid lines correspond to \(\beta _j = 0\) and remaining 5 curves (with line style \(- \cdot -\)) correspond to \(\beta _j \ne 0\). The dataset is generated using the model (21) shown in Sect. 7.1 with only 5 components of \({\varvec{\beta }}\) are non-zero, equal to 1, at equally spaced indices between 1 and \(p = 1000\), and \(n=100\), \(\rho =0.8\), and signal-to-noise ratio of 5. The parameters \(\lambda = 0.1\) and \(\delta = n\); see Sect. 5 for more discussion on how to choose \(\lambda \) and \(\delta \). (colour figure online)
4 Subset selection algorithms
Our algorithm COMBSS as stated in Algorithm 1, takes the data \([X, \textbf{y}]\), tuning parameters \(\delta , \lambda \), and an initial point \(\textbf{w}^{(0)}\) as input, and returns either a single model or multiple models of different sizes as output. It is executed in three steps.
In Step 1, \(\textsf{GradientDescent}\left(\textbf{w}^{(0)}, \nabla g_{\lambda }\right)\) calls a gradient descent method, such as the well known adam optimizer, for minimizing the objective function \(g_{\lambda }(\textbf{w})\), which takes \(\textbf{w}^{(0)}\) as the initial point and uses the gradient function \(\nabla g_{\lambda }\) for updating the vector \(\textbf{w}\) in each iteration; see, for example, Kochenderfer and Wheeler (2019) for a review of popular gradient based optimization methods. It terminates when a predefined termination condition is satisfied and returns the sequence \(\textbf{w}_{\textsf{path}} = ( \textbf{w}^{(0)}, \textbf{w}^{(1)}, \dots )\) of all the points \(\textbf{w}\) visited during its execution, where \(\textbf{w}^{(l)}\) denotes the point obtained in the lth iteration of the gradient descent. Usually, a robust termination condition is to terminate when the change in \(\textbf{w}\) (or, equivalently, in \(\textbf{t} (\textbf{w})\)) is significantly small over a set of consecutive iterations.

\(\textsf{COMBSS}\left(X, \textbf{y}, \delta , \lambda , \textbf{w}^{(0)}\right)\)
Selecting the initial point \(\textbf{w}^{(0)}\) requires few considerations. From Theorem 4, for any \({j =1, \dots , p}\), we have \(t_j(w_j) = 0\) if and only if \(w_j = 0\) and \({\partial g_{\lambda }(\textbf{w})/\partial w_j = 0}\) if \(w_j = 0\). Hence, if we start the gradient descent algorithm with \(w^{(0)}_j = 0\) for some j, both \(w_j\) and \(t_j\) can continue to take 0 forever. As a result, we might not learn the optimal value for \(w_j\) (or, equivalently for \(t_j\)). Thus, it is important to select all the elements of \(w^{(0)}\) away from 0.
Consider the second argument, \(\nabla g_{\lambda }\), in the gradient descent method. From Theorem 4, observe that computing the gradient \(\nabla g_{\lambda }(\textbf{w})\) involves finding the values of the expression of the form \(L_{\textbf{t}}^{-1} \textbf{u}\) twice, first for computing \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) (using (7)) and then for computing the vector \(\textbf{c}_{\textbf{t}}\) (defined in Theorem 4). Since \(L_{\textbf{t}}\) is of dimension \({p \times p}\), computing the matrix inversion \(L_{\textbf{t}}^{-1}\) can be computationally demanding particularly in high-dimensional cases (\(n<p\)), where p can be very large; see, for example, Golub and Van Loan (1996). Since \(L_{\textbf{t}}\) is invertible, observe that \(L_{\textbf{t}}^{-1} \textbf{u}\) is the unique solution of the linear equation \({L_{\textbf{t}} \textbf{z}= \textbf{u}}\). In Sect. 6, we first use the well-known Woodbury matrix identity to convert this p-dimensional linear equation problem to an n-dimensional linear equation problem, which is then solved using the conjugate gradient method, a popular linear equation solver. Moreover, again from Theorem 4, notice that \(\nabla g_{\lambda }(\textbf{w})\) depends on both the tuning parameters \(\delta \) and \(\lambda \). Specifically, \(\delta \) is required for computing \(L_{\textbf{t}}\) and \(\lambda \) is used in the penalty term \(\lambda \sum _{j =1}^p t_j\) of the objective function. In Sect. 5 we provide more details on the roles of these two parameters and instructions on how to choose them.
In Step 2, we obtain the sequence \(\textbf{t}_{\textsf{path}} = (\textbf{t}^{(0)}, \textbf{t}^{(1)}, \dots )\) from \(\textbf{w}_{\textsf{path}}\) by using the map (12), that is, \(\textbf{t}^{(l)} = \textbf{t}(\textbf{w}^{(l)}) = \textbf{1 }- \exp (- \textbf{w}^{(l)} \odot \textbf{w}^{(l)})\) for each l.
Finally, in Step 3, \(\textsf{SubsetMap}(\textbf{t}_{\textsf{path}})\) takes the sequence \(\textbf{t}_{\textsf{path}}\) as input to find a set of models \(\mathcal M\) correspond to the input parameter \(\lambda \). In the following subsections, we describe two versions of \(\textsf{SubsetMap}\).
The following theoretical result, Theorem 5, guarantees convergence of COMBSS. In particular, this result establishes that a gradient descent algorithm on \(g_\lambda (\textbf{w})\) converges to an \(\epsilon \)-stationary point. Towards this, we say that a point \(\widehat{\textbf{w}} \in \mathbb {R}^p\) is an \(\epsilon \)-stationary point of \(g_\lambda ( \textbf{w})\) if \(\Vert \nabla g_\lambda (\widehat{\textbf{w}})\Vert _2 \le \epsilon \). Since \(\textbf{w}\) is called a stationary point if \(\nabla g_\lambda (\textbf{w}) = \textbf{0}\), an \(\epsilon \)-stationary point provides an approximation to a stationary point.
Theorem 5
There exists a constant \(\alpha > 0\) such that the gradient decent method, starting at any initial point \(\textbf{w}^{(0)}\) and with a fixed positive learning rate smaller than \(\alpha \), converges to an \(\epsilon \)-stationary point within \(O(1/\epsilon ^2)\) iterations.
4.1 Subset Map Version 1
One simple implementation of \(\textsf{SubsetMap}\) is stated as Algorithm 2 which we call \(\textsf{SubsetMapV1}\) (where V1 stands for version 1) and it requires only the final point in the sequence \(\textbf{t}_{\textsf{path}}\) and returns only one model using a predefined threshold parameter \(\tau \in [0,1)\).

\(\textsf{SubsetMapV1}\left(\textbf{t}_{\textsf{path}}, \tau \right)\)
Due to the tolerance allowed by the termination condition of the gradient descent, some \(w_j\) in the final point of \(\textbf{w}_{\textsf{path}}\) can be almost zero but not exactly zero, even though they are meant to converge to zero. As a result, the corresponding \(t_j\) also take values close to zero but not exactly zero because of the mapping from \(\textbf{w}\) to \(\textbf{t}\). Therefore, the threshold \(\tau \) helps in mapping the insignificantly small \(t_j\) to 0 and all other \(t_j\) to 1. In practice, we call \(\textsf{COMBSS}\left(X, \textbf{y}, \delta , \lambda , \textbf{w}^{(0)}\right)\) for each \(\lambda \) over a grid of values. When \(\textsf{SubsetMapV1}\) is used, larger the value of \(\lambda \), higher the sparsity in the resulting model \(\textbf{s}\). Thus, we can control the sparsity of the output model using \(\lambda \). Since we only care about the last point in \(\textbf{t}_{\textsf{path}}\) in this version, an intuitive option for initialization is to take \(\textbf{w}^{(0)}\) to be such that \(\textbf{t}(\textbf{w}^{(0)}) = (1/2, \dots , 1/2)^\top \), the mid-point on the hypercube \([0,1]^p\), as it is at an equal distance from all the corner points, of which one is the (unknown) target solution of the best subset selection problem.
In the suplementary material, we demonstrated the efficacy of COMBSS using SubsetMapV1 in predicting the true model of the data. In almost all the settings, we observe superior performance of COMBSS in comparison to existing popular methods.
4.2 Subset Map Version 2
Ideally, there is a value of \(\lambda \) for each k such that the output model \(\textbf{s}\) obtained by \(\textsf{SubsetMapV1}\) has exactly k non-zero elements. However, when the ultimate goal is to find a best suitable model \(\textbf{s}\) for a given \(k \le q\) such that \({|\textbf{s} |= k}\), for some \(q \ll min(n, p)\), since \(\lambda \) is selected over a grid, we might not obtain any model for some values of k. Furthermore, for a given size k, if there are two models with almost the same mean square error, then the optimization may have difficulty in distinguishing them. Addressing this difficulty may involve fine tuning of hyper-parameters of the optimization algorithm.
To overcome these challenges without any hyper-parameter tuning and reduce the reliance on the parameter \(\lambda \), we consider the other points in \(\textbf{t}_{\textsf{path}}\). In particular, we propose a more optimal implementation of \(\textsf{SubsetMap}\), which we call \(\textsf{SubsetMapV2}\) and is stated as Algorithm 3. The key idea of this version is that as the gradient descent progresses over the surface of \(f_\lambda (\textbf{t})\), it can point towards some corners of the hypercube \([0,1]^p\) before finally moving towards the final corner. Considering all these corners, we can refine the results. Specifically, this version provides for each \(\lambda \) a model for every \(k \le q\). In this implementation, \(\lambda \) is seen as a parameter that allows us to explore the surface of \(f_{\lambda }(\textbf{t})\) rather than as a sparsity parameter.

\(\textsf{SubsetMapV2}\left(\textbf{t}_{\textsf{path}}\right)\)
For the execution of \(\textsf{SubsetMapV2}\), we start at Step 1 with an empty set of models \(\mathcal {M}_k\) for each \(k \le q\). In Step 2, for each \(\textbf{t}\) in \(\textbf{t}_{\textsf{path}}\), we consider the sequence of indices \(j_1, \dots , j_q\) such that \(t_{j_1} \ge t_{j_2} \ge \cdots \ge t_{j_q}\). Then, for each \(k \le q\), we take \(\textbf{s}_k\) to be a binary vector with 1’s only at \(j_1, \dots , j_k\) and add \(\textbf{s}_k\) to the set \(\mathcal {M}_k\). With this construction, it is clear that \(\mathcal {M}_k\) consists of models of size k, of which we pick a best candidate \(\textbf{s}^*_k\) as show at Step 3. Finally, the algorithm returns the set consists of \(\textbf{s}^*_1, \dots , \textbf{s}^*_q\) correspond to the given \(\lambda \). When the main COMBSS is called for a grid of m values of \(\lambda \) with \(\textsf{SubsetMapV2}\), then for each \(k \le q\) we obtain at most m models and among them the model with the minimum mean squared error is selected as the final best model for k. Since this version of COMBSS explores the surface, we can refine results further by starting from different initial points \(\textbf{w}^{(0)}\). Sect. 7 provides simulations to demonstrate the performance of COMBSS with SubsetMapV2.
Remark 4
It is not hard to observe that for each \(\lambda \), if the model obtained by Algorithm 2 is of a size \(k \le q\), then this model is present in \(\mathcal {M}_k\) of Algorithm 3, and hence, COMBSS with SubsetMapV2 always provides the same or a better solution than COMBSS with SubsetMapV1.
5 Roles of tuning parameters
In this section, we provide insights on how the tuning parameters \(\delta \) and \(\lambda \) influence the objective function \(f_{\lambda }(\textbf{t})\) (or, equivalently \(g_{\lambda }(\textbf{w})\)) and hence the convergence of the algorithm.
5.1 Controlling the shape of \(f_{\lambda }(\textbf{t})\) through \(\delta \)
The normalized cost \(\Vert \textbf{y} - X_{\textbf{t}} \widetilde{\varvec{\beta }}_{\textbf{t}} \Vert _2^2/n\) provides an estimator of the error variance. For any fixed \(\textbf{t}\), we expect this variance (and hence the objective function \(f_{\lambda }(\textbf{t})\)) to be almost the same for all relatively large values of n, particularly, in situations where the errors \(\epsilon _i\) are independent and identically distributed. This is the case at all the corner points \(\textbf{s} \in \{ 0,1\}^p\), because at these corner points, from Theorem 2, \(X_{\textbf{s}}\widetilde{\varvec{\beta }}_{\textbf{s}} = X_{[\textbf{s}]}\widehat{\varvec{\beta }}_{[\textbf{s}]}\), which is independent of \(\delta \). We would like to have a similar behavior at all the interior points \(\textbf{t} \in (0,1)^p\) as well, so that for each \(\textbf{t}\), the function \(f_{\lambda }(\textbf{t})\) is roughly the same for all large values of n. Such consistent behavior is helpful in guaranteeing that the convergence paths of the gradient descent method are approximately the same for large values of n.

Illustration of how \(\delta \) effects the objective function \(f_{\lambda }(\textbf{t})\) (with \(\lambda = 0\)). A dataset consists of 10000 samples generated from the illustrative linear model used in Fig. 1. For (a) and (b), 100 samples from the same dataset are used. (colour figure online)
Figure 3 shows surface plots of \(f_{\lambda }(\textbf{t})\) for different values of n and \(\delta \) for an example dataset obtained from a linear model with \(p = 2\). Surface plots (a) and (d) correspond to \(\delta = n\), and as we can see, the shape of the surface of \(f_{\lambda }(\textbf{t})\) over \([0, 1]^p\) is very similar in both these plots.
To make this observation more explicit, we now show that the function \(f_{\lambda }(\textbf{t})\), at any \(\textbf{t}\), takes almost the same value for all large n if we keep \(\delta = c\, n\), for a fixed constant \(c > 0\), under the assumption that the data samples are independent and identically distributed (this assumption simplifies the following discussion; however, the conclusion holds more generally).
Observe that
where \(\varvec{\gamma }_{\textbf{t}} = n^{-1}\, T_{\textbf{t}} L_{\textbf{t}}^{-1} T_{\textbf{t}} X^\top \textbf{y}\). Under the independent and identically distributed assumption, \(\textbf{y}^\top \textbf{y}/n\), \(X^\top \textbf{y}/n\), and \(X^\top X/n\) converge element-wise as n increases. Since \(T_{\textbf{t}}\) is independent of n, we would like to choose \(\delta \) such that \(L_{\textbf{t}}^{-1}\) also converges as n increases. Now recall from (6) that
It is then evident that the choice \(\delta = c\, n\) for a fixed constant c, independent of n, makes \(L_{\textbf{t}}\) converging as n increases. Specifically, the choice \(c = 1\) justifies the behavior observed in Fig. 3.
5.2 Sparsity controlling through \(\lambda \)
Intuitively, the larger the value of \(\lambda \) the sparser the solution offered by COMBSS using SubsetMapV1, when all other parameters are fixed. We now strengthen this understanding mathematically. From Theorem 4, \( \nabla f_{\lambda }(\textbf{t}) = \varvec{\zeta }_{\textbf{t}} + \lambda \textbf{1}, \quad \textbf{t} \in (0,1)^p, \) and
for \(\textbf{w} \in \mathbb {R}^p\), where \(\varvec{\zeta }_{\textbf{t}}\), given by (15), is independent of \(\lambda \). Note the following property of \(\varvec{\zeta }_{\textbf{t}}\).
Proposition 1
For any \(j = 1, \dots , p\), if all \(t_i\) for \(i \ne j\) are fixed,
This result implies that for any \(j = 1, \dots , p\), we have \(\lim _{t_j \downarrow 0}\partial f_{\lambda }(\textbf{t})/\partial t_j = \lambda ,\) where \(\lim _{t_j \downarrow 0}\) denotes the existence of the limit for any sequence of \(t_j\) that converges to 0 from the right. Since \(\varvec{\zeta }_{\textbf{t}} \) is independent of \(\lambda \), the above limit implies that there is a window \((0, a_j)\) such that the slope \(\partial f_{\lambda }(\textbf{t})/\partial t_j~>~0\) for \(t_j \in (0, a_j)\) and also the window size increases (i.e., \(a_j\) increases) as \(\lambda \) increases. As a result, for the function \(g_{\lambda }(\textbf{w})\), there exists a constant \(a'_j>0\) such that
In other words, for positive \(\lambda \), there is a ‘valley’ on the surface of \(g_{\lambda }(\textbf{w})\) along the line \(w_j = 0\) and the valley becomes wider as \(\lambda \) increases. In summary, the larger the values of \(\lambda \) the more \(w_j\) (or, equivalently \(t_j\)) have tendency to move towards 0 by the optimization algorithm and then a sparse model is selected (i.e, small number k of variables chosen). At the extreme value \(\lambda _{\max }=\left\| y\right\| ^2_{2}/n\), all \(t_j\) are forced towards 0 and thus the null model will be selected.
6 Efficient implementation of COMBSS
In this section, we focus on efficient implementation of COMBSS using the conjugate gradient method, the Woodbury matrix identity, and the Banachiewicz Inversion Formula.
6.1 Low- vs high-dimension
Recall the expression of \(L_{\textbf{t}}\) from (5):
We have noticed earlier from Theorem 4 that for computing \(\nabla g_{\lambda }(\textbf{w})\), twice we evaluate matrix–vector products of the form \(L_{\textbf{t}}^{-1} \textbf{u}\), which is the unique solution of the linear equation \(L_{\textbf{t}} \textbf{z}= \textbf{u}\). Solving linear equations efficiently is one of the important and well-studied problems in the field of linear algebra. Among many elegant approaches for solving linear equations, the conjugate gradient method is well-suited for our problem as \(L_{\textbf{t}}\) is symmetric positive-definite; see, for example, Golub and Van Loan (1996).
The running time of the conjugate gradient method for solving the linear equation \(A \textbf{z}= \textbf{u}\) depends on the dimension of A. For our algorithm, since \(L_{\textbf{t}}\) is of dimension \(p \times p\), the conjugate gradient method can return a good approximation of \(L_{\textbf{t}}^{-1}\textbf{u}\) within \(O(p^2)\) time by fixing the maximum number of iterations taken by the conjugate gradient method. This is true for both low-dimensional models (where \(p < n\)) and high-dimensional models (where \(n < p\)).
We now specifically focus on high-dimensional models and transform the problem of solving the p-dimensional linear equation \(L_{\textbf{t}}\textbf{z}= \textbf{u}\) to the problem of solving an n-dimensional linear equation problem. This approach is based on a well-known result in linear algebra called the Woodbury matrix identity. Since we are calling the gradient descent method for solving a n-dimensional problem, instead of p-dimensional, we can achieve a much lower overall computational complexity for the high-dimensional models. The following result is a consequence of the Woodbury matrix identity, which is stated as Lemma 2 in Appendix A.
Theorem 6
For \(\textbf{t} \in [0,1)^p\), let \(S_{\textbf{t}}\) be a p-dimensional diagonal matrix with the jth diagonal element being \(n/\delta (1 - t_j^2)\) and \(\widetilde{L}_{\textbf{t}} = I + X_{\textbf{t}} S_{\textbf{t}} X_{\textbf{t}}^\top /n.\) Then,
The above expression suggests that instead of solving the p-dimensional problem \(L_{\textbf{t}}\textbf{z}= \textbf{u}\) directly, we can first solve the n-dimensional problem \(\widetilde{L}_{\textbf{t}} \textbf{z}= \left(X_{\textbf{t}} S_{\textbf{t}} \textbf{u}\right)\) and substitute the result in the above expression to get the value of \(L_{\textbf{t}}^{-1} \textbf{u}\).
6.2 A dimension reduction approach
During the execution of the gradient descent algorithm, Step 1 of Algorithm 1, some of \(w_j\) (and hence the corresponding \(t_j\)) can reach zero. Particularly, for basic gradient descent and similar methods, once \(w_j\) reaches zero it remains zero until the algorithm terminates, because the update of \(\textbf{w}\) in the lth iteration of the basic gradient descent depends only on the gradient \(g_{\lambda }(\textbf{w}^{(l)})\), whose jth element
Because (16) holds, we need to focus only on \(\partial g_{\lambda }(\textbf{w})/\partial w_j\) associated with \(w_j \ne 0\) in order to reduce the cost of computing the gradient \(\nabla g_{\lambda }(\textbf{w})\). To simplify the notation, let \(\mathscr {P}= \{1, \dots , p \}\) and for any \(\textbf{t} \in [0,1)^p\), let \(\mathscr {Z}_{\textbf{t}}\) be the set of indices of the zero elements of \(\textbf{t}\), that is,
Similar to the notation used in Theorem 2, for a vector \(\textbf{u}\in \mathbb {R}^p\), we write \((\textbf{u})_{\scriptscriptstyle {+}}\) (respectively, \((\textbf{u})_{0}\)) to denote the vector of dimension \({p - |\mathscr {Z}_{\textbf{t}}|}\) (respectively, \(|\mathscr {Z}_{\textbf{t}}|\)) constructed from \(\textbf{u}\) by removing all its elements with the indices in \(\mathscr {Z}_{\textbf{t}}\) (respectively, in \(\mathscr {P}\setminus \mathscr {Z}_{\textbf{t}}\)). Similarly, for a matrix A of dimension \(p\times p\), we write \((A)_{\scriptscriptstyle {+}}\) (respectively, \((A)_0\)) to denote the new matrix constructed from A by removing its rows and columns with the indices in \(\mathscr {Z}_{\textbf{t}}\) (respectively, in \(\mathscr {P}\setminus \mathscr {Z}_{\textbf{t}}\)). Then we have the following result.
Theorem 7
Suppose \(\textbf{t} \in [0,1)^p\). Then,
Furthermore, we have
In Theorem 7, (18) shows that for every \(j \in \mathscr {Z}_{\textbf{t}}\), all the off-diagonal elements of the jth row as well as the jth column of \(L^{-1}_{\textbf{t}}\) are zero while its jth diagonal element is \(n/\delta \), and all other elements of \(L_{\textbf{t}}^{-1}\) (which constitute the sub-matrix \( \left(L_{\textbf{t}}^{-1}\right)_{\scriptscriptstyle {+}}\)) depend only on \(\left(L_{\textbf{t}}\right)_{\scriptscriptstyle {+}}\), which can be computed using only the columns of the design matrix X with indices in \(\mathscr {P}\setminus \mathscr {Z}_{\textbf{t}}\). As a consequence, (19) and (20) imply that computing \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) and \(\textbf{c}_{\textbf{t}}\) is equal to solving \(p_{\scriptscriptstyle {+}}\)-dimensional linear equations of the form \(\left(L_{\textbf{t}}^{-1}\right)_{\scriptscriptstyle {+}} \textbf{z}= \textbf{v}\), where \(p_{\scriptscriptstyle {+}} = p - |\mathscr {Z}_{\textbf{t}}|\). Since \(p_{\scriptscriptstyle {+}} \le p\), solving such a \(p_{\scriptscriptstyle {+}}\)-dimensional linear equation using the conjugate gradient can be faster than solving the original p-dimensional linear equation of the form \(L_{\textbf{t}} \textbf{z}= \textbf{u}\).
In summary, for a vector \(\textbf{t} \in [0, 1)^p\) with some elements being 0, the values of \(f_\lambda (\textbf{t})\) and \(\nabla f_{\lambda }(\textbf{t})\) do not depend on the columns j of X where \(t_j = 0\). Therefore, we can reduce the computational complexity by removing all the columns j of the design matrix X where \(t_j = 0\).
6.3 Making our algorithm fast

Running time of our algorithm at \(\lambda = 0.1\) for an example dataset using the adam optimizer, a popular gradient based method. These boxplots are based on 300 replications. Here we compare running times for COMBSS with SubsetMapV1 using only conjugate gradient (ConjGrad), conjugate gradient with Woodbury matrix identity (ConjGrad-Woodbury), and conjugate gradient with both Woodbury matrix identity and truncation improvement (ConjGrad-Woodbury-Trunc). For the truncation, \(\eta = 0.001\). The dataset for this experiment is the same dataset used for Fig. 2
In Sect. 6.2, we noted that when some elements \(t_j\) of \(\textbf{t}\) are zero, it is faster to compute the objective functions \(f_\lambda (\textbf{t})\) and \(g_\lambda (\textbf{t})\) and their gradients \(\nabla f_\lambda (\textbf{t})\) and \(\nabla g_\lambda (\textbf{t})\) by ignoring the columns j of the design matrix X. In Sect. 5.2, using Proposition 1, we further noted that for any \({\lambda > 0}\) there is a ‘valley’ on the surface of \(g_{\lambda }(\textbf{w})\) along \(w_j = 0\) for all \(j = 1, \dots , p\), and thus for any j, when \(w_j\) (or, equivalently, \(t_j\)) is sufficiently small during the execution of the gradient descent method, it will eventually become zero. Using these observations, in the implementation of our method, to reduce the computational cost of estimating the gradients, it is wise to map \(w_j\) (and \(t_j\)) to 0 when \(w_j\) is almost zero. We incorporate this truncation idea into our algorithm as follows.
We first fix a small constant \(\eta \), say at 0.001. As we run the gradient descent algorithm, when \(t_j\) becomes smaller than \(\eta \) for some \(j \in \mathscr {P}\), we take \(t_j\) and \(w_j\) to be zero and we stop updating them; that is, \(t_j\) and \(w_j\) will continue to be zero until the gradient descent algorithm terminates. In each iteration of the gradient descent algorithm, the design matrix is updated by removing all the columns corresponding to zero \(t_j\)’s. If the algorithm starts at \(\textbf{w}\) with all non-zero elements, the effective dimension \(p_{\scriptscriptstyle {+}}\), which denotes the number of columns in the updated design matrix, monotonically decreases starting from p. In an iteration, if \(p_{\scriptscriptstyle {+}} > n\), we can use Theorem 6 to reduce the complexity of computing the gradients. However, when \(p_{\scriptscriptstyle {+}}\) falls below n, we directly use conjugate gradient for computing the gradients without invoking Theorem 6.
Using a dataset, Fig. 4 illustrates the substantial improvement in the speed of our algorithm when the above mentioned improvement ideas are incorporated in its implementation.
Remark 5
From our simulations over the range of scenarios considered in Sect. 7, we have observed that the performance of our method does not vary significantly when \(\eta \) is close to zero. In particular, we noticed that any value of \(\eta \) close to or less than 0.001 is a good choice. Good, in the sense that, if \(\textbf{s}_\eta \in \{ 0, 1\}^p\) is the model selected by COMBSS, then we rarely observed \(\textbf{s}_\eta \ne \textbf{s}_0\). Thus, the Hamming distance between \(\textbf{s}_\eta \) and \(\textbf{s}_0\) is zero when \(\eta \) is close to or smaller than 0.001, except in few generated datasets. This holds when comparing the estimated true model and when comparing the best subsets.
7 Simulation experiments
Our method is available through Python and R codes via GitHubFootnote 1. The code includes examples where p is as large as of order 10,000. This code further allows to replicate our simulation results presented in this section and in the supplementary material.
In the supplementary material, we focused on demonstrating (using \(\textsf{SubsetMapV1}\)) the efficacy in predicting the true model of the data. Here, our focus is on demonstrating the efficacy of our method in retrieving best subsets of given sizes, meaning our ability to solve (1) using \(\textsf{SubsetMapV2}\). We compare our approach to forward selection, Lasso, mixed integer optimization and L0Learn (Hazimeh and Mazumder 2020).
7.1 Simulation design
The data is generated from the linear model:
Here, each row of the predictor matrix X is generated from a multivariate normal distribution with zero mean and covariance matrix \(\Sigma \) with diagonal elements \(\Sigma _{j,j} = 1\) and off-diagonal elements \(\Sigma _{i,j} = \rho ^{\vert i-j \vert }\), \(i \ne j\), for some correlation parameter \(\rho \in (-1, 1)\). Note that the noise \(\epsilon \) is a n-dimensional vector of independent and identically distributed normal variables with zero mean and variance \(\sigma ^2\). In order to investigate a challenging situation, we use \(\rho =0.8\) to mimic strong correlation between predictors. For each simulation, we fix the signal-to-noise ratio (SNR) and compute the variance \(\sigma ^2\) of the noise \(\varvec{\epsilon }\) using
We consider the following two simulation settings:
-
Case 1: The first \(k_0 =10\) components of \({\varvec{\beta }}\) are equal to 1 and all other components of \({\varvec{\beta }}\) are equal to 0.
-
Case 2: The first \(k_0 =10\) components of \({\varvec{\beta }}\) are given by \(\beta _i=0.5^{i-1}\), for \(i=1,\ldots ,k_0\) and all other components of \({\varvec{\beta }}\) are equal to 0.
Both Case 1 and Case 2 assumes strong correlation between the active predictors. Case 2 differs from Case 1 by presenting a signal decaying exponentially to 0.
For both these cases, we investigate the performance of our method in low- and high-dimensional settings. For the low-dimensional setting, we take \(n=100\) and \(p=20\) for \(\textsf{SNR} \in \{0.5, 1,2,\dots ,8\}\), while for the high-dimensional setting, \(n=100\) and \(p=1000\) for \(\textsf{SNR} \in \{2,3,\dots ,8\}\).
In the low-dimensional setting, the forward stepwise selection (FS) and the mixed integer optimization (MIO) were tuned over \(k=0,\ldots ,20\). In this simulation we ran MIO through the R package bestsubset offered in Hastie et al. (2018) while we ran L0Learn through the R package L0Learn offered in Hazimeh et al. (2023). For the high dimensional setting, we do not include MIO due to time computational constraints posed by MIO.
In low- and high-dimensional settings, the Lasso was tuned for 50 values of \(\lambda \) ranging from \(\lambda _{\max }=\left\| X^{T} \textbf{y}\right\| _{\infty }\) to a small fraction of \(\lambda _{\max }\) on a log scale, as per the default in bestsubset package. In both the low- and high-dimensional settings, COMBSS with SubsetMapV2 was called four times starting at four different initial points \(\textbf{t}^{(0)}\): \((0.5, \dots , 0.5)^\top \), \((0.99, \dots 0.99)^\top \), \((0.75, \dots , 0.75)^\top \), and \((0.3, \dots , 0.3)^\top \). For each call of COMBSS, we used at most 24 values of \(\lambda \) on a dynamic grid as follows. Starting from \(\lambda _{\max }=\left\| \textbf{y}\right\| ^2_{2}/n\), half of \(\lambda \) values were generated by \(\{\lambda _l= \lambda _{\max }/ 2^{l}\), \(l=1,\dots ,12\}\). From this sequence, the remaining \(\lambda \) values were created by \(\{(\lambda _{l+1} + \lambda _{l})/2: l=1,\dots ,12\}\).
7.2 Low-dimensional case
In low dimensional case, we use the exhaustive method to find the exact solution of the best subset for any subset size ranging from 1 to p. Then, we assess our method in retrieving the exact best subset for each subset size. Figure 5, shows the frequency of retrieving the exact best subset (provided by exhaustive search) for any subset size from \(k=1,\dots ,p\), for Case 1, over 200 replications. For each SNR level, MIO as expected retrieves perfectly the optimal best subset of any model size. Then COMBSS gives the best results to retrieve the best subset compared to FS, Lasso and L0Learn. We can also observe that each of these curves follow a U-shape, with the lowest point approximately at the middle. This behaviour seems to be related to possible \(\left( {\begin{array}{c}p\\ k\end{array}}\right) \) choices for each subset size \(k=1,\ldots ,p\), as at each k we have \(\left( {\begin{array}{c}p\\ k\end{array}}\right) \) options (corner points on \([0, 1]^p\)) to explore. Similar behaviours are reported for the low-dimensional setting of Case 2 in Fig. 6.

Frequency (over 200 replications) of retrieving the exact best subset for any subset size from \(k=1,\ldots ,p\) for Case 1. (colour figure online)

Frequency (over 200 replications) of retrieving the exact best subset for any subset size from \(k=1,\ldots ,p\) for Case 2. (colour figure online)

Ability of COMBSS (using SubsetMapV2) for providing a competing best subset for subset sizes 5 and 10 in comparison to FS, Lasso and L0Learn. The top plots are for Case 1 while the bottom plots are for Case 2. (colour figure online)
7.3 High-dimensional case
To assess the performance of our method in retrieving a competitive best subset, we compare the best subset obtained from COMBSS with other methods for two different subset sizes: 5 and 10, over 50 replications. Note that the exact best subset is unknown for the high dimensional case since it is computationally impractical to conduct an exhaustive search even for moderate subset sizes when \(p=1000\). Hence, for this comparison, we use the mean squared error (MSE) of the dataset to evaluate which method is providing a better subset for size 5 and 10. Figure 7 presents these results over 50 replications for SNR values from 2 to 8. As expected the MSE of all methods is decreasing when SNR is increasing. Overall, COMBSS is consistently same or better than other methods for providing a competing best subset. On the other hand none of the alternative methods is consistent across all the cases.
In this high-dimensional setting, as mentioned earlier, deploying MIO, which is based on the Gurobi optimizer, proves impractical (see Hastie et al. (2020)). This is due to its prohibitively long running time, extending into the order of hours. In stark contrast, COMBSS exhibits running times of a few seconds for both the cases of the simulation settings: approximately 4.5 seconds with SubsetMapV1 (for predicting the true model) and approximately 7 seconds with SubsetMapV2 (for best subset selection). We have observed that for COMBSS, SubsetMapV1 operates at approximately twice the speed of SubsetMap2. Other existing methods demonstrate even faster running times, within a fraction of a second, but with lower performance compared to COMBSS. In summary, for best subset selection, COMBSS stands out as the most efficient among the methods that can run within a few seconds. Similarly, in predicting the true model, we believe that the consistently strong performance of COMBSS positions it as a crucial method, particularly when compared to other faster methods like Lasso.
8 Conclusion and discussion
In this paper, we have introduced COMBSS, a novel continuous optimization method towards best subset selection in linear regression. The key goal of COMBSS is to extend the highly difficult discrete constrained best subset selection problem to an unconstrained continuous optimization problem. In particular, COMBSS involves extending the objective function of the best subset selection, which is defined at the corners of the hypercube \([0,1]^p\), to a differentiable function defined on the whole hypercube. For this extended function, starting from an interior point, a gradient descent method is executed to find a corner of the hypercube where the objective function is minimum.
In this paper, our simulation experiments highlight the ability of COMBSS with SubsetMapV2 for retrieving the “exact” best subset for any subset size in comparison to four existing methods: Forward Stepwise (FS), Lasso, L0Learn, and Mixed Integer Optimization (MIO). In the supplementary material, we have presented several simulation experiments in both low-dimensional and high-dimensional setups to illustrate the good performance of COMBSS with SubsetMapV1 for predicting the true model of the data in comparison to FS, Lasso, L0Learn, and MIO. Both of these empirical studies emphasize the potential of COMBSS for feature extractions. In addition to these four methods, we have also explored with the minimax concave penalty (MCP) and smoothly clipped absolute deviation (SCAD), which are available through the R package ncvreg; refer to Breheny and Huang (2011) for details of these two methods. In our simulation studies, we omitted the results for both MCP and SCAD, as their performance, although somewhat similar to the performance of Lasso, did not compete with COMBSS for best subset selection and for predicting the true model parameters.
In our algorithm, the primary operations involved are the matrix–vector product, the vector-vector element-wise product, and the scalar-vector product. Particularly, we note that most of the running time complexity of COMBSS comes from the application of the conjugate gradient method for solving linear equations of the form \(A{\textbf{z}} = {\textbf{u}}\) using off-the-shelf packages. The main operation involved in conjugate gradient is the matrix–vector product \(A{\textbf{u}}\), and such operations are known to execute faster on graphics processing unit (GPU) based computers using parallel programming. A future GPU based implementation of COMBSS could substantially increase the speed of our method. Furthermore, application of stochastic gradient descent (Bottou 2012) instead of gradient descent and randomized Kaczmarz algorithm (a variant of stochastic gradient) (Strohmer and Vershynin 2009) instead of conjugate gradient has potential to increase the speed of COMBSS as the stochastic gradient descent methods take just one data sample in each iteration.
A future direction for finding the best model of a given fixed size k is to explore different options for the penalty term of the objective function \(f_{\lambda }(\textbf{t})\). Ideally, if we select a sufficiently large penalty for \(\sum _{j = 1}^p t_j > k\) and 0 otherwise, we can drive the optimization algorithm towards a model of size k that lies along the hyperplane given by \(\sum _{j =1}^p t_j = k\). Because such a discrete penalty is not differentiable, we could use smooth alternatives. For instance, the penalty could be taken to be \(\lambda (k - \sum _{j =1}^p t_j)^2\) when \(\sum _{j = 1}^p t_j > k\) and 0 otherwise, for a tuning parameter \(\lambda > 0\).
We expect, similarly to the significant body of work that focuses on the Lasso and on MIO, respectively, that there are many avenues that can be explored and investigated for building on the presented COMBSS framework. Particularly, to tackle best subset selection when problems are ultra-high dimensional. In this paper, we have opened a novel framework for feature selection and this framework can be extended to other models beyond the linear regression model. For instance, recently Mathur et al. (2023) extended the COMBSS framework for solving column subset selection and Nyström approximation problems.
Moreover, in the context of Bayesian predictive modeling, Kowal (2022) introduced Bayesian subset selection for linear prediction or classification, and they diverged from the traditional emphasis on identifying a single best subset, opting instead to uncover a family of subsets, with notable members such as the smallest acceptable subset. For a more general task of considering variable selection, the handbook edited by Tadesse and Vannucci (2021) offered an extensive exploration of Bayesian approaches to variable selection. Extending the concept of COMBSS to encompass more general variable selection and establishing a connection with Bayesian modelling appear to be promising avenues for further research.
In addition, the objective function in (13) becomes \(\Vert \textbf{y} - X (\textbf{t} \odot {\varvec{\beta }})\Vert ^2_2/n\) when both the penalty terms are removed, where note that \(X_{\textbf{t}} {\varvec{\beta }}= X (\textbf{t} \odot {\varvec{\beta }})\). An unconstrained optimization of this function over \(\textbf{t}, {\varvec{\beta }}\in \mathbb {R}^p\) is studied in the area of implicit regularization; see, e.g., Hoff (2017); Vaskevicius et al. (2019); Zhao et al. (2019); Fan et al. (2022); Zhao et al. (2022). Gradient descent in our method minimizes over the unconstrained variable \(\textbf{w} \in \mathbb {R}^p\) to get an optimal constrained variable \(\textbf{t} \in [0,1]^p\). On the contrary, in their approach, \(\textbf{t}\) itself is unconstrained. Unlike the gradient descent of our method which terminates when it is closer to a stationary point on the hypercube \([0, 1]^p\), the gradient descent of their methods may need an early-stopping criterion using a separate test set.
Finally, our ongoing research focuses on extensions of COMBSS to non-linear regression problems including logistic regression.
Notes
References
Armstrong, M.A.: Basic topology. Undergraduate texts in mathematics. Springer, Berlin (1983)
Bertsimas, D., King, A., Mazumder, R.: Best subset selection via a modern optimization lens. Ann. Stat. 44(2), 813–852 (2016)
Bottou, L.: Stochastic Gradient Descent Tricks, pp. 421–436. Springer, Berlin (2012)
Breheny, P., Huang, J.: Coordinate descent algorithms for nonconvex penalized regression, with applications to biological feature selection. Ann. Appl. Stat. 5(1), 232–253 (2011)
Castro-González, N., Martínez-Serrano, M., Robles, J.: Expressions for the Moore-Penrose inverse of block matrices involving the Schur complement. Linear Algebra Appl. 471, 353–368 (2015)
Danilova, M., Dvurechensky, P., Gasnikov, A., et al.: Recent theoretical advances in non-convex optimization. In: Nikeghbali, A., Pardalos, P.M., Raigorodskii, A.M., Rassias, M.T. (eds.) High-dimensional optimization and probability, pp. 79–163. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-00832-0_3
Efroymson, M.A.: Stepwise regression-a backward and forward look. Presented at the Eastern Regional Meetings of of the Institute of Mathematical Statistics, Florham Park, New Jersey (1966)
Fan, J., Li, R.: Statistical challenges with high dimensionality: feature selection in knowledge discovery. In: International Congress of Mathematicians, vol. III, pp. 595–622. Eur. Math. Soc, Zürich (2006)
Fan, J., Lv, J.: A selective overview of variable selection in high dimensional feature space. Stat. Sin. 20(1), 101–148 (2010)
Fan, J., Yang, Z., Yu, M.: Understanding implicit regularization in over-parameterized single index model. J. Am. Stat. Assoc. 118(544), 1–37 (2022)
Furnival, G.M., Wilson, R.W.: Regressions by leaps and bounds. Technometrics 42, 69–79 (2000)
Golub, G.H., Van Loan, C.F.: Matrix computations, 3rd edn. Johns Hopkins Studies in the Mathematical Sciences, Johns Hopkins University Press, Baltimore (1996)
Gurobi Optimization, limited liability company: Gurobi Optimizer Reference Manual. https://www.gurobi.com (2022)
Hastie, T., Tibshirani, R., Tibshirani, R.: Bestsubset: tools for best subset selection in regression. R package version 1, 10 (2018)
Hastie, T., Tibshirani, R., Tibshirani, R.: Best subset, forward stepwise or lasso? Analysis and recommendations based on extensive comparisons. Stat. Sci. 35(4), 579–592 (2020)
Hazimeh, H., Mazumder, R.: Fast best subset selection: coordinate descent and local combinatorial optimization algorithms. Oper. Res. 68(5), 1517–1537 (2020)
Hazimeh, H., Mazumder, R., Nonet, T.: L0Learn: fast algorithms for best subset selection. R package version 2.1.0 (2023)
Hocking, R.R., Leslie, R.N.: Selection of the best subset in regression analysis. Technometrics 9, 531–540 (1967)
Hoff, P.D.: Lasso, fractional norm and structured sparse estimation using a Hadamard product parametrization. Comput. Stat. Data Anal. 115, 186–198 (2017)
Hui, F.K., Müller, S., Welsh, A.: Joint selection in mixed models using regularized PQL. J. Am. Stat. Assoc. 112(519), 1323–1333 (2017)
Kochenderfer, M.J., Wheeler, T.A.: Algorithms for optimization. Massachusetts Institute of Technology Press, Cambridge (2019)
Kowal, D.R.: Bayesian subset selection and variable importance for interpretable prediction and classification. J. Mach. Learn. Res. 23(1), 4661–4698 (2022)
Mathur, A., Moka, S., Botev, Z.: Column subset selection and Nyström approximation via continuous optimization. arXiv preprint https://arxiv.org/abs/2304.09678 (2023)
Miller, A.: Subset selection in regression, monographs on statistics and applied probability, vol. 95. Chapman & Hall/CRC, Boca Raton (2019)
Müller, S., Welsh, A.H.: On model selection curves. Int. Stat. Rev. 78(2), 240–256 (2010)
Natarajan, B.K.: Sparse approximate solutions to linear systems. SIAM J. Comput. 24(2), 227–234 (1995)
Strohmer, T., Vershynin, R.: A randomized Kaczmarz algorithm with exponential convergence. J. Fourier Anal. Appl. 15(2), 262–278 (2009)
Tadesse, M.G., Vannucci, M.: Handbook of Bayesian Variable Selection. Chapman & Hall, Boca Raton (2021)
Tarr, G., Muller, S., Welsh, A.H.: MPLOT: an R package for graphical model stability and variable selection procedures. J. Stat. Softw. 83(9), 1–28 (2018)
Tian, Y., Takane, Y.: Schur complements and Banachiewicz-Schur forms. Electron. J. Linear Algebra 13, 405–418 (2005)
Tibshirani, R.: Regression shrinkage and selection via the lasso. J. Roy. Stat. Soc. B 58(1), 267–288 (1996)
Vaskevicius, T., Kanade, V., Rebeschini, P.: Implicit regularization for optimal sparse recovery. Adv. Neural Inf. Proc. Syst. 32 (2019)
Woodbury, M.A.: Inverting modified matrices, vol. 42. Princeton University, Princeton (1950)
Zhao, P., Yang, Y., He, Q.C.: Implicit regularization via Hadamard product over-parametrization in high-dimensional linear regression. arXiv preprint arXiv:1903.09367 2(4):8 (2019)
Zhao, P., Yang, Y., He, Q.C.: High-dimensional linear regression via implicit regularization. Biometrika 109(4), 1033–1046 (2022)
Zhu, J., Wen, C., Zhu, J., et al.: A polynomial algorithm for best-subset selection problem. In: Proceedings of the National Academy of Sciences of the United States of America 117(52), 33117–33123 (2020)
Acknowledgements
Samuel Muller was supported by the Australian Research Council Discovery Project Grant #210100521.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions Funding was provided by Australian Research Council (Grant number: 10100521).
Author information
Authors and Affiliations
Contributions
All the authors contributed to developing the proposed method. Sarat Moka developed theoretical framework and written corresponding parts of the manuscript. Sarat Moka and Benoit Liquet has developed Python and R codes, respectively. All the authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendix A Proofs
Appendix A Proofs
Proof of Theorem 1
Since both \(X_{\textbf{t}}^\top X_{\textbf{t}}\) and \(T_{\textbf{t}}\) are symmetric, the symmetry of \(L_{\textbf{t}}\) is obvious. We now show that \(L_{\textbf{t}}\) is positive-definite for \(\textbf{t} \in [0, 1)^p\) by establishing
The matrix \(X_{\textbf{t}}^\top X_{\textbf{t}}\) is a positive semi-definite, because
In addition, for all \(\textbf{t} \in [0, 1)^p\), the matrix \(\delta \left(I - T_{\textbf{t}}^2\right)\) is also a positive-definite because \(\delta > 0\), and
which is strictly positive if \(\textbf{t} \in [0, 1)^p\) and \(\textbf{u}\in \mathbb {R}^{p}{\setminus } \{\varvec{0}\}\). Since positive-definite matrices are invertible, we have \(L_{\textbf{t}}^{\dagger } = L_{\textbf{t}}^{-1}\), and thus, \(\widetilde{\varvec{\beta }}_{\textbf{t}} = L_{\textbf{t}}^{-1} X_{\textbf{t}}^\top \textbf{y}/n\). \(\square \)
Theorem 8 is a collection of results from the literature that we need in our proofs. Results (i) and (ii) of Theorem 8 are well-known in the literature as Banachiewicz inversion lemma (see, e.g., Tian and Takane (2005)), and (iii) is its generalization to Moore-Penrose inverse (See Corollary 3.5 (c) in Castro-González et al. (2015)).
Theorem 8
Let M be a square block matrix of the form
with A being a square matrix. Let the Schur complement \(S = D - B A^{\dagger } C\). Suppose that D is non-singular. Then following holds.
-
(i)
If A is non-singular, then M is non-singular if and only if S is non-singular.
-
(ii)
If both A and S are non-singular, then
$$\begin{aligned} M^{-1}&= \begin{bmatrix} I &{} -A^{-1} C S^{-1} \\ 0 &{} S^{-1} \end{bmatrix} \begin{bmatrix} A^{-1} &{} 0 \\ -B A^{-1} &{} I \end{bmatrix}\nonumber \\&= \begin{bmatrix} I &{} -A^{-1} C \\ 0 &{} I \end{bmatrix} \begin{bmatrix} I &{} 0 \\ - S^{-1} B &{} S^{-1} \end{bmatrix} \begin{bmatrix} A^{-1} &{} 0 \\ 0 &{} I \end{bmatrix}. \end{aligned}$$(A1) -
(iii)
If A is singular, S is non-singular, \(B A^{\dagger } A = B\) and \( A A^{\dagger } C = C\), then
$$\begin{aligned} M^\dagger&= \begin{bmatrix} I &{} -A^{\dagger } C S^{-1} \\ 0 &{} S^{-1} \end{bmatrix} \begin{bmatrix} A^{\dagger } &{} 0 \\ -B A^{\dagger } &{} I \end{bmatrix}\nonumber \\&= \begin{bmatrix} I &{} -A^{\dagger } C \\ 0 &{} I \end{bmatrix} \begin{bmatrix} I &{} 0 \\ - S^{-1} B &{} S^{-1} \end{bmatrix} \begin{bmatrix} A^{\dagger } &{} 0 \\ 0 &{} I \end{bmatrix}. \end{aligned}$$(A2)
Proof of Theorem 2
The inverse of a matrix after a permutation of rows (respectively, columns) is identical to the matrix obtained by applying the same permutation on columns (respectively, rows) on the inverse of the matrix. Therefore, without loss of generality, we assume that all the zero-elements of \(\textbf{s} \in \{0,1\}^p\) appear at the end, in the form:
where m indicates the number of non-zeros in \(\textbf{s}\). Recall that \({X}_{[\textbf{s}]}\) is the matrix of size \(n\times |{\textbf{s}}|\) created by keeping only columns j of X for which \(s_{j} = 1\). Thus, \(L_{\textbf{s}}\) is given by,
From Theorem 8 (i), it is evident that \(L_{\textbf{s}}\) is invertible if and only if \(X_{[\textbf{s}]}^\top X_{[\textbf{s}]}\) is invertible.
First assume that \(X_{[\textbf{s}]}^\top X_{[\textbf{s}]}\) is invertible. Then, from Theorem 8 (ii),
Now recall the notations \((\widetilde{\varvec{\beta }}_{\textbf{s}})_+\) and \((\widetilde{\varvec{\beta }}_{\textbf{s}})_0\) introduced before stating Theorem 2. Then, we use (6) to obtain
This further guarantees that \({X}_{[\textbf{s}]}\widehat{\varvec{\beta }}_{[\textbf{s}]}=X_{\textbf{s}} \widetilde{\varvec{\beta }}_{\textbf{s}}\).
When \(X_{[\textbf{s}]}^\top X_{[\textbf{s}]}\) is singular, by replacing the inverse with its pseudo-inverse in the above discussion, and using Theorem 8 (iii) instead of Theorem 8 (ii), we can establish the same conclusions. This is because, the corresponding Schur complement for \(L_{\textbf{s}}\) is \(S = n\, I/\delta \), which is symmetric and positive definite. \(\square \)
Proof of Theorem 3
Consider a sequence \(\textbf{t}_{1}, \textbf{t}_{2}, \dots \in [0, 1)^p\) that converges a point \(\textbf{t} \in [0,1]^p\). We know that the converges easily holds when \(\textbf{t} \in [0,1)^p\) from the continuity of matrix inversion which states that for any sequence of invertible matrices \(Z_1, Z_2, \dots \) that converging to an invertible matrix Z, the sequence of their inverses \(Z_1^{-1}, Z_2^{-1}, \dots \) converges to \(Z^{-1}\).
Now using Theorem 8, we prove the convergence when some or all of the elements of the limit point \(\textbf{t}\) are equal to 1. Suppose \(\textbf{t}\) has exactly m elements equal to 1. Using the arguments from the proof of 2, without of loss of generality assume that all 1s in \(\textbf{t}\) appear together in the first m positions, that is,
In that case, by writing
we observe that as \(\ell \rightarrow \infty \)
Further, take
and
with \(X_1\) denoting the first m columns of X. Similarly, we can write
We now observe that
As a result,
Now define,
and
Since \(\textbf{t}_{\ell } \in [0, 1)^p\), \(L_{\textbf{t}_{\ell }}\) is non-singular (see Theorem 1), and hence we have
Note that the corresponding Schur complement \(S_\ell = D_\ell - B_\ell A_\ell ^{-1} C_\ell \) is non-singular from Theorem 8 (i). Furthermore, since
and hence,
Using (3),
and hence,
is equal to
Now by defining
we have
Since \(T_{\textbf{t}, 2} < I\), we can see that D is symmetric positive definite and hence non-singular (this can be established just like the proof of Theorem 1). Furthermore, the corresponding Schur complement \(S = D - B A^{\dagger } C\) is symmetric positive definite, and hence non-singular. The symmetry of S is easy to see from the definition because A and D are symmetric and \(B = C^\top \). To see that S is positive definite, for any \(\textbf{x}\in \mathbb {R}^{p-m}{\setminus } \{\textbf{0 }\}\), let \(z = X_{\textbf{t}, 2} x\) and thus
Since \(\left( I - X_1 (X_1^\top X_1)^\dagger X_1^\top \right)\) is a projection matrix and hence positive definite, S is also positive definite.
In addition, using the singular value decomposition (SVD) \(X_1 = U_1 \Delta _1 V_1^\top \), we have
Similarly, we can show that \(A A^\dagger C = C\). Thus, using (4), \(L_{\textbf{t}}^\dagger X_{\textbf{t}}^\top \) is equal to
Since \(\lim _{\ell \rightarrow \infty } X_{\textbf{t}_{\ell }, 2} = X_{\textbf{t}, 2}\) and \(\lim _{\ell \rightarrow \infty } B_{\ell } = B\), from (7) and (8), to show that
it is enough to show that
Since S and each of \(S_\ell \) are non-singular, (10) holds from the continuity of matrix inversion. Now observe that
To establish (11), we need to show that \(\overline{X} = \lim _{\ell \rightarrow \infty } A_{\ell }^{-1} X_1^\top \) is equal to \(X_1^\dagger \). Towards this, define
Then, we observe that both \(\eta _\ell \) and \(\epsilon _\ell \) are strictly positive and going to zero as \(\ell \rightarrow \infty \). Thus,
where for any two symmetric positive semi-definite matrices Z and \(Z'\), we write \(Z \ge Z'\) if \(Z - Z'\) is also positive semi-definite. Let
Thus, \(\underline{A}_\ell ^{-1} \ge A_{\ell }^{-1} \ge \overline{A}_\ell ^{-1}, \) or, alternatively,
Now for any matrix norm, denoting as \(\Vert \cdot \Vert \), using the triangular inequality,
Using the SVD of \(X_1 = U_1 \Delta _1 V_1^{{\top }}\), we get the SVD of \(( \underline{A}_{\ell }^{-1} - \overline{A}_\ell ^{-1} ) X_1^\top \) as
That is, suppose \(\sigma _i\) is the ith singular value of \(X_1\), then the ith singular value of \(( \underline{A}_{\ell }^{-1} - \overline{A}_\ell ^{-1} ) X_1^\top \) is 0 if \(\sigma _i = 0\), otherwise, it is
which goes to zero and thus the first term in (12) goes to zero. The second term in (12) also converges to zero because of the limit definition of pseudo-inverse that states that for any matrix Z
This completes the proof. \(\square \)
For proving Theorem 4, we use Lemma 1, which obtains the partial derivatives of \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) with respect to the elements of \(\textbf{t}\).
Lemma 1
For any \(\textbf{t} \in (0, 1)^p\), the partial derivative \(\frac{\partial \widetilde{\varvec{\beta }}_{\textbf{t}}}{\partial t_j}\) for each \(j = 1, \dots , p\) is equal to
where \(Z = n^{-1}\left(X^\top X - \delta I\right)\) and \(E_{j}\) is a square matrix of dimension \(p \times p\) with 1 at the (j, j)th position and 0 everywhere else.
Proof of Lemma 1
Existence of \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) for every \({\textbf{t} \in (0, 1)^p}\) and \({\delta > 0}\) follows from Theorem 1 which states that \(L_{\textbf{t}}\) is positive-definite and hence guarantees the invertibility of \(L_{\textbf{t}}\). Since \(\widetilde{\varvec{\beta }}_{\textbf{t}} = L_{\textbf{t}}^{-1} T_{\textbf{t}} X^\top \textbf{y}/n\), using matrix calculus, for any \(j = 1, \dots , p\),
where we used differentiation of an invertible matrix which implies
Since \(\partial T_{\textbf{t}}/\partial t_j = E_{j}\), and the fact that \(L_{\textbf{t}} = T_{\textbf{t}} Z T_{\textbf{t}} + \delta I/n\), we get
Therefore, \(L^{-1}_{\textbf{t}} \frac{\partial T_{\textbf{t}}}{\partial t_j} - L^{-1}_{\textbf{t}} \frac{\partial L_{\textbf{t}} }{\partial t_j} L^{-1}_{\textbf{t}} T_{\textbf{t}} \) is equal to
This completes the proof Lemma 1. \(\square \)
Proof of Theorem 4
To obtain the gradient \(\nabla f_{\lambda }(\textbf{t})\) for \(\textbf{t} \in (0, 1)^p\), let \(\varvec{\gamma }_{\textbf{t}} = T_{\textbf{t}} \widetilde{\varvec{\beta }}_{\textbf{t}} = \textbf{t} \odot \varvec{\widetilde{\varvec{\beta }}}_{\textbf{t}}\). Then,
Consequently,
where \(\textbf{a}_{\textbf{t}} = n^{-1}[X^\top X \varvec{\gamma }_{\textbf{t}} - X^\top \textbf{y}]\). From the definitions of \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) and \(\varvec{\gamma }_{\textbf{t}}\),
which is obtained using Lemma 1 and the fact that \(\partial T_{\textbf{t}}/\partial t_j = E_{j}\) and \({Z = n^{-1}\left(X^\top X - \delta I\right)}\). This in-turn yields that \(\frac{\partial \varvec{\gamma }_{\textbf{t}}}{\partial t_j}\) is equal to
where we recall that
For a further simplification, recall that \(\textbf{c}_{\textbf{t}} = L^{-1}_{\textbf{t}} \left( \textbf{t} \odot \textbf{a}_{\textbf{t}} \right)\) and \(\textbf{d}_{\textbf{t}} = Z\left( \textbf{t} \odot \textbf{c}_{\textbf{t}}\right)\). Then, from (15), the matrix \(\partial \varvec{\gamma }_{\textbf{t}}/\partial {\textbf{t}}\) of dimension \(p \times p\), with jth column being \(\partial \varvec{\gamma }_{\textbf{t}}/\partial t_j\), can be expressed as
From (14), with \(\textbf{1}\) representing a vector of all ones, \(\nabla f_{\lambda }(\textbf{t})\) can be expressed as
where
Finally, recall that \(g_{\lambda }(\textbf{w}) = f_{\lambda }\left(\textbf{t}(\textbf{w})\right)\), \(\textbf{w} \in \mathbb {R}^p\), where the map \(t(w) = \textbf{1 }- \exp (- w\odot w)\) and
Then, from the chain rule of differentiation, for each \(j = 1, \dots , p\),
Alternatively, in short,
\(\square \)
Proof of Theorem 5
A function \(g(\textbf{w})\) is \(\ell \)-smooth if the gradient \(\nabla g_\lambda (\textbf{w})\) is Lipschitz continuous with Lipschitz constant \(\ell > 0\), that is,
for all \(\textbf{w}, \textbf{w}' \in \mathbb {R}^p\). From Section 3 of Danilova et al. (2022), gradient descent on a \(\ell \)-smooth function \(g(\textbf{w})\), with a fixed learning rate of \(1/\ell \), starting at an initial point \(\textbf{w}^{(0)}\), achieves an \(\epsilon \)-stationary point in \(\frac{c\, \ell \, (g(\textbf{w}^{(0)}) - g^*)}{\epsilon ^2}\) iterations, where c is a positive constant, \(g^* = \min _{\textbf{w} \in \mathbb {R}^p} g(\textbf{w})\). This result (with a different constant c) holds for any fixed learning rate smaller than \(1/\ell \).
Thus, we only need to show that the objective function \(g_\lambda (\textbf{w})\) is \(\ell \)-smooth for some constant \(\ell > 0\). Using the gradient expression of \(g_\lambda (\textbf{w})\) given in Theorem 4, observe that \(\Vert \nabla g_\lambda (\textbf{w}) - \nabla g_\lambda (\textbf{w}')\Vert _2\) is upper bounded by
where \(\textbf{t} = \textbf{1 }- \exp (- \textbf{w} \odot \textbf{w})\) and \(\textbf{t}' = \textbf{1 }- \exp (- \textbf{w}' \odot \textbf{w}')\). Here, we used the fact that \(\exp (- \textbf{w} \odot \textbf{w}) = 1 - \textbf{t}\). Since \(\textbf{t}, \textbf{t}' \in [0,1]^p\), clearly, \(\Vert \textbf{t} - \textbf{t}' \Vert _2 \le 1\). In the proof of Theorem 3, we established the continuity of \(L_{\textbf{t}}^\dagger X_{\textbf{t}}^\top \) at every point on the hypercube \([0,1]^p\); see (9). This implies the continuity of \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) on \([0, 1]^p\). Using this, from the definition of \(\varvec{\xi }_{\textbf{t}}\) provided in Theorem 4, we see that \(\varvec{\xi }_{\textbf{t}}\) is also continuous on \([0, 1]^p\). Since \([0, 1]^p\) is a compact set (closed and bounded), using the extreme value theorem (Armstrong 1983), which states that the image of a compact set under a continuous function is compact, we know that each element of \(\varvec{\xi }_{\textbf{t}}\) is bounded on \([0, 1]^p\). Thus, there exists a constant \(\ell > 0\) such that \(\Vert \varvec{\xi }_{\textbf{t}} - \varvec{\xi }_{\textbf{t}'}\Vert _2 \le \ell \), and this guarantees that \(g_\lambda (\textbf{w})\) is \(\ell \)-smooth. \(\square \)
Proof of Proposition 1
From Theorem 4, we obtain \(\nabla f_{\lambda }(\textbf{t})\) as follows,
where \(\zeta _{\textbf{t}} \in \mathbb {R}^p\), recalling from Theorem 4, is given by
with \(\textbf{a}_{\textbf{t}} = n^{-1}[X^\top X ({\textbf{t}} \odot \widetilde{\varvec{\beta }}_{\textbf{t}}) - X^\top \textbf{y}]\), \(\textbf{b}_{\textbf{t}} = \textbf{a}_{\textbf{t}} - n^{-1}\delta ({\textbf{t}} \odot \widetilde{\varvec{\beta }}_{\textbf{t}})\), \(\textbf{c}_{\textbf{t}} = L^{-1}_{\textbf{t}} \left( {\textbf{t}} \odot \textbf{a}_{\textbf{t}} \right)\), and \({\textbf{d}_{\textbf{t}} = n^{-1}[X^\top X - \delta I] ( {\textbf{t}} \odot {\textbf{c}}_{\textbf{t}} )}\).
From the definition of \(\widetilde{\varvec{\beta }}_{\textbf{t}}\), we can show that for any j, if we fix \(t_i\) for all \(i \ne j\), then the jth component of \(\widetilde{\varvec{\beta }}_{\textbf{t}}\) goes to zero as \(t_j \downarrow 0\), that is, \(\lim _{t_j \downarrow 0} \widetilde{\varvec{\beta }}_{\textbf{t}}(j) = 0.\) Similarly, \(\lim _{t_j \downarrow 0} \textbf{c}_{\textbf{t}}(j) = 0\). Therefore, from the expression of \(\varvec{\zeta }_{\textbf{t}}\) in (18), we have \( \lim _{t_j \downarrow 0} \varvec{\zeta }_{\textbf{t}}(j) = 0. \) \(\square \)
For proving Theorem 6, we use Lemma 2 which is well-known as the Woodbury matrix identity or Duncan Inversion Formula; we refer to Woodbury (1950) for a proof of Lemma 2.
Lemma 2
For any conformable matrices \(A, B_1\), and \(B_2,\) and C, the matrix \(\left(A + B_1CB_2\right)^{-1}\) is equal to
Proof of Theorem 6
Recall the expression of \(L_{\textbf{t}}\):
From the definition, for \(\textbf{t} \in [0, 1)^p\),
which exists. Further, if we take
in Lemma 2, then,
Since \(S_{\textbf{t}}\) is a diagonal matrix,
is a symmetric positive-definite matrix of dimension \(n \times n\). Thus, \(\widetilde{L}_{\textbf{t}}^{-1}\) exists and
\(\square \)
Proof of Theorem 7
For the same reasons mentioned in the proof of Theorem 2, without loss of generality we can assume that all the zero elements of \(\textbf{t}\) appear at the end of \(\textbf{t}\); that is, \(\textbf{t}\) is of the form:
where m indicates the number of non-zero elements in \(\textbf{t}\). Then, \(L_{\textbf{t}}\) is given by
Since \(\textbf{t} \in [0,1)^p\), from Theorem 1, \(L_{\textbf{t}}\) is a positive-definite matrix. Every principle submatrix of a positive-definite matrix is also positive-definite. Thus, \(\left(L_{\textbf{t}}\right)_{\scriptscriptstyle {+}}\) is positive-definite and hence invertible. Using Theorem 8 (ii),
Now observe that
Since \(\widetilde{\varvec{\beta }}_{\textbf{t}} = L_{\textbf{t}}^{-1} X_{\textbf{t}}^\top \textbf{y}/n\), using (20), we establish the desired expressions for \((\widetilde{\varvec{\beta }}_t)_0\) and \((\widetilde{\varvec{\beta }}_t)_+\). Similar arguments yield the desired expressions for \((c_t)_0\) and \((c_t)_+\); hence for conciseness that proof is omitted here. \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Moka, S., Liquet, B., Zhu, H. et al. COMBSS: best subset selection via continuous optimization. Stat Comput 34, 75 (2024). https://doi.org/10.1007/s11222-024-10387-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11222-024-10387-8