
Abstract
A common goal in network modeling is to uncover the latent community structure present among nodes. For many real-world networks, the true connections consist of events arriving as streams, which are then aggregated to form edges, ignoring the dynamic temporal component. A natural way to take account of these temporal dynamics of interactions is to use point processes as the foundation of network models for community detection. Computational complexity hampers the scalability of such approaches to large sparse networks. To circumvent this challenge, we propose a fast online variational inference algorithm for estimating the latent structure underlying dynamic event arrivals on a network, using continuous-time point process latent network models. We describe this procedure for network models capturing community structure. This structure can be learned as new events are observed on the network, updating the inferred community assignments. We investigate the theoretical properties of such an inference scheme, and provide regret bounds on the loss function of this procedure. The proposed inference procedure is then thoroughly compared, using both simulation studies and real data, to non-online variants. We demonstrate that online inference can obtain comparable performance, in terms of community recovery, to non-online variants, while realising computational gains. Our proposed inference framework can also be readily modified to incorporate other popular network structures.










Similar content being viewed by others


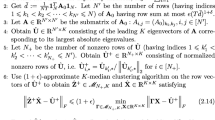
Notes
Here \(z_{-i}\) is a sub-vector of z with the ith entry removed.
The algorithm for the non-homogeneous Poisson process is similarly constructed.
The corresponding algorithm for the non-homogeneous Hawkes process is similarly constructed.
See Appendix C.
References
Alquier, P., Ridgway, J.: Concentration of tempered posteriors and of their variational approximations. Ann. Stat. 48(3), 1475–1497 (2020)
Amini, A.A., Chen, A., Bickel, P.J., Levina, E.: Pseudo-likelihood methods for community detection in large sparse networks. Ann. Stat. 41(4), 2097–2122 (2013)
Bhattacharjee, M., Banerjee, M., Michailidis, G.: Change point estimation in a dynamic stochastic block model. J. Mach. Learn. Res. 51, 4330–4388 (2020)
Bifet, A., Frank, E.: Sentiment knowledge discovery in twitter streaming data. In: International Conference on Discovery Science, pp. 1–15 (2010)
Blei, D.M., Kucukelbir, A., McAuliffe, J.D.: Variational inference: a review for statisticians. J. Am. Stat. Assoc. 112(518), 859–877 (2017)
Broderick, T., Boyd, N., Wibisono, A., Wilson, A.C., Jordan, M.I.: Streaming variational bayes. Adv. Neural Inf. Process. Syst. 26, 32 (2013)
Celisse, A., Daudin, J.-J., Pierre, L.: Consistency of maximum-likelihood and variational estimators in the stochastic block model. Electron. J. Stat. 6, 1847–1899 (2012)
Cheng, Y., Church, G.M.: Biclustering of expression data. In: Ismb, vol. 8, pp. 93–103 (2000)
Chérief-Abdellatif, B.-E., Alquier, P., Khan, M.E.: A generalization bound for online variational inference. In: Asian Conference on Machine Learning, pp. 662–677 (2019)
Daley, D.J., Jones, D.V.: An Introduction to the Theory of Point Processes: Elementary Theory of Point Processes. Springer, Berlin (2003)
Fortunato, S., Hric, D.: Community detection in networks: a user guide. Phys. Rep. 659, 1–44 (2016)
Gao, C., Ma, Z., Zhang, A.Y., Zhou, H.H.: Achieving optimal misclassification proportion in stochastic block models. J. Mach. Learn. Res. 18(1), 1980–2024 (2017)
George, T., Merugu, S.: A scalable collaborative filtering framework based on coclustering. In: Fifth IEEE International Conference on Data Mining (icdm’05), p. 4 (2005)
Gilks, W.R., Richardson, S., Spiegelhalter, D.: Markov Chain Monte Carlo in Practice. Chapman and Hall/CRC, Boco Raton (1995)
Hawkes, A.G.: Hawkes processes and their applications to finance: a review. Quant. Finance 18(2), 193–198 (2018)
Hawkes, A.G., Oakes, D.: A cluster process representation of a self-exciting process. J. Appl. Probab. 11(3), 493–503 (1974)
Heard, N.A., Weston, D.J., Platanioti, K., Hand, D.J.: Bayesian anomaly detection methods for social networks. Ann. Appl. Stat. 4(2), 645–662 (2010)
Hoffman, M., Bach, F.R., Blei, D.M.: Online learning for latent Dirichlet allocation. In: Advances in Neural Information Processing Systems, pp. 856–864 (2010)
Hoffman, M.D., Blei, D.M., Wang, C., Paisley, J.: Stochastic variational inference. J. Mach. Learn. Res. 14(1), 1303–1347 (2013)
Huang, Z., Soliman, H., Paul, S., Xu, K.S.: A mutually exciting latent space Hawkes process model for continuous-time networks. In: Uncertainty in Artificial Intelligence, pp. 863–873 (2022)
Hubert, L., Arabie, P.: Comparing partitions. J. Classif. 2(1), 193–218 (1985)
Lee, J., Li, G., Wilson, J.D.: Varyingcoefficient models for dynamic networks (2017). arXiv preprint arXiv:1702.03632
Lee, W., McCormick, T.H., Neil, J., Sodja, C., Cui, Y.: Anomaly detection in large-scale networks with latent space models. Technometrics 64(2), 241–252 (2022)
Lehmann, E.L., Casella, G.: Theory of Point Estimation. Springer, New York (2006)
Leifeld, P., Cranmer, S.J., Desmarais, B.A.: Temporal exponential random graph models with btergm: estimation and bootstrap confidence intervals. J. Stat. Softw. 83, 6 (2018)
Leskovec, J., Krevl, A.: Snap datasets: stanford large network dataset collection (2014)
Matias, C., Miele, V.: Statistical clustering of temporal networks through a dynamic stochastic block model. J. R. Stat. Soc. Ser. B Stat. Methodol. 79(4), 1119–1141 (2017)
Matias, C., Rebafka, T., Villers, F.: A semiparametric extension of the stochastic block model for longitudinal networks. Biometrika 105(3), 665–680 (2018)
Miscouridou, X., Caron, F., Teh, Y.W.: Modelling sparsity, heterogeneity, reciprocity and community structure in temporal interaction data. Adv. Neural Inf. Process. Syst. 31, 2343–2352 (2018)
Moreira-Matias, L., Gama, J., Ferreira, M., Mendes-Moreira, J., Damas, L.: Predicting taxi-passenger demand using streaming data. IEEE Trans. Intell. Transp. Syst. 14(3), 1393–1402 (2013)
Mukherjee, S.S., Sarkar, P., Wang, Y.R., Yan, B.: Mean field for the stochastic blockmodel: optimization landscape and convergence issues. Adv. Neural Inf. Process. Syst. 31, 10694–10704 (2018)
Ng, A., Jordan, M., Weiss, Y.: On spectral clustering: analysis and an algorithm. Adv. Neural Inf. Process. Syst. 14, 52 (2001)
Nowicki, K., Snijders, T.A.B.: Estimation and prediction for Stochastic blockstructures. J. Am. Stat. Assoc. 96, 1077–1087 (2001)
Ogata, Y.: Statistical models for earthquake occurrences and residual analysis for point processes. J. Am. Stat. Assoc. 83(401), 9–27 (1988)
Pensky, M., Zhang, T.: Spectral clustering in the dynamic stochastic block model. Electron. J. Stat. 13(1), 678–709 (2019)
Pontes, B., Giráldez, R., Aguilar-Ruiz, J.S.: Biclustering on expression data: a review. J. Biomed. Inform. 57, 163–180 (2015)
Rizoiu, M.-A., Lee, Y., Mishra, S., Xie, L.: A tutorial on Hawkes processes for events in social media (2017). arXiv preprint arXiv:1708.06401
Rossetti, G., Cazabet, R.: Community discovery in dynamic networks: a survey. ACM Comput. Surv. 51(2), 1–37 (2018)
Sengupta, S., Chen, Y.: A block model for node popularity in networks with community structure. J. Roy. Stat. Soc. Ser. B (Stat. Methodol.) 80(2), 365–386 (2018)
Sewell, D.K., Chen, Y.: Latent space models for dynamic networks. J. Am. Stat. Assoc. 110(512), 1646–1657 (2015)
Shalev-Shwartz, S., et al.: Online learning and online convex optimization. Found. Trends Mach. Learn. 4(2), 107–194 (2012)
Wang, Y., Feng, C., Guo, C., Chu, Y., Hwang, J.-N.: Solving the sparsity problem in recommendations via cross-domain item embedding based on co-clustering. Proceedings of the twelfth ACM international conference on web search and data mining, pp. 717–725 (2019)
Xu, H., Fang, G., Zhu, X.: Network group Hawkes process model (2020). arXiv preprint arXiv:2002.08521
Yang, Y., Etesami, J., He, N., Kiyavash, N.: Online learning for multivariate Hawkes processes. Adv. Neural Inf. Process. Syst. 85, 4937–4946 (2017)
Zhao, Y., Levina, E., Zhu, J.: Consistency of community detection in networks under degree-corrected stochastic block models. Ann. Stat. 40(4), 2266–2292 (2012)
Author information
Authors and Affiliations
Contributions
All authors were involved in writing the main manuscript and designing the experiments. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The author declares that he has no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Algorithm details
We include Algorithm 5 for the online Hawkes process as mentioned in the main text, along with Algorithm 6, which is a key step for storing useful information in this procedure. Some supporting functions used in Algorithm 5 are given below.
-
\(a+=b\) represents \(a = a+b\); \(a-=b\) represents \(a = a - b\).
-
Formula for impact(t) is \(\sum _{t_1 \in timevec} \lambda \exp \{- \lambda (t - t_1)\}\).
-
Formula for \(I_1\) is \(\sum _{t_1 \in timevec} \exp \{- \lambda (t - t_1)\}\).
-
Formula for \(I_2\) is \(\sum _{t_1 \in timevec} (t - t_1) \lambda \exp \{- \lambda (t - t_1)\}\).
-
Formula for \(integral(t,t_{end},\lambda )\) is \( 1 - \exp \{-\lambda (t_{end} - t)\}\).
-
Formula for \(integral(t,t_{start},t_{end},\lambda )\) is \( \exp \{-\lambda (t_{start} - t)\} - \exp \{-\lambda (t_{end} - t)\}\).
As discussed in main paper, we only need to store the sufficient statistics of the particular model in each setting. We show two examples in Table 3. In the homogeneous Poisson setting, we only need to store the cumulative counts for each pair of sender and receiver (\(l_{user1, user2}\)). In the Hawkes setting, we only need to store the recent historical events since the old information decays exponentially fast and thus has vanishing impact on the current event.
Appendix B: Additional simulation results and details
Here we provide additional details regarding the simulations in the main text, and we also include additional simulations experiments which were omitted from the main manuscript. Alongside this, we provide the results of similar experiments in the Hawkes process setting, similar to those considered in the main text for the inhomogeneous Poisson model. The code used to create all results in this work is available at https://github.com/OwenWard/OCD_Events. We discuss the regret properties of our online procedure. We demonstrate community recovery and other properties of our online inference procedure for Hawkes process models. We also expand on some components of the inference procedure discussed in Sect. 5.1.

Online-Hawkes

Trim
Illustrative simulation in Sect. 1. We first provide exact simulation settings for the illustrative example in the introduction. We consider a network of \(n=100\) nodes, with 2 communities, with \(40\%\) of nodes in the first community. In particular, we consider an intensity function from nodes in group \(k_1\) to nodes in group \(k_2\) of the form
where the coefficient vectors \(\varvec{a_{k_1 k_2}}=(a^1_{k_1 k_2},a^2_{k_1 k_2}, a^3_{k_1 k_2})\) for each block pair are of the form
This leads to a dense network, where we observe events between each node pair for the specified choice of \(T=100\). If we wish to identify the community structure, classical network models require a single adjacency matrix, encoding the relationship between each node pair. The simplest way to form such a matrix is to consider the count matrix with \(A_{ij}=N_{ij}(T)\), the number of events observed between a given node pair. Spectral clustering of this adjacency matrix would then lead to estimated community memberships for each node. However, for this choice of conditional intensity function the event counts do not preserve the underlying community structure.
Rather than aggregating this data to form a single adjacency matrix, an alternative approach to cluster network incorporates dynamics through the observation of a sequence of adjacency matrices at some (equally spaced) time intervals. If we wanted to apply such a method to this event data the challenge is how to form the adjacency matrices. An observation window must be chosen, with an edge between two nodes present for the corresponding adjacency matrix for that window if there is one (or more) events between them.
Simulation settings We first expand on the simulation settings used in Sect. 5.1. Unless otherwise specified we consider a network of \(n=200\) nodes and \(K=2\) equally sized communities. The block inhomgoeneous Poisson process model is given by
Here we consider \(f_h(t)\) to be step functions of common fixed length. We consider the following coefficients for these basis functions
When we vary K we consider different coefficients K which are multiplied by a constant which varies with the community. Full details of the choices of parameters are given in the associated code repository.
Window size Throughout the simulation studies in Sect. 5.1 we have used a fixed window size such that \(dT=1\). Here we wish to investigate the effect that varying this window size has on the performance of our algorithm. We compare community recovery for varying window sizes from \(dT=0.25\) to \(dT=5\), keeping all other parameters fixed as in the default simulation setting. We show boxplots of the community recovery performance, in terms of ARI, in Fig. 7. We see that in this scenario community recovery is possible, for all window sizes considered. For each choice of dT almost all simulations correctly recover the communities. We note that the choice of appropriate dT will depend somewhat on the data considered. For sufficiently small dT we might not observe any events in a given window, which would not provide any update of the model parameters. Similarly, a dT leading to a single event in each window would mirror standard Stochastic Variational inference (Hoffman et al. 2013). It appears that dT should be small enough to avoid getting stuck in local optima of the current estimate of the ELBO, while being large enough to ensure events have been observed.
We also wish to investigate the role of dT in the computation time required for this procedure. In Fig. 8 we show the computation time for our inference procedure (in seconds) as we vary dT, the window size. It appears that the window size is not clearly related to the computation time, however we would recommend against extremely small values of dT, which may lead to too many windows where no events occur.

Community recovery under block inhomogeneous Poisson simulated data for varying window size

Computation time for a fixed network setting as we vary dT, across 50 replications
Regret rate.
Quantifying the regret of an online estimation scheme is an important tool in the analysis of such a procedure. We can investigate the empirical performance of the regret for our method in simulation settings, mirroring the theoretical results. To do this, we need to consider a loss function. We define the loss function over the m-th time window as the negative normalized log-likelihood, i.e.
and define the regret as
where \(M = T/dT\). This regret function quantifies the gap of the conditional likelihood, given the true latent membership \(z^{*}\), between the online estimator and the true optimal value. We note that this regret function is conditional on the true latent assignment being known, and as such, we need to account for possible permutations of the inferred parameters, which is done using \(\Pi (\theta )\). While this regret quantity may be of theoretical interest, in practice it may be more appropriate to instead look at the empirical regret, using the estimated latent community memberships. We shall define this as
measuring the cumulative difference between the estimated and true log likelihood, as we learn both z and \(\theta \) over time.
Given these two regret definitions, we can simulate networks as in the default setting and compute the empirical regret for a fixed network, varying the range of time over which events are observed from \(T=50\) to \(T=200\). This is shown in Fig. 9. Here we compute each quantity across 100 simulations, showing loess smoothed estimates and their standard error over time. We see that as we observe these networks for a longer period this regret grows slowly.

Smoothed regret estimates as a function of time for a fixed network structure observed for varying lengths of time
1.1 Hawkes models
Hawkes community recovery The main experiments in Sect. 5.1 demonstrate the performance of our online learning algorithm where the intensity function follows an inhomogeneous Poisson process. Here we demonstrate the performance of this procedure for Hawkes block models also. We consider the same defaults in terms of network and community size and observation time. The specific parameter settings are given in the associated code repository, in each case considering 50 simulations. In Fig. 10 we first investigate the performance of our procedure for community recovery, as we increase the number of nodes. As the number of nodes increase, we can more consistently recover the true community structure.

Community recovery under the Hawkes model, in terms of ARI, as we increase the number of nodes
Hawkes, varying number of communities We can also investigate the performance of our procedure for community recovery under the Hawkes model as we increase K, the number of communities. In Fig. 11 we show the performance as we consider more communities for a fixed number of nodes. As K increases, we are less able to recover the true community structure, which is seen by a decrease in the ARI.

Community recovery for the Hawkes model as we vary the number of communities
Hawkes, online community recovery In Fig. 12 we illustrate how the community structure is learned as events are observed on the network, varying the number of nodes. Community recovery is harder than in the Poisson setting, but the average ARI increases quickly in time, before stabilising. There is considerably more uncertainty in this estimate than in the Poisson setting.

Online community recovery under the Hawkes model as the number of nodes increases, for a fixed observation period
Hawkes, parameter recovery We can also look at how we recover the true parameters of our Hawkes process as events are observed in time over the network, as was considered for the Poisson process model previously. Here we measure the recovery of both the baseline rate matrix M and the excitation parameter, B, along with the scalar decay parameter \(\lambda \). Figure 13 shows the GAM smoothed difference between the true and estimated parameters across 50 simulations, with included standard errors shown. For each of these three parameters, we see that the difference between the true and estimated parameter decreases, with the difference decreasing as we observe events for a longer time period.

Parameter Recovery for block Hawkes model as the observation time increases for a fixed network size
Appendix C: Technical conditions
In this section, we provide the details of theoretical analyses of our proposed algorithm under dense event setting, that is, integration of intensity function \(\lambda _{ij}(t)\) over window length dT is \(\Theta (1)\).
Different from the analysis of regular online algorithms, the key difficulties in our setting are (1) the model we consider is a latent class network model with complicated dynamics, (2) the proposed algorithm involves approximation steps. Before the proof of the main results, we first introduce some notation and definitions. In the following, we use variables \(c_0 - c_3\), C, and \(\delta \) to denote some constants which may vary from the place to place. \(\theta ^{*}\), \(z^{*}\) represents the true parameter and latent class membership, respectively.
-
C0
[Window size] Assume time window dT is some fixed constant which is determined a priori.
-
C1
[Expectation] Define the normalized log likelihood over a single time window,
$$\begin{aligned}{} & {} l_{w}(\theta \vert z) = \frac{1}{ \vert A \vert } \sum _{(i,j) \in A} \big \{ \int _{0}^{dT} \log \lambda _{ij}(t \vert z) dN_{ij}(t) \\{} & {} q\quad - \int _{0}^{dT} \lambda _{ij}(t \vert z) dt \big \}. \end{aligned}$$For simplicity, we assume the expectation of data process is stationary, i.e, \({\bar{l}}_w (\theta \vert z) = {\mathbb {E}}^{*} l_{\omega }(\theta \vert z)\) does not depend on the window number w. Here the expectation is taken with respect to all observed data under the true process.
-
C2
[Latent membership identification] Assume
$$\begin{aligned} {{\bar{l}}}_w(\theta \vert z) \le {{\bar{l}}}_w(\theta \vert z^{*}) - c \frac{d_m \vert z - z^{*} \vert _0}{ \vert A \vert }, \end{aligned}$$for any \(z \ne z^{*}\) and \(\theta \in B(\theta ^{*}, \delta )\). Here \(B(\theta ^{*}, \delta )\) is the \(\delta \)-ball around the true parameter \(\theta ^{*}\); \(d_m = m^{r_d} (r_d > 0)\) represents the graph connectivity and \( \vert z - z^{*} \vert _0\) is the number of individuals such that \(z_i \ne z^{*}_i\).
-
C3
[Continuity] Define Q function, \(Q(\theta , q) = {\mathbb {E}}_{q(z)} l_w(\theta \vert z)\) and \({{\bar{Q}}}(\theta , q) = {\mathbb {E}}^{*} Q(\theta , q)\). Suppose
$$\begin{aligned} {{\bar{Q}}}(\theta , q) - {{\bar{l}}} (\theta \vert z^{*}) \le c d(q, \delta _{z^{*}}) \end{aligned}$$(C1)holds, where \(\delta _{z^{*}}\) is the probability function that put all its mass on the true label vector \(z^{*}\). The distance \(d(q_1, q_2) \equiv TV(q_1, q_2)\), where \(TV(q_1, q_2)\) is the total variance between two distribution functions. Let \(\theta (q)\) be the maximizer of \({{\bar{Q}}}(\theta , q)\). Assume that \( \vert \theta (q) - \theta ^{*} \vert \le c d(q, \delta _{z^*})\) holds for any q and some constant c.
-
C4
[Gradient condition] Assume that there exists a \(\delta \) such that
-
1.
$$\begin{aligned} \frac{\partial {{\bar{Q}}}(\theta , q)}{\partial \theta }^T (\theta - \theta (q))< - c \ \vert \theta - \theta (q)\ \vert ^2 < 0 \end{aligned}$$
and
$$\begin{aligned} \ \vert \frac{\partial {{\bar{Q}}}(\theta , q)}{\partial \theta }^T (\theta - \theta (q))\ \vert \ge c \ \vert \frac{\partial {{\bar{Q}}}(\theta , q)}{\partial \theta }\ \vert ^2 \end{aligned}$$hold for \(\theta \in B(\theta (q), \delta )\) and any q with c being a universal constant.
-
2.
$$\begin{aligned} {\mathbb {E}}^{*} \frac{\partial Q(\theta , q)}{\partial \theta }^T \frac{\partial Q(\theta , q)}{\partial \theta } \le C \end{aligned}$$(C2)
holds for any \(\theta \in B(\theta (q), \delta )\) and any q.
-
1.
-
C5
[Boundedness] For simplicity, we assume the functions \(\lambda _{ij}(t \vert z)\), \(\log \lambda _{ij}(t \vert z)\) and their derivatives are continuous bounded function of parameter \(\theta \) for all z and t.
-
C6
[Network degree] Let \(d_{i}\) be the number nodes that individual i connects to. We assume that \(d_i \asymp d_n\) for all i, with \(d_n = n^{r_d}\) (\(0< r_d < 1\)) (Here \(a \asymp b\) means a and b are in the same order.)
-
C7
[Initial condition] Assume \(\theta ^{(0)} \in B(\theta ^{*}, \delta )\) for a sufficiently small radius \(\delta \) and \(q^{(0)}\) satisfies
$$\begin{aligned}{} & {} {\mathbb {E}}_{q^{(0)}(z_{-i})} {{\bar{l}}}_w(\theta ^{*} \vert z_i = z, z_{-i}) \nonumber \\{} & {} \quad \le {\mathbb {E}}_{q^{(0)}(z_{-i})} {{\bar{l}}}_w(\theta ^{*} \vert z_i = z_i^{*}, z_{-i})\nonumber \\{} & {} \qquad - c d_i / \vert A \vert \end{aligned}$$(C3)for all i and \(z \ne z_i^{*}\).
These are the regularity conditions required for the proofs of Theorem 2 and 3 in the main text. We first note some important comments on the above conditions. Here the window size dT is assumed to be any fixed constant. It can also grow with the total number of windows (e.g. \(\log T\)), the result will still hold accordingly. Condition C1 assumes the stationarity of process for ease of the proof. This condition can also be further relaxed for non stationary processes as long as Condition C2 holds for any time window. In Condition C2, we assume that there is a positive gap between log-likelihoods when the latent profile is different from the true one, which plays an important role in identification of latent profiles. Condition C3 postulates the continuity of the Q function. In other words, the difference between Q and the true conditional likelihood is small, when the approximate posterior q concentrates around the true latent labels. Condition C4 characterizes the gradient of Q function, along with the local quadratic property and boundedness. Condition C5 requires the boundedness of the intensity function. It can be easily checked that it holds for Poisson process. By using truncation techniques, the results can be naturally extended to the Hawkes process setting (Yang et al. 2017; Xu et al. 2010). We also note that \(d_n\) can be viewed as the network connectivity, the degree to which nodes in network connect with each other. Condition C6 puts the restriction on the network structure that the degrees should not diverge too much across different nodes. Then \( \vert A \vert \asymp m d_n\) controls the overall sparsity of the network. The network gets sparser when \(r_d \rightarrow 0\). Here we do not consider the regime where \(r_d = 0\) (in which case the network is super sparse, i.e. each individual has only a finite number of connections on average), which could be of interest in future work. Condition C7 puts the requirement on the initialization of model parameters and approximate q function. Note that (C3) is satisfied when q is close to the multinomial distribution which puts mass probability on the true label \(z^{*}\). Equation (C3) could also automatically hold when true model parameters of difference classes are well separated. (That is, we take \(q_i^{(0)}(z) = \text {multinom}(\frac{1}{K}, \ldots , \frac{1}{K})\) as non-informative prior so that (C3) holds.)
Appendix D: Useful Lemmas
In the main proof, we depend on the following Lemmas to ensure the uniform convergence of random quantities (e.g. likelihood, ELBO, etc.) to their population versions.
Lemma 1
Under Conditions C0, C1 and C5, it holds that
where \(g(\theta \vert z)\) is some known functions which could be taken as weighted log likelihood or its derivatives; v and M are some constants. ”\({\mathbb {E}}\)” here is the conditional expectation given fixed label z.
Proof of Lemma 1
Without loss of generality, we take \(g(\theta \vert z) = l_w(\theta \vert z)\). Define \(X_{ij} = \int _0^{dT} \log \lambda _{ij}(t \vert z) dN_{ij}(t) - \int _0^{dT} \lambda _{ij}(t \vert z)dt\) for any pair \((i,j) \in A\). According to Condition C5, we know that there exists M and \(v^2\) such that \( \vert X_{ij} - {\mathbb {E}} X_{ij} \vert \le M\) and \(\text {var}(X_{ij}) \le v^2\). Then we apply the Bernstein inequality and get that
By taking union bound over all possible z, we then have
Thus, we conclude the proof.
One immediate result from Lemma 1 is that
Corollary 1
Under the same setting stated in Lemma 1, it holds that
for any q.
Proof of Corollary 1
For any distribution function q(z), we can observe the following relation,
and get the desired result by Lemma 1. QED.
The following Lemma 2 and Lemma 3 ensure the identification of latent memberships.
Lemma 2
Under Conditions C0 - C2, C5 - C6, with probability \(1 - \exp \{ - C d_n \}\), it holds that
for any \(\theta \in B(\theta ^{*}, \delta )\) for some constants \(c_1\) and \(\delta \). Here, \(L(\theta \vert z) = \exp \{ \vert A \vert l_w (\theta \vert z)\}\).
Proof of Lemma 2
The main step of the proof is to show that
holds for all z with high probability. We take \(g(\theta \vert z)\) as \(l_w(\theta \vert z) - l_w(\theta \vert z^{*})\). Similar to the proof of Lemma 1, we have that
by noticing that there are at most \(O( \vert z - z^{*} \vert _0 d_{n})\) number of non-zero \(X_{ij}\)’s in \(l_w(\theta \vert z) - l_w(\theta \vert z^{*})\). By taking \(x = c/2\), we have
by using the fact that \(d_{max} \asymp d_n\) and adjusting the constant \({\tilde{c}}\). Hence, by union bound, we get
By Condition C2, \(d_n = n^{r_d} (r_d > 0)\), (D10) becomes
for adjusting constant C. Together with Condition C2, (D9) holds with probability \(1 - \exp \{-C d_n\}\).
By definition of \(L(\theta \vert z)\) and (D9), we get that \(L(\theta \vert z) \le L(\theta \vert z^{*}) \cdot \exp \{ - c/2 \cdot d_m \vert z - z^{*} \vert _0\}\) holds for any z with probability \(1 - \exp \{- C d_m\}\). Thus,
by adjusting constant \(c_1\). This completes the proof.
Lemma 3
For approximate function \(q^{(1)}\), it holds that
Proof of Lemma 3
We first have that
with high probability for any \(z_i \ne z_i^{*}\). Under initial condition C7, (D12) can be proved via the same technique used in Lemma 1. Secondly, we note that
We then have
By summing over all \(z_i\), it gives that
by adjusting the constant \({\tilde{c}}\). This concludes the proof.
Appendix E: Proofs of Theorem 2 and Theorem 3
With aid of useful lemmas stated in previous sections, we are ready for the proof of main theorems.
Proof of Theorem 2
According to definition of Regret, we have
Next we prove the result by the following three steps.
-
Step 1. With high probability, it holds that \(\theta ^{(m)} \in B(\theta ^{*}, \delta )\) and
$$\begin{aligned} q^{(m)} (z^{*}) \ge 1 - C \exp \{-c_1 m d_n\} \end{aligned}$$(E15)for \(m = 1, 2, \ldots \).
-
Step 2. With high probability, it holds that
$$\begin{aligned}{} & {} \sum _{m=1}^M \{ {\mathbb {E}}_{q^{(m)}} {\tilde{l}}_m(\theta ^{(m)} \vert z) - {\mathbb {E}}_{q^{(m)}} {\tilde{l}}_m(\theta ^{*} \vert z) \} \nonumber \\{} & {} \quad \le C \sqrt{M} \log (M \vert A \vert )^2, \end{aligned}$$(E16)for some constant C.
-
Step 3. With high probability, it holds that
$$\begin{aligned}{} & {} \vert \sum _{m=1}^M \{ {\mathbb {E}}_{q^{(m)}} \tilde{l}_m(\theta ^{(m)} \vert z) - {\tilde{l}}_m(\theta ^{(m)} \vert z^{*}) \} \vert \nonumber \\{} & {} \quad \le M \exp \{ - c d_n\}, \end{aligned}$$(E17)and
$$\begin{aligned}{} & {} \vert \sum _{m=1}^M \{ {\mathbb {E}}_{q^{(m)}} {\tilde{l}}_m(\theta \vert z) - {\tilde{l}}_m(\theta \vert z^{*}) \} \vert \nonumber \\{} & {} \quad \le M \exp \{ - c d_n\} \end{aligned}$$(E18)for any \(\theta \in B(\theta ^{*}, \delta )\) and some constant c.
Proof of step 1. We prove this by mathematical induction. When \(m = 0\), it is obvious that \(\theta ^{(0)} \in B(\theta ^{*}, \delta )\) according to the assumption on initialization. By Lemma 3, we have that \(\sum _{z_i \ne z_i^{*}} q_i^{(1)}(z_i) = q_i^{(1)}(z_i^{*}) O(\exp \{- \tilde{c} d_i\})\). Then \(q^{(1)}(z^{*}) = \prod _i q_i^{(1)}(z_i^{*}) \ge 1 - n O(\exp \{-c_1 d_n\})\). That is, (E15) holds for \(q^{(1)}\) by adjusting constant \(c_1\). Next we assume that \(\theta ^{(m)} \in B(\theta ^{*}, \delta )\) and (E15) holds for any \(m \le m_1\) and need to show that \(\theta ^{(m_1+1)} \in B(\theta ^{*}, \delta )\) and (E15) holds for \(m = m_1 + 1\).
We consider the following two scenarios,
-
(1)
\(0 \le \ \vert \theta ^{(m_1)} - \theta (q^{(m_1)})\ \vert < \frac{\delta }{2}\) and
-
(2)
\(\frac{\delta }{2} \le \ \vert \theta ^{(m_1)} - \theta (q^{(m_1)})\ \vert \). We can compute that
By Lemma 1, we know that \( \frac{ \partial {\mathcal {Q}}_{m_1+1}(\theta , q)}{\partial \theta } = \frac{\partial \bar{{\mathcal {Q}}}(\theta , q)}{\partial \theta } + \epsilon \) where \(\epsilon = o(1)\) for all q. Therefore, the right hand side of (E19) becomes
In the first scenario, by Condition C4, (E20) implies that
when the step size \(\eta _{m_1}\) is small (e.g.\(\eta _{m_1} \le c/2\)).
In the second scenario, by Condition C4, (E19) implies that
for \(\eta _{m_1} \le 1/2c\).
According to (E15) via induction, we have that \(d(q^{(m_1)}(z^{*}), \delta _{z^{*}}) = C \exp \{-c_1 m_1 d_n\}\). This further implies that \(\ \vert \theta (q^{(m_1)}) - \theta ^{*}\ \vert = O(\exp \{-c_1 m_1 d_n\})\) by Condition C3. By above facts, in the first scenario, we have
In the second scenario, we have
where the last inequality holds since \(\eta _{m_1} = c m_1^{-1/2}>> \exp \{-c_1m_1d_n\}\). Hence, we conclude that \(\theta ^{(m_1 + 1)} \in B(\theta ^{*}, \delta )\).
Next, we turn to study approximate distribution \(q^{(m+1)}\) to show that (E15) holds for \(m = m_1 + 1\). According to Condition C2 and Lemma 2, we have that \( \vert A \vert l_{m_1}(\theta ^{(m_1)} \vert z) \le \vert A \vert l_{m_1}(\theta ^{(m_1)} \vert z^{*}) - c d_n\) for any \(z \ne z^{*}\). This implies that
for any \(z_i \ne z_i^{*}\) and
Combining these two facts, we have that
holds for any \(z_i \ne z_i^{*}\) and some adjusted constant \(c_2\).
By recursive formula
we then have
which indicates that
Finally, noting \(q^{(m_1 + 1)}(z^{*}) = \prod _{i=1}^n q_i^{(m_1 + 1)}(z_i^{*})\) gives us
Hence, we complete Step 1 by induction. Proof of Step 2. For notational simplicity, we denote \({\mathbb {E}}_{q^{(m)}} {\tilde{l}}_m(\theta \vert z)\}\) as \(h_m(\theta )\) in the remaining part of the proof. By local convexity, we have
which is equivalent to
We know that
where \({\bar{\theta }}^{(m+1)} = \theta ^{(m)} - \eta _m \nabla h_m(\theta ^{(m)})\). By summing over m and the fact that \(d(\theta ^{(m)}, \theta ^{*}) \le d({\bar{\theta }}^{(m)}, \theta ^{*})\), we have
By Eq. (E24), we then have
where the second inequality uses (E25).
Next, we prove that \(\nabla h_m(\theta ^{(m)})\) is bounded with probability going to 1 for any m. Note that,
Let \(B_1 = \sup _{t,z} \frac{\lambda _{ij}^{'}(t \vert z)}{\lambda _{ij}(t \vert z)}\) and \(B_2 = \sup _{t, z} \lambda _{ij}^{'}(s \vert z)\). Both \(B_1\) and \(B_2\) are bounded according to Condition C5. We know that the number of events, \(M_w\), in each time window follows a Poisson distribution with mean \(\int _0^{\omega } \lambda (s) ds\). Therefore, we get \(P(M_w \ge m_w) \le \exp \{-c m_w\}\) for some constant c. We then have that \(\nabla l_m(\theta \vert z) \le C(B_1 m_w + B_2)\) with probability at least \(1 - M \vert A \vert \exp \{ - c m_w\}\).
By letting \(\eta _m = \frac{1}{\sqrt{M}}\), (E27) becomes
where we set \(m_w = c \log (M \vert A \vert )\).
Proof of step 3. We only need to show that for each m, it holds that
We know that
This implies that
This completes the proof.
Proof of Theorem 3
By the update rule, we know that \(\theta ^{(m+1)} = \theta ^{(m)} - \eta _m \nabla h_m(\theta ^{(m)})\), so
Furthermore,
where the term \(\frac{1}{\sqrt{ \vert A \vert }}\) comes from the probability bound in Lemma 1. Notice that \(\theta (q) = \theta ^{*}\) when \(q = \delta _{z^{*}}\), we have that \(- \nabla \bar{\tilde{l}}(\theta ^{(m)} \vert z^{*}) (\theta ^{(m)} - \theta ^{*}) \le - c \ \vert \theta ^{(m)} - \theta ^{*}\ \vert ^2,\) according to Condition C4. Furthermore, we know that \(d(q^{(m)}, \delta _{z^{*}}) \le \exp \{-m d_n\}\) (see (E15)). Therefore, \(\eta _m \delta d(q^{(m)}, \delta _{z^{*}})\) can be absorbed into \(\eta ^2_m \nabla h_m^2(\theta ^{(m)})\). In summary, (E29) becomes
which further gives,
by adjusting constants and noticing that \(\nabla h_m^2(\theta )\) is bounded by \((\log (M \vert A \vert ))^2\). After direct algebraic calculation, we have
For the first term in (E30), we have that
Next, we define \(x_{1t} = \eta _t (\log (M \vert A \vert ))^2\) and \(x_2 = 1/\sqrt{ \vert A \vert }\), to simplify the remainder of the proof. For the second term in (E30), we have that
by adjusting the constants. Combining the above inequalities, we have
This concludes the proof.
Appendix F: Community recovery under relaxed conditions
In this section, we relax the conditions mentioned in previous section by considering the case of uneven degree distribution. Let \(d_i\) be the number of nodes that i-th individual connects to. Then uneven degree distribution means that \(d_i\) are not in the same order. Degree \(d_i\) goes to infinity for some node i’s and is bounded for other i’s. Under this setting, we establish results for consistent community recovery. We start with introducing a few more modified conditions.
-
C2’
[Latent membership identification] Assume
$$\begin{aligned} {{\bar{l}}}_w(\theta \vert z_{{\mathcal {N}}}, z_{-{\mathcal {N}}}^{*}) \le {{\bar{l}}}_w(\theta \vert z^{*}) - c \frac{\sum _{i \in {\mathcal {N}}} d_i}{ \vert A \vert }, \end{aligned}$$for any subset \({\mathcal {N}} \subset \{1,\ldots ,n\}\) and \(z_{{\mathcal {N}}}\) and \(z_{-{\mathcal {N}}}\) are the sub-vectors of z with and without elements in \({\mathcal {N}}\) respectively.
-
C3’
[Continuity] Assume
$$\begin{aligned} {{\bar{Q}}}(\theta , q) - {{\bar{l}}}_w (\theta \vert z^{*}) \le c \frac{1}{ \vert A \vert } \sum _i d_i \cdot d(q_i, \delta _{z_i^{*}}) \end{aligned}$$(F31)holds. Also assume \( \vert \theta (q) - \theta ^{*} \vert \le c \frac{1}{ \vert A \vert } \sum _i d_i \cdot d(q_i, \delta _{z_i^{*}})\) holds for any q and some constant c.
-
C6’
[Network degree] Suppose \(\{1,\ldots ,n\}\) can be partitioned into two sets \(\mathcal N_u\) and \({\mathcal {N}}_b\). \({\mathcal {N}}_u\) is the set of nodes with degree larger than \(d_n\) and \(N_b\) is the set of nodes with bounded degree. \(d_n = m^{r_d} (r_d > 0)\). Let \(d_{i, {\mathcal {N}}_b}\) be the number of nodes within \(\mathcal N_b\) that individual i connects to. We assume \(d_{i, \mathcal N_b}\) is bounded for all i. In addition, the cardinality of \(N_b\) satisfies \( \vert {\mathcal {N}}_b \vert / \vert A \vert = o(1)\).
Lemma 4
With probability \(1 - \exp \{ - C d_n \}\), it holds that
for any \(i \in {\mathcal {N}}_{u}\) and any \(\theta \in B(\theta ^{*}, \delta )\) for some constants \(c_1\) and \(\delta \). Here \(L_i(\theta \vert z):= \exp \{ \vert A \vert l_i (\theta \vert z)\}\) and
Proof of Lemma 4
Similar to the proof of Lemma 2, we can prove that
holds for any fixed \(z_{{\mathcal {N}}}\) with probability at least \(1 - \exp \{- C(\sum _{j \in {\mathcal {N}}} d_j)\}\). Then, we can compute
by adjusting the constants. (F34) uses the fact that \(l_i(\theta \vert z)\) only depends on a finite number of nodes in \({\mathcal {N}}_{b}\). This completes the proof.
We define the estimator of latent class membership as \({\hat{z}}_i:= \arg \max _{z} q_i^{(M)}(z)\). The following result says that we can consistently estimate the latent class membership of those individuals with large degrees exponentially fast.
Theorem 5
Under Conditions C1, C4, C5, C7 and C2’, C3’, C6’, with probability \(1 - M \exp \{-C d_n\}\), we have \(q_i^{(m)}(z_i = z_i^{*}) \ge 1 - C \exp \{c_1 m d_n\}\) for all \(i \in {\mathcal {N}}_u\) and \(m = 1, \ldots , M\). Especially when \(N_u = \{1, \ldots , n\}\), we can recover true labels of all nodes.
Proof of Theorem 5
To prove this, we only need to show that \(q_i^{(m)}(z_i^{*}) \ge 1 - C \exp \{-c_1 m d_n\}\) for all \(i \in {\mathcal {N}}_u\) with probability \(1 - \exp \{-Cd_n\}\). (\(m = 1,2,\ldots \) and \(c_1\) is some small constant.) Without loss of generality, we can assume \(\theta ^{(m)}\) is always in \({\mathcal {B}}(\theta ^{*}, \delta )\). (The proof of this argument is almost same as that in the proof of Theorem 2.)
Take any \(i \in {\mathcal {N}}_u\). We first prove that \(q_i^{(1)}(z_i^{*}) \ge 1 - C \exp \{-c_1 d_n\}\) for \(i \in {\mathcal {N}}_u\). This is true by applying Condition C7. In the following, we prove the result by induction.
According to Lemma 4 and Condition C2’, we have that \( \vert A \vert l_{i}(\theta ^{(m_1)} \vert z) \le \vert A \vert l_{i}(\theta ^{(m_1)} \vert z^{*}) - c d_n\) for any z with \(z_i \ne z_i^{*}\) with probability \(1 - \exp \{-C d_n\}\). This implies that
for any \(z_i \ne z_i^{*}\) and
Combining these two facts, we have that
holds for any \(z_i \ne z_i^{*}\) and some adjusted constant \(c_2 > c_1\).
By the recursive formula
we then have
which indicates that
Hence, we complete the proof by induction.
Lastly, it is easy to see that proof of Theorem 4 is the special case of Theorem 5.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Fang, G., Ward, O.G. & Zheng, T. Online estimation and community detection of network point processes for event streams. Stat Comput 34, 35 (2024). https://doi.org/10.1007/s11222-023-10342-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11222-023-10342-z