
Abstract
Sequential Monte Carlo squared (SMC\(^2\)) methods can be used for parameter inference of intractable likelihood state-space models. These methods replace the likelihood with an unbiased particle filter estimate, similarly to particle Markov chain Monte Carlo (MCMC). As with particle MCMC, the efficiency of SMC\(^2\) greatly depends on the variance of the likelihood estimator, and therefore on the number of state particles used within the particle filter. We introduce novel methods to adaptively select the number of state particles within SMC\(^2\) using the expected squared jumping distance to trigger the adaptation, and modifying the exchange importance sampling method of Chopin et al. (J R Stat Soc: Ser B (Stat Method) 75(3):397–426, 2012) to replace the current set of state particles with the new set of state particles. The resulting algorithm is fully automatic, and can significantly improve current methods. Code for our methods is available at https://github.com/imkebotha/adaptive-exact-approximate-smc.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
We are interested in exact Bayesian parameter inference for state-space models (SSMs) where the likelihood function of the model parameters is intractable. SSMs are ubiquitous in engineering, econometrics and the natural sciences; see Cappé et al. (2005) and references therein for an overview. They are used when the process of interest is observed indirectly over time or space, i.e. they consist of a hidden or latent process \(\{X_t\}_{t\ge 1}\) and an observed process \(\{Y_t\}_{t\ge 1}\).
Particle Markov chain Monte Carlo (MCMC; Andrieu et al. 2010; Andrieu and Roberts 2009) methods such as particle marginal Metropolis-Hastings (PMMH) or particle Gibbs can be used for exact parameter inference of intractable likelihood SSMs. PMMH uses a particle filter estimator of the likelihood within an otherwise standard Metropolis-Hastings algorithm. Similarly, particle Gibbs uses a conditional particle filter to draw the latent states from their full conditional distribution, then updates the model parameters conditional on the latent states. Both PMMH and particle Gibbs are simulation consistent under mild conditions (Andrieu et al. 2010).
Chopin et al. (2012) and Duan and Fulop (2014) apply a similar approach to sequential Monte Carlo (SMC) samplers. SMC methods for static models (Chopin 2002; Del Moral et al. 2006) recursively sample through a sequence of distributions using a combination of reweighting, resampling and mutation steps. In the Bayesian setting, this sequence often starts at the prior and ends at the posterior distribution. For intractable likelihood SSMs, Chopin et al. (2012) and Duan and Fulop (2014) replace the likelihood within the sequence of distributions being traversed with its unbiased estimator. Practically, this means that each parameter particle is augmented with \(N_x\) state particles. Due to this nesting of SMC algorithms and following Chopin et al. (2012), we refer to these methods as SMC\(^2\). As with particle MCMC, for any fixed number of state particles (\(N_x\)), SMC\(^2\) targets the exact posterior distribution (Duan and Fulop 2014).
We define an ‘exact’ method as one that converges to the true posterior distribution as the number of parameter samples (\(N_{\theta }\)) goes to infinity (with finite \(N_x\)), with no extra assumptions above those required for standard MCMC or SMC. While similar methods to SMC\(^2\) are available for Bayesian parameter inference of intractable likelihood SSMs, e.g. nested particle filters (Crisan and Míguez 2017, 2018) and ensemble MCMC (Drovandi et al. 2022), they are not exact in general and so are not considered in this paper. In particular, nested particle filters target the exact posterior as \(N_{\theta }\rightarrow \infty \) and \(N_{x}\rightarrow \infty \) subject to some assumptions about the optimal filter and the parameter space. Similarly, ensemble MCMC is guaranteed to be exact only when the model is linear Gaussian.
The sampling efficiency of particle MCMC and SMC\(^2\) greatly depends on the number of state particles used within the particle filter. In particle MCMC, \(N_x\) is generally tuned manually, which can be time intensive. A significant advantage of SMC\(^2\) over particle MCMC is that \(N_x\) can be adapted automatically. Strategies to do this are proposed by Chopin et al. (2012, 2015) and Duan and Fulop (2014); however, these methods automate the adaptation of \(N_x\) at the expense of other model-specific tuning parameters, which must then be tuned manually. Furthermore, the value of \(N_x\) can be difficult to choose in practice, and has a significant effect on both the Monte Carlo error of the SMC approximation to the target distribution and the computation time. Current methods require a moderate starting value of \(N_x\) to avoid poor values in subsequent iterations, i.e. values that are too low and negatively impact the accuracy of the samples, or unnecessarily high values that increase the computation time.
Adaptation of the number of state particles is also studied outside the SMC\(^2\) context. Bhadra and Ionides (2016) propose an optimal allocation method, which uses a meta-model to estimate the variance of the incremental log-likelihood estimators. This method allocates the number of particles to be used for each timepoint in the particle filter. However, it still requires the total number of state particles (over all timepoints) to be known. Lee and Whiteley (2018) run successive particle filters, doubling the number of state particles each time, until the variance of the log-likelihood estimator is below some threshold. In the SMC\(^2\) context, this approach can be very expensive computationally, as it needs to be applied to each parameter particle. Other methods adapt the number of state particles within the particle filter itself (Fox 2003; Soto 2005; Elvira et al. 2017, 2021), leading to a random number of state particles whenever the particle filter is run. This is problematic in the context of particle MCMC (and hence in the mutation step of SMC\(^2\)) as the dimension of the augmented parameter space changes whenever the likelihood is estimated. A key point of particle MCMC is that it can be reformulated as standard MCMC on an augmented space (Andrieu and Roberts 2009; Andrieu et al. 2010). To sample from the posterior on a space of varying dimension requires methods such as reversible jump MCMC (Green 1995).
Our article introduces a novel and principled strategy to automatically tune \(N_x\), while aiming to keep an optimal balance between statistical and computational efficiency. Compared to current methods, our approach has less tuning parameters that require manual calibration. Notably, it also allows \(N_x\) to decrease, which makes our approach more robust to variability in the algorithm and the adaptation step. We find that using the expected squared jumping distance of the mutation step to adapt the number of state particles generally gives the most efficient and reliable results. To further improve the overall efficiency of the adaptation, we also modify the exchange importance sampling method of Chopin et al. (2012) to update the set of state particles once \(N_x\) is adapted. This modified version introduces no extra variability in the parameter particle weights, and outperforms the current methods.
The rest of the paper is organized as follows. Section 2 gives the necessary background on state-space models and SMC methods, including particle filters, SMC for static models and SMC\(^2\). Section 3 describes the current methods for adapting the number of state particles in SMC\(^2\). Section 4 describes our novel tuning methodology. Section 5 shows the performance of our methods on a Brownian motion model, a stochastic volatility model, a noisy theta-logistic model and a noisy Ricker model. Section 6 concludes.
2 Background
This section contains the necessary background information for understanding the novel methods discussed in Sect. 4. It covers content related to exact Bayesian inference for state-space models, particularly focussed on models with intractable transition densities.
2.1 State-space models
Consider a state-space model (SSM) with parameters \(\varvec{\theta }\in \Theta \), a hidden or latent process \(\{X_t\}_{t\ge 1}\) and an observed process \(\{Y_t\}_{t\ge 1}\). A key assumption of SSMs is that the process \(\{(X_t, Y_t), t\ge 1\}\) is Markov, and we further assume that the full conditional densities of \(Y_t = y_t\) and \(X_t = x_t\) are
and
where \(g(y_t\mid x_t, \varvec{\theta })\) and \(f(x_t\mid x_{t-1}, \varvec{\theta })\) are the observation density and transition density respectively. The density of the latent states at time \(t=1\) is \(\mu (x_1\mid \varvec{\theta })\) and the prior density of the parameters is \(p(\varvec{\theta })\).
Define \(\varvec{z}_{i:j} :=\{z_i, z_{i+1}, \ldots , z_j\}\) for \(j\ge i\). The distribution of \(\varvec{\theta }\) conditional on the observations up to time \(t \le T\) is
where
The integral in (1) gives the likelihood function \(p(\varvec{y}_{1:t}\mid \varvec{\theta })\). This integral is often analytically intractable or prohibitively expensive to compute, which means that the likelihood is also intractable. If the value of \(\varvec{\theta }\) is fixed, a particle filter targeting \(p(\varvec{x}_{1:t}\mid \varvec{y}_{1:t}, \varvec{\theta })\) gives an unbiased estimate of the likelihood as a by-product, as described in Sect. 2.2.1. Similarly, a conditional particle filter (Andrieu et al. 2010), i.e. a particle filter that is conditional on a single state trajectory \(\varvec{x}_{1:t}^k\), can be used to unbiasedly simulate latent state trajectories from \(p(\cdot \mid \varvec{x}_{1:t}^k, \varvec{y}_{1:t}, \varvec{\theta })\). Particle filters are SMC methods applied to dynamic models.
2.2 Sequential Monte Carlo
SMC methods recursively sample from a sequence of distributions, \(\pi _d(z_d) \propto \gamma _d(z_d)\), \(d = 0, \ldots , D\), where \(\pi _0(z_0)\) can generally be sampled from directly and \(\pi _{D}(z_D)\) is the target distribution (Del Moral et al. 2006).
These distributions are traversed using a combination of resample, mutation and reweight steps. Initially, \(N_{z}\) samples are drawn from \(\pi _0(z_0)\) and given equal weights \(\{z_0^{n}, W_0^n=\nicefrac {1}{N_{z}}\}_{n=1}^{N_{z}}\). For each subsequent distribution, the particles are resampled according to their weights, thus removing particles with negligible weights and duplicating high-weight particles. The resampled particles are then mutated using R applications of the mutation kernel \(K(z^n_{d-1},z^n_{d})\), and reweighted as
where \(L(z^n_{d}, z^n_{d-1})\) is the artificial backward kernel of Del Moral et al. (2006). Note that if the weights at iteration d are independent of the mutated particles \(z^n_{d}\), the reweighting step should be completed prior to the resample and mutation steps. At each iteration d, the weighted particles \(\{z_d^n, W_d^n\}_{n=1}^{N_{z}}\) form an approximation of \(\pi _d(z_d)\). See Del Moral et al. (2006) for more details.
An advantage of SMC methods is that an unbiased estimate of the normalizing constant of the target distribution can be obtained as follows (Del Moral et al. 2006)
This feature is exploited in the SMC\(^2\) methods described in Sect. 2.3.
2.2.1 Particle filters
SMC methods for dynamic models are known as particle filters. For fixed \(\varvec{\theta }\), the sequence of filtering distributions for \(d = 1, \ldots , T\), is
The bootstrap particle filter of Gordon et al. (1993) uses the transition density as the mutation kernel \(K(x_{d-1},x_{d}) = f(x_d \mid x_{d-1}, \varvec{\theta })\), and selects \(L(x_{d},x_{d-1}) = 1\) as the backward kernel. The weights are then given by
for \(m = 1, \ldots , N_x\). Algorithm 1 shows pseudo-code for the bootstrap particle filter (Gordon et al. 1993).
Define \(x_{1:d}^{1:N_x}:=\{x_1^{1:N_x}, \dots , x_d^{1:N_x}\}\), where \(d=1, \ldots , T\). The likelihood estimate with \(N_x\) state particles and d observations is then
Let \(\psi (\varvec{x}_{1:d}^{1:N_x})\) be the joint distribution of all the random variables drawn during the course of the particle filter (Andrieu et al. 2010). The likelihood estimate in (4) is unbiased in the sense that \(\mathbb {E}_{\psi (\varvec{x}_{1:d}^{1:N_x})}\left( \widehat{p_{N_x}}(\varvec{y}_{1:d}\mid \varvec{\theta }, \varvec{x}_{1:d}^{1:N_x})\right) = p(\varvec{y}_{1:d}\mid \varvec{\theta })\) (Section 7.4.2 of Del Moral, 2004; see also Pitt et al. 2012).
The notation
is used interchangeably throughout the paper.

2.2.2 SMC for static models
For static models, where inference on \(\varvec{\theta }\) is of interest, the sequence of distributions traversed by the SMC algorithm is \(\pi _d(\varvec{\theta }_d) \propto \gamma _d(\varvec{\theta }_d)\), \(d = 0, \ldots , D\), where \(\pi _0(\varvec{\theta }_0) = p(\varvec{\theta })\) is the prior and \(\pi _{D}(\varvec{\theta }_D) = p(\varvec{\theta }\mid \varvec{y}_{1:T})\) is the posterior distribution. Assuming that the likelihood function is tractable, there are at least two general ways to construct this sequence,
-
1.
likelihood tempering, which gives \(\pi _d(\varvec{\theta }) \ \propto \ p(\varvec{y}_{1:T}\mid \varvec{\theta })^{g_d}p(\varvec{\theta })\) for \(d=0,\ldots ,D\), and where \(0 = g_0 \le \cdots \le g_{D} = 1\), and
-
2.
data annealing (Chopin 2002), which gives \(\pi _d(\varvec{\theta }) \ \propto \ p(\varvec{y}_{1:d}\mid \varvec{\theta })p(\varvec{\theta })\) for \(d = 0,\ldots ,T\), where T is the number of observations and \(D=T\).
Typically, SMC for static models uses a mutation kernel which ensures that the current target \(\pi _d(\varvec{\theta })\) remains invariant. A common choice is to use R applications of an MCMC mutation kernel along with the backward kernel \(L(\varvec{\theta }_{d}, \varvec{\theta }_{d-1}) = \gamma _d(\varvec{\theta }_{d-1})K(\varvec{\theta }_{d-1}, \varvec{\theta }_{d})/\gamma _d(\varvec{\theta }_{d})\) (Chopin 2002; Del Moral et al. 2006). The weights then become
Since the weights are independent of the mutated particles \(\varvec{\theta }_{d}\), the reweighting step is completed prior to the resample and mutation steps.
2.3 SMC\(^2\)
Standard SMC methods for static models cannot be applied directly to state-space models if the parameters \(\varvec{\theta }\) are unknown except when the integral in (1) is analytically tractable. When the likelihood is intractable, SMC\(^2\) replaces it in the sequence of distributions being traversed with a particle filter estimator. Essentially, each parameter particle is augmented with a set of weighted state particles.
Since the likelihood is replaced with a particle filter estimator, the parameter particles in SMC\(^2\) are mutated using R applications of a particle MCMC mutation kernel \(K(\cdot , \cdot )\). Section 2.4 describes the particle marginal Metropolis-Hastings (PMMH) algorithm. As with SMC for static models, the parameter particle weights are given by (5).
Two general ways to construct the sequence of targets for SMC\(^2\) are the density tempered marginalised SMC algorithm of Duan and Fulop (2014) and the data annealing SMC\(^2\) method of Chopin et al. (2012), which we refer to as density tempering SMC\(^2\) (DT-SMC\(^2\)) and data annealing SMC\(^2\) (DA-SMC\(^2\)) respectively. These are described in Sects. 2.3.1 and 2.3.2.
Algorithm 2 shows pseudo-code which applies to both DT-SMC\(^2\) and DA-SMC\(^2\). The main difference between the two methods is how the sequence of targets is defined. Sections 2.3.1 and 2.3.2 describe the sequence of targets and the reweighting formulas for DT-SMC\(^2\) and DA-SMC\(^2\) respectively. For conciseness, we denote the set of weighted state particles associated with parameter particle n, \(n = 1,\ldots , N_{\theta }\) at iteration d as
where \(\varvec{S}_{d}^{1:N_x,n}\) is the set of normalised state particle weights. The nth parameter particle with its attached set of weighted state particles is denoted as \(\varvec{\vartheta }_d^n = \{\varvec{\theta }_d^n, \tilde{\varvec{x}}_d^{1:N_x, n}\}\), \(n = 1,\ldots , N_{\theta }\).
2.3.1 Density tempering SMC\(^2\)
The sequence of distributions for DT-SMC\(^2\) is
which gives the weights from (5) as
Due to the tempering parameter \(g_d\), DT-SMC\(^2\) is only exact at the first and final temperatures, i.e. \(p(\varvec{\theta })p(\varvec{y}_{1:T}\mid \varvec{\theta })^{g_d}/\int {p(\varvec{\theta })p(\varvec{y}_{1:T}\mid \varvec{\theta })^{g_d}}d\varvec{\theta }\) is a marginal distribution of \(\pi _d(\varvec{\theta })\) only at \(g_1 = 0\) and \(g_D = 1\).
2.3.2 Data annealing SMC\(^2\)
For DA-SMC\(^2\), the sequence of distributions is
and the weights from (5) are
where \(\widehat{p_{N_x}}\left( y_{d}\mid \varvec{y}_{1:d-1}, \varvec{\theta }_{d-1}^{n}\right) \) is obtained from iteration d of a particle filter (see (4) and Algorithm 1). Unlike DT-SMC\(^2\), DA-SMC\(^2\) admits \(p\left( \varvec{\theta }\mid \varvec{y}_{1:d}\right) \) as a marginal distribution of \(\pi _d(\varvec{\theta })\) for all \(d=0,\ldots ,D\).
2.4 Particle MCMC mutations
The simplest mutation of the parameter particles in SMC\(^2\) is a sequence of Markov move steps using the PMMH algorithm; see Gunawan et al. (2021) for alternatives. The PMMH method is a standard Metropolis-Hastings algorithm where the intractable likelihood is replaced by the particle filter estimate in (4). Algorithm 3 shows a single PMMH iteration.


While a PMMH mutation leaves the current target invariant, its acceptance rate is sensitive to the variance of the likelihood estimator (Andrieu et al. 2010). In practice, this means that if the variance is too high, then some particles may not be mutated during the mutation step—even with a large number of MCMC iterations.
In the context of particle MCMC samplers, Andrieu et al. (2010) show that \(N_x\) must be chosen as \(\mathcal {O}(T)\) to achieve reasonable acceptance rates, i.e. reasonable variance of the likelihood estimator. Pitt et al. (2012), Doucet et al. (2015) and Sherlock et al. (2015) recommend choosing \(N_x\) such that the variance of the log-likelihood estimator is between 1 and 3 when evaluated at, e.g., the posterior mean. This generally requires a (potentially time-consuming) tuning process for \(N_x\) before running the algorithm.
For SMC\(^2\), fewer particles may be required to achieve reasonable acceptance rates in the early stages of the algorithm. In DA-SMC\(^2\), \(N_x = \mathcal {O}(t)\), where \(t=d\), suggests starting with a small \(N_x\), and increasing it with each added observation. Likewise, in DT-SMC\(^2\), a small \(g_d\) will reduce the impact of a highly variable log-likelihood estimator. In addition, unlike particle MCMC methods, it is possible to automatically adapt \(N_x\) within SMC\(^2\). The next section describes the tuning strategies proposed by Chopin et al. (2012, 2015) and Duan and Fulop (2014).
3 Existing methods to calibrate \(N_x\) within SMC\(^2\)
There are three main stages to adapting \(N_x\): (1) triggering the adaptation, (2) choosing the new number of particles \(N_x^*\), and (3) replacing the current set of state particles \(\tilde{\varvec{x}}^{1:N_x, 1:N_{\theta }}_d\) with the new set \(\tilde{\varvec{x}}^{1:N_x^*, 1:N_{\theta }}_d\). To simplify notation, we write \(\tilde{\varvec{x}}^{1:N_x, 1:N_{\theta }}_d\) as \(\tilde{\varvec{x}}^{1:N_x}_d\).
3.1 Stage 1: Triggering the adaptation
It may be necessary to adapt \(N_x\) when the mutation step no longer achieves sufficient particle diversity. Chopin et al. (2012, 2015) and Duan and Fulop (2014) fix the number of MCMC iterations (R) and change \(N_x\) whenever the acceptance rate of a single MCMC iteration falls below some target value. This approach has two main drawbacks. First, the acceptance rate does not take the jumping distances of the particles into account, and can be made artificially high by making very local proposals. Second, both R and the target acceptance rate must be tuned—even if the exact likelihood is used, the acceptance rate may naturally be low, depending on the form of the posterior and the proposal function used within the mutation kernel. Ideally, \(N_x\) and R should be jointly adapted.
3.2 Stage 2: Choosing the new number of particles \(N_x^*\)
A new number of state particles (\(N_x^*\)) is determined in the second stage. Chopin et al. (2012) set \(N_x^* = 2\cdot N_x\) (double), while Duan and Fulop (2014) set \(N_x^* = \widehat{\sigma _{N_x}}^2 \cdot N_x\) (rescale-var), where \(\widehat{\sigma _{N_x}}^2\) is the estimated variance of the log-likelihood estimator using \(N_x\) state particles. The variance is estimated from k independent estimates of the log-likelihood (for the current SMC target) based on the sample mean of the parameter particles. This choice is motivated by the results of Pitt et al. (2012), Doucet et al. (2015) and Sherlock et al. (2015), who show that \(\sigma _{N_x}^2 \ \propto \ 1/N_x\) for any number of state particles \(N_x\). Setting \(\sigma _{N_x}^2 = \alpha /N_x\) and rearranging gives both \(\alpha = \sigma _{N_x}^2 \cdot N_x\) and \(N_x = \alpha /\sigma _{N_x}^2\). Given \(N_x\) and \(\sigma _{N_x}^2\), these expressions can be used to find a new number of state particles \(N_x^*\) such that \(\sigma _{N_x^*}^2 = 1\), by noting that \(N_x^* = \alpha /\sigma _{N_x^*}^2 = \alpha /1 = \sigma _{N_x}^2 \cdot N_x\).
We find that if the initial \(N_x\) is too small, then the double scheme of Chopin et al. (2012) can take a significant number of iterations to set \(N_x\) to a reasonable value. It can also increase \(N_x\) to an unnecessarily high value if the adaptation is triggered when the number of state particles is already large.
While the rescale-var method of Duan and Fulop (2014) is more principled, as it takes the variance of the log-likelihood estimator into account, we find that it is also sensitive to the initial number of particles. For a poorly chosen initial \(N_x\), the variance of the log-likelihood estimator can be of order \(10^2\) or higher. In this case, scaling the current number of particles by \(\widehat{\sigma _{N_x}}^2\) may give an extremely high value for \(N_x^*\).
Chopin et al. (2015) propose a third method; they set \(N_x^* = \tau /\sigma ^2_{N_x}\), where \(\tau \) is a model-specific tuning parameter, and \(\sigma ^2_{N_x}\) is the variance of the log-likelihood estimator with \(N_x\) state particles. This choice is motivated by the results from Doucet et al. (2012) (an earlier version of Doucet et al. (2015)); see Chopin et al. (2015) for further details. Since the parameter \(\tau \) must be tuned manually, this approach is not included in our numerical experiments in Sect. 5.
3.3 Stage 3: Replacing the state particle set
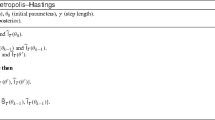
The final stage replaces the current set of state particles \(\tilde{\varvec{x}}^{1:N_x}_d\) by the new set \(\tilde{\varvec{x}}^{1:N_x^*}_d\). Chopin et al. (2012) propose a reweighting step for the parameter particles (reweight) using the generalised importance sampling method of Del Moral et al. (2006) to swap \(\tilde{\varvec{x}}^{1:N_x}_d\) with \(\tilde{\varvec{x}}^{1:N_x^*}_d\). The incremental weight function for this step (for DA-SMC\(^2\)) is
where \(L_d(\varvec{x}_{d}^{1:N_x^*}, \varvec{x}_{d}^{1:N_x})\) is the backward kernel. They use the following approximation to the optimal backward kernel (see Proposition 1 of Del Moral et al. (2006))
leading to
For density tempering, this becomes
The new parameter particle weights are then given by
While this method is relatively fast, it can significantly increase the variance of the parameter particle weights (Duan and Fulop 2014).
As an alternative to reweight, Chopin et al. (2012) propose a conditional particle filter (CPF) step to replace \(\tilde{\varvec{x}}^{1:N_x}_d\) with \(\tilde{\varvec{x}}^{1:N_x^*}_d\). Here, the state particles and the likelihood estimates are updated by running a particle filter conditional on a single trajectory from the current set of state particles. The incremental weight function of this step is 1, which means that the parameter particle weights are left unchanged. The drawback of this approach is that all the state particles must be stored, which can significantly increase the RAM required by the algorithm. Chopin et al. (2015) propose two extensions of the CPF approach which reduce the memory requirements of the algorithm at the expense of increased computation time. Their first proposal is to only store the state particles with descendants at the final time-point, i.e. using a path storage algorithm within the particle filter (Jacob et al. 2015). Their second method is to store the random seed of the pseudo-random number generator in such a way that the latent states and their associated ancestral indices can be re-generated at any point. Both variants still have a higher RAM requirement and run time compared to the reweight method.
Duan and Fulop (2014) propose a reinitialisation scheme to extend the particles (reinit). Whenever \(N_x\) is increased, they fit a mixture model \(Q(\cdot )\) informed by the current set of particles, then reinitialise the SMC algorithm with \(N_x^*\) state particles and \(Q(\cdot )\) as the initial distribution. The modified sequence of distributions for DT-SMC\(^2\) is
The reinit method aims to minimize the variance of the weights, but we find it can be very slow as the algorithm may reinitialise numerous times before completion, each time with a larger number of particles. This approach also assumes that the distribution of the set of parameter particles when reinit is triggered is more informative than the prior, which is not necessarily the case if the adaptation is triggered early.
4 Methods
This section describes our proposed approach for each of the three stages involved in adapting the number of state particles.
4.1 Triggering the adaptation
Instead of using the acceptance rate to measure particle diversity, we use the expected squared jumping distance (ESJD), which accounts for both the acceptance rate (the probability that the particles will move) and the jumping distance (how far they will move). See Pasarica and Gelman (2010), Fearnhead and Taylor (2013), Salomone et al. (2018) and Bon et al. (2021) for examples of this idea outside the SMC\(^2\) context. The ESJD at iteration d is defined as
where \(\left\Vert \varvec{\theta }_d^* - \varvec{\theta }_d\right\Vert ^2\) is the squared Mahalanobis distance between the current value of the parameters (\(\varvec{\theta }_d\)) and the proposed value (\(\varvec{\theta }_d^*\)). The ESJD of the rth MCMC iteration of the mutation step at iteration d (steps 5–7 of Algorithm 2) can be estimated as
where \(\varvec{\theta }_{d, r}^n\) is the nth parameter particle at the start of the rth MCMC iteration, \(\varvec{\theta }_{d, r}^{n, *}\) is the proposed parameter particle at the rth MCMC iteration, \(\widehat{\Sigma }\) is the covariance matrix of the current parameter particle set, and \(\alpha (\varvec{\theta }_{d, r}^n, \varvec{\theta }_{d, r}^{n,*})\) is the acceptance probability in (8). The total estimated ESJD for iteration d is \(\widehat{\text {ESJD}}_d = \sum _{r=1}^{R}{\widehat{\text {ESJD}}_{d, r}}\).
Algorithm 4 outlines how \(N_x\) and R are adapted. To summarise, the adaptation is triggered in iteration d if \(\widehat{\text {ESJD}}_{d-1}\) is below some target value (stage 1). Once triggered, the number of particles is adapted (stage 2) and the particle set is updated (stage 3). A single MCMC iteration is then run with the new number of particles, and the results from this step are used to determine how many MCMC iterations are required to reach the target ESJD, i.e. R is given by dividing the target ESJD by the estimated ESJD of the single MCMC iteration and rounding up. Once the adaptation is complete, the remaining MCMC iterations are completed. This approach gives a general framework which can be implemented with any of the stage 2 and stage 3 methods described in Sect. 3, as well as our novel methods in Sects. 4.2 and 4.3.

4.2 Choosing the new number of particles \(N_x^*\)
To set the new number of state particles \(N_x^*\), we build on the rescale-var method of Duan and Fulop (2014), which adapts the number of state particles as follows:
-
1.
Calculate \(\bar{\varvec{\theta }}_d\), the mean of the current set of parameter samples \(\varvec{\theta }_d^{1:N_{\theta }}\).
-
2.
Run the particle filter with \(N_x\) state particles k times to get k estimates of the log-likelihood evaluated at \(\bar{\varvec{\theta }}_d\).
-
3.
Calculate \(\widehat{\sigma _{N_x}}^2\), the sample variance of the k log-likelihood estimates.
-
4.
Set the new number of state particles to \(N_{x}^* = \widehat{\sigma _{N_x}}^2 \cdot N_x\).
Recall from Sect. 3, that rescale-var is based on the relation \(\sigma _{N_x}^2 \ \propto \ 1/N_x\) (Pitt et al. 2012; Doucet et al. 2015; Sherlock et al. 2015). In practice, we find that it changes \(N_x\) too drastically from one iteration to the next for two reasons. First, the sample variance may itself be highly variable, especially when \(N_x\) is small. Second, the sample mean of the parameter particles changes throughout the iterations, meaning that the number of state particles needed to reach a variance of 1 also changes throughout the iterations. The sample mean may also be a poor value at which to estimate the likelihood if the current target is multimodal or if the current set of parameter particles offers a poor Monte Carlo approximation to the current target distribution. The latter may occur if the number of parameter particles \(N_{\theta }\) is too low.
Our first attempt to overcome some of these problems is to scale the number of state particles by the standard deviation instead of the variance, i.e. we set \(N_{x}^* = \widehat{\sigma _{N_x}} \cdot N_x\) and call this method rescale-std. A variance of 1 is still the overall target, however, more moderate values of \(N_x\) are proposed when \(\widehat{\sigma _{N_x}}^2 \ne 1\). At any given iteration, the new target variance is the current standard deviation, i.e. \(N_x^*\) is chosen such that \(\widehat{\sigma _{N_x^*}}^2 = \widehat{\sigma _{N_x}}\). The main drawback of rescale-std is that the variance at the final iteration may be too high, depending on the initial value of \(N_x\) and the variability of the sample variance between iterations, i.e. it may approach a variance of 1 too slowly. In our numerical experiments in Sect. 5, however, we find that the final variance of the rescale-std method is generally between 1 and \(1.2^2\), which is fairly conservative. In their numerical experiments, Doucet et al. (2015) found that the optimal \(N_x\) generally gives a variance that is between \(1.2^2=1.44\) and \(1.5^2=2.25\).
Our second method (which we refer to as novel-var) aims to improve upon rescale-var by estimating the variance at different values of \(N_x\). To obtain our set of candidate values, \(\varvec{N}_{x, 1:M}\), we scale \(N_x\) by different fractional powers of \(\widehat{\sigma _{N_x}}^2/\sigma _{\text {target}}^2\), where \(\sigma _{\text {target}}^2\) is the target variance. Note that the candidate values \(\varvec{N}_{x, 1:M}\) will be close to \(N_x\) if \(\widehat{\sigma _{N_x}}^2\) is close to \(\sigma _{\text {target}}^2\). To avoid unnecessary computation, the current \(N_x\) is left unchanged if \(\widehat{\sigma _{N_x}}^2\) falls within some range \(\sigma _{\text {min}}^2< \sigma _{\text {target}}^2 < \sigma _{\text {max}}^2\). We also round the candidate number of state particles up to the nearest 10, which ensures that there is at least a difference of 10 between each \(N_{x, m} \in \varvec{N}_{x, 1:M}\). Once \(\varvec{N}_{x, 1:M}\) has been obtained, the variance is estimated for each \(N_{x, m}\in \varvec{N}_{x, 1:M}\), and the new number of state particles is set to the \(N_{x, m}\) that has the highest variance less than or equal to \(\sigma _{\text {max}}^2\). In our numerical experiments in Sect. 5, we set

which gives candidate values ranging from rescale-std (\(s^{0.5} \cdot N_x\)) to rescale-var (\(s^{1} \cdot N_x\)). The target, minimum and maximum variances are \(\sigma _{\text {target}}^2 = G\cdot 1\), \(\sigma _{\text {min}}^2 = G\cdot 0.95^2\) and \(\sigma _{\text {max}}^2 = G\cdot 1.05^2\) respectively, where \(G = 1\) for DA-SMC\(^2\) and \(G = 1/\max {(0.6^2, g_d^2)}\) for DT-SMC\(^2\). These values are fairly conservative and aim to keep the final variance between \(0.95^2\approx 0.9\) and \(1.05^2\approx 1.1\).
The parameter G is used to take advantage of the effect of the tempering parameter on the variance, i.e. \(\text {var}(\log {(\widehat{p_{N_x}}(\varvec{y}\mid \varvec{\theta })^{g_d})}) = g^2 \cdot \text {var}(\log {(\widehat{p_{N_x}}(\varvec{y}\mid \varvec{\theta }))})\). Capping the value of G is necessary in practice, since aiming for an excessive variance is difficult due to the variability of the variance estimate when \(N_x\) is low. By setting \(G = 1/\max {(0.6^2, g_d^2)}\), the highest variance targeted is \(1/0.36\approx 2.8\). In general, we recommend not aiming for a variance that is greater than 3 (Sherlock et al. 2015). Note that including the tempering parameter in this way is infeasible for rescale-var or rescale-std. For the former, changing the target variance only exacerbates the problem of too drastic changes of \(N_x\) between iterations. This is largely due to the increased variability of the sample variance when \(g_d < 1\). While the variability of \(\widehat{\sigma _{N_x}}^2\) is less of a problem for rescale-std, this method struggles keeping up with the changing variance target.
Compared to rescale-var, we find that both rescale-std and novel-var are significantly less sensitive to the initial number of state particles, sudden changes in the variance arising from changes in the sample mean of the parameter particles, and variability in the estimated variance of the log-likelihood estimator. The novel-var method is also more predictable in what variance is targeted at each iteration compared to rescale-std.
Our final method (novel-esjd) also compares different values of \(N_x\), but using the ESJD instead of the variance of the log-likelihood estimator. As before, the choice of candidate values \(\varvec{N}_{x, 1:M}\) is flexible; in the numerical experiments in Sect. 5, we set

where \(G = 1\) for DA-SMC\(^2\) and \(G = 1/\max {(0.6^2, g_d^2)}\) for DT-SMC\(^2\). Again, each \(N_{x, m} \in \varvec{N}_{x, 1:M}\) is rounded up to the nearest 10. A score is calculated for a particular \(N_{x, m}\in \varvec{N}_{x, 1:M}\) by first doing a mutation step with \(N_{x, m}\) state particles, then calculating the number of MCMC iterations (\(R_m\)) needed to reach the ESJD target; the score for \(N_{x, m}\) is \((N_m\cdot R_m)^{-1}\). Algorithm 5 describes the adaptive mutation step when using novel-esjd. Since the candidate \(N_x\) values are tested in ascending order (see step 2 of Algorithm 5), it is unnecessary to continue testing the values once the score starts to decrease (steps 8–17 of Algorithm 5).
This method does not target a particular variance, but instead aims to select the \(N_x\) having the cheapest mutation while still achieving the ESJD target. Compared to double and the variance-based methods, we find that novel-esjd is consistent between independent runs, in terms of the run time and the adaptation for \(N_x\). It is also relatively insensitive to the initial number of state particles, as well as variability in the variance of the likelihood estimator.
Ideally, the adaptation algorithm (Algorithm 4 or Algorithm 5) will only be triggered if \(N_x\) or R is too low (or too high, as mentioned in Sect. 5). In practice, the ESJD is variable, so the adaptation may be triggered more often than necessary. Allowing the number of state particles to decrease helps to keep the value of \(N_x\) reasonable. Also, if the estimated variance is close to the target variance, one of the candidate \(N_x\) values will be close in value to the current \(N_x\). See Table 1 for an example of the possible values of \(N_x\) for the different methods.

4.3 Replacing the state particle set
Our final contribution (denoted replace) is a variation of the reweight scheme of Chopin et al. (2012). Both reweight and replace consist of three steps. First, a particle filter (Algorithm 1) is run with the new number of state particles to obtain \(\widehat{p_{N_x^*}}(\varvec{y}_{1:d}\mid \varvec{\theta }_d, \varvec{x}_{1:d}^{1:N_x^*})\) and \(\varvec{x}_{1:d}^{1:N_x^*}\). Second, the parameter particle weights are reweighted using
where \(IW_d^n\) is the incremental weight for parameter particle n, \(n=1, \ldots , N_{\theta }\) at iteration d; then the previous likelihood estimate and set of state particles are discarded. Note that prior to this reweighting step, the parameter particles are evenly weighted as the adaptation of \(N_x\) is performed after the resampling step, i.e. \(W_d^n = 1/N_{\theta }\), for \(n = 1, \ldots , N_{\theta }\).
With the reweight method, the incremental weights for DA-SMC\(^2\) are obtained by replacing \(p(\varvec{y}_{1:d}\mid \varvec{\theta }_d)\) with \(\widehat{p_{N_x}}(\varvec{y}_{1:d}\mid \varvec{\theta }_d,\varvec{x}_{1:d}^{1:N_x})\) to approximate the optimal backward kernel, giving
see Sect. 3 for details. For DT-SMC\(^2\), the incremental weights are
The replace method uses a different approximation to the optimal backward kernel. For DA-SMC\(^2\), instead of using \(p(\varvec{y}_{1:d}\mid \varvec{\theta }_d) \approx p_{N_x}(\varvec{y}_{1:d}\mid \varvec{\theta }_d,\varvec{x}_{1:d}^{1:N_x})\), we use \(p(\varvec{y}_{1:d}\mid \varvec{\theta }_d) \approx p_{N_x^*}(\varvec{y}_{1:d}\mid \varvec{\theta }_d,\varvec{x}_{1:d}^{1:N_x^*})\), which gives the backward kernel
Using this backward kernel, the incremental weights are
Similarly, for DT-SMC\(^2\), the approximation \(p(\varvec{y}_{1:T}\mid \varvec{\theta }_d)^{g_d} \approx \widehat{p_{N_x^*}}(\varvec{y}_{1:T}\mid \varvec{\theta }_d,\varvec{x}_{1:T}^{1:N_x^*})^{g_d}\) gives the backward kernel
leading to incremental weights
Since the incremental weights reduce to 1, the replace approach introduces no extra variability in the parameter particle weights. Hence, replace leads to less variability in the mutation step compared to the reweight method of Chopin et al. (2012), i.e. the parameter particles remain evenly weighted throughout the mutation step. We also find that it is generally faster than the reinit method of Duan and Fulop (2014).
4.4 Practical considerations
The framework introduced in this section has a number of advantages over the existing methods. Most notably, the adaptation of R is automated, the stage 2 options (rescale-std, novel-var and rescale-esjd) are less sensitive to variability in the estimated variance of the log-likelihood estimator, and the parameter particle weights are unchanged by adapting \(N_x\).
Two tuning parameters remain to be specified for this method: the target ESJD (\(\text {ESJD}_{\text {target}}\)) and the number of samples to use when estimating the variance of the log-likelihood estimator (k). Our numerical experiments in Sect. 5 use \(\text {ESJD}_{\text {target}} = 6\) and \(k=100\), which both give reasonable empirical results. The target ESJD has little effect on the value of \(N_x\), due to the structure of the updates described in Sect. 4.2, but it directly controls R. Likewise, k controls the variability of \(\widehat{\sigma _{N_x}}^2\). Recall that \(\widehat{\sigma _{N_x}}^2\) is the estimated variance of the log-likelihood estimator with \(N_x\) state particles evaluated at the mean of the current set of parameter particles (\(\bar{\varvec{\theta }}_d\)). Ideally, the value of k should change with \(N_x\) and \(\bar{\varvec{\theta }}_d\); however, it is not obvious how to do this. In general, we find that if \(\sigma _{N_x}^2\approx \widehat{\sigma _{N_x}}^2\) is high, then the variance of \(\widehat{\sigma _{N_x}}^2\) also tends to be high.
Determining optimal values of \(\text {ESJD}_{\text {target}}\) and k is beyond the scope of this paper, but a general recommendation is to follow Salomone et al. (2018) and set \(\text {ESJD}_{\text {target}}\) to the weighted average of the Mahalanobis distance between the parameter particles immediately before the resampling step. We also recommend choosing k such that the variance of \(\widehat{\sigma _{N_x}}^2\) is low (\(<0.1\)) when \(\widehat{\sigma _{N_x}}^2 \approx 1\), i.e. the estimate of \(\widehat{\sigma _{N_x}}^2\) should have low variance when it is around the target value. This value of k may be difficult to obtain, but again, we find that \(k = 100\) gives reasonable performance across all the examples in Sect. 5. To mitigate the effect of a highly variable \(\widehat{\sigma _{N_x}}^2\), it is also helpful to set a lower bound on the value of \(N_x\), as well as an upper bound if a sensible one is known. An upper bound is also useful to restrict the amount of computational resources that is used by the algorithm.
Another advantage of our approach is that \(N_x\) can also be reduced. In general, we would expect \(N_x\) to increase at each iteration, based on the results \(N_x = \mathcal {O}(t)\) (Andrieu et al. 2010) and \(\text {var}(g_d\log {(\widehat{p_{N_x}}(\varvec{y}\mid \varvec{\theta }))})\) \(=\) \(g_d^2\text {var}(\log {(\widehat{p_{N_x}}(\varvec{y}\mid \varvec{\theta }))})\). The former relates to DA-SMC\(^2\) and suggests that \(N_x\) should increase as the length of the time series increases. The second result relates to DT-SMC\(^2\). In this case, to obtain \(g_d^2\text {var}(\log {(\widehat{p_{N_x}}(\varvec{y}\mid \varvec{\theta }))}) = 1\), \(\text {var}(\log {(\widehat{p_{N_x}}(\varvec{y}\mid \varvec{\theta }))})\) must decrease (i.e. \(N_x\) must increase) as \(g_d\) increases. If the value of \(N_x\) is too high however, e.g. due to variability in the adaptation step at a previous iteration or if the initial value is higher than necessary, it is possible for \(N_x\) to decrease in subsequent iterations. Note that it is not feasible to allow \(N_x\) to decrease when using double or reinit.
5 Examples
5.1 Implementation
The methods are evaluated on a simple Brownian motion model, the one-factor stochastic volatility (SV) model in Chopin et al. (2012), and two ecological models: the theta-logistic model (Peters et al. 2010; Drovandi et al. 2022) and the noisy Ricker model (Fasiolo et al. 2016).
The code is implemented in MATLAB and is available at https://github.com/imkebotha/adaptive-exact-approximate-smc. The likelihood estimates are obtained using the bootstrap particle filter (Algorithm 1) with adaptive multinomial resampling, i.e. resampling is done whenever the effective sample size (ESS) drops below \(N_x/2\). The results for all models, except for the Ricker model, are calculated from 50 independent runs, each with \(N_{\theta } = 1000\) parameter samples. Due to time and computational constraints, the Ricker model results are based on 20 independent runs, each with \(N_{\theta } = 400\) parameter samples.
For DT-SMC\(^2\), the temperatures are set adaptively using the bisection method (Jasra et al. 2010) to aim for an ESS of \(0.6\cdot N_{\theta }\). Similarly, the resample-move step is run for DA-SMC\(^2\) if the ESS falls below \(0.6\cdot N_{\theta }\). As discussed in Sect. 4.4, a target ESJD of 6 is used and the sample variance \(\widehat{\sigma _{N_x}}^2\) for rescale-var, rescale-std, novel-var, and novel-esjd is calculated using \(k = 100\) log-likelihood estimates. For all methods except reinit and double, we also trigger the adaptation whenever \(\widehat{\text {ESJD}}_{t-1} > 2\cdot \widehat{\text {ESJD}}_{\text {target}}\)—this allows the algorithm to recover if the values of \(N_x\) and/or R are set too high at any given iteration, which may occur e.g. with DA-SMC\(^2\) if there are outliers in the data. When the reinit method is used, a mixture of three Gaussians is fit to the current sample when reinitialising the algorithm.
The methods are compared based on the mean squared error (MSE) of the posterior mean averaged over the parameters, where the ground truth is taken as the posterior mean from a PMMH chain of length 1 million. As the gold standard (\(\text {GS}\)), DT-SMC\(^2\) and DA-SMC\(^2\) are also run for each model with a fixed number of state particles, while still adapting R. For each of these runs, the number of state particles is tuned such that \(\widehat{\sigma _{N_x}}^2\approx 1\) for the full dataset, and the extra tuning time is not included in the results.
We use the MSE and the total number of log-likelihood evaluations (denoted TLL) of a given method as a measure of its accuracy and computational cost respectively. Note that each time the particle filter is run for a particular parameter particle, TLL is incremented by \(N_x\times t\), where t is the current number of observations. The MSE multiplied by the TLL of a particular method gives its overall efficiency. Scores for the accuracy, computational cost and overall efficiency of a given method relative to the gold standard are calculated as
Higher values are better.
The adaptive mutation step in Algorithm 4 is used for all methods except novel-esjd, which uses the adaptive mutation step in Algorithm 5. The options for stage 2 are double, rescale-var, rescale-std, novel-var and novel-esjd. Likewise, the options for stage 3 are reweight, reinit, and our novel method replace. Since the aim of the novel-var method is to regularly increase the number of state particles throughout the iterations, the combination novel-var with reinit is not tested. Similarly, due to the number of times \(N_x\) is updated when using novel-esjd, only the combination novel-esjd with replace is tested. For all combinations (excluding double and reinit), we allow the number of state particles to decrease. Due to computational constraints, we also cap the number of state particles at 5 times the number of state particles used for the the gold standard method. Note that the double method cannot decrease \(N_x\), and reinit assumes increasing \(N_x\) throughout the iterations as the entire algorithm is reinitialised whenever \(N_x\) is updated.
To compare the different stage 2 methods, we also plot the evolution of \(N_x\) for each example. Recall that \(N_x = \mathcal {O}(t)\) for DA-SMC\(^2\) and \(\text {var}(\log {(\widehat{p_{N_x}}(\varvec{y}\mid \varvec{\theta })^{g_d})}) = g^2 \cdot \text {var}(\log {(\widehat{p_{N_x}}(\varvec{y}\mid \varvec{\theta }))})\) for DT-SMC\(^2\). Based on these two results, a roughly linear increase in \(N_x\) is desired—linear in time for DA-SMC\(^2\) and linear in \(g^2\) for DT-SMC\(^2\). Section A of the Appendix shows marginal posterior density plots. Section B in the Appendix has extra results for the stochastic volatility model with \(N_{\theta } = 100\) and \(N_{\theta } = 500\), to test the methods with fewer parameter particles. We find that the variability of the adaptation of \(N_x\) increases with lower values of \(N_{\theta }\), which affects \(Z_{\text {MSE}}\) in particular. Based on the results in Section B, we recommend setting \(N_{\theta }\) as high as possible subject to the available computational budget. There is also some evidence to suggest that higher values of \(N_x\) in the earlier iterations of DA-SMC\(^2\) may be beneficial.
5.2 Brownian motion model
The first example is a stochastic differential equation with constant drift and diffusion coefficients,
where \(B_t\) is a standard Brownian motion process ( Øksendal 2003, p. 44). The observation and transition densities are
One hundred observations are generated from this model using \(\varvec{\theta }:= (x_0, \beta , \gamma , \sigma ) = (1, 1.2, 1.5, 1)\) and the priors assigned are \(\mathcal {N}(x_0\mid 3, 5^2)\), \(\mathcal {N}(\beta \mid 2, 5^2)\), \({\text {Half-Normal}}(\gamma \mid 2^2)\), and \({\text {Half-Normal}}(\sigma \mid 2^2)\), respectively.
Results for all stage 2 and stage 3 combinations are obtained for initial \(N_x\) values of 10 and 100. The variance of the log-likelihood estimator is around 95 for \(N_x = 10\) and around 2.7 for \(N_x = 100\). The gold standard method is run with 240 state particles.
Table 2 shows the scores averaged over the two initial values of \(N_x\) for the three stage 3 options (reweight, reinit and replace). Note that these scores are relative to reweight instead of the gold standard. Apart from DT-SMC\(^2\) with double—where reinit is faster than replace—replace consistently outperforms reweight and reinit in terms of statistical and computational efficiency. Interestingly, reinit generally outperforms reweight with rescale-std and rescale-var, but not with double. The performance of reinit greatly depends on the number of times the algorithm is reinitialised and the final number of state particles, and this is generally reflected in the computation time.
Tables 3 and 4 show the scores relative to the gold standard for all the replace combinations. novel-esjd has the best overall score followed by novel-var for DT-SMC\(^2\), and rescale-var for DA-SMC\(^2\). double performs well on DT-SMC\(^2\), but poorly on DA-SMC\(^2\)—it has good statistical efficiency, but is much slower than the other methods. Interestingly, the computational efficiency is generally higher for the adaptive methods than for the gold standard, but their accuracy for DA-SMC\(^2\) is generally lower. This may be due to high variability in the variance of the log-likelihood estimator and the mean of the parameter particles during the initial iterations of DA-SMC\(^2\). Since fewer observations are used to estimate the likelihood in these early iterations (\(t < T\)), the mean of the parameter particles can change drastically from one iteration to the next, leading to similarly drastic changes in the sample variance of the log-likelihood estimator.
Figure 1 shows the evolution of \(N_x\) for replace and an initial \(N_x\) of 10. Based on these plots, double, novel-var and novel-esjd have the most efficient adaptation for DT-SMC\(^2\), and novel-esjd has the most efficient adaptation for DA-SMC\(^2\), which corresponds with the results for \(Z_{\text {TLL}}\) and Z in Tables 3 and 4.
5.3 Stochastic volatility model
Our second example is the one-factor stochastic volatility model used in Chopin et al. (2012),
The transition density of this model cannot be evaluated point-wise, but it can be simulated from.
We use a synthetic dataset with 200 observations, which is generated using \(\varvec{\theta }:= (\xi , \omega ^2, \lambda , \beta , \mu )=(4, 4, 0.5, 5, 0)\). The priors are \({\text {Exponential}}(\xi \mid 0.2)\), \({\text {Exponential}}(\omega ^2\mid 0.2)\), \({\text {Exponential}}(\lambda \mid 1)\), \(\mathcal {N}(\beta \mid 0, 2)\) and \(\mathcal {N}(\mu \mid 0, 2)\).
Results for all stage 2 and stage 3 combinations are obtained for initial \(N_x\) values of 300 and 600. The variance of the log-likelihood estimator is around 7 for 300 state particles and around 3 for 600 state particles. The gold standard method is run with 1650 state particles.

Evolution of \(N_x\) for replace and a low initial \(N_x\) for the Brownian motion model. Each coloured line represents an independent run of the given method. The maximum \(N_x\) is 1200
Table 5 shows the scores for the three stage 3 options, relative to reweight and averaged over the two initial \(N_x\) values. replace consistently outperforms reweight and reinit in terms of overall efficiency.
Tables 6 and 7 show the scores for all the replace combinations. All methods perform similarly for this model. In terms of accuracy (measured by the MSE), the optimal variance of the log-likelihood estimator seems to be smaller for this model than for the others. However, the efficiency of a smaller variance coupled with the increased computation time is fairly similar to the efficiency of a larger variance with cheaper computation. In this example, novel-esjd has the highest MSE, but the lowest computation time.
Figure 2 shows the evolution of \(N_x\) for replace and an initial \(N_x\) of 300. Based on these plots, double and novel-esjd have the most efficient adaptation for DT-SMC\(^2\), and all methods except double have good results for DA-SMC\(^2\). These methods correspond to those with the quickest run time (lowest TLL), but not to the ones with the best overall efficiency.
5.4 Theta-logistic model
The theta-logistic ecological model (Peters et al. 2010) is
We fit the model to the first 100 observations of female nutria populations measured at monthly intervals (Peters et al. 2010; Drovandi et al. 2022), using the priors \(\mathcal {N}(\beta _0\mid 0, 1)\), \(\mathcal {N}(\beta _1\mid 0, 1)\), \(\mathcal {N}(\beta _2\mid 0, 1)\), \({\text {Half-Normal}}(\exp {(x_{0})}\mid 1000^2)\), \({\text {Exponential}}(\gamma \mid 1)\), \({\text {Exponential}}(\sigma \mid 1)\) and \(\mathcal {N}(a\mid 1, 0.5^2)\).

Evolution of \(N_x\) for replace and a low initial \(N_x\) for the stochastic volatility model. Each coloured line represents an independent run. The maximum \(N_x\) is 8250

Evolution of \(N_x\) for replace and a low initial \(N_x\) for the theta-logistic model. Each coloured line represents an independent run. The maximum \(N_x\) is 23000
Scores for the accuracy, computational cost and overall efficiency are obtained for initial \(N_x\) values of 700 and 2400. The variance of the log-likelihood estimator is around 40 for 700 state particles and around 3 for 2400 state particles. The gold standard method is run with 4600 state particles. Due to time constraints, results for the double method with reweight and initial \(N_x = 700\) are not available for DA-SMC\(^2\).
Table 8 shows the scores for the three stage 3 options, averaged over the initial \(N_x\) values and relative to reweight. Except for double with DA-SMC\(^2\), both reinit and replace outperform reweight, but the results for reinit and replace are mixed. The performance of reinit greatly depends on the number of times the adaptation is triggered. On average, the algorithm is reinitialised fewer times for rescale-std for this example than for the others.
Tables 9 and 10 show the scores for all the replace combinations relative to the gold standard. In this example, novel-esjd outperforms all other methods, followed by novel-var and rescale-var. Unlike the previous examples, double and rescale-std perform poorly here. The gold standard and double have the best MSE for this example, but the worst computation time. The remaining methods have a poor MSE, which is mostly due to the parameter \(\sigma \) as Fig. 7 in Section A of the Appendix shows. The gold standard is the only method that achieves a good result for \(\sigma \).
Figure 3 shows the evolution of \(N_x\) for replace and an initial \(N_x\) of 700. novel-esjd seem to have the least variable evolution for both DT-SMC\(^2\) and DA-SMC\(^2\) compared to the other methods. Again, this is reflected in the values of \(Z_{\text {TLL}}\), particularly in Tables 9 and 10.
5.5 Noisy Ricker model
Our final example is the noisy Ricker population model (Fasiolo et al. 2016),
The Ricker model, and its variants, is typically used to represent highly non-linear or near-chaotic ecological systems, e.g. the population dynamics of sheep blowflies (Fasiolo et al. 2016). Fasiolo et al. (2016) show that the likelihood function of the noisy Ricker model exhibits extreme multimodality when the process noise is low, making it difficult to estimate the model.

Evolution of \(N_x\) for replace and a low initial \(N_x\) for the Ricker model. Each coloured line represents an independent run. The maximum \(N_x\) is 450000
We draw 700 observations using \(\varvec{\theta }:= ( \log {(\phi )}, \log {(r)}, \log {(\sigma )}) = (\log {(10)}, \log {(44.7)}, \log {(0.6)})\). Following Fasiolo et al. (2016), we assign uniform priors to the log-parameters, \(\mathcal {U}(\log {(\phi )}\mid 1.61, 3)\), \(\mathcal {U}(\log {(r)} \mid 2, 5)\) and \(\mathcal {U}(\log {(\sigma )}\mid -1.8, 1)\), respectively.
Scores for the accuracy, computational cost and overall efficiency are obtained for initial \(N_x\) values of 1000 and 20000. The variance of the log-likelihood estimator is around 13 for 1000 state particles and around 2.3 for 20000 state particles. The gold standard method is run with 90000 state particles. Due to time constraints, the ground truth for the posterior mean is based on a PMMH chain of length 200000.
An experiment was stopped if its run time exceeded 9 days. Hence, a full comparison of the stage 3 options cannot be made. Of the experiments that finished, replace had the best results in terms of overall efficiency. On average, replace outperformed reinit and reweight by at least a factor of 2. In a number of cases, the gold standard and replace were the only methods to finish within the time frame. Tables 11 and 12 show the scores for the replace combinations. novel-var and novel-esjd have the best overall results across both DT-SMC\(^2\) and DA-SMC\(^2\) for this example, while rescale-std and rescale-var perform similarly.
Figure 4 shows the evolution of \(N_x\) for replace and an initial \(N_x\) of 1000. All methods show a fairly smooth increase in \(N_x\) over the iterations.

Marginal posterior density plots for the Brownian motion model. Dashed lines are the DA-SMC\(^2\) results and dotted lines of the same colour are the corresponding DT-SMC\(^2\) results

Marginal posterior density plots for the stochastic volatility model. Dashed lines are DA-SMC\(^2\) results and dotted lines of the same colour are the corresponding DT-SMC\(^2\) results

Marginal posterior density plots for the theta-logistic model. Dashed lines are the DA-SMC\(^2\) results and dotted lines of the same colour are the corresponding DT-SMC\(^2\) results

Marginal posterior density plots for the Ricker model. Dashed lines are the DA-SMC\(^2\) results and dotted lines of the same colour are the corresponding DT-SMC\(^2\) results
6 Discussion
We introduce an efficient SMC\(^2\) algorithm which automatically updates the number of state particles throughout the algorithm. Of the methods used to select the new number of state particles, novel-esjd gives the most consistent results across all models, choice of initial \(N_x\) and between DT-SMC\(^2\) and DA-SMC\(^2\). This method uses the ESJD to determine which \(N_x\) from a set of candidate values will give the cheapest mutation—this value is selected as the new number of state particles. novel-esjd generally outperforms the other methods in terms of the computational and overall efficiency. A significant advantage of novel-esjd is that the adaptation of \(N_x\) is consistent across independent runs of the algorithm (i.e. when starting at different random seeds), substantially more so than the other methods.
Similarly, the replace method typically shows great improvement over reweight and reinit. replace modifies the approximation to the optimal backward kernel used by reweight. This modification means that, unlike reweight, replace leaves the parameter particle weights unchanged. We also find that replace is generally more reliable than reinit.
Our novel SMC\(^2\) algorithm has three tuning parameters that must be set: the target ESJD for the mutation step, the number of log-likelihood evaluations for the variance estimation (k) and the initial number of state particles. Determining optimal values of the target ESJD and k is beyond the scope of this paper, but tuning strategies are discussed in Sect. 4.4. While any initial number of state particles can be used, a small value yields the most efficient results. Compared to the currently available methods, the new approach requires minimal tuning, gives consistent results and is straightforward to use with both data annealing and density tempering SMC\(^2\). We also find that the adaptive methods generally outperform the gold standard, despite the latter being pre-tuned.
An interesting extension to the current work would be to assess the effect of the target ESJD, the target ESS and the target variance of the log-likelihood estimator when SMC\(^2\) is used for model selection. Another area of future work is extending the method for application to mixed effects models (Botha et al. 2021); for these models, it may be possible to obtain significant gains in efficiency by allowing the number of state particles to (adaptively) vary between subjects. The new method can also be used as the proposal function within importance sampling squared (Tran et al. 2020).

Scores for the overall efficiency (Z), accuracy (\(Z_{\text {MSE}}\)) and computational cost (\(Z_{\text {TLL}}\)) for \(N_{\theta } = 100, 500, 1000\) (left to right). The solid and dashed lines correspond to \(N_x = 300\) and \(N_x = 600\) respectively. The first row of plots gives the results for density tempering SMC\(^2\), and the bottom row of plots gives the results for data annealing SMC\(^2\). These results are relative to the gold standard (solid blue at \(y = 1\)), meaning that higher values are preferred

Values for the error (MSE) and computation cost (TLL) for \(N_{\theta } = 100, 500, 1000\). The solid and dashed lines correspond to \(N_x = 300\) and \(N_x = 600\) respectively. The first row of plots gives the results for density tempering SMC\(^2\), and the bottom row of plots gives the results for data annealing SMC\(^2\). The solid blue line represents the gold standard. Lower values are preferred
One area of future work is to adapt the number of parameter particles, e.g. using the adaptive particle filters of Bhadra and Ionides (2016) and Elvira et al. (2017). Another area of future work is to adapt the number of parameter particles (\(N_{\theta }\)) for a specific purpose, e.g. estimation of a particular parameter or subset of parameters. This may reduce the computational resources needed, and applies to SMC methods in general.
References
Andrieu, C., Doucet, A., Holenstein, R.: Particle Markov chain Monte Carlo methods. J. R. Stat. Soc.: Ser. B (Stat. Methodol.) 72(3), 269–342 (2010)
Andrieu, C., Roberts, G.O.: The pseudo-marginal approach for efficient Monte Carlo computations. Ann. Stat. 37(2), 697–725 (2009)
Bhadra, A., Ionides, E.L.: Adaptive particle allocation in iterated sequential Monte Carlo via approximating meta-models. Stat. Comput. 26(1–2), 393–407 (2016)
Bon, J.J., Lee, A., Drovandi, C.: Accelerating sequential Monte Carlo with surrogate likelihoods. Stat. Comput. 31(5), 1 (2021)
Botha, I., Kohn, R., Drovandi, C.: Particle methods for stochastic differential equation mixed effects models. Bayesian Anal. 16(2), 1 (2021)
Cappé, O., Moulines, E., Rydén, T.: Inference in Hidden Markov Models. Springer, New York (2005)
Chopin, N.: A sequential particle filter method for static models. Biometrika 89(3), 539–552 (2002)
Chopin, N., Jacob, P.E., Papaspiliopoulos, O.: SMC2: an efficient algorithm for sequential analysis of state space models. J. R. Stat. Soc.: Ser. B (Stat. Method.) 75(3), 397–426 (2012)
Chopin, N., Ridgway, J., Gerber, M., Papaspiliopoulos, O.: Towards automatic calibration of the number of state particles within the SMC\(^2\) algorithm. arXiv preprint arXiv:1506.00570 (2015)
Crisan, D., Míguez, J.: Uniform convergence over time of a nested particle filtering scheme for recursive parameter estimation in state-space Markov models. Adv. Appl. Probab. 49(4), 1170–1200 (2017)
Crisan, D., Míguez, J.: Nested particle filters for online parameter estimation in discrete-time state-space Markov models. Bernoulli 24(4A), 3039–3086 (2018)
Del Moral, P.: Feynman-Kac Formulae. Springer, New York (2004)
Del Moral, P., Doucet, A., Jasra, A.: Sequential Monte Carlo samplers. J. R. Stat. Soc.: Ser. B (Stat. Methodol.) 68(3), 411–436 (2006)
Doucet, A., Pitt, M.K., Deligiannidis, G., Kohn, R.: Efficient implementation of Markov chain Monte Carlo when using an unbiased likelihood estimator. Biometrika 102(2), 295–313 (2015)
Doucet, A., Pitt, M. K., and Kohn, R. (2012). Efficient implementation of Markov chain Monte Carlo when using an unbiased likelihood estimator. arXiv preprint arXiv:1210.1871v2
Drovandi, C., Everitt, R.G., Golightly, A., Prangle, D.: Ensemble MCMC: accelerating pseudo-marginal MCMC for state space models using the ensemble Kalman filter. Bayesian Anal 17(1), 1 (2022)
Duan, J.-C., Fulop, A.: Density-tempered marginalized sequential Monte Carlo samplers. J. Bus. Econ. Stat. 33(2), 192–202 (2014)
Elvira, V., Miguez, J., Djurić, P.M.: On the performance of particle filters with adaptive number of particles. Stat. Comput. 31(6), 1 (2021)
Elvira, V., Miguez, J., Djurie, P.M.: Adapting the number of particles in sequential Monte Carlo methods through an online scheme for convergence assessment. IEEE Trans. Signal Process. 65(7), 1781–1794 (2017)
Fasiolo, M., Pya, N., Wood, S.N.: A comparison of inferential methods for highly nonlinear state space models in ecology and epidemiology. Stat. Sci. 31(1), 96–118 (2016)
Fearnhead, P., Taylor, B.M.: An adaptive sequential Monte Carlo sampler. Bayesian Anal. 8(2), 411–438 (2013)
Fox, D.: Adapting the sample size in particle filters through KLD-sampling. Int. J. Robot. Res. 22(12), 985–1003 (2003)
Gordon, N.J., Salmond, D.J., Smith, A.F.M.: Novel approach to nonlinear/non-Gaussian Bayesian state estimation. IEEE Proc. F Radar Signal Process. 140(2), 107 (1993)
Green, P.J.: Reversible jump Markov chain Monte Carlo computation and Bayesian model determination. Biometrika 82(4), 711–732 (1995)
Gunawan, D., Kohn, R., Tran, M.N.: Robust Particle Density Tempering for State Space Models. arXiv preprint arXiv:1805.00649 (2021)
Jacob, P.E., Murray, L.M., Rubenthaler, S.: Path storage in the particle filter. Stat. Comput. 25(2), 487–496 (2015)
Jasra, A., Stephens, D.A., Doucet, A., Tsagaris, T.: Inference for Lévy–Driven Stochastic Volatility Models via Adaptive Sequential Monte Carlo. Scand. J. Stat. 38(1), 1–22 (2010)
Lee, A., Whiteley, N.: Variance estimation in the particle filter. Biometrika 105(3), 609–625 (2018)
Øksendal, B.: Stochastic differential equations: an introduction with applications. Springer, Berlin (2003)
Pasarica, C., Gelman, A.: Adaptively scaling the metropolis algorithm using expected squared jumped distance. Stat. Sin. 20(1), 343–364 (2010)
Peters, G.W., Hosack, G.R., Hayes, K.R.: Ecological non-linear state space model selection via adaptive particle Markov chain Monte Carlo (AdPMCMC) (2010). arXiv preprints arXiv:1005.2238
Pitt, M.K., dos Santos Silva, R., Giordani, P., Kohn, R.: On some properties of Markov chain Monte Carlo simulation methods based on the particle filter. J. Econom. 171(2), 134–151 (2012)
Salomone, R., South, L.F., Drovandi, C.C., Kroese, D.P.: Unbiased and Consistent Nested Sampling via Sequential Monte Carlo (2018). arxiv preprint arXiv:1805.03924
Sherlock, C., Thiery, A.H., Roberts, G.O., Rosenthal, J.S.: On the efficiency of pseudo-marginal random walk Metropolis algorithms. Ann. Stat. 43(1), 238–275 (2015)
Soto, A.: Self adaptive particle filter. In: IJCAI, pp. 1398–1406 (2005)
Tran, M.-N., Scharth, M., Gunawan, D., Kohn, R., Brown, S.D., Hawkins, G.E.: Robustly estimating the marginal likelihood for cognitive models via importance sampling. Behav. Res. Methods 53(3), 1148–1165 (2020)
Acknowledgements
Imke Botha was supported by an Australian Research Training Program Stipend and a QUT Centre for Data Science Top-Up Scholarship. Christopher Drovandi was supported by an Australian Research Council Discovery Project (DP200102101). We gratefully acknowledge the computational resources provided by QUT’s High Performance Computing and Research Support Group (HPC).
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
A Marginal posterior plots
This section shows the marginal posterior density plots for the examples in Sects. 5.2–5.5. Figures 5, 6, 7 and 8 are the marginal posterior density plots for each example and method. Note that the results shown are for replace using the combined samples from the independent runs, i.e. the marginal posteriors are based on \(50 \times 1000\) samples for the Brownian motion, stochastic volatility and theta-logistic models and \(20 \times 400\) samples for the Ricker model. The results shown are for a low initial \(N_x\). The plots show that the marginal posterior densities are similar between the adaptive methods. The biggest difference in densities is between DT-SMC\(^2\) and DA-SMC\(^2\), not between the adaptive methods. Figures 5, 6 and 8 show marginal posteriors from SMC\(^2\) that are very similar to the marginal posteriors from MCMC. Figure 7 shows similar marginal posteriors for the theta-logistic model from SMC\(^2\) and MCMC for all of the parameters except for \(\log {(\sigma })\). This parameter corresponds to the log of the measurement error in the nutria population data (see Sect. 5.4 of the main paper). Here, the adaptive SMC\(^2\) methods struggle to accurately capture the left tail of \(\log {(\sigma })\). SMC\(^2\) with a higher, fixed number of state particles (the gold standard method) does not have the same issue, suggesting that the number of state particles is perhaps not adapted high enough in any of the methods for this example.
B Extra results for the stochastic volatility model
This section shows extra results for the stochastic volatility model. Figure 9 shows the difference in the scores for the three values of \(N_{\theta }\). Interestingly, \(Z_{\text {TLL}}\) is fairly constant for all methods, but \(Z_{\text {MSE}}\) is variable. The latter is generally at its highest when \(N_{\theta } = 1000\) for DT-SMC\(^2\), and when \(N_{\theta } = 100\) for DA-SMC\(^2\). Recall that \(Z_{\text {MSE}}\) is relative to the gold standard. DA-SMC\(^2\) has the highest \(Z_{\text {MSE}}\) when \(N_{\theta } = 100\), but also the highest \(Z_{\text {TLL}}\). We find, on average, that the value of \(N_x\) is higher in the initial stages of DA-SMC\(^2\) when \(N_{\theta }\) is small compared to when \(N_{\theta }\) is larger. This may be due to extra variability in the adaptation of \(N_x\) resulting from a small \(N_{\theta }\). However, these results indicate that a higher number of state particles may be beneficial for DA-SMC\(^2\) at earlier iterations—something between double and the other methods.
Figure 10 shows the (non-relative) MSE and computation cost (TLL) of the methods. For all methods, including the gold standard, there is a large improvement in the MSE when increasing \(N_{\theta }\) from 100 to 500, but only a slight improvement when \(N_{\theta }\) is increased from 500 to 1000. Based on the results shown in Figs. 9 and 10, we recommend setting \(N_{\theta }\) as high as possible subject to the available computational budget.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Botha, I., Kohn, R., South, L. et al. Automatically adapting the number of state particles in SMC\(^2\). Stat Comput 33, 82 (2023). https://doi.org/10.1007/s11222-023-10250-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11222-023-10250-2