
Abstract
A well known identifiability issue in factor analytic models is the invariance with respect to orthogonal transformations. This problem burdens the inference under a Bayesian setup, where Markov chain Monte Carlo (MCMC) methods are used to generate samples from the posterior distribution. We introduce a post-processing scheme in order to deal with rotation, sign and permutation invariance of the MCMC sample. The exact version of the contributed algorithm requires to solve \(2^q\) assignment problems per (retained) MCMC iteration, where q denotes the number of factors of the fitted model. For large numbers of factors two approximate schemes based on simulated annealing are also discussed. We demonstrate that the proposed method leads to interpretable posterior distributions using synthetic and publicly available data from typical factor analytic models as well as mixtures of factor analyzers. An R package is available online at CRAN web-page.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Factor Analysis (FA) is used to explain relationships among a set of observable responses using latent variables. This is typically achieved by expressing the observed multivariate data as a linear combination of a set of unobserved and uncorrelated variables of considerably lower dimension, which are known as factors. Let \(Y_i = (Y_{i1},\ldots ,Y_{ip})^\top \) denote the i-th observation of a random sample of p dimensional observations with \(Y_i\in \mathbb R^{p}\); \(i= 1,\ldots ,n\). Let \({\mathcal {N}}_p(\mu ,\varvec{\Sigma })\) denote the p-dimensional normal distribution with mean and covariance matrix \(\mu =(\mu _1,\ldots ,\mu _p)\in {\mathbb {R}}^p\) and \(\varvec{\Sigma }\), respectively, and also denote by \({\varvec{I}}_p\) the \(p\times p\) identity matrix.
In the typical FA model (see The fundamental factor theorem in Chapter II of Thurstone (1934) or the strict factor structure of Chamberlain and Rothschild (1983)), \(Y_i\) is expressed as a linear combination of a latent vector of factors \(F_i\in \mathbb R^{q}\)
where \(q>0\) denotes the number of factors, which is assumed fixed. The \(p\times q\) dimensional matrix \(\varvec{\Lambda } = (\lambda _{rj})\) contains the factor loadings, while \(\mu = (\mu _1,\ldots ,\mu _p)\) contains the marginal mean of \(Y_i\). The unobserved vector of factors \(F_i=(F_{i1}, \ldots ,F_{iq})^\top \) lies on a lower dimensional space, that is, \(q < p\) and we will consider the special case where it consists of uncorrelated and homoscedastic features
independent for \(i = 1,\ldots ,n\), where \(0_q:=(0,\ldots ,0)^\top \) and \(\varvec{\mathrm {I}}_q\) denotes the \(q\times q\) identity matrix.
The terms \(\varepsilon _i\) (commonly referred to as uniquenesses or idiosyncratic errors) are independent from \(F_i\), that is, \( \mathrm {Cov}(F_{ij},\varepsilon _{ik})=0\), \(\forall j=1,\ldots ,q\); \(k=1,\ldots ,p\) and normally distributed
independent for \(=1,\ldots ,n\). Furthermore, \(\varepsilon _i\) consists of independent random variables \(\varepsilon _{i1},\ldots ,\varepsilon _{ip}\), that is,
The distribution of \(Y_i\) conditional on \(F_i\) is
and corresponding marginal distribution
Without loss of generality we can assume that \(\mu =0_p\), although this is not a necessary assumption. According to Eq. (6), the covariance matrix of the marginal distribution of \(Y_i\) is equal to \(\varvec{\Lambda }\varvec{\Lambda }^\top + \varvec{\Sigma }\). Thus, the latent factors are the only source of correlation among the measurements. This is the crucial characteristic of factor analytic models, where they aim to explain high-dimensional dependencies using a set of lower-dimensional uncorrelated factors (Kim and Mueller 1978; Bartholomew et al. 2011).
There are two sources of identifiability problems regarding the typical FA model in Eqs. (1)–(6). The first one concerns identifiability of \(\varvec{\Sigma }\) and the second one concerns identifiability of \(\varvec{\Lambda }\). Assuming that \(\varvec{\Sigma }\) is identifiable (see Sect. 2), we are concerned with identifiability of \(\varvec{\Lambda }\). It is well known that the factor loadings (\(\varvec{\Lambda }\)) in Eq. (1) are only identifiable up to orthogonal transformations. This identifiability issue is not of great practical importance within a frequentist context: the likelihood equations are satisfied by an infinity of solutions, all equally good from a statistical perspective (Lawley and Maxwell 1962).
On the other hand, under a Bayesian setup it complicates the inference procedure, where MCMC methods are applied to generate samples from the posterior distribution \(f(\varvec{\Lambda },\varvec{\Sigma },\varvec{F}|{\varvec{y}})\). Clearly, the invariance property makes the posterior distribution multimodal. Provided that the MCMC algorithm has converged to the target distribution, the MCMC sample will be consecutively switching among the multiple modes of the posterior surface. Despite the fact that this identifiability problem has no bearings on predictive inference or estimation of the covariance matrix in Eq. (6), factor interpretation remains challenging because both \(\varvec{\Lambda }\) and \(F_i\); \(i = 1, \ldots ,n\) are not marginally identifiable. Therefore, the standard practice of providing posterior summaries via ergodic means, or reporting Bayesian credible intervals for factor loadings becomes meaningless due to rotation invariance of the MCMC sample.
Typical implementations of the Bayesian paradigm in FA models use inverse gamma priors on the error variances and normal or truncated normal priors on the factor loadings (Arminger and Muthén 1998; Song and Lee 2001). In such cases the model is conditionally conjugate and an MCMC sample can be generated by standard Gibbs sampling (Gelfand and Smith 1990). However, the factor loadings are not marginally identifiable if \(\varvec{\Lambda }\) is not constrained. Consequently, when MCMC methods are used for estimation of the FA model, inference is not straightforward. On the other hand, in standard factor models, certain identifiability constraints induce undesirable properties, such as a priori order dependence in the off-diagonal entries of the covariance matrix (Bhattacharya and Dunson 2011). Although tailored methods (briefly reviewed in Sect. 2) for achieving identifiability and for drawing inference on sparse FA models exist (Conti et al. 2014; Mavridis and Ntzoufras 2014; Ročková and George 2016; Kaufmann and Schumacher 2017), they require extra modelling effort.
Aßmann et al. (2016) introduced an alternative approach where the rotation problem is solved ex-post. In this paper, a post-processing approach is also followed. It is demonstrated that the proposed method successfully deals with the non-identifiability of the marginal posterior distribution \(f(\varvec{\Lambda }|{\varvec{y}})\) and leads to interpretable conclusions. The number of factors (q) is considered fixed, nevertheless a by-product of our implementation is that it can help to reveal cases of overfitting, by simply inspecting simultaneous credible regions of factor loadings.
We propose to correct invariance of simulated factor loadings using a two-stage post-processing approach. At first we focus on generic rotation invariance, that is, to achieve a simple structure of factor loadings per MCMC iteration. A factor model with simple structure is one where each measurement is related to at most one latent factor (Thurstone 1934). Varimax rotations (Kaiser 1958) are used for this task. After this step, all measurements load at most on one factor while the rest of the loadings are small (close to zero). However, the rotated loadings are still not identifiable across the MCMC trace due to sign and permutation invariance. Sign switching stems from the fact that we can simultaneously switch the signs of \(F_i\) and \(\varvec{\Lambda }\) without altering \(\varvec{\Lambda } F_i\). Permutation invariance (or column switching, according to Conti et al. (2014)) is due to the fact that there is no natural ordering of the columns of the factor loading matrix. Thus, factor labels can change as the MCMC sampler progresses. That being said, the second step is to correct invariance due to specific orthogonal transformations which correspond to signed permutations across the MCMC trace.
The rest of the paper is organized as follows. Section 2 presents the identifiability issues of the FA model and briefly discusses related work. Section 3.1 gives some background on rotations and signed permutations. The contributed method is introduced in Sect. 3.2. Three approaches for minimizing the underlying objective function are described in Sect. 3.3. Section 4 applies the proposed method using simulated (Sect. 4.1) and real (Sect. 4.2) data. Finally, an application to a model-based clustering problem is given in Sect. 4.3. An appendix contains geometrical illustrations of the proposed method and additional applications and computational aspects of our method.
2 Identifiability problems and related approaches
At first we review some well known results that ensure identifiability of \(\varvec{\Sigma }\) (the uniqueness problem) and will be explicitly followed in our implementation. Given that there are q factors, the number of free parameters in the covariance matrix \(\varvec{\Lambda }\varvec{\Lambda }^\top + \varvec{\Sigma }\) is equal to \(p + pq - \frac{1}{2}q(q-1)\) [see Section 5 in Lawley and Maxwell (1962)]. The number of free parameters in the unconstrained covariance matrix of \(Y_i\) is equal to \(\frac{1}{2}p(p+1)\). Hence, if a strict factor structure is present in the data, the number of parameters in the covariance matrix is reduced by
The last expression is positive if \(q < \phi (p)\) where \(\phi (p):=\frac{2p + 1 - \sqrt{8p+1}}{2}\), a quantity which is known as the Ledermann bound (Ledermann 1937). When \(q < \phi (p)\) it can be shown that \(\varvec{\Sigma }\) is almost surely unique (Bekker and ten Berge 1997). We assume that the number of latent factors does not exceed \(\phi (p)\).
Note however that non-identifiability is not necessarily taking place when \(q>\phi (p)\). A special case of the general FA model is to assume an isotropic error model, that is, \(\varvec{\Sigma }= \sigma ^2\varvec{\mathrm {I}}_p\) in Eq. (4), resulting in the probabilistic principal component analysis framework of Tipping and Bishop (1999). In such a case, the number of factors can be as large as \(p-1\).
Another aspect of the identifiability of \(\varvec{\Sigma }\) are instances of the so-called “Heywood cases” (Heywood 1931) phenomenon. Under maximum likelihood strategies, it frequently happens that the optimal solution lies outside the parameter space, that is, \(\sigma ^2_r<0\) for one or more \(r=1,\ldots ,p\). This problem is explicitly avoided under a Bayesian setup, where the prior distribution of each idiosyncratic variance (typically a member of the inverse Gamma family of distributions) yields a posterior distribution with support on \((0,\infty )\). However, it may be frequently the case that the posterior distributions of idiosyncratic variances are multimodal, with one mode lying in areas close to zero. According to Bartholomew et al. (2011) (Sect. 3.12.3):
There is no inconsistency of a zero residual variance, it would simply mean that the variation of the manifest variable in question was wholly explained by the latent variable.
If this is unsatisfactory, then one may bound the posterior distribution of idiosyncratic variances away from zero, using the specification of the prior parameters of Frühwirth-Schnatter and Lopes (2018).
Given identifiability of \(\varvec{\Sigma }\), a second source of identifiability problems is related to orthogonal transformations of the matrix of factor loadings, which is the main focus of this paper. A square matrix \({\varvec{R}}\) is an orthogonal matrix if and only if \({\varvec{R}}^{\top }={\varvec{R}}^{-1}\), that is, its inverse equals its transpose. The determinant of any orthogonal matrix is equal to 1 or \(-1\). Orthogonal matrices represent rotations which may be proper (if the determinant is positive) or improper (otherwise). Consider a \(q\times q\) orthogonal matrix \({\varvec{R}}\) and define \({\widetilde{F}}_i = {\varvec{R}} F_i\). It follows that the representation \(Y_i = \mu +\varvec{\Lambda }{\varvec{R}}^{\top } {\widetilde{F}}_i + \varepsilon _i\) leads to the same marginal distribution of \(Y_i\) as the one in Eq. (6). Since the likelihood is invariant under orthogonal transformations, the posterior distribution will typically exhibit many modes. Essentially, the rotational invariance is a consequence of assumption (2), which ultimately yields a marginal covariance matrix of the form \(\varvec{\Lambda }\varvec{\Lambda }^\top + \varvec{\Sigma }\) in (6). Assuming heteroscedastic latent factors of the form \(F_i\sim \mathcal N_q(0_q, \varvec{\varPsi })\) instead, where \(\varvec{\varPsi }\) is a \(q\times q\) diagonal matrix with non-identical entries, the marginal covariance matrix is \(\varvec{\Lambda }\varvec{\varPsi }\varvec{\Lambda }^\top + \varvec{\Sigma }\). In such a case, the posterior distribution of factor loadings is free of rotational ambiguities but not permutations.
A popular technique (Geweke and Zhou 1996; Fokoué and Titterington 2003; West 2003; Lopes and West 2004; Lucas et al. 2006; Carvalho et al. 2008; Mavridis and Ntzoufras 2014; Papastamoulis 2018, 2020) in order to deal with rotational invariance in Bayesian FA models relies on a lower-triangular expansion of \(\varvec{\Lambda }\), first suggested by Anderson and Rubin (1956), that is:
However this approach still fails to correct the invariance due to sign-switching across the MCMC trace; see, for example, Fig. 2b in Papastamoulis (2018). Additional constraints are introduced for addressing this issue, e.g. by assuming that the diagonal elements are strictly positive (Geweke and Zhou 1996) or even fixing all diagonal elements to 1 (Aguilar and West 2000). Besides the upper triangle of the loading matrix that is fixed to zero a-priori, the remaining elements in the lower part of the matrix are also allowed to take values in areas close to zero (e.g. this is the case when the first variable does not load on any factor). In such a case, identifiability of \(\varvec{\Lambda }\) is lost; see Theorem 5.4 in Anderson and Rubin (1956). Of course this problem can be alleviated by suitably reordering the variables, however the choice of the first q response variables is crucial (Carvalho et al. 2008). In our approach we will not consider any constraint in the elements of the factor loadings matrix.
Conti et al. (2014) augment the FA model with a binary matrix, indicating the latent factor on which each variable loads. They also consider an extension of the model by allowing correlation among factors. Under suitable identification criteria, a prior distribution restricts the MCMC sampler to explore regions of the parameter space corresponding to models which are identified up to column and sign switching. Then, they deal with sign and column switching by using simple reordering heuristics which are driven by the existence of zeros in the resulting loading matrices. At each MCMC iteration, the non-zero columns are reordered such that the top elements appear in increasing order. Next, sign-switching is treated by using a benchmark factor loading (e.g., the factor loading with the highest posterior probability of being different from zero in each column) and then switching the signs at each MCMC iterations in order to agree with the benchmark.
Mavridis and Ntzoufras (2014) place a normal mixture prior on each element of \(\varvec{\Lambda }\) and introduce an additional set of latent binary indicators which is used to identify whether an item is associated with the corresponding factor. They also reorder the items such that important non-zero loadings are placed in the diagonal of \(\varvec{\Lambda }\) in Eq. (7). Ročková and George (2016) identify the FA model by expanding the parameter space using an auxiliary parameter matrix which drives the implied rotation. The whole procedure is fully model driven and it is implemented through an Expectation-Maximization type algorithm. Additionally, the varimax rotation is suggested every few iterations of the algorithm to stabilize and speed up the convergence of the algorithm.
Kaufmann and Schumacher (2017) proposed a k-medoids clustering (Kaufman and Rousseeuw 1987) approach in order to deal with the rotation problem in sparse Bayesian factor analytic models, considering a point mass normal mixture prior distribution of the loading matrix (see also Frühwirth-Schnatter (2011)). A k-medoids clustering to simultaneously estimate the factor-cluster representatives and allocate each draw uniquely to the estimated clusters is then applied, using the absolute correlation distance, which accounts for factors that are subject to sign-switching. In a final step, sign identification is achieved by switching the sign of each factor and its corresponding loadings to obtain a majority of nonzero positive factor loadings.
Aßmann et al. (2016) fix the rotation problem ex-post for static and dynamic factor models without placing any constraint on the parameter space. This is achieved by transforming the MCMC output using a sequence of orthogonal matrices, that is, Orthogonal Procrustes rotations which minimize the posterior expected loss. More details for this method are given in Sect. 3.2, where we discuss the similarities and differences with respect to the proposed approach.
3 Method
3.1 Notation and definitions
Let \({\mathcal {T}}_q\) denote the set of all q! permutations of \(\{1,\ldots ,q\}\). For a given \(\nu = (\nu _1,\ldots ,\nu _q)\in \mathcal T_q\) consider the matrix \(\varvec{{\dot{\Lambda }}}\) where the j-th column of \(\varvec{\Lambda }\) is mapped to the \(\nu _j\)-th column of \(\varvec{{\dot{\Lambda }}}\), for \(j=1,\ldots ,q\). This transformation can be expressed using a \(q\times q\) permutation matrix \({\varvec{P}}\) whose i, j element is equal to
The transformed matrix is simply written as \(\varvec{{\dot{\Lambda }}} = \varvec{\Lambda } {\varvec{P}}\). A permutation matrix is a special case of a rotation matrix.
For example, assume that \(\varvec{\Lambda }\) has three columns and that \(\nu =(3,1,2)\in {\mathcal {T}}_3\). This means that columns 1, 2, 3 becomes column 3, 1, 2, respectively. This transformation corresponds to the \(3\times 3\) permutation matrix
Obviously, \(\varvec{\Lambda } {\varvec{P}}\) results to the desired reordering of columns:
A signed permutation matrix is a square matrix which has precisely one nonzero entry in every row and column and whose only nonzero entries are 1 and/or \(-1\) [see e.g. Snapper (1979)]. A \(q\times q\) signed permutation matrix \({\varvec{Q}}\) can be expressed as
where \({\varvec{S}} = \mathrm {diag}(s_1,\ldots ,s_q)\) is a \(q\times q\) diagonal matrix with diagonal entries equal to \(s_j\in \{-1,1\}\), \(j=1,\ldots ,q\) and \({\varvec{P}}\) is a \(q\times q\) permutation matrix. For example, consider that
It is evident that applying a signed permutation \({\varvec{Q}}\) to a \(p\times q\) matrix \(\varvec{\Lambda }\) results to a transformed matrix \(\mathring{\varvec{\Lambda }}\) arising from the corresponding signed permutation of its columns. For example
is generated by first switching the signs of the first two columns and then reordering the columns according to \(\nu =(3,1,2)\).
Operations and/or special matrices of factor loadings will be denoted as follows:
- \(\varvec{{\widetilde{\Lambda }}}\):
-
Varimax rotated
- \(\varvec{{\dot{\Lambda }}}\):
-
Column-permuted
- \(\mathring{\varvec{\Lambda }}\):
-
Sign-permuted
- \(\varvec{\Lambda }^\star \):
-
Reference matrix of factor loadings
3.2 Rotation-sign-permutation post-processing algorithm
Given a \(p \times q\) matrix \(\varvec{\Lambda }\) of factor loadings, the varimax problem (Kaiser 1958) is to find a \(q \times q\) rotation matrix \(\varvec{\varPhi }\) such that the sum of the within-factor variances of squared factor loadings of the rotated matrix of loadings \(\varvec{{\widetilde{\Lambda }}} = \varvec{\Lambda } \varvec{\varPhi }\) is maximized. That is, the optimization problem is now summarized by
where \({\widetilde{\lambda }}_{rj}=\sum _{k=1}^{q}\lambda _{rk}\phi _{kj},\, r=1,\ldots ,p;\ j=1,\ldots ,q.\)
The original approach for solving the varimax problem was to increase the objective function by successively rotating pairs of factors (Kaiser 1958). Subsequent developments based on matrix formulations of the varimax problem involved the simultaneous rotation of all factors to improve the objective function (Sherin 1966; Neudecker 1981; ten Berge 1984). More recently, it has been argued (Rohe and Zeng 2020) that varimax rotation provides a unified spectral estimation strategy for a broad class of modern factor models.
We used the varimax() base function in R to solve the varimax problem. The optional arguments normalize = FALSE and eps = 1e-5 (default) were used. We note that setting normalize = TRUE has no obvious impact in our results. Assuming that we have at hand a simulated output of factor loadings \(\varvec{\Lambda }^{(t)}\), \(\varvec{\Lambda }^{(t)}=\big (\lambda _{rj}^{(t)}\big )\), \(t=1,\ldots ,T\), we denote as \(\varvec{{\widetilde{\Lambda }}}^{(t)}=\big ({\widetilde{\lambda }}_{rj}^{(t)}\big )\), \(t=1,\ldots ,T\) the rotated MCMC output, after solving the varimax problem per MCMC iteration, where T is the size of MCMC iterations.
After solving the varimax problem for each MCMC iteration, the second stage of our solution is to apply signed permutations to the MCMC output until the transformed loadings are sufficiently close to a reference value denoted as \(\varvec{\Lambda }^\star \). For instance we will assume that \(\varvec{\Lambda }^\star \) corresponds to a fixed matrix, however we will relax this assumption later. Let \({\mathcal {Q}}_q\) denote the set of \(q\times q\) signed permutation matrices. The optimization problem is stated as
where \(||{\varvec{A}}|| = \sqrt{\sum _i\sum _j\alpha _{ij}^2}\) denotes the Frobenius norm on the matrix space. Notice that Eq. (10) subject to \({\varvec{Q}}^{\top }\varvec{Q}=\varvec{\mathrm {I}}_q\) is known as the Orthogonal Procrustes problem and an analytical solution (based on the singular value decomposition of \(\varvec{\Lambda }^{\star } \left( \varvec{\Lambda }^{(t)}\right) ^{\top }\)) is available (Schönemann 1966), which is the core in the post-processing approach of Aßmann et al. (2016). Essentially, we are solving the same problem with Aßmann et al. (2016) but using a restricted parameter space, that is, the (discrete) set of \(q\times q\) signed permutation matrices \({\mathcal {Q}}_q\), instead of the set of all orthogonal matrices.
By Eq. (8) it follows that
where \(\nu =(\nu _1,\ldots ,\nu _q)\in {\mathcal {T}}_q\) denotes the permutation vector corresponding to the permutation matrix \({\varvec{P}}\). Thus, (10) can be also written as
where we have also defined

Obviously, \(\varPsi \) in (11) also depends on \(\{\varvec{{\widetilde{\Lambda }}}\}_{t=1}^{T}\) but this is already fixed at this second stage, hence we omit it from the notation on the left hand side of Eq. (11). Clearly, the reference loading matrix \(\varvec{\Lambda }^\star =(\lambda _{rj}^\star )\) is not known, thus it is approximated by a recursive algorithm. This approach is inspired by ideas used for solving identifiability problems in the context of Bayesian analysis of mixture models (Stephens 2000; Papastamoulis and Iliopoulos 2010; Rodriguez and Walker 2014), known as label switching (Papastamoulis 2016, see for a review of these methods).
The proposed Varimax Rotation-Sign-Permutation (RSP) post-processing algorithm aims to select \(\varvec{\Lambda }^\star , s, \nu \) such that we solve the problem (11). The algorithm is composed by two main steps implemented iteratively: the first minimizes \(\varPsi ( \varvec{\Lambda }^\star , s, \nu )\) with respect to \(\varvec{\Lambda }^\star \) for given values of \((s, \nu )\) (Reference-Loading Matrix Estimation, RLME, step), while the second minimizes \(\varPsi ( \varvec{\Lambda }^\star , s, \nu )\) with respect to \((s, \nu )\) given \(\varvec{\Lambda }^\star \) (SP step); see Algorithm 1 for a concise summary. For Step 2.2.1, it is straightforward to show that the minimization of \(\varPsi (\varvec{\Lambda }^\star , s, \nu )\) with respect to \(\varvec{\Lambda }^*\) for given values of \((s, \nu )\) is obtained by
for \(r=1,\ldots ,p\), \(j=1,\ldots ,q\). Step 2.2.2 is composed by the Sign-Permutation (SP) step which minimizes \(\varPsi (\varvec{\Lambda }^\star , s, \nu )\) with respect to \((s, \nu )\) for a given reference loading matrix \(\varvec{\Lambda }^\star \).
Let \({\varvec{R}}^{(t)}\) denote the varimax rotation matrix at Step 1, and \({\varvec{S}}^{(t)}, {\varvec{P}}^{(t)}\) denote the sign and permutation matrices obtained at the last iteration of Step 2.2 of the RSP algorithm, for MCMC draw \(t=1,\ldots ,T\). The overall transformation of the factor loadings \(\varvec{\Lambda }^{(t)}\) and latent factors \(F_i^{(t)}\) is

for MCMC draw \(t=1,\ldots ,T\). Notice that \(\mathring{F}_i^{(t)}\) is obtained immediately, since \({\varvec{R}}^{(t)}\), \({\varvec{S}}^{(t)}\) and \(\varvec{P}^{(t)}\) are already derived only from the loadings.
A geometrical illustration of the proposed method is given in Appendix A, using a toy-example with \(q=2\) factors. Step 2 can also serve as a stand alone algorithm, that is, without the varimax rotation step (an application is given in Appendix C, for the problem of comparing multiple MCMC chains). Alternative strategies for minimizing expression (13), are provided in Sect. 3.3 which follows.
3.3 Computational strategies for the sign-permutation (SP) step
The optimal solution of (13) can be found exactly by solving the assignment problem (Burkard et al. 2009, see) using a full enumeration of the total \(2^q\) combinations \(s^{(t)}\in \{-1,1\}^q\). Although this computational strategy avoids the evaluation of the objective function for all \(2^qq!\) feasible solutions, it still requires to solve \(2^q\) assignment problems. Thus, for models with many factors (say \(q>10\)) we propose an approximate algorithm based on simulated annealing (Kirkpatrick et al. 1983) with two alternative proposal distributions.
For typical cases of factor models (e.g. \(q\leqslant 10\)), the minimization in (13) can be performed exactly within reasonable computing time, by performing the following two-step procedure:
-
compute \(\min _{\nu \in {\mathcal {T}}_q}\left\{ {\mathcal {L}}^{(t)}_{s,\nu }\right\} \), for each of the \(2^q\) possible sign configurations s, and then
-
find the \((s,\nu )\) that correspond to the overall minimum. The first minimization requires to solve a special version of the transportation problem, known as the assignment problem (Burkard et al. 2009, see).
For a given sign matrix \(S=\mathrm {diag}(s_1,\ldots ,s_q)\in {\mathcal {S}}\), the minimization problem is stated as the assignment problem
where the \(q\times q\) cost matrix \(\varvec{C}=(c_{ij})\) of the assignment problem is defined as
and the corresponding binary decision variables \(\delta _{ij}\) are defined as
Two popular methods for solving discrete combinatorial optimization problems is the “Hungarian algorithm” (Kuhn 1955) and the “branch and bound” method (Little et al. 1963). We used the library lpSolve (Berkelaar et al. 2013) in R in order to solve the assignment problem (16), which uses the latter technique. In brief, “branch and bound” first solves the problem without the integer restrictions. In case of non-integer solutions, the model is split in sub-models and iteratively optimized, until an integer solution is found. This solution is then remembered as the best-until-now solution. Finally this procedure is repeated until no better solution can be found.
The exact SP approach is summarized in Algorithm 2 and denoted as Scheme A. This scheme is elaborate and requires the evaluation of the problem over all possible sign combinations. More specifically, it requires to solve \(2^q\) assignment problems in order to find the overall minimum. As we have already mentioned, this approach is more efficient than a brute force algorithm that requires \(2^qq!\) evaluations of the objective function. It can be applied in a reasonable way for models with \(q\le 10\) factors but its implementation becomes forbidden in terms of computational time for models with factors of higher dimension. For this reason, for models with large number of factors, we also propose strategies based on simulated annealing (Kirkpatrick et al. 1983).
Two approximate approaches for identifying the sign permutation are summarized in Algorithm 3 denoted as Scheme B and Scheme C, respectively. Both schemes are based on the Simulated Annealing (SA) framework, where candidate states \((s^\star ,\nu ^\star )\) are proposed. The proposal is either accepted as the next state or rejected and the previous state is repeated. This procedure is repeated B times, by gradually cooling down the temperature \(T_b\) which controls the acceptance probability at iteration \(b=1,\ldots ,B\). These annealing steps are implemented for each MCMC iteration t, within step 2.2.2 of Algorithm 1. In the following, two different versions of the SA approach (Schemes B and C) are introduced and described in detail.

In the first version of the SA scheme (Scheme B: full SA), the pair \((s^\star ,\nu ^\star )\) is generated independently by randomly switching one element of the current sign vector s and permuting two randomly selected indexes in \(\nu \). This scheme is referred to as full simulated annealing. It is the simplest approach that can be used to generate candidate states. For this reason, it is expected to be trapped at inferior solutions in some cases.
The second version of SA (Scheme C: partial SA) attempts to overcome this problem. It is a hybrid between the exact SA approach (Scheme A) and the full SA (Scheme B). Therefore, it is more sophisticated than full SA but computationally more demanding. Firstly, we propose a candidate sign configuration \(s^\star \) using a random perturbation of the current value as in Scheme B. Next, we proceed as in the exact approach (Scheme A), by deterministically identifying the permutation \(\nu ^\star \) which minimizes \(\big \{{\mathcal {L}}_{s^{\star },\nu }^{(t)}:\nu \in {\mathcal {T}}_q\big \}\), given \(s^\star \). We refer to this scheme as partial simulated annealing in order to emphasize that while \(s^\star \) is randomly generated from the current state, \(\nu ^\star \) is deterministically defined given \(s^{\star }\).
The overall procedure for the two simulated annealing schemes is described in Algorithm 3. Clearly, one iteration of the Partial SA scheme is more expensive computationally than one iteration of the Full SA scheme. But since the proposal mechanism in Partial SA minimizes \({\mathcal {L}}(s,\nu )\) given s, it is expected that it will converge faster to the solution compared to Full SA where both parameters are randomly proposed. This is empirically illustrated in Sect. D of the Appendix.
For both SA schemes, the cooling schedule \(\{T_b,b=1,2,\ldots \}\) is such that \(T_b>0\) for all b and \(\lim _{b\rightarrow \infty } T_b=0\). Romeo and Sangiovanni-Vincentelli (1991) showed that a logarithmic cooling schedule of the form \(T_b=\gamma /\log (b+\gamma _0)\), \(b=1,2,\ldots ,\) is a sufficient condition for convergence with probability one to the optimal solution. In our applications, a reasonable trade-off between accuracy and computing time was obtained with \(\gamma =\gamma _0=1\) and a total number of annealing loops \(20\leqslant B\leqslant 2000\).
4 Applications
Section 4.1 presents a simulation study and Sect. 4.2 analyzes a real dataset. Section 4.3 deals with mixtures of factor analyzers, using the fabMix package(Papastamoulis 2019, 2018, 2020). In all cases the input data is standardized so the sample means and variances of each variable are equal to 0 and 1 respectively. We adopt this approach because it is easier to tune the parameters of the prior distributions, however we should note that it is not crucial to the proposed post-processing method. When the difference between two subsequent evaluations of the objective function in Eq. (11) is less than \(10^{-6}Tpq\) the algorithm terminates, with T denoting the size of the retained MCMC sample. The intuition behind this empirical convergence criterion is that the objective function in Eq. (11) is a sum of Tpq terms. Dividing the objective function by Tpq corresponds to an average value across all Tpq terms. The algorithm terminates as soon as the difference of the “average loss” between successive evaluations is smaller than \(10^{-6}\).
In Sects. 4.1 and 4.2, the MCMCpack package (Martin et al. 2011, 2019) in R was used in order to fit Bayesian FA models. We have used the MCMCfactanal() function, which applies standard Gibbs sampling (Gelfand and Smith 1990) in order to generate MCMC samples from the posterior distribution. The default normal priors are placed upon the factor loadings and factor scores while inverse Gamma priors are assumed for the uniquenesses, that is,
mutually independent for \(r=1,\ldots ,p\); \(j=1,\ldots ,q\). Unless otherwise stated, we use the default prior parameters of the package, that is, \(l_0=0\), \(L_0=0\), \(a_0=b_0=0.001\). Note that the specific choices correspond to an improper prior distribution on the factor loadings and a vaguely informative prior distribution on the uniquenesses. The MCMCfactanal() function provides the “lambda.constraints” option, which can be used in order to enable possible simple equality or inequality constraints on the factor loadings, such as the typical constraints in the upper triangle of \(\varvec{\Lambda }\) described in Eq. (7). Note that in our implementation, the “lambda.constraints” option was disabled, that is, all factor loadings are assumed unconstrained.
In all cases, an MCMC sample of two million iterations was simulated, following a burn-in period of 10,000 iterations. Finally, a thinned MCMC sample of 10,000 draws was retained for inference, keeping the simulated values of every 200th MCMC iteration. Highest Posterior Density (HPD) intervals were computed by the HDIinterval package (Meredith and Kruschke 2018). Simultaneous credible regions were computed as described in Besag et al. (1995), using the implementation in the R package bayesSurv (García-Zattera et al. 2016). In Sect. 4.1 we have also used the BayesFM package (Piatek 2019) in order to compare our findings with the ones arising from the method of Conti et al. (2014).
4.1 Simulation study
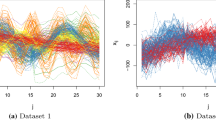
At first we illustrate the proposed approach using two simulated datasets: in dataset 1 there are \(n=100\) observations, \(p=8\) variables and \(q_{\text{ true }}=2\) factors, while in dataset 2 we set \(n=200\), \(p=24\) and \(q_{\text{ true }}=4\). The association patterns between the generated variables and the assumed underlying factors are summarized in Table 1. For more details on the simulation procedure, the reader is referred to Papastamoulis (2018, 2020).

Simulated data 1: \(99\%\) HPD intervals (black) and simultaneous \(99\%\) credible regions (red) of reordered factor loadings, when fitting Bayesian FA models with \(q=2\) (top) and \(q=3\) (bottom) factors (Dataset details: \(p=8\) variables and \(q_{\text{ true }}=2\) factors). (Color figure online)

Simulated data 2: 99% HPD intervals (black) and simultaneous 99% credible regions (red) of reordered factor loadings, when fitting Bayesian FA models with \(q=4\) (top) and \(q=5\) (bottom) factors (Dataset details: \(n=200\), \(p=24\) and \(q_{\text{ true }}=4\))
Figures 1 and 2 display the 99% highest posterior density intervals and a 99% simultaneous credible region of reordered factor loadings, when fitting Bayesian FA models with \(q_{\text{ true }}\leqslant q\leqslant q_{\text{ true }}+1\). In particular, each panel contains the intervals for each column of the \(p\times q\) matrix \(\mathring{\varvec{\Lambda }}\). Observe that for \(q>q_{\text{ true }}\) there are \(q-q_{\text{ true }}\) columns of \(\mathring{\varvec{\Lambda }}\) with all intervals including zero. For dataset 1, a detailed view of the marginal posterior distributions of raw and reordered factor loadings when the number of factors is equal to its true value (\(q=2\)) is shown in Fig. 4. The corresponding (thinned) MCMC trace is shown in Fig. 5. Note the broad range of the posterior distributions of the raw factor loadings (shown in red), which is a consequence of non-identifiability. On the other hand, the bulk of the posterior distributions of the reordered factor loadings is concentrated close to 0 or \(\pm 1\). Figure 3 diplays the true factors \(F_{ij}\), \(j=1,2\) used to generate the data versus the posterior mean estimates from the post-processed sample for simulated data 1. Note that a final signed permutation has also been applied to the estimates in order to maximize their similarity to the ground truth.
The inspection of the simultaneous credible regions reveals possible overfitting of the model being used in each case. This is indeed the case with the 3-factor model at Example 1 and the 5-factor model at Example 2. Clearly, the simultaneous credible regions in Figs. 1 and 2 are able to detect that there is one redundant column in the matrix of factor loadings. Although this is not a proper Bayesian model selection scheme, we observed that this procedure can successfully detect cases of overfitting, provided that the number of factors is indeed larger than the “true” one.

Comparison of true factor scores \(F_{ij}\), \(i=1,\ldots ,n\) and \(j=1,\ldots ,q\), with the posterior mean estimates after post-processing the MCMC sample with the RSP algorithm. The identity line is also displayed. A different symbol and color is used for each factor

Simulated data 1: marginal posterior distribution of raw and reordered factor loadings, conditional on the true number of factors (\(q=q_{\text{ true }}=2\))

Simulated data 1: MCMC trace of raw and reordered factor loadings, conditional on the true number of factors (Thinned sample of 1000 iterations; \(q=q_{\text{ true }}=2\)). (Color figure online)
In order to further assess the ability of this approach in detecting over-fitted factor models, we have simulated synthetic datasets from (1) with \(18\leqslant p\leqslant 24\). The true number of factors was set equal to \(2\leqslant q_{\text{ true }} \leqslant 6\). For each simulated dataset, the sample size (n) is chosen at random from the set \(\{100, 200,300\}\), the idiosyncratic variances are randomly drawn from the set \(\sigma ^2_r = \sigma ^2\), \(r = 1,\ldots ,p\) with \(\sigma ^2\) randomly drawn from the set \(\{400, 800, 1200\}\). We generated 30 synthetic datasets for each value of \(q_{\text{ true }}\), that is, 150 datasets in total.

The y axis corresponds to the mean absolute error for selecting the number of factors in the simulation study of Sect. 4.1. a For RSP (proposed method), OP (orthogonal Procrustes) and WOP (weighted orthogonal Procrustes) \({\hat{q}}\) denotes the “effective” number of columns of \(\mathring{\varvec{\Lambda }}\) when fitting a model with \(q_{max} > q_{\text{ true }}\) factors. BayesFM denotes the selection of the number of factors according to the method of Conti et al. (2014) and BIC denotes the selection of q according to the Bayesian Information Criterion from the raw output of MCMCpack, when considering models with \(q=1,\ldots ,q_{max}\) factors. b Selection of the number of factors resulting from marginal likelihood estimation according to bridge sampling when applied to the raw output of MCMCpack (Raw) and the reordered output of MCMCpack according to RSP, orthogonal Procrustes (OP) and weighted orthogonal Procrustes (WOP)
Let \(q_0\) denote the number of redundant columns of \(\mathring{\varvec{\Lambda }}\) for a FA model with q factors, that is, the number of columns of \(\mathring{\varvec{\Lambda }}\) where at least one interval in the \((p\times q)\)-dimensional \(99\%\) Simultaneous Credible Region (SCR) does not contain 0. Now define the number of “effective” columns of \(\mathring{\varvec{\Lambda }}\) as \({\hat{q}} = q - q_0\). We have also considered the same technique for estimating the number of factors when reordering the MCMCpack output with the Orthogonal Procrustes rotations approach (weighted or not) as described in Aßmann et al. (2016) with the addition of a final varimax rotation to the reordered output, a possibility explicitly suggested at the end of Section 3 of Aßmann et al. (2016). In order to give an empirical comparison of \({\hat{q}}\) with model selection approaches for estimating the number of factors, we compare our findings with the Bayesian Information Criterion using the same output from the MCMCpack package as well as with the stochastic search method of Conti et al. (2014) as implemented in the R package BayesFM (Piatek 2019). We have also considered estimation of the number of factors according to the bridge sampling estimator of the marginal likelihood (Gronau et al. 2020; Man and Culpepper 2020). Note that all methods, excluding BayesFM, are applied to the MCMC output of MCMCpack, considering two setups for the prior variance variance of the factor loadings: \(L_0^{-1}=100\) (this choice corresponds to a vague prior distribution) and \(L_0^{-1} = 1\) (this choice is weakly informative when comparing with the posterior range of factor loadings). The default prior settings were considered into BayesFM.
We generated MCMC samples for FA models with \(1\leqslant q\leqslant q_{max}=8\) factors. Our results are summarized in terms of the Mean Absolute Error \(|{\hat{q}}- q_{\text{ true }}|\) across the 150 simulated datasets in Fig. 6a, b. The results in Fig. 6a are averaged across the two different choices of the prior parameter \(L_0\). We conclude that the number of “effective” columns of \(\mathring{\varvec{\Lambda }}\) arising from the proposed method (RSP) outperforms OP and WOP and that it is fairly consistent with the active (that is, the number of non-zero columns in the matrix of factor loadings) number of factors inferred by BayesFM. BIC tends to underestimate the number of factors resulting in a larger Mean Absolute Error compared to RSP or BayesFM, a behaviour which was observed for the larger values of \(q_{\text{ true }}\).
The selection of the number of factors according to the marginal likelihood estimate as implemented via the bridge sampling method is largely impacted by the prior distribution, as illustrated in Fig. 6b. In the case of the vague prior distribution (\(L_0^{-1}=100\)) it tends to underestimate the number of factors. Improved results are obtained when the prior variance of factor loadings is small (\(L_0^{-1}=1\)). Note also that the marginal likelihood estimator performs better when the raw output is considered. This is expected since the distribution of interest is invariant over orthogonal rotations and the data brings no information about an ordering of the factor loadings. A similar behaviour is also obtained when considering marginal likelihood estimation of finite mixture models (Marin and Robert 2008).
Overall, the proposed method outperforms the method of Aßmann et al. (2016) which is based on (weighted) orthogonal Procrustes rotations. This is particularly the case for the estimates arising from the effective number of columns of the reordered factor loadings corresponding to factor models which overestimate q. The OP/WOP method is highly affected by the number of factors of the overfitted model (here \(q_{max}=8\)). We observed that it tends to overestimate the number of factors when \(q_{max}\) is much larger than \(q_{\text{ true }}\) (a specific example of such a behaviour is presented in Appendix B). Finally, note that the RSP algorithm leads to better estimates than OP/WOP rotations of Aßmann et al. (2016) when using bridge sampling to estimate the marginal likelihood. However, the method of Aßmann et al. (2016) is notably faster (time comparisons are reported in Table 4 of Appendix B).
Further simulation studies are presented in the Appendices. Appendix B presents an example with \(p>n\), Appendix C discusses the issue of comparing multiple chains, Appendix D compares the computational cost of the proposed schemes in high-dimensional cases with up to \(q=50\) factors, while Appendix E applies the post-processing clustering approach of Kaufmann and Schumacher (2017) in one of our simulated datasets.
4.2 The Grant-White school dataset
In this example we use measurements on nine mental ability test scores of seventh and eighth grade children from two different schools (Pasteur and Grant-White) in Chicago. The data were first published in Holzinger and Swineford (1939) and they are publicly available through the lavaan package (Rosseel 2012) in R. This is a well-known dataset used in the LISREL (Joreskog et al. 1999), AMOS (Arbuckle et al. 2010) and Mplus (Muthén and Muthén 2019) tutorials to illustrate a three-factor model for normal data. Variables 1–3 (visual perception, cubes and lozenges) denote “visual perception”, variables 4–6 (paragraph comprehension, sentence completion and word meaning) are related to “verbal ability”, and variables 7–9 (speeded addition, speeded counting of dots, speeded discrimination straight and curved capitals) are connected to “speed”. Following Jöreskog (1969); Mavridis and Ntzoufras (2014), we used the subset of 145 students from the Grant-White school.

Grant-White school dataset: marginal posterior distribution of raw and reordered factor loadings, using a \(q=3\) factor model
We fitted factor models consisting of \(q=3\) and \(q=4\) factors. The corresponding posterior mean estimates of reordered factor loadings are displayed in Table 2. When using a model with \(q=3\) factors we conclude that Factor 1 is mostly associated with variables 4–6, that is, the “verbal ability” group. Factor 2 is associated with variables 7–9, that is, the “speed” group. Factor 3 is mostly associated with variables 1–3, that is, the “visual perception” group. Notice however that variable 9 is also loading on the 3rd factor. These points are coherent with the analysis of Mavridis and Ntzoufras (2014). When using a model with \(q=4\) factors, the simultaneous 99% credible region contains zero for all loadings of the first column of \(\mathring{\varvec{\Lambda }}\), so there is evidence that there is one redundant factor. The raw and reordered outputs for the model with \(q=3\) factors is shown in Fig. 7.

Correlation matrix per cluster for the simulated dataset

Post-processed factor loadings per cluster for the simulated dataset with \(K=2\) clusters, when fitting Bayesian Mixtures of Factor Analyzers with q factors
4.3 Mixtures of factor analyzers
Mixtures of Factor Analyzers (Ghahramani et al. 1996; McLachlan et al. 2003; Fokoué and Titterington 2003; McLachlan et al. 2011; McNicholas and Murphy 2008; McNicholas 2016; Malsiner Walli et al. 2016, 2017; Frühwirth-Schnatter and Malsiner-Walli 2019; Murphy et al. 2020; Papastamoulis 2018, 2020) are generalizations of the typical FA model, by assuming that Eq. (6) becomes
where K denotes the number of mixture components. The vector of mixing proportions \({\varvec{w}} := (w_1,\ldots ,w_K)\) contains the weight of each component, with \(0\leqslant w_k\leqslant 1\); \(k = 1,\ldots ,K\) and \(\sum _{k=1}^{K}w_k = 1\). Note that the mixture components are characterized by different parameters \(\varvec{\mu }_k,\varvec{\Lambda }_k,\varvec{\Sigma }_k\), \(k = 1,\ldots ,K\). Thus, MFAs are particularly useful when the observed data exhibits unusual characteristics such as heterogeneity. We will assume that the number of factors is common across components, although this may not be the case for the true generative model [note that this need not be the case for the fitted model either, see e.g. Murphy et al. (2020)]. The reader is referred to Papastamoulis (2020) for details of the prior distributions. A difference is that now the factor loadings are assumed unconstrained, in contrast to the original modelling approach of Papastamoulis (2020) where the lower triangular expansion in Eq. (7) was enabled.
We considered a simulated dataset of \(n=100\) and \(p=10\)-dimensional observations with \(K=2\) clusters. The real values of factor loadings per cluster are shown in Table 3. The correlation matrix per cluster is shown in Fig. 8. Notice that the 1st cluster consists of 2 factors, while cluster 2 consists of 1 active factor since the second column is redundant. This is a rather challenging scenario because the posterior distribution suffers from many sources of identifiability problems: At first, all component-specific parameters (including the factor loadings per cluster) are not identifiable due to the label switching problem of Bayesian mixture models. Next, the factor loadings within each cluster are not identifiable due to rotation, sign and permutation invariance.
The fabMix package (Papastamoulis 2019, 2018, 2020) was used in order to produce an MCMC sample from the posterior distribution of the MFA model, using a prior parallel tempering scheme with 4 chains and a number of MCMC iterations equal to 1,00,000, following a burn-in period of 10000 iterations. A thinned MCMC sample of 10,000 iterations was retained for inference.
We considered overfitted mixture models with \(K_{\max }=5\) components under all constrained pgmm parameterisations (McNicholas and Murphy 2008) of the marginal covariance in (19). Two different factor levels were fitted, that is, models with \(q= 2\) and \(q=3\) factors. In both cases, the most-probable number of clusters is 2, that is, the true value, and the constraint \(\varvec{\Sigma }_1=\ldots ,\varvec{\Sigma }_K\) (the UCU model in the pgmm nomenclature) is selected according to the Bayesian Information Criterion (Schwarz 1978). Furthermore, the model with \(q=2\) factors is identified as optimal according to the BIC, though we present results for both values of factor levels. The raw output of the MCMC sampler is first post-processed according to the Equivalence Classes Representatives (ECR) algorithm (Papastamoulis and Iliopoulos 2010) in order to deal with the label switching between mixture components. Next, the proposed method was applied within each cluster in order to correct the rotation-sign-permutation invariance of factors. The resulting simultaneous 99% credible region of the reordered output of factor loadings is displayed in Fig. 9.
More specifically, when the number of factors is set equal to 2, there is one cluster (coloured red) where the simultaneous credible region of all loadings of the factor labelled as “factor 1” contains zero, while the loadings of the factor labelled as “factor 2” are different than zero for all variables \(r\geqslant 6\). This is the correct structure of loadings for cluster 2 in Table 3. In addition, there is another cluster (coloured green) where the simultaneous credible region of all loadings of the factor labelled as “factor 1” does not contain zero for all \(r\geqslant 6\), while the loadings of the factor labelled as “factor 2” are different than zero for all variables \(r\leqslant 5\). When the number of factors in the MCMC sampler is set to \(q=3\) (larger than its true value by one), observe that the simultaneous credible region of the factor labelled as “factor 3” in Fig. 9 contains zero. We conclude that, up to a switching of cluster labels and a signed permutation of factors within each cluster, the proposed approach successfully identifies the structure of true factor loadings.
Further analysis based on simulated and publicly available data is presented in the Appendices. Appendix F deals with the case where all clusters share a common idiosyncratic variance and a common matrix of factor loadings, while Appendix G presents results based on the publicly available Wave dataset (Breiman et al. 1984).
5 Discussion
The problem of posterior identification of Bayesian Factor Analytic models has been addressed using a post-processing approach. According to our simulation studies and the implementation to real datasets, the proposed method leads to meaningful posterior summaries. We demonstrated that the reordered MCMC sample can successfully identify over-fitted models, where in such cases the credible region of factor loadings contains zeros for the corresponding redundant columns of \(\varvec{\Lambda }\). Our method is also relevant to the model-based clustering community as shown in the applications on mixtures of factor analyzers (Section 4.3 and Appendix G). Comparison of multiple chains is also possible after coupling the pipeline with one extra reordering step as discussed in Appendix C.
The proposed method first proceeds by applying usual varimax rotations on the generated MCMC sample. We have also used oblique rotations (Hendrickson and White 1964) and we obtained essentially the same answers. Then, we minimize the loss function in Eq. (11), which is carried out in an iterative fashion as shown in Algorithm 1: given the sign (s) and permutation (\(\nu \)) variables, the matrix \(\varvec{\Lambda }^{*}\) is set equal to the mean of the reordered factor loadings. Given \(\varvec{\Lambda }^{*}\), s and \(\nu \) are chosen in order to minimize the expression in Equation (13). In order to minimize (13), we solve one assignment problem [see Eq. (16)] for each value of s (per MCMC iteration), as detailed in Sect. 3.3. This approach works within reasonable computing time for typical values of the number of factors (e.g. \(q\leqslant 10\)).
For larger values of q, we propose two approximate solutions based on simulated annealing. Simulation details concerning the computing time for each proposed scheme for models with different numbers of factors (up to \(q=50\)) are provided in Appendix D . In these cases we have generated MCMC samples using Hamiltonian Monte Carlo techniques implemented in the Stan (Carpenter et al. 2017; Stan Development Team 2019) programming language. According to these empirical findings, the two simulated annealing based algorithms are very effective, rapidly decreasing the objective function within reasonable computing time. Nevertheless, the partial simulated annealing algorithm should be preferred since it reaches solutions close to the true minimum faster than the full annealing scheme. This finding was expected since the proposal mechanism in Partial SA is more elaborate compared to the completely random proposal in Full SA.
As discussed after Equation (10), the proposed method solves a discretized version of the Orthogonal Procrustes problem which is the basis for the OP/WOP method of Aßmann et al. (2016). The refinement of the search space under our method leads to improved results as concluded by our simulation studies, but at the cost of an increased computing time (see Table 4 for an example). The final varimax rotation in the method of Aßmann et al. (2016) is essential when looking at the simultaneous credible intervals of factor loadings in order to obtain columns of \(\varvec{\Lambda }\) that do not include zero. Hence, the results are significantly worse without the varimax rotation step because in such a case, the resulting factors will not in general correspond to a “simple structure”. Regarding the estimation of the number of factors according to marginal likelihood estimation, the results obtained by the OP/WOP method are essentially the same with or without the varimax rotation step (that is, overestimate the number of factors regardless of the inclusion of the additional varimax rotation step).
Finally, the authors are considering the implementation of the proposed approach in combination with Bayesian variable selection methods such as stochastic search variable selection—SSVS (George and McCulloch 1993; Mavridis and Ntzoufras 2014), Gibbs variable selection—GVS (Dellaportas et al. 2002) and/or reversible jump MCMC—RJMCMC (Green 1995). The implementation of the method might solve not only identifiability problems but also provide more robust results for Bayesian variable selection methods where the specification of the prior distribution is crucial due the Lindley–Bartlett paradox. Moreover, in this paper, our proposed method is used as a post-processing tool for the estimation of the posterior distribution of factor loadings within each model. For Bayesian variable selection, the implementation of the Varimax-RSP algorithm within each MCMC might be influential for the selection of items and factor structure. For this reason, a thorough study (theoretical and empirical) and comparison between the post-processing and the within-MCMC implementation of the method is needed.
References
Aguilar, O., West, M.: Bayesian dynamic factor models and portfolio allocation. J. Bus. Econ. Stat. 18(3), 338–357 (2000). http://www.jstor.org/stable/1392266
Anderson, T.W., Rubin, H.: Statistical inference in factor analysis. In: Proceedings of the 3rd Berkeley Symposium on Mathematical Statistics and Probability, vol. 5, pp. 111–150 (1956)
Arbuckle, J.L., et al.: IBM SPSS Amos 19 User’s Guide, vol. 635. Amos Development Corporation, Crawfordville (2010)
Arminger, G., Muthén, B.O.: A Bayesian approach to nonlinear latent variable models using the Gibbs sampler and the Metropolis–Hastings algorithm. Psychometrika 63(3), 271–300 (1998)
Aßmann, C., Boysen-Hogrefe, J., Pape, M.: Bayesian analysis of static and dynamic factor models: An ex-post approach towards the rotation problem. J. Econometr. 192(1), 190–206 (2016). https://doi.org/10.1016/j.jeconom.2015.10.010
Bartholomew, D.J., Knott, M., Moustaki, I.: Latent Variable Models and Factor Analysis: A Unified Approach, vol. 904. Wiley (2011)
Bekker, P.A., ten Berge, J.M.: Generic global indentification in factor analysis. Linear Algebra Appl. 264, 255–263 (1997)
ten Berge, J.M.: A joint treatment of varimax rotation and the problem of diagonalizing symmetric matrices simultaneously in the least-squares sense. Psychometrika 49(3), 347–358 (1984)
Berkelaar, M., et al.: lpSolve: Interface to Lp_solve v. 5.5 to solve linear/integer programs. R Package Version 5.6.13.3 (2013). http://CRAN.R-project.org/package=lpSolve
Besag, J., Green, P., Higdon, D., Mengersen, K., et al.: Bayesian computation and stochastic systems. Stat. Sci. 10(1), 3–41 (1995)
Bhattacharya, A., Dunson, D.B.: Sparse Bayesian infinite factor models. Biometrika 98(2), 291–306 (2011)
Breiman, L., Friedman, J., Olshen, R., Stone, C.: Classification and Regression Trees. Wadsworth International Group, Belmont (1984)
Brooks, S.P., Gelman, A.: General methods for monitoring convergence of iterative simulations. J. Comput. Graph. Stat. 7(4), 434–455 (1998)
Burkard, R., Dell’Amico, M., Martello, S.: Assignment Problems. SIAM e-books, Society for Industrial and Applied Mathematics (SIAM, 3600 Market Street, Floor 6, Philadelphia, PA 19104) (2009). http://books.google.co.uk/books?id=nHIzbApLOr0C
Carpenter, B., Gelman, A., Hoffman, M., Lee, D., Goodrich, B., Betancourt, M., Brubaker, M., Guo, J., Li, P., Riddell, A.: Stan: a probabilistic programming language. J. Stat. Softw. 76(1), 1–32 (2017). https://doi.org/10.18637/jss.v076.i01
Carvalho, C.M., Chang, J., Lucas, J.E., Nevins, J.R., Wang, Q., West, M.: High-dimensional sparse factor modeling: applications in gene expression genomics. J. Am. Stat. Assoc. 103(484), 1438–1456 (2008)
Chamberlain, G., Rothschild, M.: Arbitrage, factor structure, and mean-variance analysis on large asset markets. Econometrica 51(5), 1281–1304 (1983). http://www.jstor.org/stable/1912275
Conti, G., Frühwirth-Schnatter, S., Heckman, J.J., Piatek, R.: Bayesian exploratory factor analysis. J. Econometr. 183(1):31 – 57 (2014). https://doi.org/10.1016/j.jeconom.2014.06.008. Internally Consistent Modeling, Aggregation, Inference and Policy
Dellaportas, P., Forster, J., Ntzoufras, I.: On Bayesian model and variable selection using MCMC. Stat. Comput. 12, 27–36 (2002)
Fokoué, E., Titterington, D.: Mixtures of factor analysers. Bayesian estimation and inference by stochastic simulation. Mach. Learn. 50(1–2), 73–94 (2003)
Frühwirth-Schnatter, S., Lopes, H.F.: Sparse Bayesian factor analysis when the number of factors is unknown. ArXiv preprint arXiv:1804.04231 (2018)
Frühwirth-Schnatter, S., Malsiner-Walli, G.: From here to infinity: Sparse finite versus Dirichlet process mixtures in model-based clustering. Adv. Data Anal. Classif. 13, 33–64 (2019)
Frühwirth-Schnatter, S.: Dealing with Label Switching under Model Uncertainty, vol. 10, pp. 213–239. Wiley (2011). https://doi.org/10.1002/9781119995678.ch10
García-Zattera, M.J., Jara, A., Komárek, A.: A flexible AFT model for misclassified clustered interval-censored data. Biometrics 72(2), 473–483 (2016). https://doi.org/10.1111/biom.12424
Gelfand, A., Smith, A.: Sampling-based approaches to calculating marginal densities. J. Am. Stat. Assoc. 85, 398–409 (1990)
Gelman, A., Rubin, D.B., et al.: Inference from iterative simulation using multiple sequences. Stat. Sci. 7(4), 457–472 (1992)
George, E., McCulloch, R.: Variable selection via Gibbs sampling. J. Am. Stat. Assoc. 88, 881–889 (1993)
Geweke, J., Zhou, G.: Measuring the pricing error of the arbitrage pricing theory. Rev. Financ Stud 9(2), 557–587 (1996)
Ghahramani, Z., Hinton, G.E., et al.: The EM algorithm for mixtures of factor analyzers. Tech. Rep., Technical Report CRG-TR-96-1, University of Toronto (1996)
Green, P.: Reversible jump Markov chain Monte Carlo computation and Bayesian model determination. Biometrika 82, 711–732 (1995)
Gronau, Q.F., Singmann, H., Wagenmakers, E.J.: Bridgesampling: an R package for estimating normalizing constants. J. Stat. Softw. 92(10), 1–29 (2020). https://doi.org/10.18637/jss.v092.i10
Hendrickson, A.E., White, P.O.: Promax: a quick method for rotation to oblique simple structure. Br. J. Stat. Psychol. 17(1), 65–70 (1964)
Heywood, H.: On finite sequences of real numbers. Proc. R. Soc. Lond. Ser. A, Contain. Pap. Math. Phys. Character 134(824), 486–501 (1931)
Holzinger, K.J., Swineford F.: A study in factor analysis: the stability of a bi-factor solution. Suppl. Educ. Monogr. 48 (1939)
Jöreskog, K.G.: A general approach to confirmatory maximum likelihood factor analysis. Psychometrika 34(2), 183–202 (1969)
Joreskog, K.G., Sorbom, D., Du Toit, S., Du Toit, M.: LISREL 8: new statistical features, pp. 6–7. Scientific Software International, Chicago (1999)
Kaiser, H.F.: The varimax criterion for analytic rotation in factor analysis. Psychometrika 23(3), 187–200 (1958)
Kaufman, L., Rousseeuw, P.: Clustering by means of medoids. In: Dodge, Y., (ed.) Statistical Data Analysis Based on the \(L_1\)-Norm and Related Methods, pp. 405–416 (1987)
Kaufmann, S., Schumacher, C.: Identifying relevant and irrelevant variables in sparse factor models. J. Appl. Economet. 32(6), 1123–1144 (2017)
Kim, J.O., Mueller, C.W.: Factor Analysis: Statistical Methods and Practical Issues, vol. 14. Sage (1978)
Kirkpatrick, S., Gelatt, C.D., Vecchi, M.P.: Optimization by simulated annealing. Science 220(4598), 671–680 (1983)
Kuhn, H.W.: The Hungarian method for the assignment problem. Naval Res. Log. Q. 2(1–2), 83–97 (1955)
Lawley, D., Maxwell, A.: Factor analysis as a statistical method. J. R. Stat. Soc. Ser. D (Stat.) 12(3), 209–229 (1962)
Ledermann, W.: On the rank of the reduced correlational matrix in multiple-factor analysis. Psychometrika 2(2), 85–93 (1937)
Little, J.D., Murty, K.G., Sweeney, D.W., Karel, C.: An algorithm for the traveling salesman problem. Oper. Res. 11(6), 972–989 (1963)
Lopes, H.F., West, M.: Bayesian model assessment in factor analysis. Stat. Sin. 14(1), 41–68 (2004)
Lucas, J., Carvalho, C., Wang, Q., Bild, A., Nevins, J.R., West, M.: Sparse statistical modelling in gene expression genomics. Bayesian Inference Gene Exp. Proteom. 1, 1 (2006)
Malsiner Walli, G., Frühwirth-Schnatter, S., Grün, B.: Model-based clustering based on sparse finite Gaussian mixtures. Stat. Comput. 26, 303–324 (2016)
Malsiner Walli, G., Frühwirth-Schnatter, S., Grün, B.: Identifying mixtures of mixtures using Bayesian estimation. J. Comput. Graph. Stat. 26, 285–295 (2017)
Man, A.X., Culpepper, S.A.: A mode-jumping algorithm for Bayesian factor analysis. J. Am. Stat. Assoc. (2020). https://doi.org/10.1080/01621459.2020.1773833
Marin, J.M., Robert, C.: Approximating the marginal likelihood in mixture models. ArXiv preprint arXiv:0804.2414 (2008)
Martin, A.D., Quinn, K.M., Park, J.H.: MCMCpack: Markov chain Monte Carlo in R. J. Stat. Softw. 42(9), 22 (2011). http://www.jstatsoft.org/v42/i09/
Martin, A.D., Quinn, K.M., Park, J.H., Vieilledent, G., Maleck, M., Blackwell, M., Poole, K., Reed, C., Goodrich, B., Ihaka, R.: “The R Development Core Team”, “The R Foundation”. L’Ecuyer P, Matsumoto M, Nishimura T (2019) MCMCpack: Markov Chain Monte Carlo (MCMC) Package, R Package Version 1.4-5. http://CRAN.R-project.org/package=MCMCpack
Mavridis, D., Ntzoufras, I.: Stochastic search item selection for factor analytic models. Br. J. Math. Stat. Psychol. 67(2), 284–303 (2014). https://doi.org/10.1111/bmsp.12019
McLachlan, G.J., Peel, D., Bean, R.: Modelling high-dimensional data by mixtures of factor analyzers. Comput. Stat. Data Anal. 41(3), 379–388 (2003)
McLachlan, G.J., Baek, J., Rathnayake, S.I.: Mixtures of factor analysers for the analysis of high-dimensional data, pp. 189–212. Estimation and Applications, Mixtures (2011)
McNicholas, P.D.: Mixture Model-based Classification. CRC Press (2016)
McNicholas, P.D., Murphy, T.B.: Parsimonious Gaussian mixture models. Stat. Comput. 18(3), 285–296 (2008)
Meredith, M., Kruschke, J.: HDInterval: Highest (Posterior) Density Intervals, R Package Version 0.2.0 (2018). https://CRAN.R-project.org/package=HDInterval
Murphy, K., Viroli, C., Gormley, I.C.: Infinite mixtures of infinite factor analysers. Bayesian Anal. 15(3), 937–963 (2020). https://doi.org/10.1214/19-BA1179
Muthén, L., Muthén, B.: Mplus. The Comprehensive Modelling Program for Applied Researchers: User’s Guide, vol. 5 (2019)
Neudecker, H.: On the matrix formulation of Kaiser’s varimax criterion. Psychometrika 46(3), 343–345 (1981)
Papastamoulis, P.: Label.switching: an R package for dealing with the label switching problem in MCMC outputs. J. Stat. Softw. 69(1), 1–24 (2016)
Papastamoulis, P.: Overfitting Bayesian mixtures of factor analyzers with an unknown number of components. Comput. Stat. Data Anal. 124, 220–234 (2018)
Papastamoulis, P.: fabMix: Overfitting Bayesian Mixtures of Factor Analyzers with Parsimonious Covariance and Unknown Number of Components, R Package Version 5.0 (2019). http://CRAN.R-project.org/package=fabMix
Papastamoulis, P.: Clustering multivariate data using factor analytic Bayesian mixtures with an unknown number of components. Stat. Comput. 30, 485–506 (2020)
Papastamoulis, P.: Post-processing MCMC outputs of Bayesian factor analytic models. R Package Version 1.2 (2021). https://cran.r-project.org/package=factor.switching
Papastamoulis, P., Iliopoulos, G.: An artificial allocations based solution to the label switching problem in Bayesian analysis of mixtures of distributions. J. Comput. Graph. Stat. 19, 313–331 (2010)
Piatek, R.: BayesFM: Bayesian Inference for Factor Modeling, R Package Version 0.1.3 (2019). https://CRAN.R-project.org/package=BayesFM
Ročková, V., George, E.I.: Fast Bayesian factor analysis via automatic rotations to sparsity. J. Am. Stat. Assoc. 111(516), 1608–1622 (2016). https://doi.org/10.1080/01621459.2015.1100620
Rodriguez, C., Walker, S.: Label switching in Bayesian mixture models: deterministic relabelling strategies. J. Comput. Graph. Stat. 23(1), 25–45 (2014)
Rohe, K., Zeng, M.: Vintage factor analysis with varimax performs statistical inference. ArXiv preprint arXiv:2004.05387 (2020)
Romeo, F., Sangiovanni-Vincentelli, A.: A theoretical framework for simulated annealing. Algorithmica 6(1–6), 302 (1991)
Rosseel, Y.: Lavaan: an R package for structural equation modeling. J. Stat. Softw. 48(2), 1–36 (2012). http://www.jstatsoft.org/v48/i02/
Schönemann, P.H.: A generalized solution of the orthogonal Procrustes problem. Psychometrika 31(1), 1–10 (1966)
Schwarz, G.: Estimating the dimension of a model. Ann. Stat. 6(2), 461–464 (1978). https://doi.org/10.1214/aos/1176344136
Sherin, R.J.: A matrix formulation of Kaiser’s varimax criterion. Psychometrika 31(4), 535–538 (1966)
Snapper, E.: Characteristic polynomials of a permutation representation. J. Comb. Theory, Ser. A 26(1), 65–81 (1979)
Song, X.Y., Lee, S.Y.: Bayesian estimation and test for factor analysis model with continuous and polytomous data in several populations. Br. J. Math. Stat. Psychol. 54(2), 237–263 (2001)
Srivastava, S., Engelhardt, B.E., Dunson, D.B.: Expandable factor analysis. Biometrika 104(3), 649–663 (2017). https://doi.org/10.1093/biomet/asx030
Stan Development Team: RStan: The R Interface to Stan, R Package Version 2.19.2 (2019). http://mc-stan.org/
Stephens, M.: Dealing with label switching in mixture models. J. R. Stat. Soc. B 62(4), 795–809 (2000)
Thurstone, L.L.: The vectors of mind. Psychol. Rev. 41(1), 1 (1934)
Tipping, M.E., Bishop, C.M.: Probabilistic principal component analysis. J. R. Stat. Soc.: Ser. B (Stat. Methodol.) 61(3), 611–622 (1999)
Trendafilov, N.T., Unkel, S.: Exploratory factor analysis of data matrices with more variables than observations. J. Comput. Graph. Stat. 20(4), 874–891 (2011). http://www.jstor.org/stable/23248938
West, M.: Bayesian factor regression models in the “large p, small n” paradigm. In: Bayesian Statistics, pp 723–732. Oxford University Press (2003)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This research was funded by the program “DRASI 1/Research project: 11338201”, coordinated by the Research Center of the Athens University of Economics and Business (RC/AUEB). Technical support was provided from the Computational and Bayesian Statistics Lab, Department of Statistics, Athens University of Economics and Business. The comments and suggestions of two anonymous reviewers substantially improved the presentation and findings of the paper.
Appendix
Appendix
-
Appendices: A: Toy example: Geometrical illustration for \(q=2\) factors. B: An example with \(p>n\). C: Comparison of multiple chains. D: Computational benchmark: Performance comparison in high dimensional factor analytic models. E: Comparison with k-medoids reordering. F: Mixtures of factor analyzers: further simulation study. G: Illustration of mixtures of factor analyzers in publicly available data: The Wave dataset. H: Analysis of the exchange rate returns dataset (Aguilar and West 2000). All benchmarks and time comparisons reported in the Appendix were implemented in a Linux workstation with the following specifications: Processor: intel Core i7-8700K CPU @ 3.7GHz \(\times \) 12, Memory: 15.6 Gb, OS: Ubuntu 20.04.2 LTS, 64 bit.
-
Contributed software: R-package factor.switching (Papastamoulis 2021) containing code implementing the methodology described in the article: http://CRAN.R-project.org/package=factor.switching
-
Reproducibility: https://github.com/mqbssppe/factor_switching This repository contains scripts that reproduce the results for both simulated and real data.
1.1 Toy example: geometrical illustration for \(q=2\) factors

Graphical demonstration of the evolution of the RSP algorithm for \(T=10\) MCMC draws. The highlighted symbols in each panel correspond to a particular MCMC draw. The black symbols in c, e denote the average loadings \((\lambda ^\star _{r1},\lambda ^\star _{r2})\) per variable across the 10 MCMC draws
A geometrical illustration of the proposed method is provided in Fig. 10, for the special case of \(q=2\) factors. Figure 10a shows the scatterplot of the ordered pairs \(\big (\lambda _{r1}^{(t)},\lambda _{r2}^{(t)}\big )\) for variable \(r = 1, 2, 3\) (corresponding to distinct symbols), where \(t =1,\ldots ,10\) denotes a given MCMC draw. The large variability of the MCMC draws suggests that the output of factor loadings is not identifiable due to rotation, sign and permutation invariance. For illustration purposes, a particular MCMC draw is emphasized, with values equal to
where each row of the matrix above corresponds to the enlarged symbols in Fig. 10a. Firstly, we apply usual varimax rotations to the whole MCMC output, as shown in Fig. 10b. The rotated values after this step are displayed in Fig. 10c. For example, \(\varvec{\Lambda }\) is transformed to
Note that a simple structure is achieved for each MCMC iteration: each variable loads to at most one factor. However, the factor loadings are still unidentified across the MCMC draws due to sign and permutation invariance.
The final step is to apply Algorithm 1, as shown in Fig. 10d. In the initialization step of Algorithm 1, the reference matrix of factor loadings is equal to
and its rows correspond to the black points shown in Fig. 10c. The objective function at the initialization step is equal to \(\sum _{t=1}^{10}\mathcal L_{s^{(t)},\nu ^{(t)}}^{(t)}\approx 13.76\). After 1 iteration of Steps 1 and 2 of Algorithm 1 the reordered factor loadings correspond to the blue points in Fig. 10d.
In this case, for each MCMC draw, the transformation consists of a permutation of the index set \({\mathcal {T}}_2 = \{1,2\}\) (first segment of the curved arrows) and a sign switching (second segment of the curved arrows). The first transformation means that, for MCMC draw t, \(\left( {\widetilde{\lambda }}_{r1}^{(t)},{\widetilde{\lambda }}_{r2}^{(t)}\right) \) is transformed to
or
for \(r=1,2,3\). The second part of this step is to apply a sign switch, thus \(\left( {\dot{\lambda }}_{r1}^{(t)},{\dot{\lambda }}_{r2}^{(t)}\right) \) may be transformed to
or to
or to
or even retain the same sign, that is,
for \(r=1,2,3\). The processed values after this step are displayed in Fig. 10e which is the final output returned by our method. Note that the processed output is switched to a simple structure which is coherent across all MCMC iterations.
For example, the values of the emphasized MCMC draw are first permuted according according to \(\nu ^{(t)} = (2,1)\) and then switched according to \(\left( s_1^{(t)},s_2^{(t)}\right) = (1,-1)\) which corresponds to a reflection with respect to the x axis. The corresponding permutation and reflection matrices are \({\varvec{P}}= \begin{pmatrix} 0 &{} 1\\ 1 &{} 0 \end{pmatrix}\) and \({\varvec{S}}=\begin{pmatrix} 1 &{} 0\\ 0 &{} -1 \end{pmatrix}\), respectively. Thus, the signed permutation matrix in this case is \({\varvec{Q}}={\varvec{S}}{\varvec{P}}= \begin{pmatrix} 0 &{} 1\\ 1 &{} 0 \end{pmatrix}\begin{pmatrix} 1 &{} 0\\ 0 &{} -1 \end{pmatrix}= \begin{pmatrix} 0 &{} -1\\ 1 &{} 0 \end{pmatrix}\), implying that \(\varvec{{\widetilde{\Lambda }}}\) is finally transformed to
The reference matrix of factor loadings is now equal to
and the objective function is \(\sum _{t=1}^{10}\mathcal L_{s^{(t)},\nu ^{(t)}}^{(t)}\approx 0.55\). Subsequent iterations do not improve further this value and Algorithm 1 terminates.
1.2 An example with \(p>n\)
In this section we consider the estimation of a factor analytic model in the case where the number of observed variables (p) is larger than the sample size (n). Such high-dimensional settings are attracting increasing interest in the literature on factor analytic models of late [see e.g. Trendafilov and Unkel (2011) and Srivastava et al. (2017)].
We generated a synthetic dataset with \(p=200\) variables and the sample size was set to \(n=180\). The “true” number of factors was equal to \(q = 2\). The parameters of the prior distribution of the factor loadings in (18) and (17) were set equal to \(a_0=b_0=0.001\), \(l_0\) and \(L_0 = 1\). Then, we used the MCMCpack in order to generate MCMC samples of \(T=10{,}000\) draws (after thinning) from factor analytic models with \(q=2,3,4,5,6\) factors.

99% credible intervals (red denotes simultaneous credible intervals and blue the individual ones) of reordered values of factor loadings according to the RSP algorithm for a synthetic dataset with \(p=200\) variables and \(n=180\) observations of Sect. B. (Color figure online)
The results are summarized in Table 4. When the number of factors of the fitted model is \(2\leqslant q \leqslant 4\) all methods indicate that the matrix of reordered factor loadings contains 2 “effective” columns, that is, the “true” number. The same continues to hold true for the proposed method (RSP—exact or SA) when in the cases where \(q = 5\) or \(q=6\). On the contrary, the method of Procrustes rotations (OP and WOP) of Aßmann et al. (2016) reveals an extra factor in these overfitting models. The method of Procrustes rotations is notably faster in all cases. Figure 11 illustrates the resulting \(99\%\) credible intervals of the post-processed output of factor loadings according to the RSP algorithm when fitting a factor model with \(q=2\) factors. We conclude that variables 1–100 load at the first factor, while the remaining ones load at the second factor. This configuration agrees with the actual scenario used to generate the synthetic dataset.
1.3 Comparison of multiple chains

Simulated data 1: trace plots of the generated loadings before and after the implementation of RSP algorithm. Gray-coloured points: raw output of factor loadings (8 parallel chains from Stan); Segments (vertical lines): 100 successive MCMC draws. Coloured points: RSP reordered factor loadings. Black trace: sign-permuted reordered traces making all chains comparable. (Color figure online)
Running parallel chains is a standard practice in MCMC applications [see e.g. Carpenter et al. (2017)] in order to assess convergence. Applying our method to each chain separately will make the factor loadings identifiable within each chain. However, the post-processed outputs will not be directly comparable between chains. Clearly, one run may be a signed permutation of another, provided that the chains have converged to their stationary distribution. Thus, it makes sense to post-process the chains in order to switch all of them in a common region.
This reduces to find a single sign-permutation per chain that will reorder all values of the given chain. Let \(\varvec{\Lambda }^{\star }_{c}\) denote the \(\varvec{\Lambda }^{\star }\) matrix (that is, the matrix which contains the estimates of posterior mean of factor loadings) for chain \(c=1,\ldots ,C\), where C denotes the total number of parallel chains. In order to find the final sign-permutations per chain we only have to apply Step 2 of Algorithm 1 on \(\varvec{\Lambda }^{\star }_{c}\), \(c=1,\ldots ,C\) (that is, without the varimax rotations step). Let now \(\mathring{\varvec{\Lambda }}^{(t,c)}\) denote the (reordered) matrix of factor loadings for chain c on iteration t and \({\varvec{Q}}^{(c)}\) the resulting sign-permutation for chain c. Then, the final step is to transform \(\mathring{\varvec{\Lambda }}^{(t,c)}\) to \(\mathring{\varvec{\Lambda }}^{(t,c)}{\varvec{Q}}^{(c)}\), for all \(t=1,\ldots ,T\), \(c=1,\ldots ,C\).
We illustrate this procedure on the simulated dataset 1 (used in Sect. 4.1). We used Stan (Carpenter et al. 2017) in order to generate 8 chains of 10000 iterations, following a burn-in period of 1000. Figure 12 displays the raw and post-processed output from successive segments of each chain. The first segment displays the first 100 raw and post-processed iterations of the first chain, the second segment displays the raw and reordered values of iterations 101–200 for the second chain, and so on. The black coloured points correspond to successive segments of the simultaneously processed chains. It is evident that all chains have been successfully switched on a common labelling. Moreover, both the point estimate and the upper limit of the 95% confidence interval of the potential scale reduction factor (Gelman et al. 1992; Brooks and Gelman 1998) are equal to 1.00 for all loadings, indicating that there are no convergence issues.
1.4 Computational benchmark: performance comparison in high dimensional factor analytic models

Comparison of the three computational schemes into four datasets for various number of factors (q) and observed variables (p). Each point in the graphs corresponds to counts of the number of iterations of Step 2.2 of Algorithm 1. The exact version demands small number of iterations in order to reach a specific state, compared to the simulated annealing algorithms. However, the time needed for a single iteration of the exact algorithm is elevated compared to the simulated annealing algorithms. Notes: Y axis: in log-scale. Exact version (Scheme A) is not applied for \(q>10\). MCMC details: 10000 iterations using Stan
Figure 13 displays the progress of successive evaluations of the objective function (13) versus the time needed in order to reach the specific iteration of the algorithm. In all cases, the number of retained MCMC draws is equal to 10,000, generated from Stan (following a burn-in period of 10,000). Note that the time required in order to generate these MCMC samples with Stan ranges from a few minutes (for \(q=5,10\)) to five days (for \(q=50\)).
In the partial simulated annealing scheme we used \(B=20\) simulated annealing steps/repetitions for \(q=5,10\) factors and \(B=200\) for \(q=30,50\) factors. In the full simulated annealing scheme we used \(B=100, 100, 500\) and 2000 simulated annealing steps/repetitions for \(q=5,10, 30\) and 50 factors, respectively. Observe that for typical values of the number of factors (e.g. \(q=5\)) the exact scheme should be preferred. As expected, the partial simulated annealing scheme performs better than the full simulated scheme and should be preferred whenever the number of factors is large (e.g. when \(q > 10\)). At first, in all cases, the algorithm under the full simulated annealing scheme (blue line) converges to a worse (i.e., larger) value of the objective function compared to all other schemes. Second, observe that when the number of factors is larger than 10, the algorithm under the full simulated annealing scheme requires a large number of iterations in order to escape from the initial values and start to descend.
The post-processed values for the dataset with the 50 factors are presented in Fig. 14, which corresponds to the output returned by the partial simulated annealing algorithm. In this case, the number of factors used to generate the specific dataset is equal to 35, thus, when fitting a 50-factor model, there should be 15 redundant columns in the resulting matrix of factor loadings. A careful inspection of the 99% Highest Density Intervals (illustrated in blue) reveals that there are 15 panels where all intervals contain zero. The same holds for the 99% simultaneous Credible Region illustrated in red, that is, the panels corresponding to factor \(j \in \{3, 10, 13, 14, 16, 17, 18, 22, 25, 26, 28, 31, 43, 45, 48\}\). The same holds for the 99% HPD intervals when using the full simulated annealing scheme (which converged to an inferior solution), but the 99% simultaneous credible region contain zero for 29 factors instead of 15 (results not shown).

Post-processed factor loadings according to RSP algorithm under the partial simulated annealing scheme, for a synthetic dataset of \(n=500\) observations and \(p=70\) variables. Fitted model: \(q=50\) factors; true factors: \(q_{True}=35\). Blue regions: 99% highest density intervals; red Regions: 99% simultaneous credible region dots: posterior means. (Color figure online)
1.5 Comparison with k-medoids reordering
We applied the method of Kaufmann and Schumacher (2017) (briefly discussed in the second to last paragraph of Sect. 2) in the MCMC output (after varimax rotations) for the simulated dataset 1 of Sect. 4.1 and the results are displayed in Fig. 15. The same MCMC output was used as input as the one that generated Fig. 4 in the main manuscript. Clearly, the estimated marginal posterior distribution of reordered factor loadings is multimodal which indicates that this simpler method is not working well in our case where the model is not sparse. Recall that (see last paragraph of Sect. 2) a crucial characteristic in the model of Kaufmann and Schumacher (2017) is the fact that the generated matrices of factor loadings contain zeros and this is not the case in our implementation. Another problem with this approach is computational: a huge amount of memory is required in order to compute the distance matrix among the generated MCMC draws. In practice, the load becomes prohibitively large when considering a few tens of thousands of MCMC iterations.


Simulation study in Appendix F: Posterior means and 99% HPD intervals for the reordered factor loadings of the CCC model (common loadings per cluster), when fitting MFA models with \(q=3\) (first row) and \(q=4\) (second row) factors

Wave dataset: assigned (21-dimensional) observations per cluster (1st row) and estimated correlation matrix per cluster (2nd row), according to a Bayesian mixture of factor analyzers with \(K= 3\) clusters and \(q = 1\) factors
1.6 Mixtures of factor analyzers: simulation study
A synthetic dataset of \(n=200\) \(p=12\)-dimensional observations was generated from a two-component MFA model where the true number of factors is equal to \(q=3\). Following the suggestion of a reviewer, we have considered that the factor loadings matrix as well as the idiosyncratic variance are common to all clusters, that is,
According to the real value for \(\varvec{\Lambda }\), variables 1–4 load to factor 1, variables 5–8 load to factor 2 and variables 9–12 load to factor 3. The mixing proportions are almost equal.
In order to estimate the MFA model, the fabMix package was used. We considered that the number of factors ranges between 1 and 4 and fitted the 8 pgmm parameterizations available in fabMix. Note that the number of clusters is estimated using overfitting mixture models, while the number of factors as well as the parameterization is estimated using BIC. The selected model corresponds to the “CCC” parameterization with \(K = 2\) clusters and \(q = 3\) factors, corresponding to the settings used to generate the data, that is, common factor loadings and common isotropic idiosyncratic variance per cluster.
We present results of our reordering approach which correspond to the selected parameterization for \(q=3\) (that is, the true number) and \(q=4\) factors. The reordered factor loadings are displayed in Fig. 16. Recall that in this model the factor loadings are shared between the two clusters. In the first row, which corresponds to the “true” number of factors we see that variables 1–4 load to factor 1, variables 5–8 load to factor to 2 and variables 9–12 load to factor 3. These results are coherent with the underlying simulation scenario described previously. In the second row of Fig. 16, (4 factor model) the same variable-to-factor relationships are displayed for factors 1, 3 and 4, while the simultaneous credible region for the loadings of the second factor is centered around zero and this indicates the presence of one redundant column in the factor loadings matrix.

Wave dataset: posterior means and 99% HPD intervals for the reordered factor loadings per cluster
1.7 Mixtures of factor analyzers: the wave dataset
We used the Wave dataset, available in the fabMix package in R. The dataset is generated from the Waveform Database Generator (Breiman et al. 1984) and consists of \(p=21\) variables, all of which include noise, and there are 3 underlying classes of waves. Papastamoulis (2018, 2020) fitted various parameterizations of the general model in Equation (19) assuming an unknown number of clusters and using the Bayesian Information Criterion (Schwarz 1978) for choosing q. The selected model corresponds to \(K=3\) clusters and \(q = 1\) factors, under the constraint that \(\varvec{\Sigma }_1=\varvec{\Sigma }_2=\varvec{\Sigma }_3\), see Table 4 in Papastamoulis (2020). The fabMix package (Papastamoulis 2019) was used in order to produce an MCMC sample from the posterior distribution of the MFA model, using a prior parallel tempering scheme with 8 chains and a number of MCMC iterations equal to 20000. The clustered data as well as the inferred correlation matrix per cluster, conditional on \(K=3\) and \(q = 1\), is shown in Fig. 17. The posterior means and 99% HPD intervals of the reordered factor loadings per cluster are presented in Fig. 18.
1.8 Exchange rate returns dataset
In this section we consider the returns on weekday closing spot rates for several currencies relative to the U.S. dollar during the period from January 1, 1992, to October 31, 1995 (1000 observations), used by Aguilar and West (2000). The currencies are the German mark (DEM), British pound (GBP), Japanese yen (JPY), French franc (FRF), Canadian dollar (CAD), and Spanish peseta (ESP). Following Aguilar and West (2000), we analyze the one-day-ahead returns, that is, \(y_{ir} = s_{ir}/s_{i-1,r}-1\) where \(s_{ir}\) denotes the original measurement at time-point \(i=1,\ldots ,1000\) and currency \(r=1,\ldots ,6\).

Exchange rate returns dataset: 99% HPD intervals (black) and simultaneous 99% credible regions (red) of reordered factor loadings, when fitting Bayesian FA models with \(q=2\) (top) and \(q=3\) (bottom) factors. (Color figure online)
As pointed out by an anonymous reviewer, this is an example where the difference between small (“zero”) and large (“non-zero”) loadings is less pronounced compared to our previous analyses. Thus, the task here is to check whether such a structure is revealed in the post-processed MCMC output of factor loadings using a typical factor model. It is to be noted that Aguilar and West (2000) modelled the dataset using dynamic factor models, which seems a more appropriate choice for such datasets. But we will focus on inference regarding the factor loadings, which are also constant across time in the dynamic factor model of Aguilar and West (2000). Aguilar and West (2000) present results for \(q=3\), however in the Discussion section of the same paper is mentioned that a two factor model might be plausible for this type of data. We have used MCMCpack to produce an MCMC sample of 20,000 iterations (after burn-in), for \(q=2\) and \(q=3\) factor models. The raw MCMC sample of factor loadings is post-processed according to the RSP algorithm. The estimates of the posterior mean for each factor loading (as well as the estimate of the posterior standard deviation in parentheses) is shown in Table 5. An asterisk indicates cases where the 99% simultaneous credible region does not contain 0. Figure 19 illustrates the individual and joint 99% HPD regions for both choices of number of factors.
There are some common findings with Aguilar and West (2000), despite the fact that we do not force any constraint on the matrix of factor loadings and that the model is different. According to Aguilar and West (2000) (Table 1 in page 346) the first column of the matrix of factor loadings positively weights the first factor for all currencies but CAD. Observe that, up to a sign-switching, this is the also the case for the first factor in Table 5: zero is not contained in all currencies but CAD and moreover all of them (except CAD) have the same (negative) sign. This holds true for both models (that is, with 2 or 3 factors). The remaining columns are not directly comparable to the analysis of Aguilar and West (2000) due to the fact that they impose the lower-triangular expansion in Eq. (7), while they also force all diagonal elements to be equal to 1. Note however that the loadings of the second factor are essentially zero (GBP, ESP: notice that zero is contained in the simultaneous credible region), small (DEM, FRF) or moderate (JPY, CAD) values, and this fact is consistent with the task of identifying factors with less pronounced differences between small and large values of loadings. When considering \(q=3\) factors, the simultaneous credible region of post-processed values contains 0 for all loadings of the 3rd factor and this is an indication that a typical factor model with 3 factors may be over-parameterized (we emphasize once again that we do not use a dynamic factor model).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Papastamoulis, P., Ntzoufras, I. On the identifiability of Bayesian factor analytic models. Stat Comput 32, 23 (2022). https://doi.org/10.1007/s11222-022-10084-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11222-022-10084-4