
Abstract
We introduce a class of Monte Carlo estimators that aim to overcome the rapid growth of variance with dimension often observed for standard estimators by exploiting the target’s independence structure. We identify the most basic incarnations of these estimators with a class of generalized U-statistics and thus establish their unbiasedness, consistency, and asymptotic normality. Moreover, we show that they obtain the minimum possible variance amongst a broad class of estimators, and we investigate their computational cost and delineate the settings in which they are most efficient. We exemplify the merger of these estimators with other well known Monte Carlo estimators so as to better adapt the latter to the target’s independence structure and improve their performance. We do this via three simple mergers: one with importance sampling, another with importance sampling squared, and a final one with pseudo-marginal Metropolis–Hastings. In all cases, we show that the resulting estimators are well founded and achieve lower variances than their standard counterparts. Lastly, we illustrate the various variance reductions through several examples.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Monte Carlo methods are sometimes said to overcome the curse of dimensionality because, regardless of the target’s dimension, their rates of convergence are square root in the number of samples drawn. In practice, however, one encounters several problems when computing high-dimensional integrals using Monte Carlo, prominent among which is the issue that the constants present in the convergence rates typically grow rapidly with the target’s dimension. Hence, even if we are able to draw independent samples from a high-dimensional target, the number of samples necessary to obtain estimates of a satisfactory accuracy is often prohibitively large (Silverman 1986; Snyder et al. 2008; Bengtsson et al. 2008; Agapiou et al. 2017). However, many of these targets possess strong independence structures [e.g., see Gelman and Hill (2006), Gelman (2006), Koller and Friedman (2009), Hoffman et al. (2013), Blei et al. (2003), and the many references therein]. In this paper, we investigate whether the rapid growth of the constants can be mitigated by exploiting these structures.
Variants of the following toy example are sometimes given to illustrate the issue [e.g., p. 95 in Chopin and Papaspiliopoulos (2020)]. Let \(\mu \) be a K-dimensional isotropic Gaussian distribution with unit means and variances, and consider the basic Monte Carlo estimator for the mean (\(\mu (\varphi )=1\)) of the product (\(\varphi (x):=x_1x_2\ldots x_K\)) of its components (\(x_1,\ldots , x_K\)):
where \((X_1^n,\dots ,X_K^n)_{n=1}^N\) denote i.i.d. samples drawn from \(\mu \). Because the estimator’s asymptotic variance equals \(2^K-1\), the number of samples required to obtain a reasonable estimate of \(\mu (\varphi )\) grows exponentially with the target’s dimension. Hence, it is impractical to use \(\mu ^N(\varphi )\) if K is even modestly large. For instance, if \(K=20\), we would require \(\approx 10^{10}\) samples to obtain an estimate with standard deviation of \(0.01=\mu (\varphi )/100\), reaching the limits of most present-day personal computers, and if \(K=30\), we would require \( \approx 10^{13}\) samples, exceeding these limits.
There is, however, a trivial way of overcoming the issue for the above example that does not require any knowledge about \(\mu \) beyond the fact that it is product-form. Because \(\mu \) is the product \(\mu _1\times \dots \times \mu _K\) of K univariate unit-mean-and-variance Gaussian distributions \(\mu _1,\dots ,\mu _K\) and \(\varphi \) is the product \(\varphi _1\cdots \varphi _K\) of K univariate functions \(\varphi _1(x_1)=x_1,\dots ,\varphi _K(x_K)=x_K\), we can express \(\mu (\varphi )\) as the product \(\mu _1(\varphi _1) \cdots \mu _K(\varphi _K)\) of the corresponding K univariate means \(\mu _1(\varphi _1),\dots ,\mu _K(\varphi _K)\). As we will see in Sect. 2.1, estimating each of these univariate means separately and taking the resulting product, we obtain an estimator for \(\mu (\varphi )\) whose asymptotic variance is K:
Consequently, the number of samples necessary for \(\mu ^N_\times (\varphi )\) to yield a reasonable estimate of \(\mu (\varphi )\) only grows linearly with the dimension, allowing us to practically deal with Ks in the millions.
The central expression in (2) makes sense regardless of whether \(\varphi \) is the product of univariate test functions. It defines a type of (unbiased, consistent, and asymptotically normal) Monte Carlo estimators for general \(\varphi \) and product-form \(\mu \) which we refer to as product-form estimators. Their salient feature is that they achieve lower variances than the standard estimator (1) given the same number of samples from the target. The reason behind the variance reduction is simple: if \((X^n_1)_{n=1}^N\),\(\dots \), \((X^n_K)_{n=1}^N\) are independent sequences of samples drawn respectively from \(\mu _1,\dots ,\mu _K\), then every ‘permutation’ of these samples has law \(\mu \), that is,
Hence, \(\mu ^N_\times (\varphi )\) in (2) averages over \(N^K\) tuples with law \(\mu \) while its conventional counterpart (1) only averages over N such tuples. This increase in tuple number leads to a decrease in estimator variance, and we say that the product-form estimator is more statistically efficient than the standard one. Moreover, obtaining these \(N^K\) tuples does not require drawing any further samples from \(\mu \) and, in this sense, product-form estimators make the most out of every sample available (indeed, we will show in Theorem 2 that they are minimum variance unbiased estimators, or MVUEs, for product-form targets). However, in contrast to the tuples in (1), those in (2) are not independent (the same components are repeated across several tuples). For this reason, product-form estimators achieve the same \(\mathcal {O}(N^{-1/2})\) rate of convergence that the standard ones do and the variance reduction materializes only in lower proportionality constants (i.e., \(\lim _{N\rightarrow \infty }\mathrm{Var}\,(\mu ^N_\times (\varphi ))/\mathrm{Var}\,(\mu ^N(\varphi ))=C\) for some constant \(C\le 1\)).
The space complexity of product-form estimators scales linearly with dimension: to utilize all \(N^K\) permuted tuples in (2) we need only store KN numbers,
However, unless the test function possesses special structure, the estimators’ time complexity scales exponentially with dimension: brute-force computation of the sum in (2) requiresFootnote 1\(\mathcal {O}(N^K)\) operations. Consequently, the use of product-form estimators for general \(\varphi \) proves to be a balancing act in which one must weigh the cost of acquiring new samples from \(\mu \) (be it a computational one if the samples are obtained from simulations, or a real-life one if they are obtained from experiments) against the extra overhead required to evaluate these estimators, and it is limited to Ks no greater than ten.
If, however, the test function \(\varphi \) possesses some ‘product structure,’ then \(\mu _\times ^N(\varphi )\) can often be evaluated in far fewer than \(\mathcal {O}(N^K)\) operations. The most extreme examples of such \(\varphi \) are functions that factorize fully and sums thereof (which we refer to as ‘sums of products’ or ‘SOPs’), for which the evaluation cost is easily lowered to just \(\mathcal {O}(KN)\). For instance, in the case of the toy Gaussian example above, we can evaluate the product-form estimator in \(\mathcal {O}(KN)\) operations by expressing it as the product of the component-wise sample averages and computing each average separately (i.e., using the final expression in (2)). This cheaper approach just amounts to a dimensionality reduction technique: we re-write a high-dimensional integral as a polynomial of low-dimension integrals, estimate each of low-dimension integral separately, and plug the estimates back into the polynomial to obtain an estimate of the original integral. More generally, if the test function can be expressed as a sum of partially factorized functions, it is often possible to lower the cost to \(\mathcal {O}(N^d)\) where \(d< K\) depends on the amount of factorization, and taking this approach also amounts to a type of dimensionality reduction (this time featuring nested integrals).
This paper has two goals. First, to provide a comprehensive theoretical characterization of product-form estimators. Second, to illustrate their use for non-product-form targets when combined with, or embedded within, other more sophisticated Monte Carlo methodology. It is in these settings, where product-form estimators are deployed to tackle the aspects of the problem exhibiting product structure or conditional independences, that we believe these estimators find their greatest use. To avoid unnecessary technical distractions, and in the interest of accessibility, we achieve the second goal using simple examples. While we anticipate that the most useful such combinations or embeddings will not be so simple, we believe that the underlying ideas and guiding principles will be the same.
Relation to the literature In their basic form, product-form estimators (2) are a subclass of generalized U-statistics [see Lee (1990) or Korolyuk and Borovskich (1994) for comprehensive surveys]: multisample U-statistics with ‘kernels’ \(\varphi \) that take as arguments a single sample per distribution for several distributions \((K>1)\). Even though product-form estimators are unnatural examples of U-statistics because the original unisample U-statistics (Hoeffding 1948a) fundamentally involve symmetric kernels that take as arguments multiple samples from a single distribution (\(K=1\)), the methods used to study either of these overlap significantly. The arguments required in the basic product-form case are simpler than those necessary for the most general case (multiple samples from multiple distributions) and, by focusing on the results that are of greatest interest from the Monte Carlo perspective, we are able to present readily accessible, intuitive, and compact proofs for the theoretical properties of (2). This said, whenever a result given here can be extracted from the U-statistics literature, we provide explicit references.
While U-statistics have been extensively studied since Hoeffding’s seminal work (Hoeffding 1948a) and are commonly employed in a variety of statistical tests [e.g., independence tests (Hoeffding 1948b), two-sample tests (Gretton et al. 2012), goodness-of-fit tests (Liu et al. 2016), and more (Lee 1990; Kowalski and Tu 2007)] and learning tasks [e.g., regression (Kowalski and Tu 2007), classification (Clémençon et al. 2008), clustering (Clémençon 2011), and more (Clémençon et al. 2008, 2016)] where they arise as natural estimators, their use in Monte Carlo seems underexplored. Exceptions include Owen (2009) which cleverly applies unisample U-statistics to make the best possible use of a collection of genuine (and hence expensive to obtain and store) uniform random variables and Hall and Marron (1987) that uses them to obtain improved estimates for the integrated squared derivatives of a density.
Product-form estimators themselves can be found peppered throughout the Monte Carlo literature, with one exception (see below), always unnamed and specialized to particular contexts. First off, in the simplest setting of integrating fully factorized functions with respect to product-form measures, it is of course well known that better performance is obtained by separately approximating the marginal integrals and taking their product (although, we have yet to locate full variance expressions quantifying quite how much better, even for this near-trivial case). Beyond the fully factorized case, product-form estimators are found not in isolation but combined with other Monte Carlo methodology: Tran et al. (2013) embeds them within therein-defined importance sampling\(^2\) (IS\(^2\)) to efficiently infer parameters of structured latent variable models, Schmon et al. (2020) employs them within pseudo-marginal MCMC to estimate intractable acceptance probabilities for similar models, Lindsten et al. (2017) and Kuntz et al. (2021) study their use within sequential Monte Carlo (SMC), and Aitchison (2019) builds on them to obtain tensor Monte Carlo (TMC), an extension of importance weighted variational autoencoders. The latter article is the aforementioned exception: its author defines the estimators in general and refers to them as ‘TMC estimators,’ but does not study them theoretically. To the best of our knowledge, there has been no previous systematic exploration of the estimators (2), their theoretical properties, and uses, a gap we intend to fill here. Furthermore, while in simple situations with fully, or almost-fully, factorized test functions [e.g., those in Tran et al. (2013) or Schmon et al. (2020)] it might be clear to most practitioners that employing a product-form estimator is the right thing to do, it may not be quite so immediately obvious how much of a difference this can make and that, in rather precise ways (cf. Theorems 2 and 4), judiciously using product-form estimators is the best thing one can do within Monte Carlo when tackling models with known independence structure but unknown conditional distributions (a common situation in practice). We aim to underscore these points through our analysis and examples.
Lastly, we remark that product-form estimators are reminiscent of classical product cubature rules (Stroud 1971). These are obtained by taking products of quadrature rules and, consequently, require computing sums over \(N^K\) points much like for product-form estimators [except for fully, or partially, factorized test functions \(\varphi \) where the cost can be similarly lowered, e.g., p. 24 in Stroud (1971)]. In fact, the high computational cost incurred by these rules for general \(\varphi \) partly motivated the development of more modern numerical integration techniques such as quasi-Monte Carlo (Dick et al. 2013), spare grid methods (Gerstner and Griebel 1998, 2003), and, of course, Monte Carlo itself. That said, we believe that these rules can be used to great effect if one is strategic in their application and the advent of the more modern methods has created many opportunities for such applications, something we intend to exemplify here using their Monte Carlo analogues: product-form estimators.
Paper structure This paper is divided into two main parts (Sects. 2 and 3), each corresponding to one of our two aims, and a discussion of our results, future research directions, and potential applications (Sect. 4).
Section 2 studies product-form estimators and their theoretical properties. In particular, we show that the estimators are strongly consistent, unbiased, and asymptotically normal, and we give expressions for their finite sample and asymptotic variances (Sect. 2.1). We argue that they are more statistically efficient than their conventional counterparts in the sense that they achieve lower variances given the same number of samples (Sect. 2.2). Lastly, we consider their computational cost (Sect. 2.3) and explore the circumstances in which they prove most computationally efficient (Sect. 2.4).
Section 3 gives simple examples illustrating how one may embed product-form estimators within standard Monte Carlo methodology and extend their use beyond product-form targets. In particular, we combine them with importance sampling and obtain estimators applicable to targets that are absolutely continuous with respect to fully factorized distributions (Sect. 3.1) and partially factorized ones (Sect. 3.2), and we consider their use within pseudo-marginal MCMC (Sect. 3.3). We then examine the numerical performance of these extensions on a simple hierarchical model (Sect. 3.4).
This paper has six appendices (provided in the supplementary material). The first five contain proofs: Appendix A those for the basic properties of product-form estimators, Appendix B that for their MVUE property, Appendix C those for the basic properties of the ‘partially product-form’ estimators introduced in Sect. 3.2, Appendix D that for the latter’s MVUE property, and Appendix E that for the statistical efficiency (vis-à-vis their non-product counterparts) of the product-form pseudo-marginal MCMC estimators considered in Sect. 3.3. Appendix F contains an additional, simple extension of product-form estimators (to targets that are mixtures of product-form distributions), omitted from the main text in the interest of brevity.
2 Product-form estimators
Consider the basic Monte Carlo problem: given a probability distribution \(\mu \) on a measurable space \((S,\mathcal {S})\) and a function \(\varphi \) belonging to the space \(L^2_\mu \) of square \(\mu \)-integrable real-valued functions on S, estimate the average
Throughout this section, we focus on the question ‘by exploiting the product-form structure of a target \(\mu \), can we design estimators of \(\mu (\varphi )\) that are more efficient than the usual ones?’. By product-form, we mean that \(\mu \) is the product of \(K>1\) distributions \(\mu _1,\dots ,\mu _K\) on measurable spaces \((S_1,\mathcal {S}_1),\dots ,(S_K,\mathcal {S}_K)\) satisfying \(S=S_1\times \dots \times S_K\) and \(\mathcal {S}=\mathcal {S}_1\times \dots \times \mathcal {S}_K\), where the latter denotes the product sigma-algebra. Furthermore, if A is a non-empty subset of \([K]:=\{1,\dots ,K\}\), then we use \(\mu _A:=\prod _{k\in A}\mu _k\) to denote the product of the \(\mu _k\)s indexed by ks in A and \(\mu _A(\varphi )\) to denote the measurable function on \(\prod _{k\not \in A}S_k\) obtained by integrating the arguments of \(\varphi \) indexed by ks in A with respect to \(\mu _A\):
for all \(x_{A^c}\) in \(\prod _{k\in A^c}S_k\), where \(A^c:=[K]\backslash A\) denotes A’s complement, under the assumption that these integrals are well defined. If A is empty, we set \(\mu _A(\varphi ):=\varphi \).
2.1 Theoretical characterization
Suppose that we have at our disposal N i.i.d. samples \(X^1,\dots ,X^N\) drawn from \(\mu \). We can view these samples as N tuples
of i.i.d. samples \(X^1_1,\dots , X^N_1\), \(\dots \), \(X^1_K,\dots , X^N_K\) independently drawn from \(\mu _1,\ldots ,\mu _k\), respectively. As we will see in Sect. 2.2, the product-form estimator,
where \(X^{\varvec{n}}\) with \(\varvec{n}=(n_1,\dots ,n_K)\) denotes the ‘permuted’ tuple \((X^{n_1}_1,\dots ,X^{n_K}_K)\) (i.e., a tuple obtained as one of the \(N^K\) component-wise permutations of the original samples), yields lower variance estimates for \(\mu (\varphi )\) than the conventional choice using the same samples,
regardless of whether the test function \(\varphi \) possesses any sort of product structure. The conventional estimator directly approximates the target with the samples’ empirical distribution,
The product-form estimator instead first approximates the marginals \(\mu _1,\dots ,\mu _K\) of the target with the corresponding component-wise empirical distributions,
and then takes the product of these to obtain an approximation of \(\mu \),
The built-in product structure in \(\mu ^N_\times \) makes it a better suited approximation to the product-form target \(\mu \) than the non-product-form \(\mu ^N\). Before pursuing this further, we take a moment to show that \(\mu _\times ^N(\varphi )\) is a well founded estimator for \(\mu (\varphi )\) and obtain expressions for its variance.
Theorem 1
If \(\varphi \) is \(\mu \)-integrable, then \(\mu ^N_\times (\varphi )\) in (4) is unbiased:
If, furthermore, \(\varphi \) belongs to \(L^2_\mu \), then \(\mu _{A^c}(\varphi )\) belongs to \(L^2_{\mu _{A}}\) for all subsets A of [K]. The estimator’s variance is given by
for every \(N>0\), where \(\left| A \right| \) and \(\left| B \right| \) denote the cardinalities of A and B and
for all \(\psi \) in \(L^2_{\mu _A}\) and \(B\subseteq A\subseteq [K]\). Furthermore, \(\mu ^N_\times (\varphi )\) is strongly consistent and asymptotically normal:
where \(\sigma _{\times }^2(\varphi ):=\sum _{k=1}^K\sigma ^2_k(\varphi )\) with
and \(\Rightarrow \) denotes convergence in distribution.
As mentioned in Sect. 1, product-form estimators are special cases of multisample U-statistics and Theorem 1 can be pieced together from various results in the U-statistics literature. For example, within Korolyuk and Borovskich (1994) one can find the unbiasedness (p. 35), variance expressions (p. 38), consistency (which also holds for \(\mu \)-integrable \(\varphi \); Theorem 3.2.1), and asymptotic normality (Theorem 4.5.1). To keep the paper self-contained we include a simple proof of Theorem 1, specially adapted for product-form estimators, in Appendix A. It has two key ingredients, the first being the following decomposition expressing the ‘global approximation error’ \(\mu ^N_\times -\mu \) as a sum of products of ‘marginal approximation errors’ \(\mu _1^N-\mu _1,\dots ,\mu _K^N-\mu _K\):
The other is the following expression for the \(L^2\) norm of a generic product of marginal errors [see p. 152 in Korolyuk and Borovskich (1994) for its multisample U-statistics analogue]. It tells us that the product of l of these errors has \(\mathcal {O}(N^{-l/2})\) norm, as one would expect given that the errors are independent and that classical theory [e.g., p. 168 in Chopin and Papaspiliopoulos (2020)] tells us that the norm of each is \(\mathcal {O}(N^{-1/2})\).
Lemma 1
If A is a non-empty subset of [K], \( \psi \) belongs to \( L^2_{\mu _A}\), and \(\sigma _{A,B}^2(\psi )\) is as in (9), then
Proof
This lemma follows from the equation
which, together with (12), is known as Hoeffding’s canonical decomposition in the U-statistics literature [e.g., p. 38 in Korolyuk and Borovskich (1994)] and ANOVA-like elsewhere (Efron and Stein 1981). Similar decomposition are commonplace in the quasi-Monte Carlo literature, e.g., Appendix A in Owen (2013). See Appendix A for the details. \(\square \)
2.2 Statistical efficiency
The product-form estimator \(\mu ^N_\times (\varphi )\) in (4) yields the best unbiased estimates of \(\mu (\varphi )\) that can be achieved using only the knowledge that \(\mu \) is product-form and N i.i.d. samples drawn from \(\mu \).
Theorem 2
For any given measurable real-valued function \(\varphi \) on \((S,\mathcal {S})\), \(\mu _\times ^N(\varphi )\) is an MVUE for \(\mu (\varphi )\): if f is a measurable real-valued function on \((S^N,\mathcal {S}^N)\) such that
whenever \(X^1,\dots ,X^N\) are i.i.d. with law \(\mu \), for all product-form \(\mu \) on \((S,\mathcal {S})\) satisfying \(\mu (\left| \varphi \right| )<\infty \), then
Proof
See Appendix B. \(\square \)
While it is well known that unisample U-statistics are MVUEs [e.g., see Clémençon et al. (2016)], we have been unable to locate an explicit proof that covers the general multisample case and, in particular, that of product-form estimators. Instead, we adapt the argument given in Chapter 1 of Lee (1990) (whose origins trace back to Halmos (1946)) for unisample U-statistics and prove Theorem 2 in Appendix B
Theorem 2 implies that product-form estimators achieve lower variances than their conventional counterparts:
Corollary 1
If \(\varphi \) belongs to \(L^2_\mu \) and \(\sigma ^2(\varphi ):=\mu ([\varphi -\mu (\varphi )]^2)\) denotes \(\mu ^N(\varphi )\)’s asymptotic variance,
Proof
See Appendix B. \(\square \)
In other words, product-form estimators are more statistically efficient than their standard counterparts: using the same number of independent samples drawn from the target, \(\mu ^N_\times (\varphi )\) achieves a lower variance than \(\mu ^N(\varphi )\). The reason behind this variance reduction was outlined in Sect. 1: the product-form estimator uses the empirical distribution of the collection \((X^{\varvec{n}})_{\varvec{n}\in [N]^K}\) of permuted tuples as an approximation to \(\mu \). Because \(\mu \) is product-form, each of these permuted tuples is as much a sample drawn from \(\mu \) as any of the original unpermuted tuples \((X^n)_{n=1}^N\). Hence, product-form estimators transform N samples drawn from \(\mu \) into \(N^K\) samples and, consequently, lower the variance. However, the permuted tuples are not independent and we get a diminishing returns effect: the more permutations we make, the greater the correlations among them, and the less ‘new information’ each new permutation affords us. For this reason, the estimator variance remains \(\mathcal {O}(N^{-1})\), cf. (8), instead of \(\mathcal {O}(N^{-K})\) as would be the case for the standard estimator using \(N^K\) independent samples. As we discuss in Sect. 4, there is also a pragmatic middle ground here: use \(N<M<N^K\) permutations instead of all \(N^K\) possible ones. In particular, by choosing these M permutations to be as uncorrelated as possible (e.g., so that they have few overlapping entries), it might be feasible to retain most of the variance reduction while avoiding the full \(\mathcal {O}(N^K)\) cost (cf. Kong and Zheng (2021) and references therein for similar feats in the U-statistics literature).
Given that the variances of both estimators are (asymptotically) proportional to each other, we are now faced with the question ‘how large might the proportionality constant be?’. If the test function is linear or constant, e.g., \(S_1=\dots =S_K=\mathbb {R}\) and
then the two estimators trivially coincide, no variance reduction is achieved, and the constant is one. However, these are the cases in which the standard estimator performs well [e.g., for (14), \(\mu ^N(\varphi )\)’s variance breaks down into a sum of K univariate integrals and, consequently, grows slowly with the dimension K]. However, if the test function includes dependencies between the components, then the proportionality constant can be arbitrarily large and the variance reduction unbounded as the following example illustrates.
Example 1
If \(K=2\), \(\mu _1=\mu _2=\mathcal {N}(0,1)\), and \(\varphi (x):=1_{\{\min (x_1,x_2)\ge \alpha \}}(x)\), then
where \(\Phi \) denotes the CDF of a standard normal, and similarly for \(\mu _2(\varphi )(x_1)\). In addition,
It then follows that
It is not difficult to glean some intuition as to why the product-form estimator yields far more accurate estimates than its standard counterpart for large \(\alpha \). In these cases, unpermuted tuples with both components greater than \(\alpha \) are extremely rare (they occur with probability \([1-\Phi (\alpha )]^2\)) and, until one arises, the standard estimator is stuck at zero (a relative error of 100%). On the other hand, for the product-form estimator to return a nonzero estimate, we only require unpermuted tuples with a single component greater than \(\alpha \), which are generated much more frequently (with probability \(1-\Phi (\alpha )\)).
Of particular interest is the case of high-dimensional targets (i.e., large K) for which obtaining accurate estimates of \(\mu (\varphi )\) proves challenging. Even though the exact manner in which the variance reduction achieved by the product-form estimator scales with dimension of course depends on the precise target and test function, it is straightforward to gain some insight by revisiting our starting example.
Example 2
Suppose that
for some univariate distribution \(\rho \) and test function \(\psi \) satisfying \(\rho (\psi )\ne 0\). In this case,
where \(CV:= {\sqrt{\rho ([\psi -\rho (\psi )]^2)}}\big /\left| \rho (\psi ) \right| \) denotes the coefficient of variation of \(\psi \) w.r.t. \(\rho \). Hence,
and we see that the reduction in variance grows exponentially with the dimension K.
At first glance, (15) might appear to imply that the number of samples required for \(\mu ^N_\times (\varphi )\) to yield a reasonable estimate of \(\mu (\varphi )\) grows exponentially with K if \(\left| \rho (\psi ) \right| >1\). However, what we deem a ‘reasonable estimate’ should take into account the magnitude of the average \(\mu (\varphi )\) we are estimating. In particular, it is natural to ask for the standard deviation of our estimates to be \(\varepsilon \left| \mu (\varphi ) \right| \) for some prescribed relative tolerance \(\varepsilon >0\). In this case, we find that the number of samples required by the product-form estimator is approximately
In the case of the conventional estimator \(\mu ^N(\varphi )\), the number required to achieve the same accuracy is instead
That is, the number of samples necessary to obtain a reasonable estimate grows linearly with dimension for \(\mu ^N_\times (\varphi )\) and exponentially for \(\mu ^N(\varphi )\).

Ensembles of unpermuted (a, c) and permuted (b, d) pairs for a peaked target (a, b) and heavy tailed one (c, d). a 10 pairs (dots) independently drawn from a two-dimensional isotropic Gaussian (contours) with mean zero and variance 0.1. b The 100 pairs (dots) obtained by permuting the pairs in a. c 20 pairs (dots) independently draw from the product of two student-t distributions (contours) with 1.5 degrees of freedom. d The 400 permuted pairs (dots) obtained by permuting the pairs in c
Notice that the univariate coefficient of variation CV features heavily in Example 2’s analysis: the greater it is, the greater the variance reduction, and the difference gets amplified exponentially with the dimension K. This observation might be explained as follows: if \(\mu \) is highly peaked (so that the coefficient is close to zero), then the unpermuted tuples are clumped together around the peak (Fig. 1a), permuting their entries only yields further tuples around the peak (Fig. 1b), and the empirical average changes little. If, on the other hand, \(\mu \) is spread out (so that the coefficient is large), then the unpermuted pairs are scattered across the space (Fig. 1c), permuting their entries reveals unexplored regions of the space (Fig. 1d), and the estimates improve. Of course, how spread out the target is must be measured in terms of the test function and we end up with the coefficient of variation in (16).
2.3 Computational efficiency
As shown in the previous section, product-form estimators are always at least as statistically efficient as their conventional counterparts: the variances of the former are bounded above by those of the latter. These gains in statistical efficiency come at a computational cost: even though both conventional and product-form estimators share the same \(\mathcal {O}(N)\) memory needs, the latter requires evaluating the test function \(N^K\) times, while the former requires only N evaluations. For this reason, the question of whether product-form estimators are more computationally efficient than their conventional counterparts (i.e., achieve smaller errors given the same computational budget) is not as straightforward. In short, sometimes but not always.
One way to answer the computational efficiency question is to compare the cost incurred by each estimator in order to achieve a desired given variance \(\sigma ^2\). To do so, we approximate the variance of \(\mu ^N_\times (\varphi )\) with its asymptotic variance divided by the sample number (as justified by Theorem 1). The number of samples required for the variance to equal \(\sigma ^2\) is \(N:=\sigma ^2(\varphi )/\sigma ^2\) for the conventional estimator and (approximately) \(N_\times :=\sigma ^2_{\times }(\varphi )/\sigma ^2\) for the product-form one. The costs of evaluating the former with N samples and the latter with \(N_\times \) samples are \(NC_{\varphi } +N C_X +N\) and \(N^K_\times C_\varphi +N_\times C_X+N^K_\times \), respectively, where \(C_\varphi \) and \(C_X\) are the costs, relative to that of a single elementary arithmetic operation, of evaluating \(\varphi \) and generating a sample from \(\mu \), respectively, and the rightmost N and \(N^K_\times \) terms account for the cost of computing the corresponding sample average once all evaluations of \(\varphi \) are carried out. It follows that \(\mu ^N_\times (\varphi )\) is (asymptotically) at least as computationally efficient as \(\mu ^N(\varphi )\) if and only if the ratio of their respective costs is no smaller than one or, after some re-arranging,
where \(C_r:=(C_\varphi +1)/C_X\) denotes the relative cost of evaluating the test function and drawing samples. Our first observation here is that above is always satisfied in the limit \(C_r\rightarrow 0\) because \(\sigma ^2(\varphi )\ge \sigma ^2_{\times }(\varphi )\) (Corollary 1). This corresponds the case where the cost of acquiring the samples dwarfs the overhead of evaluating the sample average (for instance, if the samples are obtained from long simulations or real-life experiments). If so, we do really want to make the most of the samples we have and product-form estimators enable us to do so. Conversely, if samples are cheap to generate and the test function is expensive to evaluate (i.e., \(C_r\rightarrow \infty \)), then we are better off using the basic estimator.
To investigate the case where the costs of generating samples and evaluating the test function are comparable (\(C_r\approx 1\)), note that the variance approximation \(\mathrm{Var}\,(\mu ^{N_\times }_\times (\varphi ))\approx \sigma ^2_\times (\varphi )/N_\times \) and, consequently, (17) are valid only if \(\sigma ^2_{\times }(\varphi )>\sigma ^2\). Otherwise, \(N_\times =1\) and the product-form estimator simply equals \(\varphi (X^1)\) with variance \(\sigma ^2(\varphi )\). In the high-dimensional (i.e., large K) case which is of particular interest, (17) then (approximately) reduces to
To gain insight into whether it is reasonable to expect the above to hold, we revisit Example 2.
Example 3
Setting once again our desired standard deviation to be proportional to the magnitude of the target average (i.e., \(\sigma =\varepsilon \left| \mu (\varphi ) \right| =\varepsilon \vert \rho (\psi )\vert ^K\)) and calling on (15, 16), we re-write (18) as
The expression shows that, in this full \(\mathcal {O}(N^K)\) cost case, \(\mu ^N(\varphi )\) outperforms \(\mu ^N_\times (\varphi )\) in computational terms for large dimensions K (and, even more so, for small relative tolerances \(\varepsilon \)).
In summary, unless the cost of generating samples is significantly larger than that of evaluating \(\varphi \), we expect the basic estimator to outperform the product-form one. Simply put, independent samples are more valuable for estimation than correlated permutations thereof. Hence, if independent samples are cheap to generate, then we are better off drawing further independent samples rather than permuting the ones we already have.
That is, unless we can find a way to evaluate the product-form estimator that does not require summing over all \(N^K\) permutations. Indeed, the above analysis is out of place for Example 3 because, in this case, we can express the product-form estimator as the product
of the univariate sample averages \(\mu ^N_1(\psi ),\dots ,\mu ^N_K(\psi )\) and evaluate each of these separately at a total \(\mathcal {O}(KN)\) cost. Given that the number of samples required for \(\mu ^N_\times (\varphi )\) to yield a reasonable estimate scales linearly with dimension (Example 2), it follows that the cost incurred by computing such an estimate scales quadratically with dimension. In the case of \(\mu ^N(\varphi )\), the number of samples required, and hence the cost, scales exponentially with dimension; making the product-form estimator the clear choice for this simple case. This type of trick significantly expands the usefulness of product-form estimators, as we see in the following section.
2.4 Efficient computation
Recall our starting example from Sect. 1. In that case, the product-form estimator trivially breaks down into the product of K sample averages (2) and, consequently, we can evaluate it in \(\mathcal {O}(KN)\) operations. We can exploit this trick whenever the test function possesses product-like structure: if \(\varphi \) is a sum
of univariate functions \((\varphi _k^j:S_k\rightarrow \mathbb {R})_{j\in [J],k\in [K]}\), the product-form estimator decomposes into a sum of products (SOP) of univariate averages,
where
and we are able to evaluate \(\mu _\times ^N(\varphi )\) in \(\mathcal {O}(KN)\) operations. (Of course, ‘univariate’ need not mean that the function is defined on \(\mathbb {R}\) and we can be strategic in our choice of component spaces \(S_1,\dots ,S_K\); e.g., if \(\varphi (x_1,x_2,x_3)=\varphi _1(x_1,x_2)\varphi _2(x_3)\) for some functions \(\varphi _1:\mathbb {R}^2\rightarrow \mathbb {R}\) and \(\varphi _2:\mathbb {R}\rightarrow \mathbb {R}\), we could pick \(K:=2\), \(S_1:=\mathbb {R}^2\), and \(S_2:=\mathbb {R}\).) In these cases, the use of product-form estimators amounts to nothing more than a dimensionality-reduction technique: we exploit the independence of the target to express our K-dimensional integral in terms of an SOP of one-dimensional integrals,
estimate each of these separately,
and replace the one-dimensional integrals in the SOP with their estimates to obtain an estimate for the K-dimensional integral:
By so exploiting the structure in \(\mu \) and \(\varphi \), the product-form estimator achieves a lower variance than the standard estimator (Corollary 1). Moreover, evaluating each univariate sample average \(\mu _k^N(\varphi _k^j)\) requires only \(\mathcal {O}(N)\) operations and, consequently the computational complexity of \(\mu ^N_\times (\varphi )\) is \(\mathcal {O}(KN)\). The running time can be further reduced by calculating the univariate sample averages in parallel.
Similar considerations apply if the test function \(\varphi \) is a product of low-dimensional functions (and sums thereof) instead of univariate ones, e.g., \(\varphi (x)=\prod _{i=1}^I\varphi _i((x_k)_{k\in A_i})\) for a collection of factors \(\varphi _1,\dots ,\varphi _I\) with arguments indexed by subsets \(A_1,\dots ,A_I\) of [K]. As with the SOP case, one should aim to swap as many summation and product signs in
as the factors permit. Exactly how best to do this is obvious for simple situations such as that in Example 5 in Sect. 3.1. For more complicated ones, we advice using the ‘variable elimination’ algorithm [cf. Chapter 9 in Koller and Friedman (2009)] commonly employed for inference in discrete graphical models. The complexity of the resulting procedure essentially depends on the order in which one attempts the swapping (however, it is easy to find bounds thereon; for instance, it is bounded below by both the maximum cardinality of \(A_1,\dots ,A_I\) and half the length of the longest cycle in \(\varphi \)’s factor graph). While finding the ordering with lowest complexity for general partially factorized \(\varphi \) itself proves to be a problem whose worst-case complexity is exponential in K, good suboptimal orderings can often be found using cheap heuristics [cf. Sect. 9.4.3 in Koller and Friedman (2009)].
For general \(\varphi \) lacking any sort of product structure, we are sometimes able to extend the linear-cost approach by approximating \(\varphi \) with SOPs (e.g., using truncated Taylor expansions for analytic \(\varphi \)). The idea is that if \(\varphi \approx f\) for some SOP f, then
and we can use \(\mu ^N_\times (f)\approx \mu (f)\) as a linear-cost estimator for \(\mu (\varphi )\) without significantly affecting the variance reduction. This, of course, comes at the expense of introducing a bias in our estimates, albeit one that can often be made arbitrarily small by using more and more refined approximations [these biases may in principle be removed using multilevel randomization, see McLeish (2011) or Rhee and Glynn (2015)]. The choice of approximation quality itself proves to be a balancing act as more refined approximations typically incur higher evaluation costs. If these costs are high enough, then any potential computational gains afforded by the reduction in variance are lost. In summary, this SOP approximation approach is most beneficial for test functions (a) that are effectively approximated by SOP functions (so that the bias is low), (b) whose SOP approximations are relatively cheap to evaluate (so that the cost is low), and (c) that have a high-dimensional product-form component to them (so that the variance reduction is large, cf. Sect. 2.2). In these cases, the gains in performance can be substantial as illustrated by the following toy example.
Example 4
Let \(\mu _1, \dots , \mu _K\) be uniform distributions on the interval [0, a] of length \(a>1\) and consider the function \(\varphi (x):=e^{x_{1}\dots x_K}\). The integral can be expressed in terms of the generalized hypergeometric function \({}_{p}F_{q}\),
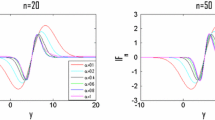
and grows super-exponentially with the dimension K (see Fig. 2a). Because
for large enough truncation cutoffs J, we have that
Using \(\mu ^N_{\times }(\varphi _J)\) instead of \(\mu ^N_{\times }(\varphi )\) as an estimator for \(\mu (\varphi )\), we lower the computational cost from \(\mathcal {O}(N^K)\) to \(\mathcal {O}(K N)\). In exchange, we introduce a bias:
As \(\sum _{j=J+1}^\infty \frac{a^{jK}}{j!}=o(a^{JK}/J!)\), the bias decays super-exponentially with the cutoff J, at least for sufficiently large J. In practice, we found it to be significant for Js smaller than \(0.8a^K\) and negligible for Js larger than \(1.2a^K\) (Fig. 2b). In particular, the cutoff J necessary for \(\mu ^N_{\times }(\varphi _J)\) to yield estimates with small bias grows exponentially with the dimension K.

a–d Plots generated for three values of a: \(a=1.4\) (blue), \(a=1.45\) (magenta), and \(a=1.5\) (yellow). a Target average \(\mu (\varphi )\) as a function of dimension K. b Bias of product-form estimator (normalized by target average) as a function of K with truncation cut-offs \(J=\lceil 0.8a^K\rceil +2\) (solid) and \(J=\lceil 1.2a^K\rceil +2\) (dashed). We added the \(+2\) to avoid trivial cutoffs for low values of \(a^K\). c Ratio of asymptotic variances \(\sigma ^2(\varphi )/\sigma ^2_\times (\varphi _J)\) (solid) with \(J=\lceil 1.2a^K\rceil +2\) (dashed) as a function of K. d Asymptotic standard deviation (normalized by target average) for conventional (solid) and biased product-form (dashed, with \(J=\lceil 1.2a^K\rceil +2\)) estimators as a function of K. e Kernel density estimator with plug-in bandwidth (Wand and Jones 1994) (blue) obtained with \(a=1.5\), \(K=10\), \(J=70\), and 100 repeats of \(\mu ^N_\times (\varphi _J)\) each involving \(N=10^6\) samples is a good match to the corresponding sampling distribution (magenta) predicted by the CLT in Theorem 1. Comparing with the target average (yellow), we find a mean absolute error across repeats of \(6.73\times 10^5\approx \mu (\varphi )/100\). f As in e but for \(\mu ^N(\varphi )\). This time, the predicted sampling distribution is extremely wide (with a standard deviation of \(6.7\times 10^{14}\)) and a poor match to the kernel density estimator (almost a Dirac delta close to zero). The mean absolute error is \(6.67\times 10^7\approx \mu (\varphi )\). The estimator’s failure stems from the extreme rarity of samples \(X^n\) achieving very large values of \(\varphi (X^n)\) (i.e., those with components that are all close to a). Because the components are independent, they are extremely unlikely to simultaneously be close to a and the aforementioned samples are not observed for realistic ensemble sizes N. The product-form estimator avoids this issue by averaging over each component separately. (colour figure online)
Similar manipulations to those above reveal that
and we find that the variance reduction achieved by \(\mu ^N_\times (\varphi _J)\) far outpaces the growth in K of the cutoff (and, thus, the computational cost of \(\mu ^N_\times (\varphi _J)\)) necessary to achieve a small bias (Fig. 2c). Indeed, the asymptotic-standard-deviation-to-mean ratio, \(\sigma (\varphi )/\mu (\varphi )\), rapidly diverges with K in the case of the standard estimator (Fig. 2d, solid). In that of the biased product-form estimator, the ratio, \(\sigma _\times (\varphi _J)/\mu (\varphi )\), also diverges with K but at a much slower rate (Fig. 2d, dashed). For this reason, the number of samples necessary for obtain a, say, \(1\%\) accuracy estimate of \(\mu (\varphi )\) using \(\mu ^N_\times (\varphi _J)\) remains manageable for a substantially larger range of as and Ks than in the case of \(\mu ^N(\varphi )\), even after factoring in the extra cost required to evaluate \(\mu ^N_\times (\varphi _J)\) for J’s large enough that the bias is insignificant. For instance, with an interval length of 1.5 and ten dimensions, a cutoff of seventy, one million samples, and less than one minute of computation time suffices for \(\mu ^N_\times (\varphi _J)\) to produce a \(1\%\) accuracy estimate of \(\mu (\varphi )\approx 6.68\times 10^7\) (Fig. 2e). Using the same one million samples and the standard estimator, we obtain very poor estimates (Fig. 2f). Indeed, \(\mu ^N(\varphi )\)’s asymptotic variance equals \(4.45\times 10^{29}\) and, so, we would need approximately \( 10^{18}\) samples for it to yield 1% accuracy estimates, something far beyond current computational capabilities.
3 Extensions to non-product-form targets
While interesting product-form distributions can be found throughout the applied probability literature—ranging from the stationary distributions of Jackson queues (Jackson 1957; Kelly 1979) and complex-balanced stochastic reaction networks (Anderson et al. 2010; Cappelletti and Wiuf 2016) to the mean-field approximations used in variational inference (Ranganath et al. 2014; Blei et al. 2017)—most target distributions encountered in practice are not product-form. In this section, we demonstrate how to combine product-form estimators with other Monte Carlo methodology and expand their utility beyond the product-form case.
We consider three simple extensions: one to targets that are absolutely continuous with respect to fully factorized distributions (Sect. 3.1), resulting in a product-form variant of importance sampling [e.g., see Chapter 8 in Chopin and Papaspiliopoulos (2020)]; another to targets that are absolutely continuous with respect to partially factorized distributions (Sect. 3.2), resulting in a product-form version of importance sampling squared (Tran et al. 2013); and a final one to targets with intractable densities arising from latent variable models (Sect. 3.3), resulting in a product-form variant of pseudo-marginal MCMC (Schmon et al. 2020). In all cases, we show theoretically that the product-form variants achieve smaller variances than their standard counterparts. We then investigate their performance numerically by applying them to a simple hierarchical model (Sect. 3.4).
A further extension, this time to targets that are mixtures of product-form distributions, can be found in Appendix F. Because many distributions may be approximated with these mixtures, this extension potentially opens the door to tackling still more complicated targets (at the expense of introducing some bias).

Product-form approximations improve state space exploration. The target, a uniform distribution on \([0,4]^2\) (dashed square), and the proposal, the product of two student-t distributions with 1.5 degrees of freedom (contours), are mismatched. Consequently, only 5 of 20 pairs independently drawn from the proposal land within the target’s support (a) and the corresponding weighted sample approximation (a, inset, dot diameter proportional to sample weight) is poor. By permuting these pairs, we improve the coverage of the state space (b), increase the number of pairs lying within the target’s support, and obtain a much better weighted sample approximation (b, inset, dot diameter proportional to sample weight)
3.1 Importance sampling
Suppose that we are given an unnormalized (but finite) unsigned target measure \(\gamma \) that is absolutely continuous with respect to the product-form distribution \(\mu \) in Sect. 2, and let \(w:=d\gamma /d\mu \) be the corresponding Radon–Nikodym derivative. Instead of the usual important sampling (IS) estimator, \(\gamma ^N(\varphi ):=\mu ^N(w\varphi )\) with \(\mu ^N\) as in (6), for \(\gamma (\varphi )\), we consider its product-form variant, \(\gamma ^N_\times (\varphi ):=\mu _\times ^N(w\varphi )\) with \(\mu ^N_\times \) as in (7). The results of Sect. 2 immediately give us the following.
Corollary 2
If \(\varphi \) is \(\gamma \)-integrable, then \(\gamma ^N_\times (\varphi )\) is an unbiased estimator for \(\gamma (\varphi )\). If, furthermore, \(w\varphi \) lies in \(L^2_\mu \) , then \(\gamma ^N_\times (\varphi )\) is strongly consistent, asymptotically normal, and its finite sample and asymptotic variances are bounded above by those of \(\gamma ^N(\varphi )\):
where \(\mathrm{Var}\,(\mu ^{N}_\times (w\varphi ))\) and \(\sigma ^2_{\times }(w\varphi )\) are as in Theorem 1.
Proof
Replace \(\varphi \) with \(w\varphi \) in Theorem 1 and Corollary 1. \(\square \)
Corollary 2 tells us that \(\gamma ^N_\times (\varphi )\) is more statistically efficient than the conventional IS estimator \(\gamma ^N(\varphi )\) regardless of whether the target \(\gamma \) is product-form or not. In a nutshell, \(\mu _\times ^N\) is a better approximation to the proposal \(\mu \) than \(\mu ^N\) and, consequently, \(\gamma ^N_\times (dx)=w(x)\mu _\times ^N(dx)\) is a better approximation to \(\gamma (dx)=w(x)\mu (dx)\) than \(\gamma ^N(dx)=w(x)\mu ^N(dx)\). Indeed, by constructing all \(N^K\) permutations of the tuples \(X^1,\dots ,X^N\), we explore other areas of the state space. This can be particularly useful when the proposal and target are mismatched as it can amplify the number of tuples landing in the target’s high probability regions (i.e., achieving high weights w) and, consequently, substantially improve the quality of the finite sample approximation (Fig. 3).
Similarly, the self-normalized version \(\pi ^N_\times (\varphi ):=\gamma ^N_\times (\varphi )/\gamma ^N_\times (S)\) of the product-form IS estimator \(\gamma ^N_\times (\varphi )\) is a consistent and asymptotically normal estimator for averages \(\pi (\varphi )\) with respect to the normalized target \(\pi :=\gamma /\gamma (S)\). As in the case of the standard self-normalized importance sampling (SNIS) estimator \(\pi ^N(\varphi ):=\gamma ^N(\varphi )/\gamma ^N(S)\), the ratio in \(\pi ^N_\times (\varphi )\)’s definition introduces an \(\mathcal {O}(N^{-1})\) bias and stops us from obtaining analytical expression for the finite sample variance (that the bias is \(\mathcal {O}(N^{-1})\) follows from an argument similar to that given for standard SNIS in p. 35 of Liu (2001) and requires making assumptions on the higher moments of \(\varphi (X^1)\)). Otherwise, \(\pi ^N_\times (\varphi )\)’s theoretical properties are analogous to those of the product-form estimator \(\mu ^N_\times (\varphi )\) and its importance sampling extension \(\gamma ^N_\times (\varphi )\):
Corollary 3
If \(w\varphi \) lies in \(L^2_\mu \), then \(\pi ^N_\times (\varphi )\) is strongly consistent, asymptotically normal, and its asymptotic variance is bounded above by that of \(\pi ^N(\varphi )\):
where \(\sigma ^2_{\times }(\gamma (S)^{-1}w[\varphi -\pi (\varphi )])\) is as in Theorem 1.
Proof
Given Theorem 1 and Corollary 1, the arguments here follow closely those for standard SNIS. In particular, because \(\pi ^N_\times (\varphi )=\gamma ^N_\times (\varphi )/\gamma ^N_\times (S)=\mu ^N_\times (w\varphi )/\mu ^N_\times (w)\) and \(\mu (w)=\gamma (S)\),
Given that \(\mu ^N_\times (w)\) tends to \(\mu (w)\) almost surely (and, hence, in probability) as N approaches infinity (Theorem 1), the strong consistency and asymptotic normality of \(\pi ^N_\times (\varphi )\) then follow from those of \(\mu ^N_\times (\gamma (S)^{-1}w[\varphi -\pi (\varphi )])\) (Theorem 1) and Slutsky’s theorem. The asymptotic variance bound follows from that in Corollary 1. \(\square \)
This type of approach is best suited for targets \(\pi \) possessing at least some product structure. The structure manifest itself in partially factorized weight functions w and substantially lowers the evaluation costs of \(\gamma ^N_\times (\varphi )\) and \(\pi ^N_\times (\varphi )\) for simple test functions \(\varphi \), as the following example illustrates.
Example 5
(A simple hierarchical model) Consider the following basic hierarchical model:
It has a single unknown parameter, the variance \(\theta \) of the latent variables \(X_1,\dots ,X_K\), which we infer using a Bayesian approach. That is, we choose a prior \(p(d\theta )\) on \(\theta \) and draw inferences from the corresponding posterior,
where \(y=(y_1,\dots ,y_K)\) denotes the vector of observations. For most priors, no analytic expressions for the normalizing constant can be found and we are forced to proceed numerically. One option is to choose the proposal
in which case
(Were we to be using standard IS instead of product-form variant, the proposal
would be the natural choice, a point we return to after the example.) Hence, to estimate the normalizing constant or any integral w.r.t. to a univariate marginal of the posterior, we need to draw samples from \(\mu \) and evaluate the product-form estimator \(\mu ^N_\times (\varphi )\) for a test function of the form \(\varphi (\theta ,x)=f(\theta )\prod _{k=1}^Kg_k(\theta ,x_k)\), the cost of which totals \(\mathcal {O}(KN^2)\) operations because
We return to this in Sect. 3.4, where we will make use of the following expression for the (unnormalized) posteriors’s \(\theta \)-marginal available due to the Gaussianity in (21):
Clearly, the above expression opens the door to simpler and more effective methods for computing integrals with respect to this marginal than estimators targeting the full posterior. However, the estimators we discuss can be applied analogously to the many commonplace hierarchical models [e.g., see Gelman and Hill (2006), Gelman (2006), Koller and Friedman (2009), Hoffman et al. (2013), Blei et al. (2003), and the many references therein] for which such expressions are not available.
When applying IS, or extensions thereof like SMC, one should choose the proposal to be as close as possible to the target [e.g., see Agapiou et al. (2017)]. In this regard, the product-form IS approach is not entirely satisfactory for the above example: by definition, the proposal must be fully factorized while the target, \(\pi \) in (22), is only partially so (the latent variables are independent only when conditioned on the parameter variable). As we show in the next section, it is straightforward to adapt this product-form IS approach to match such partially factorized targets.
3.2 Partially factorized targets and proposals
Consider a target or proposal \(\mu \) over a product space \((\Theta \times S,\mathcal {T}\times \mathcal {S})\) with the same partial product structure as the target in Example 5:
where, for each k in [K], .... \(\theta \mapsto \mathcal {M}_k(\theta ,dx_k)\) denotes a Markov kernel mapping from \((\Theta ,\mathcal {T})\) to \((S_k,\mathcal {S}_k)\). Suppose that we are given M i.i.d. samples \(\theta ^1,\dots ,\theta ^M\) drawn from \(\mu _0\) and, for each of these, N (conditionally) i.i.d. samples \(X^{m,1},\dots ,X^{m,N}\) drawn from the product kernel \(\mathcal {M}(\theta ,dx):=\prod _{k=1}^K\mathcal {M}_k(\theta ,dx_k)\) evaluated at \(\theta ^m\). Given a test function \(\varphi \) on \(\Theta \times S\), consider the following ‘partially product-form’ estimator for \(\mu (\varphi )\):
for all \(M,N>0\). It is well founded (for simplicity, we only consider the estimator’s asymptotics as \(M\rightarrow \infty \) with N fixed, but other limits can be studied by combining the approaches in Appendices A and C.
Theorem 3
If \(\varphi \) is \(\mu \)-integrable with \(\mu \) as in (26), then \(\mu ^{M,N}_\times (\varphi )\) in (27) is unbiased and strongly consistent: for all \(N>0\),
If, furthermore, \(\varphi \) belongs to \(L^2_\mu \), then \(\mathcal {M}_{[K]\backslash A}(\varphi )\) belongs to \(L^2_{\mu _0\otimes \mathcal {M}_A}\) for all subsets A of [K], where \(\mathcal {M}_A(\theta ,dx_A):=\prod _{k\in A}\mathcal {M}_k(\theta ,dx_k)\), and the estimator is asymptotically normal: for all \(N>0\), and as \(M\rightarrow \infty \),
where \(\Rightarrow \) denotes convergence in distribution and
For any \(N,M>0\), the estimator’s variance is given by \(\mathrm{Var}\,(\mu ^{M,N}_\times (\varphi ))=\sigma ^2_{\times ,N}(\varphi )/M\).
Proof
See Appendix C. \(\square \)
The partially product-form estimator (27) is more statistically efficient than its standard counterpart.
Corollary 4
For any \(\varphi \) belonging to \(L^2_\mu \) and \(N>0\),
where \(\mu ^{M,N}(\varphi ):=\frac{1}{MN}\sum _{m=1}^M\sum _{n=1}^N\varphi (\theta ^n,X^{m,n})\) and \(\sigma _{N}^2(\varphi )\) denotes its asymptotic (in M) variance.
Proof
See Appendix C. \(\square \)
In fact, modulo a small caveat (cf. Remark 1 below), \(\mu ^{M,N}_\times (\varphi )\) yields the best unbiased estimates of \(\mu (\varphi )\) achievable using only the knowledge that \(\mu \) is partially factorized and M i.i.d. samples drawn from \(\mu _0\otimes \mathcal {M}^N\): a perhaps unsurprising fact given that it is the composition of two minimum variance unbiased estimators (Theorem 2).
Theorem 4
Suppose that \(\mathcal {T}\) contains all singleton sets (i.e., \(\{\theta \}\) for all \(\theta \) in \(\Theta \)). For any given measurable real-valued function \(\varphi \) on \(\Theta \times S\), \(\mu _\times ^{M,N}(\varphi )\) is a minimum variance unbiased estimator for \(\mu (\varphi )\): if f is a measurable real-valued function on \((\Theta \times S^N)^M\) such that
whenever \((\theta ^{m},X^{m,1},\dots ,X^{m,N})_{m=1}^M\) is an i.i.d. sequence drawn from \(\mu _0\otimes \mathcal {M}^N\), for all partially factorized \(\mu =\mu _0\otimes \mathcal {M}\) on \(\Theta \times S\) satisfying \(\mu (\left| \varphi \right| )<\infty \) and
then
Proof
See Appendix D. \(\square \)
Remark 1
(The importance of (29)) Consider the extreme scenario that \(\mu _0\) is a Dirac delta at some \(\theta ^*\), so that \(\theta ^1=\dots =\theta ^M=\theta ^*\) with probability one and
In this case, we are clearly better off (at least in terms estimator variance) stacking all of our X samples into one big ensemble and replacing the partially product-form estimator with the (fully) product-form estimator,
where \((\tilde{X}^{l})_{l\in [MN]}\) denotes \((X^{m,n})_{m\in [M],n\in [N]}\) in vectorized form (indeed Theorem 2 implies that \(\mu _{\times }^{MN}(\varphi )\) is a minimum variance unbiased estimator in this situation). More generally, note that, because
\(\mu _0\) not possessing atoms, i.e., (29), is equivalent to \(\mu ^2_0(\{\theta ^1=\theta ^2\})=0\). It is then straightforward to argue that (29) is equivalent to the impossibility of several \(\theta ^m\) coinciding or, in other words, to
Were this not to be the case, the estimator in (27) would not possess the MVUE property. To recover it, we would need to amend the estimator as follows: ‘if several \(\theta ^m\)s take the same value, first stack their corresponding \(X^{m,1},\dots ,X^{m,N}\) samples, and then apply a product-form estimator to the stacked samples.’ However, to not overly complicate this section’s exposition and Theorem 4’s proof, we restrict ourselves to distributions satisfying (29).
We are now in a position to revisit Example 5 and better adapt the proposal to the target. This leads to a special case of an algorithm known as ‘importance sampling squared’ or ‘IS\(^2\)’, cf. Tran et al. (2013).
Example 6
(A simple hierarchical model, revisited) Consider again the model in Example 5. Recall that our previous choice of proposal did not quite capture the conditional independence structure in the target \(\pi \): the former was fully factorized while the latter is only partially so. It seems more natural to instead use the proposal in (24) which is also easy to sample from but both mirrors \(\pi \)’s independence structure and leads to further cancellations in the weight function (in particular, it no longer depends on \(\theta \)):
It follows that, to estimate the normalizing constant or any integral w.r.t. to a univariate marginal of the posterior, we need to draw samples from \(\mu _0\otimes \mathcal {M}^N\) and evaluate the partially product-form estimator \(\mu ^{M,N}_\times (\varphi )\) for a test function of the form \(\varphi (\theta ,x)=f(\theta )\prod _{k=1}^Kg_k(x_k)\). Because
the total cost then reduces to \(\mathcal {O}(KMN)\). We also return to this is Sect. 3.4.
3.3 Grouped independence Metropolis–Hastings
As a further example of how one may embed product-form estimators within more sophisticated Monte Carlo methodology and exploit the independence structure present in the problem, we revisit Beaumont’s Grouped Independence Metropolis–Hastings [GIMH (Beaumont 2003)], a simple and well known pseudo-marginal MCMC sampler (Andrieu and Roberts 2009). Like many of these samplers, it is intended to tackle targets whose densities cannot be evaluated pointwise but are marginals of higher-dimensional distributions whose densities can be evaluated pointwise. Our inability to evaluate the target’s density precludes us from directly applying the Metropolis–Hastings algorithm (MH, e.g., see Chapter XIII in Asmussen and Glynn (2007)) as we cannot compute the necessary acceptance probabilities. For instance, in the case of a target \(\pi (d\theta )\) on a space \((\Theta ,\mathcal {T})\) and an MH proposal \(Q(\theta ,d\tilde{\theta })\) with respective densities \(\pi (\theta )\) and \(Q(\theta ,\tilde{\theta })\), we would need to evaluate
where \(\theta \) denotes the chain’s current state and \(\tilde{\theta }\sim Q(\theta ,\cdot )\) the proposed move. GIMH instead replaces the intractable \(\pi (\theta )\) and \(\pi (\tilde{\theta })\) in the above with importance sampling estimates thereof: if \(\pi (\theta ,x)\) denotes the density of the higher-dimensional distribution \(\pi (d\theta ,dx)\) whose \(\theta \)-marginal is \(\pi (d\theta )\), and \(w(\theta ,x):=\pi (\theta ,x)/\mathcal {M}(\theta ,x)\) for a given Markov kernel \(\mathcal {M}(\theta ,dx)\) with density \(\mathcal {M}(\theta ,x)\),
where \(X^{1},\dots ,X^N\) and \(\tilde{X}^1,\dots ,\tilde{X}^N\) are i.i.d. samples drawn from \(\mathcal {M}(\theta ,\cdot )\) and \(\mathcal {M}(\tilde{\theta },\cdot )\), respectively Key in Beaumont’s approach is that the samples are recycled from one iteration to another: if \(Z^1,\dots ,Z^N\) and \(\tilde{Z}^1,\dots \tilde{Z}^N\) denote the i.i.d. samples used in the previous iteration, then \((X^1,\dots ,X^N):=(Z^1,\dots ,Z^N)\) if the previous move was rejected and \((X^1,\dots ,X^M):=(\tilde{Z}^1,\dots ,\tilde{Z}^N)\) if it was accepted.
As explained in Andrieu and Roberts (2009) [see also Andrieu and Vihola (2015)], the algorithm’s correctness does not require the density estimates to be generated by (31), only for them to be unbiased. In particular, if the estimates are unbiased, GIMH may be interpreted as an MH algorithm on an expanded state space with an extension of \(\pi (d\theta )\) as its invariant distribution. Consequently, provided that the density estimator is suitably well behaved, GIMH returns consistent and asymptotically normal estimates of the target under conditions comparable to those for standard MH algorithms [e.g., the GIMH chain is uniformly ergodic whenever the associated ‘marginal’ chain is and the estimator is uniformly bounded (Andrieu and Roberts 2009); see Andrieu and Vihola (2015) for further refinements]. Consequently, if the kernel is product-form (i.e., \(\mathcal {M}(\theta ,dx)\) is product-form for each \(\theta \)), we may replace the estimators in (31) with their product-form counterparts:
where K denotes the dimensionality of the x-variables (the unbiasedness follows from \(X^{\varvec{n}}\) and \(\tilde{X}^{\varvec{n}}\) having respective laws \(\mathcal {M}(\theta ,dx)\) and \(\mathcal {M}(\tilde{\theta },d\tilde{x})\) for any \(\varvec{n}\) in \([N]^K\)). Thanks to the results in Andrieu and Vihola (2016), it is straightforward to show that this choice leads to lower estimator variances, at least asymptotically.
Corollary 5
Let \((\theta ^{m,N})_{m=1}^\infty \) and \((\theta _\times ^{m,N})_{m=1}^\infty \) denote the GIMH chains generated using (31) and (32), respectively, and the same proposal \(Q(\theta ,d\theta )\). If \(\varphi \) belongs to \(L^2_\pi \), then
Proof
See Appendix E. \(\square \)
Given the argument used in the proof, the results of Andrieu and Vihola (2016), Theorem 10 in particular, imply much more than the variance bound in the corollary’s statement. For instance, if the target is not concentrated on points, then the spectral gap of \((\theta ^{m,N}_\times )_{m=1}^\infty \) is bounded below by that of \((\theta ^{m,N})_{m=1}^\infty \). We finish the section by returning to our running example.
Example 7
(A simple hierarchical model, re-revisited) Here, we follow Sect. 5.1 in Schmon et al. (2020). Consider once again the model in Example 5 and suppose we are interested only in the posterior’s \(\theta \)-marginal \(\pi (d\theta )\). Choosing
the weight function factorizes,
resulting in an evaluation cost of \(\mathcal {O}(KN)\) for (31, 32) and, regardless of which density estimates we use, a total cost of \(\mathcal {O}(KMN)\) where M denotes the number of steps we run the chain for. We return to this in the following section.

Empirical cumulative density functions for \(\pi (d\theta )\) obtained using the eight approximations discussed in the text (black solid lines). As guides, we also plot a high-quality approximation \(\pi _{REF}(d\theta )\) using (25) and quadrature, and the pointwise absolute difference between \(\pi _{REF}\) and the eight approximations (grey lines). Insets Wasserstein-1 distance (W\(_1\)) between \(\pi _{REF}\) and the panel’s approximation (area under the grey line, e.g., see p. 64 in Shorack and Wellner (2009)) and corresponding Kolmogorov–Smirnov statistic (KS, maximum of the grey line)
3.4 Numerical comparison
Here, we apply the estimators discussed throughout Sects. 3.1–3.3 to the simple hierarchical model introduced in Example 5 and we examine their performance. To benchmark the latter, we choose the prior to be conditionally conjugate to the model’s likelihood: \(p(d\theta )\) is the Inv-Gamma\((\alpha /2,\alpha \beta /2)\) distribution, in which case
and we can alternatively approximate the posterior, \(\pi (d\theta ,dx)\) in (22), using a Gibbs’ sampler. Note that the above expressions are unnecessary for the evaluation of the estimators in Sects. 3.1–3.3. To compare with standard methodology that also does not requires such expressions, we also approximate the posterior using Random Walk Metropolis (RWM) with the proposal variance tuned so that the mean acceptance probability (approximately) equals 25%. To keep the comparison honest, we run these two chains for \(N^2\) steps and set \(M=N\) for the estimators in Sects. 3.2 and 3.3 ; in which case all estimators incur a similar \(\mathcal {O}(KN^2)\) cost. We further fix \(K:=100\), \(\alpha :=1\), \(\beta :=1\), and \(N:=100\) and generate artificial observations \(y_1,\dots ,y_{100}\) by running (21) with \(\theta :=1\).
Figure 4 shows approximations to the posteriors’s \(\theta \)-marginal \(\pi (d\theta )\) obtained using a Gibbs sampler, RWM, IS (Sect. 3.1), IS\(^2\) (Sect. 3.2), GIMH (Sect. 3.3), and the last three’s product-form variants (PFIS, PFIS\(^2\), and PFGIMH, respectively). In the cases of Gibbs, RWM, GIMH, and PFGIMH, we used a 20% burn-in period and approximated the marginal with the empirical distribution of the \(\theta \)-components of the states visited by the chain. For GIMH and PFGIMH, we also used a random walk proposal with its variance tuned so that the mean acceptance probability hovered around 25%. For IS, PFIS, IS\(^2\), and PFIS\(^2\), we used the proposals specified in Examples 5 and 6 and computed the approximations using
(Note that for IS, we are using \(N^2\) samples instead of N so that its cost is also \(\mathcal {O}(KN^2)\).)
Our first observation is that the approximations produced by IS, IS\(^2\), and GIMH are very poor. The first two exhibit severe weight degeneracy (in either case, a single particle had over 50% of the probability mass and three had over 90%), something unsurprising given the target’s moderately high dimension of 101.Footnote 2 The third possesses a pronounced spurious peak close to zero (with over 70% of the mass) caused by large numbers of rejections in that vicinity. Replacing the i.i.d. estimators embedded within these algorithms with their product-form counterparts removes both the weight degeneracy and the spurious peak; PFIS, PFIS\(^2\), and PFGIMH return much improved approximations. The best approximation is the one returned by the Gibbs sampler: an expected outcome given that the sampler’s use of the conditional distributions makes it the estimator most ‘tailored’ or ‘well adapted’ to the target. However, these distributions are not available for most models (precluding application of these samplers to such models) and even just taking the, usually obvious, independence structure into account can make a substantial difference: the quality of the approximations returned by PFIS and PFIS\(^2\) exceeds the quality of that returned by the common, or even default, choice of RWM. Note that this is the case even though the proposal variance in RWM was tuned, while that in the other two was simply set to 1 (a reasonable choice given that \(\theta =1\) was used to generate the data, but likely not the optimal one). In fact, for this simple model, it is easy to sensibly incorporate observations into the PFIS and PFIS\(^2\) proposals [e.g., use \(p(d\theta )\prod _{k=1}^K\mathcal {N}(dx_k;y_k,1)\) for PFIS and \(p(d\theta )\prod _{k=1}^K\mathcal {N}(dx_k; y_k\theta [1+\theta ]^{-1},\theta [1+\theta ]^{-1})\) for PFIS\(^2\)] and potentially improve their performance.
To benchmark the approaches more thoroughly, we generated \(R:=100\) replicates of the eight full posterior approximations and computed various error metrics (Tables 1 and 2). For the \(\theta \)-component, we used the high-quality reference approximation \(\pi _{REF}\) described in Fig. 4’s caption to obtain the average (across repeats) W\(_1\) distance and KS statistic (as described in the caption), and the average absolute error of the posterior mean and standard deviation estimates normalized by the true mean or standard deviation (i.e., \(M_\theta ^{-1}R^{-1}\sum _{r=1}^{R}\left| M^r_\theta -M_\theta \right| \) for the posterior mean estimates, where \(M_\theta \) denotes the true mean and \(M^r_\theta \) the \(r^{th}\) estimate thereof, and similarly for the standard deviation estimates). For the x-components, we instead used high-accuracy estimates for the component-wise means and standard deviations (obtained by running a Gibbs sampler for \(N^4=10^8\) steps) to compute the corresponding total absolute errors across replicates and components (\(\sum _{k=1}^K\sum _{r=1}^{R}\left| M^{r}_{k}-M_{k} \right| \), where \(M_k\) denotes the true mean for the \(k^{th}\) x-component and \(M^r_k\) the rth estimate thereof, and similarly for the standard deviation estimates).
Once again, the product-form estimators far outperformed their i.i.d. counterparts. Moreover, they perform just as well or better than RWM. PFIS\(^2\)’s estimates are particularly accurate: a fact that does not surprise us given that its proposal has the same partially factorized structure as the target, in this sense making it the best adjusted estimator to the problem. That is, best except for the Gibbs sampler which exploits the conditional distributions (encoding more information than this structure). We conclude with an interesting detail: PFIS\(^2\) and PFIS perform similarly when approximating the \(\theta \)-marginal (cf. Table 1), but PFIS\(^2\) outperforms PFIS when approximating the latent variable marginals (cf. Table 2). This is perhaps not too surprising because, in the case of the \(\theta \)-marginal approximation, both PFIS\(^2\) and PFIS employ the same number N of \(\theta \)-samples, while, in that of \(k^{th}\) latent variable, PFIS\(^2\) uses \(N^2\) \(x_k\)-samples and PFIS uses only N such samples.
4 Discussion
The main message of this paper is that when using Monte Carlo estimators to tackle problems possessing some sort of product structure, one should endeavor to exploit this structure and improve the estimators’ performance. The resulting product-form estimators are not a panacea for the curse of dimensionality in Monte Carlo, but they are a useful and sometimes overlooked tool in the practitioner’s arsenal and make certain problems solvable when they otherwise would not be. More specifically, whenever the target, or proposal, we are drawing samples from is product-form, these estimators achieve a smaller variance than their conventional counterparts. In our experience (e.g., Examples 2 and 4), the gap in variance grows exponentially with dimension whenever the integrand does not decompose into a sum of low-dimensional functions like in the trivial case (14). For the reasons given in Sect. 2.2, we expect the variance reduction to be further accentuated by targets that are ‘spread out’ rather than peaked.
The gains in statistical efficiency come at a computational price: in the absence of exploitable structure in the test function, product-form estimators incur an \(\mathcal {O}(N^K)\) cost limiting their applicability targets of dimension \(K\le 10\), while conventional estimators only carry an \(\mathcal {O}(N)\) cost (although in practice the cost of obtaining reasonable estimates using the latter often scales poorly with K, with the effect hidden in the proportionality constant, e.g., Examples 2 and 4). Hence, for general test functions, product-form estimators are of most use when the variance reduction is particular pronounced or when samples are expensive to acquire (both estimators require drawing the same number N of samples) or store [as, for example, when one employs physical random numbers and requires reproducibility Owen (2009)]. In the latter case, product-form estimators enable us to extract the most possible from the samples we have gathered so far: by permuting the samples’ components, the estimators artificially generate further samples. Of course, the more permutations we make, the more correlated our sample ensemble becomes and we get a diminishing returns effect that results in an \(\mathcal {O}(N^{-1/2})\) rate of convergence instead of the \(\mathcal {O}(N^{-K/2})\) rate we would achieve using \(N^K\) independent samples. There is a middle ground here that remains unexplored: using \(N<M<N^K\) permutations instead of all \(N^K\) possible, so lowering the cost to \(\mathcal {O}(M)\) at the expense of some of the variance reduction [see Lin et al. (2005) or Lindsten et al. (2017) for similar ideas in the Monte Carlo literature]. In particular, by choosing the M permutations so that the correlations among them are minimized (e.g., the M permutations with least overlap among their components), it might be possible to substantially reduce the cost without sacrificing too much of the variance reduction. Indeed, by setting the number M of permutations to be such that M evaluations of the test function incurs a cost comparable to that of generating the N unpermuted tuples, one can ensure that the overall cost of the resulting estimator never greatly exceeds that of the conventional estimator. This type of approach has been studied in the sparse grid literature (Gerstner and Griebel 1998) and is closely related to the theory of incomplete U-statistics (cf. Chapter 4.3 in Lee (1990)), an area in which there are ongoing efforts directed at designing good reduced-cost estimators [e.g., see Kong and Zheng (2021)].
There are, however, settings in which product-form estimators should be applied without hesitation: if the integrand is a sum of products (SOP) of univariate functions, the cost comes down to \(\mathcal {O}(N)\) without affecting the variance reduction (Sect. 2.4). For instance, when estimating ELBO gradients to optimize mean-field approximations (Ranganath et al. 2014) of posteriors \(e^{v}\) with SOP potentials v. More generally, if the test function is a sum of partially factorized functions, the estimators’ evaluation costs can often be substantially reduced (see also Sect. 2.4) so that the variance reduction far outweighs the more mild increases in cost. For instance, as we saw with the applications of importance sampling and its product-form variant in Sect. 3.4.
For integrands lacking this sort of structure, and at the expense of introducing some bias, these types of cost reductions can sometimes be retained if one is able to find a good SOP approximation to the integrand (Example 4). How to construct these approximations for generic functions (or for function classes of interest in given applications) is an open question upon whose resolution the success of this type of approach hinges. In reality, combining product-form estimators with SOP approximations amounts to nothing more than an approximate dimensionality reduction technique: we approximate a high-dimensional integral with a linear combination of products of low-dimension integrals, estimate each of the latter separately, and plug the estimates back into the linear combination to obtain an estimate of the original integral. It is certainly not without precedents: for instance, Rahman and Xu (2004), Ma and Zabaras (2009), Gershman et al. (2012), and Braun and McAuliffe (2010) all propose, in rather different contexts, similar approximations except that the low-dimensional integrals are computed using closed-form expressions or quadrature (for a very well known example, see the delta method for moments in Oehlert (1992)). In practice, the best option will likely involve a mix of these: use closed-form expressions where available, quadrature where possible, and Monte Carlo (or Quasi Monte Carlo) for everything else.
About the computational resources required to evaluate product-form estimators, and the allocation thereof, we ought to mention one interesting variant of the estimators that we omitted from the main text to keep the exposition simple. Throughout we assumed that the same number of samples are drawn from each marginal \(\mu _1,\dots ,\mu _K\) of the product-form target or proposal \(\mu \). This need not be the case: straightforward extensions of our arguments show that the estimator
behaves much as (4) does, even if a different number of samples \(N_k\) are used per marginal \(\mu _k\). This variant potentially allows us to concentrate our computational budget on ‘the most important dimensions,’ an idea that has found significant success in other areas of numerical integration [e.g., see Gerstner and Griebel (1998, 2003) or Owen (1998)]. In our case, this could be done using the pertinent generalizations of the variance expressions in Theorem 1, which are identical except that \(N^{\left| A \right| }\) therein must be replaced by \(\prod _{k\in A}N_k\) (these can be obtained by retracing the steps in the theorem’s proof). In particular, one could estimate the terms in these expressions and adjust the sample sizes so that the estimator variance is minimized, potentially in an iterative manner leading to an adaptive scheme.
Combining product-form estimators with other Monte Carlo methodology expands their utility beyond product-form targets. We illustrated this in Sect. 3 by describing the three simplest and most readily accessible combinations we could think of: their merger with importance sampling applicable to targets that are absolutely continuous with respect to fully factorized distributions (Sect. 3.1), that with importance sampling squared applicable to targets that are absolutely continuous with respect to partially factorized distributions (Sect. 3.2, see also Tran et al. (2013)), and that with pseudo-marginal MCMC applicable to targets with intractable densities (Sect. 3.3, see also Schmon et al. (2020)). In all of these cases, we demonstrated theoretically that the resulting estimators are more statistically efficient than their standard counterparts (Corollaries 2–5). Many other extensions are possible. For instance, one can embed product-form estimators within random weight particle filters (Rousset and Doucet 2006; Fearnhead et al. 2008, 2010)—and, more generally, algorithms reliant on unbiased estimation—much the same way we did for IS\(^2\) and GIMH in Sects. 3.2–3.3. For an example of a slightly different vein, see Appendix F where we consider ‘mixture-of-product-form’ estimators applicable to targets which are mixtures of product-form distributions and, by combining these with importance sampling, we obtain a product-form version of (stratified) mixture importance sampling estimators (Oh and Berger 1993; Hesterberg 1995) that is particularly appropriate for multimodal targets. For further examples, see the divide-and-conquer SMC algorithm (Lindsten et al. 2017; Kuntz et al. 2021) obtained by combining product-form estimators with SMC and Tensor Monte Carlo (Aitchison 2019) obtained by merging the estimators with variational autoencoders.
When choosing among the resulting (and at times bewildering) constellation of estimators, we recommend following one simple principle: pick estimators that somehow ‘resemble’ or ‘mirror’ the target. Good examples of this are well parametrized Gibbs samplers which generate new samples using the target’s exact conditional distributions and, consequently, often outperform other Monte Carlo algorithms (e.g., Sect. 3.4). While for many targets these conditional distributions cannot be obtained (nor are good parametrizations known), their (conditional) independence structure is usually obvious [e.g., see Gelman and Hill (2006), Gelman (2006), Koller and Friedman (2009), Hoffman et al. (2013), Blei et al. (2003), and the many references therein] and can be mirrored using product-form estimators within one’s methodology of choice. Indeed, in the case of the simple hierarchical model (Example 5), it was the PFIS\(^2\) estimator utilizing samples with exactly the same independence structure as the model’s that performed best (besides the Gibbs sampler). Of course, this model’s independence structure was particularly simple, and so were the resulting estimators. However, we believe that broadly the same considerations apply to models with more complex structures and that product-form estimators can be adapted to such structures by following analogous steps.
To summarize, we believe that product-form estimators are of greatest use not on their own, but embedded within more complicated Monte Carlo routines to tackle the aspects of the problem exhibiting product structure. There remains much work to be done in this direction.
Notes
On our \(\mathcal {O}\) notation: The exact dependence on dimension of the estimators’ evaluation costs depends on that of the test function \(\varphi \). Hence, when discussing a generic \(\varphi \), we say that the estimator’s evaluation cost is \(\mathcal {O}(N^d)\) for some d to mean that it is \(\mathcal {O}(f(K)N^d)\) for some unspecified factor f(K) factor independent of that accounts for \(\varphi \)’s evaluation cost. When discussing classes of \(\varphi \) for which this factor is clear, we specify it. For example, we say that evaluation cost of the rightmost term in (2) is \(\mathcal {O}(KN)\) rather than \(\mathcal {O}(N)\).
One may wonder whether in the case of IS, the degeneracy could instead be due to our use of the proposal (23) rather than the more natural choice (24). It is not: the average W\(_1\) distance and KS statistic (see Fig. 4’s caption for definitions) across 100 replicates of the \(\pi (d\theta )\)’s approximation obtained using (24) and IS (with \(N^2\) samples) were 32.7 and 82.3%, respectively. In other words, a modest improvement over IS with proposal (23) (compare with Table 1), but not one sufficient to break the degeneracy: 83 approximations (out of 100) had at least 50% of their mass concentrated in 2 particles (out of 10, 000) and all but 7 had over 80% of their mass concentrated in 10 particles.
References
Agapiou, S., Papaspiliopoulos, O., Sanz-Alonso, D., et al.: Importance sampling: intrinsic dimension and computational cost. Stat. Sci. 32(3), 405–431 (2017). https://doi.org/10.1214/17-STS611
Aitchison, L.: Tensor Monte Carlo: particle methods for the GPU era. Adv. Neural Inf. Process. Syst. 32, 7148–7157 (2019)
Anderson, D.F., Craciun, G., Kurtz, T.G.: Product-form stationary distributions for deficiency zero chemical reaction networks. Bull. Math. Biol. 72(8), 1947–1970 (2010). https://doi.org/10.1007/s11538-010-9517-4
Andrieu, C., Roberts, G.O.: The pseudo-marginal approach for efficient Monte Carlo computations. Ann. Stat. 37(2), 697–725 (2009). https://doi.org/10.1214/07-AOS574
Andrieu, C., Vihola, M.: Convergence properties of pseudo-marginal Markov chain Monte Carlo algorithms. Ann. Appl. Probab. 25(2), 1030–1077 (2015). https://doi.org/10.1214/14-AAP1022
Andrieu, C., Vihola, M.: Establishing some order amongst exact approximations of MCMCs. Ann. Appl. Probab. 26(5), 2661–2696 (2016). https://doi.org/10.1214/15-AAP1158
Asmussen, S., Glynn, W.: Stochastic Simulation: Algorithms and Analysis. Springer, New York (2007). https://doi.org/10.1007/978-0-387-69033-9
Beaumont, M.A.: Estimation of population growth or decline in genetically monitored populations. Genetics 164(3), 1139–1160 (2003). https://doi.org/10.1093/genetics/164.3.1139
Bengtsson, T., Bickel, P., Li, B.: Curse-of-dimensionality revisited: collapse of the particle filter in very large scale systems. In: Probability and Statistics: Essays in Honor of David A. Freedman, vol. 2, pp. 316–334. Institute of Mathematical Statistics (2008). https://doi.org/10.1214/193940307000000518
Blei, D.M., Ng, A.Y., Jordan, M.I.: Latent Dirichlet allocation. J. Mach. Learn. Res. 3, 993–1022 (2003)
Blei, D.M., Kucukelbir, A., McAuliffe, J.D.: Variational inference: a review for statisticians. J. Am. Stat. Assoc. 112(518), 859–877 (2017). https://doi.org/10.1080/01621459.2017.1285773
Braun, M., McAuliffe, J.: Variational inference for large-scale models of discrete choice. J. Am. Stat. Assoc. 105(489), 324–335 (2010). https://doi.org/10.1198/jasa.2009.tm08030
Cappelletti, D., Wiuf, C.: Product-form Poisson-like distributions and complex balanced reaction systems. SIAM J. Appl. Math. 76(1), 411–432 (2016). https://doi.org/10.1137/15M1029916
Chopin, N., Papaspiliopoulos, O.: An Introduction to Sequential Monte Carlo. Springer, Cham, (2020). https://doi.org/10.1007/978-3-030-47845-2
Clémençon, S.: On U-processes and clustering performance. Adv. Neural. Inf. Process. Syst. 24, 37–45 (2011)
Clémençon, S., Lugosi, G., Vayatis, N.: Ranking and empirical minimization of U-statistics. Ann. Stat. 36(2), 844–874 (2008). https://doi.org/10.1214/009052607000000910
Clémençon, S., Colin, I., Bellet, A.: Scaling-up empirical risk minimization: optimization of incomplete U-statistics. J. Mach. Learn. Res. 17(76), 1–36 (2016)
Dick, J., Kuo, F.Y., Sloan, I.H.: High-dimensional integration: the quasi-Monte Carlo way. Acta Numer. 22, 133–288 (2013). https://doi.org/10.1017/S0962492913000044
Efron, B., Stein, C.: The Jackknife estimate of variance. Ann. Stat. 9(3), 586–596 (1981). https://doi.org/10.1214/aos/1176345462
Fearnhead, P., Papaspiliopoulos, O., Roberts, G.O.: Particle filters for partially observed diffusions. J. R. Stat. Soc. Ser. B Methodol. 70(4), 755–777 (2008). https://doi.org/10.1111/j.1467-9868.2008.00661.x
Fearnhead, P., Papaspiliopoulos, O., Roberts, G.O., et al.: Random-weight particle filtering of continuous time processes. J. R. Stat. Soc. Ser. B Methodol. 72(4), 497–512 (2010). https://doi.org/10.1111/j.1467-9868.2010.00744.x
Gelman, A.: Prior distributions for variance parameters in hierarchical models (comment on article by Browne and Draper). Bayesian Anal. 1(3), 515–534 (2006). https://doi.org/10.1214/06-BA117A
Gelman, A., Hill, J.: Data Analysis using Regression and Multilevel/Hierarchical Models. Cambridge University Press (2006). https://doi.org/10.1017/CBO9780511790942
Gershman, S.J., Hoffman, M.D., Blei, D.M.: Nonparametric variational inference. In: Proc. 29th Int. Conf. Mach. Learn., pp. 235–242 (2012)
Gerstner, T., Griebel, M.: Numerical integration using sparse grids. Numer. Algorithms 18(3), 209–232 (1998). https://doi.org/10.1023/A:1019129717644
Gerstner, T., Griebel, M.: Dimension-adaptive tensor-product quadrature. Computing 71(1), 65–87 (2003). https://doi.org/10.1007/s00607-003-0015-5
Gretton, A., Borgwardt, K.M., Rasch, M.J., et al.: A kernel two-sample test. J. Mach. Learn. Res. 13(25), 723–773 (2012)
Hall, P., Marron, J.S.: Estimation of integrated squared density derivatives. Stat. Probab. Lett. 6(2), 109–115 (1987). https://doi.org/10.1016/0167-7152(87)90083-6
Halmos, P.R.: The theory of unbiased estimation. Ann. Math. Stat. 17(1), 34–43 (1946). https://doi.org/10.2307/2235902
Hesterberg, T.: Weighted average importance sampling and defensive mixture distributions. Technometrics 37(2), 185–194 (1995). https://doi.org/10.1080/00401706.1995.10484303
Hoeffding, W.: A class of statistics with asymptotically normal distribution. Ann. Math. Stat. 19(3), 293–325 (1948). https://doi.org/10.1214/aoms/1177730196
Hoeffding, W.: A non-parametric test of independence. Ann. Math. Stat. 19(4), 546–557 (1948). https://doi.org/10.2307/2236021
Hoffman, M.D., Blei, D.M., Wang, C., et al.: Stochastic variational inference. J. Mach. Learn. Res. 14(1), 1303–1347 (2013)
Jackson, J.R.: Networks of waiting lines. Oper. Res. 5(4), 518–521 (1957). https://doi.org/10.1287/opre.5.4.518
Kelly, F.P.: Reversibility and Stochastic Networks, 1st edn. Wiley, Chichester (1979)
Koller, D., Friedman, N.: Probabilistic Graphical Models: Principles and Techniques. The MIT Press (2009)
Kong, X., Zheng, W.: Design based incomplete U-statistics. Stat. Sin. 31(3), 1593–1618 (2021). https://doi.org/10.5705/ss.202019.0098
Korolyuk, V.S., Borovskich, Y.V.: Theory of U-Statistics. Springer (1994)
Kowalski, J., Tu, X.M.: Modern Applied U-Statistics. Wiley-Blackwell (2007). https://doi.org/10.1002/9780470186466
Kuntz J, Crucinio FR, Johansen AM (2021) The divide-and-conquer sequential Monte Carlo algorithm: theoretical properties and limit theorems. ArXiv preprint arXiv:2110.15782
Lee, A.J.: U-Statistics: Theory and Practice. CRC Press (1990)
Lin, M.T., Zhang, J.L., Cheng, Q., et al.: Independent particle filters. J. Am. Stat. Assoc. 100(472), 1412–1421 (2005). https://doi.org/10.1198/016214505000000349
Lindsten, F., Johansen, A.M., Naesseth, C.A., et al.: Divide-and-Conquer with sequential Monte Carlo. J. Comput. Graph. Stat. 26(2), 445–458 (2017). https://doi.org/10.1080/10618600.2016.1237363
Liu, J.S.: Monte Carlo Strategies in Scientific Computing. Springer, New York (2001). https://doi.org/10.1007/978-0-387-76371-2
Liu, Q., Lee, J., Jordan, M.: A kernelized Stein discrepancy for goodness-of-fit tests. In: Proc. 33rd Int. Conf. Mach. Learn., pp. 276–284 (2016)
Ma, X., Zabaras, N.: An adaptive hierarchical sparse grid collocation algorithm for the solution of stochastic differential equations. J. Comput. Phys. 228(8), 3084–3113 (2009). https://doi.org/10.1016/j.jcp.2009.01.006
McLeish, D.: A general method for debiasing a Monte Carlo estimator. Monte Carlo Methods Appl. 17(4), 301–315 (2011). https://doi.org/10.1515/mcma.2011.013
Oehlert, G.W.: A note on the delta method. Am. Stat. 46(1), 27–29 (1992). https://doi.org/10.1080/00031305.1992.10475842
Oh, M.S., Berger, J.O.: Integration of multimodal functions by Monte Carlo importance sampling. J. Am. Stat. Assoc. 88(422), 450–456 (1993). https://doi.org/10.1080/01621459.1993.10476295
Owen, A.B.: Monte Carlo extension of quasi-Monte Carlo. In: Proc. 1998 Winter Simul. Conf., pp. 571–577 (1998). https://doi.org/10.1109/WSC.1998.745036
Owen, A.B.: Recycling physical random numbers. Electron. J. Stat. 3, 1531–1541 (2009). https://doi.org/10.1214/09-EJS541
Owen, A.B.: Monte Carlo theory, methods and examples (2013). https://statweb.stanford.edu/~owen/mc/
Rahman, S., Xu, H.: A univariate dimension-reduction method for multi-dimensional integration in stochastic mechanics. Probab. Eng. Mech. 19(4), 393–408 (2004). https://doi.org/10.1016/j.probengmech.2004.04.003
Ranganath, R., Gerrish, S., Blei, D.: Black box variational inference. In: Proc. 17th Int. Conf. Artif. Intell. Stat., pp. 814–822 (2014)
Rhee, C.H., Glynn, P.W.: Unbiased estimation with square root convergence for SDE models. Oper. Res. 63(5), 1026–1043 (2015). https://doi.org/10.1287/opre.2015.1404
Rousset, M., Doucet, A.: Discussion of “Exact and computationally efcient likelihood-based estimation for discretely observed diffusion processes” by Beskos, Papaspiliopoulos, Roberts and Fearnhead. J. R. Stat. Soc. Ser. B Methodol. 68(3), 375–376 (2006). https://doi.org/10.1111/j.1467-9868.2006.00552.x
Schmon, S.M., Deligiannidis, G., Doucet, A., et al.: Large-sample asymptotics of the pseudo-marginal method. Biometrika 108(1), 37–51 (2020). https://doi.org/10.1093/biomet/asaa044
Shorack, G.R., Wellner, A.W.: Empirical processes with applications to statistics. SIAM (2009). https://doi.org/10.1137/1.9780898719017
Silverman, B.W.: Density estimation for statistics and data analysis, Monographs on Statistics and Applied Probability, vol. 26. CRC Press (1986)
Snyder, C., Bengtsson, T., Bickel, P., et al.: Obstacles to high-dimensional particle filtering. Mon. Weather Rev. 136(12), 4629–4640 (2008). https://doi.org/10.1175/2008MWR2529.1
Stroud, A.H.: Approximate Calculation of Multiple Integrals. Prentice-Hall (1971)
Tran MH, Scharth M, Pitt MK, et al (2013) Importance sampling squared for Bayesian inference in latent variable models. ArXiv preprint arXiv:1309.3339
Wand, M.P., Jones, M.C.: Multivariate plug-in bandwidth selection. Comput. Stat. 9(2), 97–116 (1994)
Acknowledgements
JK and AMJ acknowledge support from the Engineering and Physical Sciences Research Council (EPSRC; Grant # EP/T004134/1) and the Lloyd’s Register Foundation Programme on Data-Centric Engineering at the Alan Turing Institute. FRC acknowledges support from the EPSRC and the Medical Research Council OXWASP Centre for Doctoral Training (Grant # EP/L016710/1). FRC and AMJ acknowledge further support from the EPSRC (Grant # EP/R034710/1).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kuntz, J., Crucinio, F.R. & Johansen, A.M. Product-form estimators: exploiting independence to scale up Monte Carlo. Stat Comput 32, 12 (2022). https://doi.org/10.1007/s11222-021-10069-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11222-021-10069-9