
Abstract
Software engineering (SE) experiments suffer from threats to validity that may impact their results. Replication allows researchers building on top of previous experiments’ weaknesses and increasing the reliability of the findings. Illustrating the benefits of replication to increase the reliability of the findings and uncover moderator variables. We replicate an experiment on test-driven development (TDD) and address some of its threats to validity and those of a previous replication. We compare the replications’ results and hypothesize on plausible moderators impacting results. Differences across TDD replications’ results might be due to the operationalization of the response variables, the allocation of subjects to treatments, the allowance to work outside the laboratory, the provision of stubs, or the task. Replications allow examining the robustness of the findings, hypothesizing on plausible moderators influencing results, and strengthening the evidence obtained.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Isolated experiments are being run in software engineering (SE) to assess the performance of different treatments (i.e., tools, technologies, or processes). However, isolated experiments suffer from several shortcomings (Gómez et al. 2014): (1) results may be imprecise (as the number of participants is typically low in SE experiments); (2) results might be artifactual (e.g., influenced by the programming environment rather than the treatments themselves); (3) results cannot be generalized to different contexts rather than those of the experiment; (4) results may be impacted by the materialization of unforeseen threats to validity (e.g., rivalry threat, when the effectiveness of the less “desirable” treatment gets penalized by the participants’ disinterest).
Replication of experiments may help to overcome such limitations (Shepperd 2016). For example, replications’ designs can be tweaked to overcome the threats to validity of previous experiments. This allows comparing the replications’ results and hypothesizing on whether the replications’ threats to validity might have materialized or not. Besides, replications allow the systematic variation of specific elements from baseline experiments’ configurations (e.g., the experimental task). This allows studying the effect of such changes on results, and thus, elicit moderator variables (i.e., variables rather than the treatments impacting the results (Juristo and Vegas 2009)).
As an illustrative example, here we show how we run a replication that overcame the weaknesses of a series of experiments on test-driven development (TDD) (Beck 2003). TDD is an agile software development process that enforces the creation of software systems by means of small testing-coding-refactoring cycles (Beck 2003). TDD advocates have attributed it several benefits, being the most claimed its ability to deliver high-qualityFootnote 1 software (Beck 2003). This is because, according to TDD advocates, TDD’s continuous in-built testing and refactoring cycles create an ever-growing safety net (i.e., a test bed) on which software systems rest (Beck 2003). Learning about TDD’s effectiveness in terms of quality may assist practitioners when deciding which development approach to use in their daily practice.
Specifically, we run a replication of Erdogmus et al.’s experiment on TDD (Erdogmus et al. 2005). Erdogmus et al.’s experiment has already been replicated by Fucci and Turhan (2013) retaining the same experimental design, but changing the operationalization of the response variable (i.e., quality). Even though it is not possible to rule out all the validity threats in any experiment (Shull et al. 2002), here we illustrate how it is possible increasing the robustness of the findings by running replications that overcome previous experiments’ threats to validity.
Specifically, by means of an illustrative case, here we show how to:
Build on top of previous results and increase the reliability of the findings of a series of replications—by addressing several threats to validity of earlier experiments.
Assess whether potential threats to validity may have materialized in previous experiments and observe the stability of the findings.
Identify moderator variables and propose further lines of research based on such findings.
This paper is organized as follows. In Section 2, we show the related work on replication in SE and also the related work on the effectiveness of TDD in terms of quality. In Section 3, we provide an overview of the characteristics and results of the baseline experiment and its close replication. In Section 4, we report the characteristics and results of the replication on TDD that we run. In Section 5, we compare the results and settings of the experiments and uncover potential moderators. Finally, Section 6 concludes.
2 Related work
First, we show the related work on replication (see Section 2.1). Then, we show the related work on the empirical studies on TDD (see Section 2.2).
2.1 Replication in SE
The role of replication in SE has been largely argued (Bezerra et al. 2015; Da Silva et al. 2014; de Magalhâes et al. 2015; Gómez et al. 2014; Kitchenham 2008). Phrases such as “...replication is the repetition of an experiment to double-check its results...” (Juristo and Vegas 2009) or “...a replication is a study that is run,..., whose goal is to either verify or broaden the applicability of the results of the initial study...” (Shull et al. 2004) are common in the literature. Summarizing, replications are traditionally seen in SE as a way of either increasing the reliability of the original findings or generalizing baseline experiments’ results to different contexts.
Different types of replications may serve better than others for certain purposes (Gómez et al. 2014; Kitchenham 2008). For example, identical replications (Gómez et al. 2014) may serve for verifying previous experiments’ results. On their side, conceptual replications (i.e., replications only sharing baseline experiment’s research questions and objectives) may serve for demonstrating “that an effect is robust to changes with subjects, settings, and materials...” (Kitchenham 2008).
Even though many classifications have been proposed in SE to categorize the different types of replications that can be run (Gómez et al. 2014), Gomez et al. (Gómez et al. 2014) propose to classify replications according to the dimensions that they changed with regard to baseline experiments:
Operationalization refers to the operationalization of the treatments, metrics, and measurement procedures (e.g., response variables, test cases).
Population refers to the participants’ characteristics (e.g., skills and backgrounds).
Protocol refers to the “apparatus, materials, experimental objects, forms, and procedures” used (e.g., tasks, session length).
Experimenters refers to the personnel involved (e.g., the trainer, the analyst).
We will use such classification to categorize the replication on TDD we report along this article.
2.2 Empirical studies on TDD
Empirical studies on TDD have studied different quality attributes (Munir et al. 2014a; Rafique and Mišić 2013; Shull et al. 2010). However, external quality seems the most researched so far (Munir et al. 2014a; Rafique and Mišić 2013; Shull et al. 2010). External quality is typically measured by means of acceptance test cases. The larger the number of acceptance test cases passed by an application, the larger its external quality (Rafique and Mišić 2013).
Munir et al. classified the empirical studies on TDD according to their rigor and relevance (Munir et al. 2014a). Rigor was defined as the adherence to good research and reporting practices. Relevance was defined as the practical impact and realism of the setup. Based on rigor and relevance, Munir et al. mapped the studies on TDD into a 2 × 2 grid classification (high rigor/high relevance, etc.) (Munir et al. 2014a). The nine studies in the high rigor and relevance category (industry and academic case studies and surveys) show improvements in external quality. Studies with high relevance and low rigor (industry and academic case studies) obtained similar results. Studies with low relevance and high rigor (experiments and one case study with students) mostly show no differences in terms of external quality between TDD and other development approaches. The results of studies with low relevance and rigor (experiments, a survey, and a case study with students) show both positive and neutral effects for TDD.
On their side, Shull et al. classified the studies on TDD in three categories (Shull et al. 2010): (1) controlled experiments; (2) pilot studies or small studies in industry; and (3) industry studies (i.e., studies on real projects under commercial pressures). After classifying the studies, Shull et al. claim that there is moderate evidence that TDD tends to improve external quality (Shull et al. 2010). However, they note that the inconclusive—and at times contrary—results reached in the studies might arise due to the different constructs used to measure the response variables, the different control treatments (waterfall, iterative test last, etc.), differences across environments, or the varying participants’ expertise.
The above reviews include different types of empirical studies on TDD (surveys, case studies, experiments, etc.). This might have had an impact on the conclusions reached. However, a systematic literature review was performed by Rafique and Misic (2013), including only experiments on TDD, and a series of meta-analyses (Borenstein et al. 2011) show that TDD appears to result in quality improvements (being such improvement much larger in industry than in academia (Rafique and Mišić 2013)). Also, Rafique and Misic mention that differences across experiments’ results might be due to the different control treatments applied (waterfall, iterative test last, etc.).
These observations seem to point towards the necessity of running experiments on TDD relying on similar technological environments, participant expertise, control treatments, and response variables’ operationalizations. A systematic approach towards replication on TDD’s experiments may strengthen the reliability of the findings and shed light on plausible reasons for the contradictory results observed in the literature.
3 Baseline experiment and previous replication
Along this section, we provide an overview of the settings and results of the baseline experiment on TDD (i.e., Erdogmus et al. (2005), BE onwards) and its close replication (i.e., Fucci and Turhan(2013), RE1 onwards). We follow Carver’s guidelines for reporting experimental replications (Carver 2010).
3.1 Research question and response variable
The independent variable across the replications is development approach (with TDD or ITL as the treatments). Both TDD and ITL follow the same iterative steps (i.e., decomposing the specification into small programming tasks, coding, test generation, execution, and refactoring). The only difference is the order in which the tests are created: before coding in TDD and after coding in ITL.
BE and RE1 share the same research question:
RQ: Do programmers produce higher quality programs with TDD than with ITL?
The same response variable is studied in BE and RE1: quality. The calculation of quality in BE and RE1 is based on “user stories.” User stories do not follow the traditional notion of XP’s user story (i.e., a short, high-level feature scenario written from the perspective of a particular user role, in the language of the user, with a series of success criteria typically tested with black-box acceptance test cases at the application level). Instead, user stories refer to small chunks of functionality that need implementing from a task. User stories are tested in BE and RE1 with user stories’ test suites. A user story’s test suite contains multiple test cases. A test case is comprised by one or more assert statements. Again, test cases do not follow the traditional notion of XP’s acceptance test case (i.e., typically a black-box test). Instead, test cases refer to small white box test cases that may overlap with the functionality being tested in traditional acceptance test cases.
As an example, let us imagine a task where the participants have to code some functionality that simulates a robot’s behavior in a multi-dimensional grid. A user story included within such task may be related to the “movement of the robot along the grid”. Test cases such as “test the movement of a robot to the upper left limit of the grid” or “test the movement of the robot to the upper right limit of the grid” may be testing the correct implementation of such user story. The test case to “test the movement of a robot to the upper right limit of the grid” might be comprised by two assert statements:
- 1.
Asserting whether the robot can perform multiple movements up until the upper part of the grid:
robot.init(“(0,0)”);
robot.move(“N”,10);
assert.equals(robot.getPosition(), “(10,0)”).
- 2.
Asserting whether the robot can perform movements to the right:
robot.move(“R”,10);
assert.equals(robot.getPosition(), “(10,10)”).
Quality is considered in BE and RE1 as the average quality of the delivered functionality. However, slightly different criteria have been considered for measuring QLTY across the replications. Such criteria are as follows.
BE’s calculation for QLTY requires the calculation of the quality metric of each user story (QLTYi). The quality of each user story (QLTYi) is given by the percentage of asserts from the user story’s test suite that passes. A user story is considered as delivered if at least 50% of the assert statements from such user story’s test suite pass. In the computation of QLTY, only delivered user stories are taken into account. In particular, QLTY is obtained from averaging all user stories’ QLTY (QLTYi) by their respective weight (being each weight is a proxy of the user stories’ difficulty based on the total number of asserts in the global test suite).
RE1’s researchers decided to drop the weights associated with each user story. However, as in BE, RE1’s researchers consider a user story as delivered if at least 50% of the user story’s tests pass. Overall quality (QLTY) is calculated as the average quality of the delivered user stories.
Table 1 shows a summary of the metrics used across the replications.
3.2 Participants
BE’s participants were twenty-four third-year undergraduate students taking an 8-week Java course at Politecnico di Torino, Italy. The course was part of the BSc. in Computer Science program. During the course, all the students learned object oriented and Java programming, basic design concepts (including UML), and unit testing with JUnit.
In RE1, a total of 33 graduate and 25 undergraduate students took part. The participants were from the department of Information Processing Science at the University of Oulu, Finland, and they were participating at a graduate-level course about software quality and testing. The course was comprised by 63-h lab sessions, where the participants learned about the Eclipse IDE, JUnit, Java, refactoring tools, and TDD.
3.3 Design
BE’s experiment was structured as a 2-group between-subjects design. The treatment group applied TDD, whereas the control group applied ITL.
BE’s participants’ skills were measured with a questionnaire delivered before the experiment took place. Afterwards, BE’s participants were stratified into three groups attending to their skills (low, medium, high) and then assigned to either ITL or TDD. Thirteen subjects ended up programming with ITL and 11 with TDD, totaling 24 experimental units.
BE’s participants were allowed to work on the task inside and outside the laboratory. The participants were only trained on the development approach they needed to apply (either ITL or TDD). Subjects were encouraged to adhere to the assigned development approach as closely as possible during the experiment. When the experiment concluded, the subjects were trained in the other development approach (ITL if they applied TDD and vice versa).
RE1’s experiment was also set up as a 2-group between-subjects design. Some subjects were grouped in pairs (11 in total) due to space restrictions. Subjects were randomly distributed to either ITL or TDD. Four pairs and 16 individuals ended up in the ITL group. Seven pairs and 20 individuals ended up in the TDD group. This totals to 47 experimental units. Subjects were trained in both ITL and TDD before the experimental session. Subjects were allowed to work on the task only in the laboratory.
3.4 Artifacts
BE’s and RE1’s task was a modified specification of Robert Martin’s Bowling Score Keeper (BSK) (Martin 2001). BSK was already used in previous experiments on TDD (Fucci et al. 2015; George and Williams 2004; Munir et al. 2014b). BSK’s goal is calculating the score of a single bowling game. BSK is algorithm-oriented and greenfield. It does not involve the creation of a graphic user interface (GUI). BSK does not require prior knowledge of bowling scoring rules; this knowledge is embedded in the specification.
BE’s participants were given 8 h (or more if needed) to finalize the task. Some functionality related to data input and output was dropped from RE1’s task to adapt its length to the experimental session time. However, the rest of RE1’s task specification was identical to BE’s. RE1’s participants were given 3 h to finalize the task. Despite the use of toy tasks—such as BSK—undermines the realism of the settings (at least compared with case studies, where fully edged applications are typically developed over the course of months with TDD (Rafique and Mišić 2013)), this allows studying the effectiveness of TDD in a controlled environment. This translates into greater control over external variables that may impact the results (such as the use of different IDEs, programming languages). In sum, this translates into sacrificing external validity for the sake of internal validity.
BE’s test suite was comprised by 105 test cases consisting of over 350 asserts. RE1’s test suite was formed by 48 test cases consisting of 56 asserts covering 13 user stories.
3.5 Context variables
BE’s laboratory was comprised by computers with Internet access, the Eclipse IDE (2016), JUnit (Massol and Husted 2003), and an in-built CVS client (Cederqvist et al. 2002). Subjects were not given a Java stub to quick start the experimental task.
RE1’s laboratory was similar to BE’s, but without a CVS client. Besides, a Java stub was delivered to the subjects so they could reduce the burden of setting up the environment before beginning the actual task implementation.
3.6 Summary of results
The difference in quality between TDD and ITL was not statistically significant in BE or RE1. However, ITL slightly outperformed TDD in BE, and the opposite happened in RE1.
4 Replication
Along this section, we report the replication on TDD that we run (i.e., RE2, onwards). Again, we follow Carver’s guidelines for reporting replications (Carver 2010).
4.1 Motivation for conducting the replication
RE2’s motivation was overcoming the potential limitations posed by BE’s and RE1’s threats to validity on results. Also, learning the effect of systematic experimental design changes on results. For this, we went over the replications’ designs and reflected on their shortcomings and points for improvement.
For example, BE’s and RE1’s research question (i.e., do programmers produce higher quality programs with TDD than with ITL?) tests the hypothesis that TDD is superior to ITL. However, to the best of our knowledge, there is no theory stating so. Besides, the evidence in the literature is conflicting (i.e., as positive, negative, and neutral results have been obtained). Thus, to avoid running into a threat to conclusion validity due to the directionality of the effect (as the difference in performance between TDD and ITL with a one-tailed test is more likely to be statistically significant than with a two-tailed test if TDD outperforms ITL (Cumming 2013)), we removed the directionality of the effect in the research question.
Asides, BE’s subjects were divided into three groups (low, medium, or high) based on their skills before being randomized to either ITL or TDD. This was made to balance out the distribution of the subjects’ skills to the treatments. Unfortunately, BE’s authors did not report which skills they measured—or how they measured them. Besides, there were no clear cutoff points between different categories (low, medium, or high) or a clear definition of how skill levels were combined to classify a subject within a specific category. RE1 overcame this threat to internal validity by assigning the subjects to the treatments without considering a preliminary set of skills (i.e., by means of full randomization). However, they incurred into another threat to internal validity (i.e., confounding), as some participants were grouped into pairs due to a lack of computer stations. We avoided both threats to validity by making the participants code alone and applied both treatments twice.
Nuisance factors outside the researchers’ control could have affected BE’s results—as the participants were allowed to work outside the laboratory. RE1 overcame this threat to internal validity by only allowing the participants to work inside the laboratory. Our replication follows such improvement.
Another difference across the replications is the maximum allowed time given to the participants to implement the task: 8 h or more in BE, 3 h in RE1, and 2 h and 25 min in RE2. By reducing the experimental session’s length, it is possible avoiding fatigue’ potential effect on results. Such time reduction was possible due to the provision of stubs in RE1 and RE2.
BE’s and RE1’s thresholds for considering a user story as delivered (i.e., 50% of the user story’s assert statements) are artificial and may have impacted quality results. We address this threat to construct validity in RE2 as we set no threshold for measuring quality (see below).
BE’s user stories’ weighting is another threat to construct validity—as such weights are subjective and dependent upon the test suite implementer. User stories’ weighting was removed in RE1 and R2.
BE’s and RE1’s participants only code one task. This results in a low external validity of results. In RE2, we improve the external validity of the results by using four tasks. This will allow studying the effectiveness of TDD for different tasks.
BE’s and RE1’s participants only apply one treatment. A threat to internal validity named compensatory rivalry threat might have materialized (i.e., loss of motivation due to the application of the less desirable treatment, in this case ITL). RE2’s subjects applied both treatments (ITL and TDD) instead of only one. This rules out the possible influence of the compensatory rivalry threat.
RE1’s subjects were trained in both TDD and ITL before the experimental session. This might pose a threat to internal validity: leakage from one development approach to another may materialize if subjects apply a mixed development approach in either the TDD or ITL group. This issue was addressed in BE (as subjects were only trained in their assigned treatment before the experimental session). We also addressed such threat to validity in RE2 by training the subjects only in the treatment to be immediately applied afterwards.
BE’s participants are undergraduate students. This poses a threat to the generalization of the results to other types of developers. RE1’s participants are a mixture of undergraduate and graduate students. Although this affords greater external validity, it poses a threat to internal validity due to confounding with subject type. All RE2’s participants were graduate students instead of undergraduate students: this may increase the external validity of results.
Table 2 shows the threats to validity of the experiments that were overcome in further replications. Rows with positive sign (+) represent improvements upon the experimental settings marked with negative sign (−).
As Table 2 shows, RE1 still suffers from threats to validity present in BE. Besides, RE1 also falls into a construct and internal threat that was not present in BE. RE2 overcame validity issues from both experiments (Gómez et al. 2014).
4.2 Level of interaction with original experimenters
We used Fucci et al.’s BSK task and its test suite. We had no interaction with Erdogmus et al.
4.3 Changes to the previous replications
According to the classification suggested by Gomez et al. (2014), RE2 modified all BE’s and RE1’s dimensions:
Operatationalization: because the response variable’s (i.e., quality) operationalization was changed.
Population: because the population changed from undergraduate to graduate students.
Protocol: because the tasks and session lengths were modified.
Experimenter: because the replications were run and analyzed by different researchers.
In the following, we provide greater detail on the changes made.
4.3.1 Research question and response variable
We are not aware of any theory indicating that TDD produces higher quality software than ITL. Thus, we removed the directionality of BE’s and RE1’s RQ. In particular, we restate RE2’s RQ as:
RQ: Do programmers produce equal quality programs with TDD and ITL?
RE2’ response variable is quality. We measured quality with acceptance test suites that we (i.e., the experimenters) developed. We used a standardized metric to measure quality: functional correctness. Functional correctness is one of the sub-characteristics of quality defined in ISO 25010 and is described as “the degree to which a system provides the correct results with the needed degree of precision” (ISO/IEC 25010:2011 2011). We measure functional correctness as the proportion of passing assert statements (#assert(pass)) over the total number of assert statements (#assert(all)). Specifically:
We regard this metric as more straightforward than that used in BE and RE1. First, because it does not require any subjective threshold (e.g., 50% of assert statements passing to consider a functionality as delivered). Second, because QLTY is no longer bounded between 50 and 100%, and, instead, can vary across the whole percentage interval (0–100%). Third, because our metric measures overall quality and not the quality of the delivered functionality. Thus, subjects delivering smaller amounts of high quality functionality are “penalized” compared with those delivering larger amounts of high quality functionality. A 1-week seminar on TDD was held at the Universidad Politécnica de Madrid (UPM) in March 2014. A total of 18 graduate students took part in the seminar. They all had a varying degree of experience in software development and unit testing skills. All subjects were studying for a MSc. in Computer Science or Software Engineering at the Universidad Politécnica de Madrid (UPM). Master’s students were free to join the seminar to earn extra credits for their degree program. The seminar was not graded.
Participants were informed that they were taking part in an experiment, that their data were totally confidential, and that they were free to drop out of the experiment at any time.
Before the experiment was run, the participants filled in a questionnaire. Such questionnaire asked the participants about their previous experience with programming, Java, unit testing, JUnit, and TDD. Specifically, subjects were allowed to select one of four experience values: no experience (< 2 years); novice (≤ 2 and < 5 years); intermediate (≤ 5 and < 10 years); expert (≤ 10 years). We code such experience levels with numbers between 1 and 4 (novice,..., expert). Table 3 shows RE2’s participants’ experience levels.
As Table 3 shows, most of the subjects had 5 to 10 years of experience with programming (mode = 3) and from 2 to 5 years of experience with Java (mode = 2). Besides, the participants had little experience with unit testing or JUnit: fewer than 2 years (mode = 1). Their experience with TDD was also limited (fewer than 2 years).
4.3.2 Design
RE2’s experiment was structured as 4 sessions within-subjects design. Within-subjects designs over advantages over between-subjects designs (Brooks 1980): (1) reduced variance, and thus, greater statistical power because of the study of within subjects rather than across subject differences; (2) increased number of data points, and thus, greater statistical power as each subject has as many measurements as experimental sessions; (3) subject abilities—over or below the norm—have the same impact on all the treatments (as all subjects are exposed to all the treatments).
RE2’s 18 subjects applied ITL and TDD twice in non-consecutive sessions (ITL was applied on the first and third day, whereas TDD on the second and fourth). Thus, up to a total of 18 experimental units multiplied by four sessions (72 experimental units) could be potentially used to study ITL vs. TDD. Subjects were given training according to the order of application of the treatments. Subjects only worked in the laboratory.
4.3.3 Artifacts
The participants coded four different tasks (i.e., BSK, SDK, MR, and MF).
BSK’s specifications were reused from Fucci and Turhan (2013). Appendix A shows BSK’s specification.
SDK is a greenfield programming exercise that requires the development of various checking rules against a proposed solution for a Sudoku game. Specifically, subjects must deal with string and matrix operations and with embedding such functionalities inside a single API method. We provide the SDK’s specifications in Appendix B.
MR is a greenfield programming exercise that requires the development of a public interface for controlling the movement of a fictitious vehicle on a grid with obstacles. MR is a popular exercise used by the agile community to teach and practice unit testing. Appendix C contains MR’s specifications.
MF is an application intended to run on a GPS-enabled, MP3-capable mobile phone. It resembles a real-world system with a three-tier architecture (graphical user interface, business logic, and data access). The system consists of three main components that are created and accessed using the singleton pattern. Event handling is implemented using the observer pattern. Subjects were given a description of the legacy code, including existing classes, their APIs, and a diagram of the system architecture (see Appendix D).
Table 4 shows the number of user stories, test cases, and asserts for each task’s test suite.
4.3.4 Context variables
The experiment was run in a laboratory with computers running a virtual machine (VM) (Oracle 2015) with the Eclipse IDE (2016), JUnit (Massol and Husted 2003), and a web browser. Due to time restrictions, subjects received a Java stub to help them jump start with the implementation.
4.4 Analysis approach
We run the data analysis with IBM SPSS Statistics Version 24. First, we provide descriptive statistics and box plots for QLTY. Then, we analyze the data with a linear marginal model (LMM). LMMs are linear models in which the residuals are not assumed to be independent of each other or have constant variance (West et al. 2014). Instead, LMMs can accommodate different variances and covariances across time points (i.e., each of the experimental sessions). LMMs require normally distributed residuals. In the absence of normality, data transformations can be used (e.g., Box-Cox transformations (Vegas et al. 2016)).
Particularly, we fitted a LMM with the following factors: development approach, task, and development approach by task. We included the factor task and its interaction with the development approach to reduce the unexplained variance of the model. After fitting various LMMs with different variance-covariance matrix structures, we selected the unstructured matrixFootnote 2 as the best fit to the data. This was done according to the criterion of lower 2 log likelihood and to West et al.’s suggestion (West et al. 2014).
We report the differences in quality across development approaches, tasks, and development approaches within tasks. Afterwards, we check the normality assumption of the residuals with the Kolmogorov-Smirnov test and the skewness and kurtosis z-score (Field 2009).Footnote 3 Finally, we use QQ plots to check the residuals’ normality assumption.
We complement the statistical results with Hedge’s g effect sizes (Cook et al. 1979; Hedges and Olkin 2014) (Cohen’s d small sample size correction (Cohen 1977)) and their respective 95% confidence intervals (95% CIs). This may facilitate the incorporation of the results in further meta-analyses (Borenstein et al. 2011). We report Hedge’s g due to its widespread use in SE (Kampenes et al. 2007) and its intuitive interpretation: the amount of standard deviations that one experimental group’s mean deviates from another.
4.5 Data analysis
In this section, we show the results of RE2’s data analysis. Beware that two subjects dropped from the experiment after the first experimental session, which left us with a dropout rate of 12.5%. Another two subjects did not deliver any working solution along the experimental sessions, and thus, we removed their data from the final dataset. In sum, after pre-processing, a total of 14 subjects made it to the analysis phase.
4.5.1 Descriptive statistics
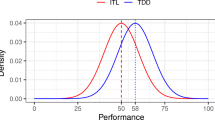
Table 5 shows the descriptive statistics for QLTY with TDD and ITL. As Table 5 shows, TDD has a lower mean and standard deviation for QLTY than ITL. This can also be seen in the box plot for QLTY with TDD and ITL (Fig. 1). However, the 95% CIs for the means overlap. Thus, quality seems similar for TDD and ITL.

QLTY by development approach: box plot
Table 6 reports the descriptive statistics for QLTY grouped by task and development approach. Figure 2 shows the corresponding box plot.

QLTY by task and development approach: box plot
As Table 6 shows, MR is the task with the lowest mean QLTY regardless of the development approach. Furthermore, there seems to be a large variability in the QLTY means across development approaches within tasks. As we can see in Table 6, mean quality within MR varies across development approaches with a 1:2.4 ratio (i.e., 15.168/6.367), while such variation seems smaller for BSK, MF, and SDK (ratios of 1:1.24, 1:1.47, and 1:1.66 respectively). Furthermore, ratios reverse depending upon the task (i.e., ITL’s mean QLTY score is lower than TDD’s in MR and BSK, and the opposite in MF and SDK). Thus, an interaction may be taking place.
4.5.2 Hypothesis testing
We fitted a LMM to analyze the data. According to the Kolmogorov-Smirnov test (p value = 0.007) and the skewness z-score (Zskewness = 2:10), the residuals seem to depart from normality. However, the normality Q-Q plot suggests that the residuals follow a normal distribution—despite a few outlying scores at the extremes of the distribution (see Appendix E).
Due to the stability of the results after applying the Box-Cox transformation, the observation that most of the residuals seem to be following a normal distribution, and the heightened complexity of interpreting the results after data transformations (Jørgensen and Pedersen 1998), here we continue interpreting the statistical results of the LMM fitted with the untransformed data. Table 7 shows the statistical significance of the factors fitted in the LMM.
As Table 7 shows, task has a statistically significant effect on QLTY at the 0.05 level (p < 0:05). Development approach*task has a statistically significant effect on QLTY at the 0.1 level (p value = 0.086). Development approach has no statistically significant effect on QLTY. As a summary of the results:
Development approaches seem to behave similarly in terms of QLTY. However, the task under development seems to moderate the effect of the development approach for QLTY. In other words, the task being developed seems to influence the difference in effectiveness between TDD and ITL.
4.5.3 Effect sizes
To ease the comparison of results with BE and RE1, here we report the effect sizes for each task. Table 8 shows that effect sizes vary from medium to large across the tasks. The largest effect size was obtained for SDK, while MF has the smallest effect size (in terms of magnitude). TDD appears to outperform ITL for MR and BSK, while the opposite happens for MF and SDK. As a summary, even though none of the effect sizes is statistically significant (as all the 95% CIs of the effect sizes cross 0), there is an observable heterogeneity of effect sizes across the tasks (as already noticed in the data analysis).
4.6 Threats to validity
In this section, we report RE2’s threats to validity following Wohlin et al.’s conventions (Wohlin et al. 2012). We prioritize the threats to validity according to Cook and Campbell’s guidelines (Cook et al. 1979).
Conclusion validity concerns the statistical analysis of results (Wohlin et al. 2012).
We provide visual and numerical evidence with regard to the validity of the required statistical assumptions. We performed data transformations (i.e., Box-Cox transformations) so as to assess the robustness of the findings. As the results were consistent across statistical analyses, for simplicity’s sake, we interpreted the untransformed data’s statistical analysis. Interested readers in the analysis of the transformed data may request them contacting the authors.
The random heterogeneity of the sample threat might have materialized, since the software development experience of the participants ranged from a few months to 10 years. This might have biased the results towards the average performance in both populations, thus resulting in non-significant results.
Internal validity is the extent to which the results are caused by the treatments and not by other variables beyond researchers’ control (Wohlin et al. 2012).
A threat to internal validity results from the participants’ usage of a non-familiar programming environment (e.g., OS and IDE). However, we tried to mitigate this threat by making all the participants use the same environment during the experiment. We expect, thus, that the environment has an equal impact on both treatments—and, thus, does not affect results.
There is a potential maturation threat: the course was a 5-day intensive course on TDD and contained multiple exercises and laboratories. As a result, factors such as tiredness or inattention might be at work. To minimize this threat, we offered the students to choose the schedule that best suited their needs before starting the experiment. We also ensured that subjects were given enough breaks. However, this threat might have materialized due to the drop in quality observed with TDD in the last session (Friday).
Training leakage effect may have distorted results. Even though this training leakage effect was out of the question in the first session (as the subjects were only trained in the development approaches when necessary), it was a possibility in the second, third, and fourth sessions. In particular, subjects might have applied a mixed development approach when they had knowledge of both development approaches. They may have also applied their preferred technique. To mitigate this threat to validity, we encouraged subjects to adhere to the development approaches as closely as possible in every experimental session.
There was also the possibility of a diffusion threat: since subjects perform different development tasks in each experimental session, they could compare notes at the end of the sessions. This would give them knowledge in advance about the tasks to code in the following days. This could lead to an improvement in their performance. To mitigate this threat, we encouraged subjects not to share any information on the tasks until the end of the 5-day training course. Furthermore, we informed the subjects that their performance was not going to have an impact on their grades. Thus, we believe that the participants did not share any information as requested. Since quality dropped in the second application of TDD, we are confident that this threat did not materialize.
Additionally, our experiment was exposed to the attrition threat (loss of two participants).
Construct validity refers to the correctness in the mapping between the theoretical constructs to be investigated and the operationalizations of the variables in the study.
The study suffers from the mono-method bias threat since only one metric was used to measure the response variable (i.e., quality). This issue was mitigated by interpreting the results jointly with BE and RE1 (see below).
The concepts underlying the cause construct used in the experiment appear to be clear enough to not constitute a threat. The TDD cycle was explained according to the literature (Beck 2003). However, some articles point out that TDD is a complex process and might not be consistently applied by developers (Aniche and Gerosa 2010). Conformance to the development approaches is one of the big threats to construct validity that might have materialized in this and most (if not all) other experiments on TDD. However, we tried to minimize this threat to validity by supervising the students while they coded and encouraging them to adhere as closely as possible to the development approaches taught during the laboratory.
There are no significant social threats, such as evaluation apprehension: all subjects participated on a voluntary basis in the experiment and were free to drop out of the sessions if they so wished.
External validity relates to the possibility of generalizing the study results beyond the study’s objects and subjects (Wohlin et al. 2012).
The experiment was exposed to the selection threat since we could not randomly select participants from a population; instead, we had to rely on convenience sampling. Convenience sampling is an endemic threat in SE experiments. This issue was taken into account when reporting the results, acknowledging that the findings are only valid for developers with no previous experience in TDD.
Java was used as the programming language for the experimental sessions and measuring the response variable with acceptance test suites. This way, we addressed possible threats regarding the use of different programming languages to measure the response variable. However, this limits the validity of our results to this language only.
Three out of the four tasks (MR, BSK, and SDK) used in the experiment were toy greenfield tasks. This affects the generalizability of the results and their applicability in industrial settings. The task domain might not be representative of real-life applications, and the duration of the experiment (2 h and 15 min to perform each task) might have had an impact on the results. We acknowledge that this might be an obstacle to the generalizability of the results outside the artificial setting of a laboratory. We take this into account when reporting our findings, as they are only valid for toy tasks.
We acknowledge as a threat to validity the use of students as subjects: however, this threat was minimized as they are graduate students close to the end of their educational programs. Even so, this still limits the generalization of our results beyond novice developers.
5 Comparison of results across replications
Table 9 shows the results achieved across the replications for the research question—both in terms of statistical significance and effect size.
As Table 9 shows, RE1’s and RE2’s results are consistent for BSK (ITL<TDD). However, such results are inconsistent with BE’s (ITL>TDD). This may be due to differences between BE’s settings and both RE1’s and RE2’s common settings. Let us focus on the differences among BE, RE1, and RE2 and their settings, and discuss whether such differences may have impacted the results (i.e., let us look for moderator variables).
The directionality of the statistical test in BE and RE1 seems not to have affected the results. This is because the difference in effectiveness between TDD and ITL was not statistically significant in any replication. This suggests that the threat to conclusion validity did not materialize neither in BE nor RE1.
We hypothesized that the participants applying ITL in BE and RE1 might be less motivated than those applying TDD—perhaps due to ITL’s lower desirability in an experiment on TDD. This may have distorted results. RE2 overcame such shortcoming as we made the participants apply both development approaches twice. RE2’s results were similar to RE1’s. However, as BE’s results are the opposite, we cannot assess whether the disagreement comes from the materialization of such threat or because other confounding factors. This could be studied in posterior replications.
In RE1, there were two confounding factors that might have affected the results: pair programming (as some subjects were paired due to space restrictions) and the participation of a mixture of graduate and undergraduate students. After eliminating such confounding factors in RE2, we noticed that RE2’s results were similar to RE1’s. However, we cannot ascertain whether such confounding factors affected RE1’s results. This is because RE1’s results do not match BE’s—where no confounding is in place either. We pose the disagreement between BE’s and RE2’s results to the different populations in the experiments—undergraduates in BE and graduates in RE2. However, this is only a hypothesis that needs further studying.
While BE’s participants could work inside and outside the laboratory, RE1’s and RE2’s participants were only allowed to work inside the laboratory. The differences in results observed across BE and both RE1 and RE2 suggest that this threat to validity may have materialized in BE. This suggests that TDD seems to outperform ITL in controlled environments, while TDD’s performance tends to deteriorate to a larger extent than ITL’s in uncontrolled environments. The stubs provided in RE1 and RE2 may have had a positive impact on the quality achieved with TDD. We make such observation because TDD outperforms ITL whenever stubs are provided—and vice versa when not, as in BE. However, we should be cautious making such interpretation. This is because the experimental session length also varied along the provision of stubs. Besides, the influence of such time reduction could not be assessed because the experimental session length was changed across all the replications. Thus, no combination of replications allowed assessing the stability of the findings after fixing session length. Again, the impact of session length on results shall be assessed in subsequent replications.
BE’s participants were assigned to either the ITL or TDD groups based on an ad hoc skill set. RE1 overcame this threat to validity by assigning the participants to the treatments by means of full randomization. RE2 by making all the participants applies both development approaches twice. As BE’s results and those of RE1 and RE2 do not match, this may suggest BE’s participant assignment based on skills may have had an impact on results.
We noticed that leakage was possible from one treatment to another in RE1. In particular, RE1’s participants might apply a mixed development approach in the experiment—as they were trained in both development approaches before the experimental session. This was solved in BE and in RE2 by only training the participants in the development approach to be applied in the immediate experimental session. However, while RE2’s results match RE1’s, they disagree with BE’s results. Such contradicting results may point towards the presence of other confounding variables impacting the results.
RE2’s within-subjects design materialized an additional threat to validity: carry over (i.e., the impact of the application of one treatment over another). In particular, as the participants already applied ITL before TDD, this may have boosted TDD’s effectiveness. Even though RE2’s results match RE1’s—where carry over is not possible—both disagree with BE’s—where carry over is neither possible. Again, such contradicting results shall be further investigated in posterior replications.
Despite RE1 used an arbitrary threshold for considering a user story as delivered (i.e., 50% of assert statements passed), RE1’s results and RE2’s agree. However, we do not know whether the variation of such element impacted the results—as the 50% threshold was also used in BE, and contradictory results were reached with regard to RE1. This issue shall be investigated in posterior replications.
BE’s user story weights may have had an impact on results because RE1’s and RE2’s results match (and they do not use such weights for measuring QLTY), and they are contrary to BE’s.
Mono-operation bias materialized in BE and RE1 because the participants only coded BSK. RE2’s different tasks (MR, MF, and SDK) made it possible studying TDD’s and ITL’s performance under a larger array of coding problems. RE2’s results suggested that the direction and magnitude of the effect size depend upon the task. In other words, some tasks favor TDD (MR and BSK) and others ITL (MF and SDK). This was not previously noticed in BE and RE1, and adds to the body of evidence.
Table 10 shows the threats to validity of the replications—grouped by the dimension to which they belong—and an assessment of their possible impact on results. As we can see, five different sources of variability may have impacted the replications’ results: the allowance to work outside the laboratory in BE, the allocation of subjects to treatments (assignment attending to skills in BE), the lack of stubs in BE, the weighting element used in the construct for QLTY in BE, and mono-operation bias in BE and RE1. The directionality of the statistical tests seems not to have any impact on the results, while the impact of the rest of the elements could not be assessed.
6 Conclusions and future work
Experiments on TDD tend to provide conflicting results (i.e., positive, negative, and neutral) in terms of external quality. This could be due to the many dimensions in which the experiments vary (e.g., experimental design, artifacts, context variables). A systematic approach towards replication may help to stabilize the experiments’ results and facilitates the discovery of previously unknown moderator variables.
We run a replication of Erdogmus et al.’s experiment on TDD (Fucci and Turhan 2013). Such experiment was already replicated by Fucci and Turhan (2013). We tweaked our replication’s design to overcome the threats to validity of the previous experiments. We also purposely varied our replication’s tasks to increase the external validity of results (i.e., by making the participants code four, instead of one task). This strengthened the evidence obtained and allowed us to see that the allowance to work outside the laboratory, the provision of stubs, the allocation of subjects to treatments, the operationalization of the response variable, and the task being developed may be affecting TDD experiments’ results on software quality.
As others did before (Offutt 2018), we propose as a further line of research to conduct replications studying other response variables rather than external quality (e.g., internal quality, maintainability). We also propose to study which tasks’ characteristics make them more suitable to be developed with TDD. This may assist practitioners when choosing development methods to create new pieces of software.
In sum, by means of an illustrative example, we showed how replications allow increasing the reliability of the findings and hypothesizing on moderator variables. By reflecting upon previous experiment’s limitations, it is possible tweaking replications’ designs and overcoming previous experiments’ weaknesses. This may aid to strengthen the evidence of the results and to uncover yet to explore lines of research.
Notes
Along this article, we focus on external quality as it is the most researched quality attribute across the literature on TDD (Rafique and Mišić 2013). We will use the terms “external quality” and “quality” interchangeably along the rest of the article.
With different within-subject variances and covariances across residuals.
Remember that the skewness and kurtosis values should be zero in a normal distribution. These scores can be converted to z-scores by dividing them by their standard error; if the resulting score is greater than 1.96, the result is significant (Field 2009). However, a significant test does not necessarily indicate whether the deviation from normality is enough to bias the statistical procedure applied to the data (Field 2009), as the significance level depends heavily on sample size (lower p values for larger sample size).
References
Aniche, M.F., Gerosa, M.A. (2010). Most common mistakes in test-driven development practice: Results from an online survey with developers. In Proceedings of the 2010 Third International Conference on Software Testing, Verification, and Validation Workshops (pp. 469–478). IEEE Computer Society.
Beck, K. (2003). Test-driven development: By example. Addison-Wesley Professional.
Bezerra, R.M., da Silva, F.Q., Santana, A.M., Magalhaes, C.V., Santos, R.E. (2015). Replication of empirical studies in software engineering: An update of a systematic mapping study. In Proceedings of the 2015 9th International Symposium on Empirical Software Engineering and Measurement (ESEM) (pp. 1–4). IEEE.
Borenstein, M., Hedges, L. V., Higgins, J. P., & Rothstein, H. R. (2011). Introduction to meta-analysis. Wiley.
Brooks, R. E. (1980). Studying programmer behavior experimentally: The problems of proper methodology. Communications of the ACM, 23(4), 207–213.
Carver, J.C. (2010). Towards reporting guidelines for experimental replications: A proposal. In 1st International Workshop on Replication in Empirical Software Engineering. Citeseer.
Cederqvist, P., Pesch, R., et al. (2002). Version management with CVS. Network Theory Ltd..
Cohen, J. (1977). Statistical power analysis for the behavioral sciences (revised ed.).
Cook, T. D., Campbell, D. T., & Day, A. (1979). Quasi-experimentation: Design & analysis issues for field settings (Vol. 351). Houghton Mifflin Boston.
Cumming, G. (2013). Understanding the new statistics: Effect sizes, confidence intervals, and meta-analysis. Routledge.
Da Silva, F. Q., Suassuna, M., França, A. C. C., Grubb, A. M., Gouveia, T. B., Monteiro, C. V., & dos Santos, I. E. (2014). Replication of empirical studies in software engineering research: a systematic mapping study. Empirical Software Engineering, 19(3), 501–557.
de Magalhâes, C. V., da Silva, F. Q., Santos, R. E., & Suassuna, M. (2015). Investigations about replication of empirical studies in software engineering: A systematic mapping study. Information and Software Technology, 64, 76–101.
Eclipse Foundation, I., IDE Documentation, E. (2016). Eclipse. http://www.eclipse.org. Accessed 2 March 2020.
Erdogmus, H., Morisio, M., & Torchiano, M. (2005). On the effectiveness of the test-first approach to programming. IEEE Trans Softw Eng, 31(3), 226–237.
Field, A. (2009). Discovering statistics using SPSS. Sage Publications.
Fucci, D., Turhan, B. (2013). A replicated experiment on the effectiveness of test-first development. In 2013 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (pp. 103–112). IEEE.
Fucci, D., Turhan, B., Oivo, M. (2015). On the effects of programming and testing skills on external quality and productivity in a test-driven development context. In Proceedings of the 19th International Conference on Evaluation and Assessment in Software Engineering (p. 25). ACM.
George, B., & Williams, L. (2004). A structured experiment of test-driven development. Information and Software Technology, 46(5), 337–342.
Gómez, O. S., Juristo, N., & Vegas, S. (2014). Understanding replication of experiments in software engineering: A classification. Information and Software Technology, 56(8), 1033–1048.
Hedges, L. V., & Olkin, I. (2014). Statistical methods for meta-analysis. Academic Press.
ISO/IEC 25010:2011 (2011). URL https://www.iso.org/obp/ui/iso:std:iso-iec:25010:ed-1:v1:en. Accessed 2 March 2020.
Jørgensen, E., Pedersen, A.R. (1998). How to obtain those nasty standard errors from transformed data-and why they should not be used.
Juristo, N., Vegas, S. (2009). Using differences among replications of software engineering experiments to gain knowledge. In Proceedings of the 2009 3rd International Symposium on Empirical Software Engineering and Measurement (ESEM) (pp. 356–366). IEEE.
Kampenes, V. B., Dyâ, T., Hannay, J. E., & Sjøberg, D. I. (2007). A systematic review of effect size in software engineering experiments. Information and Software Technology, 49(11), 1073–1086.
Kitchenham, B. (2008). The role of replications in empirical software engineering-a word of warning. Empirical Software Engineering, 13(2), 219–221.
Martin, C.(2001). Advanced principles, patterns and process of software development.
Massol, V., & Husted, T. (2003). JUnit in action. Manning Publications Co..
Munir, H., Moayyed, M., & Petersen, K. (2014a). Considering rigor and relevance when evaluating test driven development: A systematic review. Information and Software Technology, 56(4), 375–394.
Munir, H., Wnuk, K., Petersen, K., Moayyed, M. (2014b). An experimental evaluation of test driven development vs. test-last development with industry professionals. In Proceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering (p. 50). ACM.
Offutt, J. (2018). Why don’t we publish more tdd research papers? Software Testing, Verification and Reliability, 28(4), e1670.
Oracle, V. (2015). Virtualbox. User Manual-2013.
Rafique, Y., & Mišić, V. B. (2013). The effects of test-driven development on external quality and productivity: A meta-analysis. IEEE Transactions on Software Engineering, 39(6), 835–856.
Shepperd, M. (2016). Replicated results are more trustworthy. In T. Menzies, L. Williams, & T. Zimmermann (Eds.), Perspectives on data science for software engineering, chap. 10 (pp. 289–293). Morgan Kaufmann.
Shull, F., Basili, V., Carver, J., Maldonado, J.C., Travassos, G.H., Mendonça, M., Fabbri, S. (2002). Replicating software engineering experiments: addressing the tacit knowledge problem. In Empirical Software Engineering, 2002. Proceedings. 2002 International Symposium n (pp. 7–16). IEEE.
Shull, F., Mendoncça, M. G., Basili, V., Carver, J., Maldonado, J. C., Fabbri, S., Travassos, G. H., & Ferreira, M. C. (2004). Knowledge-sharing issues in experimental software engineering. Empirical Software Engineering, 9(1–2), 111–137.
Shull, F., Melnik, G., Turhan, B., Layman, L., Diep, M., & Erdogmus, H. (2010). What do we know about test-driven development? IEEE Software, 27(6), 16–19.
Vegas, S., Apa, C., & Juristo, N. (2016). Crossover designs in software engineering experiments: Bene_ts and perils. IEEE Transactions on Software Engineering, 42(2), 120–135.
West, B. T., Welch, K. B., & Galecki, A. T. (2014). Linear mixed models: A practical guide using statistical software. CRC Press.
Wohlin, C., Runeson, P., Höst, M., Ohlsson, M. C., Regnell, B., & Wesslén, A. (2012). Experimentation in software engineering. Springer Science & Business Media.
Funding
Open access funding provided by University of Oulu including Oulu University Hospital.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
ESM 1
(PDF 497 kb)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Santos, A., Vegas, S., Uyaguari, F. et al. Increasing validity through replication: an illustrative TDD case. Software Qual J 28, 371–395 (2020). https://doi.org/10.1007/s11219-020-09512-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11219-020-09512-3