
Abstract
The Sun’s activity, which is associated with the solar magnetic cycle, creates a dynamic environment in space known as space weather. Severe space weather can disrupt space-based and Earth-based technologies. Slow decadal-scale variations on solar-cycle timescales are important for radiative forcing of the Earth’s atmosphere and impact satellite lifetimes and atmospheric dynamics. Predicting the solar magnetic cycle is therefore of critical importance for humanity. In this context, a novel development is the application of machine-learning algorithms for solar-cycle forecasting. Diverse approaches have been developed for this purpose; however, with no consensus across different techniques and physics-based approaches. Here, we first explore the performance of four different machine-learning algorithms – all of them belonging to a class called Recurrent Neural Networks (RNNs) – in predicting simulated sunspot cycles based on a widely studied, stochastically forced, nonlinear time-delay solar dynamo model. We conclude that the algorithm Echo State Network (ESN) performs the best, but predictability is limited to only one future sunspot cycle, in agreement with recent physical insights. Subsequently, we train the ESN algorithm and a modified version of it (MESN) with solar-cycle observations to forecast Cycles 22 – 25. We obtain accurate hindcasts for Solar Cycles 22 – 24. For Solar Cycle 25 the ESN algorithm forecasts a peak amplitude of 131 ± 14 sunspots around July 2024 and indicates a cycle length of approximately 10 years. The MESN forecasts a peak of 137 ± 2 sunspots around April 2024, with the same cycle length. Qualitatively, both forecasts indicate that Cycle 25 will be slightly stronger than Cycle 24 but weaker than Cycle 23. Our novel approach bridges physical model-based forecasts with machine-learning-based approaches, achieving consistency across these diverse techniques.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The total number of sunspots seen in the Sun varies with an approximately 11-year cycle. This cycle itself is not a regular one, its amplitude varies with time with no particular regularity and occasionally goes through extreme phases of high or low activity (Hathaway, 2015; Saha, Chandra, and Nandy, 2022). The solar cycle plays an important role in governing space weather that in turn has major impacts on our modern society. These include disruptions of satellite operations that impact telecommunication networks and global-positioning systems, geomagnetic storms that lead to electric power grid failures and air-traffic disruptions over polar routes (Schrijver et al., 2015). The economic cost of a severe magnetic storm, say, e.g., of the magnitude of the great magnetic storm of 1859 – the Carrington event – is estimated to be greater than the economic cost of hurricane Katrina (Committee on the Societal and Economic Impacts of Severe Space Weather Events: A Workshop, 2008). Long-term solar-activity variations have stimulated the growth of the field of space climate (Nandy and Martens, 2007) with the emerging understanding that solar-activity variations have profound impacts on planetary space environments, atmospheric evolution (Bharati Das et al., 2019; Basak and Nandy, 2021), and habitability (Nandy, Valio, and Petit, 2017; Nandy et al., 2021).
Such considerations have spurred the field of solar-cycle forecasting with diverse techniques employed to forecast upcoming solar cycles (Nandy, 2021) that is deemed to be one of the most outstanding challenges in heliophysics (Daglis et al., 2021). Petrovay (2020) classified such techniques into three groups: model-based methods, precursor methods, and extrapolation methods. Each has their strengths and weaknesses. Most importantly, the first two are closely connected with the physical insight of the solar dynamo that determines the solar cycle and the last one is model-agnostic and data-based. The solar magnetic cycle is thought to originate in a dynamo mechanism through complex, nonlinear interactions between magnetic fields and plasma flows in the Sun’s convection zone (Charbonneau, 2010). It is believed to be weakly chaotic in nature (Petrovay, 2020). The extreme conditions and turbulent nature of the solar convection zone, combined with a lack of observational constraints, make computational modeling of the solar dynamo mechanism quite challenging. There have been a few model-based forecasts for Solar Cycle 24 that has just concluded (Dikpati, De Toma, and Gilman, 2006; Dikpati and Gilman, 2006; Dikpati et al., 2007; Choudhuri, Chatterjee, and Jiang, 2007; Jiang, Chatterjee, and Choudhuri, 2007). However, these model-based forecasts were highly inconsistent – which was a result of differing assumptions regarding the turbulent nature of the Sun’s convection zone (Yeates, Nandy, and Mackay, 2008). A NASA-NOAA panel that typically attempts to generate a consensus prediction before the start of a sunspot cycle made an early forecast of a very strong solar Cycle 24, which proved to be incorrect. In fact, this panel revised its forecast to a weak Cycle 24 a few years following its first forecast. This indicates the uncertainty and challenges in predicting solar cycles. We note that terrestrial weather forecasting follows a similar route. Crucially, for the case of terrestrial weather forecasting the computational models are well established, observation provides much stronger constraints, and, compared to solar cycles, massive computational resources are utilized. Moreover, the solar dynamo model and its parameters are not as well constrained by observations as models for terrestrial weather forecasting.
A recently developed physical model-based forecasting scheme relied on coupling two distinct models of magnetic-flux transport on the Sun, namely a solar surface flux-transport model and a solar convection-zone dynamo model (Bhowmik and Nandy, 2018). This physics-based modeling technique was quite successful in hindcasting and matching nearly a century of solar-cycle observations and predicted a weak, but not insignificant Solar Cycle 25 similar to or slightly stronger than the previous cycle peaking in 2024 – 2025. Independent observations indicate that Solar Cycle 25 initiated in late 2019 (Nandy, Bhatnagar, and Pal, 2020). Given major advances in both understanding the theory of solar-cycle predictability, as well as application of data-based machine-learning techniques to solar-cycle forecasting, it would be interesting to assess at this juncture whether the best of these very diverse techniques result in predictions that are consistent with each other.
A recent review on progress in solar-cycle predictions by Nandy (2021) points out that divergences and inconsistencies in solar-cycle forecasts persist across sunspot Cycles 24 and 25; however, physical model-based predictions have converged for Solar Cycle 25. Nandy (2021) argues this convergence is based on insights into solar-cycle predictability gleaned in recent times. These insights include the understanding that long-term solar-cycle forecasts are not possible as theoretical processes limit the cycle memory across only one solar cycle (Karak and Nandy, 2012; Hazra, Brun, and Nandy, 2020). This is borne out by observations (Muñoz-Jaramillo et al., 2013). However, the analysis by Nandy (2021) indicates divergence across these physics-based and data-based, model-agnostic forecasting techniques. Can we bridge this gap? This is one of the central motivations of our work.
The last decade has found machine-learning techniques to be extraordinarily successful in making forecasts. They are particularly useful in those cases where a mechanistic model is either unavailable or poorly constrained, as is the case in many astrophysical and geophysical problems. They have played an increasingly important role in making data-based forecasts in several problems in solar physics (Bobra and Couvidat, 2015; Bobra and Ilonidis, 2016; Dhuri, Hanasoge, and Cheung, 2019; Sinha et al., 2022). A recent, comprehensive analysis by Sinha et al. (2022), in particular, indicates the fidelity of machine-learning models in the domain of flare forecasting. Starting with Koons and Gorney (1990) and Fessant, Bengio, and Collobert (1996), different neural networks have been used with varying degrees of success to forecast solar cycles (Pesnell, 2012), including a few recent ones (Pala and Atici, 2019; Covas, Peixinho, and Fernandes, 2019; Benson et al., 2020) who made forecasts for the ongoing Cycle 25.
Let us note that machine-learning techniques, particularly those based on deep neural networks, although sometimes spectacularly successful, are treated mostly as black boxes by most practitioners. This may lead to mistaken conclusions, particularly when applied to limited data (Riley, 2019) – as is the case of the solar cycle. Hence, it is necessary to choose machine-learning algorithms with care and to critically review their forecasts. In this paper, we show how to make such a choice with the specific example of solar-cycle forecasting.
We use four different machine-learning algorithms, all within a general framework called Recurrent Neural Networks (RNNs). The characteristic feature of RNNs is that their connection topology possesses cycles (Jaeger, 2001). They are well known for their ability to model sequential data. In addition, we use a simple linear Autoregressive (linear AR) algorithm, which we use as a reference to compare the performance of the different RNNs. Therefore, we use five different algorithms:
-
Linear Autoregressive (linear AR).
-
Echo State Network (ESN).
-
Vanilla Recurrent Neural Network (vanilla RNN) (Chen, 2016).
-
Long Short-Term Memory Networks (LSTMs) (Hochreiter and Schmidhuber, 1997).
-
Gated Recurrent Units (GRUs) (Chung et al., 2014).
A detailed mathematical treatment of all of these RNN architectures can be found in Goodfellow, Bengio, and Courville (2016). In our problem, the ESN architecture works the best. For this reason, in the next section, we concentrate on ESN. We mention the other algorithms only for comparison purposes with ESN.
The rest of this paper is organized in the following manner: in Section 2 we give a brief introduction to the ESN algorithm. To study its limitations we use data from simulations of a stochastic dynamo model that allows us to generate an infinite amount of data. We describe this model in Section 3. In Section 4, we apply the ESN to the real sunspot data. Finally, we present the conclusions. Important implementation details regarding how to manually choose certain parameters of the ESN are listed in Appendix A. Then, in Appendix B, the reader can also find how we train the remaining RNN models.
2 Echo State Networks
In this paper we obtain the best forecasts for a particular technique called Echo State Network (ESN), (Jaeger, 2001; Maass, Natschläger, and Markram, 2002; Jaeger and Haas, 2004; Lukoševičius and Jaeger, 2009). Within the machine-learning community the name ESN is more popular, whereas in the physics community reservoir computing is the most common name used to describe this network.
It has been used successfully to forecast delay differential equations, low-dimensional chaotic systems, and even large spatiotemporally chaotic systems (Pathak et al., 2018). This method has so far not been used to forecast the solar cycle, although theoretical considerations suggest that the solar dynamo mechanism can be represented by a system of delay differential equations (Wilmot-Smith et al., 2006).
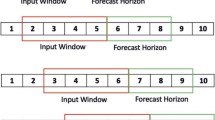
Let us first briefly introduce the idea of ESN as applied to the problem of forecasting the next solar cycle, see Figure 1. At the heart of the algorithm lies a neural network with a large number of nodes – the reservoir. Every node of this network is called a neuron. The state of the reservoir is given by the state vector \(\boldsymbol {x}\) of dimension \(N\). Every neuron receives its input from all the neurons in the network (including itself), a different input signal \(\mathit {u_{\mathrm {in}}}\) (constant), and a feedback neuron. Each neuron is updated by operating a nonlinear function (often tangent hyperbolic) on a linear combination of its inputs each multiplied by a different random weight:
The random weight that connects any two neurons of this network, \(\mathbf {W}_{\mathrm {res}}\), is given by the corresponding element of a large, sparse, random matrix whose spectral radius is less than unity. The connection weights between the feedback neuron and the reservoir are given by the feedback matrix \(\mathbf {W}_{\mathrm {fb}}\). The linear combination of the output of each individual neuron weighted by another set of weights, \(\mathbf {W}_{\mathrm {out}}\), is the output of the reservoir:
First, we must train the reservoir. This proceeds in the following manner. A time series \(\boldsymbol {y}(1),\boldsymbol {y}(2),\ldots ,\boldsymbol {y}(\mathit {T})\) is fed into the feedback neuron sequentially. At every time instant an output of the reservoir, \(\hat {\boldsymbol {y}}(\mathit {t})\), is obtained. The weights \(\mathbf {W}_{\mathrm {out}}\) and the bias \(\boldsymbol {b}\) are chosen so as to minimize the ridge regression loss function (Shalev-Shwartz and Ben-David, 2014):
We can see that the loss function \(\mathcal{C}\) has two contributions. The first is the Mean Squared Error (MSE) between the true signal \(\boldsymbol {y}\) and the forecast \(\hat {\boldsymbol {y}}\). We use the symbol \(||\cdot ||_{2}^{2}\) to indicate the square of the second norm. The second term \(\mathit{\beta} ||\mathbf {W}_{\mathrm {out}}||_{2}^{2}\) is a penalty on the second norm of \(\mathbf {W}_{\mathrm {out}}\) – this is called L2 regularization. The constant \(\mathit{\beta}\) controls the strength of this penalty term. Regularization tries to avoid the overfitting problem. If we optimize \(\mathbf {W}_{\mathrm {out}}\) such that the output of the reservoir is a very good approximation to the training data the forecast may actually become less reliable. A central feature of machine-learning techniques in general and ESN in particular is that to obtain a reliable forecast often a very large amount of training data is necessary. The forecast is expected to get better the longer the training period is, but there is no a-priori constraint on how long a training period is appropriate. This is true for almost any problem in natural sciences, particularly so for the case of forecasting of solar cycles.

The reservoir is a collection of \(N\) nodes. The state of the reservoir is given by the state vector \(\boldsymbol {x}\). The connections between nodes of the reservoir, \(\mathbf {W}_{\mathrm {res}}\), depicted by red arrows, are taken from a large, sparse, random matrix with a spectral radius less than unity. During training, the time series, \(\boldsymbol {y}(1),\boldsymbol {y}(2),\ldots ,\boldsymbol {y}(\mathit {T})\), is fed into the feedback neuron. The update rule for each node is \(\boldsymbol {x}(\mathit {t}+1) = \tanh \left ( \mathit {u_{\mathrm {in}}}\boldsymbol {w}_{\mathrm {in}}+ \mathbf {W}_{\mathrm {res}}\boldsymbol {x}( \mathit {t}) + \mathbf {W}_{\mathrm {fb}}\boldsymbol {y}(\mathit {t}) \right )\), where \(\boldsymbol {w}_{\mathrm {in}}\) and \(\mathbf {W}_{\mathrm {fb}}\) are random weights and \(u_{\mathrm{in}}\) is a constant. The output of the reservoir, \(\hat {\boldsymbol {y}}\), is a weighted sum – with weights \(\mathbf {W}_{\mathrm {out}}\) – over the state of the reservoir. To forecast, the output of the reservoir is fed into the feedback neuron.
The sunspot data is a one-dimensional time series \(\mathit {z}(1),\mathit {z}(2),\ldots ,\mathit {z}(\mathit {t}),\ldots , \mathit {z}(\mathit {T})\). The sunspot time series can be directly used in the ESN if we treat \(\boldsymbol {y}(t)\) as a scalar, i.e., \(\boldsymbol {y}(\mathit {t}) = \mathit {z}(\mathit {t})\). In this case the output \(\hat {\boldsymbol {y}}(\mathit {t}) = \hat{\mathit {z}}(\mathit {t})\) is also a scalar. We show in Section 3, see Figure 2, that this direct method generates decent, but not very good forecasts, at later times. To improve the forecast at later times, we develop a variation on the standard ESN algorithm – we call this algorithm Modified Echo State Network (MESN). This algorithm constitutes three changes in data preparation and use. One, instead of feeding the input signal one data point at a time, at time \(t\) we construct a \(\mathit{p}\)-dimensional vector \(\boldsymbol {y}(t) = [\mathit {z}(\mathit {t}), \mathit {z}(\mathit {t}-1), \ldots , \mathit {z}(\mathit {t}-\mathit{p}+1)]^{\top}\) that contains a history of \(\mathit{p}\) values. This vector is fed to the feedback neuron as per Equation (1). Two, we change the dimension of the output of the reservoir, such that we no longer forecast one time instant after every update of the reservoir, but we forecast a \(\mathit{q}\)-dimensional vector \(\hat {\boldsymbol {y}}(\mathit {t}) = [\hat{\mathit {z}}(\mathit {t}),\hat{\mathit {z}}(\mathit {t}+1), \ldots ,\hat{\mathit {z}}(\mathit {t}+\mathit{q}-1)]^{\top}\) at time \(t\) as per Equation (2). Three, the target in Equation 3 is no longer \(\boldsymbol {y}(\mathit {t})\) but rather the future points \(\boldsymbol {y}^{\ast }(\mathit {t}) = [\mathit {z}(\mathit {t}),\mathit {z}(\mathit {t}+1),\ldots , \mathit {z}(\mathit {t}+\mathit{q}-1)]^{\top}\).

In (a), we show the dynamo signal from Hazra, Passos, and Nandy (2014). We train the reservoir with this signal except for the last four cycles, which we leave for testing the forecasts obtained. The dashed line separates the training signal from the test signal. In (b), the green dotted line represents the average of an ensemble of 10 independent forecasts of the last four cycles. The standard deviation of the ensemble is plotted in orange. The red line represents the test signal. The figure exhibits that the variance of the ensemble grows after the first cycle and that the forecast is no longer accurate. In (c), we show a zoomed-in plot of the forecast obtained for the first cycle.
3 Forecast for a Dynamo Model of Solar Cycle
To study how the algorithm performs when it is not constrained by too limited data we first apply it to a model of the solar dynamo. There are several low-dimensional, stochastic models that describe the same qualitative features as the global sunspot data, namely, oscillations whose frequency and amplitude may change abruptly from one cycle to another. We use a widely studied model for this purpose (Wilmot-Smith et al., 2006; Hazra, Passos, and Nandy, 2014; Tripathi, Nandy, and Banerjee, 2021). Specifically, we follow the prescription in Hazra, Passos, and Nandy (2014) and construct a solar dynamo model consisting of two coupled time-delay differential equations:
The square of the signal \(\mathit {B}(\mathit {t})\) corresponds to the global sunspot number, that is \(\mathit {z}(\mathit {t})=\mathit {B}^{2}(\mathit {t})\) and \(\mathit {A}(\mathit {t})\) is the poloidal field strength. The parameters \(\mathit {T}_{0}\) and \(\mathit {T}_{1}\) control the time delay of the equations and the function \(\alpha (\mathit {t})\) is stochastic:
Here, \(\sigma (\mathit {t}, \mathit {\tau _{c}})\) is a uniform random number in the interval [-1, +1]. We draw a new random number from this distribution at every \(\mathit {\tau _{c}}\). The parameter \(\mathit{\delta} \in [0, 100]\) controls the strength of the noise. The function \(f_{1}\) is called the quenching factor and it involves the error function (\(\mathrm {erf}\)) and two thresholds \(\mathit {B}_{\mathrm {min}}\), \(\mathit {B}_{\mathrm {max}}\):
We use the model parameters listed in Table 1 and we choose the initial conditions \(A(\mathit {t}\leq 0) = B(\mathit {t}\leq 0) = (1/2)(\mathit {B}_{\mathrm {min}}+\mathit {B}_{\mathrm {max}})\). We solve the differential equations from \(\mathit {t}=0\) to \(\mathit {t}=1100\) with a time step \(\mathrm {d}\mathit {t}=10^{-3}\). We use the trapezoidal rule to integrate the delay terms and a second-order Runge–Kutta method for the nondelay parts. Once we obtain the solution \(B(t)\) we sample it such that the final time series has a time step of \(10^{-1}\). This is necessary, as the ESN algorithm can not forecast far in time if it learns a time series with a very short time step. We divide the time series into two parts: a long training signal that contains 52 cycles and a short test signal that are the next 4 cycles, as shown in Figure 2(a). Before feeding the training signal into the reservoir, we normalize it by dividing it by the maximum amplitude found. This helps to prevent the saturation of the tanh function in Equation (1). We use a reservoir size of \(N=1000\) neurons and a regularization parameter \(\mathit{\beta}=10^{-5}\). As the connections \(\mathbf {W}_{\mathrm {res}}\) are initialized randomly, we obtain different forecasts every time we run it. For example, we run it 10 times, generating an ensemble of 10 independent forecasts. We take the mean of the forecasts as the final result that we compare against the test data. Figures 2(b) and (c) show that we obtain good agreement for the first cycle only, as for the next three cycles the variance of the ensemble grows and the mean falls far from the true signal. We note though that the forecast for the first cycle is accurate, with a test MSE of 8.89.
Qualitatively, this result is not a particularity of the test signal we decided to forecast. For example, if we train with 60 cycles instead of 52, we keep obtaining accurate forecasts for cycle 61 only. It is at this point when we state that our ESN is a physical model-validated recurrent neural network.
4 Application to Solar Cycle
Next, we apply all the RNN algorithms to forecast solar cycles. To be specific, let us consider the case of forecasting one particular cycle, say Cycle 23. We train the algorithms with the sunspot data with a thirteen-month running average till the end of Cycle 22. Then, we continue running to produce the forecast.
In Figure 3 we show the forecasts for Solar Cycles 22, 23, and 24 using five different algorithms. In red, we show the thirteen-month running average of the sunspot data, plotted with some width to distinguish it better from the other curves. Clearly, the linear Autoregressive (linear AR) algorithm performs the worst. For Cycle 22 ESN is the best in forecasting the peak followed by vanilla RNN, LSTM, and GRU. For Cycle 23 the ESN and the vanilla RNN are able to capture the first peak of the data reasonably well. The other algorithms forecast significantly lower number of sunspots near the peak. For Cycle 24 again ESN makes the best forecast. Both vanilla RNN and LSTM make reasonable forecasts but GRU forecasts a significantly larger number of sunspots near the peak than actually observed. Overall, the forecast for Cycle 22 is the least accurate. This may be because the earlier the cycle is, the less data we have to train the algorithms. In Appendix B we provide a detailed quantitative comparison that supports the qualitative discussion here. Note that both LSTM and GRU have more fitting parameters than ESN and also require more computing resources. In general, in machine-learning problems with limited data it is often observed that algorithms with too large a number of parameters perform badly due to overfitting, whereas algorithms with too few parameters also perform badly. We conclude that ESN is not only a physical model-validated network but also the appropriate algorithm for our purpose.

Forecast for Solar Cycles 22 (a), 23 (b), and 24 (c) using five different algorithms: MESN, linear AR, vanilla RNN, GRU, and LSTM.
Next, we concentrate on our forecasts for Cycles 23, 24, and the ongoing Cycle 25 using ESN. In Figure 4, we show the mean (green) and standard deviation (orange) of an ensemble of 10 independent forecasts for each case. For Cycles 23 and 24 we compare our forecast with the thirteen-month running average of the sunspot data (red). We also indicate in light blue how noisy the original sunspot data was by painting the standard deviation of the running average. The forecast for Cycle 23, obtained with regularization \(\mathit{\beta}=10^{-7}\), is quite accurate till the first peak. The standard deviation of the forecast increases with time till the first peak, but after the peak it decreases. For Cycle 24, also with \(\mathit{\beta}=10^{-7}\), the overall agreement is better but the standard deviation is larger near the peak.

Our forecasts for Cycles 23 (a, d), 24 (b, e), and 25 (c, f). For the past Cycles 23 and 24, the red line shows the number of observed sunspots as a function of time with a thirteen-month smoothing window. The shaded-blue region shows the standard deviation of the observation gleaned from the smoothing window. The top row (a, b, c) shows our forecasts with the ESN algorithm. The green dotted line is the forecast obtained by calculating the mean of the ensemble of forecasts gleaned from ten independent realizations. The orange-shaded region shows the standard deviation of the ensemble. The bottom row (d, e, f) shows the forecasts with the MESN.
By its construction, the reliability of the forecast decreases as time progresses. This is because the forecast of one point depends on the forecast of the previous one. Consequently, small errors at early times are gradually magnified as the forecast progresses. As described in Section 2, we develop a variation on the standard ESN algorithm, which we call Modified ESN (MESN) to improve the forecasts. All forecasts given by the MESN are done with \(\mathit{\beta}=10^{-10}\), \(\mathit{p}=15\), and \(\mathit{q}=129\). Note that the value of \(\mathit{q}\) is approximately the number of months of an 11-year cycle (\(11\times 12\)), which means we forecast one cycle in one go. The forecasts are plotted in the bottom panel of Figure 4. Compared to the standard algorithm, our modified algorithm not only gives better results when tested against the observation for Cycles 23 and 24, it also gives more robust forecasts, as the standard deviation of the ensemble is smaller.
Our forecasts for the ongoing Cycle 25 with both algorithms are shown in the right-most column of Figure 4. Using the standard algorithm with \(\mathit{\beta}=10^{-6}\) we forecast that the maximum of Cycle 25 is going to happen between May and June 2024 and that the maximum number of sunspots is going to be \(113\pm 15\). Our modified algorithm gives a maximum that is flatter, almost constant between June 2023 and August 2024, with a maximum number of \(124\pm 2\) sunspots. Note that the averaged sunspot data shows a distinctive two-peak behavior in both Cycles 23 and 24 – this behavior is not present in all sunspot cycles – that is not captured by either of our algorithms. We expect the same to happen for Cycle 25 – none of our algorithms can forecast whether it may or may not have this two-peak feature. Both forecasts show that Cycle 25 is expected to reach a minimum near the beginning of the year 2030. Qualitatively, Cycle 25 is going to be weaker than Cycle 23 but stronger than Cycle 24. We note this qualitative result differs from other machine-learning based forecasts (Pala and Atici, 2019; Benson et al., 2020). The first one forecasts that Cycle 25 will have similar strength to that of Cycle 23, while the second one forecasts that Cycle 25 will be slightly weaker than Cycle 24. However, our result agrees with recent physics-based forecasts (Bhowmik and Nandy, 2018).
Next, we show how robust our forecasts are with respect to when we stop training and start forecasting. We expect the following: near the minima of the cycle the signal-to-noise ratio in the sunspot data is the lowest. Hence, if we stop training at the lowest point of a cycle we expect the worst result if the level of noise is roughly constant as a function of time. A look at the sunspot data shows that the noise is not a constant but is actually significantly larger near the peak of the cycle – the noise increases as the signal increases. Nevertheless, the signal-to-noise ratio is less than unity near the minima of the cycles. In Figure 5 we show four representative cases with the standard ESN algorithm for Cycle 24. The best forecast is obtained when we are in the rising phase of the cycle. We also discover the standard ESN algorithm becomes unstable if the training is stopped very close to the present minima. The forecast for Cycle 25 is generated in 2020, when we are very near its minimum, hence we expect our forecast to improve if we recalculate our results introducing the new data that we have now in the middle of 2022.

The forecasts depend crucially on when we stop training and start forecasting. We show four representative cases with the ESN for Solar Cycle 24. In each plot, the vertical dashed line on the left represents where we stop training and start forecasting, and the right dashed line indicates where we stop forecasting. The best forecast (d) is obtained when we stop training at the rising phase of the cycle.
We show the recalculated forecasts for each ESN algorithm in Figure 6. We observe that the ESN (a) gives a higher peak when trained with the new data, as the maximum amplitude has changed from \(113 \pm 15\) to \(131 \pm 14\) sunspots. The MESN (b) also increases the amplitude, from \(124 \pm 2\) to \(137 \pm 2\) sunspots, reaching better agreement with the ESN.

New forecasts for the ESN (a) and MESN (b) algorithms when additional training data is available. The orange dashed line gives the mean and standard deviation of the ensemble of forecasts when data until 2020 is used. The green dotted line shows the new forecast when additional data until 2022 is available and utilized in the training.
5 Summary and Conclusion
We use five different algorithms based on Recurrent Neural Networks (RNNs) to forecast Solar Cycle 25. First, we try to forecast with them Cycles 23 and 24 and we realize that the Echo State Network performs the best. We note that the ESN performs fairly well for the last five cycles (20 – 24) except for Cycle 21. But the forecasts are inaccurate beyond one cycle, even in the case of the dynamo model for which we can generate very large amounts of data. This corroborates what physical model-based studies have already demonstrated – the theoretical processes limit the cycle memory across only one solar cycle (Karak and Nandy, 2012; Muñoz-Jaramillo et al., 2013; Hazra, Brun, and Nandy, 2020).
Although we have validated the ESN with a solar dynamo model, note that we have treated the dynamo model and the solar data separately. We have not first tuned the neural network on the simulations of the dynamo model and then fine tuned it on the solar data. We leave such a technique, called transfer-learning, as future work, which may improve our forecasts, although not beyond one cycle.
This motivates the design of the Modified ESN algorithm. The MESN produces more accurate and more robust forecasts, but it also remains limited to forecasting only one cycle ahead. We also note the forecasts given by both algorithms strongly depend on when we stop training and start forecasting, and that the best forecasts are obtained when we are at the rising phase of the cycle. Therefore, we use the data until 2022 to forecast sunspot Cycle 25. The two algorithms agree that Cycle 25 is going to last for about 10 years. They also agree on the approximate time location of the peak, the ESN places the peak in July 2024, while the MESN shows it in April 2024. As for the maximum number of sunspots, the ESN forecasts it to be \(131 \pm 14\), whereas the MESN forecasts \(137 \pm 2\). Hence, both algorithms forecast that Cycle 25 will be slightly stronger than Cycle 24, but weaker than Cycle 23.
We have taken a novel approach towards bridging the gap between physics-based and machine-learning-based solar-cycle forecasts by first applying our techniques with simulated data from a physics-inspired solar dynamo model and subsequently utilizing the same algorithm on observational data. Our forecast is consistent with physical model-based approaches.
References
Basak, A., Nandy, D.: 2021, Modelling the imposed magnetospheres of Mars-like exoplanets: star-planet interactions and atmospheric losses. Mon. Not. Roy. Astron. Soc. 502, 3569. DOI. ADS.
Benson, B., Pan, W.D., Prasad, A., Gary, G.A., Hu, Q.: 2020, Forecasting solar cycle 25 using deep neural networks. Solar Phys. 295, 65. DOI. ADS.
Bharati Das, S., Basak, A., Nandy, D., Vaidya, B.: 2019, Modeling star-planet interactions in far-out planetary and exoplanetary systems. Astrophys. J. 877, 80. DOI. ADS.
Bhowmik, P., Nandy, D.: 2018, Prediction of the strength and timing of sunspot cycle 25 reveal decadal-scale space environmental conditions. Nat. Commun. 9, 5209. DOI. ADS.
Bobra, M.G., Couvidat, S.: 2015, Solar flare prediction using SDO/HMI vector magnetic field data with a machine-learning algorithm. Astrophys. J. 798, 135. DOI. ADS.
Bobra, M.G., Ilonidis, S.: 2016, Predicting coronal mass ejections using machine learning methods. Astrophys. J. 821, 127. DOI. ADS.
Charbonneau, P.: 2010, Dynamo models of the solar cycle. Living Rev. Solar Phys. 7, 3. DOI. ADS.
Che, Z., Purushotham, S., Cho, K., Sontag, D., Liu, Y.: 2018, Recurrent neural networks for multivariate time series with missing values. Nature Sci. Rep. 8, 6085. DOI. ADS.
Chen, G.: 2016, A gentle tutorial of recurrent neural network with error backpropagation. arXiv.
Choudhuri, A.R., Chatterjee, P., Jiang, J.: 2007, Predicting solar cycle 24 with a solar dynamo model. Phys. Rev. Lett. 98, 131103. DOI. ADS.
Chung, J., Gulcehre, C., Cho, K., Bengio, Y.: 2014, Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv.
Committee on the Societal and Economic Impacts of Severe Space Weather Events: A Workshop: 2008, Severe Space Weather Events–Understanding Societal and Economic Impacts Workshop Report, 131. DOI.
Covas, E., Peixinho, N., Fernandes, J.: 2019, Neural network forecast of the sunspot butterfly diagram. Solar Phys. 294, 24. DOI. ADS.
Daglis, I.A., Chang, L.C., Dasso, S., Gopalswamy, N., Khabarova, O.V., Kilpua, E., Lopez, R., Marsh, D., Matthes, K., Nandy, D., Seppälä, A., Shiokawa, K., Thiéblemont, R., Zong, Q.: 2021, Predictability of variable solar–terrestrial coupling. Ann. Geophys. 39, 1013. DOI. ADS.
Dhuri, D.B., Hanasoge, S.M., Cheung, M.C.: 2019, Machine learning reveals systematic accumulation of electric current in lead-up to solar flares. Proc. Natl. Acad. Sci. USA 116, 11141. DOI. ADS.
Dikpati, M., Gilman, P.A.: 2006, Simulating and predicting solar cycles using a flux-transport dynamo. Astrophys. J. 649, 498. DOI. ADS.
Dikpati, M., de Toma, G., Gilman, P.A.: 2006, Predicting the strength of solar cycle 24 using a flux-transport dynamo-based tool. Geophys. Res. Lett. 33, L05102. DOI. ADS.
Dikpati, M., Gilman, P.A., de Toma, G., Ghosh, S.S.: 2007, Simulating solar cycles in northern and southern hemispheres by assimilating magnetic data into a calibrated flux-transport dynamo. Solar Phys. 245, 1. DOI. ADS.
Fessant, F., Bengio, S., Collobert, D.: 1996, On the prediction of solar activity using different neural network models. Ann. Geophys. 14, 20. DOI. ADS.
Goodfellow, I., Bengio, Y., Courville, A.: 2016, Deep Learning, MIT press, Cambridge. http://www.deeplearningbook.org.
Hathaway, D.H.: 2015, The solar cycle. Living Rev. Solar Phys. 12, 4. DOI. ADS.
Hazra, S., Brun, A.S., Nandy, D.: 2020, Does the mean-field \(\alpha\) effect have any impact on the memory of the solar cycle? Astron. Astrophys. 642, A51. DOI. ADS.
Hazra, S., Passos, D., Nandy, D.: 2014, A stochastically forced time delay solar dynamo model: self-consistent recovery from a Maunder-like grand minimum necessitates a mean-field alpha effect. Astrophys. J. 789, 5. DOI. ADS.
Hochreiter, S., Schmidhuber, J.: 1997, Long short-term memory. Neural Comput. 9, 1735. DOI.
Jaeger, H.: 2001, The “echo state” approach to analysing and training recurrent neural networks. GMD Report 148, GMD – German National Research Institute for Computer Science. http://www.faculty.jacobs-university.de/hjaeger/pubs/EchoStatesTechRep.pdf.
Jaeger, H., Haas, H.: 2004, Harnessing nonlinearity: predicting chaotic systems and saving energy in wireless communication. Science 304, 78. DOI. ADS.
Jiang, J., Chatterjee, P., Choudhuri, A.R.: 2007, Solar activity forecast with a dynamo model. Mon. Not. Roy. Astron. Soc. 381, 1527. DOI. ADS.
Karak, B.B., Nandy, D.: 2012, Turbulent pumping of magnetic flux reduces solar cycle memory and thus impacts predictability of the Sun’s activity. Astrophys. J. Lett. 761, L13. DOI. ADS.
Kingma, D.P., Ba, J.: 2015, Adam: a method for stochastic optimization. In: Bengio, Y., LeCun, Y. (eds.) 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings.
Koons, H.C., Gorney, D.J.: 1990, A sunspot maximum prediction using a neural network. Eos 71, 677. DOI. ADS.
LeCun, Y., Bottou, L., Orr, G.B., Müller, K.-R., et al.: 1998, Neural Networks: Tricks of the Trade, Springer Lecture Notes in Computer Sciences 1524, 6.
Lukoševičius, M.: 2012, A Practical Guide to Applying Echo State Networks, Springer Berlin Heidelberg, Berlin, Heidelberg, 659.
Lukoševičius, M., Jaeger, H.: 2009, Reservoir computing approaches to recurrent neural network training. Comput. Sci. Rev. 3, 127. DOI.
Maass, W., Natschläger, T., Markram, H.: 2002, Real-time computing without stable states: a new framework for neural computation based on perturbations. Neural Comput. 14, 2531. DOI.
Muñoz-Jaramillo, A., Dasi-Espuig, M., Balmaceda, L.A., DeLuca, E.E.: 2013, Solar cycle propagation, memory, and prediction: insights from a century of magnetic proxies. Astrophys. J. Lett. 767, L25. DOI. ADS.
Nandy, D.: 2021, Progress in solar cycle predictions: sunspot cycles 24-25 in perspective. Solar Phys. 296, 54. DOI. ADS.
Nandy, D., Martens, P.C.H.: 2007, Space Climate and the Solar Stellar connection: what can we learn from the stars about long-term solar variability? Adv. Space Res. 40, 891. DOI. ADS.
Nandy, D., Bhatnagar, A., Pal, S.: 2020, Sunspot cycle 25 is brewing: early signs herald its onset. Res. Notes AAS 4, 30. DOI. ADS.
Nandy, D., Valio, A., Petit, P. (eds.): 2017, Living Around Active Stars 328. Proceedings of the 328th Symposium of the International Astronomical Union. DOI. ADS.
Nandy, D., Martens, P.C.H., Obridko, V., Dash, S., Georgieva, K.: 2021, Solar evolution and extrema: current state of understanding of long-term solar variability and its planetary impacts. Prog. Earth Planet. Sci. 8, 40. DOI. ADS.
Pala, Z., Atici, R.: 2019, Forecasting sunspot time series using deep learning methods. Solar Phys. 294, 50. DOI. ADS.
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Kopf, A., Yang, E., DeVito, Z., Raison, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., Chintala, S.: 2019, PyTorch: an imperative style, high-performance deep learning library. In: Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R. (eds.) Advances in Neural Information Processing Systems 32, Curran Associates, Inc., New York, US.
Pathak, J., Hunt, B., Girvan, M., Lu, Z., Ott, E.: 2018, Model-free prediction of large spatiotemporally chaotic systems from data: a reservoir computing approach. Phys. Rev. Lett. 120, 024102. DOI. ADS.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., Duchesnay, É.: 2011, Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12, 2825.
Pesnell, W.D.: 2012, Solar cycle predictions. Solar Phys. 281, 507. DOI. ADS.
Petrovay, K.: 2020, Solar cycle prediction. Living Rev. Solar Phys. 17, 2. DOI. ADS.
Ravanelli, M., Brakel, P., Omologo, M., Bengio, Y.: 2018, Light gated recurrent units for speech recognition. IEEE Trans. Emerg. Top. Comput. Intell. 2, 92. DOI.
Riley, P.: 2019, Three pitfalls to avoid in machine learning. Nature 572, 27. DOI. ADS.
Saha, C., Chandra, S., Nandy, D.: 2022, Evidence of persistence of weak magnetic cycles driven by meridional plasma flows during solar grand minima phases. Mon. Not. Roy. Astron. Soc. 517, L36. DOI. ADS.
Schrijver, C.J., Kauristie, K., Aylward, A.D., Denardini, C.M., Gibson, S.E., Glover, A., Gopalswamy, N., Grande, M., Hapgood, M., Heynderickx, D., et al.: 2015, Understanding space weather to shield society: a global road map for 2015 – 2025 commissioned by COSPAR and ILWS. Adv. Space Res. 55, 2745. DOI. ADS.
Shalev-Shwartz, S., Ben-David, S.: 2014, Chapter 13: Regularization and stability. In: Understanding Machine Learning: From Theory to Algorithms, Cambridge University Press, USA. 137. DOI.
SILSO, World Data Center - Sunspot Number and Long-term Solar Observations, Royal Observatory of Belgium on-line Sunspot Number catalogue. http://www.sidc.be/SILSO/, 1749-2022.
Sinha, S., Gupta, O., Singh, V., Lekshmi, B., Nandy, D., Mitra, D., Chatterjee, S., Bhattacharya, S., Chatterjee, S., Srivastava, N., Brandenburg, A., Pal, S.: 2022, A comparative analysis of machine-learning models for solar flare forecasting: identifying high-performing active region flare indicators. Astrophys. J. 935, 45. DOI. ADS.
Tripathi, B., Nandy, D., Banerjee, S.: 2021, Stellar mid-life crisis: subcritical magnetic dynamos of solar-like stars and the breakdown of gyrochronology. Mon. Not. Roy. Astron. Soc. 506, L50. DOI. ADS.
Wilmot-Smith, A.L., Nandy, D., Hornig, G., Martens, P.C.H.: 2006, A time delay model for solar and stellar dynamos. Astrophys. J. 652, 696. DOI. ADS.
Yeates, A.R., Nandy, D., Mackay, D.H.: 2008, Exploring the physical basis of solar cycle predictions: flux transport dynamics and persistence of memory in advection- versus diffusion-dominated solar convection zones. Astrophys. J. 673, 544. DOI. ADS.
Acknowledgment
AEF acknowledges Marta Vilademunt for useful feedback on the paper figures. We thank other participants in our SPARC project, particularly Sourangshu Bhattarcharya for stimulating discussions. DM thanks the participants in the machine-learning seminars at NORDITA organized by S-H Lim for useful inputs. DN acknowledges a Visiting Professorship grant from the Wenner-Gren Foundation for facilitating his visit to NORDITA, Stockholm in 2018 – when ideas related to this project were developed. We thank the anonymous referee for pointing out early work on the application of neural networks to forecast solar cycles and the transfer-learning technique.
Funding
Open access funding provided by Stockholm University. The collaboration between NORDITA and KTH on the one hand and IISER Kolkata on the other hand has been made possible through the SPARC project grant SPARC/2018-2019/P746/SL of the Government of India, which funded academic visits to facilitate this research. The Center of Excellence in Space Sciences India is funded by IISER Kolkata, Ministry of Education, Government of India. DM is supported by two grants from the Swedish research council, Nos. 638-2013-9243 and 2016-05225. AEF’s stay at NORDITA was supported by a grant from the Swedish Research Council. Part of the work was done during an earlier visit by AEF to NORDITA. The visit was supported by the Erasmus+ Programme, where AEF did a three-month internship at NORDITA as a recent graduate from the University of Barcelona.
Author information
Authors and Affiliations
Contributions
The project was planned by DM, DN and SC. AEF coded the two different ESN algorithms and applied them on both sunspot data and on data from the dynamo model. He is responsible for Figures 1, 2, 4, 5, 6. AG coded all remaining RNN algorithms and applied them on sunspot data, creating the forecasts shown in Figures 3, 7, 8. The paper was written largely by DM and DN with input from all the authors.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: ESN Hyperparameter Selection
Hyperparameters are those values that need to be selected by the user regarding the algorithm architecture, the optimization method, and the regularization applied. In the previous sections, we mention which reservoir size \(N\) and which regularization parameter \(\mathit{\beta}\) we use for each cycle but we do not explain why we select those values.
1.1 A.1 Selecting the Reservoir Size
We always use a reservoir size of \(N=1000\) neurons. We could have used larger sizes for the dynamo problem, as it is recommended to set a reservoir size as large as possible Lukoševičius (2012). However, using a thousand neurons is suitable for the sunspots problem considering our limited amount of training data. This is because the reservoir size determines the number of parameters we need to learn (via the matrix \(\mathbf {W}_{\mathrm {out}}\)). Too many parameters under limited data gives rise to stronger overfitting.
1.2 A.2 Appropriate Regularization for the Old ESN
We choose \(\mathit{\beta}\) by comparing different values of it against the Mean Squared Error (MSE) on the training data, as an example, we show the results for the dynamo problem of Section 3 in Table 2. We decide to select the largest regularization that still gives a low training MSE. We also want to avoid values of \(\mathit{\beta}\) that give rise to forecasts and train MSEs with large standard deviations. We think that \(10^{-5}\) is a good candidate, as it is ten times larger than \(10^{-6}\) and yet it gives a MSE of the same magnitude with a small standard deviation. We follow exactly the same procedure for choosing appropriate values of \(\mathit{\beta}\) when forecasting each solar cycle.
1.3 A.3 Appropriate Parameters for the MESN
Our MESN is much more robust to the random initialization of the reservoir weights than the classical ESN. We also find that it is capable of generating some individual forecasts of the sunspot cycles even without regularization. However, if we do not apply regularization one forecast can go completely wrong (giving thousands of sunspots) and ruin the mean and standard deviation of the ensemble. That is why we decided to just apply the smallest regularization that allows building a stable ensemble of 10 forecasts for all cycles. We find that a value for \(\mathit{\beta}=10^{-10}\) is best and we keep it constant for all forecasts produced with this algorithm. Finally, we select the amount of feedback history \(\mathit{p}\) for each cycle by taking a look at how the standard deviation of the ensemble of forecasts changes with \(p\). We study the set of values of \(\mathit{p}\in \{2^{0}, 2^{1}, \ldots , 2^{10}\}\). We observe that for values of \(\mathit{p}\) larger than 64 the standard deviation of the ensemble grows with \(\mathit{p}\). Therefore, large values such as \(p=1024\) give rise to unreliable forecasts with a standard deviation greater than a thousand sunspots. We finish by considering small values of \(\mathit{p}\) between 1 and 64. We decide to randomly set \(\mathit{p}=15\) and to use this value for all cycles.
Appendix B: Recurrent Neural Networks
The characteristic feature of Recurrent Neural Networks (RNNs) is that their connection topology possesses cycles (Jaeger (2001)). They are well known for their ability in modeling sequential data. We also use a linear Autoregressive model (linear AR) as a performance baseline for the RNN architectures. Considering we have already explained how we train an ESN, we show now how we train the remaining RNN architectures: linear AR, vanilla RNN, LSTM, and GRU. The crucial difference between the RNNs we consider in this section and the ESN algorithm is that for the RNNs the elements of the matrix \(\mathbf {W}_{\mathrm {res}}\) and \(\mathbf {W}_{\mathrm {fb}}\) are also optimized.
2.1 B.1 Dataset Preparation
A common practise that helps training machine-learning models is to normalize the data. In our case, the data normalization we use for all algorithms is called min-max scaling and it moves the signal to the interval [0, 1] with a linear transformation. Then, we create a training, validation, and test dataset according to the solar cycle we want to forecast. For example, in the task of forecasting Solar Cycle 22, the data from the 22nd solar cycle is considered as test data, while the data prior to that cycle is split into training data and validation data in the ratio \(90:10\). We use the training set for updating the model parameters (learning) and the validation set for hyperparameter tuning. Finally, we check if the forecast is accurate by comparing it with the test set, which never has to be used for training.
A RNN model is capable of predicting either a single time step ahead sequentially or multiple time steps ahead. We denote this parameter as target size (\(\mathit{q}\)) and we try to find the most suitable value for forecasting each solar cycle. Training a RNN requires learning a transformation that goes from an input to a target. Hence, from the training set, we build input–target pairs. An input is a signal time window of length \(\mathit{L}\) and its target is its future continuation. Mathematically, the \(\mathit{t}\)th input–target pair consists of a sequence of \(L\) points \(\left [\mathit {z}_{t}, \mathit {z}_{t+1}, \mathit {z}_{t+2}, \ldots , \mathit {z}_{t+L-1} \right ]\) as the input, and a sequence of \(\left [\mathit {z}_{t+L}, \ldots , \mathit {z}_{t+L+\mathit{q}-1}\right ]\) points as the target.
2.2 B.2 Training Details
We train the algorithms using batch gradient descent with a learning rate \(\eta =0.001\). We adaptively decrease \(\eta \) in a step-wise fashion by a factor of 0.9, with every one-third of the total number of epochs. One epoch is considered to be completed when the network has seen all the training examples in the training set. We find that this helps in preventing oscillations in training, in the later stages. We use Adam (Kingma and Ba, 2015) as the optimizer and we develop the RNN architectures using Python with the PyTorch library (Paszke et al., 2019). For evaluation, we use libraries from Scikit-learn (Pedregosa et al., 2011).
2.3 B.3 Hyperparameter Selection
Every RNN architecture has a set of hyperparameters that need to be tuned in order to ensure a desired performance. For our training purposes we chose to tune the following hyperparameters: number of hidden units (\(n_{H}\)) in each layer, number of hidden layers (\(\mathit{n}_{l}\)), and the number of epochs (\(\mathit{N}\)). We try to find the best set of hyperparameters by exploiting different combinations of them using grid-search (LeCun et al., 1998). As MSE is chosen as the optimization metric, we choose the best configuration of parameters as the one that provides minimum MSE on the validation set. As an example, we show in Table 3 the validation MSE for different configurations of hyperparameters for the GRU architecture. We indicate in bold the best configuration obtained. In Table 4, we directly show the best hyperparameters found for each RNN.
We also perform hyperparameter tuning for linear AR algorithms so as to have a fair comparison. For the linear AR model, the main parameter that requires tuning is the number of taps (\(n_{T}\)). We tune this parameter by using a range of different values and monitoring the MSE value on the validation set. In each case, we train the model for 4000 epochs. We choose the value of \(n_{T}\) that results in a model with the lowest MSE on the validation set. In our experiments, we choose the value of \(n_{T}\) as 34.
2.4 B.4 Evaluation Metrics
We train the algorithms by minimizing the MSE loss. For evaluating the quality of their forecasts, we again use the MSE computed between the forecast and the corresponding true signal. Additionally, we also show results using the Mean Absolute Error (MAE) and coefficient of determination (\(R^{ \mathrm{2}}\)-score) later. The \(R^{\mathrm{2}}\) score is defined as:
where \(y\), \(\hat{y}\), and \(\mu _{\mathrm{y}}\) denote the actual signal, predicted signal, and mean of the actual signal, respectively. The \(R^{\mathrm{2}}\) score gives a measure of how much of the variability of the true signal is explained by the predicted signal. The best case is when \(R^{\mathrm{2}}\) is 1.0, which indicates that the model can completely explain the signal.
2.5 B.5 Comparison of Cycle Forecasts Using Different RNN Architectures
To forecast a solar cycle, we train and forecast 10 times with each of the algorithms (MESN, vanilla RNN, LSTM, and GRU). Then, we compute the mean and standard deviation of the ensemble of forecasts together with the relevant MSE, MAE, and \(R^{\mathrm{2}}\) score metrics between the test set and the mean forecast. In Tables 5, 6, and 7, we show the metrics obtained with normalized data for Solar Cycles 22, 23, and 24, respectively. We highlight in bold the model that achieves the best performance in each case. We also show in Figures 7 and 8 the forecasts obtained for Solar Cycles 23 and 25, respectively.

Forecast of number of sunspots versus time (in years) obtained with a vanilla RNN (a), LSTM (b), and GRU (c). For each case, we generate an ensemble of 10 forecasts and we compare the mean (shown in green) with the actual Solar Cycle 23 (shown in red). We also plot in orange the area covered by the standard deviation of the ensemble.

Comparison of mean forecasts for Solar Cycle 25.
2.6 B.6 Discussion
From the results, we find that the performance of the MESN is quite impressive considering the ease of its training. In some cases, the vanilla RNN and LSTM perform comparable to or sometimes better than the MESN, but on average the MESN is found to be the best performing one. Among the RNN architectures, particularly, the performance of the vanilla RNN is quite good on average, as indicated by the MSE and MAE metrics.
The performance of the GRU model is sometimes unsatisfactory compared to MESN, which is a little surprising considering that it is widely acclaimed for several sequence modeling tasks (Chung et al., 2014; Che et al., 2018; Ravanelli et al., 2018). The linear AR model, being a pretty naive forecasting model, fails to fit the curves accurately, and performs the poorest among all the algorithms in almost all the cases where the testing data is available. For Cycle 25, we find that the vanilla RNN and LSTM models are quite in agreement, and the times corresponding to the peak amplitude of their forecast are also close to that of the MESN.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Espuña Fontcuberta, A., Ghosh, A., Chatterjee, S. et al. Forecasting Solar Cycle 25 with Physical Model-Validated Recurrent Neural Networks. Sol Phys 298, 8 (2023). https://doi.org/10.1007/s11207-022-02104-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11207-022-02104-3