
Abstract
For understanding the physical processes in the solar corona, it is helpful to reconstruct the 3D-distribution of plasma density and temperature. We introduce a new iterative method that uses multi-filter observations and an extrapolated coronal magnetic field to fit the physical parameters along the field lines to the observations. Since a model is applied only for the field extrapolation but not to the loops themselves, non-stationary plasma configurations along the loops can be captured. We demonstrate the performance of our code on a self-made model active-region corona and on active region (AR) 11087 observed by the Solar Dynamics Observatory and the Solar Terrestrial Relation Observatory-A in 2010. In the coronal parts of the model AR, the 25% quantile of the deviations of the reconstructed densities relative to the model values is −0.5 to −0.6 below the model values, the 75% quantile being 0.3. Likewise, for the logarithm of the temperature, the same quantiles are at minus and plus 0.04, respectively, relative to the model values. For AR 11087, the seven channels of the Atmospheric Imaging Assembly in the extreme ultraviolet are reproduced very well. For the four channels of the Extreme Ultra Violet Imager in that regime, the synthesised images are slightly brighter than the observations. The structure of the AR can still be identified here.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The fact that we still not know how the solar corona is heated up to several MK shows that we do not fully understand the physical processes ongoing in the corona. This is also related to the fact that, unlike in laboratory plasmas, the physical properties of the coronal plasma cannot be measured easily.
It is well known that the solar corona is structured into loops, i.e. magnetically confined structures of plasma. It would be helpful to extract the 3D-configuration of plasma temperature and density in the corona from observations. This is especially true for the corona in active regions (ARs) where the physical conditions vary from one coronal loop to another. However, since the coronal plasma is optically thin and only line-of-sight integrated intensities can be measured, this is also a very difficult task, as we can observe changes only in 2D-images.
For identifying the density and temperature along loops from observations different approaches have been used so far. First, for long, isolated sections of loops it is possible to identify the density and temperature directly from observations after an appropriate background subtraction. In observations using several filters in the X-ray and extreme ultraviolet (EUV) regime, intensity ratios carry the desired information. Usually this is retrieved by using inversions of the differential emission measure (Kashyap and Drake, 1998; Hannah and Kontar, 2012). For example, Del Zanna (2013) investigated the emission detected by the Atmospheric Imaging Assembly (AIA: Lemen et al., 2012; Boerner et al., 2012) onboard the Solar Dynamics Observatory (SDO). Schmelz et al. (2015) observed many loop segments to obtain statistical data about the physical conditions in loops. Fletcher and De Pontieu (1999) investigated moss regions, i.e. the footpoints of high-pressure loops.
This method yields information instantly, i.e. with one set of observations in each filter, and does not have to collect data over longer periods. Unfortunately, there are problems when two or even more loops are criss-crossing in the observed images. Due to the optical thinness of the corona, emitted radiation from different points along the same line-of-sight add up to a single intensity. It cannot easily be discriminated then how much radiation originates from which loop.
Thus, applying these methods to crowded parts of an AR yields only some kind of mean density and temperature along the line-of-sight. Aschwanden et al. (2013) provided an automated method for finding peak temperatures and emission measures in each pixel. Although this method provides a good idea about the physical conditions in different locations of the AR corona, it still yields only 2D-maps. Since the physical conditions vary strongly from loop to loop, and also between loops on the same line-of-sight, this is possibly not enough to understand the physical processes of the corona in detail.
Another approach is the use of tomographic methods or of stereoscopic data, which has become available with the launch of the Solar Terrestrial Relation Observatory probes (STEREO: Kaiser et al., 2008). Vásquez et al. (2011) used STEREO data of an entire Carrington rotation to determine coronal temperature and density. Aschwanden et al. (2008) determined the 3D-geometry of 30 loops from STEREO observations and the density and temperature profiles along them. They also provided a method to automatically fit a parametrised loop model to stereoscopic observations (Aschwanden et al., 2009). Unfortunately, such stereoscopic data are limited to the STEREO observations. Instead of observing the Sun from several vantage points, tomographic data can be obtained by observing the Sun over a longer time period. Such methods gain different viewing directions onto solar structures due to solar rotation (Aschwanden et al., 1995, 1999). Thus, the temporal resolution is determined by the time scales over which the viewing on the observed structures changes. These are of the order of a day, much slower than the dynamics of coronal loops.
Finally, some investigators have tried to link coronal magnetic-field lines, gained numerically, with observed coronal loops. In this way, the field line provides the 3D-structure of the loop, while the physical conditions can be retrieved from the observed loop, for example via the analysis of the differential emission measure (Kashyap and Drake, 1998; Hannah and Kontar, 2012). Warren et al. (2018) derived a method to tie field lines extrapolated from photospheric vector magnetograms to traced loops. Malanushenko et al. (2012) used observable loops for determining the coronal field lines. In such an approach, information is limited to locations where loops are visible and can be traced in the observations. This is not necessarily the case for the entire length of a linked field line. In some locations field lines may remain unused when no loop can be traced. Nevertheless, such an approach may provide sufficient information so that the physical conditions can be interpolated throughout the volume of an AR.
Our method belongs to the first approach, using single-view, multi-channel observation. We tackle the problems of LOS integration stated above with an iterative method that uses not only EUV observations but also the coronal magnetic field extrapolated from measured photospheric-field vectors.
Such extrapolations provide the magnetic-field lines in the corona. They utilise the low plasma \(\beta\) in the solar corona to assume force-freeness, i.e. the magnetic-field vectors are proportional to their own curl. For a review of field extrapolations, see Wiegelmann (2008).
Physical conditions are fitted along all field lines extrapolated from the surface. Coronal loops traced in the observations are not required.
As a starting point, let us subdivide the 3D-volume including the AR corona into \(M\) cells of equal size and shape. Each cell then has a mean density and mean temperature. Our principal goal now is to develop an algorithm that is able to find, or at least approximate, the values of the physical parameters in each cell. How can this be done?
We have to face a fundamental problem: the low optical thickness of the coronal plasma. Only the observations of an AR are available to us. Such images are projections of an AR onto the plane of the sky. Images of it are projections into the plane of the sky. Thus, if we would find a configuration for our \(M\) cells for which synthesised images match the observations, we could exchange two cells in the same line-of-sight and still get the same images. Therefore, the observations themselves do not yield unique solutions.
At this point the loops and the field lines come in. Two cells containing the same loop are magnetically connected to each other. Therefore, it can be assumed that the physical properties in the cells are somehow correlated, at least when no shock is travelling along the loop. This surely suppresses the possibilities of exchanging any two cells in the same line-of-sight, reducing the number of configurations following from observations. Bearing this in mind, we present an algorithm that iteratively corrects density and temperature in the cells until the observations are reproduced. The magnetic-field lines are used to connect the cells with each other.
In this article our goal is to demonstrate that this approach does not only reproduce the observed images, but also finds an approximate solution to the 3D-distribution of density and temperature. To do so, we first test our method with an artificial, model AR that we create within this work. This model AR is produced by combining a nonlinear force-free magnetic-field model with a simple loop model. Since we have the exact 3D-density and temperature distribution for this model AR, we can synthesise artificial observations for it. Our newly developed method is then tested by applying it to the model AR, with the artificial observations as input. We evaluate the performance by comparing the reconstructed 3D-plasma configuration with the reference values. Then we apply the algorithm to active region AR 11087, observed by SDO and STEREO-A on 15 July 2010, being about \(77^{\circ}\) apart from each other. While the observations of SDO/AIA go into the fitting process, STEREO-A provides independent observations that can be compared against the result of our method.
The advantages of our method are the, for a single-vantage-point approach, high temporal resolution, the independence from any loop model, and the providing of 3D-data instead of 2D-maps. Tomographic methods require data collected over a period of several days. Contrary to that, we need just one set of (quasi)-simultaneous observations in different filters. Therefore, the temporal resolution is determined by the cadence of the instrument used, which is much shorter than a Carrington rotation, in the case of SDO/AIA 12 seconds, for example (Lemen et al., 2012). The lack of any loop models in the code allows it to find non-stationary solutions far from hydrodynamic equilibrium. This is required since the AR corona is highly dynamical.
2 Basic Idea
Difficulties in identifying density and temperature along loops occur when two loops intersect in the image. Since the solar corona is optically thin one cannot distinguish how much emission originates from one loop and how much from another in such overlapping points. Interpolating intensities from the surrounding pixels or subtracting the background for a loop can help here. Many other intersections in the close vicinity can seriously disturb these methods, however.
Therefore, in our algorithm, FitCoPI (fitting coronal plasma iteratively), we place sample points along field lines, each sample point representing the density and the temperature at its location. Extrapolated coronal field lines serve as tracers for the sample loops. An actual tracing of observed loops, like that used by Aschwanden et al. (2013), does not take place, as such loops do not provide their position along the LOS. From the physical parameters, synthesised images in each filter of the observing instrument are generated. From comparisons of the synthesised images with the real observations an intermediate update for temperature and density at each sample point is computed. To get the update, which is finally applied to a sample point, its intermediate update is correlated to the intermediate updates of its neighbours on the same loop. This update cycle is repeated until a solution is found. Due to correlating the intermediate updates of neighbouring sample points, the algorithm can distinguish between two loops in intersection points, as sketched in Figure 1. In this figure, for example, the algorithm might want to increase the density for all diamond sample points. So it does this also for the circle sample point in the intersection area. If the other circle sample points are now bound to reduce their density, the correlation of the update among neighbouring sample points causes the circular sample point in the intersection to have its density reduced, too. This way the two sample points in the intersection can develop in different directions while being visible in the same pixel.

How two crossing loops are distinguished. A loop (with its sample points depicted as circles) passing beneath another loop (whose sample points are shown as diamonds). The two sample points in the intersection may also be located in the same pixel.
Correlating neighbours causes a flow of information along the loops, but also from loop to loop in intersections. When several loops are criss-crossing each other, two loops that do not intersect can become correlated via a third loop crossing both of the first two. Also, two pixels connected by the same loop are not independent. If a solution is found that matches the observations in a certain small area but is completely wrong in the distribution of the physical conditions, other areas of the synthesised images would be in a total mismatch with observations. These mismatches cause further changes in the values of the sample points, the numerical solution tends to settle in a solution that is close to reality.
From this approach its limitations follow immediately. Perpendicular to the loops the spatial resolution is limited by the instrument that provides the observations. Along the loop, however, the resolution is reduced to a correlation length that depends on the chosen correlation method. Sharp transitions such as shock waves travelling along the loop thus become smeared. Since all plasma in the investigated volume is treated as optically thin, this method cannot be applied when optically thick plasma, like filaments, is present in the field-of-view.
3 Implementing the Approach
In this section we describe our implementation of our approach. The performance of our implementation is tested in the next section. Since it is our goal to demonstrate the capabilities of our approach, we employ a very simple method of implementation here. Suggestions of what can be done differently and how the code might be improved are made in Section 8.
The basic numerical set-up is depicted in Figure 2. The observed volume is divided into cubic grid cells, which are an extension of the image pixels into the third dimension, perpendicular to the image plane. The top facets of the cells are the area covered by a pixel at the location of the observed AR. The lines-of-sight are assumed to be parallel to each other and are pointing into the \(-z\)-direction everywhere. The length of an edge of a cell is denoted \(d\), giving a cell a volume of \(d^{3}\). These cells will be filled with plasma of the physical conditions stored at the sample points nearby, as described below in detail. This way, the physical conditions at the zero-dimensional sample points are mapped into the 3D-volume.

The numerical set-up. The photosphere is at the bottom of the box. The grey shaded rectangle is an image pixel, as are the other facets on the top surface. By extending the pixels along the line-of-sight (vertical direction in this drawing) the volume above the active region is divided into cubic cells. The magnetic-field lines, one of which is sketched by the grey line, are within the box. Along the field lines sample points are placed with constant spacing.
In this numerical box the extrapolated field lines of the AR’s magnetic field are located. Along each field line we place the sample points that record density, temperature and radius of influence, i.e. the loop cross section, at their location. The sample points are placed on the field lines with a constant spacing of \(0.3d\), which is sufficient for the Nyquist frequency defined by the pixels (\(0.5 d\)).
The computation of field lines is performed prior to the FitCoPI code. Once the field lines are determined, they are kept fixed throughout the fitting process. Likewise, the sample points are fixed in their allocated positions.
3.1 Weights Describing the Influence Between Pixels and Sample Points
To make the following equations more easily understandable, we allocate specific indices to specific roles. Sample points are addressed with the indices \(i\) and \(j\), whereas \(l\) and \(m\) are for grid cells. The pixels are referenced by \(\mu\) and \(\nu\), while filters of the observing instrument are denoted by \(f\) and \(g\).
Only for the following determination of weights, each grid cell is divided into \(N^{3}\) sub-cells by \(N\) subdivisions in each spatial dimension. Once the weights have been computed, further storage of the sub-cells is not necessary. In a first step, each sub-cell is assigned to a sample point and then assumed to be completely filled with isothermal plasma having the density and temperature of the sample point. To do so, all sample points that are not further away from the sub-cell centre than their radius of influence are found. The sub-cell is assigned to the closest one among these sample points. Sub-cells that do not become assigned to any sample point are considered to be empty.
The fraction of the volume of a grid cell \(l\) assigned to a sample point \(i\) is the cell weight \(c_{il}\) and describes how much influence the sample point has on the grid cell. If \(M\) sub-cells of grid cell \(l\) have been assigned to sample point \(i\), one has
Due to the numerical set-up, all grid cells in a column along the \(z\)-axis contribute with their emission to the same pixel. Thus, we define a pixel weight \(p_{\mu i}\) of pixel \(\mu\) onto sample point \(i\) by summing up the cell weights of the sample point onto the cells in the pixel’s line-of-sight:
Figure 3 clarifies the roles of the cell weights and the pixel weights. For each sample point we can also define a pixel weight sum, which is used to compute means later on:
In our implementation, all weights remain fixed once they have been determined.

How pixels, sample points, and grid cells influence each other and how the weights are named.
During the iterations we make use of the response functions [\(R_{f}(T)\)] of the instrument that describe how sensitive the instrument is in a filter \(f\) to emission from a plasma of temperature \(T\). These functions are used as weights. Simply using the response functions would result in the most sensitive filters dominating over the less sensitive ones. So we deploy normalised response functions,
3.2 Synthesising the Images
The algorithm relies on iteratively updating temperatures and densities, held by the sample points, by comparing observations with synthesised images. Hence, images have to be synthesised from the current numerical conditions after each step. As stated above, each sub-cell assigned to a sample point contains plasma with the temperature and the density of that sample point. Under this isothermal condition, the emission originating from the sub-cell and detected by the instrument in a certain filter \(f\) can be approximated by
where \(A_{\mathrm{sub}}\) is the area of a sub-cell’s face in pixels, \(R_{f}\) the instrument’s temperature response function in data numbers (DN) \(\mbox{cm}^{5}\,\mbox{s}^{-1}\,\mbox{pix}^{-1}\), \(T_{\mathrm{sub}}\) the temperature of the plasma in the sub-cell in \(K\), \(n_{\mathrm{sub}}\) the electron number density in \(\mbox{cm}^{-3}\), \(\Delta z_{\mathrm{sub}}\) the LOS depth of the sub-cell in cm, and \(\Delta t\) the exposure time in seconds. For the area, \(s_{x}s_{y}~{\mbox{pix}} = d^{2}\), with \(s_{x}\) and \(s_{y}\) being scaling factors that differ from unity in the case where the observation images are rescaled. If the considered cell is indexed with \(i\), the detected intensity of emission originating from this cell [\(I_{if}\)] follows from adding up the DN values from all sub-cells. Since \(\Delta z_{\mathrm{sub}}=d/N\) and \(A_{\mathrm{sub}}=d^{2}/N^{2}\), this can be written as
Here, \(A_{\mathrm{cell}}=s_{x}s_{y}\) pixel is the area of a cell face measured in pixel units. In a case where the unmodified, original observations are taken as reference images, we have by construction \(A_{\mathrm{cell}}=1\) pixel. If the size of the observed images is changed for any reason, this must be adopted by \(A_{\mathrm{cell}}\). The intensity seen by a pixel \(\mu\) in the synthesised image now follows from summing up the intensities of all cells along the line-of-sight of that pixel,
3.3 Correlating the Neighbouring Sample Points
We correlate the updates of neighbouring sample points by smoothing the intermediate updates with a Gaussian. This kernel is defined by
although the normalised version is applied:
The parameters \(s\) and \(s_{c}\) are a smoothing length and a cut-off length, respectively.
3.4 Fitting the Physical Conditions
3.4.1 Density Update
As noted in Equation 5, the intensity of emission is proportional to the density squared. Thus we can assume that, by comparing the intensity of a pixel in a certain filter in the synthesised image with the intensity of the same pixel in the observations, we get a reasonable guess by which factor we have to modify \(n^{2}\) along the LOS of the pixel:
Since every filter might give a different new value for \(n_{\mathrm {new}}\), a compromise needs to be found. We do this by a weighted average. To get a density update from each pixel \(\mu\) the ratio of the intensity \(I_{\mu f}^{\mathrm{obs}}\) in the observation to the intensity in the reconstruction \(I_{\mu f}^{\mathrm{syn}}\) is computed in filter \(f\):
This is the correction factor mentioned above and can be interpreted as how much a filter wants a sample point affected by that pixel to change its density. For such a sample point \(i\), a weighted average of the \(\alpha\) is then computed. Filters that are more sensitive to the current temperature held by the sample point get more weight. Also, we define an additional weighting factor that grants brighter pixels a larger weight:
The filter averaged correction factor is then
Note that a sample point can be affected by several pixels. Thus, after all \(\beta_{i\mu}\) have been determined, we perform another weighted average, using the pixel weights to get the intermediate update:
After computing each of the intermediate updates we correlate these using the Gaussian smoothing kernel. This step gives the final values of densities after the iteration,
where the sum goes over all sample points on the same field line as sample point \(i\). Sample points near the ends of the field line become correlated with fewer neighbours; hence the sum is truncated at the footpoints. For these points the denominator in Equation 15 does not sum to unity.
As the final part of the density update, new synthesised images are computed.
3.4.2 Temperature Update
After the density we correct the temperature. A look at Equation 5 reveals that, for a given density, the intensity [\(I_{\mathrm{f}}\)] seen in one filter is proportional to the response function \(R_{f}\) of the filter. Hence for the ratios \(I_{fg}=I_{f}/I_{g}\) and \(R_{fg}=R_{f}/R_{g}\) we have \(I_{fg}\propto R_{fg}\). At a certain temperature \(\log T\), the change of \(I_{fg}\) with temperature can be approximated by a Taylor expansion:
Equation 16 gives a method to update the temperature by bringing the derivative to the left hand side of the equation.
We denote the intensities of a pixel \(\mu\) in two filters in the observations with \(I_{\mu,fg}^{\mathrm{obs}}=I_{\mu f}^{\mathrm {obs}}/I_{\mu g}^{\mathrm{obs}}\) and, in the same way, in the synthesised image as \(I_{\mu,fg}^{\mathrm{syn}}=I_{\mu f}^{\mathrm {syn}}/I_{\mu g}^{\mathrm{syn}}\). In our equations a ratio that is equal to or less than unity is used.
As for the \(\alpha_{\mu f}\), we determine correction differences \(\gamma_{\mu fg}\) for the logarithm of the temperatures from the intensity ratios of each pair of filters \(f\) and \(g\):
The \(\gamma_{\mu fg}\) are clamped between −1 and 1. By averaging these correction differences from each filter combination, the preliminary step size of a sample point \(i\) resulting from a single pixel \(\mu\) is obtained:
where \(F\) is the total number of filters, which are enumerated from 1 to \(F\). The function
is the derivative of the ratio of \(R_{f}(\log T)\) and \(R_{g}(\log T)\) with respect to \(\log T\). Due to the power of 1/4, the weight is of linear order, as in the density update. The intermediate update of the temperature is now done by averaging the influences of all pixels that affect sample point \(i\):
Additionally, the resulting intermediate values are clamped to the interval over which the response functions are defined. The step size [\(\Delta s\)] should not be too large, to prevent an overshooting in the correction and consequent oscillation of the values. In order to keep it as large as possible, we introduced a dynamic correction of the step size, based on tracking the total of the DN over all pixels in all synthesised images after each iteration. In the case that an oscillation of this total within the last four iterations is detected, the step size is halved. If the total instead remains nearly constant, the \(\Delta s\) becomes raised by 5%. A minimum value of 0.04 and a maximum value of 0.4 are imposed on the step size, since this is the range \(\Delta s\) adopted in our test. Initially, \(\Delta s\) is set to 0.2.
Correlating the temperature updates works as for the densities:
After this step new synthesised images are created again. The iteration might end now, or continue with another density update.
3.4.3 Exit Criteria
The algorithm terminates when the total DN count, which also governs the step size [\(\Delta s\)], does not change much any more. Two criteria must be matched for exiting the iteration: First, within the last 200 iterations, every total DN count must deviate less than 4% from the mean of the total DN values over the period. Also, the mean of the total DN values over the last 20 iterations is taken after each iteration. The last 200 of these means must not deviate more than 1% from their mean. Exit checks are performed after each temperature update.
The former criterion ensures that the total count remains in a certain range over a longer period. The latter one excludes long-term trends. Without it, the algorithm may terminate when the total DN count increases or decreases slowly enough to match the first criterion.
We added two further ways for the algorithm to terminate: a hard cap for the number of iterations, after which the code stops automatically, and the possibility of a manual, user-enforced exiting. However, the results presented in this article were obtained matching the proper exit criteria.
4 Testing the Method on a Model Active Region
In order to validate the method, an active region for which the 3D-configuration of density and temperature is known in detail is required. Since no such AR exists so far, we are forced to construct a model AR. For this reason we applied a simple loop model to the magnetic field of AR 11158, observed on 14 February 2011. This model is described in the Appendix. The photospheric magnetic field has been extrapolated by Wiegelmann et al. (2012), using their NLFFF code, to obtain the coronal field. Originally, the result of the extrapolation are the field vectors in a numerical box of \(300\times300\times160\) grid points. With each of the \(300\times300\) grid points in the bottom layer as a starting point, we interpolated the field with a fourth-order Runge–Kutta scheme to obtain the field lines. We shrank the box and the field lines by a factor of two-thirds to a \(200\times 200\times108\) grid. This reduces the required storage and computation time, since fewer sample points are required. The natural horizontal extension of the field-of-view is roughly 216 Mm. Therefore, one pixel in our setting has an edge-length of about 1080 km.
The magnetic-field lines are numerically represented as polygon curves. By applying the loop model we store the physical model conditions at each node of the polygon curves. Instead of using sample points, we use these to synthesise the model “observations”.
This image synthesising works in a similar way as during the iteration process. There are, however, two differences: First, the cells are divided into \(10\times10\times10\) sub-cells. This is to make sure that we get a smooth sampling without much influence of the discretisation, but it also increases the computation time. Second, since no sample points are used, we have to interpolate the values on the nodes. To find the temperature and density of a sub-cell, the point closest to the centre of the sub-cell is calculated on each loop. Such a closest point and its loop are dropped from further consideration when the closest point is further away from the centre of the sub-cell than the loop cross section at this point. To get this cross-section, the values on the adjacent nodes are linearly interpolated. From all points that are sufficiently close to the sub-cell centre, the closest one is selected. The density and the logarithm of the temperature of the adjacent nodes are linearly interpolated onto the chosen point and are taken for the plasma, which is to fill the sub-cell. Sub-cells that are not assigned to any point remain empty.
From this model atmosphere, synthesised “observations” are generated. These model observations serve as reference images in the fitting process. They replace the real observations used when the FitCoPI algorithm is applied to a real AR. The intensity of a sub-cell is computed according to Equation 5. Adding up the intensities of all sub-cells in a cell results in the intensity of the cell. Summing up the contributions of each cell along the LOS of a pixel yields the intensity of the pixel in the requested, artificial model observation. This procedure is repeated for each filter.
4.1 Technical Details
The process of assignment of the sub-cells to certain points can be accelerated. First a point on a loop can affect only sub-cells within its loop radius. Thus a bounding box is constructed around each loop that extends the loop on all six facets by the maximum loop cross section plus half of the length of a cell edge. If the centre of a cell is located out of the bounding box, this loop is waived for further checks because there is no chance that any point on the loop can affect any sub-cell in that cell.
Second, if a loop passes the boundary-box check, a boundary-sphere check is applied to each sample point (when assigning the cell weights) or each segment of the polygon curve (when generating the model atmosphere), respectively. In the first case a sample point is neglected by a cell if the sample point is further away from the cell centre than its radius of influence plus \(d\sqrt{3}/2\), half of the diagonal across the cell. In the second case it is checked if a node of a polygon curve and the cell centre are closer than the loop radius at the node or the radius at the next node, whichever is larger, plus \(d\sqrt{3}/2\) plus the length of the polygon segment following the node.
Finally, a multi-threading algorithm is deployed. Each cell (not sub-cell) that is yet to be checked for sub-cell assignments is kept in a list. A selection-flag for each cell tracks if the cell has been added to the list once already. Initially, one footpoint of each loop is taken. All of the cells with one or more of these footpoints are added to the list and become flagged as selected.
While the computation progresses, a thread now takes a cell from this list and checks if some of the sub-cells in this cell become filled with plasma. If and only if so, i.e. the cell is not completely empty, the six neighbouring cells, with the exception of those that have been marked as selected already, are added to the list and their selection-flag becomes set. If the list is not empty, the thread picks a further cell to continue.
Since the cells are independent of each other, the threads can run in parallel. The access to the list by the threads is synchronised properly, so that no cell becomes picked twice at the same time. Due to the selection-flag, each cell cannot be added to the list more often than once, and the list empties eventually. With this approach it is guaranteed that all cells with plasma are found while huge voids are skipped.
Also, the sub-cells are not stored, since this would require too much memory. After all sub-cells have been filled with plasma of the model atmosphere, the intensity originating from the cell in each filter is computed immediately and stored. The detailed information as regards the sub-cells can be safely dropped afterwards.
We set the radius of influence to a constant \(d\) everywhere. With \(d\approx1\) Mm this is in the range of the size of observed loop structures on the Sun, although they seem to fragment into filaments of smaller cross section (Bray et al., 1991; Cirtain et al., 2013). The loops as they are made by the code are, in principle, monoclinic and the conditions in them do not vary perpendicular to the magnetic field. However, field lines can lie close to each other. Such a pack of individual strands would form a wider, multistranded loop.
Since we are dealing with numerical values, we do not use real physical quantities but dimensionless representations for these test runs only. The values in this test correspond to an emission measure in units of \(10^{26}~\mbox{cm}^{-5}\). In Section 5, when we apply the code to real data, we describe how to deal with the physical quantities, and why such a unit for the emission measure allows one to express the numerical quantities of order unity. For now, we set \(d=\Delta z=\Delta t=1\). Also, the maximum possible density in the model is unity. The logarithm of the temperature has realistic values. As observing instrument, which enters the equations by the set of response functions \(R_{f}\), we use AIA onboard NASA’s SDO. Due to the choice of the emission measure unit we achieve count numbers of the order of unity in the faintest images.
The initial conditions for all sample points are \(n_{i}=1\) and \(\log T_{i}=6\).
On the original \(300\times300\times160\) grid of magnetic-field vectors the field lines were deduced using a Runge–Kutta iterator. This iterator was called for all points (\(x,y,z=0\)), \(x=0,\ldots,299\), \(y=0,\ldots,299\) as starting points on the bottom of the numerical box, resulting in a dense population of field lines connected to the photosphere. In the line-of-sight images (shown in Figure 4) point \((0,0)\) is in the lower-left corner.

Ground-truth synthesised images of the model corona (see text for details) and the reconstruction synthesised images from fitting densities and temperatures along the loops in the seven EUV channels of SDO/AIA. Given are the synthesised number of counts. The view is along the hypothetical line-of-sight (\(z\)-axis). In each pair, the ground-truth synthesised image is on the left, the reconstruction synthesised image in the same channel is on the right. The length of the edge of an image is about 216 Mm.
4.2 Evaluation of the Fitting Results
We then applied the code to this model AR for fitting density and temperature along the loops, as described in Section 3. We used a smoothing length of \(s=2.5\) and a cut-off length of \(s_{c}=40\). The algorithm terminated after 517 iterations.
In the following discussions, we refer to the images that are generated from the outcome of the fitting process as reconstruction synthesised images (RS-images). Likewise, images generated from the model atmosphere are referred to as ground truth synthesised images (GTS-images). Because of a small number of sample points with extremely large values compared to other points, the mean of any statistical quantity is, generally, much larger than the median. The standard deviations are enormous for the same reason. Therefore, we think that the median and other quantiles are a better measure for our statistics here than the mean and the standard deviation, and they are used throughout this article.
4.2.1 Synthesised Images
As first step, it is natural to compare the RS-images to the GTS-images, obtained as described in the introduction of Section 4. This comparison for a view along the line-of-sight (the \(z\)-axis) is shown in Figure 4. Since these GTS images are used as reference for the fitting process, a good match is expected. Obviously, there is a very good optical match between model and reconstructed images in all filters.
Measuring the relative difference between RS- and GTS-intensity, \(\Delta I_{\mathrm{rel}}=(I_{\mathrm{RS}}-I_{\mathrm{GTS}})/I_{\mathrm {GTS}}\) for each pixel supports this impression. Table 1 shows the median, the 90% quantile, and the 99% quantile of \(|\Delta I_{\mathrm{rel}}|\) for the different filters as well as for all filters together. The fraction of pixels on which the RS-intensity deviates by not more than 20% from the GTS-intensity is also given. It is found that in all filters more than the half of the pixels deviate less than 20% from the GTS-value. Taking all filters together, this holds for almost two-thirds of the pixels. The steep increase towards higher quantiles shows that the relative deviation remains small for most pixels and becomes large for only a few.
But how good are these RS-values really? Although the line-of-sight images match very well, the view from the side (along the \(y\)-axis, Figure 7) reveals that there are still a few deviations in the results from the model. Thus we have to find how well the synthesised results match their model counterparts.
4.2.2 Spatial Distribution of the Differences Between Reconstruction Synthesised and Ground Truth Synthesised Images
Figure 5 depicts the GTS-image and a display of \(\log|\Delta I_{\mathrm{rel}}|\), clamped between −1 and 1. The channels showed in this plot include the best (AIA 335) and the worst (AIA 304) channel, in terms of the median of \(|\Delta I_{\mathrm {rel}}|\). In fact, the other five channels are very similar to each other, thus we display only the deviation images for 131 Å and 211 Å. Clearly, the largest deviations appear to be in faint regions of the image, whereas bright areas tend towards rather small deviations.

Image of the model (left picture in each pair) and the logarithm of the magnitude of the relative deviation between model and synthesised images: \(\log|\Delta I_{\mathrm{rel}}|\) (right picture in each pair). In the deviation images, the missing channels are similar to the 131 Å channel and the 211 Å channel.
4.2.3 Statistics of the Deviations in Density and Temperature
In the same way we defined a relative difference [\(\Delta I_{\mathrm {rel}}\)] in the intensities of the individual pixels, we define a relative deviation for the density and the logarithm of the temperature for individual sample points:
We binned the sample points from different loops according to their position in their loop, in order to obtain location-dependent statistics. For each sample point we took the relative loop position \(x/L\), where \(x\) is the absolute position of the sample point (distance to one footpoint, measured along the loop) and \(L\) is the total loop length (from one footpoint to the other, or from the footpoint to the end of the field line if it is not closed). All points from all loops with \(0\leq x/L< 0.01\) are in the first bin, those sample points with \(0.01\leq x/L< 0.02\) are in the second, and so on. In total 100 bins have been prepared. Figure 6 displays the median, the 25% quantile, and the 75% quantile of \(\Delta n_{\mathrm {rel}}\) and \(\Delta \log T_{\mathrm{rel}}\) for each bin. In both cases these are shown taking into account only those sample points with a model density of \(10^{-2}\) (the maximum possible density for a single sample point in the model is unity). Incorporating the points with a model density below \(10^{-2}\) barely affects the median. The scatter, however, increases, especially towards higher relative deviations. The signal of such low-density points is too low, as intensity varies with density squared. Thus, their properties cannot be resolved properly.

Statistics for the relative deviation of density (a) and \(\log T\) (b). The sample points are binned according to their relative location in the loops. The footpoints (or ends where the field line leaves the box) are at bins 1 and 100, the middle of the field line is at bin 50. Only sample points with model density of at least \(10^{-2}\) (maximum is unity) have been taken into account.
The minimum value \(\Delta n_{\mathrm{rel}}\) and \(\Delta \log T_{\mathrm{rel}}\) can have is −1, and they can reach infinity. Ideally, they are zero, since this means that the density or, respectively, the temperature was reproduced correctly.
Figure 6 reveals that the sample points considered group around \(\Delta n_{\mathrm{rel}}=0\). Therefore, the iterative process indeed causes the sample points to settle with a density in the correct range. It also reveals, however, that the density is underestimated for most of the sample points, whereas it is overestimated for a still considerable fraction. In the loop centres, the median ranges between \(\Delta n_{\mathrm{rel}}=-0.15\) and \(\Delta n_{\mathrm{rel}}=-0.2\), although 0 is within the 75% quantile. The statistics remain constant over a wide range of loop lengths, but larger deviations appear at the footpoints.
The median of \(\Delta \log T_{\mathrm{rel}}\) is close to zero in the middle parts of the loops and deviates only slightly. Near the footpoints the deviations increase and the temperature is overestimated. This is due to the smoothing, which causes the chromosphere and transition region to be not resolved. Coronal temperatures are smoothed down to the photospheric footpoints of the field lines. Loops of different length and different inclination to the surface have been taken into account. Therefore the number of bins falling into the less-well-reproduced chromospheric parts varies a great deal from loop to loop, and only the central bins have values that surely can be associated unambiguously the corona.
4.2.4 Different Perspective
Since we perform numerical tests here, we can simply compare the GTS-images and the RS images generated from different perspectives. Such GTS-images from vantage points different from the one presented in Figure 4 are not used for the fitting process. However, such images should be reproduced as well, at least approximately, as the code seeks for the 3D-distribution of density and temperature, which are independent of the viewing direction. Figure 7 displays the view along the \(y\)-axis. Again, GTS-image and RS-image are opposed to each other for each channel. More differences than in the \(z\)-view come to the eye here. First, there is the chromosphere, which appears as a dark lining along the bottom edge of the GTS-images, since it is too cool to be seen by the AIA EUV channels. In the RS-images it is completely bright. Due to the smoothing, coronal temperatures reach down to the photosphere in the fitted AR and the chromospheric part becomes visible. Second, some of the larger loops do not become faint at the top as much as they do in the reference images. This appears to happen in all filters, hence the density of these loops must be too large to fit to the model values. This supports the idea, expressed in Section 4.2.3, that a fraction of the loops are too dense, relative to the model.

Horizontal view of the model AR. In Figure 4, the vertical image axis corresponds to the view direction here.
On the other hand, the lower parts of these, presumably overdense, loops are well reproduced. Also, the fans and bundles of loops visible in the model images can be identified in the fitted results.
Figure 8 (upper panel) is an oblique view on the AR and displays the column density. Here it becomes clearly visible that the overall density found by the iterative method is reproduced very well, especially in the coronal parts. Near the photosphere, some loops of unrealistic high density appear. They remain isolated, singular exceptions. Also, the thermal structure is accurately captured in the corona (lower panel). In just a bundle of loops on the left the absolute magnitude is slightly overestimated. As mentioned before, the lower parts deviate significantly.

Upper panel: column density for the test case under an oblique view. On the left the model AR, on the right the synthesised AR. In our test here, the density is a dimensionless parameter with a maximum value of unity. Lower panel: maximum \(\log T\) in each LOS. The view is horizontal here. In both panels, the vantage point is at the top-left corner of the images in Figure 4.
4.2.5 Direct Comparison
For each individual sample point we compare its density, temperature, and the “visible emissivity” in a filter, \(\varepsilon _{if}=n_{i}^{2}R_{f}(T_{i})\), according to the model with the values resulting from the fitting process. The resulting density plots are displayed in Figure 9. The plots are two-dimensional histograms of \(300 \times 300\) bins. The plotted value is the number of sample points per bin. Only sample points in the coronal part (\(z\geq3.2\)) and of considerable density (\(n\geq 10^{-2}\)) were included. Figure 9a shows that for the bulk of the points the densities are well reproduced at first. Above \(n=0.5\), the densities become slightly underestimated. Since the scatter is large, around unity over all ranges, points with overestimated density exist. The temperatures gather around 1 MK, since this is a characteristic temperature of the model (Figure 9b). A structure can be seen in the temperature plot that follows the \(x=y\) line, and therefore the temperatures were recovered well for many points. The effect mentioned above where especially the cool sample points from the chromosphere tend to end up with higher temperatures can also be read from the plot. Besides that, a group of points with a model temperature of 1 MK but a synthesised temperature of about \(\log T\approx5.5\) catches the eye in the plot.

Histograms of the comparison of the values on the sample points from model and iterative fitting. The colour scale shows the number of points in each bin. Each panel consists of \(300 \times 300\) bins. Included are sample points above \(z=3.2\), which is the coronal part of the model, and, again, a minimum model density of \(10^{-2}\). The black lines indicate the \(x=y\) lines. Points outside of the plotting range were shifted towards the closest edge of the plot, suggesting how many points are outside of the plotting range. Top row: density (a) and temperature (b). Bottom row: “visible emissivity” \(\varepsilon_{if}=n_{i}^{2} R_{f}(T_{i})\) of the sample points \(i\) for different filters \(f\). Shown here are the 304 Å channel (c) and the 335 Å channel (d). These channels are the worst and, respectively, the best according to Table 1.
Like the density, the emissivities, which vary with the density squared, exhibit a large scattering. Nevertheless, the major bulk of the points either follow the \(x=y\) line, or are aligned to it just below the line. Depicted are the worst reproduced channel (304 Å, Figure 9c) and the one reproduced best (335 Å, Figure 9d), which are surprisingly representative for the remaining five channels. The plots for the remaining EUV channels look very similar: besides a large scattering, there is a bulk extended along the \(x=y\) line. The bulk centres are located either on this line or, as in the two plot depicted, slightly below.
As a quantitative measure of how much the model values and the RS-values are correlated to each other, we computed Spearman’s rank coefficient of correlation. The coefficients for the density, temperature, and the “visible emissivity” \(n_{i}^{2}R_{f}(T_{i})\) are listed in Table 2. A two-sided test to see if two sequences of values are uncorrelated gives a critical value (see for example Müller, 1975) for the rank-correlation at
where \(N\) is the number of points included, \(\alpha\) the level of significance, and \(\Phi\) the integral over the normal distribution. In our case for \(\alpha=10^{-3}\) and \(N=3{,}526{,}987\), this critical value is \(\varrho_{\mathrm{crit}}=0.0018\). In the case the magnitude of the rank-correlation exceeds this critical value, so the hypothesis that model values and RS-values are uncorrelated must be rejected. As can be read from Table 2, this is clearly the case for all of our measures, as required.
4.2.6 Grid Cell Binning
Not only the individual loops and sample points are subject to our analysis. It is also of interest whether the reconstruction yields the correct values in the correct locations.
As for the individual sample points, we define a relative deviation in the mean density, or, respectively, in the mean logarithm of \(T\) for a grid cell \(l\):
The mean values of a cell on the right-hand sides follow immediately from the sample point values and the cell weights,
We then binned \(b\times b\times b\) cells, computed \(\Delta\langle n\rangle\) and \(\Delta\langle\log T\rangle\) for these binned super-cells and took the statistics for different bin sizes (\(b\)). These results are sketched in Figure 10. For the same reasons as in the analysis done before, only super-cells with \(\langle n\rangle\geq10^{-2}\) were included for these statistics.

Relative deviations of the physical parameters in binned super-cells of different bin size. Panel (a): density. Panel (b): logarithm of the temperature. Displayed are the median (filled diamonds) and the 25% and the 75% quantiles (open diamonds). In both cases, only binned super-cells with a model density of \(\langle n\rangle\geq10^{-2}\) were included in the statistics.
With no binning of the cells, the densities are underestimated by 10%. With increasing bin size, the null line is crossed and the densities become overestimated. From a bin size of 20 and greater, the overestimation remains near 20%. The errors do not change in size but follow the raising trend. For a bin size of 50 and 100 the errors are lower. Since there are only \(200 \times 200 \times 200\) cells, there are only a few binned super-cells of this size.
The values of \(\Delta\langle\log T\rangle\) are much closer to 0. The median is between −0.01 and −0.02 for small bin sizes and increases to 0.06 for large super-cells. Here, the overestimated temperatures near the lower boundary affect a larger and larger fraction of the super-cells. In the beginning, the errors narrow down to 0.03 for a bin size of 5. They widen afterwards and narrow again for the large super-cells.
At a bin size of 5, the median of the density deviations is close to zero, 0.02, and the errors for the temperatures are smallest. Thus, it seems that the plasma properties of our reference model were captured best on this scale length.
5 Test Application to Real Data
To conclude our performance analysis, we apply the method to the active region AR 11087, observed by SDO and the STEREO probes on 15 July 2010, between 8:10 and 8:14 UT. The AIA observations serve as reference images for the fitting while EUVI on STEREO-A (Howard et al., 2008) provides independent images the fitting results can be compared.
It is desirable to deal with numbers of the order of unity. Thus, we express the electron number density in units of \((10~\upmu \mbox{m})^{-3}\), since the typical coronal value is \(10^{9}~\mbox{cm}^{-3} = 1\) \((10~\upmu \mbox{m})^{-3}\). Hence, the response functions are also transformed into the dimension of DN \((10~\upmu \mbox{m})^{5}\,\mbox{s}^{-1}\,\mbox{pix}^{-1}\). The cell depth is of the order of 1 Mm, and indeed we put this Mm value into the equations. The now necessary, unit-balancing factor of \(10^{11}~\mbox{Mm}/(10~\upmu \mbox{m})\) is multiplied to the response functions in advance of the calculations. With the unit transformation, the numerical values of the response functions now vary between \(10^{-2}\) and \(10^{2}\) in their cores. The observation times are of the order of ten seconds and are kept as they are.
For the fitting input, we take PSF-deconvolved level 1.5 AIA images. These images were derived from level-1 images by the aia_prep.pro routine in SolarSoft (Freeland and Handy, 1998), after the PSF deconvolution via the aia_deconvolve_richardsonlucy.pro function had been applied. Both functions were provided by the AIA team. No further alignment has been applied, since we reduce the image size anyway in order to save both memory space and computation time.
We take the magnetic-field extrapolation of the AR made by Chifu, Wiegelmann, and Inhester (2017) with their S-NLFFF method. This extrapolated field is given on a \(480 \times 272 \times 240\) grid, where the last dimension refers to altitude. As in the test case, this resolution of the extrapolated field determines the number of field lines considered. We extrapolated field lines from the lower-left corner of each pixel of the lower boundary of the box. Field lines of a length below eight, measured in cell units of this box, are discarded, as discussed below. The remaining field lines, 105,652 in total, are projected into the AIA images and a cut-out of the region of interest (ROI) is taken (displayed in Figure 11).

Full-disk image of the Sun in the SDO/AIA 193 channel, as seen on 15 July 2010 at 8:14 UT. AR 11087 is placed prominently near the centre. The frame displays the cut-out region that we use for our fitting process.
This cut-out, originally of size \(926 \times 600 \times 562\) pixels, is reduced to images of \(200 \times 200\) pixels in a conservative way, meaning here that the total of the DN values over all pixels of an image are preserved. This reduction corresponds to scaling factors of \(s_{x}=4.81\) and \(s_{y}=3\), respectively. Additionally, we shrink the ROI by a factor of 4.496 in the LOS direction, yielding a final grid of \(200 \times 200 \times 125\) cells. With these settings, the cell depth (\(d\) in Equations 1 to 6) is, rounded, 1.98 Mm and the area factor (\(A_{\mathrm{cell}}\) in Equation 6) is \(4.81\times3=14.43\). For the loop cross section, we assume a constant value of unity in terms of the reduced grid cell size. In the same measure, the sample points are placed with a spacing of 0.3 along the field lines. The cut-off length of the Gaussian smoothing kernel, \(s_{c}\) in Equation 8, is set to 40. The smoothing length in the same equation has the value of \(s=2.5\). Together, this translates to a standard deviation of, roughly, 3.4 pixel sizes of the reduced image.
Please note that the field lines discarded as too short beforehand would have a total length of two pixels or less after this spatial reduction. These tiny structures would have, if more than one, few sample points concentrated in up to two, but in most cases not more than one, pixel. However, smoothing information of various pixels along a field line is the integral part of the FitCoPI code. Since this cannot be done any more on such tiny structures, we neglect these for being too small and below the resolution limit of the method imposed by the smoothing.
After the termination of the FitCoPI code and values for \(n_{e}\) and \(\log T\) have been found for each sample point, the field lines are transformed into the perspective of STEREO-A. Again, a ROI determined by the location of the field lines is cutout from the EUVI images and conservatively reduced to an image size of \(200 \times 200\) to save memory and computation time (the image generation still requires the cell weights to be determined, which is a time-consuming step).
For EUVI, the length-based response functions \(R_{f}\) as in Equation 6 are not given. Instead, the SolarSoft routine euvi_flux.pro produces the flux in DN \(\mbox{s}^{-1}\,\mbox{pix}^{-1}\) for a given volume emission measure. By dividing this flux by the volume emission measure and multiplying it with the area observed by one pixel of the instrument at the location of the corona, we gain the required, length-based response functions. For the area, we took \(1.20825~\mbox{Mm}^{2}\).
5.1 Fitting Results for AR 11087
Figure 12 displays the FitCoPI synthesised images and the observations. As in the test using the model AR, the RS 335 Å image shows the best matching with the observation, while the 304 Å channel is the one with the poorest matching. Thus, these two are displayed in the figure, along with the 94 Å and the 171 Å channel representing the other five. The similarities between the observations and the RS-images over a wide range of scale lengths are at hand. Discrepancies appear on the shortest scale lengths only. A loop in the North (at \(400^{\prime\prime} \) North and \(80^{\prime\prime}\) East) is truncated by the edge of the numerical domain. The 304 Å channel displays a few bright spots that are obviously non-physical. They do not appear in other channels.

Observations (ref) and RS-images obtained from the result of the fitting process (syn) for four SDO/AIA channels. The coordinates are relative to the disk centre. As in the test before, the 304 Å channel gives the poorest performance, while the 335 Å matches best. Hence the remaining five EUV channels are similar in the quality of matching; only two of them are displayed here.
The RS-EUVI/A images, synthesised from the reconstruction of the AR atmosphere, are depicted in Figure 13. Qualitatively, the observations are broadly reproduced. The similarities are less clear than in the AIA images, however. The bright core of the AR in the 171 Å channel can be identified. Also, the pillar of bright emission at the same place in the other channels can be found in the RS-images. A loop system in the South, prominently seen in the 171 and 195 Å channels, is just hinted at in the fitting results. On the other hand, in the 284 and 304 Å channels, the empty region in the North can be identified. In the latter two, long-wavelength channels, the emission in the observations appears to be more concentrated in the lowest parts of the atmosphere than in the RS-images. Quantitatively, the three channels of shorter wavelength are about ten times brighter than the observations, while 304 Å is just about five times brighter. Here it must be pointed out that the synthesised emissivity is very sensitive to variations in the temperature. Changes by 0.1 in \(\log T\) can already severely affect the computed intensity. If the temperatures are concentrated towards the temperatures where the channels are most sensitive, this would enhance the DN-values a great deal. Also, the intensity of emission varies with density squared. This might partially explain the brightening. However, if only the density were overestimated, the brightening factor would be the same for all four channels. Another effect coming into play here is the degradation of the detector. The response functions used for the image synthesising are launch values, derived in SolarSoft (Freeland and Handy, 1998) with the methods provided by the STEREO team. By the time of the observations, the instrument had been in space for almost four years. The degree of degradation has not been tracked for EUVI since the launch of the STEREO probes. Response functions for July 2010 are, therefore, not available. The change of the average DN-value over all pixels over the course of time hints towards a loss of sensitivity of about 15% for on-disk pixels between launch and July 2010, at least for the 304 Å channel. The degradation directly above the limb might be stronger due to a burn-in effect, but probably does not exceed 20% (J.P. Wuelser, private communication, 2019).

Observations (left) and synthesised images (right) obtained from the result of the fitting process for the STEREO-A/EUVI channels. In the observations, all pixels that do not have any signal in the synthesised images in any filter have been masked. The coordinates are relative to the disk centre.
Figure 14 shows the total DN-count added over all pixels and all seven EUV channels of AIA. The algorithm exited after 868 iterations. It can be read from the figure that, after a stage of large oscillations in the beginning, the total count decreases until it eventually settles around \(2.12\times10^{6}\) DN and does not change any more. Also displayed is the mean over the last 200 iterations (solid line) and the 4% deviation from that mean (dashed lines), which goes into the exit criteria.

Total of data number values after each iteration step, added over all pixels and all filters used. The solid line is the mean over the last 200 iterations. The dashed lines indicate the 4% deviation from this mean, defining an exit criterion.
5.1.1 Synthesised Atmosphere
In Figure 15, the synthesised atmosphere is displayed. The column densities are in the range expected for a coronal AR. Also, the highest densities can be found in the core and near the solar surface, as expected for an AR. As in the test case some isolated, low-lying, very dense loops can be found. Since their densities are orders of magnitude above the typical values of the synthesised atmosphere, they can easily be filtered out if necessary. The introduction of the factors \(b_{\mu f}\), Equation 12, prevents similar high densities among the open loops far outside of the core.

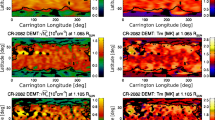
The synthesised atmosphere of AR 11087, as resulting from the fitting process. Top-left: column density in an oblique view. Top-right: maximum \(\log T\) along the LOS of the observations. Bottom-left: maximum \(\log T\) in an oblique view, with the outer parts masked away. Bottom-right: mask used for the bottom left image (see text for details). Compared to the LOS of SDO/AIA, the LOS in the plots on the left are tilted by 60 degrees. Due to there being different scale factors, 100 Mm appear to be shorter in the east–west direction than in the north–south direction.
The upper-right panel shows the maximum temperature along the LOS of each pixel. In the core, the temperatures are typical for an AR. Short but very hot loops can be seen, while the surrroundings are cooler. This is very common for coronal ARs. Outside the core, where observations are much fainter, the temperatures are not reproduced well and remain near \(10^{7}\) K.
The lower-bottom panel displays an oblique view on the core from the north western corner. Again the maximum temperatures along the LOSs are presented. In order to prevent the core being occulted by the high-temperature surrounding the core region, we restricted the 3D-data to columns related to pixels in the observations that reach at least 10% of the maximum intensity of a filter in at least two of the seven EUV channels of AIA. The mask used is also shown, plotted over the AIA 193 observation.
5.2 The Problem of a Line-of-Sight Not Fully Passing Through the Computational Domain
The northern edge of the plotting area in the RS-EUVI images, Figure 12, are spuriously bright. This is because the LOS from AIA passes through the computational domain first but leaves it again before reaching the photosphere. Observed emission from this non-computed volume is compensated for by the volume above, which is part of the computational domain. The sketch in Figure 16 demonstrates the geometric situation.

Schematic diagram showing how a problem occurs when the LOS only partially passes through the computational domain. The emission originating from part b cannot be captured since it is outside of the domain. This becomes compensated by an increased density, and hence intensity, from where the LOS crosses the domain (part a).
5.3 Computational Requirements
We performed our computations on an Intel i5 3.5 GHz quad core desktop CPU, the code being implemented in Java. For both the test case and the application to AR 11087 the cell-weight assignment required around four hours. With seven threads, the iterative fitting itself required, in total, 6 hours 20 minutes for the application to AR 11087 (868 iterations) and slightly more than two hours for the test case (517 iterations) The time requirements are dominated by the number sample points and the radii of influence. In our two cases, for example, the model had about 6.8 million sample points with non-zero pixel weight sum, while for the AR 11087, there were 10.3 million of such points, which explains the much longer computation. Almost 12 GB of RAM was needed during the computations.
6 Summary and Discussion
We introduced a numerical method to reproduce the densities and temperatures along the magnetic-field lines of an active region. Its goal is to find the 3D-distribution of the physical parameters of the coronal active-region plasma. The method uses a magnetic field extrapolated from the photospheric field. It also uses multi-channel observations of the coronal plasma in the extreme-ultraviolet regime, which are deployed to iteratively fit synthesised observations to the real data. Essential for the method is a smoothing along the field lines in each iteration that allows one to discriminate between two loops crossing each other in the observed images.
We tested the method against a self-made model active region in which, unlike real ARs, we know the exact distribution of density and temperature. For our test we used synthesised AIA images of the model AR, the ground-truth synthesised (GTS) images. To compare the reconstructed solution to the model one and evaluate the performance of the method, we looked into several aspects of the numerical result. We compared images synthesised from the resulting plasma, the reconstructed synthesised (RS) images, with GTS-images from different perspectives. We calculated statistics about the spatial dependence of the deviations between model and result as well as for the individual sample points and the (binned) grid cells, all of them representing different aspects of the numerical set-up.
The RS-images with a view along the line-of-sight of a hypothetical observer (top-down view) match very well to the GTS-images (Figure 4). It has also been shown that the strongest relative deviations in the pixel intensities appear to be in dark areas of the images. The bright areas of the AR show only small errors (Figure 5). Overall, for almost two-thirds of the pixels the synthesised intensity deviates less than 20% from the model intensity (Table 1).
The horizontal view, which has not been used for the fitting process, on the other hand, reveals slight differences between the model and the RS-images. The lowest layers of the AR, which represent photosphere and chromosphere, are invisible in the GTS-images since the plasma in these regions is too cold to be detected. Due to the smoothing, coronal temperatures reach down to the lower face of the numerical box. Hence the GTS-images are also bright down to their bottom edge. Towards the top, high-reaching model loops fade out since their densities decrease with altitude. In the GTS-images some of these loops remain visible, hinting at a too high a density. Nevertheless, the correct structures are visible in the fitting results and no larger coronal structure appears that is not visible in the GTS-observations. The fans and bundles of loops, typical for an AR corona, are reproduced (Figure 4).
We calculated statistics about the position dependence of the relative deviation of the fitted density from the model density of the sample point along the loop (Figure 6). Such statistics show that the median density in the numerical result is about 20% lower than in the model. The spread, however, allows for sample points that exceed the model value: the 75% quantile is about 30% above the reference value and is much larger when including sample points with very low model density, compared to them being ignored. This shows that sample points with low density and thus low signal tend to produce much larger relative errors. On the other hand, the 25% quantile is roughly at 40% of the reference density. Therefore, an error of 50% to 60% can be assumed for the reproduced density at a sample point. Since the density in the corona can vary by some orders of magnitude, this is still acceptably accurate. The temperatures are well reproduced in the corona, with a spread in \(\log T\) of 4%. In the median, the synthesised temperatures are far closer to the model values than this scatter. However, since the measure here is \(\log T\), an error of 4% means a difference in the logarithm of 0.24 at 1 MK. This is not very precise, but it still allows for order-of-magnitude estimations. For both physical parameters the deviations are stronger near the footpoints, which we assume to be an effect of the smoothing, especially in the case of the temperatures.
An oblique view on the column densities shows that the fitting result matches the model well in the overall structure. Near the photosphere, some loops of extremely high density appear. The temperature is well reproduced in the corona, except for one bundle of loops where it is too high. The chromospheric parts are too hot due to the smoothing (Figure 8).
We tested how well the reference model values and the fitted values are correlated for the individual sample points. To do so, density plots were created comparing model and fitted values (Figure 9). In the case of the densities, model density and fitted value correlate well for lower densities. For higher densities, the fitting process slightly underestimates the density. The temperature plot also displays a bulk of points with correctly reproduced values. There is some scatter, however, notably again for the low-lying points with cool temperatures, which are too hot in the synthesised atmosphere. On the other hand, there is also a small bulk of points of 1 MK in the model but \(3\times10^{5}\) K after fitting. For the visible emissivities \(n_{i}^{2}R_{f}(T_{i})\), reference value and synthesised value are close to each other for a majority of the sample points. The minority displays large scatter. For some of the channels, the visible emissivity is slightly underestimated.
From the data sets, we also computed the Spearman coefficient of rank correlation. These are listed in Table 2. Although the correlation between model values and fitted value is not that high, it is significant. This summarises the general impression that we got from the method: the results are not perfect, but the fitting process can outline the input atmosphere.
Finally, we compared the average values in the grid cells and in binned super-cells of different size. At a bin size of five, the spread in the temperature is lowest, while both density and temperature deviate little from the model. This indicates that the coronal plasma of the model AR is reproduced best on this scale length, which is 5.4 Mm in our model. At this bin size, the 25% quantile and the 75% quantile of the relative density deviation is −0.2 and \(+0.5\), respectively. For the logarithm of the temperature, these values are −0.04 and \(+0.02\), respectively. (Figure 10).
After the model region, we applied our algorithm to the active region AR 11087, observed on 15 July 2010. Observations by AIA were used for the fitting process. Independently, we compare our reconstruction with observations from EUVI onboard STEREO-A. The AIA images synthesised from the fitting result match the observations extremely well in all seven EUV channels. Deviations appear only on the smallest scales, i.e. the width of narrow loops. Wider loops and bundles of narrow loops, as well as larger structures, are captured by the synthesised images (Figure 12). Compared to the AIA images, the RS-images for EUVI are noisy (Figure 13). In parts where the LOS crosses the computational domain of the corona only partially, the missing intensity from the regions outside the domain is compensated for by the crossed volume inside the domain (Figure 16), leading to systematically higher densities in such regions. Additionally, the RS-EUVI images are brighter than the observations, with different factors for different channels. Partially, this is very likely caused by the fact that we used the launch values of the EUVI response functions for synthesising the images. The detector had degraded for almost four years by the time of the observations. Also, the RS-intensities are sensitive to errors in the fitted physical conditions, especially the temperature. Nevertheless, beside these deviations between RS-images and observations, the structure of the AR is still recognisable.
The physical structure of the synthesised coronal atmosphere of AR 11087 is as expected for an AR. The densities are highest in the core and fall off towards higher altitudes. The column densities are of the order of \(10^{9}\) to \(10^{10}~\mbox{cm}^{-2}\). The temperatures in the core are, in general, \(10^{6.3}\) to \(10^{6.6}\) K, but short loops of \(10^{6.8}\) K can be found in the very centre.
Different from an approach linking observed loops and magnetic-field lines, our method is not restricted to locations where loops can be traced with sufficient accuracy (Malanushenko et al., 2012; Warren et al., 2018). It produces results in the entire volume filled by extrapolated field lines. On the other hand, the loop line linking can use more robust and well-tested methods for retrieving the plasma conditions in the loop, such as analysing the differential emission measure (Kashyap and Drake, 1998; Hannah and Kontar, 2012). As a combination of the two approaches, one could think of linking some of the extrapolated field lines and traced loops, as in Warren et al. (2018), in a first step. The sample points along this field lines can obtain their monitored temperature and density directly derived from the observations. This subset of sample points can be kept fixed under the physical conditions during the fitting process of the FitCoPI code, defining a constraint to other sample points.
7 Conclusion
From all of the statistical tests with the model AR, we can draw the conclusion that, for individual sample points, the real density is correctly reproduced within the uncertainty. The median of the fitting results is about 80% of the real value. Taking the 25% quantile and the 75% quantile of relative deviations to the model values, the error of the synthesised density can be estimated to 50% to 60%, much less than the orders of magnitude by which the density can vary within the corona. The logarithm of the temperature does not scatter by more than 4% in the corona. This is already a considerable fraction of how much the temperature varies in nature. Nevertheless, order-of-magnitude estimations are possible, and cool, warm, and hot loops can be distinguished. This is not possible in the chromosphere due to the smoothing. We conclude that in the corona, for the code being something like a prototype, the plasma is reproduced very well.
In the case of the application to AR 11087, the emission is, qualitatively, well reproduced. The AIA observations, which were used for the fitting process, are matched by the synthesised images. For STEREO-A/EUVI, the synthesised images are brighter than the observations. The factor varies from five to ten depending on the filter. Thus, the brightening cannot be explained by an overestimation of the density alone. Degradation of the instrument surely plays some role, as no other than the launch values of the response functions, which we used for synthesising the images, exist. However, the response had been reduced by probably not more than 20% until the time of the observations (J.P. Wuelser, private communication, 2019), accounting for a factor of 1.25. Since the synthesised emission is very sensitive to temperature variations, a slight discrepancy in the temperatures may also contribute to this artefact. Nevertheless, the structure of the AR can also be identified in the synthesised EUVI images.
These good results are already achieved with the prototype of the approach, using very simple equations. Therefore, we think that our fitting method based on a set of EUV observations and an extrapolated magnetic field is a promising approach. By revealing the 3D-structure of density and temperature it can help understand the spatially complex physical processes of the corona. Taking time series would also give deeper insight into the temporal evolution of the active-region corona.
8 Outlook
In the future, the performance of our approach might be improved as follows: First, one might include knowledge from computer sciences for improving the flow of information along and between the loops, such as network flows or swarm intelligence.
Second allowing for multi-view observations, i.e. fitting to observations from different perspectives, is a quite natural extension. Sample points of two loops crossing each other in one pixel of the one point of view do not (necessarily) intersect in images taken from the other point of view. This allows for a better discrimination. In turn, it might be possible that the smoothing length can be reduced, so that then we can solve the problem of smoothing coronal temperatures into the chromosphere.
A third possible approach would be incorporating physical models for the chromosphere. These may be provided from observations such as those from the Interface Region Imaging Spectrograph (De Pontieu et al., 2014) and gained by chromospheric inversion codes (e.g. Milić and van Noort, 2017). Such models can set the physical parameters on the lowest sample points of the code, which are then kept fixed. While this tackles the problems that the FitCoPI code has in the lowest parts of the solar atmosphere, the flexibility and the model independence of the code in the corona is preserved.
In principle, one can think of a way to fit the loop cross sections, represented by the radii of influence of the sample points, too. However, this would require a recalculation of the cell weights and pixel weights at each iteration step. The determination is quite a time-consuming step, as noted in Section 5.3.
References
Aschwanden, M.J., Lim, J., Gary, D.E., Klimchuk, J.A.: 1995, Solar rotation stereoscopy in microwaves. Astrophys. J. 454, 512. DOI . ADS .
Aschwanden, M.J., Newmark, J.S., Delaboudinière, J.-P., Neupert, W.M., Klimchuk, J.A., Gary, G.A., Portier-Fozzani, F., Zucker, A.: 1999, Three-dimensional stereoscopic analysis of solar active region loops. I. SOHO/EIT observations at temperatures of \((1.0\,\mbox{--}\,1.5) \times 10^{6}\) K. Astrophys. J. 515, 842. DOI . ADS .
Aschwanden, M.J., Nitta, N.V., Wuelser, J.-P., Lemen, J.R.: 2008, First 3D reconstructions of coronal loops with the STEREO A+B spacecraft. II. Electron density and temperature measurements. Astrophys. J. 680, 1477. DOI . ADS .
Aschwanden, M.J., Wuelser, J.-P., Nitta, N.V., Lemen, J.R., Sandman, A.: 2009, First three-dimensional reconstructions of coronal loops with the STEREO A+B spacecraft. III. Instant stereoscopic tomography of active regions. Astrophys. J. 695, 12. DOI . ADS .
Aschwanden, M.J., Boerner, P., Schrijver, C.J., Malanushenko, A.: 2013, Automated temperature and emission measure analysis of coronal loops and active regions observed with the atmospheric imaging assembly on the solar dynamics observatory (SDO/AIA). Solar Phys. 283, 5. DOI . ADS .
Boerner, P., Edwards, C., Lemen, J., Rausch, A., Schrijver, C., Shine, R., et al.: 2012, Initial calibration of the Atmospheric Imaging Assembly (AIA) on the Solar Dynamics Observatory (SDO). Solar Phys. 275, 41. DOI . ADS .
Bray, R.J., Cram, L.E., Durrant, C.J., Loughhead, R.E.: 1991, Plasma Loops in the Solar Corona, Digitally printed first paperback edition 2005 edn. Cambridge University Press, Cambridge. ISBN: 978-0-521-02223-1.
Chifu, I., Wiegelmann, T., Inhester, B.: 2017, Nonlinear force-free coronal magnetic stereoscopy. Astrophys. J. 837, 10. DOI . ADS .
Cirtain, J.W., Golub, L., Winebarger, A.R., De Pontieu, B., Kobayashi, K., Moore, R.L., et al.: 2013, Energy release in the solar corona from spatially resolved magnetic braids. Nature 493, 501. DOI . ADS .
De Pontieu, B., Title, A.M., Lemen, J.R., Kushner, G.D., Akin, D.J., Allard, B., et al.: 2014, The Interface Region Imaging Spectrograph (IRIS). Solar Phys. 289, 2733. DOI . ADS .
Del Zanna, G.: 2013, The multi-thermal emission in solar active regions. Astron. Astrophys. 558, A73. DOI . ADS .
Fletcher, L., De Pontieu, B.: 1999, Plasma diagnostics of transition region “Moss” using SOHO/CDS and TRACE. Astrophys. J. Lett. 520, L135. DOI . ADS .
Freeland, S.L., Handy, B.N.: 1998, Data analysis with the SolarSoft system. Solar Phys. 182, 497. DOI . ADS .
Hannah, I.G., Kontar, E.P.: 2012, Differential emission measures from the regularized inversion of Hinode and SDO data. Astron. Astrophys. 539, A146. DOI . ADS .
Howard, R.A., Moses, J.D., Vourlidas, A., Newmark, J.S., Socker, D.G., Plunkett, S.P., et al.: 2008, Sun Earth Connection Coronal and Heliospheric Investigation (SECCHI). Space Sci. Rev. 136, 67. DOI . ADS .
Kaiser, M.L., Kucera, T.A., Davila, J.M., St. Cyr, O.C., Guhathakurta, M., Christian, E.: 2008, The STEREO mission: An introduction. Space Sci. Rev. 136, 5. DOI . ADS .
Kashyap, V., Drake, J.J.: 1998, Markov-chain Monte Carlo reconstruction of emission measure distributions: application to solar extreme-ultraviolet spectra. Astrophys. J. 503, 450. DOI . ADS .
Lemen, J.R., Title, A.M., Akin, D.J., Boerner, P.F., Chou, C., Drake, J.F., et al.: 2012, The Atmospheric Imaging Assembly (AIA) on the Solar Dynamics Observatory (SDO). Solar Phys. 275, 17. DOI . ADS .
Malanushenko, A., Schrijver, C.J., DeRosa, M.L., Wheatland, M.S., Gilchrist, S.A.: 2012, Guiding nonlinear force-free modeling using coronal observations: first results using a quasi-grad-Rubin scheme. Astrophys. J. 756, 153. DOI . ADS .
Milić, I., van Noort, M.: 2017, Line response functions in nonlocal thermodynamic equilibrium. Isotropic case. Astron. Astrophys. 601, A100. DOI . ADS .
Müller, P.H. (ed.): 1975, Lexikon der Stochastik, 2nd edn. Akademie Verlag, Berlin.
Rosner, R., Tucker, W.H., Vaiana, G.S.: 1978, Dynamics of the quiescent corona. Astrophys. J. 220, 643.
Schmelz, J.T., Pathak, S., Christian, G.M., Dhaliwal, R.S.S., Paul, K.S.: 2015, The coronal loop inventory project. Astrophys. J. 813, 71. DOI . ADS .
Schrijver, C.J., Sandmann, A.W., Achwanden, M.J., DeRosa, M.L.: 2004, The coronal heating mechanism as identified by full-Sun visualizations. Astrophys. J. 615, 512.
Vásquez, A.M., Huang, Z., Manchester, W.B., Frazin, R.A.: 2011, The WHI corona from differential emission measure tomography. Solar Phys. 274, 259. DOI . ADS .
Warren, H.P., Crump, N.A., Ugarte-Urra, I., Sun, X., Aschwanden, M.J., Wiegelmann, T.: 2018, Toward a quantitative comparison of magnetic field extrapolations and observed coronal loops. Astrophys. J. 860, 46. DOI . ADS .
Wiegelmann, T.: 2008, Nonlinear force-free modeling of the solar coronal magnetic field. J. Geophys. Res. 113, 3. DOI . ADS .
Wiegelmann, T., Thalmann, J.K., Inhester, B., Tadesse, T., Sun, X., Hoeksema, J.T.: 2012, How should one optimize nonlinear force-free coronal magnetic field extrapolations from SDO/HMI vector magnetograms? Solar Phys. 281, 37. DOI . ADS .
Acknowledgements
Open access funding provided by Max Planck Society. I thank the reviewer for their comments. I thank the International Max Planck Research School at the Max Planck Institute for Solar System Research, Göttingen, for funding this work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The author declares that he has no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix: AR Loop Model
Appendix: AR Loop Model
To test the code we cannot use real observations, since the detailed real 3D-distribution of density and temperature in an AR corona is unknown. Hence we have to apply a model AR, with modelled loops, where the true distributions of the physical conditions are known. In order to build a model AR we utilise some observations made in the past.
The core of an AR is made up of short, hot loops of a few MK, which are visible in the X-ray regime. The other extreme are quiet-Sun loops, i.e. loops that are not rooted in bipolar regions. Although their temperature is still about 1 MK, their density is between one and two orders of magnitude lower than those of AR loops. In between, coronal loops rooted mainly in the penumbra of sunspots can be detected in the EUV regime. Their temperatures range from one to several MK. The density of these loops can (but need not) be up an order of magnitude below the density of the core loops. Shorter loops also tend to be more dense than longer ones. Loops rooted in the umbra of a bipolar region are not heated much at all and thus remain invisible.
To emulate the chromosphere and transition region we define a coronal base height \(z_{\mathrm{base}}=3.2\) px (roughly 3.46 Mm). Associated with this height is a temperature of \(\log T_{\mathrm {base}}=5.9\). Below this coronal base height the logarithm of the temperature increases linearly with altitude from 4 at \(z=0\) to \(\log T_{\mathrm{base}}\) at \(z = z_{\mathrm{base}}\). Above \(z_{\mathrm{base}}\) it rises from \(\log T_{\mathrm{base}}\) to a maximum temperature individually set for each loop: \(T_{\mathrm{max}}\). The density generally decreases with height exponentially from \(z=0\), where it has a base value \(n_{0}\) which varies from loop to loop. The scale height is linear in \(T_{\mathrm{max}}\) of the loop: \(s_{n}=60 T_{\mathrm{max}}/1\) MK. For a 1 MK loop this results in a scale height of 60 px or about 64.8 Mm, which is larger than in the solar corona but allows one to see the loops more clearly in side views. If the loop lies entirely below \(z_{\mathrm{base}}\), the scale height is set to \(10^{6} z_{\mathrm{base}}\), which is practically infinity.
In our model AR we define three different type of loops: quiet Sun (QS) loops, AR core loops, and loops in the outer parts of an AR. To model a loop we take a field line and check for its photospheric-footpoint field strength and its length within the numerical box. Where the magnitude of the field strength is below 87 G, the field line becomes a QS loop. For stronger fields the field line is modelled as a core loop where the length is below 18.5 px (\({\approx}\,20\) Mm) and the magnitude of the field strength below 926 G.
For a QS-loop we define the maximum temperature to be \(\log T_{\mathrm {max}}=6\) and the density at the photospheric footpoint \(n_{0}=0.01\). For an active-region core loop the maximum temperature is set to \(T_{\mathrm{max}}=3\times10^{6}\) K here and the footpoint density to \(n_{0}=1\).
Although the loops in the outer parts of the AR follow the same generation rules as the other two classes of loops, they are a bit more complicated since their maximum temperature depends on the magnetic-field strength at the photospheric footpoint and the base density varies with the loop length. For setting the maximum temperature we use the equation
which is the combination of a simplified version of the scaling law of Rosner, Tucker, and Vaiana (1978, lacking the power 1/3 in our case) and the heat flux as identified by Schrijver et al. (2004) where especially the exponential fall off comes from. The parameters in the equation have been adjusted in such a way that the maximum possible value of \(T_{\mathrm{max}}\) is close to 3 MK and \(T_{\mathrm{max}}\) is 1 MK roughly at a field strength of 100 G and 1000 G. The actual values in these cases are 3.01 MK, 87.30 G, and 926.20 G, respectively. The latter values also explain the thresholds for the field strength used in the loop-class determination.
The base density of the loop decreases as the loop length increases. It is calculated on the basis of
and clamped between \(n_{\mathrm{min}}\) and \(n_{\mathrm{max}}\). For a short loop of length \(L_{\mathrm{short}}=18.5\) px (\({\approx}\,20\) Mm) the base density is \(n_{\mathrm{max}}=1\) and a rather long one with a length of \(L_{\mathrm{long}}=740\) px (\({\approx}\,799.2\) Mm) ends up with a base density of \(n_{\mathrm{min}}=0.1\).
For closed loops, we obtain two values in each point, one for each footpoint. In that case we apply an average weighted by the distance to the footpoints, i.e. if a sample point \(i\) has a loop coordinate \(x_{i}\) and the loop a total length of \(L\):
are taken, where the parameters with subscripts \(a\) and \(b\) refer to the two model solutions from the two footpoints.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Barra, S. The FitCoPI Code: Iterative Determination of the 3D Density and Temperature Configuration in the Active-Region Corona. Sol Phys 294, 101 (2019). https://doi.org/10.1007/s11207-019-1482-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11207-019-1482-y