
Abstract
Policy document mentions are useful for assessing the societal impact of scholarly papers. However, how policy document mentions can be interpreted is unclear yet. In this study, content analysis was used to examine features (mentioned element, mentioning form, and mentioning location) and motivations of policy document mention to scholarly papers. 885 policy documents were sampled for analysis from the Altmetric.com database. Results reveal that: (1) The mentioned elements of policy document mentions can be divided as five categories, summarized content (26.9%) is the most frequent one. (2) We found five types of the mentioning form of policy document mentions, the major mentioning form is references (72.3%). (3) The mentioning locations in policy documents can be divided into twelve categories, expounding (47.4%) and review (22.6%) are the core mentioning locations. (4) Motivation of policy document mentions can be broken down into five major categories and seventeen minor categories, more than 30% of motivations are to support the policy argument by listing relevant work. Analysis of the mention features of the policy document mentions gives us another way to understand how it works and how policy document mentions are motivated, with these findings we can do more work to find out the relationship between scientific articles and policy documents.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Scholarly research is often valued not only on its academic impact (usually judged from citation metrics) but also for its social impact. Wilsdon et al. (2015) defined the social impact of research as the impact of scholarly papers on education, society, culture, or the economy. Similarly, the UK has developed the research excellence framework (REF) to assess the quality of research in UK higher education institutions. In the REF 2021, impact beyond academia is defined as the effect on, change or benefit to the economy, society, culture, public policy or services, health, the environment or quality of life, accounting for 25% of the overall assessment. With the development of digital scientific communication, new types of scholarly papers and novel ways of academic communication, the methods of assessing the social impact of scholarly papers have become more diverse. One of them is based on altmetrics, which is seen as an interesting possibility to quantitatively measure the broader impact of publications (NISO Alternative Assessment Metrics Project, 2014).
One important way of indicating the societal impact of research is policy document mentions to scholarly papers. Policy document mentions support the credibility both cited authors and the policy documents themselves (Nigel Gilbert, 1977), and can possibly shed light on the relationship between academic research and policymaking (Bornmann et al., 2016). Fraser, Bräuer, & Peters (2021) investigated how the articles authored by researchers at German medical research institutions are shared on various online platforms, and the results of the term map of policy document mentions indicate articles containing clinical-related terms tend to be cited in the policy document, which different with the manifestation in citation-based evaluations. Based on this research, Lemke et al. (2022) did a further analysis about whether policy documents indeed support clinical research, the results of the word2vec-based prediction revealed policy document mentions of clinical research (45.3%) is considerably higher than others (18.6%), confirming the conclusion of Fraser et al. (2021) made. This result favors policy document mentions can be an interesting complement to academic citations in the evaluation of medical research in Germany.
Literature review
The impact of the policy document mentions
Citation in policy documents was one of eight indicators rated as highly important for the evaluation of societal outcomes by the stakeholders consulted by Willis et al. (2017). Kale et al. (2017) built classification models that predict whether a particular research work is likely to be cited in a public policy document based on the attention it received online, primarily on social media platforms. The results show that a relationship exists between the online attention that a scholarly work receives and the policy document mentions that it generates. Yin et al. (2021) investigated the connection between science and policy with respect to COVID-19 using data from Overton. They found that “many policy documents in the COVID-19 pandemic substantially access recent, peer-reviewed, and high-impact science. And policy documents that cite science are especially highly cited within the policy domain. At the same time, there is a heterogeneity in the use of science across policy-making institutions. The tendency for policy documents to cite science appears mostly concentrated within intergovernmental organizations (IGOs), such as the World Health Organization (WHO), and much less so in national governments, which consume science largely indirectly through the IGOs” (p. 128). Bornmann et al. (2022) aimed to address how research on climate change and policy is connected, one of their results is that climate change papers that are cited in climate change policy documents received significantly more citations on average than climate change papers that are not cited in these documents; they also proposed a model to explain how science impacts the policy in different document types.
However, Newson & colleagues (2018) used a “backward tracing” approach to examine 86 New South wales (NSW) childhood obesity policy documents(searched from the NSW Government website) as the starting point for analysis to determine what information these documents could provide about the utilization and impact of research, and the results show the policy document mentions, in this case, is not enough to prove the cited research had influenced the policy process. The meta-research (Abbott et al., 2022) of early published COVID-19 evidence syntheses aim to explore the relationship between the quality of review and the extent of interest from researcher, policy, and media. Although few review papers had been cited in policy documents, it was concerned that the quality of review paper did not appear to influence the policy document mention.
The coverage of previous data aggregators for policy document
Designed by Altmetric LLP,Footnote 1 the Altmetric Attention Score of a research output provides an indicator of the total amount of attention that it has received. Each source is weighted, with the weight of the Policy document being 3.
Previous studies have found the policy document mentions of research don’t have a high coverage in Altmetric.com dataset, compared with Twitter and Facebook mentions (Yu et al., 2017b). Bornmann et al. (2016) found that “only 1.2% (n = 2341) have at least one policy mention” (p. 1477). The results of Haunschild & Bornmann (2017) show that “less than 0.5% of the papers published in different subject categories are mentioned at least once in policy-related documents” (p. 1209). Tattersall & Carroll’s research (2018) found that “At present Altmetric.com tracks 96,550 research outputs at the University of Sheffield with 1,463 of them being cited by at least one policy document. This means that 1.41% of Sheffield research, across all disciplines, is cited by at least one policy document.”
Overton,Footnote 2 is a new altmetric database focusing on policy documents, the world’s largest searchable index of policy documents, guidelines, think tank publications and working papers, has a higher coverage of policy document mentions than Altmetric.com database (Szomszor & Adie, 2022). Fang & colleagues (2020) calculated the Coverage, Density, and Intensity of policy document citations recorded by Overton for a set of over 18 million Web of Science publications, which are 3.9%, 0.09 and 2.32, respectively. Pinheiro et al. (2021) used the Overton database matched Scopus to assess the relationship between cross-disciplinary research and its uptake in policy documents in publications from FP7- and H2020-supported projects, the coverage of uptake in policy-relevant literature (UPRL) is 6.0% for the entire dataset of FP-funded publications.
Possible reasons for the low proportion of research mentioned in policy documents are listed by Haunschild & Bornmann (2017) and Yu et al. (2017b), summarizing that (1) the scope of the policy document sources Altmetric.com tracked is still relatively limited, and it has not been accumulated long enough for the literature coverage. (2) Perhaps only a small fraction of the literature is truly policy-relevant, and most papers are relevant only to scientists. (3) The authors of policy-related documents are often not researchers themselves, and the number of scholarly papers that they mention or utilize is limited. Therefore, policy-related documents should generally not be expected to have a scientific citation style. At the same time, a policy-related document may not refer to every important document on which the policy-related document is based. (4) There may be barriers and low levels of interaction between researchers and policymakers. Yu et al. (2017b) also believe that the policy document mentions indicator is temporarily not applicable to actual large-scale research evaluation and requires more time for data accumulation and robust test of data comprehensiveness, validity, and applicable subject areas.
Maleki & Holmberg (2022) compared the policy coverage of 18,996 Scopus publications authored by researchers affiliated with 18 Finnish universities and institutes in eight chosen Social Science fields in Overton and Altmetric.com data source, checked and compared for coverage and overlap. The overall results suggest that on average about 39% of publications were cited in Overton and 9% in Altmetric.com. Results show that despite the larger coverage of policy citations in Overton at the institution and field level, Altmetric.com has a tiny but unique proportion of both documents cited and policy citations that are not covered by Overton. There was on average about 5% overall overlap in the coverage of documents between the two sources.
The motivations analysis of other source metrics
The motivation of policy document mentions is a research gap still, but there are some studies focused on the motivations of other social platforms (Blog, Facebook, Twitter, Sina Weibo), and most of them used interview or content analysis methods. Kjellberg (2010) interviewed a group of researchers about the purpose of scholarly blogging, and the results show that their blogging is motivated by the possibility to share knowledge, the blog aids creativity, and it provides a feeling of being connected in their work. Shema et al. (2015) used a content analysis method to create a general classification scheme for blog post content from 2010 to 2012 in Researchblogging.org’s Health category with ten major topic categories, each with several subcategories. The major topic categories include discussion, criticism, advice, trigger, extension, self, controversy, data, ethics, and other. In their results, discussion (89.3%), criticism (29.9%), and advice (27.1%) are the most frequent motivations. Using full-text citation analysis, Liu, Pan and Wei (2021) analyzed the mentioned motivation of Altmetric Attention Score Top50 papers published by Altmetric.com in 2019 and the blog posts that mentioned these papers based on Shema et.al.’ (2015) motivation classification. Nearly 60 percent of blogs were classified as discussion category, 14 percent of blogs were classified as trigger category, and nearly 9 percent of blogs were classified as data category. Na and Ye (2015) used a content analysis approach to investigate topic preferences and motivations for scholarly discussions among academic and non-academic Facebook users, which also adopted from Shema et.al.’ (2015) motivation classification. The motivation can be classified as discussion and evaluation toward articles (20.4%), data source (6%), self-promotion (6.4%), application to real life (16.5%), simple sharing (50.1%), and others (0.6%). Researchers also used Twitter as a platform for scientific communication, some studies focus on the motivation of mentioned scholarly papers on Twitter. Veletsianos (2012) analyzed 4500 tweets of 45 scholars using content analysis and determined seven motivations of scholars participating on Twitter. The most dominant motivation is information, resource, and media sharing, which count as 39%. Adopted Shema et.al. (2015) motivation classification with slight modifications, Na (2015) used content analysis to analyze user motivations of 2016 English tweets citing academic papers in the field of psychology. This study shows Twitter was mainly used to disseminate scientific findings to the public without discussing academic issues deeply. The most common main category of motivation is discussion, which covered 75.3% of the tweets, and the most common subcategory of motivation is summarizing the scientific findings of the studies/explaining the importance of scientific findings, which covered 52.88% of the tweets. Adopting an approach of content analysis on extracted Weibo, Yu et.al (2017a) determined four major motivations of scientific Weibo, and they were dissemination, discussion, marketing, and triggering.
These studies demonstrated that the motivations for users of social media platforms are strongly related to social, entertaining, and informative factors. Similarly, Syn & Oh (2015) used an online survey to test the motivation factors for Facebook and Twitter users sharing information, namely: enjoyment, efficacy, learning, personal gain, altruism, empathy, community interest, social engagement, reputation, and reciprocity. They found that users share information expecting that such activities will provide ways of being connected and engaged in an online community.
Objectives
Various studies have evaluated and elaborated on the attributes and roles of policy documents; however, the exact relationship between academic outcomes and policy documents remains untapped. The article is aimed to elucidate the relationship between scholarly papers and their policy mentions by analyzing how the cited scientific articles are mentioned in the policy document.
The objectives of the study were:
-
(i)
To detect which elements of scientific articles are mentioned, in which form and in which location within policy documents and,
-
(ii)
To analyze with what motivation these texts are included.
Methodology
Terms used
The following terms were used in this study:
Policy document: A type of document that describes policy objectives and content, including any policy or guideline documents from a government or non-governmental organization.
Policy document source platform: Including governments, independent policy institutes, topic-specific advisory committees, policy research institutes, and international development organizations. Tracked document types like guide, report, white paper, and other publications.
Policy document mentions: In this study a policy document mention is when a scholarly paper is mentioned in a policy document via a link, reference, or DOI.
Mentioned element: The element of a scholarly paper that is mentioned, namely which part of the scholarly paper is mentioned in the policy document.
Mentioning form: The format in which the policy document mention occurs: how the policy document mentions the scholarly paper.
Mentioning location: The location in the policy document where the scholarly paper is mentioned.
Data collection
Altmetric.com database has been tracking various public policy source platforms around the world since January 2013 to collect policy document mentions to scholarly papers. The altmetric policy document miner (APM) (Liu & Konkiel, 2015) is a tool that collects data primarily from policy source platform websites and uses link search, identifier analysis, and text mining to find references to scholarly papers in policy documents.
The policy document mention data were retrieved from the Altmetric database on August 19th, 2020. In total, there were 2.22 million policy document mentions from 187 policy document platforms. According to our observation, policy documents from the same platform share mostly the same characteristics. Therefore, instead of sampling directly from the policy document mention data records, we sample from each of the platforms. For each policy document platform, we randomly selected five records from its policy document mention data. For institution of which the number of policy document mentions is less than 5, all the records were selected. Eventually, the sample dataset consists of 885 records.
Basic description of the sample dataset
The study by Yu et al. (2020) showed that the policy document mentions suffering from data quality problems. In this study, records that could not be analyzed due to data quality problems were removed, and the results are shown in Table1. The proportion of valid data was 71%. There were 256 records (the percentage is 29%) that cannot be analyzed. The underlying reason can be summarized into four categories. The highest percentage of untraceable data is due to inaccessible policy documents (10%), which usually appear as “Page not found” or “404-File or directory not found”, indicating that the policy document file is no longer accessible. This is usually the case for the entire policy file source platform, and may be a result of a change in the data maintenance policy of the relevant policy file source platform. The percentage of anomalies caused by non-policy documents being misclassified as policy documents (10% of the total) is equally high. Non-policy documents are not analyzed because they are in fact: (1) papers and collections that are unrelated to policy by institutions (such as doctoral theses, conference proceedings, and conference reports, etc.), or (2) briefs, appendices, and lists, etc. that have no body text.
Content analysis of policy document mentions
Process of coding a single record
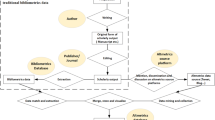
The process of coding a single record is illustrated in Fig. 1. For answering how scholarly papers are mentioned in policy documents, we have investigated the mentioning form, mentioning location and mentioned element for the policy document mention. For answering why scholarly papers are mentioned in policy documents, we have investigated the mention motivation.

Detailed steps for content analysis
Several steps were taken to ensure the record was eligible for using content analysis. Firstly, click the source URL of the policy document in the dataset downloaded from Altmetric.com. If it cannot be opened, this record will be excluded. Secondly, after opening successfully, check whether the policy document meets the definition mentioned above. If not, exclude this record. Thirdly, after confirming that the policy document meets the definition, obtain the original text of the policy document (usually in pdf format), and search for the mentioned scholarly paper features in the order of title, partial title, first author's name, DOI, link, publication Year, if the above characteristic items cannot locate the corresponding scholarly paper, it is regarded that the policy document does not mention the scholarly paper, and this record was excluded. Fourthly, after finding the corresponding scholarly paper via searching the features, check whether the mentioned scholarly paper was the policy document itself, and if so, exclude it.
We used content analysis to distinguish the mentioned element of scholarly papers in the policy document. Combining the context information in the policy document, we distinguish the mentioning motivation of scholarly papers in the policy document.
Any abnormal situation was recorded, further analyzed, and solved during the process. For example, suppose the website cannot be accessed. In that case, it will be cross-validated by switching the access network, changing the access method, and searching by the search engine, to eliminate the potential interference of the working environment to our best efforts.
Process of coding the whole sample dataset
A combination of top-down and bottom-up ways was adopted to construct the coding table, and there were 4 coders to make it. The top-down way refers to use pre-defined codes that are designed via discussion and literature review. The bottom-up way refers to code the records first and define the codes later by summarization.
In the first step, the literature survey summarizes the existing coding tables. After literature research, there are a few content analysis coding tables for policy documents to substitute measurement index data, and only one can provide a reference (Xiao, 2017). However, the content analysis of data from Twitter and Facebook has a specific reference value. For example, Thelwall et al. (2013) studied the content of scientific tweets mentioning scholarly papers, Na (2015) analyzed the motivation of scientific tweets mentioning scholarly papers, and Yu et al.(2017a) analyzed Sina Weibo's impact on scholarly papers motives for mentioning. The citation location analysis in the full-text citation analysis provides valuable inspiration for the reference location analysis of policy documents (Hu, 2014; Hu et al., 2013). The research literature on citation motivation provides a rich reference resource for analyzing motivation in policy documents (Garfield, 1965; Harwood, 2009; Erikson, 2014).
In the second step, a preliminary coding table was proposed by combining case studies and brainstorming. Five records were randomly selected from the sample dataset and analyzed by four coders together. It was aimed to find out the underlying process of conducting content analysis, and improve the coding tables of the mentioned element, mentioning form, and mentioning location of policy document mentions. Meanwhile, brainstorming was used to discuss the possible categories of mentions of policy document mention to obtain the initial coding table of mentioning motivations.
In the third step, the initial coding tables were refined, modified and improved. One hundred records were randomly selected from the sample dataset and coded by three coders using the initial coding table to test the feasibility of the coding table. During the encoding process, record any situations that cannot be encoded, including (1) situations where the encoding can be further subdivided; (2) situations where no encoding is applicable; and (3) situations in which the meaning of the encoding is similar but cannot be accurately expressed. At the same time, record the details of the specific judgment process. Intercoder reliability was calculated based on the coding results of the three coders. The coding consistency rates of the four initial coding tables were 49%, 92%, 73%, and 53%, respectively. With the participation of the fourth coder, conduct in-depth discussions on the unambiguous coding and inconsistent coding records, and improved the initial coding table again, including adding new codes, revising existing codes, and removing not applicable encoding.
In the fourth step, we checked and revised the improved coding table. Another 100 records were randomly selected from the sample dataset. Three coders used the polished coding tables to encode them to test the feasibility, and record any situations that could not be clearly coded. The coding results were checked for consistency, and the coding consistency rates of the four improved coding tables were 78%, 98%, 84%, and 71%, respectively. There were no situations in this coding that the coders thought could not be clearly coded, but some valuable details were found to help interpret the analysis results. For records with inconsistent coding, further discussions were conducted with the participation of the fourth coder, and a consensus result was reached. On this basis, the idea of discrimination is further clarified, which is reflected in the name and definition of the code, and the final code table is formed.
In the fifth step, one coder completed the coding of the sample dataset. After that, 100 records are randomly selected from the coded data, and the second coder uses the final coding table for coding to consistently check the coding results of the first coder. The coding consistency rates in Tables 2, 3, 4 and 5 are 88%, 84%, 100%, and 92% respectively, indicating that the encoding is reliable and stable.
Results
Mentioning elements of policy document mentions to scholarly papers
As shown in Table 6, there are 5 first level types and 17 s level types of mentioned elements of scholarly papers in the policy documents. The classification was based on the content structure of scholarly papers.
The content mentioned in the first three categories of scholarly papers is relatively evenly distributed, all above 20%, of which the category of ME3. Summarized content is the most common, accounting for 26.9%, followed by ME2. Fragment content (23.4%) andME1. Major content (22.3%). The category of ME4. Pure link refers to the policy document mentioning scholarly papers with a clear reference form, but the specific location of the scholarly paper cannot be found in the main body of the policy document, and the subsequent mentioning location and motivation cannot be specified. According to the analysis, it appeared 86 times, accounting for 13.6%. This category is associated with ML11. No mention in the location code table, a total of 70 pieces of data. ME5. Unable to determine means that the scholarly paper mentioned in the policy document has a clear reference form, location and motivation, but it is impossible to determine which part of the scholarly paper is mentioned in the policy document. There were 87 articles, accounting for 13.8%.
Among the sub-categories, the most frequently mentioned are ME1.4 Conclusion (15.9%), ME3.1 Summarized theme (12.4%) and ME2.6 Incomplete paragraph (10.7%). The ME1.4 Conclusion andME3.1Theme are easier to understand, while ME2.6 Piece of paragraph refer to one or two sentences or information points in the scholarly papers that are mentioned in the policy document, in the form of original sentences or rewrites. It can be seen that the reference to scholarly papers in policy documents pays more attention to the research content of scholarly papers, and the content is more likely to mention scholarly papers that have a practical effect on the policy document itself.
Mentioning form of policy document mentions to scholarly papers
The statistical results of the forms of references to scholarly papers in policy documents are shown in Table 7. From Table 7, it can be seen that formal references are the most dominant form of mentions, accounting for 72%. Besides, there are other forms of mentions as well. Mentions in the form of footnotes and endnotes are also more common in policy documents, with a percentage of 19%. List at the bottom or in appendix references account for 6.7%. Identifiable elements mentioned in the body text accounted for 1.6%. In addition, 4 hyperlinked references appear, accounting for 0.6%.
In general, the overall forms of references to scholarly papers in the policy document are formally standardized and basically consistent with the form of citation mentions, of which the three forms of standardized references, footnotes and endnotes, and hyperlinks together account for 91.7%. The standardized mentioning forms provide convenience for database capturing and improve the correct identification rate.
Mentioning location of policy document mentions to scholarly papers
The policy papers are well structured, but not all of them follow the IMRaD structure (i.e., Introduction, Methods, Results, and Discussion—with the literature and background incorporated into the Introduction). In addition to the parts similar to the structure of research articles, other parts of policy documents also mention scholarly papers. A total of six rare mention positions were found in this study during the coding process. One of them is the column section (ML7. Column), in which scholarly papers appear in the column section in two cases, one is as a separate presentation of scholarly papers, and the other is similar to the thesis statement, except that it is placed in the column position. The second is the acknowledgments (ML8. Acknowledgment); the third is the appendix (ML9. Appendix); and the fourth is the recommendation content (ML10. Recommended content). The recommendation list section often appears at the end of the policy document, where information such as the title and links to the scholarly results or other policy documents will appear. The last two are in the ML12. Other situations category of the coding sheet, one is the preface of the policy document; the other one is the glossary.
ML11. No mention corresponds to the mentioned element is ME4. Pure link, and such mentioned scholarly paper cannot be identified with mentioning location and mention motivation.
The results of the study on the citation location of the papers showed that the citations in different locations have different citation values. Among them, citations appearing in the introduction and literature review sections tend to lay the foundation for new research; citations appearing in the methods and experimental sections are used to support the methodological design as well as the implementation; citations appearing in the discussion and conclusion sections are used by research scholars to relate their findings to the conclusions of the cited literature and to provide explanations for any possible discrepancies. These four characteristics suggest that citations appearing in the Introduction, Literature review, Methods, and experimental sections are more important and contribute more to the recognition of important citations than citations appearing in other locations. This also suggests that important citations can be identified and the citation value of papers can be distinguished based on the distribution of citation positions of the cited literature in the cited literature (Bertin et al., 2015; Ding, et al., 2013). The statistical result of the mentioning location of the policy document mentions show that nearly half of the scholarly papers have the highest percentage of mention positions appearing in the ML4. Expounding. The ML4. Expounding section includes the elucidation of concepts, description of theoretical foundations, argumentation of ideas, discussion of topics and case studies. The next highest percentage of scholarly papers appeared in the ML2. Review section with 22.6%, and only 3.5% appeared in the ML3. Methodology section.
The difference between ML5. Results and countermeasures and ML4. Expounding is that the ML5. Results and countermeasures is a clear and orderly content given by policy document. When analyzing the mentioning location, the location of mentions can also be determined by the exclusion method since review, method, and result are easier to judge compared with that of exposition (Table 8).
Motivations of policy document mentions
The mention motivation is determined by combining the content of the context of the policy document and the mentioned content of the scholarly paper. It can be divided into five categories (Table 9), with 21% of the MM1. Acknowledgeable reference and 41.2% of the MM2. Persuasive reference, which are the most frequently mentioned categories of motivation. MM3. Constructive reference accounted for 7.5%, MM4. Informative reference accounted for 18.3%, and the last type MM5. Unable to judge accounted for 11.6%. The results support the conclusion of Newson and colleagues (2018):
Sometimes, the role individual publications played in the policy process was explicitly stated, while in other cases it was only possible to say with certainty that the publication was cited to establish credibility for the argument being put forward in the policy document. Research was also sometimes used to support statements that were tangential and not relevant to the overall policy direction.
MM1. Acknowledgeable reference includes 8 sub-categories, and the MM1.6 State the source of the mentioned data appeared the most, which appeared 28 times, accounting for 4.5%.
MM2. Persuasive reference means the motivation of a policy document mentioning scholarly papers to support the arguments it puts forward. In order to further clarify the motivation, argumentation citations look for similarities and differences in content and form, and from the perspective of whether they support the argument through examples, Subdivide supporting arguments into example arguments and non-example arguments. Among them, MM2.2. Support the argument by listing relevant work appeared more frequently, accounting for 30.4%, while MM2.1. Support the argument by using examples accounted for 10.8%.
MM3. Constructive reference means a policy document's reference to scholarly paper because the content of the scholarly paper is one of the components of the policy document. The MM3.1. Basis for reasoning accounted for 5.1%, which state the policy document was based on the content of scholarly papers, and then put forward new viewpoints or conclusions. And when the content of scholarly paper is one of the research objects of the policy document, the mention motivation is MM3.2. Material of meta-analysis. This type of mention motivation accounted for 2.4%. It should be noted that the meta-analysis in this motivation code table is different from the meta-analysis method as a quantitative analysis method. The meta-analysis here refers to the content of the scholarly paper mentioned as one of the research contents of the policy document, such as in the policy document. The research method collection table of the research methods mentioned in the table, in which the mention motivation of the scholarly papers of each research method source is the meta-analysis.
MM4. Informative reference includes 3 sub-categories, accounting for 18.3% in total. In the process of motivation analysis, it is hard to tell the difference between MM4.1. Provide background information and MM4.3. Help to locate relevant studies, and it is necessary to analyze the context in which scholarly papers are mentioned. The results have a link or turning point in the policy document, are used to locate or trace the research point of view, and the mention motivation is classified as MM4.1. Provide background information. When the scholarly paper mentioned in the recommendation list of policy document, the mention motivation is to provide extended reading materials, so the motivation is classified as MM4.3. Help to locate relevant studies.
MM5. Unable to judge is 2 sub-categories, which are MM5.1. Incidental citations (0.5%) and MM5.2. Pure reference without context (11.1%). MM5.2. Pure reference without context is associated with data where the mention content is ME4. Pure link, and the mentioning location is ML11. No mention.
In the coding process, the two motivations of MM2.2. Support the argument by listing relevant work and MM1.4. State the source of mentioned topic are distinguished by the location and context mentioned in the policy document. The argument is often a complete sentence proposed in the policy document. Unlike arguments in argumentative papers, a fact or a conclusion in this study counts as an argument. The topic of the policy document expresses a single word or part of a sentence. This form of expression can be summarized as incomplete subject-verb-object, but this is not a necessary condition for judgment.
Discussion and conclusions
To our best knowledge, this study is the first investigation on the underlying process of policy document mentions by looking at the details of how scholarly papers are mentioned. The policy document mentions have two major differences compared with mentions from other platforms (Social bookmarking tools; Microblogging tools; Blogs; Wikis): the mentions are stable and not easy to disappear and compared with the authors of the policy document, the organization that published the policy document is more important and can be analyzed in various ways. Meanwhile, the same aspects of these different types of mentions are the existence of time gap and the disciplinary differences (Fang, et al., 2020; Tahamtan & Bornmann, 2020; Tattersall & Carroll, 2018; Thelwall, 2017). In this study, we found the policy document mentions have some unique characteristics in the mentioning location and mentioning motivation. For instance, mentions may occur in a specific column in the text, or in the acknowledgment, appendix, and recommendations section. The study used content analysis methods to delve into policy documents and mentioned scholarly papers, and identified the mentioning form, mentioned element, mentioning location and mentioning motivation for the sample dataset.
(1) The most frequently mentioned element of scholar paper in the policy documents is the conclusion (ME1.4) of which the percentage is 16%. It is followed by the summarized theme (ME3.1) of which the percentage is 12% and piece of paragraph (ME2.6) of which the percentage is 11%. In general, the mentioned elements were classified into 5 first level categories and 17 s level categories. The major content (ME1), fragment content (ME2) and summarized content (ME3) were of similar percentage around 23%. Meanwhile, pure link (ME4, percentage is 14%) was also observed where no content was mentioned.
(2) Majority (MF1, percentage is 72%) of policy document mentions to scholar paper occurred in the reference list. This makes policy documents mention significantly different from Twitter mention or Facebook mention in that it has long pages and conforms mostly to the standards of citations. Nevertheless, several other types of mentioning forms were also observed among which 19% occurred in footnotes or endnotes (MF2). The mention could occur at the end of a chapter or “”in the appendix of policy document, or even in the body. Few of the mentioned scholarly papers were in form of links.
(3) The most frequently mentioning location is the expounding (ML5, percentage is 47%) part of the policy document. It is followed by the review (ML2, percentage is 23%) section. In total, there were 10 types of identified mentioning locations. In addition to the expounding and review sections, scholarly papers could also be found in the methodology part (ML3, percentage is 3.5%), in the results and countermeasure part (ML5, percentage is 3.8%), and even in the appendix (ML9, percentage is 2.2%), column (ML7, percentage is 2.4%) or acknowledgement (ML8, 0.3%).
(4) It was identified 4 first level categories and 15 s level categories of motivations. Persuasive reference (MM2, percentage is 41%) is above all the most commonly seen type of motivation, and is followed by acknowledgeable reference (MM1, percentage is 21%), informative reference (MM4, percentage is 18%) and constructive reference (MM3, percentage is 7.5%). For records that cannot be judged (percentage is 11%), it is mainly due to the pure reference without any context.
In summary, most policy document mentions have truly made use of the content of scholarly paper, in the critical part of policy document, and been aimed to improve its persuasion and reliability. In this regard, policy document mentions indeed could reflect the impact of scholarly papers on policymaking. Moreover, this study has revealed in detail where, how, and why scholarly papers are mentioned by policy document, and hence has revealed the underlying process of policy document mentions. This has provided a better understanding of how policy document mentions can play an effective role in science and technology communication and evaluation.
References
Abbott, R., Bethel, A., Rogers, M., Whear, R., Orr, N., Shaw, L., & Coon, J. T. (2022). Characteristics, quality and volume of the first 5 months of the COVID-19 evidence synthesis infodemic: a meta-research study. BMJ Evidence-Based Medicine, 27(3), 169–177. https://doi.org/10.1136/bmjebm-2021-111710
Bertin, M., Atanassova, I., Gingras, Y., & Larivière, V. (2015). The invariant distribution of references in scientific articles. Journal of the Association for Information Science and Technology, 67(1), 164–177. https://doi.org/10.1002/asi.23367
Bornmann, L., Haunschild, R., Boyack, K., Marx, W., & Minx, J. C. (2022). How relevant is climate change research for climate change policy? An empirical analysis based on Overton data. PLoS ONE, 17(9), e0274693. https://doi.org/10.1371/journal.pone.0274693
Bornmann, L., Haunschild, R., & Marx, W. (2016). Policy documents as sources for measuring societal impact: How often is climate change research mentioned in policy-related documents? Scientometrics, 109(3), 1477–1495. https://doi.org/10.1007/s11192-016-2115-y
Ding, Y., Liu, X., Guo, C., & Cronin, B. (2013). The distribution of references across texts: Some implications for citation analysis. Journal of Informetrics, 7(3), 583–592. https://doi.org/10.1016/j.joi.2013.03.003
Erikson, M. G., & Erlandson, P. (2014). A taxonomy of motives to cite. Social Studies of Science, 44(4), 625–637. https://doi.org/10.1177/0306312714522871
Fang, Z., & Costas, R. (2020). Studying the accumulation velocity of altmetric data tracked by Altmetric.com. Scientometrics, 123(2), 1077–1101. https://doi.org/10.1007/s11192-020-03405-9
Fraser, N., Bräuer, P., Peters, I. (2021) Altmetrics for evaluation of medical research in Germany, In: Glänzel, Wolfgang et. al. (Ed.): Proceedings of the 18th International Conference on Scientometrics & Informetrics (ISSI 2021), 12–15 July 2021, ISBN 9789080328228, International Society for Scientometrics and Informetrics (ISSI), Leuven, pp. 1471–1472, https://issi2021.org/proceedings/
Freeman, R., & Maybin, J. (2011). Documents, practices and policy. Evidence & Policy, 7(2), 155–170. https://doi.org/10.1332/174426411X579207
Garfield, E. (1965). Can citation indexing be automated. In Statistical Association Methods for Mechanized Documentation, Symposium Proceedings., 269, 189–192.
Harwood, N. (2009). An interview-based study of the functions of citations in academic writing across two disciplines. Journal of Pragmatics, 41(3), 497–518. https://doi.org/10.1016/j.pragma.2008.06.001
Haunschild, R., & Bornmann, L. (2017). How many scientific papers are mentioned in policy-related documents? An empirical investigation using Web of Science and Altmetric data. Scientometrics, 110(3), 1209–1216. https://doi.org/10.1007/s11192-016-2237-2
Hu, Z. (2014). Full-Text Citation Analysis and Applications. Dalian University of Technology.
Hu, Z., Chen, C., & Liu, Z. (2013). Where are citations located in the body of scientific articles? A study of the distributions of citation locations. Journal of Informetrics, 7(4), 887–896. https://doi.org/10.1016/j.joi.2013.08.005
Kale, B., Siravuri, H. V., Alhoori, H., & Papka, M. E. (2017). Predicting research that will be cited in policy documents. In Proceedings of the 2017 ACM on Web Science Conference 389–390
Kjellberg, S. (2010). I am a blogging researcher: Motivations for blogging in a scholarly context. First Monday. https://doi.org/10.5210/fm.v15i8.2962
Lemke, S., Witthake, A., & Peters, I. (2022). Altmetrics for German medical research: What leads to research articles achieving policy impact? 26th International Conference on Science, Technology and Innovation Indicators (STI 2022), Granada, Spain. https://doi.org/10.5281/ZENODO.6645109
Liu, J., & Konkiel, S. (2015). Understanding the impact of research on policy using Altmetric data. In Septentrio Conference Series (No. 5).
Maleki, A., & Holmberg, K. (2022). Comparing coverage of policy citations to scientific publications in Overton and Altmetric.com: Case study of Finnish research organizations in Social Science. Informaatiotutkimus, 41(2), 92–96. https://doi.org/10.23978/inf.122592
Na, J. C. (2015). User motivations for tweeting research articles: A content analysis approach. International Conference on Asian Digital Libraries (pp. 197–208). Springer.
Newson, R., Rychetnik, L., King, L., Milat, A., & Bauman, A. (2018). Does citation matter? Research citation in policy documents as an indicator of research impact – an Australian obesity policy case-study. Health Research Policy and Systems. https://doi.org/10.1186/s12961-018-0326-9
Nigel Gilbert, G. (1977). Referencing as persuasion. Social Studies of Science, 7(1), 113–122.
NISO Alternative Assessment Metrics Project. (2014). NISO Altmetrics Standards Project White Paper. Retrieved July 8, 2021, from https://www.niso.org/press-releases/2014/06/niso-issues-altmetrics-white-paper-draft-comment
Pinheiro, H., Vignola-Gagné, E., & Campbell, D. (2021). A large-scale validation of the relationship between cross-disciplinary research and its uptake in policy-related documents, using the novel Overton altmetrics database. Quantitative Science Studies, 2(2), 616–642. https://doi.org/10.1162/qss_a_00137
Shema, H., Bar-Ilan, J., & Thelwall, M. (2015). How is research blogged? A content analysis approach. Journal of the Association for Information Science and Technology, 66(6), 1136–1149. https://doi.org/10.1002/asi.23239
Syn, S. Y., & Oh, S. (2015). Why do social network site users share information on Facebook and Twitter? Journal of Information Science, 41(5), 553–569. https://doi.org/10.1177/0165551515585717
Szomszor, M., & Adie, E. (2022). Overton: A bibliometric database of policy document citations. Quantitative Science Studies, 3(3), 624–650. https://doi.org/10.1162/qss_a_00204
Tahamtan, I., & Bornmann, L. (2020). Altmetrics and societal impact measurements: Match or mismatch? A literature review. El profesional de la información, 29(1), e290102. https://doi.org/10.3145/epi.2020.ene.02
Tattersall, A., & Carroll, C. (2018). What can Altmetriccom tell us about policy citations of research? An analysis of Altmetriccom data for research articles from the University of Sheffield. Frontiers in research metrics and analytics. https://doi.org/10.3389/frma.2017.00009
Thelwall, M. (2017). Web indicators for research evaluation: A practical guide. Morgan & Claypool. https://doi.org/10.1007/978-3-031-02304-0
Thelwall, M., Tsou, A., Weingart, S., Holmberg, K., & Haustein, S. (2013). Tweeting links to academic articles(p. 17). Issues Contents.
Veletsianos, G. (2012). Higher education scholars’ participation and practices on Twitter. Journal of Computer Assisted Learning, 28(4), 336–349.
Willis, C. D., Riley, B., Stockton, L., Viehbeck, S., Wutzke, S., & Frank, J. (2017). Evaluating the impact of applied prevention research centres: Results from a modified Delphi approach. Research Evaluation, 26(2), 78–90. https://doi.org/10.1093/reseval/rvx010
Wilsdon, J., Allen, L., Belfiore, E., Campbell, P., Curry, S., Hill, S., et al. (2015). The metric tide: Report of the independent review of the role of metrics in research assessment and management. Bristol: Higher Education Funding Council for England (HEFCE).
Xiao, T. (2017). Study on Distribution Characteristics and internal mechanism of Policy Documents Altmetrics Indicator. Wuhan University.
Yin, Y., Gao, J., Jones, B. F., & Wang, D. (2021). Coevolution of policy and science during the pandemic. Science, 371(6525), 128–130. https://doi.org/10.1126/science.abe3084
Yu, H., Cao, X., Xiao, T., & Yang, Z. (2020). How accurate are policy document mentions? A first look at the role of altmetrics database. Scientometrics, 125(2), 1517–1540. https://doi.org/10.1007/s11192-020-03558-7
Yu, H., Xiao, T., Wang, Y., & Qiu, J. (2017b). Study of Distribution Characteristics of Policy Documents Altmetrics. Journal of Library Science in China, 43(5), 57–69.
Yu, H., Xu, S., Xiao, T., Hemminger, B. M., & Yang, S. (2017a). Global science discussed in local altmetrics: Weibo and its comparison with Twitter. Journal of Informetrics, 11(2), 466–482. https://doi.org/10.1016/j.joi.2017.02.011
Acknowledgements
This paper is an extended version of ISSI2021 poster entitled with” Where, how and why are scientific products mentioned in policy documents?”. This study is supported by the National Natural Science Foundation of China (No. 72274227) and the Humanity and Social Science Foundation of Ministry of Education of China (NO. 22YJA870016). Biegzat Murat is financially supported by the China Scholarly Council (202206840041). The authors would like to thank Altmetric.com for providing access to their data.
Funding
National Natural Science Foundation of China, No. 72274227, Houqiang Yu, Humanity and Social Science Foundation of Ministry of Education of China, NO. 22YJA870016, Houqiang Yu.
Author information
Authors and Affiliations
Contributions
Conceptualization: HY, BM Methodology: HY, BM Formal analysis and investigation: HY, BM, JLi, LL. Writing—original draft preparation: BM Writing—review and editing: HY, BM.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yu, H., Murat, B., Li, J. et al. How can policy document mentions to scholarly papers be interpreted? An analysis of the underlying mentioning process. Scientometrics 128, 6247–6266 (2023). https://doi.org/10.1007/s11192-023-04826-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-023-04826-y