
Abstract
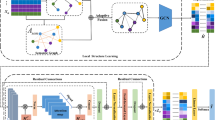
The classification task of scientific papers can be implemented based on contents or citations. In order to improve the performance on this task, we express papers as nodes and integrate scientific papers’ contents and citations into a heterogeneous graph. It has two types of edges. One type represents the semantic similarity between papers, derived from papers’ titles and abstracts. The other type represents the citation relationship between papers and the journals or proceedings of conferences of their references. We utilize a contrastive learning method to embed the nodes in the heterogeneous graph into a vector space. Then, we feed the paper node vectors into classifiers, such as the decision tree, multilayer perceptron, and so on. We conduct experiments on three datasets of scientific papers: the Microsoft Academic Graph with 63,211 scientific papers in 20 classes, the Proceedings of the National Academy of Sciences with 38,243 scientific papers in 18 classes, and the American Physical Society with 443,845 scientific papers in 5 classes. The experimental results on the multi-class task show that our multi-view method scores the classification accuracy up to 98%, outperforming state-of-the-arts.




Similar content being viewed by others


References
Achakulvisut, T., Acuna, D. E., Ruangrong, T., & Kording, K. (2016). Science concierge: A fast content based recommendation system for scientific publications. PLoS ONE, 11(7), e0158423.
Alsmadi, K. M., Omar, K., Noah, A. S., & Almarashdah, I. (2009). Performance comparison of multi-layer perceptron (back propagation, delta rule and perceptron) algorithms in Neural Networks. IEEE international advance computing conference (pp. 296–299).
Arman, C., Sergey, F., Beltagy, I., Doug, D., & Daniel, W. (2020). Specter: Document-level representation learning using citation-informed transformers. ACL (pp. 2270–2282).
Ashish, V., Noam, S., Niki, P., Jakob, U., Llion, J., Aidan, N. G., Łukasz, K., & Illia, P. (2017). Attention is all you need. NeurIPS (pp. 6000–6010).
Beltagy, I., Kyle, L., & Arman, C. (2019). Scibert: A pretrained language model for scientific text. EMNLP (pp. 3615–3620).
Breiman, L. (1996). Bagging predictors. Machine Learning, 24(2), 123–140.
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32.
Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and regression trees (Vol. 432, pp. 151–166). Belmont, CA: International Group, Wadsworth.
Chen, T., & Guestrin, C. (2016). XGBoost: A scalable tree boosting system. SIGKDD (pp. 785–794).
Cover, T., & Hart, P. (1967). Nearest neighbor pattern classification. IEEE Transactions on Information Theory, 13, 21–27.
David, B. M., Andrew, N. Y., & Michael, J. I. (2003). Latent Dirichlet Allocatio. Journal of Machine Learning Research, 3, 993–1102.
Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. NAACL (pp. 4171–4186).
Ding, K., Wang, J., Li, J., Li, D., & Liu, H. (2020). Be more with less: Hypergraph attention networks for inductive text classification. EMNLP (pp. 4927–4936).
Ech-Chouyyekh, M., Omara, H., & Lazaar, M. (2019). Scientific paper classification using convolutional neural networks. Proceedings of the 4th international conference on big data and internet of things (pp. 1–6).
Freund, Y., & Robert, E. S. (1997). A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences, 55(1), 119–139.
Ganguly, S., & Pudi, V. (2017). Paper2vec: Combining graph and text information for scientific paper representation. Advances in Information Retrieval (pp. 383–395). Berlin: Springer.
Gao, M., Chen, L., He, X., & Zhou, A. (2018). Bine: Bipartite network embedding. SIGIR (pp. 715–724).
Grave, E., Mikolov, T., Joulin, A., & Bojanowski, P. (2017). Bag of tricks for efficient text classification. EACL (pp. 427–431).
Han, E., Karypis, G., & Kumar, V. (2001). Text categorization using weight adjusted k-nearest neighbor classification. PAKDD, 13, 53–65.
Jacovi, A., Shalom, O., & Goldberg, Y. (2018). Understanding convolutional neural networks for text classification. EMNLP (pp. 56–65).
Jin, R., Lu, L., Lee, J., & Usman, A. (2019). Multi-representational convolutional neural networks for text classification. Computational Intelligence, 35(3), 599–609.
Joachims, T. (1998). Text categorization with Support Vector Machines: Learning with many relevant feature. Machine Learning: ECML-98 (pp. 137–142).
Jones, K. S. (2004). A statistical interpretation of term specificity and its application in retrieval. Journal of Documentation, 60, 493–502.
Kipf, N. T., & Welling, M. (2017). Semi-supervised classification with graph convolutional networks. ICLR.
Kong, X., Mao, M., Wang, W., Liu, J., & Xu, B. (2018). VOPRec: Vector representation learning of papers with text information and structural identity for recommendation. IEEE Transactions on Emerging Topics in Computing, 9, 226–237.
Kozlowski, D., Dusdal, J., Pang, J., & Zilian, A. (2021). Semantic and relational spaces in science of science: Deep learning models for article vectorisation. Scientometrics, 126, 5881–5910.
Le, V. Q., & Mikolov, T. (2014). Distributed representations of sentences and documents. ICML (pp. 1188–1196).
Li, X., Ding, D., Kao, B., Sun, Y., & Mamoulis, N. (2021). Leveraging meta-path contexts for classification in heterogeneous information networks. ICDE (pp. 912–923).
Lu, Y., Luo, J., Xiao, Y., & Zhu, H. (2021). Text representation model of scientific papers based on fusing multi-viewpoint information and its quality assessment. Scientometrics, 126, 6937–6963.
Luo, X. (2021). Efficient English text classification using selected Machine Learning Techniques. Alexandria Engineering Journal, 60(3), 3401–3409.
Maron, E. M. (1961). Automatic indexing: An experimental inquiry. Journal of the ACM, 1, 404–417.
Masmoudi, A., Bellaaj, H., Drira, K., & Jmaiel, M. (2021). A co-training-based approach for the hierarchical multi-label classification of research papers. Expert Systems, 38, e12613.
Mauro, D. L. T., & Julio, C. (2021). SciKGraph: A knowledge graph approach to structure a scientific field. Journal of Informetrics, 15, 101–109.
Mikolov, T., Sutskever, I., Chen, K., Corrado, G., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. NeurIPS (pp. 3111–3119).
Perozzi, B., Al-Rfou, R., & Skiena, S. (2014). Deepwalk: Online learning of social representations. SIGKDD (pp. 701–710).
Quan, J., Li, Q., & Li, M. (2014). Computer science paper classification for CSAR. ICWL, pp. 34–43.
Quinlan, J. R. (1986). Induction of decision trees. Machine Learning, 1(1), 81–106.
Quinlan, J. R. (1993). C4.5: Programs for Machine Learning. San Francisco: Morgan Kaufmann Publishers Inc.
Ramesh, B., & Sathiaseelan, J. G. R. (2015). An advanced multi class instance selection based support vector machine for text classification. Procedia Computer Science, 57, 1124–1130.
Sajid, A. N., Ahmad, M., Afzal, T. M., & Atta-ur-Rahman. (2021). Exploiting papers’ reference’s section for multi-label computer science research papers’ classification. Journal of Information and Knowledge Management, 20(01), 2150004.
Sun, Y., Han, J., Yan, X., Yu, S. P. & Wu, T. (2011) PathSim: Meta path-based top-K similarity search in heterogeneous information networks. PVLDB, 992-1003.
Tan, Z., Chen, J., Kang, Q., Zhou, M., Abusorrah, A., & Sedraoui, K. (2022). Dynamic embedding projection-gated convolutional neural networks for text classification. IEEE Transactions on Neural Networks and Learning Systems, 33(3), 973–982.
Turgut, D., & Alper, K. U. (2020). A novel term weighting scheme for text classification: TF-MONO. Journal of Informetrics, 14(4), 101076.
Velickovic, P., Cucurull, G., Casanova, A., Romero, A., Lio, P., & Bengio, Y. (2018). Graph attention networks. ICLR.
Wang, X., Ji, Ho., Shi, C., Wang, B., Ye, Y., Cui, P., &Yu, S. P. (2019). Heterogeneous graph attention network. WWW ’19 (pp. 2022–2032).
Wang, R., Li, Z., Cao, J., Chen, T., & Wang, L. (2019). Convolutional recurrent neural networks for text classification. IJCNN, pp. 1–6.
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., & Brew, J. (2019). Huggingface’s transformers: State of the art natural language processing. arXiv preprint arXiv:1910.03771.
Xu, K., Hu, W., Leskovec, J., & Jegelka, S. (2019). How powerful are graph neural networks? ICLR.
Yao, L., Mao, C., & Luo, Y. (2019). Graph convolutional networks for text classification. AAAI (pp. 7370–7377).
Zhang, Y., Zhao, F., & Lu, J. (2019). P2v: Large-scale academic paper embedding. Scientometrics, 121(1), 399–432.
Zhang, T., Kishore, V., Wu, F., Weinberger, Q. K., & Artzi, Y. (2020). BERTScore: Evaluating text generation with BERT. ICLR.
Zhang, Y., Yu, X., Cui, Z., Wu, S., Wen, Z., & Wang, L. (2020). Every document owns its structure: Inductive text classification via graph neural networks. ACL.
Zhang, C., Song, D., Huang, C., Swami, A., & Chawla, V. N. (2019). Heterogeneous graph neural network. KDD (pp. 793–803).
Zhang, M., Gao, X., Cao, D. M., & Ma, Y. (2006). Modelling citation networks for improving scientific paper classification performance. PRICAI (pp. 413–422).
Author information
Authors and Affiliations
Corresponding author
Appendix: Fine-grained study on the PNAS
Appendix: Fine-grained study on the PNAS
We divide the classes into the coarse-grained type and the fine-grained type on the PNAS dataset. The Physical sciences and Social sciences are regarded as coarse-grained subjects, while the sub-disciplines of Biological sciences are fine-grained. Here we compare the classification performance of different granularities on the MLPClssifier (Table 9). We calculate the increments of GATs, the concatenate method, and our method compared to LDA. The GATs outperform LDA on the three classification indicators, precision, recall, and F1, which shows that the semantic features captured by GATs are more useful than the topic distribution obtained by LDA. The directly concatenating method outperforms GATs, and the precision of Genetics is even 32% higher, reflecting the advantage of using citations. Our method outperforms the direct concatenating method, which shows the advantage of using contrastive learning.
To compare the coarse and fine granularity, we average the increments on labels. Table 10 shows the average incremental results in three classification indicators. It shows that our method has the most obvious improvement compared with other methods, and the increment in classification indicators of fine-grained subjects is much higher than that of coarse-grained subjects. It also shows that our method can distinguish the differences between similar disciplines. Similar disciplines are hard to classify only through semantics. Therefore, the citations contribute a lot.
Rights and permissions
About this article

Cite this article
Lv, Y., Xie, Z., Zuo, X. et al. A multi-view method of scientific paper classification via heterogeneous graph embeddings. Scientometrics 127, 4847–4872 (2022). https://doi.org/10.1007/s11192-022-04419-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-022-04419-1