
Abstract
In scientific research, the method is an indispensable means to solve scientific problems and a critical research object. With the advancement of sciences, many scientific methods are being proposed, modified, and used in academic literature. The authors describe details of the method in the abstract and body text, and key entities in academic literature reflecting names of the method are called method entities. Exploring diverse method entities in a tremendous amount of academic literature helps scholars understand existing methods, select the appropriate method for research tasks, and propose new methods. Furthermore, the evolution of method entities can reveal the development of a discipline and facilitate knowledge discovery. Therefore, this article offers a systematic review of methodological and empirical works focusing on extracting method entities from full-text academic literature and efforting to build knowledge services using these extracted method entities. Definitions of key concepts involved in this review were first proposed. Based on these definitions, we systematically reviewed the approaches and indicators to extract and evaluate method entities, with a strong focus on the pros and cons of each approach. We also surveyed how extracted method entities were used to build new applications. Finally, limitations in existing works as well as potential next steps were discussed.
Similar content being viewed by others
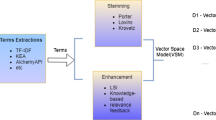

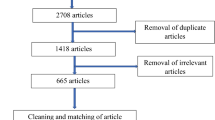
References
Alfonseca, E., & Manandhar, S. (2002). An unsupervised method for general named entity recognition and automated concept discovery. In Proceedings of the 1st international conference on general WordNet, Mysore, India (pp. 34–43).
Ammar, W., Peters, M., Bhagavatula, C., & Power, R. (2017). The AI2 system at SemEval-2017 Task 10 (ScienceIE): Semi-supervised end-to-end entity and relation extraction. In Proceedings of the 11th international workshop on semantic evaluation (SemEval-2017),Vancouver, Canada (pp. 592–596).
Anderson, C. (2008). The end of theory: The data deluge makes the scientific method obsolete | WIRED. https://www.wired.com/2008/06/pb-theory/
Appelt, D. E., Hobbs, J. R., Bear, J., Israel, D. J., & Tyson, M. (1995). SRI International FASTUS system: MUC-6 test results and analysis. In Proceedings of the 6th conference on message understanding, MUC 1995 (pp. 237–248).
Augenstein, I., Das, M., Riedel, S., Vikraman, L., & Mccallum, A. (2017). SemEval 2017 Task 10: ScienceIE-Extracting Keyphrases and Relations from Scientific Publications. Vancouver, Canada (pp. 546–555).
Bacon, F. (1878). Novum organum. Clarendon press.
Bell, G., Hey, T., & Szalay, A. (2009). Beyond the data Deluge. Science, 323(5919), 1297–1298. https://doi.org/10.1126/science.1170411
Bhatia, S., Mitra, P., & Giles, C. L. (2010). Finding Algorithms in Scientific Articles. In Proceedings of the 19th international conference on world wide web, New York, NY, USA: ACM (pp. 1061–1062). https://doi.org/10.1145/1772690.1772804
Bikel, D. M., Schwartz, R., & Weischedel, R. M. (1999). An algorithm that learns what’s in a name. Machine Learning, 34(1–3), 211–231.
Bikel D M, Miller S, Schwartz R, et al. (1998). Nymble: A high-performance learning name-finder. In Fifth conference on applied natural language processing, Washington, DC, USA (pp. 194–201).
Bird, S., Dale, R., Dorr, B. J., Gibson, B., Joseph, M. T., Kan, M.-Y., Lee, D., Powley, B., Radev, D. R., & Tan, Y. F. (2008). The ACL anthology reference Corpus: A reference dataset for bibliographic research in computational linguistics. In Proceedings of the sixth international conference on language resources and evaluation (LREC'08) (pp. 155–1759).
Blake, V. L. P. (1994). Since Shaughnessy: Research methods in library and information science dissertation, 1975–1989. Collection Management, 19(1–2), 1–42.
Boehm, B. W. (1991). Software risk management: Principles and practices. IEEE Software, 8(1), 32–41. https://doi.org/10.1109/52.62930
Boland, K., & Krüger, F. (2019, July 25). Distant supervision for silver label generation of software mentions in social scientific publications. In Proceedings of 4th joint workshop on bibliometric-enhanced information retrieval and natural language processing for digital libraries. Paris, France.
Borrega, O., Taulé, M., & Martı, M. A. (2007). What do we mean when we speak about Named Entities. In Proceedings of Corpus Linguistics, Birmingham, UK.
Borthwick, A., & Grishman, R. (1999). A maximum entropy approach to named entity recognition. New York University.
Buitelaar, P., & Eigner, T. (2009). Expertise mining from scientific literature. In Proceedings of the fifth international conference on knowledge capture, Redondo Beach California USA (pp. 171–172). https://doi.org/10.1145/1597735.1597767
Chen, Z., Trabelsi, M., Davison, B. D., & Heflin, J. (2020). Towards knowledge acquisition of metadataon AI progress. In ISWC 2020 demos and industry tracks: From novel ideas to industrial practice (ISWC-Posters 2020), Globally online (pp. 232–237).
Dessì, D., Osborne, F., Reforgiato, R. D., Buscaldi, D., Motta, E., & Sack, H. (2020). AI-KG: An automatically generated knowledge graph of artificial intelligence. Computer Science, 12507, 127–143.
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) Minneapolis, Minnesota (pp. 4171–4186). https://doi.org/10.18653/v1/N19-1423
Ding, Y., Liu, X., Guo, C., & Cronin, B. (2013a). The distribution of references across texts: Some implications for citation analysis. Journal of Informetrics, 7(3), 583–592. https://doi.org/10.1016/j.joi.2013.03.003
Ding, Y., Song, M., Han, J., Yu, Q., Yan, E., Lin, L., & Chambers, T. (2013b). Entitymetrics: Measuring the impact of entities. PloS One, 8(8), e71416.
Ding, Y., & Stirling, K. (2016). Data-driven discovery: A new Era of exploiting the literature and data. Journal of Data and Information Science, 1(4), 1–9.
Ding, R., Wang, Y., & Zhang, C. (2019). Investigating citation of algorithm in full-text of Academic articles in NLP domain: A preliminary study. In Proceedings of the 17th international conference on scientometrics and informetrics (ISSI 2019), Rome, Italy (pp. 2726–2728).
Du, C., Cohoon, J., Lopez, P., & Howison, J. (2021). Softcite dataset: A dataset of software mentions in biomedical and economic research publications. Journal of the Association for Information Science and Technology., 72, 870–884. https://doi.org/10.1002/asi.24454
Duck, G., Nenadic, G., Brass, A., Robertson, D. L., & Stevens, R. (2013a). BioNerDS: Exploring bioinformatics’ database and software use through literature mining. BMC Bioinformatics, 14(1), 194.
Duck, G., Kovacevic, A., Robertson, D. L., Stevens, R., & Nenadic, G. (2015). Ambiguity and variability of database and software names in bioinformatics. Journal of Biomedical Semantics, 29(6), 2–11.
Duck, G., Nenadic, G., Filannino, M., Brass, A., Robertson, D. L., Stevens, R., & Ranganathan, S. (2016). A survey of bioinformatics database and software usage through mining the literature. PLoS One., 11(6), e0157989.
Duck, G., Nenadic, G., Robertson, D. L., & Stevens, R. (2013b). What is bioinformatics made from? A survey of database and software usage through full-text mining. In Joint 21st annual international conference on intelligent systems for molecular biology (ISMB) and 12th European conference on computational biology (ECCB) 2013b, Berlin, Germany.
Eales, J. M., Pinney, J. W., Stevens, R. D., & Robertson, D. L. (2008). Methodology capture: Discriminating between the “best” and the rest of community practice. BMC Bioinformatics, 9, 359. https://doi.org/10.1186/1471-2105-9-359
Eckle-Kohler, J., Nghiem, T.-D., & Gurevych, I. (2013). Automatically assigning research methods to journal articles in the domain of social sciences. Proceedings of the American Society for Information Science and Technology, Montreal, Canada, 50(1), 1–8. https://doi.org/10.1002/meet.14505001049
Erera, S., Shmueli-Scheuer, M., Feigenblat, G., Nakash, O., Boni, O., Roitman, H., Cohen, D., Weiner, B., Mass, Y., Rivlin, O., Lev, G., Jerbi, A., Herzig, J., Hou, Y., Jochim, C., Gleize, M., Bonin, F., & Konopnicki, D. (2019). A Summarization System for Scientific Documents. Hong Kong, China (pp. 211–216). https://doi.org/10.18653/v1/D19-3036
Garfield, E. (1955). Citation indexes for science. Science, 122(3159), 108–111.
Garfield, E. (1963). Citation indexes in sociological and historical research. American Documentation, 14(4), 289–291. https://doi.org/10.1002/asi.5090140405
Garfield, E. (1979). Citation indexing—its theory and application in science, technology, and humanities. Wiley.
Gauch, J., & Hugh, G. (2003). Scientific method in practice. Cambridge University Press.
Goyal, A., Gupta, V., & Kumar, M. (2018). Recent named entity recognition and classification techniques: A systematic review. Computer Science Review, 29, 21–43.
Gupta S & Manning C D. (2011). Analyzing the dynamics of research by extracting key aspects of scientific papers. In Proceedings of 5th International Joint Conference on Natural Language Processing, Chiang Mai, Thailand (pp. 1–9).
Handschuh, S., & Qasemi, Z. B. (2014). The ACL RD-TEC: A dataset for benchmarking terminology extraction and classification in computational linguistics. In COLING 2014: 4th international workshop on computational terminology, Dublin, Ireland (pp. 52–63).
Hassan, S.-U., Safder, I., Akram, A., & Kamiran, F. (2018). A novel machine-learning approach to measuring scientific knowledge flows using citation context analysis. Scientometrics, 116(2), 973–996.
Heffernan, K., & Teufel, S. (2018). Identifying problems and solutions in scientific text. Scientometrics, 116(2), 1367–1382.
Hepburn, B., & Andersen, H. (2021). Scientific Method. In E. N. Zalta (Ed.), The Stanford Encyclopedia of Philosophy (Summer 2021). Metaphysics Research Lab, Stanford University. https://plato.stanford.edu/archives/sum2021/entries/scientific-method/
Hey, T., Tansley, S., & Tolle, K. (2009). The Fourth Paradigm: Data-Intensive Scientific Discovery. https://www.microsoft.com/en-us/research/publication/fourth-paradigm-data-intensive-scientific-discovery/
Hou, L., Zhang, J., Wu, O., Yu, T., Wang, Z., Li, Z., Gao, J., Ye, Y., & Yao, R. (2020). Method and Dataset Entity Mining in Scientific Literature: A CNN + Bi-LSTM Model with Self-attention. ArXiv:2010.13583 [Cs]. http://arxiv.org/abs/2010.13583
Houngbo, H., & Mercer, R. E. (2012). Method mention extraction from scientific research papers. In Proceedings of COLING 2012, Mumbai, India (pp. 1211–1222).
Howison, J., & Bullard, J. (2016). Software in the scientific literature: Problems with seeing, finding, and using software mentioned in the biology literature. Journal of the Association for Information Science and Technology, 67(9), 2137–2155.
Howison, J., Deelman, E., McLennan, M. J., da Silva, R. F., & Herbsleb, J. D. (2015). Understanding the scientific software ecosystem and its impact: Current and future measures. Research Evaluation, 24(4), 454–470. https://doi.org/10.1093/reseval/rvv014
Ibrahim, B. (2021). Statistical methods used in Arabic journals of library and information science. Scientometrics, 126(5), 4383–4416. https://doi.org/10.1007/s11192-021-03913-2
Isozaki H, Kazawa H. (2002). Efficient support vector classifiers for named entity recognition. In: Proceedings of the 19th international conference on computational linguistics. Association for Computational Linguistics, Grenoble, France (vol. 1, pp. 1–7).
ISO/IEC 9126-1:2001. (2001). ISO. https://www.iso.org/cms/render/live/en/sites/isoorg/contents/data/standard/02/27/22749.html
ISO/IEC 25010:2011. (2017). ISO. https://www.iso.org/cms/render/live/en/sites/isoorg/contents/data/standard/03/57/35733.html
Jain, S., van Zuylen, M., Hajishirzi, H., & Beltagy, I. (2020). SciREX: A Challenge Dataset for Document-Level Information Extraction. In Proceedings of the 58th annual meeting of the association for computational linguistics, Online (pp. 7506–7516). https://doi.org/10.18653/v1/2020.acl-main.670
Jarvelin, K., & Vakkari, P. (1990). Content analysis of research articles in library and information science. Library and Information Science Research, 12(4), 395–421.
Jiang, C., Zhu, Z., Shen, S., & Wang, D. (2019). Research on software entity extraction and analysis based on deep learning. In Proceedings of the 17th international conference on scientometrics and informetrics, ISSI 2019, Rome, Italy (pp. 2742–2743).
Jie Z, Xie P, Lu W, Ding R, Li L. (2019). Better modeling of incomplete annotations for named entity recognition. In: Proceedings of the 2019 conference of the North American chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Minnesota, USA (pp. 729–734).
Jinha, A. E. (2010). Article 50 million: An estimate of the number of scholarly articles in existence. Learned Publishing, 23(3), 258–263. https://doi.org/10.1087/20100308
Katsurai, M. (2021). Adoption of data mining methods in the discipline of library and information science. Journal of Library and Information Studies, 19(1), 1–17.
Kelling, S., Hochachka, W. M., Fink, D., Riedewald, M., Caruana, R., Ballard, G., & Hooker, G. (2009). Data-intensive science: A new paradigm for biodiversity studies. BioScience, 59(7), 613–620. https://doi.org/10.1525/bio.2009.59.7.12
Khan, S., Liu, X., Shakil, K. A., & Alam, M. (2017). A survey on scholarly data: From big data perspective. Information Processing & Management, 53(4), 923–944.
Knorr-Cetina, K. D. (2013). The manufacture of knowledge: An essay on the constructivist and contextual nature of science. Elsevier.
Kovačević, A., Konjović, Z., Milosavljević, B., et al. (2012). Mining methodologies from NLP publications: A case study in automatic terminology recognition. Computer Speech & Language, 26(2), 105–126.
Krippendorff, K. (2011). Computing Krippendorff’s alpha-reliability. Retrieved from http://repository.upenn.edu/asc_papers/43
Lam, C., Lai, F.-C., Wang, C.-H., Lai, M.-H., Hsu, N., & Chung, M.-H. (2016). Text mining of journal articles for sleep disorder terminologies. PLoS ONE, 11(5), e0156031. https://doi.org/10.1371/journal.pone.0156031
Lei, Z., & Wang, D. (2019). Model Entity Extraction in Academic Full Text Based on Deep Learning. In Proceedings of the 17th international conference on scientometrics and informetrics, ISSI 2019, Rome, Italy, September 2–5 (pp. 2732–2733).
Li, K. (2020). The (re-)instrumentalization of the Diagnostic and Statistical Manual of Mental Disorders (DSM) in psychological publications: A citation context analysis. Quantitative Science Studies, 5, 1–26.
Li, K., & Xu, S. (2017). Measuring the impact of R packages. Proceedings of the Association for Information Science and Technology, 54(1), 739–741.
Li, K., & Yan, E. (2018). Co-mention network of R packages: Scientific impact and clustering structure. Journal of Informetrics, 12(1), 87–100.
Li, K., Chen, P.-Y., & Yan, E. (2019). Challenges of measuring software impact through citations: An examination of the lme4 R package. Journal of Informetrics, 13(1), 449–461.
Liakata, M., Saha, S., Dobnik, S., Batchelor, C., & Rebholz-Schuhmann, D. (2012). Automatic recognition of conceptualization zones in scientific articles and two life science applications. Bioinformatics, 28(7), 991–1000.
Liakata, M., & Soldatova, L. (2008). Guidelines for the annotation of general scientific concepts.
Luan, Y., Ostendorf, M., & Hajishirzi, H. (2017). Scientific information extraction with semi-supervised neural tagging. In Proceedings of the 2017 conference on empirical methods in natural language processing, Copenhagen, Denmark (pp. 2641–2651).
Luan, Y., He, L., Ostendorf, M., & Hajishirzi, H. (2018). Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction. In Proceedings of the 2018 conference on empirical methods in natural language processing, Brussels, Belgium (pp. 3219–3232). https://doi.org/10.18653/v1/D18-1360
Luan, Y. (2018). Information Extraction from Scientific Literature for Method Recommendation. ArXiv:1901.00401 [Cs]. http://arxiv.org/abs/1901.00401
Ma, S., & Zhang, C. (2017). Using full-text to evaluate impact of different software groups information. In Proceedings of the 16th international conference on scientometrics and informetrics, ISSI 2017, Wuhan,China (pp. 1666–1667).
Macleod, C. (2020). John Stuart Mill. In E. N. Zalta (Ed.), The Stanford encyclopedia of philosophy (Summer 2020). Metaphysics Research Lab, Stanford University. https://plato.stanford.edu/archives/sum2020/entries/mill/.
McCall, J. A., Richards, P. K., & Walters, G. F. (1977). Factors in Software Quality. Volume I. Concepts and Definitions of Software Quality. General Electric Co Sunnyvale CA. https://apps.dtic.mil/sti/citations/ADA049014.
McCallum, A., & Li, W. (2003). Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In: Proceedings of the seventh conference on natural language learning. Association for Computational Linguistics, Edmonton, Canada (Vol. 4, pp. 188–191).
McHugh, M. L. (2012). Interrater reliability: The kappa statistic. Biochemia Medica, 22(3), 276–282.
Medawar, P. (1990). Is the scientific paper a fraud. Springer.
Meng, B., Hou, L., Yang, E., & Li, J. (2018). Metadata Extraction for Scientific Papers. In Chinese computational linguistics and natural language processing based on naturally annotated big data CCL 2018, NLP-NABD 2018. Changsha, China (pp. 111–122).
Merriam-webster. (2002). Scientific Method|Definition of Scientific Method by Merriam-Webster. https://www.merriam-webster.com/dictionary/scientific%20method.
Mesbah, S., Lofi, C., Torre, M. V., Bozzon, A., & Houben, G.-J. (2018). Tse-ner: An iterative approach for long-tail entity extraction in scientific publications. In International semantic web conference, Monterey, CA, USA (pp. 127–143).
Michael, F., Alexander, A., & Felix, S. (2020). Identifying used methods and datasets in scientific publications. In Proceedings of thirty-Fifth AAAI Conference on Artificial Intelligence (AAAI-21), Online.
Miller, H. J., & Goodchild, M. F. (2015). Data-driven geography. GeoJournal, 80(4), 449–461. https://doi.org/10.1007/s10708-014-9602-6
Nadeau, D., & Sekine, S. (2007). A survey of named entity recognition and classification. Lingvisticæ Investigationes, 30(1), 3–26. https://doi.org/10.1075/li.30.1.03nad
Neves, M., & Ševa, J. (2021). An extensive review of tools for manual annotation of documents. Briefings in Bioinformatics, 22(1), 146–163.
Newton, I. (1730). Opticks. Prabhat Prakashan.
Newton, I. (1802). Mathematical principles of natural philosophy. A. Strahan.
Pan, X., Yan, E., Wang, Q., & Hua, W. (2015). Assessing the impact of software on science: A bootstrapped learning of software entities in full-text papers. Journal of Informetrics, 9(4), 860–871.
Pan, X., Yan, E., & Hua, W. (2016). Disciplinary differences of software use and impact in scientific literature. Scientometrics, 109(3), 1593–1610.
Pan, X., Yan, E., Cui, M., & Hua, W. (2018). Examining the usage, citation, and diffusion patterns of bibliometric mapping software: A comparative study of three tools. Journal of Informetrics, 12(2), 481–493.
Pan, X., Yan, E., Cui, M., Hua, W., Informetrics, J., & Egghe, L. (2019). How important is software to library and information science research? A content analysis of full-text publications. Journal of Informetrics, 13(1), 397–406.
Paul, D., Singh, M., Hedderich, M. A., & Klakow, D. (2019). Handling noisy labels for robustly learning from self-training data for low-resource sequence labeling. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: Student research workshop, Minneapolis, Minnesota.
Peritz, B. C. (1977). Research in library science as reflected in the core Journals of the Profession: A Quantitative Analysis (1950–1975). [Ph.D., University of California, Berkeley]. https://www.proquest.com/docview/288081334/citation/642387AA3C974336PQ/1.
Petasis, G., Cucchiarelli, A., Velardi, P., Paliouras, G., Karkaletsis, V., & Spyropoulos, C. D. (2000). Automatic adaptation of proper noun dictionaries through cooperation of machine learning and probabilistic methods. In Proceedings of the 23rd annual international ACM SIGIR conference on research and development in information retrieval, New York, United States (pp. 128–135). https://doi.org/10.1145/345508.345563
Pitt, J. C., & Pera, M. (2012). Rational changes in science: Essays on scientific reasoning (Vol. 98). Springer.
Piwowar, H. A., & Priem. (2016). Depsy:valuing the software that powers science. | Depsy. http://depsy.org/
QasemiZadeh B & Schumann A K. (2016). The ACL RD-TEC 2.0: A language resource for evaluating term extraction and entity recognition methods. In: Proceedings of the tenth international conference on language resources and evaluation (LREC’16), Portoroz, Slovenia (pp. 1862–1868).
Sahel, J.-A. (2011). Quality versus quantity: Assessing individual research performance. Science Translational Medicine, 3(84), 84cm13.
Stack Overflow. (2020). Stack Overflow Developer Survey 2020. Stack Overflow. https://insights.stackoverflow.com/survey/2020/?utm_source=social-share&utm_medium=social&utm_campaign=dev-survey-2020
The End of Theory: The Data Deluge Makes the Scientific Method Obsolete | WIRED. (n.d.). Retrieved April 26, 2021, from https://www.wired.com/2008/06/pb-theory/.
Tjong Kim Sang, E. F. (2002). Introduction to the CoNLL-2002 shared task: Language-Independent Named Entity Recognition. In COLING-02: The 6th conference on natural language learning 2002 (CoNLL-2002). https://www.aclweb.org/anthology/W02-2024.
Tjong Kim Sang, E. F., & De Meulder, F. (2003). Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. In Proceedings of the seventh conference on natural language learning at HLT-NAACL 2003 (pp. 142–147). https://www.aclweb.org/anthology/W03-0419.
Schickore, J. (2017). About method: Experimenters, snake venom, and the history of writing scientifically. University of Chicago Press.
Schindler, D., Zapilko, B., & Krüger, F. (2020). Investigating software usage in the social sciences: A knowledge graph approach. In Proceedings of extended semantic web conference (ESWC 2020), Crete, Greece (pp. 271–286).
Settouti, N., Bechar, M. E. A., & Chikh, M. A. (2016). Statistical comparisons of the top 10 algorithms in data mining for classi cation task. International Journal of Interactive Multimedia and Artificial Intelligence, 4(1), 46–51.
Shaalan, K. (2010). Rule-based approach in Arabic natural language processing. International Journal on Information and Communication Technologies, 3(3), 11–19.
Shen, D., Zhang, J., Zhou, G., Su, J., & Tan, C.-L. (2003). Effective adaptation of hidden Markov model-based named entity recognizer for biomedical domain. In Proceedings of the ACL 2003 workshop on natural language processing in biomedicine, Sapporo, Japan (pp. 49–56). https://doi.org/10.3115/1118958.1118965
Siddiqui, T., Ren, X., Parameswaran, A., & Han, J. (2016). FacetGist: Collective extraction of document facets in large technical Corpora. In Proceedings of the 25th ACM international on conference on information and knowledge management, New York, United States (pp. 871–880). https://doi.org/10.1145/2983323.2983828
Strasser, B. J. (2012). Data-driven sciences: From wonder cabinets to electronic databases. Studies in History and Philosophy of Biological and Biomedical Sciences, 43(1), 85–87. https://doi.org/10.1016/j.shpsc.2011.10.009
Strubell, E., Ganesh, A., & McCallum, A. (2019). Energy and policy considerations for deep learning in NLP. In Proceedings of the 57th annual meeting of the association for computational linguistics, Florence, Italy (pp. 3645–3650).
Tateisi, Y., Ohta, T., Pyysalo, S., Miyao, Y., & Aizawa, A. (2016). Typed entity and relation annotation on computer science papers. In Proceedings of the tenth international conference on language resources and evaluation (LREC’16), Portorož, Slovenia (pp. 3836–3843). https://www.aclweb.org/anthology/L16-1607
Thelwall, M., & Kousha, K. (2016). Academic software downloads from Google Code: Useful usage indicators? Information Research, 21(1), 1.
Thenmalar, S., Balaji, J., & Geetha, T. V. (2015). Semi-supervised bootstrapping approach for named entity recognition. International Journal on Natural Language Computing, 4(5), 01–14. https://doi.org/10.5121/ijnlc.2015.4501
TIOBE-Index, T. (2018). Tiobe-the software quality company. TIOBE Index| TIOBE–The Software Quality Company [Electronic Resource]. Mode of Access (vol. 1) https://www.Tiobe.Com/Tiobe-Index/-Date of Access.
Tuarob, S. (2014). Information extraction and metadata annotation for algorithms in digital libraries. The Pennsylvania State University.
Veugelers, R., & Wang, J. (2019). Scientific novelty and technological impact. Research Policy, 48(6), 1362–1372. https://doi.org/10.1016/j.respol.2019.01.019
Wang, Y., & Zhang, C. (2018b). Using full-text of research articles to analyze academic impact of algorithms. In International conference on information. Sheffield, UK (pp. 395–401).
Wang, Y., & Zhang, C. (2019). Finding more methodological entities from academic articles via iterative strategy: A preliminary study. In Proceedings of the 17th international conference on scientometrics and informetrics (ISSI 2019), Rome, Italy (pp. 2702–2703).
Wang, Y., & Zhang, C. (2018a). What type of domain knowledge is cited by articles with high interdisciplinary degree? In: Proceedings of 2018 annual meeting of the association for information science and technology (ASIST’2018). Vancouver, BC, Canada.
Wang, Y., & Zhang, C. (2020). Using the full-text content of academic articles to identify and evaluate algorithm entities in the domain of natural language processing. Journal of Informetrics, 14(4), 101091. https://doi.org/10.1016/j.joi.2020.101091
Wei, Q., Zhang, Y., Amith, M., Lin, R., & Xu, H. (2020). Recognizing software names in biomedical literature using machine learning. Health Informatics Journal, 26(1), 21–33.
What are altmetrics? (2015). Altmetric. https://www.altmetric.com/about-altmetrics/what-are-altmetrics/.
Wilbanks, E. G., Facciotti, M. T., & Veenstra, G. J. C. (2010). Evaluation of algorithm performance in ChIP-Seq peak detection. PLoS ONE, 5(7), e11471.
Woolgar, S. (1983). The Canadian Journal of Sociology. Cahiers Canadiens de Sociologie, 8(4), 466–468.
Wu, X., Kumar, V., Quinlan, J. R., Ghosh, J., Yang, Q., Motoda, H., McLachlan, G. J., Ng, A., Liu, B., & Yu, P. S. (2018). Top 10 algorithms in data mining. Knowledge and Information Systems, 14(1), 1–37.
Xie, I., Babu, R., Lee, T. H., Castillo, M. D., You, S., & Hanlon, A. M. (2020). Enhancing usability of digital libraries: Designing help features to support blind and visually impaired users. Information Processing & Management, 57(3), 102110.
Yang, B., Huang, S., Wang, X., & Rousseau, R. (2018a). How important is scientific software in bioinformatics research? A comparative study between international and Chinese research communities. Journal of the Association for Information Science and Technology, 69(9), 1122–1133. https://doi.org/10.1002/asi.24031
Yang Y, Chen W, Li Z, He, Z., & Zhang, M. (2018b). Distantly supervised net with partial annotation learning and reinforcement learning. In: Proceedings of the 27th international conference on computational linguistics, Santa Fe, New-Mexico, USA (pp. 2159–2169).
Yao, R., Ye, Y., Zhang, J., Li, S., & Wu, O. (2020). AI marker-based large-scale AI literature mining. ArXiv:2011.00518 [Cs]. http://arxiv.org/abs/2011.00518.
Zha, H., Chen, W., Li, K., & Yan, X. (2019). Mining algorithm roadmap in scientific publications. In Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery and data mining, Anchorage AK USA (pp. 1083–1092).
Zhang, Q., Cheng, Q., & Lu, W. (2016a). A bootstrapping-based method to automatically identify data-usage statements in Publications. Journal of Data and Information Science, 1, 69–85. https://doi.org/10.20309/jdis.201606
Zhang, L., Jiang, L., & Li, C. (2016b). C4.5 or Naive Bayes: A Discriminative Model Selection Approach. In Proceedings of the 25th international conference on artificial neural networks, Barcelona, Spain (pp. 419–426).
Zhang, Z., Tam, W., & Cox, A. (2021). Towards automated analysis of research methods in library and information science. Quantitative Science Studies. https://doi.org/10.1162/qss_a_00123
Zhao, H., Luo, Z., Feng, C., & Ye, Y. (2019). A context-based framework for resource citation classification in scientific literatures. In Proceedings of the 42nd international ACM SIGIR conference on research and development in information retrieval (SIGIR ’19). Paris, France (pp. 1–4).
Zhao, R., & Wei, M. (2017). Impact evaluation of open source software: An Altmetrics perspective. Scientometrics, 110(2), 1017–1033. https://doi.org/10.1007/s11192-016-2204-y
Zheng, A., Zhao, H., Luo, Z., Feng, C., Liu, X., & Ye, Y. (2021). Improving on-line scientific resource profiling by exploiting resource citation information in the literature. Information Processing & Management, 58(5), 102638. https://doi.org/10.1016/j.ipm.2021.102638
Zhu, G., Yu, Z., & Li, J. (2013). Discovering relationships between data structures and algorithms. Journal of Software, 8(7), 1726–1736.
Acknowledgements
This study is supported by the National Natural Science Foundation of China (Grant No. 72074113).
Author information
Authors and Affiliations
Corresponding author
Appendix
Rights and permissions
About this article

Cite this article
Wang, Y., Zhang, C. & Li, K. A review on method entities in the academic literature: extraction, evaluation, and application. Scientometrics 127, 2479–2520 (2022). https://doi.org/10.1007/s11192-022-04332-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-022-04332-7