
Abstract
In this article, we revisit the analysis of Laband and Tollison (Appl Econ 38(14):1649–1653, 2006) who documented that articles with two authors in alphabetical order are cited much more often than non-alphabetized papers with two authors in the American Economic Review and the American Journal of Agricultural Economics. Using more than 120,000 multi-authored articles from the Web of Science economics subject category, we demonstrate first that the alphabetization rate in economics has declined over the last decade. Second, we find no statistically significant relationship between alphabetized co-authorship and citations in economics using six different regression settings (the coefficients are very small). This result holds mostly true when accounting both for journal heterogeneity and intentionally or incidentally alphabetical ordering of authors. We find some evidence that alphabetization in case of two authos increases citations rates for very high-impact journals. Third, we show that the likelihood of non-alphabetized co-authorship increases the more authors an article has.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Citations are frequently used to evaluate the usefulness of research. The novelty and popularity of research, for example, is reflected in how certain ideas are taken up by colleagues and become part of the established knowledge in a field. Citations are key factors for measuring personal and institutional success in academia. In particular, citation counts, journal impact factors (JIFs, Clarivate Analytics) and journal rankings (Bornmann et al., 2018) are key elements for authors’ and institutions’ rankings. They have an immediate impact on the career of economists as a means of competition on the academic job market. Furthermore, they serve as an important way of indicating the quality of research when it comes to decisions concerning tenures or the appropriation of research grants. However, factors other than quality potentially affect the number of citations a particular publication receives (Tahamtan & Bornmann, 2018).
Laband and Tollison (2006) (henceforth LT) investigated one of these potential effects, that of alphabetized co-authorship on citations. LT use a simple ordinary least squares (OLS) regression approach by controlling several aspects that might affect the citation rate of a paper, i.e. number of pages, authors, tables, and self-citations. LT showed that papers with two authors in alphabetical order accrue significantly more citations than those which are not. However, this finding does not hold true for three or more authors of an article. They conclude that the optimal team size for papers is two. LT based their investigation on a small sample consisting of the American Economic Review and the American Journal of Agricultural Economics, using data from the 1980s and 1990s, respectively. But does their conclusion hold true for other journals, e.g., less prestigious journals, and more recent papers? Is there a general relationship between author ordering and citations in economics?
In this article, we revisit and extend LT’s analysis using a much larger data set of more than 120,000 multi-authored papers from 1990 to 2013 published in 307 economics journals. The article is structured in three parts. First, we offer an overview of alphabetization patterns across both time and journals. Second, we investigate whether there is a relationship between alphabetized co-authorship and citations. We employ six different regression settings to ensure the robustness of the results. We check the robustness of our results also with respect to intentionally or incidentally alphabetical ordering. Third, we investigate the relationship between alphabetized co-authorship and citations for each journal in our sample and over time.
Data and descriptive statistics
In reflection of the core results by LT, we first broaden our descriptive analysis of alphabetized co-authorships over time using a data set which is more comprehensive and diverse than that employed by LT. We utilize data from the economics subject category of the Web of Science (WoS) provided by Clavariate Analytics. Our data set includes papers of the document type ’article’ ranging from 1990 to 2013. We collect citations up to the end of 2016. Thus, a citation window of at least three years is considered for each article that allows reliable impact measurements. We make two adjustments to the data set from WoS inasmuch as we keep only those journals that are listed in 2013 in the WoS economics subject category. We therefore exclude journals that have been discontinued or re-classified. Furthermore, we exclude journals with less than 100 listed articles. This lower limit is necessary to achieve sufficient statistical power for the separate regressions for each journal. The final data set consists of 207,159 articles published in 307 journals. Of these articles, 125,559 have at least two authors (61%). Building upon LT, we define three categories of multi-authored papers (strata): (1) all multi-authored articles; (2) articles with two authors and (3) articles with more than two authors. The latter two categories together constitute the first.
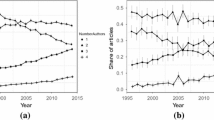
The left panel of Fig. 1 confirms the trend of increasing numbers of authors and a decline in single-authored papers in economics. This has also been documented by Nowell and Grijalva (2011), Rath and Wohlrabe (2016) as well as Kuld and O’Hagan (2018). Articles with more than two authors have become particularly more prevalent recently.
The alphabetization rate for multi-authored papers is around 70% in our sample (see Table 1) which is similar to the value reported by Waltman (2012) for economics.Footnote 1 Table 1 also shows that the alphabetization rate for articles with two authors (roughly 80%) is higher than for the overall figure. The right panel of Fig. 1 presents the development of alphabetized co-authorships over time, stratified by number of co-authors. The gold standard of alphabetized author order seems to be on the decline, especially since 2005. This holds true more or less for all author number strata. The decrease in alphabetization rate in economics is in line with the development in other subject categories in science as documented by Waltman (2012).

Development of numbers of authors and author shares (left panel) and alphabetization rates (right panel) over time
The overall decline in alphabetized co-authorships appears to be driven by two effects: First, the alphabetization rate for all strata is declining over time, not just for one specific stratum. Second, strata with a lower rate of alphabetization (larger author teams) seem to be gaining in importance. This can be deduced from the strong increase in average authors per article. Despite the declining trend in alphabetization rates, economics still ranks as one of those disciplines where alphabetical author orders are most widespread (Waltman, 2012). This is in contrast to other disciplines such as theoretical physics (50%), political science (61%), and statistics (56%). Whereas Waltman (2012) puts the overall alphabetization rate of economics papers at around 72%, our analysis further shows that this value seems to be driven by articles with two authors. Further research may reveal whether this result holds true for other disciplines. The results of Waltman (2012) suggest that there may be other academic fields with similar average numbers of authors as economics and alphabetization shares that are much closer to our estimates of economics articles, but with more than two authors.
Another source of heterogeneity in alphabetization rates is revealed in Fig. 2. The figure illustrates the distributions of average shares of articles with alphabetized co-authors by journal. Much like the historical gold standard of alphabetized co-authorship, this is at best riddled with exceptions. Nevertheless, the kernel density estimation of the distribution reveals a maximum scattered around 90%.

Histograms with kernel estimates of alphabetization rates by author strata across journals
The example of some elite journals commonly referred to as the top 5 (Card & DellaVigna, 2013) shows why the phenomenon of alphabetization may be viewed with too much confidence if one focuses on economics. For these journals, the rates of alphabetic order are consistently higher than average: Journal of Political Economy: 83%, American Economic Review: 91%, Econometrica: 94%, Quarterly Journal of Economics: 94%, Review of Economic Studies: 96%. These patterns of co-authorship alphabetizations should be subject to cautious examination, especially if they prove to have a meaningful impact on the citation performance of the article.
Empirical approach and results
Empirical approach
In order to test whether alphabetization has a statistically significant effect on citations, we estimate the following model
where \(\beta\) is the coefficient of interest. The variable AB is a dummy variable which is 1 if the authorship of an article i is stated in an alphabetical order and 0 otherwise. In case the results of LT hold in general, we have \(\beta >0\).Footnote 2 We include further variables that might influence the number of citations up to the end of 2016: number of pages, article age (2016–publication year) and the number of authors. These variables have been frequently identified as factors that may influence citations in various studies [see the overview in Tahamtan and Bornmann (2018)]. The number of pages and article age are also included in the regression model as squared terms to capture non-linear effects. We also account for journal (\(\chi _j\)) and time (\(year_t\)) fixed effects. The former accounts for specific journal quality and the latter for citation practices over time. We estimate six different models:
-
1.
Negative binomial regression (NBR) model, where citations are interpreted as counts
-
2.
Basic OLS regression model
-
3.
OLS using the natural log of citations as the dependent variable
-
4.
OLS using the inverse hyperpolic sine (IHS or asinh) transformation of citations, similar to log transformation. This was proposed by Burbidge et al. (1988) and put forward recently by Card and DellaVigna (2020) in citation analysis. The formal definition is \(asinh(z)=\ln (z+\sqrt{1+z^2})\). For \(z\ge 2\), \(asinh(z)=\ln (z)+\ln (2)\), but \(asinh(0)=0\).
-
5.
We define a percentile based indicator, the PP10%. This is a dummy variable that takes the value one when an article belongs to the 10% most cited article in a given year t and zero otherwise.Footnote 3 We employ a logit model for estimation.
-
6.
We additionally used another percentile based citation impact indicator, the cumulative percentage of the size-frequency distribution of papers (\(CP-IN\)) proposed by Bornmann and Williams (2020) as the dependent variable. The model is estimated using the fractional logit approach.Footnote 4
The last four approaches account for skewness in citation distributions which is quite common.Footnote 5 The six approaches should yield robust results with respect to both the estimation approach and the handling of the dependent variable (citations).
The results of the regression analyses which we present in the following are able to show whether there is a relationship between citation counts and alphabetical ordering of co-authors. It is not possible to reveal causal relationships between both variables.
Basic results
The results of the regression analysis are shown in Table 2 and are structured as follows. Each panel of Table 2 corresponds to an author number stratification. Each column within a panel then corresponds to one of four specifications of our regression model. In agreement with previous literature (e.g., Gnewuch & Wohlrabe, 2017), we obtain the expected sign of the coefficients for the explanatory variables and these are statistically significant in almost all cases. For instance, the longer an article or the more authors it has, the more citations an article receives. With respect to our variable of interest, we find no statistically significant association between alphabetization and citations across all six regression settings. This generally holds true for multiple authors, two authors, and more than two authors. Thus, our findings are so far in contrast to the results reported in LT.
As the period of time investigated in LT is different and the degree of alphabetization has changed over time (see above), we additionally run the regression analysis for each year separately. The results for each author strata and specification are presented in Fig. 3. This shows the estimated alphabetization coefficient (\(\beta\)) plus the 95% confidence interval bands. If the bands include the zero line, the coefficient is not statistically significant. The apparent statistical insignificance of the coefficients for alphabetized co-authorship for most of the years in our sample confirms the results in Table 2. However, there are some years in the 1990s with statistically significant coefficients that are in the time frame of LT. However, the estimated significant coefficients are small. For example, in 1993, the OLS coefficient is only around 0.25.Footnote 6 Thus, the effect of alphabetized co-authorship on citations seems marginally, even though it is statistically significant in some cases.

Alphabetization influence over time across regression approaches. Note: Each graph plots the estimated alphabetization parameter \(\beta\) plus the 95% confidence interval bands.
Accounting for heterogeneity in alphabetization rates across journal quality
Although we account for journal quality in our regression settings, our results might be biased or spurious as the alphabetization rate across journals is quite heterogeneous (see Fig. 2). Joseph et al. (2005) demonstrate that the probability of alphabetization increases with the publication hurdles, i.e. the reputation of a journal. This implies that the authors of alphabetized papers have a tendency to be of a similar and of higher quality. On the other hand, non-alphabetization becomes more likely if the perceived quality gap between the authors gets larger. This is confirmed by the analysis of Van Praag and Van Praag (2008) who show that a higher inequality of author reputations increases the likelihood of non-alphabetical ordering and vice versa. As a consequence, the results by LT may not be generalized as they focus on two top journals in which authors usually publish with high reputation.
In order to investigate this quality issue based on our data we define four journal quality tiers. These tiers are categorized by journal citation impact quantiles. Journal citation impact is defined as the ratio of total citations and number of articles over the full time span.Footnote 7 We repeat our regression analysis within the four quality tiers. Table 3 reports the coefficients and corresponding standard errors of the alphabetization dummy within all quality tiers and for all regression approaches. In almost all settings, the alphabetization dummy is statistically not significant. There are only two exceptions. In the third quality tier, statistically significant results at the 5% level emerged in case of log and IHS citations as well as \(CP-IN\). This holds true for multiple authors in general and for two-authors but not for more than two authors. In the lowest quality tier 4, there is a significant coefficient at the 10% level for two authors in the logit regression.
As the standard deviation is much larger in the highest quality tier, the results might not hold for the very top journals. We therefore repeat the analysis using only articles from the top 25 journals. Table 4 reports the corresponding results. These are quite different in terms of size and statistical significance. Across all approaches, the alphabetization dummy is statistically significant at least at the 10% level for multi-authored papers. The results further reveal that the statistically significant results are primarily prevalent at papers written by two authors. For papers written by more than two authors, we do not find any statistically significant effect. The OLS regression implies that papers with alphabetized ordering obtain on average about 7 citations more. In case of the log-level regression, this amounts to approximately 11 percentage points more citations. This is quite substantial. Thus, we can confirm the results by LT for high impact journals.
In a second analysis, we rerun the analysis for each journal separately as has been done by LT for two journals. For this exercise, we leave out the logit regression for \(PP_{10\%}\), as many journals do not have any article in the top category. Here, we have to be careful with the interpretation of the results as we run into the problem of testing multiple hypotheses on the same data set. In statistical hypothesis testing, two types of errors can occur: the erroneous rejection of an actually true null hypothesis (also referred as type I error) or the erroneous acceptance of an actually false hypothesis (type II error). In our case, the type I error is of specific relevance as we set a probability (\(\alpha\)) in advance. With multiple testing, one has to accept that statistically significant results can be obtained just by chance with a probability of \(\alpha\). Based on our sample with 307 journals and given the three significance levels of 1%, 5%, and 10%, one can expect approximately 3, 15 and 30 statistically significant results for the alphabetization parameter, respectively.
Table 5 shows the relative shares of journals where the alphabetization dummy is statistically significant at different levels across different estimation approaches and degrees of co-authorships. The results reveal journals with statistically significant effects of alphabetization on citations. There are 10 journals (3.26%) with a statistically significant alphabetization dummy given \(\alpha =1\%\) in case of multiple authors ( > 1 ) and NBR regression approach. In all cases, the relative shares are somewhat higher than that what can be expected from statistical theory. However, assuming strict confidence levels (\(\alpha \le 5\%\)) the number of journals with statistically significant results is rather small. Following LT, we take a closer look at the American Economic Review and the American Journal of Agricultural Economics. In the former case, our results confirm the results of LT. We found a statistically significant coefficient for the NBR and standard OLS regression with citations as the dependent variable for articles with two authors.Footnote 8 In all other specifications and author strata, we do not find any statistically significant effects of alphabetization. For the American Journal of Agricultural Economics, the results do not point to statistically significant effects across all specifications. Thus, in this case we cannot confirm the results by LT.
The reported results point out that our general findings (no statistically significant relationship between alphabetization and citations) hold true for most of our data set. However, we find some evidence that alphabetization increases citation rates for top journals.
Robustness with respect to intentionally alphabetical ordering
Our analysis neglects one important issue so far, whether the alphabetical ordering is intentional or incidental. Thus, although our results seem quite convincing so far: they might not be robust. The ordering of authors might be alphabetic or based on some kind of merit. The latter can be due to member characteristics of co-authors as contribution, reputation or hierarchy. It might be that for an article with two authors the ordering is alphabetical just by chance in case that the first author contributed more to the paper than the second author. Without accounting for this issue, the interpretations of the reported shares of alphabetical co-authorship and our regressions results might be misleading. In a first step, therefore, we calculate the share of intentionally alphabetical ordering (\({\hat{p}}\)) using the formula given in Waltman (2012) building on Van Praag and Van Praag (2008):
where
\(AB_i\) is the dummy variable also used in Eq. (1) which is 1 if the ordering is alphabetical and 0 otherwise. \(Authors_i\) denotes the number of authors of article i and ! the factorial. Waltman (2012) shows that \({\hat{p}}\) is an unbiased estimator of the average probability of intentionally chosen alphabetical ordering. In Table 6, we compare our empirically observed shares with the estimated shares.Footnote 9 As expected, the estimated shares are smaller than the empirical shares. For all multi-authored papers, the share drops form 70% to 55%. As the last two columns in Table 6 show this is mainly due to papers with two authors.
In order to investigate potential consequences for our conclusions based on our regression models, we run a simulation. For each model presented in Table 2 based on Eq. (1) we set the alphabetization dummy \(AB_i\) from 1 to 0 for a random selection of articles and rerun the regression. Inspired by the results in Table 6, these shares are 10%, 20%, and 30%. For each model we run 1000 regressions.Footnote 10 Table 7 shows the results of our simulation exercise. In each case, we report the mean of the alphabetization dummy coefficient over all regressions plus the corresponding standard deviation. Additionally, we count the number of statistically significant cases, where we set the significance level at \(\alpha =10\%\). The comparison of Tables 2 and 7 shows that the average coefficient for alphabetization shrinks towards zero. The shrinkage increases by decreasing the alphabetization rate. On the other side, the standard deviation increases. This holds true for the number of statistically significant cases. However, the overall number is smaller than that what can be expected from statistical theory. Given the significance level of 10%, one can expect 100 statistically significant cases. There are two exceptions: the standard OLS regression with citations as the dependent variable for articles with more than two authors and the fractional logit regression for \(CP-IN\) for article with two authors.Footnote 11 Here, the corresponding numbers are somewhat higher than 100.
As illustrated in the previous section, the choice of ordering of authors in top journals might be different compared to lower ranked journals. We therefore repeat the simulation exercise for top journals (tier 1). The results are shown in Table 8 which are similar to the results in Table 7. However, there is one notable difference: for articles with more than two authors, we find much more statistically significant results in case of the NBR, OLS regression for citations, and the logit approach. However, the means of the estimated coefficients are very small. In case of the standard OLS regression model for citations, alphabetized co-authorship increases the count only by approximately one. In a last analysis, we rerun the simulation for the top 25 journals. The results presented in Table 9 confirm those in Table 4. There is a systematic effect of alphabetization on citations rates for papers with two authors. For more than two authors, we do not find such evidence. As expected, the size of the effect gets smaller when the alphabetization rates go down.
Based on the results in Tables 7, 8, and 9, we conclude that our interpretations and conclusions remain valid even after controlling for intentionally alphabetical ordering of authors. There is only a statistically significant effect for the very top journals in economics.
Determinants of alphabetization
We also repeat the analysis of Brown et al. (2011) by asking whether the number of authors affects the probability of alphabetical ordering. We estimate a linear probability model using OLS regression and a logit regression by including the number of authors and pages as explanatory variables. Table 10 shows the corresponding estimation results. In line with Brown et al. (2011) the results reveal that more authors increase the likelihood of authors being ordered non-alphabetically. The results confirm also the results presented in Torgler and Piatti (2013) who investigated this issue for the American Economic Review.
Discussion
There is no doubt as to the importance of citations. Citations promise to be an objective, long-term measure of a researcher’s impact on the scientific discourse channeled by academic journals, as well as a proxy for the quality of precisely these journals. The important role of citations for both authors and journals naturally raises the question of what determines the number of citations per article? The quality of research contributions is an appealing answer. Bibliometric research, however, found various other potential factors of contextual (author or journal quality) and technical nature, such as title characteristics (Gnewuch & Wohlrabe, 2017) and subject category (Medoff, 2003). Bornmann and Daniel (2008) and more recently Tahamtan and Bornmann (2019) provide an overview of citing behavior and factors that potentially influence citations.
LT found that with up to two authors—alphabetization also pays off potentially in the form of more citations. The authors conclude that a team size of two is optimal. This is in line with the empirical fact that sole-authored articles in economics are in decline whereas multi-authored articles become more and more popular. This result has been revealed, for instance, by Nowell and Grijalva (2011) and more recently by Rath and Wohlrabe (2016) as well as Kuld and O’Hagan (2018). Huang (2015), based on a large set of articles from the WoS, estimated that papers whose authors’ surname initials appear earlier in the alphabet receive more citations than those with initials later in the alphabet. Thus, the results suggest a new dimension that might be considered when choosing the order of authors.Footnote 12 In contrast, Abramo and D’Angelo (2017) found no effect of the surname focusing on the individual instead of the paper level.Footnote 13 Brogaard et al. (2020) provide causal evidence that articles whose first authors are more famous than the other authors receive more citations compared to those papers where the famous author is listed second or third. The finding that authors listed earlier in the alphabet may be favored in terms of academic rewards has been confirmed in several other studies: working at top economic departments (Einav & Yariv, 2006 or Efthyvoulou, 2008) and publishing in mainstream economic journals (Van Praag & Van Praag, 2008).
Maciejovsky et al. (2009) show experimentally that scientists assign higher credits to first authors independently whether they were ordered alphabetically or not. This phenomenon has been labeled as ’alphabetical discrimination’. Authors with surnames late in the alphabet work less in large teams (Kadel and Walter 2015). Ong et al. (2018) show theoretically and empirically the following tendency: authors with late surnames write single-authored papers especially for their best ideas. Efthyvoulou (2008) found that some authors manipulate their name to move upwards in the alphabet. Li and Yi (2021) show how surname initials affect labour market decisions of Chinese economists. Weber (2018) provides a literature survey of studies on the strategical reaction to alphabetical discrimination.
This article re-investigates the issues raised by LT using a much larger data set consisting of more than 120,000 multi-authored articles published in 307 journals from the economics category in the WoS. In the first part of the study, we show that the alphabetization rate in economics has declined since the early 2000s. This is in contrast with the prediction of Engers et al. (1999) who postulated a theoretical equilibrium of all authors playing an "alphabetized order strategy". In the second part of the study, we use six different regression settings to answer the question whether the order of authors affect the article’s number of citations. We do not find any statistically significant effects of alphabetization across all investigated settings. Our findings thus contradict the conclusions by LT. We only find a statistically significant effect for the top 25 journals for author teams of size two. This result confirms the results by LT. Furthermore, our analysis also verifies the finding of LT for the American Economic Review: articles with two alphabetically ordered authors obtain statistically significantly more citations than articles with alphabetically un-ordered authors. This relationship also holds true for a few other journals. Our analysis shows that in the light of rising co-authorship (in economics), the ordering of authors seems to matter for citations if one submits a paper to a top journal in economics. Ray and Robson (2018) proposed an algorithm for random co-authorship listing. If this would be adopted by all journals, an analysis like ours would become obsolete in the future.
Notes
The theoretical model by Ong et al. (2018) implies that there is no causal effect of alphabetization on citations as team size and ordering are driven by ex-ante matching quality and corresponding selection effects.
A similar percentile indicator has been used in economics by Bornmann and Wohlrabe (2019).
A similar citation percentile approach was used in Freeman and Huang (2015) for investigating ethnic co-authorship relationships for US-based authors.
The corresponding coefficient in LT for the American Economic Review is about 32.
Note that LT have considered partially other covariates in their regression models.
Levitt and Thelwall (2013) provide evidence of intentionally alphabetical ordering for other disciplines than economics.
A similar simulation exercise can be found in Wohlrabe and Bürgi (2021).
In case of the fractional logit, the model estimation does not always converge or finds a maximum. Here, we stop the estimation after 300 iterations and retain the resulting regression results.
Arsenault and Larivière (2015) also report such findings based on a much larger sample, but do not report any size effects and evidence on statistical significance.
See Weber (2017) for a critical review of this article.
References
Abramo, G., & D’Angelo, C. A. (2017). Does your surname affect the citability of your publications? Journal of Informetrics, 11(1), 121–127.
Arsenault, C., & Larivière, V. (2015). Is paper uncitedness a function of the alphabet? In Salah, A.A., Y. Tonta, A.A. Akdag Salah, C. Sugimoto, U. Al (Eds.), Proceedings of ISSI 2015 Istanbul: 15th International Society of Scientometrics and Informetrics Conference, Istanbul, Turkey, 29 June to 3 July, 2015, Bogaziçi University Printhouse (pp. 286–287).
Bornmann, L., Butz, A., & Wohlrabe, K. (2018). What are the top five journals in economics? A new meta-ranking. Applied Economics, 50(6), 659–675.
Bornmann, L., & Daniel, H.-D. (2008). What do citation counts measure? A review of studies on citing behavior. Journal of Documentation, 64(1), 45–80.
Bornmann, L., & Williams, R. (2020). An evaluation of percentile measures of citation impact, and a proposal for making them better. Scientometrics, 124, 1457–1478.
Bornmann, L., & Wohlrabe, K. (2019). Normalisation of citation impact in economics. Scientometrics, 120(2), 841–884.
Brogaard, J., Engelberg, J., Eswar, S. & Van Wesep, E. D. (2020). On the causal effect of fame on citations. SSRN Working Papers 3565487.
Brown, C. L., Chan, K. C., & Chen, C. R. (2011). First-author conditions: Evidence from finance journal coauthorship. Applied Economics, 43(25), 3687–3697.
Burbidge, J. B., Magee, L., & Robb, A. L. (1988). Alternative transformations to handle extreme values of the dependent variable. Journal of the American Statistical Association, 83(401), 123–127.
Card, D., & DellaVigna, S. (2013). Nine facts about top journals in economics. Journal of Economic Literature, 51(1), 144–61.
Card, D., & DellaVigna, S. (2020). What do editors maximize? Evidence from four economics journals. Review of Economics and Statistics, 102(1), 195–217.
Efthyvoulou, G. (2008). Alphabet economics: The link between names and reputation. The Journal of Socio-Economics, 37(3), 1266–1285.
Einav, L., & Yariv, L. (2006). What’s in a surname? The effects of surname initials on academic success. Journal of Economic Perspectives, 20(1), 175–187.
Engers, M., Gans, J. S., Grant, S., & King, S. P. (1999). First-author conditions. Journal of Political Economy, 107(4), 859–883.
Freeman, R. B., & Huang, W. (2015). Collaborating with people like me: Ethnic coauthorship within the United States. Journal of Labor Economics, 33(S1), S289–S318.
Gnewuch, M., & Wohlrabe, K. (2017). Title characteristics and citations in economics. Scientometrics, 110(3), 1573–1578.
Henriksen, D. (2019). Alphabetic or contributor author order. What is the norm in Danish economics and political science and why? Journal of the Association for Information Science and Technology, 70(6), 607–618.
Huang, W. (2015). Do ABCs get more citations than XYZs? Economic Inquiry, 53(1), 773–789.
Joseph, K., Laband, D. N., & Patil, V. (2005). Author order and research quality. Southern Economic Journal, 71(3), 545–555.
Kadel, A., & Walter, A. (2015). Do scholars in economics and finance react to alphabetical discrimination? Finance Research Letters, 14, 64–68.
Kuld, L., & O’Hagan, J. (2018). Rise of multi-authored papers in economics: Demise of the “lone star’’ and why? Scientometrics, 114(3), 1207–1225.
Laband, D., & Tollison, R. (2006). Alphabetized coauthorship. Applied Economics, 38(14), 1649–1653.
Levitt, J. M., & Thelwall, M. (2013). Alphabetization and the skewing of first authorship towards last names early in the alphabet. Journal of Informetrics, 7(3), 575–582.
Li, W., & Yi, J. (2021). Alphabetical author order, intellectual collaboration, and high-skilled migration. The Economic Journal, 131, 1250–1268.
Maciejovsky, B., Budescu, D. V., & Ariely, D. (2009). The researcher as a consumer of scientific publications: How do name-ordering conventions affect inferences about contribution credits? Marketing Science, 28(3), 589–598.
Medoff, M. H. (2003). Article placement and market signalling. Applied Economics Letters, 10(8), 479–482.
Nowell, C., & Grijalva, T. (2011). Trends in co-authorship in economics since 1985. Applied Economics, 43(28), 4369–4375.
Ong, D., Chan, H. F., Torgler, B., & Yang, Y. A. (2018). Collaboration incentives: Endogenous selection into single and coauthorships by surname initial in economics and management. Journal of Economic Behavior & Organization, 147, 41–57.
Rath, K., & Wohlrabe, K. (2016). Recent trends in co-authorship in economics: Evidence from RePEc. Applied Economics Letters, 23(12), 897–902.
Ray, D., & Robson, A. (2018). Certified random: A new order for coauthorship. American Economic Review, 108(2), 489–520.
Seglen, P. O. (1992). The skewness of science. Journal of the American society for information science, 43(9), 628–638.
Seiler, C., & Wohlrabe, K. (2012). Ranking economists on the basis of many indicators: An alternative approach using RePEc data. Journal of Informetrics, 6(2), 389–402.
Seiler, C., & Wohlrabe, K. (2014). How robust are journal rankings based on the impact factor? Evidence from the economic sciences. Journal of Informetrics, 8(4), 904–911.
Tahamtan, I., & Bornmann, L. (2018). Core elements in the process of citing publications: Conceptual overview of the literature. Journal of Informetrics, 12(1), 203–216.
Tahamtan, I., & Bornmann, L. (2019). What do citation counts measure? An updated review of studies on citations in scientific documents published between 2006 and 2018. Scientometrics, 121(3), 1635–1684.
Torgler, B., & Piatti, M. (2013). A century of American Economic Review: Insights on critical factors in journal publishing. New York: Springer.
Van Praag, C. M., & Van Praag, B. M. (2008). The benefits of being economics professor A (rather than Z). Economica, 75(300), 782–796.
Waltman, L. (2012). An empirical analysis of the use of alphabetical authorship in scientific publishing. Journal of Informetrics, 6(4), 700–711.
Weber, M. (2017). Comment on ’does your surname affect the citability of your publications. Journal of Informetrics, 11(3), 835–837.
Weber, M. (2018). The effects of listing authors in alphabetical order: A review of the empirical evidence. Research Evaluation, 27(3), 238–245.
Wohlrabe, K., & Bornmann, L. (2019). Alphabetized co-authorship in economics reconsidered. MPRA Paper 93836. Munich, Germany: University Library of Munich.
Wohlrabe, K., & Bürgi, C. (2021). What is the benefit from publishing a working paper in a journal in terms of citations? Evidence from economics. Scientometrics, 126, 4701–4714.
Yuret, T. (2016). Does alphabetization significantly affect academic careers? Scientometrics, 108(3), 1603–1619.
Zimmermann, C. (2013). Academic rankings with RePEc. Econometrics, 1(3), 249–280.
Acknowledgements
We would like to thank Nikolai Schaffner for assisting the research presented in this paper. This manuscript is a substantially revised and extended version of the working paper by the authors (Wohlrabe & Bornmann, 2019). Two referees provided very insightful comments
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wohlrabe, K., Bornmann, L. Alphabetized co-authorship in economics reconsidered. Scientometrics 127, 2173–2193 (2022). https://doi.org/10.1007/s11192-022-04322-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-022-04322-9