
Abstract
Journal maps and classifications for 11,359 journals listed in the combined Journal Citation Reports 2015 of the Science and Social Sciences Citation Indexes are provided at https://leydesdorff.github.io/journals/ and http://www.leydesdorff.net/jcr15. A routine using VOSviewer for integrating the journal mapping and their hierarchical clusterings is also made available. In this short communication, we provide background on the journal mapping/clustering and an explanation about and instructions for the routine. We compare journal maps for 2015 with those for 2014 and show the delineations among fields and subfields to be sensitive to fluctuations. Labels for fields and sub-fields are not provided by the routine, but an analyst can add them for pragmatic or intellectual reasons. The routine provides a means of testing one’s assumptions against a baseline without claiming authority; clusters of related journals can be visualized to understand communities. The routine is generic and can be used for any 1-mode network.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Scholarly journals have been and remain the primary organizers of scientific communication. The number of journals has increased over the centuries, at times showing exponential growth (Mabe and Amin 2001; Mabe 2003; de Solla Price 1961, p. 166), but the journal form has remained remarkably stable in the social life of science. The intellectual development of the sciences and their organization, as well as growth of new specialties and disciplines, is organized, validated, and retained in scholarly journals. Ware and Mabe (2015) estimated that there were 28,100 peer-reviewed journals published in English in 2015; in the Web of Science (WoS) in that year, 11,365 journals were indexed. The source journals can be expected to account for more than 90% of citations because of the skew in the distributions (Garfield 1971; Seglen 1992).
Specialties and new fields develop at a level above individual journals. Since journals relate to one another through citations and references (de Solla Price 1965), perhaps the best way to identify networked communities is through the cross-referencing of these already aggregated citations and references into algorithmically significant clusters (Leydesdorff 1987; Tijssen et al. 1987). This article describes a method of visualizing journal-to-journal connections to create ‘macro-epistemics’ (Knorr-Cetina 2007). New developments can be expected to form new journals and journal clusters (Van den Besselaar and Leydesdorff 1996).
The classification of journals into disciplines is complicated by the many venues where one finds results. Multidisciplinary journals such as Science and Nature play important roles in scientific communication, especially in calling attention to advances in knowledge. More recently, open-access journals (e.g., PLoS ONE) have emerged which deliberately ignore disciplinary boundaries and thus tend to disturb the classification of journals. Some scholars suggest that the journal form may diminish in use in favor of archives and repositories (Harnad 2001), although the majority of scholars view journals as increasingly important (e.g., Marbán 1999). As Lavoie et al. (2014) detail, “the transition from print to a digital, networked environment likely means that decision-making around the scholarly record will have to become more consciously coordinated”.
Journals are classified into disciplinary groups by indexing services; the classifications serve a number of purposes. First, classification serves to facilitate the process of search and retrieval. Secondly, bibliometric evaluations use journal classifications to normalize citation scores (Moed et al. 1995; Schubert and Braun 1986; Schubert et al. 1986). For pragmatic reasons, it has been considered “best practice” in evaluation studies to use the WoS Subject Categories (WCs)Footnote 1 for the operationalization of fields of science even though these categories do not represent homogeneous sets (Leydesdorff and Bornmann 2016). They are attributed to journals by manual indexing and have been elaborated incrementally for more than forty years by the providers of the database (Bensman and Leydesdorff 2009; Pudovkin and Garfield 2002, p. 1113). Journals can be attributed to more than one WC.
Beyond journal names and identity through sponsorship (e.g., by learned societies), articles can be classified in terms of co-citation, bibliographic coupling, or direct citation relations (Klavans and Boyack 2016, in press). Clustering the database at the level of papers, however, requires access to large computing capacity and to entire copies of Scopus (Boyack et al. 2011) or the WoS (Waltman and van Eck 2012). The problem of the validity of the delineations remains. As Schubert et al. (1989, at p. 7) have noted, “the field/subfield classification of papers is a neuralgic point of all kind of scientometric evaluations”.
Aware of the constraints of using WCs for evaluation purposes, Glänzel and Schubert (2003) developed a new journal classification system based on a pragmatic weighting of the results of algorithmic clustering of journals in terms of citation patterns against expert judgment. The Centre for Research and Development Monitoring ECOOM of the Catholic University of Leuven (Belgium) uses this classification system for evaluations. In the meantime, fast decomposition algorithms have been developed that can be used for classifications. Klavans and Boyack (in press, at p. 12, Table 3) list seven journal-based partitions of Scopus data currently in use.
Rafols and Leydesdorff (2009) compared (1) the WCs and (2) Glänzel and Schubert’s (2003) alternative classification with two algorithmically generated ones: (3) Newman and Girvan’s (2004) algorithm applied to the matrix of 7611 citing journals contained in the Journal Citation Reports (JCR) 2006; and (4) a random-walk based algorithm used by Rosvall and Bergstrom (2008) that had been applied to 6128 journals in the JCR 2004. The concordance between the four classifications was modest: in the 40–60% range (Rafols and Leydesdorff 2009, Table 3, at p. 1828). This conclusion agrees with Boyack’s estimate of 50% correct classifications for the WCs (Boyack, personal communication, 14 September 2008). However, most of the miscategorised journals appear to occur in areas within the close vicinity of categories indicated by the other classifications. In other words, the various decompositions are roughly consistent with each other, but imprecise. Despite the low correspondence, maps based on the different classifications can be rather similar (Leydesdorff and Rafols 2009; Klavans and Boyack 2009).
In summary, there are no unique or universally valid classifications of journals. Two runs of the same algorithmic decomposition may not provide the same results; most algorithms begin by drawing a random number using the computer clock. However, Leydesdorff et al. (2016b, at p. 907) noted that VOSviewer—visualization software developed by CWTS and available free for download at http://www.vosviewer.com—can generate quasi-deterministic classifications when the seed number of the randomizer is set equal to a constant (the default is zero). Using this option, the decomposition can pragmatically be combined with visualizations in a hierarchical classification by using the output of each decomposition recursively as input to the further decomposition at a next-lower level (Waltman et al. 2010). One begins at the top-level of the complete matrix and then extracts the clusters one by one; this process can be automated in a recursive loop if an option were added to VOSviewer for writing the output files to disk when running the program from the command line (Nees Jan van Eck, personal communication, 3 and 16 May 2016).
The most recent version 1.6.5 of VOSviewer (dated September 28, 2016), among other things, enables the user to run VOSviewer in a batch job from the command line. In this short communication, we report on generating such an automatic classification and visualization of the JCR-2015 data. The resulting classifications, visualizations, and routines are available at https://leydesdorff.github.io/journals/ and http://www.leydesdorff.net/jcr15. The website provides input files for journal maps for the more than 11,000 journals contained in the JCR-2015, at the various levels of clustering.
Although developed for JCR-data, the routines are formulated so that any 1-mode matrix can be decomposed similarly in terms of mappings using VOSviewer. Note that one can also export the clusters in the Pajek format so that the files can be used for other visualizations such as in Gephi.
Data and methods
Data
Using dedicated software, the JCR 2015 data for the Science and Social Sciences Citation Indexes was first organized into a matrix of citing versus cited journals. All 11,365 journals are included so that the matrix is 1-mode, albeit asymmetrical. VOSviewer symmetrizes the asymmetrical matrix internally by summing the cells (i,j) and (j,i). Six journals are not connected (Avian Res, EDN, Neuroforum, Austrian Hist Yearb, Curric Matters, and Policy Rev), and were therefore excluded from the analysis. Thus, we work with (11,365–6 =) 11,359 journals. The results can be compared with results based on JCR-2014 data elaborated for a single branch in Leydesdorff et al. (2016b).Footnote 2 Table 1 provides descriptive statistics and network characteristics for the large components in 2015 and 2014. The intersection between these two years (using identical journal names) contains 11,009 journals.
Table 1 shows that the network increases more in terms of links than nodes. However, the density and the clustering coefficients did not change.
Methods
The routine (called “decomp.exe”)Footnote 3 presumes an input file named “level0.net” containing the 1-mode network file saved in the.net format of Pajek. Decomp.exe begins with running the following statement from the command line:
“C:\vosviewer\vosviewer -pajek_network C:\temp\level0.net -save_map C:\temp\m0.txt -save_network C:\temp\n0.txt -run_layout -run_clustering -repulsion 0 -min_cluster_size 2 -merge_small_clusters true”
VOSviewer is to be installed in the folder C:\vosviewer and one operates in the folder C:\temp. The “minimum cluster size” is set to “two” in order to suppress isolates; repulsion is set to “zero” to optimize the visualizations.
The initial output is written to the files m0.txt for the map and n0.txt for the network (at level 1), respectively. The file m0.txt contains the clustering that is used by the routine for generating an input file for each of the clusters. This next round generates output files m1.txt, m2.txt, etc., as map files of VOSviewer which contain the information for drawing maps at the next-lower level (level 2). In a next round, each of these files is further decomposed into m1_1.txt, m1_2.txt, etc. (level 3). The tree can be found at http://www.leydesdorff.net/jcr15/tree.htm. The levels are attributed to individual journals at http://www.leydesdorff.net/jcr15/index.htm. Finally, all level-3 files are run in VOSviewer in order to generate the classification at level 4. This classification is attributed to each journal as a hyperlink at http://www.leydesdorff.net/jcr15: by clicking on a journal name, one webstarts VOSviewer to generate a map of the citation environment of this journal at level 4. The user can save this map for further decomposition (at level 5; see below).
Results
The global map based on JCR 2015 data
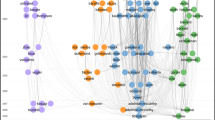
Figure 1 provides the global map based on 2015 data. One can compare this map, for example, with the 2014 map (Leydesdorff et al. 2016b, at p. 906)Footnote 4; the procedures for producing these two maps were virtually identical. However, the resulting delineations are notably different (Table 2; cf. Leydesdorff et al. 2016a, Table 4, at p. 907).

Ten clusters of 11,359 journals (largest component of the JCR matrix) based on 2015 data; VOSviewer used for classification and visualization. This map can be web-started at http://tinyurl.com/jmrwp64 or http://www.vosviewer.com/vosviewer.php?map=http://www.leydesdorff.net/jcr15/m0.txt&label_size_variation=0.3&zoom_level=1.5&cluster_colors=http://www.leydesdorff.net/jcr15/colors.txt&scale=0.9
Since the clustering is hierarchical, the extraction of different sets can sometimes become a trade-off among memberships of journals in different groups. For example, in 2014, as can be seen in Table 2, an eighth cluster of 343 neuroscience journals is distinguished. This same cluster is no longer visible in 2015; the same journals are split between a third cluster (“Medicine”) and a fifth cluster (“Biomedical”). In 2015, however, cluster seven (dark green in Fig. 1) groups 583 journals into a “bio-agricultural” cluster. The extraction of this seventh set (before the extraction of the neuroscience group as the eighth set) changes the path of the decomposition so that a different sub-optimum is reached. Note that this different branching can be caused by relatively small differences in the data.
The program does not provide the disciplinary designations; labels can be added (subjectively) to the algorithmic artifacts by the analyst depending of the objectives of the study. As shown in Table 2, a tenth field of only six journals is identified in 2015. We have labeled this cluster “data analysis” based upon the titles of the six journals (Table 3) and their combined citation environment (Fig. 2).Footnote 5 While the larger environment of the cluster (indicated as “#Big Data-US”) shows biomedicine, environmental sciences, chemistry, etc., the J Am Stat Assoc, a core journal in statistics, is mapped in close proximity to the cluster as is Commun ACM, a leading journal in computer science.

Zoom of the k = 1 (citation) environment of cluster 10 (N = 1236)
The classification in 2015 (ten clusters) can be compared with the one in 2014 (nine clusters) for the 11,009 journals that are included in the JCR versions of both years. Ten percent of the journals are differently classified between 2014 and 2015. Although the clusters are reproducible within each year, the clustering is, in our opinion, not sufficiently reliable for comparisons across years. As noted, relatively small changes in numbers of citations can affect the order of the extractions in a hierarchical decomposition.
The social-sciences cluster
In both 2014 (with 3131 journals) and 2015 (with 3274 journals), cluster 1—representing the social sciences–is the largest group. This is not a homogenous cluster; but the citation patterns in the social sciences are statistically so different from those in natural sciences and engineering that they are sorted separately in the first pass of the decomposition (at level 1). Figure 3 provides the decomposition of this cluster at level 2; the information is summarized in Table 4 and compared with the corresponding table for 2014.

Decomposition of the social-sciences cluster based on 2015 data. This file can be web-started at http://tinyurl.com/gl6unrc or http://www.vosviewer.com/vosviewer.php?map=http://www.leydesdorff.net/jcr15/m1.txt&label_size_variation=0.35&scale=0.9
Note that a light-brown cluster with 62 “library and information science” journals can be found in the middle of Fig. 1 (indicated most clearly by the journal title “Scientometrics” circled)
Library and information sciences
Figure 4 provides the map for the 62 LIS journals distinguished as a cluster in 2015. As in 2014, the group of journals related to management information is not included in the LIS set; but differently from 2014, a (green-colored) group of statistics and methods journals is now included (at the right side of the figure). One can generate this map by clicking on one of these journals at http://www.leydesdorff.net/jcr15.

Map with 62 LIS journals in 2015. This file can be web-started at http://tinyurl.com/gvyafak or http://www.vosviewer.com/vosviewer.php?map=http://www.leydesdorff.net/jcr15/m1_8.txt&network=http://www.leydesdorff.net/jcr15/n1_8.txt&label_size_variation=0.25&scale=1.25&colored_lines&curved_lines&n_lines=10000
In the “Appendix” section, the two sets (for 2015 and 2014) are compared with the WC “information science and library science”. Forty-three journals co-occur in all three lists; 49 co-occur in two of the three lists. The WC also includes 37 journals that belong mostly to the cluster of management-information-science journals (Leydesdorff and Bornmann 2016).
As noted, the JCR-2015 set includes 12 journals that belong to a “statistics and methods” cluster. Journals such as Social Networks are cited both in “information science” and in other fields such as “business and management” or “organization studies” (Leydesdorff et al. 2008). In 2014, for example, this journal is grouped with the J Artif Soc S in a cluster of 143 sociology journals, whereas Qual Quant is grouped among 335 economic journals. However, one is dis-advised to draw far-reaching conclusions on the basis of changes among two subsequent years (Leydesdorff and de Nooy 2017).
Further decomposition of the LIS set leads to six clusters which vary from three to 27 journals (Table 5). In other words, the relatively homogenous modules of the (social) sciences may be rather fine-grained. In our opinion, this leads to the question of whether one can use these clusters to normalize citation behavior above the level of individual journals. The delineations among “fields” and “subfields” (in terms of citation patterns) seem sensitive to weak fluctuations that might, from another perspective, be considered as noise (Leydesdorff 2006).
Patterns may be affected by specific events. For example, the publication of one or two special issues on the border between two specialisms may change the pattern and provide the impression of emerging new developments. From this perspective, one can question the suggestion made above that a new set of six journals were labeled as “data analysis” or “big data”. This may be an over-interpretation on our side, influenced by the hype around this topic. Moreover, many articles about “big data” appear in journals other than the six journals listed in Table 3.
Discussion and conclusions
The matrix of aggregated journal–journal citation relations represents a complex system of scientific communication that is both hierarchically layered and functionally differentiated in terms of scientific specialties and fields. Such a system cannot be decomposed unambiguously (Simon 1973). The clusters can be related in other (e.g., methodological versus theoretical) dimensions; densities of communication in subsets can vary significantly. Referencing behavior norms may differ across fields. For example, an article in a biomedical specialty may contain more than forty references, while in other fields, such as mathematics, fewer than ten references is more common (Garfield 1979; Moed 2010). However, what is measured as “differences in citation behavior among fields” can also be an artifact of the different degrees of coverage of the field-specific literature by the database (Marx and Bornmann 2015). Epistemically, references may function at research fronts to position the citing papers or acknowledge intellectual debt and/or credit to previous (that is, cited) publications (Leydesdorff et al. 2016a). Bodies of specialist literature may interact in next-order—i.e., more generalist—layers carried by quality journals such as Science and Nature.
This complex interweaving of different dynamics is further complicated because all relevant distributions are heavily skewed (Seglen 1992). Weak ties in one context can be strong ties from another perspective (Granovetter 1973). As we have seen above, hierarchical decomposition follows a path downward so that the results are path-dependent and may lead to different sub-optima. There is no objective yardstick to inform us how much better one representation is when compared with another (cf. Klavans and Boyack 2016, in press).
In addition to the statistical quality of the distinctions, the groupings have to be labeled; this adds a subjective dimension of flexible interpretations with different meanings, since the labels are not provided by the decomposition itself. The labels are added by an analyst who, as a user of the system, may wish to mix pragmatic with intellectual considerations. Ex ante, one representation is as legitimate as another and no methodological prescription can be formulated.
Within this context of uncertainty and complexity, the proposed routine provides a means for testing one’s assumptions without claiming authority; but with the advantage of reproducibility and the possibility of rich visualizations. The algorithm is semantically neutral: the routine will work on any 1-mode matrix and provide a purely algorithmic decomposition of the system into lower-level units in a series of layers. The advantages of using this decomposition and the quality of the visualizations will have to show their usefulness in bibliometric practices. The results may raise further questions and thus help to shape research ideas and agendas.
Notes
Before the introduction of WoS v.5 in 2009, the categories were referred to as ISI Subject Categories.
In 2014, the following six journals were not connected: Edn, Argos-Venezuela, Balt J Econ, Curric Matters, Econtent, and Restaurator.
Available at http://www.leydesdorff.net/jcr15/program.htm.
This environment was generated by shrinking the tenth partition of six journals into a macro-journal, of which the k = 1 neighbourhood can be determined in Pajek. This direct citation environment (citing and cited) contains 1236 journals.
References
Bensman, S. J., & Leydesdorff, L. (2009). Definition and identification of journals as bibliographic and subject entities: Librarianship versus ISI journal citation reports (JCR) methods and their effect on citation measures. Journal of the American Society for Information Science and Technology, 60(6), 1097–1117.
Boyack, K. W., Newman, D., Duhon, R. J., Klavans, R., Patek, M., Biberstine, J. R., et al. (2011). Clustering more than two million biomedical publications: Comparing the accuracies of nine text-based similarity approaches. PLoS ONE, 6(3), e18029.
de Solla Price, D. J. (1961). Science since Babylon. New Haven: Yale University Press.
de Solla Price, D. J. (1965). Networks of scientific papers. Science, 149(3683), 510–515.
Garfield, E. (1971). The mystery of the transposed journal lists—Wherein Bradford’s law of scattering is generalized according to Garfield’s law of concentration. Current Contents, 3(33), 5–6.
Garfield, E. (1979). Is citation analysis a legitimate evaluation tool? Scientometrics, 1(4), 359–375.
Glänzel, W., & Schubert, A. (2003). A new classification scheme of science fields and subfields designed for scientometric evaluation purposes. Scientometrics, 56(3), 357–367.
Granovetter, M. S. (1973). The strength of weak ties. American Journal of Sociology, 78(6), 1360–1380.
Harnad, S. (2001). Why I think research access, impact and assessment are linked. Times Higher Education Supplement, 1487, 16.
Klavans, R., & Boyack, K. (2009). Towards a consensus map of science. Journal of the American Society for Information Science and Technology, 60(3), 455–476.
Klavans, R., & Boyack, K. W. (2016). Which type of citation analysis generates the most accurate taxonomy of scientific and technical knowledge? Journal of the Association for Information Science and Technology. doi:10.1002/asi.23734.
Knorr-Cetina, K. (2007). Culture in global knowledge societies: Knowledge cultures and epistemic cultures. Interdisciplinary Science Reviews, 32(4), 361–375.
Lavoie, B., Childress, E., Erway, R., Faniel, I., Malpas, C., Schaffner, J., & Van der Werf, T. (2014). The evolving scholarly record. Dublin, Ohio: OCLC Research. http://www.oclc.org/research/publications/library/2014/oclcresearch-evolvingscholarly-record-2014.pdf.
Leydesdorff, L. (1987). Various methods for the mapping of science. Scientometrics, 11(5), 295–324.
Leydesdorff, L. (2006). Can scientific journals are classified in terms of aggregated journal–journal citation relations using the journal citation reports? Journal of the American Society for Information Science and Technology, 57(5), 601–613.
Leydesdorff, L., & Bornmann, L. (2016). The operationalization of “fields” as WoS subject categories (WCs) in evaluative bibliometrics: The cases of “library and information science” and “science & technology studies”. Journal of the Association for Information Science and Technology, 67(3), 707–714.
Leydesdorff, L., Bornmann, L., Comins, J., & Milojević, S. (2016a). Citations: Indicators of quality? The impact fallacy. Frontiers in Research Metrics and Analytics. doi:10.3389/frma.2016.00001.
Leydesdorff, L., Bornmann, L., & Zhou, P. (2016b). Construction of a pragmatic base line for journal classifications and maps based on aggregated journal–journal citation relations. Journal of Informetrics, 10(4), 902–918.
Leydesdorff, L., & de Nooy, W. (2017). Can “Hot Spots” in the sciences be mapped using the dynamics of aggregated journal–journal citation relations? Journal of the Association for Information Science and Technology, 68(1), 197–213.
Leydesdorff, L., & Rafols, I. (2009). A global map of science based on the ISI subject categories. Journal of the American Society for Information Science and Technology, 60(2), 348–362.
Leydesdorff, L., Schank, T., Scharnhorst, A., & De Nooy, W. (2008). Animating the development of Social Networks over time using a dynamic extension of multidimensional scaling. El Profesional de la Información, 17(6), 611–626.
Mabe, M. (2003). The growth and number of journals. Serials, 16(2), 191–197.
Mabe, M., & Amin, M. (2001). Growth dynamics of scholarly and scientific journals. Scientometrics, 51(1), 147–162.
Marbán, E. (1999). Inaugural editorial: A new era for circulation research. Circulation Research, 85(1), 1–3.
Marx, W., & Bornmann, L. (2015). On the causes of subject-specific citation rates in web of science. Scientometrics, 102(2), 1823–1827.
Moed, H. F. (2010). Measuring contextual citation impact of scientific journals. Journal of Informetrics, 4(3), 265–277.
Moed, H. F., De Bruin, R. E., & Van Leeuwen, T. N. (1995). New bibliometric tools for the assessment of national research performance: Database description, overview of indicators and first applications. Scientometrics, 33(3), 381–422.
Newman, M. E., & Girvan, M. (2004). Finding and evaluating community structure in networks. Physical Review E, 69(2), 026113.
Pudovkin, A. I., & Garfield, E. (2002). Algorithmic procedure for finding semantically related journals. Journal of the American Society for Information Science and Technology, 53(13), 1113–1119.
Rafols, I., & Leydesdorff, L. (2009). Content-based and algorithmic classifications of journals: Perspectives on the dynamics of scientific communication and indexer effects. Journal of the American Society for Information Science and Technology, 60(9), 1823–1835.
Rosvall, M., & Bergstrom, C. T. (2008). Maps of random walks on complex networks reveal community structure. Proceedings of the National Academy of Sciences, 105(4), 1118–1123.
Schubert, A., & Braun, T. (1986). Relative indicators and relational charts for comparative assessment of publication output and citation impact. Scientometrics, 9(5), 281–291.
Schubert, A., Glänzel, W., & Braun, T. (1986). Relative indicators of publication output and citation impact of european physics research, 1978–1980. Czechoslovak Journal of Physics, 36(1), 126–129.
Schubert, A., Glänzel, W., & Braun, T. (1989). World flash on basic research. scientometric datafiles. A comprehensive set of indicators on 2649 journals and 96 countries in all major science fields and subfields 1981–1985. Scientometrics, 16(1–6), 3–478.
Seglen, P. O. (1992). The skewness of science. Journal of the American Society for Information Science, 43(9), 628–638.
Simon, H. A. (1973). The organization of complex systems. In H. H. Pattee (Ed.), Hierarchy theory: The challenge of complex systems (pp. 1–27). New York: George Braziller Inc.
Tijssen, R., de Leeuw, J., & van Raan, A. F. J. (1987). Quasi-correspondence analysis on square scientometric transaction matrices. Scientometrics, 11(5–6), 347–361.
Van den Besselaar, P., & Leydesdorff, L. (1996). Mapping change in scientific specialties: A scientometric reconstruction of the development of artificial intelligence. Journal of the American Society for Information Science, 47(6), 415–436.
Waltman, L., & van Eck, N. J. (2012). A new methodology for constructing a publication-level classification system of science. Journal of the American Society for Information Science and Technology, 63(12), 2378–2392.
Waltman, L., van Eck, N. J., & Noyons, E. (2010). A unified approach to mapping and clustering of bibliometric networks. Journal of Informetrics, 4(4), 629–635.
Ware, M., & Mabe, M. (2015). The STM report: An overview of scientific and scholarly journal publishing. The Hague: International Association of Scientific, Technical and Medical Publishers. http://digitalcommons.unl.edu/scholcom/9/. 10 Oct 2016.
Acknowledgements
We thank Nees Jan van Eck and Ludo Waltman for the adaptation of VOSviewer and for comments and suggestions. We thank also Kevin Boyack for suggestions. We are grateful to Thomson Reuters for providing us with JCR data.
Author information
Authors and Affiliations
Corresponding author
Appendix
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Leydesdorff, L., Bornmann, L. & Wagner, C.S. Generating clustered journal maps: an automated system for hierarchical classification. Scientometrics 110, 1601–1614 (2017). https://doi.org/10.1007/s11192-016-2226-5
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-016-2226-5