
Abstract
Not much is known about the heterogeneity of risk attitudes among poor households in rich countries. This paper provides estimates from a unique data set collected among the urban poor in Atlanta, Georgia. The data set includes lab-in-the-field experiments on the relationship between risk attitudes and several household characteristics. Apart from looking at income, wealth, and education, we are particularly interested in household composition as it captures the number and kind of people who are dependant on the income of the household head. Heads of households who are less risk averse may be willing to take on the extra risk from smaller resource margins resulting from additional dependants, implying a negative relationship between household size and risk aversion. However, if the size of the household is a result of exogenous forces some heads of households may become more risk averse with more dependants. Household size can also reflect a risk management choice that involves adding non-dependant members who can provide resources and risk sharing. However, this possibility is limited to homes that are not already too crowded. We find that household size correlates positively with the risk aversion of the head, but with a large proportion of children the correlation is strongly dampened. However, this negative effect of children is conditional on the home not already being crowded. These heterogeneous findings have implications for the design of new insurance, savings, and credit programs where risk attitudes are important to the decisions to adopt.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
A new perspective on poverty, as it relates to risk in income, resources, and needs has recently emerged. Two pathbreaking studies have highlighted the new perspective on poverty: Collins et al. (2009) and Morduch and Schneider (2017). These studies expose the very complex risk management needs that poor households face due to the great variability in both income and spendings that they encounter on a daily basis. Their risk management needs are expressed through a high frequency of micro transactions, such that the total value of transactions during a month greatly exceeds the monthly earnings, often by multiples. Clearly, how well these households manage depend partly on their risk attitudes. This study adds to that literature by investigating the heterogeneity in risk attitudes among the urban poor in a rich country and a novel focus on household composition is introduced. Experimenters by now know a lot about the heterogeneity of risk attitudes, but not so much as it pertains to poor households in rich countries. Measurements of risk attitudes of poor and low-income households exist primarily for less developed countries, going back to Binswanger (1980) in India.
This paper provides measurements from a unique data set collected among the urban poor in Atlanta, Georgia.Footnote 1 This data set includes lab-in-the-field experiments on the relationship between risk attitudes and several household characteristics.Footnote 2 We follow in the tradition of Binswanger (1980) and do not make causal claims. Almost all studies that aim to relate risk attitudes to the characteristics of respondents suffer from a lack of clarity about what the underlying causation is, seemingly assuming that risk attitudes depend on other household characteristics, wealth and income in particular. However, we take the view that relationships can be bidirectional. Take income, for example: while it can be argued that a lower income may expose households to more severe consequences of risk, thus perhaps making them more risk averse, it is also the case that risk aversion comes at a cost of foregone expected earnings. Of course, some demographics, such as gender, are clearly exogenous to risk attitudes, but many others reflect at least partly some choices.
In this study we look at the usual suspects that may be associated with risk attitudes: income, wealth, education, and employment. However, we also include a novel focus on the composition of the household. We look at both the size of the household, the composition in terms of dependants and non-dependants, and especially children as dependants. This relationship can be bi-directional: on the one hand, the household composition may be determined by the risk attitude of the head, but on the other hand, it is also possible that the household composition affects the risk attitudes of the head.
As an example of the former, a household head who is not very risk averse may be willing to take in more dependant household members even if that implies a larger burden of non-discretionary expenses and thus less ability to manage risk. Some of these dependants may be permanent household members while others live only temporarily with the household and are thus members as a result of relatively recent choices by the household head. For any given income, more dependants implies that needs-based consumption such as basic food, clothing and healthcare will take up a larger share of the budget leaving a smaller discretionary share. A smaller discretionary budget increases risk since the resource margins to handle shocks are smaller, so that only heads who are relatively less risk averse may be willing to support a household with more dependants. On the other hand, the increased risk that comes from having more dependants may increase risk aversion under some circumstances or for some household heads. Similar to how other studies associate lower incomes with higher risk aversion due to the reduced ability to manage risk, the reduction in resource margins that come with having more dependants similarly lead to a reduction in the ability to manage risk. This increase in risk may lead to an increase in risk aversion, especially if the number of dependants is not an immediate choice by the household head, but a result of some other forces.
One risk management tool that households may use is to take in additional non-dependants who can contribute resources in various ways. However, the use of this tool depends on the availability of bedroom space in the home. The more crowded the house is, the less the household head can depend on this tool. Crowdedness can also have other negative effects on the household, such as stress and depression, that may correlate with risk aversion. Finally, crowdedness may be negatively correlated with other income and wealth that also affect risk management.
Understanding the relationship between risk attitudes and household composition, as well as other household characteristics, even in a purely descriptive manner, is informative to the design of public policies and privately provided solutions intended to alleviate poverty. Households that are risk averse are more likely to spend money on products and services that are designed to reduce risk, such as insurance or savings buffers. On the other hand, households that are more risk averse will also be less inclined to try out new and unfamiliar products, such as new types of insurance or credit and savings options, and this may hinder their abilities to improve their lives.
We measure risk attitudes using experimental lottery tasks with real money consequences, and characterize the households of the respondents based on survey responses. Respondents for this data set were recruited from low-income, primarily black neighborhoods in Atlanta. This is a population that has received relatively little attention in the experimental literature: the poor in a rich country. Poor households suffer from the inability to buy a lifestyle that prevails in their society (Shipler 2005), they live at the margin even if they have one or multiple jobs. Typical jobs are generally volatile by hours and earnings, while past debts and expenses are ever increasing burdens. The poverty line for a household of four, as defined by the US Department of Health and Human Services (HHS), is an annual income of $25,750 Footnote 3 and several programs base their eligibility criteria on it. Many of the working poor are just above the poverty line when considering their annual earnings, thus ineligible for such program support, although weekly and monthly earnings volatility frequently drag them under the poverty level. Further, a household that loses an income source, thereby falling below the official poverty line, will have to wait for several months for their applications to be processed before receiving any support.
Similar to some studies conducted in less developed countries we do not see a significant correlation between risk aversion and several income related variables, and when we do the correlation is negative, consistent with other studies in less developed countries and studies in developed countries on representative, primarily non-poor, populations: the less money you have the more risk averse you are. Specifically, participants with lower hourly earnings tend to be more risk averse. Our most interesting finding is that household composition measures are strongly correlated with risk attitudes. The correlation of the risk aversion with the size of the household is positive but is dampened, and even becomes negative, if the dependants are children. However, the latter negative association disappears when the housing constraint becomes tighter. Our findings cannot be explained purely by a unidirectional relationship between household composition and risk aversion. Some associations are consistent with risk attitudes being determined by the household composition. For example, households with more dependants have heads that are more risk averse, consistent with there being relatively smaller discretionary funds and with how previous studies have shown that less income leads to higher risk aversion. Other associations cannot be explained in this way, such as why heads with lower risk aversion are associated with a larger proportion of children as dependants. This could instead point to a selection effect where heads with lower risk aversion are more willing to take in children, suggesting that being responsible for children comes with greater risks.
Section 2 reviews some relevant literature. Section 3 presents the study design. Section 4 gives some descriptive results and Sect. 5 presents results from our estimation using structural maximum likelihood models. Section 6 concludes. Online appendices with additional information referred to throughout the paper are available at https://cear.gsu.edu/category/working-papers/wp-2021/ for working paper WP2021_03.
2 Literature
2.1 Experimental elicitations of risk attitudes
Binswanger (1980) is an early influential study that elicits risk attitudes experimentally from a sample of poor, rural households in India. He finds evidence of moderate risk aversion, but no consistent and significant correlation with wealth or income.Footnote 4 He does confirm that early technology adopters are generally less risk averse than others, lending support to the need to pay attention to heterogeneity in risk attitudes when predicting uptake of new financial tools or government programs. Binswanger also conjectured that the size of the household would affect risk aversion, such that a larger household would make the household head more risk averse. However, he finds no evidence for that in his sample. We discuss studies on household composition effects further in Sect. 2.2.
Many field experiments that elicit risk attitudes in developed countries include controls for wealth and income, but generally do not include many respondents from the poor population. For example, Andersen et al. (2008), found a negative income effect on a representative sample from the Danish population.Footnote 5 Noussair et al. (2014) confirm this effect for a sample representative of the Dutch population. However, these correlations do not particularly inform us about poor households, unless the linear income effect can be assumed to hold for all wealth and income levels. This may not be the case as it is shown in von Gaudecker et al. (2011) who report on an internet experiment using 1400 CentERpanel participants in the Netherlands and find that those with the second lowest wealth (€10,000–50,000) are significantly more risk averse than both those with lower and higher wealth.Footnote 6
Experiments run in less developed countries usually show either the same negative relationship between risk aversion and income or wealth, or no significant effects. Examples of no significant relationship are Mosley and Verschoor (2005) in Uganda, India and EthiopiaFootnote 7; Tanaka et al. (2010) in VietnamFootnote 8; and Cardenas and Carpenter (2013) in six major cities in Latin America.Footnote 9 Negative relations are reported in Bauer and Chytilová (2013) in India,Footnote 10 Wik et al. (2004) in Zambia,Footnote 11 Miyata (2003) in Indonesia,Footnote 12 and Yesuf and Bluffstone (2009) in Ethiopia.Footnote 13
While there have been a few studies eliciting risk attitudes in poor populations in North America, the purpose of those studies has primarily been to explain the role of risk attitudes in financial choices, such as savings, risk sharing, and education and not to correlate household characteristics with risk attitudes directly. For a Canadian low-income population, risk aversion is associated with a lower propensity to invest in education (Eckel et al. 2013). This result is similar to Binswanger’s finding that early technology adopters are less risk averse, and motivates our interest in the heterogeneity of risk attitudes. Further examples of how risk attitudes predict financial behavior among the poor is demonstrated by the finding that less risk averse individuals from a poor population in Texas are less likely to support risk sharing arrangements, i.e. are less likely to offer conditional cash payments to other experimental group members when experiencing losses (de Oliveira et al. 2014).
While this literature seems to indicate that even though there is heterogeneity in risk aversion, the correlation with income and wealth is for the most part insignificant or negative. However, there are some important exceptions to this. Henrich and McElreath (2002) report on risk elicitation experiments where they find that subsistence farmers in both Chile and Tanzania are risk loving rather than risk averse while two wealthier groups, poor urban participants and American undergraduate students, are risk averse. They explain such behavior based on a model where individuals are concerned about the risk of falling below some subsistence minimum. In such a model, those who are above the threshold will act in a risk averse way, while those who are below the threshold will act in a risk loving way.
Further examples of apparent positive correlations between income and risk aversion is the findings from non-experimental research on gambling and lottery purchases. Lang and Omori (2009) show that the least wealthy spend a higher proportion of income purchasing lottery tickets than wealthier individuals. Freund and Morris (2005) show that a significant portion of increase in income inequality during 1976–1995 was attributable to the increased prevalence of state lotteries. Barnes et al. (2011) report that neighborhood disadvantage measures are significantly correlated with increased lottery gambling intensity.
To the extent that poverty is associated with lower quality schooling and poor health, the literature relating elicited risk attitudes to education, cognition and health may be relevant as further evidence. Dave et al. (2010) conducted experiments with working poor adult Canadians and find that risk aversion is decreasing in math skills. Burks et al. (2009) present experimental tasks and cognitive tests to trainee truckers in the US and confirms that cognition is negatively related to risk aversion. Miyata (2003) reports that risk aversion and education levels in rural Indonesia are negatively related. This pattern is thus similar to that of income and wealth. On the other hand, Andersson et al. (2016) review a wider literature on cognition and risk aversion and report mixed results, indicating the possibility of heterogeneity. Further, if poor health and lack of health-seeking activities are correlated with poverty, findings relating these behaviors to risk aversion may be informative. Leonard et al. (2013) report that more risk averse individuals in the Texas study are less engaged in health-seeking physical activities, but de Oliveira et al. (2016) report that the same respondents are less obese if they are more risk averse. With the exception of obesity, these patterns confirm the negative relation between risk aversion and poverty.
This review of the literature makes it clear that heterogeneity is not only a matter of the degree of correlation but also sometimes of the sign. From this literature we conclude that there may be subsets of poor households that are less risk averse than those who are better off and thus we cannot simply assume that poor people are consistently more risk averse than less poor others.
2.2 Factors associated with poverty
In our analysis we include several variables usually associated with poverty, such as being unemployed or underemployed, having low hourly wages, lacking housing wealth, and lacking education. Based on the effect of income and wealth in many experimental studies we cite above, we expect these to be associated with higher risk aversion. The surveys we are basing our measures on include several questions associated with unemployment.Footnote 14 Combining the responses to these allows us to construct both a short-term and a long-term unemployment variable. The long-term variable captures respondents who have been continuously unemployed for the last year, while the short-term variable captures those who have experienced unemployment but have also had periods of employment during the last year.
We also include household composition, such as household size. We are not the first to show an interest in household size: several experimental elicitations of risk attitudes in less developed countries include measures of household size in their analyses. However, as far as we can tell, we are the first to do so for the poor in a rich country, and the first to make a clear distinction between household size and the number of dependants. Any household member who either shares the responsibility as a shared head of household, or who is completely financially independent, is excluded from the number of dependants. Part of the respondent sample was also directly asked which household members that are dependants, and for that part of the sample we use those responses to determine the number of dependants. However, all shared heads and individuals identified as dependants, as well as non-dependants that share finances with the household head, are included in the measure of household size. Financially independent individuals, such as renters, are not included in household size. Dependants is thus a subset of the household. We make this distinction because a larger household can imply either more dependants, thus making resources per dependant smaller and thus making risk management harder, or more non-dependant members that contribute income and other resources, but are not completely financially independent, making it easier to share the risk of income losses. If not separating out dependants from non-dependants, household size may be either positively or negatively related to risk aversion depending on the relative strength of the two effects. However, when we control for number of dependants, household size does reflect additional capacity for risk sharing and can support reductions in risk aversion. Additional household members that are non-dependants can also assist in the care for dependants, thus freeing up time for the household head.
Ward (2016) shows evidence of a negative association between the number of dependants and income per person in China supporting our notion of lower per capita income.Footnote 15 Thus, any possible efforts households may have engaged in to increase household income to compensate for more dependants appears to have been insufficient. Of course, causation may also be in the opposite direction with low-income households more inclined to have more children, perhaps as an insurance for old age. Thus, household size may be related to increased aversion to risk. Some risk elicitation experiments have included measures of household size, but without distinguishing size from dependants. Harrison et al. (2009) find no significant relation to risk aversion in experiments in India, Uganda and Ethiopia. Yesuf and Bluffstone (2009) similarly find no effect from household size in Ethiopia. Wik et al. (2004) on the other hand find that risk aversion is lower for larger households in Zambia, consistent with increased risk sharing from non-dependant household members. To control for any money contributions additional household members may be making, we also include a money income variable that includes contributions from other household members. When controlling for such contributions our measure of household size, controlling for dependants, may no longer pick up risk sharing capacity, but this should be reflected in the money contribution variable instead.
Further, we separate adult members from children, since it is likely that they do not influence household decisions in the same way. For example, adult members may be able to contribute somewhat to household income even if they are generally dependants, while this is less likely for children, at least in rich countries like the US. Some evidence that preferences of parents are associated with the number of children is provided in Bauer and Chytilová (2013). For example, mothers with young children are more patient in their choices, and this is especially strong among the poorest households.Footnote 16 While they do not find a significant relation for risk aversion, it does show that household composition can be associated with variations in preferences. Miyata (2003) shows that risk aversion is lower for respondents who live with their parents or parent-in-laws in Indonesia. Dohmen et al., (2011, Table A1) include some measures of the number of children in a household, and find that it has a positive relationship with their measure of risk aversion, which is a self-reported attitude scale response.
As a household gets bigger it puts stress on many resources, but particularly those that are less variable, such as housing. With fixed housing resources a larger household can result in significant crowding with associated negative effects on wellbeing, particularly for children. Citing several studies, Solari and Mare (2012) list many negative outcomes due to crowding: adult psychological withdrawal, loneliness, poor marital relationships, negative parent–child relations, less-responsive parenting, higher rates of being held back a grade in school, and increased child behavioral problems at school. Solari and Mare (2012) analyze the relationship between household crowdedness and several measures of the wellbeing of children, using nationally representative longitudinal data from the Panel Study of Income Dynamics’ Child Development Supplement (PSID-CDS) for 1997 and 2001, as well as the Los Angeles Family and Neighborhood Survey for 2000. They find significant effects from crowdedness on childrens’ math and reading scores, behavioral problems, and physical health. They also show that crowdedness is correlated with other household characteristics. Single mothers who have never been married live in more crowded houses, as do mothers with poor education and mothers with low-income. Stock et al. (2014) report that single-parent households tend to be in relatively deeper poverty than two-parent households. Cardenas and Carpenter (2013) include a measure of home size, but does not directly relate it to the size of the household. They do not find a significant relation between risk aversion and home size.
We conclude that there is heterogeneity in the relationship between risk aversion and household composition and size in this literature. Household size may be associated with an increase or a decrease risk aversion, although measures do not clearly distinguish between members who are dependants and those who contribute to household finances. Crowded homes can lead to many negative psychological effects, but is also a sign that the housing constraint is binding and losses in income cannot be made up by taking in more contributing individuals or moving to a smaller home.
3 Study design
The data used for this study has been made available by a research program called Portfolios of Atlanta’s Poor, financed by the Center for Economic Analysis of Risk at the Georgia State University.Footnote 17 Volunteer participants who were heads of households (single or shared) were recruited from the membership of several non-profit organizations in the greater Atlanta area that provide services for low-income working families and individuals during 2014–2017. Our respondents therefore represent people in poverty, but who are engaged in some sort of self-help. As part of the study all participants were given binary lottery tasks to elicit their risk attitudes and a demographic census as well as a financial survey. Instructions for the lottery tasks as well as the survey questions are included in Appendix B online.
Participants who were interviewed at the same time were separated for privacy.Footnote 18 All task instructions and all questionnaires were read to them privately by the interviewer, and it was also the interviewer who filled in the responses on the record sheets. All participants received either $15 or $25 as a compensation at the end of each session, depending on what tasks were included and how long the session was. In addition, they received additional earnings from the experimental tasks. Any task earnings were paid at the end of the task session, but were tracked throughout the session in a clear and transparent way. Lottery earnings average $61, with a minimum of $39 and a maximum of $79, so that even the smallest amount was larger than the participation compensation.
3.1 Risk elicitation experimental tasks
Many restrictions were imposed on the design in order to keep the cognitive load low, given that the participants come from populations where the literacy levels can be expected to be below average and where they have no prior experience with experimental tasks. Prior to conducting the tasks, they were given both instructions and practice. One important difference between the present study and most other risk elicitation experiments is that, instead of picking one task at random to play out and pay, all tasks were paid out. This payment procedure has previously been adopted by Huck and Weizsäcker (1999) and Dixit et al. (2015) to avoid the impact random payment procedures could have on risk attitudes.Footnote 19 Layers of randomness can easily become confusing to participants, particularly in the field, and we expect such confusion to be especially strong among populations with lower literacy rates. Because of our design choice, as demonstrated in Dixit et al. (2015), there can be an effect on estimated risk aversion due to the cumulative earnings throughout the session. Earnings from the lottery task depend on the risk attitudes of the participant and are therefore endogenous. In a separate specification we generate an exogenous earnings variable by estimating earnings in a model including only exogenous variables such as the parameters of the lottery tasks and the exogenous demographic variables. We use this model to predict earnings back on each participant, and these predicted earnings are then included in a robustness test of our main model estimation. We find no significant effect.Footnote 20
Participants were given a series of ten pairwise lottery choices, presented to them using colored balls that were placed in two boxes in front of them. The left box contained balls that were yellow and red and represented the safer lottery. The right box contained balls that were white and blue and represented the riskier lottery. They were also shown a page, illustrated in Fig. 1, with a picture of these two boxes where the dollar value of each colored ball was clearly marked. In this example there are 7 yellow balls with the value $1.40, 3 red balls with the value $2.50, 7 white balls with the value $0.10, and 3 blue balls with the value $8.00. The yellow balls always had a lower value than the red balls and the white balls always had a lower value than the blue balls. The probability of the high vs. low value was always the same for the two boxes, but varied across tasks. The participants were asked to choose one of the two boxes and then to put all the balls from that box into a bingo cage. The research assistant then turned the bingo cage five times counterclockwise, and then reversed the direction to let one ball fall out. The dollar value of this ball was then recorded on a sheet in front of the participant and the payoff consequence explained. Table 1 shows the probabilities and the dollar values across the ten tasks. All values and probabilities were selected to allow identification of a wide range of relative risk aversion (RRA) coefficients under Expected Utility Theory (EU). The first five rows of Table 1 show values for our Low Stake treatment and the last five rows show values for our High Stake treatment. The parameter values for these lotteries were selected such that, for a given risk attitude, the risky option becomes increasingly attractive the higher the probability of getting the high prize. Task 5 in the Low Stake treatment is an instance where all participants should choose the risky option, irrespective of risk attitudes, since there is no risk. To anticipate our results, all of our respondents chose the risky option in this task. Task 1 in the High Stake treatment has a higher expected value for the safe option than for the risky option, and only risk loving participants should choose the risky option. Task 2 in the High Stake treatment has the same expected value for both the safe and the risky option, so again only risk loving participants should choose the risky option. These predictions assume, however, that participants make choices without noise or errors, and we will allow for such errors in our analysis. Allowing for decision errors is a way of making sure our inferences about risk aversion are not confounded by decision biases that occur due to random errors, a possibility pointed out by Andersson et al. (2016).

Sample image page for binary lottery choice task. $1.40 is yellow, $2.50 is red, 10c is white, and $8.00 is blue
3.1.1 Alternative approaches to risk attitude elicitation
There are many alternative ways of designing tasks for eliciting risk attitudes, each with its own strengths and weaknesses. Harrison and Rutström (2008) provide an overview of several such designs. These designs include, for example, the Multiple Price List of Holt and Laury (2002), the Random Lottery Pairs of Hey and Orme (1994), and the Ordered Lottery Selection of Binswanger (1980, 1981).
Holt and Laury (2002) introduced a Multiple Price List (MPL) approach where several binary choice tasks are presented across rows in one table. Respondents are asked to make a choice on each row. One of these rows is then selected randomly to be played out and to determine earnings. While this approach is theoretically incentive compatible, predicting that participants should make an independent choice for each row, this may not be what they are doing. There is a large number of reported cases with a lot of switching back and forth, indicating a great deal of stochasticity in the choice process. This could be a result of confusion due to unfamiliarity with processing information in table form, or it could be that respondents see the tasks as a portfolio rather than independent choices. It has also been found that there is a slight tendency for respondents to skew their responses towards the middle of the table (Andersen et al. 2006; Harrison et al. 2005, 2007b).
Hey and Orme (1994) presented participants with 100 pairs of lotteries defined over prizes ₤0, ₤10, ₤20, and ₤30, one at a time, and in random order, thus referred to as Random Lottery Pairs (RLP). One pair was selected at random to be played out and determine earnings. They used pie charts to display the probabilities of the lotteries, but with no numeric representation. The Ordered Lottery Selection was developed by Binswanger (1980, 1981) for use in rural India with poor farmer household participants. Each participant was presented with eight lotteries, arranged in a table. All lotteries used 50/50 probabilities but the amounts that could be won varied and were displayed using pictures of money bills. A variation of this approach was introduced by Eckel and Grossman (2002, 2008) which allowed a wider range of risk aversion values to be estimated. Because of the use of only one probability (0.5) this approach cannot be used to estimate decision models that have curvature both on the utility and the probability functions. Further, the inclusion of a certainty option may bias choices or generate a reference point against which risky payoffs can be identified as gains or losses.
Harrison and Rutström (2008) compare the MPL, the RLP, and the OLS using data from a within-subject experiment conducted on students at the University of Central Florida. They conclude that the estimated risk attitudes are suggestive of robustness across these instruments. Dave et al. (2010) compare the MPL to to OLS also on a within-subject basis but on a low literacy field population. They interpret MPL as a more complex task than the OLS. They report estimates that show the point estimate in the MPL as significantly higher than in the OLS, although the difference is not very large in absolute terms (0.14). However, the error term in the MPL is a lot higher: about three times as high as in the OLS. This is consistent with a great deal of problems with understanding the MPL task, especially among participants that have relatively low numeracy skills.
The Trade-Off Method introduced by Wakker and Deneffe (1996) proceeds in two stages. In stage 1 a participant is presented with two lotteries defined as \(\left( {x_{1} , p; y, 1 - p} \right)\) and \(\left( {x_{0} ,p;Y, 1 - p} \right)\) under the restriction that \(Y > y.\) The participant is asked to state which × 1 that would make them indifferent. Subsequently, in stage 2, the participant is presented with lottery \(\left( {x_{2} , p; y, 1 - p} \right)\) and \(\left( {x_{1} , p; Y, 1 - p} \right).\) This method is not theoretically incentive compatible since the participant has an incentive to overstate x1 in stage 1 in order to be presented with more attractive lotteries in stage 2. This method is often implemented with only hypothetical choices so that there are no obvious incentives to overstate x1, but if the hypothetical setting offers no incentives to strategize in this manner then it is questionable if there are any incentives to truth tell either. In hypothetical settings it is unclear what part of the choice task that is salient and that the participant responds to.
Another popular instrument is the balloon analogue test (Lejuez et al. 2002). This is a computerized test that presents participants with a balloon that they can pump up until it either pops, or they may stop before. Each time they pump their potential, but hypothetical, earnings increase, unless the balloon pops and they make no hypothetical earnings. The problem with this task is that it does not control for the subjective beliefs about the probability that the balloon will pop after any one pump, so the risk attitudes elicited are confounded by such beliefs.
Our elicitation instrument resembles the RLP of Hey and Orme (RLP) in that we presented the probabilities as pie charts, although we did not offer them the various lottery choices in a random order but fixed the payoffs in each subset of the tasks and monotonically increased the probability associated with the higher prize within each subset. This ordered presentation is similar to what Holt and Laury (2002) do in their MPL. While Hey and Orme (1994) presented each participant with 100 tasks, we only gave our participants 10 tasks with the intent of keeping them attentive to the differences across tasks. Thus, our instrument is theoretically incentive compatible, is less complex than MPL or the original RLP, but suffers from a similar lack of precision as the OLS. Consistent with Dave et al. (2010) we find small behavioral errors, which is reassuring.
3.2 Household characteristics
Table 2 presents our measures of household characteristics, including those reflecting demographics, education, income and wealth.Footnote 21 Care has to be exercised whenever including such characteristics in empirical analyses since they are likely correlated with other household characteristics not included in the model in question. Thus, any significant or insignificant effects are due to the combined effect of the characteristics included and those not included. This is discussed and illustrated in Harrison et al., (2007a, 2007b) and is a general weakness in all analyses of this kind. An important example of this is the effect of gender: many studies have shown that women may be more risk averse than men. However, in some studies that include a wider set of demographics, such as Andersen et al. (2008); Tanaka et al. (2010); Bauer and Chytilová (2013), no such effect is reported.
We include both gender and age since these have been shown to sometimes be associated with risk aversion. We see that the proportion of Male responders is smaller (43%) than that of Female responders. This is no surprise if one considers that the Current Population Survey (CPS) shows a higher proportion of female unmarried “householders” (30%) than male unmarried “householders” (21%), where a “householder” is similar to our definition of head of household, together with the fact that almost all our respondents are unmarried. The American Community Survey (ACS) also shows that 25% of all families are those with children and a female head that is unmarried.Footnote 22,Footnote 23 In addition, the CPS shows that the proportion of women in poverty is much larger than the proportion of men in poverty, 56% and 44% of all people in poverty, respectively Footnote 24: the proportion gets larger for black women in poverty than the proportion of black men in poverty, 58% vs. 42% of all black people in poverty, respectively.Footnote 25
The CPS shows that the proportion of families in poverty in 2016, with an unmarried head was 61%, compared to 27% for the population as a whole. Thus, while our proportion of unmarried respondents is higher than this, it is still the case that sampling unmarried respondents is more likely among the poor than among all households.Footnote 26 The ACS for our selected census tracts show that 88% of the households have unmarried heads, thus a proportion very similar to the proportion for our respondents. Thus we see no obvious evidence of sample selection by female responders into the study.
With respect to age, 26% are in the Young category (younger than 26 years old) and 52% are in the Old category (older than 49 years old), implying that 22% are in the middle age range 26–49, captured by the variable Mid. Gender and age are the only covariates that can be claimed to be exogenous, even though from a sampling perspective they may still be correlated with excluded characteristics. All the others may reflect choices, at least partly, and causal claims with respect to the relationship to risk aversion can therefore not be made with certainty. This is, of course, also the case in other empirical studies that look at the relationship between various characteristics and risk aversion.
Since being unemployed lowers income and wealth, we include a measure of that called GeneralUnemployment. It is a binary variable that takes the value 1 if the individual reports unemployment during the 12 months or 30 days prior to an interview, capturing both long term and short term unemployment. 55% of our respondents are classified as having experienced unemployment by this measure. However, some of these only experienced short term, thus temporary, unemployment, captured by the variable ShortTermUnemployment. 22% are classified as only short term unemployed.Footnote 27 This is also a binary variable. It takes the value 1 for those who are classified as unemployed but may have had some work during the previous 12 months. We expect unemployment to be negatively associated with risk aversion, assuming the effect is primarily due to loss of income. Being underemployed may have similar effects on income, and we capture that with the variable WorkHours, which is the response to how many hours the respondent worked during the month preceding the interview. We see underemployment on average with 144 h, compared to the 160 h that they would have worked as full-time employed. While this may not seem like strong underemployment, it needs to be recognized that this average is calculated including both individuals who are underemployed, who are fully employed, and those who work more than one fulltime job. If we calculate the average including only those with less than full employment but not unemployed (35% of our respondents) it is much more severe with only 90 h per month.
Apart from how much work a participant has, the earnings for that work also matter for how they manage their poverty. The variable WorkEarnings measures the total reported work earnings for the month, divided by the reported number of hours. The average hourly earnings among those who worked is $13.9, thus above the minimum wage of $7.25 but somewhat below what is considered a “living wage” of $15.12 for a family of four, according to the Living Wage Model developed by Amy K. Glasmeier (Nadeau 2016). Out of those who worked for money during the prior month, 17.5% earned less than the minimum wage.Footnote 28
As mentioned earlier we also include the amount of money that is contributed by other individuals or institutions (OtherIncome). This variable includes contributions from household members, contributions from other individuals who are not part of the household, contributions and benefits received from non-profit organizations, and government benefits. The monthly average (including $0 contributions) is $1,004, equivalent to 47% of monthly work earnings.Footnote 29 Further, we include a proxy for low wealth based on homeownership; HomeLowEquity is a dummy variable that takes the value 1 if the participant either rents the home or has a mortgage on the home, and 0 if the participant owns the home without a mortgage. We observe that 85% of our participants have low home equity in this sense.
We also consider lack of education, not only because of its effect on income and finances, but also because of its effect on various forms of literacy and the impact on quality of life that such literacies have. Several studies have noted a negative correlation between risk aversion and measures of education and cognition. NoHighSchool is a dummy variable that takes the value 1 if the participant did not graduate from high school. About a third of our respondents fall into this category. The other education variable, HighEducation, measures education levels beyond high school. We observe that 39% of our participants report some education beyond high school.
3.3 Household composition
Based on the survey questions we identify several measures of household composition related to poverty, presented in Table 2. SoloResponsible captures respondents who are the sole head of the household and whose household has at least one other member. Thus, the variable SoloResponsible captures those that carry the major financial burden for the household, making all the decisions. They are more vulnerable than households that have several shared heads since their ability to risk pool is more limited (Stock et al. 2014). Slightly less than half of our respondents have the sole responsibility for the household.
With a larger number of dependants the income per capita is smaller, and there are less resources for consumption beyond basic necessities or for savings. This lack of discretionary funds implies that the household is more exposed to the risk of falling to levels where even basic necessities cannot be provided as a result of life risks, such as job losses or negative health events. Similar to findings in the literature that risk aversion increases with smaller incomes, the same can be expected from reductions in discretionary funds. The margins available for risk management are smaller, thus decreasing the willingness to take on risk (Ward 2016; Wik et al. 2004). In addition, income losses in such cases may get compounded by psychological effects as household members generally, and the household head in particular, feel a loss of control and may experience stress or depression. Such psychological reactions may also influence risk aversion.
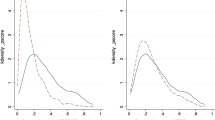
We distinguish between pure household size (HHSize) and the number of dependants (Dependants): HHSize includes all household members, both dependants and non-dependants, except the respondent. Households in our study include not only partners and children of the household head, but also grandchildren, nieces and nephews, siblings, and children of partners as shown in Fig. 2.

Proportion of types of household members, by solo or shared head
Recall that renters are not counted as household members. The effect due to HHSize thus includes both the risk and income sharing from non-dependants, potentially lowering risk aversion, as well as the additional burden from dependants that decrease the margins for managing risk and resources, potentially increasing risk aversion. On the other hand, instead of risk aversion being determined by the financial circumstances of the household, a causal direction suggested in the literature, it is also possible that risk aversion is related to a selection effect whereby household heads with low risk aversion are willing to take in the additional risk that comes with more dependants.
The average number of household members is 3.0 when not counting the respondent head of the household. This number includes both dependant and non-dependant household members. The average number of Dependants when not counting single-person households is 2.4, thus accounting for the majority of household members on average. Out of our 61 households with dependants 33% (20 households) have non-dependants who may risk and income share, while the remaining 41 have no such help.Footnote 30
We include separate measures for adults and children because it is likely that respondents are involved with the care of children in a different way than they are with adults. For example, it is possible that the emotional bond with children is stronger than with adults implying stronger altruism. If so, other preferences, like risk attitudes, may differ as well. Further, while dependant adults may be able to help somewhat in the household, this is less likely with child dependants. Thus, households with a larger proportion of children may have less overall resources making risk management more difficult, implying that only household heads who are less averse to risk would choose to have more children as dependants. We also notice in our data that households headed by a single head have a larger proportion of children living with them, as shown in Fig. 2. Thus, part of the difference between households with adults and children may be due to the head being alone and not having support to manage risk. The variable NKids includes both dependant and non-dependant children, while DependantKids includes only the former, but they are very similar in magnitude.Footnote 31 Both are shown in Table 2 conditional on NKids being positive.Footnote 32
Following our earlier discussion of the possible psychological effects of crowdedness, we include measures of the number of household members per bedroom (PersonsPerRoom) and the number of dependants per bedroom (DependantsPerRoom), both shown in Table 2 as conditioned on HHSize > 0, as well as these measures for children (KidsPerRoom and DependantKidsPerRoom), shown as conditioned on NKids > 0. If the size of the home is correlated with the wealth of the household, then the more dependants that share a space the smaller is the per capita wealth, resulting in even smaller margins for managing risk. For example, crowded households are less able to compensate for income losses by taking in paying independent renters since they are less likely to have the needed space. They are also less able to move to smaller homes in order to lower rent expenses in response to income losses, since they are already so crowded.
The average number of people per bedroom, not including single households and not counting the respondent, is 1.2 with 1 child per bedroom. This may not seem large, but Solari and Mare (2012) show that the effect of crowdedness is strongest for relatively small increases in the number of people per room. Further, the maximum number of people per bedroom in the sample is 4, which is not small.
4 Descriptive results
Figure 3 displays the proportion of safe choices by treatment (Low vs. High Stakes), separately for each task number. The proportion of safe choices decreases across tasks throughout both the Low Stake and High Stake tasks. This is consistent with the fact that the expected value of the risky lottery increases by more than the expected value of the safe lottery across tasks as the probability of the high prize increases. We confirm that nobody chooses the safe option in Task 5 Low Stake, where the probability of getting the high prize is one. This finding is contrary to findings in many previous lottery task experiments where some participants still choose the dominated option in the riskless task. This is a signal that our participants were paying attention to the details of the tasks. In Tasks 1 and 2 of the High Stake condition we see some participants choosing the risky option, consistent with risk loving behavior (absent noise in their behavior). In Task 1 this is only 4% of our participants, but in Task 2, where the expected value is the same for the safe and the risky option, it is 18%.

Proportion of safe choices in lottery, by task number
Given the parameter values used in the Low vs. High Stake lottery tasks we would expect a higher proportion choosing the safe option in the High Stake vs. the Low Stake treatment, which is what we see. Overall, the proportion choosing the safe option in the High Stake treatment is 47.9% whereas the proportion is 27.3% in the Low Stake lottery tasks.
We also look at how our covariates are correlated.Footnote 33 All household composition characteristics are strongly positively correlated with each other. Thus, if one household composition measure is omitted in an estimated model, the coefficients on the others will reflect the effect of the omitted variable as well. While they are also significantly correlated with some other variables, such as GeneralUnemployment and ShortTermUnemployment, WorkEarnings, Male, and HighEducation, these correlations are weak. The variables WorkHours and WorkEarnings are positively correlated with each other, indicating that they both reflect some latent characteristic that is the same. We therefore only include one of them, WorkEarnings, in the estimated models.Footnote 34
5 Structural estimation
We perform structural estimations of utility functions using logistic maximum likelihood models, with model parameters as functions of our poverty and control variables. We assume that agents have an expected utility \((EU_{k}^{j} )\) of lottery j (Safe or Risky) in task k defined as the probability weighted utility of each money outcome (Mj,k,t) (where t indicates low or high dollar outcome) given by u(Mj,k,t|r), where r is the risk aversion coefficient to be estimated.Footnote 35 For ease of exposition we suppress the agent index i in the expression for Expected Utility:
where S indicates the Safe and R the Risky lottery. There is no subscript j on the probability, pk,t, since it is the same for the Safe and Risky lottery in any task k. We employ a Constant Relative Risk Aversion (CRRA) utility specification: \(u{(}M_{j,k,t} {|}r) = \frac{{M_{j,k,t}^{{\left( {1 - r} \right)}} }}{1 - r}.\)Footnote 36 Risk neutrality is found when r = 0 while r > 0 indicates risk aversion and r < 0 risk loving. Following Wilcox (2011) we employ contextual normalization by dividing each EU value by the difference between the best and worst outcome in each task. This generates a heteroskedastic model, which allows us to make risk aversion comparisons in the sense of Pratt (1964).
The maximum and minimum outcomes Mk,max and Mk,min are not indexed with the lottery (j) since we identify them across both the Safe and Risky lotteries within each task. The likelihood of the observed choices being generated by the specified process is conditional on the EU specification (including the utility specification) being true. We define the conditional likelihood for choosing Risky or Safe as:
where exp denotes the exponential function. The additional parameter \(\mu\) in (5) modifies the standard logistic cumulative density function and can be interpreted as a behavioral sensitivity parameter, often referred to as a Fechner error. When the Fechner error is larger than 1, agents’ choices are less sensitive to the difference in EU than the standard logistic function would indicate, so the slope of the cumulative density function is flatter. When it is smaller than 1, agents are more sensitive than indicated by the standard logistic function. The choice becomes non-stochastic as \(\mu \to 0.\) In our estimations r is defined as a linear function of the variables listed in Table 2:
where Xdi is the vector of variables from Table 2 and they vary across participants, indexed by i. The conditional log-likelihood is
where \(y_{i,k} = 1\left( 0 \right)\) denotes the choice of the Risky (Safe) option by participant i in task k. When the choice is Risky the log of the likelihood in Eq. (3) when j = R will be added to the log likelihood function, and if \(y_{i,k} = 0\) the log of the likelihood in Eq. (3) when j = S will be added to the log likelihood function.
5.1 Structural estimation results
Table 3 presents the results of the structural estimations. We include five models: two that include only household composition covariates and three that include a fuller set of covariates. We focus on effects with a p-value of 0.01 or better, due to the exploratory nature of the study, so as to minimize the chance of rejecting non-effects too casually. The constant term in the r equation is significantly different from risk neutrality and hovers around 0.4, perfectly in line with many other experimental elicitations of risk attitudes. The Fechner errors (\(\mu\)) are around 0.1, implying that there is not much noise in the choices and they are fairly close to being deterministic.Footnote 37,Footnote 38 We take that as evidence that our respondents understood the tasks and were motivated.
We consistently see very significant associations between risk aversion and our household composition variables across these models, with the exception of PersonsPerRoom that is not significant in any of the models. A household with a larger number of members, for any given number of bedrooms, has a larger HHSize as well as PersonsPerRoom. The rate of change in PersonsPerRoom due to changes in household size depends on the number of bedrooms. If the additional person is an adult it does not change NKids or KidsPerRoom, but if the additional person is a child it also increases NKids and KidsPerRoom. Since these variables are highly correlated, it is important to include all of them in the model to avoid omitted variable biases.Footnote 39 In the models based on Dependants rather than HHSize, the same logic applies.
Before discussing the inferences that can be drawn from the estimated household composition coefficients we notice the similarity of the coefficients in Model 1 to those in Model 2. In fact, we conclude that the coefficients on HHSize and Dependants are not significantly different, and the same is true for the coefficients on NKids and KidDependants.Footnote 40 We had expected that Dependants would generate a stronger increase in CRRA than HHSize since the latter variable includes non-dependants who may be able to provide resources and risk pooling opportunities, thereby making risk management easier for the household head which may result in less risk aversion. Similarly, we find that SoloResponsible is insignificant, also indicating that shared heads also do not seem to increase the ability of the head to risk pool. Instead we find HHSize having the same positive association with CRRA as Dependants. This is contrary to findings reported in Wik, Aragie Kebede, Bergland, and Holden (2004) in Zambia, the only other significant household size effect we have encountered but where they find lower risk aversion in larger households, consistent with larger households providing such additional resources and risk pooling opportunities.
Our models show that there is heterogeneity in risk attitudes due to household composition. In all models, as NKids increases, while holding HHSize constant, it has a dampening effect on the CRRA coefficient as indicated by the negative coefficients. Thus a larger proportion of children in the household is associated with lower risk aversion. This is contrary to findings in Dohmen et al. (2011) for a representative population sample. However, our negative effect is conditional on the level of crowdedness in the household, as indicated by the positive and significant coefficients on KidsPerRoom. A large proportion of children is associated with lower risk aversion only when households are not crowded so that the negative effect of NKids dominates the positive effect of KidsPerRoom. Since the absolute value of the coefficient on KidsPerRoom is a little over twice that of the coefficient on NKids in all the models, the combined effect is to increase CRRA if the number of bedrooms is less than 3 and to decrease it otherwise.
This pattern of heterogeneity where the interaction of crowdedness with the proportion of children affects risk aversion is interesting since we do not see the same effect for adults. The fact that crowdedness is associated with higher risk aversion is not surprising if one considers that small and crowded homes may also be associated with less of other resources as well, as pointed out by Solari and Mare (2012). Even though we include controls for various income sources there may be other unobserved resource effects, such as the anticipation of not being able to take in additional non-dependants that can contribute resources.Footnote 41 It is, however, somewhat surprising that this does not appear to be the case for households that primarily have adult members. Solari and Mare (2012) show that crowded households with children are particularly exposed to stress, negative effects on parenting, and behavioral problems in children, which may alsol have effects on preferences such as risk aversion. We also notice in our data that households headed by a single head have a larger proportion of children living with them, as shown in Fig. 3. Thus, part of the difference between households with adults and children may be due to the head being alone and not having support to manage risk. While we control for SoloResponsible, there may be an uncontrolled interaction effect with children and crowdedness.
It is important to recognize that the household composition variables in these models are likely not exogenous. We consider the possibility that selection of household composition may be a function of risk attitudes of the household head. The size and composition of a household reflects choices, whether they are longrun, such as marriage and having children, or shortrun, such as allowing others, adult or children, to live in the home. The households in our study are composed not only of the partners and children of the household head, but also of grandchildren, nieces and nephews and children and grandchildren of partners as shown in Fig. 2.
Associations with risk aversion can reflect either direction of causality, or influences by other unobserved common factors. The positive effect of HHSize and Dependants on risk aversion is consistent with the head having more non-discretionary expenditures and less room to manage risk due to a larger number of dependants. Even if some adults help out in more ways than what is captured by our Other Income variable, the net effect is to increase risk aversion. This is consistent with the income effect demonstrated in the literature with causality running from the non-discretionary budget to risk attitudes. On a similar note, since children may be less helpful in the running of the household than dependant adults, with such direction of causality more children would result in even higher risk aversion for the household head. But this is the opposite effect of what we see for less crowded households with children so it is not a viable candidate to explain our finding. Instead the negative effect on risk aversion may be a reflection of a selection effect: less risk averse heads of households may be more willing to have a larger share of children in the household. Having children can come at a higher risk since they are not able to help in the same way as dependant adults.
Models 3–5 in Table 3 include additional covariates.Footnote 42 Models 3 and 4 is based on HHSize while model 5 uses Dependants.Footnote 43 Model 3 includes GeneralUnemployment while the other two also include ShortTermUnemployment.Footnote 44 We first notice that the additional covariates do not have any significant effect on the household composition variables. Further, almost all additional effects are insignificant: there is neither a gender effect nor an age effect; education levels are not associated with risk attitudes, nor is experience with unemployment or housing equity. The only variable that is significant across all three models is WorkEarnings. It is associated with less risk aversion, consistent with previous studies that found negative income effects. In Model 5 we also see a small, but significant effect of Other Income. Since in this model we base household size on Dependants, thus not including shared household heads in the count, this is not surprising since shared heads often contribute to household finances. This positive association is different from the expected negative income effect, but it is quite small: since Other Income is measured in thousands of dollars, every additional one thousand dollars is associated with a change in the CRRA coefficient in the third decimal place. On the other hand, the WorkEarnings variable is not scaled, thus the coefficient shows that a one dollar change is associated with a change in the CRRA coefficient in the second decimal.Footnote 45
6 Conclusion
We present estimates that associate risk attitudes with several measures of poverty for the urban poor in a rich country, the United States. These individuals were recruited via local non-profit organizations and are therefore representative of a group that is engaged in some sort of self-help. We include several poverty factors, both those related to earnings and those related to household composition. With the exception of hourly work earnings, we do not find significant effects from earnings variables. Neither unemployment nor the amount of underemployment is significant, and we also do not find education to have much impact. This is consistent with the lack of significance noted by Binswanger (1980), Mosley and Verschoor (2005), Tanaka et al. (2010), and Cardenas and Carpenter (2013) on correlations between risk aversion and income. The negative coefficient on hourly work earnings is consistent with findings from representative, rather than poor, populations, as reported in Andersen et al. (2008), Noussair et al. (2014), Bauer and Chytilová (2013), Wik et al. (2004), Miyata (2003), and Yesuf and Bluffstone (2009).
On the other hand, three of our household composition measures are strongly significant: the number of household members, the number of children, and how crowded the home is as a function of the number of children. Some of our findings point to the possibility that risk attitudes may be affected by the household composition, while other findings point to a possible selection effect: that the risk attitudes of the household heads affect the household composition. For example, it is possible that household heads who are less averse to risk are more inclined to have a larger share of children, as long as their home is not crowded. This could be the case if the responsibility of caring for and supporting children is seen as more risky than supporting adults. One reason for the higher riskiness may be that children are less able than dependant adults to help out in ways that assists the household head in managing risk. On the other hand, the pure size of the dependant household may increase non-discretionary expenses and thus make risk management more difficult. Following the literature that interprets risk aversion as changing based on the income of the household we see such budgetary influences as increasing the aversion to risk.
Apart from finding that the number of dependants is associated with higher risk aversion, but that the effect is dampened or even negative when the dependants are children, we also find that homes crowded with children result in extra high risk aversion. The latter effect is consistent with additional stress and behavioral issues, and with the fact that children are not able to help out to the same extent as adult dependants, if the direction of causation is to increase risk aversion when resources are running low.
We conclude that our sample from a poor population in the US is risk averse, and that risk aversion is higher among household heads that have a smaller proportion of children in their membership, or that have a larger proportion of children but in more crowded homes. These heterogeneous findings have implications for the design of new insurance, savings and credit programs. As the intent of the programs may be to reduce financial risk, the expectation would be that household heads with the highest risk aversion should be the most likely adopters. However, these most risk averse household heads also deal with the complexity and stress of crowded households with children and may view novel, formal financial instruments as adding to risk and stress.
Notes
The data is collected by the Center for Economic Analysis of Risk at Georgia State University under the umbrella of the project Portfolios of Atlanta’s Poor. A description of this project can be found in Appendix A, online at http://CEAR.gsu.edu/https://cear.gsu.edu/category/working-papers/wp-2021/ for working paper WP2021_03.
A lab-in-the-field experiment, also referred as an artefactual field experiment (Harrison & List 2004), involves implementing a controlled laboratory situation but using field participants rather than students. This gives a broader demographic base with varied work and life experiences compared to laboratory experiments using students.
2019 HHS poverty guidelines published in the Federal Register https://aspe.hhs.gov/2019-poverty-guidelines.
Income measures were restricted to salary from secure jobs. Wealth was measured by gross sales value of physical assets.
Income was measured as the self-reported total income before taxes during the year prior to the interview.
The income and wealth variables used by these two studies come from the LISS panel subject pool managed by CentERdata, affiliated with Tilburg University.
How income is measured is not reported.
Income is measured as mean household income in year before interview.
They construct an index of well-being based on home ownership, basic utility access, employment, overall economic status, perceived relative economic status, requiring government assistance, expenditures and having lost a business.
They do not report how income was measured.
They include income per capita, cash liquidity per capita and education in their models. Of these only income per capita was significant and only at 5% level.
The wealth variable is a classification into rich, middle and poor and is done by local village officers.
Wealth is measured using the number of oxen the household has.
The survey questions and the construction of our variables are documented in Appendix B and C, online.
Ward defines dependants as household members younger than 15 or older than 65, thus assuming that none of those share financial responsibilities and that everybody in the age range 16- 64 do share such responsibilities.
The suggested causal link is not tested empirically but is argued based on theoretical considerations.
Interviews were done in waves and questionnaires were adjusted somewhat between waves. In particular, additional questions were added for later waves. Information about the data collection logistics are presented in Appendix A online.
Each participant was paired with an interviewer and we tried to keep that pairing constant as much as possible throughout their participation. Scheduling constraints sometimes made that impossible. Water and snacks were provided to all participants to ensure that they were as alert as possible.
Risk attitudes could be affected by random payment procedures if the independence axiom of Expected Utility Theory is violated, or if the additional layer of randomness adds to the cognitive burden on the respondents.
This test is discussed in Appendix D Tables D12 – D14, online. The predicted earnings have no significant influence on the estimated risk attitudes, and the coefficient is very small.
Appendix C online discusses how our variables were constructed from the survey responses.
Households by Type and Age of Householder: 2017, Current Population Survey, Table 6, Census Bureau. https://www.census.gov/data/tables/2017/demo/age-and-sex/2017-age-sex-composition.html
For this statistic we include the two census tracts with the highest concentration of responders as well as immediately adjacent census tracts: CT Social Explorer, American Community Survey, 5-year estimates 2013–17, A10008 “Households by Household Type”, CT 55.01, 57, 58, 63, 65, and 120. These census tracts represent a little less than half of our respondents (45%).
POV01: Age and Sex of All People, Family Members and Unrelated Individuals Iterated by Income-to-Poverty Ratio and Race: 2017. Below 100% of Poverty – All Races.
All our respondents are Black. If we use median income as an indication of the incidence of poverty, the CPS shows that in 2016 female unmarried households have a lower median income ($41,027) than male unmarried households ($58,051) or married couple households ($87,057). CPS also shows that Black households have much lower median income than all households, $39,490 and $59,039, respectively.
Thus we are more likely to find unmarried, Black, female households among the poor than among any other group.
Table 4: Families in Poverty by Type of Family: 2015 and 2016. U.S. Census Bureau, Current Population Survey, 2016 and 2017 Annual Social and Economic Supplements. https://www.census.gov/data/tables/2017/demo/income-poverty/p60-259.html
Of those who experience long term unemployment (33%) only four respondents still report that they are looking for work. Despite so many not reporting “still looking for work” we still code them as unemployed due to the persistent longterm unemployment in the past.
It is possible to earn less than the minimum wage of $7.25 if one is self-employed, for example doing yard work or baby sitting, or if one works in restaurants, where the minimum wage is less.
While this variable includes all other money sources apart from working, it is highly correlated (0.87) with contributions from household members for the observations where the dataset has such a breakdown.
In our model estimations both HHSize and Dependants take the value 0 for single person households.
Non-dependant children are children of other household members that the head of the household is not directly responsible for.
In our model estimations we include observations of households that do not have children, i.e. where NKids is 0.
The full correlation table is included in Appendix D Table D1 online.
When we include both, neither is significant (Table D2 in Appendix D online.).
For the purposes of robustness tests we also estimated RDU models and a logit regression model, shown in Appendix D online, Tables D15-D17. The stories these models tell are consistent with our EU stories. One can view the utility transformation in EU descriptively as a summary measure of the combined influences on risk taking from utility transformation and probability transformation in RDU. If the decision weights in RDU are pessimistic, i.e. risk averse, then the utility transformation in an EU model would show greater concavity than the utility transformation in the corresponding RDU model, since the former reflects also the probability transformation.
This specification has been shown to better fit experimental data than alternatives (Camerer & Ho 1994; Wakker 2008). As a robustness test we also estimated models based on a CARA utility function, and find very similar results. The CRRA function is not defined for \(r=1\) and the likelihood function usually includes the stipulation that \(u=ln(x)\) when that is the case. In our estimations the likelihood function never brought us close to \(r=1\) so this was not an issue.
We also estimated model specifications that included covariates on the Fechner errors, as a test of the possibility that effects on risk aversion may simply be effects on decision errors, as demonstrated by Andersson et al. (2016). None of the covariates are significant at a level of p < 0.01 and we are therefore confident that our risk aversion effects are not confounded by decision errors. See Table D3 in Appendix D online.
We estimate models that include a tremble error term in addition to the Fechner error inspired by Loomes et al. (2002); Moffatt and Peters (2001). Table D4 in Appendix D report these models and show that the tremble term is not significant leaving the Fechner error effect intact. In addition, when significant, Loomes et al. (2002) suggest that the tremble term decays rapidly as subjects gain experience”.
The Pearson correlation coefficient between HHSize and PersonsPerRoom is 0.85 and between NKids and KidsPerRoom is 0.90. See the full correlation table in Appendix D Table D1.
We do not find significant differences between coefficients in Model 1 and Model 2 in expanded specifications. These tests are included in Appendix D Table D5 and test tables related to it, online. The lack of a difference is also not a result of small number differences in observations between the measures since 44% of our households have at least one non-dependant member.
Appendix D Table D6 online shows a number of model specifications as robustness tests where the the HHSize variables are interacted with SoloResponsible. Table D7 shows the same for the Dependant variables. The story does not change. The only specification in which SoloResponsible is significant is when we do not include one of the crowdedness variables, and it does not matter which one..
We use Mid rather than Young and Old for age here. We also tested a model specification with Young and Old. None of the age variables is significant. This specification can be found in Appendix D Table D8 online.
We also tested a specification with a non-linear relationship between household size (or dependants) and risk aversion. (see Table D9 in Appendix D) as well as the presence of a staying-at-home parent/adult, that may provide caring labor (see Table D10 in Appendix D online. The square terms are not significant.
We conducted a robustness test of the insignificant short term unemployment effect by using an alternative variable that captures only recent, short term unemployment (leaving out temporary unemployment earlier during the past year) and still find insignificance (see Table D11 in Appendix D).
We also estimated different specifications of our model: logit regressions (see Table D15 in Appendix D), and RDU specifications (see Table D16 and Table D17 in Appendix D).
References
Andersen, S., Harrison, G. W., Lau, M. I., & Rutström, E. E. (2006). Elicitation using multiple price list formats. Experimental Economics, 9(4), 383–405.
Andersen, S., Harrison, G. W., Lau, M. I., & Rutström, E. E. (2008). Lost in state space: Are preferences stable? International Economic Review, 49(3), 1091–1112.
Andersson, O., Holm, H. J., Tyran, J.-R., & Wengström, E. (2016). Risk aversion relates to cognitive ability: Preferences or noise? Journal of the European Economic Association, 14(5), 1129–1154.
Barnes, G. M., Welte, J. W., Hoffman, J. H., & Tidwell, M.-C.O. (2011). The co-occurrence of gambling with substance use and conduct disorder among youth in the United States. The American Journal on Addictions, 20(2), 166–173.
Bauer, M., & Chytilová, J. (2013). Women, children and patience: Experimental evidence from Indian villages. Review of Development Economics, 17(4), 662–675.
Binswanger, H. P. (1980). Attitudes toward risk: Experimental measurement in rural India. American Journal of Agricultural Economics, 62(3), 395–407.
Binswanger, H. P. (1981). Attitudes toward risk: Theoretical implications of an experiment in rural India. The Economic Journal, 91(364), 867–890.
Burks, S. V., Carpenter, J. P., Goette, L., & Rustichini, A. (2009). Cognitive skills affect economic preferences, strategic behavior, and job attachment. Proceedings of the National Academy of Sciences USA, 106(19), 7745–7750.
Camerer, C. F., & Ho, T.-H. (1994). Violations of the betweenness axiom and nonlinearity in probability. Journal of Risk and Uncertainty, 8(2), 167–196.
Cardenas, J. C., & Carpenter, J. (2013). Risk attitudes and economic well-being in Latin America. Journal of Development Economics, 103, 52–61.
Collins, D., Morduch, J., Rutherford, S., & Ruthven, O. (2009). Portfolios of the poor: How the world’s poor live on $2 a day. Princeton University Press.
Dave, C., Eckel, C. C., Johnson, C. A., & Rojas, C. (2010). Eliciting risk preferences: When is simple better? Journal of Risk and Uncertainty, 41(3), 219–243.
de Oliveira, A. C. M., Eckel, C. C., & Croson, R. T. A. (2014). Solidarity among the poor. Economics Letters, 123(2), 144–148.
de Oliveira, A.C.M., Leonard, T.C.M., Shuval, K., Skinner, C.S., Eckel, C.C., & Murdoch, J.C. (2016). Economic preferences and obesity among a low-income African American community. Journal of Economic Behavior & Organization, Special Issue Experimental and Behavioral Economics of Healthcare eds. James C. Cox, Ellen P. Green, and Heike Hennig-Schmidt, 131 Part B (November), 196–208.
Dixit, V. V., Harb, R. C., Martínez-Correa, J., & Rutström, E. E. (2015). Measuring risk aversion to guide transportation policy: Contexts, incentives, and respondents. Transportation Research Part a: Policy and Practice, 80(October), 15–34.
Dohmen, T., Falk, A., Huffman, D., Sunde, U., Schupp, J., & Wagner, G. G. (2011). Individual risk attitudes: Measurement, determinants, and behavioral consequences. Journal of the European Economic Association, 9(3), 522–550.
Eckel, C. C., & Grossman, P. J. (2002). Sex differences and statistical stereotyping in attitudes toward financial risk. Evolution and Human Behavior, 23(4), 281–295.
Eckel, C. C., & Grossman, P. J. (2008). Forecasting risk attitudes: An experimental study using actual and forecast gamble choices. Journal of Economic Behavior & Organization, 68(1), 1–17.
Eckel, C. C., Johnson, C., & Montmarquette, C. (2013). Human capital investment by the poor: Informing policy with laboratory experiments. Journal of Economic Behavior & Organization, 95, 224–239.
Freund, E. A., & Morris, I. L. (2005). The lottery and income inequality in the states. Social Science Quarterly, 86(s1), 996–1012.
Harrison, G. W., & List, J. A. (2004). Field experiments. Journal of Economic Literature, 42(4), 1009–1055.
Harrison, G. W., & Rutström, E. E. (2008). Risk aversion in the laboratory. In J. C. Cox & G. W. Harrison (Eds.), Risk aversion in experiments. Research in experimental economics (Vol. 12, pp. 41–196). Emerald Group Publishing Limited.
Harrison, G. W., Lau, M. I., Rutström, E. E., & Sullivan, M. B. (2005). Eliciting risk and time preferences using field experiments: Some methodological issues. In G. W. Harrison, J. Carpenter, & J. A. List (Eds.), Field experiments in economics. Research in experimental economics (Vol. 10, pp. 125–218). Emerald Group Publishing Limited.
Harrison, G. W., Lau, M. I., & Rutström, E. E. (2007a). Estimating risk attitudes in Denmark: A field experiment*. The Scandinavian Journal of Economics, 109(2), 341–368.
Harrison, G. W., List, J. A., & Charles Towe, C. (2007b). Naturally occurring preferences and exogenous laboratory experiments: A case study of risk aversion. Econometrica, 75(2), 433–458.
Harrison, G. W., Humphrey, S. J., & Verschoor, A. (2009). Choice under uncertainty: Evidence from Ethiopia, India and Uganda. The Economic Journal, 120(543), 80–104.
Henrich, J., & McElreath, R. (2002). Are peasants risk-averse decision makers? Current Anthropology, 43(1), 172–181.
Hey, J. D., & Orme, C. (1994). Investigating generalizations of expected utility theory using experimental data. Econometrica, 62(6), 1291–1326.
Holt, C. A., & Laury, S. K. (2002). Risk aversion and incentive effects. The American Economic Review, 92(5), 12.
Huck, S., & Weizsäcker, G. (1999). Risk, complexity, and deviations from expected-value maximization: Results of a lottery choice experiment. Journal of Economic Psychology, 20(6), 699–715.
Lang, B. K., & Omori, M. (2009). Can demographic variables predict lottery and pari-mutuel losses? An empirical investigation. Journal of Gambling Studies, 25(2), 171–183.
Lejuez, C. W., Read, J. P., Kahler, C. W., Richards, J. B., Ramsey, S. E., Stuart, G. L., Strong, D. R., Brown, R. A., & American Psychological Association. (2002). Evaluation of a behavioral measure of risk taking: The balloon analogue risk task (BART). Journal of Experimental Psychology: Applied, 8(2), 75–84.
Leonard, T., Shuval, K., de Oliveira, A., Skinner, C. S., Eckel, C., & Murdoch, J. C. (2013). Health behavior and behavioral economics: Economic preferences and physical activity stages of change in a low-income African-American community. American Journal of Health Promotion, 27(4), 211–221.
Loomes, G., Moffatt, P. G., & Sugden, R. (2002). A microeconometric test of alternative stochastic theories of risky choice. Journal of Risk and Uncertainty, 24(2), 103–130.
Miyata, S. (2003). Household’s risk attitudes in Indonesian villages. Applied Economics, 35(5), 573–583.
Moffatt, P. G., & Peters, S. A. (2001). Testing for the presence of a tremble in economic experiments. Experimental Economics, 4(3), 221–228.
Morduch, J., & Schneider, R. (2017). The financial diaries: How American families cope in a world of uncertainty. Princeton University Press.
Mosley, P., & Verschoor, A. (2005). Risk attitudes and the ‘vicious circle of poverty.’ The European Journal of Development Research, 17(1), 59–88.
Nadeau, C. (2016). New data: Calculating the living wage for U.S. states, counties and metro areas, https://livingwage.mit.edu/articles/19-new-data-calculating-the-living-wage-for-u-s-states-counties-and-metro-areas, Massachusetts Institute of Technology.
Noussair, C. N., Trautmann, S. T., & van de Kuilen, G. (2014). Higher order risk attitudes, demographics, and financial decisions. The Review of Economic Studies, 81(1), 325–355.
Pratt, J. W. (1964). Robustness of some procedures for the two-sample location problem. Journal of the American Statistical Association, 59(307), 665–680.
Shipler, D. K. (2005). The working poor: Invisible in America. Vintage Books.
Solari, C. D., & Mare, R. D. (2012). Housing crowding effects on children’s wellbeing. Social Science Research, 41(2), 464–476.
Stock, L., Corlyon, J., Serrano, C.C., & Gieve, M. (2014). Personal relationships and poverty an evidence and policy review. Tavistock Institute of Human Relations, 116. https://www.tavinstitute.org/wp-content/uploads/2014/08/Personal-Relationship-and-Poverty-Final-Report.pdf
Tanaka, T., Camerer, C. F., & Nguyen, Q. (2010). Risk and time preferences: Linking experimental and household survey data from Vietnam. American Economic Review, 100(1), 557–571.
von Gaudecker, H.-M., van Soest, A., & Wengström, E. (2011). Heterogeneity in risky choice behavior in a broad population. American Economic Review, 101(2), 664–694.
Wakker, P. P. (2008). Explaining the characteristics of the power (CRRA) utility family. Health Economics, 17(12), 1329–1344.
Wakker, P. P., & Deneffe, D. (1996). Eliciting von Neumann–Morgenstern utilities when probabilities are distorted or unknown. Management Science, 42(8), 1131–1150.
Ward, P. S. (2016). Transient poverty, poverty dynamics, and vulnerability to poverty: An empirical analysis using a balanced panel from rural China. World Development, 78(February), 541–553.
Wik, M., Kebede, T. A., Bergland, O., & Holden, S. T. (2004). On the measurement of risk aversion from experimental data. Applied Economics, 36(21), 2443–2451.
Wilcox, N. T. (2011). ‘Stochastically more risk averse:’ A contextual theory of stochastic discrete choice under risk. Journal of Econometrics, 162(1), 89–104.
Yesuf, M., & Bluffstone, R. A. (2009). Poverty, risk aversion, and path dependence in low-income countries: Experimental evidence from Ethiopia. American Journal of Agricultural Economics, 91(4), 1022–1037.
Acknowledgements
We are grateful to the Center for Economic Analysis of Risk at the Georgia State University for providing funding for this project and to participants at CEAR Academic Pre-Conference in Microinsurance 2018, and to participants at seminars at Monash University and Örebro University for valuable comments and feedback. All errors are those of the authors.
Funding
Open access funding provided by Università Cattolica del Sacro Cuore within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Galliera, A., Rutström, E.E. Crowded out: Heterogeneity in risk attitudes among poor households in the US. J Risk Uncertain 63, 103–132 (2021). https://doi.org/10.1007/s11166-021-09363-8
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11166-021-09363-8