
Abstract
Federal financial aid policies for higher education may be classified based on their “for-purchase” and “post-purchase” natures. The former include grants, loans, and workstudy and intend to help students finance or afford college attendance, persistence, and graduation. Post-purchase policies are designed to minimize financial burdens associated with having invested in college attendance and are granted as tax incentives/expenditures. One of these expenditures is the IRS’s Student Loan Interest Deduction (SLID)—which offers up to $2500 as an adjustment for taxable income based on having paid interest on student loans and has an annual cost of $12.81 billion—about 45.7% of the Pell grant cost. Despite this high cost, SLID has remained virtually unstudied. Accordingly, the study’s purpose is to assess how (in)effective SLID may be in reaching lower-income taxpayers. To address this purpose, we relied on an innovative analytic framework “multilevel modelling with spatial interaction effects” that allowed controlling for contextual and systemic observed and unobserved factors that may both affect college participation and may be related with SLID disbursements over and above income prospects. Data sources included the IRS, ACS, FBI, IPEDS, and the NPSAS:2015–2016. Findings revealed that SLID is regressive at the top, wealthier taxpayers and students attending more expensive colleges realize higher tax benefits than lower income taxpayers and students. Indeed, 75% of community college students were found to not be eligible to receive SLID—data and replication code (https://cutt.ly/COyfdKC) are provided. Is this the best use of this multibillion tax incentive? Is SLID designed to exclude the poorest, neediest students? A policy similar to Education Credits, focused on outstanding debt rather than on interest, that targets below-poverty line students with up to $5000 in debt, would represent a true commitment, and better use of public funds, to close socioeconomic gaps, by helping those more prone to default.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Student loan debt has been an issue of great public concern in the United States for over a decade. In early 2010, student loan debt surpassed all other forms of debt except mortgages (Federal Reserve Bank of New York [FRBNY], 2021) and from July of 2012 to July of 2020, student loan debt holders were the population with the highest and most serious delinquency status (i.e., holding a balance with 90 or more days in delinquent status) across all debt groups in the United States, including mortgage debt holders (FRBNY, 2021). Today, then, college goers are both the most indebted students in the history of this country (Lee et al., 2020) and the indebted group with the second highest risk of defaulting on their loans (after credit card holders).
It is well known that postsecondary financial aid in general, and student loan debt in particular, is affected by cost of attendance (COA, which include tuition and fees, books and supplies, room and board, and even childcare expenses—see Lusting, 2020). As also depicted by Lusting, this relationship may be summarized as follows, the higher the cost of attendance
-
(a)
The higher the minimum threshold for need-based aid eligibility (including non-loan-based aid or aid that does not need to be repaid) would be, and/or
-
(b)
The higher the amounts student may borrow to pay for college expenses.
Although these forms of aid depicted in points (a) and (b) have received constant attention in the higher education policy and finance literatures, they are not the only ones that the federal government has in place to help students and their families cover the financial burdens associated with higher education participation. As depicted in Fig. 1, postsecondary financial aid policies may be classified into “for-purchase” and “post-purchase.”Footnote 1 For purchase financial aid programs include grants, loans, and work-study, and are intended to help students and their families finance or afford college participation, attendance, and persistence, hence, the for-purchase nature. On the other hand, post-purchase financial aid policies (see Greer & Levin, 2015) are designed to minimize the financial burden associated with having attended college. Examples of these post-purchase policies include those reported by the Internal Revenue Service’s (IRS, 2020) Individual Income Tax ZIP Code Data: Education Credits, designed to help with the cost of higher education tuition by reducing the amount of tax owed, and the Student Loan Interest Deduction (SLID from henceforth), designed to help with loan burden by focusing on the interest paid by students resulting from their outstanding loan debt balances (see Fig. 1).

Conceptual framing of post-secondary financial aid policies
As depicted in Fig. 1, this study focuses on the intersection of loans and SLID for three reasons:
-
(1)
The documented precarious financial conditions of student loan debt holders
-
(2)
The high SLID annual costs, which in 2016, for example, reached $12.81 billion,Footnote 2 or 45.7% of the Pell grant costs ($28 billion) in the same year (Baum et al., 2016), and
-
(3)
Despite its relevance, given points (1) and (2) just mentioned, SLID has virtually remained unstudied.
Accordingly, we seek to address this gap in the literature by applying an innovative and rigorous methodological framework designed to assess.
-
(a)
The effectiveness of SLID to reach lower income taxpayers and
-
(b)
Whether there is evidence to suggest that this tax expenditure is regressive at the top (Saez & Zucman, 2019), wherein wealthier households and wealthier students who attend more expensive colleges may disproportionately realizeFootnote 3 higher tax benefits from SLID.
Despite the apparent straightforwardness of these analytically driven goals, there are significant methodological and conceptual/sociological challenges associated with conducting these assessments. To explain these challenges, the following lines describe SLID’s income caps and present empirically driven assessments to showcase such methodological and conceptual challenges and the strategies that our proposed analytic framework follows to overcome these challenges. Subsequently, we formally present the research questions addressed, along with related literature, conceptual frameworks, and methodological approaches implemented. After that we offer conclusions and practical implications.
Methodological and Conceptual Challenges and Motivation
As stated in the opening paragraph of this study, today’s college students hold the highest debt burden in the history of the United States (González Canché, 2017a; Lee et al., 2020) and, for the vast majority of the past decade, have been at the highest risk of defaulting among all debt holders (FRBNY, 2021). One financial aid policy that the Federal government has implemented to ameliorate this post-purchase debt burden is the IRS taxable income adjustment SLID. This tax benefit or subsidy offers up to $2500 as an earned income tax break to households financially burdened from paying interest on a post-secondary education student loan (IRS, 2019). Currently, to qualify for this support, single or joint returns must have modified adjusted gross income (MAGI) limits of less than $85,000 or $170,000, respectively. These caps are intended to prevent overconcentration of this subsidy among wealthy taxpayers.
Despite these household income caps, an analysis of ZIP code level SLID disbursements and income amounts relying on data reported by the IRS (2020), shows a positive correlation of 0.911 (see Figs. 2, 3). More to the point, a univariate regression analysis of these logged amounts, with SLID as the outcome of interest, indicates that for any 1% increase in income in a given ZIP code, the expected increase in SLID disbursements will be 1.33%. Figures 2 and 3 also contain a Moran’s I estimate, which measures spatial autodependence—the correlation of an indicator with the average neighbor performance in this same indicator (Bivand et al., 2013).Footnote 4 In both figures, the Moran’s \(I\) estimates are above + 0.55 (p < 0.001), suggesting a strong spatial concentration or autocorrelation of both SLID disbursements and income.Footnote 5 These findings pose methodological and conceptual challenges to assess the effectiveness of SLID in ameliorating the financial burdens associated with student loan debt.

Aggregated income distribution across ZIP codes

Aggregated SLID distribution across ZIP codes
Methodological and Conceptual/Sociological Challenges
From a methodological perspective, the existence of spatial autocorrelation violates the assumption of independence in standard regression analyses (González Canché, 2019), which, if left unmodeled, may lead to incorrect inferences (Bivand et al., 2013; Dong et al., 2015). To address this challenge, researchers may rely on spatial econometric techniques designed to account for this issue. The conceptual challenge, on the other hand, builds from the methodological one but is more complex in nature. At face value, given that zones with higher income tend to realize higher SLID benefits themselves and zones with lower income also tend to realize lower SLID disbursements, one may conclude that SLID is not being effective in reaching lower income taxpayers, who arguably need financial support the most (Dynarski, 2016a). Nonetheless, the observed geographical concentration of income and SLID may be a function of wealthier zones historically being more active in college participation (Chetty et al., 2014; Iriti et al., 2018), which increases their potential eligibility to benefit from this subsidy compared to inhabitants of zones with lower college-going rates, who also tend to have lower income levels, and experience more socioeconomic hardships, on average (Chetty et al., 2014; Rosen, 1985).
To synthetize these relationships, we could simply state that, wealthier zones benefit more from SLID, on average, than lower-income areas. Although on the aggregate this is true, the information contained in Figs. 2 and 3 suggest that this depiction is an oversimplification of these relationships. A ZIP code is not configured by neither uniform income distributions nor uniform SLID disbursements. That is, it is unlikely that all inhabitants of a given zone \(i\), belong to the same earning or income bracket and realize similar SLID breaks. More realistically, each ZIP code is configured by a distribution of both these tax expenditures and a distribution of income brackets coexisting within each of these observed geographical zones. These distributions mean that geographical zones may be more diverse in terms of income and SLID distributions than what can be captured with aggregated measures. Indeed, an important assertion of this study is that within ZIP code income diversity may be heterogeneously associated with their corresponding SLID disbursements. Accordingly, the first step to address this conceptual challenge empirically, consists of assessing whether income diversity within a given zone is actually present and then analyze SLID disbursement taking place among different income brackets within each ZIP code, an approach yet to be implemented in this line of research.
Assessing Income Diversity
The assessment of income diversity within a given geographical zone is possible given that the IRS (2020) documents the number of taxpayers within each ZIP code classified into six income brackets: inhabitants with adjusted gross incomes (1) $1 under $25,000, (2) $25,000 under $50,000, (3) $50,000 under $75,000, (4) $75,000 under $100,000, (5) $100,000 under $200,000, and (6) $200,000 or more. Using this information, a Simpson diversity index (Simpson, 1949) can be used to measure the degree of diversity in these zones. The result of this test, shown in Fig. 4, indicates that 90% of the ZIP codes across the continental United States have a diversity index of at least 0.635,Footnote 6 which reflects that ZIP codes are not dominated by one or two particular income brackets, hence corroborating that ZIP income heterogeneity is present across the continental United States.

Income diversity within ZIP codes based on Simpson’s index (Simpson, 1949)
The IRS also documents the amounts and the number of taxpayers within each income bracket that benefited from SLID in a given year, also within each ZIP code. Together, these pieces of information bring about the possibility of modeling variation in subsidy disbursements among income brackets, within ZIP codes, while also accounting for spatial autocorrelation of the outcome of interest that was detected above, an analytic strategy implemented in this study.
Considering the discussion presented so far, this study relies on three interconnected premises:
-
1.
When analyzing aggregated amounts, taxpayers living in wealthier areas are more likely to benefit from this subsidy. This positive relationship aligns with the tenets of geography of opportunity (Pastor, 2001; Tate IV, 2008) and neighborhood effects (Chetty et al., 2014, 2020), wherein inhabitants of higher income areas are more likely to participate in college than inhabitants of lower income zones. Nonetheless, as just discussed, aggregate measures are likely to oversimplify the complexity inherent to modeling the relationship between heterogeneous income distributions and tax benefits from a geographical perspective.
-
2.
Despite neighborhood interdependence (Rosen, 1985), living in a wealthier ZIP code does not mean being at the top of the income distribution of such a ZIP code or that the income distribution is uniform in those zones. Accordingly, even when aggregated or lumped income and SLID amounts depict this positive concentration, this does not mean that this subsidy is inherently overconcentrated on the wealthier inhabitants of such a ZIP code. If SLID is effective in reaching lower income taxpayers, we should observe that when SLID disbursements are realized within a given neighborhood and across different taxpayers’ income brackets, lower income households should receive at least similar amounts than their wealthier neighbors.
-
3.
Given that college participation in higher income neighborhoods is more prevalent than college participation in lower income zones (Chetty et al., 2014; Iriti et al., 2018), by modeling SLID disbursements within ZIP codes we are effectively controlling for contextual and systemic observed and unobserved factors that affect college participationFootnote 7 and hence enable the realization of SLID benefits.
These three premises open the possibility of assessing the expected SLID subsidy realization within a given geographical zone and across different income brackets, while controlling for contextual factors that may have impacted college participation in the first place—the single most important requirement to realize this post-purchase tax benefit, followed by meaningful interest accrual.
Based on this discussion, this study builds from recent developments in spatial socio-econometric modeling to test whether these tax subsidies are effective in reaching lower income taxpayers and college students following two main strategies (see Fig. 1).
The first strategy consists of conducting analyses at the ZIP code level relying on population-level data provided by the IRS, to estimate differences in average SLID disbursements across income brackets in the continental United States and across regions. In the second strategy, the analyses identify college goers from different income brackets who enrolled at colleges and universities with different costs of attendance (see Lusting, 2020), and then estimates the average expected SLID benefit they may qualify for, based on student loan interest amounts paid.
Using these two sources of data and analytic procedures, as depicted below, we can assess whether this tax break is regressive at the top (Saez & Zucman, 2019), wherein wealthier households and students attending more expensive colleges realize higher SLID benefits compared to their lower income counterparts and students attending less prestigious and more affordable colleges.
Relevance
These analyses are relevant because, despite SLID’s high cost, if mostly taxpayers in the upper end of the allowed income distribution (up to $85,000 or $170,000 of MAGI if filing single or married, respectively) and who attend expensive colleges are realizing these benefits, one can argue that, despite these MAGI caps, SLID is falling short in accomplishing the (assumed) goal of reducing student loan debt burden among taxpayers, particularly those from lower income levels who may need this aid the most (see González Canché, 2017a). However, if this subsidy, and the income limits are effective in protecting against the overconcentration of this distribution among wealthier taxpayers and students, then this expensive tax benefit would be effective in alleviating at least some of the debt burden affecting millions of individuals and their families every year. So far, however, no study exists, to our knowledge, that has embarked in addressing this gap in the post-purchase financial aid literature.
Purpose
Based on this discussion, the purpose of this study is to offer an identification framework that allows for a more nuanced analysis of the beneficiaries of SLID, after accounting for spatial interaction effects (spatial autodependence or autocorrelation of SLID disbursements among surrounding ZIP codes, traditionally modeled in spatial econometrics), proximity effects (more nuanced effects of being located in near proximity to other geolocated entities, which, in addition to controlling for the geographical size of a given ZIP code, further measure spatial autocorrelation using radii-based distances), and within ZIP code fixed effects (to control for unobserved heterogeneity). As further explained below, these analyses relied on a multilevel framework with spatial interaction effects (Dong et al., 2015), which allows one to decompose the distribution of SLID among taxpayers in different income brackets within ZIP codes, while controlling for spatial dependence, including place-based indicators that have been found to be relevant in explaining outcome variation as a function of place-based factors (see Jones & Duncan, 1995, for example) and accounting for place-based fixed effects to control for unobserved heterogeneity at the ZIP code level.
Research Questions
After controlling for all factors and indicators included in the models, and after accounting for spatial interaction and dependence, including taxpayers nesting into their respective ZIP codes as well as states fixed effects,
-
1.
Are SLID disbursements regressive at the top? That is, when SLID disbursements are realized within a given ZIP code, are these benefits more likely to be concentrated among wealthier taxpayers?
This study poses especial emphasis on geographical context and place-based predictors, accordingly, given that the variation of these subsidy disbursements may be affected by other placed-based indicators, the second and third questions are.
-
2.
Are these results consistent across the different regions of the United States?
-
3.
What other sociodemographic and economic indicators are relevant predictors of variations in SLID disbursements?
Finally, we provide an analysis of how the findings of this study can be extrapolated to a nationally representative sample of students with outstanding debt, who are the primary potential beneficiaries (conditional on interest accrual and MAGI thresholds) of this tax subsidy.
-
4.
What do these findings mean for postsecondary students across different levels (graduate and undergraduate), sectors, and income brackets? Are graduate and undergraduate students from higher income brackets and who are attending colleges and universities with higher costs of attendance expected to benefit more from SLID?
To address the first three questions, we relied on population-level data retrieved from the IRS, and for the fourth question we included federally protected data from the National Postsecondary Student Aid Study (NPSAS). An added benefit of including this database is its scope. NPSAS includes both graduate and undergraduate students across sectors, thus enabling a comprehensive analysis of the expected impact of SLID in the higher education system.
Related Literature
This section is organized into two main categories, a review of student loan debt literature and a synthesis of tax-related aid.
Student Loan Debt Literature
As depicted in Fig. 1, student loans are conceptualized as part of the “for-purchase” financial aid policy, along with grants and work-study. SLID, on the other hand, belongs to the post-purchase financial aid “camp.” The unique connection of loans and SLID is that together they form part of a continuum wherein in order to benefit from SLID, collegegoers need to meet three conditions: borrow to attend college, generate enough interests to qualify for SLID (which implies borrowing tens of thousands of dollars see Tables 4, 5), and stay within the MAGI caps discussed above. Although this study focuses on SLID, this section presents a brief review of the student loan literature with the goal of better contextualizing who may ultimately benefit from SLID as part of this continuum.
According to Cho et al. (2015), student loans can be understood as a “consumption-smoothing device” that becomes a liability after graduation (p. 233). This liability and fear of debt, particularly among students from lower income groups has been found to be a major disincentive to attend college which likely perpetuates social gaps (Chudry et al., 2011). On the other hand, “money-literate [students with prior experience with and knowledge in investment acquired at home] indicated that ‘One must take the full amount of the available student loan, even if you don’t need it, [to]’ ‘Invest in ISAs [savings or investment account protected from taxation],’ [and/or] ‘Accumulate a deposit for a house’” (Chundry et al., 2011, p. 137). These disparities in how loans are perceived given students’ socioeconomic backgrounds clearly indicate that students’ predispositions toward debt and borrowing to attend college are highly influenced by their available resources and home experiences (Chundry et al., 2011), with low income and first-generation in college students being more likely to be debt avert (Burdman, 2005), which coincidentally also reduces their chances to benefit from SLID.
Regarding the relationship between student borrowing and college attainment, Cho et al. (2015) found that the rapid growth in student loans during past decades has not translated in a boost of degree completion. These authors also found that the relationship between borrowing and completion is weaker compared to the association between tuition subsidies and completion (Johnson, 2013 in Cho et al., 2015). Financial burdens associated with college attendance, however, go beyond tuition costs. As stated in the introductory section, cost of attendance also includes cost of living, books and supplies, in addition to forgone earnings associated with not holding a full-time employment due to college attendance (Baum et al., 2018). Notably, lower income students have been found to prefer part-time employment over debt borrowing, which although may result in lower reliance on debt (and lower posterior SLID benefits) may also result in compromising their academic performance (Scott et al., 2001). Overall, one can conclude that studies on the impact of loans on college access, choice, persistence, and completion have shown negative or inconclusive effects (González Canché, 2014a, 2018b, 2020).
Another line of inquiry has focused on measuring their effects on financial hardship, which has used home ownership, retirement and saving plans, and sector of employment as the main outcomes to assess such a hardship, has also rendered inconclusive results (Elliott et al., 2013; Rothstein & Rouse, 2011). Nonetheless, Dynarski (2016b), relying on data that combined credit reports with data on college attendance from the National Student Clearinghouse (NSC), offered robust evidence of the relationship between student loan debt and home ownership. Dynarski concluded that although college graduates with debt tend to delay home ownership compared to their college graduate peers with no debt, by age 35, this gap disappears and both groups are 14 percentage points more likely to own a house than high school graduates.
Another prevalent line of research has focused on default rates (González Canché, 2018b). In this respect, Gross et al. (2009) found that degree completion is the best predictor of not default, whereas students who struggled academically to persist are also those more likely to default on their loans. Note also that students attending less selective institutions have higher default rates than their peers enrolled at more prestigious colleges and universities (González Canché, 2020; Gross et al., 2009). Relatedly, Dynarski (2016a) showed that students who owe less than $5000 are more likely to default (34% chance) than those with outstanding debt surpassing $100,000 (18% chance). Likely because, for the former this apparent lower debt amount, may represent an important financial burden when considering lower-income students’ income prospects. Another implication of these dynamics is that, as further discussed in Tables 4 and 5, students with debt balances of $5000 would not qualify for meaningful SLID amounts (our estimates indicate that a $5000 debt would translate into a $100 SLID benefit or 2 percent of the amount owed).
A common characteristic of all the discussed literature on student loan debt, so far, is its focus on undergraduate education. The literature discussing the borrowing behavior of graduate and professional students has consistently found that underrepresented, minoritized and students from lower socioeconomic backgrounds are more likely to borrow and accrue higher debt balances than their White counterparts (Belasco et al., 2014; Kim & Otts, 2010; Pyne & Grodsky, 2020; Webber & Burns, 2021), with women tending to borrow more than men (Pyne & Grodsky, 2020). Relatedly, Webber and Burns (2021) also showed that compared to their minoritized and underrepresented peers in 2000, those in 2016 realized the “largest increases in both the percentage of students borrowing and the total amount of debt” (2021, p. 725). These differences in debt amounts are so large that, Pyne and Grodsky concluded that, even though African American advanced degree-holders have especially high graduate-degree wage premiums, this comparatively large graduate student debt amounts (compared to their non-minoritized peers’ debt balances) still inhibit social mobility (p. 22).
From our review of this literature, we can draw two conclusions. First, research on undergraduate debt finds evidence that lower income and racially/ethnically minoritized may be debt-averse, whereas studies focused on graduate student loan debt has consistently found that once minoritized and lower income students reach this level, they may rely more heavily on loans than their non-minoritized counterparts. Second, our review indicates that so far there has been no study found that estimated the expected impact of SLID on reducing debt burden. From this perspective, our focus on SLID and the inclusion of graduate students, address these literature gaps. Specifically, our fourth research question and our discussion section addresses whether it may possible that SLID is being more effective (not necessarily by design) in reaching lower-income graduate students than their undergraduate counterparts, a notion that we will explore later in this study (see Table 4). The following subsection presents a synthesis of tax related literature to further contextualize this study’s contributions.
Tax Related Literature
Every year, the combined taxable amount foregone by federal, state, and local governments in the form of tax benefits surpass one trillion dollars (Chetty et al., 2014). Nonetheless, and despite the magnitude of these amounts, evidence of whether these tax benefits are effective in promoting income mobility, from a place-based perspective, has remained fairly limited (Chetty et al., 2014). Indeed, most previous studies on tax expenditures have relied on repeated cross-sectional analyses aggregated at the federal level (see Poterba, 2011). To begin addressing this gap in the literature, Chetty et al. (2014) conducted analyses at the commuting zone level to take advantage of the statistical power embedded in local spatial variation. Notably, these authors found that the level of tax expenditures at the local commuting zone level was positively correlated with mobility prospects of families’ subsequent generations, even after controlling for local place-based factors and characteristics. Specifically, Chetty et al. (2014) found that mortgage interest deductions, state income taxes, and state Earned Income Tax Credit (EITC) each have positive effects on intergenerational mobility.
Referring specifically to the impact of tax benefits and college-going prospects, Chetty et al., found that mortgage interest deduction and college attendance were positively and strongly correlated. Manoli and Turner (2018) added to this tax-benefit literature (without modeling for neighborhood effects), by finding that larger EITC disbursed amounts in high school seniors’ households were associated with increases in their college enrollment prospects. Given that EITC is a tax benefit that targets low-income taxpayers with children, Manoli and Turner’s findings align with Chetty et al.’s (2014), conclusions regarding the effectiveness of these tax benefits in strengthening social mobility prospects.
Notably, however, although the findings discussed so far shed light on the relationship between tax benefits and college attendance prospects, none of these studies focused on federal financial aid for post-secondary education per se, a topic we discussed next.
Postsecondary Federal Financial Aid
As depicted in Fig. 1, Federal financial aid for higher education expenses takes two forms (a) traditional financial aid in terms of grants, loans, and work-study and (b) tax benefits (Crandall-Hollick, 2018) also referred to as tax expenditures or costs for they are revenue forgone from taxation based on certain economic activities (Chetty et al., 2014). In the case of higher education, these activities include tuition and fees payments, work-related education expenses, savings for college, employer provided education benefits, and preferential tax treatment of student loan expenses (Crandall-Hollick, 2018).
These tax benefits represent “after-purchase” reimbursements (Greer & Levin, 2015, p. 50), whereas grants, loans and federal work-study all have in common that are used to help finance or afford college attendance while enrollment is still happening or before it takes place—hence the for-purchase connotation of these forms of aid depicted in Fig. 1. Despite this difference in the timing of aid disbursements, tax benefits research has mostly focused on using college enrollment as the main outcome of interest, whereas, as briefly discussed above, grant and loan research has included access, persistence, graduation, and even earnings as the outcomes of interest (see Deming & Dynarski, 2009; González Canché, 2020). These discrepancies in timing, based on this post-purchase nature, may help explain why the tax benefit literature has overwhelmingly found no effect on college enrollment, regardless of the type of college sector analyzed (Bergman et al., 2019; Hoxby & Bulman, 2016). In the case of grants and loans, the results are mixed. Specifically, the newest evidence suggests that Pell grants impact lower-income students’ degree completion, time to degree, propensity to major in STEM, and earnings, but does not affect enrollment (Denning et al., 2019). As depicted above, the student loans literature has found inconclusive or negative effects of loans on degree attainment and mixed effects on financial hardship and occupational choices (Elliott et al., 2013; Rothstein & Rouse, 2011).
Expanding on the null effects of tax benefits on college enrollment, researchers have suggested that these findings may be based on a lack of knowledge about such benefits (Bergman et al., 2019) and/or that that these tax expenditures make little to no impact on price sensitive students (Dynarski & Scott-Clayton, 2006) because such benefits focus on high-income households and disregard working families (Greer & Levin, 2015). However, despite these lack of effects, tax expenditure as a form of financial aid represent non-trivial amounts. Since 2017, higher education tax benefits have represented an estimated tax income revenue forgone of $26.24 billion per year (Crandall-Hollick, 2018), excluding SLID disbursements. To put these amounts into perspective, in the academic year 2015–2016 the Federal government disbursed $28 billion in federal Pell Grants (Baum et al., 2016), and an analysis of IRS (2020) data suggests that SLID alone represented a total cost of $12.81 billion in that same year. That is, despite being only one of the 14 tax benefits available (Crandall-Hollick, 2018) SLID expenditures are equivalent to about 49% of the federal estimated tax expenditure for higher education and about 45.7% of the total Pell grant disbursement per year.
As depicted in the introductory section, the present study departs from the literature on tax expenditures. The analyses presented focus on estimating the degree to which SLID benefits are reaching taxpayers from lower income brackets instead of studying the impact of higher education tax credits or benefits on college enrollment typically studied in this line of research (see Bergman et al., 2019; Hoxby & Bulman, 2016). Nonetheless, the present study aligns with the line of research pursued by Chetty et al. (2014) in that the models leverage on the variation taking place at spatially contextualized levels and also focus on measuring the effectiveness of these expenditures. However, rather than measuring whether these tax expenditures effectively impact intergenerational mobility, the study addresses questions related to the effectiveness of SLID in reaching lower income taxpayers after controlling for contextual and systemic observed and unobserved factors that both affect college participation and are related with SLID disbursements. Considering that students with loan debt currently represent the borrowing group with the highest risk of defaulting on their loans, to the extent that this policy is effectively reaching lower income households, this subsidy would also be effective in contributing to their financial wellbeing by avoiding the negative effects associated with loan default (Dynarski, & Kreisman, 2013; González Canché, 2017a).
Conceptual Lenses: Neighborhood or Place-Based Effects
Given the relevance of place and space, the conceptual framework of this study builds on the notions of concentrated disadvantage (Elijah, 1990; Jargowsky & Tursi, 2015) and geography of opportunity (Pastor, 2001; Tate, 2008) or disadvantage (Pacione, 1997).
In these frameworks, participants’ common exposure to spatially contextualized situations shape their opportunities of upward social mobility (Chetty et al., 2020; González Canché, 2019) by comprehensively affecting their cultural, racial, and socioeconomic identities (Rosen, 1985). Growing up in lower income neighborhoods, where the vast majority of individuals did not finish high school or did not enter college, translates into reduced opportunities to learn about careers that require college education, which may not only shape students’ aspirations but also affect their employment prospects, salary levels, and exposure to crime and incarceration rates (Chetty et al., 2020; Iriti et al., 2018). Furthermore, even when students, growing up in these types of neighborhoods, observe a few individuals with some college or college degrees, they may form a belief that exposure to college does not help to overcome difficulties to find employment or increase earnings (Rosen, 1985; Weicher, 1979), which may reinforce their negative views about the long-term benefits associated with a college education (Iriti et al., 2018). On the other hand, growing up in more affluent neighborhoods, either since birth or moving there from high-poverty housing at younger ages, has been found to causally affect individuals’ prospects of upward income mobility (Chetty et al., 2020). For individuals experiencing life in more affluent neighborhoods, obtaining college degrees, and securing employment are typically normalized, which translates into greater certainty about rates of return associated with investing in education and the expectation of success derived from college attendance. This certainty is not only obtained at home but also through community networks and resources (Iriti et al., 2018).
These social and cultural dynamics help explain why wealthier neighborhoods tend to realize higher college attendance rates. These dynamics also highlight the need to control for these differences in observed and unobserved factors that impact college-level attendance given its intrinsic relationship with the potential realization of SLID disbursements. That is, the after-purchase reimbursement (Greer & Levin, 2015) nature of SLID requires the realization of college attendance—and accumulation of enough debt to accrue interests on this debt. From this perspective, the nesting of the analyses within ZIP codes realizing similar college going rates, is considered an important requirement to estimate the effectiveness of SLID in reaching lower income taxpayers.
The literature on neighborhood effects and the application of the concentrated disadvantage and geography of disadvantage frameworks informed the data selection process and the methodological approach employed in this study. As depicted in Fig. 4, income diversity within ZIP codes prevails across the continental United States, accordingly, access to data distribution of income variation within ZIP codes opens the possibility of modeling how this spatial heterogeneity impacts SLID disbursements, while accounting for place-based cultural, ethnic, and socioeconomic factors typically depicted in the neighborhood effects literature (Chetty et al., 2014) and the concentrated advantage and disadvantaged frameworks (Elijah, 1990; Jargowsky & Tursi, 2015; Pastor, 2001; Tate, 2008; Weicher, 1979). The possibility of modeling this place-based income heterogeneity as a systematic source of variation of SLID disbursements is considered an important contribution to the existing literature. Conceptually speaking, failing to account for the heterogeneity of income brackets and SLID disbursements within ZIP code areas may result in aggregation biasFootnote 8 (Chetty et al., 2014) by potentially overestimating the relationship between income and tax subsidies. In closing, this literature and conceptual lenses converge to inform the data selection and methods employed to test for the effectiveness of tax subsidies in reaching lower income taxpayers, as described next.
Data and Methods
The variable selection relied on indicators used in previous studies as well as on the conceptual frameworks utilized in this paper. All indicators shown in Table 2 were retrieved from data officially released by the Internal Revenue Service (IRS), the American Community Survey (ACS), the Federal Bureau of Investigation (FBI) and the U.S. Department of Agriculture Economic Research Service (USDA ERS). These indicators allowed addressing the first three questions and can be replicated with the data and code scheme we are providing as part of this study.
Additionally, to address the second research question, focused on variations by geographic region, the models also relied on data obtained from the Integrated Postsecondary Education Data System (IPEDS), which offers a regional classification based on the Bureau of Economic Analysis (BEA). This original BEA classification is separated into eight regions (excluding outlying areas) and these regions are separated into 10 divisions by the U.S. Department of Commerce Economics and Statistics Administration (USDCE SA, 2013). One of these divisions is referred to as Pacific and includes the two non-contiguous states in the country (Alaska and Hawaii). Note that our models include all 50 states and DC. Previous versions of this study that focused only on the contiguous United States (i.e., excluded Alaska and Hawaii) rendered similar inferences to the ones presented here, which empirically tested for sensitivity of the findings given region/states configuration.
Before model estimation we reduced the eight BEA regions to six geographical zones that are economically comparable and have similar intra zone rurality levels: Northeast, Midwest, Midwest central, South, West Mountain and West.Footnote 9 These changes were based on the economic classification provided by the USDCE SA (2013). Specifically, the changes included grouping the New England and Mid East divisions in their Northeast region and the Southwest and Rocky Mountains BEA divisions into their West Mountain region depicted by the USDCE SA (2013).Footnote 10
Finally, to address the fourth research question, the analyses relied on data obtained from the NPSAS and the IPEDS. NPSAS is a nationally representative dataset administered by the National Center for Education Statistics (NCES). This dataset includes weights to represent all students across all postsecondary sectors and levels and includes data from the U.S. Department of Education’s central database for federal loans: The National Student Loan Database System (NSLDS). The 2015–2016 data release includes a dataset for undergraduate and another for graduate students that include indicators of total debt balances. To comprehensively address the fourth research question, we conducted the analyses presented in Table 4 by graduate and undergraduate levels and across all sectors reported by the NPSAS.
IRS Data
The source of tax data is the IRS (2020) Individual Income Tax Statistics (IITS)—ZIP Code Data. To make the analyses comparable with NPSAS, these data account for IRS returns based on 2015 individual income tax returns filed with the IRS published in 2018—analyses with 2016–17 returns rendered the same inferences. These data are available in two versions. The first version aggregates all amounts presented by ZIP code (such as those shown in Figs. 2, 3). The second version reports all the amounts and numbers disaggregated by adjusted gross income (AGI) levels. This latter version enabled the identification of indicators measured at the AGI level that were nested within ZIP codes. To ease the identification of these levels of measurement in the tables presented, all indicators measured at the within ZIP code level have the subscript \(i\). In the case of the aggregated indicators measured at the ZIP code level, which capture contextual factors and characteristics that are assumed to impact the geographical zone beyond individual AGI levels have the subscript \(j\). Both levels of these indicators are described next.
Disaggregated IRS Indicators—Within ZIP Code by AGI
These indicators were selected based on their assumed impact on SLID variation. For example, average taxable income per AGI group was computed by the total taxable income per AGI group divided by the total number of taxpayers in that same AGI group. Since taxable income is generally less than gross income, in theory these amounts would reflect greater economic solvency of households, which would allow them to invest in other goods and services. Nonetheless, to provide a more comprehensive analysis of the financial situation across AGIs, the models also accounted for average tax liability, or the tax amounts owed to the IRS—as detailed below we assessed for place-based multicollinearity before final model estimation.
To control for homeownership prevalence, the models incorporated average mortgage amounts within AGI groups in a given ZIP code and the proportion of taxpayers who have an active mortgage (Rosen, 1985). Given that SLID has different limits considering single or joint returns, the models controlled for proportion of joint returns across AGI levels. Finally, the models included the average number of dependents per AGI group for SLID can be used to claim this subsidy for dependents (IRS, 2019).
Outcome Variable
As stated in the introductory section, SLID disbursements are geographically autocorrelated, and the goal of the study is to estimate the distribution of this benefit across different income groups when this disbursement is realized within a given ZIP code. Accordingly, the outcome variable of interest is the within-ZIP-code average SLID amount per AGI group. That is, given that the IITS data report both the SLID amounts per income bracket and the number of taxpayers in each income bracket receiving those amounts, the SLID amounts were divided by the total number of beneficiaries per AGI group. Consequently, the outcome measures the average SLID amount per income bracket disbursed within each ZIP code. Finally, note that although the IITS reports six income brackets, an analysis of these data indicated that no taxpayers in the sixth income bracket (over $200,000) benefited from SLID. Since all these income categories were zero, their inclusion in the analyses were not relevant and all taxpayers in the sixth category were removed from the analytic samples.Footnote 11
ZIP Code Aggregated IRS Indicators
Based on the literature reviewed and conceptual lenses, the aggregated IRS indicators were selected to capture economic wellbeing in a given ZIP code that expands beyond individual income bracket groups. Specifically, these indicators, while are assumed to impact the overall demographic, cultural and economic context in a given area, they also tend to be associated with a higher or lower concentration of taxpayers in lower or higher income brackets in such an area. For example, the models included aggregated measures of the proportion of returns prepared by a third person (e.g., accountant) which may be indicative of both more complexity in the returns and/or also higher income prospects of the taxpayers relying on these services. On the other hand, the models controlled for the average amount of Earned Income Tax Credit (EITC), which both captures the prevalence of low-income taxpayers with children in a given ZIP code and has been found to increase college enrollment (Manoli & Turner, 2018). Following this rationale, other indicators that tend to apply more to certain groups of taxpayers than others are, the proportion of taxpayers with foreign income, proportion of taxpayers with energy tax benefits, proportion with educator expenses, proportion of taxpayers self-employed, and average education credits of taxpayers. Once more, these aggregated values were retrieved to capture economic and education health levels at the ZIP code area and can be identified with a \(j\) subscript following the notation presented in the methods section.
Non-IRS Indicators
In addition to IITS data, the models also relied on data estimates obtained from the ACS, USDA ERS, and FBI measured at the ZIP code level that captured place-based characteristics such as poverty-, unemployment-, education-levels, and family composition as used in previous studies (Chetty et al., 2014; Elijah, 1990; Jargowsky & Tursi, 2015; Weicher, 1979).
The ACS data relied on five-year estimates (2011–2015). This time period was selected given its increased reliability and stability compared to shorter time estimates, 1 or 3 years, for example (ACS, 2018), as the former are the result of a 60-month data collection period. To capture sociodemographic composition, the models also accounted for the proportion of inhabitants per ZIP code based on U.S. citizenship status. The citizenship categories included citizens born in the USA, citizens born outside the USA, and non-citizens. Other sociodemographic indicators included proportion of English-speaking households, proportion of employers who require a college credential, proportion of inhabitants with at least a four-year degree, proportion of households identified as White, African American, Hispanic, Native American, Asian Pacific, or having two or more ethnicities. Additionally, the models included an indicator of the proportion of households in a given ZIP code wherein the primary providers were single mothers. The last set of ACS estimates were selected to capture socioeconomic indicators that accounted for median income, median value of houses, median value of rent, rent to income ratio, proportion of owner-occupied households, and proportion of unemployed adults.
Based on differences in cost of living and expenditures in rural compared to urban zones (Hawk, 2013), the models also accounted for these indicators. Specifically, rurality levels were retrieved from the US Department of Agriculture Economic Research Service (2019). These rurality levels were classified in macropolitan (urbanized) areas with over 50,000 inhabitants, micropolitan (urbanized cluster) areas with 10,000 or more but less than 50,000 inhabitants, and remote and rural zones with less than 10,000 inhabitants (U.S. Department of Agriculture Economic Research Service, 2019). Finally, the only indicator measured at the county level was crime rates, which were gathered from FBI’s Uniform Crime Reporting (UCR) Program (2019) that contains crime statistics from 1974 to 2019. In line with the census estimates, these crime statistics corresponded to the year 2015. The crime indicator built measured the proportion of all crimes in a given state that took place in county \(c\).
Methods: Multilevel Modelling with Spatial Interaction Effects (Questions 1 to 3)
The data analyzed in this study are both multilevel and geographical in nature. They are multilevel because taxpayers are nested within ZIP code areas and geographical because these ZIP codes are georeferenced. In a traditional multilevel approach, nested units are assumed to have more similar (correlated) outcomes based on their common exposure to a nesting entity. According to Dong et al. (2015) this within group correlation or similarity is referred to as group dependence. Given that the nesting units in this study are ZIP code areas, in addition to group dependence, distance or contiguity may lead to other form of dependence that is termed place, contextual, or neighborhood effects (Dong et al., 2015). This form of dependence is typically modeled with geospatial or geostatistical techniques (González Canché, 2014b, 2017b, 2018a). As depicted in the methodological and conceptual motivation section, this spatial dependence was corroborated with the Moran’s I estimates shown in Figs. 2 and 3.
Given the multilevel and geographical structure of the data analyzed, the models presented in this study account for both within and between group correlation (Dong et al., 2015). They model residual dependence in both the outcome variable measured within ZIP code and among neighboring ZIP codes through spatial simultaneous autoregressive processes. Conceptually, this modeling approach represents an important analytic advancement given that, geographical contexts may affect the outcomes of taxpayers even after conditioning on both higher- and lower-level covariates. More specifically, as Jones and Duncan (1995) illustrated, individuals with nearly identical personal attributes and socioeconomic characteristics, but who live in different areas, tend to have divergent health conditions/outcomes. In this study, this may translate into observing that lower income taxpayers who live in active SLID zones benefit more from SLID than similar lower income taxpayers who live in less active SLID areas. From this perspective, multilevel models should not only consider nesting but also the spatial context where the nesting occurs. In short, since both nesting and spatial context effects may affect the outcome of interest, researchers should account for both sources of variation before final model estimation. The following lines depict the rationale followed by the analytic framework implemented in this study.
Statistically, a typical multilevel model specification is built as follows
where \(i\) represents taxpayers nested in \(j\) ZIP codes. From this perspective the residuals \({u}_{j}\) are captured at the ZIP code level and the residuals \({\varepsilon }_{ij}\) are captured among taxpayers within ZIP codes. Both residuals are assumed to follow independent normal distributions.
The covariates represented in Eq. (1) are measured at the ZIP code level (\({x}_{j}\)) and at the within ZIP code level (\({x}_{ij}\)) and each level has its corresponding coefficient estimates. Note, however, that, so far, this standard multilevel specification has not incorporated any spatial information even though the outcome at a particular location may be influenced by its surrounding locations and the intensity of this influence is expected to be higher the closer the units are from one another (Dong et al., 2015). To model nested data with geographical components, multilevel models require the inclusion of matrices of influence based on geographic contiguity (i.e., among higher-level units that in this study are captured by ZIP codes) and proximity (i.e., identified among lower-level units that meet a distance-based threshold), both of which, in this study represent taxpayers across different income brackets nested within and across ZIP codes located in close proximity, as depicted next.
Matrices of Influence
Polygon-Based Neighbors
Matrices of influence are square matrices where the intersection between rows and columns capture presence or absence of vicinity or potential influence. When there is an absence, this indicates that row \(y\) and column \(z\) are not neighbors, or do not meet a decision rule to be potentially influencing one another. When the units of interest are polygons (e.g., states, counties, ZIP codes), the decision rule to establish neighbors can be sharing a border, touching a point, or both (Bivand et al., 2013). Since the higher-level units in this case are polygons, ZIP codes that surround another ZIP code by sharing a border or touching a point, were defined as neighbors in the matrix \(M\) depicted in Eq. (2) below. This decision rule is referred to as the Queen’s approach (Bivand et al., 2013),Footnote 12 which, although requires more computing power, it also enables the identification and modeling of more information (Lloyd, 2010).
Radius-Based Neighbors
In addition to polygon-based influence identification, a second type of decision rule implemented in this study to identify neighbors or spatial sources of influence, followed a radius-based distance threshold. Here units located within such a distance threshold, regardless of their nesting units of ascription (or ZIP code), are defined as neighbors in their corresponding matrix of influence. This matrix, referred to as \(W\) in Eq. (2) below, captures lower-level vicinity, wherein taxpayers nested in the same or in different ZIP codes are neighbors as long as they are located within the previously defined radius-based distance threshold.
Similar to the selection of polygon- or border-based decision rules to establish a neighbor, the single most important decision in the radius-based framework to establish \(W\), is the selection of distance. In this respect, Dong et al. (2015) offered clear guidance about this selection process. These authors relied on variograms, simulations, and related literature (see Dong & Harris, 2015) to assess different distance thresholds: 1.5, 2, and 2.5 km. Their results consistently showed that the 1.5 km specification outperformed the latter two in all their assessments. Accordingly, following their findings and recommendations, lower-level units located within 1.5 km from one another in this study were considered neighbors. Note, however, that to test for sensitivity of this 1.5 km specification, all models presented in Table 3 were replicated with matrices \(W\) established with distance thresholds of 2 and 2.5 km, rendering the same inferences obtained with the 1.5 km specification. Moreover, we tested another specification relying on a 0.6 miles (or 0.965 km) threshold, as discussed by Chetty et al., 2020 (who did not rely on matrices of influence as in the case of Dong et al., 2015). Similarly, no differences in the inferences were found, accordingly, based on these sensitivity checks, the findings discussed below are not sensitive to the variations of the distance-based thresholds discussed herein (all these specifications can be tested with our replication code (https://cutt.ly/COyfdKC) provided).
To further depict the rationale followed by these higher- and lower-level matrices, Fig. 5 shows an example of the identification strategies employed in this study. In that figure, all surrounding ZIP codes are neighbors (this corresponds to matrix \(M\)), whereas some taxpayers across ZIP codes are also identified as neighbors as well (dark lines in the figure), given that their location falls within the 1.5 km threshold just described, and captured in matrix \(W\). The following description elaborates on the methodological role of these matrices \(M\) and \(W\), and introduces a third matrix \(\Delta\).

Example multilevel specification
Methodological Relevance of Matrices \(M\) and \(W\), and the Inclusion of Matrix \(\Delta\)
Let us bring all these pieces of information described so far together. In the multilevel modelling with spatial interaction effects, the observed value of a given location is allowed to be potentially influenced by the values of surrounding or nearby locations. Concurrently, this value is allowed to potentially influence its surrounding units as captured by the matrices of influence \(W\) or \(M\). This is the simultaneity issue modeled in simultaneous autoregressive (SAR) (and spatial error models) processes, which enable the modeling of spatial spillovers across higher- and lower-level units (Dong et al., 2015).
As discussed above and visually represented in Fig. 5, the matrices of influence \(M\) and \(W\) capture spatial dependence among ZIP codes and within and between ZIP codes among units that met the distance threshold. This multilevel SAR framework also requires the identification of the nesting unit to account for fixed group (or nesting) effects. This matrix is identified as \(\Delta\) in Eq. (2) and is a block diagonal design matrix that is traditionally referred to as an ascription matrix in the network analysis literature (Breiger, 1974). \(\Delta\) then, accounts for regional effects to capture unobserved heterogeneity within ZIP code areas (Dong & Harris, 2015).
These three matrices will have the following dimensions: \(M\) will be \(J\ \mathrm{by} \ J\), with \(J\) being the number of ZIP codes to be included in the models; \(W\) will be a \(N\ \mathrm{by}\ N\), with \(N\) referring to the total number of units included in the entire network, or the number of taxpayers’ income brackets represented in the dataset. Finally, \(\Delta\) will have dimensions \(N\ \mathrm{by}\ J\), which will allow identification of the taxpayers’ nesting into or their ascription to a given ZIP code. By convention, both \(M\) and \(W\) are row standardized (i.e., the sum of rows will add to 1 to ease the spillover effect calculation or spatial lags), whereas the intersection between each unit (row) and its corresponding ZIP code of ascription (column) in \(\Delta\) will have a value of 1 if a given taxpayer \(i\) belongs to a ZIP code \(j\), and zero otherwise.
With this information, Dong and Harris (2015) showed that the multilevel model with spatial interaction effects is specified as
where \(X\) is an \(N\) by \(K\) matrix denoting covariates measured at the taxpayer income level, and \(Z\) is a \(J\) by \(P\) matrix consisting of variables measured at the ZIP code level. The strength of spatial dependence of the outcome of interest at the lower level is captured by \(\rho\); \(\varepsilon\) captures the lower-level residuals (after accounting for or modeling spatial dependence at this level). Residuals at the ZIP code level (higher- or nesting level) are captured by \(\theta\), representing random contextual effects. Following the multilevel framework, \(\theta\) is modeled with \(\lambda\) capturing spatial interactions at the ZIP code level, given the matrix of influence \(M\) that identified ZIP code contiguity. The residuals \(u\) are distributed as \(N(0, {\sigma }_{u}^{2})\), similarly the \(\varepsilon\) are also distributed \(\mathrm{N}(0, {\sigma }_{e}^{2})\), so that neither the higher-level nor the lower-level units have residuals that are spatially dependent. Moreover, \(u\) and \(\varepsilon\) are independent. According to Dong and Harris (2015), if the variances associated with \(u\) and \(\varepsilon\) reach statistically significant levels, these significance levels would corroborate the need to model the variation captured by the matrices \(M\) and \(W\) as identified in Eq. (2). They go on to state that ignoring these forms of dependence may result in underestimated standard errors for covariance effects. Note that, Table 3 (as well as Table A1 in the Appendix) corroborated these significance levels of both \(u\) and \(\varepsilon\), hence empirically justifying the need to include both sources of influence in the models.
The multilevel models (also referred to as hierarchical SAR models or HSAR) are implemented via a Bayesian Markov Chain Monte Carlo (BMCMC). This modeling framework draws samples sequentially from the conditional posterior distributions of each model unknown parameter. The inferences are based on the posterior distributions of model parameters based on three MCMC chains with 10,000 iterations each and a burn-in period of 5000 (Dong & Harris, 2015).Footnote 13 The prior distribution for \(\rho\) in Eq. (2) is obtained from the minimum and maximum eigenvalues of the spatial connectivity matrices \(W\). The model also assumes a uniform prior distribution for \(\lambda\) over 1/(minimum eigenvalue of \(M\)), also shown in Eq. (2). For more details about this implementation please see Dong and Harris (2015).
Feature Selection as a Machine Learning Strategy to Deal with Place-Based Multicollinearity
The tenets of geography of advantage/disadvantage suggest that the geographical indicators selected may be highly correlated, that is, zones with high crime are likely to have high poverty levels, for example. This correlation, which is typically observed in studies modeling environmental factors (Li et al., 2016), may affect the observed variable importance of the predictors. Following Li et al. (2016) before model estimation, variable inclusion criteria relied on a Feature selection algorithm (Kursa & Rudnicki, 2010) to detect all non-redundant variables to predict SLID variation via machine learning—this process effectively addresses multicollinearity issues by identifying and easing the exclusion of redundant features. This non-redundant feature selection was implemented using the Boruta function, a Random Forest regression procedure. Boruta is a wrapper algorithm that subsets features, the \(X\) s and \(Z\) s depicted in Eq. (2) and train a model using them to try to capture all the relevant indicators with respect to an outcome variable. As depicted by Kursa and Rudnicki, relevance is identified when there is a subset of attributes in the dataset among which a given indicator is not redundant when predicting the outcome of interest. Procedurally, Boruta duplicates the dataset, and shuffles the values in each column referring to these shuffled indicators as shadow features. Then, a Random Forest algorithm is used to learn whether the actual feature performs better than its randomly generated shadow. The Boruta implementation relied on 1000 iterations; however, the optimal result was consistently found after 12 iterations indicating that each attribute had relevance levels higher than their shadow attributes.Footnote 14 In conclusion, Fig. 6 shows that all the features discussed in the data and methods section (see Table 2) were detected as non-redundant predictors of SLID tax expenditures.

Feature selection (for an interactive version of this figure see https://cutt.ly/yIJdnkb)
Methodological Procedure to Address the Fourth Research Question
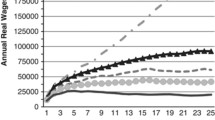
The fourth research question asked what do these findings mean for postsecondary students across different levels, sectors, and income brackets? The NPSAS data account for total loan debt accumulated and owed from all federal subsidized and unsubsidized sources, as well as private lenders (retrieved from the NSLDS). Moreover, these amounts can be disaggregated by students’ sector of enrollment, undergraduate and graduate levels, and their adjusted gross incomes. Notably, however, NPSAS does not contain information on interests accrued by students, which is a limitation of these data for the purposes of addressing our fourth research question. However, considering total student outstanding debt owed, income bracket, and expected interest rates, one can compute the expected annual interest and the corresponding average SLID amount that participants may realize when meeting all IRS’s requirements. Specifically, given that NPSAS also measures whether each student relied on federal, private, or a combination of federal and private loans, one can compute expected annual interests based on different interest rates—and even actual/expected SLID dollar amounts as shown in Table 5. When students only relied on federal loans (84.4% and 90.9% of undergraduate and graduate students in NPSAS, respectively), one can use the reported interest rates provided by the U.S. Department of Education (2020) as of 2016. These rates were 4.29% and 5.84% for undergraduate and graduate students in that academic year (U.S. Department of Education, 2020). When students reported only private sources (5.5% and 5.9% of undergraduate and graduate students also in NPSAS, respectively), the assumed interest was 10%, or the midpoint of the interest rates charged by private lenders (U.S. Department of Education, 2020). When a combination of federal and private amounts was present, the interest also represented a midpoint, but in this case this midpoint combined federal and private loans rates.Footnote 15 These midpoint rates were 9.46% and 10.38% for undergraduate and graduate students, respectively (U.S. Department of Education, 2020). However, considering that the vast majority of loans were disbursed from Federal sources, these estimates may accurately reflect the interests accrued by most students.Footnote 16
The computation of expected annual interest amounts was obtained as followsFootnote 17
where IR is interest rate given the loan type (LT), wherein type refers to federal, private or a combination of both. The number 365 refers to the length of the number of days in a fiscal year. The results from these estimates are presented in square brackets in Table 4 and will be described in the findings section—with more details described in Table 5.
Findings
This section is separated in descriptive statistics, hierarchical SAR (HSAR) models to address questions 1 to 3, and findings that discuss the actual expected impact of SLID on college students, as reflected in question 4.
Summary Statistics
Table 1 contains the identification of the two matrices of influence (\(M\) and \(W\)) and the ascription or nesting matrix (\(\Delta\)) per region, as described in Eq. (2). The dimensions represented in each row have different meanings. The matrix \(M\) indicates the number of ZIP codes represented in each region. For example, the Northeast region accounts for 5576 ZIP codes. The matrix \(W\) contains the number of AGI groups in those regions. That is, according to Table 1 there are 27,132 AGI groups represented in the northeast region. As described in the introductory section, each ZIP code has up to six AGI categories. However, after having corroborated that no individuals in the sixth AGI category received SLID, this category was removed from the analytic sample. This process left a total of up to five income brackets per ZIP code. As per the data reported by the IRS, there were some cases wherein ZIP codes had no taxpayers in some income brackets—or there were less than 20 returns in such an AGI (see IRS, 2020). This translated into the dimensions presented in \(W\) not being the product of multiplying the number of ZIP codes represented in \(M\) by 5. For example, the matrix \(W\) for the Northeast region accounts for 27,132 AGI groups. Had this region had all five income groups present in every ZIP code, the dimensions of this matrix would have been [27880, 27880], or 5576*5. Just as in the case of the removal of the sixth AGI category, the non-existence of an AGI group within a ZIP code does not constitute a source of bias or missing data, but simply reflects the specific circumstances of a ZIP code. Finally, continuing with the identification of the matrices described in Eq. (2), the matrix \(\Delta\) captures the ascription of the AGI groups to a given ZIP code. This block diagonal design matrix can be read as follows, in the South region there were 33,716 AGI groups that were ascribed to 7098 ZIP codes.
Table 2 contains the summary statistics of the outcome and predictors included in the models. The column “p value” in this table tests for mean differences among regions or differences in proportions, depending on the quantitative or categorical nature of each indicator. The first indicator presented in Table 2 is SLID amounts, measured as the mean subsidy disbursement in thousands per AGI group within ZIP code per region. As per the construction of this indicator, the amounts represented in Table 2 reflect the mean or average SLID amount received per taxpayers who benefited from this tax break. Accordingly, one can refer to these amounts as the mean subsidies per supported or awarded taxpayer within each ZIP code.
As mentioned above, the main motivation behind estimating models by region is based on the heterogeneous distribution of colleges and universities across the country. Nonetheless, as depicted in Fig. 3, this disaggregation may also capture heterogenous disbursement levels of this subsidy across the continental United States—which is congruent with economic variations, see U.S. Department of Commerce Economics and Statistics Administration (2013). The means presented in Table 2 corroborated the relevance of this decision by showing statistically significant differences in these mean amounts across regions. The Northeast and the West regions have the highest disbursements per taxpayer, with about $820 and $770 per supported/awarded taxpayer, on average. Midwest central, the zone with the highest concentration of remote and rural areas (as described below), had the lowest subsidy with $490 per awarded taxpayer, on average. All remaining zones had at least $620 per awarded taxpayer, on average.
As described above, the feature selection algorithm implemented, shown in Fig. 6, indicated that all the features shown in Table 2 were non-redundant in predicting SLID variation. Based on the study’s purpose, the main predictors of interest are indicators a.2_i ($25 k to $50 k) to a.5_i ($100 k to $200 k). These indicators represent the number (and proportion in parentheses) of taxpayers in each of the AGI brackets depicted above. Note that the category $1 to $25,000 is the reference group. Overall, we can see that the proportions of these income groups are evenly represented within and across regions.
The indicator corresponding to rurality zones resulted in significant variations across the country. The Northeast and West regions had at least 73% of their ZIP codes located in areas classified as macropolitan. The Midwest Central region had the highest concentration of ZIP codes classified as remote or rural areas, followed by West Mountain and the Midwest regions, with 23%, 16%, and 14%, respectively. Descriptively, these results indicate that zones with the highest concentration of macropolitan zones also receive the highest SLID mean amounts per awarded taxpayers, whereas the region with the highest concentration of remote and rural areas received the lowest mean SLID amounts per awarded taxpayer. The Midwest was both the region with the third highest mean SLID amount, reaching $720, and also the third region with most remote and rural areas in the continental USA. Considering that each state varies in rurality indicators, the inferential models, in addition to including these rurality levels, include state level fixed effects to capture state differences in SLID disbursements within regions.
In general, all remaining indicators included in Table 2 showed significant variations across regions. Instead of describing all these differences, the remainder of this section focuses on indicators with sizable/notable discrepancies. For example, the average mortgage amounts in the West region were the highest (about $8000) doubling and tripling the amounts found in the Midwest and Midwest central regions. In terms of number of dependents, the Northeast had the lowest average (0.58) whereas the South and the West Mountain regions had the highest with 0.74 and 0.77 dependents per filed tax return, on average. The South had the highest concentration of EITC with a quarter of the tax returns qualifying for this low-income incentive, whereas the region with the highest crime incidence was the Midwest central (0.066).
With respect to the attainment of at least a four-year degree or more, the Northeast and the West regions had the highest proportions (0.31 and 0.29, respectively) and the South had the lowest (0.20). These patterns were the same in their Median incomes, with the Northeast and the West regions having more than $30,000 and the South realizing less than $25,000. The West region, however, had the highest proportion of unemployment, with 0.057, according to these ACS five-year estimates.
The South region had the highest proportion of single mother households (0.27), which is five proportion points higher than the next region (West Mountain). Ethnicity distributions behaved as follows, the South has the highest concentration of Black and/or African American inhabitants (0.18), the West region has the highest concentration of Hispanics (0.23), followed by the West Mountain region (0.22). With regard to cost of rent, median house value and rent to income ratio the Northeast and the West regions were consistently the most expensive.
With respect to citizenship status, the West has the highest concentration of international inhabitants with almost 10% (0.09). This figure aligns with language diversity, for this regions have the lowest “English only” indicator (0.73), followed by the West Mountain region (0.81). Finally, an indicator that showed an even distribution across regions is the proportion of the population who is college age (i.e., 18–34 years of age to capture undergraduate and graduate students, see NCES, 2019). This indicator ranges from 0.19 to 022.
Multilevel Modelling with Spatial Interaction Effects Findings (Questions 1 to 3)
Table 3 contains the results of the multilevel (or HSAR) procedures with spatial interaction effects. The posterior variances identified with the matrices of influence \(M\) (variance of \(u\)) and \(W\) (variance of \(\upepsilon\)) discussed in Eq. (2) reached statistical significance across all models—shown at the bottom of the table. This finding corroborated the presence of variation at the ZIP code- and taxpayer-levels that needed to be modeled to avoid standard errors that are underestimated across the covariates included in the models (see Dong & Harris, 2015). Recall that in addition to \(M\) and \(W\), the models accounted for unobserved heterogeneity given taxpayers ascription to a given ZIP code as identified by \(\Delta\), also in Eq. (2).Footnote 18 Based on this specification, all posterior mean estimates can be read as follows: after controlling for other factors and indicators included in the model, and after accounting for spatial interaction and dependence, including taxpayers nested into their respective ZIP codes as well as states fixed effects, the posterior mean associated with changes in indicator \({X}_{i}\) has a magnitude of \({\beta }_{i}\).Footnote 19
Are SLID Disbursements Regressive at the Top? Are There Regional Variations in These Findings? (Questions 1 and 2)
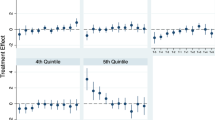
These questions asked whether SLID disbursements are more likely to be concentrated among wealthier taxpayers. Based on the information presented in Table 3, the short answer is yes, but with regional variations. Specifically, the models indicated that when SLID is disbursed, taxpayers in the lowest income bracket consistently realized the lowest posterior mean amounts. Overall, taxpayers in the second income bracket realized over $235 more, on average, than their counterparts earning less than 25,000 per year. However, analyses of regional stability or variation, suggest that these gaps among these taxpayer groups were the lowest in the West region ($235). On the other end of this distribution, the Midwest had the greatest posterior mean gap, with a magnitude of $338.
When comparing taxpayers in the third income bracket ($50,000 under $75,000), the Midwest also realized the largest gap, reaching $459. In this case, the Northeast realized the narrowest gap in this income group comparison with a posterior mean of $235.
The comparisons of taxpayers in the fourth income bracket ($75,000 under $100,000) reflected that three regions reached posterior mean gaps larger than $480. Once more, the Midwest realized the largest gap, reaching $594. Notably, the Northeast only reflected a gap of $151, the lowest across all comparisons found.Footnote 20
Finally, three regions surpassed posterior mean gaps of $465 in the fifth income bracket ($100,000 under $200,000). These regions were the South ($469), West Mountain ($520), and Midwest ($694). Once again, the Northeast region realized the lowest posterior mean gap with $246.
What Other Sociodemographic and Economic Indicators are Relevant Predictors of Variations in SLID Disbursements? (Question 3)
As discussed above, the remaining indicators included in Table 3 were measured both at the tax bracket- and at the ZIP code-levels—with only crime rates measured at the county-level. Some of these indicators behaved differently based on the region of the country. For example, in the West and Northeast regions, as the average taxable income amounts increased per taxpayers’ income brackets, the expected posterior mean SLID also increased. However, in the South, Midwest, and Midwest central regions these indicators showed no relationship, and in the West Mountain region this relationship was negative. These discrepancies in signs and significance may be a function of cost of living and income prospects because the average amounts in taxable income are similar across regions, see Table 2.
A consistent finding across regions was that average tax liability was negatively associated with SLID disbursements. The only region wherein this relationship did not reach significance was the West Mountain. Another set of consistent findings were average mortgage, average education credits amounts, and proportion of neighbors within a ZIP code who have foreign income, energy tax, education credits, and who are college age, all of which reflected positive and significant relationships with SLID disbursements. Note that education credits and SLID are both part of the higher education tax benefits, which indicates a concentration of ZIP codes eligible for this post-purchase benefits. Researchers interested in exploring these relationships could apply a similar framework presented in this study to assess variation in education credits disbursements and ZIP code income.
Proportion of bachelor’s degree holders and increases in SLID variation were significantly associated in the South, West, and Midwest Central regions. This finding, along with significant associations with proportion of inhabitants who live in single mother households (reaching significance in all regions but the West), and proportion of inhabitants holding non-professional related employment, may be indicative of diversity in the distribution of this subsidy, with respect to sociodemographic ZIP code indicators. Nonetheless, crime rates were linked to significant decreases in SLID in the South, West, and Northeast regions, and the Midwest was the only region wherein unemployment levels reached a significant and negative association with SLID variation. This last set of relationships once more indicate that SLID benefits and poverty indicators are more negatively associated in certain regions of the country than in others, hence the relevance of offering disaggregated analyses by region.
In terms of race and ethnicity (using White inhabitants as the comparison group), despite the clear concentration of specific ethnic groups across the country’s regions, this concentration did not translate into increases in SLID disbursements for those groups. For example, while the south has the highest concentration of Black inhabitants, increases of this group in a given ZIP code was negatively associated with average SLID disbursements, compared to their White counterparts. A similar finding was observed in the West and Midwest regions, with the difference that Black inhabitants were not nearly as well represented in these regions, as they were in the South (see Table 2). Nonetheless, as the concentration of Black inhabitants grew in ZIP codes in the West, the mean SLID amounts increased in this region. For Native Americans and Hawaiian pacific islanders, increases in their proportion within a given ZIP code were associated with decreases in the mean SLID disbursement in four of the six regions studied (with the exception of the West Mountain and Northeast regions where these estimates did not reach significance). In the case of the Asian subgroup, variations in their representation in the Northeast and the Midwest Central regions were associated with increases in SLID expenditures. Finally, the representation of Hispanics was negatively associated with increases in SLID in the Northeast, with no significant differences with respect to their White counterparts in any other region.
Citizenship, areas predominantly populated with citizens born in the USA realized lower levels of this tax benefit when compared with areas populated with citizens born outside of the United States. The findings also indicate that the recipients of this tax expenditure tended to be located in areas where renting, rather than homeownership, was more prevalent. This is corroborated with a negative relationship between the proportion of mortgage holders and proportion of houses occupied by owners and SLID expenditures. More to the point, the gross rent to income ratio was positively associated with SLID benefits.
With respect to rurality indicators, Macropolitan zones realized higher disbursements of SLID than rural or remote areas in three regions of the country, South, West Mountain, and Midwest. The other regions showed no differences, and micropolitan ZIP codes had similar SLID amounts than their rural and remote counterparts in the models.
Finally, note that some states realized different amounts of SLID. For example, in the South, compared to Georgia, Florida, Louisiana, and Virginia realized lower SLID amounts, whereas Arkansas, Kentucky, South Carolina, West Virginia, and Tennessee had higher mean expenditures in this tax benefit. In the West Mountain region, where the comparison state was Texas, Colorado, Idaho, Montana, Oklahoma, and Wyoming performed better in this benefit. Utah was the only state that obtained lower amounts than Texas. Notably, in the case of the West, all comparison states performed better than California with the exception of Hawaii realizing about $98 less on average. The comparison state in the Northeast was New York, which performed better than Connecticut, Massachusetts, Maryland, and Maine. Only Pennsylvania, New Jersey, and New Hampshire realized better amounts than New York. For the Midwest region, Ohio performed better than Michigan (reference state), whereas Illinois and Wisconsin obtained lower mean SLID expenditures. The last region had Iowa as the reference group. In this region Kansas, Minnesota, Missouri, and Nebraska performed lower than this comparison state, with no state realizing higher amounts than Iowa in this region.
What Do These Findings Mean for Postsecondary Students Across Different Levels, Sectors, and Income Brackets? (Question 4)
The following findings aim to provide a practical understanding of the expected impact and distribution of SLID among students with outstanding debt balances, based on their estimated interest paid, who ultimately are the potential beneficiaries of this tax benefit. Table 4 contains the results of these analyses.
Table 4 includes mean debt amounts by income categories in raw dollar values (adjusted to 2020) along with the expected SLID benefit to be applied as an income adjustment, as calculated from Eq. (3). This latter information is presented in bold font. Additionally, to depict the distribution of these indicators more clearly, this table presents the median, and the 75th percentile amounts of debt and expected SLID benefits. All these estimates are separated by sectors and graduate and undergraduate levels. Finally, as can be seen in Table 4, all income categories mirror the income brackets reported by the IRS with two purposes. The first is to ease the comparisons with the IRS data findings, and the second to assess whether there is evidence that lower income students are expected to benefit more or less from SLID. Note that although we present the over $200,000 category in this table, we do so only as an exercise to be discussed in our closing section, for these students (and their households) are not SLID eligible.
Before presenting these findings, note that the amounts shown in bold font do not reflect the actual amounts that students may receive, but the amounts they can use to adjust their taxable income. The discussion section will present an illustration of how the amounts presented next may be translated into actual dollar amounts.
How is SLID Expected to Impact Undergraduate Students’ Taxable Incomes?
Table 4 shows that community collegesFootnote 21 alone accounted for 35% of the entire undergraduate student population (and 29.9% of the total undergraduate and graduate student bodies). In line with the literature on financial constrains faced by these students, note that 45.6% of them were classified as belonging to the first income bracket and 67.88% came from households with combined incomes of up to $50,000 (see Table 4 Panel Undergraduate, Public 2-year). Notably, students in this sector constituted the only group where at least 75% of them did not qualify for SLID because they did not accumulate enough debt to generate meaningful interest as reflected by the zeroes in the 75th percentile of the interest distribution. When community college students generated enough interest, the average SLID amount these students were expected to use to adjust their taxable incomes ranged from $75 to $108, on average, across all eligible income brackets, and once more, the vast majority are effectively removed from this benefit.
Undergraduate students enrolled in the public four-year sector had average interest amounts of around $500 and at least 50% of them (see median of the distribution in Table 4) did not generate interest in all but one income bracket ($50–$75 k). Indeed, the largest interest generated by 75% of them is $762 (see first and third income groups).
Undergraduate students in the four-year, private not-for-profit sector were more likely to benefit from SLID than all students described so far, with 50% of them being able to use up to $236 as income adjustments. Moreover, the average expected benefit to be used by these students across income brackets ranged from $736 to $980, with 25% of them generating over $947 in interest per year that could then be used as an adjustment for their taxable incomes.
Undergraduate students enrolled in the for-profit sector had similar debt balances than those enrolled in the not-for-profit sector. Finally, undergraduate students attending multiple institutions had debt balances and estimated interests more similar to those of their counterparts attending public four-year institutions, which meant similar amounts that could be used as taxable income adjustments.
How is SLID Expected to Impact Graduate Students?
Graduate students enrolled in the public four-year sector, consistently had expected mean interest amounts, that could be used for SLID, surpassing the $1400 mark. In this case, students from the first income bracket were expected to realize 80% of this subsidy that can be applied to their taxable incomes (that is $2021 of the $2500). Nonetheless, Table 4 also shows that at least 50% of graduate students in the public four-year sector were not expected to realize any SLID benefit.
Graduate students enrolled in private not-for-profit colleges had much larger mean balances which translated into interests ranging from $3380 for students in the lowest income bracketFootnote 22 to $1461 for students in the $75–$100 k bracket. At least 50% of students in the lowest income bracket generated interests larger than $1000 and at least 50% of their remaining counterparts, in the other income groups, had median interest magnitudes of $0.
The most problematic cases across all sectors, in terms of balances and interest accumulation, were observed in the for-profit sector. These graduate students reached outstanding mean debt balances over $70,000 in the first three income brackets, that is, with accumulated household incomes of up to $75,000 per year. Because of these large mean debt amounts, these students consistently surpassed the maximum SLID benefit in the first four income brackets (see footnote number 22). Finally, the debt balances and estimated interest accrued by graduate students attending multiple institutions, resembled those of their for-profit sector counterparts.
Discussion, Implications, and Closing Remarks
The study’s overarching goal was to assess how effective SLID may be in reaching lower income taxpayers. To address this goal, we offered a methodological framework that leveraged and modeled place-based income and SLID heterogeneities while also considering observed and unobserved factors that may have affected inhabitants’ prospects to participate in college—the most important prerequisite for this post-purchase federal financial aid policy, followed by having accrued enough interest to benefit from SLID. The emphasis on place-base effects is particularly salient when studying SLID because college participation is not uniformly distributed across geographical zones (Chetty et al., 2014; Iriti et al., 2018). Accordingly, we relied on multilevel modelling with spatial interaction effects to avoid the underestimation of standard errors (Dong & Harris, 2015) and offer less biased estimates.
The results consistently reflected significant differences across income brackets and SLID mean disbursements, wherein taxpayers in the lowest income bracket also tended to realize the lowest average tax benefits compared to their higher income bracket counterparts. These gaps were consistently above $235 across all comparisons, except in the Northeast region, wherein taxpayers in the $75 k to $100 k category only realized $151 more in this benefit than taxpayers in the first income bracket. Indeed, one can conclude that the Northeast region of the country is the least regressive at the top, this region demonstrated the most effective distribution of SLID across the continental United States. On the other end of the effectiveness spectrum, the Midwest consistently reflected the largest gaps in these posterior mean SLID disbursements across income brackets; accordingly, one can conclude that this region had the least effective distribution (i.e., least likely to reach lower-income taxpayers) of this tax benefit.
The models also rendered strong evidence to conclude that geographical zones with certain place-based attributes are much more prone to realize higher SLID benefits, which contributes to the overall regressiveness of SLID at the top. For example, zones with foreign income, tax energy, and educator expenses materialized much higher SLID benefits, over and above their income distributions. From this view, it is clear that geography of opportunity, where place-based advantages are associated with more advantages (Jargowsky & Tursi, 2015) is a reality with this post-purchase policy.
Is SLID Also Regressive at the Top Among College Students?
As part of our analytic journey, we also asked what the actual expected impact of SLID may be for college students as depicted in question 4. The “after-purchase” reimbursement nature (Greer & Levin, 2015) of SLID implies that, for this benefit to be realized, students not only have to enroll in college, but also have to rely on student loans, generate enough interest to meaningfully qualify for this subsidy, and fall within the adjusted income bracket thresholds. Regarding the latter point, note that this benefit excludes taxpayers in the highest income bracket (over $200,000), which according to the NPSAS datasets, only account for 3.32% and 2.02% of the total undergraduate and graduate student populations, respectively (regardless of sector). From this view, the IRS’s decision to not consider students belonging to this highest income bracket as beneficiaries, can be understood as (a) a strategy to avoid overconcentration of this benefit among the wealthiest families, or (b) a clever strategic political move. If the later scenario is true, then the removal of these affluent families translates into excluding not only the smallest percent of the student body in the entire higher education system, but also the subset of the population for whom this subsidy does not represent any meaningful change to their financial well-being—and hence, may not even be interested in partaking of this benefit. To estimate the magnitude of this expected SLID benefit for students in the over $200,000 income bracket (had they been eligible to participate in SLID), Table 4 purposefully included these students, even though they are not eligible—more on this hypothetical exercise is discussed in Table 5. Overall, considering their family incomes, the expected SLID benefits would be too minimal to actually represent a meaningful point of concern for these families resulting from their exclusion from this benefit. From this view, not only do students from these households are the minority in the higher education system, but also, they both, do not need this support and are effectively less prone to rely on this benefit—see Table 5.
Who is the Other Group Effectively Being Excluded from SLID?
The community college sector has traditionally served as the point of college entry for the most financially constrained group of students (González Canché, 2018b, 2022). Table 4 corroborates this statement in the NPSAS sample. This table shows that the community college sector alone represented the largest number of undergraduates with 6.89 million, 45.6% of whom come from families in the lowest income bracket reported by the IRS. This means that 3.15 million community college students represented in the NPSAS may be classified as living below the poverty line (see U.S. Census, 2020, poverty thresholds). These financial constrains likely imply that community college students may need to rely on financial aid sources to both afford college attendance and deal with student loan debt burden. Nonetheless, and almost ironically, it is also well-known that low income and first-generation in college students (i.e., the typical community college student) are more likely to be debt avert (Burdman, 2005) and either, do not rely on loans, or borrow much less than their more affluent peers. Debt aversion then, adds another layer of complexity for low-income students to actually realize these SLID benefits.
Our review of the undergraduate and graduate loan debt literatures indicated that whereas undergraduate lower income students tend to avoid debt burden, their graduate lower-income counterparts are more likely to rely more heavily on this form of financial aid. The distributions presented in Table 4 aligned with this literature. Specifically, Table 4 indicates that graduate students from the lowest income brackets had the highest loan amounts in both the public and private not-for-profit four-year sectors, which accounted for 87 percent of the 3.56 million graduate students represented in NPSAS. This finding then indicates that, if graduate students from these lowest income backgrounds follow the steps required to realize the SLID benefits, they would tend to benefit more from this tax break on an annual basis—for this benefit can be realized as long there is enough interest accumulated and students fall withing the MAGI limits—than both their graduate peers, and their undergraduate low-income counterparts. However, more research on this topic is needed before arguing that SLID is more effective in reaching low-income graduate than undergraduate students. The reason to be cautious about this argument is that undergraduate and graduate students in the lowest income bracket may not come from the same socioeconomic backgrounds. The former are more likely to represent their family’s financial standings, whereas the latter may not. When graduate students receive a graduate assistantship stipend and enroll full-time in their programs, such as stipend may place them in the lowest income bracket, but this may not reflect neither their savings nor the financial standing of their families, hence for graduate students being in that income bracket is not an accurate reflection of being below the poverty line, whereas it may be for their undergraduate peers.
Having said this, is SLID regressive at the top, wherein wealthier students and students attending more expensive colleges realize higher SLID benefits? Once more, the answer is yes. Public four-year students and students attending multiple institutions have expected mean interests, that can be used to claim SLID benefits, five times larger than those realized by their community college counterparts. More to the point, when comparing community college students with their private not-for-profit counterparts, the latter group were expected to realize SLID claims that were at least seven times as large as those of community college students. These findings then, indicate that there is enough evidence to conclude that students from higher income backgrounds who attend costlier colleges are expected to realize higher SLID subsidies that those who arguably need this support the most.Footnote 23 The comparisons with graduate students, reach gaps 10 times as large between community college students and their graduate student counterparts.
Finally, our analyses indicated that SLID is particularly well-suited for graduate students in the not-for-profit sector, who have debt amounts and interest rates large enough that would allow them to claim the full SLID benefits—and may eventually have high enough salaries to repay their associated high debt balances that allowed them to generate enough interest to benefit from SLID in this (virtuous or vicious?) cycle.
To close this section, we note that SLID is a well-crafted and very expensive strategy that (perhaps inadvertently) distributes subsidies away from students enrolled in the lowest income sector, which prompted us to ask: Is this tax expenditure the best we can do to support students who need the help the most? Is the interest constraint the best strategy to help reduce debt burden? Students with up to $5000 in debt are 34% likely to default, compared to 18% default chance for their peers with over $100,000 (Dynarski, 2016a). As shown in Table 4, a $5000 debt balance reflects $100 SLID support—which is quite negligible. Clearly then, SLID is designed for those who are not afraid to borrow (i.e., are not debt averse), which happen to also be those who, likely have many more means to cover their student loan debts, and for whom SLID, likely represents a smaller percentage of their income. In other words, is SLID purposefully designed to exclude the poorest, neediest students?
Translation of SLID Benefit to Actual Dollar Amounts in Students’ Pockets Annually Footnote 24
To close, let us apply a case scenario using three students. As depicted in Table 5, two of these students currently fall within the eligible income thresholds and one surpasses the allowed threshold but is included as a hypothetical exercise with empirical implications. For simplicity, also assume that all three students filled taxes as single and all three generated the maximum interest amount that can be applied toward taxable income via SLID ($2500), which according to the estimates provided in Table 4, should be around $50,000 in debt.
Note that student A falls in the first tax bracket and for her, without applying SLID, the taxes would have been $1009.50 as of 2018. If she instead applied SLID as a reduction to their taxable income, as shown in Panel A of Table 5, her federal tax owed amount would have been $750. That is, for student A, SLID translated into $259.5 USD dollars or 1.18% of her net income ($22,000 in this example and $50,000 in debt). For student B, who has a net income of $81,950, the SLID benefit would have been twice as much, reaching $550, even with the exact same interest. Finally, for student C, with the same interest paid, SLID would have translated into over three times the amount actually realized by student A.
Some may argue that these dynamics and disbursements are fair because students B and C pay higher taxes than student A. However, this table shows that with the exact same interest input, which means similar debt balances (of about $50,000), those who earn more do receive more (i.e., regressive at the top) and those for whom this help represents a larger share of their actual income (or means to repay), end up receiving less of this benefit. Note also that we assumed that student A, who fell in the first income bracket, actually had a high enough debt balance to generate the maximum interest payment to apply $2500 toward her taxable income and realize $260 in SLID support. The results shown in Table 4, clearly indicated that this was never the case among undergraduate students, and even less so, among community college students. This exercise also allows us to raise the following questions, is this $260 support worth tens of thousands of dollars in debt for low-income students? Is an added risk to default worth this arguably “negligible” amount? Note, however, that we are not assuming that students with large enough debt amounts, who generated enough interest to maximize this tax benefit, engaged more heavily in borrowing based on their knowledge of SLID. Instead, we believe that these students were going to borrow those amounts regardless of the existence of SLID and (for them) having access to this benefit represented more an unexpected boost rather than the result of a strategic decision to borrow more to maximize SLID benefits. Having said this, SLID still remains largely unknown in the financial aid literature (Bergman et al., 2019) and more research is needed to discard or corroborate the hypothesis or assertion that SLID benefits are not driving students’ borrowing amount decisions.
Based on this discussion, we close by arguing that a policy with a more equitable commitment would eliminate the interest aspect of SLID and would instead simply focus on outstanding debt balances among students, similar to the Education Credits tax benefit. That is, why do we need to subject students (particularly those from low-income households) to have to generate meaningful interest based on debt amounts that potentially double or triple their annual salary prospects, to help them cover the burden associated with their student loans? Requiring them to generate more debt to realize this tax break seems counterintuitive to addressing the student debt crisis this country has been facing for the past decade, which may worsen due to COVID-19. A modified policy based on outstanding debt balances, rather than interest, could, potentially be limited to below poverty line students with outstanding debt balances of up to $5000, for example. As it currently stands, SLID seems to be purposefully designed to exclude the poorest and neediest students from this tax benefit, which is clearly not the best that the Federal government can do to help low-income students cover debt burdens. Our analyses of this understudied policy, once more demonstrated that a one size-fits-all policy remains a weak approach that in this case is falling short in being effective to reach those who actually need this support the most.
Notes
Also referred to as “after-purchase” reimbursements (Greer & Levin, 2015, p. 50).
These costs were computed by adding all the official SLID disbursements in the 2015 tax year released by the IRS in 2018 across all ZIP codes. Our replication code (https://cutt.ly/COyfdKC) produces this finding on line 364. The univariate regression results discussed in the next paragraph can also be replicated with line 402 in our code.
In this study, we will refer to “realize this benefit” as both meeting the requirements imposed by the IRS (i.e., having debt AND accruing enough interest) to be eligible for SLID and going through all the necessary steps to “cash-in” or materialize this benefit. However, note that the realization of this benefit, as fully detailed in Table 5, means that, when students or approved taxpayers have valid loan interests, they may apply these amounts as an adjustment to the taxable income, rather than actually “cashing-in” up to $2500 as a SLID benefit.
These neighbors are the adjacent ZIP code areas for each ZIP code, or areas that share a border or touch in a given spatial point (Bivand et al., 2013). Moran’s I can be replicated with lines 369 and 370 in our code.
Moran’s I is normalized to range from − 1 to + 1, with + 1 indicating a perfect spatial correlation, suggesting a 1 to 1 increase in a given outcome measured at ZIP code i and the average outcome of its neighboring ZIP code zones.
This index ranges from 0 to 1, with 0 indicating no diversity or the dominance of one group over the others in a given zone and 1 indicating both richness in the number of groups and evenness in their representation (see Freire et al., 2020, for a recent application). See lines 407–426 in our replication code (https://cutt.ly/COyfdKC).
Following Iriti et al. (2018), lower income families located in lower income zones may have limited opportunities to learn about careers that require college education, which impact their college aspirations. Relatedly, following Chetty et al. (2020) lower income families located in higher income zones (or who moved to these zones) may be more likely to be exposed to the benefits of college life from their community networks and resources, thus expanding both their postsecondary aspirations and upward social mobility prospects.
Chetty et al. (2014) obtained estimates at the county level to test for potential bias resulting from estimating effects at the commuting zone level. This study relies on an even smaller geographical zone, by estimating the models at the ZIP code level.
Northeast: CT, DC, DE, MA, MD, ME, NH, NJ, NY, PA, RI, VT; Midwest: IL, IN, MI, OH, WI; Midwest Central: IA, KS, MI, MO, ND, NE, SD; South: AL, AR, FL, GA, KY, LA, MS, NC, SC, TN, VA, WV; West Mountain: AZ, CO, ID, MT, NM, OK, TX, UT, WY; West: AK, CA, HI, NV, OR, WA.
Note, however, that we also specified models that did not combine these divisions into the Northeast and West Mountain regions, also obtaining similar inferences to the combined results presented in this study. The similarity of these results corroborates that our decision to combine these divisions given the assumed similarity of their configuring states did not affect our inferences. These results are available in the Appendix. Moreover, the code to replicate all the procedures also include these sensitivity tests. Finally, relying on these data and code, researchers may conduct further analyses including other agencies’ and organizations’ regional divisions to further test for variations.
Note that the income brackets reported by the IRS includes the category $100,000 to 200,000$. This category then, includes some households that would not be eligible for SLID benefits (those between $170,000 and $200,000). This represents a limitation in our models for it is impossible for us to identify this subset of taxpayers in this group and this limitation should be considered when discussing the findings and any of the conclusions that apply to this income group.
Other neighbor-identification decision rules include the Rook’s (sharing a border) and Bishop’s (touching a point), see Bivand et al. (2013). These are, however, more conservative than our preferred approach, which although is more computationally expensive does not exclude potential neighbors who meet one but not both conditions.
This feature selection was implemented with the Boruta package in R (see Kursa & Rudnicki, 2010) as shown in our replication code (https://cutt.ly/COyfdKC) starting on line 445 and ending on line 498.
For undergraduate students, the rages were 4.29 to 14.92, for graduate students the rage was 5.84 to 14.92.
With the caveat that private interest rates vary according to borrowers’ tax credit. Accordingly, estimates relying on private loans should be taken with extra caution.
Equation adjusted from https://www.cnbc.com/2020/12/17/how-to-calculate-student-loan-monthly-interest-payments.html to obtain annual rather than monthly interests.
Models that ignored these matrices were also estimated and can be fitted with the dataset build with our replication code (https://cutt.ly/COyfdKC). The coefficient magnitudes of those models were consistently larger than those presented in Table 3. This difference in coefficient magnitudes may be due to an overestimation of the effect due to having ignored the variation contained in the nested and spatial structure of the data as depicted by the significance section associated with matrices \(M\) and \(W\).
Due to space constraints, the 95% credible levels are not presented in Table 3.
The analyses that included divisions 1 and 2 rather than just the West region (Table 6 in the Appendix), corroborated this pattern. Indeed, the Division 2 analyses indicated that the differences between the first- and fourth-income brackets were only $80.15 USD, but these gaps remained statistically significant.
We are referring to community colleges as those classified as public 2-year institutions. Community colleges that also offer four-year degrees are not part of our definition of community colleges in this study.
Note that while our calculations show an expected value of $3380 in the first income bracket, the maximum allowed SLID benefit to be used as a taxable income adjustment is $2500. From this view, even if students had interest amounts over $2500, the maximum amount they could have used to adjust their taxable income was $2500—see the example presented in the discussion section.
Students in the lowest income bracket attending for-profit institutions represent 61% of this undergraduate student body and also may realize about seven times the SLID support than their public 2-year counterparts.
This benefit will apply for as many years students generate enough student loan interests and meet the adjust gross income requirements discussed in the introduction of this study.
References
ACS. (2018). Understanding and using American Community Survey data: What all data users need to know. US Department of Commerce, Economics and Statistics Administration, US Census Bureau. Retrieved from https://www.census.gov/content/dam/Census/library/publications/2018/acs/acs_general_handbook_2018_ch03.pdf
Baum, S., Johnson, M., & Lee, V. (2018). Understanding college affordability. Urban Institute. http://collegeaffordability.urban.org/prices-and-expenses/forgone-earnings/
Baum, S., Ma, J., Pender, M., & Welch, M. (2016). Trends in student aid 2016. The College Board. https://research.collegeboard.org/pdf/trends-student-aid-2016-full-report.pdf
Belasco, A. S., Trivette, M. J., & Webber, K. L. (2014). Advanced degrees of debt: Analyzing the patterns and determinants of graduate student borrowing. The Review of Higher Education, 37(4), 469–497.
Bergman, P., Denning, J. T., & Manoli, D. (2019). Is information enough? The effect of information about education tax benefits on student outcomes. Journal of Policy Analysis and Management, 38(3), 706–731.
Bivand, R. S., Pebesma, E. J., & Gomez-Rubio, V. (2013). Applied spatial data analysis with R (Vol. 747248717). Springer.
Breiger, R. L. (1974). The duality of persons and groups. Social Forces, 53(2), 181–190.
Burdman, P. (2005). The student debt dilemma: Debt aversion as a barrier to college access. Center for Studies in Higher Education. https://escholarship.org/uc/item/6sp9787j
Chetty, R., Hendren, N., Kline, P., & Saez, E. (2014). Where is the land of opportunity? The geography of intergenerational mobility in the United States. The Quarterly Journal of Economics, 129(4), 1553–1623.
Chetty, R., Friedman, J. N., Hendren, N., Jones, M. R., & Porter, S. R. (2020). The opportunity atlas: Mapping the childhood roots of social mobility (No. w25147). National Bureau of Economic Research. https://opportunityinsights.org/wp-content/uploads/2018/10/atlas_paper.pdf
Chudry, F., Foxall, G., & Pallister, J. (2011). Exploring attitudes and predicting intentions: Profiling student debtors using an extended theory of planned behavior. Journal of Applied Social Psychology, 41(1), 119–149.
Crandall-Hollick, M. L. (2018). Higher education tax benefits: Brief overview and budgetary effects. CRS Report R41967, Version 40. Updated. Congressional Research Service.
Deming, D., & Dynarski, S. (2010). 10. College aid (pp. 83–302). University of Chicago Press.
Denning, J. T., Marx, B. M., & Turner, L. J. (2019). ProPelled: The effects of grants on graduation, earnings, and welfare. American Economic Journal: Applied Economics, 11(3), 193–224.
Dong, G., Harris, R., Jones, K., & Yu, J. (2015). Multilevel modelling with spatial interaction effects with application to an emerging land market in Beijing, China. PLoS ONE, 10(6), e0130761.
Dong, G., & Harris, R. (2015). Spatial autoregressive models for geographically hierarchical data structures. Geographical Analysis, 47(2), 173–191.
Dynarski, S. (2016). The trouble with student loans? Low earnings, not high debt. Brookings Note. https://www.brookings.edu/research/the-trouble-with-student-loans-low-earnings-not-high-debt/
Dynarski, S. M. (2016). The dividing line between haves and have-nots in home ownership: Education, not student debt. Evidence Speaks Reports, 1(17). https://www.brookings.edu/research/the-dividing-line-between-haves-and-have-nots-in-home-ownership-education-not-student-debt/
Dynarski, S. M., & Kreisman, D. (2013). Loans for educational opportunity: Making borrowing work for today’s students. https://www.brookings.edu/wp-content/uploads/2016/06/THP_DynarskiDiscPaper_Final.pdf
Dynarski, S. M., & Scott-Clayton, J. E. (2006). The cost of complexity in federal student aid: Lessons from optimal tax theory and behavioral economics. National Tax Journal, 59(2), 319–356.
Elliott, W., Grinstein-Weiss, M., & Nam, I. (2013). Does outstanding student debt reduce asset accumulation (Tech. Rep.). CSD Working Paper 13–32. St. Louis, MO: Washington University, Center for Social Development.
Elijah, A. (1990). Streetwise: Race, class, and change in an urban community. University of Chicago.
Federal Reserve Bank of New York. (2021). Quarterly report on household debt and credit. https://www.newyorkfed.org/medialibrary/interactives/householdcredit/data/xls/HHD_C_Report_2019Q4.xlsx
Freire, A., Porcaro, L., & Gómez, E. (2020). Measuring diversity of artificial intelligence conferences. arXiv preprint https://arxiv.org/abs/2001.07038
González Canché, M. S. (2014a). Is the community college a less expensive path toward a bachelor’s degree? Public 2-and 4-year colleges’ impact on loan debt. The Journal of Higher Education, 85(5), 723–759.
González Canché, M. S. (2014b). Localized competition in the non-resident student market. Economics of Education Review, 43, 21–35.
González Canché, M. S. (2017a). Financial benefits of rapid student loan repayment: An analytic framework employing two decades of data. The ANNALS of the American Academy of Political and Social Science, 671(1), 154–182.
González Canché, M. S. (2017b). The heterogeneous non-resident student body: Measuring the effect of out-ofstate students’ home-state wealth on tuition and fee price variations. Research in Higher Education, 58(2), 141–183.
González Canché, M. S. (2018a). Geographical network analysis and spatial econometrics as tools to enhance our understanding of student migration patterns and benefits in the US higher education network. The Review of Higher Education, 41(2), 169–216.
González Canché, M. S. (2018b). Reassessing the two-year sector’s role in the amelioration of a persistent socioeconomic gap: A proposed analytical framework for the study of community college effects in the big and geocoded data and quasi-experimental era. In Higher education: Handbook of theory and research (pp. 175–238).
González Canché, M. S. (2019). Geographical, statistical, and qualitative network analysis: A multifaceted method-bridging tool to reveal and model meaningful structures in education research. In J. C. Smart (Ed.), Higher education: Handbook of theory and research (pp. 535–634). Springer.
González Canché, M. S. (2020). Community college students who attained a 4-year degree accrued lower student loan debt than 4-year entrants over 2 decades: Is a 10 percent debt accumulation reduction worth the added “risk”? If so, for whom? Research in Higher Education, 61(7), 871–915.
González Canché, M. S. (2022). Community colleges’ out-of-state transfer articulation agreements: An exploratory spatial network analysis of their prevalence, characteristics, and potential implications. In C. C. White (Ed.), Advocacy for change: Positioning community colleges for the next 75 years. New Directions for Community Colleges, 197. Wiley.
Greer, J., & Levin, E. (2015). Upside down: Higher-education tax spending. First Focus.
Gross, J. P., Cekic, O., Hossler, D., & Hillman, N. (2009). What matters in student loan default: A review of the research literature. Journal of Student Financial Aid, 39(1), 19–29.
Hawk, W. (2013). Expenditures of urban and rural households in 2011. U.S. Bureau of Labor Statistics. https://www.bls.gov/opub/btn/volume-2/expenditures-of-urban-and-rural-households-in-2011.htm
Hoxby, C. M., & Bulman, G. B. (2016). The effects of the tax deduction for postsecondary tuition: Implications for structuring tax-based aid. Economics of Education Review, 51, 23–60.
Iriti, J., Page, L. C., & Bickel, W. E. (2018). Place-based scholarships: Catalysts for systems reform to improve postsecondary attainment. International Journal of Educational Development, 58, 137–148.
IRS. (2019). Publication 970 (2019), Tax Benefits for Education. https://www.irs.gov/publications/p970/ch04.html
IRS. (2020). SOI Tax Stats-Individual Income Tax Statistics-ZIP Code Data (SOI). https://www.irs.gov/statistics/soi-tax-stats-individual-income-tax-statistics-ZIP-code-data-soi
Jargowsky, P. A., & Tursi, N. O. (2015). Concentrated disadvantage. In D. W. James (Ed.), International encyclopedia of the social and behavioral sciences (2nd ed., pp. 525–530). Elsevier.
Johnson, M. T. (2013). Borrowing constraints, college enrollment, and delayed entry. Journal of Labor Economics, 31, 669–725. https://doi.org/10.1086/669964
Jones, K., & Duncan, C. (1995). Individuals and their ecologies: Analysing the geography of chronic illness within a multilevel modelling framework. Health & Place, 1(1), 27–40.
Kim, D., & Otts, C. (2010). The effect of loans on time to doctorate degree: Differences by race/ethnicity, field of study, and institutional characteristics. The Journal of Higher Education, 81(1), 1–32.
Kursa, M. B., & Rudnicki, W. R. (2010). Feature selection with the Boruta package. Journal of Statistical Software, 36(11), 1–13.
Lee, J. C., Ciarimboli, E. B., Rubin, P. G., & González Canché, M. S. (2020). Borrowing smarter or borrowing more? Investigating the effects of a change in federal loan policy. The Journal of Higher Education, 91(4), 483–513.
Li, J., Tran, M., & Siwabessy, J. (2016). Selecting optimal random forest predictive models: A case study on predicting the spatial distribution of seabed hardness. PLoS ONE, 11(2), e0149089.
Lloyd, C. (2010). Spatial data analysis: An introduction for GIS users. Oxford University Press.
Lusting, M. (October, 2020). How cost of attendance affects student loans: Looking at a college's COA can indicate how much you may need to borrow in student loans. U.S. News & World Report. https://www.usnews.com/education/blogs/student-loan-ranger/articles/what-does-cost-of-attendance-mean-and-how-does-it-affect-my-student-loans
Manoli, D. S., & Turner, N. (2018). Cash-on-hand & college enrollment: Evidence from population tax data and policy nonlinearities. American Economic Journal: Economic Policy, 10, 242–271.
Pacione, M. (1997). The geography of educational disadvantage in Glasgow. Applied Geography, 17(3), 169–192.
Pastor, M., Jr. (2001). Geography and opportunity. In N. J. Smelser, W. J. Wilson, & F. Mitchell (Eds.), America becoming: racial trends and their consequences (Vol. 1, pp. 435–467). National Academy Press.
Poterba, J. M. (2011). Introduction: Economic analysis of tax expenditures. National Tax Journal, 64(2), 451–457.
Pyne, J., & Grodsky, E. (2020). Inequality and opportunity in a perfect storm of graduate student debt. Sociology of Education, 93(1), 20–39.
Raftery, A. E., & Lewis, S. (1991). How many iterations in the Gibbs sampler? (Tech. rep.). WASHINGTON UNIV SEATTLE DEPT OF STATISTICS. https://apps.dtic.mil/sti/pdfs/ADA640705.pdf
Rosen, H. S. (1985). Housing subsidies: Effects on housing decisions, efficiency, and equity. Handbook of Public Economics, 1(1), 375–420.
Rothstein, J., & Rouse, C. E. (2011). Constrained after college: Student loans and early-career occupational choices. Journal of Public Economics, 95(1–2), 149–163.
Saez, E., & Zucman, G. (2019). The triumph of injustice: How the rich dodge taxes and how to make them pay. WW Norton & Company.
Scott, A. J., Lewis, A., & Lea, S. E. (2001). Student debt: The causes and consequences of undergraduate borrowing. The Policy Press.
Simpson, E. H. (1949). Measurement of diversity. Nature, 163(4148), 688.
Tate, W. F., IV. (2008). “Geography of opportunity”: Poverty, place, and educational outcomes. Educational Researcher, 37(7), 397–411.
Cho, S. H., Xu, Y., & Kiss, D. E. (2015). Understanding student loan decisions: A literature review. Family and Consumer Sciences Research Journal, 43(3), 229–243.
NCES. (2019). Total fall enrollment in degree-granting postsecondary institutions, by level and control of institution and race/ethnicity of student: Selected years, 1970 through 2016. https://nces.ed.gov/programs/digest/d17/tables/xls/tabn303.40.xls
U.S. Department of Agriculture Economic Research Service. (2019). Rural-urban commuting area codes. https://www.ers.usda.gov/webdocs/DataFiles/53241/ruca2010revised.xlsx?v=8632.5
U.S. Department of Commerce Economics and Statistics Administration. (2013). Census Bureau Regions and Divisions. https://www2.census.gov/geo/pdfs/maps-data/maps/reference/us_regdiv.pdf
U.S. Census. (2020). Poverty Thresholds 2016. https://www2.census.gov/programs-surveys/cps/tables/time-series/historical-poverty-thresholds/thresh16.xls
U.S. Department of Education. (2020). Understand how interest is calculated and what fees are associated with your federal student loan. Federal Student Aid. https://studentaid.gov/understand-aid/types/loans/interest-rates
Webber, K. L., & Burns, R. (2021). Increases in graduate student debt in the US: 2000 to 2016. Research in Higher Education, 62(5), 709–732.
Weicher, J. C. (1979). Urban housing policy. In P. M. Mieszkowski & M. R. Straszheim (Eds.), Current issues in urban economics (pp. 469–508). The John Hopkins Press.
Acknowledgements
All errors remain mine. The author is thankful for all reviewers’ comments, recommendations, and suggestions.
Funding
Research sponsored by the National Academy of Education, Spencer Foundation. Findings do not represent these entities’ viewpoints.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The author reports no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Rights and permissions
About this article

Cite this article
González Canché, M.S. Post-purchase Federal Financial Aid: How (in)Effective is the IRS’s Student Loan Interest Deduction (SLID) in Reaching Lower-Income Taxpayers and Students?. Res High Educ 63, 933–986 (2022). https://doi.org/10.1007/s11162-021-09672-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11162-021-09672-6
Keywords
- Post-purchase federal financial aid policies
- Tax breaks incentives
- Multilevel modelling with spatial interaction effects
- Hierarchical simultaneous autorregressive models
- Regressive at the top policies
- Geography of disadvantage
- Policy analysis
- Machine learning
- Social stratification
- Spatial econometrics
- Higher education finance
- Community colleges & public 2-year colleges
- Taxable income
- Social and spatial context
- Geographical information systems
- Reproducible research
- Data science
- Data visualization
- Equity
- Geography of advantage and disadvantage
- Geopolitics
- Neighborhood effects
- Bayesian spatial statistics
- Social policy
- Economic sociology
- Economic geography