
Abstract
Since the late 1970s the international ICES mackerel egg survey takes place in the Northeast Atlantic to obtain an estimate of total annual egg production (TAEP), to assess the spawning stock biomass and to support the sustainable management of the mackerel stock. However, its standard calculation of TAEP has some shortcomings: egg production is estimated from arithmetic averages of individual observations regardless whether they are extreme, rarely observed values, and has shown difficulties coping with the spatial expansion of mackerel spawning observed since 2007 (increasing the number of interpolated estimates). Various previous modeling efforts attempted to map the habitat of spawning mackerel to obtain more accurate egg production estimates by using generalized additive models (GAMs). In this study, we review and improve these models by introducing new features: We model both the western and southern components of the mackerel stock with a Tweedie distribution and test more than 400 model forms, including new predictors (like population size) and complex covariate interactions. We select the best model with various metrics, including the score of a tenfold cross validation. Our results show that environmental variables should be included in the model as simple functional, unimodal terms. This leads to a model that is more similar to a generalized linear mixed model than the typical GAM with smoothers. Models including only smoothers performed worse as they have a poor skill to extrapolate beyond the sampled region. Additionally, accounting for the effect of population size on the spatial distribution of eggs was shown to be fundamental to better model performance.
Graphical abstract

Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
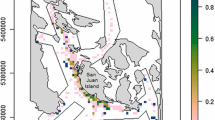
Mackerel (Scomber scombrus, Linnaeus 1758) in the Northeast Atlantic represents one of the most important fish stocks in Europe, with a total annual catch of currently almost 1 million tons valuing more than 1 billion Euros (ICES 2019a). The stock is assessed annually based on catch at age data from commercial fisheries adjusted by the results of four fishery-independent surveys organized by the International Council for the Exploration of the Sea (ICES; more details about the assessment are given in “Total annual egg production” section). One of these surveys is the triennial mackerel egg survey (see study area in Fig. 1), that commenced in 1977 (Lockwood et al. 1981), providing the only fishery independent estimate of mackerel spawning stock biomass (SSB). Mackerel SSB is estimated as a function of total annual egg production (TAEP), fecundity per gram of female weight and sex ratio (ICES 2019b) and is used as a relative index in the assessment.

Sampling region of the ICES mackerel egg survey in the Northeast Atlantic. The gray area is the enclosed mapping region (alpha shape) for the arbitrarily chosen year 2010, constructed with a Delaunay triangulation of egg sampling positions. Lines joining the positions of the egg hauls (dots) are edges of Delaunay triangles
In order to cover the spatio-temporal distribution of the spawning season from south to north along the European shelf, the survey area is sampled several times during consecutive survey periods. The survey area is divided into rectangles of 0.5° and one plankton sample is taken at the midpoint of each rectangle (replicates are taken in some rectangles, mainly in past surveys like 1992 and 1995). From each sample, all eggs are sorted, identified to species and staged. For TAEP estimation, only stage 1 eggs are used. Eggs develop faster as water temperature increases and stage-1 duration usually differs from 24 h. Therefore, a temperature dependent stage duration function from laboratory experiments (Mendiola et al. 2006) is used to estimate the daily egg production per m2. Sample replicates are averaged (arithmetic mean) inside each rectangle for each survey period. In case of unsampled rectangles inside the survey area, daily egg production per m2 is interpolated from the immediately neighboring (i.e. 2–8 adjacent) sampled rectangles for each survey period. Linear interpolation from neighboring rectangles is undertaken for all unsampled rectangles that have at least two sampled rectangles in their immediate neighborhood. These values, sampled, averaged or interpolated, are then projected to the entire area of the sampled rectangle and subsequently summed over the entire survey area of the respective sampling period. Multiplication with the duration of the spawning period results in the total egg production. For sampling periods that are not directly consecutive, the egg production of the intermediate period is also calculated by linear interpolation. The sum of the total egg production of all periods delivers the TAEP. More details of this analysis are given in “Total annual egg production” section below and in the manual of the Working Group on Mackerel and Horse Mackerel Egg Survey (WGMEGS; ICES 2019b).
While this standard method for TAEP is a useful first approximation to the problem, its simplicity implies also some shortcomings: the distribution of egg counts are often skewed and, for skewed distributions (and small subsamples), the arithmetic mean used for replicates and interpolation can be a poor estimate of central tendency in comparison to other statistics like the median (Le 2003; Urdan 2005; Shahbaba 2012) or in comparison to more advanced statistical methods like generalized linear or additive models (GLMs/GAMs). These methods account for skewness by means of an assumed distribution of model residuals and use of a link function. Moreover, in 2007, the mackerel spawning area started to expand towards the North and North West, far beyond the original survey boundaries. Since then, due limited survey budgets, it was not possible to cover the complete spawning area anymore. Failure to include all contributions results in a biased low (i.e. less accurate) egg production (EP) per sampling period. Additionally, the associated decrease in replicates and the increase of unsampled spaces between observations reduces the precision of EP. Furthermore, the standard method weighs every individual observation equally, independently of its probability of occurrence. Therefore, rarely observed extreme values can potentially inflate the total egg production if their magnitude is disproportionally large in comparison to their probability of occurrence. Finally, the standard method cannot extrapolate egg production estimates to regions beyond the survey boundaries, which could be useful for survey planning. GLMs/GAMs can extrapolate geographically provided that adequate functional forms for the response are used and exploiting the relation between response and environmental variables (meaning an interpolation not only in geographical coordinates but also in the space of environmental variables).
Six previous studies (Borchers et al. 1997; Augustin et al. 1998; Beare and Reid 2002; Hughes et al. 2014; Bruge et al. 2016; Brunel et al. 2018; see also Table S1) developed habitat models to study the spatio-temporal distribution of mackerel eggs in the Northeast Atlantic, two of them (Borchers et al. 1997; Augustin et al. 1998) with the explicit intention of overcoming the problems of the standard calculation of TAEP. All previous studies used Generalized Additive Models (GAMs; Hastie and Tibshirani 1986). Until now, no one had compared these methods or tested their performance to obtain a realistic estimate of TAEP beyond a single year (1992 in the case of Borchers et al. 1997; 1995 in the case of Augustin et al. 1998). Therefore, the ability of previous modeling efforts to replace the standard method for TAEP remains unclear. The main goal of this study is also to use habitat modeling to map the spawning habitat in order to improve the calculation of TAEP over both the standard method and previous modeling efforts. Therefore, we review previous model configurations, evaluate their ability to replace the standard method and introduce various novel modeling approaches for improvement: Predictors that have yet to be tested (like spatially resolved bathymetry gradient or average population size), definition of an alpha shape mapping region, use of the Tweedie distribution (Tweedie 1984), test of a large number (452) of non-linear functional forms (including many complex interactions between predictors) and a model selection approach using tenfold cross validation.
Data
Egg production data
The Annual Egg Production Method used for the Northeast Atlantic mackerel stock to determine its spawning stock biomass, consists on the estimation of the TAEP. TAEP is calculated from the daily production of recently spawned mackerel eggs over the entire spawning area, covering an area west of the Iberian Peninsula up to the Norwegian Sea, progressing from South to North over the whole spawning season between January and July. The spawning season is partitioned into a small number of discrete survey ‘periods’, within which a reasonable proportion of the spawning area has been sampled.
The egg surveys involve collecting samples of ichthyoplankton from predefined rectangles. The survey vessels sail along latitudinal transects, collecting samples at 0.5°W intervals until no more mackerel eggs are encountered. The ships will then turn around and sample a parallel transect. Each transect is separated by 0.5°N, so that the samples represent half an ICES statistical rectangle. The mackerel eggs are then identified and extracted from the samples, staged, and counted. Only the number of stage I eggs are considered, which are freshly spawned eggs, from fertilization until first signs of the developing embryo, i.e. the formation of the primitive streak (Simpson 1959; Lockwood et al. 1981). All other stages (i.e. stages II–V), characterized by growth of the embryo are excluded from egg production estimation. The reason for this is to avoid accounting for highly variable mortality rates of the developing eggs owing e.g. predation, cannibalism, disease, unfavorable temperatures and oxygen levels (Hempel 1979).
Stage I mackerel eggs were sorted from samples taken during ICES joint expeditions every three years from 1992 to 2019 (ICES 2019b), counted and standardized to numbers per m2 sea surface utilizing flowmeter data for filtered volume of water and maximum sampling depth, i.e. 200 m or 5 m above the seafloor, whichever occurred first during sampling (ICES 2019b; data freely available at ICES 2019c). Data collected before 1992 had not been quality checked and, therefore, were not considered in the present study.
Egg production (EP) per square meter per day (daily egg production) was calculated using the model of Mendiola et al. (2006) for stage duration:
where I is the incubation time in hours of stage I and T is temperature in °C. These data were then divided into six sampling periods of roughly 30 days, defined by the Julian day as shown in Table 1. The regular sampling periods were preferred for the present modelling study and still closely resembled the irregular survey periods used in the standard methodology. The spawning stock biomass (SSB) from the 2020 advice (ICES 2020) was used to compare the TAEP from the habitat model (i.e., as goodness-of-fit criterion; “Total annual egg production” and “Model selection” sections below).
Environmental data
We used data of various environmental variables to model the spatiotemporal variations of mackerel EP. When choosing these model predictors, we kept in mind the previous studies (Table S1), in order to complement or improve them. Most previous studies (Borchers et al. 1997; Augustin et al. 1998; Beare and Reid 2002; Hughes et al. 2014) used in situ observations. However, Núñez-Riboni et al. (2021) showed that the use of in situ data in fish habitat models is only advisable when focusing on small-scale variations, such as the influence of eddies. As the current study analyses features at large spatial scales (i.e., climatic variations), we intentionally did not use in situ data and also did not interpolate gridded environmental variables to fit to sampling sites (Núñez-Riboni et al. 2021). Instead, we downsampled (i.e., filtered and decimated) gridded environmental variables and aggregated observed EP to a resolution of 1° in both, N–S and W–E direction, to fit the habitat model. The scale of 1° was chosen because it is roughly twice the average distance between egg sampling stations, while predictions were made on the original resolution of the survey (0.5°; see Núñez-Riboni et al. 2021). The use of gridded data as predictors is similar to that of Bruge et al. (2016) and Brunel et al. (2018).
We tested all variables that were used as predictors in previous studies (see Table S1), i.e. bathymetry, sea surface temperature (SST), sampling position, mixed layer depth (MLD), surface salinity, sea surface height (SSH) and measures of time like Julian day and year. We used bathymetry (with 1’ resolution) from the Global Relief Model ETOPO1 (Amante and Eakins 2009), while SST, surface salinity, MLD, SSH and current speed (all with resolution 1° × 1/3°) were obtained from the Global Ocean Data Assimilation System (GODAS) from the U.S. National Centers for Environmental Prediction (NCEP; Behringer and Xue 2004; GODAS 2021). The same ocean model (or ocean “reanalysis”) was used by Bruge et al. (2016). We extracted all data in the region 23°W to 5°E and 35° to 64°N.
We tested additional variables to fit the habitat model. Borchers et al. (1997), Augustin et al. (1998) and Beare and Reid (2002) used the distance to the 200 m isobath as a predictor. This follows the idea that the European continental shelf break has an effect and should be used as a proxy for spawning activity (Beare and Reid 2002). In this study, we model this effect with the magnitude of the ETOPO1 bathymetry gradient (in geographical degrees), which is similar to the approach of Borchers et al. (1997) and is justified in detail in “Effect of bathymetry gradient” section. To calculate the bathymetry gradient, it makes a difference to first downsample and then calculate the gradient than doing it the other way round. We chose to first calculate the gradient from the 1′-bathymetry and then downsample (to 0.5° and 1.0°) because the inverse procedure seemed to distort the bathymetry gradient.
In this study we tested for the first time the association of two variables with egg production: Eddy Kinetic Energy (EKE; see Richardson 1983), which is a measure of current speed variance, and (relative) vorticity (Stewart 2008, his Eq. 12.2), which is a measure of local rotational flow. The motivation for testing these variables is that regions of high egg density could result from retention following high turbulence, eddies or gyral circulation.
Ocean reanalyses like GODAS allow designing the habitat model by testing various environmental variables potentially influencing EP, with some variables (MLD and current speed) which cannot be observed at large spatial scales. As a drawback, models can potentially be inaccurate and, most importantly, their outputs are rarely updated (once a year or less). This contrasts with satellite imagery, which is a direct observation of ocean conditions and is updated daily or weekly. Because (as it will be shown in “Best model” section below) SST was the only GODAS variable included in the optimal model, once the habitat model was designed with GODAS, observed SST from the Operational Sea Surface Temperature and Ice Analysis (OSTIA; Copernicus 2021) was additionally incorporated in the analysis. This allows modeling of the recent or even current spatial distribution of EP, which could be an important support tool for survey design.
We did not use satellite surface chlorophyll as a predictor as used in previous studies (Bruge et al. 2016), because the time series starts in 1998, i.e., it does not cover the entire time series of the survey. Additionally, Bruge et al. (2016) found that this variable only explained a small amount of model deviance in comparison to the other variables and that its temporal trends were not statistically significant (concluding that it did not influence the observed spatial shift of the spawning area). We also did not test country (or, equivalently, sampling vessel) because this variable was not selected in the optimal model of Borchers et al. (1997) by their backward stepwise selection, which corresponds to the idea of a good survey design (i.e., there is no vessel bias in the sampling). A summary of relevant environmental data and variables used as predictors in this study is shown in Table 2.
Methods
Modeling the mackerel spawning habitat
We modeled EP as function of environmental variables using various generalized additive models (GAM; Hastie and Tibshirani 1986). A novel approach in this study in comparison to the previous ones is the use of a Tweedie distribution (Tweedie 1984). A detailed justification for the use of the Tweedie model over the methods used in previous studies (like the hurdle model of Bruge et al. 2016) will be given in “Comparison with previous modeling efforts” section below. Further, we chose a logarithmic link, which is the canonical link of the Tweedie distribution, and which has been used in all previous modeling efforts of mackerel EP except for Hughes et al. (2014), who used a logit link. GAMs were fitted using the package “mgcv” (Mixed GAM Computation Vehicle; Wood 2017) from R, version 3.6.3.
All variables shown in Table 2 were tested (together with EKE and vorticity), either as individual model terms (i.e., added up in the model equation) or combined as interactive model terms (i.e., a multiplication of one or more simple functions of a variable). Only a few variables were not tested in combination because they were strongly correlated to each other. In this case, either one or the other variable was used, but not both. “Strongly correlated” was defined as Pearson correlation ρ ≥ 0.6. Strongly correlated variables, spatially and/or temporally, were temperature and salinity, temperature and SSH, bathymetry and MLD (only spatially), current speed and EKE, as well as SSH and MLD (only spatially).
In addition to the environmental variables, we tested a measure of population size S as a predictor. Although Brunel et al. (2018) also addressed this issue, explicitly including the effect of population size in the habitat model is also a novel approach for mackerel eggs. For this we tested the sum, median and average EP of each sampling period. The use of population size averages as predictor should take into account fluctuations that apply to the entire stock (i.e. unlocalized) due to population dynamics (fishery and recruitment). Pinsky et al. (2013) used annual average biomass as predictor while Stige et al. (2017) used average individual weight (related to egg abundance of the spawning stock). To account for the effect of population size on the spatial distribution of fish, a measure of population size should appear in the model as an interaction with spatially-resolved predictors such as temperature (Núñez-Riboni et al. 2019). More details about this are given in Section S1 of the Supplement.
We tested 452 GAMs based on various model terms including all predictors described above and their combinations (Table 2). Some of the model terms were defined as penalized thin-plate spline smoothers (Wood 2017) of individual predictors, which was the common approach in previous studies (Table S1). We also tested smoothers of the geographical position of EP or time with thin-plate (Wood 2017) and Gaussian-Process bases (Kammann and Wand 2003). These smoothers should deal with unresolved (residual) spatial or temporal autocorrelation due to intrinsic factors or with geographical attachment (see for instance Planque et al. 2011; Brunel et al. 2018; Núñez-Riboni et al. 2019). As in all previous studies (except Hughes et al. 2014), we tested smoothers with a low basis dimension k (between 3 and 7), which should be similar to the concept of the ecological niche of Hutchinson (1957), i.e. habitat suitability has a single optimum inside a range of environmental values, beyond which the suitability decreases to zero. In addition, we also tested large basis dimensions (as large as k = 150) for some of the smoothers, like the geographical attachment. The time variables like year or Julian day were treated as continuous variables (inside non-penalized spline smoothers) and not as factor, similar to Augustin et al. (1998).
In addition to the penalized smoothers, we also tested individual model terms defined as simple functions of one or more variables, i.e. similar to a generalized linear model (GLM; McCullagh and Nelder 1989), sometimes also in combination with smoothers (i.e., still a GAM by definition, in spite of the simple functions; Wood 2017). By exploring the individual scatter plots of EP against environmental variables (see Figure S2 in the Supplement), these functional terms were chosen as combinations of polynomials with degree ≤ 2. Predictors were sometimes transformed with functions logarithmic, square-root or inverse multiplicative (Table 2). In combination with the logarithmic link, such polynomials result in a unimodal relationship (possibly asymmetric), similar to the low-k smoothers and thus, also resembling Hutchinson’s ecology niche (Núñez-Riboni et al. 2021). These simple functions have even fewer degrees of freedom than the low-k smoothers and are, thus, less prone to boundary problems and more appropriate for extrapolation (Núñez-Riboni et al. 2021). While some studies tested similar models (Borchers et al. 1997; Augustin et al. 1998; Beare and Reid 2002), they only used linear predictors. To date, no mackerel egg modeling study tried the quadratic polynomials required (in combination with the logarithmic link) to obtain unimodal responses.
An arbitrarily chosen example of one of the 452 GAMs tested is:
where \(\widehat{EP}\) is the modeled egg production, \(\nabla B\) is the bathymetry gradient, T is temperature, sGP is a Gaussian-Process smooth, lon is longitude, lat is latitude and the αn’s the model parameters to be fitted. Before describing the model selection in “Model selection” section, we describe the calculation of total annual egg production (TAEP) because it was used as one criterion of goodness-of-fit.
Total annual egg production
For each tested model, we calculated the resulting total annual egg production (TAEP). To map EP with the model, a regular grid with the same average resolution of the ICES survey (0.5° × 0.5°) was constructed matching the majority of the survey’s sampling positions. For calculation of the TAEP, the exact region where the EP estimates are calculated is fundamental, particularly considering the poor extrapolation properties of spline smoothers (Núñez-Riboni et al. 2021). Therefore, EP was predicted with the model only on grid points lying inside an enclosed region defined with the EP sampling positions. This so-called “alpha shape” (Edelsbrunner et al. 1983) was constructed from Delaunay triangles (Swan and Sandilands 1995) with all three sides smaller than three geographical degrees. Such mapping region ensures that the model estimates arise only from observations within the edges of the sampling region. Therefore, extrapolated estimates (or “boundary effects” of the smoothing splines) are limited. Points outside the Delaunay triangulation but close to one observation at a distance of 0.1° or less were also included in the mapping grid (to include mapping points located on isolated tracks). Any grid point lying on land was excluded from the mapping grid. An alpha shape mapping region was constructed for each survey year, allowing time interpolation between sampling periods and some spatial extrapolation (particularly in the first and last sampling periods). An example of a mapping region is shown in Fig. 1.
Once EP was mapped with a GAM over all periods, the TAEP was calculated following the standard method (Sect. 10.2 of ICES 2019b). First, the area Ai of the ith model grid cell was calculated with:
where R is the Earth’s radius, i.e., R = 6,371,000 m and the cell size S = 0.5°, as mentioned above. The total daily EP (DEP) in the ith grid cell is:
where the upper script c emphasizes that this is DEP per grid cell. Therefore, the total DEP for the whole mapping region, year Y and sampling period P was the sum over all n grid cells:
Finally, the total annual EP for year Y was obtained by integrating each of the individual contributions \({EP}_{Y}^{P}\) over all six sampling periods:
where dDP is the length of the Pth sampling period (see Table 1).
To evaluate the improvement of the modeled TAEP over the standard method, results from both were converted to SSB utilizing the correspondence between EP and fecundity. Female fecundity is calculated from data collected immediately prior to spawn and is corrected for atresia (eggs reabsorbed during the spawning season; ICES 2019b, d, 2021). Fecundity varies over time and is determined from adult mackerel samples taken during each survey. The resulting SSB estimate is compared to SSB from the ICES advice, called from now on SSB(assess). This is considered to be the most accurate estimate of SSB because of the many data sources used in the assessment (ICES 2020).Footnote 1 Therefore, estimates of SSB from both standard and modeled TAEP were calculated using the dependence between EP and fish fecundity:
where K is a correction factor (1.08) to adjust pre-spawning to average spawning fish weight (ICES 1987, 1993), the sex-ratio value is 0.5 assuming equal weight of males and females and the realized fecundity is the average number of eggs per g female. These time series will be called SSB(TAEPst) and SSB(TAEPmod) for the standard and the modeled TAEP respectively. Equation 4 is also used to estimate 68% confidence limits for SSB(TAEPst), defined with SSB(TAEPst ± σ), where σ is the spatial standard deviation of egg production in each year (the uncertainty of fecundity is considered negligible).
Confidence limits for SSB(TAEPmod), accounting for the uncertainty in both, the model term parameters and smoothing parameter λ, were calculated following a procedure described by Wood (2017, Sects. 6.10 and 7.2.7): Model pseudo-parameters are constructed randomly according to a multivariate normal distribution centered on the fitted parameters of the best model. The width of the distribution is given by the theoretical variance–covariance matrix of the model parameters as calculated from their Bayesian posterior distribution. Following this approach, we generated 1000 sets of pseudo-parameters, evaluated the resulting models and calculated a SSB(TAEPmod) for each parameter set. This led to a distribution of 1000 estimates of SSBy(TAEPmod) per year Y, which in turn allowed the calculation of the 0.05 and 0.95 quantiles from their empirical histograms.
Model selection
In a first stage of our model design, we intentionally rejected an automatic search for the best model using performance metrics and went through the more arduous process of visually evaluating the individual output of 179 models. A similar evaluation of model output was followed by Borchers et al. (1997) and Augustin et al. (1998). In our case, we rejected a model if at least one of the following four quality criteria was not fulfilled:
-
1.
The shape of the partial effect of at least one environmental predictor was unreasonable. For instance, the bathymetry curve did not favor shallow waters, bathymetry gradient or temperature curves were unbounded (growing up to infinity) or did not show an optimum within a reasonable range of values. These criteria follow the concept of environmental niche (Hutchinson 1957) and the notion that biomass is always finite, as well as scatter plots of EP against environmental variables (Figure S2) which show, e.g., that EP is generally higher in shallow waters;
-
2.
One model term was not significant with at least 90% confidence (i.e., p value > 0.1).
-
3.
TAEPmod differed from TAEPst or SSB(TAEPmod) from SSB(assess) in more than one order of magnitude;
-
4.
The modeled annual egg production curves remained open at the beginning or the end of the year, instead of converging to zero (see examples of this in Figure S3 in the supplement).
With this preliminary analysis, we gained insight into the failure of penalized smoothers to extrapolate or to interpolate over large regions, the importance of variable interactions and the explicit inclusion of population size S as predictor to correctly model the EP monthly changes. At the end of this first modeling stage, we selected a small number (eight) of models (Table S2 in the supplement) fulfilling all four quality criteria above. These eight models were compared and further developed, now with a semi-automated method using a series of performance metrics. Because the most realistic models do not always have the best performance metrics (Burnham and Anderson 2002) and different performance metrics often select different models, we did not base our model selection on one single metric alone but on the following:
-
1.
Two parsimony metrics: The Akaike Information Criterion (AIC; Akaike 1974) and the Bayesian Information Criterion (BIC; Schwarz 1978). Use of AIC is similar to Beare and Reid (2002), Hughes et al. (2014) and Bruge et al. (2016). The two metrics differ in that BIC should tend to select more simple models than AIC (Schwarz 1978), while there is some evidence that AIC should perform better in selecting the best model (e.g., Sect. 6.4.3 of Burnham and Anderson 1998);
-
2.
The root mean square (RMS) difference between the TAEPmod and TAEPst as well as between the modeled SSB(TAEPmod) and the SSB(assess) time series;
-
3.
As the most prominent performance criterion and novel approach for modeling mackerel egg production, we considered a tenfold cross validation (CV; Hastie et al. 2011): We divided the original EP data into 10 randomly sampled subsets with 10% of data per year. Afterwards, we aggregated the EP data in 0.5° and 1.0° scales and matched them to the environmental data as described in “Environmental data” section above. The model was then trained by combining nine of the 1° datasets (i.e., with 90% of the data) and predicted with the 0.5° dataset (i.e., 10% of the data) excluded from the training sets. The total deviance for Tweedie distribution (see Appendix 2 of Candy 2004) was used as performance criterion (“CV score”, from now on). See Figure S4 of the Supplement for a descriptive diagram of the cross validation.
Based on the performance metrics of the initial eight models, the selected best model was further developed by combining it with other model terms, resulting in further new models. In each case we considered our four quality criteria from above, further rejecting models which did not comply with one of them. At the end, we compared a total of 273 models (including the visually tested models 452 models in total). The best model was chosen as the one with the lowest CV score that met all four quality criteria and had values of the other four performance metrics below their median over all tested models. More details about this will be given in “Modeled TAEP and SSB” section. In addition to the best model, the choice of a single GAM (Hughes et al. 2014; Bruge et al. 2016; Brunel et al. 2018) or a series of one GAM per year (Beare and Reid 2002) was also cross-validated.
A model selection criterion tested by others (Bruge et al. 2016; Brunel et al. 2018), i.e., maximizing the explained deviance, was intentionally rejected here because it can lead to partially explaining noise with the model (i.e., model over-fitting).
Once the best model was chosen, the spatial distribution of eggs was mapped for all sampling periods of the survey. Fisher normalized absolute differences between observations and model output were used to evaluate the skill of the model to reproduce the observed distribution of eggs. This analysis allowed the identification of specific time periods and geographical regions where the model performed particularly well or poorly.
Comparison with previous modeling efforts
A detailed, quantitative comparison with previous studies by testing the exact models used and calculating metrics is extremely challenging given the large variety of data distributions, input data, response data and different methods used to match them (interpolation or aggregation). Such a comparison is probably even impossible, considering that some input data products have been discontinued (as seems to be the case of PSY3V3 of Brunel et al. 2018). Since the common denominator of all these studies is the use of spline smoothers with low basis dimension k (Table S1), we compare here with a similar model, namely that of the most recent study, Brunel et al. (2018, see their Table 1):
where the variable names are defined in our Table 2 and the basis dimension is constrained to k = 4. All other model characteristics (including response variable and distribution) were kept identical to our optimal model (“Modeling the mackerel spawning habitat” above and “Best model” sections below).
Results
Best model
The cross validation showed that the best results were obtained with a single GAM (not with individual annual GAMs). Therefore, only the results of the single-GAM approach will be described and discussed.
Scatter plots between the performance metrics against each other (Fig. 2) show that they are broadly consistent with each other, with values of one metric generally increasing in proportion to the values of all the others. AIC and BIC (panel j) as well as the RMS metrics (panel e) stand out with clear linear relationships. The large scatter between the metrics means that the absolute minimum of one metric is not necessarily associated with the minimum of another. Therefore, selecting the best model is not straightforward. To select a model that performs well across all metrics, we chose the model with the lowest CV score that met all four quality criteria of “Model selection” section and had values of the other four metrics (AIC, BIC and RMS differences) below their median over all tested models. Given the large spatial auto-correlation of fish distributions, it is possible that selecting an optimal model by using the minimum CV score may not lead to the model that is closest to nature (Roberts et al. 2017). This is one of the reasons why this study selected the optimal model based on various performance metrics (e.g., the RMS differences), not only on a CV score. This model (gray square in all panels of Fig. 2) is in most cases close to the lower left corner of the scatter plots, indicating that it is roughly evaluated as a good model under most metrics. The only exception is the AIC, which shows an intermediate value for the selected model (panels f, h or j).

Scatter plots of performance metrics of 273 tested GAMs. Specific models are shown with gray symbols: best model (square), model with only smoothers (triangle), model with smallest CV score (cross), model including S as only predictor (diamond) and model excluding S as predictor (disk)
The model selected as the best was:
with B bathymetry, ∇B bathymetry gradient, T temperature, S the average DEP per m2 over all sampled stations for each fixed model period (i.e., \(S=\overline{DEP }\) is a proxy of population size), sGP a Gaussian-Process smooth (with range of 2°) and the αn’s the model parameters. The dependence of \(\widehat{EP}\) on S in Eq. 6 follows the idea of modeling the effect of changes in population size (over sampling periods and years) on the spatial distribution of spawning mackerel. A general justification for using S as model predictor is given in Section S1 and a more detailed discussion of the role of S in our specific model is given in “Effect of population size” section below. Note also that S enters the model equation in a logarithmic transformation, which is consistent with our logarithmic link function.
Examples of the spatial distribution of EP from this model are shown in Fig. 3. Based on the Fisher normalized absolute differences between observations and model output, we selected three sampling periods for which the model performed well (top panels), averagely (middle panels) and poorly (bottom panels). The example of average performance (middle panels) illustrates the capability of the model to effectively interpolate data over large regions of the Bay of Biscay and the continental slope. The example of poor performance (bottom panels) illustrates the limitation of the model to predict zero EP at the beginning of the year in the north-western part of the study region (where there are no observations).

Modeled TAEP and SSB
The SSB(TAEPmod) resulting from Eqs. 4 and 6 is shown in Fig. 4 (black continuous curve) together with SSB(TAEPst) (light gray curve) and SSB(assess) (dashed black curve). The shaded areas around the SSB curves represent the uncertainty estimates. There are conspicuous differences between SSB(TAEPmod) and SSB(TAEPst): SSB(TAEPmod) reached its minimum in 2001 and then strongly increased to its maximum in 2010. SSB(TAEPst) reached its minimum later (in 2004) while oscillating around 4000 ktons, and the maximum was found in 2013, but without the previous strong increase seen in both SSB(TAEPmod) and SSB(assess). These differences are, however, within the uncertainty range of SSB(TAEPst). Of the two time series, SSB(TAEPmod) is most similar to SSB(assess): RMS differences and correlation coefficient between SSB(assess) and SSB(TAEPst) are 1276 ktons and 0.1, while for SSB(TAEPmod) they are 1122 ktons and 0.7.

SSB estimates per year calculated with Eq. 4, from the best GAM (Eq. 6; SSB(TAEPmod); black continuous curve) and from the standard method (SSB(TAEPst), gray curve), as well as from the 2020 ICES advice (SSB(assess); dashed curve). Error bars of SSB(TAEPmod) are 0.05 and 0.95 quantiles from bootstrapping (1000 iterations; dark gray shaded area), for SSB(assess) (medium gray shaded area) the 95% confidence intervals are calculated according to ICES (2020) (see their Table 8.7.3.1) and for SSB(TAEPst) (light gray shaded area) they correspond to 68% interval as obtained by using the spatial standard deviation of egg production in Eq. 4. RMSD stands for root means square difference and ρ is the Pearson cross-correlation, both calculated against SSB(assess) considering only the egg survey years (dots; i.e. no interpolation in time has been performed for TAEP)
Nowcasts and forecasts of EP distribution
To exemplify how Eq. 6 can be used in an operational way, we predicted the most likely region of high EP for an arbitrarily chosen month of April, 2021. This is a “future” month, which was not used to calibrate the model (the last survey took place in 2019). This prediction (Fig. 5) was calculated with Eq. 6 by replacing T with a map of satellite SST from OSTIA for April 2021 (roughly the 3rd sampling period; Table 1). Two scenarios, for a low (dark gray) and a high (light gray) mackerel population (S in Eq. 6), were estimated based on the average EP of 2001 and 2010, respectively (see Fig. 4). To isolate the effect of (inter-annual) population size changes on the fish spatial distribution from the effect of seasonal changes, the interactive S terms (i.e., those multiplying model terms with T and ∇B in Eq. 6) were replaced by their average annual values in each of the years 2001 and 2010. To eliminate the year effects, the averaged all-record S was used in the independent term log(S + 1). Values of \(\widehat{EP}\) inside the gray regions are larger than the 0.05 percentile of all EP observations over all years and sampling periods, roughly representing regions with a 95% probability of finding eggs. Similar graphics can be used to plan upcoming surveys. For instance, once the survey budget and the maximum possible number of sampling stations are known, they could be uniformly distributed throughout the region where spawning activity is predicted.

Prediction of areas where spawning takes place in April 2021 (corresponding to the third survey sampling period) using our habitat model (Eq. 6). The solid areas represent regions with 95% probability of finding eggs assuming a low (dark gray) and high (light gray) population size S
Discussion
The aim of this study was to model the spatiotemporal distribution of spawning mackerel in the Northeast Atlantic in order to improve estimates of TAEP. A model predicting realistic egg production should potentially improve both the survey design and the sustainable management of the mackerel stock. Such a model could also further improve our understanding of the mechanisms driving the spatial distribution of spawning mackerel. We discuss all of these topics in this section, also in the light of previous studies. Only two relatively new aspects of the dynamics of spawning mackerel (i.e., population size effect and bathymetry gradient) will be discussed here, while other aspects that have been widely considered previously (like temperature and bathymetry) are discussed in Section S3 of the supplement.
TAEP
Because of logistics, bad weather and the climate-driven shift of the spawning area, the sampling periods and the spatial distribution of observations of the mackerel egg survey vary from year to year. However, statistical methods such as GAMs and GLMs are specifically designed to deal with inhomogeneities and biases in the sampling. For this reason, they have become popular tools for standardizing data in fisheries studies (e.g., Venables and Dichmont 2004). Therefore, the use of a habitat model (such as ours) to estimate the TAEP is an obvious advantage over the standard method.
In general, differences between the three time series, SSB(TAEPmod), SSB(TAEPst) and SSB(assess) (Fig. 4), cannot be easily and fully explained because all three methods have their own uncertainties and errors. From the three time series, it is expected that SSB(assess) is the most accurate, considering the various sources of information used in the ICES advice (together with the standard TAEP, also biomass estimates from commercial fisheries and an independent scientific survey). Therefore, a comparison of both SSB(TAEPmod) and SSB(TAEPst) with SSB(assess) seems to be a reasonable approach to assess the potential improvement of our model over the standard method for TAEP. Such an analysis is similar to a cross-validation where the validating data are only partially independent, a situation not uncommon in ecology due to spatial and temporal auto-correlations (e.g., Roberts et al. 2017).
Therefore, SSB(TAEPmod) being more similar to SSB(assess) than SSB(TAEPst) (see RMS differences and Pearson correlation in Fig. 4), clearly shows that the habitat model used to estimate SSB(TAEPmod) is an improvement over the standard method for TAEP. It seems that the use of environmental variables in the modelling of egg production can partially compensate for the lack of information (i.e., commercial fishery and biomass survey data) compared to the assessment. This is an encouraging result, although there is still room for improvement. Most multi-year trends in SSB(TAEPmod) match either those of SSB(TAEPst) or of SSB(assess) (Fig. 4). For instance, SSB(TAEPmod) changes in 2001–2004–2007 differ from the standard method but match those of SSB(assess). The increase of SSB(TAEPmod) in 2016–2019 is the only one that does not agree with both SSB(TAEPst) and SSB(TAEPst). The disagreement between SSB(TAEPst) and SSB(assess) in 2016–2019 may not be very serious given that the uncertainty estimates for this period overlap completely. One reason for the disagreement appears to be the model’ prediction of suitable spawning areas in the unsampled region northeast of the United Kingdom during the second sampling period in 2019 (Fig. 3, bottom panels). As indicated by Fig. 3, the performance of the model tends to decline over time, being better in the early years of the survey than in more recent years. This time-dependence of model performance suggests that, as the spawning area expands northwards, a factor poorly captured by the model becomes more important. If the sampling design copes with the northward displacement of fish in the future surveys, it is expected that the accuracy of the model will improve.
Characteristics of the TAEP error bars (like its asymmetry) and the methodology used to calculate them are discussed in Section S4 of the Supplement.
Comparison with previous modeling efforts
The utilization of habitat models in the analysis of spawning stock dynamics in space and time dates back to the late 1980s/early 1990s (e.g. MacCall 1990; Mangel and Smith 1990). Based on presence/absence or total counts only, these models were rather probabilistic without explicitly taking into account environmental covariates such as temperature, salinity, depth or production data. Such models are, therefore, unable to respond to changes in the physical environment. More recent habitat modelling includes such data in order to analyze dynamics of marine fish egg production in space and time (e.g. Maynou et al. 2020; Mbaye et al. 2020; Erauskin-Extramiana et al. 2019; Gordó-Vilaseca et al. 2021) and are potentially able to forecast egg production habitats under a warming climate. Our approach attempted to achieve both the analysis of egg production dynamics in space and time as well as the estimation of daily and total annual egg production to determine spawning stock biomass thus facilitating management advice.
For the specific case of mackerel eggs in the Northeast Atlantic, we were aware of at least six previous peer-reviewed studies focusing on the spatial modeling of mackerel eggs, all of them using GAMs (Table S1). In “Data” and “Methods” sections, we have already provided ample justification for accepting or rejecting elements of previous model configurations. The main differences between our and previous studies are the modeling of the mackerel spawning stock (both southern and western components together) with spatially resolved bathymetry gradient, stock size, use of the Tweedie distribution, use of an alpha shape mapping region with a Delaunay triangulation and the analysis of a large number (more than 450) of non-linear functional forms for habitat (including complex interactions). Furthermore, standard TAEP, SSB and cross validation were used as criteria for model selection. While previous studies tested some predictor interactions, they were limited to first-order linear interactions. In the present study we included also more complex interactions, like division between variables and multiplications with quadratic terms and with logarithms. In addition, Bruge et al. (2016) also performed cross validation (as described in their supplement), but did not use it for model selection. We are confident that all of these measures constitute a considerable improvement of the model and its predictive ability.
The use of the Tweedie distribution (Tweedie 1984) over the previous approaches (Table S1) was motivated in our study by a number of reasons. The Tweedie distribution is a natural representation for fisheries-related data (Peel et al. 2013), similar to the hurdle (or delta) model used in Bruge et al. (2016). The hurdle model is a popular approach to model fishery data due to their zero-inflation (Maunder and Punt 2004), where the habitat is modeled as the multiplication of a “presence/absence” model (usually a binomial model) and a “biomass” or “abundance” model (usually a log-normal, Gamma or Poisson model). In comparison, an advantage of the Tweedie model is its simplicity, as no transformation to presence/absence data is required and only one model (instead of two) is fitted and used to predict from. Note also that in the hurdle model, the binomial part represents the probability of catching (or encountering) fish, which is influenced not only by the amount of fish but also by the aggregation of fish in clusters or schools (the larger the aggregation, the lower the probability of encounter). While the relationship between fish aggregation and habitat suitability is unclear, there is a general agreement that fish abundance or biomass is a good proxy for habitat suitability. The Tweedie model, which is only related to fish abundance or biomass, therefore appears to be a better representation of fish habitat suitability than the hurdle model. Another advantage of the Tweedie distribution is its generality, as it can be reduced to other distributions such as normal, Gamma and (discrete) Poisson. Therefore, the Tweedie distribution is suitable for modeling both continuous data (as we do in our study) and count data that would commonly be modeled with a Poisson distribution. Wood and Fasiolo (2017) even state that Tweedie provides a much better fit to egg count data than Poisson, for which the egg and fishery data tend to be highly over-dispersed. Other studies modeling fish habitat with the Tweedie distribution have been Candy (2004), Shono (2008), Augustin et al. (2013), Berg et al. (2014) and Núñez-Riboni et al. (2021).
Our results show that our optimal model Eq. 6 performs better than the general model representing previous modeling approaches, i.e., the model with only smoothers of Brunel et al. (2018) (Eq. 5; see also “Model selection” section above). Most of the performance metrics (the CV score, AIC and BIC) are below the median from all tested models (triangle in Fig. 2). Particularly, Eq. 5 matches both the standard estimate of TAEP and the SSB(assess) (panel e) worse than our best model (square). While Brunel et al. (2018) used another data product (PSY3V3), response variable (egg counts) and distribution (negative binomial), the comparison of model functional forms shows that our model is a step forward compared to previous approaches.
These results clearly indicate that the classical approach to modelling the spatial distribution of mackerel eggs, i.e., the spline smoothers (Table S1), is not the best method. With environmental variables appearing in simple functional forms instead of smoothers, our model (Eq. 6) is more similar to a Generalized Linear Mixed Model (GLMM) than to the typical GAM. While some studies have tested GLM-similar models (Borchers et al. 1997; Augustin et al. 1998), these models have been limited to linear predictors, and none have attempted the quadratic polynomials needed in combination with the log link to obtain a unimodal response (see “Modeling the mackerel spawning habitat” section). When designing the model, we realized that such simple functions considerably increased the model’s ability to extrapolate in space in comparison to spline smoothers. This agrees with Waldock et al. (2022), who observed a better performance of GLMs compared to GAMs (and Random Forest) when transferring models to unknown conditions. The improved extrapolation ability of our model is an important improvement: Augustin et al. (1998) and Beare and Reid (2002) addressed the poor extrapolation capabilities of smoothers by constraining the modeled EP by inserting artificial zeros beyond the sampling region. Using our unimodal responses based on simple functions represents a better alternative, as it does not subjectively modify the response variable.
Only two previous studies had the explicit goal of improving the estimation of the TAEP, but they focused only on the single years 1992 (Borchers et al. 1997) and 1995 (Augustin et al. 1998) rather than calculating time series over several years. Moreover, none of the previous studies have compared their results with SSB(assess), which (due to the additional information that it contains) is a (partially) independent source for measuring goodness-of-fit. Therefore, the ability of all previous studies to replace the standard method has remained unclear. Here, we clearly show a general improvement of our modeling approach in comparison to previous ones, making it a better candidate to replace the standard method one day. In addition, a major reason why none of the modeling approaches to date have been able to replace the standard method for TAEP seems to be the lack of expertise in the application of such methods in the ICES working group responsible for the survey (WGMEGS). Achieving one day better methods to estimate the TAEP should be aided now by the regular participation of some of the coauthors of the present study in the annual meetings of the WGMEGS.
Metrics for model selection
While the performance metrics were generally consistent with each other, none of them were consistent over all aspects evaluated. Therefore, if a single metric were to be used, it is highly probable that a deficient model would be selected, showing poor results when evaluated under another metric. A good example is the model that yielded the smallest CV score (cross in Fig. 2). This model is based on a tensor product spline, which yielded excellent EP distributions for sampling periods when the data availability was high. However, that model extrapolated large (non-existing) EP values onto the northern region in the first sampling period (where there were no observations). Thus, after the modeled EP has been integrated in space, the resulting TAEPmod differed significantly from TAEPst and SSB(TAEPmod) from SSB(assess) (Fig. 2e). Since high and unrealistic modeled values outside the sampled area had no observational counterparts, the CV score could not indicate poor model performance. In other words: The CV is unable to evaluate a model’s ability to extrapolate because it is impossible to cross-validate what has not been measured. This underlines the importance of using other (even if more extenuating) quality criteria, like observing if the response functions or the production curves are open. Alternatively, some authors suggest CVs specifically designed to test the extrapolation capacity of the model (Roberts et al. 2017; Waldock et al. 2022).
Effect of population size
Our results showed that an important predictor of the spatial distribution of mackerel eggs is the size of the spawning stock, here represented by the proxy \(S=\overline{DEP }\). To understand how S modifies the predicted spatial distribution of spawning mackerel, it is important to consider the model construction. Note that all model terms of Eq. 6 behave as interactions because of the logarithmic link and the additive property of the exponential function (exp (A + B) = exp(A) · exp(B)). Therefore, habitat suitability is high only at the intersection of the regions where all four model partial effects are large (Fig. 6). Similarly, it decreases to zero in any region where one model term is near-zero (like B in deep waters or ∇B in flat topographic regions).

Partial effects of temperature (a), bathymetry gradient (b), bathymetry (c) and geographical attachment sGP(lon, lat) (d) of the best model (Eq. 6), together with scatter plots of egg production (dots in panels a–c). Year effects were eliminated by averaging the independent S term over the complete sampling record, whereas interactive S terms were averaged over corresponding sampling periods. Numbered curves in panels (a) and (b) identify partial effects for each sampling period and, thus, for different population sizes. Note that the y-axis in (a) has been constrained to 140 egg/day/m.2
The effect of S on the spatial distribution of mackerel is modeled through its interactions with temperature T and bathymetry gradient ∇B (Eq. 6). These interactions represent how population size S modifies the preference of fish for each environmental variable and associated region. As the year progresses and the number of spawning individuals increases, the relative importance of environmental variables and, hence, habitat preference changes. The largest contribution to EP is given by temperature during sampling period (SP) 2 (Fig. 6a), with an amplitude about three times that of the other variables. For this SP, waters with temperatures ranging from 9 to 17 °C (covering nearly the complete study area) are as suitable as shallow waters or the shelf break. Because of its large spatial range of action in comparison to the other environmental variables, temperature seems to play a limiting (physiological) effect, except for extremely cold (< 9 °C) and warm (> 17 °C) waters. While the seasonal warming opens a wider area with suitable spawning temperatures, starting in SP 3, the importance of temperature reduces below the one of ∇B (Fig. 6b) and bathymetry B (Fig. 6c), which then become the two main driving variables of the spatial distribution.
For SP 1, B is the most important variable (i.e., fish favor shallow waters), while ∇B has a weak effect with a maximum near zero (i.e. fish favor flat topography like the continental shelf). Therefore, during this period of low fish densities, fish show a high preference for coastal waters. During SP 2, the effect of the bathymetry gradient increases considerably, reaching an asymptotic maximum and indicating a shift towards the shelf break. This situation slowly reverses during SP 3 to 5 and, in SP 6 the situation is again similar to SP 1, i.e. fish move back towards the coast. These changes suggest that fish preference for the shelf break increases as fish density and hence competition increases near the coast.
Use of S as predictor might give the wrong idea that our model is tautological in the logical sense, i.e., a model where independent and dependent variables are the same. This deserves clarification because there is little value in predicting a variable in a model if the very same variable is used as predictor. First, we would like to stress again that the predictor S is fundamental for the model to “distinguish” variations of EP related to population size from those related to the spatial distribution of environmental characteristics. Previous studies following a similar approach are Pinsky et al. (2013), Stige et al. (2017) and Núñez-Riboni et al. (2019). More details justifying the role of a measure of population size in habitat models are given in Section S1. In addition, note also that, while the model predicts the spatial distribution of EP (i.e., a two-dimensional field), S is only a single scalar with no spatial structure. Thus, while the ability of the model to predict the spatial distribution of EP is supported by S, this alone is not the key factor. To explore the relative importance of S for model performance, we compared metrics of a model including S as only predictor (diamond in Fig. 2) with a model similar to Eq. 6 but excluding S as predictor (disk in Fig. 2). The CV score and, particularly, both AIC and BIC indicated a better performance of the excluded-S model in comparison to the only-S model (for instance, panels c and j). These metrics indicated that the excluded-S model performs similar to the best model, with even smaller AIC and BIC values (probably because it has fewer parameters). This suggests that the main factor contributing to model performance is not S, but the spatial distribution of environmental variables.
However, best results (i.e., Eq. 6) can only be achieved if both aspects (population size and spatial distribution of environmental variables) are considered. Particularly, the only-S model yields better RMS metrics than the excluded-S model (Fig. 2e). Because the RMS metrics reflect the ability of the model to extrapolate (“Metrics for model selection” section), use of S as predictor seems fundamental to correctly model the annual EP onset (see an example of this in Figure S3). Other proxies of population size (like the annual EP or SSB averages) resulted in wide, open annual production curves and were, thus, less appropriate.
Although Brunel et al. (2018) discussed the role of population size on the spatial distribution of spawning mackerel, the present study is the first modeling effort including a measure of population size as a predictor. Finding a replacement for S in terms of environmental variables is appealing but does not seem a trivial task. The average surface temperature over the whole study area, lagged by two months, yielded a good proxy for S (correlation ρ = − 0.7), but still a poorer model performance.
Effect of bathymetry gradient
Borchers et al. (1997), Augustin et al. (1998) and Beare and Reid (2002) used the distance to the 200 m isobath as predictor based on the idea that the European continental shelf break is a proxy for spawning location (Beare and Reid 2002). The main morphological characteristic of the shelf break is a strong change in depth in a short distance, i.e., at the shelf break the bathymetry gradient is at its maximum. Therefore, a simpler and more natural variable representing the effect of the shelf break is the bathymetry gradient, which we chose as predictor in the present study. The importance of the bathymetry gradient on the spatial distribution of mackerel eggs is evident when comparing a map of this variable (Fig. 7) with an observed egg distribution (e.g., Fig. 3).

Magnitude of the ETOPO1 bathymetry gradient (m/º)
Hughes et al. (2014) rejected the 200 m-isobath as predictor arguing that features like the Rockall Bank imply a second 200 m contour, which makes a definition of distance to the shelf edge problematic. Instead, they argued that the distance to the 200 m isobath could be replaced with a smoother in eastings and northings. This idea is confirmed by (Brunel et al. 2018) (who did not include the bathymetry gradient as predictor) because our bathymetry gradient (Fig. 7) is similar to their smoother s(lon, lat) for geographical attachment (their Fig. 3). However, smoothers of position can include the effect of any variable not explicitly considered in the habitat model, i.e., in this particular case, the effect of factors other than the shelf edge. Moreover, correctly identifying variables playing a role in a process is key to understanding the mechanisms behind the process. Therefore, the use of the bathymetry gradient in a habitat model is to our understanding a clear advantage and should be encouraged. The first modeling study of mackerel eggs, Borchers et al. (1997), is the only one using a similar variable, but it was unfortunately not considered in the subsequent studies.
The influence of the shelf break or bathymetry gradient on the distribution of spawning mackerel could result from hydrodynamic processes. The European Slope Current (ESC; Neves et al. 1998) is one of the known important driving forces for egg and larval drift to prospective nurseries (Bartsch and Coombs 2004). We found here that current speeds explain little variance in comparison to the bathymetry gradient, in agreement with Brunel et al. (2018)—the only previous modeling study also using current speeds. However, and similar to the case of MLD, this could be an indication of poor modeling of the currents rather than a lack of influence. While a direct observation of surface currents is possible over SSH from satellite altimetry, the ESC is driven either by wind or density differences and bottom relief (Huthnance 1984; Neves et al. 1998) and is, thus, “invisible” to SSH, which can only identify geostrophic currents. This would explain, in turn, why in this study SSH explained little variance, in agreement with Bruge et al. (2016). The ESC underlies a strong seasonality, weakening between spring and summer due to changes in the general wind field (Mohn 2000), which may also explain the weakening influence of the bathymetry gradient on egg production during sampling periods later in the year.
Forecasting the spawning region
We briefly discuss here two last issues about forecasting spawning areas (Fig. 5). Firstly, when this study was carried out, April 2021 had already passed. However, real future predictions of SST could also be made. Such SST predictions can be obtained using ocean forecasting models or calculated statistically using past temperature data, either with a spatially resolved seasonal composite or with auto-regressive models. Secondly, in addition to their operational potential, maps like those of Fig. 5 reveal the effect of population size on habitat preferences (see “Effect of bathymetry gradient” section): During periods of low population size, a suitable habitat for spawning mackerel (dark gray region in Fig. 5) is mostly found at the shelf break and in regions of high ∇B. During periods of high abundance (light gray), fish are widely dispersed.
Conclusions
We reviewed previous spatio-temporal modeling approaches of mackerel’s EP in the Northeast Atlantic aiming to improve TAEP estimates. Our results outperform both the standard method (compare RMS differences and correlation coefficient in Fig. 4) and previous modeling efforts with spline smoothers (compare triangle and square in Fig. 2). While spline smoothers were so far the typical approach to model the spatial distribution of mackerel EP (Table S1), our results indicate that such an approach is not the best solution. Our metrics showed that environmental variables should appear in simple functional forms that resemble unimodal responses (“Modeling the mackerel spawning habitat” section), yielding a best model (Eq. 6) which is more similar to a GLMM than to the typical GAM with smoothers. Additionally, taking into account the effect of population size on the spatial distribution of eggs (through interactions with environmental variables) proved to be a fundamental advantage for model performance, particularly for modeling the seasonality of EP. Despite the efforts made in the present study and the improvements over previous studies, the resulting model still has some shortcomings. Future modeling efforts for mackerel eggs should focus on the model’s ability to extrapolate beyond survey boundaries without subjectively inserting artificial zeros.
Data availability
The data-sets analyzed during the current study (e.g., ICES egg production, GODAS, OSTIA and ETOPO1) are all in the public domain and freely available. All data sources with Internet links are given in the reference list and cross-referenced in Sects. “Egg production data” and “Environmental data” of the manuscript.
Notes
The assessment uses the state-space-assessment model (SAM, Nielsen and Berg 2014). Input data are age segregated catch, weight and maturity data from commercial landings. Tuning data are steel and RFID tagging-recapture data and three survey indices: SSB index from the MEGS (1992–2022), recruitment abundance indices from the IBTS surveys 1998–2020, and from the IESSNS ages 3–11 (2010, and 2012–2022). Natural mortality (0.15 for all ages and years) is based on tagging studies from the early 1980s.
References
Akaike H (1974) A new look at the statistical model identification. IEEE Trans Autom Control 19:716–723. https://doi.org/10.1109/TAC.1974.1100705
Amante C, Eakins BW (2009) ETOPO1 1 arc-minute global relief model: procedures, data sources and analysis. NOAA Technical Memorandum NESDIS NGDC-24. National Geophysical Data Center. Marine Geology and Geophysics Division. Boulder, Colorado
Augustin NH, Borchers DL, Clarke ED, Buckland ST, Walsh M (1998) Spatiotemporal modelling for the annual egg production method of stock assessment using generalized additive models. Can J Fish Aquat Sci 55:2608–2621. https://doi.org/10.1139/f98-143
Augustin NH, Trenkel VM, Wood SN, Lorance P (2013) Space-time modelling of blue ling for fisheries stock management. Environmetrics 24:109–119. https://doi.org/10.1002/env.2196
Bartsch J, Coombs SH (2004) An individual-based model of the early life history of mackerel (Scomber scombrus) in the eastern North Atlantic, simulating transport, growth and mortality. Fish Oceanogr 13(6):365–379. https://doi.org/10.1111/j.1365-2419.2004.00305.x
Beare DJ, Reid DG (2002) Investigating spatio-temporal change in spawning activity by Atlantic mackerel between 1977 and 1998 using generalized additive models. ICES J Mar Sci 59:711–724. https://doi.org/10.1006/jmsc.2002.1207
Behringer DW, Xue Y (2004) Evaluation of the global ocean data assimilation system at NCEP: The Pacific Ocean. In: Eighth symposium on integrated observing and assimilation systems for atmosphere, oceans, and land surface, AMS 84th annual meeting, Washington State Convention and Trade Center, Seattle, Washington, pp 11–15
Berg CW, Nielsen A, Kristensen K (2014) Evaluation of alternative age-based methods for estimating relative abundance from survey data in relation to assessment models. Fish Res 151:91–99. https://doi.org/10.1016/j.fishres.2013.10.005
Borchers D, Buckland S, Priede I, Ahmadi S (1997) Improving the precision of the daily egg production method using generalized additive models. Can J Fish Aquat Sci 54:2727–2742. https://doi.org/10.1139/f97-134
Burnham KP, Anderson DR (1998) Model Selection and Inference. Springer, New York. https://doi.org/10.1007/978-1-4757-2917-7
Bruge A, Alvarez P, Fontán A, Cotano U, Chust G (2016) Thermal niche tracking and future distribution of atlantic mackerel spawning in response to ocean warming. Front Mar Sci. https://doi.org/10.3389/fmars.2016.00086
Brunel T, van Damme CJG, Samson M, Dickey-Collas M (2018) Quantifying the influence of geography and environment on the northeast Atlantic mackerel spawning distribution. Fish Oceanogr 27:159–173. https://doi.org/10.1111/fog.12242
Candy SG (2004) Modelling catch and effort data using generalized linear models, the Tweedie distribution, random vessel effects and random stratum-by-year effects. CCAMLR Sci 11:59–80
Copernicus (2021) Operational sea surface temperature and sea ice analysis (OSTIA) of the UK meteorological office. https://resources.marine.copernicus.eu/?option=com_csw&task=results. Accessed June 2021
Edelsbrunner H, Kirkpatrick DG, Seidel R (1983) On the shape of a set of points in the plane. IEEE Trans Inf Theory 29(4):551–559. https://doi.org/10.1109/TIT.1983.1056714
Erauskin-Extramiana M, Alvarez P, Arrizabalaga H, Ibaibarriaga L, Uriarte A, Cotano U, Santos M, Ferrer L, Cabré A, Irigoien X, Chust G (2019). Deep sea research part II: Topical studies in oceanography, vol 159, pp 169–182. https://doi.org/10.1016/j.dsr2.2018.07.007
GODAS (2021) Data from the NCEP global ocean data assimilation system. https://psl.noaa.gov/data/gridded/data.godas.html. Accessed June 2021
Gordó-Vilaseca C, Grazia Pennino M, Albo-Puigserver M, Wolff M, Coll M (2021) Modelling the spatial distribution of Sardina pilchardus and Engraulis encrasicolus spawning habitat in the NW Mediterranean Sea. Mar Environ Res 169:15. https://doi.org/10.1016/j.marenvres.2021.105381
Hastie T, Tibshirani R (1986) Generalized additive models. Stat Sci 1:297–310. Institute of Mathematical Statistics. https://doi.org/10.1214/ss/1177013604
Hastie T, Tibshirani R, Friedman J (2011) The elements of statistical learning. Springer, New York, p 739
Hempel G (1979) Early life history of marine fish. The egg stage. Washington Sea Grant Publication, University of Washington Press, Seattle, p 70
Hughes KM, Dransfeld L, Johnson MP (2014) Changes in the spatial distribution of spawning activity by north-east Atlantic mackerel in warming seas: 1977–2010. Mar Biol 161:2563–2576. https://doi.org/10.1007/s00227-014-2528-1
Hutchinson GE (1957) Concluding remarks. In: Cold spring harbor symposium on quantitative biology, vol 22, pp 415–427. https://doi.org/10.1101/SQB.1957.022.01.039
Huthnance JM (1984) Slope currents and “jEBAR.” J Phys Oceangr 14:795–810. https://doi.org/10.1175/1520-0485(1984)014%3c0795:SCA%3e2.0.CO;2
ICES (1987) Report of the mackerel working group. ICES CM 1987/Assess: 11. https://doi.org/10.17895/ices.pub.19261061
ICES (1993) Report of the mackerel / horse mackerel egg production workshop. C.M. 1993/H:4
ICES (2019a) Workshop on a research roadmap for mackerel (WKRRMAC). ICES Scientific Reports, vol 1, p 48. https://doi.org/10.17895/ices.pub.5541
ICES (2019b) Manual for mackerel and horse mackerel egg surveys, sampling at sea. Series of ICES survey protocols SISP 6. https://doi.org/10.17895/ices.pub.5140
ICES (2019c) ICES fish eggs and larvae database (eggs and larvae), extraction 22th of July, 2019, mackerel and horse mackerel egg survey (MEGS). Internet repository: https://www.ices.dk/data/data-portals/Pages/Eggs-and-larvae.aspx; ICES, Copenhagen
ICES (2019d) Manual for the AEPM and DEPM estimation of fecundity in mackerel and horse mackerel. Series of ICES Survey Protocols SISP 5. https://doi.org/10.17895/ices.pub.5139
ICES. 2020. Working group on widely distributed stocks (WGWIDE). ICES Scientific Reports, vol 2, p 82. https://doi.org/10.17895/ices.pub.7475
ICES (2021) ICES working group on mackerel and horse mackerel egg surveys (WGMEGS: outputs from 2020 meeting). ICES Scientific Reports, vol 3, p 11. https://doi.org/10.17895/ices.pub.7899
Kammann EE, Wand MP (2003) Geoadditive models. J R Stat Soc Ser C (appl Stat) 52:1–18. https://doi.org/10.1111/1467-9876.00385
Le CT (2003) Introductory biostatistics. Wiley-Interscience. Chapter 2.2.1 (Mean). https://doi.org/10.1002/0471308889
Lockwood SJ, Nichols JH, Dawson WA (1981) The estimation of a mackerel (Scomber scombrus L.) spawning stock size by plankton survey. J Plankton Res 3:217–233. https://doi.org/10.1093/plankt/3.2.217
MacCall AD (1990) Dynamic geography of marine fish populations. Washington Sea Grant Program. University of Washington Press, Seattle, p 153
Mangel M, Smith PE (1990) Presence-absence sampling for fisheries management. Can J Fish Aquat Sci 47:1875–1887
Maunder MN, Punt AE (2004) Standardizing catch and effort data: a review of recent approaches. Models Fish Res Glms GAMS GLMMs 70:141–159. https://doi.org/10.1016/j.fishres.2004.08.002
Maynou F, Sabatés A, Raya V (2020) Changes in the spawning habitat of two small pelagic fish in the Northwestern Mediterranean. Fish Oceanogr 29:201–213. https://doi.org/10.1111/fog.12464
Mbaye B, Doniol-Valcroze T, Brosset P, Castonguay M, Van Beveren E, Smith A, Lehoux A, Brickman D, Wang Z, Plourde S (2020) Modelling Atlantic mackerel spawning habitat suitability and its future distribution in the north-west Atlantic. Fish Oceanogr 29:84–99. https://doi.org/10.1111/fog.12456
McCullagh P, Nelder JA (1989) Generalized linear models. Chapman & Hall, London, p 511. https://doi.org/10.1007/978-1-4899-3242-6
Mendiola D, Alvarez P, Cotano U, Etxebeste E, de Murguia AM (2006) Effects of temperature on development and mortality of Atlantic mackerel fish eggs. Fish Res 80:158–168. https://doi.org/10.1016/j.fishres.2006.05.004
Mohn C (2000) Über Wassermassen und Strömungen im Bereich des europäischen Kontinentalrandes westlich von Irland. Dissertation Universität Hamburg. 138 pp. https://ediss.sub.uni-hamburg.de/handle/ediss/477
Neves RJJ, Coelho HS, Leitao PC, Martins H, Santos A (1998) A numerical investigation of the slope current along the Western European margin. WIT Trans Ecol Envir 24:369–376. https://doi.org/10.2495/CMWR980462
Nielsen A, Berg CW (2014) Estimation of time-varying selectivity in stock assessment using state–space models. Fish Res 158:96–101. https://doi.org/10.1016/j.fishres.2014.01.014
Núñez-Riboni I, Taylor MH, Kempf A, Püts M, Mathis M (2019) Spatially resolved past and projected changes of the suitable thermal habitat of North Sea cod (Gadus morhua) under climate change. ICES J Mar Sci 76:2389–2403. https://doi.org/10.1093/icesjms/fsz132
Núñez-Riboni I, Akimova A, Sell AF (2021) Effect of data spatial scale on the performance of fish habitat models. Fish Fish 22:955–973. https://doi.org/10.1111/faf.12563
Peel D, Bravington MV, Kelly N, Wood SN, Knuckey I (2013) A model-based approach to designing a fishery-independent survey. J Agric Biol Environ Stat 18:1–21. https://doi.org/10.1007/s13253-012-0114-x
Pinsky ML, Worm B, Fogarty MJ, Sarmiento JL, Levin SA (2013) Marine taxa track local climate velocities. Science 341:1239–1242. https://doi.org/10.1126/science.1239352
Planque B, Loots C, Petitgas P, Lindstrøm U, Vaz S (2011) Understanding what controls the spatial distribution of fish populations using a multi-model approach. Fish Oceanogr 20:1–17. https://doi.org/10.1111/j.1365-2419.2010.00546.x
Richardson PL (1983) Eddy kinetic energy in the North Atlantic from surface drifters. J Geophys Res Oceans 88:4355–4367. https://doi.org/10.1029/JC088iC07p04355
Roberts DR, Bahn V, Ciuti S, Boyce MS, Elith J, Guillera-Arroita G, Hauenstein S, Lahoz-Monfort JJ, Schröder B, Thuiller W, Warton D-I, Wintle BA, Hartig F, Dormann CF (2017) Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 40:913–929. https://doi.org/10.1111/ecog.02881
Schwarz G (1978) Estimating the Dimension of a Model. Ann Statist 6:461–464. https://doi.org/10.1214/aos/1176344136
Shahbaba B (2012) Biostatistics with R—an introduction to statistics through biological data. Springer, New York
Shono H (2008) Application of the Tweedie distribution to zero-catch data in CPUE analysis. Fish Res 93:154–162. https://doi.org/10.1016/j.fishres.2008.03.006
Simpson AC (1959) The spawning of plaice (Pleuronectes platessa) in the North Sea. Fish Invest Lond (ser II) 22(7):111
Stewart RH (2008) Introduction to physical oceanography. Department of Oceanography, Texas A & M University, 345pp
Stige LC, Yaragina NA, Langangen Ø, Bogstad B, Stenseth NC, Ottersen G (2017) Effect of a fish stock’s demographic structure on offspring survival and sensitivity to climate. PNAS 114:1347–1352. https://doi.org/10.1073/pnas.1621040114
Swan ARH, Sandilands M (1995) Introduction to geological data analysis. Blackwell, New York
Tweedie MCK (1984) An index which distinguishes between some important exponential families. In: Ghosh JK, Roy J (eds) Statistics: applications and new directions. Proceedings of the Indian Statistical Institute Golden Jubilee International Conference. Indian Statistical Institute, Calcutta, pp 579–604
Urdan TC (2005) Statistics in plain English, 2nd edn. Lawrence Erlbaum Associates, New York. https://doi.org/10.4324/9781410612816
Venables WN, Dichmont CM (2004) GLMs, GAMs and GLMMs: an overview of theory for applications in fisheries research. Fish Res 70(2):319–337. https://doi.org/10.1016/j.fishres.2004.08.011
Waldock C, Stuart-Smith RD, Albouy C, Cheung WWL, Edgar GJ, Mouillot D, Tjiputra J, Pellissier L (2022) A quantitative review of abundance-based species distribution models. Ecography. https://doi.org/10.1111/ecog.05694
Wood S (2017) Generalized Additive models: an introduction with R. Texts in statistical science, 2nd edn. Chapman & Hall/CRC, London, p 476
Wood SN, Fasiolo M (2017) A generalized Fellner–Schall method for smoothing parameter optimization with application to Tweedie location, scale and shape models. Biometrics 73:1071–1081. https://doi.org/10.1111/biom.12666
Acknowledgements
We appreciate comments from Thomas Brunel (WUR, Netherlands), as well as from colleagues of the ICES Working Groups on Mackerel and Horse Mackerel Egg Surveys (WGMEGS) and on Improving use of Survey Data for Assessment and Advice (WGISDAA), particularly from Casper Berg (DTU Aqua, Denmark). Comments from two anonymous reviewers considerably improved the manuscript. GODAS data were provided by the NOAA/OAR/ESRL PSL, Boulder, Colorado, USA, from their Web site at https://psl.noaa.gov/data/gridded/data.godas.html. The graphical abstract has been designed using resources from Flaticon.com.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Núñez-Riboni, I., Costas, G., Diekmann, R. et al. Reviewing and improving spatiotemporal modeling approaches for mackerel’s total annual egg production. Rev Fish Biol Fisheries 33, 1523–1546 (2023). https://doi.org/10.1007/s11160-023-09795-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11160-023-09795-2