
Abstract
The literature on differential taxation of asset specific payoffs presents different representations of security market lines (SMLs), with puzzling features such as parallel lines and lines with the same intercept but different slopes - a security market fan. We show that these results can be traced back to using different combinations of pre-tax and after-tax figures for betas and expected returns. Above all, for betas based on returns and a stochastic discount factor (SDF), there is a single SML in after-tax expected return and after-tax beta space. Using pre-tax values for betas and/or expected returns leads to different representations in the respective beta and expected return space. With betas that use the market return instead of the SDF, it is important to distinguish whether tax payments are redistributed back to the agents. If they are, a single SML can only be obtained through a beta using the pre-tax market return and the after-tax return of single assets. In addition to SML representations, we also discuss differential taxation with respect to mean-variance frontiers in expected return and standard deviation spaces.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The security market line (SML) is a representation of a pricing model (usually the mean-variance CAPM), which, when applied in practice, shows under- or overvalued securities versus the used model. Therefore, it is a valuable tool for many investors. New versions of SMLs, such as a security market fan and a set of parallel SMLs, appeared in Eikseth and Lindset (2009) and Benninga and Sarig (2003). Both articles consider differential taxation of assets, i.e., different tax rates on payoffs of different assets or classes of assets. We see asset type specific taxation for example in the U.S. for municipal bonds or bonds issued to finance non-profit projects.Footnote 1 Payoffs of different asset classes such as equities and bonds are also taxed differently.
Benninga and Sarig (2003) model a complete set of equity securities besides a complete set of debt securities. Each asset class has a different tax rate on payoffs. They obtain an SML for each sub-market, which are equal in slope but differ in their intercepts. They are especially interested in conditions for what they call an extended Miller equilibrium (EME), based on Miller (1977). Eikseth and Lindset (2009), in turn, introduce a different tax rate on the return of each single asset in the mean-variance CAPM. They conclude that each single asset has a different SML, whereas all SMLs have the same origin in the risk-free rate. They call this a security market fan. They also comment shortly on the different result of Benninga and Sarig (2003) with their two parallel SMLs and state that the prerequisite of two complete markets leads to the outcome different from their own.
We have a critical eye on the SML representations in the two papers also from a practical point of view. We show that their common starting point is the representation in a pure after-tax beta and expected return space. From there, one can shift in an out tax terms to obtain different representations, such as the fan and parallel SMLs. We model all tax rates as asset-specific tax rates and not personal tax rates.
We show in the stochastic discount factor (SDF) language how the different SMLs can be obtained. Using betas of returns and the SDF, there are four basic results: (1) a single SML in pure after-tax space, (2) the security market fan as in Eikseth and Lindset (2009) for the pre-tax beta and after-tax expected return space, (3) parallel lines with different intercepts as in Benninga and Sarig (2003) for a pure pre-tax space, and (4) SMLs with different slopes and intercepts in after-tax beta and pre-tax expected return space. All of this can be shown by shifting around the asset-specific tax term in the expected return equations. For investors, the first representation, i.e., the after-tax representation, is the one to look at. For differential asset taxation, only after-tax payoffs matter and prices reflect the value of those after-tax payoffs.
When using the CAPM, we look at two cases: taxes are redistributed to investors as in Eikseth and Lindset (2009) or they are not. If taxes are not redistributed, we obtain a single SML in a pure after-tax space. For all other combinations of pre- and after-tax values the graphical representations change again. An additional complication is that we need a third dimension in cases when we want to form a space out of pre-tax betas. If taxes are redistributed, the average investor receives all tax payments back. Therefore, the relevant CAPM-SDF uses pre-tax cash flows or pre-tax returns. To obtain an after-tax version, we have to take out the tax part, so that we obtain, again, an additional tax beta. For example, in pre-tax market beta and after-tax expected return space, there is a Security Market Fan. This is the result of Eikseth and Lindset (2009). In another case, in the space formed from a beta of pre-tax market return and after-tax asset returns and after-tax expected returns, there is a single SML. Since taxes are redistributed, everything is priced related to the pre-tax market return. This is also the most useful representation for investors who live in such a CAPM world.
We also discuss other return representations such as efficient frontiers and capital market lines (CMLs). For efficient frontier analyses, the after-tax frontier should be the tool for taxable investors and the pre-tax one for investors that do not pay taxes. Adding CAPM results, the risk-free asset will be mean-variance efficient in any representation, because its variance is zero before or after taxes (risky tax rates may change this). The after-tax market return is efficient for the case without tax redistributions. If taxes are redistributed, investors have some kind of non-tradable outside income, which leads to the pre-tax market return being on the after-tax frontier. This does not not necessarily hold for the after-tax market return.
With our findings, we contribute to the literature of tax effects on asset pricing, putting some of the results of Benninga and Sarig (2003) and Eikseth and Lindset (2009) on a common ground and into a larger context. SMLs became prominent through the CAPM (compare Sharpe (1964), Lintner (1965) and Mossin (1966)), which initially did not include tax considerations. In the subsequent years a strand of literature evolved, which focused primarily on corporate taxes and its implications. We see Modigliani and Miller (1958) and Modigliani and Miller (1963) as important works initiating this literature stream. Apart from risk-adjusted discount rates, their work also shows implications on the corporate capital structure. Leland (1994), Leland and Toft (1996) and Goldstein et al. (2001) have further developed continuous time models for optimal capital structure analysis. Another literature stream includes personal taxes. This is what Brennan (1970) does. He models differential personal taxation instead of asset-specific taxation and derives equations for expected returns in a CAPM context. Miller (1977) looks at progressive personal taxes and the realization of an equilibrium bond rate. Litzenberger and Ramaswamy (1979) and Litzenberger and Ramaswamy (1980) analyze tax rate progression in an asset pricing context. Most of those works are based on the mean-variance CAPM. Cochrane (2005) shows a more general approach to asset pricing through the use of SDFs. Benninga and Sarig (2003) also use this approach and only turn afterwards to a CAPM-structure. We will also start from this more general approach and then analyze two formulations of the CAPM - one without and one with redistribution of taxes.
There is also a large literature stream that uses SMLs (and CMLs) in empirical studies to test pricing relations with respect to different influencing factors. Frazzini and Pedersen (2014) explain the relative flatness of the U.S. SML with investors that cannot use leverage, and, therefore, buy more high-beta assets than investors that can use leverage. This lowers those assets’ returns and makes the SML flatter. Hong and Sraer (2016) use SMLs and information about pricing agreement on high beta stocks to show that with high disagreement expected returns can decrease with beta, whereas with agreement, the SML has the usual upward sloping form. Jylhä (2018) uses the SML of the U.S. stock market for an empirical examination of changes of margin requirements. Hens and Naebi (2020) use the SML in a study of CAPM relationships with mean-variance and non mean-variance investors. They find that two thirds of the investors need to be non mean-variance investors to explain the low-beta anomaly, which is one of the CAPM anomalies. Blitz (2020) applies the SML concept to look for the risk-free asset implied by bonds of different maturities. He finds that medium-term bonds fit best his theoretical model instead of the traditionally used short-term Treasury bills. Very recently, Pedersen et al. (2021) use CMLs in an approach with additional ESG metrics. For each ESG score, they plot an efficient frontier with the respective CML. Chan and Marsh (2021) use SMLs to study effects of political uncertainty on asset prices. They find highly elevated U.S. equity premiums in the months after midterm congressional elections over the last 145 years. We can see that the classic SML from the CAPM framework is still an important benchmark against which researchers hold more refined models. In our case, we add asset-specific tax rates to the general model.
In the following section, we discuss the meaning of asset-specific tax rates and how they appear in in practice. Afterwards, we establish the notation and basic pricing framework. In Sect. 4, we show how the change of perspective, i.e., a change of the beta and expected return space, change the representation of the SML(s). In this part, we use betas with the more general SDF. In Sect. 5, we specify the SDF as being linear in the market return, which leads to CAPM representations. Betas include the market return. We discuss efficient frontier and CML representations in Sect. 6. Section 7 summarizes and addresses possible applications. The final section concludes. In the appendix, we provide details on how the numerical example is computed that lead to the figures that, we use throughout to illustrate the different SML patterns.
2 Asset-specific and personal taxation
To have a consistent terminology with the underlying literature, we follow Eikseth and Lindset (2009) and their understanding of asset-specific taxation. We do not have a clear-cut definition rather than an understanding based on examples. They use various examples such as the taxation of coupons for the fixed income asset class, which differs from the taxation of dividends for equities. They also mention tax benefits for owner occupied real estate. Thus, they go along a bigger asset class scheme with equities, fixed income and real estate with the notion that the tax differential among those asset classes may be exploited in certain tax strategies. They also mention different tax bases such as payoffs (coupons and dividends) and capital gains. However, they ignore that distinction in their model, in which they only look at accrual-based capital gains taxes. They also do not regard taxation at the company level, so that we will exclude that view here as well.
In turn, a personal tax rate depends on the investor characteristics of who received the tax base and who has to pay taxes on this tax base. An example are tax rates on income from employment. Those tax rates usually depend on the pre-tax income bracket of the individual.
In practice, different types of taxation show up together. Special tax-advantages of certain assets usually come together with other rules that are related to personal taxation. For example, dividends in the U.S. are taxed at tax rates specific to dividends. However, those tax rates are also tied to the investors’ income. For 2021, according to the Internal Revenue Service the three applicable tax rates are 0%, 15% and, 20%, which depend on three income tax brackets. Thus, there is an asset-specific and a personal component to those tax rates. Interest income from bonds, in turn, are taxed at the income tax rate, which is more a personal type of taxation.
As examples for more pure asset-specific taxation, municipal bonds in the U.S. are exempt from federal taxes and sometimes from state and local taxes as well. Investor characteristics have no influence on this kind of taxation. A special type of investment vehicles are 401(k) or 403(b) accounts. They are tax advantaged investment vehicles that can contain different types of assets. One may see such an account as an asset itself. However, there may be an investor-specific component in that not everybody may be able to hold such accounts.
Thus, we find many practical examples of asset-specific taxation. However, usually they are not as clear cut as in the mostly theoretical papers such as the one by Benninga and Sarig (2003) and Eikseth and Lindset (2009).
3 Pricing framework with taxes
3.1 Payoffs and taxes
We assume two times: \(t=0\), when valuation takes place and \(t=1\), when payoffs are distributed. We do not use time subscripts here, since it will be clear from the analysis, which variables belong to which time. There are N risky basis assets with payoffs \(X_j\) \((j=1,...,N)\). Additionally, there is a risk-free payoff \(X_0\). The risk-free asset is in zero net supply. Those payoffs form the pre-tax payoff space \({\underline{X}}\).
Assets are taxed at an asset specific tax rate \(\tau _j\). Furthermore, tax rates are certain as in Eikseth and Lindset (2009). In Benninga and Sarig (2003) tax rates are state dependent, which makes their analysis more general. The price of any asset j is denoted as \(p_j\) for the pre-tax price, i.e., the price of the pre-tax payoff \(X_j\), and \(p_j^{\tau }\) for the after-tax price, i.e., the price of the after-tax payoff \(X_j^{\tau }\). We assume throughout this paper that tax payments on financial assets are capitalized into the prices of the financial assets.Footnote 2 Agents consider tax payments when valuing assets, and prices reflect the share of payments that is lost due to taxes. It follows that prices, which are revealed through trading, are after-tax prices \(p_j^{\tau }\). The law of one price holds. Thus, we can write prices as operators: \(p_j^{\tau }=p(X_j^{\tau })\). We use two cases for the tax base:
-
1.
payoffs \(X_j\) with taxes \(T_j = \tau _j X_j\) or
-
2.
capital gains \(X_j - p_j^{\tau }\) with taxes \(T_j=\tau (X_j - p_j^{\tau })\)
After-tax payoffs are pre-tax payoffs less tax payments \(X_j^{\tau }=X_j - T_j\). They span the after-tax payoff space \({\underline{X}}^{\tau }\). Notice that the pre-tax and the after-tax payoff space are the same. When the tax base is \(X_j\), taxes \(T_j\) are just a scaled version of the original payoff, and, therefore, are also within the pre-tax payoff space. When capital gains are the tax base, taxes consist of a scaled version of the pre-tax payoff, i.e., of \(\tau _j X_j\) and of a risk-free quantity \(\tau _j p_j^{\tau }\)Footnote 3. Again both payoffs are within the pre-tax payoff space so that the tax payment \(T_j\) on a payoff \(X_j\) is also within the pre-tax payoff space.
3.2 Return definitions
We define \(R_j^{\tau }=\frac{X_j^{\tau }}{p(X_j^{\tau })}\) to be the after-tax gross return and \(R_j^p=\frac{X_j}{p(X_j^{\tau })}\) to be the pre-tax gross return. In both cases the observed price with the capitalized taxes is used in the denominator. We define \(R_j=\frac{X_j}{p(X_j)}\) as simple gross return, which is the return on an untaxed asset with equal pre-tax payoffs as the respective taxed asset.
Net returns are \(r_j^{\tau }=R_j^{\tau }-1=\frac{X_j^{\tau } - p(X_j^{\tau })}{p(X_j^{\tau })}\) for after-tax returns, \(r_j^{p}=R_j^{p}-1=\frac{X_j - p(X_j^{\tau })}{p(X_j^{\tau })}\) for pre-tax returns, and \(r_j=R_j-1=\frac{X_j - p(X_j)}{p(X_j)}\) for simple returns.
Benninga and Sarig (2003) tax payoffs directly so that \(T_j=\tau _j X_j\). In this case, the law of one price shows that after-tax returns must be equal to simple returns: \(R_j^{\tau }=\frac{X_j(1-\tau _j)}{p(X_j(1 - \tau _j))}=\frac{X_j}{p(X_j)}=R_j\). Furthermore, for the cash flow tax we obtain:
In contrast to Benninga and Sarig (2003), Eikseth and Lindset (2009) introduce taxes on returns, i.e., taxes on capital gains. The after-tax cash flow is \(X_j^{\tau }=X_j - T_j = X_j - \tau _j(X_j - p(X_j^{\tau }))\). Negative returns lead to negative tax payments. After-tax returns are \(R_j^{\tau }=\frac{X_j - \tau _j(X_j - p(X_j^{\tau }))}{p(X_j^{\tau })}=\frac{X_j(1-\tau _j) - p(X_j^{\tau })(1 - \tau _j) + p(X_j^{\tau })}{p(X_j^{\tau })}=\frac{X_j - p(X_j^{\tau })}{p(X_j^{\tau })}(1 - \tau _j) + 1=r^p_j(1 - \tau _j) + 1\)or
Thus, the pre-tax and after-tax relation resembles the one for taxes on payoffs except that the relation is between net returns. In the case of taxes on returns, it is easier to work with net returns.Footnote 4
3.3 Price and return equations
The following equations follow from Cochrane (2005, p.6-16). The law of one price implies the existence of an SDF within the payoff space, which we denote m. The SDF generates after-tax prices \(p_j^{\tau }\) from after-tax payoffs \(X_j^{\tau }\). The pricing equation for any asset j is
where \(E(\cdot )\) is an expectations operator. To obtain an expected return equation, we need to define the risk-free return. The price of a risk-free cash flow of one is \(p(1)=E(m)=\frac{1}{R_f}\), where \(R_f\) is the gross risk-free rate: \(R_f=1 + r_f\). Any two assets that yield a risk-free payoff and that are taxed differently must have the same risk-free rate of return after-tax in an unrestricted market, no matter whether payoffs or returns are taxed.Footnote 5 Without restrictions, nobody would want to hold a risk-free asset that has a lower after-tax return than another risk-free asset so that returns and prices have to adjust. It follows that \(R_f=R_f^{\tau }\), since \(R_f\) is just a risk-free return with a tax rate of zero.
We state the pricing equation as
Dividing by the price and rearranging, we obtain the expected return equation
Benninga and Sarig (2003) use this equation as an SML represention before they specify a CAPM SML representation.
Definition 3.1
(SDF beta) We define the SDF beta as
The pre-tax version \(\beta _{m,j}^p\) with the respective superscript uses the pre-tax return in the covariance and the after-tax version \(\beta _{m,j}^{\tau }\) uses the after-tax return. We use the expected return-beta representation from Cochrane (2005):
As in Cochrane (2005, p.19), we restate the SDF within the payoff space as follows: \(m=a+bR_{mv}^{\tau }\). The SDF is represented as a linear combination of the constant a and a mean-variance efficient return \(R_{mv}^{\tau }\) multiplied by the factor b. Mean variance-efficient returns are returns that have a representation on the after-tax mean-variance frontier. Using this, the expected return equation can be restated in terms of a risk premium and beta:
in which \(\beta _{mv,j}^{\tau }=\frac{Cov(R_{mv}^{\tau },R_j^{\tau })}{Var(R_{mv}^{\tau })}\). This equation represents the SML, in which \(R_f\) is the intercept and \(-b R_f Var(R_{mv}^{\tau })\) the slope. For the no-tax CAPM, the market return \(R_M\) is a mean-variance efficient return. With taxes and depending on whether they are redistributed, the mean-variance efficient return may change to the after-tax market return. We come back to this in the CAPM section of our analysis.
In incomplete markets the SDFs of agents can differ, but there is one SDF m in the space of tradable assets that prices all assets. The relation of m with any investor specific \(m^i\) is \(m+\epsilon ^i=m^i\), in which \(\epsilon ^i\) is an error term with zero expectation and zero covariance with m or any asset payoff. Thus, the error term has no pricing implication, and it does not matter for pricing whether one uses m or \(m^i\). The assumption of complete markets (unique SDF) or equilibrium are not needed for the following.
4 Differential asset taxation in different beta and expected return spaces
In this section, we will explain the different results for SMLs that appeared in the literature for differential taxation.
4.1 SMLs in different beta and expected return spaces
In after-tax beta and after-tax expected return space, there is only one SML. However, different spaces yield different representations of the SML. We look at four possibilities for combinations of pre- and after-tax betas end expected returns: (1) after-tax beta and after-tax expected return space, (2) pre-tax beta and after-tax expected return space, (3) pre-tax beta and pre-tax expected return space, and (4) after-tax beta and pre-tax expected return space.
We start with asset-specific tax rates as in Eikseth and Lindset (2009), and then turn to tax rates for sub-markets, which is more in the fashion of Benninga and Sarig (2003). We express equations in terms of gross returns \(R_j\). Those equations are valid for the cash flow tax as in Benninga and Sarig (2003) and the tax on returns as in Eikseth and Lindset (2009). The difference between the two return expressions is just a constant: \(R_j=1+r_j\). For after tax returns the same is true with \(R(1 - \tau )=1 - \tau + r_j(1 - \tau _j)\) for cash flow taxes and with \(1 + r_j(1- \tau )\) for taxes on returns. For the covariances in the betas it does not matter whether the gross or net return is taxed. The gross return has just an additional constant that has no effect on covariances.Footnote 6
4.1.1 Asset-specific tax rates
We start with asset-specific tax rates.
4.1.1.1 After-tax beta–after-tax expected return space
Proposition 4.1
(After-tax beta–after-tax expected return space) In after-tax beta and after-tax expected return space, with a specific tax rate on every risky basis asset, there is only one SML.
Proof
The proposition follows directly from Equation (3.7). There is only one intercept, which is \(R_f\) or \(R_f^{\tau }\), which are both the same, and one slope, which is \(-R_f Var(m)\). Both are the same for each asset and each tax rate. \(\square \)
Figure 1 shows an example of an SML in this space. The exact computation of the SML can be found in the appendix. The same is true for all of the following graphs.

Representation in after-tax beta and after-tax expected return space, Source: Own depiction from numerical example in the appendix
4.1.1.2 Pre-tax beta–after-tax expected return space
Proposition 4.2
(Pre-tax beta–after-tax expected return space) In pre-tax beta and after-tax expected return space, with a specific tax rate on every risky basis asset, there is an SML, each with a different slope, for each unique tax rate. All of those SMLs have the same intercept.
Proof
We use the beta representation from Equation (3.7). The equation for the pre-tax beta and after-tax expected return representation becomes
The intercept is \(R_f^{\tau }\) and the slope is \(-R_f Var(m)(1 - \tau _j)\). Thus, there is one intercept but many slopes, one for every asset with its unique tax rate. \(\square \)
An SML for asset j represents all combinations of pre-tax beta and after-tax expected returns for portfolios out of asset j and the risk-free asset. The graphical representation is a security market fan as mentioned in Eikseth and Lindset (2009). Figure 2 shows an example of a security market fan. Slope variations are only due to the different tax rate. Higher tax rates are associated with smaller tax terms \(1 - \tau _j\) and with flatter lines.

Representation in pre-tax beta and after-tax expected return space, Source: Own depiction from numerical example in the appendix
Generalizing to portfolios, we obtain
with \(\sum _{n=1}^N w_n=1\). Thus, with a portfolio there is still a single intercept. The slope changes with the more complex tax term \(\bigg (1 - \sum _{n=1}^N \frac{w_n\beta _{m,n}^p\tau _n}{\beta ^p_{m,pf}}\bigg )\). Including portfolios, the representation in the pre-tax beta and after-tax expected return space is still a fan. The SML including a portfolio of risky assets represents portfolios of the risk-free rate and the portfolio of risky assets. One can think of the SML of a portfolio as the weighted average line of the SMLs of the assets that are included in the portfolio. For a two-asset portfolio the line would go through the after-tax risk-free rate for a beta of zero, and it would be between the SMLs of the two assets for other betas.
Eventually, the fan shows that for the same after-tax expected return, a more negative pre-tax beta is required for assets with higher tax rates. It is also possible to compute the additional pre-tax beta that is required to make up for a certain increase of the tax rate.
4.1.1.3 Pre-tax beta–pre-tax expected return space
Proposition 4.3
(Pre-tax beta–pre-tax expected return space) In pre-tax beta and pre-tax expected return space, with a specific tax rate on every risky basis asset, there is an SML, each with the same slope, but a different intercept, for each unique tax rate.
Proof
We divide Equation (3.7) by \((1-\tau _j)\) to obtain the pre-tax beta and pre-tax expected return equation
The intercept changes now with the asset’s tax rate but the slope is constant. There is an SML for every single asset. All of those SMLs are parallel. \(\square \)
However, the interpretation is not straightforward. It does not represent the pre-tax expected return of a portfolio of the risk-free asset and the risky asset when \(\tau _0\) and \(\tau _j\) are not equal.
Figure 3 shows an example.

Representation in pre-tax beta and pre-tax expected return space, Source: Own depiction from numerical example in the appendix
For completeness, we present the equation for portfolios:
4.1.1.4 After-tax beta–pre-tax expected return space
Proposition 4.4
(After-tax beta – pre-tax expected return space) In after-tax beta and pre-tax expected return space, with a specific tax rate on the return of every risky basis asset, there is an SML, each with a different slope and a different intercept, for each unique tax rate.
Proof
The after-tax beta–pre-tax expected return representation turns out to be
Observation of the equation shows that the asset-specific tax terms lead to a different intercept and slope for each the tax rate. \(\square \)
We write Equation (4.5) as a weighted average to obtain a representation for a portfolio. The result is
This equation is written in terms of after-tax betas of the single assets that constitute the portfolio but not of the after-tax portfolio beta. Portfolio weights and the tax rate terms cannot be separated to achieve this.
Figure 4 shows an example of a graphical representation. For reasons we explained, the graph only shows representations of basis assets but not of portfolios. The light gray lines are parallel to the lowest line to visualize better that slopes change as well.

Representation in after-tax beta and pre-tax expected return space, Source: Own depiction from numerical example in the appendix
4.1.2 Sub-markets with different tax rates
As in Benninga and Sarig (2003), we establish different sub-markets. However, we do not restrict tradability through some kind of segmentation. Any agent can trade any asset. Here, the term sub-markets does only mean that we re-categorize assets according to how they are taxed. The payoff space does not need to be complete. We split each of the N risky basis assets and the risk-free asset into S sub-groups. Doing this we obtain S sub-markets with all basis assets and the risk-free asset included. In each of the sub-markets, there is just one tax rate \(\tau _s\) with \(s=1,..,S\). We use the notation \(X_{j,s}^{\tau }\) for sub-group s of asset j which is taxed at the tax rate \(\tau _s\). The S sub-markets have exactly the same assets and pre-tax payoffs, but different after-tax payoffs.
Of any asset j, the different sub-classes of the asset must yield the same after-tax return and expected after-tax returns: \(R_{j,1}^{\tau }=R_{j,2}^{\tau }=...=R_{j,S}^{\tau }\) and \(E(R_{j,1}^{\tau })=E(R_{j,2}^{\tau })=...=E(R_{j,S}^{\tau })\) for \(s=1,...,S\). Otherwise the law of one price would be violated. Furthermore, after-tax returns must be equal to the simple returns, i.e., that \(R_{j,s}^{\tau }=R_j\), and after-tax expected returns must be equal to expected simple returns, i.e., that \(E(R_{j,s}^{\tau })=E(R_j)\), for all j and s. This follows immediately from the fact that simple returns can be seen as after-tax returns, whereas the tax rate is zero. The same is true for the risk-free rate: \(R_{f,s}^{\tau }=R_f^{\tau }=R_f\).
For this reason, we can write any equation without using the j, s subscripts. We do not show graphs here, because they are virtually the same as in the four cases above. There is just a different context in that tax rates are attached to different sub-markets.
Corollary 4.1
(Different tax rates for different sub-markets) The results for different tax rates for different assets from Proposition 4.1 to 4.4 can be transferred to the equivalent combinations of pre- and after-tax betas and expected returns of different tax rates for different sub-markets.
For example for the after-tax beta and after-tax expected return space, we can use Equation (3.7), only changing subscripts:
The slope \(R_f\) and intercept \(-R_f Var(m)\) can be directly observed from the equation. As explained earlier, \(R_f=R_{f,s}^{\tau }\), \(E(R_{j,s}^{\tau })=E(R_{j}^{\tau })\) and \(\beta _{m,js}^{\tau }=\beta _{m,j}^{\tau }\).
In pre-tax beta and after-tax expected return space, with sub-market specific tax rates, there are SMLs with the same intercept but different slopes, one slope for each sub-market. This leads to the Security Market Fan as in Eikseth and Lindset (2009). However, in this case there will be S lines, i.e., one line for every sub-market, each with the same intercept but with a different slope.
In pre-tax beta and pre-tax expected return space, with sub-market specific tax rates, there are SMLs with the same slope but different intercepts. Benninga and Sarig (2003) show this for two sub markets, a debt and an equity market, in their Proposition 1. They fold tax terms into state prices and into the SDFs, which we do not herein. Since they assume a higher tax rate in the debt securities sub-market than for equity securities, the state prices for the debt securities market are lower than for equities to account for this difference.
5 Differential taxation with CAPM betas
In a CAPM context, betas are usually represented with respect to the market return. Therefore, we turn now to the beta representations that use returns instead of an SDF.
Definition 5.1
We define the CAPM beta as
with \(R_M\) as the market return.
In a similar fashion, \(\beta ^{\tau }_{M,j}\) is the after-tax beta containing only after-tax returns, and \(\beta ^p_{M,j}\) is the pre-tax beta using only pre-tax returns.
It is important to distinguish two different cases. The first case is that all taxes paid are lost, i.e., they cannot be consumed in any way. This case is usually regarded in the finance literature. Benninga and Sarig (2003) and Brennan (1970) with their classic tax-CAPM use this approach. The second case is that taxes are redistributed through some distribution rule to the agents in a lump sum form. This case is regarded in Eikseth and Lindset (2009) and in Kruschwitz and Löffler (2009). In what follows, we will not treat the division in different sub-markets, and we will keep it with asset-specific tax rates alone. The case of different sub-markets would not add much to the analysis. We will start with the first case.
5.1 The case of lost taxes
When tax payments are lost, the CAPM SDF is linear in the after-tax payoff or return and can be represented by
For linearity of the CAPM SDF in the return of the wealth or market portfolio see Chapter 9 in Cochrane (2005). Since for the case at hand agents consume only after-tax payoffs, the CAPM is derived on this after-tax basis and the after-tax market return is the mean-variance efficient return. The after-tax return is just a scaled version of the after-tax payoff so that the SDF is also linear in the after-tax market return.
5.1.1 After-tax beta–after-tax expected return space
Proposition 5.1
(After-tax beta–after-tax expected return space, CAPM, lost taxes) With the CAPM with lost taxes, in after-tax beta and after-tax expected return space, with a specific tax rate on every risky basis asset, there is only one SML.
Proof
We use Equation (3.7), substitute in (5.2) and multiply \(\frac{Var(R_M^{\tau })}{Var(R_M^{\tau })}\) to obtain the expected return equation in after-tax beta and after-tax expected return space
The result is a single SML with intercept \(R_f\) and slope \(- b R_f Var(R_M^{\tau })\). \(\square \)
We remind here that \(R_f=R_f^{\tau }\). Figure 5 shows an example. The parameter b is negative so that the slope becomes positive.

Representation in after-tax beta and after-tax expected return space, Source: Own depiction from numerical example in the appendix
5.1.2 Pre-tax betas–after-tax expected return space
Definition 5.2
For a shorthand notation, we use \({\mathcal {T}}_M=\sum _{n=1}^N w_n \tau _n R_n^p\) for the market tax term.
Definition 5.3
We define the pre-tax beta for the tax part of the market return as \(\beta ^p_{{\mathcal {T}}_M,j}=\frac{Cov({\mathcal {T}}_M,R_{j}^p)}{Var({\mathcal {T}}_M)}\).
Due to the additional tax term, we have two betas, so that SMLs lie an a three-dimensional space. Each of the two betas form an axis, and the expected return is represented through the third axis.
Proposition 5.2
(Pre-tax betas–after-tax expected return space, CAPM, lost taxes) For the CAPM with lost taxes, in pre-tax beta and after-tax expected return space, there are many SMLs with is a single intercept but with one slope for each tax rate.
Proof
Equation (5.2) can be rewritten in pre-tax terms as follows
Using this in the after-tax return equation leads to
from which we can read intercept and slope terms.Footnote 7\(\square \)
Figure 6 shows an example of SMLs in this three dimensional space. Since \(b<0\), the expected after-tax returns increase with the pre-tax market beta. However, they decrease with the beta on the market tax term. The second observation is a mathematical artifact since taxes are subtracted from the pre-tax returns so that the covariance changes its mathematical sign.

Representation in pre-tax beta and after-tax expected return space. The vertical lines at \(\beta ^p_{M,j}=2\) are there to better visualize the different heights of the different SMLs of the different assets. Source: Own depiction from numerical example in the appendix
5.1.3 Pre-tax betas–pre-tax expected return space
Proposition 5.3
(Pre-tax betas–pre-tax expected return space, CAPM, lost taxes) For the CAPM with lost taxes, in pre-tax beta and pre-tax expected return space, there are many SMLs with different intercepts but with equal slopes for each beta dimension.
Proof
Dividing Equation (5.5) by \(1 - \tau _j\), we obtain
This leads to a different intercept \(R_f^p\frac{1 - \tau _0}{1 - \tau _j}\) for each basis asset. The slopes in each dimension, \(- b R_f Var(R_M^p)\) and \(b R_f Var({\mathcal {T}}_M)\), do not depend on tax terms. \(\square \)
In the three-dimensional space the SMLs of every asset lie in planes that are collinear to each other. Equation (5.6) defines those planes - one per each tax rate.
However, the single SMLs within two different planes do not have to be collinear. Figure 7 shows examples of SMLs in such a space. To get back to two dimensions, one can construct a mixed beta that uses the after-tax market return together with pre-tax asset returns. This would lead to parallel SMLs.

Representation in pre-tax beta and pre-tax expected return space. The vertical lines at \(\beta ^p_{M,j}=2\) are there to better visualize the different heights of the different SMLs of the different assets. Source: Own depiction from numerical example in the appendix
5.1.4 After-tax beta–pre-tax expected return space
Proposition 5.4
(After-tax beta–pre-tax expected return space, CAPM, lost taxes) For the CAPM with lost taxes, in after-tax beta and pre-tax expected return space, there is a different SML for each different tax rate, each of those SMLs with a different intercept and a different slope.
Proof
With the after-tax beta, we obtain a two-dimensional space for the SML. The expected return equation is
Intercepts and slopes change with the tax terms of the basis assets. \(\square \)
The interpretation is as with the SDF beta. We covered this case graphically for the SDF beta in Fig. 4.
5.2 Taxes are fully redistributed
We turn to the case when all tax payments are redistributed back to investors. The CAPM SDF is linear in the pre-tax payoff or return and can be represented by
For linearity of the CAPM SDF in the return of the wealth or market portfolio see Chapter 9 in Cochrane (2005). Since for the case at hand agents consume after-tax payoffs plus redistributed taxes, in the aggregate, the pre-tax market payoff \(X_M\) is consumed and is the basis for the mean-variance efficient market return. The pre-tax return is just a scaled version of the pre-tax payoff so that the SDF is also linear in the pre-tax market return.
Using the above equation in Equation (3.5), gives the basic pricing equation in terms of the market return:
Expected returns are generated using the pre-tax market return.
5.2.1 After-tax betas–after-tax expected return space
To show the SMLs for after-tax figures, we will have to break down the pre-tax market return into its after-tax return component and into the tax itself:
We will use the additional market tax beta with after-tax returns \(\beta ^{\tau }_{{\mathcal {T}}_M,j}\).
Proposition 5.5
(After-tax betas–after-tax expected return space, CAPM, redistributed taxes) In the CAPM with redistributed taxes, in three dimensional after-tax beta and after-tax expected return space, with a specific tax rate on every risky basis asset, there are SMLs with a single intercept and the same slope parameter for each of the two betas. All SMLs lie in one plane.
Proof
Using Equation (5.10) and the market tax beta leads to the following expected return equation:
The equation shows a single intercept \(R_f\) and a single slope for each dimension: \(-bR_f Var(R_M^{\tau })\) and \(- b R_f Var({\mathcal {T}}_M)\). SMLs are in three dimensional space in which all SMLs lie in a single plane, which is defined by the equation in the proposition. \(\square \)
Figure 8 shows a graphical representation from the numerical example for the case with full tax redistribution.

Representation in after-tax beta and after-tax expected return space. The vertical lines at \(\beta ^{\tau }_{M,j}=2\) are there to better visualize the different heights of the different SMLs of the different assets. Source: Own depiction from numerical example in the appendix
5.2.2 Pre-tax beta–after-tax expected return space
Proposition 5.6
(Pre-tax beta–after-tax expected return space, CAPM, redistributed taxes) With the CAPM with redistributed taxes, in pre-tax beta and after-tax expected return space, with a specific tax rate on the return of every risky basis asset, there are SMLs with a single intercept, but particular slopes for each tax rate.
Proof
We take the tax term out of the covariance term in the beta:
The equation shows a single intercept \(R_f\) and different slopes - one for each different tax rate \(\tau _j\). \(\square \)
In the pre-tax beta and after-tax expected return space, we obtain a security market fan. For SDF betas and also in the pre-tax beta and after-tax expected return space, the graphical representation is also a fan (compare Fig. 2).
5.2.3 Pre-tax beta–pre-tax expected return space
Proposition 5.7
(Pre-tax beta–pre-tax expected return space, CAPM, redistributed taxes) In the CAPM with redistributed taxes, in pre-tax beta and pre-tax expected return space, with a specific tax rate on every risky basis asset, there are parallel SMLs with different intercepts for each tax rate.
Proof
Dividing Equation (5.12) by the tax term, we obtain
The resulting lines for the basis assets in pre-tax beta and pre-tax expected return space have different intercepts and but similar slopes. \(\square \)
This can also be observed for the SDF beta in Fig. 3.
5.2.4 After-tax betas–pre-tax expected return space
Proposition 5.8
(After-tax betas–pre-tax expected return space, CAPM, redistributed taxes) With the CAPM with redistributed taxes, in three-dimensional after-tax beta and pre-tax expected return space, with a specific tax rate on every risky basis asset, there are SMLs with different intercepts and different slopes all varying with the tax rate.
Proof
Dividing Equation (5.11) by the tax term yields
The slopes in each dimension vary with the tax term as does the intercept. \(\square \)
The graphical representation is comparable to the one for the SDF beta in Fig. 4, with the addition that here we have an additional dimension. When taxes are not redistributed the graphical representation also consists of lines with different intercepts and slopes.
5.2.5 Mixed pre-tax/after-tax beta–after-tax expected return space
The four cases using the priorily defined betas do not yield a representation with a single SML.
Definition 5.4
We need to define another beta to have a single SML. The definition is
which mixes the pre-tax market return with the after-tax return of the asset.
Proposition 5.9
(Mixed pre-tax/after-tax beta–after-tax expected return space, CAPM, redistributed taxes) With the CAPM with redistributed taxes, in after-tax beta (with the beta as defined above) and after-tax expected return space, with a specific tax rate on every risky basis asset, there is a single SML.
Proof
The just defined beta together with Equation (5.11) leads to
The equation shows a single intercept and slope. \(\square \)
Through the tax redistribution the pre-tax market return is the reference return in this economy. This is also the representation that has most practical relevance in such an economy.
Before discussing the results and their applications, we provide a brief discussion on other widely used graphical representations in finance, which are efficient frontiers and the CML.
6 Other return representations – efficient frontiers and the CML
In addition to the analysis of return representations in beta–expected return space, we briefly discuss another widely used representation of portfolio returns. This probably warrants a paper on its own, however some potential issues can be discussed already herein in a more informal way.
The classic mean-variance efficient frontier (MVF), usually displayed in mean-standard deviation space for ex-post returns or in expected return–standard deviation space for expected returns, is a tool to identify efficient portfolios. One can also present classic CAPM results in this space, such as the market return being on the efficient frontier of risky assets and the CML as the line connecting the risk-free return and the market return representations. In addition to that, the CML is tangent to the efficient frontier of risky assets and the tangent point is the representation of the market return.Footnote 8
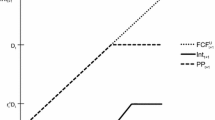
Figure 9 shows a typical graph in expected return–standard deviation space. It shows the MVF of risky assets as a full line. The CML is the dotted line tangent to the MVF of risky assets. As such it represents the efficient frontier of all assets, including the risk-free asset. As in the classic CAPM the market return representation is the tangent point.

Efficient frontier of risky assets (full line), CML (dotted line), point Rf represents the risk-free rate and point M represents the market return
6.1 Mean-variance frontiers without a CAPM context
We first look at the MVF, without a CAPM context. Investors either form efficient portfolios on a pre-tax basis, using pre-tax returns as inputs, and obtaining the MVF with pre-tax figures. Or they do the optimization on an after-tax basis, with the results best presented with after-tax figures. One can also mix pre-tax expected returns with after-tax standard deviation and vice versa. We make a couple of statements regarding such a mix based on the following proposition:
Proposition 6.1
(Linear relation of pre- and after-tax portfolio returns for optimal weights) For weights of portfolios with return representations on the mean-variance frontier of risky assets, pre- and after-tax returns of such portfolios have a linear relationship.
Proof
The linear relationship an be formally stated as \(R_{pf,o}^{\tau }=R_{pf,o}^p m + n\) or \(\sum _n^N w_{n,o} R^{\tau }_n=\sum _n^N w_{n,o} R^p_n m + n\) in which m and n are constants, and \(w_{n,o}\) are portfolio weights based after-tax or pre-tax optimization.
We use the equations that generate the frontier of risky assets from Cochrane (2005, pp. 82-83). Optimal weights based on after-tax returns are:
in which \(A^{\tau }, B^{\tau }\), and \(C^{\tau }\) are constants based on after-tax returns, \(\varvec{(\Sigma ^{\tau })^{-1}}\) is the inverse of the coveriance matrix of after-tax returns, \(\mathbf {E(r^{\tau })}\) is the vector of expected after-tax returns of all basis assets, \({\mathbf {1}}\) is a vector of ones, and \(E(r^{\tau }_p)\) is an after-tax portfolio return – the input to the equation to generate optimal weights. The first derivative of \({\mathbf {w}}_o\left( E(r^{\tau }_p) \right) \) with respect to \(E(r^{\tau }_p)\) leads to a vector of constants for the changes of optimal weights. It follows that for changes of the expected return, the optimal weights always change in constant proportions. Let the change of optimal weight on asset 1 be \(\Delta \), then the change of the optimal weight on asset 2 is \(\Delta K_2\), with \(K_2\) being a constant, for the optimal weight on asset 3 the change is \(\Delta K_3\) with \(K_3\) as constant and so forth.
We define some arbitrary optimal weights vector \({\mathbf {w}}_o^*\) and the respective pre- and after-tax returns: \(R^{\tau *}_{pf,o}=\sum _n^N w_{n,o}^* R_n^p (1 - \tau _n)\) and \(R^{p*}_{pf,o}=\sum _n^N w_{n,o}^* R_n^p\). We use them as constants. We can establish any other optimal portfolio return through changing those weights: \(R^{\tau }_{pf,o}=\sum _n^N (w_{n,o}^* + \Delta K_n) R_n^p (1 - \tau _n)\) and \(R^{p}_{pf,o}=\sum _n^N (w_{n,o}^* + \Delta K_n) R_n^p\), where we define that \(K_1=1\). With that notation, the following holds:
Equation (6.2) is the same as \(R_{pf,o}^{\tau }=R_{pf,o}^pm + n\). One can also start with pre-tax optimal weights and follow the same logic to arrive at the linearity of pre- and after-tax returns based on those pre-tax optimal weights. \(\square \)
Whether returns are random variables or ex-post returns does not matter. For the MVF of risky assets, the relation between variance \(Var(r^{\tau })\) and expected returns \(E(r^{\tau })\), here using after-tax returns, is:
Using \(r^{\tau }=r^pm+n\) in this equation shows that the graph for pre-tax expected returns and after-tax standard deviation or for after-tax expected returns and pre-tax variance must also be cone shaped, but, depending on parameters m and n will be scaled and dislocated. Nobody stops one from using optimal weights from Equation (6.1) for after-tax portfolios and apply them to pre-tax returns to obtain a pre-tax portfolio return. However, one has to understand that for an investor who does not pay taxes this portfolio is most likely not optimal, and such an investor should compute optimal weights using pre-tax parameters in the above equation.
For use cases, generally, a taxable investor should use after-tax returns and a tax-free one, the pre-tax returns for the mean-variance analysis. Sensible cases for combinations of pre- and after-tax figures still need to be found.
6.2 Mean-variance frontiers in a CAPM context
We turn to CAPM results. Rational investors consider their consumption after taxes and redistributions. Asset prices reflect those considerations. With certain tax rates, the risk-free asset will always have zero variance and, therefore, be mean-variance efficient.
Without redistributions, the after-tax market return will be on MVF of risky assets in after-tax return space. The reason is that this is just the usual mean-variance CAPM in which a different set of payoffs, i.e., after-tax payoffs, is used. Presenting the outcomes in a consistent way, i.e., in after-tax space, will reflect classic CAPM results. From pre-tax returns and parameters based on them, one can still create an MVF. This is just a statistical exercise. However, the pre-tax market return does not have to be on this pre-tax MVF. With asset-specific tax rates one cannot easily take the tax term out of portfolio returns, because each asset has a different tax rate. Thus, there is no simple proportional conversion of pre- into after-tax portfolio returns and vice versa. That also means the efficient portfolios based on after-tax figures will not generally be pre-tax efficient.
With redistributions as in Eikseth and Lindset (2009), the CAPM mechanics change a bit. As above, we assume a CAPM world in which investors maximize utility of after-tax payoffs plus redistributions. However, in the aggregate the pre-tax payoffs are available for consumption. Therefore, the resulting expected return equation does not include the after-tax market return, but the pre-tax market return. The pre-tax market return representation is actually on the after-tax MVF of risky assets, whereas the after-tax market return is not generally efficient. To see this, we use Equation (9) from Eikseth and Lindset (2009). In our notation it reads
The equivalent return generating equation is
in which \(\epsilon \) has an expected value of zero and is uncorrelated with \(r^P_M\).Footnote 9 We create a return \(r^{\tau }_j=r^P_M + \epsilon \), with \(E(\epsilon )=0\) and \(Cov(\epsilon ,r^P_M)=0\). The zero expectation of \(\epsilon \) leads to \(r^{\tau }_j\) and \(r^P_M\) having the same expected values, and the zero covariance makes the equation fulfill the return generating equation (6.7). The variance is \(Var(r^{\tau }_j)=Var(r^P_M) + Var(\epsilon )\), which shows that there is no return \(r^{\tau }_j\) with \(E(r^{\tau }_j)=E(r^P_M)\) that has a smaller variance than \(r^P_M\). Thus, the pre-tax market return is on the MVF of risky assets.
As those brief discussion show, a deeper analysis of asset-specific tax rates and its consequences in expected return and standard deviation space may be warranted.
7 Summary and discussion of the cases and their applications
There are two general use cases for SMLs. One is the identification of misvalued assets versus a pricing model that implies a beta. In our case, we used a general SDF model and a more specific CAPM – which has an SDF linear in some type of market return. As a second use case, certain risk and return measures can be derived from the SML or from representations in the beta-expected return graph. One such important risk measure is the Treynor ratio, which, in its ex-ante version, is defined as expected excess return of an asset over the risk-free return and the beta of the asset. It measures expected excess return per unit of systematic risk. It is best suited as a measure of return per unit of risk for well diversified portfolios, which have little idiosyncratic risk.
Table 1 below shows the four cases for SDF betas. Any of the four cases will fulfill the first use case and show misvalued assets. If a representation of an asset in beta-expected return space is not on the SML of the asset, then it is overvalued if below or undervalued if above the SML. For a single SML in the pure after-tax space (case 1 in Table 1) this is easily observed. For graphical representations with several SMLs, it is necessary to compare the assets to the SML with the same asset-specific tax rate (all other cases in Table 1).
The pure after-tax space (i.e., case one in Tables 1, 2, 3, and case five in Table 4) is the most straight forward graphical representation for our assumption of taxable investors. Thus, the question is what are the other cases useful for? In our simplified model and also in the models of the underlying two articles, asset-specific tax rates are easily identified. However, we argued initially that tax rates are often not purely asset-specific, but also depend on investor characteristics – mostly their income tax bracket. Investors often do not or not fully disclose their tax information to portfolio managers. Therefore, they often resort to pre-tax return information or do only include withholding taxes in return calculations. Another challenge is that in most countries capital gains taxes are realization based (as opposed to accrual based). A single period model such as the CAPM cannot properly account for that. So once again, managers and advisers may feel more confident using pre-tax returns and construct pre-tax betas and expected returns from them.
Care must be taken interpreting pre-tax representations in pre-tax beta and expected return space. For an ex-post analysis, a scatter plot in such a space may lead to a cloud of dots, from which one may infer a single regression line. Assuming this line as a proper SML and basing decisions on it would be incorrect. The reason is that a pure pre-tax space, as in Fig. 3 above, would produce an SML for each asset-specific tax rate. The SML with the highest tax rate is above all other SMLs, i.e., assets with this tax rate have the highest pre-tax returns. A scatter plot of actual ex-post pre-tax return data would distribute dots all over this graph with dots from high-tax assets more in the upper part and dots from low-tax assets in the lower part. A single regression line would not be appropriate and mislead the observer. Assets that are taxed equally need to be separated from assets that are taxed differently. For each group of assets with the same tax rate a separate SML needs to be formed and held against the respective assets for analysis purposes.
Furthermore, the pre-tax graph may be important for investors that are different from most other investors. For examples, most investors may be taxable, however, there may be a group that is not. They would use pre-tax return and risk measures for their portfolios. Assets with the highest pre-tax return, but the same pre-tax beta, are most attractive for them. Through selling low tax assets and buying high tax assets at equal betas, market neutral strategies to exploit the tax differences are possible. There may be arbitrage possibilities as long as market frictions do not restrict them.
Case 2 with pre-tax beta and after-tax expected returns in Tables 1, 2 and 4 together with Fig. 2 lead to a security market fan similar to the one in Eikseth and Lindset (2009). In this graph, one may fix an expected return, for example 20% in Fig. 2, and observe the pre-tax systematic risk needed for differently taxed assets. The SML with the lowest tax rate is the steepest one in this graph. With higher tax rates, SMLs become less steep. At an expected return of 20% the beta differs a little bit less than 0.2 between an asset with lowest tax rate of 5% and the highest tax rate of 25%. Thus, the high-tax assets need an about 0.2 higher pre-tax beta to generate the same 20% of after-tax return. Eikseth and Lindset (2009) state that such a graph shows asset heterogeneity of the tax system. They see the pre-tax beta as the traditional risk measure, however, they later turn to the after-tax beta, which leads back to the pure after-tax representation with a single SML. We believe that there is no substantial application for security market fan. We also cannot find a good interpretation in Eikseth and Lindset (2009). The same holds also for other representations that mix pre- and after-tax figures (for example case four in Table 1). So the point we make here is that for the practical applications that we can think of pre- and after-tax figures should not be mixed up.
After those remarks, we briefly discuss some specifics regarding Tables 2, 3, and 4 below.
Table 2, which shows the cases for the sub-markets, basically resembles Table 1. Benninga and Sarig (2003) find an application of case three with the parallel lines. They look at two sub-markets – one with debt and one with equity securities. For a relevering procedure, they find an asset beta and a representation of the asset pre-tax expected return in their Proposition (6), which basically is a version of Equation (4.3). To see this, let \(\tau _E\) and \(\tau _D\) be tax rates on equity and debt cash flows, respectively. Benninga and Sarig (2003) establish that \(\frac{1 - \tau _D}{1 - \tau _E}=1-\tau ^C\)Footnote 10, with \(\tau ^C\) as the corporate tax rate. Replacing the term \(1 - \tau ^C\) in Benninga and Sarig (2003) Proposition (6) with the ratio of \(\frac{1 - \tau _D}{1 - \tau _E}\) leads to an equation in the style of Equation (4.3).
In Table 3, we look at the CAPM without redistributions of taxes. Defining the pre-tax beta with the pre-tax market return, as in the cases two and three in the table, we need to add a new beta for the taxes on the market portfolio. Otherwise, we would miss an important element that forms expected returns. Therefore, cases two and three have three dimensional spaces. Apart from that, the logic of the four cases follows the one of Tables 1 and 2. Case three shows representations of SMLs in pure pre-tax space. Figure 7 above shows an example. There are two betas, which may be folded into one with an after-tax market return and a pre-tax asset return. In any case, assets with the same tax rate need to be analyzed together with their respective SML as outlined above. The market tax beta shows the contribution to pre-tax returns from the return correlation with aggregate taxes paid. Assets with a negative correlation with the tax term will have a higher expected return and lower prices. On average, those assets pay higher pre-tax returns when aggregate taxes are low and lower pre-tax returns when aggregate taxes are high.
Eventually, the CAPM with tax redistribution, the case that Eikseth and Lindset (2009) analyze, leads to a different set of representations as before. Through the tax redistribution the relevant SDF is linear in the pre-tax market and not the after-tax market return. Additionally, the after-tax market return is not just a scaled pre-tax return. That only works for the case of a single tax rate for all assets, but not for different tax rates for different assets. Thus, to obtain an after-tax market beta, we need the additional beta for the tax term. This is the first case in Table 4. For the pure after-tax space, we obtain three dimensions, which is different from the pure after-tax representations in the prior tables. Case two in the table shows the security market fan as in Eikseth and Lindset (2009). However, the relevant representation to look at for the investors should be case five, which features a single SML. This case uses a beta defined differently than before. It uses the pre-tax market return but after-tax returns of the single asset that is to be valued. The tax redistribution feature of this economy makes the pre-tax market return the reference point for valuations.
Bottom line is that for practical applications, the pure pre- or after-tax space should be used. Combinations of pre- and after-tax figures show tax rate heterogeneity, but, beyond that, we do not see reasonable use cases.
8 Conclusion
Prior papers on SMLs with differential asset taxation lead to interesting graphical representations such as a security market fan or parallel SMLs instead of a single SML. Starting from a general pricing framework and then using CAPM-specifications, we reconcile those results and present overviews of different representations of SMLs for different pricing frameworks. We conclude that the different graphical representations are primarily due to manipulations of a basic pricing equation, in which tax terms are shifted in and out of betas or expected returns. Differential taxation of asset-specific payoffs or returns lead to a single SML in after-tax expected return and after-tax beta space – with a minor exception for the case of the CAPM with redistribution of taxes. Furthermore, for asset-specific taxes, one can price all after-tax payoffs with a single SDF. Assumptions used in prior articles, such as market completeness or the CAPM, are not necessary for most of those results.
Notes
See Internal Revenue Code (IRC) 501(c)(3) for tax-exempt bond income related charitable organizations. See IRC 103 for tax exempt bonds.
Doing this would be rational.
The price is know at time zero, so that it is certain.
Benninga and Sarig (2003) state that tax arbitrage restrictions are in place that may lead to market segmentation and different risk-free rates in their model.
We can write
$$\begin{aligned} Cov(m,R_j^p(1 - \tau ))=Cov(m,(1 + r_j^p)(1 - \tau ))=Cov(m,r_j^p(1 - \tau ))=Cov(m,1 + r_j^p(1 - \tau )). \end{aligned}$$The first term is an after-tax gross return for a cash flow tax. The second one is the same but broken down into net returns. The third term is an after-tax net return with taxes on returns. The constant \(1 - \tau \) was taken out. The last term includes the after-tax gross return for the case of taxes on returns. We just added a one, which does not change the covariance.
One can go further and express the parameter b in terms of the pre-tax market return \(R_M^p\). Therefore, we substitute in \(R_M^p\) and obtain
$$\begin{aligned} E(R_M^p)=R_f - b R_f Cov\bigg (R_M^p - \sum _{n=1}^N w_n \tau _n R_n^p, R_M^p\bigg ), \end{aligned}$$We rearrange for the parameter b:
$$\begin{aligned} b&=-\frac{E(R_M^p) - R_f}{ R_f(Var(R_M^p) - \sum _{n=1}^N w_n \tau _n Cov(R_n^p, R_M^p))}\\&=-\frac{E(R_M^p) - R_f}{ R_f Var(R_M^p)(1 - \sum _{n=1}^N w_n \tau _n \beta _{n,M}^p)} \end{aligned}$$This expression can be reused in the pricing equation
$$\begin{aligned} E(R_j^{\tau })=R_f + \frac{(1 - \tau _j)(E(R_M^p) - R_f)}{ 1 - \sum _{n=1}^N w_n \tau _n \beta _{n,M}^p}\bigg (\beta ^p_{M,j} + \sum _{n=1}^N w_n \tau _n \frac{Cov(R_n^p,R_{j}^p)}{Var(R_M^p)}\bigg ). \end{aligned}$$The mathematics of efficient frontiers and CAPM results are explained in detail in Roll (1977).
That means that \(Cov(\epsilon ,r^P_M)=0\). To see this, rearrange the prior Equation (6.7) for \(\epsilon \), substitute the resulting term into the prior covariance equation and solve it.
See for example their proof for Proposition (4).
The basis assets are non-redundant.
References
Benninga S, Sarig O (2003) Risk, returns, and values in the presence of differential taxation. J Bank Financ 27:1123–1138
Bergstresser D, Poterba J (2002) Do after-tax returns affect mutual fund inflows? J Financ Econ 63:381–414
Blitz D (2020) The risk-free asset implied by the market: medium-term bonds instead of short-term bills. J Portfolio Manage 46(8):120–132
Brennan MJ (1970) Taxes, market valuation and corporate financial policy. Nat Tax J 23(4):417–427
Chan KF, Marsh T (2021) Asset prices, midterm elections, and political uncertainty. J Financ Econ 141(1):276–296
Cochrane JH (2005) Asset pricing, Revised. Princeton University Press, New Jersey
Eikseth HM, Lindset S (2009) A note on capital asset pricing and heterogeneous taxes. J Bank Financ 33:573–577
Frazzini A, Pedersen LH (2014) Betting against beta. J Financ Econ 111(1):1–25
Goldstein R, Ju N, Leland H (2001) An ebit-based model of dynamic capital structure. J Business 74(4):483–512
Hens T, Naebi F (2020) Behavioural heterogeneity in the capital asset pricing model with an application to the low-beta anomaly. Appl Econ Lett 28(6):501–507
Hong H, Sraer DA (2016) Speculative Betas. J Financ 71(5):2095–2144
Jylhä P (2018) Margin requirements and the security market line. J Financ 73(3):1281–1321
Kruschwitz L, Löffler J (2009) Do taxes matter in the capm? BuR - Business Res 2(2):171–178
Leland HE (1994) Corporate debt value, bond covenants, and optimal capital structure. J Financ 49(4):1213–1252
Leland HE, Toft KB (1996) Optimal capital structure, endogenous bankruptcy, and the term structure of credit spreads. J Financ 51(3):987–1019
Lintner J (1965) The valuation of risky assets and the selection of risky investments in stock portfolios and capital budgets. Rev Econ Stat 47(1):13–37
Litzenberger RH, Ramaswamy K (1979) The effect of personal taxes and dividends on capital asset prices: Theory and empirical evidence. J Financ Econ 7(2):163–195
Litzenberger RH, Ramaswamy K (1980) Dividends, short selling restrictions, tax-induced investor clienteles, and market equilibrium. J Financ 35(2):469–482
Miller MH (1977) Debt and taxes. J Financ 32(2):261–275
Modigliani F, Miller MH (1958) The cost of capital, corporation finance and the theory of investment. Am Econ Rev 48(3):261–297
Modigliani F, Miller MH (1963) Corporate income taxes and the cost of capital: A correction. Am Econ Rev 53(3):433–443
Mossin J (1966) Equilibrium in a capital asset market. Econometrica 34:768–783
Pedersen LH, Fitzgibbons S, Pomorski L (2021) Responsible investing: the ESG-efficient frontier. J Financ Econ 142(2):572–597
Roll R (1977) A critique of the asset pricing theory’s tests part i: on past and potential testability of the theory. J Financ Econ 4(2):129–176
Sharpe WF (1964) Capital asset prices: a theory of market equilibrium under conditions of risk. J Financ 19(3):425–442
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Computation of the numerical example
Computation of the numerical example
In the following, we will explain how to compute the numerical example which resulted in the graphs that we used throughout the paper. We use four assets. The asset indexed with a zero is the risk-free asset. The other three basis assetsFootnote 11 are risky. We tax cash flows. The tax rates are shown in Table 5.
The gross risk-free rate is 1.02. We use six states. Table 6 shows the payoffs per state. Every state is equally likely. Adding up the payoffs of the risky assets yields the payoffs for each state for all risky assets. This is also the market payoff since we assume the risk-free asset in zero net supply. After-tax payoffs are as shown in Table 7.
1.1 CAPM with taxes not redistributed
To obtain returns, we need to compute prices first. We express Equation (5.2) in terms of the market payoff: \( m=a + c X_M^{\tau }\). We use this in Equation (3.4) to obtain
The CAPM prices everything relative to the market payoff. Thus, we price \(X_M^{\tau }\) to obtain an expression for c:
Substituting this back into Equation (A.1) gives the price equation
We fix the price of the market payoff \(p(X^{\tau }_M)\) at 1.1. This is the reference point for valuation in this economy. It implicitly sets the equity premium. Using this and the information given in Table 7, we compute prices of the risky basis assets. The prices of the risky assets add up to the one of the market portfolio (see Table 8).
We compute all of the returns, their expectations, covariances and return-betas (see Table 9).
To find the parameter a in Equation (A.5), we use \(E(m)=\frac{1}{R_f}\), which leads to
Given the numbers from the example \(c=-0.835\) and \(a=2.177\). Alternatively, \(m=a + b R^{\tau }_M\), from which follows that \(b=c p(X^{\tau }_M)\), so that in the example \(b=-0.918\). With those parameters, we compute the SDF and the betas with the SDF (Tables 10, 11).
Tables 12, 13, and 14 show pre-tax figures. Notice that pre-tax figures as defined herein use pre-tax cash flows and prices of after-taxed cash flows.
1.2 CAPM with redistributed taxes
We express Equation (5.2) in terms of the pre-tax market payoff
and use this in Equation (3.4) to obtain
For redistributed taxes, the CAPM prices all asset payoffs relative to the pre-tax market payoff. We price \(X_M\) to obtain an expression for c:
Notice that it is also possible to price the after-tax market return. In this case the equation for c reads
This version is more like the one in Eikseth and Lindset (2009). We will continue with the prior version, because this is the one that we used above.
Substituting this back into Equation (A.9) gives the price equation
We fix the pre-tax price of the market payoff \(p(X_M)\) at 1.256, which results in the same after-tax price for the market payoff as in the case without tax redistribution, i.e., \(p(X_M^{\tau })=1.1\). With Table 15, we compute prices of the risky basis assets. The table shows that the after-tax prices of the basis assets differ from the after-tax prices in Table 8.
Table 16 shows expectations, covariances and return-betas.
The SDF generated in this economy does not have to be the same as in the example without tax redistribution. Thus, to compute betas with the SDF, we again need to find the parameter a in Equation (A.5). Using \(E(m)=\frac{1}{R_f}\) leads to
Given the numbers from the example, \(c=-0.6804\) and \(a=2.114\) (\(b=-0.748\)). That is because we determined the pre-tax price to be the same as in the prior example. All the remaining values that make up the equation of c are pre-tax values and are exogenous, i.e., they are the same in both cases. However, the parameter a is different because the pre-tax expected market return has to be used to compute it and this figure is different from the after-tax market return, which is used in the prior case. With those parameters, we compute the SDF and the betas with the SDF (Table 17).
Tables 18, 19, 20 and 21 show pre-tax figures.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Krause, M., Lahmann, A. Differential taxation and security market lines–a clarification. Rev Quant Finan Acc 59, 171–203 (2022). https://doi.org/10.1007/s11156-022-01040-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11156-022-01040-4