
Abstract
The computation of Value at Risk has traditionally been a troublesome issue in commercial real estate. Difficulties mainly arise from the lack of appropriate data, the non-normality of returns, and the inapplicability of many of the traditional methodologies. As a result, calculation of this risk measure has rarely been done in the real estate field. However, following a spate of new regulations such as Basel II, Basel III, NAIC and Solvency II, financial institutions have increasingly been required to estimate and control their exposure to market risk. As a result, financial institutions now commonly use “internal” Value at Risk (V a R) models in order to assess their market risk exposure. The purpose of this paper is to estimate distribution functions of real estate V a R while taking into account non-normality in the distribution of returns. This is accomplished by the combination of the Cornish-Fisher expansion with a certain rearrangement procedure. We demonstrate that this combination allows superior estimation, and thus a better V a R estimate, than has previously been obtainable. We also show how the use of a rearrangement procedure solves well-known issues arising from the monotonicity assumption required for the Cornish-Fisher expansion to be applicable, a difficulty which has previously limited the useful of this expansion technique. Thus, practitioners can find a methodology here to quickly assess Value at Risk without suffering loss of relevancy due to any non-normality in their actual return distribution. The originality of this paper lies in our particular combination of Cornish-Fisher expansions and the rearrangement procedure.














Similar content being viewed by others

Notes
Note that V a R does not give any information about the likely severity of a loss. An associated measure that solves this difficulty is the expected shortfall (ES), which measures the expected loss of a portfolio, conditional on the portfolio loss exceeding the chosen quantile. More information about ES is reported in Rockafellar and Uryasev (2002)
See Appendix A for the formal definition of a quantile function, the inverse of a distribution function.
In terms of gains rather than losses, the V a R at confidence level α for a market rate of return X whose distribution function is denoted F X (x)≡P[X≤x] and whose quantile at level α is denoted q α (X) is:
$$-VaR_{\alpha}(X) = \text{sup} \left\{x:F_{X}(x) \leq {1 - \alpha} \right\}\equiv q_{1 - \alpha}(\textit{X}). $$An ideal risk measure ought to be coherent; i.e., it should obey the properties of monotonicity, sub-additivity, homogeneity, and translational invariance. However, V a R does not always respect the sub-additivity property, meaning that the risk of a portfolio can be larger than the sum of the stand-alone risks of its components, as measured by V a R. This failing has been emphasized by Artzner et al. (1999) and Acerbi (2002), who have consequently proposed such alternatives to V a R as ES. However, it should be noted that the practical consequences of this potential difficulty with V a R have been minimized by the findings of Daníelsson et al. (2013), who show that the violation of subadditivity by V a R seldom occurs in practice, and that “ V a R is [generally] subadditive in the relevant tail region.” In any case, the methodology proposed here can easily be adapted to most of the alternative risk measures that have been proposed, and in particular to ES.
For instance, the former encompasses REITs.
This approximation is based on the Taylor series developed, for example, in Kendall et al. (1994)
At the third order, the approximation is: \(\forall \alpha \in (0,1), z_{CF,\alpha }=z_{\alpha }+\frac {1}{6}(z_{\alpha }^{2}-1)S \).
Notice that in presence of a Gaussian distribution (S=0 and K=3), Eq. (2) reduces to the Gaussian quantile z α .
For example, inequality (5) implies a kurtosis coefficient higher than 3 (a positive excess of kurtosis), which indicates a leptokurtic distribution. Thus, unadjusted CF expansion is not appropriate in the presence of thin tails.
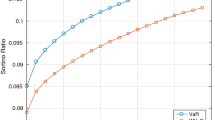
See the first figure presented in Chernozhukov et al. (2010). Note that the non-rearranged quantile function encountered might be even more severely non-monotonic (and therefore could provide poorer approximations of the distribution function) than the one presented in Fig. 2. We note that \(\tilde {z}_{CF,0.001}=-1.4\), whereas z C F,0.001 is clearly biased, being equal to −0.3.
An extensive presentation of the desmoothing technique can be found in Geltner et al. (2007), p.682. However, we note that the impact of the desmoothing is negligible in our case because of offsetting impacts on each of the first four moments
This raises a questions concerning the window length of the data set chosen by regulators. A shorter window length leads to higher skewness and kurtosis coefficients nearer the present, since the subprime and mortgage crisis then have more weight.
The halt in estimation is due to the lack of data required for kernel estimation.
References
Acerbi, C. (2002). Spectral measures of risk: A coherent representation of subjective risk aversion. Journal of Banking & Finance, 26 (7), 1505–1518.
Artzner, P., Delbaen, F., Eber, J.-M., Heath, D. (1999). Coherent measures of risk. Mathematical finance, 9 (3), 203–228.
Barndorff-Nielsen, O., & Cox, D. (1989). Asymptotic techniques for use in statistics. Springer.
Barton, D.E., & Dennis, K.E. (1952). The conditions under which gram-charlier and edgeworth curves are positive definite and unimodal. Biometrika, 39 (3-4), 425–427.
Bóna, M. (2004). A simple proof for the exponential upper bound for some tenacious patterns. Advances in Applied Mathematics, 33 (1), 192–198.
Booth, P., Matysiak, G., Ormerod, P. (2002). Risk measurement and management for real estate portfolios (Tech. Rep.) London.
Byrne, P., & Lee, S. (1997). Real estate portfolio analysis under conditions of non-normality: The case of NCREIF. Journal of Real Estate Portfolio Management, 3 (1), 37–46.
Chernozhukov, V., Fernndez-Val, I., Galichon, A. (2010). Rearranging EdgeworthCornishFisher expansions. Economic Theory, 42 (2), 419–435.
Cho, H., Kawaguchi, Y., Shilling, J. (2003). Unsmoothing commercial property returns: A revision to fishergeltnerwebb’s unsmoothing methodology. The Journal of Real Estate Finance and Economics, 27 (3), 393–405.
Cornish, E., & Fisher, R. (1937). Moments and cumulants in the specification of distributions. Revue de l’Institut International de Statistique / Review of the International Statistical Institute, 5 (4), 307–320.
Daníelsson, J., Jorgensen, B.N., Samorodnitsky, G., Sarma, M., de Vries, C.G. (2013). Fat tails, VaR and subadditivity. Journal of econometrics, 172 (2), 283–291.
Draper, N.R., & Tierney, D.E. (1973). Exact formulas for additional terms in some important series expansions. Communications in Statistics, 1 (6), 495–524.
Edelstein, R.H., & Quan, D.C. (2006). How does appraisal smoothing bias real estate returns measurement?. The Journal of Real Estate Finance and Economics, 32 (1), 41–60.
European Insurance and Occupational Pensions Authority. (2010). Solvency II Calibration Paper, CEIOPS-SEC-40-10. European Commission.
Fallon,W. (1996). Calculating value-at-risk Wharton, Financial Institutions Center, before (Working Paper No. 96-49).
Farrelly, K. (2012).Measuring the risk of unlisted property funds - a forward looking analysis. 19th Annual European Real Estate Society Conference in Edinburgh, Scotland.
Fisher, J.D., Geltner, D.M., Webb, R.B. (1994). Value indices of commercial real estate: A comparison of index construction methods. The Journal of Real Estate Finance and Economics, 9 (2), 137–164.
Geltner, D. (1993). Estimating market values from appraised values without assuming an efficient market. Journal of Real Estate Research, 8 (3), 325–345.
Geltner, D., Miller, N., Clayton, J., Eichholtz, P. (2007). Commercial real estate analysis and investments, 2nd edition. Cincinnati: South-Western College Publishing Co/Cengage Learning.
Gordon, J.N., & Tse, E.W.K. (2003). VaR: a tool to measure leverage risk. The Journal of Portfolio Management, 29 (5), 62–65.
Jorion, P. (2007). Value at risk: the new benchmark for managing financial risk. New York: McGraw-Hill.
Kendall, M.G., Stuart, A., Ord, J.K., O’Hagan, A. (1994). Kendall’s advanced theory of statistics, vol.1. London: Edward Arnold.
Lee, S., & Higgins, D. (2009). Evaluating the Sharpe performance of the Australian property investment markets. Pacific Rim Property Research Journal, 15 (3), 358–370.
Liow, K.H. (2008). Extreme returns and value at risk in international securitized real estate markets. Journal of Property Investment & Finance, 26 (5), 418–446.
Lizieri, C., & Ward, C. (2000). Commercial real estate return distributions: A review of literature and empirical evidence (Working Paper No. rep-wp2000- 01).
Lorentz, G.G. (1953). An inequality for rearrangements. The American Mathematical Monthly, 60 (3), 176.
Myer, F.C.N., & Webb, J.R. (1994). Statistical properties of returns: Financial assets versus commercial real estate. The Journal of Real Estate Finance and Economics, 8 (3), 267–82.
Pritsker, M. (1997). Evaluating value at risk methodologies: Accuracy versus computational time. Journal of Financial Services Research, 12 (2-3), 201–242.
Rockafellar, R.T., & Uryasev, S. (2002). Conditional value-at-risk for general loss distributions. Journal of Banking & Finance, 26 (7), 1443–1471.
Spiring, F. (2011). The refined positive definite and unimodal regions for the gram-charlier and edgeworth series expansion. Advances in Decision Sciences, 2011, 1–18.
Young, M., & Graff, R. (1995). Real estate is not normal: A fresh look at real estate return distributions. The Journal of Real Estate Finance and Economics, 10 (3), 225–59.
Young, M., Lee, S., Devaney, S. (2006). Non-normal real estate return distributions by property type in the UK. Journal of Property Research, 23 (2), 109–133.
Young, M.S. (2008). Revisiting non-normal real estate return distributions by property type in the U.S. The Journal of Real Estate Finance and Economics, 36 (2), 233–248.
Zangari, P. (1996). How accurate is the delta-gamma methodology. RiskMetrics Monitor, 3rd quarter, 12-29.
Zhou, J., & Anderson, R. (2012). Extreme risk measures for international REIT markets. The Journal of Real Estate Finance and Economics, 45 (1), 152–170.
Author information
Authors and Affiliations
Corresponding author
Additional information
The authors wish to thank Labex MME D-II program, the University of Cergy-Pontoise and Fondation Palladio for their generous support.
Appendices
Appendix A: Quantile Functions
The quantile function (or inverse cumulative distribution function) of the probability distribution of a random variable specifies, for a given probability, the value which the random variable will fall below with that specified probability. In fact it is an alternative to the probability density function (pdf).
Let X be a random variable with a distribution function F, and let α∈(0,1). A value of x such that F(x)=P(X≤x)=α is called a quantile of order α for the distribution. Then we can define the quantile function by:
The quantile function q α (X) thus yields the value which the random variable of the given distribution will fail to exceed with probability α.
Appendix B: Skewness and Kurtosis
Given a probability distribution f(x) of the random variable X and a real-valued function g(x), one defines the expectation \(E[g(X)]=\int g(x)f(x)dx\), in which case the first moment is μ=E[X], whereas the higher central moments are then defined as μ k =E[(X−μ)k]. The first task in almost all statistical analyses is to characterize the location and variability of a data set. This is captured by the moments of order one and two, usually called the mean μ and the variance σ 2=μ 2, respectively. A further characterization of the data often includes the standardized moments of order three and four, called the skewness S=μ 3/σ 3 and kurtosis K=μ 4/σ 4, respectively. These last two measurements further describe the shape of a probability distribution. We briefly recall the significance of these two last parameters.
Skewness is a measure of symmetry, or more precisely, the lack of symmetry. A distribution, or data set, is symmetric if it looks the same to the right and left of its center (which is then the mean μ). The skewness of any symmetric distribution, such as a Gaussian one, is necessarily zero. Negative values for the skewness coefficient indicate data that are skewed to the left whereas positive values indicate that the data that are right skewed (see Fig. 15), with left-skewness meaning that the left tail of the distribution is long relative to the right one.

Example of a right skewed distribution (S=1.75)
Kurtosis refers to whether the data are peaked or flat relative to a normal distribution. That is, data sets with high kurtosis tend to have a distinct peak near the mean, then decline rather rapidly, but still have heavy tails (see Fig. 16). Data sets with low kurtosis tend to have a flat top near the mean rather than a sharp peak. The kurtosis formula measures the degree of this peakedness, where the kurtosis of a Gaussian distribution turns out to be 3.

Example of a fat tailed distribution (K=9)
Appendix C: The Cornish-Fisher Procedure
The Cornish-Fisher expansion is a useful tool for quantile estimation. For any α∈(0,1), the αth-quantile of F n is defined by q n (α)=s u p{x:F n (x)≤α}, where F n denotes the cdf of \(\xi _{n}=(\sqrt {n}/\sigma )(\bar {X}-\mu )\) and \(\bar {X}\) is the sample mean of i.i.d. observations X 1,…,X n . If z α denotes the upper αth-quantile of N(0,1), then, the fourth order Cornish-Fisher expansion can be expressed as:
where S and K are the skewness and kurtosis of the observations X i .
The Cornish-Fisher expansion is useful because it allows one to obtain more accurate results than using the central limit theorem (CLT) approximation, which would be just the z α defined in the body. A demonstration and example of the greater accuracy that the Cornish-Fisher expansion brings compared to the CLT approximation is reported in Barndorff-Nielsen and Cox (1989), p. 119.
Appendix D: The Rearrangement Procedure
This paper applies a procedure called rearrangement, or more precisely, increasing rearrangement. We use this procedure to restore the monotonicity of the Cornish-Fisher expansions. The procedure is briefly described here.Footnote 15
A convenient way to think of the rearrangement is as a sorting operation: given values of a data set, we simply sort the values in an increasing order. The function created is the rearranged function.
Following Chernozhukov et al. (2010), we define the procedure more precisely as follows. “Let χ be a compact interval. Without loss of generality, it is convenient to take this interval to be X=[0,1]. Let f(x) be a measurable function mapping χ to K, a bounded subset of \(\mathbb {R}\). Let \(F_{f}(x)={\int }_{\chi }1 \left \lbrace f(u)\leq y\right \rbrace du\) denote the distribution of f(x) when X follows the uniform distribution on [0,1]. Let
be the quantile function of F f (y). Thus,
This function f ∗ is called the increasing rearrangement of the function f.”
In our approach, this allows us to respect one of the basic conditions of the probability distribution function: monotonicity. As a result, Value at Risk becomes inversely proportional to the threshold, and so, as expected, one has V a R 0.5 % ≥V a R 5 % .
The rearrangement procedure also has the practical implication, demonstrated by Chernozhukov et al. (2010), that the resulting rearranged estimate has a smaller estimation error (in the Lebesgue norm) than does the original estimate whenever the latter is not monotone. This property is independent of the sample size and of the way the original approximation is obtained. Thus, the benefits of using a rearrangement procedure in our paper are both to obtain estimates of the distribution satisfying the logically necessary monotonicity restriction and also to obtain better approximation properties.
Appendix E: Comparison of Cornish-Fisher VaR for Various Window Lengths
Here, we revisit the length of window choice. In Figs. 17 and 18, V a R of the 10, 11, 12.5, 14 and 15-year periods are represented simultaneously. Before the middle of 2008, the longer the window, the higher is the V a R. After that date, we observe the opposite effect. Modifications created by the window length are qualitatively the same for the Gaussian and Cornish-Fisher V a Rs. The difference between these two approaches to V a R is stable whatever the choice of windows (the order of the curves appears in the same order). This illustrates that effects of window length is not relative to the Cornish-Fisher expansion but to the V a R computation, and more generally to distribution estimation. As mentioned previously, regulators often fix the length exogenously, with a 10-year window being chosen in much financial analysis.

Gaussian VaR for various window lengths

Cornish-Fisher corrected VaR for various window lengths
Rights and permissions
About this article

Cite this article
Amédée-Manesme, CO., Barthélémy, F. & Keenan, D. Cornish-Fisher Expansion for Commercial Real Estate Value at Risk. J Real Estate Finan Econ 50, 439–464 (2015). https://doi.org/10.1007/s11146-014-9476-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11146-014-9476-x