
Abstract
Purpose
Patient-reported outcome (PRO) results from clinical trials can inform clinical care, but PRO interpretation is challenging. We evaluated the interpretation accuracy and perceived clarity of various strategies for displaying clinical trial PRO findings.
Methods
We conducted an e-survey of oncology clinicians and PRO researchers (supplemented by one-on-one clinician interviews) that randomized respondents to view one of the three line-graph formats (average scores over time for two treatments on four domains): (1) higher scores consistently indicating “better” patient status; (2) higher scores indicating “more” of what was being measured (better for function, worse for symptoms); or (3) normed scores. Two formats displayed proportions changed (pie/bar charts). Multivariate modeling was used to analyze interpretation accuracy and clarity ratings.
Results
Two hundred and thirty-three clinicians and 248 researchers responded; ten clinicians were interviewed. Line graphs with “better” directionality were more likely to be interpreted accurately than “normed” line graphs (OR 1.55; 95% CI 1.01–2.38; p = 0.04). No significant differences were found between “better” and “more” formats. “Better” formatted graphs were also more likely to be rated “very clear” versus “normed” formatted graphs (OR 1.91; 95% CI 1.44–2.54; p < 0.001). For proportions changed, respondents were less likely to make an interpretation error with pie versus bar charts (OR 0.35; 95% CI 0.2–0.6; p < 0.001); clarity ratings did not differ between formats. Qualitative findings informed the interpretation of the survey findings.
Conclusions
Graphic formats for presenting PRO data differ in how accurately they are interpreted and how clear they are perceived to be. These findings will inform the development of best practices for optimally reporting PRO findings.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
An emphasis on patient-centered care has increased the demand for patient-reported outcomes (PROs), data collected directly from patients about health conditions and impacts of treatments [1, 2]. PROs can inform patient care in a variety of ways [3, 4], including data representing ‘the voice of the patient’ in randomized clinical trials to inform decision-making by patients and clinicians based on trial results [4,5,6,7]. Oncologists have endorsed the use of PROs for this purpose, and there is evidence that PRO results can influence treatment choices [8,9,10,11].
The optimal integration of PRO results from clinical trials, and other comparative research into clinical care requires that clinicians understand and interpret PROs accurately and be able to communicate PRO findings to their patients where appropriate. This understanding can be challenging because of the variety of PRO questionnaires, variation in their scoring (e.g., higher scores indicating better or worse outcomes), their scaling (e.g., scores ranging from 0 to 100 as worst-to-best, or scores normed to a defined population), and how statistical and clinical significance of the findings are addressed [9, 12,13,14,15].
This study was part of a larger research program designed to examine approaches for presenting PRO data to promote their understanding and use. Previously, we evaluated existing approaches to presenting study PRO results [15]. We then partnered with stakeholder workgroups of clinicians and patients to develop improved graphical presentation approaches [14]. In a separate research stream, we focused on the communication of PROs to patients (e.g., in educational materials or decision aids) [16]. In this study, we focused on the reporting of PROs from clinical trials to clinicians and PRO researchers, building on our earlier study findings that identified the visual presentation strategies with the greatest potential for effective data communication [14, 15]. In the context of a clinical trial randomizing patients to one of the two treatment groups, we addressed between-group comparisons of mean scores over time, and between-group comparisons of the proportions of patients changed from baseline (improved, stable, or worsened). Our objective was to evaluate interpretation accuracy, clarity, and preferences for these candidate presentation approaches in a broad population of clinicians and PRO researchers.
Methods
Study design
We conducted a cross-sectional, mixed-methods study comprising a survey of cancer clinicians and PRO researchers, complemented by qualitative interviews with clinicians. We used an internet-based survey to evaluate how clinician and PRO researcher respondents interpret graphically displayed PRO results from a hypothetical clinical trial comparing Treatments “X” and “Y”. We supplemented the survey findings by administering it to cancer clinicians using one-on-one interviews, thus obtaining qualitative data on their responses. As the focus of the project was on clinicians’ understanding and communication of PRO data in clinical practice, we did not undertake on-one-one interviews with PRO researchers. The Johns Hopkins School of Medicine Institutional Review Board approved the project. The funding source had no role in study design, data collection, analysis, interpretation, writing, or publication decision.
Population and setting
We invited oncology clinicians and PRO researchers to complete the online survey by recruiting a convenience sample using a “snow-ball” approach. We partnered with our study Stakeholder Advisory Board to distribute the survey link to a variety of target populations in order to achieve diversity among respondents. Recipients were encouraged to share the information with other individuals who fit the eligibility criteria. Survey eligibility was self-identification as a health care provider to cancer patients, or PRO researcher.
Respondents who completed the one-on-one interviews were recruited from the Johns Hopkins Clinical Research Network (JHCRN), a consortium of academic and community health systems in Maryland, Virginia, and the District of Columbia (USA). Eligible clinicians were active oncologists (medical, radiation, surgical, gynecologic/urologic), nurse practitioners/physician assistants, or fellows. Purposive sampling was done to include various specialties and JHCRN sites.
Study procedures
The online survey randomized each eligible respondent to one of the eighteen survey versions. Each version sequentially presented five formats for graphically presenting clinical trial results comparing two treatments. Specifically, three line-graph format variations showing average group scores over time were displayed, followed by two formats showing proportions changed (better/worse/about the same) at 9 months after initiating treatment. The formats were chosen based on our earlier research that identified the most promising formats for effective PRO data communication [14, 15]. For each format, results for four PRO domains (two functions, two symptoms) were displayed on a single screen (Fig. 1).

Example illustrating average group scores over time, formatted for higher scores indicating “more” of what was being measured. The example shows the “confidence limit” annotation variation used across format types
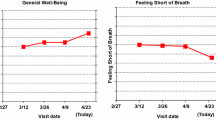
Respondents were randomized to one of the three line-graph format types: one-third of the sample saw graphs wherein PRO results indicated “more” of what was being measured (e.g., as per the EORTC QLQ-C30 [17].): a line trending up for functional domains indicated improvement, whereas a line trending up for symptom domains indicated worsening (more symptoms, Fig. 1). For one-third of respondents, lines trending up consistently indicated improvement (“better”) outcomes for both function and symptom domains (e.g., the HUI [18] Fig. 2). The remaining one-third viewed data normed to a general population average of 50 (Fig. 3). Within each line-graph type (“more,” “better,” “normed”), three variations were displayed: “plain” lines (p values only, Fig. 3); clinically significant between-arm differences indicated by an asterisk (but no confidence limits, Fig. 2); and confidence limits in addition to the asterisk indicating clinical significance (Fig. 1). Following presentation of line graphs, respondents viewed formats illustrating the proportions of patients either improved, stable, or worsened at 9 months (as typically reported in RCTs by classifying each patient as improved or worsened, compared to baseline, as defined by a clinically important difference established for the PRO measure used in the trial). Respondents viewed these proportions as both pie charts and bar charts (Fig. 4). In sum, all respondents saw one type of line graph (“more,” “normed,” or “better” scaling), presented in three variations (“plain,” “clinical significance,” and “confidence limits”) followed by two proportions changed formats.

Example of average group scores over time, formatted for higher scores indicating “better” outcomes. The example shows the “clinical significance” annotation variation used across format types

Example of average group scores over time, formatted to be normed to the general U.S. population. The example shows the “plain” variation (no additional annotations) used across format types

Examples of formats illustrating the proportions of patients changed at 9 months (compared to baseline). a Pie chart format. b Bar chart format
We controlled for potential order effects by randomizing respondents to order of line-graph variation and order of proportion format display. Supplemental Table S1 summarizes the formats and orders used across survey versions. The underlying hypothetical clinical trial results were the same across orders.
Study outcomes included respondents’ accuracy of interpreting between-group differences, their ratings of format clarity, and their preferred format. Two accuracy questions were asked on the first line-graph format seen (one for a function and one for a symptom domain). For example, for Fig. 1 we asked “On which treatment do patients report better PHYSICAL function over time?” (Response options: “Treatment ‘X,’ Treatment ‘Y,’ Treatments are about the same”). The third response option was coded as “correct” if the p value was not significant. One accuracy question was asked on the second and third line-graph format seen. This design enabled us to compare the accuracy of interpretation across the line types, and to test if accuracy rates were associated with added clinical and statistical significance annotations. For the two formats showing proportions changed, two accuracy questions were asked on each (e.g., “At 9 months, on which treatment did more patients improve with regard to PHYSICAL activities?”; same response categories).
Upon completion of accuracy questions for each format, respondents rated its clarity (“very confusing,” “somewhat confusing,” “somewhat clear,” or “very clear”). An open-ended text box allowed comments. After viewing all five formats, respondents were asked to select the proportion they thought was most useful for showing trial results, and which line-graph variation was most useful. Upon conclusion, respondents could enter for a chance to receive a $100 Amazon gift card.
One-on-one interview respondents were randomly assigned to complete one of the online survey versions. Respondents were asked to think aloud as they completed the survey. The interviewer prompted for comments concerning a format’s clarity or about preferences for particular format. At the end of the interview, respondents were given an opportunity to share any overall feedback that was not captured during survey completion.
Analysis
Quantitative data included respondents’ demographic characteristics, their accuracy and clarity responses, interpretations of statistical and clinical significance, and format preferences. These data were first summarized descriptively. We used multivariable generalized estimating equation (GEE) logistic regression models (with the individual as the cluster unit) to test differences in accuracy and clarity by format while controlling for format order and respondent type. Two outcomes were used to evaluate interpretation accuracy: (1) accuracy on the two questions for the first format seen and (2) accuracy for the four questions on each format across all orders (and, therefore, all respondents). Fixed effects for the specific questions were included in the model that included all questions. For calculating accuracy rates, we coded responses as “correct” when they matched the intended response. Given the potential ambiguity in how respondents selected the “treatments are about the same” response, we also calculated the proportion of respondents that responded incorrectly in absolute terms (i.e., picking Treatment “X” when “Y” was correct).
Qualitative data obtained from the one-on-one interviews were analyzed by a coding scheme based on the study objectives, interview structure, and interview content. Codes were created to capture positive or negative comments, misinterpretations, directional concerns, preferences, and other comments. One member of the research team coded each transcript using ATLAS.ti, [19] a second member reviewed coding, and a report was then generated to identify themes. Open-ended text box comments obtained from online survey respondents were sorted into broad, preexisting categories of “positive” and “negative.”
Results
Study sample
The internet sample included 233 clinicians and 248 PRO researchers (total N = 481) (Table 1). Clinicians reported an average time in practice of 16.5 years, 55% practiced medical oncology, and half were located in the US. Among PRO researchers, 38% had > 10 years’ experience, and 43% were from the US. The in-person interviewees included ten clinicians: one medical oncologist, one radiation oncologist, one urologist, one oncology nurse practitioner, three surgical oncologists, and three oncology fellows; five were from Johns Hopkins.
Findings for line-graph formats
Participants’ accuracy of interpretations varied across the three line-graph types: clinicians were more likely to answer both initial accuracy questions correctly if they saw the “better” line graphs (68%), versus 62% for “more” line graphs and 61% for “normed” line graphs. The same was true for researchers: 68% correct for “better,” versus 64% for “more,” and 54% for “normed.” Complete descriptions of the responses by format can be found in Table 2. Multivariate model results (Table 3) indicate that “better” line graphs were significantly more likely to be interpreted accurately vs. “normed” (OR 1.55; 95% CI 1.01–2.38; p = 0.04). With regard to “incorrect” responses, respondents were significantly more likely to select an incorrect response for “normed” graphs compared to “better” or “more” when controlling for other factors (Table 3). The odds ratios are shown graphically in Fig. 5.

Multivariable modeling results displayed as odds ratios (ORs) for accuracy and clarity ratings for line-graph formats. The point-estimate of each OR indicates the preferred comparitor (format more accurately interpreted or more clearly rated). Significant findings are displayed in bold-face
The clarity ratings for clinicians and researchers randomized to “more,” “better,” or “normed” line graphs also varied by format type. The multivariate models indicated that “normed” versions were less likely to be rated “very” clear (OR 0.66; 95% CI 0.50–0.88; p = 0.005) compared to “more” types (Table 3). Further, the “better” line types were more likely to be rated “very” clear compared to “normed” (OR 1.91; 95% CI 1.44–2.54; p < 0.0001), whereas ratings for “more” vs “better” line type did not differ significantly. Similar patterns were seen for combined “somewhat” and “very” clear rating categories. These data are described in full in Table 2 and displayed graphically in Fig. 5.
Across clinicians and researchers, and regardless of randomization to “better,” “more,” or “normed” versions, the format variations with asterisks indicating clinical significance and with confidence limits were not associated significantly with accuracy of interpretations compared to “plain” line-graph formats (Table 3). The variation with only clinical significance indicated was most likely to be rated “somewhat” or “very” clear, compared to the plain or confidence limit variations (Table 3). With regard to individuals’ expressed preferences, both clinicians and researchers preferred the confidence limit variation (52 and 49%, respectively; both p < 0.001, Table 4).
Qualitative comments, reflecting both support and lack of support for each of the formats, are tabulated in Table 5. Some respondents randomized to the “more” line type found the difference in direction of scoring for function versus symptom domains confusing, whereas others randomized to the “better” line type found higher symptom scores indicating improvement in symptoms to be counterintuitive. Some respondents valued the additional statistical information provided by confidence limits while some preferred asterisks alone. Others noted potential confusion regarding the use of asterisks to indicate clinical importance, since asterisks are also commonly used for statistical significance. Some respondents questioned how clinical importance was determined.
Findings for formats illustrating proportions changed
Regarding accuracy of interpreting formats illustrating proportions changed, clinicians who saw pie charts were more likely to respond correctly to the first two accuracy questions than those who saw bar graphs (20 vs. 17%), though the opposite was true for researchers (7% for pie charts vs. 15% for bar graphs), see Table 6. The most common response was selection of the treatment that was better in absolute terms, rather than “about the same,” which was deemed to be the correct answer given that the between-treatment differences were not statistically significant as indicated by the p value (Fig. 4). With regard to selecting the wrong (incorrect) treatment, researchers and clinicians were less likely to select the incorrect treatment when pie charts were displayed (5.1 and 1.6%, respectively) compared to bar charts (14.7 and 11.2%, respectively). Multivariable modeling analyses showed that the odds of selecting the “correct” response did not differ significantly by chart format or by respondent type, whereas the odds of selecting the “incorrect” treatment were significantly lower with the pie charts (OR 0.35; 95% CI 0.2–0.6; p < 0.001) but did not significantly differ by respondent type (OR 1.48; 95% CI 0.82–2.67; p = 0.198, Table 3). Complete descriptive results are listed in Table 6, and the modeling results are displayed graphically in Fig. 6.

Multivariable modeling results displayed as odds ratios for accuracy and clarity ratings for proportions changed formats. For interpretation please see Fig. 5 legend
Regarding format clarity ratings, 74% of clinicians and 71% of researchers rated pie charts “somewhat” or “very” clear, and 70% of clinicians and 71% of researchers rated bar graphs “somewhat” or “very” clear. These differences were not statistically significant in the multivariate models, when testing for an association with chart format or for an association with responder type (Table 3). In terms of their preferences, more respondents overall preferred bar charts (52.8%) over pie charts (47.2%, p = 0.03); clinicians were equally split between bar and pie formats (50 vs. 50%) but more researchers preferred bar charts (56% bar vs. 44% pie charts, p = 0.11).
Qualitative themes coded from the one-on-one interviews and online comments are summarized in Table 5. Illustrative comments reveal that several respondents were negative about pie charts, whereas others were negative about bar charts, each for different reasons. Further, comments concerning the p-value annotations reflected uncertainty about the meaning of p = 0.10 for the physical domain, as well as uncertainty about how to clinically interpret a significant p-value below 0.05.
Discussion
With the increasing prevalence of PROs in clinical trials and other comparative research studies, information on how to present PRO findings so that clinicians can understand them and incorporate them into clinical practice is critical. In previous research, clinicians often expressed difficulty interpreting PROs, [11, 20] so research evaluating clinicians and researchers’ accuracy of interpretation, and presentation factors associated with these interpretations is critically needed [21]. Our survey of clinicians and researchers showed that differences in displays of longitudinal PRO data were associated with differences in how accurately they were interpreted and on how clear they were rated to be.
A key finding is that clinicians and PRO researchers sometimes misinterpreted simple graphs of PRO scores when displayed in an array of function and symptom domains. This misinterpretation resulted in the incorrect treatment being chosen as superior for PROs, and was consistently observed across formats for both clinicians and researchers, suggesting a need to report PRO findings as clearly as possible. For graphing mean PRO study results over time, scale direction impacted on the misinterpretation rate, as did presenting normed data. Further, clarity ratings were also higher when directionality was consistent (higher = better results). Annotations of line graphs to illustrate clinical or statistical significance were favored by the majority of respondents, and did not decrease interpretation accuracy. For displays of proportions of patients changed from baseline, misinterpretation occurred with both pie charts and bar charts and among both researchers and clinicians (although no differences were detected between the two responder groups).
These findings should be interpreted in the context of the study design and its limitations.
The internet survey relied on convenience samples using online platforms, and on self-reported eligibility. Although a variety of target populations were identified, a snow-ball sampling approach can lead to a less diverse sample as individuals tend to recruit others like themselves. The overall sample size was sufficiently powered to detect statistically significant results, but provided limited power for subgroup analyses. Further, we did not ascertain how familiar respondents were with the presentation formats, and learning effects may have affected the findings. Accuracy of interpretation required attention to the displayed p-value (but analysis of “incorrect” responses overcame this limitation). We limited the scope of presentation issues to representation of the trial PRO results, and did not include additional information such as compliance tables or number of patients providing data at given time points; further research is required to address these issues. Strengths of the study include the large sample resulting from online distribution, thus including participants from a variety of locations. The survey design including 18 versions to control for order effects improved the robustness of the findings. The one-on-one interviews permitted purposive sampling and provided qualitative data that supplemented the online comments and complemented our previous qualitative findings [14, 15].
Improving the accuracy of interpretation of PRO study findings remains a challenge for the field in many ways. First, using graphic presentations that most clinicians and researchers intuitively understand may help, and findings from the present study could inform the selection of optimal data presentations. Second, our quantitative and qualitative findings make clear that no one approach for either longitudinal data or proportions changed is universally appealing, nor is free of misinterpretation errors. Thus, additional strategies beyond design of presentation are required. Third, consistency of PRO presentation is very likely to have value. In oncology for example, survival curves and toxicity data from randomized clinical trials are typically reported consistently across trials, whereas PRO data reporting is highly variable. Fourth, our qualitative findings suggest that challenges in interpreting constructs that underlie the data—such as the nature of cut-points used to categorize patients into proportions changed, or the meaning of a particular numeric group score—also contribute to the perceived clarity and understanding of PRO displays. Our findings suggest that adding annotations such as indications of score meaning and clinical significance may assist with clinical interpretation.
In conclusion, this study with its large sample, combination of quantitative and qualitative data, and careful design can inform best practices for presentation of PRO data to improve interpretability. No presentation formats were free of interpretation error; however, respondents were less likely to make interpretation errors when mean group data were not normed, and when proportions changed were displayed in pie charts. These results can inform best practices for displaying of PRO data.
References
US FDA: Guidance for industry. Patient-reported outcomes measures: Use in medical product development to support labeling claims; Federal Registrer, 2009, pp. 65132–65133.
Acquadro, C., Berzon, R., Dubois, D., Leidy, N. K., Marquis, P., Revicki, D., & Rothman, M., PRO Harmonization Group. (2003) Incorporating the patient’s perspective into drug development and communication: an ad hoc task force report of the Patient-Reported Outcomes (PRO) Harmonization Group meeting at the Food and Drug Administration, February 16, 2001. Value in Health, 6, 522–531.
Greenhalgh, J., Long, A. F., & Flynn, R. (2005). The use of patient reported outcome measures in routine clinical practice: Lack of impact or lack of theory? Social Science & Medicine, 60, 833–843.
Greenhalgh, J. (2009). The applications of PROs in clinical practice: What are they, do they work, and why? Quality of Life Research, 18, 115–123.
Till, J. E., Osoba, D., Pater, J. L., & Young, J. R. (1994). Research on health-related quality of life: Dissemination into practical applications. Quality of Life Research, 3, 279–283.
Au, H.-J., Ringash, J., Brundage, M., Palmer, M., Richardson, H., & Meyer, R. M., NCIC CTG Quality of Life Committee.(2010). Added value of health-related quality of life measurement in cancer clinical trials: The experience of the NCIC CTG. Expert Review of Pharmacoeconomics & Outcomes Research, 10(2), 119–128.
Bruner, D. W., Bryan, C. J., Aaronson, N., Blackmore, C. C., Brundage, M., Cella, D., Ganz, P. A., Gotay, C., Hinds, P. S., Kornblith, A. B., Movsas, B., Sloan, J., Wenzel, L., & Whalen, G. (2007). National Cancer Institute: Issues and challenges with integrating patient-reported outcomes in clinical trials supported by the National Cancer Institute-sponsored clinical trials networks. Journal of Clinical Oncology, 25, 5051–5057.
Brundage, M. D., Feldman-Stewart, D., Bezjak, A., Leis, A., Degner, L., Fleming, S., Tu, D., Velji, K., & Pater, J. (2005). The value of quality of life information in a cancer treatment decision. Quality of Life Research: An International Journal of Quality of Life Aspects of Treatment, Care and Rehabilitation, 11–15 (abstract).
Brundage, M., Bass, B., Jolie, R., & Foley, K. (2011). A knowledge translation challenge: Clinical use of quality of life data from cancer clinical trials. Quality of Life Research, 20, 979–985.
Bezjak, A., Ng, P., Skeel, R., DePetrillo, A. D., Comis, R., & Taylor, K. M. (2001). Oncologists’ use of quality of life information: Results of a survey of Eastern Cooperative Oncology Group physicians. Quality of Life Research, 10, 1–13.
Rouette, J., Blazeby, J., King, M., Calvert, M., Peng, Y., Meyer, R. M., Ringash, J., Walker, M., & Brundage, M. D. (2015). Integrating health-related quality of life findings from randomized clinical trials into practice: an international study of oncologists’ perspectives. Quality of Life Research, 24, 1317–1325.
PROQOLID, the Patient-Reported Outcome and Quality of Life Instruments Database (2012). http://www.proquolid.org.
Snyder, C. F., & Aaronson, N. K. (2009). Use of patient-reported outcomes in clinical practice. Lancet, 374(9687), 369–370.
Smith, K. C., Brundage, M. D., Tolbert, E., Little, E. A., Bantug, E. T., & Snyder, C. F. PRO Data Presentation Stakeholder Advisory Board. (2016). Engaging stakeholders to improve presentation of patient-reported outcomes data in clinical practice. Supportive Care in Cancer, 24:4149–4157.
Brundage, M. D., Smith, K. C., Little, E. A., Bantug, E. T., & Snyder, C. F. PRO Data Presentation Stakeholder Advisory Board. (2015). Communicating patient-reported outcome scores using graphic formats: results from a mixed-methods evaluation. Quality of Life Research, 24, 2457–2472.
Tolbert, E., Snyder, C., Bantug, E., Blackford, A., & Brundage, M. PRO Data Presentation Stakeholder Advisory Board. (2016). Graphing group-level data from research studies for presentation to patients in educational materials and decision aids. Quality of Life Research: An International Journal of Quality of Life Aspects of Treatment, Care and Rehabilitation, 25, 17 (abstract).
Aaronson, N. K., Ahmedzai, S., Bergman, B., Bullinger, M., Cull, A., Duez, N. J., Filiberti, A., Flechtner, H., Fleishman, S. B., & de Haes, J. C. (1993). The European Organization for Research and Treatment of Cancer QLQ-C30: A quality-of-life instrument for use in international clinical trials in oncology. Journal of the National Cancer Institute, 85, 365–376.
Santana, M. J., Feeny, D., Johnson, J. A., McAlister, F. A., Kim, D., Weinkauf, J., & Lien, D. C. (2010). Assessing the use of health-related quality of life measures in the routine clinical care of lung-transplant patients. Quality of Life Research, 19, 371–379.
AtlasTi: ATLAS.ti Scientific Software Development, 2014.
Snyder, C. F., Aaronson, N. K., Choucair, A. K., Elliott, T. E., Greenhalgh, J., Hess, R., Miller, D., Reeve, B., & Santana, M. (2012). Implementing patient-reported outcomes assessment in clinical practice: A review of the options and considerations. Quality of Life Research, 21(8), 1305–1314.
Bantug, E. T., Coles, T., Smith, K. C., Snyder, C. F., Rouette, J., & Brundage, M. D. PRO Data Presentation Stakeholder Advisory Board. (2016). Graphical displays of patient-reported outcomes (PRO) for use in clinical practice: What makes a pro picture worth a thousand words? Patient Education & Counseling, 99, 483–490.
Acknowledgements
The PRO Data Presentation Stakeholder Advisory Board includes Neil K. Aaronson, PhD (Netherlands Cancer Institute); Patricia A. Ganz, MD (University of California-Los Angeles and Jonsson Comprehensive Cancer Center); Ravin Garg, MD (Anne Arundel Medical Center); Michael Fisch, MD (The University of Texas MD Anderson Cancer Center); Vanessa Hoffman, MPH (Bladder Cancer Advocacy Network); Bryce B. Reeve, PhD (University of North Carolina at Chapel Hill and Lineberger Comprehensive Cancer Center); Eden Stotsky-Himelfarb (Johns Hopkins Sidney Kimmel Comprehensive Cancer Center); Ellen Stovall (National Coalition for Cancer Survivorship); and Matthew Zachary (Stupid Cancer). The Johns Hopkins Clinical Research Network (JHCRN) site investigators and staff include Ravin Garg, MD, and Steven P. DeMartino, CCRC, CRT, RPFT (Anne Arundel Medical Center); Melissa Gerstenhaber, MAS, MSN, RN, CCRN (JHCRN/Anne Arundel Medical Center); Gary Cohen, MD, and Cynthia MacInnis, BS, CCRP (Greater Baltimore Medical Center); Sandra Schaefer, BSN, RN, OCN (JHCRN/Inova Health System); Paul Zorsky, MD, Lynne Armiger, MSN, CRNP, ANP-C, Sandra L. Heineken, BS, RN, OCN, and Nancy J. Mayonado, MS (Peninsula Regional Medical Center); Michael Carducci, MD (Johns Hopkins Sibley Memorial Hospital); Carolyn Hendricks, MD, Melissa Hyman, RN, BSN, OCN, and Barbara Squiller, MSN, MPH, CRNP (Suburban Hospital). We are most appreciative to all the individuals and organizations who assisted us in circulating the internet survey.
Funding
Financial support for this study was provided by the Patient-Centered Outcomes Research Institute (R-1410-24904); the funding agreement ensured the authors’ independence in designing the study, interpreting the data, writing, and publishing the report. Drs. Snyder and Smith are members of the Sidney Kimmel Comprehensive Cancer Center at Johns Hopkins (P30CA006973). Dr. Brundage was supported by a research chair award from Cancer Care Ontario and the Ontario Ministry of Health, Ontario, Canada.
Author information
Authors and Affiliations
Consortia
Corresponding author
Ethics declarations
Conflict of interest
All authors have declared no conflict of interest.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. The Johns Hopkins School of Medicine Institutional Review Board deemed the online survey exempt and approved the in-person interview study. The instructions to the online survey indicated that survey completion represented consent; interview participants provided written consent.
Additional information
Presented in part at the 2016 International Society for Quality of Life Research Annual Meeting.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Brundage, M., Blackford, A., Tolbert, E. et al. Presenting comparative study PRO results to clinicians and researchers: beyond the eye of the beholder. Qual Life Res 27, 75–90 (2018). https://doi.org/10.1007/s11136-017-1710-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11136-017-1710-6