
Abstract
In this paper I exploit Google searches for the topics “symptoms”, “unemployment” and “news” as a proxy for how much attention people pay to the health and economic situation and the amount of news they consume, respectively. I then use an integrable nonautonomous Lotka–Volterra model to study the interactions among these searches in three U.S. States (Mississippi, Nevada and Utah), the District of Columbia and in the U.S. as a whole. I find that the results are very similar in all areas analyzed, and for different specifications of the model. Prior to the pandemic outbreak, the interactions among health searches, unemployment searches and news consumption are very weak, i.e. an increase in searches for one of these topics does not affect the amount of searches for the others. However, from around the beginning of the pandemic these interactions intensify greatly, suggesting that the pandemic has created a tight link between the health and economic situation and the amount of news people consume. I observe that from March 2020 unemployment predates searches for news and for symptoms. Consequently, whenever searches for unemployment increase, all the other searches decrease. Conversely, when searches for any of the other topics considered increase, searches for unemployment also increase. This underscores the importance of mitigating the impact of COVID-19 on unemployment to avoid that this issue swallows all others in the mind of the people.
Similar content being viewed by others
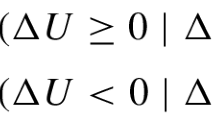

Avoid common mistakes on your manuscript.
1 Introduction
The COVID-19 pandemic is a threat for public health (Heymann and Shindo 2020) and the economy (Atkeson 2020; Baker 2020; McKibbin and Fernando 2020). As of January 2021, the virus has caused over 389,000 deaths in the U.S. and almost 2 millions worldwide (Worldometers 2020). When COVID-19 first started spreading across the US in early March 2020, States and the Federal Government were forced to limit or shut down a wide array of economic activities to protect public health. This had catastrophic consequences on the economy. The GDP decreased at an annual rate of 31.7% in the second quarter of 2020 (Bureau of Economic Analysis 2020), and 33 million people filed for unemployment between March and May 2020 (The Guardian 2020). These statistics dwarf the impact of the 2007 financial crisis. In turn, this strong economic downturn is likely to have negative repercussions on the healthcare system. As unemployment keeps rising and GDP decreasing, many unemployed Americans become unable to afford the expensive health insurance premia while the States and Federal Governments may not be able to increase public spending to support them. Additionally, despite claims that insurance companies would pay for testing and waive co-payments for treatments, even Americans with a coverage have some reason to worry. Some insurance plans have already set out limitations to their waivers of co-payments (for instance they might waive them only in specific months) and others, such as plans that are not compliant with the Affordable Care Act, may not cover the costs associated with testing at all (CBS 2020). The importance of this cannot be overstated, as recent estimates suggest that total payments to hospitals for treating uninsured patients under the Trump administration policy could range from $13.9 billion to $41.8 billion. At the top end of the range, these payments would consume more than 40% of the $100 billion Fund the Congress created to help hospitals and others respond to the COVID-19 epidemic (KFF 2020). Against this background, it is unsurprising that over 50% of Americans report feeling scared and overwhelmed, and that one of the reactions to the pandemic has been consuming more news (Horowitz Research Center 2020). However, this could trigger a vicious circle because people who consume more news during a time of severe crisis are likely to become even more worried. In fact, Garfin (2020) warn that an increased media exposure during COVID-19 might affect people’s mental health and their level of worry, resulting in damaging consequences to the individuals and society as a whole. The elevated emotional response associated with extreme events, like the pandemic, is also likely to make people more pessimistic, and to heighten anxiety and physical and mental distress.
There are many reasons why news consumption may increase in proximity of the outbreak of a new virus. To begin with, news consumption could increase because of the economic state of country and due to the scientific uncertainty surrounding the virus. State and national governments, along with the WHO and the CDC, are continuously updating guidelines and regulations aimed at containing the virus, so citizens wishing to be informed are likely to read more news and try to understand common symptoms on a regular basis. The economic crisis could also motivate searches for news, as a crisis of this magnitude creates great uncertainty, and people might look at news outlets to help navigating this uncertainty. Additionally, at the beginning of the COVID-19 pandemic the increased volume of searches related to news could be further influenced by the large amount of misinformation circulating on the internet (Imhoff and Lamberty 2020; Pennycook 2020), which led to a 900% increase in fact checks in English language between January and March 2020 (Brennan 2020).
Hence, on the one hand, people are likely to search for more news to better understand the causes and the unfolding of the health and economic crises. On the other hand, causality could go also in the opposite direction, as people who consume more news during a pandemic are likely to become more preoccupied with the health and economic crises and search more terms related to them.
Against this background, it becomes important to find out the relationship between news consumption, symptoms searches and searches related to unemployment. Understanding how some searches can affect citizens to make others can help policymakers communicate more effectively with citizens and structure targeted interventions. For instance, finding that people are extremely preoccupied with unemployment, so much that this search predates all others, can be a signal that absent good welfare protections people are not able to pay sufficient attention to other issues like health. Failing to address citizens’ growing concerns risks jeopardising any new attempt at economic restrictions, e.g. shorter opening times for shops or forbidding gatherings, which may become necessary if a second wave arises. Moreover, the interactions between these common searches can help to identify people’s perceived priorities and their likely reactions to policies.
Many studies have already investigated how COVID-19 affected the level of concern for the health and the economic situation (Mertens 2020; Trueblood 2020), or people’s increased searches for news (Horowitz Research Center 2020) and unemployment filings (Tian and Goetz 2020). However, no study has looked at the simultaneous interactions among these three key consequences of the pandemic. Additionally, addictive behaviors like porn and alcohol consumption can increase exponentially during a time of crisis (Mestre-Bach 2020), can affect people’s mental and physical health (Grubbs et al. 2015; Clay and Parker 2020) and mediate the relationships between searches for news, unemployment and symptoms. Therefore, I carry out the analysis both without including additional mediators in the model, and including them.
I use Google topic searches for the words “symptoms”, “unemployment”, “news” as proxy for the attention that people pay to the health and economic crises and for how much news they consume. Moreover, I use “porn” and “alcoholic drinks” searches as potential mediators. Importantly, the searches considered are not those for the specific terms, but refer to the topics considered and hence encompass all searches related with these topics.
The use and gratification theory suggests possible reasons behind internet usage and which websites people visit (Eighmey and McCord 1998). This theory posits that people actively choose the media to use to satisfy their needs and be gratified (Yi-Cheng et al. 2013). The motivations and needs to satisfy can vary from knowledge enhancement, entertainment and relaxation, social interaction and reward to remuneration (Ko et al. 2005). Among these (Kate Maddox 1998) stresses that obtaining information is of paramount importance. While the scope of this paper is not to identify the primary reason behind the searches made, it is likely that this is even more true in trying times, such as a pandemic. Notwithstanding the many reasons that could drive to these searches, here I focus their interactions. To do so, I use the the nonautonomous Lotka–Volterra model developed in Marasco (2016), and Marasco and Romano (2018a, 2018b) to study how these searches “interact” with each other. I say that there is an interaction between topics when an increase (decrease) in the searches for one has an impact on the number of searches for the other.
There are three advantages in using this nonautonomous Lotka Volterra model to study these interactions. First, since the interaction coefficients are dependent on time, the model allows me to capture changes in the way in which different searches interact and when these changes take place (Dominioni 2019, 2020). This allows me to identify whether the pandemic outbreak affected the strength and type of interactions between the searches Americans make. Second, this model allows me to derive these interactions without having to ask for stated behaviors. Finally, because the solutions of the model are known I do not have to estimate the parameters using expensive numerical methods like genetic algorithms (Romano 2016). Instead, I can derive the competitive roles from the data.
I carry out the analysis with respect to different areas and find that the results are largely identical for all areas included, for all combinations of factors considered and for different specifications of the model. Therefore, they can be considered robust. I find that prior to the COVID-19 outbreak the interactions among health searches, unemployment searches, news and porn (alcoholic drinks) are very weak, but as the pandemic approaches they intensify. These findings show how these factors become tightly interconnected during the pandemic, and therefore that analysing the existing interactions among them is key to understand the consequences of the pandemic. In particular, I find that during the pandemic searches for unemployment predate all others, including searches for symptoms. This suggests a widespread attention for the economic crisis that predates all other factors considered. Conversely, the other searches proceed in mutualism with each other.
2 Materials and method
To study the interactions between Google topic searches for unemployment, symptoms, news and porn (alcoholic drinks) I collect weekly data from Google Trends. Google Trends offers information on how popular a given search is on Google. The user can analyze searches for a given “term” or for a “topic”. The former includes only data on searches for a specific term, whereas the latter includes data for all searches related with a given topic, even if searched through different wording. For instance, searches for “unemployment” as a topic would also include searches for “Cares Act” and searches for “news” would include searches for “CNN”. In line with the literature making use of these data, in this paper I use search data for topics. In fact, this kind of data has been used to to forecast short-term economic indicators such as consumer confidence, unemployment and unemployment filings (Varian and Choi 2012; Baker and Fradkin 2017; D'Amuri and Marcucci 2017; Pavlicek and Kristoufek 2015; Tian and Goetz 2020), to understand the magnitude of traffic for porn (Gmeiner 2015) and even to predict the spread of diseases, including COVID-19 (Carneiro and Mylonakis 2009; Ginsberg et al. 2009; Mavragani and Gillas 2020; Nuti et al. 2014; Lu and Reis 2020).
The output of Google Trends data is not the actual number of searches for a specific term or for a topic. Instead, it shows the interest for a given term or topic relative to the other terms or topics included in the analysis. Each data point is normalized by dividing the number of searches for the term by the total number of all searches in that area. Therefore, the algorithm controls for both population differences and the differences in search volume among areas. Google Trends also eliminates repeated searches by a single individual in a short period of time to prevent a single individual from skewing the results. Additionally, data from Google Trends is freely available, highly representative and almost real-time, which makes it a compelling alternative to surveys or social media, which may only capture the opinions of a few people at a specific moment and suffer from self-selection. Moreover, understanding whether searches for some topics affects the share of searches for others through stated behaviors, e.g. in a survey, would require asking respondents directly whether an increase in their searches for a topic, e.g. news, affects their number of searches for others, e.g. unemployment. This can lead to biased results due to focusing bias (the experimenter would need to ask respondents to recall such a relationship) and lack of memory. Additionally, it would raise the costs of research. However, the nature of the data means that individual-level interpretations of the sequencing of searches over time are not warranted and can only be hypothesised.
The areas selected for my search are the United States as a whole, the District of Columbia (DC), Mississippi, Nevada and Utah. These areas were chosen using the following procedure. I input the four search topics considered on Google Trends and restrict the area to United States and time to twelve months, i.e. from May, 5th 2019 to May 5th 2020. After selecting the four topics, it becomes possible to rank the States and U.S. territories by the relative interest in one of the topics compared to the other three topics. Thus, for example, if we rank States for the relative (to the other three topics) interest in unemployment, we see that Nevada comes on top. I select the States that lead for each of the topics. In other words, I select the four “corner” areas based on the idea that the external validity of this study would be higher if the results hold for areas that are at the extremes in term of interest for the topics considered. A side benefit is that this choice of territories allows me to consider two States with a Republic Governor (Mississippi and Utah) and Nevada and DC that have a Democratic Governor and a Democratic major, respectively. Importantly, I choose not to include coronavirus among the topics, as it would dwarf all others. Not only is interest for coronavirus enormous, but the search for coronavirus as a topic would include searches for symptoms and news related to the pandemic, making it impossible to separate searches for the different domains considered here. Hence, to avoid this issue, I do not include the topic coronavirus among the searches considered. To analyze this data I apply the integrable nonautonomous Lotka Volterra model developed in Marasco (2016) and Marasco and Romano (2018a) for which the solutions are known. For an accurate description of the model and the relative formal proof I refer the reader to Marasco (2016). The search shares are written in the form of a logit model. In line with Marasco (2016) the market share \(S_{i}(t)\) at time t of a search i in a given area is the probability of searching topic i from all possible \(N+1\) topics via the logit model, i.e.
where \(f_{i}\left( t\right)\) is the utility function for the users to search topic i at time t. Each utility function \(f_{i}\left( t\right)\) is defined as a (linear or nonlinear) function of all aspects and attributes impacting the choice between alternative searches. In this case the topic searches are: unemployment (\(i=1\)), symptoms (\(i=2\)), news (\(i=3\)), porn (alcoholic drinks) (\(i=4\)). Other topic searches ( \(i=0\)) play the role of the outside search. Then, following the microeconomics utility theory (McFadden 1974) Eq. (1) becomes
where \(S_{0}(t)=1-\sum \nolimits _{i=1}^{N}S_{i}(t)\) at any time t. In mathematical terms, the utility functions \(f_{i}\left( t\right)\) are defined as a linear or nonlinear combination of suitable time-varying variables \(V_{h},h=1,...,M\), and each of them can have a positive or negative influence on the utility functions. Moreover, the market shares of the i-th search increases when its utility function \(f_{i}\left( t\right)\) increases and decreases when the utility function \(f_{j}\left( t\right)\) of any other competitor increases, i.e. when searching one topic is perceived as relatively better (i.e. yields more utility) than searching another. If we assume that all the utility functions \(f_{i}\left( t\right) ,i=1,...,N,\) are of class \(C^{2}\left( \left[ t_{0},+\infty \right) \right)\) Eqs. (3) are the unique (global) solution of the Cauchy problem
where the dot denotes the time derivative of a share, \(t\in \left[ t_{0},+\infty \right)\) and \(S_{0}(t)=1-\sum \nolimits _{i=1}^{N}S_{i}(t).\) The model can be used to study the interaction coefficients between the different searches. In fact, owing to Marasco (2016), Romano (2016) and Marasco and Romano (2018b), Eq. (3)\(_{\text {1}}\) belong to the following class of integrable nonautonomous Lotka–Volterra systems
where \(g_{i}\left( t\right) =\dot{f}_{i}\left( t\right)\) for all \(t\in \left[ t_{0},+\infty \right) .\) Eq. (4) then describes the interaction between the i-th and j-th topic search and allows competitive roles to change over time. The evolution of the market share \(S_{i}(t)\) of the i-th topic search is mathematically determined by two factors: the logistic growth rate function \(g_{i}\left( t\right)\) and the competition functions \(g_{j}\left( t\right)\) between the i-th and j-th topic searches. Last, the maximum capacity related to the saturation value of \(S_{i}(t),i=1,...N,\) is 1 (i.e., the maximum potential percentage of the market shares). The coefficients \(g_{i}\left( t\right)\) in Eq. (4) are constant if and only if the utility functions are linear combinations of the variables \(V_{h}\) and these variables depend linearly on time. Then, in most cases the system (4 ) is nonautonomous. How market shares \(S_{i}(t)\) vary in time in response to variations of one or more utility functions can be evaluated by Eq. (2). Tables 3, 4, 5, 6 and 7 report the descriptive statistics for each of the variables considered, with the values they take before they are transformed into shares. The descriptive statistics show that people in DC have a relatively high interest for news, whereas people in Mississippi have a relatively high interest for porn. Despite these differences, news is the most searched topic in all territories considered, apart from Mississippi. It is also interesting to note that in Utah people search very little for unemployment, while people in Nevada are the ones searching unemployment the most. To determine the competitive roles between any two variables we look at the signs of the interaction coefficients, i.e. the functions \(g_{i}\left( t\right)\) and their intensity by the sum of their absolute values. Hence, according to Table 1 the LV model (4) is able to capture all the possible kinds of competitive interactions.
Importantly, I have data on searches, but not on the utility functions. Consequently, I derive the utility functions from the historical data on searches (transformed in shares) using a fitting procedure. As standard in the literature, I use a Fourier series. The results are similar when using a fourth degree polynomial to fit the data. An example of fitting is reported in Fig. 1. The utility functions are evaluated from \(f_{i}\left( t\right)\) starting from the data on market shares as follows
Eq. (5) allows us to determine a discrete set of values for each utility function starting from historical data on market shares.
Therefore, the indirect determination of the analytical form of these functions is obtained by a fitting procedure using the Fourier series of order n
where \(\tau =T_{1}/2\) if \(f_{i}\left( t\right)\) is a periodic function with period \(T_{1}\), or \(\tau =kT_{1}\) for a suitable \(k\ge 1\) otherwise

This figure, in order from top to bottom (left to right), shows the fitting for unemployment (red), symptoms (black), porn (blue) and news (green) for United States. (Color figure online)
The findings from different specification are largely the same and do not depend on the variables considered. Therefore, while the analysis below refers to the specification that considers unemployment, symptoms, news and porn, the considerations made apply also to the specifications with: (i) unemployment, symptoms, news, and alcoholic drink, and (ii) unemployment, symptoms and news.
2.1 Accuracy of the model
I assess the accuracy and reliability of the model using the mean squared error (MSE), a standard measure of error. The MSE of an estimator (in this case the fitting procedure) measures the average of the squares of the errors that is, the average squared difference between the estimated values and the actual value. The MSE is calculated as follows.
where \(h_{i}\) and \(p_{i}\) are respectively the historical and predicted values. The measures of error are reported in Table 2.
3 Results
3.1 Results of the LV model
As noted in Sect. 2, I run the analysis with different combinations of searches for unemployment, symptoms, news, porn and alcoholic drinks. While the analysis refers to the combination unemployment, symptoms, news and porn, it can be applied also to the other two combinations tested: (i) unemployment, symptoms and news, and (ii) unemployment, symptoms, news and alcoholic drinks. When considering alcoholic drinks instead of porn in (ii), the searches for alcoholic drinks behave like the searches for porn in the specification described. That is, the results are consistent across all combinations considered and excluding the mediators (porn or alcoholic drinks) from the analysis does not affect the type of interactions the remaining variables have, e.g. excluding from the analysis searches for porn still leaves searches for unemployment as the predator of all other topics from the beginning of the pandemic. Figures 2, 3, 4, 5 and 6 show the interaction coefficients between the four searches in each of the areas considered, with time on the horizontal axis and the value of the interaction coefficients on the vertical axis. The kind of interaction remains fairly stable—the intensity of such interactions fairly weak—prior to the pandemic. Before the spring of 2019, news and porn (alcoholic drinks) are almost in neutralism, whereas they are in amensalism with searches for symptoms and in commensalism with searches for unemployment. Unemployment and symptoms are in a predator–prey relationship but the intensity of the interaction is really low. The trend of weak interactions changes completely around the beginning of the pandemic, as the intensity of the interactions explodes. This indicates that prior to the pandemic the four aspects considered—health, economy, porn (alcoholic drinks) and news—were only loosely connected in internet users’ minds. However, they became deeply intertwined during the pandemic. Second, after the outbreak of COVID-19, unemployment starts predating all other variables. In other words, an increase in searches for unemployment during this period leads to a decrease in searches for all the other topics considered. At the same time, increases in the searches for symptoms, porn (alcoholic drinks) and news lead to an increases in the share of searches for unemployment. The reason behind this finding could be that the United States have a limited welfare state compared to other western countries, so being unemployed can have immediate and grave repercussions. This means that unemployment crises swallow all other issues, and thus most Americans turn their attention away from other issues and focus on the economic crisis. At the same time, more news consumption in a time of severe crisis might also increase searches for unemployment. As people become more aware of the dire situation in which the US economy is, they become more concerned that many Americans—or even themselves and people they know—might remain unemployed. In fact, as unemployment increases, fears over the ability to pay even just for food have led some Americans to skip some meals (New York Times 2020). A perhaps more unexpected finding reveals the unique nature of this crisis. Usually, unemployment tends to be associated with worsened health conditions (Paul and Moser 2009), and therefore presumably with more Google searches related to symptoms. In this case, however, unemployment predates those searches. A preliminary caveat is that we are observing macro-level data on searches and hence individual level explanations are affected by the ecological fallacy. However, with this in mind, a possible explanation for this finding could be that unemployed people spend less time outside of their home, and therefore have a lower risk of contracting COVID-19. Thus, paradoxically, at least in the short-term unemployment has a positive impact on health during this pandemic. This would be reflected in a lower number of searches for symptoms. The pandemic can also help explaining the other side of the coin, namely why health is a prey of unemployment: when people are more worried about symptoms they also become more worried about unemployment. Contracting the virus could result in loss of job or income, and hence negative symptoms also cause worry in terms of unemployment. Moreover, unemployed people might search more for unemployment benefits and which medical bills would be covered under Cares Act or unemployment benefits, both part of searches for “unemployment” on Google Trends. A similar hypothesis can be advanced to explain the predator–prey relation between unemployment and porn (alcoholic drinks). As people become more worried about the ability of millions of Americans, and possibly themselves or their family and friends, to maintain a semblance of normal life, the refuge offered by these searches (and consumption of porn or alcohol) becomes insufficient. Therefore, those seeking a momentary distraction might be reminded of their more urgent issues and start searching for unemployment again. This dynamic suggests that when searches for unemployment increase, search for porn and alcohol are predated. Other interactions are also worth discussing. During the pandemic, porn (alcoholic drinks), news and symptoms proceed in mutualism, so when people search more for one of these topics, they also search more for the others. Therefore, for instance, as people read more news they also make more searches about symptoms. This could be because reading more news make them more worried about the pandemic, and hence make more searches about symptoms. Evidence from micro-level studies supports this hypothesis. For instance, a recent study finds a high correlation between people’s worry about the health crises caused by the pandemic and the amount of news they consume (Romano 2020). Moreover, as people become increasingly interested in news they also search more for porn and alcoholic drinks, maybe as a way to escape the anxiety created by the negative news. However, this is merely a conjecture as this study does not use micro-level data, and therefore explanation at the individual level might be affected by the ecological fallacy. The external validity of these results is higher because the States analysed and DC implemented different sets of restrictions, have been hit by the virus with different intensity and started at different levels of unemployment. Moreover, their governors and mayor are at different ends of the political spectrum. Therefore, it seems that the type of interactions between these searches are general and are not driven by specific features of the areas considered.

This figure shows the interaction coefficients of unemployment (red), symptoms (black), porn (blue) and news (green) for the United States

This figure shows the interaction coefficients of unemployment (red), symptoms (black), porn (blue) and news (green) for DC

This figure shows the interaction coefficients of unemployment (red), symptoms (black), porn (blue) and news (green) for Mississippi

This figure shows the interaction coefficients of unemployment (red), symptoms (black), porn (blue) and news (green) for Nevada

This figure shows the interaction coefficients of unemployment (red), symptoms (black), porn (blue) and news (green) for Utah
4 Conclusions
The dynamics governing people’s Google searches are far more interesting than one could expect. Many people are likely to approach searches in the same way, so that looking at the interactions among topics searched can inform policymakers about people’s main sources of interest and how they interact with each other. Doing so through Google Trends data offers policymakers (and researchers) several advantages. First, Google Trends offers the possibility to freely browse through (almost) real-time information on what people search for. Second, unlike in surveys, Google Trends data allows policymakers to rely on revealed preferences, rather than stated preferences of participants. For searches like porn and alcohol this has substantial advantages, as people may not declare how often they search for these topics in a survey or on social media. People may intentionally post or avoid posting some content over others out of appearance concerns, which would bias any analysis. Finally, the format of this data, combined with Lotka–Volterra models, allows policymakers to derive the interactions among the topics searched. This work shows that not only the type but also the intensity of relationships between different searches can change during trying times. Moreover, there are common trends also across areas with different characteristics, therefore the lessons that can be learned here are likely to have external validity. More specifically, I find that the COVID-19 pandemic changed the type and the intensity of the interactions among searches for unemployment, symptoms, news and porn (alcoholic drinks). As the pandemic develops unemployment searches start predating all others. This first finding can be explained by the increase in unemployment that the U.S. has experienced from the beginning of the epidemic, coupled with a limited welfare state and worries about insurance coverage. Notably, instead of increasing people’s interest in health, the effect of the pandemic is to reduce the searches for symptoms relative to those for unemployment. This could be due to the specific nature of this pandemic, forcing many of the unemployed Americans at home due to restrictions to movement, and hence making them less exposed to the virus. The other variables are in a mutualistic relationship. As searches for news increase, so do searches for symptoms and porn, and as searches for symptoms and porn increase, so do searches for news. I find the same interactions in all the areas considered, despite the different policies adopted in the different states and the different incidence of the virus. Future research could investigate whether searches for news, unemployment and symptoms interact differently in other countries. For instance, one could replicate the analysis in a country with a more extensive welfare state. Alternatively, one could extend the analysis to other common searches that are likely to be related. One of such avenues could be looking at the type of online shopping websites people are looking for to understand whether they are prioritising purchases of essential items.
References
Atkeson, A.: What will be the economic impact of covid-19 in the us? rough estimates of disease scenarios. NBER Working Paper No. 26867, 2020. https://doi.org/10.3386/w26867
Baker, S.R., et al.: Covid-induced economic uncertainty. NBER Working Paper No. 26983, 2020. https://doi.org/10.3386/w26983
Baker, S.R., Fradkin, A.: The impact of unemployment insurance on job search: evidence from google search data. Rev. Econ. Stat. 99(5), 756–768 (2017)
Brennan, J.S.F., et al.: Types, sources, and claims of covid-19 misinformation. Reuters Institute (2020)
Bureau of Economic Analysis: Gross domestic product. Bureau of Economic Analysis (2020)
Carneiro, H.A., Mylonakis, E.: Google trends: a web-based tool for real-time surveillance of disease outbreaks. Clin. Infect. Dis. 49(10), 1557–1564 (2009)
CBS: Does your health insurance cover you for covid-19? CBS (2020)
Clay, J.M., Parker, M.O.: Alcohol use and misuse during the covid-19 pandemic: a potential public health crisis? Lancet Public Health 5(5), e259 (2020)
DAmuri, F., Marcucci, J.: The predictive power of google searches in forecasting us unemployment. Int. J. Forecast. 33(4), 801–816 (2017)
Dominioni, G., et al.: A quantitative study of the interactions between oil price and renewable energy sources stock prices. Energies 21(9), 1693 (2019)
Dominioni, G., et al.: Trust spillovers among national and European institutions. Eur. Union Polit. 21(2), 276–293 (2020)
Eighmey, John, McCord, Lola: Adding value in the information age: Uses and gratifications of sites on the world wide web. J. Bus. Res. 41(3), 187–194 (1998)
Garfin, D.R., et al.: The novel coronavirus (covid-2019) outbreak: amplification of public health consequences by media exposure. Health Psychol. 5(39), 355–357 (2020)
Ginsberg, J., Mohebbi, M.H., Patel, R.S., Brammer, L., Mark, S.S., Larry, B.: Detecting influenza epidemics using search engine query data. Nature 457(7232), 1012–1014 (2009)
Gmeiner, M., et al.: A review of pornography use research: methodology and results from four sources. Cyberpsychol. J. Psychosoc. Res. Cyberspace 9(4), 4 (2015)
Grubbs, J.B., Stauner, N., Exline, J.J., Pargament, K.I., Lindberg, M.J.: Perceived addiction to internet pornography and psychological distress: examining relationships concurrently and over time. Psychol. Addict. Behav. 29(4), 1056 (2015)
Heymann, D.L., Shindo, N.: Covid-19: what is next for public health. Lancet 395(10224), 542–545 (2020)
Horowitz Research Center: When advertising in the age of coronavirus, crisis-sensitive messaging is most powerful. Horowitz Research Center (2020)
Imhoff, R., Lamberty, P.: A bioweapon or a hoax? the link between distinct conspiracy beliefs about the coronavirus disease (covid-19) outbreak and pandemic behavior. PsyArXiv Preprints (2020). https://doi.org/10.31234/osf.io/ye3ma
Kate, M., Blankenhorn, D.: E-commerce becoming reality. Advert. Age 69(43), s1 (1998)
KFF: Estimated cost of treating the uninsured hospitalized with covid-19. KFF (2020)
Ko, H., Cho, C.-H., Roberts, M.S.: Internet uses and gratifications: a structural equation model of interactive advertising. J. Advert. 34(2), 57–70 (2005)
Lu, T., Reis, B.Y.: Internet search patterns reveal clinical course of disease progression for covid-19 and predict pandemic spread in 32 countries. medRxiv (2020)
Marasco, A., et al.: Market share dynamics using lotkavolterra models. Technol. Forecast. Soc. Change 105, 49–62 (2016)
Marasco, A., Romano, A.: Inter-port interactions in the le havre-hamburg range: a scenario analysis using a nonautonomous lotka volterra model. J. Transp. Geogr. 69, 49–62 (2018)
Marasco, A., Romano, A.: Deterministic modeling in scenario forecasting: estimating the effects of two public policies on intergenerational conflict. Qual. Quant. 52, 2345–2371 (2018)
Mavragani, A., Gillas, K.: On the predictability of covid-19 in usa: a google trends analysis, preprint available at https://assets.researchsquare.com/files/rs-27189/v1_stamped.pdf (2020)
McFadden, D.: Conditional logit analyses of qualitative choice behavior. In: Zarembka, P. (ed.) Frontiers in Econometrics, pp. 105–142. Academic Press, New York (1974)
McKibbin, W.J., Fernando, R.: The global macroeconomic impacts of covid-19: seven scenarios. CAMA Working Paper No. (19/2020). https://doi.org/10.2139/ssrn.3547729
Mertens, G. et al.: Fear of the coronavirus (covid-19): predictors in an online study conducted in march. PsyArXiv Preprints (2020). https://doi.org/10.31234/osf.io/2p57j
Mestre-Bach, G., et al.: Pornography use in the setting of the covid-19 pandemic. J. Behav. Addict 15, 181–183 (2020)
New York Times: Coronavirus and poverty: a mother skips meals so her children can eat. New York Times (2020)
Nuti, S.V., Wayda, B., Ranasinghe, I., Wang, S., Dreyer, R.P., Chen, S.I., Murugiah, K.: The use of google trends in health care research: a systematic review. PloS One 9(10), e109583 (2014)
Paul, K.I., Moser, K.: Unemployment impairs mental health: meta-analyses. J. Vocat. Behav. 74(3), 264–282 (2009)
Pavlicek, Jaroslav, Kristoufek, Ladislav: Nowcasting unemployment rates with google searches: evidence from the visegrad group countries. PloS One 10(5), e0127084 (2015)
Pennycook, G., et al.: Fighting covid-19 misinformation on social media: experimental evidence for a scalable accuracy nudge intervention. PsyArXiv Preprints (2020). https://doi.org/10.31234/osf.io/uhbk9
Romano, A.: A study of tourism dynamics in three italian regions using a nonautonomous integrable lotkavolterra model. PLoS ONE 11(9), e0162559 (2016)
Romano, A. et al.: Covid-19 data: the logarithmic scale misinforms the public and affects policy preferences. PsyArXiv Preprints (2020). https://doi.org/10.31234/osf.io/42xfm
The Guardian: Coronavirus map of the us: latest cases state by state. The Guardian (2020)
Tian, Z., Goetz, S.: Google searches predict initial unemployment insurance claims. NERCRD COVID-19 Issues Brief No. 2020-5 (2020)
Trueblood, J. et al.: A tale of two crises: financial fragility and beliefs about the spread of covid-19. PsyArXiv Preprints (2020). https://doi.org/10.31234/osf.io/xfrz3
Varian, H., Choi, H.: Predicting the present with Google Trends. Econ. Rec. 88, 2–9 (2012)
Worldometers: Data on covid-19. Worldometers (2020)
Yi-Cheng, Ku, Chu, Tsai-Hsin, Tseng, Chen-Hsiang: Gratifications for using cmc technologies: a comparison among sns, im, and e-mail. Comput. Hum. Behav. 29(1), 226–234 (2013)
Funding
No funding was received for conducting this study. The author has no affiliations with or involvement in any organization or entity with any financial interest or non-financial interest in the subject matter or materials discussed in this manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical approval
No ethical approval was necessary to carry out the study as there is no primary data used in the paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sotis, C. How do Google searches for symptoms, news and unemployment interact during COVID-19? A Lotka–Volterra analysis of google trends data. Qual Quant 55, 2001–2016 (2021). https://doi.org/10.1007/s11135-020-01089-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11135-020-01089-0