
Abstract
We consider the Feynman–Kitaev formalism applied to a spin chain described by the transverse-field Ising model. This formalism consists of building a Hamiltonian whose ground state encodes the time evolution of the spin chain at discrete time steps. To find this ground state, variational wave functions parameterised by artificial neural networks—also known as neural quantum states (NQSs)—are used. Our work focuses on assessing, in the context of the Feynman–Kitaev formalism, two properties of NQSs: expressivity (the possibility that variational parameters can be set to values such that the NQS is faithful to the true ground state of the system) and trainability (the process of reaching said values). We find that the considered NQSs are capable of accurately approximating the true ground state of the system, i.e. they are expressive enough ansätze. However, extensive hyperparameter tuning experiments show that, empirically, reaching the set of values for the variational parameters that correctly describe the ground state becomes ever more difficult as the number of time steps increase because the true ground state becomes more entangled, and the probability distribution starts to spread across the Hilbert space canonical basis.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
A central problem of quantum physics, be it fundamental quantum physics or applications for quantum technology, is the ground state problem. It can be defined as finding a state vector \(\vert \Psi \rangle \) that minimises the expected value of the Hamiltonian \(\hat{H}\) that represents the energetic interactions between the different parts that make up a quantum physical system. It is well known that the difficulty of solving the ground state problem for a physical system arises from the exponential growth of the Hilbert space with respect to the number of the system components and their dimension. Therefore, techniques such as exact diagonalisation of \(\hat{H}\) quickly render insufficient to find the ground state, and other approximate methods have to be used.
Interestingly, other central problems of quantum physics such as finding the evolution of a quantum system can be cast into the ground state problem, as demonstrated by the Feynman–Kitaev formalism [24]. An immediate implication of using this formalism is that the computational tools historically developed for solving the ground state problem can be used to find the dynamics of a physical system. Broadly speaking, the Feynman–Kitaev formalism appends a clock as an auxiliary subsystem of the main physical system, i.e. the Hilbert space \(\mathscr {H}\) of the whole system is \(\mathscr {H} = \mathscr {P}\otimes \mathscr {C}\), where \(\mathscr {P}\) is the Hilbert space of the main physical system and \(\mathscr {C}\) is the Hilbert space of the clock. It is possible to build a Hamiltonian \(\hat{\mathcal {H}}:\mathscr {H}\rightarrow \mathscr {H}\) whose ground state \(\vert \Psi \rangle \propto \sum _t \vert \psi (t)\rangle \otimes \vert t\rangle \) encodes the time evolution history of the main physical system, where \(\vert \psi (t)\rangle \) its state at time t, and \(\vert t\rangle \) is the state of the clock labelling time t [27]. Therefore, getting the state of the physical system at a particular time t can be done straight-forwardly by projecting the ground state \(\vert \Psi \rangle \) onto the clock state \(\vert t\rangle \), i.e. \(\vert \psi (t)\rangle \propto \langle \Psi \vert t\rangle \) (only the clock part is projected).
Recently, Barison et al. [6] showed how to compute the ground state of the Feynman–Kitaev associated Hamiltonian for a spin chain described by the transverse-field Ising model (TFIM) using a variational wave function based on variational quantum circuits, also known as parameterised quantum circuits. They mapped this Feynman–Kitaev Hamiltonian \(\hat{\mathcal {H}}\) to a qubit Hamiltonian \(\hat{\mathcal {H}}_Q\) with the same spectrum, and they found its ground state using the variational quantum eigensolver [23] (VQE). VQE consists of using a quantum computer to build a circuit composed of rotation gates whose angles are parameters that can be optimised. Such a circuit might be written as \(V(\vec {\vartheta })\), where \(\vec {\vartheta }\) are the gate parameters. Then, the circuit prepares the normalised quantum state \(\vert \phi _{\vec {\vartheta }}\rangle = V(\vec {\vartheta })\vert 0,\ldots ,0\rangle \), where the state \(\vert 0,\ldots ,0\rangle \) is the trivial all-zeros state that is normally used when initialising a quantum circuit. After preparing the quantum state, it is used to measure the exact variational energy \(E_{\vec {\vartheta }} = \langle \phi _{\vec {\vartheta }}\vert \hat{\mathcal {H}}_Q\vert \phi _{\vec {\vartheta }}\rangle \), and also to measure its derivatives with respect to each variational parameter. Then, a classical computer is used to update the parameters, given an optimisation routine such as stochastic gradient descent. However, we emphasise that the quantum circuit of VQE is simulated on a classical computer, which enables the exact access to the variational state \(\vert \phi _{\vec {\vartheta }}\rangle \). Therefore, the variational energy \(E_{\vec {\vartheta }}\) is not estimated, as it would be on a real quantum device, but can be computed exactly. The same occurs with the gradients of the variational energy with respect to variational parameters. On a real quantum device, however, these quantities have to be estimated, which is both time-consuming and introduces inaccuracy. Moreover, scalability of VQE to study large spin chains might be endangered by trainability issues in variational quantum circuits [4] such as the onset of barren plateaus [28].
The aforementioned limitations of the standard VQE motivate us to approach the Feynman–Kitaev Hamiltonian through one of the most successful methods to solve the ground state problem: variational Monte Carlo (VMC) [8], which aims to solve the problem \(\min _{\vec {\theta }} \langle \Psi _{\vec {\theta }}\vert {\hat{H}}\vert \Psi _{\vec {\theta }}\rangle / \langle \Psi _{\vec {\theta }}\vert \Psi _{\vec {\theta }}\rangle \) (for any Hamiltonian \(\hat{H}\)), where \(\vert \Psi _{\vec {\theta }}\rangle \) is a variational wave function, parameterised by some parameters \(\vec {\theta }\). VMC stands out because it does not compute the variational energy exactly; instead, VMC estimates the variational energy in a computationally efficient manner, by taking advantage of the fact that Hamiltonians that describe local interactions tend to follow an area-law scaling for the entanglement [14] (with notable exceptions [39]), which ultimately means that only a small subset of elements of the Hilbert space basis is needed to accurately characterise the ground state (see more details about VMC in Sect. 3).
Of course, it is not obvious how to propose such a variational wave function \(\vert \Psi \rangle _{\vec {\theta }}\). Recently, it has been shown that an outstanding parameterisation of variational wave functions can be achieved by bringing tools from the machine learning community; in particular, wave functions can be parameterised by artificial neural networks, giving birth to the so-called neural quantum states (NQSs)Footnote 1 [11]. Unfortunately, this means that the open questions from artificial neural networks also permeate their application to quantum physics. In particular, there are two main areas of concern: expressivity and trainability. Expressivity refers to the capacity that a parameterisation has to reproduce arbitrary wave functions [18, 29, 32]. More precisely, a parameterised wave function defines a subset of all the possible wave functions; the larger this subset is, the more expressive the parameterisation is [33, 35]. On the other hand, trainability refers to the capacity that an algorithm has to update the parameters so that a cost function—the expected value of \(\hat{H}\)—is minimised, taking into account the intricacy of said cost function [44]. We emphasise that the present study aims to characterise expressivity and trainability of NQSs in the Feynman–Kitaev setting, but there are powerful alternatives such as direct integration of equations of motion for the variational parameters in NQSs through real-time evolution methods based on Monte Carlo sampling [13, 16, 19, 30, 31]. Nevertheless, these are found to require exponentially many parameters to represent the quantum state at a given accuracy with respect to time [25], and suffer from numerical instabilities [22], especially near dynamical quantum phase transitions.
Limitations in expressivity and trainability in machine learning models used as NQSs also limit the possibility to successfully find ground states of Hamiltonians. Therefore, it is imperative to understand what features found in a Hamiltonian can expose such limitations. Therefore, the purpose of this work is to study the feasibility of an alternative to compute dynamics of quantum systems; that alternative being expressing the ground state of the associated Feynman–Kitaev Hamiltonian through an NQS.
We provide a systematic study of trainability and show that training NQSs through VMC to find the ground state of the Hamiltonian \(\mathcal {H}\) is particularly difficult because the clock’s degrees of freedom entangle with the main physical system, making the ground state \(\vert \Psi \rangle \) not only highly entangled, but also in need of a large portion of the canonical basis of the Hilbert space \(\mathscr {H}\) to be described.
This paper is divided as follows. In Sect. 2, we introduce the Feynman–Kitaev formalism. In Sect. 3, we present the NQSs used in our work and explain how VMC works. Then, we present the results, which include an extensive study of VMC and NQSs hyperparameters, in Sect. 4. We discuss our empirical findings in Sect. 5. Finally, we conclude in Sect. 6.
2 The Feynman–Kitaev formalism
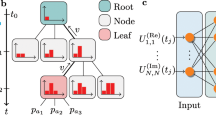
One of the earliest proposals for performing a quantum computation was precisely that of the time evolution of a quantum system [15]. The idea behind this proposal is that the quantum state of a physical system can be described along with the quantum state of a clock [27]. In particular, the clock can be in the states \(\vert 0\rangle , \vert 1\rangle ,\ldots \vert N\rangle \in \mathscr {C}\), i.e. it is a \(N+1\)-level system in the Hilbert space \(\mathscr {C}\). In this paper, we encode the \(N+1\)-level system that describes the clock in \(N_T = \lceil \log _2(N+1)\rceil \) spinsFootnote 2 using the reflected binary code (also known as Gray encoding) to map a state \(\vert t\rangle \) to the state of \(N_T\) spins because in this code, two consecutive states \(\vert t\rangle \) and \(\vert t+1\rangle \) are mapped to states of \(N_T\) spins where only one spin is different. Thus, the physical spin chain is enlarged with spins representing the state of the clock, as shown in Fig. 1a.

Representation of the physical spin chain enlargement with a clock state (a); and properties of the ground state of the enlarged Hamiltonian in Eq. (2) found with exact diagonalisation. b shows the second Rényi entropy per spin of a sub-chain of physical spins and c shows the ratio of the canonical basis of the Hilbert space that is needed to explain 99% of the probability of the ground state. The main text (Sect. 4) explains these plots in-depth
McClean et al. [27] showed that a variational principle can help in constructing a Hamiltonian \(\hat{\mathcal {H}}\) of the physical + clock system such that its ground state is precisely
The Hamiltonian of the enlarged spin chain system can be written as [6, 10, 27]
where \(I_{\mathscr {P}}\) is the identity of the physical system’s Hilbert space \(\mathscr {P}\) and \(\hat{\mathcal {H}}_0 = \hat{H}_0\otimes \vert 0\rangle \langle 0\vert \) is a term that breaks the degeneracy of the ground state by fixing the initial state at \(t=0\). For instance, Barison et al. [6] take \(\hat{H}_0 = I_{\mathscr {P}} - \vert \psi (0)\rangle \langle \psi (0)\vert \), for any desired initial state of the physical system \(\vert \psi (0)\rangle \). Remarkably, the ground state of Eq. (2) is exactly Eq. (1), and its energy is \(\langle \hat{\mathcal {H}}\vert *\vert \hat{\mathcal {H}}\rangle {\Psi }=0\). This property is important because it allows us to quantify how close the algorithm is to converge to the true ground state of the system. It is worth highlighting that, even though whatever Hamiltonian \(\hat{H}\) under consideration is sparse, \(\hat{U}(T)\) need not be sparse, especially for large values of T [3]. Therefore, computing the matrix representation of \(\hat{U}(T)\) involves a considerable computational effort. It is much easier to compute \(\hat{U}(\Delta t)\) for \(\Delta t = T/N \ll T\) for large N, as \(\hat{U}(\Delta t)\) in Eq. (2) becomes just a perturbation of the identity.
In this work, we study the dynamics of the prototypical TFIM Hamiltonian defined on a one-dimensional chain of \(N_S\) (ordered) spins:
where \(\hat{\sigma }^{z(x)}_{i}\) is the Z(X) Pauli operator acting only on spin i. Throughout the paper, we use \(J=0.25\) and \(h=1\).
3 Variational Monte Carlo and neural quantum states
The variational Monte Carlo (VMC) method leverages the variational method of quantum mechanics to problems with intractable Hilbert spaces [8]. The variational method proposes a parameterised ansatz \(\vert \Psi _{\vec {\theta }}\rangle \) and poses the problem \(\min _{\vec {\theta }} \langle \Psi _{\vec {\theta }}\vert {\hat{\mathcal {H}}}\vert \Psi _{\vec {\theta }}\rangle /\langle \Psi _{\vec {\theta }}\vert \Psi _{\vec {\theta }}\rangle \), where the energy is minimised, under the principle that it is only the ground state that has the minimum energy possible. The problem is often difficult due to the non-convexity of the function to be minimised. However, it is the dimensionality of the problem that renders it prohibitive to solve. Indeed, by considering the completeness relation \(I_{\mathscr {H}}=\sum _{\sigma }\vert \sigma \rangle \langle \sigma \vert \) of a Hilbert space \(\mathscr {H}\) with an orthonormal basis \(\{\vert \sigma \rangle \}\) (\(\vert \sigma \rangle \) is a spin configuration—in the case of the TFIM expanded with a clock—of the explicit form \(\vert \sigma \rangle = \vert \sigma _1\rangle \otimes \vert \sigma _2\rangle \otimes \cdots \otimes \vert \sigma _{N_S+N_T}\rangle \equiv \vert \sigma _1,\ldots ,\sigma _{N_S+N_T}\rangle \) with \(\vert \sigma _i\rangle \in \{\vert \uparrow \rangle , \vert \downarrow \rangle \}\)), we have that the variational energy is
where \(P_{\vec {\theta }}(\sigma ) = \vert \Psi _{\vec {\theta }}(\sigma )\vert ^2/\sum _{\sigma ^\prime }\vert \Psi _{\vec {\theta }}(\sigma ^\prime )\vert ^2\) is the probability of the configuration \(\sigma \). The usual minimisation of \(E_{\vec {\theta }}\) with respect to the parameters of the wave function can be performed using any optimisation algorithm. However, as mentioned, it is practically impossible to perform the double summation because of the size of the Hilbert space \(\mathscr {H}\). Instead, VMC estimates \(E_{\vec {\theta }}\) by virtue of the empirical fact that for many local-interaction Hamiltonians, \(P_{\vec {\theta }}(\sigma ) \approx 0\) for almost every \(\sigma \), except for a small subset of the basis. Therefore, the estimation of the variational energy is simply [8, 11]
where the average is taken only using configurations from a sample \(\mathcal {M}\) that is built according to the distribution \(P_{\vec {\theta }}(\sigma )\). Remarkably, since \(\hat{\mathcal {H}}\) is usually sparse in the canonical basis \(\{\vert \sigma \rangle \}\), the matrix elements \(\langle \sigma \vert \hat{\mathcal {H}}\vert \sigma ^\prime \rangle \) are zero for most configurations \(\sigma ^\prime \) given a fixed \(\sigma \). Another important feature of Eq. (5) is that the wave function need not be normalised to estimate the energy, or any other observable. We also emphasise that in the case of the Feynman–Kitaev Hamiltonian (Eq. 2), estimations of observables have to be multiplied by \(N+1\) to account for the normalisation factor of the history state in Eq. (1).
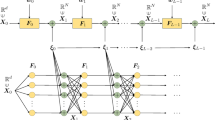
Carleo and Troyer [11] introduced the idea of using neural networks to represent the wave function, i.e. the parameters \(\vec {\theta }\) are the parameters of a neural network that takes as input a configuration \(\sigma \) and outputs a complex number \(\Psi _{\vec {\theta }}(\sigma )\). These models receive the name of neural quantum states (NQSs). A common choice of neural network is the restricted Boltzmann machine (RBM) [11], which induces the ansatz:
where \(N_H\) is the number of hidden units of the RBM and \(\{a_j, b_j,W_{\ell ,j}\}\) is the set of complex parameters. The total number of parameters of this ansatz is \(N_H(N_S+N_T + 1)\).
The sample \(\mathcal {M}\) is built, in the case of the RBM, with the Metropolis–Hastings algorithm [20] because it is able to sample from a non-normalised distribution, such as the one induced by Eq. (6). Indeed, normalising the RBM ansatz is computationally intractable for long spin chains. The Metropolis–Hastings algorithm chosen in this study comprises the following steps: (i) A random configuration \(\sigma ^{(0)}\) is generated. (ii) At iteration \(r\ge 1\), we take the configuration \(\sigma ^{(r-1)}\) and randomly flip one spin, forming a candidate configuration \(\tilde{\sigma }^{(r)}\). (iii) \(\sigma ^{(r)}\) is set to \(\tilde{\sigma }^{(r)}\) with probability \(\vert \Psi ^{\text {RBM}}_{\vec {\theta }}(\tilde{\sigma }^{(r)})\vert ^2 / \vert \Psi ^{\text {RBM}}_{\vec {\theta }}(\sigma ^{(r-1)})\vert ^2\), else it is set to \(\sigma ^{(r-1)}\). Usually, these steps are repeated until thermalisation, which means that the Markov chain stabilises, and only then one starts to collect configurations to build the sample \(\mathcal {M}\).
However, stabilising Markov chains can be difficult, and in some cases might require a prohibitive amount of sampling in order to get a good representation of the probability distribution that needs to be approximated [40]. For this reason, we also consider autoregressive models whose probability distribution can be sampled exactly, meaning that the sample \(\mathcal {M}\) can be gathered by directly accessing the probability distribution \(P_{\vec {\theta }}(\sigma )\). In principle, avoiding the inherent practical problems of Markov chains for Monte Carlo sampling should bring an advantage; however, the performance of these autoregressive models did not meet these expectations. We explain autoregressive models and report results based thereof in appendix A.
4 Results
We find the ground state of Eq. (2), which encodes the time evolution of a system governed by the TFIM Hamiltonian in Eq. (3). The initial state is set as \(\vert \uparrow ,\ldots ,\uparrow \rangle \), achieved by setting \(\hat{H}_0=\frac{1}{2}\sum _{i=1}^{N_S}(1 - \hat{\sigma }^{z}_i)\). There is an intrinsic difficulty in the Feynman–Kitaev Hamiltonian, which is that a lot of information (the quantum state of the Ising chain at each time step) needs to be stored in the ground state. Such difficulty is evident from analysing the structure of the ground state of Eq. (2), which we now denote by \(\vert \Phi (N_S,N_T)\rangle \), where we explicitly denote the number of physical spins \(N_S\) and the number of spins \(N_T\) assigned to encode the temporal state.
Let us consider a system where the total number of spins is \(N_T + N_S = 9\), which fixes the Hilbert space size to \(\vert \mathscr {H}\vert = 2^9\). We can quantify the entanglement scale of the system by measuring the second Rényi entropy per physical spin \(-\log (\textrm{Tr}[\rho _{N_P}^2])/N_S\) [36]. Here, \(\rho _{N_P}\) is the reduced density matrix of a sub-chain of \(N_P\) physical spins, namely \(N_P \le N_S\). This reduced density matrix is obtained by tracing over all the spin degrees of freedom except for the first \(N_P\) spins. The second Rényi entropy is an entanglement quantifier and can be interpreted as follows: if a bipartite system is non-separable, when tracing the degrees of freedom of one part of the system, one is left with a reduced mixed state \(\rho _{N_P}\) as a result; therefore, its decomposition will not have rank 1, and \(\textrm{Tr}[\rho ^2_{N_P}]\) will be less than 1. The more mixed the reduced density matrix, the smaller this trace will be, and the greater the second Rényi entropy will be. Figure 1b shows the second Rényi entropy by considering different physical spin sub-chains, indicating that the entanglement increases between the first \(N_P\) physical spins and the rest of the system as more spins are dedicated to encode time steps, and as we add more spins to the sub-chains. Indeed, the last point of each curve in Fig. 1b shows that the entanglement between the time spins and the physical spins increase as long as more spins are used to encode the quantum state of the clock.
Another insightful analysis that summarises the complexity of the ground state of Eq. (2) is the proportion of the canonical basis elements needed to capture 99% of the probability distribution given by the ground state \(\vert \Phi (N_S, N_T)\rangle \) for different values of physical spins \(N_S\) and temporal spins \(N_T\), shown in Fig. 1c. The larger this ratio is, the larger the Monte Carlo sample \(\mathcal {M}\) should be in Eq. (5) to be able to describe the expected energy to a given degree of error. More formally stated, let the canonical basis \(\{\sigma \}\) be indexed such that \(\vert \langle \sigma ^{(i)}\vert \Phi (N_S,N_T)\rangle \vert ^2 \ge \vert \langle \sigma ^{(i+1)}\vert \Phi (N_S,N_T)\rangle \vert ^2\). Then, Fig. 1c shows the ratio \(r/2^{N_S+N_T}\), where r is the smallest integer such that \(\sum _{i=1}^r \vert \langle \sigma ^{(i)}\vert \Phi (N_S,N_T)\rangle \vert ^2 > 0.99\). It is clear from Fig. 1c that for a fixed number of total spins \(N_S+N_T\), the larger \(N_T\) is, the highest the ratio of elements in the canonical basis needed to explain the ground state is.
Figure 1 showed that the ground state, for large values of \(N_T\), a well-spread and highly entangled ground state forms. Figure 2 reflects this fact on the increasing difficulty of training an RBM as an NQS for the ground state through VMC as \(N_T\) grows. Again, we fixed the total number of spins \(N_S + N_T = 9\), as in Fig. 1b. For each value of \(N_T\) (between 1 and 4), we performed hyperparameter tuning for 100 iterations with Optuna [2], aiming to minimise the variational energy in Eq. (5). Details of the optimisation and hyperparameter tuning can be found in appendix B. Figure 2a–d shows the time evolution of the spin chain for the hyperparameters that produced the smallest infidelities.

Time evolution approximated with an RBM as an NQS. a–d show the expected value of the average magnetisation \(\langle =\vert \hat{\sigma }^z\vert =\rangle \frac{1}{N_S}\sum _{i=1}^{N_S} \langle {{{{\hat{\sigma }}_i}^z}}\rangle \). In each panel, curves are shown for the average magnetisation obtained through exact diagonalisation (ground state), estimation of the variational magnetisation with a sample \(\mathcal {M}\) (RBM) and exact variational magnetisation (exact RBM), which results from using the complete state vector instead of a sample. The shaded region indicates the estimated fluctuations of magnetisation using the sample \(\mathcal {M}\). The lines serve as a guide for the eye only. e Shows a box plot of infidelity (\(1-\vert \langle \Phi (N_S,N_T)\vert \Psi ^{\text {RBM}}_{\vec {\theta ^\star }}\rangle \vert ^2\)) for the best 10 hyperparameter experiments, where \(\vec {\theta }^\star \) indicates that parameters have been optimised until convergence
It is seen in Fig. 2a–d that, overall, the evolution of the average magnetisation is in accordance to the average magnetisation obtained through exact diagonalisation for all the values of \(N_T\). In the plots, the exact RBM line refers to magnetisation measured using the complete state vector from the RBM, instead of estimating the magnetisation through a sample. However, the qualitative agreement of magnetisation curves does not exhibit the difficulty of training the RBM as \(N_T\) increases. Indeed, the infidelities for Fig. 2a–d are 0.018, 0.032, 0.144 and 0.145, respectively. The increasing infidelity, as \(N_T\) grows, indicates that training becomes more difficult, despite the Hilbert space always having the same size. However, these are only the best states found after hyperparameter tuning. Figure 2e shows a box plot of the infidelities of the best 10 hyperparameter tuning states, where a clear trend appears: the larger \(N_T\) is, the more difficult it is to find the correct ground state.
5 Discussion
In this section, we discuss the results so far presented in light of the recent study by Barison et al. [6]. Compared to VQE, as we saw in the previous section, VMC struggles with finding an accurate approximation of the true ground state, presenting infidelities at least one order of magnitude higher than infidelities reported by Barison et al. [6]. Unlike VMC, VQE directly handles a normalised quantum state in the whole Hilbert space, and its parameterisation consists of local transformations that preserve the norm. A natural set of questions that arise are: what is it that makes NQSs have larger infidelities than VQE? Is it expressivity? Is it trainability? [1, 41] If the NQS can represent the ground state of Eq. (2) with low infidelity, it means that the NQS is expressive enough, but trainability hampers the possibility of describing the correct ground state, as shown in Fig. 2.
Considering the previous discussion, let us explore the expressivity of the RBM NQS. The most challenging experiment tackled in this paper is the one of \(N_S=5\) and \(N_T=4\), which is perfectly tractable for a classical computer. We consider the problem of finding parameters for the RBM ansatz that are able to faithfully describe the ground state of Eq. (2) by giving the RBM the ability to access the whole Hilbert space. To this end, we directly minimise the infidelity \(1 - \vert \langle \Phi (N_S=5,N_T=4)\vert \Psi ^{\text {RBM}}_{\vec {\theta }}\rangle \vert ^2\). Experimentation with the ansatz in Eq. (6) shows that training leads to local minima of the infidelity landscape, hinting convergence to stable excited states of Eq. (2). Therefore, we turned over to a similar RBM ansatz, which defines an RBM for the modulus and another for the phase of the wave function, namely the Modulus-Phase-RBM or MP-RBM [36]
where \(\Psi ^{\text {RBM}}_{\vec {\theta }_{\Re }}\) and \(\Psi ^{\text {RBM}}_{\vec {\theta }_{\Im }}\) are RBMs defined by Eq. (6), with real-only parameters \(\vec {\theta }_{\Re }\) and \(\vec {\theta }_{\Im }\). Training the MP-RBM ansatz in Eq. (7) to minimise the estimated variational energy (see Eq. 5) with VMC yields similar infidelities than the RBM ansatz after hyperparameter tuning (0.160 for the \(N_S=5, N_T=4\) case). However, it is easier to train the MP-RBM when minimising the infidelity (even without hyperparameter tuning). In fact, we see that the MP-RBM is capable of learning the ground state with an infidelity of \(2\times 10^{-3}\), as depicted by the excellent agreement between the MP-RBM magnetisation curve and the exact one in the bottom panel of Fig. 3.

Probability of each element of the canonical basis of \(\mathscr {H}\) and time evolution of magnetisation for an MP-RBM ansatz. The top panel shows the \(2^9\) probabilities associated to each element of the canonical basis of \(\mathscr {H}\) for the ground states obtained through exact diagonalisation, through variational minimisation of the infidelity, and through variational minimisation of the estimated energy in the left, middle and right sub-panels, respectively. The bottom panel shows the average magnetisation obtained with each of these states, where the “ground state” line corresponds to the magnetisation obtained with exact diagonalisation, the “MP-RBM” line is obtained through variational minimisation of the estimated energy, and the “infidelity MP-RBM” is obtained through variational minimisation of the infidelity
Figure 3 exhibits the probability distribution of each state induced onto the canonical basis of the Hilbert space \(\mathscr {H}\). Since the infidelity-optimised MP-RBM leads to a very low infidelity, differences between its distribution (top middle panel) and the exact ground state distribution (top left panel) are minimal. However, differences with the MP-RBM obtained through VMC are larger (cf. Fig. 3 top left and top right panels). This is reflected onto the average magnetisation curves, shown in the bottom panel of Fig. 3. These results are in agreement with the study by Deng et al. [12], who show that NQSs based on RBMs have a wide expressivity, able to represent many highly entangled quantum states.
This result supports the fact that NQSs are able to accurately approximate highly entangled ground states with widely spread probability distributions. The problem, however, resides on trainability when performing VMC. An important final remark is that knowing the reason why infidelity optimisation consistently fails for NQSs with complex-only parameters remains an open question.
6 Conclusions
We studied the time evolution of a transverse-field Ising model through the Feynman–Kitaev Hamiltonian, which encodes the state of a physical system at a given set of equidistant time instances into the state of an enlarged quantum mechanical system (it is enlarged by the state of a clock). The ground state of the Feynman–Kitaev Hamiltonian was systematically searched by tuning hyperparameters of neural quantum state ansätze through the variational Monte Carlo method.
We showed that neural quantum states encounter difficulty in representing a highly entangled ground state whose probability distribution is well spread across the canonical basis of the Hilbert space. As the number of clock states increased, we consistently saw that the performance of neural quantum states deteriorated, yielding lower fidelities to the true ground state of the Feynman–Kitaev Hamiltonian. The characterisation of such ground state showed that as the number of clock states increased, both entanglement quantifiers and probability spread also increased. These features explain that the ground state is ever more complicated for the neural quantum state to learn through variational Monte Carlo.
However, we also saw that the degrading performance of neural quantum states was not because of a lack of expressivity of the neural quantum state per se, as also supported by previous literature. Instead, we provide evidence that trainability—in the variational Monte Carlo setup—is the main source of under-performance, even for autoregressive models, which sample directly from the probability distribution induced by the variational state. This supports the hypothesis that optimisation techniques, and not sampling, degrade the quality of the learnt ground state, accompanied by the fact that energy convergence does not ensure convergence of the state (at least not in the same timescale) [5, 37].
Notes
Many of the different methods associated to NQSs have even been standardised in open-source libraries such as NetKet [38], which facilitates the use of these tools for researchers. All of the experiments of this paper involving VMC were done using NetKet.
The purpose of this encoding is to have common ground with the study by Barison et al. [6] for benchmarking reasons, but a true \(N+1\)-level system can be used instead.
References
Abbas, A., Sutter, D., Zoufal, C., Lucchi, A., Figalli, A., Woerner, S.: The power of quantum neural networks. Nat. Comput. Sci. 1(6), 403–409 (2021). https://doi.org/10.1038/s43588-021-00084-1
Akiba, T., Sano, S., Yanase, T., Ohta, T., Koyama, M.: Optuna: A next-generation hyperparameter optimization framework. In: Proceedings of the 25rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (2019)
Alhambra, Á.M.: Quantum many-body systems in thermal equilibrium. arXiv:2204.08349 (2022)
Anschuetz, E.R., Kiani, B.T.: Beyond barren plateaus: Quantum variational algorithms are swamped with traps. arXiv:2205.05786 (2022)
Ballentine, L.E.: Quantum Mechanics: A Modern Development. World Scientific Publishing Company, Singapore (2014)
Barison, S., Vicentini, F., Cirac, I., Carleo, G.: Variational dynamics as a ground-state problem on a quantum computer. arXiv:2204.03454 (2022)
Barrett, T.D., Malyshev, A., Lvovsky, A.I.: Autoregressive neural-network wavefunctions for ab initio quantum chemistry. Nat. Mach. Intell. 4(4), 351–358 (2022). https://doi.org/10.1038/s42256-022-00461-z
Becca, F., Sorella, S.: Quantum Monte Carlo Approaches for Correlated Systems. Cambridge University Press, Cambridge (2017)
Bergstra, J., Bardenet, R., Bengio, Y., Kégl, B.: Algorithms for hyper-parameter optimization. In: Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., Weinberger, K.Q. (eds) Advances in Neural Information Processing Systems, Vol 24. Curran Associates, Inc. (2011). https://proceedings.neurips.cc/paper/2011/file/86e8f7ab32cfd12577bc2619bc635690-Paper.pdf
Caha, L., Landau, Z., Nagaj, D.: Clocks in Feynman’s computer and Kitaev’s local Hamiltonian: bias, gaps, idling, and pulse tuning. Phys. Rev. A 97, 062306 (2018). https://doi.org/10.1103/PhysRevA.97.062306
Carleo, G., Troyer, M.: Solving the quantum many-body problem with artificial neural networks. Science 355(6325), 602–606 (2017)
Deng, D.-L., Li, X., Das Sarma, S.: Quantum entanglement in neural network states. Phys. Rev. X 7, 021021 (2017). https://doi.org/10.1103/PhysRevX.7.021021
Donatella, K, Denis, Z., Le Boité, A., Ciuti, C.: Dynamics with autoregressive neural quantum states: application to critical quench dynamics. arXiv:2209.03241 (2022)
Eisert, J., Cramer, M., Plenio, M.B.: Colloquium: area laws for the entanglement entropy. Rev. Mod. Phys. 82, 277–306 (2010). https://doi.org/10.1103/RevModPhys.82.277
Feynman, R.P.: Quantum mechanical computers. Opt. News 11(2), 11–20 (1985). https://doi.org/10.1364/ON.11.2.000011
Freitas, N., Morigi, G., Dunjko, V.: Neural network operations and susuki-trotter evolution of neural network states. Int. J. Quantum Inf. 16(08), 1840008 (2018). https://doi.org/10.1142/S0219749918400087
Frey, B.J.:Graphical Models for Machine Learning and Digital Communication. Adaptive Computation and Machine Learning. The MIT Press (1998). ISBN: 026206202X; 9780262062022
Linyan, G., Huang, J., Yang, L.: On the representational power of restricted Boltzmann machines for symmetric functions and Boolean functions. IEEE Trans. Neural Netw. Learn. Syst. 30(5), 1335–1347 (2019). https://doi.org/10.1109/TNNLS.2018.2868809
Gutiérrez, I.L., Mendl, C.B.: Real time evolution with neural-network quantum states. Quantum 6, 627 (2022). https://doi.org/10.22331/q-2022-01-20-627
Hastings, W.K.: Monte Carlo sampling methods using Markov chains and their applications. Biometrika 57(1), 97–109 (1970). https://doi.org/10.1093/biomet/57.1.97
Hibat-Allah, M., Ganahl, M., Hayward, L.E., Melko, R.G., Carrasquilla, J.: Recurrent neural network wave functions. Phys. Rev. Res. 2, 023358 (2020). https://doi.org/10.1103/PhysRevResearch.2.023358
Hofmann, D., Fabiani, G., Mentink, J.H., Carleo, G., Sentef, M.A.: Role of stochastic noise and generalization error in the time propagation of neural-network quantum states. Sci. Post Phys. 12, 165 (2022). https://doi.org/10.21468/SciPostPhys.12.5.165
Kandala, A., Mezzacapo, A., Temme, K., Takita, M., Brink, M., Chow, J.M., Gambetta, J.M.: Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets. Nature 549(7671), 242–246 (2017). https://doi.org/10.1038/nature23879
Kitaev, A.Y., Shen, A., Vyalyi, M.N., Vyalyi, M.N.: Classical and Quantum Computation. American Mathematical Soc, New York (2002)
Lin, S.-H., Pollmann, F.: Scaling of neural-network quantum states for time evolution. Phys. Status Solidi (b) 259(5), 2100172 (2022). https://doi.org/10.1002/pssb.202100172
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv:1711.05101 (2017)
McClean, J.R., Parkhill, J.A., Aspuru-Guzik, A.: Feynman’s clock, a new variational principle, and parallel-in-time quantum dynamics. Proc. Natl. Acad. Sci. 110(41), E3901–E3909 (2013). https://doi.org/10.1073/pnas.1308069110
McClean, J.R., Boixo, S., Smelyanskiy, V.N., Babbush, R., Neven, H.: Barren plateaus in quantum neural network training landscapes. Nat. Commun. 9(1), 4812 (2018). https://doi.org/10.1038/s41467-018-07090-4
Montufar, G.F., Rauh, J., Ay, N.: Expressive power and approximation errors of restricted Boltzmann machines. In: Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., Weinberger, K.Q. (eds) Advances in Neural Information Processing Systems, Vol. 24. Curran Associates, Inc. https://proceedings.neurips.cc/paper/2011/file/8e98d81f8217304975ccb23337bb5761-Paper.pdf (2011)
Reh, M., Schmitt, M., Gärttner, M.: Time-dependent variational principle for open quantum systems with artificial neural networks. Phys. Rev. Lett. 127, 230501 (2021). https://doi.org/10.1103/PhysRevLett.127.230501
Schmitt, M., Heyl, M.: Quantum many-body dynamics in two dimensions with artificial neural networks. Phys. Rev. Lett. 125, 100503 (2020). https://doi.org/10.1103/PhysRevLett.125.100503
Schuld, M., Sweke, R., Meyer, J.J.: Effect of data encoding on the expressive power of variational quantum-machine-learning models. Phys. Rev. A 103, 032430 (2021). https://doi.org/10.1103/PhysRevA.103.032430
Sharir, O., Shashua, A., Carleo, G.: Neural tensor contractions and the expressive power of deep neural quantum states. arXiv:2103.10293 (2021)
Sorella, S., Casula, M., Rocca, D.: Weak binding between two aromatic rings: feeling the van der waals attraction by quantum Monte Carlo methods. J. Chem. Phys. 127(1), 014105 (2007). https://doi.org/10.1063/1.2746035
Sun, X.-Q., Nebabu, T., Han, X., Flynn, M.O., Qi, X.-L.: Entanglement features of random neural network quantum states. arXiv:2203.00020 (2022)
Torlai, G., Mazzola, G., Carrasquilla, J., Troyer, M., Melko, R., Carleo, G.: Neural-network quantum state tomography. Nat. Phys. 14(5), 447–450 (2018). https://doi.org/10.1038/s41567-018-0048-5
Vargas-Calderón, V., Vinck-Posada, H., González, F.A.: Phase diagram reconstruction of the bose-hubbard model with a restricted Boltzmann machine wavefunction. J. Phys. Soc. Jpn. 89(9), 094002 (2020)
Vicentini, F., Hofmann, D., Szabó, A., Wu, D., Roth, C., Giuliani, C., Pescia, G., Nys, J., Vargas-Calderon, V., Astrakhantsev, N., Carleo, G.: Netket 3: Machine learning toolbox for many-body quantum systems. arXiv:2112.10526 (2021)
Vitagliano, G., Riera, A., Latorre, J.I.: Volume-law scaling for the entanglement entropy in spin-1/2 chains. New J. Phys. 12(11), 113049 (2010). https://doi.org/10.1088/1367-2630/12/11/113049
Vivas, D.R., Madroñero, J., Bucheli, V., Gómez, L.O., Reina, J.H.: Neural-network quantum states: a systematic review. arXiv:2204.12966 (2022)
Wright, L.G., McMahon, P.L.: The capacity of quantum neural networks. In: Conference on Lasers and Electro-Optics, pp. JM4G.5. Optica Publishing Group. http://opg.optica.org/abstract.cfm?URI=CLEO_QELS-2020-JM4G.5 (2020)
Wu, D., Wang, L., Zhang, P.: Solving statistical mechanics using variational autoregressive networks. Phys. Rev. Lett. 122, 080602 (2019). https://doi.org/10.1103/PhysRevLett.122.080602
Wu, D., Rossi, R., Carleo, G.: Unbiased Monte Carlo cluster updates with autoregressive neural networks. Phys. Rev. Res. 3, L042024 (2021). https://doi.org/10.1103/PhysRevResearch.3.L042024
Xiao, L., Pennington, J., Schoenholz, S.: Disentangling trainability and generalization in deep neural networks. In: Daumé, H., Singh, A. (eds) Proceedings of the 37th International Conference on Machine Learning, Volume 119 of Proceedings of Machine Learning Research, PMLR, pp. 10462–10472 (2020)
Zhao, T., De, S., Chen, B., Stokes, J., Veerapaneni, S.: Overcoming barriers to scalability in variational quantum Monte Carlo. In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’21, New York. Association for Computing Machinery. ISBN 9781450384421. https://doi.org/10.1145/3458817.3476219 (2021)
Acknowledgements
V. V.-C. and H. V.-P. acknowledge funding from Universidad Nacional de Colombia project HERMES 48528.
Funding
Open Access funding provided by Colombia Consortium.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflicts of interest. Further, data and code will be made available upon request to the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A: Autoregressive ansatz
We adopt a chain-type Bayesian network [17, 42, 43, 45] as the building block of the autoregressive model, which defines
Here, \(q_{\vec {\theta }}(\sigma _i \vert \sigma _1,\ldots ,\sigma _{i-1})\) models the probability that the i-th spin has a specified value conditioned on the observed values for the previous spins. Thus, Eq. (A1) reads: the probability of the spin configuration \(\sigma \) is the probability (assigned by the model parameterised with variational parameters \(\vec {\theta }\)) that the first spin has value \(\sigma _1\), times the probability that the second spin has value \(\sigma _2\) given that the first spin had value \(\sigma _1\), and so on. In other words, it is a straight-forward application of Bayes’ rule.
Note that Eq. (A1) is not concerned with the phase structure of the quantum state, i.e. \(P_\theta (\sigma )\) is equivalent to \(\vert \Psi _\theta ^\text {AR}(\sigma )\vert ^2\). In the same fashion, we can connect the wave function model to this probabilistic model through Born’s rule, i.e. \(q_{\vec {\theta }}(\sigma _i\vert \sigma _1,\ldots ,\sigma _{i-1}) \equiv \vert \Psi ^{\text {AR}}_{\vec {\theta }}(\sigma _i\vert \sigma _1,\ldots ,\sigma _{i-1})\vert ^2\). However, we need for an explicit model for \(\Psi ^{\text {AR}}_{\vec {\theta }}(\sigma _i\vert \sigma _1,\ldots ,\sigma _{i-1})\) that complies with the aforementioned relations. Thus, to describe the phase structure of the wave function, we express it as
where we have introduced the notation \(\vec {\sigma }_i\) to denote the vector \((1, 0)^T\) for \(\sigma _i = +1\) or \((0, 1)^T\) for \(\sigma _i = -1\), and \(\vec {\eta }_{\vec {\theta }}=(\eta _{\vec {\theta }}^{(1)}, \eta _{\vec {\theta }}^{(2)})^T\) denotes the needed complex vector generalisation of \(q_{\vec {\theta }}\) such that \(\vert \eta _{\vec {\theta }}^{(1)}\vert ^2+ \vert \eta _{\vec {\theta }}^{(2)}\vert ^2=1\), which ensures the correct normalisation of the probability model.
Figure 4 shows the evolution of magnetisation for the autoregressive ansatz in Eq. (A2). Qualitatively, results with this ansatz are similar to those of the RBM (cf. Fig. 2), but they show worse performance in terms of correctly describing the evolution of magnetisation. This is further confirmed by poor infidelities when \(N_T\) is large. The lowest infidelities achieved after hyperparameter tuning (see section B for details) were 0.025, 0.063, 0.517 and 0.850 for Fig. 4a–d, respectively. Even though one can sample directly from the probability distribution induced by the autoregressive ansatz, avoiding issues with the Markov chain sampling, it is clear that capturing the ground state of Eq. (2) is more challenging for the autoregressive ansatz than the RBM ansatz.
From Fig. 4 stands out the fact that, in some cases, the average magnetisation exceeds the upper bound limit for the average magnetisation, which is one. This can be understood from the construction of the Feynman–Kitaev history state Eq. (1). Explicitly, an observable \(\hat{O}\) at time t is measured as
Therefore, it is possible that the probability associated to a particular time of the clock is greater than \(1/(N + 1)\), making it possible to measure average magnetisations greater than one.

Finally, we found that optimising the infidelity (instead of minimising the variational energy) for the ansatz in Eq. (A2) traps the NQS into an excited state of Eq. (2), which is why we turned over to an autoregressive ansatz that explicitly divides the modulus and phase of the wave function, similar to the works by Hibat-Allah et al. [21] and Barrett et al. [7]. In this setup, we divide the autoregressive neural network \(\vec {\eta }\) into two autoregressive neural networks, one for the modulus, and the other for the phase of the wave function. Training this ansatz to minimise the estimated variational energy with VMC, yields high infidelity of 0.920 after hyperparameter tuning for the \(N_S=5,N_T=4\) case, which is a similar infidelity to the one obtained by the ansatz in Eq. (A2). On the other hand, the infidelity optimisation (without any hyperparameter tuning) yields an infidelity of \(3.5\times 10^{-3}\), comparable to that of the MP-RBM. These findings are further evidence for NQSs being able to express highly entangled ground states with widely spread probability distributions, pin-pointing trainability as the main problem for learning ground states.
Appendix B: Optimisation of neural quantum states
Both VMC and NQS training have hyperparameters that dictate the behaviour of the variational energy optimisation. Since the aim of this study is to train NQSs in the VMC setup with the greatest possible quality, we adopt a fruitful machine learning strategy that targets the best set of hyperparameters, namely hyperparameter tuning. Hyperparameter tuning is a difficult meta-optimisation task that, in our case, thrives to answer the questions: what is the best structure of the training algorithm, and what is the NQS architecture that produces the lowest variational energy?
Let us start by stating the hyperparameters for VMC. The two main components of VMC are the sampler and the optimiser. The sampler dictates how the sample \(\mathcal {M}\) of Eq. (5) is built, and the optimiser is a rule for updating the parameters \(\vec {\theta }\) of the NQS.
In the NQS literature, it is common to find that stochastic reconfiguration (SR) [34] is used in combination with stochastic gradient descent (SGD) as an optimiser. SR takes into account the geometry of the variational energy landscape to update parameters in the directions that yield maximum descent. However, we experimented on optimisation instances that used the RBM NQS (Eq. 6) with different numbers of hidden neurons using both SR+SGD and AdamW [26] and found no significant difference in performance. On the contrary, AdamW was faster, which is why we chose it as the optimisation method for all of the experiments shown in the main text. We consider its learning rate as the sole hyperparameter of the optimiser. Regarding the sampler, we consider the number of parallel Markov chains and the number of total samples as its two hyperparameters. In the case of an autoregressive NQS, no Markov chains are considered, and the sampler only has the number of total samples hyperparameter.
The hyperparameters for the architecture of the NQSs are different for the RBM and the autoregressive ansätze. For the RBM, the hyperparameter is \(\alpha :=N_H/(N_S+N_T)\), which specifies the proportion of hidden neurons with respect to the visible neurons of the RBM. For the autoregressive ansatz, the autoregressive neural network \(\vec {\eta }\) in Eq. (A2) has two hyperparameters: the number of layers \(N_L\), and the number of hidden neurons \(N_H\) of each layer, with the property that the layers are masked in such a way that the conditional probability of a spin taking a value depends only on the values of the previous spins.
The hyperparameter tuning algorithm that we used is the tree-structured Parzen estimator (TPE) [9] provided in the Optuna package [2]. In summary, TPE works by jointly modelling the distribution \(\ell (x)\) of features that have corresponding figures of merit below a given threshold \(y^*\) and, similarly, the distribution g(x) of features with corresponding figures of merit above said threshold. The models \(\ell \) and g are tree-structured models with single-variable priors for each hyperparameter, which are shown in table 1. Hyperparameter tuning was conducted for 100 different hyperparameter sets for each ansatz, and for each combination of number of physical spins \(N_S\) and number of time spins \(N_T\).
1.1 B.1: Turning on the clock adiabatically
We adopt the strategy by Barison et al. [6] of turning on the clock gradually. This means that we perform the energy (or infidelity) minimisation of Eq. (2) for a total time \(T_k = kT/20\), starting from \(k=1\) and ending at \(k=20\). This strategy simplifies learning overall, as it gradually increases the learning problem difficulty: for small k, the evolution is for small times, meaning that the state of the physical system remains almost unchanged throughout evolution. As k gets larger, the state of the physical system starts to significantly change between consecutive time steps.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Vargas-Calderón, V., Vinck-Posada, H. & González, F.A. An empirical study of quantum dynamics as a ground state problem with neural quantum states. Quantum Inf Process 22, 165 (2023). https://doi.org/10.1007/s11128-023-03902-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11128-023-03902-9