
Abstract
We present a detailed study of portfolio optimization using different versions of the quantum approximate optimization algorithm (QAOA). For a given list of assets, the portfolio optimization problem is formulated as quadratic binary optimization constrained on the number of assets contained in the portfolio. QAOA has been suggested as a possible candidate for solving this problem (and similar combinatorial optimization problems) more efficiently than classical computers in the case of a sufficiently large number of assets. However, the practical implementation of this algorithm requires a careful consideration of several technical issues, not all of which are discussed in the present literature. The present article intends to fill this gap and thereby provides the reader with a useful guide for applying QAOA to the portfolio optimization problem (and similar problems). In particular, we will discuss several possible choices of the variational form and of different classical algorithms for finding the corresponding optimized parameters. Viewing at the application of QAOA on error-prone NISQ hardware, we also analyse the influence of statistical sampling errors (due to a finite number of shots) and gate and readout errors (due to imperfect quantum hardware). Finally, we define a criterion for distinguishing between ‘easy’ and ‘hard’ instances of the portfolio optimization problem.
Similar content being viewed by others

Explore related subjects
Find the latest articles, discoveries, and news in related topics.Avoid common mistakes on your manuscript.
1 Introduction
The solution of combinatorial optimization problems with QAOA, i.e. the quantum approximate optimization algorithm [1] or its generalized version known as quantum alternating operator ansatz [2], is often mentioned as one of the most promising candidates for realizing an advantage of quantum computers with respect to classical computers in a relatively near future. This expectation is based upon the fact that the quantum circuits required for QAOA are shorter than those of other algorithms, e.g. the Shor [3] or HHL [4] algorithm, for which an exponential advantage compared to classical algorithms can be proven (under the assumption that quantum computers with sufficiently many error-corrected qubits are available). In contrast to those cases, a quantum advantage of QAOA has not yet been rigorously proven. Since QAOA involves a numerical classical optimization of variational circuit parameters (which, in itself, is an NP-hard problem [5]), analytical results concerning the performance of QAOA for a large number of qubits are not available. Nevertheless, extrapolations of results obtained for small numbers of qubits towards larger numbers suggest that a quantum speed-up (for the Max-Cut problem) could be expected with several hundred qubits [6]. As pointed out there, the main limitation of QAOA is imposed by the exponential cost required for optimizing the variational parameters. This conclusion, however, might change if the exponential cost can be reduced by finding more efficient heuristic strategies for performing the classical optimization of these parameters. Indeed, there are indications that this is possible: for example, instead of starting the optimization from randomly chosen initial values, as it is done in [6], a strategy making use of observed patterns in the optimal parameters requires exponentially less time in order to achieve a similar performance [7]. In general, the performance of QAOA critically depends on how exactly the parameter optimization is carried out, in particular how the initial values fed into the classical optimization routine are chosen. Whereas [7] contains an in-depth study of the performance of QAOA on rather abstract Max-Cut problems, the present paper provides a similar analysis for the use case of portfolio optimization, which constitutes one of the most discussed problems in finance [8,9,10,11,12,13,14]. In addition to previous works on portfolio optimization by QAOA [15,16,17], the present paper therefore focuses on a number of technical issues relevant for the practical implementation of QAOA, not all of which are discussed in the present literature. By presenting the details of our implementation, which we have found to yield consistently good results, we provide a useful guide for all readers who want to apply QAOA to portfolio optimization or similar optimization problems. Furthermore, since the QAOA performance varies for different instances (i.e. different assets from which the portfolio is chosen), we present a new criterion for distinguishing between ‘easy’ and ‘hard’ instances of the portfolio optimization problem. Finally, viewing at the application of QAOA on error-prone hardware, we also analyse how the QAOA performance is modified by the presence of errors.
Correspondingly, the paper is organized as follows: In Sect. 2, we define the portfolio optimization problem as a quadratic binary optimization problem including a constraint given by the total number of assets to be included in the portfolio. In order to measure the performance of a given portfolio, we modify the standard definition of the so-called approximation ratio r such that it is independent of the particular way how the constraint is implemented (see Sect. 2.2). Since one such way consists of adding a penalty term, we explain our method for appropriately choosing the corresponding penalty factor A (see Sect. 2.3).
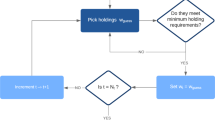
Section 3 exposes the required concepts for solving the portfolio optimization problem using QAOA. In general, this method consists of a p-fold alternating application of two different operators (phase-separating and mixing operators) depending on respective parameters \(\mathbf {\gamma }=(\gamma _1,\dots ,\gamma _p)\) and \(\mathbf {\beta }=(\beta _1,\dots ,\beta _p)\). Apart from the standard implementation [1] (using a ‘soft constraint’ based on the above-mentioned penalty term), we outline several possible modifications for incorporating the constraint in an alternative way (‘hard constraint’) by using the so-called XY mixing operators [2] (see Sect. 3.1). Furthermore, we present in detail our strategy for performing the optimization of the QAOA parameters (see Sect. 3.2). This includes the suitable choice of a global scaling factor \(\lambda \) (the relevance of which has, to our knowledge, not been recognized in the present literature) as well as four different heuristic methods for choosing appropriate initial values of the parameters \(\mathbf {\gamma }\) and \(\mathbf {\beta }\) for increasing depth p. Our process of solving the portfolio optimization problem with QAOA is sketched in Fig. .

Flow chart of the method for solving the portfolio optimization problem with QAOA as proposed in this article
The results obtained by applying our algorithm to different instances of portfolio problems based on real market data (taken from the German index DAX) are presented in Sect. 4. Starting with ideal, error-free simulations (using Qiskit’s statevector simulator), we show that two of the five variants of \(\textit{XY}\) mixers outperform the other ones by achieving the fastest convergence towards the optimal solution for increasing depth p (see Sect. 4.1). Similar results are obtained when including statistical sampling noise due to a finite number of shots (using the qasm simulator). In the following, we compare the algorithm’s performance on different problem instances (see Sect. 4.2). We define characteristic measures for an instance and show that the performance correlates with these. An explanation for this performance dependencies is given by analysing the energy landscape of the respective optimization problem.
To account for the noise-affected nature of today’s quantum computers, we systematically investigate the impact of errors on QAOA, thus adding a further dimension to its analysis (see Sect. 4.3). Considering, both, the error-affected optimization landscapes and the final outcome of the optimization, we find, for the first time, that noise of varying strengths affects different mixers differently. We conclude that the expected noise levels on the quantum platform to be used should be taken into account when choosing a specific version of QAOA. The notations used in this paper are given in Table .
2 Definition of the portfolio optimization problem
Portfolio optimization is one of the classic problems of finance: How should a financial investor put together a portfolio of assets (e.g. stocks) so that it generates the highest possible return on the one hand, but contains the lowest possible risk on the other? The solution to this problem was formulated in 1952 by Markowitz [18] as a mathematical optimization problem. In its original form, continuous portfolio weights are allowed, i.e. it is assumed that, e.g. a stock is also tradable ‘in parts’. For a more realistic formulation, however, it is necessary to assume binary or at least integer portfolio weights. In the binary formulation, the portfolio weight of a stock is 1 or 0, depending on whether the stock is part of the portfolio or not. The portfolio optimization problem can then be formulated as follows: Consider the cost function
which consists of the portfolio weights \(z_i=0\) or 1 of stock i, the covariance matrix of the stock returns \(\sigma _{ij}\) and the expected return \(\mu _i\). Furthermore, n is the number of available assets and the factor q sets the risk preference of the investor: \(q=1\) would be used if the investor is fully risk-averse, i.e. he wants to choose the portfolio with the lowest risk, irrespective of the return. \(q=0\) would be used in the case of an aggressive investor who takes only the return of the stocks into account. In real-world applications, however, q is set between 0 and 1.
Usually, an investment strategy consists in investing a fixed budget of money into a portfolio of securities. This budget constraint can be formulated in the binary optimization problem as follows:
The parameter B defines the number of assets to be chosen for the portfolio and thereby constrains the money invested. In the following, we will refer to those portfolios \(z_1,z_2,\dots ,z_n\) which fulfil the constraint as ‘feasible’ portfolios, whereas the remaining ones will be called ‘unfeasible’ [15].
2.1 Covariances and returns
In order to solve the portfolio optimization problem, the covariance matrix and the return vector must be provided. Here, we use the following prescription to calculate these values: If the portfolio consists of n assets, we use \(m+1\) historical daily prices \(p^{(i)}_{k}\) where \(i=1,2,\dots ,n\) and \(k=0,1,\dots ,m\). Out of these values, we compute the daily percentage price change via
and the annualized return of the portfolio:
The annualized covariance matrix is calculated with the equation
where \(\overline{r^{(i)}}=\frac{1}{m}\sum _{k=1}^m r^{(i)}_k\) is the mean of the daily price changes of asset i.
To investigate the portfolio optimization problem for different market segments, we calculated the annualized returns and covariance matrices for the German DAX 30 (as of 1/2/2021) between 01/01/2016 and 31/12/2020 (see supplementary material). In the following, we will investigate different instances of the portfolio optimization problem with a given total number of assets \(n=5\) (with budget \(B=2\)) or \(n=10\) (with budget \(B=5\)). For given n, different instances of the problem are obtained by randomly selecting n out of the 30 Dax assets. The risk preference factor will be set to \(q=1/3\).
2.2 Performance measures
In order to quantify which values of the function F correspond to ‘good’ or ‘bad’ portfolios, we first determine the minimum and maximum value of F among all feasible portfolios:
Then, we define the approximation ratio of a given portfolio:
Note that the optimal portfolio yields \(r=1\), whereas \(r=0\) corresponds to the worst feasible or an unfeasible portfolio. Let us note that this definition of the approximation ratio is independent of the particular method used to enforce the constraint (see below) [17].
The QAOA algorithm returns different portfolios with different probabilities, with corresponding average approximation ratio r. An alternative measure for the performance of QAOA is the probability P of obtaining the optimal portfolio. In contrast to the approximation ratio, however, the latter does not take into account the possibility that alternative portfolios might exhibit values of F very close to \(F_{\textrm{min}}\), which would also be acceptable for the portfolio manager.
2.3 Penalty factor
In the standard version of QAOA (see below), the minimization is performed with respect to all states, including those which do not fulfil the budget constraint, Eq. (2). In order to deal with the latter, a penalty term can be added to the function F as follows:
The prefactor A should be chosen large enough such that, on the one hand, all unfeasible states (i.e. those which do not fulfil the constraint) yield \(F^{(A)}>F_{\textrm{min}}\). On the other hand, if A is chosen too large, the performance of QAOA is expected to deteriorate. It has been suggested to choose A such that all unfeasible states yield \(F^{(A)}>F_{\textrm{max}}\) [15, 17]. As we have found, however, this choice of A is unnecessarily large: After all, it is not our primary objective to separate feasible from unfeasible states, but to identify those states which exhibit values very close to \(F_{\textrm{min}}\). For this purpose, it is sufficient to choose A such that
i.e. the minimum value of \(F^{(A)}\) among all unfeasible states, is not ‘too close’ to \(F_{\textrm{min}}\). More precisely, we use the following procedure to ensure that
where
denotes the mean value of F over all feasible states:
-
(i)
Use a classical algorithm to determine \(F_{\textrm{min}}\) and \(\overline{F}\). Start with \(A=0\).
-
(ii)
Use a classical algorithm to determine \(F_{\textrm{min}}^\mathrm{(nf)}\), see Eq. (10).
-
(iii)
Check whether Eq. (11) is fulfilled. If yes, return the value A. If not, increase A by \(\Delta A\), where
$$\begin{aligned} \Delta A = \frac{\frac{1}{2}(F_{\textrm{min}}+\overline{F})-F_{\textrm{min}}^\mathrm{(nf)}}{\left( \sum _i z_i^*-B\right) ^2} \end{aligned}$$(13)and \(z_1^*,\dots ,z_n^*\) denotes the state where the minimum in Eq. (10) is reached. Repeat (ii) and (iii) until the condition, Eq. (11), is fulfilled.
In this paper, we will only consider examples with a small number n of assets (limited by the number of qubits in present NISQ devices or simulators), where \(F_{\textrm{min}}\), \(F^{\mathrm{(nf)}}_{\textrm{min}}\) and \(\overline{F}\) can be exactly determined with a classical brute force search. For a larger number of assets (when a larger number of qubits will be available in the future), the brute force search will have to be replaced by an efficient classical algorithm in order to determine these quantities at least approximately. If the value of A determined as described above then turns out to be too small (i.e. if the optimal solution found by the QAOA algorithm, see Sect. 3, violates the constraint), the algorithm can then be rerun with a larger value of A.
3 QAOA algorithm
To solve the above optimization problem on a quantum computer, we convert the function \(F^{(A)}\) into a quantum operator:
where \(\hat{I}_j\) and \(\hat{Z}_j\) denote the identity and the Pauli-\(\hat{Z}\) operator, respectively, acting on qubit j. Additionally, we scale the function by a constant factor \(\lambda >0\), the significance of which will be explained below. Taking into account Eqs. (1, 9), we can write \(\hat{F}\) as a sum of two-qubit and single-qubit operators (plus an irrelevant constant term c)
where \(W_{ij}=\frac{\lambda }{2}(q\sigma _{ij}+A)\) and \(w_i=\frac{\lambda }{2} \left[ (1-q)\mu _i+A (2B-n)-q \sum _{j=1}^n \sigma _{ij}\right] \).
The QAOA variational quantum circuit then generates the following quantum state \(\vert \psi _{\mathbf {\gamma },\mathbf {\beta }}\rangle \) depending on the parameters \(\mathbf {\gamma }=(\gamma _1,\dots ,\gamma _p)\) and \(\mathbf {\beta }=(\beta _1,\dots ,\beta _p)\) (with number of iterations p, also referred to as ‘QAOA depth’ in the following):
where the initial state \(\vert \psi _0\rangle _M\) and the operator \(\hat{U}_M(\beta )\) depend on the choice of the mixer M, see below. Finally, all qubits are measured with respect to the standard basis in order to determine the mean value
This information is then passed to a classical optimization routine, which suggests new values for the parameters \(\mathbf {\gamma }\) and \(\mathbf {\beta }\) in order to minimize the expectation value \(\langle F\rangle _{\mathbf {\gamma },\mathbf {\beta }}\). Similar approaches, where optimized parameters of a quantum circuit are found in a hybrid quantum classical process, are also used in other fields such as quantum circuit learning [19] or Hamiltonian learning [20].
As explained in [1], this particular choice, Eq. (16), of the QAOA circuit is motivated by the principle of adiabatic quantum computing. With \(\hat{U}_M(\beta )=e^{-i\beta \hat{M}}\), the circuit can be interpreted as a Trotterized time evolution transferring the eigenstate \(\vert \psi _0\rangle _M\) of the mixing operator \(\hat{M}\) to the desired eigenstate of the operator \(\hat{F}\). For a finite depth p, however, the optimal choice of the angles \(\mathbf {\beta }\) and \(\mathbf {\gamma }\) may also amount to a non-adiabatic annealing path [7].
3.1 Mixer
3.1.1 Standard QAOA
In the originally proposed [1] version of QAOA (\(M={\textrm{standard}}\)), the mixing operation is realized by single-qubit rotations applied to each qubit:
The corresponding initial state is \(\vert \psi _0\rangle _{\textrm{standard}} = \vert +\cdots +\rangle \), where \(\vert +\rangle = (\vert 0\rangle +\vert 1\rangle )/\sqrt{2}\). This state is the eigenstate of the mixing operator \(\hat{M}_{\textrm{standard}}=-\sum _i \hat{X}_i\) associated with its smallest eigenvalue (\(-n\)).
3.1.2 XY-mixers
Alternatively, the initial state and the mixer can be adapted such that only states \(\vert \varvec{z}\rangle =\vert z_1,\dots ,z_n\rangle \) fulfilling the budget constraint, see Eq. (2), are populated during the algorithm [2, 21]. Correspondingly, the initial state is chosen as a uniform superposition (Dicke state [22])
This state is an eigenstate of the operator \((\hat{X}_i\hat{X}_j+\hat{Y}_i\hat{Y}_j)\) (for all pairs of qubits i and j), which essentially swaps two qubits populating different states (i.e. \(\vert 01\rangle \leftrightarrow \vert 10\rangle \)), thereby keeping the total budget (or number of excitations) constant. Therefore, the basic ingredient of the XY-mixers is given by the following two-qubit operation:
Different versions \(M_{XY}\) of the XY-mixer are now obtained by applying this operation to different sets \(S_{M_{XY}}\) of qubit pairs:
We will investigate the following four versions:
-
(i)
Ring mixer (\(M_{XY}=\textrm{ring}\))
In the ring mixer, the operation \(\hat{R}^{(XY)}_{i,j}(\beta )\) is applied only to neighbouring pairs of qubits, i.e. \(S_{\textrm{ring}}=\{(1,2),(2,3),\dots ,(n-1,n),(n,n+1)\}\), where qubit \(n+1\) is identified with qubit 1. Note that, since \([\hat{R}^{(XY)}_{i,j},\hat{R}^{(XY)}_{j,k}]\ne 0\) for mutually distinct qubits i, j and k, the ordering in which the individual operations \(\hat{R}^{(XY)}_{i,j}\) are applied in Eq. (21) is relevant. It is given by the order in which the corresponding qubit pairs appear in the above set \(S_{\textrm{ring}}\), i.e. first (1, 2), then (2, 3), etc.
-
(ii)
Parity ring mixer (\(M_{XY}=\mathrm{par\_ring}\))
In the parity ring mixer , this ordering is changed such as to obtain two subsets of commuting operations \(\hat{R}^{(XY)}_{i,i+1}\) with odd or even i, respectively, i.e. \(S_{\mathrm{par\_ring}}=\{(1,2),(3,4),\dots ,(n_o,n_o+1), (2,3),(4,5),\dots ,(n_e,n_e+1)\}\), where \(n_e\) (or \(n_o\)) is the largest even (or odd) number \(n_e\le n\) (or \(n_o\le n\)) (and, again, qubit \(n+1\) is identified with qubit 1).
-
(iii)
Full mixer (\(M_{XY}=\textrm{full}\))
In the full XY-mixer (\(M_{XY}=\textrm{full}\)), the set \(S_{\textrm{full}}\) contains all pairs of qubits, where the ordering is chosen such that as many gates as possible can be performed in parallel, thus minimizing the depth of the circuit. If n is odd, the \(\hat{R}^{(XY)}_{i,j}\)’s are arranged into n subsets of \((n-1)/2\) commuting operations, where \(i+j\, \textrm{mod}\, n =k\) in subset k. (For example, for \(n=5\): \(S_{\textrm{full}}=\{(1,5),(2,4),(2,5),(3,4),(2,1),(3,5),(3,1),(4,5),(3,2),(4,1)\}\) with subsets \(\{(1,5),(2,4)\}\), \(\{(2,5),(3,4)\}\), etc.) If n is even, we first generate the subsets for \(n-1\) as described above and add the missing pair of qubits to each subset. (For example, for \(n=6\), we add (3, 6) to the first subset \(\{(1,5),(2,4)\}\), (1, 6) to the second, etc., i.e. \(S_{\textrm{full}}=\{(1,5),(2,4),(3,6),(2,5),(3,4),(1,6),\ldots \}\).)
Together with the phase separation operator \(e^{-i\gamma \hat{F}}\), a single iteration step in the full XY-mixer QAOA algorithm, see Eq. (16), reads as follows:
$$\begin{aligned} \hat{U}_{\textrm{full}}(\beta )e^{-i\gamma \hat{F}} = \prod _{(i,j)\in S_{\textrm{full}}} \hat{R}^{(XY)}_{i,j}(\beta ) \prod _{(i,j)\in S_{\textrm{full}}}e^{-i\gamma W_{ij}\hat{Z}_i\hat{Z}_j} \prod _{i=1}^n e^{-i\gamma w_{i}\hat{Z}_i} \end{aligned}$$(22) -
(iv)
Quantum alternate mixer-phase ansatz (\(M_{XY}=\textrm{QAMPA}\))
Finally, we modify the full mixer according to the recently proposed quantum alternate mixer-phase ansatz (QAMPA) [23]. Instead of applying the operator \(e^{-i\gamma \hat{F}}\) to all qubits before applying the mixer, we reorder the terms such that, for each pair of qubits, the gates corresponding to the mixer and the phase separation are contracted as follows:
$$\begin{aligned} \hat{U}_{{MP}}(\beta ,\gamma ) = \prod _{(i,j)\in S_{\textrm{full}}}e^{i\beta (\hat{X}_i\hat{X}_j+\hat{Y}_i\hat{Y}_j)-i\gamma W_{ij} \hat{Z}_i\hat{Z}_j} \prod _{i=1}^n e^{-i\gamma w_{i}\hat{Z}_i} \end{aligned}$$(23)Thereby, the QAOA circuit, see Eq. (16) is modified as follows:
$$\begin{aligned} \vert \psi _{\mathbf {\gamma },\mathbf {\beta }}\rangle _M=\hat{U}_{MP}(\beta _p,\gamma _p)\dots \hat{U}_{MP}(\beta _2,\gamma _2) \hat{U}_{MP}(\beta _1,\gamma _1) \vert \psi _0\rangle _{M_{XY}} \end{aligned}$$(24)As evident from Fig. in Appendix A, this reduces the number of CNOT gates by a factor 3/4. Since the CNOT gates constitute the most important source of errors in present NISQ devices, we may expect that this version is more resilient against errors than the full XY mixer.
3.2 Optimization of the QAOA parameters
The most critical step in the actual implementation of QAOA consists of choosing the classical optimization procedure used to minimize the expectation value \(\langle F\rangle _{\mathbf {\gamma },\mathbf {\beta }}\), see Eq. (17). Before outlining our procedure, let us discuss the significance of the scaling factor \(\lambda \) introduced above in Eq. (14), which, to our knowledge, has not yet been pointed out in the present literature.
3.2.1 Global scaling factor
At first sight, the scaling \(\hat{F}\rightarrow \lambda \hat{F}\) appears to have no relevant effect. Indeed, due to the phase separation operators \(e^{i\gamma _j \hat{F}}\) (\(j=1,\dots ,p\)) in Eq. (16), this factor only leads to a rescaling \(\gamma _j\rightarrow \gamma _j/\lambda \) of the angles \(\mathbf {\gamma }\), whereas the angles \(\mathbf {\beta }\) remain unchanged. Nevertheless, we have observed that such a scaling can have an important influence on the classical optimization. Since the optimizer used for this purpose is usually imported from a standard numerical library, it, a priori, treats all the parameters \(\mathbf {\gamma }\) and \(\mathbf {\beta }\) on the same footing. Numerical difficulties may arise if the optimal values of the parameters \(\mathbf {\gamma }\) differ by orders of magnitude from those of \(\mathbf {\beta }\). In contrast, the best performance is expected if all parameters exhibit approximately the same order of magnitude.
For this reason, our idea is to choose \(\lambda \) such that the operator \(\hat{F}\) exhibits a similar spectral width as the mixing operator \(\hat{M}\). The latter reads \(\hat{M}_{\textrm{standard}}=-\sum _i \hat{X}_i\) (standard mixer) or \(\hat{M}_{XY}=-\sum _{(i,j)\in S_{M_{XY}}} (\hat{X}_i\hat{X}_j+\hat{Y}_i\hat{Y}_j)\) (XY mixers), respectively. (Note that, in the latter case, \(\hat{U}_{M_{XY}}(\beta )\ne e^{-i\beta \hat{M}_{XY}}\) due to non-commuting terms. Nevertheless, we use \(\hat{M}_{XY}\) for obtaining a rough estimate of a suitable \(\lambda \) value.) The corresponding spectral width, defined as the difference between largest and smallest eigenvalue of \(\hat{M}\), is \(\Delta M=2n\) (standard, XY ring and XY ring_par) or \(\Delta M=n(n-1)\) (XY full and XY QAMPA), respectively.
Without scaling (i.e. for \(\lambda =1\)), the largest eigenvalue of \(\hat{F}\) is either \(F_{\textrm{max}}\) or \(F^{\mathrm{(nf)}}_{\textrm{max}}\), see Eq. (10) with ‘\(\max \)’ instead of ‘\(\min \)’. Since, in the case of the XY-mixers, states which do not fulfil the constraint are not populated, we define \(\Delta F=F_{\textrm{max}}-F_{\textrm{min}}\) as effective spectral width. In the case of the standard mixer, we take into account both \(F_{\textrm{max}}\) and \(F^\mathrm{(nf)}_{\textrm{max}}\) (where the latter is typically much larger and determined by one of the few states that violate the constraint most strongly) and define \(\Delta F=\left[ \left( F_{\textrm{max}}-F_{\textrm{min}}\right) \left( F^{\mathrm{(nf)}}_{\textrm{max}}-F_{\textrm{min}}\right) \right] ^{1/2}\). Finally, to make the spectra of \(\hat{M}\) and \(\hat{F}\) comparable, we set \(\lambda = \Delta M/\Delta F\).
3.2.2 Initial values of parameters for \(p=1\)
Another important aspect concerns the initial values of \((\mathbf {\gamma },\mathbf {\beta })\) fed into the classical optimization routine. The latter usually converges to a local minimum in the vicinity of the initial point. Therefore, the quality of the solution can be enhanced by providing a good starting point which is close to the desired global minimum. In previous work [7], it has been found that a suitable initial point can be extracted from the optimal values determined previously for QAOA depth \(p-1\).
Concerning the lowest depth \(p=1\), it is possible to examine a relatively large range of possible parameters \(\gamma \) and \(\beta \) and plot the corresponding landscape \(\langle \hat{F}\rangle _{\gamma ,\beta }\). Due to the periodicity of the mixers introduced above, values of \(\beta \) can be restricted to the interval \([0,\pi ]\), but the same is not true for \(\gamma \). An example of the landscape for an exemplary portfolio optimization instance with \(n=10\) assets is shown in Fig. a. We see several local minima, where three of them achieve similar values (two on the left, i.e. at small \(m_1\), and one at \(m_1\simeq 3\), \(m_2\simeq 4\)). As we have checked, however, not all of them are equally suitable as starting points for the extrapolation towards larger depths p. This can be seen by employing the following simple, linear ansatz for \((\mathbf {\gamma },\mathbf {\beta })\):
where
For \(m_1,m_2>0\), the angles \(\gamma _i^{(\textrm{lin},p)}(m_1)\) increase with increasing i (i.e. in the same order in which they are also applied in the QAOA circuit), whereas \(\beta _i^{(\textrm{lin},p)}(m_2)\) decrease. This agrees with the interpretation of QAOA as quantum annealing, where \(\hat{F}\) is gradually switched on while \(\hat{M}\) is switched off.

a QAOA parameter landscape at \(p=1\), for an exemplary portfolio optimization instance with \(n=10\) assets. To enable a direct comparison with (b), the parameters \(\gamma ,\beta \) are expressed in terms of \(m_1=2\gamma \) and \(m_2=2\beta \), respectively. The colour code shows the deviation of \(\langle \hat{F}\rangle _{\gamma ,\beta }=\langle \hat{F}\rangle ^{(\textrm{lin},1)}_{m_1,m_2}\) from the optimal solution \(F_{\textrm{min}}\) on a logarithmic scale. Three pronounced minima are visible in black. b For higher depth \(p=7\) with linear ansatz for the parameters \(\mathbf {\gamma }\) and \(\mathbf {\beta }\), see Eqs. (25, 26), only one of these minima (close to the bottom left corner) survives (Color figure online)
If we now plot
as a function of \(m_1,m_2\) for larger p (e.g. \(p=7\)), we see that only one single pronounced local minimum remains, see Fig. 2b. To find a suitable starting point for \(p=1\), we therefore try 100 different combinations of parameters \(m_1,m_2\) (in a logarithmically spaced grid with \(\frac{1}{100}< m_1 <100\) and \(\frac{\pi }{100}< m_2 < \pi \)) and choose the one yielding the smallest value of \(\langle \hat{F}\rangle ^\mathrm{(lin,p_{\textrm{max}})}_{m_1,m_2}\) (where \(p_{\textrm{max}}\) denotes the maximum depth, see below) as a starting point for the minimization of \(\langle \hat{F}\rangle _{\gamma ,\beta }\) (where \(\beta =m_2/2\) and \(\gamma =m_1/2\) for \(p=1\)), in order to arrive at the one local minimum which is suitable for extrapolation towards larger p.
3.2.3 Initial values of parameters for larger p
The minimization of \(\langle \hat{F}\rangle \) is now performed for increasing values of \(p=2,3,\dots , p_{\textrm{max}}\). For each p, we apply the interpolation method described below for choosing a suitable initial point based on the optimal parameters previously found for depth \(p-1\). Since we cannot strictly exclude the possibility to get stuck in a local minimum different from the global one (which is a generic problem in high-dimensional optimization), we repeat the optimization three times with additional starting points determined by different methods. In summary, we perform, for each depth p, four optimization runs starting from the following initial parameters:
-
(i)
We consider the optimized parameters \(\mathbf {\gamma }^{(p-1)}=(\gamma ^{(p-1)}_1,\dots ,\gamma ^{(p-1)}_{p-1})\) from the previous depth \(p-1\) and want to determine angles \(\mathbf {\gamma }^{(p)}=(\gamma ^{(p)}_1,\dots ,\gamma ^{(p)}_{p})\) as starting point for the optimization at depth p. To determine \(\gamma ^{(p)}_i\) (\(i=1,\dots ,p\)), we first select the two points \(x^{(p-1)}_j\) and \(x^{(p-1)}_{j+1}\), which are closest to \(x^{(p)}_i\). Then, we define a straight line \(\gamma (x)=a x +b\) such that \(\gamma \left( x^{(p-1)}_j\right) =\gamma ^{(p-1)}_j\) and \(\gamma \left( x^{(p-1)}_{j+1}\right) =\gamma ^{(p-1)}_{j+1}\) and choose \(\gamma ^{(p)}_i=\gamma \left( x^{(p)}_i\right) \). The same is repeated with the angles \(\beta \).
-
(ii)
First determine \(m_1\) and \(m_2\) by minimizing \(\langle \hat{F}\rangle ^{(\textrm{lin},p)}(m_1,m_2)\) (where we take \(m_1\) and \(m_2\) from the previous depth \(p-1\) as initial point), and then use \(\mathbf {\gamma }^{(\textrm{lin},p)}(m_1)\) and \(\mathbf {\beta }^{(\textrm{lin},p)}(m_2)\) as initial point for minimizing \(\langle \hat{F}\rangle _{\mathbf {\gamma },\mathbf {\beta }}\)
-
(iii)
The same is repeated using a quadratic ansatz
$$\begin{aligned} \left[ \mathbf {\gamma }^{(\textrm{quad},p)}(a_1,b_1,c_1)\right] _i= & {} a_1 + b_1 x_i^{(p)} + c_1 \left( x_i^{(p)}\right) ^2\end{aligned}$$(29)$$\begin{aligned} \left[ \mathbf {\beta }^{(\textrm{quad},p)}(a_2,b_2,c_2)\right] _i= & {} a_2 + b_2 x_i^{(p)} + c_2 \left( x_i^{(p)}\right) ^2 \end{aligned}$$(30)First, \(\langle \hat{F}\rangle ^{(\textrm{quad},p)}(a_1,b_1,c_1,a_2,b_2,c_2)= \langle \hat{F}\rangle _{{\mathbf {\gamma }^{(\textrm{quad},p)}(a_1,b_1,c_1),\mathbf {\beta }^{(\textrm{quad},p)}(a_2,b_2,c_2)}}\) is minimized to determine optimal values for the six parameters \(a_1,\dots ,c_2\) (where, for \(p>2\), the optimized values from the previous depth \(p-1\) are taken as initial values, whereas for \(p=2\), we choose initial values \((a_1,b_1,c_1,a_2,b_2,c_2)=(0,m_1,0,m2,-m2,0)\) with \(m_1\) and \(m_2\) as determined by the grid search described in Sect. 3.2.2), then the corresponding angles \(\mathbf {\gamma }^{(\textrm{quad},p)}\) and \(\mathbf {\beta }^{(\textrm{quad},p)}\) are taken as initial point for minimizing \(\langle \hat{F}\rangle _{\mathbf {\gamma },\mathbf {\beta }}\)
-
(iv)
Finally, we take the optimal angles for depth \(p-1\) and add \(\gamma _p=\beta _p=0\). Thereby, we recover at least the same value as for \(p-1\) and ensure that \(\langle \hat{F}\rangle \) monotonically decreases with increasing depth p.
Among these four optimization runs, we select the one achieving the smallest expectation value \(\langle \hat{F}\rangle \). Before proceeding to the next depth (\(p+1\)), we finally rescale \(\hat{F}\rightarrow \mu \hat{F}\) together with \(\mathbf {\gamma }\rightarrow \mathbf {\gamma }/\mu \) (see Sect. 3.2.1), with \(\mu \) chosen such that \(\sum _i\vert \gamma _i\vert =\sum _i\vert \beta _i\vert \), to ensure that the parameters \(\gamma \) and \(\beta \) retain a similar order of magnitude.
3.2.4 Classical optimizers
Apart from trying different initial values \((\mathbf {\gamma },\mathbf {\beta })\) as explained above, we can choose between different routines for optimizing these values. Concerning the simulation of the QAOA circuits, we distinguish between two different methods: on the one hand, Qiskit’s ‘statevector simulator’ allows us to precisely calculate the expectation value, Eq. (17), without any statistical sampling error. On the other hand, the ‘qasm simulator’ includes the measurement process which, for a finite number of shots (in our case: 1000), leads to a statistical sampling error due to the random measurement outcomes.
According to our experience, the gradient-based optimization routine ‘SLSQP’ (which is included in the function ‘minimize’ of the Python package ‘scipy.optimize’) yields good results in the case of the statevector simulator. The gradient-based optimization routines ‘gradient descent’ (GD) and ‘stochastic gradient descent’ (SGD) show a similar performance for the standard mixer, but perform less well than SLSQP for the XY-mixers. In the case of the qasm simulator, more robust gradient-free methods (COBYLA and Nelder–Mead) are preferable, since the sampling noise prevents a precise evaluation of the gradient. Here, we choose the method ‘Nelder–Mead’ with the following parameters: the size of the initial simplex is set to 0.5 (i.e. the simplex consists of the initial point plus 2p additional points obtained from the initial point by adding 0.5 to one of the 2p parameters) and the maximum number of iterations is limited to 10 times the number of parameters (2p).
4 Results
4.1 Different mixers
In this section, we give a presentation and discussion of our QAOA simulation results for the different mixers. For this purpose, we discuss the approximation ratio and the ground state probability plotted as a function of the QAOA depth p for a given number of assets that, in turn, coincides with the number of qubits in the circuit. The results are generated using both simulator methods (without and with measurement noise) with respective optimization routines as previously introduced.
For the comparison, we generate an ensemble of 20 different portfolio optimization instances with given total number \(n=5\) or \(n=10\) of randomly selected assets as described in Sect. 2.1. We compare the convergence of approximation ratio and ground state probability of each mixer and simulation method with increasing QAOA depth p (up to \(p_{\textrm{max}}=7\)).
Figure shows the approximation ratio r as well as the ground state population P for 20 instances with \(n=5\) assets as a function of the QAOA depth p using the statevector, Fig. 3a, b, and qasm simulator, Fig. 3c, d. Already at \(p=1\), the XY-mixers outperform the standard mixer. This can simply be explained by the fact that, in the case of the XY-mixers, the optimization is restricted to a smaller space [24], since, in contrast to the standard mixer, all unfeasible portfolios (i.e. those not satisfying the budget constraint) are never populated during the algorithm (see Sect. 3.1.2). With increasing p, the full and the QAMPA mixer show the fastest convergence towards the optimal solution, achieving approximation ratios \(r>99\%\) without measurement noise, see Fig. 3a. The superiority of the full XY mixer (and its variant QAMPA) as compared to the ring mixers can be traced back to their higher degree of symmetry [25]. Indeed, the full XY and QAMPA mixer contain all pairs of qubits, whereas only pairs of neighbouring qubits occur in the ring mixers. The full mixers therefore completely mix across all basis states at the first attempt, whereas the ring mixers take several rounds [24].
Concerning the probability P of obtaining the optimal portfolio, see Fig. 3b, the above-discussed difference between the various mixers is less clearly visible. Taking into account the different scales (logarithmic scale for \(1-r\) vs. linear scale for P), this is due to larger fluctuations among the 20 random instances (see error bars), such that small differences between values of P close to 1 cannot be resolved. These larger fluctuations, in turn, originate from the fact that the probability P depends on the population of only a single state (i.e. the optimal one), whereas the approximation ratio results from an expectation value taking into account also other feasible states, which might achieve values of the cost function close to the optimal value \(F_{\textrm{min}}\).
The results of the qasm simulator (with 1000 shots per circuit) in Fig. 3c, d show a similar behaviour. Only in the case of the XY-mixers at larger values of p, the statistical fluctuations due to the measurement noise lead to a slower convergence towards the optimal solution.
Figure displays the results of a similar analysis with larger instances consisting of \(n=10\) assets with budget \(B=5\) (instead of \(n=5\) and \(B=2\), as in Fig. 3). Basically, they confirm our above conclusions concerning, e.g. the superiority of the full XY and the QAMPA mixer. Not surprisingly, the values of r and P are smaller than in Fig. 3, since the total number of possible portfolios is much larger (i.e. \(10 \atopwithdelims ()5 = 252\) instead of \(5 \atopwithdelims ()2=10\) feasible portfolios). Nevertheless, using one of the two best mixers (full XY or QAMPA), we still find approximation ratios as large as \(r\simeq 0.98\), with corresponding probability \(P\simeq 0.6\) of obtaining the optimal solution.
4.2 Easy and hard instances
As we have seen in the previous section, the QAOA performance, especially the probability P of obtaining the optimal solution, varies a lot over a set of different instances of the portfolio optimization problem. Some instances are easier to optimize than others. A possible cause for this performance differences could lie in the respective distributions of correlations and returns characterizing an instance. We examine performance dependencies on these instance statistics. For this purpose, we use the variances of the returns and correlation distributions as a measure of ‘hardness’ of a given instance:
The correlation is normalized to a value between \(-1\) and 1 (Pearson coefficients). This normalization resulted in more pronounced differences in statistics than using the raw correlations.
Each instance generates an energy landscape, composed of the objective function values \(F(\varvec{z})\) of all possible portfolios represented by the string \(\varvec{z} = z_1,z_2,\dots ,z_n\). We characterize the energy landscape by the mean and variance of the energy value distribution:
In the course of a Monte Carlo walk, we optimized 2400 randomly generated baskets and evaluated the performance of each instance with the measure
We kept the 20 best and the 20 worst performing instances and examined their statistics. The instances were generated as described in Sect. 2.1. We restricted the size of the instances to \(n=10\) and the investment constraint to \(B=5\) assets. For the optimization, we used a QAOA version with standard mixer. To enable a clearer comparison, we chose the same penalty factor \(A=0.2\) and scaling factor \(\lambda =6\) for all instances. We further implemented ‘linear interpolation’ as described in [7] for angle initialization and optimized up to \(p=6\). The algorithm was simulated using the statevector simulator and the SLSQP method for the classical optimization step.
As can be seen in Fig. , the performance of an instance correlates with the variance of its asset correlations and returns, as well as with the mean and variance of its associated energy landscape. We repeated this procedure with historical data from MDAX 50 and found similar distributions.
These results can be interpreted as follows. Instances consisting of stocks with broadly distributed correlations are easier to optimize than those with more similar correlations. The same holds for returns. A possible reason can be found by looking at the energy landscapes created by the cost function (1). High variances of correlations \(\sigma _{ij}\) and returns \(\mu _i\) get propagated to high variance of \(F(\varvec{z})\) over possible \(\varvec{z}\). This could make the optimization step easier since the energy landscape becomes more distinct. Or, to put it figuratively: when the possible portfolios that can be built from an instance look more different in terms of correlations and returns, it is easier to choose the best one. Consequently, this dependency is an effect of the classical part of QAOA and not of the quantumness of the algorithm. It should therefore be interesting to look for this behaviour in purely classical portfolio optimization as well. The criteria at hand should not be understood as a strict condition, but rather as a tendency hinting at good or bad performance. For a given instance with high values of \(s^2_{\text {ret/cor}}\), good performance is not guaranteed since the energy landscape could be dominated by other peculiarities of the specific problem. Given the statistical nature of the criteria, we recommend to use it whenever one samples out of a large set of instances and compares performances. In this case, the samples should be ensured to show similar values of \(s^2_{\text {ret/cor}}\). Besides the characterizing statistics shown, we looked for dependencies in the eigenvalue spectra of the covariance matrices. Here, we could not find any differences for good or bad performing instances. Nevertheless, there could be other measures characterizing the instances which lead to the same, or even a more extreme performance dependency.
4.3 Evaluation of QAOA under noise
In this section, we study the effect of noise on a given QAOA instance. In particular, we first investigate the optimization landscape of QAOA to outline convergence issues with an increasing noise strength and then discuss the probability P of obtaining the optimal solution and the approximation ratio r of QAOA subject to varying noise strengths.
The evaluations in this section were performed on a QAOA instance of a portfolio optimization problem while varying the QAOA parameter p, the employed QAOA mixer (see Sect. 3.1) and noise strength. The used portfolio optimization problem consists of \(n=5\) assets, i.e. five qubits, out of which \(B=2\) assets must be optimally selected with a risk–return factor \(q=1/3\). The corresponding covariances \(\sigma _{ij}\) and returns \(\mu _i\) are listed in Appendix B.
4.3.1 Employed noise model
In order to compute QAOA subject to noise, we employ the depolarizing channel [26]. The depolarizing channel \(\mathcal {E}\) acting on n qubits described by a density matrix \(\rho \) is defined as
where \(\eta \) is the depolarizing noise strength and I denotes the identity operator. After each single-qubit or two-qubit (CNOT) gate occurring in the QAOA ansatz circuit, the depolarizing channel is applied to the respective qubit(s).

a Mean deviation \(1-r\) of the approximation ratio from the optimal solution as a function of the QAOA depth p for 20 randomly chosen portfolio optimization instances with \(n=5\) assets (and budget \(B=2\)), using different mixers (see legend) and the statevector simulator (without measurement noise). The error bars display the standard deviation among the 20 random instances. The full XY-mixer and QAMPA (which requires less CNOT gates) show the fastest convergence towards the optimal solution. b Mean probability P of obtaining the optimal portfolio with standard deviation (error bars) as a function of QAOA depth p for the statevector simulator. c, d Same as a, b, but using the qasm simulator including measurement noise due to a finite number of 1000 shots instead of the statevector simulator. Significant differences with respect to the statevector simulator are only visible in the vicinity of the optimal solution (r and P close to 1)


a Variance of returns \(s_{\text {ret}}^2\) and normalized correlations \(s_{\text {cor}}^2\) for instances of good/bad performance. b Mean \(\mu _{\text {energy}}\) and variance \(s_{\text {energy}}^2\) of associated energy landscape (right)

Expectation value of the investigated QAOA instance for the standard mixer, the ring XY-mixer, the parity ring XY-mixer, the QAMPA, and the full XY-mixer (from left to right) and noise strength \(\tilde{\eta } \in \{0, 0.1, 1, 2, 4, 10 \}\) (from bottom to top), where \(\tilde{\eta }\) is the noise strength normalized by the size of the quantum computation, i.e. the number of quantum gates in the QAOA ansatz circuit
4.3.2 Optimization landscape of QAOA under noise
In this section, we show the optimization landscape of the investigated QAOA instance for depth \(p=1\) subject to depolarizing noise for varying noise strengths and QAOA mixers. Figure shows the optimization landscape of the investigated QAOA instance, i.e. for a each pair \((\gamma ,\beta )\) of parameters, the expectation value of the optimization function (see Eq. 17) is plotted. The parameter \(\gamma \) is varied from 0.025 to \(2\pi \) while \(\beta \) is varied from 0.025 to \(\pi \) in steps of size 0.025. From the left to the right column, the optimization landscape of QAOA is shown for the standard mixer, the ring XY-mixer, the parity ring XY-mixer, the QAMPA and the full XY-mixer. From the bottom to the top row, the normalized noise strength is varied as \(\tilde{\eta }\in \{0, 0.1, 1, 2, 4, 10\}\). Here, the normalized noise strength \(\tilde{\eta }\) is the noise strength \(\eta \) divided by the size of the quantum computation, i.e. the number of quantum gates in the QAOA ansatz circuit. This normalization is used to better study the vulnerability of specific structures within different ansatz circuits to noise. Without such normalization, the performance of circuits under a constant noise level would be dominated by the circuit size, as a circuit with more gates will tend to exhibit more errors. The x- and y-axes of the figures in Fig. 6 show the parameters \(\gamma \) and \(\beta \) of QAOA, while the expectation value of the optimization function is shown on z-axis.
In the error-free case (bottom row of Fig. 6), the ring XY-mixer finds the best (lowest) value of the expectation value \((-2.90)\), followed by the parity ring XY-mixer \((-2.85)\), QAMPA \((-2.76)\), full XY-mixer \((-2.74)\) and lastly the standard mixer \((-1.04)\). However, with increasing noise strength, the order of the mixers with respect to the yielded minimal expectation value first becomes constant at \(\tilde{\eta }=0.1\) and then reverts for \(\tilde{\eta }=1\), such that the full XY-mixer is able to yield a lower expectation value than all other mixers. At a noise strength of \(\tilde{\eta }=2\) and \(\tilde{\eta }=4\), the standard mixer yields the best expectation value until, at \(\tilde{\eta }\ge 10\), the optimization landscape is dominated by noise for all mixers.
For higher noise strengths, e.g. \(\tilde{\eta }\ge 1\), the optimization landscape begins to flatten and to deteriorate for each mixer. The expectation value tends to become less regular and more sensitive to small changes in the parameters \(\gamma \) and \(\beta \). These effects impair the ability of the classical optimization algorithms to converge to the global minimum of the expectation value, eventually leading to a noise-induced barren plateau that incurs an exponential runtime overhead [27]. As demonstrated in the top rows of Fig. 6, the optimization landscape deteriorates stronger for XY-mixers than for the standard mixer at the same noise strength \(\tilde{\eta }\).
The results in Fig. 6 demonstrate that XY-mixers yield a better expectation value compared to the standard mixer as long as the noise strength remains below some threshold. After that threshold is exceeded, the standard mixer tends to yield a better expectation value, making the standard mixer a better option.
Overall, the optimization landscape of the standard mixer tends to be less complex, with less local optima compared to the XY-mixers. With an increasing noise strength, the deterioration of such simpler landscapes tends to be less pronounced. This may imply a faster convergence, requiring less optimization steps, to reach the respective global minimum with the standard mixer compared to XY-mixers for higher noise levels.
4.3.3 Evaluation of QAOA at specific noise strengths
In this section, the investigated QAOA instance is computed subject to the depolarizing channel for different QAOA depth p, mixers and noise strength \(\eta \in \{0, 0.001, 0.002, \ldots , 0.01\}\). Note that \(\eta \) is not normalized, in contrast to \(\tilde{\eta }\) employed to generate optimization landscapes in Fig. 6. Therefore, larger circuits are more affected by noise. We use the approximation ratio r and the probability P of obtaining the optimal solution (also called ‘ground state probability’ in the following) as a metric to evaluate the performance of QAOA subject to noise. A higher value of the approximation ratio or the ground state probability indicates a better performance.

The approximation ratio of the investigated QAOA instance as a function of depolarizing noise strength \(\eta \) for different mixers using a density matrix simulator with 8192 measurement samples. The classical optimizer COBYLA [28] was used
Figure shows the approximation ratio of QAOA for the investigated mixers and QAOA depth p. For \(p=1\), the XY-mixers outperform the standard mixer for all considered values of \(\eta \). For larger p, the standard mixer outperforms XY-mixers starting with a specific larger depolarizing noise strength, and this threshold goes down with increasing p (around 0.003, 0.002 and 0.001 for p equal to 3, 5 and 7, respectively). One reason for such behaviour is the larger size of the XY-mixers, where each of the additional gates is associated with a constant noise contribution. This explanation is consistent with the dependency on p, where circuits for a higher p, both, are larger in absolute terms and have a larger size difference between standard and XY-mixers.
The ring XY-mixer and parity ring XY-mixer show better results subject to noise compared to the QAMPA and full XY-mixer at the same noise strength. This again can be explained by their smaller sizes.

The ground state probability of the investigated QAOA instance as a function of depolarizing noise strength \(\eta \) for different mixers using a density matrix simulator with 8192 measurement samples. The classical optimizer COBYLA [28] was used
The results for ground state probability are shown in Fig. . Again, for \(p=1\), the parity ring XY-mixer outperforms all other mixers. Similar to the observations for the approximation ratio, the standard mixer is able to achieve a higher ground state probability as compared to the XY-mixers for larger p and higher noise strengths. For \(p=3\), \(p=5\) and \(p=7\), the standard mixer yields a better result than the XY-mixers at noise strengths 0.008, 0.005 and 0.003. Out of the \(\textit{XY}\)-mixers, the parity ring XY-mixer performs better subject to noise than others.
Another reason for a worsening performance of XY-mixers under higher noise levels in terms of both approximation ratio and ground state probability is their reliance on Dicke states [22] (see Sect. 3.1). This restriction makes them more efficient in the error-free case, but noise occurring during the circuit execution can gradually destroy the Dicke state, thus violating the algorithm’s assumptions. Moreover, the standard mixer requires an equal superposition as an initial state that can be prepared efficiently with a linear number of single-qubit gates, while the Dicke state needed as an input for XY-mixers must be prepared by more complex gate sequences, including multiple layers of two-qubit gates [29].
5 Conclusion
The present paper contains a detailed study of portfolio optimization using different versions of the quantum approximate optimization algorithm (QAOA). The portfolio optimization problem is formulated as a quadratic binary optimization problem with a constraint corresponding to a given number B (budget) of assets to be chosen from a list of n assets (Sect. 2). We discuss all the technical aspects which are necessary to run different versions of the QAOA algorithm for solving the portfolio optimization problem with good performance: first, the magnitude of the penalty factor A (needed to implement the constraint in the case of the standard mixer) should not be chosen larger than necessary (see Sect. 2.3). Furthermore, we propose to appropriately scale the cost function F such as to align the spectra of F and of the mixer M with each other. Of crucial importance are the initial values of the circuit parameters \(\mathbf {\gamma }\) and \(\mathbf {\beta }\) fed into the classical optimization routine: similarly to [7], we perform the optimization for increasing values of the QAOA depth p, using an extrapolation method to deduce initial values from the optimized values of \(\mathbf {\gamma }\) and \(\mathbf {\beta }\) obtained previously for depth \(p-1\). Additionally (to avoid getting trapped in a local minimum), we perform, at each depth p, three additional optimization runs with initial values obtained from a linear ansatz, a quadratic ansatz, and adding zero angles (to ensure monotonicity, see Sect. 3.2.3). Concerning the parameter landscape \(\langle \hat{F}\rangle _{\gamma ,\beta }\) at depth \(p=1\), we observe several local minima and show a method for selecting one which is most suitable for extrapolation towards larger p (see Sect. 3.2.2). Finally, the proper choice of the classical optimization method depends on whether the simulation takes into account noise: in the ideal, noise-free case (using the statevector simulator), we use a gradient-based method (e.g. SLSQP), whereas more robust, gradient-free methods like Nelder–Mead or COBYLA are preferable in the presence of measurement noise due to a finite number of shots (see Sect. 3.2.4).
The performance of different mixers in solving 20 randomly chosen instances of the portfolio optimization problem with \(n=5\) and \(n=10\) assets is investigated in Sect. 4.1. Not surprisingly, the XY-mixers are superior to the standard mixer, since they restrict the optimization to the subspace of ‘feasible’ portfolios (i.e. to those that satisfy the budget constraint). The best results are achieved by the full XY-mixer and the QAMPA (quantum alternate mixer-phase ansatz, see Sect. 3.1), which differs from the full XY-mixer in the ordering of mixing and phase-separating operators applied to all pairs of qubits. For selecting \(B=5\) out of \(n=10\) assets with QAOA depth \(p=7\), both find the optimal portfolio with probability \(P\simeq 0.6\). Their better performance as compared to the two ring mixers is attributed to their higher degree of symmetry with respect to qubit permutations. Moreover, we find that the measurement noise (with 1000 shots) does not significantly reduce the performance as compared to the ideal case corresponding to an infinite number of shots, except in cases with extremely high approximation ratio (close to about 99%).
When considering noise, the XY-mixers are in general demonstrated to be more sensitive than the standard mixer. This underscores the importance of considering the noise levels expected on the target quantum hardware when selecting the best variety of QAOA. From our specific results, purely noise-free analysis demonstrates a clear superiority of XY-mixers. However, this finding is only valid for sufficiently low noise levels, and the decision should be reverted if the actual available quantum hardware is more noisy.
Concerning the performance dependency on external factors we find clear connections with the statistics of the optimized instance, namely the variance of the correlation’s and return’s distributions. Broader distributions lead to a more pronounced energy landscape, simplifying the classical optimization step. Similar behaviour could be found for other optimization problems. Therefore, when benchmarking QAOA’s performance the instances should be carefully picked regarding their statistics.
6 Supplementary information
The files ‘DAX30_Daily_Covar_5y.csv’ and ‘DAX30_Daily_Returns_5y.csv’ attached to this submission as ancillary files contain the annualized covariance matrices and returns for the German DAX 30, calculated from data between 2016 and 2021 as described in Sect. 2.1.
Data availability
All data generated or analyzed during this study are included in this published article and its supplementary information files.
References
Farhi, E., Goldstone, J., Gutmann, S.: A quantum approximate optimization algorithm. arXiv:1411.4028 (2014)
Hadfield, S., Wang, Z., O’Gorman, B., Rieffel, E.G., Venturelli, D., Biswas, R.: From the quantum approximate optimization algorithm to a quantum alternating operator ansatz. Algorithms 12, 34 (2019)
Shor, P.W.: Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer. SIAM J. Comput. 26, 1484 (1997)
Harrow, A.W., Hassidim, A., Lloyd, S.: Quantum algorithm for linear systems of equations. Phys. Rev. Lett. 103, 150502 (2009)
Bittel, L., Kliesch, M.: Training variational quantum algorithms is NP-hard. Phys. Rev. Lett. 127, 120502 (2021)
Guerreschi, G.G., Matsuura, A.Y.: QAOA for max-cut requires hundreds of qubits for quantum speed-up. Sci. Rep. 9, 6903 (2019)
Zhou, L., Wang, S.-T., Choi, S., Pichler, H., Lukin, M.D.: Quantum approximate optimization algorithm: performance, mechanism, and implementation on near-term devices. Phys. Rev. X 10, 021067 (2020)
Mansini, R., Speranza, M.G.: Heuristic algorithms for the portfolio selection problem with minimum transaction lots. Eur. J. Oper. Res. 114, 219 (1999)
Detemple, J.: Portfolio selection: a review. J. Optim. Theory Appl. 161, 1 (2014)
Mansini, R., Ogryczak, W., Speranza, M.G.: Linear and Mixed Integer Programming for Portfolio Optimization. Springer, Cham (2015)
Kalayci, C.B., Ertenlice, O., Akbay, M.A.: A comprehensive review of deterministic models and applications for mean-variance portfolio optimization. Expert Syst. Appl. 125, 345 (2019)
Mugel, S., Kuchkovsky, C., Sánchez, E., Fernández-Lorenzo, S., Luis-Hita, J., Lizaso, E., Orús, R.: Dynamic portfolio optimization with real datasets using quantum processors and quantum-inspired tensor networks. Phys. Rev. Res. 4, 013006 (2022)
Slate, N., Matwiejew, E., Marsh, S., Wang, J.B.: Quantum walk-based portfolio optimisation. Quantum 5, 513 (2021)
Phillipson, F., Bhatia, H.S.: Portfolio optimisation using the d-wave quantum annealer. In: Paszynski, M., Kranzlmüller, D., Krzhizhanovskaya, V.V., Dongarra, J.J., Sloot, P.M.A. (eds.) Computational Science—ICCS 2021, pp. 45–59. Springer, Cham (2021)
Hodson, M., Ruck, B., Ong, H., Garvin, D., Dulman, S.: Portfolio rebalancing experiments using the quantum alternating operator ansatz. arXiv:1911.05296 (2019)
Egger, D.J., Gambella, C., Marecek, J., McFaddin, S., Mevissen, M., Raymond, R., Simonetto, A., Woerner, S., Yndurain, E.: Quantum computing for finance: state of the art and future prospects. IEEE Trans. Quantum Eng. 1, 1 (2020)
Baker, J.S., Radha, S.K.: Wasserstein solution quality and the quantum approximate optimization algorithm: a portfolio optimization case study. arXiv:2202.06782 (2022)
Markowitz, H.: Portfolio selection. J. Finance 7, 77 (1952)
Shi, J., Tang, Y., Lu, Y., Feng, Y., Shi, R., Zhang, S.: Quantum circuit learning with parameterized boson sampling. IEEE Trans. Knowl. Data Eng., 1–1 (2021)
Shi, J., Wang, W., Lou, X., Zhang, S., Li, X.: Parameterized Hamiltonian learning with quantum circuit. IEEE Trans. Pattern Anal. Mach. Intell. 1–10 (2022)
Wang, Z., Rubin, N.C., Dominy, J.M., Rieffel, E.G.: XY mixers: analytical and numerical results for the quantum alternating operator ansatz. Phys. Rev. A 101, 012320 (2020)
Dicke, R.H.: Coherence in spontaneous radiation processes. Phys. Rev. 93, 99 (1954)
LaRose, R., Rieffel, E., Venturelli, D.: Mixer-phaser ansätze for quantum optimization with hard constraints. arXiv:2107.06651 (2021)
Cook, J., Eidenbenz, S., Bärtschi, A.: The quantum alternating operator ansatz on maximum k-vertex cover. In: 2020 IEEE International Conference on Quantum Computing and Engineering (QCE), pp. 83–92 (2020)
Fuchs, F.G., Lye, K.O., Nilsen, H.M., Stasik, A.J., Sartor, G.: Constraint preserving mixers for the quantum approximate optimization algorithm. Algorithms 15, 202 (2022)
Nielsen, M.A., Chuang, I.L.: Quantum Computation and Quantum Information: 10th Anniversary Edition. Cambridge University Press, Cambridge (2010)
Wang, S., Fontana, E., Cerezo, M., Sharma, K., Sone, A., Cincio, L., Coles, P.J.: Noise-induced barren plateaus in variational quantum algorithms. Nat. Commun. 12, 1 (2021)
Powell, M.J.: A direct search optimization method that models the objective and constraint functions by linear interpolation. In: Gomez, S., Hennart, J.-P. (eds.) Advances in Optimization and Numerical Analysis, pp. 51–67. Springer, Dordrecht (1994)
Mukherjee, C.S., Maitra, S., Gaurav, V., Roy, D.: Preparing Dicke states on a quantum computer. IEEE Trans. Quantum Eng. 1, 1 (2020)
Acknowledgements
This work is funded by the Ministry of Economic Affairs, Labour and Tourism Baden Württemberg in the frame of the Competence Center Quantum Computing Baden-Württemberg (project ‘QORA’).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Appendices
Appendix A: Decomposition of mixer operators
Here, we show that using the reshuffled \(\textit{XY}\) mixer reduces the number of CNOT gates by a factor 3/4 as compared to the full \(\textit{XY}\) mixer. For this purpose, Fig. 9 shows quantum circuit representations of the two-qubit operations applied to a given pair of qubits (i, j) during a single QAOA iteration step. The full \(\textit{XY}\) mixer, see Eq. (22), contains the circuits shown in Fig. 9a, b, amounting to 4 CNOT gates for each pair of qubits. In contrast, the reshuffled \(\textit{XY}\) mixer, see Eq. (23), only requires 3 CNOT gates, see Fig. 9c.

Quantum circuits of the two-qubit operations a \(e^{i\beta (\hat{X}_i\hat{X}_j+\hat{Y}_i\hat{Y}_j)}\) with 2 CNOT gates, b \(e^{-i\gamma W_{ij} \hat{Z}_i\hat{Z}_j}\) with 2 CNOT gates and c \(e^{i\beta (\hat{X}_i\hat{X}_j+\hat{Y}_i\hat{Y}_j)-i\gamma W_{ij} \hat{Z}_i\hat{Z}_j}\) with 3 CNOT gates. Apart from the CNOT gates, the following single-qubit gates are used: H (Hadamard gate), \(R_X(\phi )=e^{-i\frac{\phi }{2} \hat{X}}\), \(R_Z(\phi )=e^{-i\frac{\phi }{2} \hat{Z}}\) and the general single-qubit gate \(U(\theta ,\phi ,\lambda )=R_Z(\phi )R_Y(\theta )R_Z(\lambda )\)
Appendix B: Data for covariances and returns
The covariances and returns of the portfolio optimization instance used in Sect. 4.3 are provided in Tables and .
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Brandhofer, S., Braun, D., Dehn, V. et al. Benchmarking the performance of portfolio optimization with QAOA. Quantum Inf Process 22, 25 (2023). https://doi.org/10.1007/s11128-022-03766-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11128-022-03766-5