
Abstract
We propose a novel penalized splines method to estimate a stochastic frontier model in which the frontier is linear and the inefficiency has a single index structure with unknown link function and a linear index. The approach is more flexible than the traditional methodology requiring a parametric link function and, at the same time, it does not incur the curse of dimensionality as a fully non-parametric approach. The procedure can be easily implemented using existing software. We give conditions for the model to be identified and provide some asymptotic results. We also use Monte Carlo simulations to show that the approach works well in finite samples in many situations when compared to the well specified maximum likelihood estimator. An application to the residential energy demand of US states is considered. In this case, the penalized splines approach estimates inefficiency functions that deviate substantially from those resulting from parametric maximum likelihood methods previously implemented.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Stochastic Frontier Analysis is widely used to compare the efficiency of organizations and inform policy decisions across a variety of sectors including health, environmental, energy, etc. The estimation of stochastic frontier models often involves strong parametric assumptions regarding the specification of both the efficient frontier and the inefficiency. Although the measures of inefficiency (at least in the sense of Jondrow et al. 1982) seem to be robust to the distribution of the inefficiency (e.g. Ondrich and Ruggiero 2001), there is no evidence about their robustness to the parametric specification of the determinants of inefficiency.
Concerns for the impact of the specification of the efficient frontier and the inefficiency has led to attempts to specify these non-parametrically. Important contributions include Fan et al. (1996), Kumbhakar (2007) and Simar et al. (2017) for the efficient frontier and Tran and Tsionas (2009) and Parmeter et al. (2017) for the determinants of inefficiency. However, fully non-parametric estimators of the frontier and/or the inefficiency have slow rates of convergence. Even in the case where the number of explanatory variables is as small as 4, the computational costs may be very high in any real-world application - especially when the smoothing parameter is selected for each dimension using cross-validation criteria.
This paper builds on these previous attempts to relax the parametric assumptions traditionally used in specifying the inefficiency of a stochastic frontier model and proposes an alternative semi-parametric approach which imposes weaker assumptions on the inefficiency. Although not as general as the fully non-parametric methodology suggested by Tran and Tsionas (2009) and Parmeter et al. (2017), the approach does not incur the curse of dimensionality. Instead, it leads to a fast and accurate estimator of the inefficiency even when the number of explanatory variables is large.
The proposed semi-parametric approach relies on writing the inefficiency as a single-index with unknown link function. By so doing, the linear stochastic frontier model becomes equivalent to a partially linear single index model for which an extensive literature exists (e.g. among others Carroll et al. 1997; Yu and Ruppert 2002; Xia and Härdle 2006; Lian et al. 2015). The paper provides an identification condition which is more natural for a stochastic frontier model than those used in the literature on partially linear single index models (e.g. Xia et al. 1999; Lin and Kulasekera 2007; Dong et al. 2016; Lian et al. 2015), and proposes an estimation procedure based on penalized cubic splines which can be easily implemented with existing statistical software. This offers practitioners the possibility to easily apply this methodology. We illustrate the approach by analyzing an application of stochastic frontier models to energy demand for US states.
A standard assumption used for identification in the literature on partially linear single index model requires the orthogonality of the parameters of the linear and the single index parts. This paper suggests a new test for this assumption implemented through a bootstrap procedure.
The rest of the paper is organized as follows. The second section describes the model. The third section proposes a methodology to estimate it. Its asymptotic properties are discussed in the fourth section. A Monte Carlo simulation comparing the new method with standard maximum likelihood procedures is presented in the fifth section. The sixth section illustrates an empirical application to the rebound effect for the US states energy demand.
2 The model
We consider a linear stochastic frontier (SF) model (e.g. Aigner et al. 1977; Meeusen and van Den Broeck 1977) of the form:
where Y is the logarithm of output, \({X}^{{\prime} }\beta\) is the efficient frontier with p dimensional vector of inputs X, η is the intercept, β is a p dimensional vector of coefficients, U ≥ 0 is an unobserved inefficiency term, and V is an unobserved idiosyncratic error. It is typically assumed that U and V are uncorrelated given X.
Traditionally, a SF model is estimated using Maximum Likelihood (ML) under the assumptions that \(U \sim | N\left(0,{\sigma }_{U}^{2}\right)|\) and \(V \sim N\left(0,{\sigma }_{V}^{2}\right)\) - although other distributions may be used (e.g. Greene 1990). Under standard assumptions, the slope parameters, β, can also be consistently estimated by Ordinary Least Squares (OLS). Since, E[U∣X] = g(X) > 0, the intercept η is identified only through distributional assumptions of U and V. More generally, the distribution of the inefficiency U may depend on a vector of observables. In this case, the OLS estimator of β may not be consistent. ML is typically used to estimate model (1) because it yields a consistent and efficient estimator when the model is well specified. Since economic theory provides little insight into the mechanism generating the inefficiency or even its determinants, the likelihood function must rely on strong and often restrictive assumptions.
In the presence of determinants of inefficiency, model (1) can be written as:
where \(\varepsilon =V-\left(U-E[U| X]\right)\) and E[ε∣X] = 0. Moreover, since U captures the inefficiency it is reasonable to assume that E[U∣X] > 0.
We assume that E[U∣X] has a single-index structure, i.e. \(E[U| X]=g({X}^{{\prime} }\alpha )\ge 0\). Let \(E[g({X}^{{\prime} }\alpha )]=\delta \,> \,0\) and define \(\lambda ({X}^{{\prime} }\alpha )=g({X}^{{\prime} }\alpha )-\delta\). The SF model can be expressed as:
where μ = η − δ and \(E[\lambda ({X}^{{\prime} }\alpha )]=0\). Under some conditions discussed below, μ, β, α and λ are identified.
Theorem 1 Assume that
-
1.
\({\alpha }^{{\prime} }\alpha =1\) and the first non-zero component of α is positive;
-
2.
E[X] is finite;
-
3.
\(E[\lambda ({X}^{{\prime} }\alpha )]=0\);
-
4.
X has a positive density on an open subset S of \({{\mathbb{R}}}^{p}\);
-
5.
\({\lambda }^{{\prime} }\) is continuously differentiable everywhere on its support and \({\lambda }^{{\prime} }({X}_{0}^{{\prime} }\alpha )=0\) at a point X0 in the closure of S;
-
6.
\({\lambda }^{{\prime\prime} }({X}^{{\prime} }\alpha )\,\ne \,0\) in an open subset of S.
Then μ, β, α and λ are identified.
The proof of this result is in the appendix. We will now discuss the conditions required by Theorem 1. Conditions 1, 2, 3 and 6 are standard for single index models and are needed for the identification of λ and α. Condition 2, is normally implied by the consistency conditions of ordinary least squares when there is no inefficiency term. Precisely, one normally requires that E∣∣Xi∣∣1+δ < Δ < ∞ for some δ > 0 and i = 1,..., n which implies 2. In the case under consideration, Condition 3 is satisfied by construction. Condition 6 excludes the case where the function λ is linear. In such case, \(\lambda ({X}^{{\prime} }\alpha )={\mu }_{1}+c{X}^{{\prime} }\alpha\), and \(Y=(\mu -{\mu }_{1})+{X}^{{\prime} }(\beta -c\alpha )+\varepsilon\) and the parameters cannot be identified. Condition 4 is discussed in (Xia et al. 1999) and is required to make sure that the model can be written uniquely as in (2).
Condition 5 is non-standard, and requires some discussion. By construction, \(E(Y| X)=\mu +{X}^{{\prime} }\beta -\lambda ({X}^{{\prime} }\alpha )\) so by taking derivatives with respect to the components of X:
there is a limit point X0 and a sequence Xj ∈ S, j = 1,... such that Xj → X0 and:
Hence, in a small neighborhood of X0 it is possible to vary the level of production without affecting the inefficiency. Of course, this assumption could be replaced by the condition that \({\alpha }^{{\prime} }\beta =0\) (e.g. Xia et al. 1999; Lin and Kulasekera 2007). To see how this differs from condition 5, let v be a p − dimensional vector on a unit sphere \({v}^{{\prime} }v=1\). The directional derivative of E(Y∣X) in the direction v is:
So if \({\alpha }^{{\prime} }\beta =0\) it is possible to choose v in the space spanned by β (and orthogonal to α) such that \({v}^{{\prime} }{\nabla }_{X}E(Y| X)={v}^{{\prime} }\beta\) for all X ∈ S. Therefore, it is possible to modify the input X to change the output and leave the inefficiency unaffected for each X. On the other hand, if condition 5 holds, this could happen only at a limit point X0.
Notice that although μ is identified, its components γ and δ are not. Hence, without further assumptions, \(g({X}^{{\prime} }\alpha )=\lambda ({X}^{{\prime} }\alpha )+\delta\) can be identified up to an additive constant only. However, since \(g({X}^{{\prime} }\alpha )\ge 0\), one can identify δ by further requiring that δ is finite and \(\mathop{\inf }\limits_{X}g({X}^{{\prime} }\alpha )=0\). Such an assumption is quite natural as it implies that there is a vector X where the expected inefficiency is arbitrarily close to zero. In this case, one can set \(\delta =-\mathop{\inf }\nolimits_{X}\lambda ({X}^{{\prime} }\alpha )\).
A special case of model (2) is the SF model with separability between the inputs to the efficient frontier and the determinants of the inefficiency (e.g. Simar and Wilson 2007; Wang and Schmidt 2002). Partitioning X as \(X={({X}_{1}^{{\prime} }{X}_{2}^{{\prime} })}^{{\prime} }\), separability implies that \(\alpha ={(0{\alpha }_{2}^{{\prime} })}^{{\prime} }\) and \(\beta ={({\beta }_{1}^{{\prime} }0)}^{{\prime} }\). This is normally justified by appealing, for instance, to the managers’ natural skills which are increased or reduced by the variables in X2 but do not depend on the firm’s characteristics in X1. This assumption is often violated as X2 may contain some of the variables in X1 either directly or after a transformation.
Model (2) contains the class of SF models satisfying the scaling property (e.g. Simar et al. 1994; Wang and Schmidt 2002). In this case, \(U={\sigma }_{U}({X}^{{\prime} }\alpha ){U}^{* }\) where U* ≥ 0 has a fixed and known distribution independent of X. For instance, if U* ~ ∣N(0, 1)∣, then \(E[U| X]=\sqrt{2/\pi }{\sigma }_{U}({X}^{{\prime} }\alpha )\). The latent variable U* can be interpreted as the firm’s base efficiency level (e.g. Alvarez et al. 2006, p. 203). However, notice that model (2) also contains some important specifications considered in the SF literature that do not satisfy the scaling property (e.g. Battese and Coelli 1995; Kumbhakar et al. 1991; Deprins and Simar 1989). Parametric stochastic frontier models with the scaling property are normally estimated by non-linear least squares (e.g. Simar et al. 1994; Deprins and Simar 1989; Paul and Shankar 2017; Parmeter and Kumbhakar 2014) or ML (e.g. Simar et al. 1994; Wang and Schmidt 2002)).
Fully non-parametric specifications for the inefficiency are considered by Tran and Tsionas (2009) and Parmeter et al. (2017) who employ the approach of Robinson (1988). Although very general, these methodologies are subject to the curse of dimensionality unless X contains only a small number of variables.
Partially linear single-index models like (2) have been studied in the statistics literature where most papers assume separability between the linear and the non-linear parts (e.g. Carroll et al. 1997; Yu and Ruppert 2002; Xia and Härdle 2006; Yuan 2011). A few articles focus on models without separability and discuss their identification (e.g. Xia et al. 1999; Lin and Kulasekera 2007; Dong et al. 2016; Lian et al. 2015), traditionally based on three assumptions: (a) \({\alpha }^{{\prime} }\alpha =1\) with the first nonzero element positive; (b) \({\beta }^{{\prime} }\alpha =0\) and (c) some regularity conditions regarding the unknown function λ. Dong et al. (2016) have recently shown that a sufficient condition for identification is that (i) λ is bounded - with some regularity conditions - and (ii) the support of X is unbounded (precisely X is a unit root process). Some of the assumptions may be too restrictive for the estimation of a stochastic frontier model. For example \({\beta }^{{\prime} }\alpha =0\) implies that a firm can always change the composition of inputs to reduced the inefficiency without affecting the level of production. Similarly, boundedness is violated by the standard assumption that the inefficiency term is exponential.
Notice that one could consider a panel data version of (1) by allowing for for instance for fixed effects. Provided α, β and λ are the same over both the cross-section and the time-series dimensions, the model is identified and can be estimated using the procedure described below. Although the time series dependence makes the asymptotic theory more complex, the bootstrap could be used to construct confidence intervals and tests (e.g. Kapetanios 2008). Full investigation of this case is beyond the scope of the paper.
3 Estimation of the model
In this section, we propose a procedure to estimate model (2) by penalized splines. This method is well-established in the statistical literature (e.g. Ruppert et al. 2003) and can be implemented using standard software.
The fundamental idea is that for fixed α, β and γ, the function λ can be estimated by minimizing:
with respect to λ, where \(1/{w}_{i}^{2}\) is a suitable weight. The second term is a penalization that prevents over-fitting. If λ belongs to a Sobolev space, it can be shown that the solution of this problem is a natural cubic spline with continuous first and second derivatives at each knot located at the unique points \({X}_{i}^{{\prime} }\alpha\), i = 1, . . . , n (e.g. among others Hastie and Tibshirani 1993, p. 151). However, evaluating λ at each observation is not only time-consuming but also unnecessary when the complexity of λ is moderate. Instead, we approximate the unknown function λ by a linear combination of L + 3 < n cubic splines S1(u), . . . , SL+3(u):
where \(c={\left({c}_{0},{c}_{1},...,{c}_{L+3}\right)}^{{\prime} }\) and \(S(u)=\left[1,{S}_{1}(u),...,{S}_{L+3}(u)\right]\) such that S1(u) = u, S2(u) = u2, S3(u) = u3 and
l = 4, . . . , L + 3 and ξ4 < . . . < ξL+3 are L fixed knots in the support of λ. If the function λ is smooth and unimodal or monotonic, a number of knots between L = 5 and L = 10 is usually sufficient to make the approximation accurate (e.g. Yu and Ruppert 2002; Ruppert 2002). Notice that in this case we can write Qn,γ(μ, α, β, c).
Notice that we can set the parameter δ as \(\hat{\delta }=-\inf \hat{\lambda }({X}_{i}^\prime\hat{\alpha})\) to guarantee that \(\hat{g}({X}^{{\prime} }\alpha )=\hat{\delta }+\hat{\lambda }({X}^{{\prime} }\alpha )\ge 0\) (see Parmeter et al. 2017) for a way to enforce positivity of g when this is fully nonparameteric).
The parameters α, β and c (defined in (7)) can be estimated for a given γ by minimizing (6). Hence, we can estimate α, β, c as detailed in Algorithm 1. Notice that we impose the sample version of Condition 3 of Theorem 1 as \({n}^{-1}\mathop{\sum }\nolimits_{i = 1}^{n}\lambda ({u}_{i})=0\).
The tuning parameter γ can be chosen in different ways: (i) it can be taken as fixed; (ii) it can be allowed to tend to zero as the sample size n tends to infinity; (iii) it can be chosen to minimize criteria based on the prediction error such as GC, GCV or more classical criteria such as AIC or Mallows Cp (e.g. Yu and Ruppert 2002; Wood 2008); (iv) it can be based on the Restricted Maximum Likelihood (REML) criterion following Wood (2011).
The weights \(1/{w}_{i}^{2}\) could be taken to be 1. However, to improve efficiency, one may employ a two-stage procedure in which they are updated along the lines of Lian et al. (2015) so that \({{{\rm{Var}}}}(\varepsilon | X)=\exp \{\phi ({X}^{{\prime} }\nu )\}\). Hence, one can use the residuals \({\hat{\varepsilon }}_{i}={Y}_{i}-\mu -{X}_{i}^{{\prime} }\hat{\beta }+\hat{\lambda }({X}_{i}^{{\prime} }\hat{\alpha })\) to fit a single index model by minimizing:
with a cubic spline approximation to ϕ. Then the weights \({w}_{i}=exp(\widehat{\phi }({X}_{i}^{{\prime} }\widehat{\nu }))\) are updated and the model is re-estimated. Alternatively one could model the squared residuals instead of the absolute residuals.
One referee brought to our attention that estimation based on a penalization, as in the procedure suggested above, could potentially hide identification issues.
The following algorithm describes the estimation procedure.
Algorithm 1
Iterative procedure to estimate α, β, c and γ
-
1.
Set starting values for \(\hat{\gamma }\ge 0\), \(\hat{\alpha }\) with first element being non-negative and satisfying \({\hat{\alpha }}^{{\prime} }\hat{\alpha }=1\), \(\hat{\beta }\) and wi = 1
-
2.
Minimize \({Q}_{n,\hat{\gamma }}\left(\hat{\mu },\hat{\alpha },\hat{\beta },c\right)\) with respect to c
-
3.
Estimate \(\hat{\gamma }\) by REML (or other criteria such as GCV, AIC, Cp)
-
4.
Repeat from 2 until a convergence criterion is satisfied
-
5.
Minimize \({Q}_{n,\hat{\gamma }}\left(\mu ,\alpha ,\beta ,\hat{c}\right)\) with respect to μ, α and β subject to the constraints \({\alpha }^{{\prime} }\alpha =1\)
-
6.
Repeat from 2 until a convergence criterion is satisfied
-
7.
Update \({w}_{i}^{2}\)
-
8.
Repeat from 2 until a convergence criterion is satisfied
Although Qn,γ(μ, α, β, c) can be minimized in several way, Algorithm 1 has the advantage that it can be easily implemented with existing software. Essentially Algorithm 1 separates the estimation of α and β from the estimation of λ (or more precisely c and γ). For example, in R estimation of λ can be implemented with the mgcv package (Wood 2020) while estimation of α and β solves a nonlinear least squares problem which relies on an optimization package like optim (R Core Team 2013) or, for global optimization using genetic algorithms, the GA package (Scrucca 2013). We have experimented with alternatives to Algorithm 1 and found them less reliable.
The algorithm is similar to the one used by Yu and Ruppert (2002). However, there are some important differences. Firstly, their model separates the variables appearing in the linear and the nonlinear part and thus it is a special case of (2). Secondly, Yu and Ruppert (2002) choose the value of the tuning parameter γ by GCV which penalizes over-fitting less severely than the REML criterion of Wood (2011). We use REML as Wood (2011) convincingly argues that this approach exhibits good stability properties.
Alternative series expansion can be used instead of natural cubic splines. For example Dong et al. (2016) use an orthogonal series expansion in terms of Hermite polynomials with the number of terms in the series selected by GCV. Orthogonal series expansions have two drawbacks due to their global nature. First, they are sensitive to outliers (Li and Racine 2007, p. 446; Green and Silverman 1994, p. 2). Second, they tend to exhibit a poor fit in those parts of the support with few observations (Ramsay and Silverman 1997, p. 48; Hastie et al., 2001, p. 140).
Kernel estimation could be used as an alternative to penalized splines. Xia et al. (1999) use an alternative two-stage estimation procedure in which they first approximate \(E[Y| {X}^{{\prime} }\alpha ]\) and \(E[X| {X}^{{\prime} }\alpha ]\beta\), two functions of \({X}^{{\prime} }\alpha\) only, with leave-one-out kernel series, that we denote \({\widehat{E}}_{h}[Y| {X}_{i}^{{\prime} }\alpha ]\) and \({\widehat{E}}_{h}[X| {X}_{i}^{{\prime} }\alpha ]\) where h is the bandwidth. Firstly, α, β and h are estimated by minimizing:
Secondly, the function λ is estimated as \(\hat{\lambda }(a)=\widehat{E[Y| a]}-\widehat{E[X| a]}\hat{\beta }\). Tran and Tsionas (2009) and Parmeter et al. (2017) use a similar approach to estimate a SF model without imposing a single index structure on λ.
Kernel methods and penalized splines tend to be asymptotically equivalent (Messer 1991). In finite samples, the penalized splines approach tends to estimate λ with lower variance than kernel estimation (e.g. Eilers and Marx 1996). Eilers and Marx (1996) also suggest that the penalized splines can often be preferable from a computational point of view in the one-dimensional case and if the number of knots is substantially smaller than the sample size - as in the case considered here.
4 Asymptotic properties
The asymptotic properties of the procedure outlined in the previous section can be derived following the work of Yu and Ruppert (2002). Therefore, we will only report the results here.
Let α be parameterized as:
for \(\phi \in {{\mathbb{R}}}^{p-1}\) and \({\phi }^{{\prime} }\phi \le 1\). Moreover, let
Let ϕ*, μ*, β*, c* denote the true parameters. We make the following assumptions.
Assumption C.
-
1.
m(Xi; ϕ, μ, β, c) is continuous on a compact parameter space Θ for each Xi.
-
2.
\(\frac{1}{n}\mathop{\sum }\nolimits_{i = 1}^{n}{\left(m({X}_{i};\phi ,\mu ,\beta ,c)-m({X}_{i};{\phi }_{* },{\mu }_{* },{\beta }_{* },{c}_{* })\right)}^{2}\) converges uniformly in probability to a function Q*(ϕ, μ, β, c) which has a unique minimum at (ϕ*, μ*, β*, c*) being an interior point of Θ.
Assumption AN. Let m(1)(Xi; ϕ, μ, β, c) and m(2)(Xi; ϕ, μ, β, c) denote respectively the gradient and the Hessian of m(Xi; ϕ, μ, β, c) with respect to the parameters ϕ, μ, β and c.
-
1.
m(Xi; ϕ, μ, β, c) is twice continuously differentiable in a neighborhood of (ϕ*, μ*, β*, c*).
-
2.
\(\frac{1}{n}\mathop{\sum }\nolimits_{i = 1}^{n}{m}^{(1)}({X}_{i};\phi ,\mu ,\beta ,c){m}^{(1)}{({X}_{i};\phi ,\mu ,\beta ,c)}^{{\prime} }\) converges uniformly in probability in a neighborhood of (ϕ*, μ*, β*, c*) to
$${{\Omega }}(\phi ,\mu ,\beta ,c)=\mathop{\lim }\limits_{n\to \infty }\frac{1}{n}\mathop{\sum }\limits_{i=1}^{n}{m}^{(1)}({X}_{i};\phi ,\mu ,\beta ,c){m}^{(1)}{({X}_{i};\phi ,\mu ,\beta ,c)}^{{\prime} }$$and Ω(ϕ*, μ*, β*, c*) is non-singular.
-
3.
\(\frac{1}{n}\mathop{\sum }\nolimits_{i = 1}^{n}{m}^{(2)}({X}_{i};\phi ,\mu ,\beta ,c)\) converges uniformly in probability as n → ∞ in a neighborhood of (ϕ*, μ*, β*, c*).
These assumptions are standard. Assumption C is needed to make sure our estimator is consistent while assumptions C and AN imply asymptotic normality.
Theorem 2 Let \(\theta ={({\phi }^{{\prime} },\mu ,{\beta }^{{\prime} },{c}^{{\prime} })}^{{\prime} }\), \({\theta }_{* }={({\phi }_{* }^{{\prime} },{\mu }_{* },{\beta }_{* }^{{\prime} },{c}_{* }^{{\prime} })}^{{\prime} }\) and \(\hat{\theta }\) be an estimator of θ. The following results hold.
-
a.
Under Assumption C, if the smoothing parameter γ = o(1), then a sequence of penalized least squares estimators minimizing expression (6) exists and is a strongly consistent estimator of θ*.
-
b.
Under Assumptions C and AN, if the smoothing parameter \(\gamma =o\left({n}^{-1/2}\right)\), then a sequence of constrained penalized least squares estimator of θ exists, is consistent, and is asymptotically normally distributed
$$\sqrt{n}\left(\hat{\theta }-{\theta }_{* }\right){\to }^{D}N\left(0,{\sigma }^{2}{{\Omega }}{({\theta }_{* })}^{-1}\right).$$ -
c.
Under Assumptions C and AN, if γ > 0 is given, then
$$\sqrt{n}\left(\hat{\theta }\,-{\theta }_{* }\left(\gamma \right)\right){\to }^{D}N\left(0,{{\Delta }}{\left({\theta }_{* }\left(\gamma \right)\right)}^{-1}G\left({\theta }_{* }\left(\gamma \right)\right){\left({{\Delta }}{\left({\theta }_{* }\left(\gamma \right)\right)}^{-1}\right)}^{{\prime} }\right)$$as n → ∞, where θ*(γ) solves:
$$\frac{1}{n}\mathop{\sum }\limits_{i=1}^{n}E\left[{\psi }_{i}(\theta )\right]=0,$$with
$$\begin{array}{l}{\psi }_{i}(\theta )=-\frac{1}{\sqrt{{w}_{i}}}\left({Y}_{i}-m({X}_{i};\phi ,\mu ,\beta ,c)\right)\frac{\partial }{\partial \theta }\\ m({X}_{i};\phi ,\mu ,\beta ,c) +\gamma \left(\int{S}^{{\prime\prime} }(u){S}^{{\prime\prime} }{(u)}^{{\prime} }du\right)c,\end{array}$$and
$${{\Delta }}\left({\theta }_{* }(\gamma )\right)=\mathop{\lim }\limits_{n\to \infty }E\left[\frac{1}{n}\mathop{\sum }\limits_{i=1}^{n}\frac{\partial }{\partial {\theta }^{{\prime} }}{\psi }_{i}\left({\theta }_{* }(\gamma )\right)\right],$$$$G({\theta }_{* }(\gamma ))=\mathop{\lim }\limits_{n\to \infty }E\left[\frac{1}{n}\mathop{\sum }\limits_{i=1}^{n}{\psi }_{i}\left(({\theta }_{* }(\gamma )){\psi }_{i}{\left({\theta }_{* }(\gamma )\right)}^{{\prime} }\right]\right..$$
The proof of Theorem 2 follows closely the proofs of Theorems 1 and 2 of Yu and Ruppert (2002), and is not reported here. Theorem 2 allows one to construct tests of hypotheses and confidence intervals based on the asymptotic standard errors. Alternatively, robust standard errors can be obtained using bootstrap procedures. In the example of application discussed later we will use the wild bootstrap.
It was shown in the discussion following Theorem 1 that one could replace condition 5 with the stronger but more traditional condition \({\alpha }^{{\prime} }\beta =0\). A test for \({H}_{0}:{\alpha }^{{\prime} }\beta =0\) can be based on the statistic \({\hat{\alpha }}^{{\prime} }\hat{\beta }\) a the following result shows.
Theorem 3 Assume that as n → ∞:
-
1.
\(\sqrt{n}(\hat{\xi }-{\xi }_{* }){\to }^{d}N(0,{{{\Sigma }}}_{* })\) where \({\xi }_{* }=({\beta }_{* }^{{\prime} },{\phi }_{* }^{{\prime} })\) and \(\hat{\xi }=(\hat{\beta }^{\prime} ,\hat{\phi }^{\prime} )\), where α(ϕ) is parameterized as in (9);
-
2.
\(\hat{\phi }{\to }^{p}{\phi }_{* }\);
-
3.
\(\hat{{{\Sigma }}}{\to }^{p}{{{\Sigma }}}_{* }\).
Let α* = α(ϕ*) and \({\omega }_{* }^{2}=\left(\begin{array}{l}{\alpha }_{* }\\ {\nabla }_{\phi }\left({\beta }_{* }^{{\prime} }\alpha ({\phi }_{* })\right)\end{array}\right)^{\prime} {{{\Sigma }}}_{* }\left(\begin{array}{l}{\alpha }_{* }\\ {\nabla }_{\phi }\left({\beta }_{* }^{{\prime} }\alpha (\phi * )\right)\end{array}\right)\) and \({\hat{\omega }}^{2}\to {\omega }_{* }^{2}\). Then,
-
under the null hypothesis \({H}_{0}:{\alpha }_{* }^{{\prime} }{\beta }_{* }=0\), \(n{({\hat{\alpha }}^{{\prime} }\hat{\beta })}^{2}/{\hat{\omega }}^{2}{\to }^{d}{\chi }^{2}(1)\); and
-
under the local alternative \({H}_{0}:{\alpha }_{* }^{{\prime} }{\beta }_{* }=\varrho /\sqrt{n}\), \(n{({\hat{\alpha }}^{{\prime} }\hat{\beta })}^{2}/{\hat{\omega }}^{2}{\to }^{d}{\chi }^{2}\left(1,\frac{{\varrho }^{2}}{2{\omega }_{* }^{2}}\right)\).
Precise estimation of the asymptotic variance-covariance matrix Σ* in Theorem 3 is difficult since it requires estimation of the covariance matrices in Theorem 2 parts b and c which have large dimensions. However, this problem can be overcome by noticing that Theorem 3 requires the estimation of \({\sigma }_{* }^{2}\) only, and this can be estimated as the bootstrapped variance of \(\sqrt{n}\hat{\alpha }{^\prime} \hat{\beta }\) obtained from bootstrapping the residuals of the estimated model.
5 Numerical comparison
This section investigates the finite sample properties of the methodology developed in Section 4 and compares it to the parametric methods traditionally implemented in the SF literature using Monte Carlo simulations.
We consider a simplified version of the stochastic frontier model (1) with four explanatory variables \({X}_{i}=\left[{X}_{1i},\,{X}_{2i},\,{X}_{3i},{X}_{4i}\right]^{\prime}\). We also assume that:
-
1.
n = 200.
-
2.
\({\left[({X}_{i},{Y}_{i})\right]}_{i = 1}^{n}\), are independent random variables
-
3.
Xi, Vi, and \({U}_{i}^{* }\) are independent of each other.
-
4.
X1i, X2i, X4i are sampled independently of each other from a normal distribution with mean 4 and variance 4, and X3i = 0.5 × X2i + 0.5 × N(4, 4).
-
5.
\({V}_{i} \sim N(0,{\sigma }_{V}^{2})\).
-
6.
\({U}_{i}=\kappa {\sigma }_{U}(X^{{\prime} }_{i}\alpha ){U}_{i}^{* }\) where \({U}_{i}^{* } \sim | N\left(0,1\right)|\), κ captures the strength of the signal in Ui in relation to the signal of \(X^{\prime} \beta\) in (1) and the noise Var(Vi). Precisely,
-
i.
The signal of the frontier is the variance of \(X^{\prime} \beta\); in our case, this is
$${{{\rm{Var}}}}(X^{\prime} \beta )=4\left({\beta }_{1}^{2}+{({\beta }_{2}+{\beta }_{3}/2)}^{2}+{\beta }_{3}^{2}+{\beta }_{4}^{2}\right);$$ -
ii.
The signal of the inefficiency is measured by the variance of Ui
$$\begin{array}{l}{{{\rm{Var}}}}\left({U}_{i}\right)={\kappa }^{2}\left(1-2/\pi \right)E\left({\sigma }_{U}^{2}(X^{{\prime} }_{i}\alpha )\right)\\ \qquad\qquad+\left(2{\kappa }^{2}/\pi \right){{{\rm{Var}}}}\left({\sigma }_{U}^{2}(X^{{\prime} }_{i}\alpha )\right).\end{array}$$The variable κ is chosen so that Var(Ui) is slightly less than half the signal in the frontier, \({{{\rm{Var}}}}({U}_{i})=0.\overline{45}{{{\rm{Var}}}}({X}_{i}^{\prime}\beta )\)
-
iii.
The noise parametrized by \({\sigma }_{V}^{2}=0.1{{{\rm{Var}}}}({U}_{i})\) is dominated by the signal of the inefficiency Ui.
-
i.
-
7.
Three specifications for the inefficiency are considered:
-
i.
exponential σU(x) = ex;
-
ii.
logistic \({\sigma }_{U}(x)={\left(1+{e}^{-x}\right)}^{-1}\); and
-
iii.
trigonometric: \({\sigma }_{U}(x)=1+\cos (x)\);
-
iv.
partially linear
$${\sigma }_{U}(x)=\left\{\begin{array}{ll}25+22(x+0.5)+5{(x+0.5)}^{2}&x\le -\frac{5}{2}\\ 5+2(x+0.5)&x\, > -\frac{5}{2}\end{array}\right.$$ -
v.
partially constant
$${\sigma }_{U}(x)=\left\{\begin{array}{ll}1+\cos (2.25x)&x \,< -\frac{4\pi }{9}\\ 0&-\frac{4\pi }{9}\le x\le \frac{4\pi }{9}\\ 1+\cos (2.25x)&x\, >\, \frac{4\pi }{9}\end{array}\right..$$
-
i.
-
8.
Both situations where the input to the production function and the determinants of inefficiency are separable and non-separable are considered.
Assumption 6 imposes the scaling property on the inefficiency. This is done for simplicity as it allows us to control the strengths of the signals/noise in Xiβ, Ui and Vi.
The exponential and the logistic specifications of the inefficiency in (7.i) and (7.ii) respectively are often used in practical applications of stochastic frontier and they make a natural comparison. They are usually estimated using maximum likelihood, which is asymptotically efficient if the model is well specified, and as such they also represent a useful benchmark. Specifications (7.iii)-(7.v) are used to investigate the case where the inefficiency is not monotonic in \({X}_{i}^{{\prime} }\alpha\), or it is linear or constant over a certain interval. The first case captures, for example, the possibility that a young farmer’s productivity increases with age but then the productivity decreases when the farmer is old (e.g. Wang 2002). Specifications (7.iv) and (7.v) capture inefficiencies in which the parameters are close to be unidentified because the inefficiency is linear or constant on part of the support of the link function.
We compare the following estimators:
-
the penalized spline estimator with uniform weights - PS;
-
the penalized spline estimator with weights adjusted for heteroskedasticity as in (8) - WPS.
-
the maximum likelihood estimator which assumes an exponential inefficiency - ML(e); when separability is also imposed in the estimation, it will be denoted by MLs(e).
-
the maximum likelihood estimator which assumes a logistic inefficiency - ML(l); when separability is also imposed in the estimation it will be denoted by MLs(l).
We investigate how the penalized splines estimators compare to the maximum likelihood estimator both when the latter is well specified and when it is misspecified. The criteria used to compare the estimators are the Median Bias (MB) and the Median Absolute Deviance (MAD). Both criteria are robust to the potential lack of moments of the estimators.
The results of 10,000 simulations are summarized in Tables 1–5 covering respectively, exponential, logistic, trigonometric, locally linear and partially constant inefficiencies. In Tables 1 and 2, the correctly specified ML estimator is highlighted in gray. This is the asymptotically efficient estimator, and can represent a benchmark for comparison.
As expected, Tables 1 and 2 show that—when correctly specified—the ML estimator tends to perform better than all other estimators of α and β in terms of both MB and MAD. The PS and WPS estimator perform slightly worse in terms of both MB and MAD, while the ML estimator for the incorrectly specified inefficiency can have a large bias for α but no for β. Imposing separability, when this holds, helps the estimation of both α and β for both correctly and misspecified estimators.
The PS and WPS estimator of μ performs well in terms of MB but not so well in terms of MAD. Notice that η and δ are identified in the parametric model through the parametric assumptions. However, with semiparametric inefficiency they are not identified. As discussed earlier, in this case, we set \(\hat{\delta }\) equal to the smallest upward shift which makes \(g(x^{\prime} \hat{\alpha })=\hat{\lambda }(x^{\prime} \hat{\alpha })+\hat{\delta }\) non-negative over the observed sample. So it can be quite far from the “true” δ. This also affects the estimation of η for the penalized spline estimators.
In Tables 3–5 the inefficiency are specified respectively as trigonometric, partially linear and partially constant. In this case, the PS and WPS estimators are not compared to the correctly specified ML estimator but to incorrectly specified ML estimators resulting from assuming that the inefficiency is exponential or logistic. The tables show that the PS and WPS estimators of α and β perform well overall. It is important to note that the ML estimator of α based on the logistic inefficiency can perform particularly badly in terms of both MB and MAD. If the model generating the data satisfies the separability property, large MB and MAD are observed on the misspecified ML estimators. Both incorrectly and correctly specified ML estimators are improved by imposing the separability restriction. Estimation of the constants δ, η and μ does not show a clear winner.
To summarize, when compared to the correctly specified ML estimators, the PS and WPS estimators of α and β tend to be close the ML in terms of both MB and MAD. However, correcting for heteroskedasticity in the penalized spline estimator does not improve the performance. Overall, Tables 1–5 suggest that the PS estimator of α and β works well in all situations considered.
We now turn to the test for orthogonality of α and β. Table 6 shows the rejection probability for the test of orthogonality based on the PS estimator for different specification of the inefficiency. The reported numbers are the proportion of 1000 simulations for which the test statistic is larger that the 10% and 5% critical values from a χ2 distribution with one degree of freedom. The data has been generated through the eight steps detailed above. For the case of orthogonality, \(\alpha ={(0.6,-0.8,0.0,0.0)}^{{\prime} }\), β = (0, 0, −0.3, 0.8). For the model without orthogonality, \(\alpha ={(0.5,-0.5,-0.5,0.5)}^{\prime}\) and \(\beta ={(0.75,-0.25,-0.25,0.75)}^{{\prime} }\). The variance of \(\sqrt{n}{\hat{\alpha }}^{{\prime} }\hat{\beta }\) is estimated using 100 bootstrap replications. Table 6 shows that when α and β are orthogonal the 10% and 5% rejection probabilities can be up to two and half times higher than the nominal size. When they are not orthogonal, the rejection probability are, as expected, much higher.
6 An application to US residential energy demand
Orea et al. (2015) estimate a stochastic frontier model for residential aggregate energy demand using a panel of 48 US states for the period 1995 to 2011. Their dependent variable is the log of energy consumption (\(\ln (Q)\)) and their explanatory variables are:
where Y is the real disposal personal income, P is the real price of energy, POP is the population size, HDD indicates the heating degree days, CDD indicates the cooling degree days, AHS is the average household size and SDH is the share of detached houses in each state. All variables are de-meaned and time dummies are included in the linear frontier but not in the inefficiency.
Orea et al. (2015) assume that the inefficiency satisfies the scaling property, \(U={\sigma }_{U}(X^{\prime} \alpha ){U}^{* }\) where \({U}^{* } \sim | N(0,{\sigma }_{{U}^{* }}^{2})|\). They specify two parametric forms for σU, exponential \({\sigma }_{U}(X^{\prime} \alpha )={e}^{-{\alpha }_{0}-X^{\prime} \alpha }\), and logistic \({\sigma }_{U}(X^{\prime} \alpha )={\left(1+{e}^{{\alpha }_{0}+X^{\prime} \alpha }\right)}^{-1}\), that are referred to respectively as the PA and SC (for partial and super-conservative rebound) specifications by Orea et al. (2015). Notice that α0 and \({\sigma }_{{U}^{* }}^{2}\) cannot be both identified in the exponential case. Hence, to identify all the parameters of the stochastic frontier model with exponential σU, Orea et al. (2015) set \({\sigma }_{{U}^{* }}^{2}=1\). Notice also that \(\lambda (X^{\prime} \alpha )=\sqrt{2/\pi }{\sigma }_{U}(X^{\prime} \alpha )-\sqrt{2/\pi }E\left[{\sigma }_{U}(X^{\prime} \alpha )\right]\).
Orea et al. (2015) restrict the parameter α in the inefficiency. Precisely, they assume that the coefficients of \(\ln ({{{\rm{HDD}}}})\), \(\ln ({{{\rm{CDD}}}})\) and SDH are zero and that the composite variable \(\ln (Y/{{{\rm{POP}}}})\) is a determinant of inefficiency (so that the coefficients of \(\ln (Y)\) and \(\ln ({{{\rm{POP}}}})\) are opposite). The penalized spline estimation is implemented with and without these restrictions (with the resulting estimators denoted by PS(r) and PS(u) or WPS(r) and WPS(u) when correcting for heteroskedasticity).
Table 7 displays the estimated parameters and corresponding standard errors for the frontier and the inefficiencies. The table shows the ML estimates and standard errors assuming exponential and logistic inefficiency obtained by Orea et al. (2015) when imposing constraints on α, the PS and WPS estimates imposing constraints on α (denoted respectively by PS(r) and WPS(r)) and the PS and WPS estimates for an unconstrained α (denoted respectively by PS(u) and WPS(u)). The standard errors for the PS and WPS estimators are obtained using the wild bootstrap.
When imposing restrictions on α as in Orea et al. (2015), the estimates of the coefficients of the frontier are very close. However, the estimates of α are different because the PS method imposes the standardization \(\alpha ^{\prime} \alpha =1\). When the PS estimator is unconstrained, the estimated coefficients ln(POP), ln(P) and ln(AHS) in the frontier are close to the corresponding ML estimates constraining α, but the remaining estimates of the coefficient of the frontier and the inefficiency are quite different. Notice that correcting for heteroskedasticity leads to the same estimates as for the PS estimator.
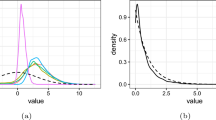
Figure 1 shows the residuals of the frontier estimation (i.e. \(Y-X^{\prime} \hat{\beta }\)) as a function of \(X^{\prime} \hat{\alpha }\) plotted with the predicted value of the inefficiency \(\hat{\lambda }\). The estimated inefficiencies under the logistic and the exponential specifications are very similar but not identical. The form of the estimated inefficiency is quite different from that of PS(r) and WPS(r). Notice that the correlation between the residuals of the frontier and between the single indices for the different estimators are very high (see Table 8) with the exception of PS(u). A close look at the graph suggests that extreme observations are important in determining the estimated inefficiency and that the implicit assumption of monotonicity and convexity (everywhere for the exponential and for positive values for the logistic) may be important. In fact, if one re-estimates the PS(r) specification imposing monotonicity and convexity of λ, the resulting inefficiency has a shape much closer to that of Orea et al. (2015) as illustrated by Fig. 2. Thus, the assumption of logistic or exponential inefficiency implicitly shapes the rebound effect.

Estimated inefficiency \(\hat{\lambda }(X^{\prime} \hat{\alpha })\) and residuals \(Y-X^{\prime} \hat{\beta }\). For the PS estimator of the semiparametric inefficiency a confidence interval for the inefficiency is constructed by using 1000 wild bootstrap simulations to obtain estimates of the coefficients α and β and c in (7) and to construct a 95% prediction interval for each Xi

Estimated inefficiency with (dashed line) and without (solid line) monotonicity and convexity constraints in the PS(r) specification
Figure 1 also shows the estimated inefficiency when the restrictions of Orea et al. (2015) are not imposed. In this case, the estimated λ is concave on the left-hand-side indicating that the rebound to efficiency occurs slowly for small values of \(X^{\prime} \alpha\). To check the sensitivity of the estimated inefficiency to the estimation procedure, we re-estimate it (a) imposing a large penalty parameter γ = 100 to make the estimated line smoother (larger values only marginally change the estimated inefficiency) and (b) imposing monotonicity (see Fig. 3). The estimated inefficiencies are very close, suggesting that they are less sensitive to the underlying assumption than the restrictive specification described earlier.

Estimated inefficiency. The solid line is the estimated inefficiency with the penalty parameter chosen by REML, the dash-dotted line uses a penalty parameter of 100, and the dashed line has been estimated subject to a monotonicity constraint
7 Conclusion
The paper suggests a novel procedure to estimate a stochastic frontier model with a semi-parametric specification for the inefficiency. This is achieved by recasting a stochastic frontier model into a partially linear single index model. The resulting approach is easy to implement, uses existing software and is computationally efficient in comparison to a fully non-parametric specification. It also allows to test orthogonality between the coefficients of the stochastic frontier and those of the single index in the inefficiency, an assumption often made in partially linear single index models.
Monte Carlo simulations have been used to compare the performance of the penalized spline procedure with the maximum likelihood estimator - with both a correctly and incorrectly specified inefficiency. The performance of the penalized spline procedure is close to that of the correctly specified maximum likelihood estimator, which is efficient, and it considerably improves upon a maximum likelihood estimator with an incorrectly specified inefficiency.
An application to the residential energy demand of US states highlights the practical importance of relaxing the parametric assumptions.
Data availability
The dataset for the application in “An application to US residential energy demand” section is available as online Supplementary Material to Orea et al. (2015) in the Dataverse repository, https://doi.org/10.1016/j.eneco.2015.03.016.
Code availability
The R code used in the “Numerical comparison” section will be made available on GitHub at https://github.com/gforchini/SFA_Semiparametric_inefficiency.
References
Aigner D, Lovell CK, Schmidt P (1977) Formulation and estimation of stochastic frontier production function models. J Econom 6(1):21–37. https://doi.org/10.1016/0304-4076(77)90052-5
Alvarez A, Amsler C, Orea L et al. (2006) Interpreting and testing the scaling property in models where inefficiency depends on firm characteristics. J Product Anal 25(3):201–212. https://doi.org/10.1007/s11123-006-7639-3
Battese GE, Coelli TJ (1995) A model for technical inefficiency effects in a stochastic frontier production function for panel data. Empir Econ 20(2):325–332. https://doi.org/10.1007/BF01205442
Carroll RJ, Fan J, Gijbels I et al. (1997) Generalized partially linear single-index models. J Am Stat Assoc 92(438):477–489. https://doi.org/10.2307/2965697
Deprins D, Simar L (1989) Estimating technical inefficiencies with correction for environmental conditions: with an application to railway companies. Ann Public Coop Econ 60(1):81–102. https://doi.org/10.1111/j.1467-8292.1989.tb02010.x
Dong C, Gao J, Tjøstheim D (2016) Estimation for single-index and partially linear single-index integrated models. Ann Stat 44(1):425–453. https://doi.org/10.1214/15-AOS1372
Eilers PHC, Marx BD (1996) Flexible smoothing with b-splines and penalties. Stat Sci 11(2):89–102. https://doi.org/10.1214/ss/1038425655
Fan Y, Li Q, Weersink A (1996) Semiparametric estimation of stochastic production frontier models. J Bus Econ Stat 14(4):460–468. https://doi.org/10.1080/07350015.1996.10524675
Green P, Silverman B (1994) Nonparametric regression and generalized linear models: a roughness penalty approach. Chapman and Hall, United Kingdom
Greene WH (1990) A gamma-distributed stochastic frontier model. J Econom 46(1-2):141–163. https://doi.org/10.1016/0304-4076(90)90052-U
Hastie T, Tibshirani R (1993) Varying-coefficient models. J R Stat Soc Ser B Methodol 55(4):757–796. https://doi.org/10.1111/j.2517-6161.1993.tb01939.x
Hastie T, Tibshirani R, Friedman J (2001) The elements of statistical learning. Springer series in statistics. Springer New York Inc., New York, NY, USA
Jondrow J, Lovell CK, Materov IS et al. (1982) On the estimation of technical inefficiency in the stochastic frontier production function model. J Econom 19(2-3):233–238. https://doi.org/10.1016/0304-4076(82)90004-5
Kapetanios G (2008) A bootstrap procedure for panel data sets with many cross-sectional units. Econom J 11(2):377–395
Kumbhakar SC, Ghosh S, McGuckin JT (1991) A generalized production frontier approach for estimating determinants of inefficiency in U.S. dairy farms. J Bus Econ Stat 9(3):279–286. https://doi.org/10.1080/07350015.1991.10509853
Kumbhakar SC, Park BU, Simar L et al. (2007) Nonparametric stochastic frontiers: a local maximum likelihood approach. J Econom 137(1):1–27. https://doi.org/10.1016/j.jeconom.2006.03.006
Li Q, Racine JS (2007) Nonparametric econometrics: theory and practice. Princeton University Press, Princeton
Lian H, Liang H, Carroll RJ (2015) Variance function partially linear single-index models. J R Stat Soc Ser B Stat Methodol 77(1):171–194. https://doi.org/10.1111/rssb.12066
Lin W, Kulasekera K (2007) Identifiability of single-index models and additive-index models. Biometrika 94(2):496–501. https://doi.org/10.1093/biomet/asm029
Meeusen W, van Den Broeck J (1977) Efficiency estimation from Cobb-Douglas production functions with composed error. Int Econ Rev 435–444. https://doi.org/10.2307/2525757
Messer K (1991) A comparison of a spline estimate to its equivalent kernel estimate. Ann Stat 19(2):817–829. https://doi.org/10.1214/aos/1176348122
Ondrich J, Ruggiero J (2001) Efficiency measurement in the stochastic frontier model. Eur J Oper Res 129(2):434–442. https://doi.org/10.1016/S0377-2217(99)00429-4
Orea L, Llorca M, Filippini M (2015) A new approach to measuring the rebound effect associated to energy efficiency improvements: an application to the US residential energy demand. Energy Econ 49:599–609. https://doi.org/10.1016/j.eneco.2015.03.016
Parmeter CF, Kumbhakar SC (2014) Efficiency analysis: a primer on recent advances. Found Trends Econom 7(3-4):191–385. https://doi.org/10.1561/0800000023
Parmeter CF, Wang HJ, Kumbhakar SC (2017) Nonparametric estimation of the determinants of inefficiency. J Product Anal 47(3):205–221. https://doi.org/10.1007/s11123-016-0479-x
Paul S, Shankar S (2017) An alternative specification for technical efficiency effects in a stochastic frontier production function. Crawford School Research Papers 1703, Crawford School of Public Policy, The Australian National University. https://doi.org/10.2139/ssrn.2913313
R Core Team (2013) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria
Ramsay J, Silverman B (1997) Functional data analysis. Springer, New York. https://doi.org/10.1007/978-1-4757-7107-7
Robinson PM (1988) Root-N-consistent semiparametric regression. Econometrica 931–954. https://doi.org/10.2307/1912705
Ruppert D (2002) Selecting the number of knots for penalized splines. J Comput Graph Stat 11(4):735–757. https://doi.org/10.1198/106186002853
Ruppert D, Wand MP, Carroll RJ (2003) Semiparametric regression. Cambridge series in statistical and probabilistic mathematics. Cambridge University Press, Cambridge (UK). https://doi.org/10.1017/CBO9780511755453
Scrucca L (2013) GA: a package for genetic algorithms in R. J Stat Softw 53(4):1–37. https://doi.org/10.18637/jss.v053.i04
Simar L, Wilson PW (2007) Estimation and inference in two-stage, semi-parametric models of production processes J Econom 136(1):31–64. https://doi.org/10.1016/j.jeconom.2005.07.009
Simar L, Lovell CAK, van den Eeckaut P (1994) Stochastic frontiers incorporating exogenous influences on efficiency. Discussion Papers No 9403, Institut de Statistique, Universite de Louvain. http://hdl.handle.net/2078.1/123589
Simar L, Van Keilegom I, Zelenyuk V (2017) Nonparametric least squares methods for stochastic frontier models. J Product Anal 47(3):189–204. https://doi.org/10.1007/s11123-016-0474-2
Tran KC, Tsionas EG (2009) Estimation of nonparametric inefficiency effects stochastic frontier models with an application to british manufacturing. Econ Model 26(5):904–909. https://doi.org/10.1016/j.econmod.2009.02.011
Wang HJ (2002) Heteroscedasticity and non-monotonic efficiency effects of a stochastic frontier model. J Product Anal 18(3):241–253
Wang HJ, Schmidt P (2002) One-step and two-step estimation of the effects of exogenous variables on technical efficiency levels. J Product Anal 18(2):129–144. https://doi.org/10.1023/A:1016565719882
Wood SN (2008) Fast stable direct fitting and smoothness selection for generalized additive models. J R Stat Soc Ser B Stat Methodol 70(3):495–518. https://doi.org/10.1111/j.1467-9868.2007.00646.x
Wood SN (2011) Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. J R Stat Soc Ser B Stat Methodol 73(1):3–36. https://doi.org/10.1111/j.1467-9868.2010.00749.x
Wood SN (2020) mgcv: mixed GAM computation vehicle with automatic smoothness estimation. r package version 1.8-33. https://CRAN.R-project.org/package=mgcv
Xia Y, Härdle W (2006) Semi-parametric estimation of partially linear single-index models. J Multivar Anal 97(5):1162–1184. https://doi.org/10.1016/j.jmva.2005.11.005
Xia Y, Tong H, Li W (1999) On extended partially linear single-index models. Biometrika 86(4):831–842. https://doi.org/10.1093/biomet/86.4.831
Yu Y, Ruppert D (2002) Penalized spline estimation for partially linear single-index models. J Am Stat Assoc 97(460):1042–1054. https://doi.org/10.1198/016214502388618861
Yuan M (2011) On the identifiability of additive index models. Stat Sin 1901–1911. https://doi.org/10.5705/ss.2008.117
Acknowledgements
We thank an associate editor and a referee for their insightful comments and suggestions that improved the paper. The computations were enabled by resources provided by the Swedish National Infrastructure for Computing (SNIC) at Umeå Universitet partially funded by the Swedish Research Council through grant agreement no. 2018-05973.
Funding
GF is supported by Handelsbanken Program Grant P19-0110. RT is supported by Browaldhstipendier Bh17-0009. Open access funding provided by Umea University.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A
1.1 Proof of Theorem 1
Notice that the model is identified if
implies μ1 = μ2, β1 = β2, α1 = α2 and λ1 = λ2.
From conditions 1 and 2 it follows that
Hence μ + E[x]β is identified.
Differentiating both sides of (A1) with respect to the components of X one obtains:
If p≥2 it is possible to find a vector v such that \(v^{\prime} v=1\) and \(v^{\prime} {\alpha }_{1}=v^{\prime} {\alpha }_{2}\). There are several v satisfying this. So choose the v for which ∥vα1∥ is the largest. Assume without loss of generality that X0 = 0 (otherwise recenter at X0). Let X = Xv then \(X{\alpha }_{1}=X{\alpha }_{2}= X v^{\prime} {\alpha }_{i}\). Since S is convex one can allow X → 0 and conclude that β1 = β2 by conditions 4 and 5.
Since both μ + E[X]β and β are identified and E[X] is finite, then μ1 = μ2.
Then (A1) implies that \(-{\lambda }_{1}(X^{\prime} {\alpha }_{1})=-{\lambda }_{2}(X^{\prime} {\alpha }_{2})\). This is a single index model and α1 = α2 and λ1 = λ2 because of conditions 1 and 6 along with the Theorem 1 of Yuan (2011) with M = 1 or Theorem 1 of Lin and Kulasekera (2007). □
Appendix B
2.1 Proof of Theorem 3
The following intermediate result is needed.
Proposition 4
Assume that \(\sqrt{T}(\hat{\xi }-{\xi }_{* }){\to }^{d}N(0,{{{\Sigma }}}_{* })\) where \({\xi }_{* }=({\beta }_{* }^{{\prime} },{\phi }_{* }^{{\prime} })\) and \(\hat{\xi }=(\hat{\beta }^{\prime} ,\hat{\phi }^{\prime} )\), α(ϕ) is parameterizated as in (9). Then,
where \({\sigma }_{* }^{2}=\left(\begin{array}{l}{\alpha }_{* }\\ {\nabla }_{\phi }\left({\beta }_{* }^{{\prime} }\alpha ({\phi }_{* })\right)\end{array}\right)^{\prime} {{{\Sigma }}}_{* }\left(\begin{array}{l}{\alpha }_{* }\\ {\nabla }_{\phi }\left({\beta }_{* }^{{\prime} }\alpha ({\phi }_{* })\right)\end{array}\right).\)
Proof. Let \(g\left(\begin{array}{l}\hat{\beta }\\ \hat{\phi }\end{array}\right)={\alpha }_{* }^{{\prime} }\hat{\beta }+{\beta }_{* }^{{\prime} }\alpha (\hat{\phi })\). Notice, that is a continuously differentiable function of θ so we can apply the multivariate delta method and conclude that \(\sqrt{n}\left(g\left(\begin{array}{l}\hat{\beta }\\ \hat{\phi }\end{array}\right)-g\left(\begin{array}{l}{\beta }_{* }\\ {\phi }_{* }\end{array}\right)\right)\to N(0,{\sigma }_{* }^{2})\). □
We can now prove Theorem 3.
Write
If \({\alpha }_{* }^{{\prime} }{\beta }_{* }=0\), the last term of (B2) is zero. Notice that since \(\alpha (\hat{\phi })=\alpha ({\phi }_{* })+{o}_{p}(1)\),
Proposition (B2) implies that
an first part of Theorem 3 follows.
If \({\alpha }_{* }^{{\prime} }{\beta }_{* }=\varrho /\sqrt{n}\) and \(\alpha (\hat{\phi })=\alpha ({\phi }_{* })+{o}_{p}(1)\), (B2) becomes
and using Proposition (B2),
The second part of Theorem 3 follows. □
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Forchini, G., Theler, R. Semi-parametric modelling of inefficiencies in stochastic frontier analysis. J Prod Anal 59, 135–152 (2023). https://doi.org/10.1007/s11123-022-00656-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11123-022-00656-x
Keywords
- Stochastic frontier
- Partially linear single-index model
- Semi-parametric
- Penalized splines
- Energy economics