
Abstract
There is a huge importance for the localization system in underwater visible light communication (VLC) systems as in petroleum, military and diving fields. To enhance the localization system, we use the Kalman filter (KF) algorithm with average received signal strength (RSS) method to obtain the nearest estimated positions. In this paper, two channel modeling weighted double Gamma functions (WDGF) are applied and a combination exponential arbitrary power function (CEAPF) for enhancing localization in VLC underwater systems. Using the proposed KF enhances the localization by ~ 60% as compared to the than average RSS technique for WDGF channel modeling and ~ 78% for the CEAPF channel modeling. Based on the estimate of received signal strength (RSS) by deep learning models (DLMs), underwater localization utilizing VLC is introduced. Our proposed framework is categorized into two phases. First, data collection is collected based on MATLAB software. Second, the training and testing of DLMs, SSD, RetinaNet, ResNet50V2 and InceptionResNetV2 techniques are applied. The channel gains are the DLMs’ input data set, while the DLMs’ output is the RSS intensity technique coordinates for each detector. The DLMs are then developed and trained using Python software. The ResNet50V2 based on average RSS technique hybrid with KF in CEAPF channel model achieves 99.98% accuracy, 99.97% area under the curve, 98.99% precision, 98.88% F1-score, 0.101 RMSE and 0.32 s testing time.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
VLC system is used in underwater application in a wide range due to its advantages as high reliability, bandwidth and data rate. The channel modeling used in underwater systems differs according to the features of water types (Shawky et al. 2020; Ehiremen et al. 2020; Tang et al. 2014; Yiming et al. 2018). The underwater systems used radio frequency (RF) and acoustic systems for several years, before the recent use of VLC. The acoustic system has a limitation in spectrum, high complexity and high latency. Also, the RF suffers attenuation for short ranges, so, it cannot achieve the optimum long-range localization (Mapunda et al. 2020).
Recent traditional ways to localization the VLC systems content the arrival of time (TOA) technique, depending on the real time of arrival for the received optical signal (Wang et al. 2013), arrival angle (AOA) method, which using the intersection the angle direction received signals’ lines (Islam et al. 2012; Yang et al. 2014; Sahin et al. 2015), time difference of arrival (TDOA) technique, based on the different among received signals in the arrival times that for three transmitters at least (Jung et al. 2011), and received signal strength (RSS) method where it uses the measuring of the received power of the optical signals strengths for more than two transmitters (Islam et al. 2012; Yang et al. 2014; Sahin et al. 2015; Jung et al. 2011).
In Vegni et al. (2021), authors presented a foot-printing positioning method depending on the optical signal in the spectrum of VLC. The approach technique combined between Radio Frequency (RF) and VLC network. The sensor of RF holds a map of channel gain in the environment to calculate the estimation of the localization. The localization technique utilized to evaluate the localization using the accuracy of centimeter-base for turbidity scenarios. Underwater localization using VLC was presented in Ghonim et al. (2021) depending on the neural networks (NNs) and RSS was estimated in two stages: collection the data and NN training. Firstly, data have been collected using Zemax and Monte Carlo ray tracing software. The gains of the channel used as the data set input to the NN, where the outputs of the NN were the coordinates of the detector depending on the intensity of RSS method. Secondly, an NN system has been built and trained using the aid of orange data mining software.
In a similar vein, many studies have used DLMs hybrid with VLC systems to improve system performance (Chaleshtori et al. 2019; Ma et al. 2019; Irshad et al. 2019; Alonso-González et al. 2018). Chaleshtori et al. investigated the effect of training algorithms in an artificial neural network (ANN) equalizer in VLC systems using an organic light source (Jung et al. 2011). Ma et al. looked into the design and implementation of machine-learning-based demodulation methods in the physical layer of VLC systems (Zhang et al. 2016). Zhang et al. proposed a localization approach for underwater acoustic wireless sensor networks based on a mobility prediction and a particle swarm optimization algorithm in Saeed et al. (2018) by evaluating the mobility patterns of water near the seashore. In contrast, Saeed et al. proposed an RSS-based localization technique for underwater optical wireless sensor networks (Teruyama et al. 2013).
The main aim of this paper is trying to obtain the nearest estimation of the receiver’s location in underwater systems using VLC. This estimation uses KF with averaging which outperforms the RSS average method in the accuracy of the localization as shown in the obtained results. The harbor water is applied with two channel models: WDGF and CEAPF. The average method depends on taking multi-number of samples for the received power at the receiver and determine their estimate by Kalman filter (KF), then, taking the average estimated power output from KF to get the position (x, y) of the receiver by using RSS technique.
To increase the enhancement and decrease the localization error of using KF with averaging only, we use DLMS. Our proposed framework is based on utilizing different DLMs, SSD, RetinaNet, ResNet50V2 and InceptionResNetV2 techniques to determine the 2D positioning system, in order to approximate the Cartesian coordinates. The proposed framework processes a grid of RSSs using the (x, y) coordinates. The received signal power is used as the DLMs input for training and testing the data sets. The proposed system is distinguished by its ability to determine the exact coordinates of any object under seawater according to absorption and scattering. This system is characterized by high precision, low cost, and low computational complexity, allowing a feasible hardware system.
This paper is sectioned as the following; Sect. 2 discusses the optical channel modeling of an underwater VLC system with the impulse response modeling. Section 3 illustrates the methods of the localization techniques with the proposed averaging technique and the algorithm of KF and localization based on DLMs. Simulation analysis is displayed and discussed in Sect. 4. Finally, Sect. 5 concludes the work.
2 Underwater optical channel
According to Tang et al. (2014) and Yiming et al. (2018), the scattering and absorption represent the main parameters affecting light propagation in underwater systems, where both of them are related to the light wavelength ((\(\uplambda \)). The losing intensity is meant by absorption which depends on the refractive index of water. The spectral absorption coefficient, a(λ) m−1, is the intrinsic optical property to get the model of water absorption. The scattering coefficient, b(λ) m−1, is the light deflection in underwater system from the real track, that is resulted from presence the diffraction, or via some of substances with several values of refractive index (refraction). The extinction coefficient, \(c\left(\lambda \right)\) m−1, is defined as a summation of \(a(\lambda )\) and \(b(\lambda )\):
The difference between the types of water is according to both of view of matter and quality. Yiming et al. (2018) shows the values of water coefficients for different types of water, pure, ocean, coastal and harbor water.
2.1 Optical characterization of seawater
According to Yiming et al. (2018), there are four parameters for absorption effect
In Eq. (2), the absorbing parameter of pure sea water is expressed as \({a}_{w}(\lambda )\). Where the absorption resulted from Chromophoric Dissolved Organic Matter (CDOM) and phytoplankton are \({a}_{CDOM}(\lambda )\) and \({a}_{phy}\left(\lambda \right),\) respectively. The coefficient of absorption caused by detritus is assumed as \({a}_{det}(\lambda )\).
Depending on the effects of scattering, the intensity of the received signal can be deduced and provides inter-symbol interference where the rate of bits isn’t dropped to accommodate the temporal scattering. The scattering is dependent on low wavelength and is based on the huge number of several particles in underwater (Yiming et al. 2018).
Here, the scattering parameters related to CDOM is expressed as \({b}_{CDOM}(\lambda )\), while the scattering for phytoplankton is written as \({b}_{phy}(\lambda )\). \({b}_{w}(\lambda )\) and \({b}_{det}(\lambda )\) represent scattering due to pure seawater and detritus, respectively.
The value of the extinction coefficient, c(\(\lambda \)), is varying according to the water depths and water types. The main characteristics of water can be classified in two main groups: inherent and apparent. Inherent properties describe optical parameters which depend only on the medium; more specifically the composition and particulate substances present. The apparent is based on both of the channel through transmission and the geometric structure of the illumination, so, it is a directional property.
2.2 Impulse response in the channel modeling
For the impulse response used in clouds, the WDGF is supposed in Mapunda et al. (2020) to characterize the channel impulse response (CIR). While the output of result has high performance for using four degrees of freedom, the clouds characteristics are several from those of the water. CIR can be expressed as (Mapunda et al. 2020)
where \({c}_{1}\), \({c}_{2}\), \({c}_{3}\) and \({c}_{4}\) are the four factors to be computed utilizing the Monte-Carlo simulations.
The model of function depending on CEAPF was recently assumed in Ghonim et al. (2021)
where \( c_{1} > 0,\;c_{2} > 0,\;\alpha > - 1\;{\text{and}}\;\beta {\text{ > 0}} \), are the four parameters to be found and \(v\) is speed of light in water. These parameters can be calculated from Monte-Carlo simulation results using the nonlinear least square criterion. Note that none of these CIR models are valid for water types in which the effect of scattering is not as dominant as in turbid environments. In addition, these models do not take into account channel path loss. Tables 1 and 2 show the main parameters of CIR for different values of fields of view (FOV) of harbor water for CEAPF and WDGF, respectively. L refers to the distance between transmitter and receiver, where we use it = 5.47 m.
3 Methodology
3.1 Proposed localization methodology using averaging RSS technique
The conventional trilateration localization method is applied as modeled in Shawky et al. (2020) to obtain the receiver location, using the RSS technique from 3 LEDs that having the highest received levels (Teruyama et al. 2013).
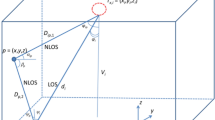
The simulation is done in a cube of glass that contains harbor water with dimension (5, 5, 5.47) m as shown in Fig. 1. Tx,i = (xi, yi, zi) refers to the position of the transmitter, Rx = (xo, yo, zo) represents the location of the receiver, Vi is the vertical distance between transmitter and receiver, di is the actual distance between transmitter and receiver, \(\mathrm{\varphi i}\) is the irradiance angle, and \(\uppsi \) i is the incidence angle.

The glass cube containing the water
We suppose that the transmitter at the ceiling of the cube and the receiver at the bottom of the cube. Thus, the fixed distance between transmitter and the receiver is the height of the cube = 5.47 m. The estimation of the receiver location depends on fixing the height difference between transmitters and receivers and locate the (x, y) dimensions to the cube of glass. To make our simulation, this cube contains 4 walls and there are 3 transmitters in the celling of the cube and the receiver is in the bottom of the cube. As shown in Fig. 1, there is a direct signal from the transmitter and the receiver as line of sight (LoS).
The propose aims to take an average of the estimated receiver location using number of the measurements resulted from RSS method to deduce the error of the localization. Figure 2 shows the block diagram that demonstrates this approach.

Localization based on RSS averaging
Using Eq. (1) in Shawky et al. (2020) and RSS technique, the received power line of sight (LoS) from transmitter \(i \in \{1, 2, 3, 4,..\}\) can be expressed as (Chen et al. 2021)
where \({P}_{R,i}\) represents the received power from a certain LED (i), \({P}_{T,i}\) represents the power transmitted from LED (ith).where \({P}_{R,i}\) represents the received power from a certain LED (i), \({P}_{T,i}\) represents the power transmitted from LED (ith) and m is the Lambertian index, where both optical filter gain and optical concentrator gain are assumed unity. Also, we suppose that \(\mathrm{\varphi i}=\uppsi \)i, where \(\mathrm{\varphi i}\) is the irradiance angle, \(\uppsi \)i is the incidence angle, that is calculated from Fig. 1 as Teruyama. et al. (2013)
where \(V\) is the height between receiver and transmitter and is supposed as a constant value. The distance, \({d}_{i},\) between both of the receiver and transmitter which can be expressed as:
3.2 Localization using KF in conjunction with averaging
The KF algorithm can estimate the state of the linear system by utilizing some series of the noisy measurements and produces the estimation of unknown variables to get more accurate results than those based only on a single measurement (Chen et al. 2021). The KF algorithm aims to enhance the estimation of receiver location. The estimation starts by estimation of KF to some samples for measured received powers in different times where the time difference between each sample nearly 1 × 10–9 s. Then, an average is calculated for those estimated powers. Utilizing average power estimation can calculate the position of the receiver with RSS method. There is a block diagram of KF with averaging technique is shown in Fig. 3a. Figure 3b illustrates the flowchart of using the proposed KF as in Shawky et al. (2020).

a Proposed KF with averaging technique, b Flowchart of using KF with average method
Figure 3 shows the block diagram of the sequence of using received signal strength (RSS) technique to determine the position of the receiver (x, y). The averaging method depends on using samples of the received powers at the same position of the receiver in a very short time. Each of these powers is used in RSS technique for determine (x, y) for each sample. By storing these positions, one can take the average of them to obtain the certain position (x, y) for the receiver.
3.3 Kalman algorithm
As applied in Salama et al. (2022) the channel is modeled as an auto-regressive (AR) process in the model of space state. The AR models and past values take the current values effects. The scheme is based on the enhancement of the estimation accuracy. In the KF, the state vector is denoted as x. This vector measures the state of the received power and some of samples in the process, depending on the estimation at the iteration \(k-1\), and has the state \({x}_{k-1/k-1}\). Next \(k\) of the dynamics system, \({x}_{k/k-1}\), is calculated in predict and measurement stages as illustrated in Teruyama et al. (2013).
3.4 Dataset
To use DLMS, we should prepare the dataset for using this model in accurate way. The dataset used in the DLMS is based on the average received power in the receiver. The average RSS technique uses the average received power for the samples for each point in the position of the track. We take these samples for measured received powers in different times, where the time difference between each sample is nearly 1 ns, where this is a very tiny time to ensure that there is not any extra change between samples. While the average KF method uses the estimated average received power for the samples, where the estimation is performed using the KF algorithm.
3.5 Proposed DLMs based under water localization
To solve various problems, pre-trained models are trained on a large benchmark dataset. For the localization process in this study, four different pre-trained models (e.g., SSD, RetinaNet, ResNet50V2, and InceptionResNetV2) were used. All of the models have different convolution and pooling layers that are used to localize under water.
3.5.1 ResNet50V2 and InceptionResNetV2 DLMs
The ResNet50V2 (Chen et al. 2021) is the upgrade version of ResNet50. This architecture is based on skip connection, which allows us to take activation from one layer and feed it to the future layer. While, Inception-ResNet-v2 (Sarker et al. 2021) is the mutual architecture of the Inception with residual connections. Average Pooling 2D is used in the training process for ResNet50V2, and InceptionResNetV2 models to calculate the average for each patch of the feature map. Following that, we flattened the activations to create a vectorized feature map and connected two fully connected layers: one with 128 nodes and the other with 2-class classification \((x,z)\). The activations from the second fully connected layer were then fed into a softmax layer, which calculated the probability for each coordinate \((x,z)\). The DLMs parameters are explained in Table 3.
3.5.2 SSD DLMs
The SSD (Single Shot Detector) algorithm (Wulandari et al. 2022) is a one-stage detection model that allows object localization and classification to be performed in a single neural network forward pass. SSD algorithm is said to be faster and simpler to train. The elimination of region proposals and the feature resampling stage results in a significant increase in speed. The received signal power are fed into the network, and the 2D cartesian coordinates \((x,z)\) are predicted using a single network. In several feature layers, SSD predicts the offset for default boxes of varying sizes and aspect ratios, and then applies a \(3 \times 3\) convolution to each feature dimension to provide box and class outputs. The outputs are then combined at the network's end to apply non-maximum suppression.
3.5.3 RetinaNet DLMs
Resnet-101 serves as the backbone network for RetinaNet (Wang et al. 2019), which is followed by two task-specific subnetworks: the classification subnet and the box regression subnet. The classification subnet is a fully convolutional network (FCN) that is connected to each FPN level and predicts the likelihood of an object being present at each spatial position. Furthermore, each pyramid level has a box regression subnet, which is also a small FCN. This subnet is in charge of regressing each anchor box's offset.
4 Results and discussion
4.1 Evaluation metrics
In order to achieve the superb robustness of proposed technique, various DL models are utilized. Here, we evaluate the performance of underwater localization for several DL models based on different strategies.
The metric evaluation depends mainly on calculating four parameters: the number of true positives (TP), true negatives (TN), false negatives (FN), and false positives (FP). The classification performance is identified in terms of accuracy, AUC, Pr, F1-score, RMSE and computational time. The \(ACC\) is used to evaluate the rate of correct classification, \(Pr\) is the positive predictive value that matches the original value, and \(Se\) is the true positive values. The F1-score is the harmonic mean of \(Pr\) and \(Se\). It represents a more generalized form for balancing both \(Pr\). The \(AUC\) measures the entire two-dimensional area underneath the entire ROC curve. The RMSE is an error metric that obtains a cumulative estimate of error. It is evaluated as the square root of the arithmetic mean of squares of error in our dataset. It provides an aggregate measure of performance across all possible classification thresholds. All these metrics are defined as in Ghonim et al. (2021).
Table 4 shows that the proposed CEAPF SSD model require less training and testing time than the other models. However, when the proposed DL models localization capability is examined, these computational durations are reasonable for underwater localization.
Figure 4a–h clarifies the various strategies, RSS techniques, average positions, and KF positions based on DLMs for two the different channel models, CEAPF and WDGF. Although the SSD algorithm is claimed to be faster and easier to train, but it suffers from low accuracy. While RetinaNet achieves better accuracy than SDD, but takes more time. Furthermore, ResNet50V2 achieves the best performance in the shortest amount of time.



a RSS technique based on WDGF channel RSS + DLMS, b RSS technique based on WDGF channel RSS+KF+DLMS, c RSS technique based on WDGF channel AVG RSS+DLMS, d RSS technique based on WDGF channel AVG KF+RSS+DLMS, e RSS technique based on CEAPF channel RSS+DLMS, f RSS technique based on CEAPF channel RSS+KF+DLMS, g RSS technique based on CEAPF channel average RSS+DLMS, h RSS technique based on CEAPF channel average KF+RSS+DLMS
According to the experimental results.
Figure 5 explains the performance for all different strategies based on DLMs. The ResNet50V2 based on the average KF position technique in the CEAPF channel model achieves 99.98% accuracy, 99.97% AUC, 98.99% precision, 98.88% F1-score, 0.101 RMSE, and 0.32 s testing time. We would like to mention that the obtained RMSE is related to the ResNet50V2 model, which has been determined to have superior performance probabilities.

Performance of different strategies based on DLMs
As shown in Table 5, our proposed framework is compared to others in the literature, showing that our proposed framework outperforms others in terms of ACC, Pr, AUC, F1-score, and RMSE.
5 Conclusion
We introduced multi-techniques to improve localization, including the RSS technique, the average position technique, and the KF position technique based on the WDGF and CEAPF channel models. The estimated track of the receiver output \((x,z)\) was the input of the DL models-based localization system for underwater localization system. For the WDGF channel model, the enhancement ratio of using KF average method than RSS average method is nearly 60% while this improvement is increased to 78% for CEAPF, when using the KF average method than RSS average method. Thus, using CEAPF outperforms WDGF by about 18%.
It is depicted that combining the KF technique with the DLMs based on the CEAPF channel model significantly improves the performance of our proposed framework. According to the results of our trials, the proposed framework achieves a reasonable localization accuracy for underwater localization. When compared to previously published work, our proposed framework outperforms that found in many references, achieving 99.98% accuracy, 99.97% AUC, 98.99% precision, 99.88% F1-score, 0.101 RMSE, and 0.32 s for testing time. As a result, our proposed system has high accuracy, low complexity, and a small error distance while requiring very little training time.
Availability of data and materials
The data used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Change history
06 February 2023
In the original publication ORCID for author Moustafa H. Aly was not included.
References
Alonso-González, I., Sánchez-Rodrguez, D., Ley-Bosch, C., Quintana-Suárez, M.A.: Discrete indoor three-dimensional localization system based on neural networks using visible light communication. Sensors 18, 1040 (2018)
Chaleshtori, Z.N., Haigh, P.A., Chvojka, P., Zvanovec, S., Ghassemlooy, Z.: Performance evaluation of various training algorithms for an equalization in visible light communications with an organic led. In: 2nd West Asian colloquium on optical wireless communications (WACOWC), pp. 11–15, IEEE (2019)
Chatterjee B., Poullis, C.: On building classification from remote sensor imagery using deep neural networks and the relation between classification and reconstruction accuracy using border localization as proxy. In: 16th Conference on computer and robot vision (CRV), pp. 41–48. IEEE (2019)
Chen, Y.C., Li, D.C.: Selection of key features for PM2. 5 predictions using a wavelet model and RBF-LSTM. Appl. Intell. 51(4), 2534–2555 (2021)
Ehiremen, A., Ebehiremen, I., Edeko, O.O.: High-capacity data rate system: review of visible light communications technology. J. Electron Sci. Technol. 18(3), 100055 (2020)
Ghonim, A.M., Salama, W.M., El-Fikky, A.E.-R.A., Khalaf, A.A.M., Shalaby, H.M.H.: Underwater localization system based on visible-light communications using neural networks. Appl. Opt. 60, 3977–3988 (2021)
Irshad, M., Liu, W., Wang, L., Khalil, M.U.R.: Cogent machine learning algorithm for indoor and underwater localization using visible light spectrum. Wirel. Pers. Commun. 116, 993–1008 (2019)
Islam, M.S., Klukas, R.: Indoor positioning through integration of optical angles of arrival with an inertial measurement unit. In: Proceedings of the 2012 IEEE/ION position, location and navigation symposium, pp. 408–413 (2012)
Jung, S., Hann, S., Park, C.: TDOA-based optical wireless indoor localization using LED ceiling lamps. IEEE Trans. Consum. Electron. 57, 1592–1597 (2011)
Ma, S., Dai, J., Lu, S., Li, H., Zhang, H., Du, C., Li, S.: Signal demodulation with machine learning methods for physical layer visible light communications: prototype platform, open dataset, and algorithms. IEEE Access 7, 30588–30598 (2019)
Mapunda, G.A., Ramogomana, R., Marata, L., Basutli, B., Khan, A.S., Chuma, J.M.: Indoor visible light communication: a tutorial and survey. Wirel. Commn. Mob. Comput. 2020, 8881305 (2020)
Saeed, N., Celik, A., Al-Naffouri, T.Y., Alouini, M.-S.: Underwater optical sensor networks localization with limited connectivity. In: IEEE international conference on acoustics, speech and signal processing (ICASSP) pp. 3804–3808, IEEE (2018)
Sahin, A., Eroglu, Y.S., Güvenç, I., Pala, N., Yüksel, M.: Hybrid 3-D localization for visible light communication systems. J. Lightwave Technol. 33, 4589–4599 (2015)
Salama, W.M., Aly, M.H., Amer, E.S.: Enhanced deep learning-based channel estimation for indoor VLC systems. Opt. Quantum Electron. 54, 535 (2022). https://doi.org/10.1007/s11082-022-03904-4
Sarker, S., Tan, L., Ma, W., Rong, S., Osibo, B.K., Darteh, O.F.: Multi-classification network for identifying COVID-19 cases using deep convolutional neural networks. J. Internet Things 3(2), 39–42 (2021)
Shawky, E., El-Shimy, M., Mokhtar, A., El-Badawy, E.-S.A., Shalaby, H.M.H.: Improving the visible light communication localization system using Kalman filtering with averaging. J. Opt. Soc. Am. B 37(11), A130–A138 (2020)
Tang, S., Dong, Y., Zhang, X.: Impulse response modeling for underwater wireless optical communication links. IEEE Trans. Commun. 62, 226–234 (2014)
Teruyama, Y., Watanabe, T.: Effectiveness of variable-gain Kalman filter based on angle error calculated from acceleration signals in lowerlimb angle measurement with inertial sensors. Comput. Math. Methods Med. 10(398042), 1–12 (2013)
Vegni, A.M., Hammouda M., Loscrí, V.: A VLC-based footprinting localization algorithm for internet of underwater things in 6G networks. In: 2021 17th International symposium on wireless communication systems (ISWCS), pp. 1–6 (2021)
Wang, T.Q., Sekercioglu, Y.A., Neild, A., Armstrong, J.: Position accuracy of time-of-arrival based ranging using visible light with application in indoor localization systems. J. Lightwave Technol. 31, 3302–3308 (2013)
Wang, Y., Wang, C., Zhang, H., Dong, Y., Wei, S.: Automatic ship detection based on RetinaNet using multi-resolution Gaofen-3 imagery. Remote Sens. 11(5), 531–536 (2019)
Wulandari, N., Ardiyanto, I., Nugroho, H.A.: A Comparison of deep learning approach for underwater object detection. J. RESTI (Rekayasa Sist. Teknol. Inf.) 6(2), 252–258 (2022)
Yang, S., Kim, H., Son, Y., Han, S.: Three-dimensional visible light indoor localization using AOA and RSS with multiple optical receivers. J. Lightwave Technol. 32, 2480–2485 (2014)
Yiming, L., Mark, S.L., Xiaofeng, L.: Impulse response modeling for underwater optical wireless channels. Appl. Opt. 57, 4815–4823 (2018)
Zhang, Y., Liang, J., Jiang, S., Chen, W.: A localization method for underwater wireless sensor networks based on mobility prediction and particle swarm optimization algorithms. Sensors 16, C1–C17 (2016)
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB). The authors did not receive any funds to support this research.
Author information
Authors and Affiliations
Contributions
WMS, MHA, ESM have directly participated in the planning, execution, and analysis of this study. WMS drafted the manuscript. All authors have read and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Conflict of interest
The authors declare that they have no competing interests.
Ethical approval
Not Applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Salama, W.M., Aly, M.H. & Amer, E.S. Deep learning/Kalman filter-based underwater localization in VLC systems. Opt Quant Electron 55, 180 (2023). https://doi.org/10.1007/s11082-022-04458-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11082-022-04458-1